- 浏览: 188502 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
bluky999:
这个存在同步问题,会导致你的写入串行或者顺序不符合预期,需要加 ...
Python多线程写文件实例 -
jveqi:
...
【转】MySql主主(主从)同步配置详解 -
yinjh:
GBK对英文字符编码也采用2个字节?
不是这样吧?
00-7F ...
MySQL中GBK与UTF-8的区别 -
jerry.yan.mj:
我觉得你的心态需要调整。如果忙碌的工作和不断的学习对你来说是辛 ...
2012年年终总结 -
michael8335:
kekenow 写道兄弟!不要气馁,继续努力!我是做了6年的建 ...
2012年年终总结
NOSQL has become a very heated topic for large web-scale deployment where
scalability and semi-structured data driven the DB requirement towards NOSQL.
There has been many NOSQL products evolving in over last couple years. In my
past blogs, I have been covering the underlying distributed system theory of NOSQL, as well as some specific products such as CouchDB and Cassandra/HBase.
Last Friday I was very lucky to meet with Jared
Rosoff from 10gen in a technical conference and have a discussion about the
technical architecture of MongoDb. I found the information is very useful and
want to share with more people.
One thing I am very impressed by MongoDb is that
it is extremely easy to use and the underlying architecture is also very easy
to understand.
Here are some simple admin steps to start/stop
MongoDb server
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
# Install MongoDB
mkdir /data/lib
# Start Mongod server
.../bin/mongod # data stored in /data/db
# Start the command shell
.../bin/mongo
> show dbs
> show collections
# Remove collection
> db.person.drop()
# Stop the Mongod server from shell
> use admin
> db.shutdownServer()
Major difference from RDBMS
MongoDb differs from RDBMS in the following way
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
- Unlike an RDBMS record which is "flat" (a fixed number of simple data type), the basic unit of MongoDb is "document" which is "nested" and can contain multi-value fields (arrays, hash).
- Unlike RDBMS where all records stored in a table must be confined to the table schema, documents of any structure can be stored in the same collection.
- There is no "join" operation in the query. Overall, data is encouraged to be organized in a more denormalized manner and the more burden of ensuring data consistency is pushed to the application developers
- There is no concept of "transaction" in MongoDb. "Atomicity" is guaranteed only at the document level (no partial update of a document will occurred).
- There is no concept of "isolation", any data read by one client may have its value modified by another concurrent client.
By removing some of those features that a classical RDBMS will provide,
MongoDb can be more light-weight and be more scalable in processing big data.
Query processingMongoDb belongs to the
type of document-oriented DB. In this model, data is organized as JSON
document, and store into a collection. Collection can be thought for equivalent
to Table and Document is equivalent to records in RDBMS world.
Here are some basic example.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
# create a doc and save into a collection
> p = {firstname:"Dave", lastname:"Ho"}
> db.person.save(p)
> db.person.insert({firstname:"Ricky", lastname:"Ho"})
# Show all docs within a collection
> db.person.find()
# Iterate result using cursor
> var c = db.person.find()
> p1 = c.next()
> p2 = c.next()
To specify the search criteria, an example
document containing the fields that needs to match against need to be provided.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
> p3 = db.person.findone({lastname:"Ho"})
Notice that in the query, the value portion need to be determined before
the query is made (in other words, it cannot be based on other attributes of
the document). For example, lets say if we have a collection of
"Person", it is not possible to express a query that return person
whose weight is larger than 10 times of their height.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
# Return a subset of fields (ie: projection)
> db.person.find({lastname:"Ho"}, {firstname:true})
# Delete some records
> db.person.remove({firstname:"Ricky"})
To speed up the query, index can be used. In MongoDb, index is stored as a
BTree structure (so range query is automatically supported). Since the document
itself is a tree, the index can be specified as a path and drill into deep
nesting level inside the document.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
# To build an index for a collection
> db.person.ensureIndex({firstname:1})
# To show all existing indexes
> db.person.getIndexes()
# To remove an index
> db.person.dropIndex({firstname:1})
# Index can be build on a path of the doc.
> db.person.ensureIndex({"address.city":1})
# A composite key can be used to build index
> db.person.ensureIndex({lastname:1, firstname:1})
Index can also be build on an multi-valued attribute such as an array. In
this case, each element in the array will have a separate node in the BTree.
Building an index can be done in both offline
foreground mode or online background mode. Foreground mode will proceed much
faster but the DB cannot be access during the build index period. If the system
is running in a replica set (describe below), it is recommended to rotate each
member DB offline and build the index in foreground.
When there are multiple selection criteria in a
query, MongoDb attempts to use one single best index to select a candidate set
and then sequentially iterate through them to evaluate other criteria.
When there are multiple indexes available for a
collection. When handling a query the first time, MongoDb will create multiple
execution plans (one for each available index) and let them take turns (within certain
number of ticks) to execute until the fastest plan finishes. The result of the
fastest executor will be returned and the system remembers the corresponding
index used by the fastest executor. Subsequent query will use the remembered
index until certain number of updates has happened in the collection, then the
system repeats the process to figure out what is the best index at that time.
Since only one index will be used, it is
important to look at the search or sorting criteria of the query and build
additional composite index to match the query better. Maintaining an index is
not without cost as index need to be updated when docs are created, deleted and
updated, which incurs overhead to the update operations. To maintain an optimal
balance, we need to periodically measure the effectiveness of having an index
(e.g. the read/write ratio) and delete less efficient indexes.
Storage Model
Written in C++, MongoDB uses a memory map file
that directly map an on-disk data file to in-memory byte array where data
access logic is implemented using pointer arithmetic. Each document collection
is stored in one namespace file (which contains metadata information) as well
as multiple extent data files (with an exponentially/doubling increasing size).
The data structure uses doubly-linked-list
extensively. Each collection of data is organized in a linked list of extents
each of which represents a contiguous disk space. Each extent points to a
head/tail of another linked list of docs. Each doc contains a linked list to
other documents as well as the actual data encoded in BSON format.
Data modification happens in place. In case the
modification increases the size of record beyond its originally allocated
space, the whole record will be moved to a bigger region with some extra
padding bytes. The padding bytes is used as an growth buffer so that future
expansion doesn't necessary require moving the data again. The amount of
padding is dynamically adjusted per collection based on its modification
statistics. On the other hand, the space occupied by the original doc will be
free up. This is kept tracked by a list of free list of different size.
As we can imagine holes will be created over
time as objects are created, deleted or modified, this fragmentation will hurt
performance as less data is being read/write per disk I/O. Therefore, we need
to run the "compact" command periodically, which copy the data to a
contiguous space. This "compact" operation however is an exclusive
operation and has to be done offline. Typically this is done in a replica
setting by rotating each member offline one at a time to perform the
compaction.
Index are implemented as BTree. Each BTree node
contains a number of keys (within this node), as well as pointers to left
children BTree nodes of each key.
Data update and Transaction
To update an existing doc, we can do the
following
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
var p1 = db.person.findone({lastname:"Ho"})
p1["address"] = "San Jose"
db.person.save(p1)
# Do the same in one command
db.person.update({lastname:"Ho"},
{$set:{address:"San Jose"}},
false,
true)
Write by default doesn't wait. There are various wait options that the
client can specified what conditions to wait before the call returns (this can
also achievable by a followup "getlasterror" call), such as where the
changes is persisted on disk, or changes has been propagated to sufficient
members in the replica set. MongoDb also provides a sophisticated way to assign
tags to members of replica set to reflect their physical topology so that
customized write policy for each collection can be made based on their
reliability requirement.
In RDBMS, "Serializability" is a very
fundamental concept about the net effect of concurrently executing work units
is equivalent to as if these work units are arrange in some order of sequential
execution (one at a time). Therefore, each client can treat as if the DB is
exclusively available. The underlying implementation of DB server many use
LOCKs or Multi-version to provide the isolation. However, this concept is not
available in MongoDb (and many other NOSQL as well)
In MongoDb, every data you read should be
treated as a snapshot of the past, which means by the time you look at it, it
may have been changed in the DB. Therefore, if you are making a modification
based on some previously read data, by the time you send the modification
request, the condition where your modification is based on may have changed. If
this is not acceptable for your application's consistency requirement, you may
need to re-validate the condition at the time you request the modification (ie:
a "conditional_modify" should be made).
Under this scheme, a "condition" is
attached along with the modification request so that the DB server can validate
the condition before applying the modification. (of course, the condition
checking and modification must be atomic so no update can happen in between).
In MongoDb, this can be achieved by the "findAndModify" call.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
var account = db.bank.findone({id:1234})
var old_bal = account['balance']
var new_bal = old_bal + fund
# Pre-condition is specified in search criteria
db.bank.findAndModify({id:1234, balance:old_bal},
{$set: {balance: new_bal}})
# Check if the prev command successfully
var success =
db.runCommand({getlasterror:1,j:true})
if (!success) {
#retry_from_beginning
}
The concept of "transaction" is also missing in MongoDb. While
MongoDb guarantee each document will be atomically modified (so no partial
update will happen within a doc), but if the update modifies multiple
documents, then there are no guarantee on the atomicity across documents.
Therefore, it is the application developers
responsibility to implement the multi-update atomicity across multiple
documents. We describe a common design pattern to achieve that. This technique
is not specific to MongoDb and applicable to other NOSQL store, which can at
least guarantee atomicity at the single record level.
The basic idea is to first create a separate
document (called transaction) that links together all the documents that you
want to modify. And then create a reverse link from each document (to be
modified) back to the transaction. By carefully design the sequence of update
in the documents and the transaction, we can achieve the atomicity of modifying
multiple documents.
MongoDb's web site has also described a similar technique here (based on the same concept but the
implementation is slightly different).
Replication Model
High availability is achieved in MongoDb via
Replica Set, which provides data redundancy across multiple physical servers,
including a single primary DB as well as multiple secondary DBs. For data
consistency, all modifications (insert / update / deletes) request go to the primary
DB where modification is made and asynchronously replicated to the other
secondary DBs.
Within the replica set, members are
interconnected with each other to exchange heartbeat message. A crashed server
with missing heartbeat will be detected by other members and removed from the
replica set membership. After the dead secondary recovers in future, it can
rejoin the cluster by connecting to the primary to catchup the latest update
since its last crashed. If the crashes happens in a lengthy period of time
where the change log from the primary doesn't cover the whole crash period,
then the recovered secondary need to reload the whole data from the primary (as
if it was a brand new server).
In case of the primary DB crashes, a leader
election protocol will be run among the remaining members to nominate the new
primary, based on many factors such as the node priority, node uptime ... etc.
After getting majority vote, the new primary server will take place. Notice
that due to async replication, the newly elected primary DB doesn't necessary
having all the latest updated from the crashed DB.
Client lib provides the API for the App to
access the MongoDB server. At startup, the client lib will connect to some
member (based on a seed list) of the Replica set and issue a
"isMaster" command to gather the current picture of the set (who is
the primary and secondaries). After that, the client lib connect to the single
primary (where it will send all DB modification request) and some number of
secondaries (where it will send read-only queries). The client library will
periodically re-run the "isMaster" command to detect if any new
members has joined the set. When an existing member in the set is crashed,
connections to all existing clients will be dropped and forces a
resynchronization of the latest picture.
There is also a special secondary DB called
slave delay, which guarantee the data is propagated with a certain time lag
with the master. This is used mainly to recover data after accidental deletion
of data.
For data modification request, the client will
send the request to the primary DB, by default the request will be returned
once written to the primary, an optional parameter can be specified to indicate
a certain number of secondaries need to receive the modification before return
so the client can ensure the majority portion of members have got the request.
Of course there is a tradeoff between latency and reliability.
For query request, by default the client will
contact the primary which has the latest updated data. Optionally, the client
can specify its willingness to read from any secondaries, and tolerate that the
returned data may be outdated. This provide an opportunity to load balance the
read request across all secondaries. Notice that in this case, a subsequent
read following a write may not seen the update.
For read-mostly application, reading form any
secondaries can be a big performance improvement. To select the fastest
secondary DB member to issue query, the client driver periodically pings the
members and will favor issuing the query to the one with lowest latency. Notice
that read request is issued to only one node, there is no quorum read or read
from multiple nodes in MongoDb.
The main purpose of Replica set is to provide
data redundancy and also load balance read-request. It doesn't provide load
balancing for write-request since all modification still has to go to the
single master.
Another benefit of replica set is that members
can be taken offline on an rotation basis to perform expensive operation such
as compaction, indexing or backup, without impacting online clients using the
alive members.
Sharding Model
To load balance write-request, we can use
MongoDb shards. In the sharding setup, a collection can be partitioned (by a
partition key) into chunks (which is a key range) and have chunks distributed
across multiple shards (each shard will be a replica set). MongoDb sharding
effectively provide an unlimited size for data collection, which is important
for any big data scenario.
To reiterate, in the sharding model, a single
partition key will be specified for each collection that is stored in the
sharding cluster. The key space of the partition key is divided into contiguous
key range called chunk, which is hosted by corresponding shards.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
# To define the partition key
db.runcommand({shardcollection: "testdb.person",
key: {firstname:1, lastname:1}})
In the shard setting, the client lib connects to a stateless routing
server "MongoS", which behaves as if the "MongoD". The
routing server plays an important role in forwarding the client request to the
appropriate shard server according to the request characteristics.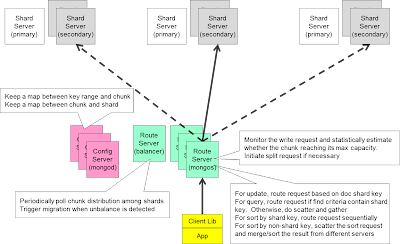
For insert/delete/update request containing the
partition key, based on the chunk/shard mapping information (obtained from the
config Server and cache locally), the route server will forward the request to
the corresponding primary server hosting the chunk whose key range covers the
partition key of the modified doc. Given a particular partition key, the
primary server containing that chunk can be unambiguously determined.
In case of query request, the routing server
will examine whether the partition key is part of the selection criteria and if
so will only "route" the request to the corresponding shard (primary
or secondary). However, if the partition key is not part of the selection
criteria, then the routing server will "scatter" the request to every
shard (pick one member of each shard) which will compute its local search, and
the result will be gathered at the routing server and return to the client.
When the query requires the result to be sorted, and if the partition key is
involved in the sort order, the routing server will route the request
sequentially to multiple shards as the client iterate the result. In case the
sort involves other key which is not the partition key, the router server will
scatter the request to all shards which will perform its local sort, and then
merge the result at the routing server (basically a distributed merge-sort).
As data are inserted into chunk and get close to
its full capacity, we need to split the chunk. The routing server can detect
this situation statistically based on the number of requests it forward as well
as the number of other routing server exist. Then the routing server will
contact the primary server of the shard that contains the full chunk and
request for a chunk split. The shard server will compute the mid point of the
key range that can evenly distribute the data and then split the chunk and
update the configuration server about its split point. Notice that so far there
is no data movement as data is still residing in the same shard server.
On the other hand, there is another
"balancer" process (running in one of the routing server) whose job
is to make sure each shard carry approximately same number of chunks. When the
unbalance condition is detected, the balancer will contact the busy shard to
trigger a chunk migration process. This migration process happens online where
the origination contacts the destination to initiate a data transfer, and data
will start to be copied from the origination to the destination. This process
may take some time (depends on the data volume) during which update can happen
continuously at the origination. These changes will be tracked at the
origination and when the copy finishes, delta will then transfer and applied to
the destination. After multiple rounds of applying deltas, the migration enters
the final round and the origination will halt and withhold all request coming
from the routing server. After the last round of changes have been applied to
the destination, the destination will update the configuration server about the
new shard configuration and notify the origination shard (which is still
withholding the request) to return a StaleConfigException to the Routing
server, which will then re-read the latest configuration from the configServer
and re-submit the previous requests. At some future point in time, data at the
origination will be physically deleted.
It is possible that under a high frequency
update condition, the changes being applied to the destination is unable to
catch up with the update rate happen at the origination. When this situation is
detected, the whole migration process will be aborted. The routing server may
pick a different chunk to start the migration afterwards.
Map/Reduce Execution
MongoDb provide a Map/Reduce framework to
perform parallel data processing. The concept is similar toHadoop Map/Reduce, but with the
following small differences ...
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
- It takes input from the query result of a collection rather than HDFS directory
- The reduce output can be append to an existing collection rather than an empty HDFS directory
Map/Reduce in Mongo works in a slightly different way as follows
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
- Client define a map function, reduce function, query that scope the input data, and an output collection that store the output result.
- Client send the request to the MongoS routing server
- MongoS forward the request to the appropriated shards (route or scatter depends on whether partition key appears in the query). Notice that MongoS will pick one member of each shard, currently always send to the primaryDB
- Primary DB of each shard executes the query and pipe output to the user-defined map function, which emit a bunch of key value pairs stored in memory buffer. When the memory buffer is full, a user-defined reducer function will be invoked that partially reduce the key values pairs in the memory buffer, result stored on the local collection.
- When step (4) completes, the reduce function will be executed on all the previous partially reduced result to merge a single reduced result on this server.
- When step (5) finishes, MongoS notifies the corresponding shard servers that will store the output collection. (if the output collection is non-partitioned, only a single shard will be notified, otherwise all shards will be notified).
- The primary db of the shard(s) storing the final collection will call for every shard to collect the partially reduced data previously done. It will only ask for the result based on its corresponding key range.
- The primary db run the reduce() function again on the list of partially reduced result. Then store the final reduced result locally. If the user provide a finalize function, it will be invoked as well.
Here is a simple example to build an inverted index from document to
topics
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
db.book.insert({title:"NOSQL",
about:["software", "db"]})
db.book.insert({title:"Java programming",
about:["software", "program"]})
db.book.insert({title:"Mongo",
about:["db", "technology"]})
db.book.insert({title:"Oracle",
about:["db", "software"]})
db.book.find()
m = function() {
for (var i in this.about) {
emit(this.about[i], this.title)
}
}
r = function(k, vals) {
return({topic:k, title:vals})
}
db.book.mapReduce(m, r, {query:{},
out:{replace:"mroutput"}})
db.mroutput.find()
Overall speaking, I found MongoDb is very powerful and easy to use. I look
forward to use MongoDb with Node.js and will share my experience in future
blogs.
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
Especially thanks to Jared Rosoff who provides me a lot of details of how MongoDb is implemented.
转自【http://horicky.blogspot.jp/2012/04/mongodb-architecture.html】


发表评论

-
MySQL中GBK与UTF-8的区别
2013-02-11 17:19 4139在MySQL中,如果数据库只需要支持一般中文,数据量 ... -
【转】MySql主主(主从)同步配置详解
2012-12-12 11:43 1508一、MySQL复制概述 MySQL支持单向、异步复制,复制 ... -
MySQL实现远程跨库操作
2012-11-27 10:43 3803现在需要实现将两个远程数据库中的数据归并到第三个数据库中,需要 ... -
MySQL单节点双实例双主架构问题
2012-11-25 22:18 1085公司用三台机器搭建了一套双主主数据库服务器,三台服务器分别是3 ... -
理解MySQL——复制(Replication)
2012-11-25 08:54 1565公司用三台机器搭建了� ... -
MongoDB系列之三:java操作MongoDB
2012-09-23 17:16 8731第三章:Java连接MongoDB� ... -
MongoDB系列之二:简单操作
2012-09-11 11:02 1267第一步:先进入MongoDB安 ... -
MongoDB系列之一:windows安装
2012-08-30 23:44 892时下NoSQL比较火,不知今后如何,本人也就盲目跟风一把,先搞 ...
相关推荐
MongoDB作为一种流行的NoSQL数据库管理系统,以其高性能、高可用性以及易于扩展的特性获得了市场的广泛认可。下面从MongoDB架构的角度,深入分析其关键知识点: 1. MongoDB架构的优势:在最新版的MongoDB架构指南中...
MongoDB架构指南向我们介绍了一个非关系型数据库系统MongoDB的设计原理和管理方式。作为数据库领域的重要组成部分,MongoDB的设计和实现代表了大数据时代对于存储解决方案的新要求。 首先,MongoDB的架构设计与传统...
MongoDB架构指南是一份介绍MongoDB数据库系统架构特点的详细文档,该文档强调MongoDB的灵活性、高性能和易用性,以及如何适应现代应用构建和运维的需要。Eliot Horowitz,MongoDB的联合创始人和CTO,在引言部分阐述...
MongoDB是一种流行的开源文档数据库系统,以其灵活性、可扩展性和高性能而受到...提供的“MongoDB_Architecture_Guide.pdf”和“MongoDB.docx”文件会进一步详细介绍这些内容,帮助学习者深入掌握MongoDB的相关知识。
MongoDB Architecture Guide 白皮书 目录: Table of Contents Industry Context 1 Document Model & MongoDB Query Language 2 Multi-Cloud, Global Database 5 MongoDB Cloud with Search, Data Lake, and Mobile ...
### MongoDB 架构指南 3.2 知识点概览 #### 一、引言与设计理念 **MongoDB 的设计理念**:MongoDB 不是在实验室里设计出来的,而是基于其创建者在构建大规模、高可用性系统过程中的实际经验而诞生的。其核心在于...
综上所述,MongoDB-architecture-guide-july-2018涵盖了MongoDB的核心组件“mongod”的工作原理、复制集和分片等高级特性,以及MongoDB与Python的交互。这份指南对于希望深入了解MongoDB架构并优化其性能的开发人员...
在 “Architecture” 部分,选择 “ARM 64 (aarch64)” 作为您的系统架构。 根据您的需求(例如,是否需要服务端和客户端二进制文件),下载相应的压缩文件。 下载完成后,解压文件并按照 MongoDB 安装指南进行安装...
Practical Guide to MongoDB covers the data model, underlying architecture, coding with Mongo Shell, and administrating the MongoDB platform, among other topics. The book also provides clear guidelines...
1. 查看 PHP 版本:首先,需要查看 PHP 的版本号和 Architecture 项(x86 或 x64),以及 PHP Extension Build 项(支持 TS 或 NTS)。 2. 下载 MongoDB 扩展文件:访问 PECL 官方网站,下载适合自己 PHP 版本的 ...
分片集群架构(Sharded Cluster Architectures)通常分为生产环境架构(Production Cluster Architecture)和测试环境架构(Sharded Cluster Test Architecture)。 在分片集群的部署和维护方面,文档提供了详细的...
They cover the data model, underlying architecture, how to code using Mongo Shell, and administration of the MongoDB platform, among other topics. The book also provides clear guidelines and ...
Its schema-free design encourages rapid application development, and built-in replication and auto-sharding architecture allow for massive parallel distribution. Production deployments at SourceForge...
[Replica Set 架构图](https://example.com/images/replica_set_architecture.png) 4. **测试环境配置** - 使用三台服务器(CentOS 7.8),分别为: - **192.168.56.200** (Master) - **192.168.56.201** (Slave) ...
Seata(Simple Extensible Autonomous Transaction Architecture)是阿里巴巴开源的分布式事务解决方案,它提供了AT、TCC、SAGA和XA四种事务模式,用于解决微服务架构下的分布式事务问题。Seata的主要特点是高性能、...
Node.js中的Clean Architecture用例,其中包括Express.js,MongoDB和Redis作为主要(但可替换)基础架构。 概述 此示例是一个简单的RESTful API应用程序,用户可以在其中使用Clean Architecture创建/更新/删除/查找...
Java Bases Log Framework with Elastic Search Distributed Architecture & MongoDB Map Reduce based Recommendation Logging 建筑学 建筑学 弹性搜索 MongoDB 和 Map Reduce 部署说明 要快速使用 Loggio,您必须...