
简介
如果一个事务中含有X,则该事务中很可能含有Y。具体形式为{X}→{Y},即通常可以描述为:当一个事务中顾客购买了一样东西{钢笔}(这里X=“钢笔”),则很可能他同时还购买了{墨水}(这里Y= "墨水"),这就是关联规则。
关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basket analysis)。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是"尿布和啤酒"的故事了。
先验算法[1]是关联式规则中的经典算法之一。在关联式规则中,一般对于给定的项目集合(例如,零售交易集合,每个集合都列出的
单个商品的购买信息),算法通常尝试在项目集合中找出至少有C个相同的子集。先验算法采用自底向上的处理方法,即频繁子集每次只扩展一个对象(该步骤被称为候选集产生),并且候选集由数据进行检验。当不再产生符合条件的扩展对象时,算法终止。
相关定义
设: I={i1,i2......,im}是所有项目的集合, D是所有事务的集合(即数据库),每个事务T是一些项目的集合,T包含在I中, 每个事务可以用唯一的标识符TID来标识。 设X为某些项目的集合,如果X包含在T中,则称事务T包含X,关联规则则表示为如下形式(X包含在T)=>(Y包含在T)的蕴涵式,这里X包含在I中,Y包含在I中,并且X∧Y=Φ。 其意义在于一个事务中某些项的出现,可推导出另一些项在同一事务中也出现。这里将(X包含在T)=>(Y包含在T)表示为X=>Y,这里,‘=>’称为‘关联’操作, X称为关联规则的先决条件,Y称为关联规则的结果。
事务集D中的规则X=>Y是由支持度s(support)和置信度c(confidence)约束,置信度表示规则的强度, 支持度表示在规则中出现的频度。
规则X=>Y的支持度s定义为: 在D中包含X∪Y的事务所占比例为s%, 表示同时包含X和Y的事务数量与D的总事务量之比; 规则X=>Y的置信度c定义为: 在D中,c%的事务包含X的同时也包含Y, 表示D中包含X的事务中有多大可能性包含Y。
最小支持度阈值minsupport表示数据项集在统计意义上的最低主要性。 最小置信度阈值mincontinence表示规则的最低可靠性。 如果数据项集X满足X。support>=minsupport, 则X是最大数据项集。 一般由用户给定最小置信度阈值和最小支持度阈值。
置信度和支持度大于相应阈值的规则称为强关联规则, 反之称为弱关联规则。 发现关联规则的任务就是从数据库中发现那些置信度、支持度大小等于给定值的强壮规则。
Apriori算法描述
在Apriori算法中,寻找最大项目集的基本思想是: 算法需要对数据集进行多步处理.第一步,简单统计所有含一个元素项目集出现的频率,并找出那些不小于最小支持度的项目集, 即一维最大项目集. 从第二步开始循环处理直到再没有最大项目集生成. 循环过程是: 第k步中, 根据第k-1步生成的(k-1)维最大项目集产生k维侯选项目集, 然后对数据库进行搜索, 得到侯选项目集的项集支持度, 与最小支持度比较, 从而找到k维最大项目集.
算法图例说明
假设有一个数据库D,其中有4个事务记录,分别表示为:
| T1 | I1,I3,I4 |
| T2 | I2,I3,I5 |
| T3 | I1,I2,I3,I5 |
| T4 | I2,I5 |
这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
| T1 | I1,I3,I4 |
| T2 | I2,I3,I5 |
| T3 | I1,I2,I3,I5 |
| T4 | I2,I5 |
扫描D,对每个候选项进行支持度计数得到表C1:
| {I1} | 2 |
| {I2} | 3 |
| {I3} | 3 |
| {I4} | 1 |
| {I5} | 3 |
比较候选项支持度计数与最小支持度minSupport,产生1维最大项目集L1:
| {I1} | 2 |
| {I2} | 3 |
| {I3} | 3 |
| {I5} | 3 |
由L1产生候选项集C2:
| {I1,I2} |
| {I1,I3} |
| {I1,I5} |
| {I2,I3} |
| {I2,I5} |
| {I3,I5} |
扫描D,对每个候选项集进行支持度计数:
| {I1,I2} | 1 |
| {I1,I3} | 2 |
| {I1,I5} | 1 |
| {I2,I3} | 2 |
| {I2,I5} | 3 |
| {I3,I5} | 2 |
比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:
| {I1,I3} | 2 |
| {I2,I3} | 2 |
| {I2,I5} | 3 |
| {I3,I5} | 2 |
由L2产生候选项集C3:
| {I2,I3,I5} |
扫描D,对每个候选项集进行支持度计数:
| {I2,I3,I5} | 2 |
比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:
| {I2,I3,I5} | 2 |
算法终止。
例子
一个大型超级市场根据最小存货单位(SKU)来追踪每件物品的销售数据。从而也可以得知哪里物品通常被同时购买。通过采用先验算法来从这些销售数据中建立频繁购买商品组合的清单是一个效率适中的方法。假设交易数据库包含以下子集{1,2,3,4},{1,2},{2,3,4},{2,3},{1,2,4},{3,4}。每个标号表示一种商品,如“黄油”或“面包”。先验算法首先要分别计算单个商品的购买频率。下表解释了先验算法得出的单个商品购买频率。
| 商品编号 | 购买次数 |
| 1 | 3 |
| 2 | 6 |
| 3 | 4 |
| 4 | 5 |
然后我们可以定义一个最少购买次数来定义所谓的“频繁”。在这个例子中,我们定义最少的购买次数为3。因此,所有的购买都为频繁购买。接下来,就要生成频繁购买商品的组合及购买频率。先验算法通过修改树结构中的所有可能子集来进行这一步骤。然后我们仅重新选择频繁购买的商品组合:
| 商品编号 | 购买次数 |
| {1,2} | 3 |
| {2,3} | 3 |
| {2,4} | 4 |
| {3,4} | 3 |
并且生成一个包含3件商品的频繁组合列表(通过将频繁购买商品组合与频繁购买的单件商品联系起来得出)。在上述例子中,不存在包含3件商品组合的频繁组合。最常见的3件商品组合为{1,2,4}和{2,3,4},但是他们的购买次数为2,低于我们设定的最低购买次数。
算法评价
先验算法具有显著的历史地位,它的优点是简单、易理解、数据要求低,但从算法执行过程也可以看到Apriori算法的缺点: 1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此Apriori算法中的一些低效与权衡弊端也进而引致了许多其他的算法的产生,例如FP-growth算法。候选集产生过程生成了大量的子集(先验算法在每次对数据库进行扫描之前总是尝试加载尽可能多的候选集)。并且自底而上的子集浏览过程(本质上为宽度优先的子集格遍历)也直到遍历完所有 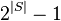 个可能的子集之后才寻找任意最大子集S。
个可能的子集之后才寻找任意最大子集S。
摘自:



相关推荐
数据挖掘是一种从大量...总的来说,朴素贝叶斯算法是数据挖掘中一个基础且实用的工具,尤其适用于大规模数据集和实时预测。通过理解和应用这种算法,可以为商业决策提供有力的支持,帮助预测用户行为并优化营销策略。
数据挖掘18大算法实现以及其他相关经典DM算法数据挖掘算法算法目录18大DM算法包名 目標 算法关联分析 数据挖掘先验 Apriori-关联规则挖掘算法关联分析 数据挖掘_FPTree FPTree-频繁模式树算法Bagging 和 Boosting ...
k-clique算法(简称k-clique)是一种自动子空间聚类算法,它由IBM Almaden研究中心的数据挖掘团队研发。该算法能够在高维数据的子空间中识别稠密的聚类,并以易于理解的形式提供聚类说明。k-clique算法的核心在于...
在IT领域,关联规则挖掘是一种重要的数据挖掘技术,主要用于发现数据集中的有趣关系或模式。在本主题中,我们将深入探讨“matlab开发-关联规则挖掘的先验算法”。Apriori算法是关联规则挖掘中的一种经典算法,由 ...
算法目录常用的标准数据挖掘算法包名 目標 算法关联分析 数据挖掘先验 Apriori-关联规则挖掘算法关联分析 数据挖掘_FPTree FPTree-频繁模式树算法Bagging 和 Boosting 数据挖掘_AdaBoost AdaBoost-装袋提升算法分类 ...
### 数据挖掘与数据分析应用案例:基于C++的k-means算法探究实践 #### k-means算法概述 k-means算法是一种广泛应用于数据挖掘和机器学习领域的统计聚类算法。其核心在于通过迭代的方式将数据集划分为多个簇...
聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。K-means算法中的k代表类簇个数,means代表类簇内数据对象的均值...
数据挖掘是一种从海量数据中提取有价值信息的过程,而贝叶斯算法和KNN算法是两种常用的分类技术。本文档主要探讨了如何利用这两种算法对newsgroup18828文档集进行分类。 首先,贝叶斯算法是一种基于概率的分类方法...
数据挖掘是信息技术领域的一个关键分支,它涉及到从大量数据中发现有价值的信息和知识。序列模式挖掘是数据挖掘的一种,专注于在时间序列数据中寻找频繁出现的模式或序列。在这种背景下,GSP(Growth-Share-Pruning...
FP-Growth算法是一种高效的数据挖掘方法,用于找出数据库中频繁项集。在大规模交易数据中,如超市购物篮数据,这种算法比Apriori等早期算法更为高效,因为它避免了多次扫描数据库和生成大量中间结果。C++是广泛应用...
在MATLAB开发关联规则挖掘的先验算法时,可以使用数据挖掘工具箱中的`apriori`函数。该函数基于Apriori算法,这是一种经典的挖掘频繁项集的算法,它遵循“频繁项集的子集也必须频繁”的原则,从而减少计算量。在使用...
相比于其他数据挖掘技术,粗糙集理论的一个显著特点是不需要额外的先验知识,能够直接从数据本身出发进行分析。 #### 三、粗糙集理论的基本概念 - **信息表**:是粗糙集理论的基础,通常包含一组对象(样本)和一...
### 基于数据挖掘的基因调控网络集成分析系统算法设计与实现 #### 概述 随着生物芯片技术的进步,大量的基因表达数据被积累并存储于基因表达数据库中,为基因组水平上的研究提供了坚实的基础。基因调控网络的构建与...
3. 并行处理能力:基于粗糙集的挖掘算法适合并行执行,这对于处理大规模数据库中的数据挖掘任务至关重要,可以显著提高效率。 4. 属性约简:粗糙集方法可以通过去除冗余属性来简化数据,提升数据挖掘的效率。 5. ...
K-Means算法是一种经典的聚类方法,在数据挖掘和机器学习领域广泛应用,特别是在图像分割中。这个名为"K-Means图像分割_K._k-means_k-means算法改进_图像分割"的压缩包文件,主要关注了如何用K-Means算法对图像进行...
"数据挖掘十大经典算法" 数据挖掘十大经典算法是机器学习和数据挖掘领域中最重要的算法之一。这些算法被广泛应用于数据分析、预测和分类等领域。 一、C4.5算法 C4.5算法是机器学习算法中的一种分类决策树算法,其...
本资源聚焦于数据挖掘中的十大经典算法,这些算法是数据科学家和分析师在处理各种实际问题时常用的工具。由李文波和吴素研翻译的《数据挖掘十大算法》一书,由清华大学出版社出版,为读者提供了深入理解这些算法的...
吴信东教授是数据挖掘领域的知名专家,他所提及的“数据挖掘十大算法”是一本深入探讨该领域核心技术的经典著作,英文版名为《The Top Ten Algorithms in Data Mining》。这本书为读者揭示了数据挖掘中最常用且具有...
频繁模式分析是一种在大量数据集中发现频繁出现的模式或项集的技术,它对于多种数据挖掘任务至关重要,如关联规则挖掘、序列模式挖掘等。本章将从基本概念出发,深入探讨频繁项集挖掘方法,并介绍如何评估模式的兴趣...