- 浏览: 33221 次
- 性别:

- 来自: 深圳
-

文章分类
DOM4J
与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
先来看看dom4j中对应XML的DOM树建立的继承关系
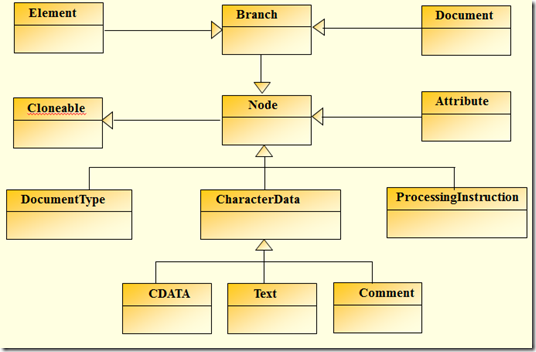
针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:
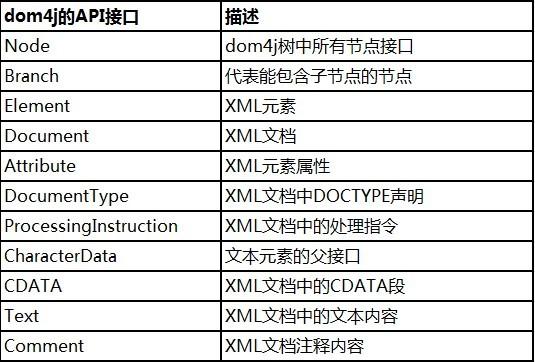
同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
· read 提供多种读取xml文件的方式,返回一个Domcument对象
interface org.dom4j.Document
· iterator 使用此法获取node
· getRootElement 获取根节点
interface org.dom4j.Node
· getName 获取node名字,例如获取根节点名称为bookstore
· getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
· getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
interface org.dom4j.Element
· attributes 返回该元素的属性列表
· attributeValue 根据传入的属性名获取属性值
· elementIterator 返回包含子元素的迭代器
· elements 返回包含子元素的列表
interface org.dom4j.Attribute
· getName 获取属性名
· getValue 获取属性值
interface org.dom4j.Text
· getText 获取Text节点值
interface org.dom4j.CDATA
· getText 获取CDATA Section值
interface org.dom4j.Comment
· getText 获取注释
实例一:
1 //先加入dom4j.jar包
2 import java.util.HashMap;
3 import java.util.Iterator;
4 import java.util.Map;
5
6 import org.dom4j.Document;
7 import org.dom4j.DocumentException;
8 import org.dom4j.DocumentHelper;
9 import org.dom4j.Element;
10
11 /**
12 * @Title: TestDom4j.java
13 * @Package
14 * @Description: 解析xml字符串
15 * @author 无处不在
16 * @date 2012-11-20 下午05:14:05
17 * @version V1.0
18 */
19 public class TestDom4j {
20
21 public void readStringXml(String xml) {
22 Document doc = null;
23 try {
24
25 // 读取并解析XML文档
26 // SAXReader就是一个管道,用一个流的方式,把xml文件读出来
27 //
28 // SAXReader reader = new SAXReader(); //User.hbm.xml表示你要解析的xml文档
29 // Document document = reader.read(new File("User.hbm.xml"));
30 // 下面的是通过解析xml字符串的
31 doc = DocumentHelper.parseText(xml); // 将字符串转为XML
32
33 Element rootElt = doc.getRootElement(); // 获取根节点
34 System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称
35
36 Iterator iter = rootElt.elementIterator("head"); // 获取根节点下的子节点head
37
38 // 遍历head节点
39 while (iter.hasNext()) {
40
41 Element recordEle = (Element) iter.next();
42 String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值
43 System.out.println("title:" + title);
44
45 Iterator iters = recordEle.elementIterator("script"); // 获取子节点head下的子节点script
46
47 // 遍历Header节点下的Response节点
48 while (iters.hasNext()) {
49
50 Element itemEle = (Element) iters.next();
51
52 String username = itemEle.elementTextTrim("username"); // 拿到head下的子节点script下的字节点username的值
53 String password = itemEle.elementTextTrim("password");
54
55 System.out.println("username:" + username);
56 System.out.println("password:" + password);
57 }
58 }
59 Iterator iterss = rootElt.elementIterator("body"); ///获取根节点下的子节点body
60 // 遍历body节点
61 while (iterss.hasNext()) {
62
63 Element recordEless = (Element) iterss.next();
64 String result = recordEless.elementTextTrim("result"); // 拿到body节点下的子节点result值
65 System.out.println("result:" + result);
66
67 Iterator itersElIterator = recordEless.elementIterator("form"); // 获取子节点body下的子节点form
68 // 遍历Header节点下的Response节点
69 while (itersElIterator.hasNext()) {
70
71 Element itemEle = (Element) itersElIterator.next();
72
73 String banlce = itemEle.elementTextTrim("banlce"); // 拿到body下的子节点form下的字节点banlce的值
74 String subID = itemEle.elementTextTrim("subID");
75
76 System.out.println("banlce:" + banlce);
77 System.out.println("subID:" + subID);
78 }
79 }
80 } catch (DocumentException e) {
81 e.printStackTrace();
82
83 } catch (Exception e) {
84 e.printStackTrace();
85
86 }
87 }
88
89 /**
90 * @description 将xml字符串转换成map
91 * @param xml
92 * @return Map
93 */
94 public static Map readStringXmlOut(String xml) {
95 Map map = new HashMap();
96 Document doc = null;
97 try {
98 // 将字符串转为XML
99 doc = DocumentHelper.parseText(xml);
100 // 获取根节点
101 Element rootElt = doc.getRootElement();
102 // 拿到根节点的名称
103 System.out.println("根节点:" + rootElt.getName());
104
105 // 获取根节点下的子节点head
106 Iterator iter = rootElt.elementIterator("head");
107 // 遍历head节点
108 while (iter.hasNext()) {
109
110 Element recordEle = (Element) iter.next();
111 // 拿到head节点下的子节点title值
112 String title = recordEle.elementTextTrim("title");
113 System.out.println("title:" + title);
114 map.put("title", title);
115 // 获取子节点head下的子节点script
116 Iterator iters = recordEle.elementIterator("script");
117 // 遍历Header节点下的Response节点
118 while (iters.hasNext()) {
119 Element itemEle = (Element) iters.next();
120 // 拿到head下的子节点script下的字节点username的值
121 String username = itemEle.elementTextTrim("username");
122 String password = itemEle.elementTextTrim("password");
123
124 System.out.println("username:" + username);
125 System.out.println("password:" + password);
126 map.put("username", username);
127 map.put("password", password);
128 }
129 }
130
131 //获取根节点下的子节点body
132 Iterator iterss = rootElt.elementIterator("body");
133 // 遍历body节点
134 while (iterss.hasNext()) {
135 Element recordEless = (Element) iterss.next();
136 // 拿到body节点下的子节点result值
137 String result = recordEless.elementTextTrim("result");
138 System.out.println("result:" + result);
139 // 获取子节点body下的子节点form
140 Iterator itersElIterator = recordEless.elementIterator("form");
141 // 遍历Header节点下的Response节点
142 while (itersElIterator.hasNext()) {
143 Element itemEle = (Element) itersElIterator.next();
144 // 拿到body下的子节点form下的字节点banlce的值
145 String banlce = itemEle.elementTextTrim("banlce");
146 String subID = itemEle.elementTextTrim("subID");
147
148 System.out.println("banlce:" + banlce);
149 System.out.println("subID:" + subID);
150 map.put("result", result);
151 map.put("banlce", banlce);
152 map.put("subID", subID);
153 }
154 }
155 } catch (DocumentException e) {
156 e.printStackTrace();
157 } catch (Exception e) {
158 e.printStackTrace();
159 }
160 return map;
161 }
162
163 public static void main(String[] args) {
164
165 // 下面是需要解析的xml字符串例子
166 String xmlString = "<html>" + "<head>" + "<title>dom4j解析一个例子</title>"
167 + "<script>" + "<username>yangrong</username>"
168 + "<password>123456</password>" + "</script>" + "</head>"
169 + "<body>" + "<result>0</result>" + "<form>"
170 + "<banlce>1000</banlce>" + "<subID>36242519880716</subID>"
171 + "</form>" + "</body>" + "</html>";
172
173 /*
174 * Test2 test = new Test2(); test.readStringXml(xmlString);
175 */
176 Map map = readStringXmlOut(xmlString);
177 Iterator iters = map.keySet().iterator();
178 while (iters.hasNext()) {
179 String key = iters.next().toString(); // 拿到键
180 String val = map.get(key).toString(); // 拿到值
181 System.out.println(key + "=" + val);
182 }
183 }
184
185 }
实例二:
1 /**
2 * 解析包含有DB连接信息的XML文件
3 * 格式必须符合如下规范:
4 * 1. 最多三级,每级的node名称自定义;
5 * 2. 二级节点支持节点属性,属性将被视作子节点;
6 * 3. CDATA必须包含在节点中,不能单独出现。
7 *
8 * 示例1——三级显示:
9 * <db-connections>
10 * <connection>
11 * <name>DBTest</name>
12 * <jndi></jndi>
13 * <url>
14 * <![CDATA[jdbc:mysql://localhost:3306/db_test?useUnicode=true&characterEncoding=UTF8]]>
15 * </url>
16 * <driver>org.gjt.mm.mysql.Driver</driver>
17 * <user>test</user>
18 * <password>test2012</password>
19 * <max-active>10</max-active>
20 * <max-idle>10</max-idle>
21 * <min-idle>2</min-idle>
22 * <max-wait>10</max-wait>
23 * <validation-query>SELECT 1+1</validation-query>
24 * </connection>
25 * </db-connections>
26 *
27 * 示例2——节点属性:
28 * <bookstore>
29 * <book category="cooking">
30 * <title lang="en">Everyday Italian</title>
31 * <author>Giada De Laurentiis</author>
32 * <year>2005</year>
33 * <price>30.00</price>
34 * </book>
35 *
36 * <book category="children" title="Harry Potter" author="J K. Rowling" year="2005" price="$29.9"/>
37 * </bookstore>
38 *
39 * @param configFile
40 * @return
41 * @throws Exception
42 */
43 public static List<Map<String, String>> parseDBXML(String configFile) throws Exception {
44 List<Map<String, String>> dbConnections = new ArrayList<Map<String, String>>();
45 InputStream is = Parser.class.getResourceAsStream(configFile);
46 SAXReader saxReader = new SAXReader();
47 Document document = saxReader.read(is);
48 Element connections = document.getRootElement();
49
50 Iterator<Element> rootIter = connections.elementIterator();
51 while (rootIter.hasNext()) {
52 Element connection = rootIter.next();
53 Iterator<Element> childIter = connection.elementIterator();
54 Map<String, String> connectionInfo = new HashMap<String, String>();
55 List<Attribute> attributes = connection.attributes();
56 for (int i = 0; i < attributes.size(); ++i) { // 添加节点属性
57 connectionInfo.put(attributes.get(i).getName(), attributes.get(i).getValue());
58 }
59 while (childIter.hasNext()) { // 添加子节点
60 Element attr = childIter.next();
61 connectionInfo.put(attr.getName().trim(), attr.getText().trim());
62 }
63 dbConnections.add(connectionInfo);
64 }
65
66 return dbConnections;
67 }


发表评论

相关推荐
### DOM4J解析XML详解 #### 一、DOM4J简介与特性 DOM4J是一个由dom4j.org开发的开源XML解析包,专为Java平台设计,它不仅支持DOM、SAX和JAXP标准,还巧妙地融入了Java集合框架,使其成为Java开发者在处理XML数据时...
使用 dom4j 解析 XML dom4j 解析 XML dom4j解析xml
**DOM4J解析XML** DOM4J是一个强大的Java库,专门用于处理XML文档。它提供了灵活、高效且功能丰富的API,使得XML的读取、创建、修改和查询变得简单易行。DOM4J的主要特点包括对XPath的支持、事件驱动的解析、以及与...
无论是读取XML文件,解析XML字符串,还是创建、修改和遍历XML结构,DOM4J都提供了简洁的接口,极大地简化了开发者的工作。在实际的开发中,掌握DOM4J的使用,能够帮助你更有效地处理XML数据,提高代码的可维护性和...
### DOM4J解析XML知识点详解 #### 一、DOM4J简介 DOM4J是一个Java库,用于处理XML文档。它的设计目标是为了提供一个简单、易于使用的API来处理XML文件,同时保持性能上的优势。与Java标准库中的DOM实现相比,DOM4J...
Java DOM4J解析XML是一种常见的处理XML文档的技术,它提供了灵活且高效的API,使得开发者能够方便地读取、写入、修改以及操作XML文件。DOM4J是Java中一个非常强大的XML处理库,它结合了DOM、SAX和JDOM的优点,同时也...
在“dom4j解析xml文件(增删改查)”这个主题中,我们将深入探讨如何使用DOM4J来实现XML文档的四种基本操作:增加元素、删除元素、更新元素内容以及查询元素。 首先,让我们了解DOM4J的基本用法。在解析XML文件时,...
**DOM4J解析XML实例详解** 在Java编程中,处理XML文档是一项常见的任务。DOM4J是一个非常流行的、强大的Java XML API,它提供了灵活且高效的方式来解析、创建、修改XML文档。本文将深入探讨如何使用DOM4J进行XML...
在这个实例中,我们将深入探讨如何使用DOM4J解析XML文件,并通过`Dom4jTest1.java`这个示例程序来理解其工作原理。 首先,我们需要了解XML(Extensible Markup Language)是一种标记语言,常用于存储和传输数据。...
本人自己研究的解析方法,主要用dom4j解析XML文件,进而获取里面的信息
通过这种方式,我们可以利用DOM4J解析XML文件,同时借助Java反射机制将解析结果动态地映射到自定义的Java类中。这在处理XML数据时提供了很大的灵活性,尤其在需要将XML数据与业务对象关联时,反射机制显得尤为重要。
在本示例中,我们将深入探讨如何使用DOM4J解析XML文件,以`CacheInit.java`作为我们的核心代码示例,并参考`emailTemplateConfig.xml`作为实际操作的对象。 首先,让我们了解XML(eXtensible Markup Language)。...
1. **DOM4J解析XML**:DOM4J通过创建一个可操作的树形结构来表示XML文档,这棵树称为文档对象模型。解析XML时,DOM4J首先读取XML文件并构建一个节点结构,然后你可以通过API遍历和修改这个结构。例如,你可以通过...
【使用dom4j解析XML】 dom4j是一个强大的开源XML框架,它提供了处理XML文档的各种功能,包括解析、创建、修改等。相比W3C DOM API,dom4j的优势在于其内置的XPath支持,允许更方便地定位和操作XML文档中的节点。 *...
1、xml文档解析 2、 dom4j解析xml 3、实现xml文件解析 xml字符串解析 xml MAP键值对解析 4、实现xml写入与生成文件
为了在Java项目中使用DOM4J解析XML,你需要将这两个jar文件(dom4j-1.6.1和jaxen-1.1-beta-7.jar)添加到你的类路径(classpath)中。这可以通过在IDE中配置构建路径,或者在命令行中指定 `-cp` 参数来完成。一旦...
在本实例中,我们将深入探讨如何使用DOM4J解析XML,并利用这些数据连接Oracle数据库进行数据操作。 首先,让我们了解DOM4J的基本用法。DOM4J的主要类包括`Document`、`Element`、`Attribute`和`Namespace`。`...
2. **XML解析**:DOM4J支持多种解析方式,包括SAX(Simple API for XML)和DOM。SAX是基于事件的解析,适用于处理大文件;DOM则将整个XML文档加载到内存,适合小规模或内存允许的情况。DOM4J还提供了StAX(Streaming...
dom4j解析xml字符串实例