
зЃАдїЛ
жµПиІИеЩ®еσ俕襀聧䪯жШѓдљњзФ®жЬАеєњж≥ЫзЪДиљѓдїґпЉМжЬђжЦЗе∞ЖдїЛзїНжµПиІИеЩ®зЪДеЈ• дљЬеОЯзРЖпЉМжИСдїђе∞ЖзЬЛеИ∞пЉМдїОдљ†еЬ®еЬ∞еЭАж†ПиЊУеЕ•google.comеИ∞дљ†зЬЛеИ∞googleдЄїй°µињЗз®ЛдЄ≠йГљеПСзФЯдЇЖдїАдєИгАВ
е∞ЖиЃ®иЃЇзЪДжµПиІИеЩ®
дїК姩пЉМжЬЙдЇФзІНдЄїжµБжµПиІИеЩ®вАФвАФIEгАБFirefoxгАБSafariгАБChromeеПКOperaгАВ
жЬђжЦЗе∞ЖеЯЇдЇОдЄАдЇЫеЉАжЇРжµПиІИеЩ®зЪДдЊЛе≠РвАФвАФFirefoxгАБ ChromeеПКSafariпЉМSafariжШѓйГ®еИЖеЉАжЇРзЪДгАВ
ж†єжНЃW3CпЉИWorld Wide Web Consortium дЄЗзїізљСиБФзЫЯпЉЙзЪДжµПиІИеЩ®зїЯиЃ°жХ∞жНЃпЉМељУеЙНпЉИ2011еєі9жЬИпЉЙпЉМFirefoxгАБSafariеПКChromeзЪДеЄВеЬЇеН†жЬЙзОЗзїЉеРИеЈ≤ењЂжО•ињС50пЉЕгАВпЉИеОЯжЦЗдЄЇ2009еєі10жЬИпЉМжХ∞жНЃж≤°жЬЙ姙姲еПШеМЦпЉЙеЫ†ж≠§пЉМеПѓдї•иѓіеЉАжЇРжµПиІИеЩ®е∞ЖињСеН†жНЃдЇЖжµПиІИеЩ®еЄВеЬЇзЪДеНКе£Бж±Яе±±гАВ
жµПиІИеЩ®зЪДдЄїи¶БеКЯиГљ
жµПиІИеЩ®зЪДдЄїи¶БеКЯиГљжШѓе∞ЖзФ®жИЈйАЙжЛ©еЊЧwebиµДжЇРеСИзО∞еЗЇжЭ•пЉМеЃГйЬАи¶БдїОжЬНеК°еЩ®иѓЈж±ВиµДжЇРпЉМеєґе∞ЖеЕґжШЊз§ЇеЬ®жµПиІИеЩ®з™ЧеП£дЄ≠пЉМиµДжЇРзЪДж†ЉеЉПйАЪеЄЄжШѓHTMLпЉМдєЯеМЕжЛђPDFгАБimageеПКеЕґдїЦж†ЉеЉПгАВзФ®жИЈзФ®URIпЉИUniform Resource Identifier зїЯдЄАиµДжЇРж†ЗиѓЖзђ¶пЉЙжЭ•жМЗеЃЪжЙАиѓЈж±ВиµДжЇРзЪДдљНзљЃпЉМеЬ®зљСзїЬдЄАзЂ†жЬЙжЫіе§ЪиЃ®иЃЇгАВ
 
HTMLеТМCSSиІДиМГдЄ≠иІДеЃЪдЇЖжµПиІИеЩ®иІ£йЗКhtmlжЦЗж°£зЪДжЦєеЉПпЉМзФ± W3CзїДзїЗеѓєињЩдЇЫиІДиМГињЫи°МзїіжК§пЉМW3CжШѓиіЯиі£еИґеЃЪwebж†ЗеЗЖзЪДзїДзїЗгАВ
HTMLиІДиМГзЪДжЬАжЦ∞зЙИжЬђжШѓHTML4(http://www.w3.org/TR/html401/)пЉМHTML5ињШеЬ®еИґеЃЪдЄ≠пЉИиѓСж≥®пЉЪдЄ§еєіеЙНпЉЙпЉМжЬАжЦ∞зЪДCSSиІДиМГзЙИжЬђжШѓ2пЉИhttp://www.w3.org/TR/CSS2пЉЙпЉМCSS3дєЯињШж≠£еЬ®еИґеЃЪдЄ≠пЉИиѓСж≥®пЉЪеРМж†ЈдЄ§еєіеЙНпЉЙгАВ
ињЩдЇЫеєіжЭ•пЉМжµПиІИеЩ®еОВеХЖзЇЈзЇЈеЉАеПСиЗ™еЈ±зЪДжЙ©е±ХпЉМеѓєиІДиМГзЪДйБµеЊ™еєґдЄНеЃМеЦДпЉМињЩдЄЇwebеЉАеПСиАЕеЄ¶жЭ•дЇЖдЄ•йЗНзЪДеЕЉеЃєжАІйЧЃйҐШгАВ
дљЖжШѓпЉМжµПиІИеЩ®зЪДзФ®жИЈзХМйЭҐеИЩеЈЃдЄНе§ЪпЉМеЄЄиІБзЪДзФ®жИЈзХМйЭҐеЕГзі†еМЕжЛђпЉЪ
- зФ®жЭ•иЊУеЕ•URIзЪДеЬ∞еЭАж†П
- еЙНињЫгАБеРОйААжМЙйТЃ
- дє¶з≠ЊйАЙй°є
- зФ®дЇОеИЈжЦ∞еПКжЪВеБЬељУеЙНеК†иљљжЦЗж°£зЪДеИЈжЦ∞гАБжЪВеБЬжМЙйТЃ
- зФ®дЇОеИ∞иЊЊдЄїй°µзЪДдЄїй°µжМЙйТЃ
е•ЗжА™зЪДжШѓпЉМеєґж≤°жЬЙеУ™дЄ™ж≠£еЉПеЕђеЄГзЪДиІДиМГеѓєзФ®жИЈзХМйЭҐеБЪеЗЇиІДеЃЪпЉМињЩдЇЫжШѓе§ЪеєіжЭ•еРДжµПиІИеЩ®еОВеХЖдєЛйЧізЫЄдЇТж®°дїњеТМдЄНжЦ≠жФєињЫеЊЧзїУжЮЬгАВ
HTML5еєґж≤°жЬЙиІДеЃЪжµПиІИеЩ®ењЕй°їеЕЈжЬЙзЪДUIеЕГзі†пЉМдљЖеИЧеЗЇдЇЖдЄАдЇЫеЄЄзФ®еЕГзі†пЉМеМЕжЛђеЬ∞еЭАж†ПгАБзКґжАБж†ПеПКеЈ•еЕЈж†ПгАВињШжЬЙдЄАдЇЫжµПиІИеЩ®жЬЙиЗ™еЈ±дЄУжЬЙеЊЧеКЯиГљпЉМжѓФе¶ВFirefoxеЊЧдЄЛиљљзЃ°зРЖгАВжЫіе§ЪзЫЄеЕ≥еЖЕеЃєе∞ЖеЬ®еРОйЭҐиЃ®иЃЇзФ®жИЈзХМйЭҐжЧґдїЛзїНгАВ
жµПиІИеЩ®зЪДдЄїи¶БжЮДжИРHigh Level Structure
жµПиІИеЩ®зЪДдЄїи¶БзїДдїґеМЕжЛђпЉЪ
- зФ®жИЈзХМйЭҐпЉН еМЕжЛђеЬ∞еЭАж†ПгАБеРОйАА/еЙНињЫжМЙйТЃгАБдє¶з≠ЊзЫЃељХз≠ЙпЉМдєЯе∞±жШѓдљ†жЙАзЬЛеИ∞зЪДйЩ§дЇЖзФ®жЭ•жШЊз§Їдљ†жЙАиѓЈж±Вй°µйЭҐзЪДдЄїз™ЧеП£дєЛе§ЦзЪДеЕґдїЦйГ®еИЖ
- жµПиІИеЩ®еЉХжУОпЉН зФ®жЭ•жߕ胥еПКжУНдљЬжЄ≤жЯУеЉХжУОзЪДжО•еП£
- жЄ≤жЯУеЉХжУОпЉН зФ®жЭ•жШЊз§ЇиѓЈж±ВзЪДеЖЕеЃєпЉМдЊЛе¶ВпЉМе¶ВжЮЬиѓЈж±ВеЖЕеЃєдЄЇhtmlпЉМеЃГиіЯиі£иІ£жЮРhtmlеПКcssпЉМеєґе∞ЖиІ£жЮРеРОзЪДзїУжЮЬжШЊз§ЇеЗЇжЭ•
- зљСзїЬпЉН зФ®жЭ•еЃМжИРзљСзїЬи∞ГзФ®пЉМдЊЛе¶ВhttpиѓЈж±ВпЉМеЃГеЕЈжЬЙеє≥еП∞жЧ†еЕ≥зЪДжО•еП£пЉМеПѓдї•еЬ®дЄНеРМеє≥еП∞дЄКеЈ•дљЬ
- UI еРОзЂѓпЉН зФ®жЭ•зїШеИґз±їдЉЉзїДеРИйАЙжЛ©ж°ЖеПКеѓєиѓЭж°Жз≠ЙеЯЇжЬђзїДдїґпЉМеЕЈжЬЙдЄНзЙєеЃЪдЇОжЯРдЄ™еє≥еП∞зЪДйАЪзФ®жО•еП£пЉМеЇХе±ВдљњзФ®жУНдљЬз≥їзїЯзЪДзФ®жИЈжО•еП£
- JSиІ£йЗКеЩ®пЉН зФ®жЭ•иІ£йЗКжЙІи°МJSдї£з†Б
- жХ∞жНЃе≠ШеВ®пЉН е±ЮдЇОжМБдєЕе±ВпЉМжµПиІИеЩ®йЬАи¶БеЬ®з°ђзЫШдЄ≠дњЭе≠Шз±їдЉЉcookieзЪДеРДзІНжХ∞жНЃпЉМHTML5еЃЪдєЙдЇЖweb databaseжКАжЬѓпЉМињЩжШѓдЄАзІНиљїйЗПзЇІеЃМжХізЪДеЃҐжИЈзЂѓе≠ШеВ®жКАжЬѓ
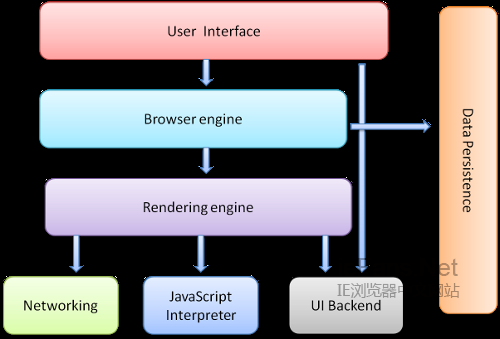
еЫЊ1пЉЪжµПиІИеЩ®дЄїи¶БзїДдїґ
йЬАи¶Бж≥®жДПзЪДжШѓпЉМдЄНеРМдЇОе§ІйГ®еИЖжµПиІИеЩ®пЉМChromeдЄЇжѓПдЄ™TabеИЖйЕНдЇЖеРДиЗ™зЪДжЄ≤жЯУеЉХжУОеЃЮдЊЛпЉМжѓПдЄ™Tabе∞±жШѓдЄАдЄ™зЛђзЂЛзЪДињЫз®ЛгАВ
еѓєдЇОжЮДжИРжµПиІИеЩ®зЪДињЩдЇЫзїДдїґпЉМеРОйЭҐдЉЪйАРдЄАиѓ¶зїЖиЃ®иЃЇгАВ
зїДдїґйЧізЪДйАЪдњ° Communication between the components
FirefoxеТМChromeйГљеЉАеПСдЇЖдЄАдЄ™зЙєжЃКзЪДйАЪдњ°зїУжЮДпЉМеРОйЭҐе∞ЖжЬЙдЄУйЧ®зЪДдЄАзЂ†ињЫи°МиЃ®иЃЇгАВ
жЄ≤жЯУеЉХжУО The rendering engine
жЄ≤жЯУеЉХжУОзЪДиБМиі£е∞±жШѓжЄ≤жЯУпЉМеН≥еЬ®жµПиІИеЩ®з™ЧеП£дЄ≠жШЊз§ЇжЙАиѓЈж±ВзЪДеЖЕеЃєгАВ
йїШиЃ§жГЕеЖµдЄЛпЉМжЄ≤жЯУеЉХжУОеПѓдї•жШЊз§ЇhtmlгАБxmlжЦЗж°£еПКеЫЊзЙЗпЉМеЃГдєЯеПѓдї•еАЯеК©жПТдїґпЉИдЄАзІНжµПиІИеЩ®жЙ©е±ХпЉЙжШЊз§ЇеЕґдїЦз±їеЮЛжХ∞жНЃпЉМдЊЛе¶ВдљњзФ®PDFйШЕиѓїеЩ®жПТдїґпЉМеПѓдї•жШЊз§ЇPDFж†ЉеЉПпЉМе∞ЖзФ±дЄУйЧ®дЄАзЂ†иЃ≤иІ£жПТдїґеПКжЙ©е±ХпЉМињЩйЗМеП™иЃ®иЃЇжЄ≤жЯУеЉХжУОжЬАдЄїи¶БзЪДзФ®йАФвАФвАФжШЊз§ЇеЇФзФ®дЇЖCSSдєЛеРОзЪДhtmlеПКеЫЊзЙЗгАВ
жЄ≤жЯУеЉХжУО Rendering engines
жЬђжЦЗжЙАиЃ®иЃЇеЊЧжµПиІИеЩ®вАФвАФFirefoxгАБChromeеТМSafariжШѓеЯЇдЇОдЄ§зІНжЄ≤жЯУеЉХжУОжЮДеїЇзЪДпЉМFirefoxдљњзФ®GeokoвАФвАФMozillaиЗ™дЄїз†ФеПСзЪДжЄ≤жЯУеЉХжУОпЉМSafariеТМChromeйГљдљњзФ®webkitгАВ
WebkitжШѓдЄАжђЊеЉАжЇРжЄ≤жЯУеЉХжУОпЉМеЃГжЬђжЭ•жШѓдЄЇlinuxеє≥еП∞з†ФеПСзЪДпЉМеРОжЭ•зФ±AppleзІїж§НеИ∞MacеПКWindowsдЄКпЉМзЫЄеЕ≥еЖЕеЃєиѓЈеПВиАГhttp://webkit.orgгАВ
дЄїжµБз®Л The main flow
жЄ≤жЯУеЉХжУОй¶ЦеЕИйАЪињЗзљСзїЬиОЈеЊЧжЙАиѓЈж±ВжЦЗж°£зЪДеЖЕеЃєпЉМйАЪеЄЄдї•8KеИЖеЭЧзЪДжЦєеЉПеЃМжИРгАВ
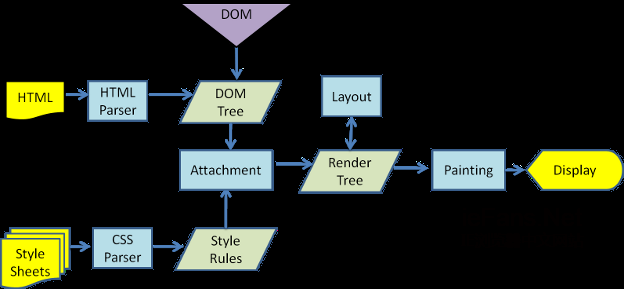
дЄЛйЭҐжШѓжЄ≤жЯУеЉХжУОеЬ®еПЦеЊЧеЖЕеЃєдєЛеРОзЪДеЯЇжЬђжµБз®ЛпЉЪ
иІ£жЮРhtmlдї•жЮДеїЇdomж†С->жЮДеїЇrenderж†С->еЄГе±Аrenderж†С->зїШеИґrenderж†С

еЫЊ2пЉЪжЄ≤жЯУеЉХжУОеЯЇжЬђжµБз®Л
жЄ≤жЯУеЉХжУОеЉАеІЛиІ£жЮРhtmlпЉМеєґе∞Жж†Зз≠ЊиљђеМЦдЄЇеЖЕеЃєж†СдЄ≠зЪДdomиКВзВєгАВжО•зЭАпЉМеЃГиІ£жЮРе§ЦйГ®CSSжЦЗдїґеПКstyleж†Зз≠ЊдЄ≠зЪДж†ЈеЉПдњ°жБѓгАВињЩдЇЫж†ЈеЉПдњ°жБѓдї•еПКhtmlдЄ≠зЪДеПѓиІБжАІжМЗдї§е∞Ж襀зФ®жЭ•жЮДеїЇеП¶дЄАж£µж†СвАФвАФrenderж†СгАВ
Renderж†СзФ±дЄАдЇЫеМЕеРЂжЬЙйҐЬиЙ≤еТМе§Іе∞Пз≠Йе±ЮжАІзЪДзߩ嚥зїДжИРпЉМеЃГдїђе∞Ж襀жМЙзЕІж≠£з°ЃзЪДй°ЇеЇПжШЊз§ЇеИ∞е±ПеєХдЄКгАВ
Renderж†СжЮДеїЇе•љдЇЖдєЛеРОпЉМе∞ЖдЉЪжЙІи°МеЄГе±АињЗз®ЛпЉМеЃГе∞Жз°ЃеЃЪжѓПдЄ™иКВзВєеЬ®е±ПеєХдЄКзЪДз°ЃеИЗеЭРж†ЗгАВеЖНдЄЛдЄАж≠•е∞±жШѓзїШеИґпЉМеН≥йБНеОЖrenderж†СпЉМеєґдљњзФ®UIеРОзЂѓе±ВзїШеИґжѓПдЄ™иКВзВєгАВ
еАЉеЊЧж≥®жДПзЪДжШѓпЉМињЩдЄ™ињЗз®ЛжШѓйАРж≠•еЃМжИРзЪДпЉМдЄЇдЇЖжЫіе•љзЪДзФ®жИЈдљУй™МпЉМжЄ≤жЯУеЉХжУОе∞ЖдЉЪе∞љеПѓиГљжЧ©зЪДе∞ЖеЖЕеЃєеСИзО∞еИ∞е±ПеєХдЄКпЉМеєґдЄНдЉЪз≠ЙеИ∞жЙАжЬЙзЪДhtmlйГљиІ£жЮРеЃМжИРдєЛеРОеЖНеОїжЮДеїЇеТМеЄГе±Аrenderж†СгАВеЃГжШѓиІ£жЮРеЃМдЄАйГ®еИЖеЖЕеЃєе∞±жШЊз§ЇдЄАйГ®еИЖеЖЕеЃєпЉМеРМжЧґпЉМеПѓиГљињШеЬ®йАЪињЗзљСзїЬдЄЛиљљеЕґдљЩеЖЕеЃєгАВ
еЫЊ3пЉЪwebkitдЄїжµБз®Л
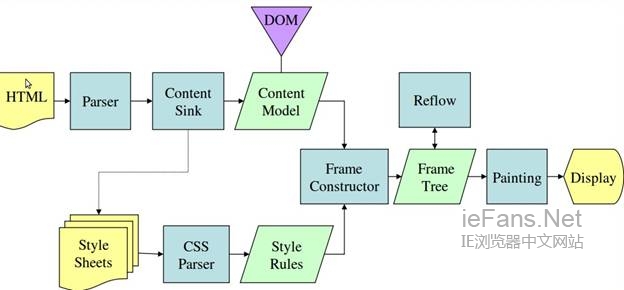
еЫЊ4пЉЪMozillaзЪДGeoko жЄ≤жЯУеЉХжУОдЄїжµБз®Л
дїОеЫЊ3еТМ4дЄ≠еПѓдї•зЬЛеЗЇпЉМе∞љзЃ°webkitеТМGeckoдљњзФ®зЪДжЬѓиѓ≠з®НжЬЙдЄНеРМпЉМдїЦдїђзЪДдЄїи¶БжµБз®ЛеЯЇжЬђзЫЄеРМгАВGeckoзІ∞еПѓиІБзЪДж†ЉеЉПеМЦеЕГзі†зїДжИРзЪДж†СдЄЇframeж†СпЉМжѓПдЄ™еЕГзі†йГљжШѓдЄАдЄ™frameпЉМwebkitеИЩдљњзФ®renderж†СињЩдЄ™еРНиѓНжЭ•еСљеРНзФ±жЄ≤жЯУеѓєи±°зїДжИРзЪДж†СгАВWebkitдЄ≠еЕГзі†зЪДеЃЪдљНзІ∞дЄЇеЄГе±АпЉМиАМGeckoдЄ≠зІ∞дЄЇеЫЮжµБгАВWebkitзІ∞еИ©зФ®domиКВзВєеПКж†ЈеЉПдњ°жБѓеОїжЮДеїЇrenderж†СзЪДињЗз®ЛдЄЇattachmentпЉМGeckoеЬ®htmlеТМdomж†СдєЛйЧійЩДеК†дЇЖдЄАе±ВпЉМињЩе±ВзІ∞дЄЇеЖЕеЃєжО•жФґеЩ®пЉМзЫЄељУеИґйА†domеЕГзі†зЪДеЈ•еОВгАВдЄЛйЭҐе∞ЖиЃ®иЃЇжµБз®ЛдЄ≠зЪДеРДдЄ™йШґжЃµгАВ
иІ£жЮР ParsingпЉНgeneral
жЧҐзДґиІ£жЮРжШѓжЄ≤жЯУеЉХжУОдЄ≠дЄАдЄ™йЭЮеЄЄйЗНи¶БзЪДињЗз®ЛпЉМжИСдїђе∞Жз®НеЊЃжЈ±еЕ•зЪДз†Фз©ґеЃГгАВй¶ЦеЕИзЃАи¶БдїЛзїНдЄАдЄЛиІ£жЮРгАВ
иІ£жЮРдЄАдЄ™жЦЗж°£еН≥е∞ЖеЕґиљђжНҐдЄЇеЕЈжЬЙдЄАеЃЪжДПдєЙзЪДзїУжЮДвАФвАФзЉЦз†БеПѓдї•зРЖиІ£еТМдљњзФ®зЪДдЄЬи•њгАВиІ£жЮРзЪДзїУжЮЬйАЪеЄЄжШѓи°®иЊЊжЦЗж°£зїУжЮДзЪДиКВзВєж†СпЉМзІ∞дЄЇиІ£жЮРж†СжИЦиѓ≠ж≥Хж†СгАВ
дЊЛе¶ВпЉМиІ£жЮРвАЬ2пЉЛ3пЉН1вАЭињЩдЄ™и°®иЊЊеЉПпЉМеПѓиГљињФеЫЮињЩж†ЈдЄАж£µж†СгАВ
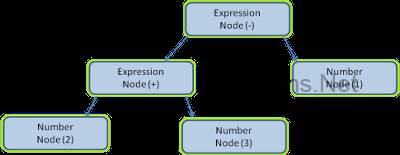
еЫЊ5пЉЪжХ∞е≠¶и°®иЊЊеЉПж†СиКВзВє
жЦЗж≥Х Grammars
иІ£жЮРеЯЇдЇОжЦЗж°£дЊЭжНЃзЪДиѓ≠ж≥ХиІДеИЩвАФвАФжЦЗж°£зЪДиѓ≠и®АжИЦж†ЉеЉПгАВжѓПзІНеПѓиҐЂиІ£жЮРзЪДж†ЉеЉПењЕй°їеЕЈжЬЙзФ±иѓНж±ЗеПКиѓ≠ж≥ХиІДеИЩзїДжИРзЪДзЙєеЃЪзЪДжЦЗж≥ХпЉМзІ∞дЄЇдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХгАВдЇЇз±їиѓ≠и®АдЄНеЕЈжЬЙињЩдЄАзЙєжАІпЉМеЫ†ж≠§дЄНиÚ襀дЄАиИђзЪДиІ£жЮРжКАжЬѓжЙАиІ£жЮРгАВ
иІ£жЮРеЩ®пЉНиѓНж≥ХеИЖжЮРеЩ® ParserпЉНLexer combination
иІ£жЮРеПѓдї•еИЖдЄЇдЄ§дЄ™е≠РињЗз®ЛвАФвАФиѓ≠ж≥ХеИЖжЮРеПКиѓНж≥ХеИЖжЮР
иѓНж≥ХеИЖжЮРе∞±жШѓе∞ЖиЊУеЕ•еИЖиІ£дЄЇзђ¶еПЈпЉМзђ¶еПЈжШѓиѓ≠и®АзЪДиѓНж±Зи°®вАФвАФеЯЇжЬђжЬЙжХИеНХеЕГзЪДйЫЖеРИгАВеѓєдЇОдЇЇз±їиѓ≠и®АжЭ•иѓіпЉМеЃГзЫЄељУдЇОжИСдїђе≠ЧеЕЄдЄ≠еЗЇзО∞зЪДжЙАжЬЙеНХиѓНгАВ
иѓ≠ж≥ХеИЖжЮРжМЗеѓєиѓ≠и®АеЇФзФ®иѓ≠ж≥ХиІДеИЩгАВ
иІ£жЮРеЩ®дЄАиИђе∞ЖеЈ•дљЬеИЖйЕНзїЩдЄ§дЄ™зїДдїґвАФвАФиѓНж≥ХеИЖжЮРеЩ®пЉИжЬЙжЧґдєЯеПЂеИЖиѓНеЩ®пЉЙиіЯиі£е∞ЖиЊУеЕ•еИЖиІ£дЄЇеРИж≥ХзЪДзђ¶еПЈпЉМиІ£жЮРеЩ®еИЩж†єжНЃиѓ≠и®АзЪДиѓ≠ж≥ХиІДеИЩеИЖжЮРжЦЗж°£зїУжЮДпЉМдїОиАМжЮДеїЇиІ£жЮРж†СпЉМиѓНж≥ХеИЖжЮРеЩ®зЯ•йБУжАОдєИиЈ≥ињЗз©ЇзЩљеТМжНҐи°МдєЛз±їзЪДжЧ†еЕ≥е≠Чзђ¶гАВ
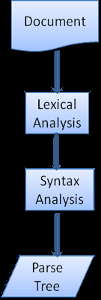
еЫЊ6пЉЪдїОжЇРжЦЗж°£еИ∞иІ£жЮРж†С
иІ£жЮРињЗз®ЛжШѓињ≠дї£зЪДпЉМиІ£жЮРеЩ®дїОиѓНж≥ХеИЖжЮРеЩ®е§ДеПЦйБУдЄАдЄ™жЦ∞зЪДзђ¶еПЈпЉМеєґиѓХзЭАзФ®ињЩдЄ™зђ¶еПЈеМєйЕНдЄАжЭ°иѓ≠ж≥ХиІДеИЩпЉМ е¶ВжЮЬеМєйЕНдЇЖдЄАжЭ°иІДеИЩпЉМињЩдЄ™зђ¶еПЈеѓєеЇФзЪДиКВзВєе∞Ж襀棿еК†еИ∞иІ£жЮРж†СдЄКпЉМзДґеРОиІ£жЮРеЩ®иѓЈж±ВеП¶дЄАдЄ™зђ¶еПЈгАВе¶ВжЮЬж≤°жЬЙеМєйЕНеИ∞иІДеИЩпЉМиІ£жЮРеЩ®е∞ЖеЬ®еЖЕйГ®дњЭе≠Шиѓ•зђ¶еПЈпЉМеєґдїОиѓНж≥ХеИЖжЮРеЩ® еПЦдЄЛдЄАдЄ™зђ¶еПЈпЉМзЫіеИ∞жЙАжЬЙеЖЕйГ®дњЭе≠ШзЪДзђ¶еПЈиГље§ЯеМєйЕНдЄАй°єиѓ≠ж≥ХиІДеИЩгАВе¶ВжЮЬжЬАзїИж≤°жЬЙжЙЊеИ∞еМєйЕНзЪДиІДеИЩпЉМиІ£жЮРеЩ®е∞ЖжКЫеЗЇдЄАдЄ™еЉВеЄЄпЉМињЩжДПеС≥зЭАжЦЗж°£жЧ†жХИжИЦжШѓеМЕеРЂиѓ≠ж≥ХйФЩиѓѓгАВ
иљђжНҐ Translation
еЊИе§ЪжЧґеАЩпЉМиІ£жЮРж†СеєґдЄНжШѓжЬАзїИзїУжЮЬгАВиІ£жЮРдЄАиИђеЬ®иљђжНҐдЄ≠дљњзФ®вАФвАФе∞ЖиЊУеЕ•жЦЗж°£иљђжНҐдЄЇеП¶дЄАзІНж†ЉеЉПгАВзЉЦиѓСе∞±жШѓдЄ™дЊЛе≠РпЉМзЉЦиѓСеЩ®еЬ®е∞ЖдЄАжЃµжЇРз†БзЉЦиѓСдЄЇжЬЇеЩ®з†БзЪДжЧґеАЩпЉМеЕИе∞ЖжЇРз†БиІ£жЮРдЄЇиІ£жЮРж†СпЉМзДґеРОе∞Жиѓ•ж†СиљђжНҐдЄЇдЄАдЄ™жЬЇеЩ®з†БжЦЗж°£гАВ
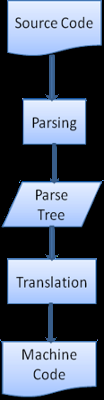
еЫЊ7пЉЪзЉЦиѓСжµБз®Л
иІ£жЮРеЃЮдЊЛ Parsing example
еЫЊ5дЄ≠пЉМжИСдїђдїОдЄАдЄ™жХ∞е≠¶и°®иЊЊеЉПжЮДеїЇдЇЖдЄАдЄ™иІ£жЮРж†СпЉМињЩйЗМеЃЪдєЙдЄАдЄ™зЃАеНХзЪДжХ∞е≠¶иѓ≠и®АжЭ•зЬЛдЄЛиІ£жЮРињЗз®ЛгАВ
иѓНж±Зи°®пЉЪжИСдїђзЪДиѓ≠и®АеМЕжЛђжХіжХ∞гАБеК†еПЈеПКеЗПеПЈгАВ
иѓ≠ж≥ХпЉЪ
1. иѓ•иѓ≠и®АзЪДиѓ≠ж≥ХеЯЇжЬђеНХеЕГеМЕжЛђи°®иЊЊеЉПгАБtermеПКжУНдљЬзђ¶
2. иѓ•иѓ≠и®АеПѓдї•еМЕжЛђе§ЪдЄ™и°®иЊЊеЉП
3. дЄАдЄ™и°®иЊЊеЉПеЃЪдєЙдЄЇдЄ§дЄ™termйАЪињЗдЄАдЄ™жУНдљЬзђ¶ињЮжО•
4. жУНдљЬзђ¶еПѓдї•жШѓеК†еПЈжИЦеЗПеПЈ
5. termеПѓдї•жШѓдЄАдЄ™жХіжХ∞жИЦдЄАдЄ™и°®иЊЊеЉП
зО∞еЬ®жЭ•еИЖжЮРдЄАдЄЛвАЬ2пЉЛ3пЉН1вАЭињЩдЄ™иЊУеЕ•
зђђдЄАдЄ™еМєйЕНиІДеИЩзЪДе≠Ре≠Чзђ¶дЄ≤жШѓвАЬ2вАЭпЉМж†єжНЃиІДеИЩ5пЉМеЃГжШѓдЄАдЄ™termпЉМзђђдЇМдЄ™еМєйЕНзЪДжШѓвАЬ2пЉЛ3вАЭпЉМеЃГзђ¶еРИзђђ2жЭ°иІДеИЩвАФвАФдЄАдЄ™жУНдљЬзђ¶ињЮжО•дЄ§дЄ™termпЉМдЄЛдЄАжђ°еМєйЕНеПСзФЯеЬ®иЊУеЕ•зЪДзїУжЭЯе§ДгАВвАЬ2пЉЛ3пЉН1вАЭжШѓдЄАдЄ™и°®иЊЊеЉПпЉМеЫ†дЄЇжИСдїђеЈ≤зїПзЯ•йБУвАЬ2пЉЛ3вАЭжШѓдЄАдЄ™termпЉМжЙАдї•жИСдїђжЬЙдЇЖдЄАдЄ™termзіІиЈЯзЭАдЄАдЄ™жУНдљЬзђ¶еПКеП¶дЄАдЄ™termгАВвАЬ2пЉЛпЉЛвАЭе∞ЖдЄНдЉЪеМєйЕНдїїдљХиІДеИЩпЉМеЫ†ж≠§жШѓдЄАдЄ™жЧ†жХИиЊУеЕ•гАВ
иѓНж±Зи°®еПКиѓ≠ж≥ХзЪДеЃЪдєЙ
иѓНж±Зи°®йАЪеЄЄеИ©зФ®ж≠£еИЩи°®иЊЊеЉПжЭ•еЃЪдєЙгАВ
дЊЛе¶ВдЄКйЭҐзЪДиѓ≠и®АеПѓдї•еЃЪдєЙдЄЇпЉЪ
INTEGERпЉЪ0пљЬпЉї1пЉН9пЉљпЉї0пЉН9пЉљпЉК
PLUSпЉЪпЉЛ
MINUSпЉЪпЉН
ж≠£е¶ВзЬЛеИ∞зЪДпЉМињЩйЗМзФ®ж≠£еИЩи°®иЊЊеЉПеЃЪдєЙжХіжХ∞гАВ
иѓ≠ж≥ХйАЪеЄЄзФ®BNFж†ЉеЉПеЃЪдєЙпЉМжИСдїђзЪДиѓ≠и®АеПѓдї•еЃЪдєЙдЄЇпЉЪ
expression :пЉЭ term operation term
operation := PLUS | MINUS
term := INTEGER | expression
е¶ВжЮЬдЄАдЄ™иѓ≠и®АзЪДжЦЗж≥ХжШѓдЄКдЄЛжЦЗжЧ†еЕ≥зЪДпЉМеИЩеЃГеПѓдї•зФ®ж≠£еИЩиІ£жЮРеЩ®жЭ•иІ£жЮРгАВеѓєдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХзЪДдЄАдЄ™зЫіиІВзЪДеЃЪдєЙжШѓпЉМиѓ•жЦЗж≥ХеПѓдї•зФ®BNFжЭ•еЃМжХізЪДи°®иЊЊгАВеПѓжЯ•зЬЛhttp://en.wikipedia.org/wiki/Context-free_grammarгАВ
иІ£жЮРеЩ®з±їеЮЛ Types of parsers
жЬЙдЄ§зІНеЯЇжЬђзЪДиІ£жЮРеЩ®вАФвАФиЗ™й°ґеРСдЄЛиІ£жЮРеПКиЗ™еЇХеРСдЄКиІ£жЮРгАВжѓФиЊГзЫіиІВзЪДиІ£йЗКжШѓпЉМиЗ™й°ґеРСдЄЛиІ£жЮРпЉМжЯ•зЬЛиѓ≠ж≥ХзЪДжЬАйЂШе±ВзїУжЮДеєґиѓХзЭАеМєйЕНеЕґдЄ≠дЄАдЄ™пЉЫиЗ™еЇХеРСдЄКиІ£жЮРеИЩдїОиЊУеЕ•еЉАеІЛпЉМйАРж≠•е∞ЖеЕґиљђжНҐдЄЇиѓ≠ж≥ХиІДеИЩпЉМдїОеЇХе±ВиІДеИЩеЉАеІЛзЫіеИ∞еМєйЕНйЂШе±ВиІДеИЩгАВ
жЭ•зЬЛдЄАдЄЛињЩдЄ§зІНиІ£жЮРеЩ®е¶ВдљХиІ£жЮРдЄКйЭҐзЪДдЊЛе≠РпЉЪ
иЗ™й°ґеРСдЄЛиІ£жЮРеЩ®дїОжЬАйЂШе±ВиІДеИЩеЉАеІЛвАФвАФеЃГеЕИиѓЖеИЂеЗЇвАЬ2пЉЛ3вАЬпЉМе∞ЖеЕґиІЖдЄЇдЄАдЄ™и°®иЊЊеЉПпЉМзДґеРОиѓЖеИЂеЗЇвАЭ2пЉЛ3пЉН1вАЬдЄЇдЄАдЄ™и°®иЊЊеЉПпЉИиѓЖеИЂи°®иЊЊеЉПзЪДињЗз®ЛдЄ≠еМєйЕНдЇЖеЕґдїЦиІДеИЩпЉМдљЖеЗЇеПСзВєжШѓжЬАйЂШе±ВиІДеИЩпЉЙгАВ
иЗ™еЇХеРСдЄКиІ£жЮРдЉЪжЙЂжППиЊУеЕ•зЫіеИ∞еМєйЕНдЇЖдЄАжЭ°иІДеИЩпЉМзДґеРОзФ®иѓ•иІДеИЩеПЦдї£еМєйЕНзЪДиЊУеЕ•пЉМзЫіеИ∞иІ£жЮРеЃМжЙАжЬЙиЊУеЕ•гАВйГ®еИЖеМєйЕНзЪДи°®иЊЊеЉП襀жФЊзљЃеЬ®иІ£жЮРе†Жж†ИдЄ≠гАВ
|
Stack |
Input |
| ¬† | 2 + 3 вАУ 1 |
| term | + 3 - 1 |
| term operation | 3 вАУ 1 |
| expression | - 1 |
| expression operation | 1 |
| expression |   |
иЗ™еЇХеРСдЄКиІ£жЮРеЩ®зІ∞дЄЇshift reduce иІ£жЮРеЩ®пЉМеЫ†дЄЇиЊУеЕ•еРСеП≥зІїеК®пЉИжГ≥и±°дЄАдЄ™жМЗйТИй¶ЦеЕИжМЗеРСиЊУеЕ•еЉАеІЛе§ДпЉМеєґеРСеП≥зІїеК®пЉЙпЉМеєґйАРжЄРзЃАеМЦдЄЇиѓ≠ж≥ХиІДеИЩгАВ
иЗ™еК®еМЦиІ£жЮР Generating parse
иІ£жЮРеЩ®зФЯжИРеЩ®ињЩдЄ™еЈ•еЕЈеПѓдї•иЗ™еК®зФЯжИРиІ£жЮРеЩ®пЉМеП™йЬАи¶БжМЗеЃЪиѓ≠и®АзЪДжЦЗж≥ХвАФвАФиѓНж±Зи°®еПКиѓ≠ж≥ХиІДеИЩпЉМеЃГе∞±еПѓдї•зФЯжИРдЄАдЄ™иІ£жЮРеЩ®гАВеИЫеїЇдЄАдЄ™иІ£жЮРеЩ®йЬАи¶БеѓєиІ£жЮРжЬЙжЈ±еЕ•зЪДзРЖиІ£пЉМиАМдЄФжЙЛеК®зЪДеИЫеїЇдЄАдЄ™зФ±иЊГе•љжАІиГљзЪДиІ£жЮРеЩ®еєґдЄНеЃєжШУпЉМжЙАдї•иІ£жЮРзФЯжИРеЩ®еЊИжЬЙзФ®гАВWebkitдљњзФ®дЄ§дЄ™зЯ•еРНзЪДиІ£жЮРзФЯжИРеЩ®вАФвАФзФ®дЇОеИЫеїЇиѓ≠ж≥ХеИЖжЮРеЩ®зЪДFlexеПКеИЫеїЇиІ£жЮРеЩ®зЪДBisonпЉИдљ†еПѓиГљжО•иІ¶ињЗLexеТМYaccпЉЙгАВFlexзЪДиЊУеЕ•жШѓдЄАдЄ™еМЕеРЂдЇЖзђ¶еПЈеЃЪдєЙзЪДж≠£еИЩи°®иЊЊеЉПпЉМBisonзЪДиЊУеЕ•жШѓзФ®BNFж†ЉеЉПи°®з§ЇзЪДиѓ≠ж≥ХиІДеИЩгАВrs automatically
HTMLиІ£жЮРеЩ® HTML Parser
HTMLиІ£жЮРеЩ®зЪДеЈ•дљЬжШѓе∞Жhtmlж†ЗиѓЖиІ£жЮРдЄЇиІ£жЮРж†СгАВ
HTMLжЦЗж≥ХеЃЪдєЙ The HTML grammar definition
W3CзїДзїЗеИґеЃЪиІДиМГеЃЪдєЙдЇЖHTMLзЪДиѓНж±Зи°®еТМиѓ≠ж≥ХгАВ
йЭЮдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥Х Not a context free grammar
ж≠£е¶ВеЬ®иІ£жЮРзЃАдїЛдЄ≠жПРеИ∞зЪДпЉМдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХзЪДиѓ≠ж≥ХеПѓдї•зФ®з±їдЉЉBNFзЪДж†ЉеЉПжЭ•еЃЪдєЙгАВ
дЄНеєЄзЪДжШѓпЉМжЙАжЬЙзЪДдЉ†зїЯиІ£жЮРжЦєеЉПйГљдЄНйАВзФ®дЇОhtmlпЉИељУзДґжИСжПРеЗЇеЃГдїђеєґдЄНеП™жШѓеЫ†дЄЇе•љзО©пЉМеЃГдїђе∞ЖзФ®жЭ•иІ£жЮРcssеТМjsпЉЙпЉМhtmlдЄНиГљзЃАеНХзЪДзФ®иІ£жЮРжЙАйЬАзЪДдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХжЭ•еЃЪдєЙгАВ
Html жЬЙдЄАдЄ™ж≠£еЉПзЪДж†ЉеЉПеЃЪдєЙвАФвАФDTDпЉИDocument Type Definition жЦЗж°£з±їеЮЛеЃЪдєЙпЉЙвАФвАФдљЖеЃГеєґдЄНжШѓдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХпЉМhtmlжЫіжО•ињСдЇОxmlпЉМзО∞еЬ®жЬЙеЊИе§ЪеПѓзФ®зЪДxmlиІ£жЮРеЩ®пЉМhtmlжЬЙдЄ™xmlзЪДеПШдљУвАФвАФxhtmlпЉМеЃГдїђйЧізЪДдЄНеРМеЬ®дЇОпЉМhtmlжЫіеЃљеЃєпЉМеЃГеЕБиЃЄењљзХ•дЄАдЇЫзЙєеЃЪж†Зз≠ЊпЉМжЬЙжЧґеПѓдї•зЬБзХ•еЉАеІЛжИЦзїУжЭЯж†Зз≠ЊгАВжАїзЪДжЭ•иѓіпЉМеЃГжШѓдЄАзІНsoftиѓ≠ж≥ХпЉМдЄНеГПxmlеСЖжЭњгАБеЫЇжЙІгАВ
жШЊзДґпЉМињЩдЄ™зЬЛиµЈжЭ•еЊИе∞ПзЪДеЈЃеЉВеНіеЄ¶жЭ•дЇЖеЊИе§ІзЪДдЄНеРМгАВдЄАжЦєйЭҐпЉМињЩжШѓhtmlжµБи°МзЪДеОЯеЫ†вАФвАФеЃГзЪДеЃљеЃєдљњwebеЉАеПСдЇЇеСШзЪДеЈ•дљЬжЫіеК†иљїжЭЊпЉМдљЖеП¶дЄАжЦєйЭҐпЉМињЩдєЯдљњеЊИйЪЊеОїеЖЩдЄАдЄ™ж†ЉеЉПеМЦзЪДжЦЗж≥ХгАВжЙАдї•пЉМhtmlзЪДиІ£жЮРеєґдЄНзЃАеНХпЉМеЃГжЧҐдЄНиГљзФ®дЉ†зїЯзЪДиІ£жЮРеЩ®иІ£жЮРпЉМдєЯдЄНиГљзФ®xmlиІ£жЮРеЩ®иІ£жЮРгАВ
HTML DTD
HtmlйАВзФ®DTDж†ЉеЉПињЫи°МеЃЪдєЙпЉМињЩдЄАж†ЉеЉПжШѓзФ®дЇОеЃЪдєЙSGMLеЃґжЧПзЪДиѓ≠и®АпЉМеМЕжЛђдЇЖеѓєжЙАжЬЙеЕБиЃЄеЕГзі†еПКеЃГдїђзЪДе±ЮжАІеТМе±Вжђ°еЕ≥з≥їзЪДеЃЪдєЙгАВж≠£е¶ВеЙНйЭҐжПРеИ∞зЪДпЉМhtml DTDеєґж≤°жЬЙзФЯжИРдЄАзІНдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХгАВ
DTDжЬЙдЄАдЇЫеПШзІНпЉМж†ЗеЗЖж®°еЉПеП™йБµеЃИиІДиМГпЉМиАМеЕґдїЦж®°еЉПеИЩеМЕеРЂдЇЖеѓєжµПиІИеЩ®ињЗеОїжЙАдљњзФ®ж†Зз≠ЊзЪДжФѓжМБпЉМињЩдєИеБЪжШѓдЄЇдЇЖеЕЉеЃєдї•еЙНеЖЕеЃєгАВжЬАжЦ∞зЪДж†ЗеЗЖDTDеЬ®http://www.w3.org/TR/html4/strict.dtd
DOM
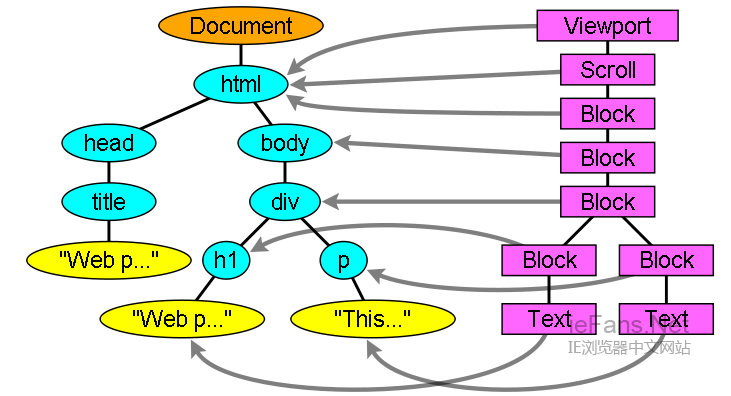
иЊУеЗЇзЪДж†СпЉМдєЯе∞±жШѓиІ£жЮРж†СпЉМжШѓзФ±DOMеЕГзі†еПКе±ЮжАІиКВзВєзїДжИРзЪДгАВDOMжШѓжЦЗж°£еѓєи±°ж®°еЮЛзЪДзЉ©еЖЩпЉМеЃГжШѓhtmlжЦЗж°£зЪДеѓєи±°и°®з§ЇпЉМдљЬдЄЇhtmlеЕГзі†зЪДе§ЦйГ®жО•еП£дЊЫjsз≠Йи∞ГзФ®гАВ
ж†СзЪДж†єжШѓвАЬdocumentвАЭеѓєи±°гАВ
DOMеТМж†Зз≠ЊеЯЇжЬђжШѓдЄАдЄАеѓєеЇФзЪДеЕ≥з≥їпЉМдЊЛе¶ВпЉМе¶ВдЄЛзЪДж†Зз≠ЊпЉЪ
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=вАЭexample.pngвАЭ /></div>
</body>
</html>
е∞ЖдЉЪ襀蚐жНҐдЄЇдЄЛйЭҐзЪДDOMж†СпЉЪ
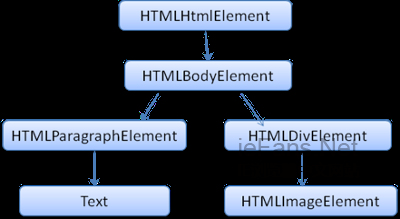
еЫЊ8пЉЪз§ЇдЊЛж†Зз≠ЊеѓєеЇФзЪДDOMж†С
еТМhtmlдЄАж†ЈпЉМDOMзЪДиІДиМГдєЯжШѓзФ±W3CзїДзїЗеИґеЃЪзЪДгАВиЃњйЧЃhttp://www.w3.org/DOM/DOMTRпЉМињЩжШѓдљњзФ®жЦЗж°£зЪДдЄАиИђиІДиМГгАВдЄАдЄ™ж®°еЮЛжППињ∞дЄАзІНзЙєеЃЪзЪДhtmlеЕГзі†пЉМеПѓдї•еЬ®http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.htm¬†жЯ•зЬЛhtmlеЃЪдєЙгАВ
ињЩйЗМжЙАи∞УзЪДж†СеМЕеРЂдЇЖDOMиКВзВєжШѓиѓіж†СжШѓзФ±еЃЮзО∞дЇЖDOMжО•еП£зЪДеЕГзі†жЮДеїЇиАМжИРзЪДпЉМжµПиІИеЩ®дљњзФ®еЈ≤襀жµПиІИеЩ®еЖЕйГ®дљњзФ®зЪДеЕґдїЦе±ЮжАІзЪДеЕЈдљУеЃЮзО∞гАВ
иІ£жЮРзЃЧж≥Х The parsing algorithm
ж≠£е¶ВеЙНйЭҐзЂ†иКВдЄ≠иЃ®иЃЇзЪДпЉМhmtlдЄНиÚ襀дЄАиИђзЪДиЗ™й°ґеРСдЄЛжИЦиЗ™еЇХеРСдЄКзЪДиІ£жЮРеЩ®жЙАиІ£жЮРгАВ
еОЯеЫ†жШѓпЉЪ
1. ињЩйЧ®иѓ≠и®АжЬђиЇЂзЪДеЃљеЃєзЙєжАІ
2. жµПиІИеЩ®еѓєдЄАдЇЫеЄЄиІБзЪДйЭЮж≥ХhtmlжЬЙеЃєйФЩжЬЇеИґ
3. иІ£жЮРињЗз®ЛжШѓеЊАе§НзЪДпЉМйАЪеЄЄжЇРз†БдЄНдЉЪеЬ®иІ£жЮРињЗз®ЛдЄ≠еПСзФЯжФєеПШпЉМдљЖеЬ®htmlдЄ≠пЉМиДЪжЬђж†Зз≠ЊеМЕеРЂзЪДвАЬdocument.write вАЭеПѓиГљжЈїеК†ж†Зз≠ЊпЉМињЩиѓіжШОеЬ®иІ£жЮРињЗз®ЛдЄ≠еЃЮйЩЕдЄКдњЃжФєдЇЖиЊУеЕ•
дЄНиГљдљњзФ®ж≠£еИЩиІ£жЮРжКАжЬѓпЉМжµПиІИеЩ®дЄЇhtmlеЃЪеИґдЇЖдЄУе±ЮзЪДиІ£жЮРеЩ®гАВ
Html5иІДиМГдЄ≠жППињ∞дЇЖињЩдЄ™иІ£жЮРзЃЧж≥ХпЉМзЃЧж≥ХеМЕжЛђдЄ§дЄ™йШґжЃµвАФвАФзђ¶еПЈеМЦеПКжЮДеїЇж†СгАВ
зђ¶еПЈеМЦжШѓиѓНж≥ХеИЖжЮРзЪДињЗз®ЛпЉМе∞ЖиЊУеЕ•иІ£жЮРдЄЇзђ¶еПЈпЉМhtmlзЪДзђ¶еПЈеМЕжЛђеЉАеІЛж†Зз≠ЊгАБзїУжЭЯж†Зз≠ЊгАБе±ЮжАІеРНеПКе±ЮжАІеАЉгАВ
зђ¶еПЈиѓЖеИЂеЩ®иѓЖеИЂеЗЇзђ¶еПЈеРОпЉМе∞ЖеЕґдЉ†йАТзїЩж†СжЮДеїЇеЩ®пЉМеєґиѓїеПЦдЄЛдЄАдЄ™е≠Чзђ¶пЉМдї•иѓЖеИЂдЄЛдЄАдЄ™зђ¶еПЈпЉМињЩж†ЈзЫіеИ∞е§ДзРЖеЃМжЙАжЬЙиЊУеЕ•гАВ
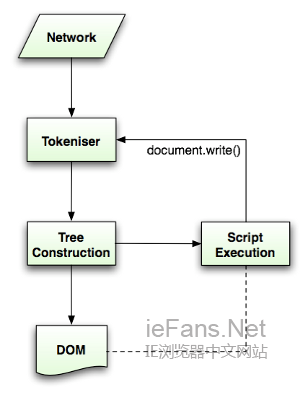
еЫЊ9пЉЪHTMLиІ£жЮРжµБз®Л
зђ¶еПЈиѓЖеИЂзЃЧж≥Х The tokenization algorithm
зЃЧж≥ХиЊУеЗЇhtmlзђ¶еПЈпЉМиѓ•зЃЧж≥ХзФ®зКґжАБжЬЇи°®з§ЇгАВжѓПжђ°иѓїеПЦиЊУеЕ•жµБдЄ≠зЪДдЄАдЄ™жИЦе§ЪдЄ™е≠Чзђ¶пЉМеєґж†єжНЃињЩдЇЫе≠Чзђ¶иљђзІїеИ∞дЄЛдЄАдЄ™зКґжАБпЉМељУеЙНзЪДзђ¶еПЈзКґжАБеПКжЮДеїЇж†СзКґжАБеЕ±еРМељ±еУНзїУжЮЬпЉМињЩжДПеС≥зЭАпЉМиѓїеПЦеРМж†ЈзЪДе≠Чзђ¶пЉМеПѓиГљеЫ†дЄЇељУеЙНзКґжАБзЪДдЄНеРМпЉМеЊЧеИ∞дЄНеРМзЪДзїУжЮЬдї•ињЫеЕ•дЄЛдЄАдЄ™ж≠£з°ЃзЪДзКґжАБгАВ
ињЩдЄ™зЃЧж≥ХеЊИе§НжЭВпЉМињЩйЗМзФ®дЄАдЄ™зЃАеНХзЪДдЊЛе≠РжЭ•иІ£йЗКињЩдЄ™еОЯзРЖгАВ
еЯЇжЬђз§ЇдЊЛвАФвАФзђ¶еПЈеМЦдЄЛйЭҐзЪДhtmlпЉЪ
<html>
<body>
Hello world
</body>
</html>
еИЭеІЛзКґжАБдЄЇвАЬData StateвАЭпЉМељУйБЗеИ∞вАЬ<вАЭе≠Чзђ¶пЉМзКґжАБеПШдЄЇвАЬTag open stateвАЭпЉМиѓїеПЦдЄАдЄ™aпЉНzзЪДе≠Чзђ¶е∞ЖдЇІзФЯдЄАдЄ™еЉАеІЛж†Зз≠Њзђ¶еПЈпЉМзКґжАБзЫЄеЇФеПШдЄЇвАЬTag name stateвАЭпЉМдЄАзЫідњЭжМБињЩдЄ™зКґжАБзЫіеИ∞иѓїеПЦеИ∞вАЬ>вАЭпЉМжѓПдЄ™е≠Чзђ¶йГљйЩДеК†еИ∞ињЩдЄ™зђ¶еПЈеРНдЄКпЉМдЊЛе≠РдЄ≠еИЫеїЇзЪДжШѓдЄАдЄ™htmlзђ¶еПЈгАВ
ељУиѓїеПЦеИ∞вАЬ>вАЭпЉМељУеЙНзЪДзђ¶еПЈе∞±еЃМжИРдЇЖпЉМж≠§жЧґпЉМзКґжАБеЫЮеИ∞вАЬData stateвАЭпЉМвАЬ<body>вАЭйЗНе§НињЩдЄАе§ДзРЖињЗз®ЛгАВеИ∞ињЩйЗМпЉМhtmlеТМbodyж†Зз≠ЊйГљиѓЖеИЂеЗЇжЭ•дЇЖгАВзО∞еЬ®пЉМеЫЮеИ∞вАЬData stateвАЭпЉМиѓїеПЦвАЬHello worldвАЭдЄ≠зЪДе≠Чзђ¶вАЬHвАЭе∞ЖеИЫеїЇеєґиѓЖеИЂеЗЇдЄАдЄ™е≠Чзђ¶зђ¶еПЈпЉМињЩйЗМдЉЪдЄЇвАЬHello worldвАЭдЄ≠зЪДжѓПдЄ™е≠Чзђ¶зФЯжИРдЄАдЄ™е≠Чзђ¶зђ¶еПЈгАВ
ињЩж†ЈзЫіеИ∞йБЗеИ∞вАЬ</body>вАЭдЄ≠зЪДвАЬ<вАЭгАВзО∞еЬ®пЉМеПИеЫЮеИ∞дЇЖвАЬTag open stateвАЭпЉМиѓїеПЦдЄЛдЄАдЄ™е≠Чзђ¶вАЬ/вАЭе∞ЖеИЫеїЇдЄАдЄ™йЧ≠еРИж†Зз≠Њзђ¶еПЈпЉМеєґдЄФзКґжАБиљђзІїеИ∞вАЬTag name stateвАЭпЉМињШжШѓдњЭжМБињЩдЄАзКґжАБпЉМзЫіеИ∞йБЗеИ∞вАЬ>вАЭгАВзДґеРОпЉМдЇІзФЯдЄАдЄ™жЦ∞зЪДж†Зз≠Њзђ¶еПЈеєґеЫЮеИ∞вАЬData stateвАЭгАВеРОйЭҐзЪДвАЬ</html>вАЭе∞ЖеТМвАЬ</body>вАЭдЄАж†Је§ДзРЖгАВ
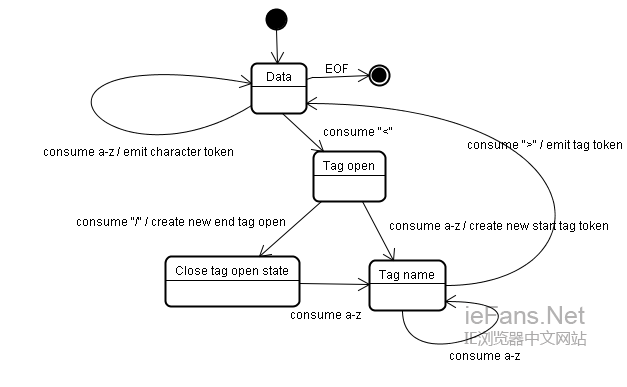
еЫЊ10пЉЪзђ¶еПЈеМЦз§ЇдЊЛиЊУеЕ•
ж†СзЪДжЮДеїЇзЃЧж≥Х Tree construction algorithm
еЬ®ж†СзЪДжЮДеїЇйШґжЃµпЉМе∞ЖдњЃжФєдї•DocumentдЄЇж†єзЪДDOMж†СпЉМе∞ЖеЕГзі†йЩДеК†еИ∞ж†СдЄКгАВжѓПдЄ™зФ±зђ¶еПЈиѓЖеИЂеЩ®иѓЖеИЂзФЯжИРзЪДиКВзВєе∞ЖдЉЪ襀ж†СжЮДйА†еЩ®ињЫи°Ме§ДзРЖпЉМиІДиМГдЄ≠еЃЪдєЙдЇЖжѓПдЄ™зђ¶еПЈзЫЄеѓєеЇФзЪДDomеЕГзі†пЉМеѓєеЇФзЪДDomеЕГзі†е∞ЖдЉЪ襀еИЫеїЇгАВињЩдЇЫеЕГзі†йЩ§дЇЖдЉЪ襀棿еК†еИ∞Domж†СдЄКпЉМињШе∞Ж襀棿еК†еИ∞еЉАжФЊеЕГзі†е†Жж†ИдЄ≠гАВињЩдЄ™е†Жж†ИзФ®жЭ•зЇ†ж≠£еµМе•ЧзЪДжЬ™еМєйЕНеТМжЬ™йЧ≠еРИж†Зз≠ЊпЉМињЩдЄ™зЃЧж≥ХдєЯжШѓзФ®зКґжАБжЬЇжЭ•жППињ∞пЉМжЙАжЬЙзЪДзКґжАБйЗЗзФ®жПТеЕ•ж®°еЉПгАВ
жЭ•зЬЛдЄАдЄЛз§ЇдЊЛдЄ≠ж†СзЪДеИЫеїЇињЗз®ЛпЉЪ
<html>
<body>
Hello world
</body>
</html>
жЮДеїЇж†СињЩдЄАйШґжЃµзЪДиЊУеЕ•жШѓзђ¶еПЈиѓЖеИЂйШґжЃµзФЯжИРзЪДзђ¶еПЈеЇПеИЧгАВ
й¶ЦеЕИжШѓвАЬinitial modeвАЭпЉМжО•жФґеИ∞htmlзђ¶еПЈеРОе∞ЖиљђжНҐдЄЇвАЬbefore htmlвАЭж®°еЉПпЉМеЬ®ињЩдЄ™ж®°еЉПдЄ≠еѓєињЩдЄ™зђ¶еПЈињЫи°МеЖНе§ДзРЖгАВж≠§жЧґпЉМеИЫеїЇдЇЖдЄАдЄ™HTMLHtmlElementеЕГзі†пЉМеєґе∞ЖеЕґйЩДеК†еИ∞ж†єDocumentеѓєи±°дЄКгАВ
зКґжАБж≠§жЧґеПШдЄЇвАЬbefore headвАЭпЉМжО•жФґеИ∞bodyзђ¶еПЈжЧґпЉМеН≥дљњињЩйЗМж≤°жЬЙheadзђ¶еПЈпЉМдєЯе∞ЖиЗ™еК®еИЫеїЇдЄАдЄ™HTMLHeadElementеЕГзі†еєґйЩДеК†еИ∞ж†СдЄКгАВ
зО∞еЬ®пЉМиљђеИ∞вАЬin headвАЭж®°еЉПпЉМзДґеРОжШѓвАЬafter headвАЭгАВеИ∞ињЩйЗМпЉМbodyзђ¶еПЈдЉЪ襀еЖНжђ°е§ДзРЖпЉМе∞ЖеИЫеїЇдЄАдЄ™HTMLBodyElementеєґжПТеЕ•еИ∞ж†СдЄ≠пЉМеРМжЧґпЉМиљђзІїеИ∞вАЬin bodyвАЭж®°еЉПгАВ
зДґеРОпЉМжО•жФґеИ∞е≠Чзђ¶дЄ≤вАЬHello worldвАЭзЪДе≠Чзђ¶зђ¶еПЈпЉМзђђдЄАдЄ™е≠Чзђ¶е∞ЖеѓЉиЗіеИЫеїЇеєґжПТеЕ•дЄАдЄ™textиКВзВєпЉМеЕґдїЦе≠Чзђ¶е∞ЖйЩДеК†еИ∞иѓ•иКВзВєгАВ
жО•жФґеИ∞bodyзїУжЭЯзђ¶еПЈжЧґпЉМиљђзІїеИ∞вАЬafter bodyвАЭж®°еЉПпЉМжО•зЭАжО•жФґеИ∞htmlзїУжЭЯзђ¶еПЈпЉМињЩдЄ™зђ¶еПЈжДПеС≥зЭАиљђзІїеИ∞дЇЖвАЬafter after bodyвАЭж®°еЉПпЉМељУжО•жФґеИ∞жЦЗдїґзїУжЭЯзђ¶жЧґпЉМжХідЄ™иІ£жЮРињЗз®ЛзїУжЭЯгАВ
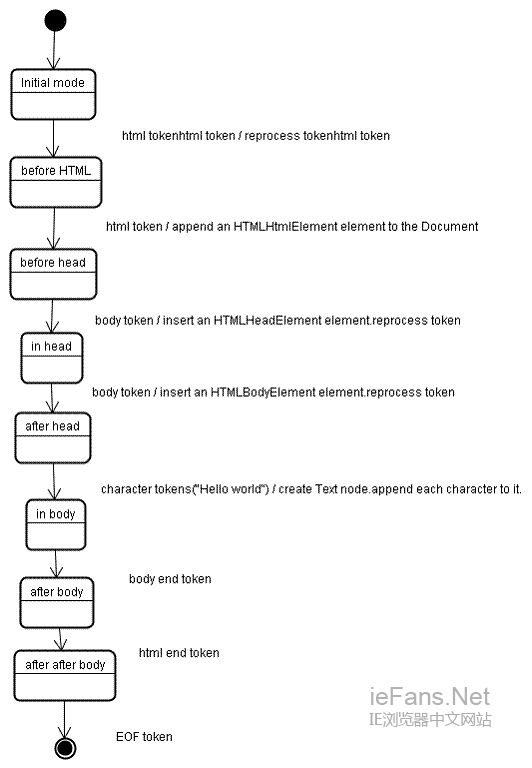
еЫЊ11пЉЪз§ЇдЊЛhtmlж†СзЪДжЮДеїЇињЗз®Л
иІ£жЮРзїУжЭЯжЧґзЪДе§ДзРЖ Action when the parsing is finished
еЬ®ињЩдЄ™йШґжЃµпЉМжµПиІИеЩ®е∞ЖжЦЗж°£ж†ЗиЃ∞дЄЇеПѓдЇ§дЇТзЪДпЉМеєґеЉАеІЛиІ£жЮРе§ДдЇОеїґжЧґж®°еЉПдЄ≠зЪДиДЪжЬђвАФвАФињЩдЇЫиДЪжЬђеЬ®жЦЗж°£иІ£жЮРеРОжЙІи°МгАВ
жЦЗж°£зКґжАБе∞Ж襀职皁䪯еЃМжИРпЉМеРМжЧґиІ¶еПСдЄАдЄ™loadдЇЛдїґгАВ
Html5иІДиМГдЄ≠жЬЙзђ¶еПЈеМЦеПКжЮДеїЇж†СзЪДеЃМжХізЃЧж≥Х(http://www.w3.org/TR/html5/syntax.html#html-parser)гАВ
жµПиІИеЩ®еЃєйФЩ Browsers error tolerance
дљ†дїОжЭ•дЄНдЉЪеЬ®дЄАдЄ™htmlй°µйЭҐдЄКзЬЛеИ∞вАЬжЧ†жХИиѓ≠ж≥ХвАЭињЩж†ЈзЪДйФЩиѓѓпЉМжµПиІИеЩ®дњЃе§НдЇЖжЧ†жХИеЖЕеЃєеєґзїІзї≠еЈ•дљЬгАВ
дї•дЄЛйЭҐињЩжЃµhtmlдЄЇдЊЛпЉЪ
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
ињЩжЃµhtmlињЭеПНдЇЖеЊИе§ЪиІДеИЩпЉИmytagдЄНжШѓеРИж≥ХзЪДж†Зз≠ЊпЉМpеПКdivйФЩиѓѓзЪДеµМе•Чз≠Йз≠ЙпЉЙпЉМдљЖжШѓжµПиІИеЩ®дїНзДґеПѓдї•ж≤°жЬЙдїїдљХжА®и®АзЪДзїІзї≠жШЊз§ЇпЉМеЃГеЬ®иІ£жЮРзЪДињЗз®ЛдЄ≠дњЃе§НдЇЖhtmlдљЬиАЕзЪДйФЩиѓѓгАВ
жµПиІИеЩ®йГљеЕЈжЬЙйФЩиѓѓе§ДзРЖзЪДиГљеКЫпЉМдљЖжШѓпЉМеП¶дЇЇжГКиЃґзЪДжШѓпЉМињЩеєґдЄНжШѓhtmlжЬАжЦ∞иІДиМГзЪДеЖЕеЃєпЉМе∞±еГПдє¶з≠ЊеПКеЙНињЫеРОйААжМЙйТЃдЄАж†ЈпЉМеЃГеП™жШѓжµПиІИеЩ®йХњжЬЯеПСе±ХзЪДзїУжЮЬгАВдЄАдЇЫжѓФиЊГзЯ•еРНзЪДйЭЮж≥ХhtmlзїУжЮДпЉМеЬ®иЃЄе§ЪзЂЩзВєдЄ≠еЗЇзО∞ињЗпЉМжµПиІИеЩ®йГљиѓХзЭАдї•дЄАзІНеТМеЕґдїЦжµПиІИеЩ®дЄАиЗізЪДжЦєеЉПеОїдњЃе§НгАВ
Html5иІДиМГеЃЪдєЙдЇЖињЩжЦєйЭҐзЪДйЬАж±ВпЉМwebkitеЬ®htmlиІ£жЮРз±їеЉАеІЛйГ®еИЖзЪДж≥®йЗКдЄ≠еБЪдЇЖеЊИе•љзЪДжАїзїУгАВ
иІ£жЮРеЩ®е∞Жзђ¶еПЈеМЦзЪДиЊУеЕ•иІ£жЮРдЄЇжЦЗж°£еєґеИЫеїЇжЦЗж°£пЉМдљЖдЄНеєЄзЪДжШѓпЉМжИСдїђењЕй°їе§ДзРЖеЊИе§Ъж≤°жЬЙеЊИе•љж†ЉеЉПеМЦзЪДhtmlжЦЗж°£пЉМиЗ≥е∞Си¶Бе∞ПењГдЄЛйЭҐеЗ†зІНйФЩиѓѓжГЕеЖµгАВ
1. еЬ®жЬ™йЧ≠еРИзЪДж†Зз≠ЊдЄ≠жЈїеК†жШОз°Ѓз¶Бж≠ҐзЪДеЕГзі†гАВињЩзІНжГЕеЖµдЄЛпЉМеЇФиѓ•еЕИе∞ЖеЙНдЄАж†Зз≠ЊйЧ≠еРИ
2. дЄНиГљзЫіжО•жЈїеК†еЕГзі†гАВжЬЙдЇЫдЇЇеЬ®еЖЩжЦЗж°£зЪДжЧґеАЩдЉЪењШдЇЖдЄ≠йЧідЄАдЇЫж†Зз≠ЊпЉИжИЦиАЕдЄ≠йЧіж†Зз≠ЊжШѓеПѓйАЙзЪДпЉЙпЉМжѓФе¶ВHTML HEAD BODY TR TD LIз≠Й
3. жГ≥еЬ®дЄАдЄ™и°МеЖЕеЕГзі†дЄ≠жЈїеК†еЭЧзКґеЕГзі†гАВеЕ≥йЧ≠жЙАжЬЙзЪДи°МеЖЕеЕГзі†пЉМзЫіеИ∞дЄЛдЄАдЄ™жЫійЂШзЪДеЭЧзКґеЕГзі†
4. е¶ВжЮЬињЩдЇЫйГљдЄНи°МпЉМе∞±йЧ≠еРИељУеЙНж†Зз≠ЊзЫіеИ∞еПѓдї•жЈїеК†иѓ•еЕГзі†гАВ
дЄЛйЭҐжЭ•зЬЛдЄАдЇЫwebkitеЃєйФЩзЪДдЊЛе≠РпЉЪ
</br>жЫњдї£<br>
дЄАдЇЫзљСзЂЩдљњзФ®</br>жЫњдї£<br>пЉМдЄЇдЇЖеЕЉеЃєIEеТМFirefoxпЉМwebkitе∞ЖеЕґзЬЛдљЬ<br>гАВ
дї£з†БпЉЪ
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
NoteпЉНињЩйЗМзЪДйФЩиѓѓе§ДзРЖеЬ®еЖЕйГ®ињЫи°МпЉМзФ®жИЈзЬЛдЄНеИ∞гАВ
ињЈиЈѓзЪДи°®ж†Љ
ињЩжМЗдЄАдЄ™и°®ж†ЉеµМе•ЧеЬ®еП¶дЄАдЄ™и°®ж†ЉдЄ≠пЉМдљЖдЄНеЬ®еЃГзЪДжЯРдЄ™еНХеЕГж†ЉеЖЕгАВ
жѓФе¶ВдЄЛйЭҐињЩдЄ™дЊЛе≠РпЉЪ
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
webkitе∞ЖдЉЪе∞ЖеµМе•ЧзЪДи°®ж†ЉеПШдЄЇдЄ§дЄ™еЕДеЉЯи°®ж†ЉпЉЪ
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
дї£з†БпЉЪ
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
webkitдљњзФ®е†Жж†Ие≠ШжФЊељУеЙНзЪДеЕГзі†еЖЕеЃєпЉМеЃГе∞ЖдїОе§ЦйГ®и°®ж†ЉзЪДе†Жж†ИдЄ≠еЉєеЗЇеЖЕйГ®зЪДи°®ж†ЉпЉМеИЩеЃГдїђеПШдЄЇдЇЖеЕДеЉЯи°®ж†ЉгАВ
еµМе•ЧзЪДи°®еНХеЕГзі†
зФ®жИЈе∞ЖдЄАдЄ™и°®еНХеµМе•ЧеИ∞еП¶дЄАдЄ™и°®еНХдЄ≠пЉМеИЩзђђдЇМдЄ™и°®еНХе∞Ж襀圚зХ•гАВ
дї£з†БпЉЪ
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
姙棱зЪДж†Зз≠ЊзїІжЙњ
www.liceo.edu.mxжШѓдЄАдЄ™зФ±еµМе•Че±Вжђ°зЪДзЂЩзВєзЪДдЊЛе≠РпЉМжЬАе§ЪеП™еЕБиЃЄ20дЄ™зЫЄеРМз±їеЮЛзЪДж†Зз≠ЊеµМе•ЧпЉМе§ЪеЗЇжЭ•зЪДе∞Ж襀圚зХ•гАВ
дї£з†БпЉЪ
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
жФЊйФЩдЇЖеЬ∞жЦєзЪДhtmlгАБbodyйЧ≠еРИж†Зз≠Њ
еПИдЄАжђ°дЄНи®АиЗ™жШОгАВ
жФѓжМБдЄНеЃМжХізЪДhtmlгАВжИСдїђдїОжЭ•дЄНйЧ≠еРИbodyпЉМеЫ†дЄЇдЄАдЇЫжДЪ膥зЪДзљСй°µжАїжШѓеЬ®ињШжЬ™зЬЯж≠£зїУжЭЯжЧґе∞±йЧ≠еРИеЃГгАВжИСдїђдЊЭиµЦи∞ГзФ®endжЦєж≥ХеОїжЙІи°МеЕ≥йЧ≠зЪДе§ДзРЖгАВ
дї£з†БпЉЪ
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
жЙАдї•пЉМwebеЉАеПСиАЕи¶Бе∞ПењГдЇЖпЉМйЩ§йЭЮдљ†жГ≥жИРдЄЇwebkitеЃєйФЩдї£з†БзЪДиМГдЊЛпЉМеР¶еИЩињШжШѓеЖЩж†ЉеЉПиЙѓе•љзЪДhtmlеРІгАВ
CSSиІ£жЮР CSS parsing
ињШиЃ∞еЊЧзЃАдїЛдЄ≠жПРеИ∞зЪДиІ£жЮРзЪДж¶ВењµеРЧпЉМдЄНеРМдЇОhtmlпЉМcssе±ЮдЇОдЄКдЄЛжЦЗжЧ†еЕ≥жЦЗж≥ХпЉМеПѓдї•зФ®еЙНйЭҐжЙАжППињ∞зЪДиІ£жЮРеЩ®жЭ•иІ£жЮРгАВCssиІДиМГеЃЪдєЙдЇЖcssзЪДиѓНж≥ХеПКиѓ≠ж≥ХжЦЗж≥ХгАВ
зЬЛдЄАдЇЫдЊЛе≠РпЉЪ
жѓПдЄ™зђ¶еПЈйГљзФ±ж≠£еИЩи°®иЊЊеЉПеЃЪдєЙдЇЖиѓНж≥ХжЦЗж≥ХпЉИиѓНж±Зи°®пЉЙпЉЪ
comment ///*[^*]*/*+([^/*][^*]*/*+)*//
num [0-9]+|[0-9]*вАЭ.вАЭ[0-9]+
nonascii [/200-/377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
вАЬidentвАЭжШѓиѓЖеИЂеЩ®зЪДзЉ©еЖЩпЉМзЫЄељУдЇОдЄАдЄ™classеРНпЉМвАЬnameвАЭжШѓдЄАдЄ™еЕГзі†idпЉИзФ®вАЬпЉГвАЭеЉХзФ®пЉЙгАВ
иѓ≠ж≥ХзФ®BNFињЫи°МжППињ∞пЉЪ
ruleset
: selector [ ',' S* selector ]*
вАШ{вАЩ S* declaration [ ';' S* declaration ]* вАШ}вАЩ S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: вАШ.вАЩ IDENT
;
element_name
: IDENT | вАШ*вАЩ
;
attrib
: вАШ[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] вАШ]вАЩ
;
pseudo
: вАШ:вАЩ [ IDENT | FUNCTION S* [IDENT S*] вАШ)вАЩ ]
;
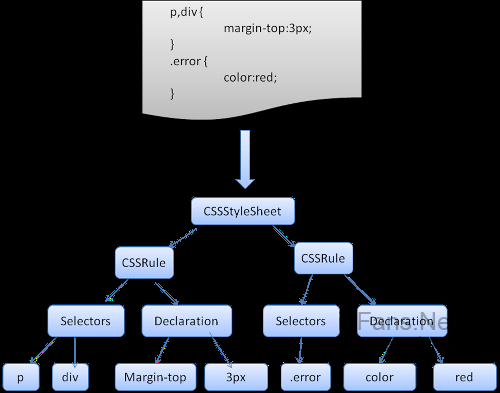
иѓіжШОпЉЪдЄАдЄ™иІДеИЩйЫЖеРИжЬЙињЩж†ЈзЪДзїУжЮД
div.error , a.error {
color:red;
font-weight:bold;
}
div.errorеТМa.errorжЧґйАЙжЛ©еЩ®пЉМе§ІжЛђеПЈдЄ≠зЪДеЖЕеЃєеМЕеРЂдЇЖињЩжЭ°иІДеИЩйЫЖеРИдЄ≠зЪДиІДеИЩпЉМињЩдЄ™зїУжЮДеЬ®дЄЛйЭҐзЪДеЃЪдєЙдЄ≠ж≠£еЉПзЪДеЃЪдєЙдЇЖпЉЪ
ruleset
: selector [ ',' S* selector ]*
вАШ{вАЩ S* declaration [ ';' S* declaration ]* вАШ}вАЩ S*
;
ињЩиѓіжШОпЉМдЄАдЄ™иІДеИЩйЫЖеРИеЕЈжЬЙдЄАдЄ™жИЦжШѓеПѓйАЙдЄ™жХ∞зЪДе§ЪдЄ™йАЙжЛ©еЩ®пЉМињЩдЇЫйАЙжЛ©еЩ®дї•йАЧеПЈеТМз©Їж†ЉпЉИSи°®з§Їз©Їж†ЉпЉЙињЫи°МеИЖйЪФгАВжѓПдЄ™иІДеИЩйЫЖеРИеМЕеРЂе§ІжЛђеПЈеПКе§ІжЛђеПЈдЄ≠зЪДдЄАжЭ°жИЦе§ЪжЭ°дї•еИЖеПЈйЪФеЉАзЪДе£∞жШОгАВе£∞жШОеТМйАЙжЛ©еЩ®еЬ®еРОйЭҐињЫи°МеЃЪдєЙгАВ
Webkit CSS иІ£жЮРеЩ® Webkit CSS parser
WebkitдљњзФ®FlexеТМBisonиІ£жЮРзФЯжИРеЩ®дїОCSSиѓ≠ж≥ХжЦЗдїґдЄ≠иЗ™еК®зФЯжИРиІ£жЮРеЩ®гАВеЫЮењЖдЄАдЄЛиІ£жЮРеЩ®зЪДдїЛзїНпЉМBisonеИЫеїЇдЄАдЄ™иЗ™еЇХеРСдЄКзЪДиІ£жЮРеЩ®пЉМFirefoxдљњзФ®иЗ™й°ґеРСдЄЛиІ£жЮРеЩ®гАВеЃГдїђйГљжШѓе∞ЖжѓПдЄ™cssжЦЗдїґиІ£жЮРдЄЇж†ЈеЉПи°®еѓєи±°пЉМжѓПдЄ™еѓєи±°еМЕеРЂcssиІДеИЩпЉМcssиІДеИЩеѓєи±°еМЕеРЂйАЙжЛ©еЩ®еТМе£∞жШОеѓєи±°пЉМдї•еПКеЕґдїЦдЄАдЇЫзђ¶еРИcssиѓ≠ж≥ХзЪДеѓєи±°гАВ
еЫЊ12пЉЪиІ£жЮРcss
иДЪжЬђиІ£жЮР Parsing scripts
жЬђзЂ†е∞ЖдїЛзїНJavascriptгАВ
е§ДзРЖиДЪжЬђеПКж†ЈеЉПи°®зЪДй°ЇеЇП The order of processing scripts and style sheets
иДЪжЬђ
webзЪДж®°еЉПжШѓеРМж≠•зЪДпЉМеЉАеПСиАЕеЄМжЬЫиІ£жЮРеИ∞дЄАдЄ™scriptж†Зз≠ЊжЧґзЂЛеН≥иІ£жЮРжЙІи°МиДЪжЬђпЉМеєґйШїе°ЮжЦЗж°£зЪДиІ£жЮРзЫіеИ∞иДЪжЬђжЙІи°МеЃМгАВе¶ВжЮЬиДЪжЬђжШѓе§ЦеЉХзЪДпЉМеИЩзљСзїЬењЕй°їеЕИиѓЈж±ВеИ∞ињЩдЄ™иµДжЇРвАФвАФињЩдЄ™ињЗз®ЛдєЯжШѓеРМж≠•зЪДпЉМдЉЪйШїе°ЮжЦЗж°£зЪДиІ£жЮРзЫіеИ∞иµДжЇР襀胣ж±ВеИ∞гАВињЩдЄ™ж®°еЉПдњЭжМБдЇЖеЊИе§ЪеєіпЉМеєґдЄФеЬ®html4еПКhtml5дЄ≠йГљзЙєеИЂжМЗеЃЪдЇЖгАВеЉАеПСиАЕеПѓдї•е∞ЖиДЪжЬђж†ЗиѓЖдЄЇdeferпЉМдї•дљњеЕґдЄНйШїе°ЮжЦЗж°£иІ£жЮРпЉМеєґеЬ®жЦЗж°£иІ£жЮРзїУжЭЯеРОжЙІи°МгАВHtml5еҐЮеК†дЇЖж†ЗиЃ∞иДЪжЬђдЄЇеЉВж≠•зЪДйАЙй°єпЉМдї•дљњиДЪжЬђзЪДиІ£жЮРжЙІи°МдљњзФ®еП¶дЄАдЄ™зЇњз®ЛгАВ
йҐДиІ£жЮР Speculative parsing
WebkitеТМFirefoxйГљеБЪдЇЖињЩдЄ™дЉШеМЦпЉМељУжЙІи°МиДЪжЬђжЧґпЉМеП¶дЄАдЄ™зЇњз®ЛиІ£жЮРеЙ©дЄЛзЪДжЦЗж°£пЉМеєґеК†иљљеРОйЭҐйЬАи¶БйАЪињЗзљСзїЬеК†иљљзЪДиµДжЇРгАВињЩзІНжЦєеЉПеПѓдї•дљњиµДжЇРеєґи°МеК†иљљдїОиАМдљњжХідљУйАЯеЇ¶жЫіењЂгАВйЬАи¶Бж≥®жДПзЪДжШѓпЉМйҐДиІ£жЮРеєґдЄНжФєеПШDomж†СпЉМеЃГе∞ЖињЩдЄ™еЈ•дљЬзХЩзїЩдЄїиІ£жЮРињЗз®ЛпЉМиЗ™еЈ±еП™иІ£жЮРе§ЦйГ®иµДжЇРзЪДеЉХзФ®пЉМжѓФе¶Ве§ЦйГ®иДЪжЬђгАБж†ЈеЉПи°®еПКеЫЊзЙЗгАВ
ж†ЈеЉПи°® Style sheets
ж†ЈеЉПи°®йЗЗзФ®еП¶дЄАзІНдЄНеРМзЪДж®°еЉПгАВзРЖиЃЇдЄКпЉМжЧҐзДґж†ЈеЉПи°®дЄНжФєеПШDomж†СпЉМдєЯе∞±ж≤°жЬЙењЕи¶БеБЬдЄЛжЦЗж°£зЪДиІ£жЮРз≠ЙеЊЕеЃГдїђпЉМзДґиАМпЉМе≠ШеЬ®дЄАдЄ™йЧЃйҐШпЉМиДЪжЬђеПѓиГљеЬ®жЦЗж°£зЪДиІ£жЮРињЗз®ЛдЄ≠иѓЈж±Вж†ЈеЉПдњ°жБѓпЉМе¶ВжЮЬж†ЈеЉПињШж≤°жЬЙеК†иљљеТМиІ£жЮРпЉМиДЪжЬђе∞ЖеЊЧеИ∞йФЩиѓѓзЪДеАЉпЉМжШЊзДґињЩе∞ЖдЉЪеѓЉиЗіеЊИе§ЪйЧЃйҐШпЉМињЩзЬЛиµЈжЭ•жШѓдЄ™иЊєзЉШжГЕеЖµпЉМдљЖз°ЃеЃЮеЊИеЄЄиІБгАВFirefoxеЬ®е≠ШеЬ®ж†ЈеЉПи°®ињШеЬ®еК†иљљеТМиІ£жЮРжЧґйШїе°ЮжЙАжЬЙзЪДиДЪжЬђпЉМиАМchromeеП™еЬ®ељУиДЪжЬђиѓХеЫЊиЃњйЧЃжЯРдЇЫеПѓиÚ襀жЬ™еК†иљљзЪДж†ЈеЉПи°®жЙАељ±еУНзЪДзЙєеЃЪзЪДж†ЈеЉПе±ЮжАІжЧґжЙНйШїе°ЮињЩдЇЫиДЪжЬђгАВ
жЄ≤жЯУж†СзЪДжЮДйА† Render tree construction
ељУDomж†СжЮДеїЇеЃМжИРжЧґпЉМжµПиІИеЩ®еЉАеІЛжЮДеїЇеП¶дЄАж£µж†СвАФвАФжЄ≤жЯУж†СгАВжЄ≤жЯУж†СзФ±еЕГзі†жШЊз§ЇеЇПеИЧдЄ≠зЪДеПѓиІБеЕГзі†зїДжИРпЉМеЃГжШѓжЦЗж°£зЪДеПѓиІЖеМЦи°®з§ЇпЉМжЮДеїЇињЩж£µж†СжШѓдЄЇдЇЖдї•ж≠£з°ЃзЪДй°ЇеЇПзїШеИґжЦЗж°£еЖЕеЃєгАВ
Firefoxе∞ЖжЄ≤жЯУж†СдЄ≠зЪДеЕГзі†зІ∞дЄЇframesпЉМwebkitеИЩзФ®rendererжИЦжЄ≤жЯУеѓєи±°жЭ•жППињ∞ињЩдЇЫеЕГзі†гАВ
дЄАдЄ™жЄ≤жЯУеѓєи±°зЫіеИ∞жАОдєИеЄГе±АеПКзїШеИґиЗ™еЈ±еПКеЃГзЪДchildrenгАВ
RenderObjectжШѓWebkitзЪДжЄ≤жЯУеѓєи±°еЯЇз±їпЉМеЃГзЪДеЃЪдєЙе¶ВдЄЛпЉЪ
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
жѓПдЄ™жЄ≤жЯУеѓєи±°зФ®дЄАдЄ™еТМиѓ•иКВзВєзЪДcssзЫТж®°еЮЛзЫЄеѓєеЇФзЪДзߩ嚥еМЇеЯЯжЭ•и°®з§ЇпЉМж≠£е¶Вcss2жЙАжППињ∞зЪДйВ£ж†ЈпЉМеЃГеМЕеРЂиѓЄе¶ВеЃљгАБйЂШеТМдљНзљЃдєЛз±їзЪДеЗ†дљХдњ°жБѓгАВзЫТж®°еЮЛзЪДз±їеЮЛеПЧиѓ•иКВзВєзЫЄеЕ≥зЪДdisplayж†ЈеЉПе±ЮжАІзЪДељ±еУНпЉИеПВиАГж†ЈеЉПиЃ°зЃЧзЂ†иКВпЉЙгАВдЄЛйЭҐзЪДwebkitдї£з†БиѓіжШОдЇЖе¶ВдљХж†єжНЃdisplayе±ЮжАІеЖ≥еЃЪжЯРдЄ™иКВзВєеИЫеїЇдљХзІНз±їеЮЛзЪДжЄ≤жЯУеѓєи±°гАВ
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
вА¶
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
вА¶
}
return o;
}
еЕГзі†зЪДз±їеЮЛдєЯйЬАи¶БиАГиЩСпЉМдЊЛе¶ВпЉМи°®еНХжОІдїґеТМи°®ж†ЉеЄ¶жЬЙзЙєжЃКзЪДж°ЖжЮґгАВ
еЬ®webkitдЄ≠пЉМе¶ВжЮЬдЄАдЄ™еЕГзі†жГ≥еИЫеїЇдЄАдЄ™зЙєжЃКзЪДжЄ≤жЯУеѓєи±°пЉМеЃГйЬАи¶Бе§НеЖЩвАЬcreateRendererвАЭжЦєж≥ХпЉМдљњжЄ≤жЯУеѓєи±°жМЗеРСдЄНеМЕеРЂеЗ†дљХдњ°жБѓзЪДж†ЈеЉПеѓєи±°гАВ
жЄ≤жЯУж†СеТМDomж†СзЪДеЕ≥з≥ї The render tree relation to the DOM tree
жЄ≤жЯУеѓєи±°еТМDomеЕГзі†зЫЄеѓєеЇФпЉМдљЖињЩзІНеѓєеЇФеЕ≥з≥їдЄНжШѓдЄАеѓєдЄАзЪДпЉМдЄНеПѓиІБзЪДDomеЕГзі†дЄНдЉЪ襀жПТеЕ•жЄ≤жЯУж†СпЉМдЊЛе¶ВheadеЕГзі†гАВеП¶е§ЦпЉМdisplayе±ЮжАІдЄЇnoneзЪДеЕГзі†дєЯдЄНдЉЪеЬ®жЄ≤жЯУж†СдЄ≠еЗЇзО∞пЉИvisibilityе±ЮжАІдЄЇhiddenзЪДеЕГзі†е∞ЖеЗЇзО∞еЬ®жЄ≤жЯУж†СдЄ≠пЉЙгАВ
ињШжЬЙдЄАдЇЫDomеЕГзі†еѓєеЇФеЗ†дЄ™еПѓиІБеѓєи±°пЉМеЃГдїђдЄАиИђжШѓдЄАдЇЫеЕЈжЬЙе§НжЭВзїУжЮДзЪДеЕГзі†пЉМжЧ†ж≥ХзФ®дЄАдЄ™зߩ嚥жЭ•жППињ∞гАВдЊЛе¶ВпЉМselectеЕГзі†жЬЙдЄЙдЄ™жЄ≤жЯУеѓєи±°вАФвАФдЄАдЄ™жШЊз§ЇеМЇеЯЯгАБдЄАдЄ™дЄЛжЛЙеИЧи°®еПКдЄАдЄ™жМЙйТЃгАВеРМж†ЈпЉМељУжЦЗжЬђеЫ†дЄЇеЃљеЇ¶дЄНе§ЯиАМжКШи°МжЧґпЉМжЦ∞и°Ме∞ЖдљЬдЄЇйҐЭе§ЦзЪДжЄ≤жЯУеЕГ糆襀棿еК†гАВеП¶дЄАдЄ™е§ЪдЄ™жЄ≤жЯУеѓєи±°зЪДдЊЛе≠РжШѓдЄНиІДиМГзЪДhtmlпЉМж†єжНЃcssиІДиМГпЉМдЄАдЄ™и°МеЖЕеЕГзі†еП™иГљдїЕеМЕеРЂи°МеЖЕеЕГзі†жИЦдїЕеМЕеРЂеЭЧзКґеЕГзі†пЉМеЬ®е≠ШеЬ®жЈЈеРИеЖЕеЃєжЧґпЉМе∞ЖдЉЪеИЫеїЇеМњеРНзЪДеЭЧзКґжЄ≤жЯУеѓєи±°еМЕи£єдљПи°МеЖЕеЕГзі†гАВ
дЄАдЇЫжЄ≤жЯУеѓєи±°еТМжЙАеѓєеЇФзЪДDomиКВзВєдЄНеЬ®ж†СдЄКзЫЄеРМзЪДдљНзљЃпЉМдЊЛе¶ВпЉМжµЃеК®еТМзїЭеѓєеЃЪдљНзЪДеЕГзі†еЬ®жЦЗжЬђжµБдєЛе§ЦпЉМеЬ®дЄ§ж£µж†СдЄКзЪДдљНзљЃдЄНеРМпЉМжЄ≤жЯУж†СдЄКж†ЗиѓЖеЗЇзЬЯеЃЮзЪДзїУжЮДпЉМеєґзФ®дЄАдЄ™еН†дљНзїУжЮДж†ЗиѓЖеЗЇеЃГдїђеОЯжЭ•зЪДдљНзљЃгАВ
еЫЊ12пЉЪжЄ≤жЯУж†СеПКеѓєеЇФзЪДDomж†С
еИЫеїЇж†СзЪДжµБз®Л The flow of constructing the tree
FirefoxдЄ≠пЉМи°®ињ∞дЄЇдЄАдЄ™зЫСеРђDomжЫіжЦ∞зЪДзЫСеРђеЩ®пЉМе∞ЖframeзЪДеИЫеїЇеІФжіЊзїЩFrame ConstructorпЉМињЩдЄ™жЮДеїЇеЩ®иЃ°зЃЧж†ЈеЉПпЉИеПВзЬЛж†ЈеЉПиЃ°зЃЧпЉЙеєґеИЫеїЇдЄАдЄ™frameгАВ
WebkitдЄ≠пЉМиЃ°зЃЧж†ЈеЉПеєґзФЯжИРжЄ≤жЯУеѓєи±°зЪДињЗз®ЛзІ∞дЄЇattachmentпЉМжѓПдЄ™DomиКВзВєжЬЙдЄАдЄ™attachжЦєж≥ХпЉМattachmentзЪДињЗз®ЛжШѓеРМж≠•зЪДпЉМи∞ГзФ®жЦ∞иКВзВєзЪДattachжЦєж≥Хе∞ЖиКВзВєжПТеЕ•еИ∞Domж†СдЄ≠гАВ
е§ДзРЖhtmlеТМbodyж†Зз≠Ње∞ЖжЮДеїЇжЄ≤жЯУж†СзЪДж†єпЉМињЩдЄ™ж†єжЄ≤жЯУеѓєи±°еѓєеЇФ襀cssиІДиМГзІ∞дЄЇcontaining blockзЪДеЕГзі†вАФвАФеМЕеРЂдЇЖеЕґдїЦжЙАжЬЙеЭЧеЕГзі†зЪДй°ґзЇІеЭЧеЕГзі†гАВеЃГзЪДе§Іе∞Пе∞±жШѓviewportвАФвАФжµПиІИеЩ®з™ЧеП£зЪДжШЊз§ЇеМЇеЯЯпЉМFirefoxзІ∞еЃГдЄЇviewPortFrameпЉМwebkitзІ∞дЄЇRenderViewпЉМињЩдЄ™е∞±жШѓжЦЗж°£жЙАжМЗеРСзЪДжЄ≤жЯУеѓєи±°пЉМж†СдЄ≠еЕґдїЦзЪДйГ®еИЖйГље∞ЖдљЬдЄЇдЄАдЄ™жПТеЕ•зЪДDomиКВзº襀еИЫеїЇгАВ
ж†ЈеЉПиЃ°зЃЧ Style Computation
еИЫеїЇжЄ≤жЯУж†СйЬАи¶БиЃ°зЃЧеЗЇжѓПдЄ™жЄ≤жЯУеѓєи±°зЪДеПѓиІЖе±ЮжАІпЉМињЩеПѓдї•йАЪињЗиЃ°зЃЧжѓПдЄ™еЕГзі†зЪДж†ЈеЉПе±ЮжАІеЊЧеИ∞гАВ
ж†ЈеЉПеМЕжЛђеРДзІНжЭ•жЇРзЪДж†ЈеЉПи°®пЉМи°МеЖЕж†ЈеЉПеЕГзі†еПКhtmlдЄ≠зЪДеПѓиІЖеМЦе±ЮжАІпЉИдЊЛе¶ВbgcolorпЉЙпЉМеПѓиІЖеМЦе±ЮжАІиљђеМЦдЄЇcssж†ЈеЉПе±ЮжАІгАВ
ж†ЈеЉПи°®жЭ•жЇРдЇОжµПиІИеЩ®йїШиЃ§ж†ЈеЉПи°®пЉМеПКй°µйЭҐдљЬиАЕеТМзФ®жИЈжПРдЊЫзЪДж†ЈеЉПи°®вАФвАФжЬЙдЇЫж†ЈеЉПжШѓжµПиІИеЩ®зФ®жИЈжПРдЊЫзЪДпЉИжµПиІИеЩ®еЕБиЃЄзФ®жИЈеЃЪдєЙеЦЬ搥зЪДж†ЈеЉПпЉМдЊЛе¶ВпЉМеЬ®FirefoxдЄ≠пЉМеПѓдї•йАЪињЗеЬ®Firefox ProfileзЫЃељХдЄЛжФЊзљЃж†ЈеЉПи°®еЃЮзО∞пЉЙгАВ
иЃ°зЃЧж†ЈеЉПзЪДдЄАдЇЫеЫ∞йЪЊпЉЪ
1. ж†ЈеЉПжХ∞жНЃжШѓйЭЮеЄЄе§ІзЪДзїУжЮДпЉМдњЭе≠Ше§ІйЗПзЪДж†ЈеЉПе±ЮжАІдЉЪеЄ¶жЭ•еЖЕе≠ШйЧЃйҐШ
2. е¶ВжЮЬдЄНињЫи°МдЉШеМЦпЉМжЙЊеИ∞жѓПдЄ™еЕГзі†еМєйЕНзЪДиІДеИЩдЉЪеѓЉиЗіжАІиГљйЧЃйҐШпЉМдЄЇжѓПдЄ™еЕГзі†жЯ•жЙЊеМєйЕНзЪДиІДеИЩйГљйЬАи¶БйБНеОЖжХідЄ™иІДеИЩи°®пЉМињЩдЄ™ињЗз®ЛжЬЙеЊИе§ІзЪДеЈ•дљЬйЗПгАВйАЙжЛ©зђ¶еПѓиГљжЬЙе§НжЭВзЪДзїУжЮДпЉМеМєйЕНињЗз®Ле¶ВжЮЬж≤њзЭАдЄАжЭ°еЉАеІЛзЬЛдЉЉж≠£з°ЃпЉМеРОжЭ•еͳ襀иѓБжШОжШѓжЧ†зФ®зЪДиЈѓеЊДпЉМеИЩењЕй°їеОїе∞ЭиѓХеП¶дЄАжЭ°иЈѓеЊДгАВ
дЊЛе¶ВпЉМдЄЛйЭҐињЩдЄ™е§НжЭВйАЙжЛ©зђ¶
div div div divпљЫвА¶пљЭ
ињЩжДПеС≥зЭАиІДеИЩеЇФзФ®еИ∞дЄЙдЄ™divзЪДеРОдї£divеЕГзі†пЉМйАЙжЛ©ж†СдЄКдЄАжЭ°зЙєеЃЪзЪДиЈѓеЊДеОїж£АжЯ•пЉМињЩеПѓиГљйЬАи¶БйБНеОЖиКВзВєж†СпЉМжЬАеРОеНіеПСзО∞еЃГеП™жШѓдЄ§дЄ™divзЪДеРОдї£пЉМеєґдЄНдљњзФ®иѓ•иІДеИЩпЉМзДґеРОеИЩйЬАи¶Бж≤њзЭАеП¶дЄАжЭ°иЈѓеЊДеОїе∞ЭиѓХ
3. еЇФзФ®иІДеИЩжґЙеПКйЭЮеЄЄе§НжЭВзЪДзЇІиБФпЉМеЃГдїђеЃЪдєЙдЇЖиІДеИЩзЪДе±Вжђ°
жИСдїђжЭ•зЬЛдЄАдЄЛжµПиІИеЩ®е¶ВдљХе§ДзРЖињЩдЇЫйЧЃйҐШпЉЪ
еЕ±дЇЂж†ЈеЉПжХ∞жНЃ
webkitиКВзВєеЉХзФ®ж†ЈеЉПеѓєи±°пЉИжЄ≤жЯУж†ЈеЉПпЉЙпЉМжЯРдЇЫжГЕеЖµдЄЛпЉМињЩдЇЫеѓєи±°еσ俕襀иКВзВєйЧіеЕ±дЇЂпЉМињЩдЇЫиКВзВєйЬАи¶БжШѓеЕДеЉЯжИЦжШѓи°®еЕДеЉЯиКВзВєпЉМеєґдЄФпЉЪ
- ињЩдЇЫеЕГзі†ењЕй°їе§ДдЇОзЫЄеРМзЪДйЉ†ж†ЗзКґжАБпЉИжѓФе¶ВдЄНиГљдЄАдЄ™е§ДдЇОhoverпЉМиАМеП¶дЄАдЄ™дЄНжШѓпЉЙ
- дЄНиГљжЬЙеЕГзі†еЕЈжЬЙid
- ж†Зз≠ЊеРНењЕй°їеМєйЕН
- classе±ЮжАІењЕй°їеМєйЕН
- еѓєеЇФзЪДе±ЮжАІењЕй°їзЫЄеРМ
- йУЊжО•зКґжАБењЕй°їеМєйЕН
- зД¶зВєзКґжАБењЕй°їеМєйЕН
- дЄНиГљжЬЙеЕГ糆襀е±ЮжАІйАЙжЛ©еЩ®ељ±еУН
- еЕГзі†дЄНиГљжЬЙи°МеЖЕж†ЈеЉПе±ЮжАІ
- дЄНиГљжЬЙзФЯжХИзЪДеЕДеЉЯйАЙжЛ©еЩ®пЉМwebcoreеЬ®дїїдљХеЕДеЉЯйАЙжЛ©еЩ®зЫЄйБЗжЧґеП™жШѓзЃАеНХзЪДжКЫеЗЇдЄАдЄ™еЕ®е±АиљђжНҐпЉМеєґдЄФеЬ®еЃГдїђжШЊз§ЇжЧґдљњжХідЄ™жЦЗж°£зЪДж†ЈеЉПеű䯀姱жХИпЉМињЩдЇЫеМЕжЛђпЉЛйАЙжЛ©еЩ®еТМз±їдЉЉ:first-childеТМ:last-childињЩж†ЈзЪДйАЙжЛ©еЩ®гАВ
FirefoxиІДеИЩж†С Firefox rule tree
FirefoxзФ®дЄ§дЄ™ж†СзФ®жЭ•зЃАеМЦж†ЈеЉПиЃ°зЃЧпЉНиІДеИЩж†СеТМж†ЈеЉПдЄКдЄЛжЦЗж†СпЉМwebkitдєЯжЬЙж†ЈеЉПеѓєи±°пЉМдљЖеЃГдїђеєґж≤°жЬЙе≠ШеВ®еЬ®з±їдЉЉж†ЈеЉПдЄКдЄЛжЦЗж†СињЩж†ЈзЪДж†СдЄ≠пЉМеП™жШѓзФ±DomиКВзВєжМЗеРСеЕґзЫЄеЕ≥зЪДж†ЈеЉПгАВ
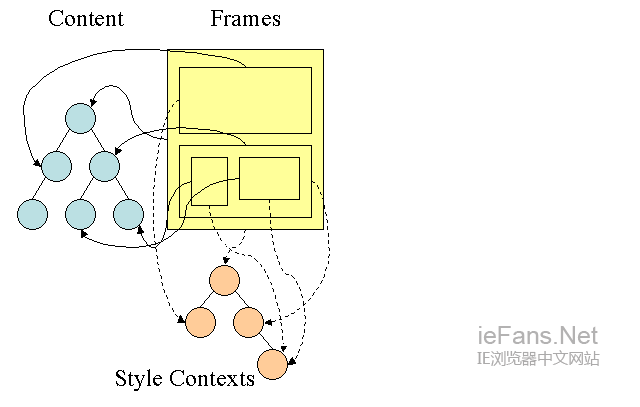
еЫЊ14пЉЪFirefoxж†ЈеЉПдЄКдЄЛжЦЗж†С
ж†ЈеЉПдЄКдЄЛжЦЗеМЕеРЂжЬАзїИеАЉпЉМињЩдЇЫеАЉжШѓйАЪињЗдї•ж≠£з°Ѓй°ЇеЇПеЇФзФ®жЙАжЬЙеМєйЕНзЪДиІДеИЩпЉМеєґе∞ЖеЃГдїђзФ±йАїиЊСеАЉиљђжНҐдЄЇеЕЈдљУзЪДеАЉпЉМдЊЛе¶ВпЉМе¶ВжЮЬйАїиЊСеАЉдЄЇе±ПеєХзЪДзЩЊеИЖжѓФпЉМеИЩйАЪињЗиЃ°зЃЧе∞ЖеЕґиљђеМЦдЄЇзїЭеѓєеНХдљНгАВж†ЈеЉПж†СзЪДдљњзФ®з°ЃеЃЮеЊИеЈІе¶ЩпЉМеЃГдљњеЊЧеЬ®иКВзВєдЄ≠еЕ±дЇЂзЪДињЩдЇЫеАЉдЄНйЬАи¶Б襀е§Ъжђ°иЃ°зЃЧпЉМеРМжЧґдєЯиКВзЬБдЇЖе≠ШеВ®з©ЇйЧігАВ
жЙАжЬЙеМєйЕНзЪДиІДеИЩйГље≠ШеВ®еЬ®иІДеИЩж†СдЄ≠пЉМдЄАжЭ°иЈѓеЊДдЄ≠зЪДеЇХе±ВиКВзВєжЛ•жЬЙжЬАйЂШзЪДдЉШеЕИзЇІпЉМињЩж£µж†СеМЕеРЂдЇЖжЙАжЙЊеИ∞зЪД жЙАжЬЙиІДеИЩеМєйЕНзЪДиЈѓеЊДпЉИиѓСж≥®пЉЪеПѓдї•еПЦеЈІзРЖиІ£дЄЇжѓПжЭ°иЈѓеЊДеѓєеЇФдЄАдЄ™иКВзВєпЉМиЈѓеЊДдЄКеМЕеРЂдЇЖиѓ•иКВзВєжЙАеМєйЕНзЪДжЙАжЬЙиІДеИЩпЉЙгАВиІДеИЩж†СеєґдЄНжШѓдЄАеЉАеІЛе∞±дЄЇжЙАжЬЙиКВзВєињЫи°МиЃ°зЃЧпЉМиАМжШѓ еЬ®жЯРдЄ™иКВзВєйЬАи¶БиЃ°зЃЧж†ЈеЉПжЧґпЉМжЙНињЫи°МзЫЄеЇФзЪДиЃ°зЃЧеєґе∞ЖиЃ°зЃЧеРОзЪДиЈѓеЊДжЈїеК†еИ∞ж†СдЄ≠гАВ
жИСдїђе∞Жж†СдЄКзЪДиЈѓеЊДзЬЛжИРиЊЮеЕЄдЄ≠зЪДеНХиѓНпЉМеБЗе¶ВеЈ≤зїПиЃ°зЃЧеЗЇдЇЖе¶ВдЄЛзЪДиІДеИЩж†СпЉЪ
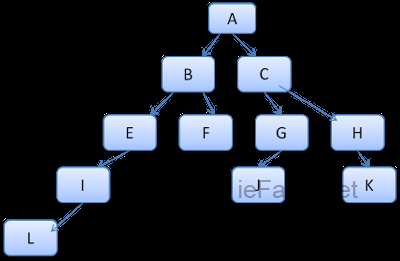
еБЗе¶ВйЬАи¶БдЄЇеЖЕеЃєж†СдЄ≠зЪДеП¶дЄАдЄ™иКВзВєеМєйЕНиІДеИЩпЉМзО∞еЬ®зЯ•йБУеМєйЕНзЪДиІДеИЩпЉИдї•ж≠£з°ЃзЪДй°ЇеЇПпЉЙдЄЇB-E-IпЉМеЫ†дЄЇжИСдїђеЈ≤зїПиЃ°зЃЧеЗЇдЇЖиЈѓеЊДA-B-E-I-LпЉМжЙАдї•ж†СдЄКеЈ≤зїПе≠ШеЬ®дЇЖињЩжЭ°иЈѓеЊДпЉМеЙ©дЄЛзЪДеЈ•дљЬе∞±еЊИе∞СдЇЖгАВ
зО∞еЬ®жЭ•зЬЛдЄАдЄЛж†Се¶ВдљХдњЭе≠ШгАВ
зїУжЮДеМЦ
ж†ЈеЉПдЄКдЄЛжЦЗжМЙзїУжЮДеИТеИЖпЉМињЩдЇЫзїУжЮДеМЕжЛђз±їдЉЉborderжИЦcolorињЩж†ЈзЪДзЙєеЃЪеИЖз±їзЪДж†ЈеЉПдњ°жБѓгАВдЄАдЄ™зїУжЮДдЄ≠зЪДжЙАжЬЙзЙєжАІдЄНжШѓзїІжЙњзЪДе∞±жШѓйЭЮзїІжЙњзЪДпЉМеѓєзїІжЙњзЪДзЙєжАІпЉМйЩ§йЭЮеЕГзі†иЗ™иЇЂжЬЙеЃЪдєЙпЉМеР¶еИЩе∞±дїОеЃГзЪДparentзїІжЙњгАВйЭЮзїІжЙњзЪДзЙєжАІпЉИзІ∞дЄЇresetзЙєжАІпЉЙе¶ВжЮЬж≤°жЬЙеЃЪдєЙпЉМеИЩдљњзФ®йїШиЃ§зЪДеАЉгАВ
ж†ЈеЉПдЄКдЄЛжЦЗж†СзЉУе≠ШеЃМжХізЪДзїУжЮДпЉИеМЕжЛђиЃ°зЃЧеРОзЪДеАЉпЉЙпЉМињЩж†ЈпЉМе¶ВжЮЬеЇХе±ВиКВзВєж≤°жЬЙдЄЇдЄАдЄ™зїУжЮДжПРдЊЫеЃЪдєЙпЉМеИЩдљњзФ®дЄКе±ВиКВзВєзЉУе≠ШзЪДзїУжЮДгАВ
дљњзФ®иІДеИЩж†СиЃ°зЃЧж†ЈеЉПдЄКдЄЛжЦЗ
ељУдЄЇдЄАдЄ™зЙєеЃЪзЪДеЕГзі†иЃ°зЃЧж†ЈеЉПжЧґпЉМй¶ЦеЕИиЃ°зЃЧеЗЇиІДеИЩж†СдЄ≠зЪДдЄАжЭ°иЈѓеЊДпЉМжИЦжШѓдљњзФ®еЈ≤зїПе≠ШеЬ®зЪДдЄАжЭ°пЉМзДґеРОдљњ зФ®иЈѓеЊДдЄ≠зЪДиІДеИЩеОїе°ЂеЕЕжЦ∞зЪДж†ЈеЉПдЄКдЄЛжЦЗпЉМдїОж†ЈеЉПзЪДеЇХе±ВиКВзВєеЉАеІЛпЉМеЃГеЕЈжЬЙжЬАйЂШдЉШеЕИзЇІпЉИйАЪеЄЄжШѓжЬАзЙєеЃЪзЪДйАЙжЛ©еЩ®пЉЙпЉМйБНеОЖиІДеИЩж†СпЉМзЫіеИ∞е°Ђжї°зїУжЮДгАВе¶ВжЮЬеЬ®йВ£дЄ™иІДеИЩиКВзВє ж≤°жЬЙеЃЪдєЙжЙАйЬАзЪДзїУжЮДиІДеИЩпЉМеИЩж≤њзЭАиЈѓеЊДеРСдЄКпЉМзЫіеИ∞жЙЊеИ∞иѓ•зїУжЮДиІДеИЩгАВ
е¶ВжЮЬжЬАзїИж≤°жЬЙжЙЊеИ∞иѓ•зїУжЮДзЪДдїїдљХиІДеИЩеЃЪдєЙпЉМйВ£дєИе¶ВжЮЬињЩдЄ™зїУжЮДжШѓзїІжЙњеЮЛзЪДпЉМеИЩжЙЊеИ∞еЕґеЬ®еЖЕеЃєж†СдЄ≠зЪДparentзЪДзїУжЮДпЉМињЩзІНжГЕеЖµдЄЛпЉМжИСдїђдєЯжИРеКЯзЪДеЕ±дЇЂдЇЖзїУжЮДпЉЫе¶ВжЮЬињЩдЄ™зїУжЮДжШѓresetеЮЛзЪДпЉМеИЩдљњзФ®йїШиЃ§зЪДеАЉгАВ
е¶ВжЮЬзЙєеЃЪзЪДиКВзВєжЈїеК†дЇЖеАЉпЉМйВ£дєИйЬАи¶БеБЪдЄАдЇЫйҐЭе§ЦзЪДиЃ°зЃЧдї•е∞ЖеЕґиљђжНҐдЄЇеЃЮйЩЕеАЉпЉМзДґеРОеЬ®ж†СдЄКзЪДиКВзВєзЉУе≠Шиѓ•еАЉпЉМдљњеЃГзЪДchildrenеПѓдї•дљњзФ®гАВ
ељУдЄАдЄ™еЕГзі†еТМеЃГзЪДдЄАдЄ™еЕДеЉЯеЕГзі†жМЗеРСеРМдЄАдЄ™ж†СиКВзВєжЧґпЉМеЃМжХізЪДж†ЈеЉПдЄКдЄЛжЦЗеσ俕襀еЃГдїђеЕ±дЇЂгАВ
жЭ•зЬЛдЄАдЄ™дЊЛе≠РпЉЪеБЗиЃЊжЬЙдЄЛйЭҐињЩжЃµhtml
<html>
<body>
<div class=вАЭerrвАЭ id=вАЭdiv1вА≥>
<p>this is a
<span class=вАЭbigвАЭ> big error </span>
this is also a
<span class=вАЭbigвАЭ> very big error</span>
error
</p>
</div>
<div class=вАЭerrвАЭ id=вАЭdiv2вА≥>another error</div>
</body>
</html>
дї•еПКдЄЛйЭҐињЩдЇЫиІДеИЩ
1. div {margin:5px;color:black}
2. .err {color:red}
3. .big {margin-top:3px}
4. div span {margin-bottom:4px}
5. #div1 {color:blue}
6. #div2 {color:green}
зЃАеМЦдЄЛйЧЃйҐШпЉМжИСдїђеП™е°ЂеЕЕдЄ§дЄ™зїУжЮДвАФвАФcolorеТМmarginпЉМcolorзїУжЮДеП™еМЕеРЂдЄАдЄ™жИРеСШпЉНйҐЬиЙ≤пЉМmarginзїУжЮДеМЕеРЂеЫЫиЊєгАВ
зФЯжИРзЪДиІДеИЩж†Се¶ВдЄЛпЉИиКВзВєеРНпЉЪжМЗеРСзЪДиІДеИЩпЉЙ
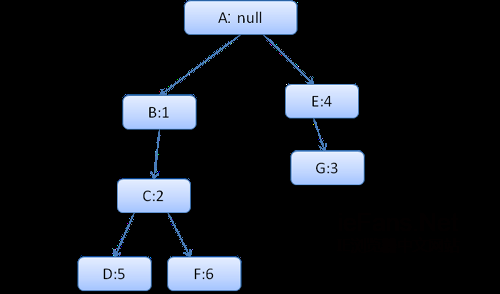
дЄКдЄЛжЦЗж†Се¶ВдЄЛпЉИиКВзВєеРНпЉЪжМЗеРСзЪДиІДеИЩиКВзВєпЉЙ
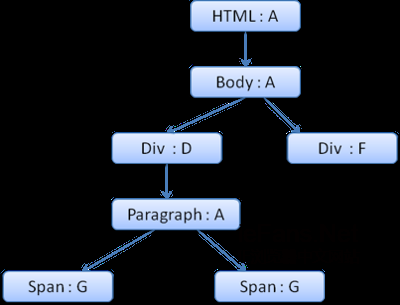
еБЗиЃЊжИСдїђиІ£жЮРhtmlпЉМйБЗеИ∞зђђдЇМдЄ™divж†Зз≠ЊпЉМжИСдїђйЬАи¶БдЄЇињЩдЄ™иКВзВєеИЫеїЇж†ЈеЉПдЄКдЄЛжЦЗпЉМеєґе°ЂеЕЕеЃГзЪДж†ЈеЉПзїУжЮДгАВ
жИСдїђињЫи°МиІДеИЩеМєйЕНпЉМжЙЊеИ∞ињЩдЄ™divеМєйЕНзЪДиІДеИЩдЄЇ1гАБ2гАБ6пЉМжИСдїђеПСзО∞иІДеИЩж†СдЄКеЈ≤зїПе≠ШеЬ®дЇЖдЄАжЭ°жИСдїђеПѓдї•дљњзФ®зЪДиЈѓеЊД1гАБ2пЉМжИСдїђеП™йЬАдЄЇиІДеИЩ6жЦ∞еҐЮдЄАдЄ™иКВзВєжЈїеК†еИ∞дЄЛйЭҐпЉИе∞±жШѓиІДеИЩж†СдЄ≠зЪДFпЉЙгАВ
зДґеРОеИЫеїЇдЄАдЄ™ж†ЈеЉПдЄКдЄЛжЦЗеєґе∞ЖеЕґжФЊеИ∞дЄКдЄЛжЦЗж†СдЄ≠пЉМжЦ∞зЪДж†ЈеЉПдЄКдЄЛжЦЗе∞ЖжМЗеРСиІДеИЩж†СдЄ≠зЪДиКВзВєFгАВ
зО∞еЬ®жИСдїђйЬАи¶Бе°ЂеЕЕињЩдЄ™ж†ЈеЉПдЄКдЄЛжЦЗпЉМеЕИдїОе°ЂеЕЕmarginзїУжЮДеЉАеІЛпЉМжЧҐзДґжЬАеРОдЄАдЄ™иІДеИЩиКВзВєж≤°жЬЙжЈїеК†marginзїУжЮДпЉМж≤њзЭАиЈѓеЊДеРСдЄКпЉМзЫіеИ∞жЙЊеИ∞зЉУе≠ШзЪДеЙНйЭҐжПТеЕ•иКВзВєиЃ°зЃЧеЗЇзЪДзїУжЮДпЉМжИСдїђеПСзО∞BжШѓжЬАињСзЪДжМЗеЃЪmarginеАЉзЪДиКВзВєгАВеЫ†дЄЇеЈ≤зїПжЬЙдЇЖcolorзїУжЮДзЪДеЃЪдєЙпЉМжЙАдї•дЄНиГљдљњзФ®зЉУе≠ШзЪДзїУжЮДпЉМжЧҐзДґcolorеП™жЬЙдЄАдЄ™е±ЮжАІпЉМдєЯе∞±дЄНйЬАи¶Бж≤њзЭАиЈѓеЊДеРСдЄКе°ЂеЕЕеЕґдїЦе±ЮжАІгАВиЃ°зЃЧеЗЇжЬАзїИеАЉпЉИе∞Же≠Чзђ¶дЄ≤иљђжНҐдЄЇRGBз≠ЙпЉЙпЉМеєґзЉУе≠ШиЃ°зЃЧеРОзЪДзїУжЮДгАВ
зђђдЇМдЄ™spanеЕГзі†жЫізЃАеНХпЉМињЫи°МиІДеИЩеМєйЕНеРОеПСзО∞еЃГжМЗеРСиІДеИЩGпЉМеТМеЙНдЄАдЄ™spanдЄАж†ЈпЉМжЧҐзДґжЬЙеЕДеЉЯиКВзВєжМЗеРСеРМдЄАдЄ™иКВзВєпЉМе∞±еПѓдї•еЕ±дЇЂеЃМжХізЪДж†ЈеЉПдЄКдЄЛжЦЗпЉМеП™йЬАжМЗеРСеЙНдЄАдЄ™spanзЪДдЄКдЄЛжЦЗгАВ
еЫ†дЄЇзїУжЮДдЄ≠еМЕеРЂзїІжЙњиЗ™parentзЪДиІДеИЩпЉМдЄКдЄЛжЦЗж†СеБЪдЇЖзЉУе≠ШпЉИcolorзЙєжАІжШѓзїІжЙњжЭ•зЪДпЉМдљЖFirefoxе∞ЖеЕґиІЖдЄЇresetеєґеЬ®иІДеИЩж†СдЄ≠зЉУе≠ШпЉЙгАВ
дЊЛе¶ВпЉМе¶ВжЮЬжИСдїђдЄЇдЄАдЄ™paragraphзЪДжЦЗе≠ЧжЈїеК†иІДеИЩпЉЪ
p {font-family:Verdana;font size:10px;font-weight:bold}
йВ£дєИињЩдЄ™pеЬ®еЖЕеЃєж†СдЄ≠зЪДе≠РиКВзВєdivпЉМдЉЪеЕ±дЇЂеТМеЃГparentдЄАж†ЈзЪДfontзїУжЮДпЉМињЩзІНжГЕеЖµеПСзФЯеЬ®ж≤°жЬЙдЄЇињЩдЄ™divжМЗеЃЪfontиІДеИЩжЧґгАВ
WebkitдЄ≠пЉМеєґж≤°жЬЙиІДеИЩж†СпЉМеМєйЕНзЪДе£∞жШОдЉЪ襀йБНеОЖеЫЫжђ°пЉМеЕИжШѓеЇФзФ®йЭЮimportantзЪДйЂШдЉШеЕИзЇІе±ЮжАІпЉИдєЛжЙАдї•еЕИеЇФзФ®ињЩдЇЫе±ЮжАІпЉМжШѓеЫ†дЄЇеЕґдїЦзЪДдЊЭиµЦдЇОеЃГдїђпЉНжѓФе¶ВdisplayпЉЙпЉМеЕґжђ°жШѓйЂШдЉШеЕИзЇІimportantзЪДпЉМжО•зЭАжШѓдЄАиИђдЉШеЕИзЇІйЭЮimportantзЪДпЉМжЬАеРОжШѓдЄАиИђдЉШеЕИзЇІimportantзЪДиІДеИЩгАВињЩж†ЈпЉМеЗЇзО∞е§Ъжђ°зЪДе±ЮжАІе∞Ж襀жМЙзЕІж≠£з°ЃзЪДзЇІиБФй°ЇеЇПињЫи°Ме§ДзРЖпЉМжЬАеРОдЄАдЄ™зФЯжХИгАВ
жАїзїУдЄАдЄЛпЉМеЕ±дЇЂж†ЈеЉПеѓєи±°пЉИзїУжЮДдЄ≠еЃМжХіжИЦйГ®еИЖеЖЕеЃєпЉЙиІ£еЖ≥дЇЖйЧЃйҐШ1еТМ3пЉМFirefoxзЪДиІДеИЩж†СеЄЃеК©дї•ж≠£з°ЃзЪДй°ЇеЇПеЇФзФ®иІДеИЩгАВ
еѓєиІДеИЩињЫи°Ме§ДзРЖдї•зЃАеМЦеМєйЕНињЗз®Л
ж†ЈеЉПиІДеИЩжЬЙеЗ†дЄ™жЭ•жЇРпЉЪ
¬Ј е§ЦйГ®ж†ЈеЉПи°®жИЦstyleж†Зз≠ЊеЖЕзЪДcssиІДеИЩ
¬Ј и°МеЖЕж†ЈеЉПе±ЮжАІ
¬Ј htmlеПѓиІЖеМЦе±ЮжАІпЉИжШ†е∞ДдЄЇзЫЄеЇФзЪДж†ЈеЉПиІДеИЩпЉЙ
еРОйЭҐдЄ§дЄ™еЊИеЃєжШУеМєйЕНеИ∞еЕГзі†пЉМеЫ†дЄЇеЃГдїђжЙАжЛ•жЬЙзЪДж†ЈеЉПе±ЮжАІеТМhtmlе±ЮжАІеПѓдї•е∞ЖеЕГзі†дљЬдЄЇkeyињЫи°МжШ†е∞ДгАВ
е∞±еГПеЙНйЭҐйЧЃйҐШ2жЙАжПРеИ∞зЪДпЉМcssзЪДиІДеИЩеМєйЕНеПѓиГљеЊИзЛ°зМЊпЉМдЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеПѓдї•еЕИеѓєиІДеИЩињЫи°Ме§ДзРЖпЉМдї•дљњеЕґжЫіеЃєжШУ襀聜йЧЃгАВ
иІ£жЮРеЃМж†ЈеЉПи°®дєЛеРОпЉМиІДеИЩдЉЪж†єжНЃйАЙжЛ©зђ¶жЈїеК†дЄАдЇЫhashжШ†е∞ДпЉМжШ†е∞ДеПѓдї•жШѓж†єжНЃidгАБclassгАБж†Зз≠ЊеРНжИЦжШѓдїїдљХдЄНе±ЮдЇОињЩдЇЫеИЖз±їзЪДзїЉеРИжШ†е∞ДгАВе¶ВжЮЬйАЙжЛ©зђ¶дЄЇidпЉМиІДеИЩе∞Ж襀棿еК†еИ∞idжШ†е∞ДпЉМе¶ВжЮЬжШѓclassпЉМеИЩ襀棿еК†еИ∞classжШ†е∞ДпЉМз≠Йз≠ЙгАВ
ињЩдЄ™е§ДзРЖжШѓеМєйЕНиІДеИЩжЫіеЃєжШУпЉМдЄНйЬАи¶БжЯ•зЬЛжѓПдЄ™е£∞жШОпЉМжИСдїђиГљдїОжШ†е∞ДдЄ≠жЙЊеИ∞дЄАдЄ™еЕГзі†зЪДзЫЄеЕ≥иІДеИЩпЉМињЩдЄ™дЉШеМЦдљњеЬ®ињЫи°МиІДеИЩеМєйЕНжЧґеЗПе∞СдЇЖ95пЉЛпЉЕзЪДеЈ•дљЬйЗПгАВ
жЭ•зЬЛдЄЛйЭҐзЪДж†ЈеЉПиІДеИЩпЉЪ
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}
зђђдЄАжЭ°иІДеИЩе∞Ж襀жПТеЕ•classжШ†е∞ДпЉМзђђдЇМжЭ°жПТеЕ•idжШ†е∞ДпЉМзђђдЄЙжЭ°жШѓж†Зз≠ЊжШ†е∞ДгАВ
дЄЛйЭҐињЩдЄ™htmlзЙЗжЃµпЉЪ
<p class=вАЭerrorвАЭ>an error occurred </p>
<div id=вАЭ messageDivвАЭ>this is a message</div>
жИСдїђй¶ЦеЕИжЙЊеИ∞pеЕГзі†еѓєеЇФзЪДиІДеИЩпЉМclassжШ†е∞Де∞ЖеМЕеРЂдЄАдЄ™вАЬerrorвАЭзЪДkeyпЉМжЙЊеИ∞p.errorзЪДиІДеИЩпЉМdivеЬ®idжШ†е∞ДеТМж†Зз≠ЊжШ†е∞ДдЄ≠йГљжЬЙзЫЄеЕ≥зЪДиІДеИЩпЉМеЙ©дЄЛзЪДеЈ•дљЬе∞±жШѓжЙЊеЗЇињЩдЇЫзФ±keyеѓєеЇФзЪДиІДеИЩдЄ≠еУ™дЇЫз°ЃеЃЮжШѓж≠£з°ЃеМєйЕНзЪДгАВ
дЊЛе¶ВпЉМе¶ВжЮЬdivзЪДиІДеИЩжШѓ
table div {margin:5px}
ињЩдєЯжШѓж†Зз≠ЊжШ†е∞ДдЇІзФЯзЪДпЉМеЫ†дЄЇkeyжШѓжЬАеП≥иЊєзЪДйАЙжЛ©зђ¶пЉМдљЖеЃГеєґдЄНеМєйЕНињЩйЗМзЪДdivеЕГзі†пЉМеЫ†дЄЇињЩйЗМзЪДdivж≤°жЬЙtableз•ЦеЕИгАВ
WebkitеТМFirefoxйГљдЉЪеБЪињЩдЄ™е§ДзРЖгАВ
дї•ж≠£з°ЃзЪДзЇІиБФй°ЇеЇПеЇФзФ®иІДеИЩ
ж†ЈеЉПеѓєи±°жЛ•жЬЙеѓєеЇФжЙАжЬЙеПѓиІБе±ЮжАІзЪДе±ЮжАІпЉМе¶ВжЮЬзЙєжАІж≤°жЬЙ襀俿дљХеМєйЕНзЪДиІДеИЩжЙАеЃЪдєЙпЉМйВ£дєИдЄАдЇЫзЙєжАІеПѓдї•дїОparentзЪДж†ЈеЉПеѓєи±°дЄ≠зїІжЙњпЉМеП¶е§ЦдЄАдЇЫдљњзФ®йїШиЃ§еАЉгАВ
ињЩдЄ™йЧЃйҐШзЪДдЇІзФЯжШѓеЫ†дЄЇе≠ШеЬ®дЄНж≠ҐдЄАе§ДзЪДеЃЪдєЙпЉМињЩйЗМзФ®зЇІиБФй°ЇеЇПиІ£еЖ≥ињЩдЄ™йЧЃйҐШгАВ
ж†ЈеЉПи°®зЪДзЇІиБФй°ЇеЇП
дЄАдЄ™ж†ЈеЉПе±ЮжАІзЪДе£∞жШОеПѓиГљеЬ®еЗ†дЄ™ж†ЈеЉПи°®дЄ≠еЗЇзО∞пЉМжИЦжШѓеЬ®дЄАдЄ™ж†ЈеЉПи°®дЄ≠еЗЇзО∞е§Ъжђ°пЉМеЫ†ж≠§пЉМеЇФзФ®иІДеИЩзЪДй°ЇеЇПиЗ≥еЕ≥йЗНи¶БпЉМињЩдЄ™й°ЇеЇПе∞±жШѓзЇІиБФй°ЇеЇПгАВж†єжНЃcss2зЪДиІДиМГпЉМзЇІиБФй°ЇеЇПдЄЇпЉИдїОдљОеИ∞йЂШпЉЙпЉЪ
1. жµПиІИеЩ®е£∞жШО
2. зФ®жИЈе£∞жШО
3. дљЬиАЕзЪДдЄАиИђе£∞жШО
4. дљЬиАЕзЪДimportantе£∞жШО
5. зФ®жИЈimportantе£∞жШО
жµПиІИеЩ®е£∞жШОжШѓжЬАдЄНйЗНи¶БзЪДпЉМзФ®жИЈеП™жЬЙеЬ®е£∞жШО襀ж†ЗиЃ∞дЄЇimportantжЧґжЙНдЉЪи¶ЖзЫЦдљЬиАЕзЪДе£∞жШОгАВеЕЈжЬЙеРМз≠ЙзЇІеИЂзЪДе£∞жШОе∞Жж†єжНЃspecifityдї•еПКеЃГ俐襀еЃЪдєЙжЧґзЪДй°ЇеЇПињЫи°МжОТеЇПгАВHtmlеПѓиІЖеМЦе±ЮжАІе∞Ж襀蚐жНҐдЄЇеМєйЕНзЪДcssе£∞жШОпЉМеЃГ俐襀иІЖдЄЇжЬАдљОдЉШеЕИзЇІзЪДдљЬиАЕиІДеИЩгАВ
Specifity
Css2иІДиМГдЄ≠еЃЪдєЙзЪДйАЙжЛ©зђ¶specifityе¶ВдЄЛпЉЪ
¬Ј е¶ВжЮЬе£∞жШОжЭ•иЗ™styleе±ЮжАІпЉМиАМдЄНжШѓдЄАдЄ™йАЙжЛ©еЩ®зЪДиІДеИЩпЉМеИЩиЃ°1пЉМеР¶еИЩиЃ°0пЉИпЉЭaпЉЙ
¬Ј иЃ°зЃЧйАЙжЛ©еЩ®дЄ≠idе±ЮжАІзЪДжХ∞йЗПпЉИпЉЭbпЉЙ
¬Ј иЃ°зЃЧйАЙжЛ©еЩ®дЄ≠classеПКдЉ™з±їзЪДжХ∞йЗПпЉИпЉЭcпЉЙ
¬Ј иЃ°зЃЧйАЙжЛ©еЩ®дЄ≠еЕГзі†еРНеПКдЉ™еЕГзі†зЪДжХ∞йЗПпЉИпЉЭdпЉЙ
ињЮжО•aпЉНbпЉНcпЉНdеЫЫдЄ™жХ∞йЗПпЉИзФ®дЄАдЄ™е§ІеЯЇжХ∞зЪДиЃ°зЃЧз≥їзїЯпЉЙе∞ЖеЊЧеИ∞specifityгАВињЩйЗМдљњзФ®зЪДеЯЇжХ∞зФ±еИЖз±їдЄ≠жЬАйЂШзЪДеЯЇжХ∞еЃЪдєЙгАВдЊЛе¶ВпЉМе¶ВжЮЬaдЄЇ14пЉМеПѓдї•дљњзФ®16ињЫеИґгАВдЄНеРМжГЕеЖµдЄЛпЉМaдЄЇ17жЧґпЉМеИЩйЬАи¶БдљњзФ®йШњжЛЙдЉѓжХ∞е≠Ч17дљЬдЄЇеЯЇжХ∞пЉМињЩзІНжГЕеЖµеПѓиГљеЬ®ињЩдЄ™йАЙжЛ©зђ¶жЧґеПСзФЯhtml body div div вА¶пЉИйАЙжЛ©зђ¶дЄ≠жЬЙ17дЄ™ж†Зз≠ЊпЉМдЄАиИђдЄН姙еПѓиГљпЉЙгАВ
дЄАдЇЫдЊЛе≠РпЉЪ
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style=вАЭ" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
иІДеИЩжОТеЇП
иІДеИЩеМєйЕНеРОпЉМйЬАи¶Бж†єжНЃзЇІиБФй°ЇеЇПеѓєиІДеИЩињЫи°МжОТеЇПпЉМwebkitеЕИе∞Же∞ПеИЧи°®зФ®еЖТж≥°жОТеЇПпЉМеЖНе∞ЖеЃГдїђеРИеєґдЄЇдЄАдЄ™е§ІеИЧи°®пЉМwebkitйАЪињЗдЄЇиІДеИЩе§НеЖЩвАЬ>вАЭжУНдљЬжЭ•жЙІи°МжОТеЇПпЉЪ
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
йАРж≠•е§ДзРЖ Gradual process
webkitдљњзФ®дЄАдЄ™ж†ЗењЧдљНж†ЗиѓЖжЙАжЬЙй°ґе±Вж†ЈеЉПи°®йГљеЈ≤еК†иљљпЉМе¶ВжЮЬеЬ®attchжЧґж†ЈеЉПж≤°жЬЙеЃМеЕ®еК†иљљпЉМеИЩжФЊзљЃеН†дљНзђ¶пЉМеєґеЬ®жЦЗж°£дЄ≠ж†ЗиЃ∞пЉМдЄАжЧ¶ж†ЈеЉПи°®еЃМжИРеК†иљље∞±йЗНжЦ∞ињЫи°МиЃ°зЃЧгАВ
еЄГе±А Layout
ељУжЄ≤жЯУ僺豰襀еИЫеїЇеєґжЈїеК†еИ∞ж†СдЄ≠пЉМеЃГдїђеєґж≤°жЬЙдљНзљЃеТМе§Іе∞ПпЉМиЃ°зЃЧињЩдЇЫеАЉзЪДињЗз®ЛзІ∞дЄЇlayoutжИЦreflowгАВ
HtmlдљњзФ®еЯЇдЇОжµБзЪДеЄГе±Аж®°еЮЛпЉМжДПеС≥зЭАе§ІйГ®еИЖжЧґйЧіпЉМеПѓдї•дї•еНХдЄАзЪДйАФеЊДињЫи°МеЗ†дљХиЃ°зЃЧгАВжµБдЄ≠йЭ†еРОзЪДеЕГзі†еєґдЄНдЉЪељ±еУНеЙНйЭҐеЕГзі†зЪДеЗ†дљХзЙєжАІпЉМжЙАдї•еЄГе±АеПѓдї•еЬ®жЦЗж°£дЄ≠дїОеП≥еРСеЈ¶гАБиЗ™дЄКиАМдЄЛзЪДињЫи°МгАВдєЯе≠ШеЬ®дЄАдЇЫдЊЛе§ЦпЉМжѓФе¶Вhtml tablesгАВ
еЭРж†Зз≥їзїЯзЫЄеѓєдЇОж†єframeпЉМдљњзФ®topеТМleftеЭРж†ЗгАВ
еЄГе±АжШѓдЄАдЄ™йАТељТзЪДињЗз®ЛпЉМзФ±ж†єжЄ≤жЯУеѓєи±°еЉАеІЛпЉМеЃГеѓєеЇФhtmlжЦЗж°£еЕГзі†пЉМеЄГе±АзїІзї≠йАТељТзЪДйАЪињЗдЄАдЇЫжИЦжЙАжЬЙзЪДframeе±ВзЇІпЉМдЄЇжѓПдЄ™йЬАи¶БеЗ†дљХдњ°жБѓзЪДжЄ≤жЯУеѓєи±°ињЫи°МиЃ°зЃЧгАВ
ж†єжЄ≤жЯУеѓєи±°зЪДдљНзљЃжШѓ0,0пЉМеЃГзЪДе§Іе∞ПжШѓviewportпЉНжµПиІИеЩ®з™ЧеП£зЪДеПѓиІБйГ®еИЖгАВ
жЙАжЬЙзЪДжЄ≤жЯУеѓєи±°йГљжЬЙдЄАдЄ™layoutжИЦreflowжЦєж≥ХпЉМжѓПдЄ™жЄ≤жЯУеѓєи±°и∞ГзФ®йЬАи¶БеЄГе±АзЪДchildrenзЪДlayoutжЦєж≥ХгАВ
Dirty bit з≥їзїЯ
дЄЇдЇЖдЄНеЫ†дЄЇжѓПдЄ™е∞ПеПШеМЦйГљеЕ®йГ®йЗНжЦ∞еЄГе±АпЉМжµПиІИеЩ®дљњзФ®дЄАдЄ™dirty bitз≥їзїЯпЉМдЄАдЄ™жЄ≤жЯУеѓєи±°еПСзФЯдЇЖеПШеМЦжИЦж؃襀棿еК†дЇЖпЉМе∞±ж†ЗиЃ∞еЃГеПКеЃГзЪДchildrenдЄЇdirtyпЉНйЬАи¶БlayoutгАВе≠ШеЬ®дЄ§дЄ™ж†ЗиѓЖпЉНdirtyеПКchildren are dirtyпЉМchildren are dirtyиѓіжШОеН≥дљњињЩдЄ™жЄ≤жЯУеѓєи±°еПѓиГљж≤°йЧЃйҐШпЉМдљЖеЃГиЗ≥е∞СжЬЙдЄАдЄ™childйЬАи¶БlayoutгАВ
еЕ®е±АеТМеҐЮйЗП layout
ељУlayoutеЬ®жХіж£µжЄ≤жЯУж†СиІ¶еПСжЧґпЉМзІ∞дЄЇеЕ®е±АlayoutпЉМињЩеПѓиГљеЬ®дЄЛйЭҐињЩдЇЫжГЕеЖµдЄЛеПСзФЯпЉЪ
1. дЄАдЄ™еЕ®е±АзЪДж†ЈеЉПжФєеПШељ±еУНжЙАжЬЙзЪДжЄ≤жЯУеѓєи±°пЉМжѓФе¶Ве≠ЧеПЈзЪДжФєеПШ
2. з™ЧеП£resize
layoutдєЯеПѓдї•жШѓеҐЮйЗПзЪДпЉМињЩж†ЈеП™жЬЙж†ЗењЧдЄЇdirtyзЪДжЄ≤жЯУеѓєи±°дЉЪйЗНжЦ∞еЄГе±АпЉИдєЯе∞ЖеѓЉиЗідЄАдЇЫйҐЭе§ЦзЪДеЄГе±АпЉЙгАВеҐЮйЗП layoutдЉЪеЬ®жЄ≤жЯУеѓєи±°dirtyжЧґеЉВж≠•иІ¶еПСпЉМдЊЛе¶ВпЉМељУзљСзїЬжО•жФґеИ∞жЦ∞зЪДеЖЕеЃєеєґжЈїеК†еИ∞Domж†СеРОпЉМжЦ∞зЪДжЄ≤жЯУеѓєи±°дЉЪжЈїеК†еИ∞жЄ≤жЯУж†СдЄ≠гАВ
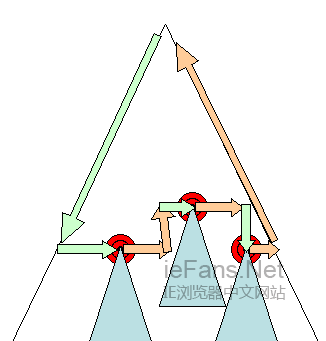
еЫЊ20пЉЪеҐЮйЗП layout
еЉВж≠•еТМеРМж≠•layout
еҐЮйЗПlayoutзЪДињЗз®ЛжШѓеЉВж≠•зЪДпЉМFirefoxдЄЇеҐЮйЗПlayoutзФЯжИРдЇЖreflowйШЯеИЧпЉМдї•еПКдЄАдЄ™и∞ГеЇ¶жЙІи°МињЩдЇЫжЙєе§ДзРЖеСљдї§гАВWebkitдєЯжЬЙдЄАдЄ™иЃ°жЧґеЩ®зФ®жЭ•жЙІи°МеҐЮйЗПlayoutпЉНйБНеОЖж†СпЉМдЄЇdirtyзКґжАБзЪДжЄ≤жЯУеѓєи±°йЗНжЦ∞еЄГе±АгАВ
еП¶е§ЦпЉМељУиДЪжЬђиѓЈж±Вж†ЈеЉПдњ°жБѓжЧґпЉМдЊЛе¶ВвАЬoffsetHeightвАЭпЉМдЉЪеРМж≠•зЪДиІ¶еПСеҐЮйЗПеЄГе±АгАВ
еЕ®е±АзЪДlayoutдЄАиИђйГљжШѓеРМж≠•иІ¶еПСгАВ
жЬЙдЇЫжЧґеАЩпЉМlayoutдЉЪ襀дљЬдЄЇдЄАдЄ™еИЭеІЛlayoutдєЛеРОзЪДеЫЮи∞ГпЉМжѓФе¶ВжїСеК®жЭ°зЪДжїСеК®гАВ
дЉШеМЦ
ељУдЄАдЄ™layoutеЫ†дЄЇresizeжИЦжШѓжЄ≤жЯУдљНзљЃжФєеПШпЉИеєґдЄНжШѓе§Іе∞ПжФєеПШпЉЙиАМиІ¶еПСжЧґпЉМжЄ≤жЯУеѓєи±°зЪДе§Іе∞Пе∞ЖдЉЪдїОзЉУе≠ШдЄ≠иѓїеПЦпЉМиАМдЄНдЉЪйЗНжЦ∞иЃ°зЃЧгАВ
дЄАиИђжГЕеЖµдЄЛпЉМе¶ВжЮЬеП™жЬЙе≠Рж†СеПСзФЯжФєеПШпЉМеИЩlayoutеєґдЄНдїОж†єеЉАеІЛгАВињЩзІНжГЕеЖµеПСзФЯеЬ®пЉМеПШеМЦеПСзФЯеЬ®еЕГзі†иЗ™иЇЂеєґдЄФдЄНељ±еУНеЃГеС®еЫіеЕГзі†пЉМдЊЛе¶ВпЉМе∞ЖжЦЗжЬђжПТеЕ•жЦЗжЬђеЯЯпЉИеР¶еИЩпЉМжѓПжђ°еЗїйФЃйГље∞ЖиІ¶еПСдїОж†єеЉАеІЛзЪДйЗНжОТпЉЙгАВ
layoutињЗз®Л
layoutдЄАиИђжЬЙдЄЛйЭҐињЩеЗ†дЄ™йГ®еИЖпЉЪ
1. parentжЄ≤жЯУеѓєи±°еЖ≥еЃЪеЃГзЪДеЃљеЇ¶
2. parentжЄ≤жЯУеѓєи±°иѓїеПЦchilidrenпЉМеєґпЉЪ
1. жФЊзљЃchildжЄ≤жЯУеѓєи±°пЉИиЃЊзљЃеЃГзЪДxеТМyпЉЙ
2. еЬ®йЬАи¶БжЧґпЉИеЃГдїђељУеЙНдЄЇdirtyжИЦжШѓе§ДдЇОеЕ®е±АlayoutжИЦиАЕеЕґдїЦеОЯеЫ†пЉЙи∞ГзФ®childжЄ≤жЯУеѓєи±°зЪДlayoutпЉМињЩе∞ЖиЃ°зЃЧchildзЪДйЂШеЇ¶
3. parentжЄ≤жЯУеѓєи±°дљњзФ®childжЄ≤жЯУеѓєи±°зЪДзіѓзІѓйЂШеЇ¶пЉМдї•еПКmarginеТМpaddingзЪДйЂШеЇ¶жЭ•иЃЊзљЃиЗ™еЈ±зЪДйЂШеЇ¶пЉНињЩе∞Ж襀parentжЄ≤жЯУеѓєи±°зЪДparentдљњзФ®
4. е∞Жdirtyж†ЗиѓЖиЃЊзљЃдЄЇfalse
FirefoxдљњзФ®дЄАдЄ™вАЬstateвАЭеѓєи±°пЉИnsHTMLReflowStateпЉЙеБЪдЄЇеПВжХ∞еОїеЄГе±АпЉИfirefoxзІ∞дЄЇreflowпЉЙпЉМstateеМЕеРЂparentзЪДеЃљеЇ¶еПКеЕґдїЦеЖЕеЃєгАВ
FirefoxеЄГе±АзЪДиЊУеЗЇжШѓдЄАдЄ™вАЬmetricsвАЭеѓєи±°пЉИnsHTMLReflowMetricsпЉЙгАВеЃГеМЕжЛђжЄ≤жЯУеѓєи±°иЃ°зЃЧеЗЇзЪДйЂШеЇ¶гАВ
еЃљеЇ¶иЃ°зЃЧ
жЄ≤жЯУеѓєи±°зЪДеЃљеЇ¶дљњзФ®еЃєеЩ®зЪДеЃљеЇ¶гАБжЄ≤жЯУеѓєи±°ж†ЈеЉПдЄ≠зЪДеЃљеЇ¶еПКmarginгАБborderињЫи°МиЃ°зЃЧгАВдЊЛе¶ВпЉМдЄЛйЭҐињЩдЄ™divзЪДеЃљеЇ¶пЉЪ
<div style=вАЭwidth:30%вАЭ/>
webkitдЄ≠еЃљеЇ¶зЪДиЃ°зЃЧињЗз®ЛжШѓпЉИRenderBoxз±їзЪДcalcWidthжЦєж≥ХпЉЙпЉЪ
¬Ј еЃєеЩ®зЪДеЃљеЇ¶жШѓеЃєеЩ®зЪДеПѓзФ®еЃљеЇ¶еТМ0дЄ≠зЪДжЬАе§ІеАЉпЉМињЩйЗМзЪДеПѓзФ®еЃљеЇ¶дЄЇпЉЪcontentWidth=clientWidth()-paddingLeft()-paddingRight()пЉМclientWidthеТМclientHeightдї£и°®дЄАдЄ™еѓєи±°еЖЕйГ®зЪДдЄНеМЕжЛђborderеТМжїСеК®жЭ°зЪДе§Іе∞П
¬Ј еЕГзі†зЪДеЃљеЇ¶жМЗж†ЈеЉПе±ЮжАІwidthзЪДеАЉпЉМеЃГеПѓдї•йАЪињЗиЃ°зЃЧеЃєеЩ®зЪДзЩЊеИЖжѓФеЊЧеИ∞дЄАдЄ™зїЭеѓєеАЉ
¬Ј еК†дЄКж∞іеє≥жЦєеРСдЄКзЪДborderеТМpadding
еИ∞ињЩйЗМжШѓжЬАдљ≥еЃљеЇ¶зЪДиЃ°зЃЧињЗз®ЛпЉМзО∞еЬ®иЃ°зЃЧеЃљеЇ¶зЪДжЬАе§ІеАЉеТМжЬАе∞ПеАЉпЉМе¶ВжЮЬжЬАдљ≥еЃљеЇ¶е§ІдЇОжЬАе§ІеЃљеЇ¶еИЩдљњзФ®жЬАе§ІеЃљеЇ¶пЉМе¶ВжЮЬе∞ПдЇОжЬАе∞ПеЃљеЇ¶еИЩдљњзФ®жЬАе∞ПеЃљеЇ¶гАВжЬАеРОзЉУе≠ШињЩдЄ™еАЉпЉМељУйЬАи¶БlayoutдљЖеЃљеЇ¶жЬ™жФєеПШжЧґдљњзФ®гАВ
Line breaking
ељУдЄАдЄ™жЄ≤жЯУеѓєи±°еЬ®еЄГе±АињЗз®ЛдЄ≠йЬАи¶БжКШи°МжЧґпЉМеИЩжЪВеБЬеєґеСКиѓЙеЃГзЪДparentеЃГйЬАи¶БжКШи°МпЉМparentе∞ЖеИЫеїЇйҐЭе§ЦзЪДжЄ≤жЯУеѓєи±°еєґи∞ГзФ®еЃГдїђзЪДlayoutгАВ
зїШеИґ Painting
зїШеИґйШґжЃµпЉМйБНеОЖжЄ≤жЯУж†Сеєґи∞ГзФ®жЄ≤жЯУеѓєи±°зЪДpaintжЦєж≥Хе∞ЖеЃГдїђзЪДеЖЕеЃєжШЊз§ЇеЬ®е±ПеєХдЄКпЉМзїШеИґдљњзФ®UIеЯЇз°АзїДдїґпЉМињЩеЬ®UIзЪДзЂ†иКВжЬЙжЫіе§ЪзЪДдїЛзїНгАВ
еЕ®е±АеТМеҐЮйЗП
еТМеЄГе±АдЄАж†ЈпЉМзїШеИґдєЯеПѓдї•жШѓеЕ®е±АзЪДпЉНзїШеИґеЃМжХізЪДж†СпЉНжИЦеҐЮйЗПзЪДгАВеЬ®еҐЮйЗПзЪДзїШеИґињЗз®ЛдЄ≠пЉМдЄАдЇЫжЄ≤жЯУеѓєи±°дї•дЄНељ±еУНжХіж£µж†СзЪДжЦєеЉПжФєеПШпЉМжФєеПШзЪДжЄ≤жЯУеѓєи±°дљњеЕґеЬ®е±ПеєХдЄКзЪДзߩ嚥еМЇеЯЯ姱жХИпЉМињЩе∞ЖеѓЉиЗіжУНдљЬз≥їзїЯе∞ЖеЕґзЬЛдљЬdirtyеМЇеЯЯпЉМеєґдЇІзФЯдЄАдЄ™paintдЇЛдїґпЉМжУНдљЬз≥їзїЯеЊИеЈІе¶ЩзЪДе§ДзРЖињЩдЄ™ињЗз®ЛпЉМеєґе∞Же§ЪдЄ™еМЇеЯЯеРИеєґдЄЇдЄАдЄ™гАВChromeдЄ≠пЉМињЩдЄ™ињЗз®ЛжЫіе§НжЭВдЇЫпЉМеЫ†дЄЇжЄ≤жЯУеѓєи±°еЬ®дЄНеРМзЪДињЫз®ЛдЄ≠пЉМиАМдЄНжШѓеЬ®дЄїињЫз®ЛдЄ≠гАВChromeеЬ®дЄАеЃЪз®ЛеЇ¶дЄКж®°жЛЯжУНдљЬз≥їзїЯзЪДи°МдЄЇпЉМи°®зО∞дЄЇзЫСеРђдЇЛдїґеєґжіЊеПСжґИжБѓзїЩжЄ≤жЯУж†єпЉМеЬ®ж†СдЄ≠жЯ•жЙЊеИ∞зЫЄеЕ≥зЪДжЄ≤жЯУеѓєи±°пЉМйЗНзїШињЩдЄ™еѓєи±°пЉИеЊАеЊАињШеМЕжЛђеЃГзЪДchildrenпЉЙгАВ
зїШеИґй°ЇеЇП
css2еЃЪдєЙдЇЖзїШеИґињЗз®ЛзЪДй°ЇеЇПпЉНhttp://www.w3.org/TR/CSS21/zindex.htmlгАВињЩдЄ™е∞±жШѓеЕГзі†еОЛеЕ•е†Жж†ИзЪДй°ЇеЇПпЉМињЩдЄ™й°ЇеЇПељ±еУНзЭАзїШеИґпЉМе†Жж†ИдїОеРОеРСеЙНињЫи°МзїШеИґгАВ
дЄАдЄ™еЭЧжЄ≤жЯУеѓєи±°зЪДе†Жж†Ий°ЇеЇПжШѓпЉЪ
1. иГМжЩѓиЙ≤
2. иГМжЩѓеЫЊ
3. border
4. children
5. outline
FirefoxжШЊз§ЇеИЧи°®
FirefoxиѓїеПЦжЄ≤жЯУж†СеєґдЄЇзїШеИґзЪДзߩ嚥еИЫеїЇдЄАдЄ™жШЊз§ЇеИЧи°®пЉМиѓ•еИЧи°®дї•ж≠£з°ЃзЪДзїШеИґй°ЇеЇПеМЕеРЂињЩдЄ™зߩ嚥зЫЄеЕ≥зЪДжЄ≤жЯУеѓєи±°гАВ
зФ®ињЩж†ЈзЪДжЦєж≥ХпЉМеПѓдї•дљњйЗНзїШжЧґеП™йЬАжЯ•жЙЊдЄАжђ°ж†СпЉМиАМдЄНйЬАи¶Бе§Ъжђ°жЯ•жЙЊвАФвАФзїШеИґжЙАжЬЙзЪДиГМжЩѓгАБжЙАжЬЙзЪДеЫЊзЙЗгАБжЙАжЬЙзЪДborderз≠Йз≠ЙгАВ
FirefoxдЉШеМЦдЇЖињЩдЄ™ињЗз®ЛпЉМеЃГдЄНжЈїеК†дЉЪ襀йЪРиЧПзЪДеЕГзі†пЉМжѓФе¶ВеЕГзі†еЃМеЕ®еЬ®еЕґдїЦдЄНйАПжШОеЕГзі†дЄЛйЭҐгАВ
Webkitзߩ嚥е≠ШеВ®
йЗНзїШеЙНпЉМwebkitе∞ЖжЧІзЪДзߩ嚥дњЭе≠ШдЄЇдљНеЫЊпЉМзДґеРОеП™зїШеИґжЦ∞жЧІзߩ嚥зЪДеЈЃйЫЖгАВ
еК®жАБеПШеМЦ
жµПиІИеЩ®жАїжШѓиѓХзЭАдї•жЬАе∞ПзЪДеК®дљЬеУНеЇФдЄАдЄ™еПШеМЦпЉМжЙАдї•дЄАдЄ™еЕГзі†йҐЬиЙ≤зЪДеПШеМЦе∞ЖеП™еѓЉиЗіиѓ•еЕГзі†зЪДйЗНзїШпЉМеЕГзі†дљНзљЃзЪДеПШеМЦе∞Же§ІиЗіеЕГзі†зЪДеЄГе±АеТМйЗНзїШпЉМжЈїеК†дЄАдЄ™DomиКВзВєпЉМдєЯдЉЪе§ІиЗіињЩдЄ™еЕГзі†зЪДеЄГе±АеТМйЗНзїШгАВдЄАдЇЫдЄїи¶БзЪДеПШеМЦпЉМжѓФе¶ВеҐЮеК†htmlеЕГзі†зЪДе≠ЧеПЈпЉМе∞ЖдЉЪеѓЉиЗізЉУе≠Ш姱жХИпЉМдїОиАМеЉХиµЈжХіжХ∞зЪДеЄГе±АеТМйЗНзїШгАВ
жЄ≤жЯУеЉХжУОзЪДзЇњз®Л
жЄ≤жЯУеЉХжУОжШѓеНХзЇњз®ЛзЪДпЉМйЩ§дЇЖзљСзїЬжУНдљЬдї•е§ЦпЉМеЗ†дєОжЙАжЬЙзЪДдЇЛжГЕйГљеЬ®еНХдЄАзЪДзЇњз®ЛдЄ≠е§ДзРЖпЉМеЬ®FirefoxеТМSafariдЄ≠пЉМињЩжШѓжµПиІИеЩ®зЪДдЄїзЇњз®ЛпЉМChromeдЄ≠ињЩжШѓtabзЪДдЄїзЇњз®ЛгАВ
зљСзїЬжУНдљЬзФ±еЗ†дЄ™еєґи°МзЇњз®ЛжЙІи°МпЉМеєґи°МињЮжО•зЪДдЄ™жХ∞жШѓеПЧйЩРзЪДпЉИйАЪеЄЄжШѓ2пЉН6дЄ™пЉЙгАВ
дЇЛдїґеЊ™зОѓ
жµПиІИеЩ®дЄїзЇњз®ЛжШѓдЄАдЄ™дЇЛдїґеЊ™зОѓпЉМеЃГ襀职聰䪯жЧ†йЩРеЊ™зОѓдї•дњЭжМБжЙІи°МињЗз®ЛзЪДеПѓзФ®пЉМз≠ЙеЊЕдЇЛдїґпЉИдЊЛе¶ВlayoutеТМpaintдЇЛдїґпЉЙеєґжЙІи°МеЃГдїђгАВдЄЛйЭҐжШѓFirefoxзЪДдЄїи¶БдЇЛдїґеЊ™зОѓдї£з†БгАВ
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 еПѓиІЖж®°еЮЛ CSS2 visual module
зФїеЄГ The Canvas
ж†єжНЃCSS2иІДиМГпЉМжЬѓиѓ≠canvasзФ®жЭ•жППињ∞ж†ЉеЉПеМЦзЪДзїУжЮДжЙАжЄ≤жЯУзЪДз©ЇйЧівАФвАФжµПиІИеЩ®зїШеИґеЖЕеЃєзЪДеЬ∞жЦєгАВзФїеЄГеѓєжѓПдЄ™зїіеЇ¶з©ЇйЧійГљжШѓжЧ†йЩРе§ІзЪДпЉМдљЖжµПиІИеЩ®еЯЇдЇОviewportзЪДе§Іе∞ПйАЙжЛ©дЇЖдЄАдЄ™еИЭеІЛеЃљеЇ¶гАВ
ж†єжНЃhttp://www.w3.org/TR/CSS2/zindex.htmlзЪДеЃЪдєЙпЉМзФїеЄГе¶ВжЮЬжШѓеМЕеРЂеЬ®еЕґдїЦзФїеЄГеЖЕеИЩжШѓйАПжШОзЪДпЉМеР¶еИЩжµПиІИеЩ®дЉЪжМЗеЃЪдЄАдЄ™йҐЬиЙ≤гАВ
CSSзЫТж®°еЮЛ
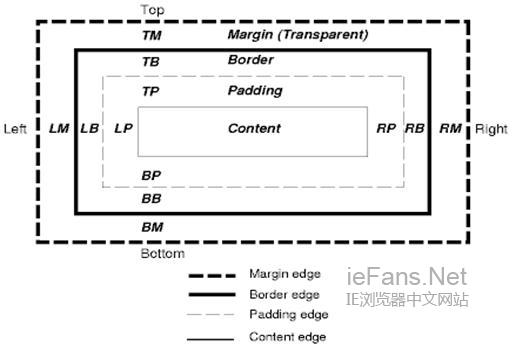
CSSзЫТж®°еЮЛжППињ∞дЇЖзߩ嚥зЫТпЉМињЩдЇЫзߩ嚥зЫТжШѓдЄЇжЦЗж°£ж†СдЄ≠зЪДеЕГзі†зФЯжИРзЪДпЉМеєґж†єжНЃеПѓиІЖзЪДж†ЉеЉПеМЦж®°еЮЛињЫи°МеЄГе±АгАВжѓПдЄ™boxеМЕжЛђеЖЕеЃєеМЇеЯЯпЉИе¶ВеЫЊзЙЗгАБжЦЗжЬђз≠ЙпЉЙеПКеПѓйАЙзЪДеЫЫеС®paddingгАБborderеТМmarginеМЇеЯЯгАВ
жѓПдЄ™иКВзВєзФЯжИР0пЉНnдЄ™ињЩж†ЈзЪДboxгАВ
жЙАжЬЙзЪДеЕГзі†йГљжЬЙдЄАдЄ™displayе±ЮжАІпЉМзФ®жЭ•еЖ≥еЃЪеЃГдїђзФЯжИРboxзЪДз±їеЮЛпЉМдЊЛе¶ВпЉЪ
blockпЉНзФЯжИРеЭЧзКґbox
inlineпЉНзФЯжИРдЄАдЄ™жИЦе§ЪдЄ™и°МеЖЕbox
noneпЉНдЄНзФЯжИРbox
йїШиЃ§зЪДжШѓinlineпЉМдљЖжµПиІИеЩ®ж†ЈеЉПи°®иЃЊзљЃдЇЖеЕґдїЦйїШиЃ§еАЉпЉМдЊЛе¶ВпЉМdivеЕГзі†йїШиЃ§дЄЇblockгАВеПѓдї•иЃњйЧЃhttp://www.w3.org/TR/CSS2/sample.htmlжЯ•зЬЛжЫіе§ЪзЪДйїШиЃ§ж†ЈеЉПи°®з§ЇдЊЛгАВ
еЃЪдљНз≠ЦзХ• Position scheme
ињЩйЗМжЬЙдЄЙзІНз≠ЦзХ•пЉЪ
1. normalпЉНеѓєи±°ж†єжНЃеЃГеЬ®жЦЗж°£зЪДдЄ≠дљНзљЃеЃЪдљНпЉМињЩжДПеС≥зЭАеЃГеЬ®жЄ≤жЯУж†СеТМеЬ®Domж†СдЄ≠дљНзљЃдЄАиЗіпЉМеєґж†єжНЃеЃГзЪДзЫТж®°еЮЛеТМе§Іе∞ПињЫи°МеЄГе±А
2. floatпЉНеѓєи±°еЕИеГПжЩЃйАЪжµБдЄАж†ЈеЄГе±АпЉМзДґеРОе∞љеПѓиГљзЪДеРСеЈ¶жИЦжШѓеРСеП≥зІїеК®
3. absoluteпЉНеѓєи±°еЬ®жЄ≤жЯУж†СдЄ≠зЪДдљНзљЃеТМDomж†СдЄ≠дљНзљЃжЧ†еЕ≥
staticеТМrelativeжШѓnormalпЉМabsoluteеТМfixedе±ЮдЇОabsoluteгАВ
еЬ®staticеЃЪдљНдЄ≠пЉМдЄНеЃЪдєЙдљНзљЃиАМдљњзФ®йїШиЃ§зЪДдљНзљЃгАВеЕґдїЦз≠ЦзХ•дЄ≠пЉМдљЬиАЕжМЗеЃЪдљНзљЃвАФвАФtopгАБbottomгАБleftгАБrightгАВ
BoxеЄГе±АзЪДжЦєеЉПзФ±ињЩеЗ†й°єеЖ≥еЃЪпЉЪboxзЪДз±їеЮЛгАБboxзЪДе§Іе∞ПгАБеЃЪдљНз≠ЦзХ•еПКжЙ©е±Хдњ°жБѓпЉИжѓФе¶ВеЫЊзЙЗе§Іе∞ПеТМе±ПеєХе∞ЇеѓЄпЉЙгАВ
Boxз±їеЮЛ
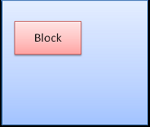
Block boxпЉЪжЮДжИРдЄАдЄ™еЭЧпЉМеН≥еЬ®жµПиІИеЩ®з™ЧеП£дЄКжЬЙиЗ™еЈ±зЪДзߩ嚥
Inline boxпЉЪеєґж≤°жЬЙиЗ™еЈ±зЪДеЭЧзКґеМЇеЯЯпЉМдљЖеМЕеРЂеЬ®дЄАдЄ™еЭЧзКґеМЇеЯЯеЖЕ
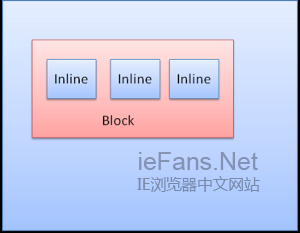
blockдЄАдЄ™жМ®зЭАдЄАдЄ™еЮВзЫіж†ЉеЉПеМЦпЉМinlineеИЩеЬ®ж∞іеє≥жЦєеРСдЄКж†ЉеЉПеМЦгАВ
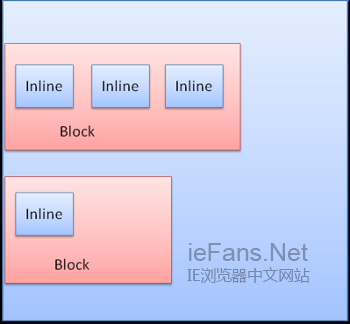
InlineзЫТж®°еЮЛжФЊзљЃеЬ®и°МеЖЕжИЦжШѓline boxдЄ≠пЉМжѓПи°МиЗ≥е∞СеТМжЬАйЂШзЪДboxдЄАж†ЈйЂШпЉМељУboxдї•baselineеѓєйљРжЧґвАФвАФеН≥дЄАдЄ™еЕГзі†зЪДеЇХйГ®еТМеП¶дЄАдЄ™boxдЄКйЩ§еЇХйГ®дї•е§ЦзЪДжЯРзВєеѓєйљРпЉМи°МйЂШеПѓдї•жѓФжЬАйЂШзЪДboxйЂШгАВељУеЃєеЩ®еЃљеЇ¶дЄНе§ЯжЧґпЉМи°МеЖЕеЕГзі†е∞Ж襀жФЊеИ∞е§Ъи°МдЄ≠пЉМињЩеЬ®дЄАдЄ™pеЕГзі†дЄ≠зїПеЄЄеПСзФЯгАВ
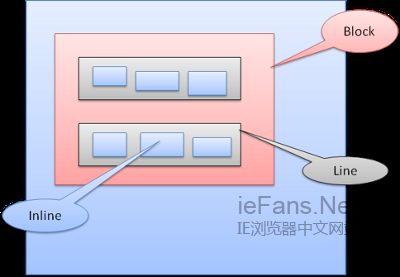
еЃЪдљН Position
Relative
зЫЄеѓєеЃЪдљНвАФвАФеЕИжМЙзЕІдЄАиИђзЪДеЃЪдљНпЉМзДґеРОжМЙжЙАи¶Бж±ВзЪДеЈЃеАЉзІїеК®гАВ
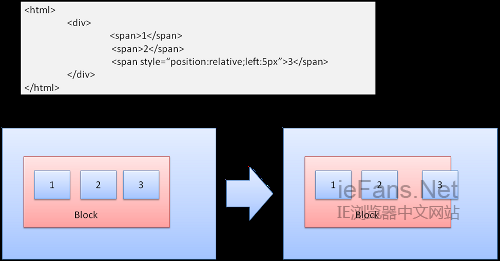
Floats
дЄАдЄ™жµЃеК®зЪДboxзІїеК®еИ∞дЄАи°МзЪДжЬАеЈ¶иЊєжИЦжШѓжЬАеП≥иЊєпЉМеЕґдљЩзЪДboxеЫізїХеЬ®еЃГеС®еЫігАВдЄЛйЭҐињЩжЃµhtmlпЉЪ
<p>
<img style=вАЭfloat:rightвАЭ src=вАЭimages/image.gifвАЭ width=вАЭ100вА≥ height=вАЭ100вА≥>Lorem ipsum dolor sit amet, consectetuerвА¶
</p>
е∞ЖжШЊз§ЇдЄЇпЉЪ

AbsoluteеТМFixed
ињЩзІНжГЕеЖµдЄЛзЪДеЄГе±АеЃМеЕ®дЄНй°ЊжЩЃйАЪзЪДжЦЗж°£жµБпЉМеЕГзі†дЄНе±ЮдЇОжЦЗж°£жµБзЪДдЄАйГ®еИЖпЉМе§Іе∞ПеПЦеЖ≥дЇОеЃєеЩ®гАВFixedжЧґпЉМеЃєеЩ®дЄЇviewportпЉИеПѓиІЖеМЇеЯЯпЉЙгАВ
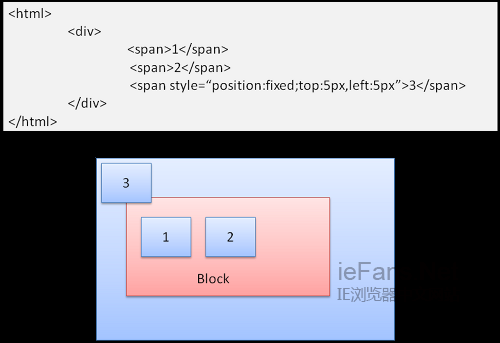
еЫЊ17пЉЪfixed
ж≥®жДПпЉНfixedеН≥дљњеЬ®жЦЗж°£жµБжїЪеК®жЧґдєЯдЄНдЉЪзІїеК®гАВ
Layered representation
ињЩдЄ™зФ±CSSе±ЮжАІдЄ≠зЪДz-indexжМЗеЃЪпЉМи°®з§ЇзЫТж®°еЮЛзЪДзђђдЄЙдЄ™е§Іе∞ПпЉМеН≥еЬ®zиљідЄКзЪДдљНзљЃгАВBoxеИЖеПСеИ∞е†Жж†ИдЄ≠пЉИзІ∞дЄЇе†Жж†ИдЄКдЄЛжЦЗпЉЙпЉМжѓПдЄ™е†Жж†ИдЄ≠йЭ†еРОзЪДеЕГзі†е∞Ж襀иЊГжЧ©зїШеИґпЉМж†Ий°ґйЭ†еЙНзЪДеЕГзі†з¶їзФ®жИЈжЬАињСпЉМељУеПСзФЯдЇ§еП†жЧґпЉМе∞ЖйЪРиЧПйЭ†еРОзЪДеЕГзі†гАВе†Жж†Иж†єжНЃz-indexе±ЮжАІжОТеЇПпЉМжЛ•жЬЙz-indexе±ЮжАІзЪДbox嚥жИРдЇЖдЄАдЄ™е±АйГ®е†Жж†ИпЉМviewportжЬЙе§ЦйГ®е†Жж†ИпЉМдЊЛе¶ВпЉЪ
<STYLE type=вАЭtext/cssвАЭ>
div {
position: absolute;
left: 2in;
top: 2in;
}
</STYLE>
<P>
<DIV
style=вАЭz-index: 3;background-color:red; width: 1in; height: 1in; вАЬ>
</DIV>
<DIV
style=вАЭz-index: 1;background-color:green;width: 2in; height: 2in;вАЭ>
</DIV>
</p>
зїУжЮЬжШѓпЉЪ

иЩљзДґзїњиЙ≤divжОТеЬ®зЇҐиЙ≤divеРОйЭҐпЉМеПѓиГљеЬ®ж≠£еЄЄжµБдЄ≠дєЯеЈ≤зїП襀зїШеИґеЬ®еРОйЭҐпЉМдљЖz-indexжЬЙжЫійЂШдЉШеЕИзЇІпЉМжЙАдї•еЬ®ж†єboxзЪДе†Жж†ИдЄ≠жЫійЭ†еЙНгАВ
еЫље§ЦдєЯжЬЙзљСеПЛж†єжНЃжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖзїШеИґдЇЖеЗ†еЉ†еЈ•дљЬжµБз®ЛеЫЊпЉМжЦєдЊње§ІеЃґйАЪињЗзЃАжШУзЪДеЫЊзЙЗжЭ•дЇЖиІ£ињЩдЄ™иЊЫиЛ¶зЪДињЗз®ЛпЉЪ




зЫЄеЕ≥жО®иНР
#### еЫЫгАБдЄЇдљХе≠¶дє†жµПиІИеЩ®еЈ•дљЬеОЯзРЖпЉЯ 1. **еЗЖз°ЃиѓДдЉ∞WebеЉАеПСй°єзЫЃзЪДеПѓи°МжАІ**пЉЪзРЖиІ£жµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖжЬЙеК©дЇОеЉАеПСиАЕеЗЖз°ЃиѓДдЉ∞й°єзЫЃзЪДеПѓи°МжАІпЉМзЙєеИЂжШѓеЬ®жґЙеПКеИ∞йЂШжАІиГљйЬАж±ВжЧґгАВ 2. **дЉШеМЦWebеЇФзФ®жАІиГљ**пЉЪдЇЖиІ£жµПиІИеЩ®е¶ВдљХиІ£жЮРгАБ...
жµПиІИеЩ®жШѓдЇТиБФзљСдЄЦзХМзЪДйЗНи¶БеЕ•еП£пЉМеЃГзЪДеЈ•дљЬеОЯзРЖжґЙеПКеИ∞иЃЄе§Ъе§НжЭВзЪДзїДдїґеТМињЗз®ЛгАВжЬђжЦЗдЄїи¶БжОҐиЃ®дЇЖдЄїжµБжµПиІИеЩ®е¶ВIEгАБFirefoxгАБSafariгАБChromeдї•еПКOperaзЪДеЈ•дљЬжµБз®ЛпЉМе∞§еЕґжШѓйТИеѓєеЉАжЇРжµПиІИеЩ®FirefoxгАБChromeеТМSafariзЪДеИЖжЮРгАВ ...
жµПиІИеЩ®жШѓзО∞дї£дЇТиБФзљСдЇ§дЇТзЪДж†ЄењГеЈ•еЕЈпЉМеЕґеЖЕйГ®еЈ•дљЬеОЯзРЖеѓєдЇОWebеЉАеПСиАЕжЭ•иѓіиЗ≥еЕ≥йЗНи¶БгАВжЬђзѓЗжЦЗзЂ†е∞ЖжЈ±еЕ•жОҐиЃ®жµПиІИеЩ®зЪДеРДдЄ™зїДдїґеПКеЕґеКЯиГљпЉМдї•дЊњжЫіе•љеЬ∞зРЖиІ£дїОиЊУеЕ•URLеИ∞й°µйЭҐжШЊз§ЇзЪДжХідЄ™ињЗз®ЛгАВ й¶ЦеЕИпЉМжµПиІИеЩ®зЪДдЄїи¶БеКЯиГљжШѓиОЈеПЦеєґеСИзО∞...
жЬђиµДжЇРжШѓжЬђдЇЇеЬ®е≠¶дє†жµПиІИеЩ®еЈ•дљЬеОЯзРЖзЪДињЗз®ЛдЄ≠пЉМжЧ†жДПйЧіеЬ®GitHubдЄКжЙЊеИ∞зЪДиµДжЇРпЉМиЃ≤иІ£зЪДжµЕжШЊжШУжЗВгАВеЖЕеЃєеМЕжЛђжµПиІИеЩ®зЪДеЯЇжЬђзїУжЮДгАБжЄ≤жЯУеЉХжУОгАБжЄ≤жЯУж†СгАБеЄГе±АгАБзїШеЫЊгАБжµПиІИеЩ®еЉХжУОзЪДзЇњз®Лз≠ЙеЖЕеЃєгАВеИЖдЇЂеЗЇжЭ•пЉМеЄМжЬЫеѓєжГ≥и¶БдЇЖиІ£жµПиІИеЩ®еЈ•дљЬ...
2. жµПиІИеЩ®еЈ•дљЬеОЯзРЖзЪДе§НжЭВжАІпЉЪжЦЗж°£еЉЇи∞ГдЇЖжµПиІИеЩ®еЈ•дљЬжЦєеЉПзЪДе§НжЭВжАІпЉМињЩзІНе§НжЭВжАІжШѓзФ±иЃЄе§ЪдЄНеРМзЪДж†ЗеЗЖеЖ≥еЃЪзЪДгАВдЄНеРМзЪДжµПиІИеЩ®жЬЙиЗ™еЈ±зЪДеЃЮзО∞жЦєеЉПпЉМеЫ†ж≠§дЄНеПѓиГљеЬ®еНХдЄАзЪДдїЛзїНдЄ≠жΥ糥жµПиІИеЩ®еЈ•дљЬзЪДжЙАжЬЙзїЖиКВгАВ 3. жµПиІИеЩ®зЪДж®°еЭЧеМЦеТМ...
WEB жµПиІИеЩ®еЈ•дљЬеОЯзРЖ WEB жµПиІИеЩ®еЈ•дљЬеОЯзРЖжШѓеЯЇдЇОеЃҐжИЈжЬЇ/жЬНеК°еЩ®иЃ°зЃЧж®°еЮЛпЉМзФ± Web жµПиІИеЩ®пЉИеЃҐжИЈжЬЇпЉЙеТМ Web жЬНеК°еЩ®пЉИжЬНеК°еЩ®пЉЙжЮДжИРпЉМдЄ§иАЕдєЛйЧійЗЗзФ®иґЕжЦЗжЬђдЉ†йАБеНПиЃЃпЉИHTTPпЉЙињЫи°МйАЪдњ°гАВHTTP еНПиЃЃжШѓеЯЇдЇО TCP/IP еНПиЃЃдєЛдЄКзЪДеНПиЃЃ...
### жµПиІИеЩ®еЈ•дљЬеОЯзРЖжµЕжЮР #### дЄАгАБеЉХи®А зО∞дї£дЇТиБФзљСзЪДеПСе±Хз¶їдЄНеЉАжµПиІИеЩ®пЉМдљЬдЄЇзФ®жИЈдЄОдЄЗзїізљСдЇ§дЇТзЪДйЗНи¶БеЈ•еЕЈпЉМдЇЖиІ£жµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖеѓєдЇОеЙНзЂѓеЉАеПСиАЕеТМзљСзЂЩеЈ•з®ЛеЄИиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНжµПиІИеЩ®зЪДдЄїи¶БзїДжИРйГ®еИЖеПКеЕґеЈ•дљЬ...
е∞љзЃ°жµПиІИеЩ®зІНз±їзєБе§ЪпЉМдљЖеЃГдїђзЪДеЯЇжЬђеЈ•дљЬеОЯзРЖжШѓз±їдЉЉзЪДгАВжЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖпЉМдї•еПКеЕґзїДжИРйГ®еИЖеТМжЄ≤жЯУжµБз®ЛгАВ дЄАгАБжµПиІИеЩ®зЪДдЄїи¶БеКЯиГљдЄОжЮДжИР жµПиІИеЩ®зЪДдЄїи¶БеКЯиГљжШѓе∞ЖзФ®жИЈжЙАйАЙжЛ©зЪДWebиµДжЇРеСИзО∞еЗЇжЭ•гАВељУзФ®жИЈеЬ®еЬ∞еЭАж†П...
### жµПиІИеЩ®еЈ•дљЬеОЯзРЖиѓ¶иІ£ #### дЄАгАБеЉХи®А йЪПзЭАдЇТиБФзљСзЪДжЩЃеПКдЄОеПСе±ХпЉМжµПиІИеЩ®еЈ≤жИРдЄЇжИСдїђжЧ•еЄЄзФЯжіїдЄ≠дЄНеПѓжИЦзЉЇзЪДдЄАйГ®еИЖгАВжЬђжЦЗжЧ®еЬ®жЈ±еЕ•еЙЦжЮРжµПиІИеЩ®зЪДеЈ•дљЬжЬЇеИґпЉМеЄЃеК©иѓїиАЕжЫіе•љеЬ∞зРЖиІ£дїОиЊУеЕ•URLеИ∞зљСй°µеЃМжХіе±Хз§ЇињЩдЄАињЗз®ЛиГМеРОзЪДе§НжЭВ...
дљЬдЄЇдЄАеРНзљСзїЬеЉАеПСдЇЇеСШпЉМе≠¶дє†жµПиІИеЩ®зЪДеЖЕйГ®еЈ•дљЬеОЯзРЖе∞ЖжЬЙеК©дЇОжВ®дљЬеЗЇжЫіжШОжЩЇзЪДеЖ≥з≠ЦпЉМеєґзРЖиІ£йВ£дЇЫжЬАдљ≥еЉАеПСеЃЮиЈµзЪДдЄ™дЄ≠зЉШзФ±гАВе∞љзЃ°ињЩжШѓдЄАзѓЗзЫЄељУйХњзЪДжЦЗж°£пЉМдљЖжШѓжИСдїђеїЇиЃЃжВ®иК±дЇЫжЧґйЧіжЭ•дїФзїЖйШЕиѓїпЉЫиѓїеЃМдєЛеРОпЉМжВ®иВѓеЃЪдЉЪиІЙеЊЧжЙАиієдЄНиЩЪгАВ...
жµПиІИеЩ®жШѓжИСдїђжЧ•еЄЄдЄКзљСзЪДдЄїи¶БеЈ•еЕЈпЉМеЃГзЪДеЈ•дљЬеОЯзРЖе§НжЭВиАМз≤Ње¶ЩпЉМжґЙеПКеИ∞зљСзїЬйАЪдњ°гАБиІ£жЮРжЄ≤жЯУгАБJavaScriptжЙІи°Мз≠Йе§ЪдЄ™зОѓиКВгАВињЩзѓЗеНЪжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®жЦ∞еЉПзљСзїЬжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖпЉМжП≠з§ЇеЕґеєХеРОзЪДжКАжЬѓзїЖиКВгАВ й¶ЦеЕИпЉМжИСдїђи¶БзРЖиІ£жµПиІИеЩ®зЪД...
жµПиІИеЩ®жШѓеЙНзЂѓеЉАеПСиАЕжЧ•еЄЄеЈ•дљЬдЄ≠иЗ≥еЕ≥йЗНи¶БзЪДеЈ•еЕЈпЉМеЕґеЖЕйГ®еЈ•дљЬеОЯзРЖеѓєдЇОзРЖиІ£еТМдЉШеМЦзљСй°µжАІиГљиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®жµПиІИеЩ®зЪДдЄїи¶БзїДдїґеТМеЈ•дљЬжµБз®ЛпЉМдї•еЄЃеК©еЙНзЂѓеЉАеПСиАЕжЫіе•љеЬ∞зРЖиІ£дїОиЊУеЕ•URLеИ∞й°µйЭҐе±Хз§ЇзЪДжХідЄ™ињЗз®ЛгАВ й¶ЦеЕИпЉМ...
### зО∞дї£жµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖ #### жµПиІИеЩ®ж¶ВиІИдЄОйЗНи¶БжАІ жµПиІИеЩ®дљЬдЄЇдЇТиБФзљСжЧґдї£жЬАдЄЇжЩЃеПКзЪДеЇФзФ®иљѓдїґдєЛдЄАпЉМеЕґйЗНи¶БжАІдЄНи®АиАМеЦїгАВжЧ†иЃЇжШѓжЧ•еЄЄзЪДдњ°жБѓжµПиІИгАБеЬ®зЇњиі≠зЙ©ињШжШѓињЬз®ЛеКЮеЕђпЉМеЗ†дєОжЙАжЬЙзЪДеЬ®зЇњжіїеК®йГљйЬАи¶БйАЪињЗжµПиІИеЩ®жЭ•ињЫи°МгАВ...
иЃ≤ињ∞дЇЖжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖпЉМдЄ≠иЛ±жЦЗеѓєзЕІзЙИпЉМдїОзїДжИРпЉМеИ∞иІ£жЮРпЉМжЄ≤жЯУз≠ЙињЗз®ЛйГљжЬЙгАВ
жµПиІИеЩ®зЪДеЯЇжЬђеЃЮзО∞еОЯзРЖпЉМеМЕжЛђеНПиЃЃпЉМзКґжАБз†БпЉМиѓЈж±ВжЦєеЉПз≠Й
### WebжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖ #### жµПиІИеЩ®ж¶ВиІИдЄОйЗНи¶БжАІ жµПиІИеЩ®дљЬдЄЇдЇТиБФзљСжЧґдї£дЄНеПѓжИЦзЉЇзЪДеЈ•еЕЈдєЛдЄАпЉМеЗ†дєОеЈ≤зїПжИРдЄЇдЇЇдїђжЧ•еЄЄзФЯжіїдЄ≠дљњзФ®йҐСзОЗжЬАйЂШзЪДиљѓдїґгАВжЬђжЦЗжЧ®еЬ®жЈ±еЕ•иІ£жЮРдЄїжµБжµПиІИеЩ®зЪДеЈ•дљЬеОЯзРЖпЉМеЄЃеК©еЉАеПСиАЕжЫіе•љеЬ∞зРЖиІ£дїОиЊУеЕ•...