
Distributed RPC
The idea behind distributed RPC (DRPC) is to parallelize the computation of really intense functions on the fly using Storm. The Storm topology takes in as input a stream of function arguments, and it emits an output stream of the results for each of those function calls.
DRPC is not so much a feature of Storm as it is a pattern expressed from Storm's primitives of streams, spouts, bolts, and topologies. DRPC could have been packaged as a separate library from Storm, but it's so useful that it's bundled with Storm.
High level overview
Distributed RPC is coordinated by a "DRPC server" (Storm comes packaged with an implementation of this). The DRPC server coordinates receiving an RPC request, sending the request to the Storm topology, receiving the results from the Storm topology, and sending the results back to the waiting client. From a client's perspective, a distributed RPC call looks just like a regular RPC call. For example, here's how a client would compute the results for the "reach" function with the argument "http://twitter.com":
DRPCClient client = new DRPCClient("drpc-host", 3772);
String result = client.execute("reach", "http://twitter.com");
The distributed RPC workflow looks like this:
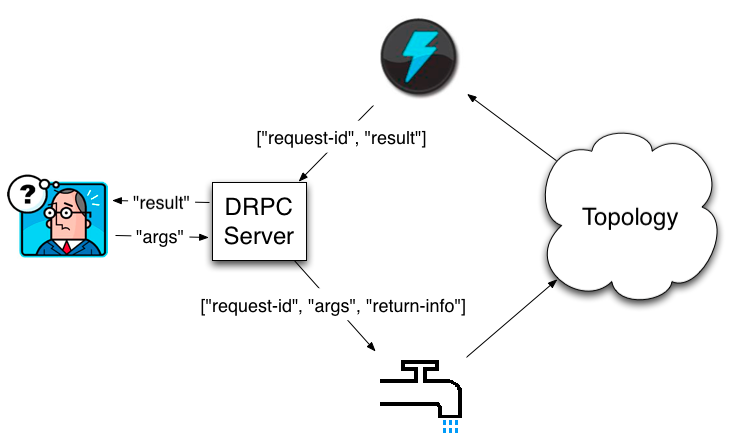
A client sends the DRPC server the name of the function to execute and the arguments to that function. The topology implementing that function uses a DRPCSpout to receive a function invocation stream from the DRPC server. Each function invocation is tagged with a unique id by the DRPC server. The topology then computes the result and at the end of the topology a bolt called ReturnResults connects to the DRPC server and gives it the result for the function invocation id. The DRPC server then uses the id to match up that result with which client is waiting, unblocks the waiting client, and sends it the result.
LinearDRPCTopologyBuilder
Storm comes with a topology builder called LinearDRPCTopologyBuilder that automates almost all the steps involved for doing DRPC. These include:
- Setting up the spout
- Returning the results to the DRPC server
- Providing functionality to bolts for doing finite aggregations over groups of tuples
Let's look at a simple example. Here's the implementation of a DRPC topology that returns its input argument with a "!" appended:
public static class ExclaimBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
// ...
}
As you can see, there's very little to it. When creating the LinearDRPCTopologyBuilder, you tell it the name of the DRPC function for the topology. A single DRPC server can coordinate many functions, and the function name distinguishes the functions from one another. The first bolt you declare will take in as input 2-tuples, where the first field is the request id and the second field is the arguments for that request.LinearDRPCTopologyBuilder expects the last bolt to emit an output stream containing 2-tuples of the form [id, result]. Finally, all intermediate tuples must contain the request id as the first field.
In this example, ExclaimBolt simply appends a "!" to the second field of the tuple. LinearDRPCTopologyBuilder handles the rest of the coordination of connecting to the DRPC server and sending results back.
Local mode DRPC
DRPC can be run in local mode. Here's how to run the above example in local mode:
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
System.out.println("Results for 'hello':" + drpc.execute("exclamation", "hello"));
cluster.shutdown();
drpc.shutdown();
First you create a LocalDRPC object. This object simulates a DRPC server in process, just like how LocalCluster simulates a Storm cluster in process. Then you create the LocalCluster to run the topology in local mode. LinearDRPCTopologyBuilder has separate methods for creating local topologies and remote topologies. In local mode the LocalDRPC object does not bind to any ports so the topology needs to know about the object to communicate with it. This is why createLocalTopology takes in the LocalDRPC object as input.
After launching the topology, you can do DRPC invocations using the execute method on LocalDRPC.
Remote mode DRPC
Using DRPC on an actual cluster is also straightforward. There's three steps:
- Launch DRPC server(s)
- Configure the locations of the DRPC servers
- Submit DRPC topologies to Storm cluster
Launching a DRPC server can be done with the storm script and is just like launching Nimbus or the UI:
bin/storm drpc
Next, you need to configure your Storm cluster to know the locations of the DRPC server(s). This is how DRPCSpout knows from where to read function invocations. This can be done through the storm.yaml file or the topology configurations. Configuring this through thestorm.yaml looks something like this:
drpc.servers:
- "drpc1.foo.com"
- "drpc2.foo.com"
Finally, you launch DRPC topologies using StormSubmitter just like you launch any other topology. To run the above example in remote mode, you do something like this:
StormSubmitter.submitTopology("exclamation-drpc", conf, builder.createRemoteTopology());
createRemoteTopology is used to create topologies suitable for Storm clusters.
A more complex example
The exclamation DRPC example was a toy example for illustrating the concepts of DRPC. Let's look at a more complex example which really needs the parallelism a Storm cluster provides for computing the DRPC function. The example we'll look at is computing the reach of a URL on Twitter.
The reach of a URL is the number of unique people exposed to a URL on Twitter. To compute reach, you need to:
- Get all the people who tweeted the URL
- Get all the followers of all those people
- Unique the set of followers
- Count the unique set of followers
A single reach computation can involve thousands of database calls and tens of millions of follower records during the computation. It's a really, really intense computation. As you're about to see, implementing this function on top of Storm is dead simple. On a single machine, reach can take minutes to compute; on a Storm cluster, you can compute reach for even the hardest URLs in a couple seconds.
A sample reach topology is defined in storm-starter here. Here's how you define the reach topology:
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 3);
builder.addBolt(new GetFollowers(), 12)
.shuffleGrouping();
builder.addBolt(new PartialUniquer(), 6)
.fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new CountAggregator(), 2)
.fieldsGrouping(new Fields("id"));
The topology executes as four steps:
-
GetTweetersgets the users who tweeted the URL. It transforms an input stream of[id, url]into an output stream of[id, tweeter]. Eachurltuple will map to manytweetertuples. -
GetFollowersgets the followers for the tweeters. It transforms an input stream of[id, tweeter]into an output stream of[id, follower]. Across all the tasks, there may of course be duplication of follower tuples when someone follows multiple people who tweeted the same URL. -
PartialUniquergroups the followers stream by the follower id. This has the effect of the same follower going to the same task. So each task ofPartialUniquerwill receive mutually independent sets of followers. OncePartialUniquerreceives all the follower tuples directed at it for the request id, it emits the unique count of its subset of followers. - Finally,
CountAggregatorreceives the partial counts from each of thePartialUniquertasks and sums them up to complete the reach computation.
Let's take a look at the PartialUniquer bolt:
public class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
Set<String> _followers = new HashSet<String>();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
PartialUniquer implements IBatchBolt by extending BaseBatchBolt. A batch bolt provides a first class API to processing a batch of tuples as a concrete unit. A new instance of the batch bolt is created for each request id, and Storm takes care of cleaning up the instances when appropriate.
When PartialUniquer receives a follower tuple in the execute method, it adds it to the set for the request id in an internal HashSet.
Batch bolts provide the finishBatch method which is called after all the tuples for this batch targeted at this task have been processed. In the callback, PartialUniquer emits a single tuple containing the unique count for its subset of follower ids.
Under the hood, CoordinatedBolt is used to detect when a given bolt has received all of the tuples for any given request id.CoordinatedBolt makes use of direct streams to manage this coordination.
The rest of the topology should be self-explanatory. As you can see, every single step of the reach computation is done in parallel, and defining the DRPC topology was extremely simple.
Non-linear DRPC topologies
LinearDRPCTopologyBuilder only handles "linear" DRPC topologies, where the computation is expressed as a sequence of steps (like reach). It's not hard to imagine functions that would require a more complicated topology with branching and merging of the bolts. For now, to do this you'll need to drop down into using CoordinatedBolt directly. Be sure to talk about your use case for non-linear DRPC topologies on the mailing list to inform the construction of more general abstractions for DRPC topologies.
How LinearDRPCTopologyBuilder works
- DRPCSpout emits [args, return-info]. return-info is the host and port of the DRPC server as well as the id generated by the DRPC server
- constructs a topology comprising of:
- DRPCSpout
- PrepareRequest (generates a request id and creates a stream for the return info and a stream for the args)
- CoordinatedBolt wrappers and direct groupings
- JoinResult (joins the result with the return info)
- ReturnResult (connects to the DRPC server and returns the result)
- LinearDRPCTopologyBuilder is a good example of a higher level abstraction built on top of Storm's primitives
Advanced
- KeyedFairBolt for weaving the processing of multiple requests at the same time
- How to use
CoordinatedBoltdirectly
Distributed RPC
The idea behind distributed RPC (DRPC) is to parallelize the computation of really intense functions on the fly using Storm. The Storm topology takes in as input a stream of function arguments, and it emits an output stream of the results for each of those function calls.
DRPC is not so much a feature of Storm as it is a pattern expressed from Storm's primitives of streams, spouts, bolts, and topologies. DRPC could have been packaged as a separate library from Storm, but it's so useful that it's bundled with Storm.
High level overview
Distributed RPC is coordinated by a "DRPC server" (Storm comes packaged with an implementation of this). The DRPC server coordinates receiving an RPC request, sending the request to the Storm topology, receiving the results from the Storm topology, and sending the results back to the waiting client. From a client's perspective, a distributed RPC call looks just like a regular RPC call. For example, here's how a client would compute the results for the "reach" function with the argument "http://twitter.com":
DRPCClient client = new DRPCClient("drpc-host", 3772);
String result = client.execute("reach", "http://twitter.com");
The distributed RPC workflow looks like this:
A client sends the DRPC server the name of the function to execute and the arguments to that function. The topology implementing that function uses a DRPCSpout to receive a function invocation stream from the DRPC server. Each function invocation is tagged with a unique id by the DRPC server. The topology then computes the result and at the end of the topology a bolt called ReturnResults connects to the DRPC server and gives it the result for the function invocation id. The DRPC server then uses the id to match up that result with which client is waiting, unblocks the waiting client, and sends it the result.
LinearDRPCTopologyBuilder
Storm comes with a topology builder called LinearDRPCTopologyBuilder that automates almost all the steps involved for doing DRPC. These include:
- Setting up the spout
- Returning the results to the DRPC server
- Providing functionality to bolts for doing finite aggregations over groups of tuples
Let's look at a simple example. Here's the implementation of a DRPC topology that returns its input argument with a "!" appended:
public static class ExclaimBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
// ...
}
As you can see, there's very little to it. When creating the LinearDRPCTopologyBuilder, you tell it the name of the DRPC function for the topology. A single DRPC server can coordinate many functions, and the function name distinguishes the functions from one another. The first bolt you declare will take in as input 2-tuples, where the first field is the request id and the second field is the arguments for that request.LinearDRPCTopologyBuilder expects the last bolt to emit an output stream containing 2-tuples of the form [id, result]. Finally, all intermediate tuples must contain the request id as the first field.
In this example, ExclaimBolt simply appends a "!" to the second field of the tuple. LinearDRPCTopologyBuilder handles the rest of the coordination of connecting to the DRPC server and sending results back.
Local mode DRPC
DRPC can be run in local mode. Here's how to run the above example in local mode:
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
System.out.println("Results for 'hello':" + drpc.execute("exclamation", "hello"));
cluster.shutdown();
drpc.shutdown();
First you create a LocalDRPC object. This object simulates a DRPC server in process, just like how LocalCluster simulates a Storm cluster in process. Then you create the LocalCluster to run the topology in local mode. LinearDRPCTopologyBuilder has separate methods for creating local topologies and remote topologies. In local mode the LocalDRPC object does not bind to any ports so the topology needs to know about the object to communicate with it. This is why createLocalTopology takes in the LocalDRPC object as input.
After launching the topology, you can do DRPC invocations using the execute method on LocalDRPC.
Remote mode DRPC
Using DRPC on an actual cluster is also straightforward. There's three steps:
- Launch DRPC server(s)
- Configure the locations of the DRPC servers
- Submit DRPC topologies to Storm cluster
Launching a DRPC server can be done with the storm script and is just like launching Nimbus or the UI:
bin/storm drpc
Next, you need to configure your Storm cluster to know the locations of the DRPC server(s). This is how DRPCSpout knows from where to read function invocations. This can be done through the storm.yaml file or the topology configurations. Configuring this through thestorm.yaml looks something like this:
drpc.servers:
- "drpc1.foo.com"
- "drpc2.foo.com"
Finally, you launch DRPC topologies using StormSubmitter just like you launch any other topology. To run the above example in remote mode, you do something like this:
StormSubmitter.submitTopology("exclamation-drpc", conf, builder.createRemoteTopology());
createRemoteTopology is used to create topologies suitable for Storm clusters.
A more complex example
The exclamation DRPC example was a toy example for illustrating the concepts of DRPC. Let's look at a more complex example which really needs the parallelism a Storm cluster provides for computing the DRPC function. The example we'll look at is computing the reach of a URL on Twitter.
The reach of a URL is the number of unique people exposed to a URL on Twitter. To compute reach, you need to:
- Get all the people who tweeted the URL
- Get all the followers of all those people
- Unique the set of followers
- Count the unique set of followers
A single reach computation can involve thousands of database calls and tens of millions of follower records during the computation. It's a really, really intense computation. As you're about to see, implementing this function on top of Storm is dead simple. On a single machine, reach can take minutes to compute; on a Storm cluster, you can compute reach for even the hardest URLs in a couple seconds.
A sample reach topology is defined in storm-starter here. Here's how you define the reach topology:
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 3);
builder.addBolt(new GetFollowers(), 12)
.shuffleGrouping();
builder.addBolt(new PartialUniquer(), 6)
.fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new CountAggregator(), 2)
.fieldsGrouping(new Fields("id"));
The topology executes as four steps:
-
GetTweetersgets the users who tweeted the URL. It transforms an input stream of[id, url]into an output stream of[id, tweeter]. Eachurltuple will map to manytweetertuples. -
GetFollowersgets the followers for the tweeters. It transforms an input stream of[id, tweeter]into an output stream of[id, follower]. Across all the tasks, there may of course be duplication of follower tuples when someone follows multiple people who tweeted the same URL. -
PartialUniquergroups the followers stream by the follower id. This has the effect of the same follower going to the same task. So each task ofPartialUniquerwill receive mutually independent sets of followers. OncePartialUniquerreceives all the follower tuples directed at it for the request id, it emits the unique count of its subset of followers. - Finally,
CountAggregatorreceives the partial counts from each of thePartialUniquertasks and sums them up to complete the reach computation.
Let's take a look at the PartialUniquer bolt:
public class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
Set<String> _followers = new HashSet<String>();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
PartialUniquer implements IBatchBolt by extending BaseBatchBolt. A batch bolt provides a first class API to processing a batch of tuples as a concrete unit. A new instance of the batch bolt is created for each request id, and Storm takes care of cleaning up the instances when appropriate.
When PartialUniquer receives a follower tuple in the execute method, it adds it to the set for the request id in an internal HashSet.
Batch bolts provide the finishBatch method which is called after all the tuples for this batch targeted at this task have been processed. In the callback, PartialUniquer emits a single tuple containing the unique count for its subset of follower ids.
Under the hood, CoordinatedBolt is used to detect when a given bolt has received all of the tuples for any given request id.CoordinatedBolt makes use of direct streams to manage this coordination.
The rest of the topology should be self-explanatory. As you can see, every single step of the reach computation is done in parallel, and defining the DRPC topology was extremely simple.
Non-linear DRPC topologies
LinearDRPCTopologyBuilder only handles "linear" DRPC topologies, where the computation is expressed as a sequence of steps (like reach). It's not hard to imagine functions that would require a more complicated topology with branching and merging of the bolts. For now, to do this you'll need to drop down into using CoordinatedBolt directly. Be sure to talk about your use case for non-linear DRPC topologies on the mailing list to inform the construction of more general abstractions for DRPC topologies.
How LinearDRPCTopologyBuilder works
- DRPCSpout emits [args, return-info]. return-info is the host and port of the DRPC server as well as the id generated by the DRPC server
- constructs a topology comprising of:
- DRPCSpout
- PrepareRequest (generates a request id and creates a stream for the return info and a stream for the args)
- CoordinatedBolt wrappers and direct groupings
- JoinResult (joins the result with the return info)
- ReturnResult (connects to the DRPC server and returns the result)
- LinearDRPCTopologyBuilder is a good example of a higher level abstraction built on top of Storm's primitives
Advanced
- KeyedFairBolt for weaving the processing of multiple requests at the same time
- How to use
CoordinatedBoltdirectly
come from github wiki



相关推荐
Storm支持的使用案例包括流处理(Stream Processing)、分布式远程过程调用(Distributed RPC)以及连续计算(Continuous Computation)。 在早期版本中,Storm的扩展性较为困难,容错能力欠佳,编程相对繁琐。用户...
- **分布式远程过程调用(Distributed RPC)**:允许不同节点之间进行远程调用。 #### Storm 集群架构 - **主节点(Master Node)**:类似于 Hadoop 的 JobTracker,负责集群协调任务。 - **工作节点(Worker Node)**:...
PyTorch 1.5官方文档中介绍了分布式RPC框架(Distributed RPC Framework),这是一个在多台机器上进行模型训练的机制,提供了基本的远程通信机制和高级API,用以自动区分分布在多个机器上的模型。分布式RPC框架的...
RPC.rar_distributed system这个压缩包文件很可能包含了关于分布式系统以及RPC技术的相关资料,尤其关注在Unix环境下的应用。在此,我们将深入探讨这两个关键领域的知识。 分布式系统是由多台计算机通过网络连接并...
The Art of Distributed Applications -- Programming Techniques for Remote Procedure Calls 1991 by Sun Microsystems, Inc RPC
- **DRPC(Distributed RPC)**:分布式远程过程调用,允许多个客户端向集群发送请求并获取结果,支持实时计算服务。 - **Executor、Worker 和 Task**:Executor 是在 Worker 进程中执行的线程,负责处理 Tuple。...
- **分布式远程过程调用(Distributed RPC)**:在分布式环境中提供高效的服务调用。 #### Storm 与 Hadoop 的对比 尽管两者都属于大数据处理领域,但它们有着明显的区别: - **处理类型**:Hadoop主要用于批处理...
分布式RPC(distributedRPC,DRPC)用于对Storm上大量的函数调用进行并行计算过程。对于每一次函数调用,Storm集群上运行的拓扑接收调用函数的参数信息作为输入流,并将计算结果作为输出流发射出去。DRPC本身算不上...
- **`drpc.port`**:设置Storm DRPC的服务端口,DRPC(Distributed RPC)允许外部系统调用Storm中定义的函数。 #### Supervisor 配置 - **`supervisor.slots.ports`**:定义supervisor上能够运行workers的端口列表...
**DRPC**(Distributed RPC):一种特殊的 Spout,支持分布式远程过程调用,使得客户端可以直接向 Storm 集群发送请求,并获得响应。 #### 第五章 Bolts **Bolt 生命周期**: - **初始化**:在 Bolt 创建时调用。 ...
在标签中提到的"ncs"(Network Computing System)和"DCE"(Distributed Computing Environment)是早期的RPC实现。NCS是由Sun Microsystems开发的,它提供了一种标准的方式来构建分布式应用。DCE是OSF(Open ...
本文介绍了一种名为RPC-DDSF(Remote Procedure Call - Distributed Data Sharing Framework)的分布式数据共享框架,该框架建立在Sun公司的ONC RPC(Open Network Computing Remote Procedure Call)框架基础之上。...
- **dcomrpc攻击**:一种针对Microsoft Distributed Component Object Model (DCOM) RPC服务的远程代码执行漏洞利用方式。 - **背景**:DCOM是Microsoft的一种分布式对象技术,允许在不同计算机之间进行通信。RPC...
标题中提到的"C 706 Technical Standard (DCE1.1 RPC)"指的是一个技术标准,其中DCE1.1 RPC指的是分布式计算环境(Distributed Computing Environment)版本1.1的远程过程调用(Remote Procedure Call)技术规范。...
DCE (Distributed Computing Environment) RPC (Remote Procedure Call) 是一种广泛应用于分布式系统中的远程过程调用协议,它允许程序通过网络调用另一个地址空间中的函数或过程,如同调用本地过程一样。...
在Windows中,通常使用NCACN(NetBIOS over TCP/IP)或者DCOM(Distributed Component Object Model)。 在"hellorpc"这个文件中,很可能包含了实现RPC调用的基本结构和逻辑,可能包括客户端的调用代码、服务器端的...
- **HDFS(Hadoop Distributed File System)**:分布式文件系统,用于存储大规模数据集。 - **YARN(Yet Another Resource Negotiator)**:资源管理和调度系统,为应用程序分配计算资源。 - **MapReduce**:分布式...
分布式共享内存(Distributed Shared Memory, DSM)是一种用于在松散耦合的分布式系统中模拟共享内存模型的技术。通过软件层来提供共享内存的抽象,使得应用程序可以像在单个处理器上那样访问远程内存中的数据。本文将...