
这里先大致介绍一下Hadoop.
本文大部分内容都是从官网Hadoop上来的。其中有一篇介绍HDFS的pdf文档,里面对Hadoop介绍的比较全面了。我的这一个系列的Hadoop学习笔记也是从这里一步一步进行下来的,同时又参考了网上的很多文章,对学习Hadoop中遇到的问题进行了归纳总结。
言归正传,先说一下Hadoop的来龙去脉。谈到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一个应用程序,而是提供了一个纯Java的高性能全文索引引擎工具包,它可以方便的嵌入到各种实际应用中实现全文搜索/索引功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,还有数据抓取的功能。在nutch0.8.0版本之前,Hadoop还属于Nutch的一部分,而从nutch0.8.0开始,将其中实现的NDFS和MapReduce剥离出来成立一个新的开源项目,这就是Hadoop,而nutch0.8.0版本较之以前的Nutch在架构上有了根本性的变化,那就是完全构建在Hadoop的基础之上了。在Hadoop中实现了Google的GFS和MapReduce算法,使Hadoop成为了一个分布式的计算平台。
其实,Hadoop并不仅仅是一个用于存储的分布式文件系统,而是设计用来在由通用计算设备组成的大型集群上执行分布式应用的框架。
Hadoop包含两个部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系统)
HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
下面是HDFS的结构:
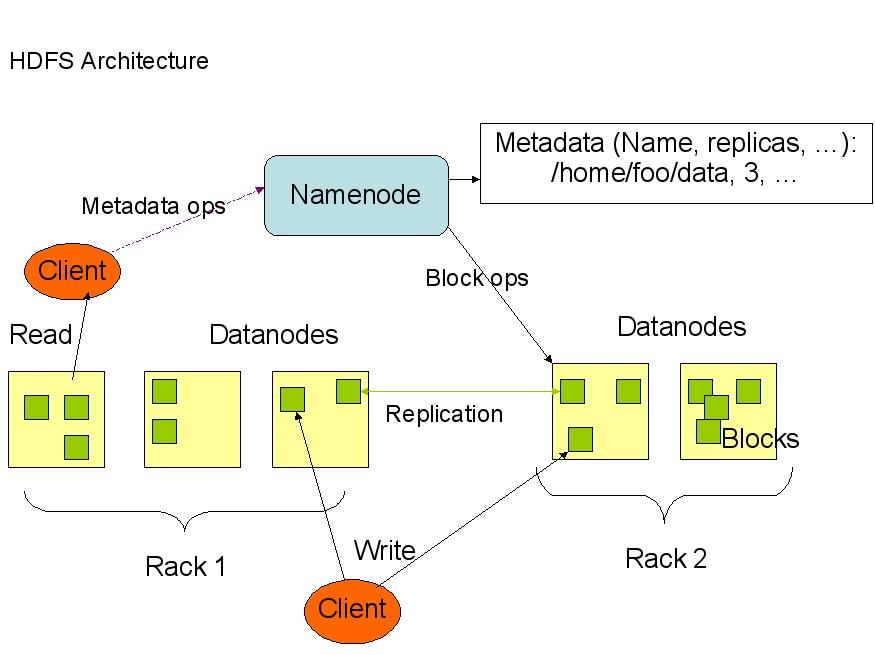
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有实现,但是正在进行中,相信不久就可以出来了。
2、MapReduce的实现
MapReduce是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
MapReduce的名字源于这个模型中的两项核心操作:Map和 Reduce。也许熟悉Functional Programming(函数式编程)的人见到这两个词会倍感亲切。简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
关于MapReduce的内容,建议看看孟岩的这篇MapReduce:The Free Lunch Is Not Over!



相关推荐
### HADOOP学习知识点 #### 一、Hadoop概述与历史 - **Hadoop官方网站**:作为学习Hadoop的第一步,官方站点提供了丰富的资源和技术文档,包括最新的版本更新和技术动态等。 - **起源与发展**:Hadoop项目起源于...
Hive是一个建立在Hadoop上的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,从而将SQL语句转换为MapReduce任务进行运行。Hive适合进行数据摘要和查询,但不适合需要复杂操作的...
Hadoop学习笔记,自己总结的一些Hadoop学习笔记,比较简单。
根据提供的信息,我们可以详细地解析出关于Hadoop学习时间轴中的关键知识点,这些知识点主要集中在Hadoop的基础架构、MapReduce工作原理以及Hive在实际应用中的优化等方面。 ### Hadoop学习时间轴概述 Hadoop是一...
这个"**Hadoop简单应用案例**"涵盖了Hadoop生态系统中的多个关键组件,包括MapReduce、HDFS、Zookeeper以及Hive,这些都是大数据处理的核心工具。下面将详细讲解这些知识点。 1. **MapReduce**:MapReduce是Hadoop...
本手册旨在为完全没有Java基础的学习者提供一个从零开始学习Hadoop的路线图。Hadoop是一个能够处理大量数据的大规模分布式计算框架,其核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。 #### 二、...
Hadoop是一种开源的分布式存储和计算系统,它由Apache软件基金会开发。在初学者的角度,理解Hadoop的组成部分以及其架构设计是学习Hadoop的基础。 首先,Hadoop的分布式文件系统(HDFS)是其核心组件之一,它具有高...
包括了“Hadoop权威操作指南.pdf”、“Hadoop搭建操作文档(集群、伪分布式)”、“HDFS简单接口实现文档”以及“Hadoop API参考手册”和相关的Java API源码,非常适合初学者系统学习。 首先,"Hadoop权威操作指南...
【HADOOP学习笔记】 Hadoop是Apache基金会开发的一个开源分布式计算框架,是云计算领域的重要组成部分,尤其在大数据处理方面有着广泛的应用。本学习笔记将深入探讨Hadoop的核心组件、架构以及如何搭建云计算平台。...
在IT行业中,Hadoop是一个广泛使用的开源框架,主要用于大数据处理和分析。这个“Hadoop学习资料1”的压缩包包含了几个重要的资源,...总的来说,这份“Hadoop学习资料1”是一个全面了解和掌握Hadoop的宝贵资源集合。
### Hadoop学习步骤详解 #### 一、选择合适的Hadoop版本并熟悉Hadoop原理 在开始学习Hadoop之前,首先需要选择一个合适的Hadoop版本。Hadoop作为一个分布式计算框架,经历了多个版本的发展,包括Hadoop 1.x、...
**Hadoop介绍** Hadoop是Apache软件基金会的一个开源项目,主要设计用于处理和存储大量数据。这个分布式计算框架使得在普通硬件集群上处理PB级别的数据成为可能,它以高容错性和可扩展性著称,是大数据分析的核心...
### Hadoop 学习资源概览 #### 一、Hadoop 官方文档 ...以上资源覆盖了Hadoop学习的各个方面,从理论到实践,从基础到高级,旨在帮助初学者系统地掌握Hadoop及其相关技术。希望这些资源能够对你有所帮助!
在本实验报告中,我们将介绍Hadoop的安装和配置过程,并结合Eclipse进行项目开发。 一、Hadoop安装 Hadoop的安装过程可以按照官方文档进行,整个过程包括了在Java JDK和JRE的安装、SSH服务的开启以及Hadoop配置...
"hadoop介绍" Hadoop 是基于 JAVA 语言开发的 Apache 开元框架,支持跨计算机集群的大规模数据集的分布式处理。Hadoop 子项目家族包括 HDFS、MapReduce 等。 HDFS(Hadoop File System)是 Hadoop 的核心组件之一...
【Hadoop学习总结(面试必备)】 Hadoop作为大数据处理的核心框架,因其分布式存储和计算的能力,成为业界处理海量数据的首选工具。本总结将深入探讨Hadoop的主要组件、工作原理以及在面试中可能遇到的相关知识点。...
#### 一、Hadoop学习体系概览 Hadoop是一个能够对大量数据进行分布式处理的软件框架。它通过提供一个高可靠性、高性能、可扩展的平台来处理海量数据集,适用于大数据分析领域。为了更好地掌握Hadoop技术栈,本篇...
### Hadoop快速入门介绍 #### 一、Hadoop简介 Hadoop是一款开源软件框架,用于分布式存储和处理大型数据集。它能够在廉价的商用硬件上运行,并且具有高可靠性和可扩展性。Hadoop的核心组件包括HDFS(Hadoop ...
【标题】"基于hadoop的简易云盘实现.zip"揭示了这个项目是关于利用Hadoop框架构建一个简单的云存储服务。Hadoop是一个开源的分布式计算框架,它允许处理和存储大量数据,尤其适合大数据处理场景。这个简易云盘的实现...