这是跳表的作者,上面介绍的William Pugh给出的解释:
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
下面来研究一下跳表的核心思想:
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。

如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

这基本上就是跳表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
<3>.跳表的数据存储模型
我们定义:
如果一个基点存在k个向前的指针的话,那么陈该节点是k层的节点。
一个跳表的层MaxLevel义为跳表中所有节点中最大的层数。
下面给出一个完整的跳表的图示:

那么我们该如何将该数据结构使用二进制存储呢?通过上面的跳表的很容易设计这样的数据结构:
定义每个节点类型:
// 这里仅仅是一个指针
typedef struct nodeStructure *node;
typedef struct nodeStructure
{
keyType key;// key值
valueType value;// value值
// 向前指针数组,根据该节点层数的
// 不同指向不同大小的数组
node forward[1];
};

上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的forward将指向一个只含一个元素的数组,以此类推。
定义跳表数据类型:
// 定义跳表数据类型
typedef struct listStructure{
int level; /* Maximum level of the list
(1 more than the number of levels in the list) */
struct nodeStructure * header; /* pointer to header */
} * list;
跳表数据类型中包含了维护跳表的必要信息,level表明跳表的层数,header如下所示:
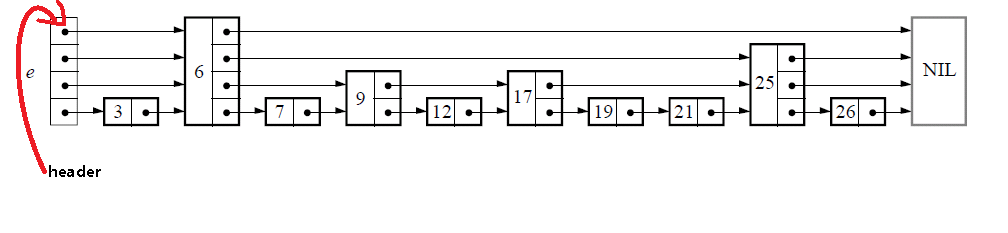
定义辅助变量:
定义上图中的NIL变量:node NIL;
#define MaxNumberOfLevels 16
#define MaxLevel (MaxNumberOfLevels-1)
定义辅助方法:
// newNodeOfLevel生成一个nodeStructure结构体,同时生成l个node *数组指针
#define newNodeOfLevel(l) (node)malloc(sizeof(struct nodeStructure)+(l)*sizeof(node *))
好的基本的数据结构定义已经完成,接下来来分析对于跳表的一个操作。
<4>. 跳表的代码实现分析
4.1 初始化
初始化的过程很简单,仅仅是生成下图中红线区域内的部分,也就是跳表的基础结构:
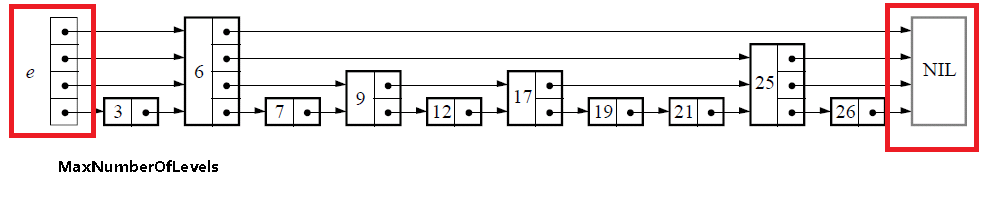
list newList()
{
list l;
int i;
// 申请list类型大小的内存
l = (list)malloc(sizeof(struct listStructure));
// 设置跳表的层level,初始的层为0层(数组从0开始)
l->level = 0;
// 生成header部分
l->header = newNodeOfLevel(MaxNumberOfLevels);
// 将header的forward数组清空
for(i=0;i<MaxNumberOfLevels;i++) l->header->forward[i] = NIL;
return(l);
};
4.2 插入操作
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的level变量。
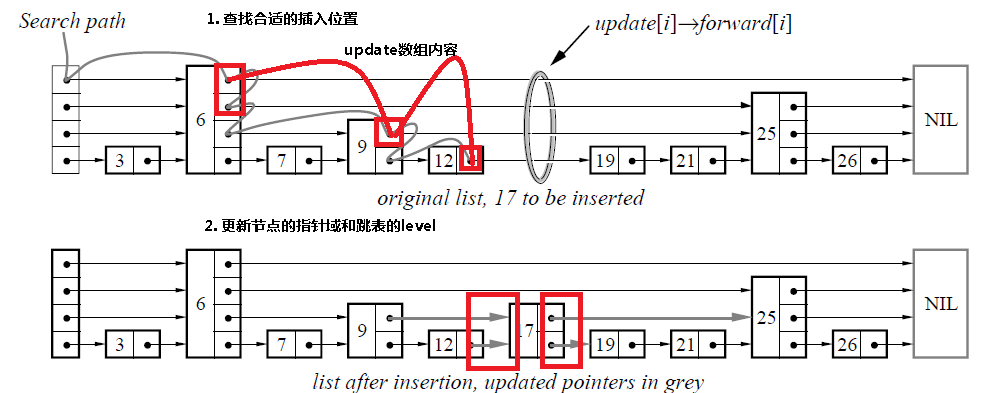
boolean insert(l,key,value)
register list l;
register keyType key;
register valueType value;
{
register int k;
// 使用了update数组
node update[MaxNumberOfLevels];
register node p,q;
p = l->header;
k = l->level;
/*******************1步*********************/
do {
// 查找插入位置
while (q = p->forward[k], q->key < key)
p = q;
// 设置update数组
update[k] = p;
} while(--k>=0);// 对于每一层进行遍历
// 这里已经查找到了合适的位置,并且update数组已经
// 填充好了元素
if (q->key == key)
{
q->value = value;
return(false);
};
// 随机生成一个层数
k = randomLevel();
if (k>l->level)
{
// 如果新生成的层数比跳表的层数大的话
// 增加整个跳表的层数
k = ++l->level;
// 在update数组中将新添加的层指向l->header
update[k] = l->header;
};
/*******************2步*********************/
// 生成层数个节点数目
q = newNodeOfLevel(k);
q->key = key;
q->value = value;
// 更新两个指针域
do
{
p = update[k];
q->forward[k] = p->forward[k];
p->forward[k] = q;
} while(--k>=0);
// 如果程序运行到这里,程序已经插入了该节点
return(true);
}
4.3 删除某个节点
和插入是相同的,首先查找需要删除的节点,如果找到了该节点的话,那么只需要更新指针域,如果跳表的level需要更新的话,进行更新。
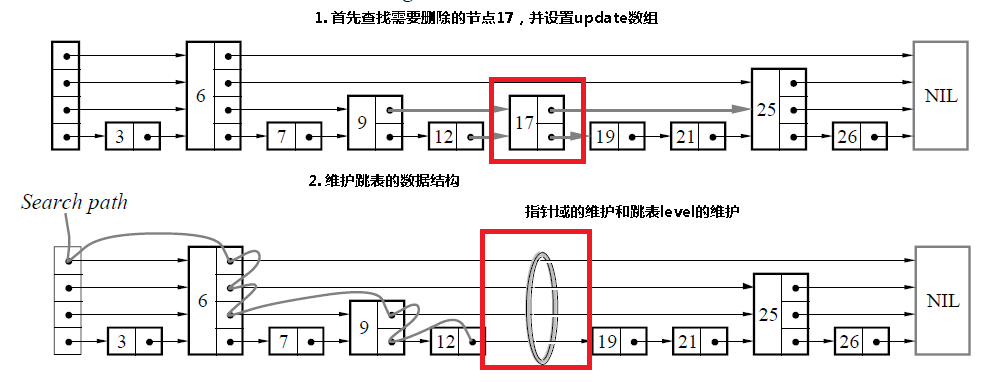
boolean delete(l,key)
register list l;
register keyType key;
{
register int k,m;
// 生成一个辅助数组update
node update[MaxNumberOfLevels];
register node p,q;
p = l->header;
k = m = l->level;
// 这里和查找部分类似,最终update中包含的是:
// 指向该节点对应层的前驱节点
do
{
while (q = p->forward[k], q->key < key)
p = q;
update[k] = p;
} while(--k>=0);
// 如果找到了该节点,才进行删除的动作
if (q->key == key)
{
// 指针运算
for(k=0; k<=m && (p=update[k])->forward[k] == q; k++)
// 这里可能修改l->header->forward数组的值的
p->forward[k] = q->forward[k];
// 释放实际内存
free(q);
// 如果删除的是最大层的节点,那么需要重新维护跳表的
// 层数level
while( l->header->forward[m] == NIL && m > 0 )
m--;
l->level = m;
return(true);
}
else
// 没有找到该节点,不进行删除动作
return(false);
}
4.4 查找
查找操作其实已经在插入和删除过程中包含,比较简单,可以参考源代码。
<5>. 论文,代码下载及参考资料
SkipList论文
/Files/xuqiang/skipLists.rar
//--------------------------------------------------------------------------------
增加跳表c#实现代码 2011-5-29下午
上面给出的数据结构的模型是直接按照跳表的模型得到的,另外还有一种数据结构的模型:
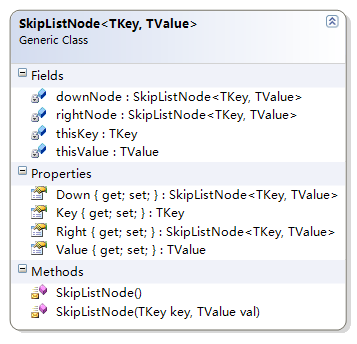
跳表节点类型,每个跳表类型中仅仅存储了左侧的节点和下面的节点:
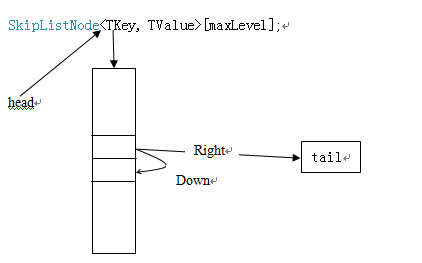
我们现在来看对于这种模型的操作代码:
1. 初始化完成了如下的操作:
2. 插入操作:和上面介绍的插入操作是类似的,首先查找到插入的位置,生成update数组,然后随机生成一个level,然后修改指针。
3. 删除操作:和上面介绍的删除操作是类似的,查找到需要删除的节点,如果查找不到,抛出异常,如果查找到的需要删除的节点的话,修改指针,释放删除节点的内存。
代码下载:
/Files/xuqiang/skiplist_csharp.rar
http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html




相关推荐
简单得实现跳表相关功能 SkipList<Integer> skipList = new SkipList(maxLevel); 提供insert和seach接口 删除接口可做类似操作
SkipList skipList; // 插入测试数据 for (int i = 1; i ; ++i) { skipList.insert(i); } // 查找测试 for (int i = 1; i ; ++i) { assert(skipList.search(i) != nullptr); } // 删除测试 for (int i ...
### Skip List (跳表)详解 #### 一、引言 在计算机科学中,数据结构的设计与选择对于算法效率有着至关重要的影响。其中,跳表(Skip List)是一种非传统但非常高效的数据结构,它结合了链表和二叉搜索树的优点,在...
在详细讲解二叉搜索树、B树、Skiplist跳表和哈希表的过程中,我们首先需要了解数据结构的定义及其特性,然后针对不同数据结构在大数据环境下的应用进行探究。 1. 二叉搜索树(BST): 二叉搜索树是一种特殊的二叉树...
2. **定义跳表结构体**:接着,定义一个`SkipList`结构体,它包含一个指向第一个节点的指针(Head)以及一个随机数生成器,用于确定跳表的高度。 ```go type SkipList struct { Head *Node Level int } ``` 3. *...
1. 跳表(Skiplist)数据结构的基础知识: - 跳表是一种可以替代平衡二叉树的数据结构。 - 它的核心思想是利用随机化算法在概率上保证数据访问时间的平衡性。 - 跳表的数据不需要以树形结构存储,因此在进行并行...
2. SkipList.java: 这是跳表的主要实现文件,可能包含了一个名为`SkipList`的类,实现了跳表的数据结构和相关的操作方法,如插入、删除、查找等。这个类可能包括了节点结构的设计,以及如何随机决定每个节点的层级等...
跳表(Skip List)是一种高效的查找数据结构,它利用了概率算法来提高查询效率,通常用于数据库和搜索引擎中。在C++中实现跳表,我们可以利用STL中的容器和算法库来简化工作,同时理解其背后的原理至关重要。 跳表...
在Redis中,跳表(Skip List)被用于实现有序集合(ZSET,Sorted Set),而不是使用红黑树。以下是对这一决策背后原因的详细分析: 1. **内存效率**: - 跳表在内存占用方面相对较低,可以通过调整节点层级的概率...
在给定的压缩包文件中,`SkipList`很可能包含了实现跳表的Java源代码,包括`Node`类以及跳表的主类,可能还有测试用例。这些代码提供了实际的实现细节,可以帮助我们更深入地理解跳表的工作原理和Java编程技巧。通过...
跳表是一种高效的数据结构,常用于数据库和搜索引擎的索引构建。它的主要优点在于查找、插入和删除操作的时间复杂度通常为O(logN),与平衡二叉搜索树类似,但实现更为简单,空间效率较高。 跳表的核心思想是通过...
这个是跳表的头文件
跳表是一种高效的数据结构,主要用于有序数据的快速查找、插入和删除操作。它的设计灵感来源于二分查找,但不局限于数组,而是适用于链表。在传统链表的基础上,跳表通过增加多级索引来实现近似的二分查找,从而提高...
C++是一种面向对象的计算机程序设计语言,由美国AT&T贝尔实验室的本贾尼·斯特劳斯特卢普博士在20世纪80年代初期发明并实现(最初这种语言被称作“C with Classes”带类的C)。它是一种静态数据类型检查的、支持多重...
main.cpp 包含skiplist.h使用跳表进行数据操作 skiplist.h 跳表核心实现 README.md 中文介绍 README-en.md 英文介绍 bin 生成可执行文件目录 makefile 编译脚本 store 数据落盘的文件存放在这个文件夹 stress_test_...
在压缩包`skiplist-master`中,可能包含了实现跳表算法的源代码。通过对源代码的分析和学习,我们可以更深入地理解跳表的内部机制,包括节点的创建、连接、查找、插入和删除等操作。这有助于我们更好地运用跳表解决...
综上所述,"skipList.zip"项目提供了一个跳表的C++实现,通过对跳表的原理、数据结构、查找算法、插入和删除操作的理解,开发者可以学习到如何在实际编程中应用这一高效的数据结构。同时,通过对源代码的分析,还...
class SkipList { private: Comparator const compare_; std::unique_ptr<Node> head_; Random rnd_; std::map, int> heights; public: // 构造函数和析构函数 SkipList(); ~SkipList(); // 插入元素 ...
在这个名为"Skiplist-CPP-master"的项目中,开发者使用C++语言实现了一个基于跳表的轻量级键值存储系统。下面我们将深入探讨跳表的基本原理、C++实现的关键点以及在键值存储中的应用。 1. 跳表基本原理: - 跳表是...