
HadoopйЫЖзЊ§пЉИзђђ7жЬЯпЉЙ_EclipseеЉАеПСзОѓеҐГиЃЊзљЃ
1гАБHadoopеЉАеПСзОѓеҐГзЃАдїЛ
1.1 HadoopйЫЖзЊ§зЃАдїЛ
гААгААJavaзЙИжЬђпЉЪjdk-6u31-linux-i586.bin
гААгААLinuxз≥їзїЯпЉЪCentOS6.0
гААгААHadoopзЙИжЬђпЉЪhadoop-1.0.0.tar.gz
1.2 WindowsеЉАеПСзЃАдїЛ
гААгААJavaзЙИжЬђпЉЪjdk-6u31-windows-i586.exe
гААгААWinз≥їзїЯпЉЪWindows 7 жЧЧиИ∞зЙИ
гААгААEclipseиљѓдїґпЉЪeclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip
гААгААHadoopиљѓдїґпЉЪhadoop-1.0.0.tar.gz
гААгААHadoop Eclipse жПТдїґпЉЪhadoop-eclipse-plugin-1.0.0.jar
гААгААдЄЛиљљеЬ∞еЭАпЉЪhttp://download.csdn.net/detail/xia520pi/4113746
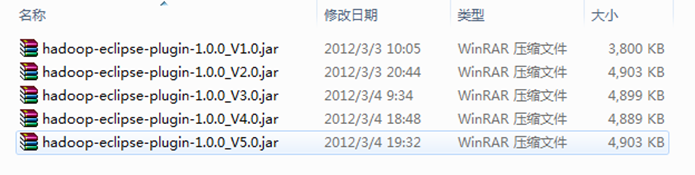
гААгААе§Зж≥®пЉЪдЄЛйЭҐжШѓзљСдЄКжФґйЫЖзЪДжФґйЫЖзЪД"hadoop-eclipse-plugin-1.0.0.jar"пЉМйЩ§"зЙИжЬђ2.0"жШѓж†єжНЃ"V1.0"жМЙзЕІ"еЄЄиІБйЧЃйҐШFAQ_1"жФєзЪДдєЛе§ЦпЉМеЙ©дљЩзЪД"V3.0"гАБ"V4.0"еТМ"V5.0"еТМ"V2.0"дЄАж†ЈжШѓеИЂдЇЇеЈ≤зїПеЉДе•љзЪДпЉМиАМдЄФжИСеЈ≤зїПйГљжµЛиѓХињЗпЉМж≤°жЬЙдїїдљХйЧЃйҐШпЉМеПѓдї•жФЊењГдљњзФ®гАВжИСдїђињЩйЗМйАЙжЛ©зђђ"V5.0"дљњзФ®гАВиЃ∞еЊЧеЬ®дљњзФ®жЧґйЗНжЦ∞еСљеРНдЄЇ"hadoop-eclipse-plugin-1.0.0.jar"гАВ
 
2гАБHadoop EclipseзЃАдїЛеТМдљњзФ®
2.1 EclipseжПТдїґдїЛзїН
гААгААHadoopжШѓдЄАдЄ™еЉЇе§ІзЪДеєґи°Мж°ЖжЮґпЉМеЃГеЕБиЃЄдїїеК°еЬ®еЕґеИЖеЄГеЉПйЫЖзЊ§дЄКеєґи°Ме§ДзРЖгАВдљЖжШѓзЉЦеЖЩгАБи∞ГиѓХHadoopз®ЛеЇПйГљжЬЙеЊИе§ІйЪЊеЇ¶гАВж≠£еЫ†дЄЇе¶В ж≠§пЉМHadoopзЪДеЉАеПСиАЕеЉАеПСеЗЇдЇЖHadoop EclipseжПТдїґпЉМеЃГеЬ®HadoopзЪДеЉАеПСзОѓеҐГдЄ≠еµМеЕ•дЇЖEclipseпЉМдїОиАМеЃЮзО∞дЇЖеЉАеПСзОѓеҐГзЪДеی嚥еМЦпЉМйЩНдљОдЇЖзЉЦз®ЛйЪЊеЇ¶гАВеЬ®еЃЙи£ЕжПТдїґпЉМйЕНзљЃHadoopзЪД зЫЄеЕ≥дњ°жБѓдєЛеРОпЉМе¶ВжЮЬзФ®жИЈеИЫеїЇHadoopз®ЛеЇПпЉМжПТдїґдЉЪиЗ™еК®еѓЉеЕ•HadoopзЉЦз®ЛжО•еП£зЪДJARжЦЗдїґпЉМињЩж†ЈзФ®жИЈе∞±еПѓдї•еЬ®EclipseзЪДеی嚥еМЦзХМйЭҐдЄ≠зЉЦеЖЩгАБи∞Г иѓХгАБињРи°МHadoopз®ЛеЇПпЉИеМЕжЛђеНХжЬЇз®ЛеЇПеТМеИЖеЄГеЉПз®ЛеЇПпЉЙпЉМдєЯеПѓдї•еЬ®еЕґдЄ≠жЯ•зЬЛиЗ™еЈ±з®ЛеЇПзЪДеЃЮжЧґзКґжАБгАБйФЩиѓѓдњ°жБѓеТМињРи°МзїУжЮЬпЉМињШеПѓдї•жЯ•зЬЛгАБзЃ°зРЖHDFSдї•еПКжЦЗдїґгАВ жАїеЬ∞жЭ•иѓіпЉМHadoop EclipseжПТдїґеЃЙи£ЕзЃАеНХпЉМдљњзФ®жЦєдЊњпЉМеКЯиГљеЉЇе§ІпЉМе∞§еЕґжШѓеЬ®HadoopзЉЦз®ЛжЦєйЭҐпЉМжШѓHadoopеЕ•йЧ®еТМHadoopзЉЦз®ЛењЕдЄНеПѓе∞СзЪДеЈ•еЕЈгАВ
2.2 HadoopеЈ•дљЬзЫЃељХзЃАдїЛ
гААгААдЄЇдЇЖдї•еРОжЦєдЊњеЉАеПСпЉМжИСдїђжМЙзЕІдЄЛйЭҐжККеЉАеПСдЄ≠зФ®еИ∞зЪДиљѓдїґеЃЙи£ЕеЬ®ж≠§зЫЃељХдЄ≠пЉМJDKеЃЙи£ЕйЩ§е§ЦпЉМжИСињЩйЗМжККJDKеЃЙи£ЕеЬ®CзЫШзЪДйїШиЃ§еЃЙи£ЕиЈѓеЊДдЄЛпЉМдЄЛйЭҐжШѓжИСзЪДеЈ•дљЬзЫЃељХпЉЪ
 
¬†¬†¬† з≥їзїЯз£БзЫШпЉИEпЉЪпЉЙ
        |---HadoopWorkPlat
            |--- eclipse
            |--- hadoop-1.0.0
            |--- workplace
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† |---вА¶вА¶
 
гААгААжМЙзЕІдЄКйЭҐзЫЃељХжККEclipseеТМHadoopиІ£еОЛеИ∞"E:\HadoopWorkPlat"дЄЛйЭҐпЉМеєґеИЫеїЇ"workplace"дљЬдЄЇEclipseзЪДеЈ•дљЬз©ЇйЧігАВ
 
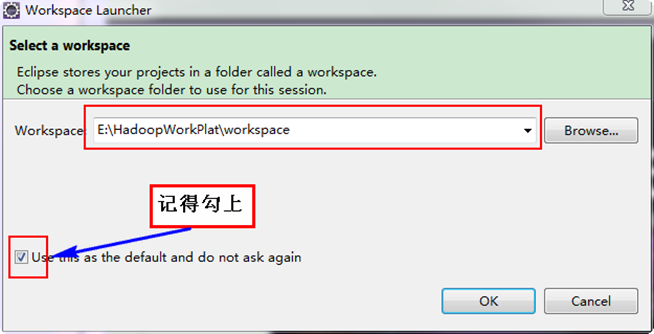
 
гААгААе§Зж≥®пЉЪе§ІеЃґеПѓдї•жМЙзЕІиЗ™еЈ±зЪДжГЕеЖµпЉМдЄНдЄАеЃЪжМЙзЕІжИСзЪДзїУжЮДжЭ•иЃЊиЃ°гАВ
2.3 дњЃжФєз≥їзїЯзЃ°зРЖеСШеРНе≠Ч
гААгААзїПињЗ䪧姩е§Ъжђ°жΥ糥пЉМдЄЇдЇЖдљњEclipseиГљж≠£еЄЄеѓєHadoopйЫЖзЊ§зЪДHDFSдЄКзЪДжЦЗдїґиГљињЫи°МдњЃжФєеТМеИ†йЩ§пЉМжЙАдї•дњЃжФєдљ†еЈ•дљЬжЧґжЙАзФ®зЪДWin7з≥їзїЯзЃ°зРЖеСШеРНе≠ЧпЉМйїШиЃ§дЄАиИђдЄЇ"Administrator"пЉМжККеЃГдњЃжФєдЄЇ"hadoop"пЉМ ж≠§зФ®жИЈеРНдЄОHadoopйЫЖзЊ§жЩЃйАЪзФ®жИЈдЄАиЗіпЉМе§ІеЃґеЇФиѓ•иЃ∞еЊЧжИСдїђHadoopйЫЖзЊ§дЄ≠жЙАжЬЙзЪДжЬЇеЩ®йГљжЬЙдЄАдЄ™жЩЃйАЪзФ®жИЈвАФвАФhadoopпЉМиАМдЄФHadoopињРи°МдєЯжШѓзФ® ињЩдЄ™зФ®жИЈињЫи°МзЪДгАВдЄЇдЇЖдЄНиЗ≥дЇОдЄЇжЭГйЩРиЛ¶жБЉпЉМжИСдїђеПѓдї•дњЃжФєWin7дЄКз≥їзїЯзЃ°зРЖеСШзЪДеІУеРНпЉМињЩж†Је∞±йБњеЕНеЗЇзО∞иѓ•зФ®жИЈеЬ®HadoopйЫЖзЊ§дЄКж≤°жЬЙжЭГйЩРз≠ЙйГљзЦЉйЧЃйҐШпЉМдЉЪеѓЉиЗі еЬ®EclipseдЄ≠еѓєHadoopйЫЖзЊ§зЪДHDFSеИЫеїЇеТМеИ†йЩ§жЦЗдїґеПЧељ±еУНгАВ
гААгААдљ†еПѓдї•еБЪдЄАдЄЛеЃЮй™МпЉМжЯ•зЬЛMaster.HadoopжЬЇеЩ®дЄК"/usr/hadoop/logs"дЄЛйЭҐзЪДжЧ•ењЧгАВеПСзО∞жЭГйЩРдЄНе§ЯпЉМдЄНиГљињЫи°М"Write"жУНдљЬпЉМзљСдЄКжЬЙеЗ†зІНиІ£еЖ≥жЦєж°ИпЉМдљЖжШѓеѓєHadoop1.0дЄНиµЈдљЬзФ®пЉМиѓ¶жГЕиІБ"еЄЄиІБйЧЃйҐШFAQ_2"гАВдЄЛйЭҐжИСдїђињЫи°МдњЃжФєзЃ°зРЖеСШеРНе≠ЧгАВ
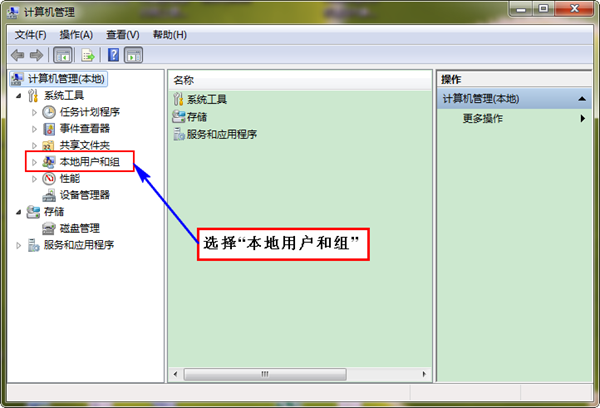
гААгААй¶ЦеЕИ"еП≥еЗї"ж°МйЭҐдЄКеЫЊж†З"жИСзЪДзФµиДС"пЉМйАЙжЛ©"зЃ°зРЖ"пЉМеЉєеЗЇзХМйЭҐе¶ВдЄЛпЉЪ
 
 
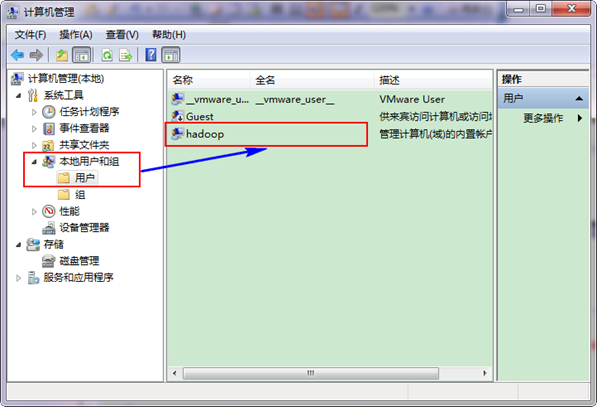
гААгААжО•зЭАйАЙжЛ©"жЬђеЬ∞зФ®жИЈеТМзїД"пЉМе±ХеЉА"зФ®жИЈ"пЉМжЙЊеИ∞з≥їзїЯзЃ°зРЖеСШ"Administrator"пЉМдњЃжФєеЕґдЄЇ"hadoop"пЉМжУНдљЬзїУжЮЬе¶ВдЄЛеЫЊпЉЪ
 
 
гААгААжЬАеРОпЉМжККзФµиДСињЫи°М"ж≥®йФА"жИЦиАЕ"йЗНеРѓзФµиДС"пЉМињЩж†ЈжЙНиГљдљњзЃ°зРЖеСШжЙНиГљзФ®ињЩдЄ™еРНе≠ЧгАВ
2.4 EclipseжПТдїґеЉАеПСйЕНзљЃ
гААгААзђђдЄАж≠•пЉЪжККжИСдїђзЪД"hadoop-eclipse-plugin-1.0.0.jar"жФЊеИ∞EclipseзЪДзЫЃељХзЪД"plugins"дЄ≠пЉМзДґеРОйЗНжЦ∞EclipseеН≥еПѓзФЯжХИгАВ
 
¬†¬†¬† з≥їзїЯз£БзЫШпЉИEпЉЪпЉЙ
        |---HadoopWorkPlat
            |--- eclipse
                |--- plugins
                    |--- hadoop-eclipse-plugin-1.0.0.jar
 
гААгААдЄКйЭҐжШѓжИСзЪД"hadoop-eclipse-plugin"жПТдїґжФЊзљЃзЪДеЬ∞жЦєгАВйЗНеРѓEclipseе¶ВдЄЛеЫЊпЉЪ
 
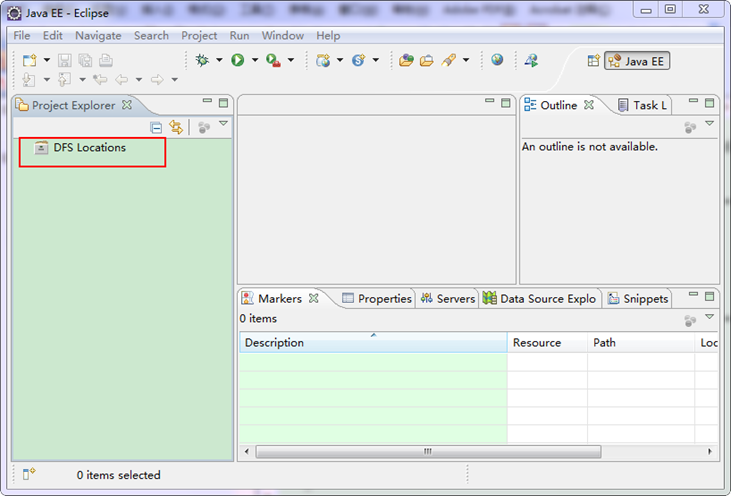
 
гААгААзїЖењГзЪДдљ†дїОдЄКеЫЊдЄ≠еЈ¶дЊІ"Project Explorer"дЄЛйЭҐеПСзО∞"DFS Locations"пЉМиѓіжШОEclipseеЈ≤зїПиѓЖеИЂеИЪжЙНжФЊеЕ•зЪДHadoop EclipseжПТдїґдЇЖгАВ
 
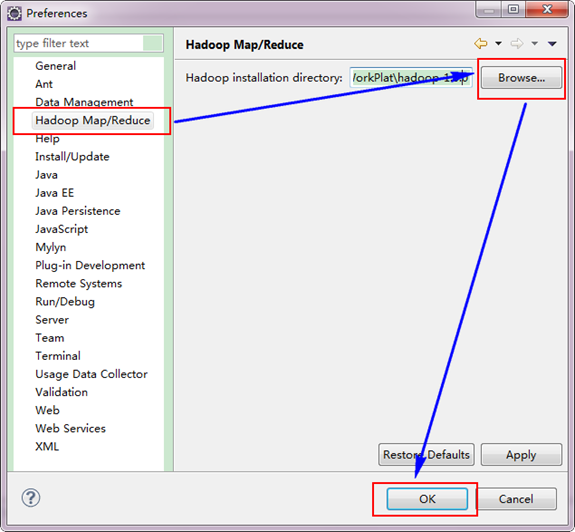
гААгААзђђдЇМж≠•пЉЪйАЙжЛ©"Window"иПЬеНХдЄЛзЪД"Preference"пЉМзДґеРОеЉєеЗЇдЄАдЄ™з™ЧдљУпЉМеЬ®з™ЧдљУзЪДеЈ¶дЊІпЉМжЬЙдЄАеИЧйАЙй°єпЉМйЗМйЭҐдЉЪе§ЪеЗЇ"Hadoop Map/Reduce"йАЙй°єпЉМзВєеЗїж≠§йАЙй°єпЉМйАЙжЛ©HadoopзЪДеЃЙи£ЕзЫЃељХпЉИе¶ВжИСзЪДHadoopзЫЃељХпЉЪE:\HadoopWorkPlat\hadoop-1.0.0пЉЙгАВзїУжЮЬе¶ВдЄЛеЫЊпЉЪ
 
 
гААгААзђђдЄЙж≠•пЉЪеИЗжНҐ"Map/Reduce"еЈ•дљЬзЫЃељХпЉМжЬЙдЄ§зІНжЦєж≥ХпЉЪ
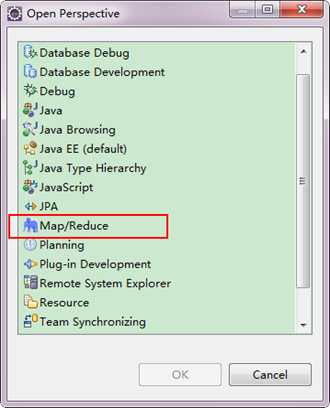
гААгАА1пЉЙйАЙжЛ©"Window"иПЬеНХдЄЛйАЙжЛ©"Open Perspective"пЉМеЉєеЗЇдЄАдЄ™з™ЧдљУпЉМдїОдЄ≠йАЙжЛ©"Map/Reduce"йАЙй°єеН≥еПѓињЫи°МеИЗжНҐгАВ
 
 
гААгАА2пЉЙеЬ®EclipseиљѓдїґзЪДеП≥дЄКиІТпЉМзВєеЗїеЫЊж†З" "дЄ≠зЪД"
"дЄ≠зЪД" "пЉМзВєеЗї"Other"йАЙй°єпЉМдєЯеПѓдї•еЉєеЗЇдЄКеЫЊпЉМдїОдЄ≠йАЙжЛ©"Map/Reduce"пЉМзДґеРОзВєеЗї"OK"еН≥еПѓз°ЃеЃЪгАВ
"пЉМзВєеЗї"Other"йАЙй°єпЉМдєЯеПѓдї•еЉєеЗЇдЄКеЫЊпЉМдїОдЄ≠йАЙжЛ©"Map/Reduce"пЉМзДґеРОзВєеЗї"OK"еН≥еПѓз°ЃеЃЪгАВ
гААгААеИЗжНҐеИ∞"Map/Reduce"еЈ•дљЬзЫЃељХдЄЛзЪДзХМйЭҐе¶ВдЄЛеЫЊжЙАз§ЇгАВ
 
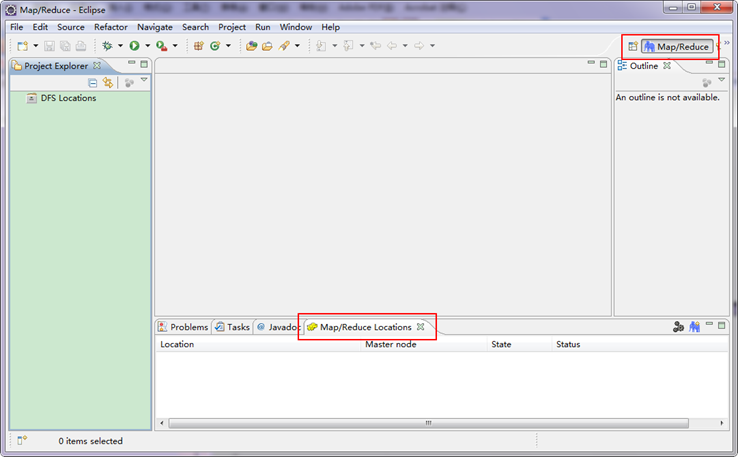
 
гААгААзђђеЫЫж≠•пЉЪеїЇзЂЛдЄОHadoopйЫЖзЊ§зЪДињЮжО•пЉМеЬ®EclipseиљѓдїґдЄЛйЭҐзЪД"Map/Reduce Locations"ињЫи°МеП≥еЗїпЉМеЉєеЗЇдЄАдЄ™йАЙй°єпЉМйАЙжЛ©"New Hadoop Location"пЉМзДґеРОеЉєеЗЇдЄАдЄ™з™ЧдљУгАВ
 

 
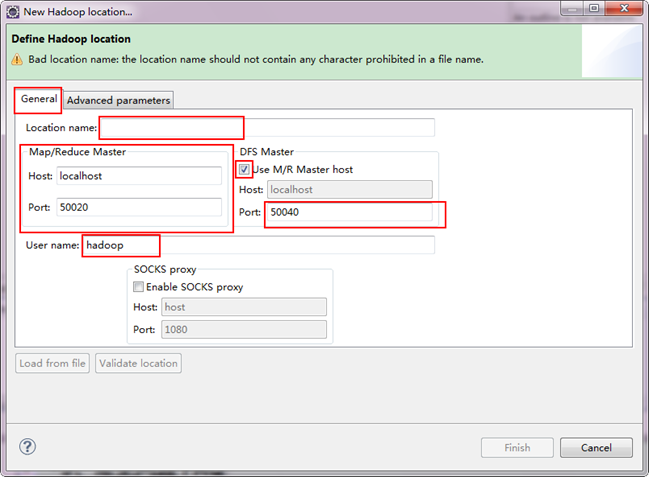
 
гААгААж≥®жДПдЄКеЫЊдЄ≠зЪДзЇҐиЙ≤ж†Зж≥®зЪДеЬ∞жЦєпЉМжШѓйЬАи¶БжИСдїђеЕ≥ж≥®зЪДеЬ∞жЦєгАВ
-
Location NameпЉЪеПѓдї•дїїжДПеЕґпЉМж†ЗиѓЖдЄАдЄ™"Map/Reduce Location"
-
Map/Reduce Master
HostпЉЪ192.168.1.2пЉИMaster.HadoopзЪДIPеЬ∞еЭАпЉЙ
PortпЉЪ9001
-
DFS Master
Use M/R Master hostпЉЪеЙНйЭҐзЪДеЛЊдЄКгАВпЉИеЫ†дЄЇжИСдїђзЪДNameNodeеТМJobTrackerйГљеЬ®дЄАдЄ™жЬЇеЩ®дЄКгАВпЉЙ
PortпЉЪ9000
-
User nameпЉЪhadoopпЉИйїШиЃ§дЄЇWinз≥їзїЯзЃ°зРЖеСШеРНе≠ЧпЉМеЫ†дЄЇжИСдїђдєЛеЙНжФєдЇЖжЙАдї•ињЩйЗМе∞±еПШжИРдЇЖhadoopгАВпЉЙ
 
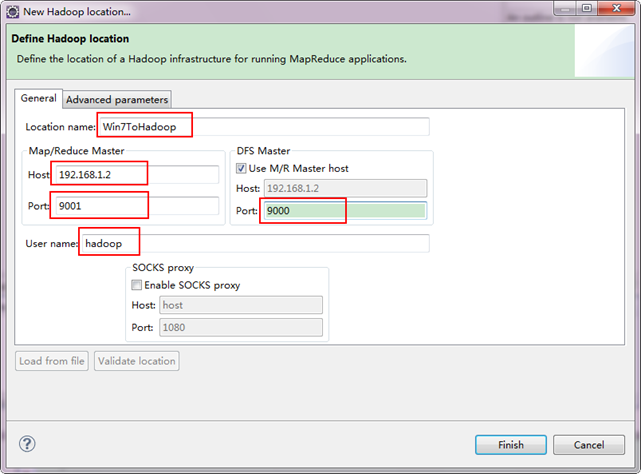
 
гААгААе§Зж≥®пЉЪињЩйЗМйЭҐзЪДHostгАБPortеИЖеИЂдЄЇдљ†еЬ®mapred-site.xmlгАБcore-site.xmlдЄ≠йЕНзљЃзЪДеЬ∞еЭАеПКзЂѓеП£гАВдЄНжЄЕж•ЪзЪДеПѓдї•еПВиАГ"HadoopйЫЖзЊ§_зђђ5жЬЯ_HadoopеЃЙи£ЕйЕНзљЃ_V1.0"ињЫи°МжЯ•зЬЛгАВ
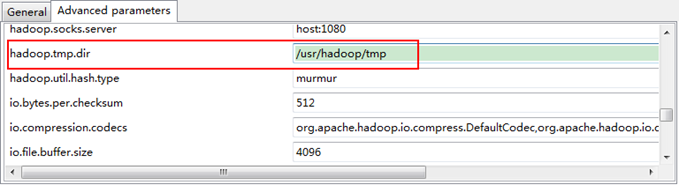
¬†гААгААжО•зЭАзВєеЗї"Advanced parameters"дїОдЄ≠жЙЊиІБ"hadoop.tmp.dir"пЉМдњЃжФєжИРдЄЇжИСдїђHadoopйЫЖзЊ§дЄ≠иЃЊзљЃзЪДеЬ∞еЭАпЉМжИСдїђзЪДHadoopйЫЖзЊ§жШѓ"/usr/hadoop/tmp"пЉМињЩдЄ™еПВжХ∞еЬ®"core-site.xml"ињЫи°МдЇЖйЕНзљЃгАВ
 
 
гААгААзВєеЗї"finish"дєЛеРОпЉМдЉЪеПСзО∞EclipseиљѓдїґдЄЛйЭҐзЪД"Map/Reduce Locations"еЗЇзО∞дЄАжЭ°дњ°жБѓпЉМе∞±жШѓжИСдїђеИЪжЙНеїЇзЂЛзЪД"Map/Reduce Location"гАВ
 

    
гААгААзђђдЇФж≠•пЉЪжЯ•зЬЛHDFSжЦЗдїґз≥їзїЯпЉМеєґе∞ЭиѓХеїЇзЂЛжЦЗдїґе§єеТМдЄКдЉ†жЦЗдїґгАВзВєеЗїEclipseиљѓдїґеЈ¶дЊІзЪД"DFS Locations"дЄЛйЭҐзЪД"Win7ToHadoop"пЉМе∞±дЉЪе±Хз§ЇеЗЇHDFSдЄКзЪДжЦЗдїґзїУжЮДгАВ
 
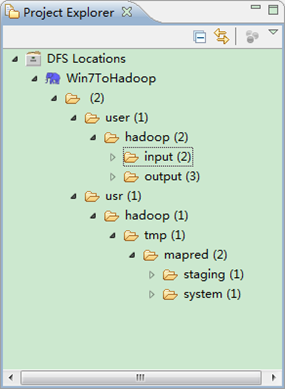
    
гААгААеП≥еЗї"Win7ToHadoop√†user√†hadoop"еПѓдї•е∞ЭиѓХеїЇзЂЛдЄАдЄ™"жЦЗдїґе§є--xiapi"пЉМзДґеРОеП≥еЗїеИЈжЦ∞е∞±иГљжЯ•зЬЛжИСдїђеИЪжЙНеїЇзЂЛзЪДжЦЗдїґе§єгАВ
 
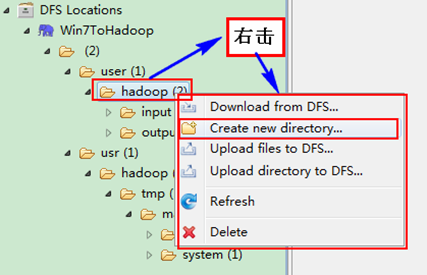
 
гААгААеИЫеїЇеЃМдєЛеРОпЉМеєґеИЈжЦ∞пЉМжШЊз§ЇзїУжЮЬе¶ВдЄЛпЉЪ
 
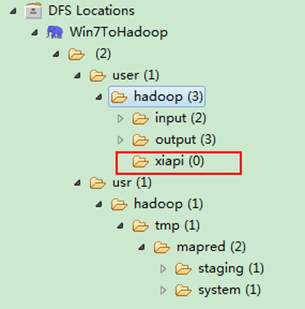
 
гААгААзФ®SecureCRTињЬз®ЛзЩїељХ"Master.Hadoop"жЬНеК°еЩ®пЉМзФ®дЄЛйЭҐеСљдї§жЯ•зЬЛжШѓеР¶еЈ≤зїПеїЇзЂЛдЄАдЄ™"xiapi"зЪДжЦЗдїґе§єгАВ
 
hadoop fs -ls
 

    
гААгААеИ∞ж≠§дЄЇж≠ҐпЉМжИСдїђзЪДHadoop EclipseеЉАеПСзОѓеҐГеЈ≤зїПйЕНзљЃеЃМжѓХпЉМдЄНе∞љеЕізЪДеРМе≠¶еПѓдї•дЄКдЉ†зВєжЬђеЬ∞жЦЗдїґеИ∞HDFSеИЖеЄГеЉПжЦЗдїґдЄКпЉМеПѓдї•дЇТзЫЄеѓєжѓФжДПиІБжЦЗдїґжШѓеР¶еЈ≤зїПдЄКдЉ†жИРеКЯгАВ
3гАБEclipseињРи°МWordCountз®ЛеЇП
3.1 йЕНзљЃEclipseзЪДJDK
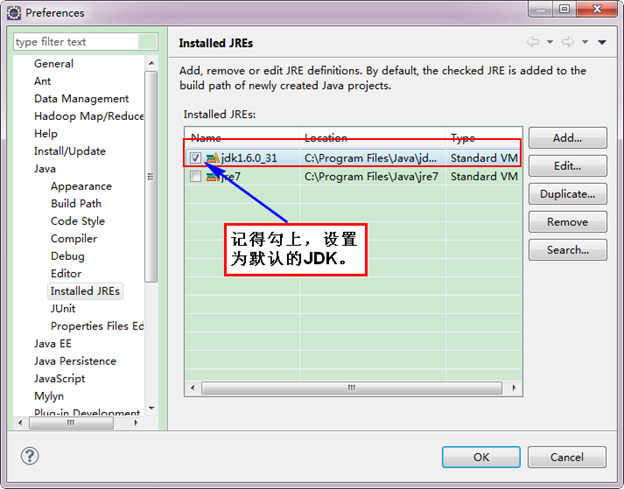
гААгААе¶ВжЮЬзФµиДСдЄКдЄНдїЕдїЕеЃЙи£ЕзЪДJDK6.0пЉМйВ£дєИи¶Бз°ЃеЃЪдЄАдЄЛEclipseзЪДеє≥еП∞зЪДйїШиЃ§JDKжШѓеР¶6.0гАВдїО"Window"иПЬеНХдЄЛйАЙжЛ©"Preference"пЉМеЉєеЗЇдЄАдЄ™з™ЧдљУпЉМдїОз™ЧдљУзЪДеЈ¶дЊІжЙЊиІБ"Java"пЉМйАЙжЛ©"Installed JREs"пЉМзДґеРОжЈїеК†JDK6.0гАВдЄЛйЭҐжШѓжИСзЪДйїШиЃ§йАЙжЛ©JREгАВ
 
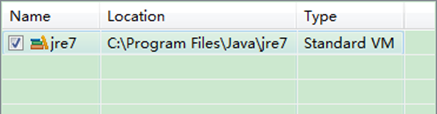
 
гААгААдЄЛйЭҐжШѓж≤°жЬЙжЈїеК†дєЛеЙНзЪДиЃЊзљЃе¶ВдЄЛпЉЪ
 
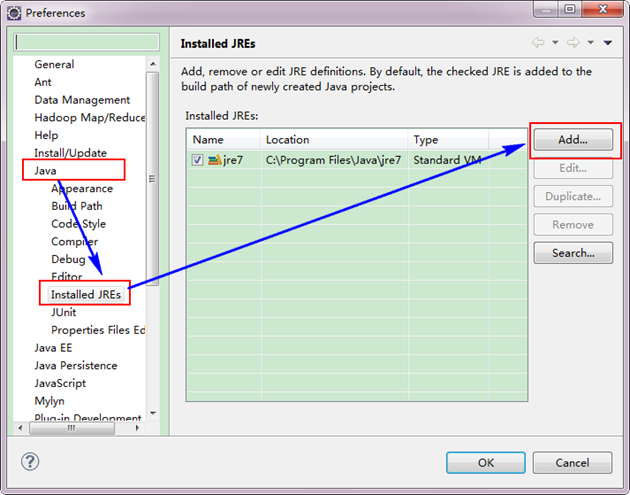
 
гААгААдЄЛйЭҐжШѓжЈїеК†еЃМJDK6.0дєЛеРОзїУжЮЬе¶ВдЄЛпЉЪ
 
 
гААгААжО•зЭАиЃЊзљЃComplierгАВ
 
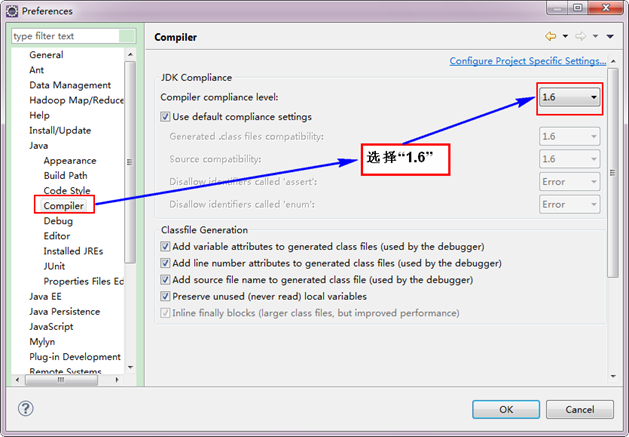
 
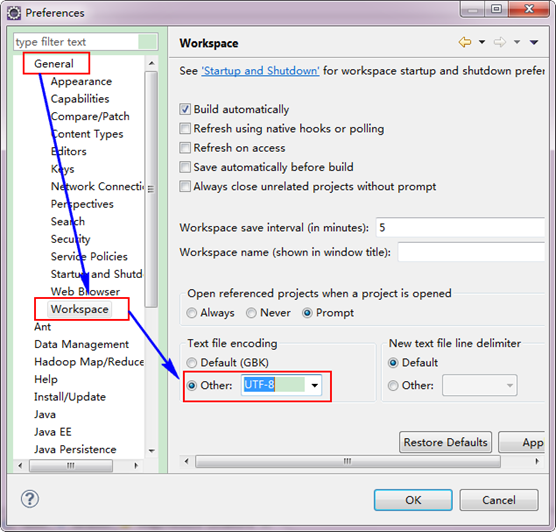
3.2 иЃЊзљЃEclipseзЪДзЉЦз†БдЄЇUTF-8
 
 
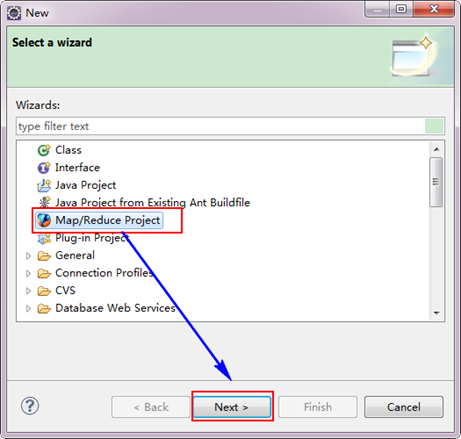
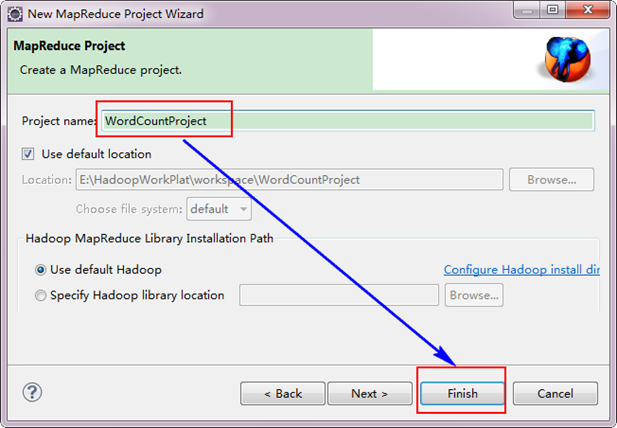
3.3 еИЫеїЇMapReduceй°єзЫЃ
¬†гААгААдїО"File"иПЬеНХпЉМйАЙжЛ©"Other"пЉМжЙЊеИ∞"Map/Reduce Project"пЉМзДґеРОйАЙжЛ©еЃГгАВ
 
    
гААгААжО•зЭАпЉМе°ЂеЖЩMapReduceеЈ•з®ЛзЪДеРНе≠ЧдЄЇ"WordCountProject"пЉМзВєеЗї"finish"еЃМжИРгАВ
 
 
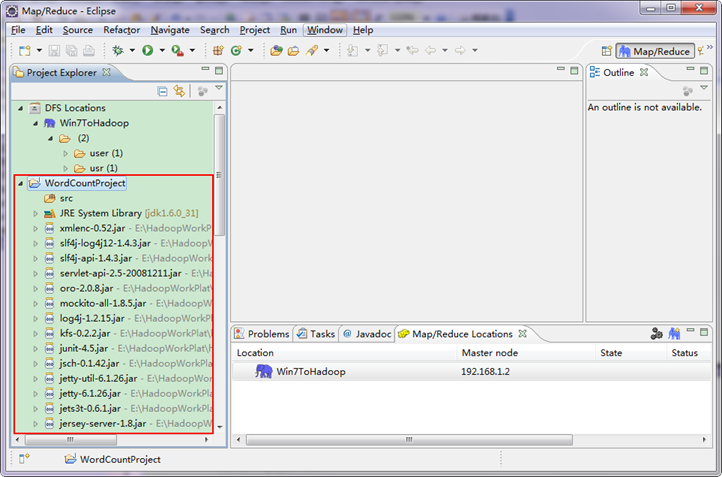
гААгААзЫЃеЙНдЄЇж≠ҐжИСдїђеЈ≤зїПжИРеКЯеИЫеїЇдЇЖMapReduceй°єзЫЃпЉМжИСдїђеПСзО∞еЬ®EclipseиљѓдїґзЪДеЈ¶дЊІе§ЪдЇЖжИСдїђзЪДеИЪжЙНеїЇзЂЛзЪДй°єзЫЃгАВ
 
 
3.4 еИЫеїЇWordCountз±ї
гААгААйАЙжЛ©"WordCountProject"еЈ•з®ЛпЉМеП≥еЗїеЉєеЗЇиПЬеНХпЉМзДґеРОйАЙжЛ©"New"пЉМжО•зЭАйАЙжЛ©"Class"пЉМзДґеРОе°ЂеЖЩе¶ВдЄЛдњ°жБѓпЉЪ
 
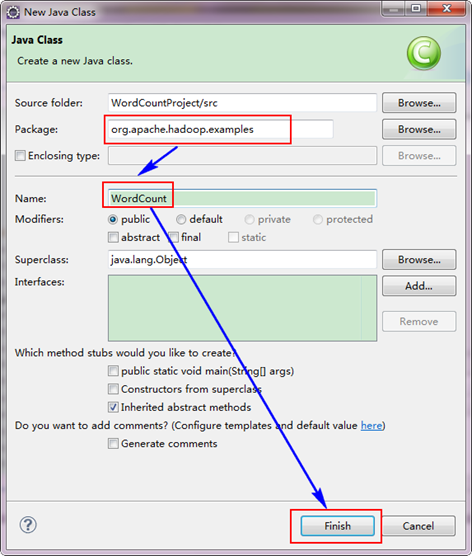
 
гААгААеЫ†дЄЇжИСдїђзЫіжО•зФ®Hadoop1.0.0иЗ™еЄ¶зЪДWordCountз®ЛеЇПпЉМжЙАдї•жК•еРНйЬАи¶БеТМдї£з†БдЄ≠зЪДдЄАиЗідЄЇ"org.apache.hadoop.examples"пЉМз±їеРНдєЯењЕй°їдЄАиЗідЄЇ"WordCount"гАВињЩдЄ™дї£з†БжФЊеЬ®е¶ВдЄЛзЪДзїУжЮДдЄ≠гАВ
 
    hadoop-1.0.0
        |---src
            |---examples
                |---org
                    |---apache
                        |---hadoop
                            |---examples
 
гААгААдїОдЄКйЭҐзЫЃељХдЄ≠жЙЊиІБ"WordCount.java"жЦЗдїґпЉМзФ®иЃ∞дЇЛжЬђжЙУеЉАпЉМзДґеРОжККдї£з†Бе§НеИґеИ∞еИЪжЙНеїЇзЂЛзЪДjavaжЦЗдїґдЄ≠гАВељУзДґжЇРз†БжЬЙдЇЫеПШеК®пЉМеПШеК®зЪДзЇҐиЙ≤еЈ≤зїПж†ЗиЃ∞еЗЇгАВ
 
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
package org.apache.hadoop.examples;
 
import java.io.IOException;
import java.util.StringTokenizer;
 
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
 
public class WordCount {
 
  public static class TokenizerMapper
       extends Mapper<Object, Text, Text, IntWritable>{
         private final static IntWritable one = new IntWritable(1);
    private Text word = new Text();
           public void map(Object key, Text value, Context context
                    ) throws IOException, InterruptedException {
      StringTokenizer itr = new StringTokenizer(value.toString());
      while (itr.hasMoreTokens()) {
        word.set(itr.nextToken());
        context.write(word, one);      }
    }
  }
     public static class IntSumReducer
       extends Reducer<Text,IntWritable,Text,IntWritable> {
    private IntWritable result = new IntWritable();
 
    public void reduce(Text key, Iterable values,
                       Context context
                       ) throws IOException, InterruptedException {
      int sum = 0;
      for (IntWritable val : values) {
        sum += val.get();
      }
      result.set(sum);
      context.write(key, result);
    }
  }
 
  public static void main(String[] args) throws Exception {
    Configuration conf = new Configuration();
    conf.set("mapred.job.tracker", "192.168.1.2:9001");
    String[] ars=new String[]{"input","newout"};
    String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
    if (otherArgs.length != 2) {
      System.err.println("Usage: wordcount  ");
      System.exit(2);
    }
    Job job = new Job(conf, "word count");
    job.setJarByClass(WordCount.class);
    job.setMapperClass(TokenizerMapper.class);
    job.setCombinerClass(IntSumReducer.class);
    job.setReducerClass(IntSumReducer.class);
    job.setOutputKeyClass(Text.class);
    job.setOutputValueClass(IntWritable.class);
    FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
    FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
    System.exit(job.waitForCompletion(true) ? 0 : 1);
  }
} |
 
гААгААе§Зж≥®пЉЪе¶ВжЮЬдЄНеК†"conf.set("mapred.job.tracker", "192.168.1.2:9001");"пЉМе∞ЖжПРз§Їдљ†зЪДжЭГйЩРдЄНе§ЯпЉМеЕґеЃЮзЕІжИРињЩж†ЈзЪДеОЯеЫ†жШѓеИЪжЙНиЃЊзљЃзЪД"Map/Reduce Location"еЕґдЄ≠зЪДйЕНзљЃдЄНжШѓеЃМеЕ®иµЈдљЬзФ®пЉМиАМжШѓеЬ®жЬђеЬ∞зЪДз£БзЫШдЄКеїЇзЂЛдЇЖжЦЗдїґпЉМеєґе∞ЭиѓХињРи°МпЉМжШЊзДґжШѓдЄНи°МзЪДгАВжИСдїђи¶БиЃ©EclipseжПРдЇ§дљЬдЄЪеИ∞HadoopйЫЖзЊ§дЄКпЉМжЙАдї•жИСдїђињЩйЗМжЙЛеК®жЈїеК†JobињРи°МеЬ∞еЭАгАВиѓ¶зїЖеПВиАГ"еЄЄиІБйЧЃйҐШFAQ_3"гАВ
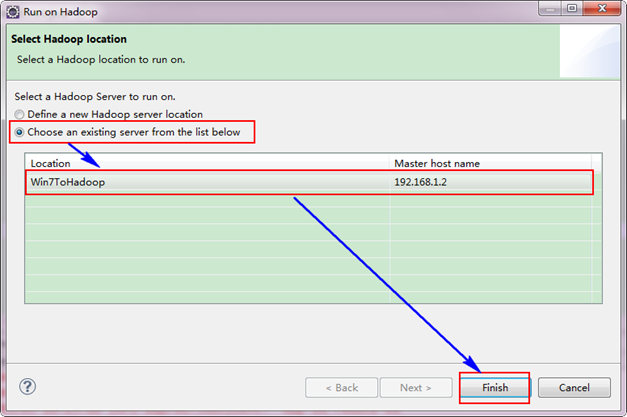
3.5 ињРи°МWordCountз®ЛеЇП
гААгААйАЙжЛ©"Wordcount.java"з®ЛеЇПпЉМеП≥еЗїдЄАжђ°жМЙзЕІ"Run AS√†Run on Hadoop"ињРи°МгАВзДґеРОдЉЪеЉєеЗЇе¶ВдЄЛеЫЊпЉМжМЙзЕІдЄЛеЫЊињЫи°МжУНдљЬгАВ
 
 
гААгААињРи°МзїУжЮЬе¶ВдЄЛпЉЪ
 
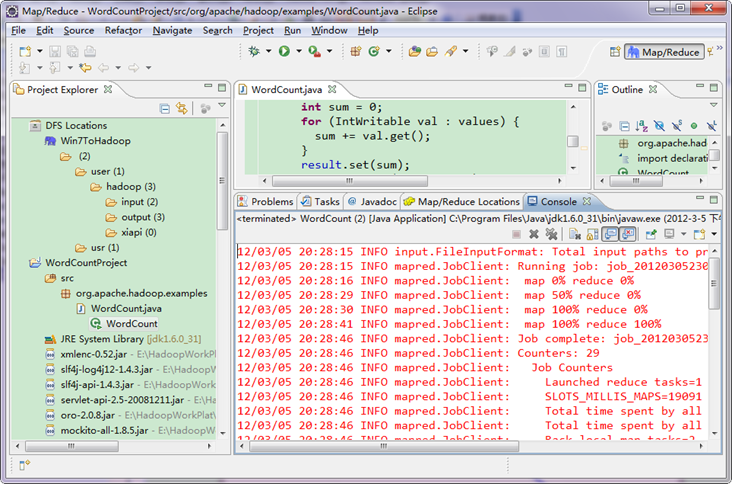
 
гААгААдїОдЄКеЫЊдЄ≠жИСдїђеЊЧзЯ•жИСдїђзЪДз®ЛеЇПеЈ≤зїПињРи°МжИРеКЯдЇЖгАВ
3.6 жЯ•зЬЛWordCountињРи°МзїУжЮЬ
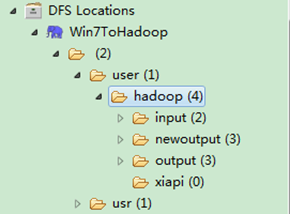
гААгААжЯ•зЬЛEclipseиљѓдїґеЈ¶дЊІпЉМеП≥еЗї"DFS Locations√†Win7ToHadoop√†user√†hadoop"пЉМ зВєеЗїеИЈжЦ∞жМЙйТЃ"Refresh"пЉМжИСдїђеИЪжЙНеЗЇзО∞зЪДжЦЗдїґе§є"newoutput"дЉЪеЗЇзО∞гАВиЃ∞еЊЧ"newoutput"жЦЗдїґе§єжШѓињРи°Мз®ЛеЇПжЧґиЗ™еК®еИЫеїЇзЪДпЉМе¶ВжЮЬеЈ≤ зїПе≠ШеЬ®зЫЄеРМзЪДзЪДжЦЗдїґе§єпЉМи¶БдєИз®ЛеЇПжНҐдЄ™жЦ∞зЪДиЊУеЗЇжЦЗдїґе§єпЉМи¶БдєИеИ†йЩ§HDFSдЄКзЪДйВ£дЄ™йЗНеРНжЦЗдїґе§єпЉМдЄНзДґдЉЪеЗЇйФЩгАВ
 
 
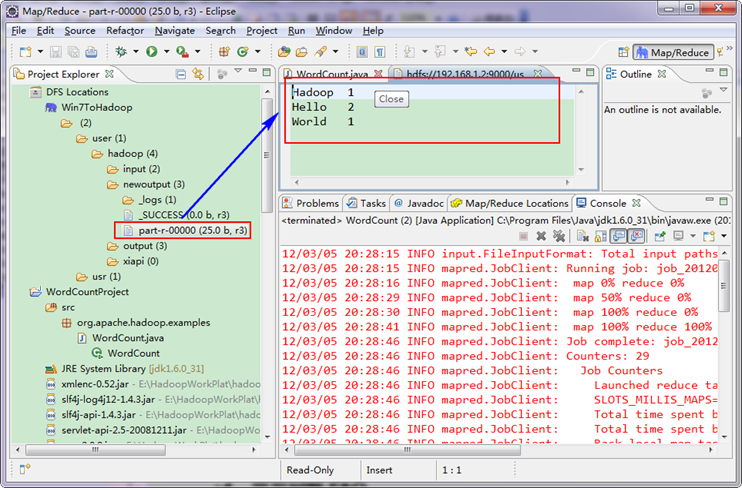
гААгААжЙУеЉА"newoutput"жЦЗдїґе§єпЉМжЙУеЉА"part-r-00000"жЦЗдїґпЉМеПѓдї•зЬЛиІБжЙІи°МеРОзЪДзїУжЮЬгАВ
 
 
гААгААеИ∞ж≠§дЄЇж≠ҐпЉМEclipseеЉАеПСзОѓеҐГиЃЊзљЃеЈ≤зїПеЃМжѓХпЉМеєґдЄФжИРеКЯињРи°МWordcountз®ЛеЇПпЉМдЄЛдЄАж≠•жИСдїђзЬЯж≠£еЉАеІЛHadoopдєЛжЧЕгАВ
4гАБеЄЄиІБйЧЃйҐШFAQ
4.1 "error: failure to login"йЧЃйҐШ
гААгААдЄЛйЭҐдї•зљСдЄКжЙЊзЪД"hadoop-0.20.203.0"дЄЇдЊЛпЉМжИСеЬ®дљњзФ®"V1.0"жЧґдєЯеЗЇзО∞ињЩж†ЈзЪДжГЕеЖµпЉМеОЯеЫ†е∞±жШѓйВ£дЄ™"hadoop-eclipse-plugin-1.0.0_V1.0.jar"пЉМжШѓзЫіжО•жККжЇРз†БзЉЦиѓСиАМжИРпЉМжХЕиАМзЉЇе∞СзЫЄеЇФзЪДJarеМЕгАВеЕЈдљУжГЕеЖµе¶ВдЄЛ
гААгААиѓ¶зїЖеЬ∞еЭАпЉЪhttp://blog.csdn.net/chengfei112233/article/details/7252404
гААгААеЬ®жИСеЃЮиЈµе∞ЭиѓХдЄ≠пЉМеПСзО∞hadoop-0.20.203.0зЙИжЬђзЪДиѓ•еМЕе¶ВжЮЬзЫіжО•е§НеИґеИ∞eclipseзЪДжПТдїґзЫЃељХдЄ≠пЉМеЬ®ињЮжО•DFSжЧґдЉЪеЗЇзО∞йФЩиѓѓпЉМжПРз§Їдњ°жБѓдЄЇпЉЪ "error: failure to login"гАВ
гААгААеЉєеЗЇзЪДйФЩиѓѓжПРз§Їж°ЖеЖЕеЃєдЄЇ"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". зїПињЗеѓЯзЬЛEclipseзЪДlogпЉМеПСзО∞жШѓзЉЇе∞СjarеМЕеѓЉиЗізЪДгАВињЫдЄАж≠•жЯ•жЙЊиµДжЦЩеРОпЉМеПСзО∞зЫіжО•е§НеИґhadoop-eclipse-plugin-0.20.203.0.jarпЉМиѓ•еМЕдЄ≠libзЫЃељХдЄЛзЉЇе∞СдЇЖjarеМЕгАВ
гААгААзїПињЗзљСдЄКиµДжЦЩжРЬйЫЖпЉМж≠§е§ДзїЩеЗЇж≠£з°ЃзЪДеЃЙи£ЕжЦєж≥ХпЉЪ
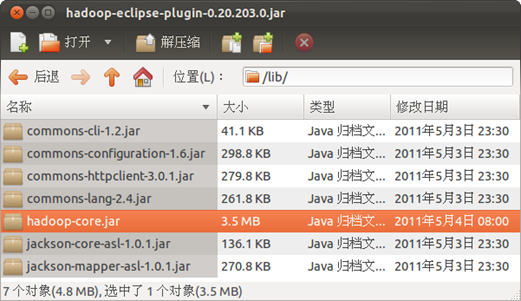
гААгААй¶ЦеЕИи¶Беѓєhadoop-eclipse-plugin-0.20.203.0.jarињЫи°МдњЃжФєгАВзФ®ељТж°£зЃ°зРЖеЩ®жЙУеЉАиѓ•еМЕпЉМеПСзО∞еП™жЬЙcommons-cli-1.2.jar еТМhadoop-core.jarдЄ§дЄ™еМЕгАВе∞Жhadoop/libзЫЃељХдЄЛзЪДпЉЪ
-
commons-configuration-1.6.jar ,
-
commons-httpclient-3.0.1.jar ,
-
commons-lang-2.4.jar ,
-
jackson-core-asl-1.0.1.jar
-
jackson-mapper-asl-1.0.1.jar
дЄАеЕ±5дЄ™еМЕе§НеИґеИ∞hadoop-eclipse-plugin-0.20.203.0.jarзЪДlibзЫЃељХдЄЛпЉМе¶ВдЄЛеЫЊпЉЪ
 
 
гААгААзДґеРОпЉМдњЃжФєиѓ•еМЕMETA-INFзЫЃељХдЄЛзЪДMANIFEST.MFпЉМе∞ЖclasspathдњЃжФєдЄЇдЄАдЄЛеЖЕеЃєпЉЪ
 
Bundle-ClassPath:classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-httpclient-3.0.1.jar,lib/jackson-core-asl-1.0.1.jar,lib/jackson-mapper-asl-1.0.1.jar,lib/commons-configuration-1.6.jar,lib/commons-lang-2.4.jar
 
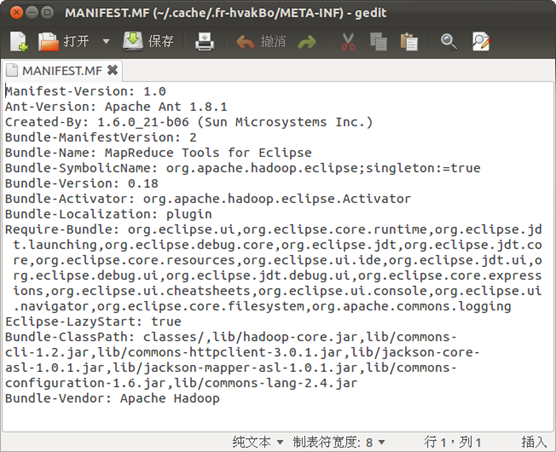
 
гААгААињЩж†Је∞±еЃМжИРдЇЖеѓєhadoop-eclipse-plugin-0.20.203.0.jarзЪДдњЃжФєгАВ
гААгААжЬАеРОпЉМе∞Жhadoop-eclipse-plugin-0.20.203.0.jarе§НеИґеИ∞EclipseзЪДpluginsзЫЃељХдЄЛгАВ
гААгААе§Зж≥®пЉЪдЄКйЭҐзЪДжУНдљЬеѓє"hadoop-1.0.0"дЄАж†ЈйАВзФ®гАВ
4.2 "Permission denied"йЧЃйҐШ
гААгААзљСдЄКиѓХдЇЖеЊИе§ЪпЉМжЬЙжПРеИ∞"hadoop fs -chmod 777 /user/hadoop "пЉМжЬЙжПРеИ∞"dfs.permissions зЪДйЕНзљЃй°єпЉМе∞ЖvalueеАЉжФєдЄЇ false"пЉМжЬЙжПРеИ∞"hadoop.job.ugi"пЉМдљЖжШѓйАЪйАЪж≤°жЬЙжХИжЮЬгАВ
гААгААеПВиАГжЦЗзМЃпЉЪ
¬†¬†¬†¬†¬†¬†¬† еЬ∞еЭА1пЉЪhttp://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
¬†¬†¬†¬†¬†¬†¬† еЬ∞еЭА2пЉЪhttp://sunjun041640.blog.163.com/blog/static/25626832201061751825292/
гААгАА¬†¬†йФЩиѓѓз±їеЮЛпЉЪorg.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=*********, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
гААгАА¬† иІ£еЖ≥жЦєж°ИпЉЪ
гААгААгААгААжИСзЪДиІ£еЖ≥жЦєж°ИзЫіжО•жККз≥їзїЯзЃ°зРЖеСШзЪДеРНе≠ЧжФєжИРдљ†зЪДHadoopйЫЖзЊ§ињРи°МhadoopзЪДйВ£дЄ™зФ®жИЈгАВ
4.3 "Failed to set permissions of path"йЧЃйҐШ
гААгААгААеПВиАГжЦЗзМЃпЉЪhttps://issues.apache.org/jira/browse/HADOOP-8089
гААгААгААйФЩиѓѓдњ°жБѓе¶ВдЄЛпЉЪ
гААгААгААгААERROR security.UserGroupInformation: PriviledgedActionException as: hadoop cause:java.io.IOException Failed to set permissions of path:\usr\hadoop\tmp\mapred\staging\hadoop753422487\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\hadoop\tmp \mapred\staging\hadoop753422487\.staging to 0700
гААгААгААиІ£еЖ≥жЦєж≥ХпЉЪ
 
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "[server]:9001");
 
гААгАА¬†"[server]:9001"дЄ≠зЪД"[server]"дЄЇHadoopйЫЖзЊ§MasterзЪДIPеЬ∞еЭАгАВ
4.4 "hadoop mapredжЙІи°МзЫЃељХжЦЗдїґжЭГ"йЩРйЧЃйҐШ
гААгААгААеПВиАГжЦЗзМЃпЉЪhttp://blog.csdn.net/azhao_dn/article/details/6921398
гААгААгААйФЩиѓѓдњ°жБѓе¶ВдЄЛпЉЪ
гААгААгААjob Submission failed with exception 'java.io.IOException(The ownership/permissions on the staging directory /tmp/hadoop-hadoop-user1/mapred/staging/hadoop-user1/.staging is not as expected. It is owned by hadoop-user1 and permissions are rwxrwxrwx. The directory must be owned by the submitter hadoop-user1 or by hadoop-user1 and permissions must be rwx------)
гААгААгААдњЃжФєжЭГйЩРпЉЪ
 




зЫЄеЕ≥жО®иНР
ињЩдЄ™жПТдїґеЕБиЃЄеЉАеПСиАЕзЫіжО•еЬ®IDEдЄ≠еѓєHadoopйЫЖзЊ§ињЫи°МжУНдљЬпЉМе¶ВеИЫеїЇгАБзЉЦиЊСеТМињРи°МMapReduceдїїеК°пЉМжЮБе§ІеЬ∞жПРеНЗдЇЖеЉАеПСжХИзОЗгАВжЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНињЩдЄ§дЄ™зЙИжЬђзЪДHadoop Eclipse PluginвАФвАФ1.2.1еТМ2.8.0гАВ й¶ЦеЕИпЉМHadoop-Eclipse-Plugin...
гАРж†ЗйҐШгАСпЉЪвАЬHadoopйЫЖзЊ§EclipseеЃЙи£ЕйЕНзљЃжМЗеНЧ30й°µ.pdfвАЭ ињЩдЄ™еОЛзЉ©жЦЗдїґвАЬhadoopйЫЖзЊ§eclipseеЃЙи£ЕйЕНзљЃеЕ±30й°µ.pdf.zipвАЭжШЊзДґеМЕеРЂдЇЖеЕ≥дЇОе¶ВдљХеЬ®EclipseзОѓеҐГдЄ≠йЕНзљЃHadoopйЫЖзЊ§зЪДиѓ¶зїЖжХЩз®ЛгАВHadoopжШѓдЄАдЄ™еЉАжЇРж°ЖжЮґпЉМдЄїи¶БзФ®дЇО...
windowsдЄЛ eclipseжУНдљЬhadoopйЫЖзЊ§ жПТдїґ
ињЩжђЊжПТдїґжШѓHadoopзФЯжАБз≥їзїЯзЪДзїДжИРйГ®еИЖпЉМеЃГдљњеЊЧJavaеЉАеПСиАЕиГље§ЯжЫіеК†зЫіиІВеЬ∞дЄОHadoopйЫЖзЊ§ињЫи°МдЇ§дЇТпЉМиАМжЧ†йЬАз¶їеЉАзЖЯжВЙзЪДEclipseеЈ•дљЬз©ЇйЧігАВ 1. **Hadoopж¶Вињ∞**пЉЪ HadoopжШѓдЄАдЄ™еЉАжЇРж°ЖжЮґпЉМзФ±ApacheеЯЇйЗСдЉЪзїіжК§пЉМдЄїи¶БзФ®дЇОе§ДзРЖеТМ...
UbuntuиЩЪжЛЯжЬЇHADOOPйЫЖзЊ§жР≠еїЇeclipseзОѓеҐГ hadoop-eclipse-plugin-3.3.1.jar
3. **ињРи°МдЄОи∞ГиѓХ**пЉЪжПТдїґеЕБиЃЄеЉАеПСиАЕзЫіжО•еЬ®EclipseдЄ≠жПРдЇ§MapReduceдљЬдЄЪеИ∞HadoopйЫЖзЊ§дЄКињРи°МпЉМжЧ†йЬАз¶їеЉАIDEгАВеРМжЧґпЉМеЃГжФѓжМБињЬз®Ли∞ГиѓХпЉМеПѓдї•еЬ®дї£з†БдЄ≠иЃЊзљЃжЦ≠зВєпЉМиІВеѓЯеПШйЗПзКґжАБпЉМжОТжЯ•йЧЃйҐШгАВ 4. **зЙИжЬђеЈЃеЉВ**пЉЪ - **2.7.1**пЉЪ...
ињЩдЄ™жПТдїґйАЪињЗжПРдЊЫдЄАз≥їеИЧзЙєжАІеТМеЈ•еЕЈпЉМжЮБе§ІеЬ∞дЄ∞еѓМдЇЖEclipseзЪДеКЯиГљпЉМдљњеЕґеПѓдї•ињЮжО•еИ∞HadoopйЫЖзЊ§пЉМжµПиІИHDFSжЦЗдїґз≥їзїЯпЉМжПРдЇ§еТМзЫСжОІMapReduceдїїеК°пЉМзЉЦиЊСеТМињРи°МHadoopжµБз≠ЙгАВињЩдљњеЊЧеЉАеПСиАЕеПѓдї•еЬ®зЉЦеЖЩHadoopеЇФзФ®з®ЛеЇПжЧґпЉМжЧ†йЬАз¶їеЉА...
- **иµДжЇРзЃ°зРЖ**пЉЪеПѓдї•жЯ•зЬЛеТМзЃ°зРЖHadoopйЫЖзЊ§зЪДиµДжЇРпЉМе¶ВиКВзВєзКґжАБгАБдїїеК°жЙІи°МжГЕеЖµз≠ЙгАВ - **жЦЗдїґжУНдљЬ**пЉЪжФѓжМБHDFSпЉИHadoop Distributed File SystemпЉЙжЦЗдїґзЪДдЄКдЉ†гАБдЄЛиљљгАБжЯ•зЬЛз≠ЙжУНдљЬгАВ 4. **зЙИжЬђеЈЃеЉВ**пЉЪ - дЄНеРМзЙИжЬђзЪД...
Hadoop-eclipse-plugin-2.7.2ж≠£жШѓдЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеЃГдЄЇEclipseжПРдЊЫдЇЖдЄОHadoopйЫЖзЊ§жЧ†зЉЭеѓєжО•зЪДеКЯиГљпЉМдљњеЊЧеЉАеПСиАЕеПѓдї•еЬ®зЖЯжВЙзЪДEclipseзОѓеҐГдЄ≠зЉЦеЖЩгАБи∞ГиѓХеТМињРи°МHadoop MapReduceз®ЛеЇПгАВ й¶ЦеЕИпЉМиЃ©жИСдїђжЈ±еЕ•дЇЖиІ£Hadoop-...
Hadoop-eclipse-pluginжШѓHadoopзФЯжАБз≥їзїЯдЄ≠зЪДдЄАдЄ™йЗНи¶БеЈ•еЕЈпЉМеЃГеЕБиЃЄеЉАеПСиАЕдљњзФ®Eclipse IDEзЫіжО•еЬ®HadoopйЫЖзЊ§дЄКеЉАеПСгАБжµЛиѓХеТМйГ®зљ≤MapReduceз®ЛеЇПгАВињЩдЄ™жПТдїґжЮБе§ІеЬ∞зЃАеМЦдЇЖHadoopеЇФзФ®з®ЛеЇПзЪДеЉАеПСжµБз®ЛпЉМдљњеЊЧJavaеЉАеПСиАЕиГље§ЯеИ©зФ®...
йАЪињЗиѓ•жПТдїґпЉМеЉАеПСиАЕеПѓдї•е∞ЖJavaдї£з†БзЉЦеЖЩгАБзЉЦиѓСеТМжµЛиѓХзЪДжµБз®ЛжЧ†зЉЭйЫЖжИРеИ∞зЖЯжВЙзЪДEclipseзХМйЭҐдЄ≠пЉМжЧ†йЬАз¶їеЉАIDEе∞±иГљеѓєHadoopйЫЖзЊ§ињЫи°МжУНдљЬгАВ еЬ®еЃЙи£ЕHadoop-Eclipse-Plugin-2.6.4.jarдєЛеРОпЉМеЉАеПСиАЕеПѓдї•йАЪињЗEclipseзЪД"New -> ...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХдљњзФ®Eclipse IDEзїУеРИhadoop-eclipse-plugin-2.6.0.jarжПТдїґпЉМеЃЮзО∞еЬ®WindowsзОѓеҐГдЄЛињЫи°МињЬз®ЛињЮжО•еИ∞HadoopйЫЖзЊ§пЉМе∞§еЕґйАВзФ®дЇО64дљНжУНдљЬз≥їзїЯгАВ й¶ЦеЕИпЉМжИСдїђи¶БзРЖиІ£HadoopзЪДж†ЄењГж¶ВењµгАВHadoopжШѓзФ±ApacheеЯЇйЗС...
иАМдЄЇдЇЖжЦєдЊњеЉАеПСиАЕеЬ®EclipseињЩж†ЈзЪДйЫЖжИРеЉАеПСзОѓеҐГдЄ≠зЫіжО•жУНдљЬHadoopйЫЖзЊ§пЉМHadoop Eclipse PluginеЇФињРиАМзФЯгАВжЬђжЦЗе∞Жиѓ¶зїЖжОҐиЃ®Hadoop Eclipse Plugin 2.6.5ињЩдЄАзЙИжЬђпЉМдї•еПКе¶ВдљХдљњзФ®еЃГжЭ•жПРеНЗHadoopеЉАеПСжХИзОЗгАВ Hadoop Eclipse ...
Hadoop Eclipse Plugin 2.6.0жШѓдЄАжђЊдЄУдЄЇEclipseйЫЖжИРеЉАеПСзОѓеҐГиЃЊиЃ°зЪДжПТдїґпЉМеЃГдљњеЊЧеЉАеПСиАЕиГље§ЯеЬ®зЖЯжВЙзЪДEclipseзОѓеҐГдЄ≠зЫіжО•жУНдљЬеТМзЃ°зРЖHadoopйЫЖзЊ§пЉМжЮБе§ІеЬ∞жПРеНЗдЇЖHadoopеЇФзФ®зЪДеЉАеПСжХИзОЗгАВињЩжђЊжПТдїґеЬ®HadoopзФЯжАБз≥їзїЯдЄ≠жЙЃжЉФзЭА...
3. **дљЬдЄЪжПРдЇ§**пЉЪеЉАеПСиАЕеПѓдї•зЫіжО•еЬ®EclipseдЄ≠зЉЦиѓСгАБжЙУеМЕеТМжПРдЇ§MapReduceдљЬдЄЪеИ∞HadoopйЫЖзЊ§пЉМжЧ†йЬАжЙЛеК®жЙІи°МеСљдї§и°МжУНдљЬпЉМжЮБе§ІеЬ∞зЃАеМЦдЇЖеЉАеПСжµБз®ЛгАВ 4. **и∞ГиѓХжФѓжМБ**пЉЪжПТдїґжПРдЊЫдЇЖеЉЇе§ІзЪДи∞ГиѓХеКЯиГљпЉМеПѓдї•еЬ®жЬђеЬ∞ж®°жЛЯињРи°М...
Hadoop_HadoopйЫЖзЊ§пЉИзђђ7жЬЯпЉЙ_EclipseеЉАеПСзОѓеҐГиЃЊзљЃ Hadoop_HadoopйЫЖзЊ§пЉИзђђ8жЬЯпЉЙ_HDFSеИЭжОҐдєЛжЧЕ Hadoop_HadoopйЫЖзЊ§пЉИзђђ9жЬЯпЉЙ_MapReduceеИЭзЇІж°ИдЊЛ Hadoop_HadoopйЫЖзЊ§пЉИзђђ10жЬЯпЉЙ_MySQLеЕ≥з≥їжХ∞жНЃеЇУ WebпЉИJson-Libз±їеЇУдљњзФ®...
4. **жПРдЇ§дїїеК°**пЉЪзЫіжО•еЬ®EclipseдЄ≠е∞ЖMapReduceдљЬдЄЪжПРдЇ§еИ∞HadoopйЫЖзЊ§пЉМжЧ†йЬАз¶їеЉАIDEгАВ 5. **иµДжЇРзЃ°зРЖ**пЉЪжПТдїґжФѓжМБиµДжЇРзЃ°зРЖеЩ®иІЖеЫЊпЉМдЊњдЇОжЯ•зЬЛеТМзЃ°зРЖHDFSдЄКзЪДжЦЗдїґеТМзЫЃељХгАВ 6. **зЙИжЬђеЕЉеЃєжАІ**пЉЪйТИеѓєHadoop 2.7.4зЪДдЉШеМЦпЉМ...
1. **й°єзЫЃйЕНзљЃ**пЉЪеЬ®EclipseдЄ≠еПѓдї•зЫіжО•еИЫеїЇHadoop MapReduceй°єзЫЃпЉМиЃЊзљЃHadoopйЫЖзЊ§зЪДйЕНзљЃдњ°жБѓпЉМе¶В Namenode еТМ JobTracker зЪДеЬ∞еЭАгАВ 2. **иµДжЇРзЃ°зРЖ**пЉЪйАЪињЗжПТдїґеПѓдї•жµПиІИHDFSжЦЗдїґз≥їзїЯпЉМдЄКдЉ†жИЦдЄЛиљљжЦЗдїґпЉМжЯ•зЬЛжЦЗдїґе±ЮжАІ...
- **и∞ГиѓХдЄОињРи°М**пЉЪжЧ†йЬАз¶їеЉАIDEпЉМеПѓдї•зЫіжО•еЬ®EclipseеЖЕжПРдЇ§дїїеК°еИ∞HadoopйЫЖзЊ§пЉМжЯ•зЬЛжЧ•ењЧпЉМзФЪиЗ≥ињЫи°МеНХж≠•и∞ГиѓХпЉМе§Іе§ІзЃАеМЦдЇЖеЉАеПСжµБз®ЛгАВ 5. **еЕЉеЃєжАІдЄОзЙИжЬђ** Hadoop Eclipse Plugin 1.1.2 зЙИжЬђйАВзФ®дЇОзЙєеЃЪзЙИжЬђзЪДHadoopеТМ...