http://blog.csdn.net/hguisu/article/details/7282050
hadoop、hbase的安装见前面的文章
下面是hive的安装
1、下载
http://mirror.bit.edu.cn/apache/hive/stable/
一 、简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类, 大致意思如图所示: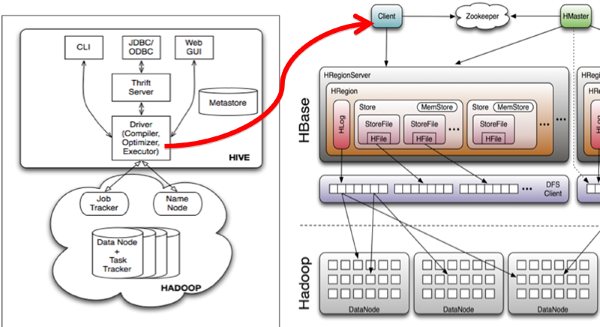
二、安装步骤:
1 .Hadoop和Hbase都已经成功安装了
Hadoop集群配置:http://blog.csdn.net/hguisu/article/details/723739
hbase安装配置:http://blog.csdn.net/hguisu/article/details/7244413
2 . 拷贝hbase-0.90.4.jar和zookeeper-3.3.2.jar到hive/lib下。
注意:如何hive/lib下已经存在这两个文件的其他版本(例如zookeeper-3.3.2.jar),建议删除后使用hbase下的相关版本。
2. 修改hive/conf下hive-site.xml文件,在底部添加如下内容:
- <!--
-
<property>
-
<name>hive.exec.scratchdir</name>
-
<value>/usr/local/hive/tmp</value>
-
-
</property>
- -->
-
-
<property>
-
<name>hive.querylog.location</name>
-
<value>/usr/local/hive/logs</value>
-
</property>
-
-
<property>
-
<name>hive.aux.jars.path</name>
-
<value>file:///usr/local/hive/lib/hive-hbase-handler-0.8.0.jar,file:///usr/local/hive/lib/hbase-0.90.4.jar,file:///usr/local/hive/lib/zookeeper-3.3.2.jar</value>
-
-
</property>
注意:如果hive-site.xml不存在则自行创建,或者把hive-default.xml.template文件改名后使用。
3. 拷贝hbase-0.90.4.jar到所有hadoop节点(包括master)的hadoop/lib下。
4. 拷贝hbase/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的hadoop/conf下。
注意,如果3,4两步跳过的话,运行hive时很可能出现如下错误:
- [html]viewplaincopy
- org.apache.hadoop.hbase.ZooKeeperConnectionException:HBaseisabletoconnecttoZooKeeperbuttheconnectionclosesimmediately.
- Thiscouldbeasignthattheserverhastoomanyconnections(30isthedefault).ConsiderinspectingyourZKserverlogsforthaterrorand
- thenmakesureyouarereusingHBaseConfigurationasoftenasyoucan.SeeHTable'sjavadocformoreinformation.atorg.apache.hadoop.
- hbase.zookeeper.ZooKeeperWatcher.
以下是我的hive-site.xml文件内容:
</property>
<!--
<property>
<name>hive.exec.scratchdir</name>
<value>/home/cheng/hive-0.8.1/tmp</value>
</property>
-->
<property>
<name>hive.querylog.location</name>
<value>/home/cheng/hive-0.8.1/logs</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///home/cheng/hive-0.8.1/lib/hive-hbase-handler-0.8.1.jar,file:///home/cheng/hive-0.8.1/lib/hbase-0.89.0-SNAPSHOT.jar,file:///home/cheng/hive-0.8.1/lib/zookeeper-3.4.3.jar</value>
</property>
</configuration>
我没有找到hbase-0.90.4.jar这个文件,就使用hive自带的
然后将hive打包scp到相应的各个机器上。
三、启动Hive
1.单节点启动
#bin/hive -hiveconf hbase.master=master:490001
2 集群启动:
#bin/hive -hiveconf hbase.zookeeper.quorum=node1,node2,node3
如何hive-site.xml文件中没有配置hive.aux.jars.path,则可以按照如下方式启动。
bin/hive --auxpath /usr/local/hive/lib/hive-hbase-handler-0.8.0.jar, /usr/local/hive/lib/hbase-0.90.5.jar,
/usr/local/hive/lib/zookeeper-3.3.2.jar -hiveconf hbase.zookeeper.quorum=node1,node2,node3
四、测试:
1.创建hbase识别的数据库:
- CREATETABLEhbase_table_1(keyint,valuestring)
- STOREDBY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
- WITHSERDEPROPERTIES("hbase.columns.mapping"=":key,cf1:val")
- TBLPROPERTIES("hbase.table.name"="xyz");
hbase.table.name 定义在hbase的table名称
hbase.columns.mapping 定义在hbase的列族
2.使用sql导入数据
1) 新建hive的数据表:
CREATE TABLE pokes (foo INT, bar STRING);
2)批量插入数据:
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE
3)使用sql导入hbase_table_1:
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=86;
3. 查看数据
hive> select * from hbase_table_1;
这时可以登录Hbase去查看数据了
#bin/hbase shell
hbase(main):001:0> describe 'xyz'
hbase(main):002:0> scan 'xyz'
hbase(main):003:0> put 'xyz','100','cf1:val','www.360buy.com'
这时在Hive中可以看到刚才在Hbase中插入的数据了。
4 hive访问已经存在的hbase
使用CREATE EXTERNAL TABLE:
- CREATEEXTERNALTABLEhbase_table_2(keyint,valuestring)
- STOREDBY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
- WITHSERDEPROPERTIES("hbase.columns.mapping"="cf1:val")
- TBLPROPERTIES("hbase.table.name"="some_existing_table");
内容参考:http://wiki.apache.org/hadoop/Hive/HBaseIntegration
在
创建hbase识别的数据库总是报错误:
hive> CREATE TABLE hbase_table_1(key int, value string)
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
> TBLPROPERTIES ("hbase.table.name" = "xyz");
FAILED: Error in metadata: java.lang.IllegalArgumentException: Not a host:port pair: 锟?
还没有解决
解决:
其实还是上面的安装步骤有问题导致了一直报这个错误,需要注意的是这一步:
拷贝hbase-0.90.4.jar和zookeeper-3.3.2.jar到hive/lib下。
其中hbase-0.92.1.jar所在的路径是/home/cheng/hbase-0.92.1/hbase-0.92.1.jar(我的hbase版本高),原来弄错了以为是在hbase的lib路径下那。然后将该jar包拷贝到hive/lib以及hadoop/lib下就可以了
cheng@ip83 hive-0.8.1]$ ./bin/hive --auxpath file:///home/cheng/hive-0.8.1/lib/hive-hbase-handler-0.8.1.jar,file:///home/cheng/hive-0.8.1/lib/hbase-0.92.1.jar,file:///home/cheng/hive-0.8.1/lib/zookeeper-3.4.3.jar -hiveconf hbase.zookeeper.quorum=ip81,ip82,ip83
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Logging initialized using configuration in jar:file:/home/cheng/hive-0.8.1/lib/hive-common-0.8.1.jar!/hive-log4j.properties
Hive history file=/home/cheng/hive-0.8.1/logs/hive_job_log_cheng_201205151131_1369166340.txt
hive> CREATE TABLE hbase_table_1(key int, value string)
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
> TBLPROPERTIES ("hbase.table.name" = "xyz");
OK
Time taken: 9.152 seconds
hive>
其中
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
好像是个bug可以忽略,到此hadoop+hbase+hive集群安装完成
分享到:





相关推荐
"HIVE安装及详解" HIVE是一种基于Hadoop的数据仓库工具,主要用于处理和分析大规模数据。下面是关于HIVE的安装及详解。 HIVE基本概念 HIVE是什么?HIVE是一种数据仓库工具,主要用于处理和分析大规模数据。它将...
【大数据技术基础实验报告-Hive安装配置与应用】 在大数据处理领域,Apache Hive是一个非常重要的组件,它提供了基于Hadoop的数据仓库工具,用于数据查询、分析以及存储。本实验报告将详细阐述如何安装、配置Hive,...
本压缩包文件"hive"可能包含了Hive安装过程中所需的配置文件,这些文件对于正确、高效地运行Hive至关重要。以下是对Hive安装配置文件的详细解释: 1. **`core-site.xml`**: 这个文件包含了Hadoop核心的配置参数,...
hive安装
### Hive安装知识点详解 #### 一、Hive简介与安装目的 Hive 是基于 Hadoop 的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行...
### Hive安装与配置详解 #### 一、软件准备与环境规划 在进行Hive的安装与配置之前,首先需要对所需的软件及环境进行规划。以下为本次安装与配置的环境规划: - **操作系统**: Ubuntu - **Java版本**: Java 1.6.0...
6. Hive安装完成后,需要创建元数据库。Hive默认使用derby数据库,但为了生产环境的稳定性和性能,建议使用MySQL。配置文件位于$HIVE_HOME/conf目录下,需要修改hive-site.xml来指定MySQL连接信息: ```xml ...
内容包括hive如何安装与启动,以及如何使用python访问hive,希望对大家有帮助。
Hive安装指南,Hive 嵌入模式安装指南 Hive 是一个基于 Hadoop 的数据仓库工具,提供了 类似 SQL 的查询语言 HiveQL,能够快速地查询和分析大规模数据。Hive 安装指南将指导您完成 Hive 的安装和配置。 知识点 1: ...
从提供的文件内容中,我们可以提取到关于Hive安装与配置的相关知识点,同时也包括了MySQL的安装知识,因为MySQL是Hive常用的后端数据库。接下来,我将详细介绍这些知识点。 **Hive的安装与配置** 1. Hive是一个...
hive安装依赖以及启动脚本 文件包含如下: 01_mysql-community-common-5.7.29-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm 03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm 04_...
在本压缩包中,"文档.pdf" 和 "资料必看.zip" 可能包含了关于 Hive 安装与配置的详细步骤和指南。现在,我们将深入探讨 Hive 的安装与配置过程。 首先,安装 Hive 需要先确保你已经安装了 Hadoop 环境,因为 Hive ...
Hadoop之Hive安装 本篇文章将指导您如何在CentOS 6.4下安装Hive,并解决可能遇到的错误。 环境及软件介绍 本篇文章使用的环境是CentOS 6.4-x86_64-bin-DVD1.iso,软件版本为Hadoop 2.2.0和Hive 0.12.0,以及MySQL...
Hive安装讲义(linux_hive windows_mysql) Hive是基于Hadoop的数据仓库工具,用于存储、查询和分析大规模数据。为了实现Hive的安装和配置,需要满足一定的前提条件和环境要求。下面是Hive安装讲义的详细步骤和相关...
Hive安装讲义(linux_hive linux_mysql) Hive安装讲义中涵盖了Hive的安装过程,包括Hadoop和MySQL的安装。下面是从给定的文件中生成的相关知识点: 一、Hadoop 安装 * Hadoop 安装是Hive 运行环境的前提条件 * ...
cdh5.5.0下的hive的安装部署详细操作。hive的安装其实有两部分组成,一个是Server端、一个是客户端,所谓服务端其实就是Hive管理Meta的那个Hive,服务端可以装在任何节点上,当hive服务并发量不高时推荐部署在数据...
本压缩包“Hive安装配套资源.zip”提供了在Linux CentOS环境下安装Hive所需的关键组件,包括Hive安装包、MySQL连接器、环境配置文件以及Hive的配置文件。 首先,`apache-hive-3.1.2-bin.tar.gz`是Hive的安装包,...