
前言
在我们的日常web应用开发当中memcached可以算作是当今的标准开发配置了。相信memcache的基本原理大家也都了解过了,memcache虽然是分布式的应用服务,但分布的原则是由client端的api来决定的,api根据存储用的key以及已知的服务器列表,根据key的hash计算将指定的key存储到对应的服务器列表上。
基本的原理以及分布
在这里我们通常使用的方法是根据 key的hash值%服务器数取余数 的方法来决定当前这个key的内容发往哪一个服务器的。这里会涉及到一个hash算法的分布问题,哈希的原理用一句话解释就是两个集合间的映射关系函数,在我们通常的应用中基本上可以理解为 在集合A(任意字母数字等组合,此处为存储用的key)里的一条记录去查找集合B(如0-2^32)中的对应记录。(题外话:md5的碰撞或者说冲突其实就是发生在这里,也就是说多个A的记录映射到了同一个B的记录)
实际应用
显然在我们的应用中集合A的记录应该更均匀的分布在集合B的各个位置,这样才能尽量避免我们的数据被分布发送到单一的服务器上,在danga的memcached的原始版本(perl)中使用的是crc32的算法用java的实现写出来:
private static int origCompatHashingAlg( String key ) {
int hash = 0;
char[] cArr = key.toCharArray();
for ( int i = 0; i < cArr.length; ++i ) {
hash = (hash * 33) + cArr[i];
}
return hash;
}
这里还有另一个改进版本的算法:
private static int newCompatHashingAlg( String key ) {
CRC32 checksum = new CRC32();
checksum.update( key.getBytes() );
int crc = (int) checksum.getValue();
return (crc >> 16) & 0x7fff;
}
分布率测试
有人做过测试,随机选择的key在服务器数量为5的时候所有key在服务器群组上的分布概率是:
origCompatHashingAlg:
0 10%
1 9%
2 60%
3 9%
4 9%
newCompatHashingAlg:
0 19%
1 19%
2 20%
3 20%
4 20%
显然使用旧的crc32算法会导致第三个memcached服务的负载更高,但使用新算法会让服务之间的负载更加均衡。
其他常用的hash算法还有FNV-1a Hash,RS Hash,JS Hash,PJW Hash,ELF Hash,AP Hash等等。有兴趣的童鞋可以查看这里:
http://www.partow.net/programming/hashfunctions/
http://hi.baidu.com/algorithms/blog/item/79caabee879ece2a2cf53440.html
小结
至此我们了解到了在我们的应用当中要做到尽量让我们的映射更加均匀分布,可以使服务的负载更加合理均衡。
新问题
但到目前为止我们依然面对了这样一个问题:就是服务实例本身发生变动的时候,导致服务列表变动从而会照成大量的cache数据请求会miss,几乎大部分数据会需要迁移到另外的服务实例上。这样在大型服务在线时,瞬时对后端数据库/硬盘照成的压力很可能导致整个服务的crash。
一致性哈希(Consistent Hashing)
在此我们采用了一种新的方式来解决问题,处理服务器的选择不再仅仅依赖key的hash本身而是将服务实例(节点)的配置也进行hash运算。
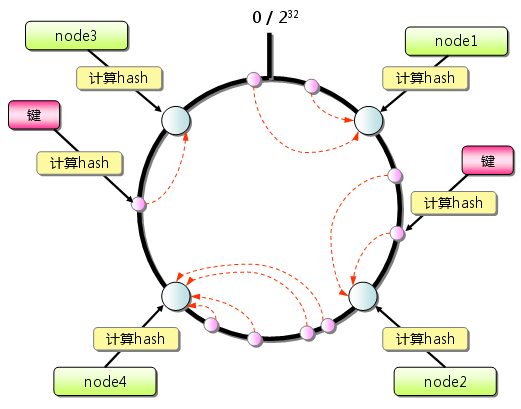
- 首先求出每个服务节点的hash,并将其配置到一个0~2^32的圆环(continuum)区间上。
- 其次使用同样的方法求出你所需要存储的key的hash,也将其配置到这个圆环(continuum)上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务节点上。如果超过2^32仍然找不到服务节点,就会保存到第一个memcached服务节点上。
整个数据的图例:
当增加服务节点时:
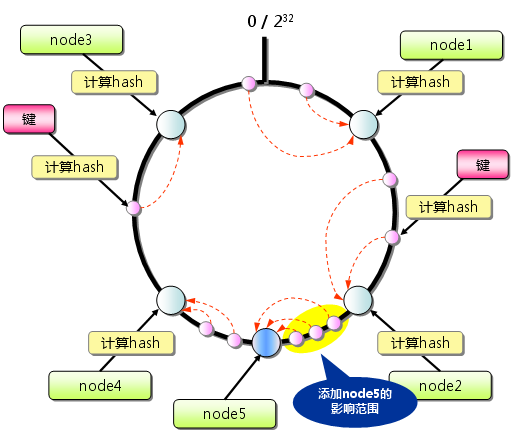
其他:只有在圆环上增加服务节点的位置为逆时针方向的第一个服务节点上的键会受到影响。
小结
一致性哈希算法最大程度的避免了key在服务节点列表上的重新分布,其他附带的改进就是有的一致性哈希算法还增加了虚拟服务节点的方法,也就是一个服务节点在环上有多个映射点,这样就能抑制分布不均匀,
最大限度地减小服务节点增减时的缓存重新分布。
应用
在memcached的实际应用,虽然官方的版本并不支持Consistent Hashing,但是已经有了现实的Consistent Hashing实现以及虚节点的实现,第一个实现的是last.fm(国外流行的音乐平台)开发的libketama,
其中调用的hash的部分的java版本的实现(基于md5):
/**
* Calculates the ketama hash value for a string
* @param s
* @return
*/
public static Long md5HashingAlg(String key) {
if(md5==null) {
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
log.error( "++++ no md5 algorythm found" );
throw new IllegalStateException( "++++ no md5 algorythm found");
}
}
md5.reset();
md5.update(key.getBytes());
byte[] bKey = md5.digest();
long res = ((long)(bKey[3]&0xFF) << 24) | ((long)(bKey[2]&0xFF) << 16) | ((long)(bKey[1]&0xFF) << 8) | (long)(bKey[0]&0xFF);
return res;
}
在一致性哈希的算法/策略环境中,按照测试来说时间和分布性都是综合来说比较让人满意的,参见:
http://www.javaeye.com/topic/346682
总结
在我们的web开发应用中的分布式缓存系统里哈希算法承担着系统架构上的关键点。
使用分布更合理的算法可以使得多个服务节点间的负载相对均衡,可以最大程度的避免资源的浪费以及服务器过载。
使用一致性哈希算法,可以最大程度的降低服务硬件环境变化带来的数据迁移代价和风险。
使用更合理的配置策略和算法可以使分布式缓存系统更加高效稳定的为我们整体的应用服务。
展望
一致性哈希的算法/策略来源于p2p网络,其实纵观p2p网络应用的场景,在许多地方与我们的应用有很多相似的地方,可以学习借鉴。
参考文章:
对等网络(P2P)中主流分布式哈希算法比较分析
http://www.ppcn.net/n3443c38.aspx
其他参考文章:
http://www.taiwanren.com/blog/article.asp?id=840
http://www.iwms.net/n923c43.aspx
http://tech.idv2.com/2008/07/24/memcached-004/
相关代码:
last.fm的ketama代码
http://static.last.fm/rj/ketama.tar.bz2
php版的Consistent Hashing实现:Flexihash
主页:
http://paul.annesley.cc/articles/2008/04/flexihash-consistent-hashing-php
google code上的代码主页:
http://code.google.com/p/flexihash/
现在已经移居到github上了:
http://github.com/pda/flexihash/
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
1 基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
2 hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。(这一段应该是翻译的,当缓冲区大小变化时Consistent hashing尽量保护已分配的内容不会被重新映射到新缓冲区)
容易看到,上面的简单 一致性哈希算法hash 算法 hash(object)%N 难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
3.1 环形hash 空间
考虑通常的hash算法都是将value映射到一个32位为的key值,也即是0~2^32-1次方的数值空间(通常生产环境会重新考虑);我们可以将这个空间想象成一个首(0)尾(2^32-1)相接的圆环,如下面图1所示的那样。
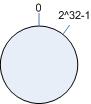
图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑4个对象object1~object4,通过hash函数(哪些哈希函数可以使用呢?)计算出的hash值key在环上的分布如图2所示。
hash(object1) = key1;
… …
hash(object4) = key4;
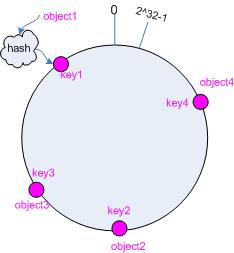
图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash 值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为 hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2 和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时, cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。
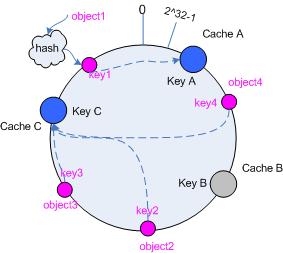
图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和 object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。
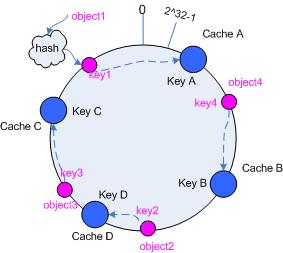
图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。
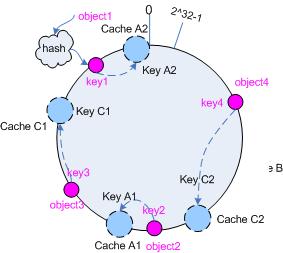
图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache 时的映射关系如图 7 所示。
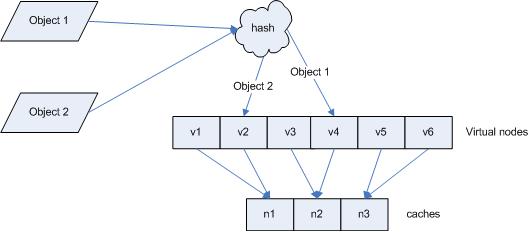
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为 202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”);// cache A1
Hash(“202.168.14.241#2”);// cache A2
5 小结
Consistent hashing 的基本原理就是这些,具体的分布性等理论分析应该是很复杂的,不过一般也用不到。
http://weblogs.java.net/blog/2007/11/27/consistent-hashing 上面有一个 java 版本的例子,可以参考。
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx 转载了一个 PHP 版的实现代码。
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本
一些参考资料地址:
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx



相关推荐
一致性哈希算法是一种分布式哈希(Distributed Hash Table, DHT)技术,旨在解决在分布式环境中数据分布不均匀的问题。Ketama算法是基于一致性哈希的一种优化实现,由Last.fm公司的Simon Willison提出,其目标是在...
一致性哈希算法是一种分布式哈希...总的来说,基于C#实现一致性哈希算法是一项涉及哈希函数、节点分布策略以及冲突解决机制的复杂任务。通过理解和实现这一算法,开发者可以构建更加稳定和高效的分布式系统。
一致性哈希算法是一种在分布式系统中解决数据分片和负载均衡问题的算法,它主要解决了在动态添加或移除节点时,尽可能少地改变已经存在的数据分布。在云计算和大数据处理领域,一致性哈希被广泛应用,例如在分布式...
一致性哈希算法最初由麻省理工学院的K等人提出,并被广泛应用于分布式系统中,以解决节点动态变化时数据一致性问题。其核心思想是通过引入哈希环,将数据对象均匀分布在哈希环上的不同节点中,以此降低节点变更对...
通过运行此项目,你可以看到随着节点数量的变化,数据项的分布如何动态调整,这有助于深入理解一致性哈希算法在实际应用中的价值。此外,C#语言的实现使得代码易于阅读和学习,对于熟悉或想要学习C#编程的人来说,这...
然而,一致性哈希算法也存在一些问题,比如在节点数量较少时,节点间的数据分布可能不均匀,这会导致某些节点成为瓶颈。 针对一致性哈希算法存在的问题,文中提出了改进方案。该方案主要从以下几个方面进行改进:...
* 高效的数据分布:Mycat的一致性哈希分片算法可以将数据分布式存储在多个数据库节点中,提高数据存取效率和系统可扩展性。 * 轻松的维护和管理:Mycat的一致性哈希分片算法可以轻松地添加或删除数据库节点,简化了...
一致性哈希算法就是为了解决这种系统中的数据分布和路由问题,它具有高效、稳定和可扩展的特点。 一致性哈希算法的基本思想是在哈希空间中将数据和服务器映射到相同的范围内。传统的哈希算法可能会导致数据集中在...
Mycat在处理大规模数据时,通过一致性哈希算法将数据均匀地分布到各个节点上,确保每个节点负责一部分数据,形成数据分片。当增加或减少节点时,一致性哈希可以保持数据分布的稳定性,降低对系统的影响。 三、Mycat...
本文针对这一问题,深入研究了一致性哈希算法在分布式数据库扩展中的应用,并提出了一种创新的扩展方法,旨在提高扩展效率,降低扩展成本,为大数据环境下的数据库管理带来新的优化方案。 一致性哈希算法最初由...
一致性哈希算法应用及优化是IT领域中分布式系统设计的核心技术之一,特别是在处理大规模数据分布与缓存系统中,其重要性不言而喻。本文将深入探讨一致性哈希算法的基本概念、工作原理以及在实际场景中的应用和优化...
一致性哈希算法是一种用于解决分布式系统中节点动态变化导致的数据重新分布问题的关键技术。它通过将哈希空间映射到一个循环的空间中,实现了数据节点的高效定位,并有效减少了节点加入或离开系统时引起的数据迁移量...
一致性哈希算法(Consistent Hashing)是一种在分布式系统中平衡数据分布的策略,尤其适用于缓存服务如Memcached或Redis。它的核心思想是通过哈希函数将对象映射到一个固定大小的环形空间中,然后将服务器也映射到这个...
1. 一致性(Consistency):相同的输入会产生相同的哈希值。 2. 压缩性(Compression):无论输入多大,哈希函数都能将其压缩成固定长度的输出。 3. 有损性(Lossiness):仅凭哈希值无法恢复原始输入。 四、密码学...
与传统的哈希算法不同,一致性哈希算法在处理节点增减时,能够最小化重新分配数据的数量,从而提高系统的稳定性与扩展性。 简单哈希算法是一种基础的、直接的哈希计算方式,通过计算数据对象的哈希值,再对存储节点...
2. **一致性哈希算法**: - 一致性哈希解决了普通哈希扩容时大量元素移动的问题,特别适用于分布式系统中节点的动态增减。 - 哈希空间被组织成一个固定大小的环,每个节点分配到环上的一个或多个位置,负责其...
一致性哈希算法(Consistent Hashing)是一种在分布式系统中实现负载均衡的算法,尤其在分布式缓存如Memcached和Redis等场景下广泛使用。它解决了传统哈希算法在节点增减时导致的大量数据迁移问题,提高了系统的可用...
一致性哈希算法的php版,希望能帮到phper了解一致性哈希