- 浏览: 1053837 次
-

文章分类
最新评论
-
cjh_android:
我想你是对的,至少对于现实是对的,不过对于技术岗位竞争越来越激 ...
程序员的思考--终于确定了自己的技术发展方向 -
dongbiying:
现在情况如何 。。
创业,不能兼职 -
jackyrong:
ie 9 下时,老显示关闭窗口提示,有办法去掉么,就是关闭掉那 ...
jquery右下角弹窗效果 -
lmaxjj:
加点班如果都称得上是累,只能说明还没体会到真正的生活。。
IT男的进化论 -
馨雨轩:
IT男要进化需要先穿越
IT男的进化论
一网打尽中文编码转换---6种编码30个方向的转换
1.问题提出
在学编程序时,曾经有人问过“你可以编一个记事本程序吗?”当时很不屑一顾,但是随着学习MFC的深入,了解到记事本程序也并非易事,难点就是四种编码之间的转换。
对于编码,这是一个令初学者头疼的问题,特别是对于编码的转换,更是难以捉摸。笔者为了完成毕业设计中的一个编码转换模块,研究了中文编码和常见的字符集后,决定解决"记事本"程序的编码问题,更进一步完成GB2312、Big5、GBK、Unicode 、Unicode big endian、UTF-8共6种编码之间的任意转换。
2.问题解决
(1)编码基础知识
a.了解编码和字符集
这部分内容,我不在赘述,可参见CSDN Ancky的专栏中《各种字符集和编码详解》
博客地址:http://blog.csdn.net/ancky/article/details/2034809
b.单字节、双字节、多字节
这部分内容,可参见我先前翻译的博文《C++字符串完全指南--第一部分:win32字符编码》
博客地址:http://blog.csdn.net/ziyuanxiazai123/article/details/7482360
c.区域和代码页
这部分内容,可参见博客 http://hi.baidu.com/tzpwater/blog/item/bd4abb0b60bff1db3ac7636a.html
d.中文编码GB2312、GBK、Big5,这部分内容请参见CSDN lengshine 博客中《GB2312、GBK、Big5汉字编码
》,博客地址:http://blog.csdn.net/lengshine/article/details/5470545
e.Windows程序的字符编码
这部分内容,可参见博客http://blog.sina.com.cn/s/blog_4e3197f20100a6z2.html 中《Windows程序的字符编码》
(2)编码总结
a.六种编码的特点
六种编码的特点如下图所示:

b.编码存储差别
ANSI(在简体中文中默认为GB2312)、Unicode、Unicode big endian 、UTF-8存储存在差别。
以中文"你好"二字为例,他们存贮格式如下图所示:
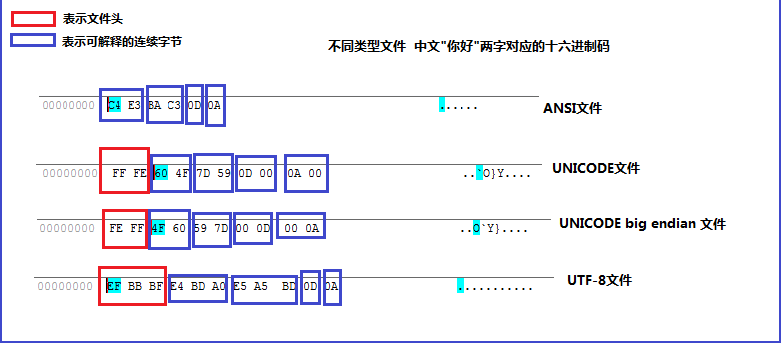
c.GB2312、Big5、GBK编码的区别
三者中汉字均采用二个字节表示,但是字节表示的值范围有所不同,如下图所示:

(3)编码转换方式
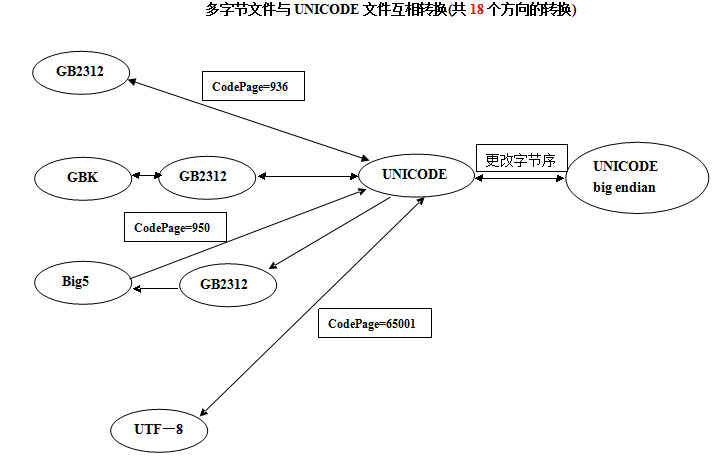
6种编码互相转换,由排列组合知识知道共有30个方向的转换.笔者采用的转换方法,
多字节文件与Unicode文件转换如下图所示:
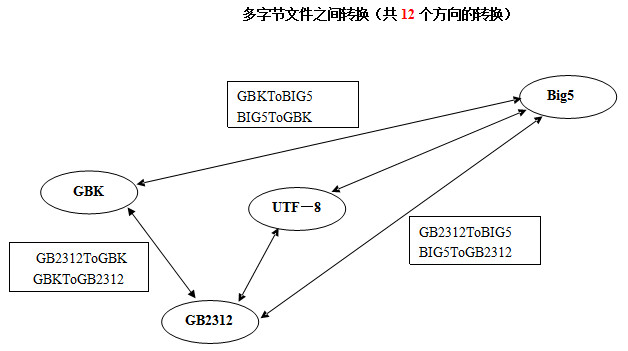
多字节文件之间转换如下图所示:
(4)编码转换使用的三个函数
a.MultiByteToWideChar
该函数完成多字节字符串向Unicode宽字符串的转换.
函数原型为:
int MultiByteToWideChar( UINT CodePage, // 代码页 DWORD dwFlags, // 转换标志 LPCSTR lpMultiByteStr, // 待转换的字符串 int cbMultiByte, // 待转换字符串的字节数目 LPWSTR lpWideCharStr, // 转换后宽字符串的存储空间 int cchWideChar // 转换后宽字符串的存储空间大小 以宽字符大小为单位 ); b.WideCharToMultiByte 该函数完成Unicode宽字符串到多字节字符串的转换,使用方法具体参见MSDN。 以上两个函数可以完成大部分的字符串转换,可以将其封装成多字节和宽字节之间的转换函数:c.LCMapString 依赖于本地机器的字符转换函数,尤其是中文编码在转换时要依赖于本地机器, 直接利用上述a、b中叙述的函数会产生错误,例如直接从GB2312转换到Big5,利用
- wchar_t*Coder::MByteToWChar(UINTCodePage,LPCSTRlpcszSrcStr)
- {
- LPWSTRlpcwsStrDes=NULL;
- intlen=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,NULL,0);
- lpcwsStrDes=newwchar_t[len+1];
- if(!lpcwsStrDes)
- returnNULL;
- memset(lpcwsStrDes,0,sizeof(wchar_t)*(len+1));
- len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,lpcwsStrDes,len);
- if(len)
- returnlpcwsStrDes;
- else
- {
- delete[]lpcwsStrDes;
- returnNULL;
- }
- }
- char*Coder::WCharToMByte(UINTCodePage,LPCWSTRlpcwszSrcStr)
- {
- char*lpszDesStr=NULL;
- intlen=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,NULL,0,NULL,NULL);
- lpszDesStr=newchar[len+1];
- memset(lpszDesStr,0,sizeof(char)*(len+1));
- if(!lpszDesStr)
- returnNULL;
- len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,lpszDesStr,len,NULL,NULL);
- if(len)
- returnlpszDesStr;
- else
- {
- delete[]lpszDesStr;
- returnNULL;
- }
- }
MultiByteToWideChar函数将GB2312转换到Unicode字符串,然后从Unicode字符串利用函数WideCharToMultiByte转换成Big5,将会发生错误,错误的结果如下图所示:测试程序运行效果如下图所示:因此中文编码转换时适当使用LCMapString函数,才能完成正确的转换. 例如:
(5)编码实现 实现Coder类完成编码转换工作. Coder类的代码清单如下:
- //简体中文GB2312转换成繁体中文BIG5
- char*Coder::GB2312ToBIG5(constchar*szGB2312Str)
- {
- LCIDlcid=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
- intnLength=LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,NULL,0);
- char*pBuffer=newchar[nLength+1];
- if(!pBuffer)
- returnNULL;
- LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,pBuffer,nLength);
- pBuffer[nLength]=0;
- wchar_t*pUnicodeBuff=MByteToWChar(CP_GB2312,pBuffer);
- char*pBIG5Buff=WCharToMByte(CP_BIG5,pUnicodeBuff);
- delete[]pBuffer;
- delete[]pUnicodeBuff;
- returnpBIG5Buff;
- }
- //Coder.h:interfacefortheCoderclass.
- //
- //////////////////////////////////////////////////////////////////////
- #if!defined(AFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_)
- #defineAFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_
- #if_MSC_VER>1000
- #pragmaonce
- #endif//_MSC_VER>1000
- //-----------------------------------------------------------------------------------------------
- //程序用途:实现GB2312、big5、GBK、Unicode、Unicodebigendian、UTF-8六种编码的任意装换
- //程序作者:湖北师范学院计算机科学与技术学院王定桥
- //核心算法:根据不同编码特点向其他编码转换
- //测试结果:在Windows7VC6.0环境下测试通过
- //制作时间:2012-04-24
- //代码版权:代码公开供学习交流使用欢迎指正错误改善算法
- //-----------------------------------------------------------------------------------------------
- //Windows代码页
- typedefenumCodeType
- {
- CP_GB2312=936,
- CP_BIG5=950,
- CP_GBK=0
- }CodePages;
- //txt文件编码
- typedefenumTextCodeType
- {
- GB2312=0,
- BIG5=1,
- GBK=2,
- UTF8=3,
- UNICODE=4,
- UNICODEBIGENDIAN=5,
- DefaultCodeType=-1
- }TextCode;
- classCoder
- {
- public:
- Coder();
- virtual~Coder();
- public:
- //默认一次转换字节大小
- UINTPREDEFINEDSIZE;
- //指定转换时默认一次转换字节大小
- voidSetDefaultConvertSize(UINTnCount);
- //编码类型转换为字符串
- CStringCodeTypeToString(TextCodetc);
- //文件转到另一种文件
- BOOLFileToOtherFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur=DefaultCodeType);
- //Unicode和Unicodebigendian文件之间转换
- BOOLUnicodeEndianFileConvert(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo);
- //多字节文件之间的转换
- BOOLMBFileToMBFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur=DefaultCodeType);
- //Unicode和Unicodebigendian文件向多字节文件转换
- BOOLUnicodeFileToMBFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo);
- //多字节文件向Unicode和Unicodebigendian文件转换
- BOOLMBFileToUnicodeFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur=DefaultCodeType);
- //获取文件编码类型
- TextCodeGetCodeType(CStringfilepath);
- //繁体中文BIG5转换成简体中文GB2312
- char*BIG5ToGB2312(constchar*szBIG5Str);
- //简体中文GB2312转换成繁体中文BIG5
- char*GB2312ToBIG5(constchar*szGB2312Str);
- //简繁中文GBK编码转换成简体中文GB2312
- char*GBKToGB2312(constchar*szGBkStr);
- //简体中文GB2312编码转换成简繁中文GBK
- char*GB2312ToGBK(constchar*szGB2312Str);
- //简繁中文GBK转换成繁体中文Big5
- char*GBKToBIG5(constchar*szGBKStr);
- //繁体中文BIG5转换到简繁中文GBK
- char*BIG5ToGBK(constchar*szBIG5Str);
- //宽字符串向多字节字符串转换
- char*WCharToMByte(UINTCodePage,LPCWSTRlpcwszSrcStr);
- //多字节字符串向宽字符串转换
- wchar_t*MByteToWChar(UINTCodePage,LPCSTRlpcszSrcStr);
- protected:
- //获取编码类型对应的代码页
- UINTGetCodePage(TextCodetccur);
- //多字节向多字节转换
- char*MByteToMByte(UINTCodePageCur,UINTCodePageTo,constchar*szSrcStr);
- //Unicode和Unicodebigendian字符串之间的转换
- voidUnicodeEndianConvert(LPWSTRlpwszstr);
- //文件头常量字节数组
- conststaticbyteUNICODEBOM[2];
- conststaticbyteUNICODEBEBOM[2];
- conststaticbyteUTF8BOM[3];
- };
- #endif//!defined(AFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_)
3.运行效果 在win7 VC 6.0下测试六种编码的转换测试通过,30个方向的转换如下图所示:
- //Coder.cpp:implementationoftheCoderclass.
- //
- //////////////////////////////////////////////////////////////////////
- #include"stdafx.h"
- #include"Coder.h"
- #include"Encoding.h"
- #ifdef_DEBUG
- #undefTHIS_FILE
- staticcharTHIS_FILE[]=__FILE__;
- #definenewDEBUG_NEW
- #endif
- //////////////////////////////////////////////////////////////////////
- //Construction/Destruction
- //////////////////////////////////////////////////////////////////////
- //初始化文件头常量
- /*static*/constbyteCoder::UNICODEBOM[2]={0xFF,0xFE};
- /*static*/constbyteCoder::UNICODEBEBOM[2]={0xFE,0xFF};
- /*static*/constbyteCoder::UTF8BOM[3]={0xEF,0xBB,0xBF};
- Coder::Coder()
- {
- PREDEFINEDSIZE=2097152;//默认一次转换字节大小2M字节
- }
- Coder::~Coder()
- {
- }
- //繁体中文BIG5转换成简体中文GB2312
- char*Coder::BIG5ToGB2312(constchar*szBIG5Str)
- {
- CStringmsg;
- LCIDlcid=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
- wchar_t*szUnicodeBuff=MByteToWChar(CP_BIG5,szBIG5Str);
- char*szGB2312Buff=WCharToMByte(CP_GB2312,szUnicodeBuff);
- intnLength=LCMapString(lcid,LCMAP_SIMPLIFIED_CHINESE,szGB2312Buff,-1,NULL,0);
- char*pBuffer=newchar[nLength+1];
- if(!pBuffer)
- returnNULL;
- memset(pBuffer,0,sizeof(char)*(nLength+1));
- LCMapString(0x0804,LCMAP_SIMPLIFIED_CHINESE,szGB2312Buff,-1,pBuffer,nLength);
- delete[]szUnicodeBuff;
- delete[]szGB2312Buff;
- returnpBuffer;
- }
- //GB2312转GBK
- char*Coder::GB2312ToGBK(constchar*szGB2312Str)
- {
- intnStrLen=strlen(szGB2312Str);
- if(!nStrLen)
- returnNULL;
- LCIDwLCID=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
- intnReturn=LCMapString(wLCID,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,nStrLen,NULL,0);
- if(!nReturn)
- returnNULL;
- char*pcBuf=newchar[nReturn+1];
- if(!pcBuf)
- returnNULL;
- memset(pcBuf,0,sizeof(char)*(nReturn+1));
- wLCID=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
- LCMapString(wLCID,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,nReturn,pcBuf,nReturn);
- returnpcBuf;
- }
- //GBK转换成GB2312
- char*Coder::GBKToGB2312(constchar*szGBKStr)
- {
- intnStrLen=strlen(szGBKStr);
- if(!nStrLen)
- returnNULL;
- LCIDwLCID=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_BIG5);
- intnReturn=LCMapString(wLCID,LCMAP_SIMPLIFIED_CHINESE,szGBKStr,nStrLen,NULL,0);
- if(!nReturn)
- returnNULL;
- char*pcBuf=newchar[nReturn+1];
- memset(pcBuf,0,sizeof(char)*(nReturn+1));
- wLCID=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_BIG5);
- LCMapString(wLCID,LCMAP_SIMPLIFIED_CHINESE,szGBKStr,nReturn,pcBuf,nReturn);
- returnpcBuf;
- }
- //简繁中文GBK转换成繁体中文Big5
- char*Coder::GBKToBIG5(constchar*szGBKStr)
- {
- char*pTemp=NULL;
- char*pBuffer=NULL;
- pTemp=GBKToGB2312(szGBKStr);
- pBuffer=GB2312ToBIG5(pTemp);
- delete[]pTemp;
- returnpBuffer;
- }
- //繁体中文BIG5转换到简繁中文GBK
- char*Coder::BIG5ToGBK(constchar*szBIG5Str)
- {
- char*pTemp=NULL;
- char*pBuffer=NULL;
- pTemp=BIG5ToGB2312(szBIG5Str);
- pBuffer=GB2312ToGBK(pTemp);
- delete[]pTemp;
- returnpBuffer;
- }
- //简体中文GB2312转换成繁体中文BIG5
- char*Coder::GB2312ToBIG5(constchar*szGB2312Str)
- {
- LCIDlcid=MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
- intnLength=LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,NULL,0);
- char*pBuffer=newchar[nLength+1];
- if(!pBuffer)
- returnNULL;
- LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,pBuffer,nLength);
- pBuffer[nLength]=0;
- wchar_t*pUnicodeBuff=MByteToWChar(CP_GB2312,pBuffer);
- char*pBIG5Buff=WCharToMByte(CP_BIG5,pUnicodeBuff);
- delete[]pBuffer;
- delete[]pUnicodeBuff;
- returnpBIG5Buff;
- }
- //获取文件编码类型
- //Unicode编码文件通过读取文件头判别
- //中文编码通过统计文件编码类别来判别判别次数最多为30次
- //中文编码的判别存在误差
- TextCodeCoder::GetCodeType(CStringfilepath)
- {
- CFilefile;
- bytebuf[3];//unsignedchar
- TextCodetctemp;
- if(file.Open(filepath,CFile::modeRead))
- {
- file.Read(buf,3);
- if(buf[0]==UTF8BOM[0]&&buf[1]==UTF8BOM[1]&&buf[2]==UTF8BOM[2])
- returnUTF8;
- else
- if(buf[0]==UNICODEBOM[0]&&buf[1]==UNICODEBOM[1])
- returnUNICODE;
- else
- if(buf[0]==UNICODEBEBOM[0]&&buf[1]==UNICODEBEBOM[1])
- returnUNICODEBIGENDIAN;
- else
- {
- inttime=30;
- while(file.Read(buf,2)&&time)
- {
- if((buf[0]>=176&&buf[0]<=247)&&(buf[1]>=160&&buf[1]<=254))
- tctemp=GB2312;
- else
- if((buf[0]>=129&&buf[0]<=255)&&((buf[1]>=64&&buf[1]<=126)||(buf[1]>=161&&buf[1]<=254)))
- tctemp=BIG5;
- else
- if((buf[0]>=129&&buf[0]<=254)&&(buf[1]>=64&&buf[1]<=254))
- tctemp=GBK;
- time--;
- file.Seek(100,CFile::current);//跳过一定字节利于统计全文
- }
- returntctemp;
- }
- }
- else
- returnGB2312;
- }
- //多字节文件转换为UNICODE、UNICODEbigendian文件
- BOOLCoder::MBFileToUnicodeFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur)
- {
- TextCodecurtc;
- CFilefilesource,filesave;;
- char*pChSrc=NULL;
- char*pChTemp=NULL;
- wchar_t*pwChDes=NULL;
- DWORDfilelength,readlen,len;
- intbufferlen,strlength;
- UINTCodePage;
- //由于存在误差允许用户自定义转换
- if(tcCur!=DefaultCodeType)
- curtc=tcCur;
- else
- curtc=GetCodeType(filesourcepath);
- if(curtc>UTF8||tcTo<UNICODE||curtc==tcTo)
- returnFALSE;
- //源文件打开失败或者源文件无内容后者保存文件建立失败均返回转换失败
- if(!filesource.Open(filesourcepath,CFile::modeRead)||0==(filelength=filesource.GetLength()))
- returnFALSE;
- if(!filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))
- returnFALSE;
- //预分配内存分配失败则转换失败
- if(filelength<PREDEFINEDSIZE)
- bufferlen=filelength;
- else
- bufferlen=PREDEFINEDSIZE;
- pChSrc=newchar[bufferlen+1];
- if(!pChSrc)
- returnFALSE;
- //根据当前文件类别指定转换代码页
- switch(curtc)
- {
- caseGB2312:
- CodePage=CP_GB2312;
- break;
- caseGBK:
- CodePage=CP_GB2312;//特殊处理
- break;
- caseBIG5:
- CodePage=CP_BIG5;
- break;
- caseUTF8:
- CodePage=CP_UTF8;
- break;
- default:
- break;
- }
- //UTF8文件跳过文件
- if(UTF8==curtc)
- filesource.Seek(3*sizeof(byte),CFile::begin);
- //写入文件头
- if(UNICODEBIGENDIAN==tcTo)
- filesave.Write(&UNICODEBEBOM,2*sizeof(byte));
- else
- filesave.Write(&UNICODEBOM,2*sizeof(byte));
- //读取文件分段转换知道结束
- while(filelength>0)
- {
- memset(pChSrc,0,sizeof(char)*(bufferlen+1));
- if(filelength>PREDEFINEDSIZE)
- len=PREDEFINEDSIZE;
- else
- len=filelength;
- readlen=filesource.Read(pChSrc,len);
- if(!readlen)
- break;
- //GBK转换为GB2312处理
- if(GBK==curtc)
- {
- pChTemp=pChSrc;
- pChSrc=GBKToGB2312(pChSrc);
- }
- pwChDes=MByteToWChar(CodePage,pChSrc);
- if(pwChDes)
- {
- if(UNICODEBIGENDIAN==tcTo)
- UnicodeEndianConvert(pwChDes);
- strlength=wcslen(pwChDes)*2;//这里注意写入文件的长度
- filesave.Write(pwChDes,strlength);
- filesave.Flush();
- filelength-=readlen;
- }
- else
- break;
- }
- delete[]pChSrc;
- delete[]pChTemp;
- delete[]pwChDes;
- returnTRUE;
- }
- //
- wchar_t*Coder::MByteToWChar(UINTCodePage,LPCSTRlpcszSrcStr)
- {
- LPWSTRlpcwsStrDes=NULL;
- intlen=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,NULL,0);
- lpcwsStrDes=newwchar_t[len+1];
- if(!lpcwsStrDes)
- returnNULL;
- memset(lpcwsStrDes,0,sizeof(wchar_t)*(len+1));
- len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,lpcwsStrDes,len);
- if(len)
- returnlpcwsStrDes;
- else
- {
- delete[]lpcwsStrDes;
- returnNULL;
- }
- }
- char*Coder::WCharToMByte(UINTCodePage,LPCWSTRlpcwszSrcStr)
- {
- char*lpszDesStr=NULL;
- intlen=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,NULL,0,NULL,NULL);
- lpszDesStr=newchar[len+1];
- memset(lpszDesStr,0,sizeof(char)*(len+1));
- if(!lpszDesStr)
- returnNULL;
- len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,lpszDesStr,len,NULL,NULL);
- if(len)
- returnlpszDesStr;
- else
- {
- delete[]lpszDesStr;
- returnNULL;
- }
- }
- //Unicode和Unicodebigendian之间字节序的转换
- voidCoder::UnicodeEndianConvert(LPWSTRlpwszstr)
- {
- wchar_twchtemp[2];
- longindex;
- intlen=wcslen(lpwszstr);
- if(!len)
- return;
- //交换高低字节直到遇到结束符
- index=0;
- while(index<len)
- {
- wchtemp[0]=lpwszstr[index];
- wchtemp[1]=lpwszstr[index+1];
- unsignedcharhigh,low;
- high=(wchtemp[0]&0xFF00)>>8;
- low=wchtemp[0]&0x00FF;
- wchtemp[0]=(low<<8)|high;
- high=(wchtemp[1]&0xFF00)>>8;
- low=wchtemp[1]&0x00FF;
- wchtemp[1]=(low<<8)|high;
- lpwszstr[index]=wchtemp[0];
- lpwszstr[index+1]=wchtemp[1];
- index+=2;
- }
- }
- //Unicode和Unicodebigendian文件向多字节文件转换
- BOOLCoder::UnicodeFileToMBFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo)
- {
- TextCodecurtc;
- CFilefilesource,filesave;;
- char*pChDes=NULL;
- char*pChTemp=NULL;
- wchar_t*pwChSrc=NULL;
- DWORDfilelength,readlen,len;
- intbufferlen,strlength;
- UINTCodePage;
- curtc=GetCodeType(filesourcepath);
- //文件转换类型错误则转换失败
- if(curtc<=UTF8||tcTo>UTF8||curtc==tcTo)
- returnFALSE;
- //源文件打开失败或者源文件无内容后者保存文件建立失败均转换失败
- if(!filesource.Open(filesourcepath,CFile::modeRead)||0==(filelength=filesource.GetLength()))
- returnFALSE;
- if(!filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))
- returnFALSE;
- //预分配内存分配失败则转换失败
- if(filelength<PREDEFINEDSIZE)
- bufferlen=filelength;
- else
- bufferlen=PREDEFINEDSIZE;
- pwChSrc=newwchar_t[(bufferlen/2)+1];
- if(!pwChSrc)
- returnFALSE;
- //预先决定代码页
- switch(tcTo)
- {
- caseGB2312:
- CodePage=CP_GB2312;
- break;
- caseGBK:
- CodePage=CP_GB2312;//特殊处理
- break;
- caseBIG5:
- CodePage=CP_GB2312;//特殊处理
- break;
- caseUTF8:
- CodePage=CP_UTF8;
- break;
- default:
- break;
- }
- filesource.Seek(sizeof(wchar_t),CFile::begin);
- while(filelength>0)
- {
- memset(pwChSrc,0,sizeof(wchar_t)*((bufferlen/2)+1));
- if(filelength>PREDEFINEDSIZE)
- len=PREDEFINEDSIZE;
- else
- len=filelength;
- readlen=filesource.Read(pwChSrc,len);
- if(!readlen)
- break;
- if(UNICODEBIGENDIAN==curtc)
- UnicodeEndianConvert(pwChSrc);
- pChDes=WCharToMByte(CodePage,pwChSrc);
- //GBK无法直接转换BIG5直接转换会产生错误二者均先转到GB2312然后再转到目的类型
- if(GBK==tcTo)
- {
- pChTemp=pChDes;
- pChDes=GB2312ToGBK(pChDes);
- }
- if(BIG5==tcTo)
- {
- pChTemp=pChDes;
- pChDes=GB2312ToBIG5(pChDes);
- }
- if(pChDes)
- {
- strlength=strlen(pChDes);
- filesave.Write(pChDes,strlength);
- filesave.Flush();
- filelength-=readlen;
- }
- else
- break;
- }
- delete[]pChDes;
- delete[]pChTemp;
- delete[]pwChSrc;
- returnTRUE;
- }
- //多字节文件转为多字节文件
- //多字节转为多字节时,一般先转为UNICODE类型,再转换到指定目的类型,实行两次转换
- BOOLCoder::MBFileToMBFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur)
- {
- BOOLbret=FALSE;
- TextCodecurtc;
- CFilefilesource,filesave;
- char*pChDes=NULL;
- char*pChSrc=NULL;
- DWORDfilelength,readlen,len;
- intbufferlen,strlength;
- UINTCodePageCur,CodePageTo;
- //由于存在误差允许用户自定义转换
- if(DefaultCodeType!=tcCur)
- curtc=tcCur;
- else
- curtc=GetCodeType(filesourcepath);
- //转换类型错误则返回转换失败
- if(curtc>UTF8||tcTo>UTF8||curtc==tcTo)
- returnFALSE;
- //源文件打开失败或者源文件无内容后者保存文件建立失败均返回转换失败
- if(!filesource.Open(filesourcepath,CFile::modeRead)||0==(filelength=filesource.GetLength()))
- returnFALSE;
- if(!filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))
- returnFALSE;
- //预分配内存分配失败则转换失败
- if(filelength<PREDEFINEDSIZE)
- bufferlen=filelength;
- else
- bufferlen=PREDEFINEDSIZE;
- pChSrc=newchar[bufferlen+1];
- if(!pChSrc)
- returnFALSE;
- if(UTF8==curtc)
- filesource.Seek(3*sizeof(byte),CFile::begin);
- CodePageCur=GetCodePage(curtc);
- CodePageTo=GetCodePage(tcTo);
- while(filelength>0)
- {
- memset(pChSrc,0,sizeof(char)*(bufferlen+1));
- if(filelength>PREDEFINEDSIZE)
- len=PREDEFINEDSIZE;
- else
- len=filelength;
- readlen=filesource.Read(pChSrc,len);
- if(!readlen)
- break;
- pChDes=MByteToMByte(CodePageCur,CodePageTo,pChSrc);
- if(pChDes)
- {
- strlength=strlen(pChDes);
- filesave.Write(pChDes,strlength);
- filelength-=readlen;
- }
- else
- break;
- }
- delete[]pChSrc;
- delete[]pChDes;
- returnTRUE;
- }
- //Unicode和Unicodebigendian文件之间转换
- BOOLCoder::UnicodeEndianFileConvert(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo)
- {
- TextCodecurtc=GetCodeType(filesourcepath);
- if(curtc!=UNICODE&&curtc!=UNICODEBIGENDIAN)
- returnFALSE;
- if(curtc==tcTo)
- returnFALSE;
- CFilefilesource,filesave;;
- wchar_t*pwChDes;
- DWORDlength;
- if(!filesource.Open(filesourcepath,CFile::modeRead)||!filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))
- returnFALSE;
- length=filesource.GetLength();
- if(!length)
- returnFALSE;
- pwChDes=newwchar_t[(length/2)+1];
- if(!pwChDes)
- returnFALSE;
- memset(pwChDes,0,sizeof(wchar_t)*((length/2)+1));
- filesource.Read(pwChDes,length);
- UnicodeEndianConvert(pwChDes);
- length=wcslen(pwChDes)*2;
- if(UNICODE==tcTo)
- filesave.Write(&UNICODEBOM,2*sizeof(byte));
- else
- filesave.Write(&UNICODEBEBOM,2*sizeof(byte));
- filesave.Write(pwChDes,length);
- filesave.Flush();
- delete[]pwChDes;
- returnTRUE;
- }
- //文件转到另一种文件
- //6种格式文件两两转换共计30种转换
- BOOLCoder::FileToOtherFile(CStringfilesourcepath,CStringfilesavepath,TextCodetcTo,TextCodetcCur)
- {
- TextCodecurtc;
- BOOLbret=FALSE;
- if(DefaultCodeType!=tcCur)
- curtc=tcCur;
- else
- curtc=GetCodeType(filesourcepath);
- if(curtc==tcTo)
- returnFALSE;
- //UNICODE和UNICODEbigendian文件之间转换共2种
- if(curtc>=UNICODE&&tcTo>=UNICODE)
- bret=UnicodeEndianFileConvert(filesourcepath,filesavepath,tcTo);
- else
- //多字节文件向UNICODE和UNICODEbigendian文件之间转换共8种
- if(curtc<UNICODE&&tcTo>=UNICODE)
- bret=MBFileToUnicodeFile(filesourcepath,filesavepath,tcTo,curtc);
- else
- //UNICODE和UNICODEbigendian文件向多字节文件转换共8种
- if(curtc>=UNICODE&&tcTo<UNICODE)
- bret=UnicodeFileToMBFile(filesourcepath,filesavepath,tcTo);
- else
- //多字节文件之间转换共12种
- if(curtc<UNICODE&&tcTo<UNICODE)
- bret=MBFileToMBFile(filesourcepath,filesavepath,tcTo,curtc);
- returnbret;
- }
- //编码类型转换为字符串
- CStringCoder::CodeTypeToString(TextCodetc)
- {
- CStringstrtype;
- switch(tc)
- {
- caseGB2312:
- strtype=_T("GB2312");
- break;
- caseBIG5:
- strtype=_T("Big5");
- break;
- caseGBK:
- strtype=_T("GBK");
- break;
- caseUTF8:
- strtype=_T("UTF-8");
- break;
- caseUNICODE:
- strtype=_T("Unicode");
- break;
- caseUNICODEBIGENDIAN:
- strtype=_T("Unicodebigendian");
- break;
- }
- returnstrtype;
- }
- //多字节向多字节转换
- char*Coder::MByteToMByte(UINTCodePageCur,UINTCodePageTo,constchar*szSrcStr)
- {
- char*pchDes=NULL;
- char*pchTemp=NULL;
- wchar_t*pwchtemp=NULL;
- //三种中文编码之间转换
- if(CodePageCur!=CP_UTF8&&CodePageTo!=CP_UTF8)
- {
- switch(CodePageCur)
- {
- caseCP_GB2312:
- {
- if(CP_BIG5==CodePageTo)
- pchDes=GB2312ToBIG5(szSrcStr);
- else
- pchDes=GB2312ToGBK(szSrcStr);
- break;
- }
- caseCP_BIG5:
- {
- if(CP_GB2312==CodePageTo)
- pchDes=BIG5ToGB2312(szSrcStr);
- else
- pchDes=BIG5ToGBK(szSrcStr);
- break;
- }
- caseCP_GBK:
- {
- if(CP_GB2312==CodePageTo)
- pchDes=GBKToGB2312(szSrcStr);
- else
- pchDes=GBKToBIG5(szSrcStr);
- break;
- }
- }
- }
- else
- {//从UTF-8转到其他多字节直接转到GB2312其他形式用GB2312做中间形式
- if(CP_UTF8==CodePageCur)
- {
- pwchtemp=MByteToWChar(CodePageCur,szSrcStr);
- if(CP_GB2312==CodePageTo)
- {
- pchDes=WCharToMByte(CP_GB2312,pwchtemp);
- }
- else
- {
- pchTemp=WCharToMByte(CP_GB2312,pwchtemp);
- if(CP_GBK==CodePageTo)
- pchDes=GB2312ToGBK(pchTemp);
- else
- pchDes=GB2312ToBIG5(pchTemp);
- }
- }
- //从其他多字节转到UTF-8
- else
- {
- if(CP_GBK==CodePageCur)
- {
- pchTemp=GBKToGB2312(szSrcStr);
- pwchtemp=MByteToWChar(CP_GB2312,pchTemp);
- }
- else
- pwchtemp=MByteToWChar(CodePageCur,szSrcStr);
- pchDes=WCharToMByte(CodePageTo,pwchtemp);
- }
- }
- delete[]pchTemp;
- delete[]pwchtemp;
- returnpchDes;
- }
- //获取编码类型对应的代码页
- UINTCoder::GetCodePage(TextCodetccur)
- {
- UINTCodePage;
- switch(tccur)
- {
- caseGB2312:
- CodePage=CP_GB2312;
- break;
- caseBIG5:
- CodePage=CP_BIG5;
- break;
- caseGBK:
- CodePage=CP_GBK;
- break;
- caseUTF8:
- CodePage=CP_UTF8;
- break;
- caseUNICODEBIGENDIAN:
- caseUNICODE:
- break;
- }
- returnCodePage;
- }
- //指定转换时默认一次转换字节大小
- voidCoder::SetDefaultConvertSize(UINTnCount)
- {
- if(nCount!=0)
- PREDEFINEDSIZE=nCount;
- }
GB2312转换到GBK编码效果如下图所示:
UTF-8转换到Big5编码的效果如下图所示:
本文代码及转码程序下载 :http://download.csdn.net/user/ziyuanxiazai123
4.尚未解决的问题
(1)LCMapString函数的理解还不完全熟悉,其中参数偏多,理解需要一定基础知识。
(2)为什么记事本程序的转码后存在些乱码,乱码是正确的吗?因为我的程序使用了中间过渡形式,因此没有任何乱码。
(3)是否有更简单和清晰的方式实现编码转换,待进一步研究。




发表评论

相关推荐
在详细解读“中文编码规则,一网打尽”这一主题之前,我们首先需要明确几个关键概念,包括字符编码、Unicode、ASCII、以及中文编码的特殊规则。这些概念对于理解文本所描述的中文编码规则至关重要。 首先,字符编码...
6. **联系作者**:"双击联系作者.url"可能是一个快捷方式,允许用户直接联系到软件的开发者,获取技术支持或报告问题。这是获取官方帮助的重要途径。 综上所述,QCP格式的音频文件转换涉及到特定的工具和流程,用户...
foxfire编码识别编译版 - byvoid,我只是打包编译了一下. 编码问题一网打尽 - wangjieest的专栏 - http://blog.csdn.net/wangjieest/article/details/8097035
旋风转换器是文件格式转换工具,是专业智能的办公软件,支持上百种文件格式转换与操作,将你的办公需求一网打尽。能够转换多种格式互相转换,还能够进行图片压缩。 软件特色 支持pdf转word,pd
本文将深入探讨“一网打尽Android-UI”中的关键知识点,包括各种UI组件的使用和功能。 1. **关于Android的一些设计**: Android的设计原则强调简洁、直观和一致。开发者应遵循Material Design指南,提供清晰的层次...
+全新推出简体中文、英文、繁体中文三个语言版本。欢迎推荐给使用这些语言有朋友 +独家支持RTMP协议FLV流媒体的抓取 *修正本地缓存另存的BUG,同时修改为“快速保存” 2009-01-08 酷抓6 Beta Build090108 *强制退出...
一网打尽18种主流数据库:12种SQL+6种NoSQL
只需选择输入和输出格式,软件会自动进行编码优化,确保转换后的视频质量和原始文件相差无几。 此外,影音转霸的用户界面友好,操作流程直观,即使是对电脑操作不熟悉的用户也能快速上手。软件还提供了批量处理功能...
一款很专业视频个转换器软件,好多专业视频制作网站都是用这个软件,支持视频、音频、DVD格式转换的终极解决方案。它可以高速转换任何视频格式、音频格式、DVD,输出100多种格式的音视频格式,RM、AVI、WMV、MP4、...
今天我们要探究的,正是这样一个涵盖“八木”、“双菱”和“长城”等关键字的图片资源压缩包,它以“一网打尽”的形式,展示了这些主题相关的多样图片内容。 首先,我们必须明白“八木”、“双菱”和“长城”在这里...
业风险承担水平大合集,十余种衡量方法的测算结果一网打尽,附赠测算过程的所有原始数 据、操作代码和10篇权威期刊的参考文献(我本人也有资本市场和公司治理的项目,个人 认为对选题和方向具有极高的价值),一定让...
"AVI MPEG WMV RM to MP3 Converter"正是这样一款能够解决多种音频格式转换问题的软件,它将各种音频格式一网打尽,让用户告别因格式不兼容带来的不便。 AVI、MPEG、WMV和RM是常见的视频格式,它们内含的音频部分...
“一网打尽:四级考试历年真题集(2016年12月-2023年6月)” 想要顺利拿下英语四级考试?别再东拼西凑找资料了!我们为您精心整理了从2016年12月至2023年6月的所有四级真题,一网打尽,不留死角。这不仅仅是一本...
无论是AVI、DivX、XviD这类常见的编码格式,还是MPEG、DAT、WMV、ASF等多媒体容器格式,甚至包括网络上流行的RM、RMVB、MOV、QT以及新兴的MP4格式,这款软件都能一网打尽,实现无缝转换。 首先,我们来详细了解AVI...
【一网打尽绿色创新,数据大合集值得信赖】 附件为我国1990-2022绿色专利绿 色创新数据大合集,又称绿色专利(绿色创新)数据库。总计上百万个观测值,几十张数据 表格,一网打尽涉及绿色专利和绿色创新的所有数据。...
·海量资源库,完全免费采集(快播,迅播,web9,皮皮,高清视频)一网打尽 --------------------------------------- 为什么选择 舟舟影视系统 --------------------------------------- 1.卓越的访问速度和负载...
6. exclude v. 排斥、排除,不包括在内。例如:“The restaurant excludes anyone who is not properly dressed from entering.”(衣冠不整者不得进入该餐馆。) 7. extinguish v. 熄灭(火),使沉默或暗淡。例如...