
Xpath . 分类: XML2012-06-12 15:33315人阅读评论(0)收藏举报 文档xml测试xslt电话encoding 目录(?)[+] 概述 XPath在设计之初主要用于XSLT和XPointer(用于Xlink,还未普及),随着XSLT 2.0的发布,已经发展到XPath 2.0(06年6月),并成为XSLT 2.0和XQuery 2.0的基础 XPath以“路径”方式查询XML文档,XPath表达式的基本形式是“/结点/子结点/二级子结点”,从左到右(即从外至内)匹配XML文档的结点 XPath表达式分为定位表达式和求值表达式。定位表达式用于匹配XML文档的结点,而求值表达式则返回定位结果数值(字符串、布尔值、数值等) XML文档的模型 对于良构的XML文档,有三种模型表示: XPath数据模型:把XML文档的多数内容表示为一棵结点树,树的根结点代表文档本身,其他结点有元素结点、属性结点、文本结点、名称空间结点、注释结点等。XML声明、DOCTYPE等不能表示为结点 DOM:采用树形层次结构表示XML文档 XML信息表(Infoset):把XML文档看作由信息项组成的一棵树,每个信息项相当于XPath的一个结点,信息项可有若干属性,属性值表示信息项的特性

基本概念 层次结构
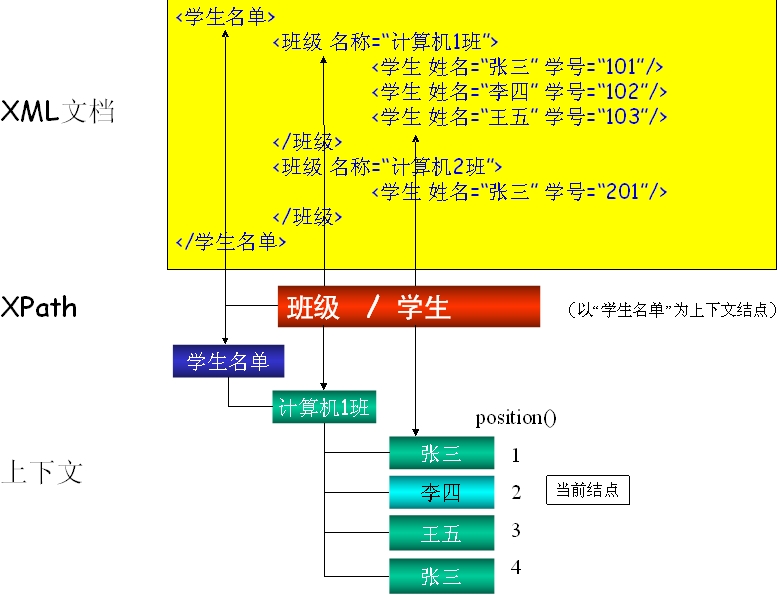
基本概念 层次结构 XPath表达式以“/”分隔表示分层结构 XPath表达式最左边的“/”表示从根结点开始 XPath表达式中间出现的“/”用于分隔上下两层结构,表示父子关系 串联的若干“/”分隔的部分形成先代(Ancestor)、后代(Descendant)关系 线性结构 同属一个父结点的结点间形成线性的兄弟(Sibling)关系 兄弟之间有先后,前面的是后面的“前导(Preceding)兄弟”,后面的是前面的“后继(Following)兄弟” 可以用position()函数获取结点在线性结构中的位置 XPath定位操作返回的是结点列表 XPath定位表达式返回的是匹配的结点的列表,不是返回值 XPath求值表达式可以返回结点集 根结点不是根元素 XPath的根结点与XML文档结点对应,包含了文档的所有内容,不是XML文档的根元素,根元素是XML文档包含其它元素的结点,是根结点的一个子结点(根结点的其它子结点包括XML声明、 DOCTYPE、注释等) 绝对定位和相对定位 若XPath表达式以“/”开始,则对应为绝对定位;否则为相对定位 XPath的概念 XPath路径的构造方法 由于XML文档是层次结构的,定位元素不可能像平面结构的关系数据库可以根据主键一步到位,只能是分步渐进的,每个分步称为一个“定位步(location step)” XPath的路径有两种: 串联定位:使用“/”分隔符连接多个定位步 如:/我的电脑/硬盘/分区 先定位根结点,然后是“我的电脑”,接着是“硬盘”,最后是“分区” 并联定位:使用“|”分隔符连接多个定位步 如:硬盘 | 内存 在上下文结点的子结点中定位所有“硬盘”和“内存”结点 XPath表达式的上下文 在某结点下的XPath表达式的计算结果——结点列表构成上下文,该结点称为上下文结点(Context node) XPath表达式的结点列表中包含的结点的数目称为该上下文的大小(Context Size) 在遍历XPath的结点列表时,遍历游标所到达的结点,称为当前结点 在遍历XPath的结点列表时,遍历游标所到达的结点,称为当前结点
定位步的组成
定位步的组成 XPath的定位步由三部分组成,格式为: 轴::结点测试[谓项] 其中“轴”和“谓项”部分可以省略 轴(Axis):表示从当前结点开始,向哪个方向开后匹配结点。XPath定义了13条轴 结点测试:表示匹配轴方向上的哪些结点 谓项(Predicate):表示匹配的条件,是在轴和结点测试基础上的进一步筛选 轴和结点测试 13条轴 结点测试 在XPath中,结点测试必须位于轴的后面或放在谓项中,而函数的返回值只能出现在谓项中 结点测试:不支持DTD的DOCTYPE、ENTITY等 元素名称 : 具有特定名称的结点 名称空间前缀:元素名称 : 名称空间 processing-instruction(“名称") : 处理指令 node() : 任何类型的结点 * : 现节点下所有元素,具有任何名称的结点 */elem : 现节点下所有节点的子节点中为elem的节点 @Prop : 属性值 @* : 所有现节点的属性 . : 现节点 .. : 现节点上级 elem[i] : 现节点下第i个叫做elem的元素 elem[posetion()=1] : 同上 elem/[@prop="somevalue"] : 现节点下,名字为elem,具有prop的属性,并且属性值为somevalue的那个元素 elem1|elem2 : 现节点下,名字为elem1或elem2的元素 .//elem : 现节点下,可以跨越级别,所有的名字叫做elem的元素 elem1//elem2 : 现节点下,可以跨越级别,所有的名字叫做elem2,且elem2的上级中有人叫elem1,且elem1是现节点的子元素的元素 text() : 现节点的子元素中所有的文字节点 comment() : 注释 函数:不能直接出现在轴的后边或结点测试的后边 contains(串1,串2) :包含检查 id(结点集等) :返回具有id属性的结点 name() :结点名称 position() :当前结点在上下文中的位置 starts-with(串1,串2) :“串1”以“串2”开始 count() : count(PERSON[name='tom']) 计数 number() : select="number(book/price)" 转成数字 substring(value,start,length) : select="substring(name,1,3)" sum() : select="sum(//price)" 求和 谓项 谓项(Predicate)以一对方括号“[“和”]”为标记,中间为条件表达式,置于XPath中,构成筛选条件,格式为: [值1 操作符 值2] 若谓项条件不成立,则从XPath结点列表中剔除该结点 确定结点是否存在 谓项的格式为:[结点测试] 例如:[姓名] 、[@姓名] 用关系表达式表示筛选条件 谓项格式为:[值1 关系运算符 值2] 例如:[年龄>=“20”] 、 [@性别!=“男”] 关系元素符包括:=、!=、<、<=、>=、> 用布尔运算表示复合条件 谓项格式为:[布尔值1 布尔运算符 布尔值2] 例如:[年龄=“20” and @性别=“女”] 布尔运算符包括:or(或)、and(与) 用数值表达式构造复杂运算 数值运算符包括: +、-、*、div(除)、mod(求模)、-(取反) 例如: [html] view plaincopy 01.<?xml version="1.0" encoding="utf-8"?> 02.<学生名单> 03. <班级 名称="计算机1班"> 04. <学生 姓名="张三" 学号="101"/> 05. <学生 姓名="李四" 学号="102"/> 06. <学生 姓名="王五" 学号="103"/> 07. <班长 学号="103"> 08. <电话 号码="13512345678"/> 09. </班长> 10. <介绍>该班为优良学风班</介绍> 11. </班级> 12. <班级 名称="计算机2班"> 13. <学生 姓名="张三" 学号="201"/> 14. </班级> 15.</学生名单> 实例1:假设上下文结点为“/学生名单/班级”,XPath匹配结果分别为: 学生 所有学生结点 班长/电话 所有电话结点 .. 班级结点 ../.. 学生名单结点 ./介绍 介绍结点 //学生 所有学生结点 self::*//学生 当前结点下含有学生子结点的任意结点 /descendant::node() 根节点的所有后代结点 //node() 所有节点 .//node() 当前结点下的所有结点 “介绍”文本 介绍/text() 每个“学生”的“姓名”学生/@姓名 参照实例(1),假设上下文结点为“学生名单”,写出路径的XPath: 有“班长”的所有班级 班级[班长] 包含“电话”子结点的所有结点 班级/*[电话] 叫“张三”的“学生” 班级/学生[@姓名="张三"] “计算机1班”叫“张三”的“学生” 班级[@名称="计算机1班"]/学生[@姓名="张三"] 名称空间 结点的本地名称可以用函数local-name()获取 例如: //*[local-name()=“学生”] 结点的名称空间可用函数namespace-uri()获取 例如: //*[namespace-uri()=“myurn:computer”] 在XPath中使用名称空间前缀限定名称空间 例如: //学籍管理:学生[@学籍管理:姓名=“张三”]



相关推荐
XPath(XML Path Language)是一种在XML文档中查找信息的语言,它是W3C组织制定的一种标准查询语言,用于选取XML文档中的节点,包括元素、属性、文本等。在本项目“Xpath生成器,自动生成XPATH,C#版”中,开发者...
XPath,全称XML Path Language,是一种在XML文档中查找信息的语言。它被设计用来选取XML文档中的节点,如元素、属性、文本等。在IE浏览器下,为了方便开发者获取XML或HTML文档中的XPath路径,存在一种小工具,本文将...
XPath(XML Path Language)是一种在XML文档中查找信息的语言,它允许我们通过路径表达式来选取节点,比如元素、属性和文本等。XPath 2.0是XPath的第二个主要版本,增加了更多的功能和优化。 在没有XPath Helper的...
XPath Helper是一款非常实用的工具,尤其对于Web开发者和数据抓取者来说,它极大地简化了在网页中查找和提取信息的过程。版本2.0.2是这个插件的一个更新,旨在提供更稳定、高效的功能。XPath(XML Path Language)是...
本压缩包文件"xpath-helper.crx"很可能是一个Chrome浏览器的扩展程序,旨在提供实时的XPath查询支持。 XPath(XML Path Language)是一种在XML文档中查找信息的语言,它允许我们通过路径表达式来选取节点,如元素、...
Xpath生成器,可以通过输入的文件,进行匹配,生成全部可用的Xpath,犹豫HTML中部分标签允许无结束,如:("LINK" ,"META","SCRIPT","IMG" ,"INPUT", "FORM")故已经被忽略,如有朋友发现其中有问题,请告诉我哦...
XPathHelper_2.0.2.zip 是一个包含XPath Helper Chrome扩展程序的压缩文件,版本为2.0.2。XPath Helper是一款非常实用的工具,它专为Chrome浏览器设计,帮助开发者和网页爬虫工程师高效地测试和调试XPath表达式。...
XPathHelper 2.0.2 版本专注于XPath的查询与应用,特别适合于Web自动化测试和网页数据抓取。 XPath在Web开发中的主要用途有以下几点: 1. **元素定位**:XPath允许开发者通过路径表达式来选取XML或HTML文档中的...
XPath,全称XML Path Language,是一种在XML文档中查找信息的语言。它被设计用来选取XML文档中的节点,包括元素、属性、文本等。XPath基于W3C标准,其1.0版本是XPath语言的基础,提供了强大的查询和导航功能。本教程...
XPath,全称XML Path Language,是一种在XML文档中查找信息的语言。它被设计用来选取XML文档中的节点,包括元素、属性、文本等。XPath基于W3C标准,为XML处理提供了一种强大而灵活的方式。以下是对“XPath指南”中...
火狐老版本与XPath插件的组合在Python网络爬虫领域具有重要的应用价值。XPath是一种在XML文档中查找信息的语言,对于数据提取和解析尤其有效。在这个压缩包中,我们找到了火狐的老版本浏览器和一个专门针对XPath的...
XPath是一种强大的查询语言,用于在XML文档中定位元素、属性和其他节点。本文将深入探讨JDOM库中XPath的相关方法——`selectNodes()`和`selectSingleNode()`,以及它们的用法。 首先,我们来理解JDOM的基本概念。...
XPath Helper是一款强大的Chrome浏览器插件,专为网页元素定位和数据提取而设计。它使得开发者和数据抓取者能够方便地生成和测试XPath表达式,从而高效地在HTML文档中定位所需信息。XPath(XML Path Language)是一...
XPath,全称XML Path Language,是一种在XML文档中查找信息的语言。它被设计用来允许对XML文档中的元素、属性和其他节点进行快速定位。XPath使用路径表达式来选取XML文档中的节点,这些路径表达式类似于我们在文件...
XPath(XML Path Language)是一种在XML文档中查找信息的语言,它是W3C推荐的标准,用于选取XML文档中的节点,如元素、属性、文本等。XPath测试工具是开发者用来验证和调试XPath表达式的重要辅助手段,它能够快速地...
XPath Helper是一款针对网页数据提取和爬虫开发的强大工具,它主要设计用于Chrome浏览器,并通过扩展程序的形式集成在浏览器中。用户可以通过安装CRX文件(即`xpath-helper.crx`)来添加这个插件。XPath(XML Path ...
XPath是XML处理中的一种强大的查询语言,用于在XML文档中查找特定的信息。它允许开发者根据节点的名称、属性、值甚至是它们之间的关系来定位XML数据。在这个“xpath 依赖包及开发手册”中,我们主要关注XPath的使用...
XPath Helper是一款针对Chrome浏览器的强大工具,它专门用于帮助开发者和数据爬取者高效地解析和提取网页中的数据。XPath(XML Path Language)是一种在XML文档中查找信息的语言,而XPath Helper则是Chrome浏览器的...
XPath 使用路径表达式来选取节点,如元素、属性、文本等。本篇文章将详细探讨如何查看网页元素的 XPath,并介绍其相关知识点。 首先,XPath 的基本概念: 1. **节点**:在 XML 或 HTML 文档中,节点可以是元素(如...
XPath Helper是一款针对谷歌浏览器(Chrome)的插件,主要用于帮助前端开发者和网页抓取工程师便捷地测试和调试XPath表达式。XPath是一种在XML文档中查找信息的语言,它能够选取XML文档中的节点,如元素、属性、文本...