
еҜјиҜ»пјҡеҰӮжғізӣҙжҺҘиҺ·зҹҘй…ҚзҪ®agentзҡ„ж–№жі•пјҢиҜ·йҳ…иҜ»Setting up an agentе°ҸиҠӮгҖӮ
В
Overview
жҰӮиҝ°
Apache FlumeжҳҜдёҖдёӘй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„еҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—收йӣҶгҖҒиҒҡеҗҲгҖҒдј иҫ“зі»з»ҹгҖӮе®ғеҸҜд»Ҙд»ҺдёҚеҗҢзҡ„ж—Ҙеҝ—жәҗйҮҮйӣҶж•°жҚ®е№¶йӣҶдёӯеӯҳеӮЁгҖӮ
В
Flumeд№ҹз®—жҳҜHadoopз”ҹжҖҒзі»з»ҹзҡ„дёҖйғЁеҲҶпјҢжәҗдәҺClouderaпјҢзӣ®еүҚжҳҜApacheеҹәйҮ‘дјҡзҡ„йЎ¶зә§йЎ№зӣ®д№ӢдёҖгҖӮFlumeжңүдёӨжқЎдә§е“ҒзәҝпјҢ0.9.xзүҲжң¬е’Ң1.xзүҲжң¬гҖӮжң¬ж–Үдё»иҰҒд»Ӣз»ҚFlume 1.3.0пјҢеҚі"NG"дә§е“ҒзәҝдёҠзҡ„жңҖж–°зЁіе®ҡзүҲгҖӮ(BTWпјҢFlumeжҳҜApache 2.0 В License)
В
Resource
иө„жәҗ
Architecutre
жһ¶жһ„
В
ж•°жҚ®жөҒжЁЎеһӢ
Flumeд»ҘagentдёәжңҖе°Ҹзҡ„зӢ¬з«ӢиҝҗиЎҢеҚ•дҪҚгҖӮдёҖдёӘagentе°ұжҳҜдёҖдёӘJVMгҖӮеҚ•agentз”ұSourceгҖҒSinkе’ҢChannelдёүеӨ§з»„件жһ„жҲҗпјҢеҰӮдёӢеӣҫ(еӣҫзүҮж‘ҳиҮӘFlumeе®ҳж–№зҪ‘з«ҷ)пјҡ
В

Flumeзҡ„ж•°жҚ®жөҒз”ұдәӢ件(Event)иҙҜз©ҝе§Ӣз»ҲгҖӮдәӢ件жҳҜFlumeзҡ„еҹәжң¬ж•°жҚ®еҚ•дҪҚпјҢе®ғжҗәеёҰж—Ҙеҝ—ж•°жҚ®(еӯ—иҠӮж•°з»„еҪўејҸ)并且жҗәеёҰжңүеӨҙдҝЎжҒҜпјҢиҝҷдәӣEventз”ұAgentеӨ–йғЁзҡ„SourceпјҢжҜ”еҰӮдёҠеӣҫдёӯзҡ„Web Serverз”ҹжҲҗгҖӮеҪ“SourceжҚ•иҺ·дәӢ件еҗҺдјҡиҝӣиЎҢзү№е®ҡзҡ„ж јејҸеҢ–пјҢ然еҗҺSourceдјҡжҠҠдәӢ件жҺЁе…Ҙ(еҚ•дёӘжҲ–еӨҡдёӘ)ChannelдёӯгҖӮдҪ еҸҜд»ҘжҠҠChannelзңӢдҪңжҳҜдёҖдёӘзј“еҶІеҢәпјҢе®ғе°ҶдҝқеӯҳдәӢ件зӣҙеҲ°SinkеӨ„зҗҶе®ҢиҜҘдәӢ件гҖӮSinkиҙҹиҙЈжҢҒд№…еҢ–ж—Ҙеҝ—жҲ–иҖ…жҠҠдәӢ件жҺЁеҗ‘еҸҰдёҖдёӘSourceгҖӮ
В
еҫҲзӣҙзҷҪзҡ„и®ҫи®ЎпјҢе…¶дёӯеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢFlumeжҸҗдҫӣдәҶеӨ§йҮҸеҶ…зҪ®зҡ„SourceгҖҒChannelе’ҢSinkзұ»еһӢгҖӮдёҚеҗҢзұ»еһӢзҡ„Source,Channelе’ҢSinkеҸҜд»ҘиҮӘз”ұз»„еҗҲгҖӮз»„еҗҲж–№ејҸеҹәдәҺз”ЁжҲ·и®ҫзҪ®зҡ„й…ҚзҪ®ж–Ү件пјҢйқһеёёзҒөжҙ»гҖӮжҜ”еҰӮпјҡChannelеҸҜд»ҘжҠҠдәӢ件жҡӮеӯҳеңЁеҶ…еӯҳйҮҢпјҢд№ҹеҸҜд»ҘжҢҒд№…еҢ–еҲ°жң¬ең°зЎ¬зӣҳдёҠгҖӮSinkеҸҜд»ҘжҠҠж—Ҙеҝ—еҶҷе…ҘHDFS, HBaseпјҢз”ҡиҮіжҳҜеҸҰеӨ–дёҖдёӘSourceзӯүзӯүгҖӮ
В
еҰӮжһңдҪ д»ҘдёәFlumeе°ұиҝҷдәӣиғҪиҖҗйӮЈе°ұеӨ§й”ҷзү№й”ҷдәҶгҖӮFlumeж”ҜжҢҒз”ЁжҲ·е»әз«ӢеӨҡзә§жөҒпјҢд№ҹе°ұжҳҜиҜҙпјҢеӨҡдёӘagentеҸҜд»ҘеҚҸеҗҢе·ҘдҪңпјҢ并且ж”ҜжҢҒFan-inгҖҒFan-outгҖҒContextual RoutingгҖҒBackup RoutesгҖӮ
В
й«ҳеҸҜйқ жҖ§
дҪңдёәз”ҹдә§зҺҜеўғиҝҗиЎҢзҡ„иҪҜ件пјҢй«ҳеҸҜйқ жҖ§жҳҜеҝ…йЎ»зҡ„гҖӮ
д»ҺеҚ•agentжқҘзңӢпјҢFlumeдҪҝз”ЁеҹәдәҺдәӢеҠЎзҡ„ж•°жҚ®дј йҖ’ж–№ејҸжқҘдҝқиҜҒдәӢд»¶дј йҖ’зҡ„еҸҜйқ жҖ§гҖӮSourceе’ҢSinkиў«е°ҒиЈ…иҝӣдёҖдёӘдәӢеҠЎгҖӮдәӢ件被еӯҳж”ҫеңЁChannelдёӯзӣҙеҲ°иҜҘдәӢ件被еӨ„зҗҶпјҢChannelдёӯзҡ„дәӢ件жүҚдјҡ被移йҷӨгҖӮиҝҷжҳҜFlumeжҸҗдҫӣзҡ„зӮ№еҲ°зӮ№зҡ„еҸҜйқ жңәеҲ¶гҖӮ
В
д»ҺеӨҡзә§жөҒжқҘзңӢпјҢеүҚдёҖдёӘagentзҡ„sinkе’ҢеҗҺдёҖдёӘagentзҡ„sourceеҗҢж ·жңүе®ғ们зҡ„дәӢеҠЎжқҘдҝқйҡңж•°жҚ®зҡ„еҸҜйқ жҖ§гҖӮ
В
еҸҜжҒўеӨҚжҖ§
В иҝҳжҳҜйқ ChannelгҖӮжҺЁиҚҗдҪҝз”ЁFileChannelпјҢдәӢ件жҢҒд№…еҢ–еңЁжң¬ең°ж–Ү件系з»ҹйҮҢ(жҖ§иғҪиҫғе·®)гҖӮ
В
жҰӮеҝөеҲ°жӯӨдёәжӯўпјҢдёӢйқўејҖе§Ӣе®һжҲҳгҖӮ
В
В
Setting up an agent
AgentйңҖиҰҒзҹҘйҒ“е“Әдәӣ组件е°Ҷиў«еҗҜз”ЁпјҢ组件еҰӮдҪ•иҝһжҺҘжқҘжһ„жҲҗж•°жҚ®жөҒгҖӮз”ЁжҲ·еҸӘйңҖиҰҒз®ҖеҚ•ең°жҸҗдҫӣдёҖдёӘй…ҚзҪ®ж–Ү件жқҘе‘ҠиҜүagentиҜҘеҰӮдҪ•еҺ»еҒҡеҚіеҸҜгҖӮ
В
дҫӢеӯҗпјҡдәӢ件жәҗдәҺдёҖдёӘnetcat sourceпјҢдҪҝз”ЁеҶ…еӯҳChannelпјҢжңҖеҗҺдҪҝз”Ёlogger SinkжҠҠж—Ҙеҝ—иҫ“еҮәеҲ°жҺ§еҲ¶еҸ°дёҠгҖӮ(дҫӢеӯҗжәҗдәҺFlumeе®ҳж–№ж–ҮжЎЈпјҢиҜ·еҮҶеӨҮеҘҪLinuxзҺҜеўғ)
В
AgentжҳҜз”ЁдёҖдёӘеҗҚдёәflume-ngзҡ„и„ҡжң¬жқҘеҗҜеҠЁзҡ„пјҡ
Flume 1.3:
В
$ bin/flume-ng agent -n $agent_name -c conf -f $property_file_path
В
В
Flume 1.2е’Ңд№ӢеүҚзүҲжң¬:
В
$ bin/flume-ng node -c conf -f $property_file_path -n $agent_nameВ
В
$agent_name: В agentзҡ„еҗҚеӯ—пјҢйҡҸдҫҝз»ҷдёӘеҗҚеҗ§пјҢжіЁж„Ҹе’Ңpropertyж–Ү件йҮҢagentеҗҚдёҖиҮҙ
$property_file_path: й…ҚзҪ®ж–Ү件и·Ҝеҫ„гҖӮ
В
дёӢйқўз»ҷеҮәй…ҚзҪ®ж–Ү件гҖӮ(ж–°е»әдёҖдёӘж–Ү件example.confпјҢзІҳиҙҙд»ҘдёӢеҶ…е®№пјҢ并дҝқеӯҳ)
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
В
иҜҘй…ҚзҪ®ж–Ү件дёӯagentзҡ„еҗҚеӯ—жҳҜa1пјҢжүҖд»Ҙдҝ®ж”№еҗҜеҠЁе‘Ҫд»Өпјҡ
$ bin/flume-ng agent --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
В 1.2еҸҠжӣҙдҪҺзүҲжң¬зҡ„з”ЁжҲ·пјҢиҜ·жҠҠе‘Ҫд»Өдёӯзҡ„agentж”№дёәnodeгҖӮ
В
В жҺҘзқҖйҖҹйҖҹеҗҜеҠЁFlume agentеҗ§гҖӮеҗҜеҠЁеүҚзЎ®дҝқ44444з«ҜеҸЈжІЎжңүиў«еҚ з”ЁгҖӮ
В
еҗҜеҠЁжҲҗеҠҹеҗҺпјҢдҪҝз”Ёtelnetеҗ‘AgentеҸ‘йҖҒж—Ҙеҝ—пјҡ
$ telnet localhost 44444
В дјҡзңӢеҲ°еҰӮдёӢж—Ҙеҝ—пјҡ
Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'.
В иҫ“е…ҘдҪ зҡ„ж—Ҙеҝ—еҶ…е®№пјҢжҜ”еҰӮпјҡHello world!еӣһиҪҰеҸ‘йҖҒгҖӮ
В еҫ—еҲ°еҰӮдёӢж—Ҙеҝ—пјҢиҜҙжҳҺдҪ е·Із»ҸжҲҗеҠҹеҸ‘йҖҒж—Ҙеҝ—пјҡ
$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. Hello world! <ENTER> OK
В
еңЁFlume agentзҡ„жҺ§еҲ¶еҸ°йҮҢдҪ еҸҜд»ҘзңӢеҲ°еҰӮдёӢдҝЎжҒҜпјҡ
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
В
иҮіжӯӨпјҢжҒӯе–ңдҪ пјҒдёҖдёӘжңҖз®ҖеҚ•зҡ„Flume agentе·Із»ҸжӯЈеёёе·ҘдҪңдәҶпјҒ
В
В
Setting multi-agent flow
и®ҫзҪ®еӨҡagentзҡ„жөҒ
В
е…Ҳз»ҷеҮ еј е®ҳзҪ‘зҡ„еӣҫпјҡ

В
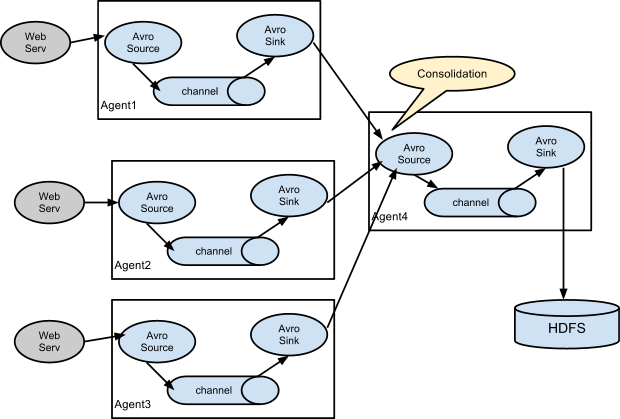
В
В еӨ§е®¶еҸҜд»ҘжҢүз…§е®ҳж–№з”ЁжҲ·жүӢеҶҢжқҘж·ұе…ҘеӯҰд№ гҖӮ
В
В
В
В



зӣёе…іжҺЁиҚҗ
еҲӣе»әдёҖдёӘж–Ү件 `1.log` 并еҶҷе…Ҙ `hello flume`пјҢ然еҗҺжҹҘзңӢ Flume зҡ„жҺ§еҲ¶еҸ°ж—Ҙеҝ—пјҢеә”еҪ“зңӢеҲ°еҰӮдёӢиҫ“еҮәпјҡ ``` 2017-03-20 15:13:51,868 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO -org.apache.flume.sink....
- дҪҝз”Ё `telnet localhost 5858` еҸ‘йҖҒж•°жҚ®пјҢеҰӮпјҡ`hello world`гҖӮ #### дёүгҖҒKafkaй…ҚзҪ®иҜҰи§Ј 1. **дёӢиҪҪKafkaпјҡ** - дҪҝз”Ёе‘Ҫд»Ө `wget ...
- е°ҶжөӢиҜ•ж•°жҚ®еҶҷе…ҘеҲ°FlumeжҢҮе®ҡзҡ„дҪҚзҪ®пјҢеҰӮе‘Ҫд»Ө`echo "helloworld" > /usr/local/apache-flume-1.6.0/file`гҖӮ - иҝҷйҮҢеҒҮи®ҫFlumeжңүдёҖдёӘCollectorжқҘиҜ»еҸ–ж–Ү件дёӯзҡ„ж•°жҚ®пјҢ并е°Ҷе…¶иҪ¬еҸ‘еҲ°KafkaгҖӮ 5. **дҪҝз”ЁAvroе®ўжҲ·з«Ҝеҗ‘Flume...
Flume жҳҜ Apache ејҖжәҗйЎ№зӣ®дёӯзҡ„дёҖдёӘеҲҶеёғејҸгҖҒеҸҜйқ дё”еҸҜз”ЁдәҺжңүж•Ҳ收йӣҶгҖҒиҒҡеҗҲе’Ң移еҠЁеӨ§йҮҸж—Ҙеҝ—ж•°жҚ®зҡ„е·Ҙе…·гҖӮеңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢе®ғжҳҜдёҖдёӘйҮҚиҰҒзҡ„ж•°жҚ®йҮҮйӣҶжЎҶжһ¶пјҢе°Өе…¶йҖӮз”ЁдәҺе®һж—¶ж•°жҚ®жөҒзҡ„йҮҮйӣҶгҖӮFlume 1.7.0 зүҲжң¬жҳҜиҜҘиҪҜ件зҡ„дёҖдёӘзЁіе®ҡ...
Flume жҳҜ Apache ејҖжәҗйЎ№зӣ®дёӯзҡ„дёҖдёӘеҲҶеёғејҸгҖҒеҸҜйқ дё”еҸҜз”ЁдәҺжңүж•Ҳ收йӣҶгҖҒиҒҡеҗҲе’Ң移еҠЁеӨ§йҮҸж—Ҙеҝ—ж•°жҚ®зҡ„е·Ҙе…·гҖӮеңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢFlume жҳҜдёҖдёӘиҮіе…ійҮҚиҰҒзҡ„组件пјҢе°Өе…¶еңЁж—Ҙеҝ—з®ЎзҗҶе’Ңе®һж—¶ж•°жҚ®еҲҶжһҗдёӯжү®жј”зқҖж ёеҝғи§’иүІгҖӮ"flume-1.9.0.tgz...
### Flumeзҡ„е®үиЈ…дёҺдҪҝз”ЁиҜҰи§Ј #### дёҖгҖҒFlumeз®Җд»Ӣ Apache Flume жҳҜдёҖдёӘеҲҶеёғејҸзҡ„гҖҒеҸҜйқ зҡ„гҖҒй«ҳеҸҜз”Ёзҡ„жңҚеҠЎпјҢз”ЁдәҺжңүж•Ҳең°ж”¶йӣҶгҖҒиҒҡеҗҲе’Ң移еҠЁеӨ§йҮҸж—Ҙеҝ—ж•°жҚ®гҖӮFlume ж”ҜжҢҒз®ҖеҚ•зҒөжҙ»зҡ„й…ҚзҪ®пјҢиҝҷдҪҝеҫ—е®ғеҸҜд»ҘйҖӮз”ЁдәҺеҗ„з§ҚеңәжҷҜдёӯзҡ„ж•°жҚ®...
hello,flume ``` #### дёүгҖҒеә”з”ЁжЎҲдҫӢ **1гҖҒжЎҲдҫӢжҸҸиҝ°** жң¬жЎҲдҫӢдё»иҰҒд»Ӣз»ҚеҰӮдҪ•еҲ©з”ЁFlumeе°Ҷж•°жҚ®йҮҮйӣҶе№¶дј иҫ“еҲ°KafkaжңҚеҠЎдёӯпјҢ然еҗҺеҶҚз”ұKafkaиҝӣиЎҢж•°жҚ®зҡ„еҲҶеҸ‘дёҺж¶Ҳиҙ№гҖӮ **2гҖҒеҲӣе»әKafkaй…ҚзҪ®** дёәдәҶе°Ҷж•°жҚ®дј е…ҘKafkaпјҢйңҖиҰҒй…ҚзҪ®...
然еҗҺпјҢе®ғз”ҹжҲҗ并еҸ‘йҖҒ 10 дёӘеҢ…еҗ« "Hello Flume!" ж•°жҚ®зҡ„дәӢ件гҖӮжҜҸдёӘдәӢ件йғҪжҳҜйҖҡиҝҮ `sendDataToFlume` ж–№жі•еҸ‘йҖҒзҡ„пјҢиҜҘж–№жі•жһ„е»әдәҶдёҖдёӘ `Event` еҜ№иұЎпјҢ并дҪҝз”Ё `EventBuilder` е°Ҷж•°жҚ®е°ҒиЈ…дёә UTF-8 зј–з Ғзҡ„еӯ—иҠӮгҖӮеҰӮжһңеңЁеҸ‘йҖҒ...
- дҪҝз”Ё netcat еҸ‘йҖҒж•°жҚ®еҲ° Flume зӣ‘еҗ¬зҡ„з«ҜеҸЈпјҢдҫӢеҰӮпјҡ`echo "Hello, World!" | nc -lk 44444` 4. жҹҘзңӢз»“жһңпјҡ - еҪ“ж•°жҚ®еҸ‘йҖҒеҗҺпјҢFlume е°ҶжҚ•иҺ·иҝҷдәӣдҝЎжҒҜ并еҶҷе…Ҙ HDFSпјҢдҪ еҸҜд»ҘдҪҝз”Ё HDFS е‘Ҫд»ӨиЎҢе·Ҙе…·жҲ– Hadoop зҡ„ Web UI ...
echo "Hello, World!" | nc localhost 44444 ``` еҸ‘йҖҒзҡ„ж¶ҲжҒҜе°Ҷдјҡиў«FlumeжҚ•иҺ·пјҢеӯҳеӮЁеңЁ`memory-channel`дёӯпјҢ然еҗҺз”ұ`console-sink`иҫ“еҮәеҲ°жҺ§еҲ¶еҸ°гҖӮ дёәдәҶзӣ‘жҺ§з«ҜеҸЈдёӯзҡ„е…·дҪ“дҝЎжҒҜпјҢдҪ еҸҜиғҪйңҖиҰҒз»“еҗҲе…¶д»–зӣ‘жҺ§е·Ҙе…·пјҢеҰӮ`tcpdump...
еҗ‘`/opt/module/data/flume.log`ж–Ү件иҝҪеҠ ж•°жҚ®пјҢдҫӢеҰӮ`echo hello >> /opt/module/data/flume.log`пјҢ然еҗҺи§ӮеҜҹKafkaж¶Ҳиҙ№иҖ…жҳҜеҗҰиғҪж¶Ҳиҙ№еҲ°иҝҷдәӣж–°ж•°жҚ®гҖӮ йҖҡиҝҮдёҠиҝ°й…ҚзҪ®е’Ңж“ҚдҪңпјҢжҲ‘们еҸҜд»Ҙе®һзҺ°Flumeд»ҺжҢҮе®ҡзҡ„ж—Ҙеҝ—ж–Ү件дёӯ收йӣҶ...
ж–ҮжЎЈиҝҳеұ•зӨәдәҶеҰӮдҪ•зј–еҶҷдёҖдёӘиҮӘе®ҡд№үSourceпјҢиҜҘSourceз”ҹжҲҗйҡҸжңәеӯ—з¬ҰдёІпјҲ"Hello world" + йҡҸжңәж•°пјү并е°Ҷе…¶дҪңдёәдәӢд»¶дј йҖ’з»ҷеҗҺз»ӯзҡ„Channelе’ҢSinkгҖӮејҖеҸ‘иҖ…еҸҜд»ҘйҖҡиҝҮе®һзҺ°`AbstractSource`гҖҒ`Configurable`е’Ң`PollableSource`жҺҘеҸЈ...
жӯӨжЁЎжқҝеә”з”ЁзЁӢеәҸеұ•зӨәдәҶеҰӮдҪ•дҪҝз”Ё angularjsгҖҒphoenixгҖҒflume з»„з»ҮжӮЁзҡ„еә”з”ЁзЁӢеәҸгҖӮ е°қиҜ•дёҖдёӢ ејҖеҸ‘жЁЎејҸ иҝӣе…ҘйЎ№зӣ®ж №зӣ®еҪ• жҙ»еҢ–еүӮ и·‘жӯҘ з”ҹдә§жЁЎејҸ иҝӣе…ҘйЎ№зӣ®ж №зӣ®еҪ• жҙ»еҢ–еүӮ йӣҶдјҡ иҪ¬еҲ°зӣ®ж Үзӣ®еҪ•е№¶жүҫеҲ°еә”з”ЁзЁӢеәҸзҡ„иғ– jar java -...
CISC 525 Apache FlumeйЎ№зӣ®иҝҗиЎҢFlumeд»ЈзҗҶжәҗspooldir-йҖҡйҒ“ж–Ү件-жҺҘ收еҷЁи®°еҪ•еҷЁmkdir /tmp/spooldirflume-ng agent --conf-file spool-to-logger.properties --name agent1 --conf $FLUME_HOME /conf -Dflume.root....
<artifactId>spark-streaming-flume_2.10 ${spark.version} <groupId>org.apache.spark <artifactId>spark-sql_2.10 ${spark.version} ``` д»ҘдёҠжӯҘйӘӨе®ҢжҲҗдәҶ Spark ејҖеҸ‘зҺҜеўғзҡ„еҹәжң¬жҗӯе»әпјҢжҺҘдёӢжқҘе°ұеҸҜд»Ҙ...
- Apache FlumeпјҡйҖҡиҝҮжҸ’件пјҢFlumeиғҪеӨҹе°Ҷж•°жҚ®жөҒејҸдј иҫ“еҲ°HBaseпјҢиҝӣиҖҢеҸҜд»Ҙиў«PhoenixжҹҘиҜўгҖӮ - Apache KafkaпјҡPhoenixдёҺKafkaзҡ„йӣҶжҲҗе…Ғи®ёдҪ е°ҶKafkaж¶ҲжҒҜеҶҷе…ҘHBaseпјҢжҲ–иҖ…д»ҺHBaseиҜ»еҸ–ж•°жҚ®гҖӮ - Python DriverпјҡPhoenixиҝҳ...
- **Scribeе’ҢFlume**: йҮҮз”ЁжҺЁйҖҒжЁЎејҸпјҢз”ұbrokerеҶіе®ҡж¶ҲжҒҜжҺЁйҖҒйҖҹзҺҮпјҢеҸҜиғҪеҜјиҮҙж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№иҝҮж…ўиҖҢеҙ©жәғгҖӮ - **Kafkaзҡ„жӢүжЁЎејҸ**: е…Ғи®ёж¶Ҳиҙ№иҖ…жҢүйңҖжӢүеҸ–пјҢеҮҸе°‘зі»з»ҹиҝҮиҪҪзҡ„йЈҺйҷ©пјҢжҸҗй«ҳзі»з»ҹзҡ„зЁіе®ҡжҖ§е’ҢеҸҜжҺ§жҖ§гҖӮ ### Kafkaзҡ„й«ҳеҸҜз”ЁжҖ§...
<artifactId>spark-streaming-flume_2.10 ${spark.version} <groupId>org.apache.spark <artifactId>spark-sql_2.10 ${spark.version} ``` йҖҡиҝҮд»ҘдёҠжӯҘйӘӨпјҢжӮЁе·Із»ҸжҲҗеҠҹең°жҗӯе»әдәҶдёҖдёӘеҹәдәҺApache Spark...
е®ғзҡ„еҸ‘еұ•еҸ—еҲ°Googleзҡ„FlumeJava APIзҡ„еҪұе“ҚпјҢиҜҘAPIз”ЁдәҺжһ„е»әеҹәдәҺGoogleиҮӘиә«MapReduceе®һзҺ°зҡ„ж•°жҚ®з®ЎйҒ“гҖӮCrunchжҸҗдҫӣдәҶеҜ№MapReduceзҡ„и–„еұӮжҠҪиұЎпјҢе…¶и®ҫи®Ўзӣ®зҡ„жҳҜи®©ејҖеҸ‘иҖ…иғҪеӨҹжңүж•ҲдҪҝз”ЁMapReduceжқҘзј–еҶҷеҝ«йҖҹгҖҒеҸҜйқ зҡ„зЁӢеәҸпјҢиҝҷдәӣ...