
ĶĮ¼ĶĮĮ’╝Ühttp://hqman.iteye.com/blog/92684’╝īĶÖĮńäȵś»õĖĆń»ćÕŠłĶĆüńÜäµ¢ćń½ĀÕ»╣õ║ÄÕ░ÅńÖĮĶ┐śµś»µ£ēÕŠłÕż¦ńÜäķśģĶ»╗õ╗ĘÕĆ╝ŃĆé
Õ»╣õ║ÄńÉåĶ¦ŻJ2EEķøåńŠżµŖƵ£»õĖŹķöÖńÜäµ¢ćń½Ā’╝īĶÖĮńäȵś»SunńÜäµŖƵ£»õ║║ÕæśµÆ░ÕåÖńÜä’╝īÕ¤║µ£¼Ķ¦éńé╣Ķ┐śń«ŚÕ«óĶ¦é’╝īÕåģÕ«╣µĘ▒µĄģµü░ÕĮō’╝īķØ×ÕĖĖķĆéÕÉłÕłÜÕłÜµÄźĶ¦”ķøåńŠżńÜäµ£ŗÕÅŗķśģĶ»╗’╝īµĢģµŁżÕż¦Ķāåń┐╗Ķ»æĶ┐ćµØź’╝īµöŠÕ£©Ķ┐ÖķćīÕÆīÕż¦Õ«ČÕģ▒õ║½’╝īķöÖĶ»»ķÜŠÕģŹ’╝īµ¼óĶ┐ĵī浣ŻŃĆé
ÕĤķōŠµÄź
Uncover the hood of J2EE Clustering
┬Ā
===================================================================================
4 webÕ▒éķøåńŠżÕ«×ńÄ░
webÕ▒éķøåńŠżµś»J2EEķøåńŠżõĖŁµ£ĆķćŹĶ”üÕÆīÕ¤║ńĪĆńÜäÕŖ¤ĶāĮŃĆéwebÕ▒éķøåńŠżµŖƵ£»Õīģµŗ¼’╝ÜWebĶ┤¤ĶĮĮÕØćĶĪĪÕÆīHTTPSessionÕż▒µĢłĶĮ¼ń¦╗ŃĆé
4.1 webĶ┤¤ĶĮĮÕØćĶĪĪ
J2EEµÅÉõŠøÕĢåµ£ēÕŠłÕżÜµ¢╣µ│ĢÕ«×ńÄ░webĶ┤¤ĶĮĮÕØćĶĪĪ’╝īÕ¤║µ£¼ńÜä’╝īÕ£©µĄÅĶ¦łÕÖ©ÕÆīwebµ£ŹÕŖĪÕÖ©õ╣ŗķŚ┤µöŠńĮ«Ķ┤¤ĶĮĮÕØćĶĪĪÕÖ©ŃĆé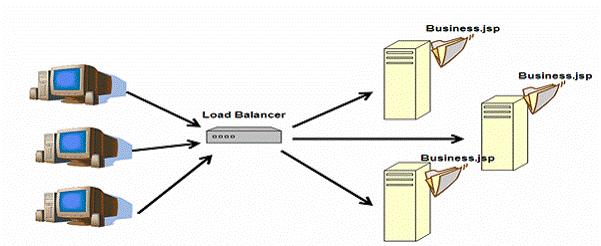
ÕøŠ5’╝ÜwebĶ┤¤ĶĮĮÕØćĶĪĪ
Ķ┤¤ĶĮĮÕØćĶĪĪÕÖ©ÕÅ»õ╗źµś»ńĪ¼õ╗Čõ║¦ÕōüÕ”éF5 Ķ┤¤ĶĮĮÕØćĶĪĪÕÖ©’╝īõ╣¤ÕÅ»õ╗źµś»ÕÅ”õĖĆõĖ¬ÕĖ”µ£ēĶ┤¤ĶĮĮÕØćĶĪĪµÅÆõ╗ČńÜäwebµ£ŹÕŖĪÕÖ©ŃĆéń«ĆÕŹĢńÜäÕĖ”µ£ēipchainsńÜälinux boxõ╣¤ÕÅ»õ╗źµē¦ĶĪīĶ┤¤ĶĮĮÕØćĶĪĪńÜäÕŖ¤ĶāĮŃĆ鵌ĀĶ«║õĮĢń¦ŹµŖƵ£»’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©ķĆÜÕĖĖµ£ēõ╗źõĖŗńē╣µĆ¦’╝Ü
*Õ«×ńÄ░Ķ┤¤ĶĮĮÕØćĶĪĪń«Śµ│Ģ
ÕĮōÕ«óµłĘń½»Ķ»Ęµ▒éĶŠŠÕł░µŚČ’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©Õå│Õ«ÜÕ”éõĮĢÕłåÕÅæĶ»Ęµ▒éÕł░ÕÉÄń½»µ£ŹÕŖĪÕÖ©Õ«×õŠŗŃĆéķĆÜÕĖĖńÜäń«Śµ│ĢÕīģµŗ¼Round-Robin’╝ī(µīćńÜ䵜»õĮ┐ń╗äõĖŁµēƵ£ēµłÉÕæśķāĮĶāĮÕØćńŁēÕ£░õ╗źµ¤Éń¦ŹÕÉłńÉå ńÜäķĪ║Õ║ÅĶó½ķĆēµŗ®Õł░ńÜäõĖĆń¦ŹÕ«ēµÄƵ¢╣Õ╝Å’╝ī ķĆÜÕĖĖµś»õ╗ÄÕłŚĶĪ©ńÜäÕż┤Ķć│Õ░Š’╝īĶĆīÕÉÄÕæ©ĶĆīÕżŹÕ¦ŗ)’╝īķÜŵ£║ÕÆīÕ¤║õ║ĵØāķćŹŃĆé Ķ┤¤ĶĮĮÕØćĶĪĪÕÖ©Ķ»ĢÕøŠõĮ┐µ»ÅõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕ«īµłÉńøĖÕÉīńÜäÕĘźõĮ£ķćÅ’╝īõĮåõ╗źõĖŖń«Śµ│ĢķāĮõĖŹĶāĮń£¤µŁŻĶŠŠÕł░ńÉåµā│ńÜäńŁēķćÅ’╝īÕøĀõĖ║õ╗¢õ╗¼ÕŬµś»Õ¤║õ║ÄÕłåÕÅæÕł░µ¤ÉõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗĶ»Ęµ▒éńÜäµĢ░ķćÅµØźĶ«Īń«ŚŃĆéõĖĆõ║øĶü¬ µśÄńÜäĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©Õ«×ńÄ░ńē╣Õł½ńÜäń«Śµ│Ģ’╝īõ╗¢õ╗¼õ╝ܵĄŗĶ»Ģµ»ÅõĖ¬µ£ŹÕŖĪÕÖ©ńÜäÕĘźõĮ£Ķ┤¤ĶĮĮµØźÕå│Õ«ÜÕłåÕÅæĶ»Ęµ▒éŃĆé
*Õ┐āĶĘ│µŻĆµĄŗ
ÕĮōõĖĆõ║øµ£ŹÕŖĪÕÖ©Õ«×õŠŗÕż▒µĢłµŚČ’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©Õ║öĶ»źµŻĆµĄŗÕł░Õż▒µĢł’╝īÕ╣ČõĖŹÕåŹÕłåÕÅæĶ»Ęµ▒éÕł░Õż▒µĢłńÜäµ£ŹÕŖĪÕÖ©õĖŖŃĆéĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©õ╣¤ķ£ĆĶ”üńøæĶ¦åµ£ŹÕŖĪÕÖ©µüóÕżŹńŖČÕåĄ’╝īÕ╣Čń╗ÖÕ«āķ揵¢░ÕłåÕÅæĶ»Ęµ▒éŃĆé
*õ╝ÜĶ»Øń▓śĶ┐×
ÕćĀõ╣ĵ»ÅõĖ¬webÕ║öńö©ķāĮµ£ēõ╝ÜĶ»ØńŖȵĆü’╝īõĮ┐ÕŠŚĶ«░õĮÅńö©µłĘµś»ÕÉ”ńÖ╗ķÖåµł¢Ķ┤Łńē®ĶĮ”ÕÅśÕŠŚķØ×ÕĖĖń«ĆÕŹĢŃĆéÕøĀõĖ║HTTPÕŹÅĶ««µ£¼Ķ║½µ▓Īµ£ēńŖȵĆü’╝īõ╝ÜĶ»ØńŖȵĆüķ£ĆĶ”üÕŁśÕ£©µ¤ÉõĖ¬Õ£░µ¢╣’╝īÕ╣ČÕÆīµĄÅĶ¦łõ╝ÜĶ»ØÕģ│ ĶüöĶĄĘµØź’╝īÕÅ»õ╗źÕ£©õĖŗõĖƵ¼ĪĶ»Ęµ▒鵌ČÕŠłÕ«╣µśōÕ£░Ķó½µŻĆń┤óÕł░ŃĆéÕĮōĶ┤¤ĶĮĮÕØćĶĪĪµŚČ’╝īµ£ĆÕźĮķĆēµŗ®ÕłåÕÅæńøĖÕÉīńÜ䵥ÅĶ¦łÕÖ©õ╝ÜĶ»ØĶ»Ęµ▒éÕł░ÕÉīõĖĆÕÅ░µ£ŹÕŖĪÕÖ©Õ«×õŠŗõĖŖ’╝īÕÉ”ÕłÖÕ║öńö©ÕĘźõĮ£õ╝ÜõĖŹµŁŻÕĖĖŃĆé
ÕøĀõĖ║õ╝ÜĶ»ØńŖȵĆüÕŁśÕé©Õ£©µ¤ÉõĖ¬webµ£ŹÕŖĪÕÖ©Õ«×õŠŗńÜäÕåģÕŁśõĖŁ’╝īŌĆ£õ╝ÜĶ»Øń▓śĶ┐×ŌĆØÕ»╣õ║ÄĶ┤¤ĶĮĮÕØćĶĪĪķØ×ÕĖĖķćŹĶ”üŃĆéõĮå’╝īÕ”éµ×£õĖĆÕÅ░µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕøĀõĖ║µ¤Éõ║øÕĤÕøĀÕż▒µĢł’╝łµ»öՔ鵢ŁńöĄ’╝ē’╝īķéŻõ╣łĶ»źµ£ŹÕŖĪ ÕÖ©õĖŖÕżÜµ£ēńÜäõ╝ÜĶ»ØńŖȵĆüÕ░▒õĖóÕż▒õ║åŃĆéĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©µŻĆµĄŗÕł░õ║åĶ»źÕż▒µĢł’╝īõĖŹÕåŹÕÉæÕģČÕłåÕÅæĶ»Ęµ▒éŃĆéõĮåÕŁśÕé©Õ£©Õż▒µĢłµ£ŹÕŖĪÕÖ©õĖŖńÜäõ╝ÜĶ»ØńÜäķéŻõ║øĶ»Ęµ▒éÕ░åõĖóÕż▒õ╝ÜĶ»Øõ┐Īµü»’╝īĶ┐Öń¦ŹµāģÕåĄõ╝ÜÕ╝ĢĶĄĘķöÖĶ»»’╝ī ÕøĀµŁżõ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗Õł░µØźõ║å’╝ü
4.2 HTTPSessionÕż▒µĢłĶĮ¼ń¦╗
ÕćĀõ╣ĵēƵ£ēńÜ䵥üĶĪīńÜäJ2EEµÅÉõŠøÕĢåķāĮÕ£©õ╗¢õ╗¼ńÜäķøåńŠżõ║¦ÕōüõĖŁÕ«×ńÄ░õ║åHTTPSessionÕż▒µĢłĶĮ¼ń¦╗’╝īńĪ«õ┐صēƵ£ēńÜäÕ«óµłĘĶ»Ęµ▒éÕÅ»õ╗źõĖŹÕøĀõĖ║õĖĆõ║øµ£ŹÕŖĪÕÖ©Õ«×õŠŗńÜäÕż▒µĢłĶĆīõĖóÕż▒õ╗╗ õĮĢõ╝ÜĶ»ØńŖȵĆüŃĆéÕ”éÕøŠ6µēĆńż║’╝īÕĮōµĄÅĶ¦łÕÖ©Ķ«┐ķŚ«õĖĆõĖ¬µ£ēńŖȵĆüńÜäwebÕ║öńö©’╝łń¼¼1’╝ī2µŁź’╝ē’╝īµŁżÕ║öńö©ÕÅ»õ╗źÕ£©ÕåģÕŁśõĖŁÕłøÕ╗║õ╝ÜĶ»ØÕ»╣Ķ▒ĪÕŁśÕé©õ┐Īµü»õ╗źÕżćÕÉÄńö©ŃĆéÕÉīµŚČ’╝īÕÉæµĄÅĶ¦łÕÖ©ķĆüÕø× HTTPSession ID’╝īńö©µØźµĀćĶ«░Ķ»źõ╝ÜĶ»ØÕ»╣Ķ▒Ī’╝łń¼¼3µŁź’╝ēŃĆ鵥ÅĶ¦łÕÖ©õ╗źcookieńÜäµ¢╣Õ╝ÅÕŁśÕé©Ķ»źID’╝īÕ╣Čõ╝ÜÕ£©õĖŗµ¼ĪÕÅæĶĄĘĶ»Ęµ▒鵌ČķĆüÕø×webµ£ŹÕŖĪÕÖ©ŃĆéõĖ║õ║åµö»µīüõ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗’╝īõ╝ÜĶ»ØÕ»╣Ķ▒ĪÕ░å Õ£©µ¤ÉµŚČµ¤ÉÕżäÕ░åÕ«āĶć¬ÕĘ▒Õżćõ╗Į’╝łń¼¼4µŁź’╝ēŃĆéĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©ÕÅ»õ╗źµŻĆµĄŗÕż▒µĢł’╝łń¼¼5’╝ī6µŁź’╝ē’╝īÕłåÕÅæĶ»Ęµ▒éÕł░ÕģČõ╗¢µ£ŹÕŖĪÕÖ©Õ«×õŠŗ’╝łń¼¼7µŁź’╝ēŃĆéÕøĀõĖ║õ╝ÜĶ»ØÕ»╣Ķ▒ĪÕĘ▓ń╗ÅĶó½Õżćõ╗Į’╝īµ¢░ńÜäwebµ£Ź ÕŖĪÕÖ©Õ«×õŠŗÕÅ»õ╗źµüóÕżŹĶ»źõ╝ÜĶ»ØÕ╣ȵŁŻńĪ«Õ£░ÕżäńÉåĶ»Ęµ▒éŃĆé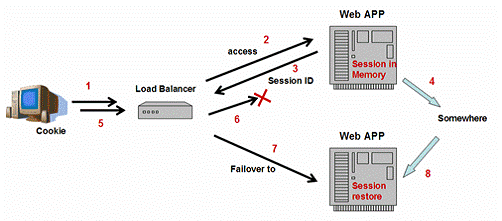
ÕøŠ6’╝ÜHTTPSessionÕż▒µĢłĶĮ¼ń¦╗
õĖ║õ║åÕ«×ńÄ░õ╗źõĖŖÕŖ¤ĶāĮ’╝īµ│©µäÅõĖŗÕłŚķŚ«ķóś’╝Ü
*Õģ©Õ▒ĆHTTPSession ID
Õ”éõĖŖµēĆĶ┐░’╝īHTTPSession IDńö©µØźµĀćĶ«░µ¤ÉõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕåģÕŁśõĖŁńÜäõ╝ÜĶ»ØÕ»╣Ķ▒ĪŃĆéÕ£©J2EEõĖŁ’╝īHTTPSession IDõŠØĶĄ¢õ║ÄJVMÕ«×õŠŗŃĆéµ»ÅõĖ¬JVMÕ«×õŠŗÕÅ»õ╗źµÄ¦ÕłČÕżÜõĖ¬webÕ║öńö©’╝īµ»ÅõĖ¬Õ║öńö©ÕÅłÕÅ»õ╗źµÄ¦ÕłČĶ«ĖÕżÜõĖŹÕÉīńö©µłĘńÜäHTTPSession’╝īHTTPSession IDµś»ÕŁśÕÅ¢ÕĮōÕēŹJVMÕ«×õŠŗõĖŁńøĖÕģ│õ╝ÜĶ»ØÕ»╣Ķ▒ĪńÜäķö«ŃĆéÕ£©õ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗Õ«×ńÄ░õĖŁ’╝īĶ”üµ▒éõĖŹÕÉīńÜäJVMÕ«×õŠŗõĖŹÕ║öĶ»źõ║¦ńö¤õĖżõĖ¬ÕÉīµĀĘńÜäHTTPSession ID’╝īÕøĀõĖ║Õż▒µĢłµŚČ’╝īÕ£©õĖĆõĖ¬JVMńÜäõ╝ÜĶ»ØÕÅ»ĶāĮÕ£©ÕÅ”õĖĆõĖ¬JVMõĖŁÕżćõ╗ĮÕÆīµüóÕżŹŃĆéµēĆõ╗ź’╝īÕ║öĶ»źÕ╗║ń½ŗÕģ©Õ▒ĆńÜäHTTPSession IDµ£║ÕłČŃĆé
*Õ”éõĮĢÕżćõ╗Įõ╝ÜĶ»ØńŖȵĆü
Õ”éõĮĢÕżćõ╗Įõ╝ÜĶ»ØńŖȵĆüµś»õĖĆõĖ¬õĮ┐ÕŠŚJ2EEµ£ŹÕŖĪÕÖ©õĖÄõ╝ŚõĖŹÕÉīńÜäÕģ│ķö«ÕøĀń┤ĀŃĆéõĖŹÕÉīńÜäµÅÉõŠøÕĢåÕ«×ńÄ░õĖŹÕÉīŃĆé
*Õżćõ╗ĮķóæńÄćÕÆīń▓ÆÕ║”
HTTPSessionńŖȵĆüÕżćõ╗Įµ£ēµĆ¦ĶāĮµČłĶĆŚ’╝īÕīģµŗ¼CPUÕ橵£¤’╝īńĮæń╗£ÕĖ”Õ«ĮÕÆīÕåÖńŻüńøśÕÆīµĢ░µŹ«Õ║ōńÜäIOµČłĶĆŚŃĆéÕżćõ╗ĮķóæńÄćÕÆīń▓ÆÕ║”õĖźķćŹÕĮ▒ÕōŹķøåńŠżńÜäµĆ¦ĶāĮŃĆé
4.3 µĢ░µŹ«Õ║ōµīüõ╣ģÕī¢µ¢╣µĪł
ÕćĀõ╣ĵēƵ£ēńÜäJ2EEķøåńŠżõ║¦ÕōüÕģüĶ«ĖõĮĀķĆÜĶ┐ćJDBCµÄźÕÅŻõĮ┐ńö©Õģ│ń│╗µĢ░µŹ«Õ║ōÕżćõ╗Įõ╝ÜĶ»ØńŖȵĆüŃĆéÕ”éÕøŠ7µēĆńż║’╝īĶ»źµ¢╣µĪłÕŬµś»ń«ĆÕŹĢÕ£░Ķ«®µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕ║ÅÕłŚÕī¢õ╝ÜĶ»ØÕåģÕ«╣’╝īÕ╣ČÕ£©ķĆéÕĮōńÜäµŚČ ÕĆÖÕåÖÕģźµĢ░µŹ«Õ║ōŃĆéÕĮōÕż▒µĢłĶĮ¼ń¦╗ÕÅæńö¤µŚČ’╝īÕÅ”õĖĆõĖ¬ÕÅ»ńö©ńÜäµ£ŹÕŖĪÕÖ©Õ«×õŠŗĶ┤¤Ķ┤ŻÕż▒µĢłńÜäµ£ŹÕŖĪÕÖ©’╝īÕ╣Čõ╗ĵĢ░µŹ«Õ║ōõĖŁµüóÕżŹõ╝ÜĶ»ØńŖȵĆüŃĆé Õ»╣Ķ▒ĪÕ║ÅÕłŚÕī¢µś»Õģ│ķö«ńé╣’╝īõĮ┐ÕŠŚÕåģÕŁśõ╝ÜĶ»ØÕ»╣Ķ▒ĪµĢ░µŹ«µīüõ╣ģÕī¢ÕÆīÕÅ»ń¦╗ÕŖ©ŃĆéµø┤ÕżÜÕ»╣Ķ▒ĪÕ║ÅÕłŚÕī¢õ┐Īµü»Ķ»ĘÕÅéĶĆā
http://java.sun.com/j2se/1.5.0/docs/guide/serialization/index.html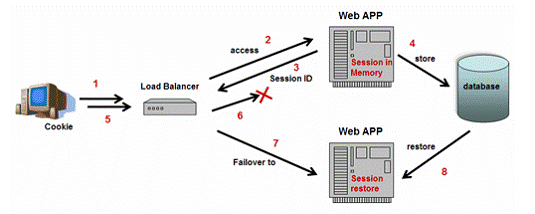
ÕøŠ7’╝ÜÕżćõ╗Įõ╝ÜĶ»ØńŖȵĆüÕł░µĢ░µŹ«Õ║ō
Ķ▒ĪµĢ░µŹ«Õ║ōõ║ŗÕŖĪõĖƵĀĘõ╗Żõ╗ʵśéĶ┤Ą’╝īĶ»źµ¢╣µĪłńÜäõĖ╗Ķ”üń╝║ńé╣µś»µ£ēķÖÉńÜäõ╝Ėń╝®µĆ¦’╝ÜÕĮōÕŁśÕé©Õż¦ķćÅõ╝ÜĶ»ØõĖŁńÜäÕ»╣Ķ▒ĪµŚČŃĆéĶ«ĖÕżÜõĮ┐ńö©µĢ░µŹ«Õ║ōõ╝ÜĶ»Øµīüõ╣ģÕī¢ńÜäÕ║öńö©µ£ŹÕŖĪÕÖ©ķ╝ōÕÉ╣ HTTPSessionńÜäµ£ĆÕ░ÅķÖÉÕ║”ńÜäõĮ┐ńö©’╝īõĮåÕģČÕ«×õ╗¢õ╗¼Ķ┐śķÖÉÕłČõ║åõĮĀńÜäÕ║öńö©µ×ȵ×äÕÆīĶ«ŠĶ«Ī’╝īńē╣Õł½µś»Õ”éµ×£õĮĀõĮ┐ńö©HTTPSessionÕŁśÕé©ń╝ōÕå▓ńö©µłĘµĢ░µŹ«ŃĆé
µĢ░µŹ«Õ║ōµ¢╣µĪłõ╣¤µ£ēõĖĆõ║øõ╝śńé╣.
*Õ«×ńÄ░ń«ĆÕŹĢŃĆéµ▒¤õ╝ÜĶ»ØÕżćõ╗ĮÕżäńÉåÕÆīĶ»Ęµ▒éÕżäńÉåÕłåń”╗’╝īõĮ┐ÕŠŚķøåńŠżµśōõ║Äń«ĪńÉåÕ╣ȵ»öĶŠāÕüźÕŻ«ŃĆé
*õ╝ÜĶ»ØÕÅ»õ╗źÕż▒µĢłĶĮ¼ń¦╗Õł░õ╗╗õĮĢÕģČÕ«āµ£║ÕÖ©õĖŖ’╝īÕøĀõĖ║õĮ┐ńö©Õģ▒õ║½µĢ░µŹ«Õ║ōŃĆé
*õ╝ÜĶ»ØµĢ░µŹ«ÕÅ»õ╗źÕ£©µĢ┤õĖ¬ķøåńŠżÕż▒µĢłÕÉÄõ╗ŹńäČńö¤ÕŁśŃĆé
4.4 ÕåģÕŁśÕżŹÕłČµ¢╣µĪł
ńö▒õ║ĵƦĶāĮķŚ«ķóś’╝īõĖĆõ║øJ2EEµ£ŹÕŖĪÕÖ©(Tomcat,JBoss,WebLogicÕÆīWebSphere)µÅÉõŠøÕÅ”õĖĆń¦ŹÕ«×ńÄ░’╝ÜÕåģÕŁśÕżŹÕłČŃĆé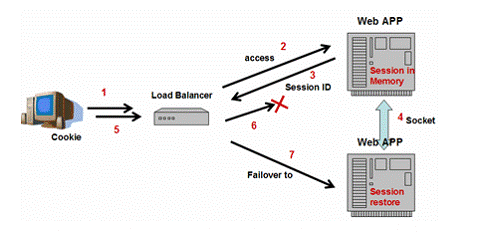
ÕøŠ8’╝ÜÕåģÕŁśÕżŹÕłČ
Õ¤║õ║ÄÕåģÕŁśńÜäõ╝ÜĶ»Øµīüõ╣ģÕī¢ÕŁśÕé©õ╝ÜĶ»Øõ┐Īµü»’╝īĶ»źµ¢╣µĪłńö▒õ║ĵƦĶāĮÕźĮķØ×ÕĖĖµĄüĶĪīŃĆéÕÆīµĢ░µŹ«Õ║ōµ¢╣µĪłµ»öĶŠā’╝īÕ£©ÕĤզŗµ£ŹÕŖĪÕÖ©ÕÆīÕżćõ╗Įµ£ŹÕŖĪÕÖ©õ╣ŗķŚ┤ńø┤µÄźńĮæń╗£ķĆÜõ┐Īµś»ķØ×ÕĖĖĶĮ╗ķćÅń║¦ńÜäŃĆéĶ»Ęµ│©µäÅĶ»źµ¢╣µĪł’╝īµĢ░µŹ«Õ║ōµ¢╣µĪłõĖŁńÜäŌĆ£µüóÕżŹŌĆØķśČµ«Ąµś»õĖŹķ£ĆĶ”üńÜäŃĆéĶ»Ęµ▒éÕł░µØźµŚČ’╝īµēƵ£ēńÜäõ╝ÜĶ»ØµĢ░µŹ«ÕĘ▓ń╗ÅÕŁśÕ£©õ║ÄÕżćõ╗Įµ£ŹÕŖĪÕÖ©ńÜäÕåģÕŁśõĖŁõ║åŃĆé
ŌĆØJavaGroupsŌĆصś»ńø«ÕēŹJBossÕÆīTomcatķøåńŠżńÜäķĆÜĶ«»Õ▒é’╝īJavaGroups µś»õĖĆõĖ¬Õ«×ńÄ░ńŠżķĆÜĶ«»ÕÆīń«ĪńÉåńÜäÕĘźÕģĘÕīģŃĆéÕ«āµÅÉõŠøńÜäµĀĖÕ┐āńē╣µĆ¦µś»ŌĆ£Group membership protocolsŌĆØÕÆīŌĆ£message multicastŌĆصø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆāhttp://www.jgroups.org/javagroupsnew/docs/index.html
4.4.1 Tomcatµ¢╣µĪł’╝ÜÕżÜµ£║ÕżŹÕłČ
ÕåģÕŁśÕżŹÕłČÕŁśÕ£©ÕŠłÕżÜÕÅśõĮōµ¢╣µĪłŃĆéõĖĆõĖŁÕŖ×µ│Ģµś»ĶĘ©ķøåńŠżõĖŁńÜäÕżÜĶŖéńé╣ÕżŹÕłČõ╝ÜĶ»ØńŖȵĆüŃĆéTomcat5õ╗źµŁżµ│ĢÕ«×ńÄ░ÕåģÕŁśÕżŹÕłČŃĆé
ÕøŠ9’╝ÜÕżÜµ£║ÕżŹÕłČ
Õ”éÕøŠ9µēĆńż║’╝īÕĮōõĖĆõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗńÜäõ╝ÜĶ»ØńŖȵĆüµö╣ÕÅśµŚČ’╝īÕ«āÕ░åÕÉæķøåńŠżõĖŁµēƵ£ēµ£ŹÕŖĪÕÖ©Õżćõ╗ĮÕ«āńÜäµĢ░µŹ«ŃĆéÕ”éµ×£ÕģČõĖŁõĖĆõĖ¬Õ«×õŠŗÕż▒µĢł’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©ÕÅ»ķĆēµŗ®ÕģČÕ«āõ╗╗õĮĢÕÅ»ńö©ńÜäµ£ŹÕŖĪÕÖ©Õ«×õŠŗ õĮ£õĖ║ÕģČÕżćõ╗Įµ£ŹÕŖĪÕÖ©ŃĆéõĮåĶ»źµ¢╣µĪłÕ£©õ╝Ėń╝®µĆ¦õĖŖµ£ēń╝║ķÖĘŃĆéÕ”éµ×£ķøåńŠżõĖŁµ£ēÕŠłÕżÜÕ«×õŠŗ’╝īńĮæń╗£ķĆÜĶ«»µČłĶĆŚÕ░▒õĖŹÕÅ»Õ┐ĮńĢźõ║å’╝īĶ┐Öń¦ŹµāģÕåĄÕ░åõĖźķćŹķÖŹõĮĵƦĶāĮÕÆīńĮæń╗£õ║żķĆÜ’╝īµłÉõĖ║ńōČķółķŚ«ķóśŃĆé
4.4.2 Weblogic, Jboss and WebSphereńÜäµ¢╣µĪł--ķģŹÕ»╣ÕżŹÕłČ
ÕøĀõĖ║µĆ¦ĶāĮÕÆīõ╝Ėń╝®µĆ¦ķŚ«ķóś’╝īWeblogic, JBoss and Websphere ķāĮµÅÉõŠøõ║åÕÅ”õĖĆń¦Źµ¢╣µ│ĢÕ«×ńÄ░ÕåģÕŁśÕżŹÕłČ’╝ܵ»ÅõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗķĆēµŗ®õ╗╗õĖĆõĖ¬Õżćõ╗ĮÕ«×õŠŗÕŁśÕé©õ╝ÜĶ»Øõ┐Īµü»’╝īÕ”éÕøŠ10ŃĆé
µīēĶ┐Öń¦Źµ¢╣Õ╝Å’╝īµ»ÅõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗµŗźµ£ēÕ«āĶć¬ÕĘ▒ńÜäķģŹÕ»╣Õżćõ╗Įµ£ŹÕŖĪÕÖ©ĶĆīõĖŹµś»µēƵ£ēÕģČÕ«āµ£ŹÕŖĪÕÖ©ŃĆéĶ»źµ¢╣µĪłµČłķÖżõ║åõ╝Ėń╝®µĆ¦ķŚ«ķóśŃĆé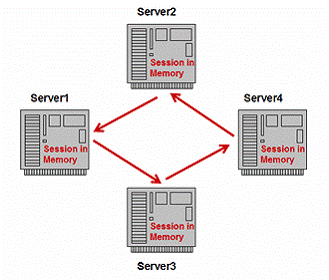
ÕøŠ10’╝ÜķģŹÕ»╣ÕżŹÕłČ
ĶÖĮńäČĶ»źµ¢╣µĪłÕ«×ńÄ░õ║åõ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗ńÜäķ½śµĆ¦ĶāĮÕÆīķ½śõ╝Ėń╝®µĆ¦’╝īõ╗Źńäȵ£ēõĖŗÕłŚķÖÉÕłČ’╝Ü
*ń╗ÖĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©ÕĖ”µØźõ║åÕżŹµØéµĆ¦ŃĆéÕĮōõĖĆÕÅ░µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕż▒µĢł’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©Õ┐ģķĪ╗Ķ«░õĮÅÕō¬õĖ¬Õ«×õŠŗµś»ÕģČķģŹÕ»╣Õżćõ╗Įµ£ŹÕŖĪÕÖ©’╝īń╝®Õ░Åõ║åĶ┤¤ĶĮĮÕØćĶĪĪÕÖ© ńÜäķĆēµŗ®ĶīāÕø┤’╝īõĖĆõ║øńĪ¼õ╗ČÕØćĶĪĪÕÖ©õĖŹĶāĮÕ£©µŁżń╗ōµ×äõĖŁõĮ┐ńö©ŃĆé
* ķÖżõ║åÕżäńÉåµŁŻÕĖĖńÜäĶ»Ęµ▒é’╝īµ£ŹÕŖĪÕÖ©ÕÉīµŚČĶ┤¤Ķ┤ŻÕżŹÕłČŃĆéµ»ÅõĖ¬µ£ŹÕŖĪÕÖ©Õ«×õŠŗ’╝īĶ»Ęµ▒éÕżäńÉåÕ«╣ķćÅĶó½ÕćÅÕ░Å’╝īÕøĀõĖ║CPUÕ橵£¤ķ£ĆĶ”üÕ«īµłÉÕżŹÕłČĶüīĶ┤ŻŃĆé
*ķÖżõ║åµŁŻÕĖĖÕżäńÉå’╝īĶ«ĖÕżÜÕåģÕŁśĶó½ńö©µØźÕŁśÕé©Õżćõ╗Įõ╝ÜĶ»ØńŖȵĆü’╝īÕŹ│õĮ┐µ▓Īµ£ēÕż▒µĢłĶĮ¼ń¦╗ÕÅæńö¤’╝īõ╣¤Õó×ÕŖĀõ║åJVMÕ×āÕ£ŠµöČķøåńÜäµČłĶĆŚŃĆé
*ķøåńŠżõĖŁńÜäµ£ŹÕŖĪÕÖ©Õ«×õŠŗń╗䵳ÉÕżŹÕłČķģŹÕ»╣ŃĆéµēĆõ╗źÕ”éµ×£õ╝ÜĶ»Øń▓śĶ┐×Õż▒µĢłńÜäõĖ╗µ£ŹÕŖĪÕÖ©’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕÖ©ĶāĮÕÅæķĆüÕż▒µĢłĶĮ¼ń¦╗Ķ»Ęµ▒éÕł░Õżćõ╗Įµ£ŹÕŖĪÕÖ©õĖŖŃĆéÕżćõ╗Įµ£ŹÕŖĪÕÖ©Õ░åÕ£©Ķ┐øÕģźńÜäĶ»Ęµ▒éõĖŁķüćÕł░ķ║╗ńā”’╝īÕ╝ĢĶĄĘµĆ¦ĶāĮķŚ«ķóśŃĆé
õĖ║õ║åÕģŗµ£Źõ╗źõĖŖķÖÉÕłČ,õĖŹÕÉīńÜäµÅÉõŠøÕĢåńÜäÕÅśń¦Źõ║¦ńö¤õ║åŃĆéWeblogic õĖ║µ»ÅõĖ¬õ╝ÜĶ»ØĶĆīõĖŹµś»µ£ŹÕŖĪÕÖ©Õ«Üõ╣ēõ║åÕżćõ╗ĮķģŹÕ»╣ŃĆéÕĮōõĖĆÕÅ░µ£ŹÕŖĪÕÖ©Õ«×õŠŗÕż▒µĢł’╝īÕż▒µĢłµ£ŹÕŖĪÕÖ©õĖŖńÜäõ╝ÜĶ»ØĶó½ÕłåµĢŻÕł░õĖŹÕÉīÕżćõ╗Įµ£ŹÕŖĪÕÖ©õĖŖ’╝īÕ╣ČõĖöĶó½ÕłåµĢŻÕ£░ĶŻģĶĮĮŃĆé
4.4.4 IBMńÜäµ¢╣µĪł--õĖŁÕż«ńŖȵĆüµ£ŹÕŖĪÕÖ©
Websphere ÕÅ”õĖĆõĖ¬ÕÅ»ńö©ńÜäÕåģÕŁśÕżŹÕłČķĆēµŗ®µś»:Õżćõ╗Įõ╝ÜĶ»Øõ┐Īµü»Õł░õĖĆõĖ¬õĖŁÕż«ńŖȵĆüµ£ŹÕŖĪÕÖ©’╝īÕ”éÕøŠ11ŃĆé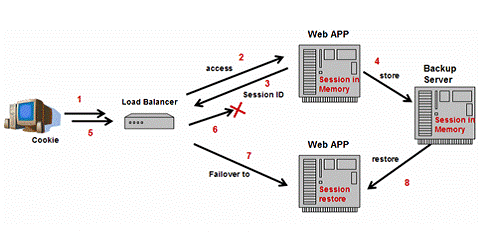
ÕøŠ11’╝ÜõĖŁÕż«µ£ŹÕŖĪÕÖ©ÕżŹÕłČ
ÕÆīµĢ░µŹ«Õ║ōµ¢╣µĪłķØ×ÕĖĖńøĖõ╝╝’╝īõĖŹÕÉīńÜ䵜»õĖĆõĖ¬õĖōķŚ©ńÜäŌĆ£õ╝ÜĶ»ØÕżćõ╗Įµ£ŹÕŖĪÕÖ©ŌĆØõ╗Żµø┐õ║åµĢ░µŹ«Õ║ōµ£ŹÕŖĪÕÖ©ŃĆéĶ»źµ¢╣µĪłÕģ╝µ£ēµĢ░µŹ«Õ║ōÕÆīÕåģÕŁśÕżŹÕłČńÜäõ╝śńé╣’╝Ü
*Õłåń”╗ńÜäĶ»Ęµ▒éÕżäńÉåÕÆīõ╝ÜĶ»ØÕżćõ╗Į’╝īõĮ┐ÕŠŚķøåńŠżµø┤Õ╝║ÕŻ«ŃĆé
*µēƵ£ēńÜäõ╝ÜĶ»ØµĢ░µŹ«Õżćõ╗ĮÕł░õĖōķŚ©ńÜäµ£ŹÕŖĪÕÖ©õĖŖŃĆébuķ£ĆĶ”üµ£ŹÕŖĪÕÖ©Õ«×õŠŗµĄ¬Ķ┤╣ÕåģÕŁśÕī║õ┐ØÕŁśÕģČÕ«āµ£ŹÕŖĪÕÖ©ńÜäÕżćõ╗Įõ╝ÜĶ»ØµĢ░µŹ«ŃĆé
*õ╝ÜĶ»ØÕÅ»õ╗źÕż▒µĢłĶĮ¼ń¦╗Õł░ÕģČÕ«āõ╗╗õĮĢÕ«×õŠŗõĖŖŃĆéÕøĀõĖ║õ╝ÜĶ»ØÕżćõ╗Įµ£ŹÕŖĪÕÖ©µś»Ķó½ķøåńŠżõĖŁńÜäµēƵ£ēĶŖéńé╣Õģ▒õ║½ńÜäŃĆéµēĆõ╗ź’╝īÕż¦ÕżÜµĢ░Ķ┤¤ĶĮĮÕØćĶĪĪĶĮ»õ╗ČÕÆīńĪ¼õ╗ČÕÅ»õ╗źÕ£©µŁżķøåńŠżõĖŁõĮ┐ńö©ŃĆéµø┤ķćŹĶ”üńÜ䵜»’╝īĶ»Ęµ▒éĶŻģĶĮĮÕ£©Õż▒µĢłµŚČÕ░åÕØćÕīĆÕłåµĢŻŃĆé
*ÕøĀõĖ║Õ║öńö©µ£ŹÕŖĪÕÖ©ÕÆīõ╝ÜĶ»ØÕżćõ╗Įµ£ŹÕŖĪÕÖ©õ╣ŗķŚ┤ńÜäsocketķĆÜĶ«»µś»ĶĮ╗ķćÅń║¦ńÜäńøĖÕ»╣õ║ÄķćŹÕ×ŗńÜäµĢ░µŹ«Õ║ōĶüöµÄźŃĆéÕ«āµ»öµĢ░µŹ«Õ║ōµ¢╣µĪłµ£ēńØƵø┤ÕźĮńÜäµĆ¦ĶāĮÕÆīõ╝Ėń╝®µĆ¦ŃĆé
ńäČĶĆī’╝īńö▒õ║ÄŌĆ£µüóÕżŹŌĆØķśČµ«ĄĶ”åńø¢Õż▒µĢłµ£ŹÕŖĪÕÖ©ńÜäõ╝ÜĶ»ØµĢ░µŹ«’╝īÕ«āńÜäµĆ¦ĶāĮÕÆīńø┤µÄźµł¢ķģŹÕ»╣ÕåģÕŁśÕżŹÕłČµ¢╣µĪłõĖŹõĖƵĀĘ’╝īķÖäÕŖĀńÜäõ╝ÜĶ»ØÕżćõ╗Įµ£ŹÕŖĪÕÖ©Õ»╣ń«ĪńÉåÕæśõ╣¤Õó×ÕŖĀõ║åÕżŹµØéµĆ¦’╝īµĆ¦ĶāĮńōČķółńö▒Õżćõ╗Įµ£ŹÕŖĪÕÖ©Ķć¬ÕĘ▒ńÜäµĆ¦ĶāĮµēĆķÖÉÕłČŃĆé
4.4.5 SunńÜäµ¢╣µĪł--ńē╣µ«ŖńÜäµĢ░µŹ«Õ║ō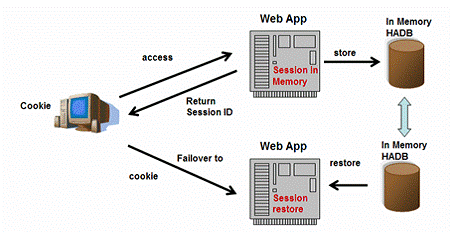
ÕøŠ12
┬Ā
Sun JESÕ║öńö©µ£ŹÕŖĪÕÖ©ķććńö©õ║åÕł½ńÜäµ¢╣Õ╝ÅÕ«×ńÄ░õ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗’╝īÕ”éÕøŠ12µēĆńż║’╝īÕ«āń£ŗõĖŖÕÄ╗ÕŠłÕāŵĢ░µŹ«Õ║ōńÜäµ¢╣Õ╝Å’╝īÕøĀõĖ║Õ«āķććńö©Õģ│ń│╗µĢ░µŹ«Õ║ōÕŁśÕé©õ╝ÜĶ»ØÕ╣ČķĆÜĶ┐ćJDBCĶ«┐ķŚ«µēƵ£ēõ╝ÜĶ»ØµĢ░µŹ«ŃĆéõĮåµś»JESÕåģķā©µēĆõĮ┐ńö©ńÜäÕģ│ń│╗µĢ░µŹ«Õ║ōń¦░õĖ║HADB’╝īÕĘ▓ń╗ÅõĖ║Ķ«┐ķŚ«õ╝ÜĶ»ØÕüÜõ║åńē╣Õł½õ╝śÕī¢’╝īÕ╣ČõĖöÕ░åÕćĀõ╣ĵēƵ£ēńÜäõ╝ÜĶ»ØµĢ░µŹ«ÕŁśÕ£©ÕåģÕŁśõĖŁŃĆéĶ┐ÖµĀĘ’╝īõĮĀÕÅ»õ╗źĶ»┤Õ«āµø┤ÕāÅõĖŁÕż«ńŖȵĆüµ£ŹÕŖĪÕÖ©ńÜäµ¢╣Õ╝ÅŃĆé
┬Ā
µĆ¦ĶāĮÕøĀń┤Ā┬Ā┬Ā
┬ĀĶĆāĶÖæÕ”éõĖŗķŚ«ķóś’╝Ü
┬Ā ┬Ā ┬ĀõĖĆÕÅ░WEBµ£ŹÕŖĪÕÖ©õĖŁÕÅ»ĶāĮĶ┐ÉĶĪīńØĆĶ«ĖÕżÜWEBÕ║öńö©’╝īÕ«āõ╗¼õĖŁµ»ÅõĖĆõĖ¬ķāĮÕÅ»ĶāĮĶó½µłÉńÖŠńÜäÕ╣ČÕÅæńö©µłĘĶ«┐ķŚ«’╝īĶĆīµ»ÅõĖ¬ńö©µłĘķāĮõ╝Üõ║¦ńö¤µĄÅĶ¦łÕÖ©õ╝ÜĶ»Øńö©õ║ÄĶ«┐ķŚ«ńē╣Õ«ÜńÜäÕ║öńö©ŃĆéµēƵ£ēõ╝ÜĶ»Øõ┐Īµü»ķāĮÕ░åÕżćõ╗Įõ╗źõŠ┐µ£ŹÕŖĪÕÖ©Õż▒µĢłÕÉÄĶāĮĶĮ¼ń¦╗Õł░ÕģČõ╗¢µ£ŹÕŖĪÕÖ©Õ«×õŠŗõĖŁŃĆéµø┤ń│¤ńÜ䵜»’╝īõ╝ÜĶ»Øõ╝Üńö▒õ║ÄõĖƵ¼Īµ¼ĪńÜäÕÅæńö¤õ╗źõĖŗµāģÕåĄĶĆīÕÅśÕī¢’╝īÕīģµŗ¼ÕłøÕ╗║ŃĆüÕż▒µĢłŃĆüÕó×ÕŖĀÕ▒׵ƦŃĆüÕłĀķÖżÕ▒׵ƦŃĆüõ┐«µö╣Õ▒׵ƦÕĆ╝ŃĆéńöÜĶć│µś»õ╗Ćõ╣łķāĮµ▓ĪÕÅś’╝īõĮåńö▒õ║ĵ£ēµ¢░ńÜäĶ«┐ķŚ«ĶĆīõĮ┐µ£ĆÕÉÄĶ«┐ķŚ«µŚČķŚ┤ÕÅśõ║å’╝łńö▒µŁżÕłżµ¢Łõ╗Ćõ╣łµŚČÕĆÖÕż▒µĢłõ╝ÜĶ»Ø’╝ēŃĆéÕøĀµŁż’╝īµĆ¦ĶāĮÕ£©õ╝ÜĶ»ØÕż▒µĢłĶĮ¼ń¦╗ńÜäĶ¦ŻÕå│µ¢╣µĪłõĖŁµś»õĖ¬ÕŠłÕż¦ńÜäÕøĀń┤ĀŃĆéõŠøÕ║öÕĢåķĆÜÕĖĖõ╝ܵÅÉõŠøõĖĆõ║øÕÅ»Ķ░āńÜäÕÅéµĢ░µö╣ÕÅśµ£ŹÕŖĪÕÖ©ĶĪīõĖ║’╝īõĮ┐õ╣ŗķĆéÕ║öµĆ¦ĶāĮķ£Ćµ▒éŃĆé
┬Ā
Õżćõ╗ĮµŚČµ£║
ÕĮōÕ«óµłĘń½»ńÜäĶ»Ęµ▒éĶó½ÕżäńÉåÕÉÄ’╝īõ╝ÜĶ»ØķÜŵŚČµö╣ÕÅśŃĆéńö▒õ║ĵƦĶāĮÕøĀń┤Ā’╝īÕ«×µŚČÕżćõ╗Įõ╝ÜĶ»Øµś»õĖŹµśÄµÖ║ńÜäŃĆéķĆēµŗ®Õżćõ╗ĮķóæńÄćķ£ĆĶ”üÕ╣│ĶĪĪŃĆéÕ”éµ×£Õżćõ╗ĮÕŖ©õĮ£ÕÅæńö¤ÕŠŚÕż¬ķóæń╣ü’╝īµĆ¦ĶāĮÕ░åµĆźÕē¦õĖŗķÖŹŃĆéÕ”éµ×£õĖżµ¼ĪÕżćõ╗ĮńÜäķŚ┤ķÜöÕż¬ķĢ┐’╝īķéŻõ╣łÕ£©Ķ┐ÖķŚ┤ķÜöõ╣ŗķŚ┤µ£ŹÕŖĪÕÖ©Õż▒µĢłÕÉÄ’╝īÕŠłÕżÜõ╝ÜĶ»Øõ┐Īµü»Õ░åõ╝ÜõĖóÕż▒ŃĆéõĖŹń«ĪµēƵ£ēńÜäµ¢╣Õ╝Å’╝īÕīģµŗ¼µĢ░µŹ«Õ║ōÕÆīÕåģÕŁśÕżŹÕłČ’╝īõĖŗķØ󵜻Õå│Õ«ÜÕżćõ╗ĮķóæńÄćńÜäÕĖĖńö©ńÜäķĆēķĪ╣ŃĆé
- µīēWEBĶ»Ęµ▒é




ńøĖÕģ│µÄ©ĶŹÉ
### J2EEµē½ńø▓õ╣ŗ-µÅŁÕ╝ĆJ2EEķøåńŠżńÜäńź×ń¦śķØóń║▒ #### 1. ÕēŹĶ©Ć ķÜÅńØĆõ║ÆĶüöńĮæõĖÜÕŖĪńÜäĶ┐ģķƤÕÅæÕ▒ĢõĖÄõ╝üõĖÜõ┐Īµü»Õī¢µ░┤Õ╣│ńÜäõĖŹµ¢ŁµÅÉÕŹć’╝īĶČŖµØźĶČŖÕżÜńÜäÕģ│ķö«µĆ¦Õ║öńö©ń©ŗÕ║ÅķĆēµŗ®Õ¤║õ║ÄJ2EE’╝łJava 2 Platform, Enterprise Edition’╝ēÕ╣│ÕÅ░Ķ┐øĶĪīµ×äÕ╗║ŃĆéõŠŗÕ”é’╝ī...
Ķ»║Õ¤║õ║ܵēŗµ£║µē½ńø▓Ķ┤┤’╝Ź’╝ŹÕ”éõĮĢķē┤Õł½NOkiaµēŗµ£║ÕōüĶ┤©
µ£¼µ¢ćÕ░åµĘ▒ÕģźĶ¦Żµ×ÉOracle 11g RACõĖŁńÜäķøåńŠżÕ║öńö©Õ▒éÕæĮõ╗ż’╝īńē╣Õł½µś»ńö©õ║Äń╗┤µŖżÕÆīńøæµÄ¦ńÜäÕģ│ķö«ÕĘźÕģĘŃĆé 1. **SRVCTL**’╝Ü SRVCTLµś»Oracle ClusterwareµÅÉõŠøńÜäõĖĆõĖ¬ÕæĮõ╗żĶĪīµÄźÕÅŻ’╝īńö©õ║Äń«ĪńÉåÕÆīµÄ¦ÕłČRACńÄ»ÕóāõĖŁńÜäµ£ŹÕŖĪŃĆüÕ«×õŠŗŃĆüĶŖéńé╣ŃĆüńøæÕɼÕÖ©ńŁē...
ŃĆɵ▒ĮĶĮ”Õ¤║ńĪĆń¤źĶ»åĶ¦Żµ×ÉŃĆæ µ▒ĮĶĮ”õĮ£õĖ║µŚźÕĖĖńö¤µ┤╗õĖŁķćŹĶ”üńÜäõ║żķĆÜÕĘźÕģĘ’╝īÕģČÕĘźõĮ£ÕĤńÉåÕÆīµŖƵ£»ń╗åĶŖéÕ»╣õ║ÄĶ┤ŁĶĮ”ĶĆģµØźĶ»┤µś»ķØ×ÕĖĖķćŹĶ”üńÜäŃĆéõĖŗķØóµłæõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©õĖĆõ║øµ▒ĮĶĮ”ńÜäÕ¤║ńĪĆń¤źĶ»åŃĆé 1. **ÕÅæÕŖ©µ£║ń▒╗Õ×ŗ’╝ÜSOHC vs DOHC** SOHC’╝łÕŹĢķĪČńĮ«ÕćĖĶĮ«ĶĮ┤’╝ēÕÆī...
01-µē½ńø▓ń»ć-µĖŚķĆÅÕģźÕØæõĖōõĖܵ£»Ķ»Łń¤źÕżÜÕ░æ.md
MATLAB µś»õĖĆń¦ŹÕ╝║Õż¦ńÜäµĢ░ÕŁ”ĶĮ»õ╗Č’╝īńö▒ńŠÄÕøĮMathWorksÕģ¼ÕÅĖÕ╝ĆÕÅæ’╝īõĖ╗Ķ”üÕŖ¤ĶāĮÕīģµŗ¼µĢ░ÕĆ╝Ķ«Īń«ŚŃĆüń¼”ÕÅĘĶ«Īń«ŚÕÆīÕøŠÕĮóÕÅ»Ķ¦åÕī¢ŃĆéMATLAB ńÜäÕÉŹń¦░µØźµ║Éõ║Ä"Matrix Laboratory"’╝īÕ«āõ╗źÕģČõĖ░Õ»īńÜäĶ┐Éń«Śń¼”ÕÆīÕ║ōÕćĮµĢ░’╝īń«Ćµ┤üńÜäĶ»ŁĶ©Ćń╗ōµ×ä’╝īķ½śµĢłńÜäń╝¢ń©ŗµĢłńÄćĶĆī...
µŖźĶŁ”ń│╗ń╗¤µē½ńø▓
Õż¦µ©ĪÕ×ŗµś»µīćÕģʵ£ēµĢ░ÕŹāõĖćńöÜĶć│µĢ░õ║┐ÕÅéµĢ░ńÜäµĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗŃĆéĶ┐æÕ╣┤µØź’╝īķÜÅńØĆĶ«Īń«Śµ£║µŖƵ£»ÕÆīÕż¦µĢ░µŹ«ńÜäÕ┐½ķƤÕÅæÕ▒Ģ’╝īµĘ▒Õ║”ÕŁ”õ╣ĀÕ£©ÕÉäõĖ¬ķóåÕ¤¤ÕÅ¢ÕŠŚõ║åµśŠĶæŚńÜäµłÉµ×£’╝īÕ”éĶć¬ńäČĶ»ŁĶ©ĆÕżäńÉå’╝īÕøŠńēćńö¤µłÉ’╝īÕĘźõĖܵĢ░ÕŁŚÕī¢ńŁēŃĆéõĖ║õ║åµÅÉķ½śµ©ĪÕ×ŗńÜäµĆ¦ĶāĮ’╝īńĀöń®ČĶĆģõ╗¼õĖŹµ¢Ł...
Ķ┐Öõ╗ĮŌĆ£ńöĄÕŁÉµŖƵ£»µē½ńø▓ĶĄäµ¢ÖŌĆصŚ©Õ£©ÕĖ«ÕŖ®ÕłØÕŁ”ĶĆģõ╗ÄÕ¤║ńĪĆÕ╝ĆÕ¦ŗńÉåĶ¦ŻÕ╣ȵÄīµÅĪńöĄÕŁÉµŖƵ£»ńÜäÕ¤║µ£¼µ”éÕ┐ĄÕÆīÕģāõ╗ČŃĆ鵳æõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©ńöĄķś╗ŃĆüńöĄÕ«╣ŃĆüńöĄµä¤õ╗źÕÅŖõ║īµ×üń«ĪÕÆīõĖēµ×üń«ĪĶ┐Öõ║öń¦ŹÕ¤║µ£¼ńöĄÕŁÉÕģāõ╗ČŃĆé ķ”¢Õģł’╝īńöĄķś╗µś»ńöĄÕŁÉńöĄĶĘ»õĖŁµ£ĆÕĖĖĶ¦üńÜäÕģāõ╗Č’╝īÕ«āĶāĮķÖÉÕłČ...
VMware Workstationµś»õĖƵ¼ŠÕ╝║Õż¦ńÜäĶÖܵŗ¤µ£║ĶĮ»õ╗Č’╝īÕ«āÕģüĶ«Ėńö©µłĘÕ£©ÕŹĢõĖ¬ńē®ńÉåĶ«Īń«Śµ£║õĖŖÕłøÕ╗║ÕÆīĶ┐ÉĶĪīÕżÜõĖ¬ńŗ¼ń½ŗńÜäĶÖܵŗ¤µ£║ŃĆéĶ┐Öõ║øĶÖܵŗ¤µ£║ÕÅ»õ╗źµ©Īµŗ¤õĖŹÕÉīńÜäµōŹõĮ£ń│╗ń╗¤ÕÆīńĮæń╗£ńÄ»Õóā’╝īÕ»╣õ║ÄÕ╝ĆÕÅæŃĆüµĄŗĶ»ĢÕÆīÕŁ”õ╣ĀÕÉäń¦ŹITµŖƵ£»ķØ×ÕĖĖµ£ēńö©ŃĆé...
nVIDIA/ATiµśŠÕŹĪÕÉäńēłµ£¼ń║¦Õł½õ╣ŗÕÉŹĶ»ŹĶ¦Żµ×É’╝łµä¤Ķ░óńĮæÕÅŗzg1haoµÅÉõŠøĶĄäµ¢Ö’╝ē 7µź╝’╝ÜÕåģÕŁśń▒╗ 1. ÕåģÕŁśńÜäCLÕĆ╝ÕÆīÕåģÕŁśÕ╗ČĶ┐¤ 2. õĖ║õ╗Ćõ╣łDDR2-667ńÜäõĖ╗ķóæµś»667MHz’╝īĶĆīÕĘźõĮ£ķóæńÄćÕŹ┤µś»333MHz’╝¤ 3. DDRŃĆüDDR2ÕÆīDDR3ÕåģÕŁśõ╗ŗń╗ŹÕÆīµ»öĶŠā 4. ECC...
Makefileµś»LinuxÕÆīUnixń│╗ń╗¤õĖŁńö©õ║ÄĶć¬ÕŖ©Õī¢µ×äÕ╗║ŃĆüń╝¢Ķ»æŃĆüµĄŗĶ»ĢńŁēõ╗╗ÕŖĪńÜäĶäܵ£¼µ¢ćõ╗Č’╝īÕ«āńÜäÕŁśÕ£©µ×üÕż¦Õ£░µÅÉķ½śõ║åÕ╝ĆÕÅæµĢłńÄć’╝īńē╣Õł½µś»Õ£©Õż¦Õ×ŗķĪ╣ńø«õĖŁŃĆé...ÕĖīµ£øĶ┐Öń»ćµē½ńø▓Ķ┤┤ĶāĮÕĖ«ÕŖ®õĮĀÕ╝ĆÕÉ»MakefileńÜäÕŁ”õ╣Āõ╣ŗµŚģ’╝īĶ«®õĮĀÕ£©LinuxÕ╝ĆÕÅæõĖŁµø┤ÕŖĀÕŠŚÕ┐āÕ║öµēŗŃĆé
µĄüµ░┤ń║┐µĢ░µŹ«µĄüµē½ńø▓ ARMµ×ȵ×äõĖŁńÜäõĖēń║¦µĄüµ░┤ ARMÕŠ«µ×ȵ×äń¤źĶ»åńé╣ńÜäµĆØĶĆā gicÕÆīõĖŁµ¢Ł MMUµē½ńø▓ cacheµē½ńø▓ Store bufferÕÆīInvalidate queue õ╗Ćõ╣łµś»Trustzone’╝¤ õ╗Ćõ╣łµś»TEE’╝¤ TEEµē½ńø▓ ĶÖܵŗ¤Õī¢µ×ȵ×äµē½ńø▓ RME/GPC/MPE µē½ńø▓ ARMńÜäÕģ│ķö«...
### LabWindows/CVI µē½ńø▓µŖĆÕʦĶ»”Ķ¦Ż #### õĖĆŃĆüLabWindows/CVI µ”éĶ┐░ 1. **Õ«Üõ╣ē**’╝ÜLabWindows/CVI µś»õĖƵ¼Šńö▒ National Instruments’╝łń«Ćń¦░ NI’╝ēÕ╝ĆÕÅæńÜä ANSI C ķøåµłÉÕ╝ĆÕÅæńÄ»Õóā’╝łIDE’╝ēŃĆéÕ«āõĖ║ÕĘźń©ŗÕĖłÕÆīń¦æÕŁ”Õ«ČµÅÉõŠøõ║åÕłøÕ╗║µĄŗĶ»ĢõĖÄ...
Oracleµē½ńø▓-ń¼¼õĖĆĶ«▓-ÕłøÕ╗║ÕÆīń«ĪńÉåĶĪ©PPTĶ»Šõ╗Č µ£¼ĶĄäµ║ÉõĖ╗Ķ”üĶ«▓Ķ┐░OracleµĢ░µŹ«Õ║ōń«ĪńÉåń│╗ń╗¤ńÜäÕ¤║µ£¼ń¤źĶ»å’╝īÕīģµŗ¼ÕłøÕ╗║ÕÆīń«ĪńÉåĶĪ©ńÜäµ¢╣µ│ĢŃĆüµĢ░µŹ«ń▒╗Õ×ŗŃĆüCREATE TABLEĶ»ŁÕÅźŃĆüµĢ░µŹ«ÕŁŚÕģĖńŁēŃĆé ń¤źĶ»åńé╣1’╝ܵĢ░µŹ«ń▒╗Õ×ŗ OracleµĢ░µŹ«Õ║ōõĖŁµ£ēÕżÜń¦ŹµĢ░µŹ«ń▒╗Õ×ŗ’╝ī...
µĖŚķĆŵĄŗĶ»Ģ ĶĪīõĖܵ£»Ķ»Łµē½ńø▓-µØźµ║É-Õģ¼õ╝ŚÕÅĘ-moonsec
Õ╝║Õī¢ÕŁ”õ╣Āµē½ńø▓Ķ┤┤’╝Üõ╗ÄQ-learningÕł░DQN Õ╝║Õī¢ÕŁ”õ╣Āµś»µ£║ÕÖ©ÕŁ”õ╣ĀńÜäõĖĆõĖ¬Õłåµö»’╝īńø«µĀ浜»Ķ«Łń╗āµÖ║ĶāĮõĮōÕ£©ńÄ»ÕóāõĖŁĶ┐øĶĪīÕå│ńŁ¢õ╗źµ£ĆÕż¦Õī¢Õź¢ÕŖ▒ŃĆéÕ£©Õ╝║Õī¢ÕŁ”õ╣ĀõĖŁ’╝īQ-learningµś»õĖĆõĖ¬Õ¤║µ£¼ńÜäoff-policy TDµ¢╣µ│Ģ’╝īÕ«āÕÅ»õ╗źÕŁ”õ╣ĀńŖȵĆü-ÕŖ©õĮ£Õ»╣ńÜäõ╗ĘÕĆ╝ÕćĮµĢ░’╝ī...
ÕģĘõĮōµÅÅĶ┐░Ķ¦ü’╝Ü https://blog.csdn.net/BjarneCpp/article/details/80370986
Õ£©VXLANµ×ȵ×äõĖŗ’╝īõ╝Āń╗¤ńÜäõ║īÕ▒éńĮæń╗£Ķó½µē®Õ▒ĢÕł░õ║åõĖēÕ▒éńĮæń╗£õ╣ŗõĖŖŃĆéńĮæń╗£õĖŁńÜäĶ«ŠÕżćĶó½ń¦░õĖ║VTEP’╝łVXLAN Tunnel End Point’╝ē’╝īĶ┤¤Ķ┤ŻÕ»╣õ║īÕ▒éµĢ░µŹ«ÕīģĶ┐øĶĪīÕ░üĶŻģÕÆīĶ¦ŻÕ░üĶŻģŃĆéVXLANķĆÜĶ┐ćõĮ┐ńö©IPÕżÜµÆŁµł¢ĶĆģÕŹĢµÆŁńÜäµ¢╣Õ╝ÅÕ╗║ń½ŗķܦķüō’╝īÕ£©ķܦķüōõĖżń½»ńÜäVTEPõ╣ŗķŚ┤...
µ£¼ĶĄäµ║ÉŌĆ£Õ╝║Õī¢ÕŁ”õ╣Āµē½ńø▓Ķ┤┤’╝Üõ╗ÄQ-learningÕł░DQN.rarŌĆØĶüÜńä”õ║ÄĶ┐ÖõĖĆõĖ╗ķóś’╝īµŚ©Õ£©ÕĖ«ÕŖ®ÕłØÕŁ”ĶĆģńÉåĶ¦ŻÕ╣ȵÄīµÅĪÕ╝║Õī¢ÕŁ”õ╣ĀńÜäÕ¤║µ£¼µ”éÕ┐Ą’╝īńē╣Õł½µś»Q-learningÕÆīDeep Q-Network’╝łDQN’╝ēĶ┐ÖõĖżń¦ŹķćŹĶ”üńÜäń«Śµ│ĢŃĆé Q-learningµś»Õ╝║Õī¢ÕŁ”õ╣ĀõĖŁńÜäõĖĆń¦Źµ©ĪÕ×ŗ-...