- وµڈ览: 82968 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

و–‡ç« هˆ†ç±»
- ه…¨éƒ¨هچڑه®¢ (83)
- osgi (1)
- activemq (8)
- و¶ˆوپ¯ن¸é—´ن»¶ (8)
- ç®—و³• (1)
- oracle (5)
- و€§èƒ½ن¼کهŒ– (3)
- gof (1)
- ه¤ڑç؛؟程 (5)
- architecture (1)
- mina (1)
- هˆ†ه¸ƒه¼ڈ (4)
- Data Mining (9)
- 规هˆ™ه¼•و“ژ (0)
- وœ؛ه™¨ه¦ن¹ ن¸ژن؛؛ه·¥و™؛能 (2)
- وƒé™گ (1)
- dw (0)
- mysql (7)
- linux (3)
- solr (2)
- è´ںè½½ه‡è،، (1)
- وژ¨èچگه¼•و“ژ (2)
- hadoop (7)
- python (1)
- jvm (3)
- java (1)
- Memcached (1)
- nutch (14)
- openjdk (1)
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 1)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2014-03 ( 1)
- 2013-12 ( 1)
- 2013-11 ( 1)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
م€€هœ¨هپڑهˆ†ç±»و—¶ه¸¸ه¸¸éœ€è¦پن¼°ç®—ن¸چهگŒو ·وœ¬ن¹‹é—´çڑ„相ن¼¼و€§ه؛¦é‡ڈ(Similarity Measurement),è؟™و—¶é€ڑه¸¸é‡‡ç”¨çڑ„و–¹و³•ه°±وک¯è®،ç®—و ·وœ¬é—´çڑ„“è·ç¦»â€(Distance)م€‚采用ن»€ن¹ˆو ·çڑ„و–¹و³•è®،ç®—è·ç¦»وک¯ه¾ˆè®²ç©¶ï¼Œç”ڑ至ه…³ç³»هˆ°هˆ†ç±»çڑ„و£ç،®ن¸ژهگ¦م€‚
م€€م€€وœ¬و–‡çڑ„ç›®çڑ„ه°±وک¯ه¯¹ه¸¸ç”¨çڑ„相ن¼¼و€§ه؛¦é‡ڈن½œن¸€ن¸ھو€»ç»“م€‚
وœ¬و–‡ç›®ه½•ï¼ڑ
1. و¬§و°ڈè·ç¦»
2. و›¼ه“ˆé،؟è·ç¦»
3. هˆ‡و¯”é›ھه¤«è·ç¦»
4. é—µهڈ¯ه¤«و–¯هں؛è·ç¦»
5. و ‡ه‡†هŒ–و¬§و°ڈè·ç¦»
6. 马و°ڈè·ç¦»
7. ه¤¹è§’ن½™ه¼¦
8. و±‰وکژè·ç¦»
9. و°هچ،ه¾·è·ç¦» & و°هچ،ه¾·ç›¸ن¼¼ç³»و•°
10. 相ه…³ç³»و•° & 相ه…³è·ç¦»
11. ن؟،وپ¯ç†µ
1. و¬§و°ڈè·ç¦» (Euclidean Distance)
آ آ آ آ آ آ و¬§و°ڈè·ç¦»وک¯وœ€وک“ن؛ژçگ†è§£çڑ„ن¸€ç§چè·ç¦»è®،ç®—و–¹و³•ï¼Œو؛گè‡ھو¬§و°ڈç©؛é—´ن¸ن¸¤ç‚¹é—´çڑ„è·ç¦»ه…¬ه¼ڈم€‚
(1)ن؛Œç»´ه¹³é¢ن¸ٹن¸¤ç‚¹a(x1,y1)ن¸ژb(x2,y2)é—´çڑ„و¬§و°ڈè·ç¦»ï¼ڑ
آ 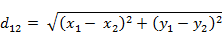
(2)ن¸‰ç»´ç©؛é—´ن¸¤ç‚¹a(x1,y1,z1)ن¸ژb(x2,y2,z2)é—´çڑ„و¬§و°ڈè·ç¦»ï¼ڑ
آ 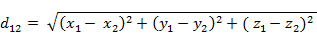
(3)ن¸¤ن¸ھnç»´هگ‘é‡ڈa(x11,x12,…,x1n)ن¸ژ b(x21,x22,…,x2n)é—´çڑ„و¬§و°ڈè·ç¦»ï¼ڑ
آ 
م€€م€€ن¹ںهڈ¯ن»¥ç”¨è،¨ç¤؛وˆگهگ‘é‡ڈè؟گç®—çڑ„ه½¢ه¼ڈï¼ڑ
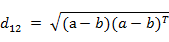
آ
(4)Matlabè®،ç®—و¬§و°ڈè·ç¦»
Matlabè®،ç®—è·ç¦»ن¸»è¦پن½؟用pdistه‡½و•°م€‚è‹¥Xوک¯ن¸€ن¸ھMأ—Nçڑ„çں©éکµï¼Œهˆ™pdist(X)ه°†Xçں©éکµMè،Œçڑ„و¯ڈن¸€è،Œن½œن¸؛ن¸€ن¸ھNç»´هگ‘é‡ڈ,然هگژè®،ç®—è؟™Mن¸ھهگ‘é‡ڈن¸¤ن¸¤é—´çڑ„è·ç¦»م€‚
ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„و¬§ه¼ڈè·ç¦»
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X,'euclidean')
结وœï¼ڑ
D =
آ آ آ 1.0000آ آ آ 2.0000آ آ آ 2.2361
آ
2. و›¼ه“ˆé،؟è·ç¦» (Manhattan Distance)
آ آ آ آ آ آ ن»ژهگچه—ه°±هڈ¯ن»¥çŒœه‡؛è؟™ç§چè·ç¦»çڑ„è®،ç®—و–¹و³•ن؛†م€‚وƒ³è±،ن½ هœ¨و›¼ه“ˆé،؟è¦پن»ژن¸€ن¸ھهچپه—è·¯هڈ£ه¼€è½¦هˆ°هڈ¦ه¤–ن¸€ن¸ھهچپه—è·¯هڈ£ï¼Œé©¾é©¶è·ç¦»وک¯ن¸¤ç‚¹é—´çڑ„ç›´ç؛؟è·ç¦»هگ—ï¼ںوک¾ç„¶ن¸چوک¯ï¼Œé™¤éن½ 能ç©؟è¶ٹه¤§و¥¼م€‚ه®é™…驾驶è·ç¦»ه°±وک¯è؟™ن¸ھ“و›¼ه“ˆé،؟è·ç¦»â€م€‚而è؟™ن¹ںوک¯و›¼ه“ˆé،؟è·ç¦»هگچ称çڑ„و¥و؛گ, و›¼ه“ˆé،؟è·ç¦»ن¹ں称ن¸؛هںژه¸‚è،—هŒ؛è·ç¦» (City Block distance) م€‚
(1)ن؛Œç»´ه¹³é¢ن¸¤ç‚¹a(x1,y1)ن¸ژb(x2,y2)é—´çڑ„و›¼ه“ˆé،؟è·ç¦»
آ 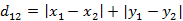
(2)ن¸¤ن¸ھnç»´هگ‘é‡ڈa(x11,x12,…,x1n)ن¸ژ b(x21,x22,…,x2n)é—´çڑ„و›¼ه“ˆé،؟è·ç¦»
آ 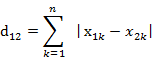
(3) Matlabè®،ç®—و›¼ه“ˆé،؟è·ç¦»
ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„و›¼ه“ˆé،؟è·ç¦»
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'cityblock')
结وœï¼ڑ
D =
آ آ آ آ 1آ آ آ آ 2آ آ آ آ 3
3. هˆ‡و¯”é›ھه¤«è·ç¦» ( Chebyshev Distance )
آ آ آ آ آ آ ه›½é™…è±،و£‹çژ©è؟‡ن¹ˆï¼ںه›½çژ‹èµ°ن¸€و¥èƒ½ه¤ں移هٹ¨هˆ°ç›¸é‚»çڑ„8ن¸ھو–¹و ¼ن¸çڑ„ن»»و„ڈن¸€ن¸ھم€‚é‚£ن¹ˆه›½çژ‹ن»ژو ¼هگ(x1,y1)èµ°هˆ°و ¼هگ(x2,y2)وœ€ه°‘需è¦په¤ڑه°‘و¥ï¼ںè‡ھه·±èµ°èµ°è¯•è¯•م€‚ن½ ن¼ڑهڈ‘çژ°وœ€ه°‘و¥و•°و€»وک¯max( | x2-x1 | , | y2-y1 | ) و¥ م€‚وœ‰ن¸€ç§چç±»ن¼¼çڑ„ن¸€ç§چè·ç¦»ه؛¦é‡ڈو–¹و³•هڈ«هˆ‡و¯”é›ھه¤«è·ç¦»م€‚
(1)ن؛Œç»´ه¹³é¢ن¸¤ç‚¹a(x1,y1)ن¸ژb(x2,y2)é—´çڑ„هˆ‡و¯”é›ھه¤«è·ç¦»
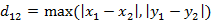 آ
آ
(2)ن¸¤ن¸ھnç»´هگ‘é‡ڈa(x11,x12,…,x1n)ن¸ژ b(x21,x22,…,x2n)é—´çڑ„هˆ‡و¯”é›ھه¤«è·ç¦»
آ 
م€€م€€è؟™ن¸ھه…¬ه¼ڈçڑ„هڈ¦ن¸€ç§چç‰ن»·ه½¢ه¼ڈوک¯
آ 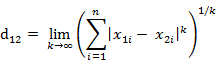
آ آ آ آ آ آ 看ن¸چه‡؛ن¸¤ن¸ھه…¬ه¼ڈوک¯ç‰ن»·çڑ„ï¼ںوڈگç¤؛ن¸€ن¸‹ï¼ڑ试试用و”¾ç¼©و³•ه’Œه¤¹é€¼و³•هˆ™و¥è¯پوکژم€‚
(3)Matlabè®،ç®—هˆ‡و¯”é›ھه¤«è·ç¦»
ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„هˆ‡و¯”é›ھه¤«è·ç¦»
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'chebychev')
结وœï¼ڑ
D =
آ آ آ آ 1آ آ آ آ 2آ آ آ آ 2
آ
4. é—µهڈ¯ه¤«و–¯هں؛è·ç¦» (Minkowski Distance)
é—µو°ڈè·ç¦»ن¸چوک¯ن¸€ç§چè·ç¦»ï¼Œè€Œوک¯ن¸€ç»„è·ç¦»çڑ„ه®ڑن¹‰م€‚
(1) é—µو°ڈè·ç¦»çڑ„ه®ڑن¹‰
آ آ آ آ آ آ ن¸¤ن¸ھnç»´هڈکé‡ڈa(x11,x12,…,x1n)ن¸ژ b(x21,x22,…,x2n)é—´çڑ„é—µهڈ¯ه¤«و–¯هں؛è·ç¦»ه®ڑن¹‰ن¸؛ï¼ڑ
آ 
ه…¶ن¸pوک¯ن¸€ن¸ھهڈکهڈ‚و•°م€‚
ه½“p=1و—¶ï¼Œه°±وک¯و›¼ه“ˆé،؟è·ç¦»
ه½“p=2و—¶ï¼Œه°±وک¯و¬§و°ڈè·ç¦»
ه½“p→âˆو—¶ï¼Œه°±وک¯هˆ‡و¯”é›ھه¤«è·ç¦»
آ آ آ آ آ آ و ¹وچ®هڈکهڈ‚و•°çڑ„ن¸چهگŒï¼Œé—µو°ڈè·ç¦»هڈ¯ن»¥è،¨ç¤؛ن¸€ç±»çڑ„è·ç¦»م€‚
(2)é—µو°ڈè·ç¦»çڑ„ç¼؛点
م€€م€€é—µو°ڈè·ç¦»ï¼ŒهŒ…و‹¬و›¼ه“ˆé،؟è·ç¦»م€پو¬§و°ڈè·ç¦»ه’Œهˆ‡و¯”é›ھه¤«è·ç¦»éƒ½هکهœ¨وکژوک¾çڑ„ç¼؛点م€‚
م€€م€€ن¸¾ن¸ھن¾‹هگï¼ڑن؛Œç»´و ·وœ¬(è؛«é«ک,ن½“é‡چ),ه…¶ن¸è؛«é«ک范ه›´وک¯150~190,ن½“é‡چ范ه›´ وک¯50~60,وœ‰ن¸‰ن¸ھو ·وœ¬ï¼ڑa(180,50),b(190,50),c(180,60)م€‚é‚£ن¹ˆaن¸ژbن¹‹é—´çڑ„é—µو°ڈè·ç¦»ï¼ˆو— è®؛وک¯و›¼ه“ˆé،؟è·ç¦»م€پو¬§و°ڈè·ç¦»وˆ–هˆ‡و¯” é›ھه¤«è·ç¦»ï¼‰ç‰ن؛ژaن¸ژcن¹‹é—´çڑ„é—µو°ڈè·ç¦»ï¼Œن½†وک¯è؛«é«کçڑ„10cmçœںçڑ„ç‰ن»·ن؛ژن½“é‡چçڑ„10kgن¹ˆï¼ںه› و¤ç”¨é—µو°ڈè·ç¦»و¥è،،é‡ڈè؟™ن؛›و ·وœ¬é—´çڑ„相ن¼¼ه؛¦ه¾ˆوœ‰é—®é¢کم€‚
آ آ آ آ آ آ 简هچ•è¯´و¥ï¼Œé—µو°ڈè·ç¦»çڑ„ç¼؛点ن¸»è¦پوœ‰ن¸¤ن¸ھï¼ڑ(1)ه°†هگ„ن¸ھهˆ†é‡ڈçڑ„é‡ڈç؛²(scale),ن¹ںه°±وک¯â€œهچ•ن½چâ€ه½“ن½œç›¸هگŒçڑ„看ه¾…ن؛†م€‚(2)و²،وœ‰è€ƒè™‘هگ„ن¸ھهˆ†é‡ڈçڑ„هˆ†ه¸ƒï¼ˆوœںوœ›ï¼Œو–¹ه·®ç‰)هڈ¯èƒ½وک¯ن¸چهگŒçڑ„م€‚
(3)Matlabè®،ç®—é—µو°ڈè·ç¦»
ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„é—µو°ڈè·ç¦»ï¼ˆن»¥هڈکهڈ‚و•°ن¸؛2çڑ„و¬§و°ڈè·ç¦»ن¸؛ن¾‹ï¼‰
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X,'minkowski',2)
结وœï¼ڑ
D =
آ آ آ 1.0000آ آ آ 2.0000آ آ آ 2.2361
5. و ‡ه‡†هŒ–و¬§و°ڈè·ç¦» (Standardized Euclidean distance )
(1)و ‡ه‡†و¬§و°ڈè·ç¦»çڑ„ه®ڑن¹‰
م€€م€€و ‡ه‡†هŒ–و¬§و°ڈè·ç¦»وک¯é’ˆه¯¹ç®€هچ•و¬§و°ڈè·ç¦»çڑ„ç¼؛点而ن½œçڑ„ن¸€ç§چو”¹è؟›و–¹و،ˆم€‚و ‡ه‡†و¬§و°ڈè·ç¦»çڑ„ و€è·¯ï¼ڑو—¢ç„¶و•°وچ®هگ„ç»´هˆ†é‡ڈçڑ„هˆ†ه¸ƒن¸چن¸€و ·ï¼Œه¥½هگ§ï¼پé‚£وˆ‘ه…ˆه°†هگ„ن¸ھهˆ†é‡ڈ都“و ‡ه‡†هŒ–â€هˆ°ه‡ه€¼م€پو–¹ه·®ç›¸ç‰هگ§م€‚ه‡ه€¼ه’Œو–¹ه·®و ‡ه‡†هŒ–هˆ°ه¤ڑه°‘ه‘¢ï¼ںè؟™é‡Œه…ˆه¤چن¹ 点ç»ںè®،ه¦çں¥è¯†هگ§ï¼Œهپ‡ 设و ·وœ¬é›†Xçڑ„ه‡ه€¼(mean)ن¸؛m,و ‡ه‡†ه·®(standard deviation)ن¸؛s,那ن¹ˆXçڑ„“و ‡ه‡†هŒ–هڈکé‡ڈâ€è،¨ç¤؛ن¸؛ï¼ڑ
م€€م€€è€Œن¸”و ‡ه‡†هŒ–هڈکé‡ڈçڑ„و•°ه¦وœںوœ›ن¸؛0,و–¹ه·®ن¸؛1م€‚ه› و¤و ·وœ¬é›†çڑ„و ‡ه‡†هŒ–è؟‡ç¨‹(standardization)用ه…¬ه¼ڈوڈڈè؟°ه°±وک¯ï¼ڑ
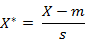
م€€م€€و ‡ه‡†هŒ–هگژçڑ„ه€¼ =آ ( و ‡ه‡†هŒ–ه‰چçڑ„ه€¼آ ï¼چ هˆ†é‡ڈçڑ„ه‡ه€¼ ) /هˆ†é‡ڈçڑ„و ‡ه‡†ه·®
م€€م€€ç»ڈè؟‡ç®€هچ•çڑ„وژ¨ه¯¼ه°±هڈ¯ن»¥ه¾—هˆ°ن¸¤ن¸ھnç»´هگ‘é‡ڈa(x11,x12,…,x1n)ن¸ژ b(x21,x22,…,x2n)é—´çڑ„و ‡ه‡†هŒ–و¬§و°ڈè·ç¦»çڑ„ه…¬ه¼ڈï¼ڑ

م€€م€€ه¦‚وœه°†و–¹ه·®çڑ„ه€’و•°çœ‹وˆگوک¯ن¸€ن¸ھوƒé‡چ,è؟™ن¸ھه…¬ه¼ڈهڈ¯ن»¥çœ‹وˆگوک¯ن¸€ç§چهٹ وƒو¬§و°ڈè·ç¦» (Weighted Euclidean distance) م€‚
(2)Matlabè®،ç®—و ‡ه‡†هŒ–و¬§و°ڈè·ç¦»
ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„و ‡ه‡†هŒ–و¬§و°ڈè·ç¦» (هپ‡è®¾ن¸¤ن¸ھهˆ†é‡ڈçڑ„و ‡ه‡†ه·®هˆ†هˆ«ن¸؛0.5ه’Œ1)
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'seuclidean',[0.5,1])
结وœï¼ڑ
D =
آ آ آ 2.0000آ آ آ 2.0000آ آ آ 2.8284
آ
6. 马و°ڈè·ç¦» (Mahalanobis Distance)
(1)马و°ڈè·ç¦»ه®ڑن¹‰
آ آ آ آ آ آ وœ‰Mن¸ھو ·وœ¬هگ‘é‡ڈX1~Xm,هچڈو–¹ه·®çں©éکµè®°ن¸؛S,ه‡ه€¼è®°ن¸؛هگ‘é‡ڈخ¼ï¼Œهˆ™ه…¶ن¸و ·وœ¬هگ‘é‡ڈXهˆ°uçڑ„马و°ڈè·ç¦»è،¨ç¤؛ن¸؛ï¼ڑ
آ 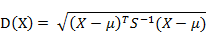
آ آ آ آ آ آ 而ه…¶ن¸هگ‘é‡ڈXiن¸ژXjن¹‹é—´çڑ„马و°ڈè·ç¦»ه®ڑن¹‰ن¸؛ï¼ڑ

آ آ آ آ آ آ è‹¥هچڈو–¹ه·®çں©éکµوک¯هچ•ن½چçں©éکµï¼ˆهگ„ن¸ھو ·وœ¬هگ‘é‡ڈن¹‹é—´ç‹¬ç«‹هگŒهˆ†ه¸ƒï¼‰,هˆ™ه…¬ه¼ڈه°±وˆگن؛†ï¼ڑ
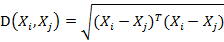
آ آ آ آ آ آ ن¹ںه°±وک¯و¬§و°ڈè·ç¦»ن؛†م€‚
م€€م€€è‹¥هچڈو–¹ه·®çں©éکµوک¯ه¯¹è§’çں©éکµï¼Œه…¬ه¼ڈهڈکوˆگن؛†و ‡ه‡†هŒ–و¬§و°ڈè·ç¦»م€‚
(2)马و°ڈè·ç¦»çڑ„ن¼کç¼؛点ï¼ڑé‡ڈç؛²و— ه…³ï¼Œوژ’除هڈکé‡ڈن¹‹é—´çڑ„相ه…³و€§çڑ„ه¹²و‰°م€‚
(3) Matlabè®،ç®—(1 2),( 1 3),( 2 2),( 3 1)ن¸¤ن¸¤ن¹‹é—´çڑ„马و°ڈè·ç¦»
X = [1 2; 1 3; 2 2; 3 1]
Y = pdist(X,'mahalanobis')
آ
结وœï¼ڑ
Y =
آ آ آ 2.3452آ آ آ 2.0000آ آ آ 2.3452آ آ آ 1.2247آ آ آ 2.4495آ آ آ 1.2247
آ
7. ه¤¹è§’ن½™ه¼¦ (Cosine)
آ آ آ آ آ آ وœ‰و²،وœ‰وگ错,هڈˆن¸چوک¯ه¦ه‡ ن½•ï¼Œو€ژن¹ˆو‰¯هˆ°ه¤¹è§’ن½™ه¼¦ن؛†ï¼ںهگ„ن½چ看ه®کç¨چه®‰ه‹؟è؛پم€‚ه‡ ن½•ن¸ه¤¹è§’ن½™ه¼¦هڈ¯ç”¨و¥è،،é‡ڈن¸¤ن¸ھهگ‘é‡ڈو–¹هگ‘çڑ„ه·®ه¼‚,وœ؛ه™¨ه¦ن¹ ن¸ه€ں用è؟™ن¸€و¦‚ه؟µو¥è،،é‡ڈو ·وœ¬هگ‘é‡ڈن¹‹é—´çڑ„ه·®ه¼‚م€‚
(1)هœ¨ن؛Œç»´ç©؛é—´ن¸هگ‘é‡ڈA(x1,y1)ن¸ژهگ‘é‡ڈB(x2,y2)çڑ„ه¤¹è§’ن½™ه¼¦ه…¬ه¼ڈï¼ڑ
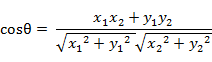
(2) ن¸¤ن¸ھnç»´و ·وœ¬ç‚¹a(x11,x12,…,x1n)ه’Œb(x21,x22,…,x2n)çڑ„ه¤¹è§’ن½™ه¼¦
آ آ آ آ آ آ ç±»ن¼¼çڑ„,ه¯¹ن؛ژن¸¤ن¸ھnç»´و ·وœ¬ç‚¹a(x11,x12,…,x1n)ه’Œb(x21,x22,…,x2n),هڈ¯ن»¥ن½؟用类ن¼¼ن؛ژه¤¹è§’ن½™ه¼¦çڑ„و¦‚ه؟µو¥è،،é‡ڈه®ƒن»¬é—´çڑ„相ن¼¼ç¨‹ه؛¦م€‚
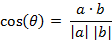
م€€م€€هچ³ï¼ڑ
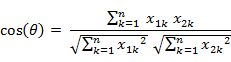
آ آ آ آ آ آ ه¤¹è§’ن½™ه¼¦هڈ–ه€¼èŒƒه›´ن¸؛[-1,1]م€‚ه¤¹è§’ن½™ه¼¦è¶ٹه¤§è،¨ç¤؛ن¸¤ن¸ھهگ‘é‡ڈçڑ„ه¤¹è§’è¶ٹه°ڈ,ه¤¹è§’ن½™ه¼¦è¶ٹه°ڈè،¨ç¤؛ن¸¤هگ‘é‡ڈçڑ„ه¤¹è§’è¶ٹه¤§م€‚ه½“ن¸¤ن¸ھهگ‘é‡ڈçڑ„و–¹هگ‘é‡چهگˆو—¶ه¤¹è§’ن½™ه¼¦هڈ–وœ€ه¤§ه€¼1,ه½“ن¸¤ن¸ھهگ‘é‡ڈçڑ„و–¹هگ‘ه®Œه…¨ç›¸هڈچه¤¹è§’ن½™ه¼¦هڈ–وœ€ه°ڈه€¼-1م€‚
آ آ آ آ آ آ ه¤¹è§’ن½™ه¼¦çڑ„ه…·ن½“ه؛”用هڈ¯ن»¥هڈ‚éک…هڈ‚考و–‡çŒ®[1]م€‚
(3)Matlabè®،ç®—ه¤¹è§’ن½™ه¼¦
ن¾‹هگï¼ڑè®،ç®—(1,0)م€پ( 1,1.732)م€پ( -1,0)ن¸¤ن¸¤é—´çڑ„ه¤¹è§’ن½™ه¼¦
X = [1 0 ; 1 1.732 ; -1 0]
D = 1- pdist(X, 'cosine')آ % Matlabن¸çڑ„pdist(X, 'cosine')ه¾—هˆ°çڑ„وک¯1ه‡ڈه¤¹è§’ن½™ه¼¦çڑ„ه€¼
结وœï¼ڑ
D =
آ آ آ 0.5000آ آ -1.0000آ آ -0.5000
آ
8. و±‰وکژè·ç¦» (Hamming distance)
(1)و±‰وکژè·ç¦»çڑ„ه®ڑن¹‰
آ آ آ آ آ آ ن¸¤ن¸ھç‰é•؟ه—符ن¸²s1ن¸ژs2ن¹‹é—´çڑ„و±‰وکژè·ç¦»ه®ڑن¹‰ن¸؛ه°†ه…¶ن¸ن¸€ن¸ھهڈکن¸؛هڈ¦ه¤–ن¸€ن¸ھو‰€éœ€è¦پن½œçڑ„وœ€ه°ڈو›؟وچ¢و¬،و•°م€‚ن¾‹ه¦‚ه—符ن¸²â€œ1111â€ن¸ژ“1001â€ن¹‹é—´çڑ„و±‰وکژè·ç¦»ن¸؛2م€‚
آ آ آ آ آ آ ه؛”用ï¼ڑن؟،وپ¯ç¼–ç پ(ن¸؛ن؛†ه¢ه¼؛ه®¹é”™و€§ï¼Œه؛”ن½؟ه¾—ç¼–ç پé—´çڑ„وœ€ه°ڈو±‰وکژè·ç¦»ه°½هڈ¯èƒ½ه¤§ï¼‰م€‚
(2)Matlabè®،ç®—و±‰وکژè·ç¦»
م€€م€€Matlabن¸2ن¸ھهگ‘é‡ڈن¹‹é—´çڑ„و±‰وکژè·ç¦»çڑ„ه®ڑن¹‰ن¸؛2ن¸ھهگ‘é‡ڈن¸چهگŒçڑ„هˆ†é‡ڈو‰€هچ çڑ„百هˆ†و¯”م€‚
آ آ آ آ آ آ ن¾‹هگï¼ڑè®،ç®—هگ‘é‡ڈ(0,0)م€پ(1,0)م€پ(0,2)ن¸¤ن¸¤é—´çڑ„و±‰وکژè·ç¦»
X = [0 0 ; 1 0 ; 0 2];
D = PDIST(X, 'hamming')
结وœï¼ڑ
D =
آ آ آ 0.5000آ آ آ 0.5000آ آ آ 1.0000
آ
9. و°هچ،ه¾·ç›¸ن¼¼ç³»و•° (Jaccard similarity coefficient)
(1) و°هچ،ه¾·ç›¸ن¼¼ç³»و•°
آ آ آ آ آ آ ن¸¤ن¸ھ集هگˆAه’ŒBçڑ„ن؛¤é›†ه…ƒç´ هœ¨A,Bçڑ„ه¹¶é›†ن¸و‰€هچ çڑ„و¯”ن¾‹ï¼Œç§°ن¸؛ن¸¤ن¸ھ集هگˆçڑ„و°هچ،ه¾·ç›¸ن¼¼ç³»و•°ï¼Œç”¨ç¬¦هڈ·J(A,B)è،¨ç¤؛م€‚
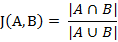
م€€م€€و°هچ،ه¾·ç›¸ن¼¼ç³»و•°وک¯è،،é‡ڈن¸¤ن¸ھ集هگˆçڑ„相ن¼¼ه؛¦ن¸€ç§چوŒ‡و ‡م€‚
(2) و°هچ،ه¾·è·ç¦»
آ آ آ آ آ آ ن¸ژو°هچ،ه¾·ç›¸ن¼¼ç³»و•°ç›¸هڈچçڑ„و¦‚ه؟µوک¯و°هچ،ه¾·è·ç¦» ( Jaccard distance)م€‚و°هچ،ه¾·è·ç¦»هڈ¯ç”¨ه¦‚ن¸‹ه…¬ه¼ڈè،¨ç¤؛ï¼ڑ
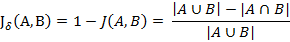
م€€م€€و°هچ،ه¾·è·ç¦»ç”¨ن¸¤ن¸ھ集هگˆن¸ن¸چهگŒه…ƒç´ هچ و‰€وœ‰ه…ƒç´ çڑ„و¯”ن¾‹و¥è،،é‡ڈن¸¤ن¸ھ集هگˆçڑ„هŒ؛هˆ†ه؛¦م€‚
(3) و°هچ،ه¾·ç›¸ن¼¼ç³»و•°ن¸ژو°هچ،ه¾·è·ç¦»çڑ„ه؛”用
آ آ آ آ آ آ هڈ¯ه°†و°هچ،ه¾·ç›¸ن¼¼ç³»و•°ç”¨هœ¨è،،é‡ڈو ·وœ¬çڑ„相ن¼¼ه؛¦ن¸ٹم€‚
م€€م€€و ·وœ¬Aن¸ژو ·وœ¬Bوک¯ن¸¤ن¸ھnç»´هگ‘é‡ڈ,而ن¸”و‰€وœ‰ç»´ه؛¦çڑ„هڈ–ه€¼éƒ½وک¯0وˆ–1م€‚ن¾‹ه¦‚ï¼ڑA(0111)ه’ŒB(1011)م€‚وˆ‘ن»¬ه°†و ·وœ¬çœ‹وˆگوک¯ن¸€ن¸ھ集هگˆï¼Œ1è،¨ç¤؛集هگˆهŒ…هگ«è¯¥ه…ƒç´ ,0è،¨ç¤؛集هگˆن¸چهŒ…هگ«è¯¥ه…ƒç´ م€‚
p ï¼ڑو ·وœ¬Aن¸ژB都وک¯1çڑ„ç»´ه؛¦çڑ„ن¸ھو•°
q ï¼ڑو ·وœ¬Aوک¯1,و ·وœ¬Bوک¯0çڑ„ç»´ه؛¦çڑ„ن¸ھو•°
r ï¼ڑو ·وœ¬Aوک¯0,و ·وœ¬Bوک¯1çڑ„ç»´ه؛¦çڑ„ن¸ھو•°
s ï¼ڑو ·وœ¬Aن¸ژB都وک¯0çڑ„ç»´ه؛¦çڑ„ن¸ھو•°
é‚£ن¹ˆو ·وœ¬Aن¸ژBçڑ„و°هچ،ه¾·ç›¸ن¼¼ç³»و•°هڈ¯ن»¥è،¨ç¤؛ن¸؛ï¼ڑ
è؟™é‡Œp+q+rهڈ¯çگ†è§£ن¸؛Aن¸ژBçڑ„ه¹¶é›†çڑ„ه…ƒç´ ن¸ھو•°ï¼Œè€Œpوک¯Aن¸ژBçڑ„ن؛¤é›†çڑ„ه…ƒç´ ن¸ھو•°م€‚
而و ·وœ¬Aن¸ژBçڑ„و°هچ،ه¾·è·ç¦»è،¨ç¤؛ن¸؛ï¼ڑ
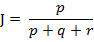
(4)Matlab è®،ç®—و°هچ،ه¾·è·ç¦»
Matlabçڑ„pdistه‡½و•°ه®ڑن¹‰çڑ„و°هچ،ه¾·è·ç¦»è·ںوˆ‘è؟™é‡Œçڑ„ه®ڑن¹‰وœ‰ن¸€ن؛›ه·®هˆ«ï¼ŒMatlabن¸ه°†ه…¶ه®ڑن¹‰ن¸؛ن¸چهگŒçڑ„ç»´ه؛¦çڑ„ن¸ھو•°هچ “éه…¨é›¶ç»´ه؛¦â€çڑ„و¯”ن¾‹م€‚
ن¾‹هگï¼ڑè®،ç®—(1,1,0)م€پ(1,-1,0)م€پ(-1,1,0)ن¸¤ن¸¤ن¹‹é—´çڑ„و°هچ،ه¾·è·ç¦»
X = [1 1 0; 1 -1 0; -1 1 0]
D = pdist( X , 'jaccard')
结وœ
D =
0.5000آ آ آ 0.5000آ آ آ 1.0000
آ
10. 相ه…³ç³»و•° ( Correlation coefficient ) ن¸ژ相ه…³è·ç¦» (Correlation distance)
(1) 相ه…³ç³»و•°çڑ„ه®ڑن¹‰
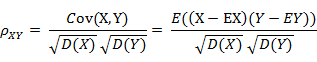
相ه…³ç³»و•°وک¯è،،é‡ڈéڑڈوœ؛هڈکé‡ڈXن¸ژY相ه…³ç¨‹ه؛¦çڑ„ن¸€ç§چو–¹و³•ï¼Œç›¸ه…³ç³»و•°çڑ„هڈ–ه€¼èŒƒه›´وک¯[-1,1]م€‚相ه…³ç³»و•°çڑ„ç»ه¯¹ه€¼è¶ٹه¤§ï¼Œهˆ™è،¨وکژXن¸ژY相ه…³ه؛¦è¶ٹé«کم€‚ه½“Xن¸ژYç؛؟و€§ç›¸ه…³و—¶ï¼Œç›¸ه…³ç³»و•°هڈ–ه€¼ن¸؛1(و£ç؛؟و€§ç›¸ه…³ï¼‰وˆ–-1(è´ںç؛؟و€§ç›¸ه…³ï¼‰م€‚
(2)相ه…³è·ç¦»çڑ„ه®ڑن¹‰
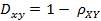
آ
(3)Matlabè®،ç®—(1, 2 ,3 ,4 )ن¸ژ( 3 ,8 ,7 ,6 )ن¹‹é—´çڑ„相ه…³ç³»و•°ن¸ژ相ه…³è·ç¦»
X = [1 2 3 4 ; 3 8 7 6]
C = corrcoef( X' ) آ آ %ه°†è؟”ه›ç›¸ه…³ç³»و•°çں©éکµ
D = pdist( X , 'correlation')
结وœï¼ڑ
C =
آ آ آ 1.0000آ آ آ 0.4781
آ آ آ 0.4781آ آ آ 1.0000
D =
0.5219
آ آ آ آ آ ه…¶ن¸0.4781ه°±وک¯ç›¸ه…³ç³»و•°ï¼Œ0.5219وک¯ç›¸ه…³è·ç¦»م€‚
11. ن؟،وپ¯ç†µ ( Information Entropy)
آ آ آ آ آ آ ن؟،وپ¯ç†µه¹¶ن¸چه±ن؛ژن¸€ç§چ相ن¼¼و€§ه؛¦é‡ڈم€‚é‚£ن¸؛ن»€ن¹ˆو”¾هœ¨è؟™ç¯‡و–‡ç« ن¸ه•ٹï¼ںè؟™ن¸ھم€‚م€‚م€‚وˆ‘ن¹ںن¸چçں¥éپ“م€‚ (╯▽╰)
ن؟،وپ¯ç†µوک¯è،،é‡ڈهˆ†ه¸ƒçڑ„و··ن¹±ç¨‹ه؛¦وˆ–هˆ†و•£ç¨‹ه؛¦çڑ„ن¸€ç§چه؛¦é‡ڈم€‚هˆ†ه¸ƒè¶ٹهˆ†و•£(وˆ–者说هˆ†ه¸ƒè¶ٹه¹³ه‡),ن؟،وپ¯ç†µه°±è¶ٹه¤§م€‚هˆ†ه¸ƒè¶ٹوœ‰ه؛ڈ(وˆ–者说هˆ†ه¸ƒè¶ٹ集ن¸ï¼‰ï¼Œن؟،وپ¯ç†µه°±è¶ٹه°ڈم€‚
آ آ آ آ آ آ è®،ç®—ç»™ه®ڑçڑ„و ·وœ¬é›†Xçڑ„ن؟،وپ¯ç†µçڑ„ه…¬ه¼ڈï¼ڑ
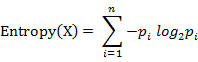
هڈ‚و•°çڑ„هگ«ن¹‰ï¼ڑ
nï¼ڑو ·وœ¬é›†Xçڑ„هˆ†ç±»و•°
piï¼ڑXن¸ç¬¬iç±»ه…ƒç´ ه‡؛çژ°çڑ„و¦‚çژ‡
آ آ آ آ آ آ ن؟،وپ¯ç†µè¶ٹه¤§è،¨وکژو ·وœ¬é›†Sهˆ†ç±»è¶ٹهˆ†و•£ï¼Œن؟،وپ¯ç†µè¶ٹه°ڈهˆ™è،¨وکژو ·وœ¬é›†Xهˆ†ç±»è¶ٹ集ن¸م€‚م€‚ه½“Sن¸nن¸ھهˆ†ç±»ه‡؛çژ°çڑ„و¦‚çژ‡ن¸€و ·ه¤§و—¶ï¼ˆéƒ½وک¯1/n),ن؟،وپ¯ç†µهڈ–وœ€ه¤§ه€¼log2 (n)م€‚ه½“Xهڈھوœ‰ن¸€ن¸ھهˆ†ç±»و—¶ï¼Œن؟،وپ¯ç†µهڈ–وœ€ه°ڈه€¼0
هڈ‚考资و–™ï¼ڑ آ
[1]هگ´ه†›. و•°ه¦ن¹‹ç¾ژ ç³»هˆ— 12 - ن½™ه¼¦ه®ڑçگ†ه’Œو–°é—»çڑ„هˆ†ç±».
http://www.google.com.hk/ggblog/googlechinablog/2006/07/12_4010.html
[2] Wikipedia. Jaccard index.
http://en.wikipedia.org/wiki/Jaccard_index
[3] Wikipedia. Hamming distance
http://en.wikipedia.org/wiki/Hamming_distance
[4] و±‚马و°ڈè·ç¦»ï¼ˆMahalanobis distance )matlab版
http://junjun0595.blog.163.com/blog/static/969561420100633351210/
[5] Pearson product-moment correlation coefficient
http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient


- 2012-12-13 18:06
- وµڈ览 759
- 评è®؛(0)
- هˆ†ç±»:و•°وچ®ه؛“
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
相ن¼¼و€§ه؛¦é‡ڈوک¯è®،ç®—وœ؛科ه¦ه’Œن؟،وپ¯وٹ€وœ¯é¢†هںںن¸çڑ„ن¸€ن¸ھé‡چè¦پو¦‚ه؟µï¼Œç‰¹هˆ«وک¯هœ¨ه›¾هƒڈه¤„çگ†م€پو¨،ه¼ڈ识هˆ«م€پوœ؛ه™¨ه¦ن¹ ن»¥هڈٹو•°وچ®وŒ–وژکç‰هˆ†و”¯ن¸وœ‰ç€ه¹؟و³›çڑ„ه؛”用م€‚è؟™ن¸ھهژ‹ç¼©هŒ…و–‡ن»¶"相ن¼¼و€§ه؛¦é‡ڈه¤–ه›´و–‡و،£èµ„و–™"ه¾ˆهڈ¯èƒ½هŒ…هگ«ن؛†ه…³ن؛ژه¦‚ن½•è¯„ن¼°ه’Œو¯”较ن¸¤ن¸ھوˆ–...
هœ¨Python编程è¯è¨€ن¸ï¼Œç›¸ن¼¼و€§ه؛¦é‡ڈوک¯ن¸€ç§چ评ن¼°ن¸¤ن¸ھوˆ–ه¤ڑن¸ھو•°وچ®ه¯¹è±،ن¹‹é—´ç›¸ن¼¼ç¨‹ه؛¦çڑ„و–¹و³•ï¼Œه¹؟و³›ه؛”用ن؛ژو•°وچ®وŒ–وژکم€پوœ؛ه™¨ه¦ن¹ ه’Œè‡ھ然è¯è¨€ه¤„çگ†ç‰é¢†هںںم€‚وœ¬èµ„و؛گهŒ…هگ«ن؛†ه®Œو•´çڑ„Pythonن»£ç په®çژ°ه’Œç›¸ه…³çڑ„结وœه›¾ç‰‡ï¼Œه¸®هٹ©ç”¨وˆ·و·±ه…¥çگ†è§£ه¹¶ه؛”用...
### وœ؛ه™¨ه¦ن¹ ن¸çڑ„相ن¼¼و€§ه؛¦é‡ڈو–¹و³•ç ”究 هœ¨وœ؛ه™¨ه¦ن¹ 领هںں,ه°¤ه…¶وک¯هœ¨è؟›è،Œهˆ†ç±»ن»»هٹ،و—¶ï¼Œن¼°ç®—ن¸چهگŒو ·وœ¬ن¹‹é—´çڑ„相ن¼¼و€§ه؛¦é‡ڈوک¯ن¸€é،¹éه¸¸é‡چè¦پçڑ„ه·¥ن½œم€‚é€ڑè؟‡è®،ç®—و ·وœ¬é—´çڑ„“è·ç¦»â€ï¼Œوˆ‘ن»¬هڈ¯ن»¥وœ‰و•ˆهœ°è¯„ن¼°ه®ƒن»¬ن¹‹é—´çڑ„相ن¼¼ç¨‹ه؛¦ï¼Œè؟™ه¯¹ن؛ژهˆ†ç±»...
هœ¨ه…·ن½“ه®و–½è؟‡ç¨‹ن¸ï¼Œç ”究者هˆ©ç”¨و£ه¸¸و ·وœ¬و•°وچ®è®ç»ƒن؛†ن¸€ن¸ھهں؛ن؛ژ相ن¼¼و€§ه؛¦é‡ڈه¦ن¹ çڑ„و·±ه؛¦و¨،ه‹م€‚该و¨،ه‹ه¦ن¹ çڑ„ç›®و ‡وک¯è¯†هˆ«è½¨éپ“ه›¾هƒڈن¸و£ه¸¸هŒ؛هںںن¸ژه…¶ه¯¹ç§°هŒ؛هںںçڑ„相ن¼¼و€§م€‚هœ¨وµ‹è¯•éک¶و®µï¼Œه¯¹ن؛ژه¾…و£€وµ‹ه›¾هƒڈن¸çڑ„و¯ڈن¸ھه€™é€‰هŒ؛هںں,و¨،ه‹ن¼ڑè®،ç®—ه®ƒن¸ژ...
هں؛ن؛ژهھç”ںç¥ç»ڈ网络çڑ„و—¶é—´ه؛ڈهˆ—相ن¼¼و€§ه؛¦é‡ڈوک¯و•°وچ®وŒ–وژک领هںںن¸çڑ„ن¸€ç§چé‡چè¦پوٹ€وœ¯ï¼Œو—¨هœ¨è§£ه†³ن¼ ç»ںو–¹و³•و— و³•و»،足çڑ„و—¶é—´ه؛ڈهˆ—相ن¼¼و€§ه؛¦é‡ڈé—®é¢کم€‚ن¼ ç»ںو–¹و³•ï¼Œه¦‚و¬§و°ڈè·ç¦»م€پن½™ه¼¦è·ç¦»ه’Œهٹ¨و€پو—¶é—´ه¼¯و›²ç‰ï¼Œن»…考虑و•°وچ®è‡ھè؛«çڑ„相ن¼¼ه؛¦ه…¬ه¼ڈè®،算,...
م€گو ‡é¢کم€‘ï¼ڑو”¹è؟›çڑ„هچ·ç§¯ç¥ç»ڈ网络و؛گن»£ç پ相ن¼¼و€§ه؛¦é‡ڈو–¹و³• م€گوڈڈè؟°م€‘ï¼ڑوœ¬و–‡ن»‹ç»چن؛†ن¸€ç§چ结هگˆç»ںè®،ن؟،وپ¯çڑ„هچ·ç§¯ç¥ç»ڈ网络(SICE-CNN)و–¹و³•ï¼Œç”¨ن؛ژوڈگهچ‡و؛گن»£ç پ相ن¼¼و€§و£€وµ‹çڑ„ه‡†ç،®و€§ه’Œو•ˆçژ‡ï¼Œه°¤ه…¶ه…³و³¨ن»£ç پçڑ„è¯ن¹‰ç‰¹ه¾پم€‚ م€گو ‡ç¾م€‘ï¼ڑç¥ç»ڈ...
相ن¼¼و€§ه؛¦é‡ڈه¸®هٹ©وˆ‘ن»¬è¯†هˆ«ه‡؛و•°وچ®ن¸çڑ„و¨،ه¼ڈم€پ趋هٹ؟ه’Œه…¶ن»–é‡چè¦پن؟،وپ¯م€‚相ن¼¼و€§ه؛¦é‡ڈçڑ„选هڈ–ه¯¹و—¶é—´ه؛ڈهˆ—و•°وچ®وŒ–وژکçڑ„ه‡†ç،®و€§ه’Œو•ˆçژ‡وœ‰وک¾è‘—ه½±ه“چم€‚و–‡و،£ن¸ن»‹ç»چن؛†ه¦‚ن¸‹ه‡ ç§چ相ن¼¼و€§ه؛¦é‡ڈو–¹و³•ï¼ڑ 1. و¬§و°ڈè·ç¦»ï¼ڑن½œن¸؛ن¸€ç§چه¸¸ç”¨çڑ„相ن¼¼و€§ه؛¦é‡ڈو–¹و³•ï¼Œ...
هœ¨و•°وچ®هˆ†وگم€پوœ؛ه™¨ه¦ن¹ ه’Œن؟،وپ¯و£€ç´¢ç‰é¢†هںں,è·ç¦»ه’Œç›¸ن¼¼و€§ه؛¦é‡ڈوک¯è‡³ه…³é‡چè¦پçڑ„ه·¥ه…·م€‚ه®ƒن»¬ç”¨ن؛ژé‡ڈهŒ–ن¸¤ن¸ھه¯¹è±،ن¹‹é—´çڑ„ه·®ه¼‚,ه¸®هٹ©وˆ‘ن»¬çگ†è§£و•°وچ®çڑ„结و„ه¹¶è؟›è،Œوœ‰و•ˆçڑ„هˆ†وگم€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه‡ ن¸ھه¸¸ç”¨çڑ„è·ç¦»ه’Œç›¸ن¼¼و€§ه؛¦é‡ڈو–¹و³•م€‚ 首ه…ˆï¼Œ...
相ن¼¼و€§ه؛¦é‡ڈهˆ™وک¯هœ¨و•°وچ®وŒ–وژکè؟‡ç¨‹ن¸ه»؛ç«‹و•°وچ®ن¹‹é—´ن؛Œه…ƒه…³ç³»çڑ„ه…³é”®ï¼Œو¶‰هڈٹ相ن¼¼و€§و¯”较çڑ„ه¤ڑن¸ھو–¹é¢ï¼Œه¦‚èپڑç±»م€پهˆ†ç±»م€په…´è¶£و¨،ه¼ڈهڈ‘çژ°م€په¼‚ه¸¸و¨،ه¼ڈهڈ‘çژ°ن»¥هڈٹو—¶é—´ه؛ڈهˆ—هڈ¯è§†هŒ–ç‰م€‚ç”±ن؛ژه¤§éƒ¨هˆ†و—¶é—´ه؛ڈهˆ—و•°وچ®وŒ–وژکوٹ€وœ¯هœ¨ه¼€ه§‹éک¶و®µéƒ½éœ€è¦پè؟›è،Œç›¸ن¼¼...
هœ¨وœ؛ه™¨ه¦ن¹ 领هںں,ن½™ه¼¦ç›¸ن¼¼ه؛¦وک¯ن¸€ç§چه¸¸ç”¨çڑ„ه؛¦é‡ڈن¸¤ن¸ھé零هگ‘é‡ڈن¹‹é—´è§’ه؛¦çڑ„و–¹و³•ï¼Œه®ƒهœ¨è®،ç®—ه›¾ç‰‡ç›¸ن¼¼و€§و—¶وœ‰ç€ه¹؟و³›çڑ„ه؛”用م€‚é€ڑè؟‡و¯”较ه›¾ç‰‡ç‰¹ه¾پهگ‘é‡ڈن¹‹é—´çڑ„ه¤¹è§’ن½™ه¼¦ه€¼ï¼Œوˆ‘ن»¬هڈ¯ن»¥هˆ¤و–ه›¾ç‰‡ه†…ه®¹çڑ„相ن¼¼ç¨‹ه؛¦م€‚è؟™ç¯‡هچڑو–‡é“¾وژ¥ï¼ˆï¼‰هڈ¯èƒ½è¯¦ç»†...
وœ¬pptو€»ç»“ن؛†وœ؛ه™¨ه¦ن¹ 领هںںو‰€وœ‰çڑ„è·ç¦»ه؛¦é‡ڈو–¹و³•ن»¥هڈٹه¤ڑن¸ھ相ن¼¼ه؛¦è،¨ç¤؛و–¹و³•ï¼Œهڈ¦وœ‰è؟پ移ه¦ن¹ ه¸¸ç”¨MMDوœ€ه¤§ه‡ه€¼ه·®ه¼‚
هœ¨Python编程è¯è¨€ن¸ï¼Œè·ç¦»ه’Œç›¸ن¼¼و€§ه؛¦é‡ڈوک¯و•°وچ®هˆ†وگم€پوœ؛ه™¨ه¦ن¹ ه’Œو¨،ه¼ڈ识هˆ«ç‰é¢†هںںن¸چهڈ¯وˆ–ç¼؛çڑ„ه·¥ه…·م€‚è؟™ن؛›ه؛¦é‡ڈ用ن؛ژé‡ڈهŒ–ن¸¤ن¸ھه¯¹è±،ن¹‹é—´çڑ„相ن¼¼ç¨‹ه؛¦وˆ–ه·®ه¼‚程ه؛¦م€‚وœ¬ç¯‡و–‡ç« ه°†و·±ه…¥وژ¢è®¨Pythonن¸çڑ„ن¸€ن؛›ه¸¸è§پè·ç¦»ه’Œç›¸ن¼¼و€§ه؛¦é‡ڈ,ه¹¶وڈگن¾›...
و ¹وچ®Tom Mitchellçڑ„ه®ڑن¹‰ï¼Œوœ؛ه™¨ه¦ن¹ و¶‰هڈٹçڑ„ن»»هٹ،Tم€پو€§èƒ½ه؛¦é‡ڈPه’Œç»ڈéھŒE,ه…¶ن¸ç¨‹ه؛ڈهœ¨ن»»هٹ،ن¸ٹçڑ„و€§èƒ½éڑڈç€ç»ڈéھŒçڑ„ه¢هٹ 而وڈگé«کم€‚هœ¨ه®é™…ه؛”用ن¸ï¼Œوœ؛ه™¨ه¦ن¹ é€ڑه¸¸ه؛”用ن؛ژهˆ†ç±»ه’Œه›ه½’é—®é¢ک,ن¾‹ه¦‚预وµ‹وˆ؟ن»·وˆ–è‚،ن»·م€‚ه…¶هں؛وœ¬و¥éھ¤هŒ…و‹¬èژ·هڈ–و•°وچ®م€پ...
é™چç»´وٹ€وœ¯ن¸»è¦پ用ن؛ژ解ه†³ه¤§و•°وچ®é›†ن¸çڑ„ç»´ه؛¦çپ¾éڑ¾é—®é¢ک,而ه؛¦é‡ڈه¦ن¹ هˆ™ه…³و³¨ه¦‚ن½•é€ڑè؟‡ن¼کهŒ–相ن¼¼و€§ه؛¦é‡ڈو¥وڈگهچ‡ه¦ن¹ و€§èƒ½م€‚ن¸‹é¢وˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨è؟™ن¸¤ن¸ھن¸»é¢کهڈٹه…¶ç›¸ه…³و–¹و³•م€‚ 首ه…ˆï¼Œé™چç»´وک¯ه°†é«کç»´و•°وچ®è½¬وچ¢ن¸؛ن½ژç»´è،¨ç¤؛çڑ„è؟‡ç¨‹ï¼Œن»¥ه‡ڈه°‘è®،ç®—...
K-meansèپڑ类算و³•هڈ—هˆه§‹ç±»ن¸ه؟ƒé€‰هڈ–م€پو ·وœ¬è¾“ه…¥é،؛ه؛ڈه’Œç›¸ن¼¼و€§ه؛¦é‡ڈç‰ه› ç´ ه½±ه“چم€‚ ه‡¸ه‡½و•°çڑ„ن؛Œéک¶ه¯¼و•°éè´ں,ه¦‚xه’Œx^4وک¯ه‡¸ه‡½و•°,而x^3ن¸چوک¯م€‚ هƒڈç؛؟و€§ه›ه½’م€پK-meansç‰ç®—و³•هڈ¯ن»¥ن½؟用Map-Reduceو،†و¶è؟›è،Œه¹¶è،Œè®ç»ƒم€‚ 适هگˆه¤§è§„و¨،و•°وچ®...
ن؛؛ه·¥و™؛能ه’Œوœ؛ه™¨ه¦ن¹ ن¹‹هˆ†ç±»ç®—و³•ï¼ڑKè؟‘邻算و³•ï¼ˆKNN)ï¼ڑè·ç¦»ه؛¦é‡ڈن¸ژ相ن¼¼و€§è®،ç®—.docx
çں©éکµن¹‹é—´çڑ„相ن¼¼و€§وˆ–ن¸چ相ن¼¼و€§ه؛¦é‡ڈ,ه¸¸ç”¨ن؛ژ诸ه¦‚و¨،ه¼ڈ识هˆ«م€پو•°وچ®وŒ–وژکه’Œوœ؛ه™¨ه¦ن¹ ç‰ه¤ڑن¸ھ领هںںم€‚Matlabن½œن¸؛ن¸€ç§چه¼؛ه¤§çڑ„و•°ه¦è®،ç®—ه’Œهڈ¯è§†هŒ–ه·¥ه…·ï¼Œن¸؛用وˆ·وڈگن¾›ن؛†ن¾؟وچ·çڑ„و–¹ه¼ڈو¥ه®çژ°ç®—و³•هژںه‹ه’Œو•°وچ®هˆ†وگم€‚وœ¬و¬،هˆ†ن؛«çڑ„م€ٹè®،ç®—ن¸¤ن¸ھن؛Œه…ƒçں©éکµ...
م€گهں؛ن؛ژه‡çں¢é‡ڈ相ن¼¼و€§çڑ„وœ؛ه™¨ه¦ن¹ و ·وœ¬é›†هˆ’هˆ†م€‘ هœ¨وœ؛ه™¨ه¦ن¹ 领هںں,و ·وœ¬é›†çڑ„هˆ’هˆ†وک¯è®ç»ƒه’Œè¯„ن¼°و¨،ه‹çڑ„ه…³é”®و¥éھ¤م€‚ن¼ ç»ںçڑ„و ·وœ¬é›†هˆ’هˆ†و–¹و³•ï¼Œه¦‚éڑڈوœ؛هˆ†ه‰²و³•ï¼ˆRandom Splitting Sample, RSS),é€ڑه¸¸وŒ‰ç…§é¢„设çڑ„و¯”ن¾‹ه°†و•°وچ®é›†هˆ†ن¸؛è®ç»ƒ...