
еОЯеЭАе¶ВдЄЛпЉЪhttp://blog.csdn.net/chen77716/article/details/5949166
 
 
¬†зЫіеИ∞зО∞еЬ®дЄЇж≠ҐпЉМдЄАиЗіжАІеУИеЄМдєЯж≤°жЬЙдЄАдЄ™йЭЮеЄЄжШОз°ЃзЪДеЃЪдєЙпЉМе§ЪжХ∞жЦЗзМЃињШжШѓдїОеЕґеЇФзФ®еЬЇжЩѓдєЛдЄКеѓєдЄАиЗіжАІеУИеЄМињЫи°МжППињ∞гАВвАЬеУИеЄМвАЭжГ≥ењЕе§ІеЃґйГљеЈ≤зїПдЇЖиІ£пЉМйЧЃйҐШжШѓдљХдЄЇвАЬдЄАиЗіжАІвАЭпЉЯ
 
- дЄАиЗіжАІ
¬†¬†еЬ®иЃ®иЃЇдЄАиЗіжАІеУИеЄМдєЛеЙНпЉМеЕИиЃ§иѓЖдЄЛвАЬйЭЮдЄАиЗіжАІеУИеЄМвАЭпЉМжШЊзДґHashMapе±ЮдЇОж≠§еИЧгАВ
¬†¬†ељУдљњзФ®HashMapжЧґпЉМkey襀еЭЗеМАеЬ∞жШ†е∞ДеИ∞жХ∞зїДдєЛдЄКпЉМжШ†е∞ДжЦєж≥Хе∞±жШѓеИ©зФ®keyзЪДhashдЄОжХ∞зїДйХњеЇ¶еПЦж®°(йАЪињЗ&ињРзЃЧ)гАВ
¬†¬†ељУputзЪДжХ∞жНЃиґЕињЗиіЯиљљеЫ†е≠РloadFactor√Ч2LenжЧґпЉМHashMapдЉЪжМЙзЕІ2襀зЪДеЃєйЗПжЙ©еЃєгАВжЦ∞putињЫжЭ•зЪДжХ∞жНЃдЉЪйАЪињЗдЄОжЦ∞жХ∞зїДзЪДйХњеЇ¶еПЦж®°зЪДжЦєеЉПињЫи°МжШ†е∞ДгАВйВ£дєЛеЙНеЈ≤зїПжШ†е∞ДзЪДжХ∞жНЃиѓ•жАОдєИеКЮпЉЯйАЪињЗжЯ•зЬЛHashMapдї£з†БзЪДresizeжЦєж≥ХдЉЪеПСзО∞пЉМжѓПжђ°жЙ©еЃєйГљдЉЪжККдєЛеЙНзЪДkeyйЗНжЦ∞жШ†е∞ДгАВ
¬†¬†жЙАдї•еѓєHashMapиАМи®Аи¶БжГ≥иОЈеЊЧиЊГе•љзЪДжАІиГљењЕй°їи¶БжПРеЙНдЉ∞иЃ°жЙАжФЊжХ∞жНЃйЫЖеРИзЪДе§Іе∞ПпЉМдї•иЃЊиЃ°еРИйАВзЪДеИЭеІЛеМЦеЃєйЗПеТМиіЯиљљеЫ†е≠РгАВ
 
¬† 2. еЃЪдєЙ
¬†дљЖдЄНжШѓжѓПдЄ™еЬЇжЩѓйГљеГПHashMapињЩдєИзЃАеНХпЉМжѓФе¶ВеЬ®е§ІеЮЛзЪДP2PзљСзїЬдЄ≠е≠ШеЬ®дЄКзЩЊдЄЗеП∞ServerпЉМиµДжЇРдЄОServerзЪДеЕ≥з≥їжШѓдї•KeyзЪД嚥еЉПжШ†е∞ДиАМжИРпЉМдєЯе∞±жШѓиѓіжШѓдЄАдЄ™е§ІзЪДHashMapпЉМзїіжК§зЭАжѓПдЄ™KeyеЬ®еУ™дЄ™ServerдєЛдЄКпЉМе¶ВжЮЬжЬЙжЦ∞зЪДиКВзВєеК†еЕ•жИЦйААеЗЇP2PзљСзїЬпЉМиЈЯHashMapдЄАж†ЈпЉМдєЯдЉЪеѓЉиЗіжШ†е∞ДеЕ≥з≥їзЪДеПШеМЦпЉМжШЊзДґдЄНеПѓиГљжККжЙАжЬЙзЪДKeyдЄОServerзЪДжШ†е∞ДеЕ≥з≥їйГљи∞ГжХідЄАйБНгАВињЩе∞±йЬАи¶БдЄАзІНжЦєж≥ХпЉМеЬ®еУИеЄМй°єеПСзФЯеПШеМЦжШѓпЉМдЄНйЬАи¶Би∞ГжХіжЙАжЬЙзЪДиКВзВєпЉМиАМиЊЊеИ∞зїІзї≠зїіжК§еУИеЄМжШ†е∞ДзЪДеЕ≥з≥їгАВеЫ†ж≠§дЄАиЗіжАІеУИеЄМеЃЪдєЙдЄЇпЉЪ
"Consistent hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots".(http://en.wikipedia.org/wiki/Consistent_hashing)
е∞±жШѓиѓіпЉМвАЭдЄАиЗіжАІеУИеЄМпЉМе∞±жШѓжПРдЊЫдЄАдЄ™hashtable,еЃГиГљеЬ®иКВзВєеК†еЕ•з¶їеЉАжЧґдЄНдЉЪеѓЉиЗіжШ†е∞ДеЕ≥з≥їзЪДйЗНе§ІеПШеМЦвАЬгАВ
 
 
3.еЃЮзО∞
дЄАиЗіжАІеУИеЄМзЪДеЃЪдєЙйЩ§дЇЖжППињ∞дЄАдЄ™еЃЪдєЙжИЦиАЕдЄАзІНжГ≥ж≥Хеєґж≤°жЬЙзїЩеЗЇдїїдљХеЃЮзО∞жЦєйЭҐзЪДжППињ∞пЉМжЙАжЬЙзїЖеМЦзЪДйЧЃйҐШйГљзХЩзїЩеЉАеПСиАЕеОїжАЭиАГгАВдљЖдЄАиИђзЪДеЃЮзО∞жАЭиЈѓе¶ВдЄЛпЉЪ
- еБЗеЃЪеУИеЄМзЪДеЭЗеМАKeyеИЖеЄГеЬ®дЄАдЄ™зОѓдЄКпЉМжѓФе¶ВжЙАжЬЙиКВзВєйГљйАЪињЗSHA-1жИЦMD5ињЫи°МеУИеЄМжШ†е∞Д
- жЙАжЬЙзЪДиКВзВєдєЯйГљеИЖеЄГеЬ®еРМдЄАзОѓдЄКпЉИжѓФе¶ВServerзЪДIPеЬ∞еЭАзїПињЗSHA-1пЉЙ
- жѓПдЄ™иКВзВєеП™иіЯиі£дЄАйГ®еИЖKeyпЉМељУиКВзВєеК†еЕ•гАБйААеЗЇжЧґеП™ељ±еУНеК†еЕ•йААеЗЇзЪДиКВзВєеТМеЕґйВїе±ЕиКВзВєжИЦиАЕеЕґдїЦиКВзВєеП™жЬЙе∞СйЗПзЪДKeyеПЧељ±еУН
еБЗе¶ВжЬЙnдЄ™иКВзВєпЉМmдЄ™keyпЉМељУиКВзВєеҐЮеК†жЧґе§ІзЇ¶жЬЙO(m/n)зЪДиКВзВєйЬАи¶БзІїеК®гАВдљЖдЄАиИђдЄАиЗіжАІеУИеЄМйЬАи¶Бжї°иґ≥дЄЛйЭҐеЗ†дЄ™жЭ°дїґжЙНеѓєеЃЮйЩЕз≥їзїЯжЬЙжДПдєЙпЉЪ
- еє≥и°°жАІ(Balance)пЉЪе∞±жШѓжМЗеУИеЄМзЃЧж≥Хи¶БеЭЗеМАеИЖеЄГпЉМдЄНиГљжЬЙжШОжШЊзЪДжШ†е∞ДиІДеЊЛпЉМињЩеѓєдЄАиИђзЪДеУИеЄМеЃЮзО∞дєЯжШѓењЕй°їзЪД
- еНХи∞ГжАІ(Monotonicity)пЉЪе∞±жШѓжМЗжЬЙжЦ∞иКВзВєеК†еЕ•жЧґпЉМеЈ≤зїПе≠ШеЬ®зЪДжШ†е∞ДеЕ≥з≥їдЄНиГљеПСзФЯеПШеМЦ
- еИЖжХ£жАІ(Spread)пЉЪе∞±жШѓйБњеЕНдЄНеРМзЪДеЖЕеЃєжШ†е∞ДеИ∞зЫЄеРМзЪДдљНзљЃеТМзЫЄеРМзЪДеЖЕеЃєжШ†е∞ДеИ∞дЄНеРМзЪДдљНзљЃ
еЕґеЃЮдЄАиЗіжАІеУИеЄМпЉИеУИеЄМпЉЙжЬЙдЄ™жШОжШЊзЪДдЉШзВєе∞±жШѓиіЯиљљеЭЗи°°пЉМеП™и¶БеУИеЄМеЗљжХ∞иЃЊиЃ°еЊЧељУпЉМжѓПдЄ™зВєе∞±жШѓеѓєз≠ЙзЪДеПѓдї•еЭЗеМАеЬ∞еИЖеЄГз≥їзїЯиіЯиљљгАВ
 
4.Memcached
зЬЛдЇЖдЄКйЭҐзЪДеЃЪдєЙеТМеЃЮзО∞еПѓиГљињШжШѓжѓФиЊГињЈиМЂпЉМйВ£е∞±дЄЊдЄ™еЃЮйЩЕдЊЛе≠РгАВ
Memcachedеѓєе§ІеЃґеЇФиѓ•дЄНйЩМзФЯпЉМйАЪињЗжККKeyжШ†е∞ДеИ∞Memcached ServerдЄКпЉМеЃЮзО∞ењЂйАЯиѓїеПЦгАВжИСдїђеПѓдї•еК®жАБеѓєеЕґиКВзВєеҐЮеК†пЉМеєґжЬ™ељ±еУНдєЛеЙНеЈ≤зїПжШ†е∞ДеИ∞еЖЕе≠ШзЪДKeyдЄОmemcached ServerдєЛйЧізЪДеЕ≥з≥їпЉМињЩе∞±жШѓеЫ†дЄЇдљњзФ®дЇЖдЄАиЗіжАІеУИеЄМгАВ
еЫ†дЄЇMemcachedзЪДеУИеЄМз≠ЦзХ•жШѓеЬ®еЕґеЃҐжИЈзЂѓеЃЮзО∞зЪДпЉМеЫ†ж≠§дЄНеРМзЪДеЃҐжИЈзЂѓеЃЮзО∞дєЯжЬЙеМЇеИЂпЉМдї•SpymemcacheгАБXmemcacheдЄЇдЊЛпЉМйГљжШѓдљњзФ®дЇЖKETAMAдљЬдЄЇеЕґеЃЮзО∞гАВ
 
KETAMAеЃЮзО∞жЦєеЉПе¶ВдЄЛпЉЪ
- жККServerзЪДIPеЬ∞еЭАеТМзЂѓеП£ињЫи°МMD5еУИеЄМпЉМMD5зЪДзїУжЮЬдЄЇдЄАдЄ™160bitзЪДжХ∞е≠ЧпЉМеПЦеЕґеЙН32дљНдљЬдЄЇдЄАдЄ™Integer
- жККзЉУе≠Шеѓєи±°зЪДKeyеБЪMD5еУИеЄМпЉМеРМж†ЈеЊЧеИ∞дЄАдЄ™жХіжХ∞
- еПѓдї•иЃЊжГ≥пЉМServerзЪДжХіжХ∞дЉЪж†єжНЃе§Іе∞П嚥жИРдЄАдЄ™жХ∞е≠ЧзОѓпЉМиАМKeyзЪДеУИеЄМеИЩеИЖеЄГеЬ®ињЩдЇЫжХ∞е≠ЧдЄКжИЦдЄ≠йЧі
- е¶ВжЮЬServerзЪДеУИеЄМз≠ЙдЇОKeyзЪДеУИеЄМпЉМеИЩжККKeyе≠ШжФЊеЬ®иѓ•ServerдЄКпЉЫеР¶еИЩпЉМеѓїжЙЊзђђдЄАдЄ™е§ІдЇОKeyеУИеЄМзЪДServerпЉМзФ®дЇОе≠ШжФЊKey
- дљЖжЬЙServerеҐЮеК†гАБеИ†йЩ§жЧґпЉМеП™и¶БеПШеК®еС®иЊєзЪДServerжШ†е∞ДеЕ≥з≥їеН≥еПѓпЉМдЄНзФ®еЕ®йГ®йЗНжЦ∞еУИеЄМгАВдєЛжЙАдї•жЬЙињЩж†ЈдЉШиЙѓзЪДзЙєжАІжШѓеЫ†дЄЇпЉМServerеТМKeyйЗЗзФ®дЇЖеРМж†ЈзЪДеАЉеЯЯ
дљЖжШѓињЩж†ЈеБЪзЪДжХИжЮЬеєґдЄНзРЖжГ≥пЉМеОЯеЫ†жШѓеУИеЄМиЩљзДґжШѓйЪПжЬЇзЪДпЉМдљЖеЊАеЊАйЪПжЬЇзЪДдЄНе¶ВдЇЇжДПпЉМе∞§еЕґжШѓеЬ®ServerиКВзВєжХ∞йЗПдЄКзЪДжГЕеЖµдЄЛпЉМServerдЄНдЉЪеЭЗеМАеИЖеЄГеЬ®еУИеЄМзОѓдЄКпЉМињЩдЉЪеѓЉиЗіеУИеЄМдЄНеЭЗеМАпЉМжЯРдЇЫServerдЉЪжЙњжЛЕеЊИе§ЪзЪДKeyпЉМиАМеП¶дЄАдЇЫдЉЪеЊИе∞СпЉМе¶ВеЫЊпЉЪ
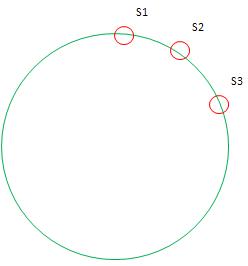
зїЭе§Іе§ЪжХ∞KeyдЉЪжШ†е∞ДеИ∞Server1пЉМеЫ†ж≠§KETAMAеЉХеЕ•дЇЖиЩЪиКВзВєзЪДж¶ВењµпЉМе∞±жШѓеБЗи±°жѓПдЄ™ServerжШ†е∞ДеИ∞NдЄ™иКВзВєпЉИж†єжНЃжµЛиѓХNеЬ®100пљЮ200жЧґиЊГдЉШеМЦпЉЙпЉМдљЖKeyзЪДеУИеЄМжШ†е∞ДеИ∞ињЩNдЄ™иКВзВєжЧґеЃЮйЩЕйГљжЬЙиѓ•ServerжЭ•жЙШзЃ°гАВињЩж†ЈеБЪзЪДжДПдєЙеЬ®дЇОпЉМдљњеЫ†дЄЇеЃЮйЩЕиКВзВєе∞СиАМеѓЉиЗіе§ІзЙЗжܙ襀жШ†е∞ДзЪДеМЇеИЂжЬЙиЩЪиКВзВєеОїе°ЂеЕЕпЉМдїОиАМдљњеЃЮиКВзВєжЬЙдЇЖе§ДзРЖжЬђдЄНе±ЮдЇОиЗ™еЈ±еМЇйЧізЪДKeyгАВжЬЙиЩЪиКВзВєеРОзЪДзОѓе¶ВдЄЛпЉЪ
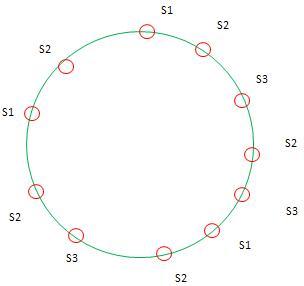
жЦ∞еҐЮзЪДеРМеРНиКВзВєеН≥дЄЇиЩЪиКВзВєгАВ
ињШжЬЙжЬАеРОдЄАдЄ™йЧЃйҐШпЉМиЩЪиКВзВєжШѓе¶ВдљХдЇІзФЯзЪДеСҐпЉЯдєЯйЭЮеЄЄзЃАеНХпЉМе∞±жШѓеЬ®жѓПдЄ™ServerеК†дЄ™еРОзЉАпЉМеЬ®еБЪMD5еУИеЄМпЉМеПЦеЕґ32дљНгАВ
еЕЈдљУиѓЈеПВиАГKETAMAзЪДжЇРз†БпЉЪhttp://www.chris.de/archives/288-libketama-a-consistent-hashing-algo-for-memcache-clients.html
 



зЫЄеЕ≥жО®иНР
еЬ®PythonзЪД`ConsistentHashing`еЇУдЄ≠пЉМзФ®жИЈеПѓдї•жЦєдЊњеЬ∞еЃЮзО∞дЄАиЗіжАІеУИеЄМзЪДеКЯиГљгАВиѓ•еЇУеПѓиГљжПРдЊЫдЇЖдї•дЄЛеКЯиГљпЉЪ 1. **еИЫеїЇдЄАиЗіжАІеУИеЄМзОѓ**пЉЪзФ®жИЈеПѓдї•йАЪињЗжМЗеЃЪиКВзВєжХ∞йЗПеТМиЩЪжЛЯиКВзВєеАНжХ∞жЭ•жЮДеїЇдЄАиЗіжАІеУИеЄМзОѓгАВиЩЪжЛЯиКВзВєзЪДеЉХеЕ•жШѓдЄЇдЇЖ...
еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМеЄЄеЄЄйЬАи¶БдљњзФ®зЉУе≠ШпЉМиАМдЄФйАЪеЄЄжШѓйЫЖзЊ§пЉМиЃњйЧЃзЉУе≠ШеТМжЈїеК†зЉУе≠ШйГљйЬАи¶БдЄАдЄ™ hash зЃЧж≥ХжЭ•еѓїжЙЊеИ∞еРИйАВзЪД Cache иКВзВєгАВдљЖпЉМйАЪеЄЄдЄНжШѓзФ®еПЦдљЩhashпЉМиАМжШѓдљњзФ®жИСдїђдїК姩зЪДдЄїиІТвАФвАФ дЄАиЗіжАІ hash зЃЧж≥ХгАВ
жЬђжЦЗжПРеИ∞зЪДеЕ≥йФЃзЯ•иѓЖзВєеМЕжЛђдЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙгАБйЪПжЬЇж†СпЉИRandom TreesпЉЙгАБеИЖеЄГеЉПзЉУе≠ШеНПиЃЃпЉИDistributed Caching ProtocolsпЉЙгАБдї•еПКзљСзїЬдЄ≠зЪДзГ≠зВєзЉУиІ£пЉИRelieving Hot SpotsпЉЙгАВдЄЇдЇЖжЫіе•љеЬ∞иІ£йЗКињЩдЇЫж¶ВењµпЉМ...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНзФ®дЇОеИЖеЄГеЉПз≥їзїЯзЪДеУИеЄМзЃЧж≥ХпЉМдЄїи¶БеЇФзФ®дЇОеИЖеЄГеЉПзЉУе≠ШгАБеИЖеЄГеЉПжХ∞жНЃеЇУз≠ЙеЬЇжЩѓпЉМзЫЃзЪДжШѓеЬ®иКВзВєеК®жАБеҐЮеЗПжЧґдњЭжМБеУИеЄМи°®зЪДз®≥еЃЪжАІпЉМдїОиАМжЬАе∞ПеМЦжХ∞жНЃињБзІїзЪДељ±еУНгАВеЃГиІ£еЖ≥дЇЖдЉ†зїЯеУИеЄМеПЦж®°жЦєж≥ХеЬ®...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓиЃ°зЃЧжЬЇзІСе≠¶дЄ≠зЪДдЄАдЄ™иСЧеРНзЃЧж≥ХпЉМеєњж≥ЫеЇФзФ®дЇОеИЖеЄГеЉПз≥їзїЯгАБиіЯиљљеЭЗи°°гАБзЉУе≠Шз≥їзїЯз≠ЙйҐЖеЯЯпЉМдї•иІ£еЖ≥дЉ†зїЯеУИеЄМзЃЧж≥ХеЬ®еИЖеЄГеЉПзОѓеҐГдЄЛзЪДжЙ©е±ХжАІйЧЃйҐШгАВдЄАиЗіжАІеУИеЄМзЃЧж≥ХзЪДжПРеЗЇпЉМжШѓдЄЇдЇЖиІ£еЖ≥еЫ†з≥їзїЯжЙ©е±ХжИЦ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠еЃЮзО∞иіЯиљљеЭЗи°°зЪДзЃЧж≥ХпЉМе∞§еЕґеЬ®еИЖеЄГеЉПзЉУе≠Ше¶ВMemcachedеТМRedisз≠ЙеЬЇжЩѓдЄЛеєњж≥ЫдљњзФ®гАВеЃГиІ£еЖ≥дЇЖдЉ†зїЯеУИеЄМзЃЧж≥ХеЬ®иКВзВєеҐЮеЗПжЧґеѓЉиЗізЪДе§ІйЗПжХ∞жНЃињБзІїйЧЃйҐШпЉМжПРйЂШдЇЖз≥їзїЯзЪДеПѓзФ®...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМзЃЧж≥ХпЉМдЄїи¶БеЇФзФ®дЇОеИЖеЄГеЉПзЉУе≠ШгАБиіЯиљљеЭЗи°°з≠ЙйҐЖеЯЯпЉМдЊЛе¶ВMemcachedеТМRedisз≠Йз≥їзїЯгАВеЃГиІ£еЖ≥дЇЖеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖзЙЗдЄОиКВзВєеК®жАБеҐЮеЗПжЧґпЉМе∞љйЗПеЗПе∞СжХ∞жНЃињБзІїзЪДйЧЃйҐШгАВеЄ¶иЩЪжЛЯ...
дЄАиЗіжАІеУИеЄМ consistent-hash Implementing Consistent Hashing in Kotlin Java KotlinеЃЮзО∞зЪДдЄАиЗіжАІеУИеЄМеЈ•еЕЈ зЃАеНХз§ЇдЊЛ val a = HostPortPhysicalNode("A", "192.169.1.1", 8080) val b = HostPortPhysicalNode("B", ...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНзЙєжЃКзЪДеУИеЄМзЃЧж≥ХпЉМеЃГеЬ®еИЖеЄГеЉПзЉУе≠ШеТМиіЯиљљеЭЗи°°з≠ЙеЬЇжЩѓдЄ≠襀府ж≥ЫеЇФзФ®гАВеЃГйАЪињЗе∞ЖжХ∞жНЃеТМжЬНеК°еЩ®иКВзВєжШ†е∞ДеИ∞дЄАдЄ™еУИеЄМзОѓдЄКпЉМжПРдЊЫдЇЖдЄАзІНеЬ®иКВзВєеҐЮеЗПжЧґиГље§ЯжЬАе∞ПеМЦжХ∞жНЃйЗНжЦ∞еИЖйЕНзЪДжЬЇеИґгАВжЬђжЦЗе∞Ж...
дЄАиЗіжАІеУИеЄМзЃЧж≥Х(Consistent Hashing)жШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠еє≥и°°жХ∞жНЃеИЖеЄГзЪДз≠ЦзХ•пЉМе∞§еЕґйАВзФ®дЇОзЉУе≠ШжЬНеК°е¶ВMemcachedжИЦRedisгАВеЃГзЪДж†ЄењГжАЭжГ≥жШѓйАЪињЗеУИеЄМеЗљжХ∞е∞Жеѓєи±°жШ†е∞ДеИ∞дЄАдЄ™еЫЇеЃЪе§Іе∞ПзЪДз΃嚥穯йЧідЄ≠пЉМзДґеРОе∞ЖжЬНеК°еЩ®дєЯжШ†е∞ДеИ∞ињЩдЄ™...
вАЬConsistentHashingandRandomTrees: Distributed Caching Protocols for Relieving Hot Spots on the Worldwide WebвАЭжМЗзЪДжШѓзФ±David Kargerз≠ЙдЇЇжТ∞еЖЩзЪДеЕ≥дЇОдЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙдї•еПКе¶ВдљХињРзФ®иѓ•зЃЧж≥Х...
libconhash is a consistent hashing libraray, which can be compiled both on Windows and Linux platform. High performance, easy to use, and easy to scale according to node's processing capacity.
иЈ≥иЈГдЄАиЗіеУИеЄМиЃ°зЃЧ зФЪиЗ≥жЬНеК°еЩ®дєЛйЧізЪДжХ∞жНЃеИЖеЄГдєЯйЭЮеЄЄйЗНи¶БпЉЪеП¶дЄАдЄ™йЗНи¶БжЦєйЭҐжШѓиГље§Я... еЕ≥дЇОдЄАиЗіжАІеУИеЄМпЉМдљњзФ®зЪДзЃЧж≥ХжШѓи∞Јж≠МзЪДиЃЇжЦЗвАЬA Fast, Minimal Memory, Consistent Hash AlgorithmвАЭдЄ≠жПРеЗЇзЪДJump Consistent HashingгАВ
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМзЃЧж≥ХпЉМдЄїи¶БеЇФзФ®дЇОеИЖеЄГеЉПзЉУе≠ШгАБиіЯиљљеЭЗи°°з≠ЙйҐЖеЯЯпЉМдЊЛе¶ВеЬ®RedisгАБMemcachedз≠Йз≥їзїЯдЄ≠еєњж≥ЫдљњзФ®гАВеЃГиІ£еЖ≥дЇЖдЉ†зїЯеУИеЄМзЃЧж≥ХеЬ®иКВзВєеК®жАБеҐЮеЗПжЧґеѓЉиЗізЪДе§ІйЗПжХ∞жНЃињБзІїйЧЃйҐШгАВеЬ®JavaдЄ≠...
дЄАиЗіжАІеУИеЄМзЃЧж≥Х
lua дЄАиЗіжАІеУИеЄМеЯЇдЇО yaoweibin зЪДдЄАиЗіжАІеУИеЄМеИЖжФѓпЉИ пЉЙеЬ® lua дЄ≠йЗНжЦ∞еЃЮзО∞дЄАиЗіжАІеУИеЄМзФ®ж≥Х local chash = require " chash "chash. add_upstream ( " 192.168.0.251 " )chash. add_upstream ( " 192.168.0.252 " )chash...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙжШѓдЄАзІНеЄЄзФ®дЇОеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДжХ∞жНЃеИЖзЙЗз≠ЦзХ•пЉМеЃГжЬЙжХИеЬ∞иІ£еЖ≥дЇЖжХ∞жНЃеЬ®е§ЪеП∞жЬНеК°еЩ®йЧіеЭЗеМАеИЖеЄГзЪДйЧЃйҐШпЉМеРМжЧґеЗПе∞СдЇЖеЫ†иКВзВєеК†еЕ•жИЦз¶їеЉАжЧґзЪДжХ∞жНЃињБзІїжИРжЬђгАВ й¶ЦеЕИпЉМдЄАиЗіжАІеУИеЄМзЪДеЯЇжЬђеОЯзРЖжШѓе∞Ж...
дЄАиЗізЪДжХ£еИЧињЩжШѓдЄАиЗіжАІеУИеЄМзЪДзЃАеНХJavaScriptеЃЮзО∞гАВ жЬЙеЕ≥дЄАиЗіжАІеУИеЄМзЪДжЫіе§Ъдњ°жБѓпЉМиѓЈеПВиІБгАВеЃЙи£ЕдљњзФ®дї•дЄЛеСљдї§еЃЙи£ЕдЊЭиµЦй°єпЉЪ $ npm install зФ®ж≥Хvar ConsistentHashing = require ( './consistent_hashing' ) ;var node...
жЬђжЦЗе∞ЖдЉЪдїОеЃЮйЩЕеЇФзФ®еЬЇжЩѓеЗЇеПСпЉМдїЛзїНдЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙеПК еЕґеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДеЇФзФ®гАВй¶ЦеЕИжЬђжЦЗдЉЪжППињ∞дЄАдЄ™еЬ®жЧ•еЄЄеЉАеПСдЄ≠зїПеЄЄдЉЪйБЗеИ∞зЪДйЧЃйҐШ еЬЇжЩѓпЉМеАЯж≠§дїЛзїНдЄАиЗіжАІеУИеЄМзЃЧж≥Хдї•еПКињЩдЄ™зЃЧж≥Хе¶ВдљХиІ£еЖ≥ж≠§йЧЃйҐШпЉЫжО•...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠иІ£еЖ≥жХ∞жНЃеИЖзЙЗйЧЃйҐШзЪДзЃЧж≥ХпЉМеЃГеЬ®Goиѓ≠и®АдЄ≠зЪДеЃЮзО∞еѓєдЇОжЮДеїЇеПѓжЙ©е±ХдЄФеЃєйФЩзЪДжЬНеК°иЗ≥еЕ≥йЗНи¶БгАВеЬ®GoеЉАеПСдЄ≠пЉМе∞§еЕґжШѓеЬ®жґЙеПКеИЖеЄГеЉПзЉУе≠ШгАБиіЯиљљеЭЗи°°з≠ЙеЬЇжЩѓдЄЛпЉМдЄАиЗіжАІеУИеЄМиГље§Я...