一,安装java
1,下载java (以下为下载在/work目录下操作)
wgethttp://download.oracle.com/otn-pub/java/jdk/7u2-b13/jdk-7u2-linux-i586.tar.gz
2,解压下载文件并改名
tar-zxvf jdk-7u2-linux-i586.tar.gz
mvjdk1.7.0_02 java
rmjdk-7u2-linux-i586.tar.gz
3,在/etc/profile中加入以下语句:
exportJAVA_HOME=/work/java
exportJRE_HOME=$JAVA_HOME/jre
exportPATH=$PATH:$JAVA_HOME/bin
二,安装hadoop
1, 下载hadoop压缩包(下载在/work目录下)
wget
http://mirror.bit.edu.cn/apache//hadoop/common/hadoop-1.0.0/hadoop-1.0.0.tar.gz
2, 解压压缩包并改名
tar -zxvf hadoop-1.0.0.tar.gz
mv hadoop-1.0.0 hadoop
rm hadoop-1.0.0.tar.gz
3, 修改/etc/profile至
exportJAVA_HOME=/work/java
exportJRE_HOME=$JAVA_HOME/jre
exportHADOOP_HOME=/work/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
三,配置hadoop
1, 配置conf/hadoop-env.sh
export JAVA_HOME=/work/java
export HADOOP_HEAPSIZE=2000
2, 配置conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://da-free-test1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/work/hadoopneed/tmp</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/work/hadoop/conf/dfs.hosts.exclude</value>
</property>
</configuration>
3, 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/work/hadoopneed/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/work/hadoopneed/data/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>30</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>5</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>10737418240</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
</configuration>
4, 配置mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>da-free-test1:9001/</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/work/hadoopneed/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/tmp/hadoop/mapred/system</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx512</value>
<final>true</final>
</property>
<property>
<name>mapred.job.tracker.handler.count</name>
<value>30</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>100</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>12</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>63</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>6</value>
</property>
5, 配置masters
da-free-test1
6, 配置slaves
da-free-test2
da-free-test3
da-free-test4
四,其他节点的安装
1, 将hadoo和java目录拷贝到其他三个节点对应目录下
scp -rhadoop da-free-test2:/work
scp -rhadoop da-free-test3:/work
scp -rhadoop da-free-test4:/work
scp -rjava da-free-test2:/work
scp -rjava da-free-test3:/work
scp -r java da-free-test4:/work
2, 修改三个节点的/etc/profile,加入以下语句并执行一遍。
exportJAVA_HOME=/work/java
exportJRE_HOME=$JAVA_HOME/jre
exportHADOOP_HOME=/work/hadoop
exportPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
至此,算是安装完成,之后遇到的都当问题来处理。
六,格式化文件系统
1, 遇到问题:
[root@da-free-test1bin]# ./hadoop namenode -format
Warning:$HADOOP_HOME is deprecated.
Error: dlfailure on line 875
Error:failed /work/java/jre/lib/i386/server/libjvm.so, because/work/java/jre/lib/i386/server/libjvm.so: cannot restore segment prot afterreloc: Permission denied
Error: dlfailure on line 875
Error: failed /work/java/jre/lib/i386/server/libjvm.so,because /work/java/jre/lib/i386/server/libjvm.so: cannot restore segment protafter reloc: Permission denied
解决方法:关闭selinux:
修改/etc/selinux/config
SELINUX=disabled
更改其他三个节点,并重启系统。
解决报警
Warning: $HADOOP_HOME is deprecated.
将刚才添加到/etc/profile中的关于$HADOOP_HOME的删除并重新登录。
2, 成功格式化
[root@da-free-test1~]# hadoop namenode -format
12/02/0812:01:21 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG:Starting NameNode
STARTUP_MSG: host = da-free-test1/172.16.18.202
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.0
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0-r 1214675; compiled by 'hortonfo' on Thu Dec 15 16:36:35 UTC 2011
************************************************************/
12/02/0812:01:21 INFO util.GSet: VM type =32-bit
12/02/0812:01:21 INFO util.GSet: 2% max memory = 35.55625 MB
12/02/0812:01:21 INFO util.GSet: capacity =2^23 = 8388608 entries
12/02/0812:01:21 INFO util.GSet: recommended=8388608, actual=8388608
12/02/0812:01:21 INFO namenode.FSNamesystem: fsOwner=root
12/02/0812:01:21 INFO namenode.FSNamesystem: supergroup=supergroup
12/02/0812:01:21 INFO namenode.FSNamesystem: isPermissionEnabled=true
12/02/0812:01:21 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
12/02/0812:01:21 INFO namenode.FSNamesystem: isAccessTokenEnabled=falseaccessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
12/02/0812:01:21 INFO namenode.NameNode: Caching file names occuring more than 10 times
12/02/0812:01:22 INFO common.Storage: Image file of size 110 saved in 0 seconds.
12/02/0812:01:22 INFO common.Storage: Storage directory /work/hadoopneed/name has beensuccessfully formatted.
12/02/0812:01:22 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG:Shutting down NameNode at da-free-test1/172.16.18.202
************************************************************/
七,启动hadoop
1, 启动hadoop日志报错
./start-all.sh
WARN org.apache.hadoop.hdfs.DFSClient: DataStreamerException: org.apache.hadoop.ipc.RemoteException: java.io.IOException: File/tmp/hadoop/mapred/system/jobtracker.info could only be replicated to 0 nodes,instead
of 1
解决方法:关闭hadoop安全模式:hadoop dfsadmin -safemode leave(此时并未关闭hadoop)。
等待一会,hadoop自动恢复成功。
观察日志hadoop-root-jobtracker-da-free-test1.log,可以看到:
2012-02-08 12:14:07,804 INFOorg.apache.hadoop.ipc.Server: IPC Server Responder: starting
2012-02-08 12:14:07,804 INFOorg.apache.hadoop.ipc.Server: IPC Server listener on 9001: starting
2012-02-08 12:14:07,805 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 0 on 9001: starting
2012-02-08 12:14:07,805 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 1 on 9001: starting
2012-02-08 12:14:07,805 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 2 on 9001: starting
2012-02-08 12:14:07,805 INFO org.apache.hadoop.ipc.Server:IPC Server handler 3 on 9001: starting
2012-02-08 12:14:07,805 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 4 on 9001: starting
2012-02-08 12:14:07,805 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 5 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 6 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 7 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 8 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 9 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 10 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 11 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 12 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 13 on 9001: starting
2012-02-08 12:14:07,806 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 14 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 15 on 9001: starting
2012-02-08 12:14:07,807 INFO org.apache.hadoop.ipc.Server:IPC Server handler 16 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 17 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 18 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 19 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 20 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 21 on 9001: starting
2012-02-08 12:14:07,807 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 22 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 23 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 25 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 26 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 27 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 28 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.mapred.JobTracker: Starting RUNNING
2012-02-08 12:14:07,808 INFO org.apache.hadoop.ipc.Server:IPC Server handler 29 on 9001: starting
2012-02-08 12:14:07,808 INFOorg.apache.hadoop.ipc.Server: IPC Server handler 24 on 9001: starting
2012-02-08 12:14:12,623 INFOorg.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/da-free-test4
2012-02-08 12:14:12,625 INFOorg.apache.hadoop.mapred.JobTracker: Adding trackertracker_da-free-test4:da-free-test1/127.0.0.1:42182 to host da-free-test4
2012-02-08 12:14:12,743 INFOorg.apache.hadoop.net.NetworkTopology: Adding a new node:/default-rack/da-free-test3
2012-02-08 12:14:12,744 INFOorg.apache.hadoop.mapred.JobTracker: Adding trackertracker_da-free-test3:da-free-test1/127.0.0.1:53695 to host da-free-test3
2012-02-08 12:14:12,802 INFOorg.apache.hadoop.net.NetworkTopology: Adding a new node:/default-rack/da-free-test2
2012-02-08 12:14:12,802 INFOorg.apache.hadoop.mapred.JobTracker: Adding trackertracker_da-free-test2:da-free-test1/127.0.0.1:47259 to host da-free-test2
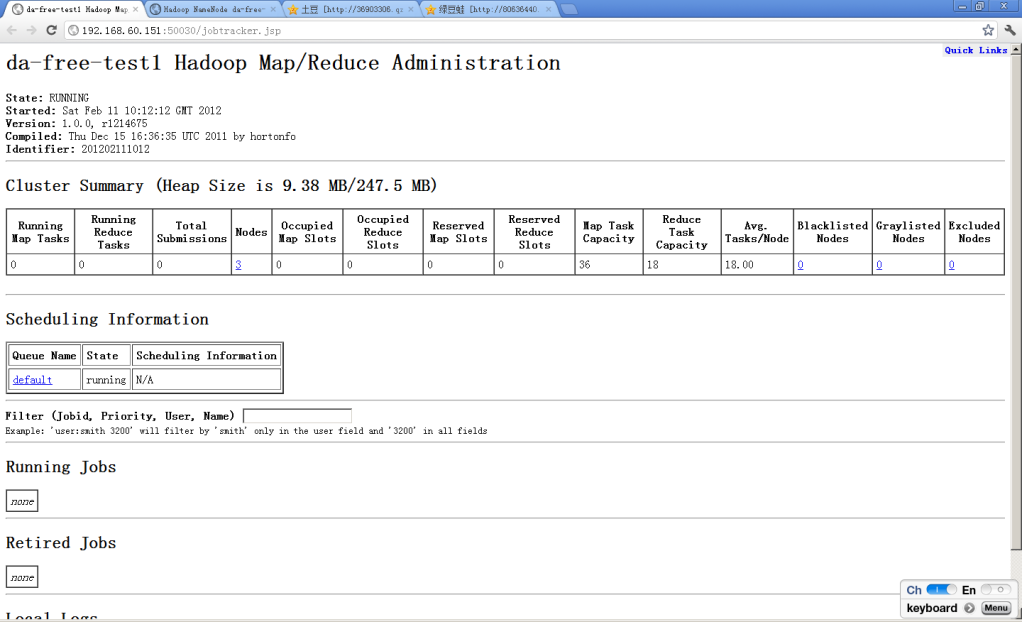
打开浏览器,输入http://172.16.18.202:50030,可以看到节点数量为3。
上传一个文件:dfs -put hadoop-root-namenode-da-free-test1.log /usr/testfile
查看上传的文件:hadoop dfs -ls /usr/
Found 1 items
-rw-r--r--3 root supergroup 845332012-02-08 12:20 /usr/testfile
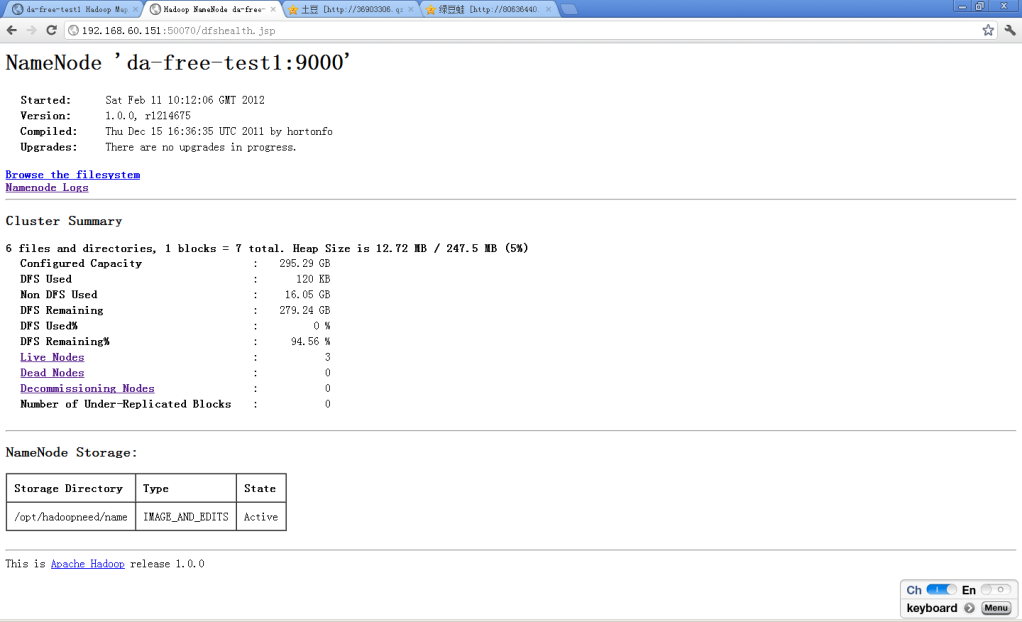
查看http://172.16.18.202:50070,发现已用空间为396k。
暂时验证通过。
===========================
分享到:




相关推荐
本文将深入探讨“Hadoop集群配置文件备份”的重要性、步骤和最佳实践。 **1. Hadoop配置文件概述** Hadoop的配置文件主要包括`core-site.xml`、`hdfs-site.xml`、`yarn-site.xml`、`mapred-site.xml`等,这些XML...
hadoop集群配置,详细安装教程,超详细的的资源将被移除
《Hadoop集群配置及MapReduce开发手册》是针对大数据处理领域的重要参考资料,主要涵盖了Hadoop分布式计算框架的安装、配置以及MapReduce编程模型的详细解析。Hadoop作为Apache基金会的一个开源项目,因其分布式存储...
hadoop集群配置范例及问题总结 Hadoop集群配置是大数据处理的关键步骤,本文将详细介绍Hadoop集群配置的步骤和注意事项。 一、硬件环境配置 Hadoop集群需要多台机器组成,通常使用虚拟机来模拟多台机器。 VMware ...
hadoop集群配置文档
Hadoop集群配置范例及问题总结 Hadoop集群配置是一个复杂的过程,需要详细的规划和实施。以下是Hadoop集群配置的相关知识点: 1. 硬件环境:Hadoop集群需要至少两台机器,安装ubuntu11操作系统,并采用桥接模式,...
Hadoop 集群配置是一个复杂的过程,涉及到多台服务器之间的通信和数据存储。在这个详解中,我们将深入理解如何在Fedora和Ubuntu系统上搭建一个Hadoop集群。 首先,为了确保集群中的节点能够相互识别,我们需要配置...
在Hadoop集群配置过程中,安装和配置Hive是一个重要环节。这个过程中需要保证Hadoop集群本身已经搭建好并且运行正常。在安装Hive之前,一般需要先安装和配置好MySQL数据库,因为Hive会使用MySQL来存储其元数据。元...
hadoop配置详细教程,涵盖了Hadoop集群配置从头到尾的所有细节部署,其中注意点已用红色标记,此文档曾用于企业Hadoop集群搭建教程,涵盖了 准备篇---配置篇----启动测试篇---问题篇,解决网络上Hadoop集群配置教程...
### Hadoop集群配置及MapReduce开发手册知识点梳理 #### 一、Hadoop集群配置说明 ##### 1.1 环境说明 本手册适用于基于CentOS 5系统的Hadoop集群配置,具体环境配置如下: - **操作系统**:CentOS 5 - **JDK版本...
Hadoop 集群配置详解 Hadoop_Hadoop集群(第1期)_CentOS安装配置 Hadoop_Hadoop集群(第2期)_机器信息分布表 Hadoop_Hadoop集群(第4期)_SecureCRT使用 Hadoop_Hadoop集群(第5期)_Hadoop安装配置 Hadoop_Hadoop...
本压缩包包含的文件是全面的Hadoop集群配置集合,旨在帮助用户顺利构建和管理自己的Hadoop环境。以下将详细解释其中涉及的关键知识点。 1. **Hadoop架构**:Hadoop是由Apache软件基金会开发的一个开源分布式计算...
【基于CentOS 7的Hadoop集群配置的研究与实现】 Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据。本论文详细探讨了在CentOS 7操作系统上配置和实施Hadoop集群的过程,这对于理解和掌握大数据处理...
### Eclipse链接Hadoop集群配置详解 #### 一、前言 在大数据处理领域,Hadoop因其卓越的分布式处理能力而备受青睐。为了更好地利用Hadoop的强大功能,开发人员经常需要在本地开发环境中与Hadoop集群进行交互。本文...
"hadoop集群配置三节点" 通过这篇文章,我们可以了解如何配置一个三节点的Hadoop集群。该集群包括一个Master节点和两个Slave节点(Slave1和Slave2)。下面是配置步骤的详细说明: 步骤一:安装CentOS 7操作系统 ...