
一、 安装环境介绍
这个实例要介绍的是web+mysql集群的构建,整个RHCS集群共有四台服务器组成,分别由两台主机搭建web集群,两台主机搭建mysql集群,在这种集群构架下,任何一台web服务器故障,都有另一台web服务器进行服务接管,同时,任何一台mysql服务器故障,也有另一台mysql服务器去接管服务,保证了整个应用系统服务的不间断运行。如下图所示:
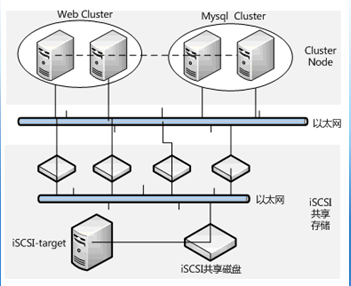
二、 安装前准备工作
Centos是RHEL的克隆版本,并且RHCS所有功能组件都免费提供,因此下面的讲述以Centos为准。
操作系统:统一采用Centos5.3版本。为了方便安装RHCS套件,在安装操作系统时,建议选择如下这些安装包:
? 桌面环境:xwindows system、GNOME desktop environment。
? 开发工具:development tools、x software development、gnome software development、kde software development。
地址规划如下:
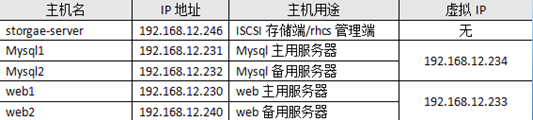
iSCSI-target的安装与使用已经在前面文章中做过介绍,不再讲述,这里假定共享的磁盘是/dev/sdb。
三、 安装Luci
Luci是RHCS基于web的集群配置管理工具,可以从系统光盘找到对应的Luci安装包,安装如下:
[root@storgae-server ~]#rpm -ivh luci-0.12.2-12.el5.centos.1.i386.rpm
安装完成,执行luci初始化操作:
[root@storgae-server ~]#luci_admin init
Initializing the Luci server
Creating the 'admin' user
Enter password:
Confirm password:
Please wait...
The admin password has been successfully set.
Generating SSL certificates...
Luci server has been successfully initialized
输入两次密码后,就创建了一个默认登录luci的用户admin。
最后,启动luci服务即可:
[root@storgae-server ~]# /etc/init.d/luci start
服务成功启动后,就可以通过https://ip:8084访问luci了。
为了能让luci访问集群其它节点,还需要在/etc/hosts增加如下内容:
192.168.12.231 Mysql1
192.168.12.232 Mysql2
192.168.12.230 web1
192.168.12.240 web2
到这里为止,在storgae-server主机上的设置完成。
四、在集群节点安装RHCS软件包
为了保证集群每个节点间可以互相通信,需要将每个节点的主机名信息加入/etc/hosts文件中,修改完成的/etc/hosts文件内容如下:
127.0.0.1 localhost
192.168.12.230 web1
192.168.12.240 web2
192.168.12.231 Mysql1
192.168.12.232 Mysql2
将此文件依次复制到集群每个节点的/etc/hosts文件中。
RHCS软件包的安装有两种方式,可以通过luci管理界面,在创建Cluster时,通过在线下载方式自动安装,也可以直接从操作系统光盘找到所需软件包进行手动安装,由于在线安装方式受网络和速度的影响,不建议采用,这里通过手动方式来安装RHCS软件包。
安装RHCS,主要安装的组件包有cman、gfs2和rgmanager,当然在安装这些软件包时可能需要其它依赖的系统包,只需按照提示进行安装即可 ,下面是一个安装清单,在集群的四个节点分别执行 :
#install cman
rpm -ivh perl-XML-NamespaceSupport-1.09-1.2.1.noarch.rpm
rpm -ivh perl-XML-SAX-0.14-8.noarch.rpm
rpm -ivh perl-XML-LibXML-Common-0.13-8.2.2.i386.rpm
rpm -ivh perl-XML-LibXML-1.58-6.i386.rpm
rpm -ivh perl-Net-Telnet-3.03-5.noarch.rpm
rpm -ivh pexpect-2.3-3.el5.noarch.rpm
rpm -ivh openais-0.80.6-16.el5_5.2.i386.rpm
rpm -ivh cman-2.0.115-34.el5.i386.rpm
#install ricci
rpm -ivh modcluster-0.12.1-2.el5.centos.i386.rpm
rpm -ivh ricci-0.12.2-12.el5.centos.1.i386.rpm
#install gfs2
rpm -ivh gfs2-utils-0.1.62-20.el5.i386.rpm
#install rgmanager
rpm -ivh rgmanager-2.0.52-6.el5.centos.i386.rpm
五、在集群节点安装配置iSCSI客户端
安装iSCSI客户端是为了和iSCSI-target服务端进行通信,进而将共享磁盘导入到各个集群节点,这里以集群节点web1为例,介绍如何安装和配置iSCSI,剩余其它节点的安装和配置方式与web1节点完全相同 。
iSCSI客户端的安装和配置非常简单,只需如下几个步骤即可完成:
[root@web1 rhcs]# rpm -ivh iscsi-initiator-utils-6.2.0.871-0.16.el5.i386.rpm
[root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# iscsiadm -m discovery -t sendtargets -p 192.168.12.246
[root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# fdisk -l
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
64 heads, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Disk /dev/sdb doesn't contain a valid partition table
通过fdisk的输出可知,/dev/sdb就是从iSCSI-target共享过来的磁盘分区。
至此,安装工作全部结束。
六、配置RHCS高可用集群
配置RHCS,其核心就是配置/etc/cluster/cluster.conf文件,下面通过web管理界面介绍如何构造一个cluster.conf文件。
在storgae-server主机上启动luci服务,然后通过浏览器访问https://192.168.12.246:8084/,就可以打开luci登录界面,如图1所示:
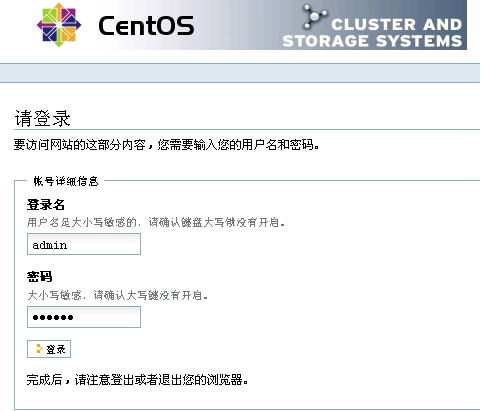
图1
成功登录后,luci有三个配置选项,分别是homebase、cluster和storage,其中,cluster主要用于创建和配置集群系统,storage用于创建和管理共享存储,而homebase主要用于添加、更新、删除cluster系统和storage设置,同时也可以创建和删除luci登录用户。如图2所示:
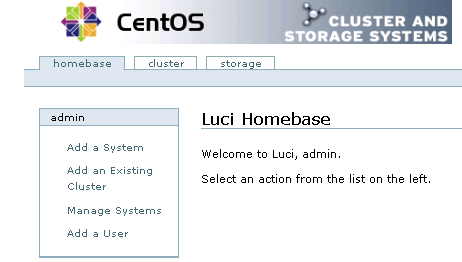
图2
1、创建一个cluster
登录luci后,切换到cluster选项,然后点击左边的clusters选框中的“Create a new cluster”,增加一个cluster,如图3所示:

图3
在图3中,创建的cluster名称为mycluster,“Node Hostname”表示每个节点的主机名称,“Root Password”表示每个节点的root用户密码。每个节点的root密码可以相同,也可以不同。
在下面的五个选项中,“Download packages”表示在线下载并自动安装RHCS软件包,而“Use locally installed packages”表示用本地安装包进行安装,由于RHCS组件包在上面的介绍中已经手动安装完成,所以这里选择本地安装即可。剩下的三个复选框分别是启用共享存储支持(Enable Shared Storage Support)、节点加入集群时重启系统(Reboot nodes before joining cluster)和检查节点密码的一致性(Check if node passwords are identical),这些创建cluster的设置,可选可不选,这里不做任何选择。
“View SSL cert fingerprints”用于验证集群各个节点与luci通信是否正常,并检测每个节点的配置是否可以创建集群,如果检测失败,会给出相应的错误提示信息。如果验证成功,会输出成功信息。
所有选项填写完成,点击“Submit”进行提交,接下来luci开始创建cluster,如图4所示:

图4
在经过Install----Reboot----Configure----Join四个过程后,如果没有报错,“mycluster”就创建完成了,其实创建cluster的过程,就是luci将设定的集群信息写入到每个集群节点配置文件的过程。Cluster创建成功后,默认显示“mycluster”的集群全局属性列表,点击cluster-->Cluster list来查看创建的mycluster的状态,如图5所示:

图5
从图5可知,mycluster集群下有四个节点,正常状态下,节点Nodes名称和Cluster Name均显示为绿色,如果出现异常,将显示为红色。
点击Nodes下面的任意一个节点名称,可以查看此节点的运行状态,如图6所示:

图6
从图6可以看出,cman和rgmanager服务运行在每个节点上,并且这两个服务需要开机自动启动,它们是RHCS的核心守护进程,如果这两个服务在某个节点没有启动,可以通过命令行方式手工启动,命令如下:
/etc/init.d/cman start
/etc/init.d/rgmanager start
服务启动成功后,在图6中点击“Update node daemon properties”按钮,更新节点的状态。
通过上面的操作,一个简单的cluster就创建完成了,但是这个cluster目前还是不能工作的,还需要为这个cluster创建Failover Domain、Resources、Service、Shared Fence Device等,下面依次进行介绍。
2、创建Failover Domain
Failover Domain是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间,下面的操作将创建两个失败转移域,分别是webserver-failover和mysql-failover。
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster栏中点击Failover Domains-->Add a Failover Domain,增加一个Failover Domain,如图7所示:
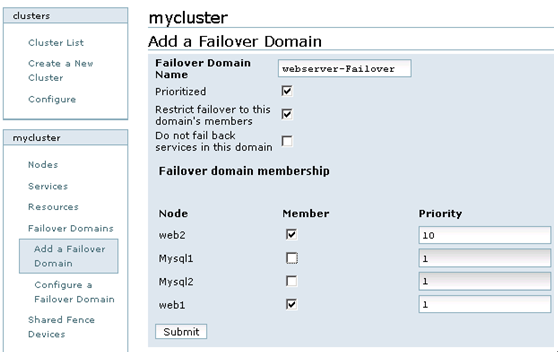
图7
在图7中,各个参数的含义如下:
? Failover domain name:创建的失败转移域名称,起一个易记的名字即可。
? Prioritized:是否在Failover domain 中启用域成员优先级设置,这里选择启用。
? Restrict Failover to this domain’s member:表示是否在失败转移域成员中启用服务故障切换限制。这里选择启用。
? Do not fail back services in this domain:表示在这个域中使用故障切回功能,也就是说,主节点故障时,备用节点会自动接管主节点服务和资源,当主节点恢复正常时,集群的服务和资源会从备用节点自动切换到主节点。
然后,在Failover domain membership的Member复选框中,选择加入此域的节点,这里选择的是web1和web2节点,然后,在“priority”处将web1的优先级设置为1,web2的优先级设置为10。需要说明的是“priority”设置为1的节点,优先级是最高的,随着数值的降低,节点优先级也依次降低。
所有设置完成,点击Submit按钮,开始创建Failover domain。
按照上面的介绍,继续添加第二个失败转移域mysql-failover,在Failover domain membership的Member复选框中,选择加入此域的节点,这里选择Mysql1和Mysql2节点,然后,在“priority”处将Mysql1的优先级设置为2,Mysql2的优先级设置为8。
3、创建Resources
Resources是集群的核心,主要包含服务脚本、IP地址、文件系统等,RHCS提供的资源如图8所示:
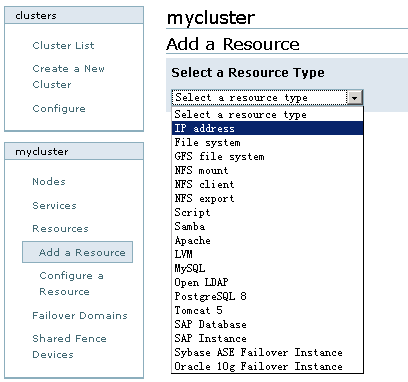
图8
依次添加IP资源、http服务资源、Mysql管理脚本资源、ext3文件系统,如图9所示:
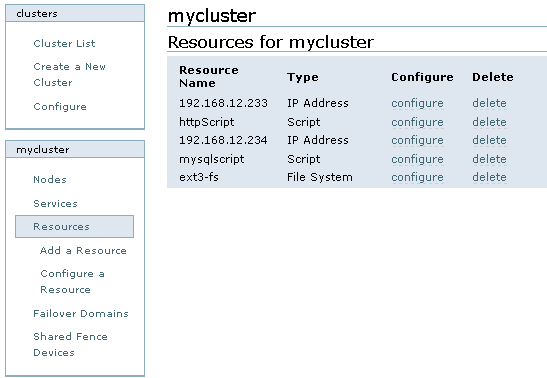
图9
4、创建Service
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster栏中点击Services-->Add a Service,在集群中添加一个服务,如图10所示:

图10
所有服务添加完成后,如果应用程序设置正确,服务将自动启动,点击cluster,然后在Cluster list中可以看到两个服务的启动状态,正常情况下,均显示为绿色。如图11所示:
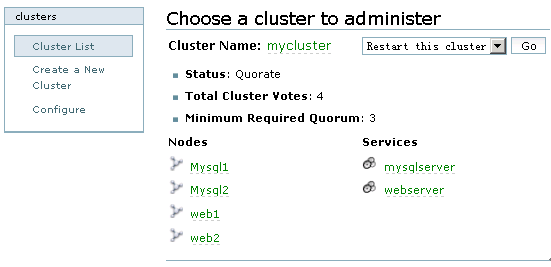
图11
七、配置存储集群GFS
在上面章节中,我们已经通过storgae-server主机将一个磁盘分区共享给了集群系统的四个节点,接下来将进行磁盘分区、格式化、创建文件系统等操作。
(1) 对磁盘进行分区
可以在集群系统任意节点对共享磁盘分区进行磁盘的分区和格式化,这里选择在节点web1上进行,首先对共享磁盘进行分区,操作如下:
[root@web1 ~]# fdisk /dev/sdb
这里将共享磁盘分为三个有效分区,分别将/dev/sdb5用于GFS文件系统,将/dev/sdb6用于ext3文件系统,而将/dev/sdb7用于表决磁盘,关于表决磁盘,下面马上会进行讲述。
(2) 格式化磁盘
接下来,在web1节点将磁盘分区分别格式化为ext3和gfs2文件系统,操作如下:
[root@web1 ~]# mkfs.ext3 /dev/sdb6
[root@web1 ~]# mkfs.gfs2 -p lock_dlm -t mycluster:my-gfs2 -j 4 /dev/sdb5
其中:
? -p lock_dlm
定义为DLM锁方式,如果不加此参数,当在两个系统中同时挂载此分区时就会像EXT3格式一样,两个系统的信息不能同步。
? -t mycluster:my-gfs2
指定DLM锁所在的表名称,mycluster就是RHCS集群的名称,必须与cluster.conf文件中Cluster标签的name值相同。
? -j 4
设定GFS2文件系统最多支持多少个节点同时挂载,这个值可以通gfs2_jadd命令在使用中动态调整。
? /dev/sdb5
指定要格式化的分区设备标识。
所有操作完成后,重启集群所有节点,保证划分的磁盘分区能够被所有节点识别。
(3)挂载磁盘
所有节点重新启动后,就可以挂载文件系统了,依次在集群的每个节点执行如下操作,将共享文件系统挂载到/gfs2目录下:
[root@web1 ~]#mount -t gfs2 /dev/sdb5 /gfs2 –v
/sbin/mount.gfs2: mount /dev/sdb5 /gfs2
/sbin/mount.gfs2: parse_opts: pts = "rw"
/sbin/mount.gfs2: clear flag 1 for "rw", flags = 0
/sbin/mount.gfs2: parse_opts: flags = 0
/sbin/mount.gfs2: write "join /gfs2 gfs2 lock_dlm mycluster:my-gfs2 rw /dev/sdb5"
//sbin/mount.gfs2: mount(2) ok
/sbin/mount.gfs2: lock_dlm_mount_result: write "mount_result /gfs2 gfs2 0"
/sbin/mount.gfs2: read_proc_mounts: device = "/dev/sdb5"
/sbin/mount.gfs2: read_proc_mounts: pts = "rw,hostdata=jid=3:id=65540:first=0“
通过“-v”参数可以输出挂载gfs2文件系统的过程,有助于理解gfs2文件系统和问题排查。
为了能让共享文件系统开机自动挂载磁盘,将下面内容添加到每个集群节点的/etc/fstab文件中。
#GFS MOUNT POINTS
/dev/sdb5 /gfs2 gfs2 defaults 1 1
八、配置表决磁盘
(1)使用表决磁盘的必要性
在一个多节点的RHCS集群系统中,一个节点失败后,集群的服务和资源可以自动转移到其它节点上,但是这种转移是有条件的,例如,在一个四节点的集群中,一旦有两个节点发生故障,整个集群系统将会挂起,集群服务也随即停止,而如果配置了存储集群GFS文件系统,那么只要有一个节点发生故障,所有节点挂载的GFS文件系统将hung住。此时共享存储将无法使用,这种情况的出现,对于高可用的集群系统来说是绝对不允许的,解决这种问题就要通过表决磁盘来实现了。
(2)表决磁盘运行机制
表决磁盘,即Quorum Disk,在RHCS里简称qdisk,是基于磁盘的Cluster仲裁服务程序,为了解决小规模集群中投票问题,RHCS引入了Quorum机制机制,Quorum表示集群法定的节点数,和Quorum对应的是Quorate,Quorate是一种状态,表示达到法定节点数。在正常状态下,Quorum的值是每个节点投票值再加上 QDisk分区的投票值之和。
QDisk是一个小于10MB的共享磁盘分区,Qdiskd进程运行在集群的所有节点上,通过Qdiskd进程,集群节点定期评估自身的健康情况,并且把自身的状态信息写到指定的共享磁盘分区中,同时Qdiskd还可以查看其它节点的状态信息,并传递信息给其它节点。
(3)RHCS中表决磁盘的概念
和qdisk相关的几个工具有mkdisk、Heuristics。
mkdisk是一个集群仲裁磁盘工具集,可以用来创建一个qdisk共享磁盘也可以查看共享磁盘的状态信息。mkqdisk操作只能创建16个节点的投票空间,因此目前qdisk最多可以支持16个节点的RHCS高可用集群。
有时候仅靠检测Qdisk分区来判断节点状态还是不够的,还可以通过应用程序来扩展对节点状态检测的精度,Heuristics就是这么一个扩充选项,它允许通过第三方应用程序来辅助定位节点状态,常用的有ping网关或路由,或者通过脚本程序等,如果试探失败,qdiskd会认为此节点失败,进而试图重启此节点,以使节点进入正常状态。
(4)创建一个表决磁盘
在上面章节中,已经划分了多个共享磁盘分区,这里将共享磁盘分区/dev/sdb7作为qdisk分区,下面是创建一个qdisk分区:
[root@web1 ~]# mkqdisk -c /dev/sdb7 -l myqdisk
[root@web1 ~]# mkqdisk –L #查看表决磁盘信息
(5)配置Qdisk
这里通过Conga的web界面来配置Qdisk,首先登录luci,然后点击cluster,在Cluster list中点击“mycluster”,然后选择“Quorum Partition”一项,如图12所示:
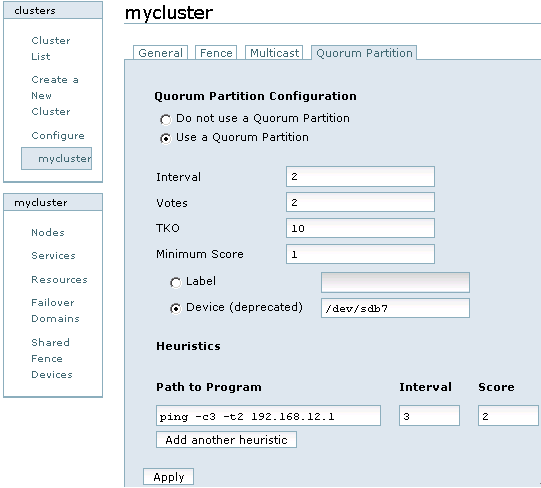
图12
对图12中每个选项的含义解释如下:
? Interval:表示间隔多长时间执行一次检查评估,单位是秒。
? Votes:指定qdisk分区投票值是多少。
? TKO:表示允许检查失败的次数。一个节点在TKO*Interval时间内如果还连接不上qdisk分区,那么就认为此节点失败,会从集群中隔离。
? Minimum Score:指定最小投票值是多少。
? Label:Qdisk分区对应的卷标名,也就是在创建qdisk时指定的“myqdisk”,这里建议用卷标名,因为设备名有可能会在系统重启后发生变化,但卷标名称是不会发生改变的。
? Device:指定共享存储在节点中的设备名是什么。
? Path to program: 配置第三方应用程序来扩展对节点状态检测的精度,这里配置的是ping命令
? Score:设定ping命令的投票值。
? interval:设定多长时间执行ping命令一次。
(6)启动Qdisk服务
在集群每个节点执行如下命令,启动qdiskd服务:
[root@web1 ~]# /etc/init.d/qdiskd start
qdiskd启动后,如果配置正确,qdisk磁盘将自动进入online状态:
[root@web1 ~]# clustat -l
Cluster Status for mycluster @ Sat Aug 21 01:25:40 2010
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
Web 1 Online, rgmanager
Mysql1 2 Online, rgmanager
Mysql2 3 Online, rgmanager
web1 4 Online, Local, rgmanager
/dev/sdb7 0 Online, Quorum Disk
至此,Qdisk已经运行起来了。
九、配置Fence设备
配置Fence设备 是RHCS集群系统中必不可少的一个环节,通过Fence设备可以防止集群资源(例如文件系统)同时被多个节点占有,保护了共享数据的安全性和一致性节,同时也可以防止节点间脑裂的发生。
GFS是基于集群底层架构来传递锁信息的,或者说是基于RHCS的一种集群文件系统,因此使用GFS文件系统也必须要有fence设备。
RHCS提供的fence device有两种,一种是内部fence设备。常见的有:
IBM服务器提供的RSAII卡
HP服务器提供的iLO卡
DELL服务器提供的DRAC卡
智能平台管理接口IPMI
常见的外部fence设备有:UPS、SAN SWITCH、NETWORK SWITCH,另外如果共享存储是通过GNBD Server实现的,那么还可以使用GNBD的fence功能。
点击cluster,然后点击“cluster list”中的“mycluster”,在左下角的mycluster栏目中选择Shared Fence Devices-->Add a Sharable Fence Device,在这里选择的Fence Device为“WTI Power Switch”,Fence的名称为“WTI-Fence”,然后依次输入IP Address和Password,如图13所示:
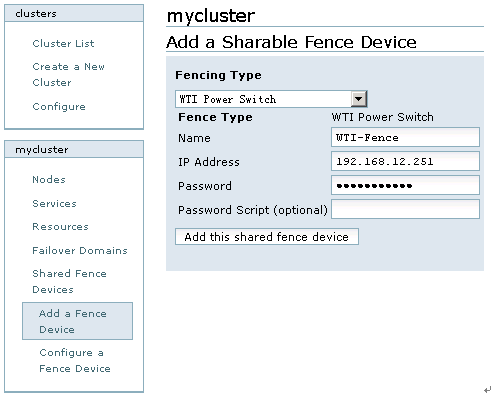
图13
至此,基于web界面的RHCS配置完成。



相关推荐
由国内著名技术社区联合推荐的2012年IT技术力作:《高性能Linux服务器构建实战:运维监控、性能调优与集群应用》,即将上架发行,此书从Web应用、数据备份与恢复、网络存储应用、运维监控与性能优化、集群高级应用等...
书中内容以实战为导向,所有内容均来自于笔者多年实践经验的总结和对新知识的拓展,同时也针对运维人员、dba等相关工作者会遇到的有代表性的疑难问题给出了实用的情景模拟,并给出了解决方案。不论你目前有没有遇到...
毕业设计选题 -未来生鲜运输车设计.pptx
内容概要:本文详细探讨了基于樽海鞘算法(SSA)优化的极限学习机(ELM)在回归预测任务中的应用,并与传统的BP神经网络、广义回归神经网络(GRNN)以及未优化的ELM进行了性能对比。首先介绍了ELM的基本原理,即通过随机生成输入层与隐藏层之间的连接权重及阈值,仅需计算输出权重即可快速完成训练。接着阐述了SSA的工作机制,利用樽海鞘群体觅食行为优化ELM的输入权重和隐藏层阈值,从而提高模型性能。随后分别给出了BP、GRNN、ELM和SSA-ELM的具体实现代码,并通过波士顿房价数据集和其他工业数据集验证了各模型的表现。结果显示,SSA-ELM在预测精度方面显著优于其他三种方法,尽管其训练时间较长,但在实际应用中仍具有明显优势。 适合人群:对机器学习尤其是回归预测感兴趣的科研人员和技术开发者,特别是那些希望深入了解ELM及其优化方法的人。 使用场景及目标:适用于需要高效、高精度回归预测的应用场景,如金融建模、工业数据分析等。主要目标是提供一种更为有效的回归预测解决方案,尤其是在处理大规模数据集时能够保持较高的预测精度。 其他说明:文中提供了详细的代码示例和性能对比图表,帮助读者更好地理解和复现实验结果。同时提醒使用者注意SSA参数的选择对模型性能的影响,建议进行参数敏感性分析以获得最佳效果。
2025年中国生成式AI大会PPT(4-1)
内容概要:本文详细介绍了基于Simulink平台构建无刷直流电机(BLDC)双闭环调速系统的全过程。首先阐述了双闭环控制系统的基本架构,即外层速度环和内层电流环的工作原理及其相互关系。接着深入探讨了PWM生成模块的设计,特别是占空比计算方法的选择以及三角波频率的设定。文中还提供了详细的电机参数设置指导,如转动惯量、电感、电阻等,并强调了参数选择对系统性能的影响。此外,针对PI控制器的参数整定给出了具体的公式和经验值,同时分享了一些实用的调试技巧,如避免转速超调、处理启动抖动等问题的方法。最后,通过仿真实验展示了系统的稳定性和鲁棒性,验证了所提出方法的有效性。 适用人群:从事电机控制研究的技术人员、自动化工程领域的研究生及科研工作者。 使用场景及目标:适用于需要深入了解和掌握无刷直流电机双闭环调速系统设计与优化的人群。主要目标是帮助读者学会利用Simulink进行BLDC电机控制系统的建模、仿真和参数优化,从而提高系统的稳定性和响应速度。 其他说明:文章不仅提供了理论知识,还包括了许多实践经验和技术细节,有助于读者更好地理解和应用相关技术。
内容概要:本文详细介绍了西门子S7-1200 PLC与施耐德ATV310/312变频器通过Modbus RTU进行通讯的具体实现步骤和调试技巧。主要内容涵盖硬件接线、通讯参数配置、控制启停、设定频率、读取运行参数的方法以及常见的调试问题及其解决方案。文中提供了具体的代码示例,帮助读者理解和实施通讯程序。此外,还强调了注意事项,如地址偏移量、数据格式转换和超时匹配等。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是那些需要将西门子PLC与施耐德变频器进行集成的工作人员。 使用场景及目标:适用于需要通过Modbus RTU协议实现PLC与变频器通讯的工程项目。目标是确保通讯稳定可靠,掌握解决常见问题的方法,提高调试效率。 其他说明:文中提到的实际案例和调试经验有助于读者避免常见错误,快速定位并解决问题。建议读者在实践中结合提供的代码示例和调试工具进行操作。
内容概要:本文详细介绍了如何使用Verilog在FPGA上实现IIC(Inter-Integrated Circuit)主从机驱动。主要内容包括从机和主机的设计,特别是状态机的实现、寄存器读取、时钟分频策略、SDA线的三态控制等关键技术。文中还提供了详细的代码片段,展示了从机地址匹配逻辑、主机时钟生成逻辑、顶层模块的连接方法以及仿真实验的具体步骤。此外,文章讨论了一些常见的调试问题,如总线竞争、时序不匹配等,并给出了相应的解决方案。 适合人群:具备一定FPGA开发基础的技术人员,尤其是对IIC协议感兴趣的嵌入式系统开发者。 使用场景及目标:适用于需要在FPGA平台上实现高效、可靠的IIC通信的应用场景。主要目标是帮助读者掌握IIC协议的工作原理,能够独立完成IIC主从机系统的开发和调试。 其他说明:文章不仅提供了理论讲解,还包括了大量的实战经验和代码实例,有助于读者更好地理解和应用所学知识。同时,文章还提供了一个思考题,引导读者进一步探索多主设备仲裁机制的设计思路。
内容概要:本文介绍了一款基于C#开发的拖拽式Halcon可视化抓边、抓圆控件,旨在简化机器视觉项目中的测量任务。该控件通过拖拽操作即可快速生成测量区域,自动完成边缘坐标提取,并提供实时反馈。文中详细描述了控件的工作原理和技术细节,如坐标系转换、卡尺生成、边缘检测算法封装以及动态参数调试等功能。此外,还讨论了一些常见问题及其解决方案,如坐标系差异、内存管理等。 适合人群:从事机器视觉开发的技术人员,尤其是熟悉C#和Halcon的开发者。 使用场景及目标:适用于需要频繁进行边缘和圆形特征测量的工业自动化项目,能够显著提高测量效率并减少编码工作量。主要目标是将复杂的测量任务转化为简单的拖拽操作,使非专业人员也能轻松完成测量配置。 其他说明:该控件已开源发布在GitHub上,提供了完整的源代码和详细的使用指南。未来计划扩展更多高级功能,如自动路径规划和亚像素级齿轮齿距检测等。
内容概要:本文详细介绍了西门子200Smart PLC与维纶触摸屏在某疫苗车间控制系统的具体应用,涵盖配液、发酵、纯化及CIP清洗四个主要工艺环节。文中不仅展示了具体的编程代码和技术细节,还分享了许多实战经验和调试技巧。例如,在配液罐中,通过模拟量处理确保温度和液位的精确控制;发酵罐部分,着重讨论了PID参数整定和USS通讯控制变频器的方法;纯化过程中,强调了双PID串级控制的应用;CIP清洗环节,则涉及复杂的定时器逻辑和阀门联锁机制。此外,文章还提到了一些常见的陷阱及其解决方案,如通讯干扰、状态机切换等问题。 适合人群:具有一定PLC编程基础的技术人员,尤其是从事工业自动化领域的工程师。 使用场景及目标:适用于需要深入了解PLC与触摸屏集成控制系统的工程师,帮助他们在实际项目中更好地理解和应用相关技术和方法,提高系统的稳定性和可靠性。 其他说明:文章提供了大量实战经验和代码片段,有助于读者快速掌握关键技术点,并避免常见错误。同时,文中提到的一些优化措施和调试技巧对提升系统性能非常有帮助。
计算机网络课程的结课设计是使用思科模拟器搭建一个中小型校园网,当时花了几天时间查阅相关博客总算是做出来了,现在免费上传CSDN,希望小伙伴们能给博客一套三连支持
《芋道开发指南文档-2023-10-27更新》是针对软件开发者和IT专业人士的一份详尽的资源集合,旨在提供最新的开发实践、范例代码和最佳策略。这份2023年10月27日更新的文档集,包含了丰富的模板和素材,帮助开发者在日常工作中提高效率,保证项目的顺利进行。 让我们深入探讨这份文档的可能内容。"芋道"可能是一个开源项目或一个专业的技术社区,其开发指南涵盖了多个方面,例如: 1. **编程语言指南**:可能包括Java、Python、JavaScript、C++等主流语言的编码规范、最佳实践以及常见问题的解决方案。 2. **框架与库的应用**:可能会讲解React、Vue、Angular等前端框架,以及Django、Spring Boot等后端框架的使用技巧和常见应用场景。 3. **数据库管理**:涵盖了SQL语言的基本操作,数据库设计原则,以及如何高效使用MySQL、PostgreSQL、MongoDB等数据库系统。 4. **版本控制**:详细介绍了Git的工作流程,分支管理策略,以及与其他开发工具(如Visual Studio Code、IntelliJ IDEA)的集成。 5. **持续集成与持续部署(CI/CD)**:包括Jenkins、Travis CI、GitHub Actions等工具的配置和使用,以实现自动化测试和部署。 6. **云服务与容器化**:可能涉及AWS、Azure、Google Cloud Platform等云计算平台的使用,以及Docker和Kubernetes的容器化部署实践。 7. **API设计与测试**:讲解RESTful API的设计原则,Swagger的使用,以及Postman等工具进行API测试的方法。 8. **安全性与隐私保护**:涵盖OAuth、JWT认证机制,HTTPS安全通信,以及防止SQL注入、
内容概要:本文介绍了一种先进的综合能源系统优化调度模型,该模型将风电、光伏、光热发电等新能源与燃气轮机、燃气锅炉等传统能源设备相结合,利用信息间隙决策(IGDT)处理不确定性。模型中引入了P2G(电转气)装置和碳捕集技术,实现了碳经济闭环。通过多能转换和储能系统的协同调度,提高了系统的灵活性和鲁棒性。文中详细介绍了模型的关键组件和技术实现,包括IGDT的鲁棒性参数设置、P2G与碳捕集的协同控制、储能系统的三维协同调度等。此外,模型展示了在极端天气和负荷波动下的优异表现,显著降低了碳排放成本并提高了能源利用效率。 适合人群:从事能源系统优化、电力调度、碳交易等相关领域的研究人员和工程师。 使用场景及目标:适用于需要处理多种能源形式和不确定性的综合能源系统调度场景。主要目标是提高系统的灵活性、鲁棒性和经济效益,减少碳排放。 其他说明:模型具有良好的扩展性,可以通过修改配置文件轻松集成新的能源设备。代码中包含了详细的注释和公式推导,便于理解和进一步改进。
毕业设计的论文撰写、终期答辩相关的资源
该是一个在 Kaggle 上发布的数据集,专注于 2024 年出现的漏洞(CVE)信息。以下是关于该数据集的详细介绍:该数据集收集了 2024 年记录在案的各类漏洞信息,涵盖了漏洞的利用方式(Exploits)、通用漏洞评分系统(CVSS)评分以及受影响的操作系统(OS)。通过整合这些信息,研究人员和安全专家可以全面了解每个漏洞的潜在威胁、影响范围以及可能的攻击途径。数据主要来源于权威的漏洞信息平台,如美国国家漏洞数据库(NVD)等。这些数据经过整理和筛选后被纳入数据集,确保了信息的准确性和可靠性。数据集特点:全面性:涵盖了多种操作系统(如 Windows、Linux、Android 等)的漏洞信息,反映了不同平台的安全状况。实用性:CVSS 评分提供了漏洞严重程度的量化指标,帮助用户快速评估漏洞的优先级。同时,漏洞利用信息(Exploits)为安全研究人员提供了攻击者可能的攻击手段,有助于提前制定防御策略。时效性:专注于 2024 年的漏洞数据,反映了当前网络安全领域面临的新挑战和新趋势。该数据集可用于多种研究和实践场景: 安全研究:研究人员可以利用该数据集分析漏洞的分布规律、攻击趋势以及不同操作系统之间的安全差异,为网络安全防护提供理论支持。 机器学习与数据分析:数据集中的结构化信息适合用于机器学习模型的训练,例如预测漏洞的 CVSS 评分、识别潜在的高危漏洞等。 企业安全评估:企业安全团队可以参考该数据集中的漏洞信息,结合自身系统的实际情况,进行安全评估和漏洞修复计划的制定。
内容概要:本文档作为建模大赛的入门指南,详细介绍了建模大赛的概念、类型、竞赛流程、核心步骤与技巧,并提供实战案例解析。文档首先概述了建模大赛,指出其以数学、计算机技术为核心,主要分为数学建模、3D建模和AI大模型竞赛三类。接着深入解析了数学建模竞赛,涵盖组队策略(如三人分别负责建模、编程、论文写作)、时间安排(72小时内完成全流程)以及问题分析、模型建立、编程实现和论文撰写的要点。文中还提供了物流路径优化的实战案例,展示了如何将实际问题转化为图论问题并采用Dijkstra或蚁群算法求解。最后,文档推荐了不同类型建模的学习资源与工具,并给出了新手避坑建议,如避免过度复杂化模型、重视可视化呈现等。; 适合人群:对建模大赛感兴趣的初学者,特别是高校学生及希望参与数学建模竞赛的新手。; 使用场景及目标:①了解建模大赛的基本概念和分类;②掌握数学建模竞赛的具体流程与分工;③学习如何将实际问题转化为数学模型并求解;④获取实战经验和常见错误规避方法。; 其他说明:文档不仅提供了理论知识,还结合具体实例和代码片段帮助读者更好地理解和实践建模过程。建议新手从中小型赛事开始积累经验,逐步提升技能水平。
该资源为protobuf-6.30.1-cp310-abi3-win32.whl,欢迎下载使用哦!
内容概要:本文档详细介绍了基于Linux系统的大数据环境搭建流程,涵盖从虚拟机创建到集群建立的全过程。首先,通过一系列步骤创建并配置虚拟机,包括设置IP地址、安装MySQL数据库等操作。接着,重点讲解了Ambari的安装与配置,涉及关闭防火墙、设置免密登录、安装时间同步服务(ntp)、HTTP服务以及配置YUM源等关键环节。最后,完成了Ambari数据库的创建、JDK的安装、Ambari server和agent的部署,并指导用户创建集群。整个过程中还提供了针对可能出现的问题及其解决方案,确保各组件顺利安装与配置。 适合人群:具有Linux基础操作技能的数据工程师或运维人员,尤其是那些需要构建和管理大数据平台的专业人士。 使用场景及目标:适用于希望快速搭建稳定可靠的大数据平台的企业或个人开发者。通过本指南可以掌握如何利用Ambari工具自动化部署Hadoop生态系统中的各个组件,从而提高工作效率,降低维护成本。 其他说明:文档中包含了大量具体的命令行指令和配置细节,建议读者按照顺序逐步操作,并注意记录下重要的参数值以便后续参考。此外,在遇到问题时可参照提供的解决方案进行排查,必要时查阅官方文档获取更多信息。
内容概要:本文详细介绍了如何在MATLAB R2018A中使用最小均方(LMS)自适应滤波算法对一维时间序列信号进行降噪处理,特别是针对心电图(ECG)信号的应用。首先,通过生成模拟的ECG信号并加入随机噪声,创建了一个带有噪声的时间序列。然后,实现了LMS算法的核心部分,包括滤波器阶数、步长参数的选择以及权重更新规则的设计。文中还提供了详细的代码示例,展示了如何构建和训练自适应滤波器,并通过图形化方式比较了原始信号、加噪信号与经过LMS处理后的降噪信号之间的差异。此外,作者分享了一些实用的经验和技术要点,如参数选择的影响、误差曲线的解读等。 适用人群:适用于具有一定MATLAB编程基础并对信号处理感兴趣的科研人员、工程师或学生。 使用场景及目标:本教程旨在帮助读者掌握LMS算法的基本原理及其在实际项目中的应用方法,特别是在生物医学工程、机械故障诊断等领域中处理含噪信号的任务。同时,也为进一步探索其他类型的自适应滤波技术和扩展到不同的信号处理任务奠定了基础。 其他说明:尽管LMS算法在处理平稳噪声方面表现出色,但在面对突发性的强干扰时仍存在一定局限性。因此,在某些特殊场合下,可能需要与其他滤波技术相结合以获得更好的效果。
内容概要:本文详细介绍了基于TMS320F2812 DSP芯片的光伏并网逆变器设计方案,涵盖了主电路架构、控制算法、锁相环实现、环流抑制等多个关键技术点。首先,文中阐述了双级式结构的主电路设计,前级Boost升压将光伏板输出电压提升至约600V,后级采用三电平NPC拓扑的IGBT桥进行逆变。接着,深入探讨了核心控制算法,如电流PI调节器、锁相环(SOFGI)、环流抑制等,并提供了详细的MATLAB仿真模型和DSP代码实现。此外,还特别强调了PWM死区时间配置、ADC采样时序等问题的实际解决方案。最终,通过实验验证,该方案实现了THD小于3%,MPPT效率达98.7%,并有效降低了并联环流。 适合人群:从事光伏并网逆变器开发的电力电子工程师和技术研究人员。 使用场景及目标:适用于光伏并网逆变器的研发阶段,帮助工程师理解和实现高效稳定的逆变器控制系统,提高系统的性能指标,减少开发过程中常见的错误。 其他说明:文中提供的MATLAB仿真模型和DSP代码可以作为实际项目开发的重要参考资料,有助于缩短开发周期,提高成功率。