此算法的主要作用:屏幕上很多的点,把相邻的点聚到离他最近的点。
k-means algorithm算法是一个聚类算法,把n个对象根据他们的属性分为k个分割,k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。
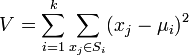
php实现算法代码如下:
class Cluster
{
public $points;
public $avgPoint;
function calculateAverage($maxX, $maxY)
{
if (count($this->points)==0)
{
$this->avgPoint->x = rand(0, $maxX);
$this->avgPoint->y = rand(0,$maxY);
//we didn't get any clues at all :( lets just randomize and hope for better...
return;
}
foreach($this->points as $p)
{
$xsum += $p->x;
$ysum += $p->y;
}
$count = count($this->points);
$this->avgPoint->x = $xsum / $count;
$this->avgPoint->y = $ysum / $count;
}
}
class Point
{
public $x;
public $y;
function getDistance($p)
{
$x1 = $this->x - $p->x;
$y1 = $this->y - $p->y;
return sqrt($x1*$x1 + $y1*$y1);
}
}
function distributeOverClusters($k, $arr)
{
foreach($arr as $p)
{ if ($p->x > $maxX)
$maxX = $p->x;
if ($p->y > $maxY)
$maxY = $p->y;
}
$clusters = array();
for($i = 0; $i < $k; $i++)
{
$clusters[] = new Cluster();
$tmpP = new Point();
$tmpP->x=rand(0,$maxX);
$tmpP->y=rand(0,$maxY);
$clusters[$i]->avgPoint = $tmpP;
}
#deploy points to closest center.
#recalculate centers
for ($a = 0; $a < 200; $a++) # run it 200 times
{
foreach($clusters as $cluster)
$cluster->points = array(); //reinitialize
foreach($arr as $pnt)
{
$bestcluster=$clusters[0];
$bestdist = $clusters[0]->avgPoint->getDistance($pnt);
foreach($clusters as $cluster)
{
if ($cluster->avgPoint->getDistance($pnt) < $bestdist)
{
$bestcluster = $cluster;
$bestdist = $cluster->avgPoint->getDistance($pnt);
}
}
$bestcluster->points[] = $pnt;//add the point to the best cluster.
}
//recalculate the centers.
foreach($clusters as $cluster)
$cluster->calculateAverage($maxX, $maxY);
}
return $clusters;
}
$p = new Point();
$p->x = 2;
$p->y = 2;
$p2 = new Point();
$p2->x = 3;
$p2->y = 2;
$p3 = new Point();
$p3->x = 8;
$p3->y = 2;
$arr[] = $p;
$arr[] = $p2;
$arr[] = $p3;
var_dump(distributeOverClusters(2, $arr));
参考地址:http://en.wikipedia.org/wiki/K-means_clustering
分享到:




相关推荐
Java实现的k-means聚类算法详解 k-means聚类算法是一种常用的无监督学习算法,用于对数据进行聚类分析。该算法的主要思想是将相似的数据点聚类到一起,形成不同的簇。Java语言是实现k-means聚类算法的不二之选。 ...
基于K-means聚类算法的图像分割 算法的基本原理: 基于K-means聚类算法的图像分割以图像中的像素为数据点,按照指定的簇数进行聚类,然后将每个像素点以其对应的聚类中心替代,重构该图像。 算法步骤: ①随机选取...
K-Means聚类算法的原理是将数据点分组成K个簇,每个簇的中心点是该簇中所有点的平均值。算法的主要步骤包括: 1. 随机选择K个样本作为初始聚类中心 2. 针对数据集中每个样本,分别计算该样本到K个聚类中心的距离,...
《K-means聚类算法在计算机视觉中的应用与MATLAB实现》 K-means聚类算法,作为一种简单而有效的无监督机器学习方法,被广泛应用于数据挖掘和图像处理领域,尤其是在计算机视觉中,它能够对图像进行自动分类,识别...
《基于K-means聚类算法的图像分割在MATLAB中的实现》 图像分割是计算机视觉领域中的基础任务,它旨在将图像划分为多个区域或对象,每个区域具有相似的特征。K-means聚类算法是一种广泛应用的数据分析方法,它通过...
通过观看这样的动画,初学者可以更好地理解k-means算法的工作原理,以及数据分布和类别中心变动如何影响聚类结果。同时,这也是一种生动的教学工具,有助于增强对复杂统计概念的理解。在"k-means动画聚类"的压缩包中...
K-means聚类算法是一种广泛应用的无监督学习方法,主要用于数据的分组或分类,尤其在数据挖掘和机器学习领域。它的目标是将数据集划分为k个互不重叠的簇,使得同一簇内的数据点间的相似度尽可能高,而不同簇之间的...
基于k-means聚类算法的研究涉及了数据挖掘领域中的关键算法,该研究由黄韬、刘胜辉、谭艳娜三位研究人员共同完成,其研究机构分别为哈尔滨理工大学计算机科学与技术学院、软件学院和哈尔滨工程大学计算机科学与技术...
标题“基于 K-means 聚类算法的图像区域分割”揭示了这是一个关于利用K-means算法处理图像处理问题的项目。K-means聚类是一种常见的无监督学习方法,用于将数据集划分为K个互不重叠的类别,每个类别由其内部数据点的...
基于 K-means 聚类算法的图像区域分割,首先从数据样本种选取K个点作为初始聚类中心,其次计算各个样本到聚类的距离,把样本归到离它最近的那个聚类中心所在的累,计算新形成的每个聚类的数据对象的平均值来得到新的...
Spark ML Bisecting k-means 聚类算法使用实验 Spark ML 中的 Bisecting k-means 聚类算法是 Spark ML 库中的一种常用的聚类算法,它可以将数据聚类成多个簇,以便更好地理解数据的分布和模式。下面是 Bisecting k...
在这个项目中,"ABC-K"可能是ABC算法的一种变体,专门用于k-means的初始化。通过ABC算法寻找的最优质心可以提高k-means聚类的稳定性和准确性,减少对初始条件的依赖,从而获得更优的聚类结果。同时,由于描述提到有...
k-means聚类是一种广泛应用的数据挖掘技术,常用于无监督学习场景,旨在将数据集划分为K个不同的簇,使得每个簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。这种算法基于距离度量,如欧几里得距离,以...
K-MEANS聚类算法的实现 K-MEANS聚类算法是一种常用的无监督机器学习算法,主要用于对数据进行聚类分析。该算法的主要思想是将相似的数据对象划分到同一个簇中,使得簇内的数据对象尽量相似,而簇间的数据对象尽量...
实验五 K-Means聚类算法.ipynb
PPT用于初步理解K-means算法,且基于K-means算法衍生出了三类算法:K-medoids,k-means++,FCM。该PPT的传输来自导师的资源分享,不涉及商用,用于大家对K-means算法的理解。如有侵权,本人将撤销资源上传。以上。
在本实验中,我们将深入探讨如何使用Python编程语言和K-Means聚类算法来对MNIST数据集中的手写数字图像进行分类。MNIST数据集是机器学习领域的一个经典基准,它包含了大量的0到9的手写数字图像,用于训练和测试图像...
k-means聚类算法是其中最简单且广泛使用的算法之一,尤其适用于处理大规模数据集。本篇文章将深入探讨如何在Matlab环境下实现k-means算法对三维数据进行分类,并结合提供的源代码进行解析。 首先,k-means算法的...