
1、下载Heritrix 3.1
Heritrix 3.1的下载地址是:http://sourceforge.net/projects/archive-crawler/files/heritrix3/3.1.0/ 我把heritrix-3.1.0-dist.zip和heritrix-3.1.0-src.zip两个包都下载下来,二者都会用到。将这两个压缩包分别解压。
2、建立Eclipse项目
1)新建项目
2)添加库文件
在项目中建立一个lib目录,并将heritrix-3.1.0-dist.zip解压后的lib目录下的所有jar文件(heritrix- commons-3.1.0.jar,heritrix-engine-3.1.0.jar,heritrix-modules-3.1.0.jar随着 代码的加入可以逐步删除)拷贝到项目的lib目录下。然后再项目属性--java Build path中将这些jar引用到项目中。
3)添加代码
将heritrix-3.1.0\engine\src\main\java(对应heritrix-engine-3.1.0.jar)添加到 Eclipse的src目录,此时Heritrix 3.1就可以运行了。为了看代码方便,还是将其他部分的代码都加入到项目,分别是:heritrix-3.1.0\commons\src\main \java目录(对应heritrix-commons-3.1.0.jar)和heritrix-3.1.0\modules\src\main \java目录(对应heritrix-modules-3.1.0.jar)。这样你就可以删除heritrix-commons- 3.1.0.jar,heritrix-engine-3.1.0.jar,heritrix-modules-3.1.0.jar三个包的引用,直接使 用源代码运行。
3、运行Heritrix 3.1
Heritrix 3.1运行以后可以通过一个web服务器来管理他。但首先要将他运行起来。在org.archive.crawler有个带main函数的 Heritrix,启动它就可以将Heritrix3.1运行起来。但要设置启动参数-a admin:admin(输入启动账号),在Eclipse的 Run configuration中设置如下图:
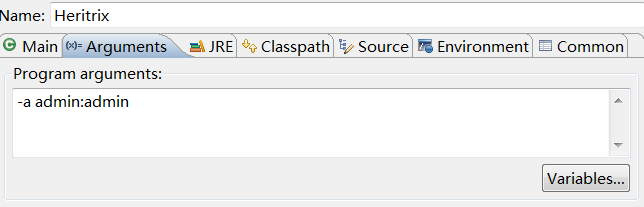
然后运行Heritrix.java,如果一切正常你可以通过:https://localhost:8443访问Heritrix 3.1的管理网站。
不过这时系统里还一片空白,你需要建立一个网页抓取的任务(job).
4、建立和配置抓取任务
登录管理控制台(用户名admin密码admin),在管理界面首页找到如下图这个位置:

输入一个名称(如myjob),然后点击“Create”按钮。
这时候根据默认模版生成了一个抓取任务,但还不能抓取任何东西,我们需要通过配置文件的修改告诉服务器,我们要抓取什么。
在管理控制台的Job Directories中选择要配置的job(下图中myjob)
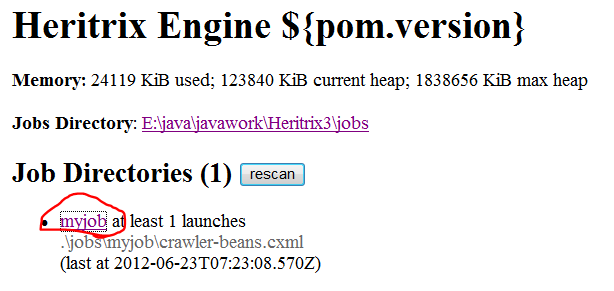
进入myjob的管理界面,如下图:
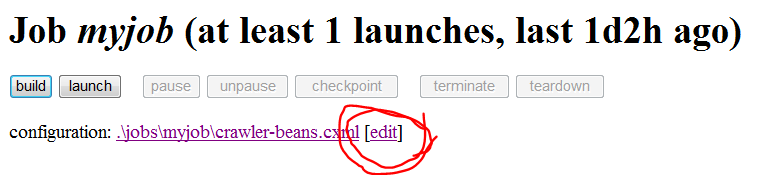
点击edit按钮,开始编辑配置文件,配置需要修改的地方如下图所示,先从简单的做起:
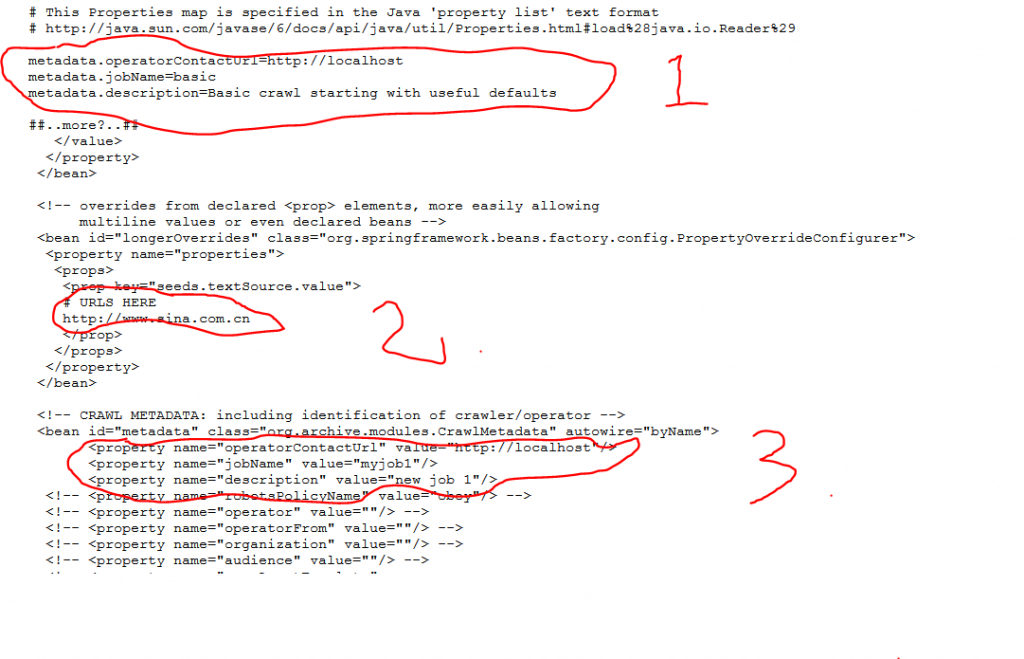
配置1和3的配置内容是一样的,operatorContactUrl写成http://localhost, jobName和description随便写点东西即可。
配置2则是配置搜索种子网站的列表,我这里先写了一个http://www.sina.com.cn,先抓取新浪网站试试。
点击最上面的“Save changes"保存所有的配置文件。
这三个地方配置好就可以运行这个抓取任务试试了。
这时候需要执行如下操作(回到myjob的配置界面),让任务运行起来:
1)点击“build”编译当前的配置。
2)点击“launch”按钮运行当前任务至挂起状态,如果job已经运行,则先点击“checkpoint”按钮;
3)这时任务处于挂起状态,点击“unpause”即立即启动任务。
如果系统正常运行,会有如下类似提示信息:

在项目的jobs\myjob\20120623061610\warcs目录下有一个逐步增大的文件,这就是抓取下来的网页。
如果要看到每个抓取的页面,可以将配置文件的warcWriter这个bean的class改为 org.archive.modules.writer.MirrorWriterProcessor,这样就下载的网页是以镜像文件的形式保存在,一般 存放在项目根目录下的mirror目录下。



相关推荐
配置过程中,应根据实际需求逐步调整参数,并通过试验和错误找出最佳设置。同时,文档阅读和社区交流也是学习Heritrix配置的重要途径。记得在实践中不断测试和完善配置,以实现高效、可控的网络爬取任务。
### Heritrix安装详细过程及配置指南 #### 一、Heritrix简介 Heritrix是一款开源的网络爬虫工具,被广泛应用于互联网资源的抓取与归档工作。相较于其他爬虫工具,Heritrix提供了更为精细的控制机制,能够帮助用户...
对于Heritrix3种子载入的配置,建议用户仔细阅读官方文档和相关配置指南,因为不当的配置可能会导致爬虫运行时出现错误,甚至会影响到爬虫的稳定性和性能。如果在阅读配置时遇到了技术上的障碍,例如OCR扫描出的文字...
配置过程还包括将`src\conf\`目录下的所有文件和文件夹拖入Eclipse的`Heritrix`工程的`src`目录。`heritrix.properties`文件是Heritrix的主要配置文件,你可以在这里设置管理界面的用户名和密码,例如"admin:admin...
在配置过程中可能会遇到的错误是 `java.lang.UnsupportedClassVersionError`,这通常表示你的 Java 运行环境版本与 Heritrix 需要的版本不匹配。解决这个问题的方法是检查你的 JDK 版本,确保它与 Heritrix 的需求...
Heritrix是一款强大的开源网络爬虫工具,由互联网档案...总的来说,配置Heritrix涉及多个方面,从理解工作流机制到解决实际抓取过程中遇到的问题。通过深入学习和实践,可以有效地利用Heritrix构建自己的网络爬虫系统。
3. **readme.txt**:这个文件通常包含关于如何安装、配置和运行Heritrix的基本指南。它可能还会包括版本信息、版权声明和开发者注意事项等内容。确保仔细阅读此文件以获取正确操作Heritrix的指导。 4. **heritrix-...
首先,Heritrix的下载过程非常简单。你可以访问www.sourceforge.net网站,搜索"heritrix",然后下载两个版本的文件:heritrix-1.14.0-RC1.zip(预编译版本)和heritrix-1.14.0-RC1-src.zip(源码版本)。下载完成后...
#### 二、Heritrix下载、安装与配置 ##### 2.1 下载 - **下载地址**: 通常可以从Heritrix的官方网站或GitHub仓库获取最新版本。 - **版本选择**: 根据给定的信息,选择了版本1.14.4进行安装。 ##### 2.2 安装 - **...
这种绿色配置通常意味着它不需要复杂的安装过程,用户可以直接解压并运行,减少了系统环境的依赖,便于在不同环境中部署。 Heritrix的工作流程主要包括以下几个关键部分: 1. **启动与配置**:在开始抓取前,用户...
配置过程中,需要修改项目conf目录下的heritrix.properties文件。将@VERSION@替换为1.14.3,并设置Heritrix的管理用户名和密码,例如改为`heritrix.cmdline.admin = admin:xxm`。同时,根据实际情况,你可能需要更改...
Heritrix的核心是工作流模型,它将爬取过程分为多个阶段,如URL发现、下载、解析、存储等。每个阶段都可以通过编写或选择合适的处理器来实现。Heritrix支持多种协议,包括HTTP、HTTPS、FTP等,并且能够处理各种MIME...
3. **配置文件**:Heritrix的配置文件是XML格式的,用于定义爬虫的行为,如爬取深度、并发度、重试策略、排除规则等。你需要根据实际需求修改这些配置来定制爬虫行为。 4. **源码编译与运行**:下载Heritrix 1.14.4...
运行过程中,Heritrix将按照配置进行网络爬行,抓取的网页会被存储在本地或者指定的存储位置。 对于学习网络爬虫技术的人来说,Heritrix提供了一个很好的平台,不仅可以了解爬虫的基本工作原理,还可以深入研究如何...
1. **爬虫容器(Crawler Container)**: Heritrix 3 是基于Java的,其核心是爬虫容器,它负责管理所有爬虫组件并协调爬行过程。 2. **模块化设计**: Heritrix 3 的功能通过一系列可插拔的模块实现,包括抓取策略、...