由于本人正在准备将heritrix1.14升级到3.1 ,觉得这篇文章挺有用的,于是就cp一下,记录下来,非本人所原创,下面是原创的文章:
网上已经有几篇Heritrix 1.14版本的Eclipse搭建的文章,说的比较详细。本人下载了Heritrix 3.1,该版本相对Heritrix 1.14版本变化已经较大,在研究Heritrix零星的几个文档以后终于把环境搭建成功了,并把过程记录下来,希望对大家有所帮助。
Heritrix 3.1需要jdk1.6或以上版本。本人用的Eclipse是3.7 JEE版本(非必须条件)。操作步骤如下:
1、下载Heritrix 3.1
Heritrix 3.1的下载地址是:http://sourceforge.net/projects/archive-crawler/files/heritrix3/3.1.0/ 我把heritrix-3.1.0-dist.zip和heritrix-3.1.0-src.zip两个包都下载下来,二者都会用到。将这两个压缩包分别解压。
2、建立Eclipse项目
1)新建项目
理论上建立普通java项目即可,我是建立的一个web项目,否则提示“不能访问sun.security.tools.KeyTool.java”,知道原因的同志告诉我。
2)添加库文件
在项目中建立一个lib目录,并将heritrix-3.1.0-dist.zip解压后的lib目录下的所有jar文件(heritrix-commons-3.1.0.jar,heritrix-engine-3.1.0.jar,heritrix-modules-3.1.0.jar随着代码的加入可以逐步删除)拷贝到项目的lib目录下。然后再项目属性--java Build path中将这些jar引用到项目中。
3)添加代码
将heritrix-3.1.0\engine\src\main\java(对应heritrix-engine-3.1.0.jar)添加到Eclipse的src目录,此时Heritrix 3.1就可以运行了。为了看代码方便,还是将其他部分的代码都加入到项目,分别是:heritrix-3.1.0\commons\src\main\java目录(对应heritrix-commons-3.1.0.jar)和heritrix-3.1.0\modules\src\main\java目录(对应heritrix-modules-3.1.0.jar)。这样你就可以删除heritrix-commons-3.1.0.jar,heritrix-engine-3.1.0.jar,heritrix-modules-3.1.0.jar三个包的引用,直接使用源代码运行。
3、运行Heritrix 3.1
Heritrix 3.1运行以后可以通过一个web服务器来管理他。但首先要将他运行起来。在org.archive.crawler有个带main函数的Heritrix,启动它就可以将Heritrix3.1运行起来。但要设置启动参数-a admin:admin(输入启动账号),在Eclipse的 Run configuration中设置如下图:
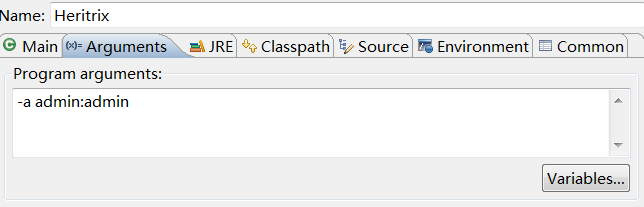
然后运行Heritrix.java,如果一切正常你可以通过:http://localhost:8443 访问Heritrix 3.1的管理网站。
不过这时系统里还一片空白,你需要建立一个网页抓取的任务(job).
4、建立和配置抓取任务
登录管理控制台(用户名admin密码admin),在管理界面首页找到如下图这个位置:

输入一个名称(如myjob),然后点击“Create”按钮。
这时候根据默认模版生成了一个抓取任务,但还不能抓取任何东西,我们需要通过配置文件的修改告诉服务器,我们要抓取什么。
在管理控制台的Job Directories中选择要配置的job(下图中myjob)
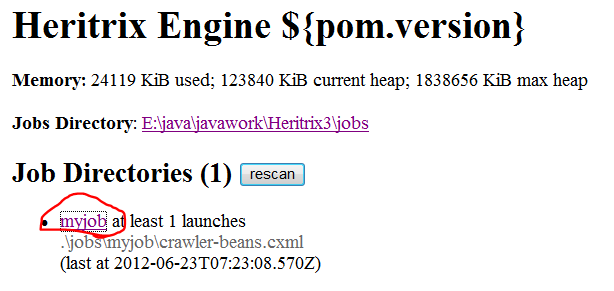
进入myjob的管理界面,如下图:
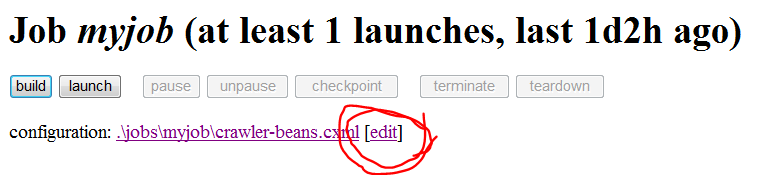
点击edit按钮,开始编辑配置文件,配置需要修改的地方如下图所示,先从简单的做起:
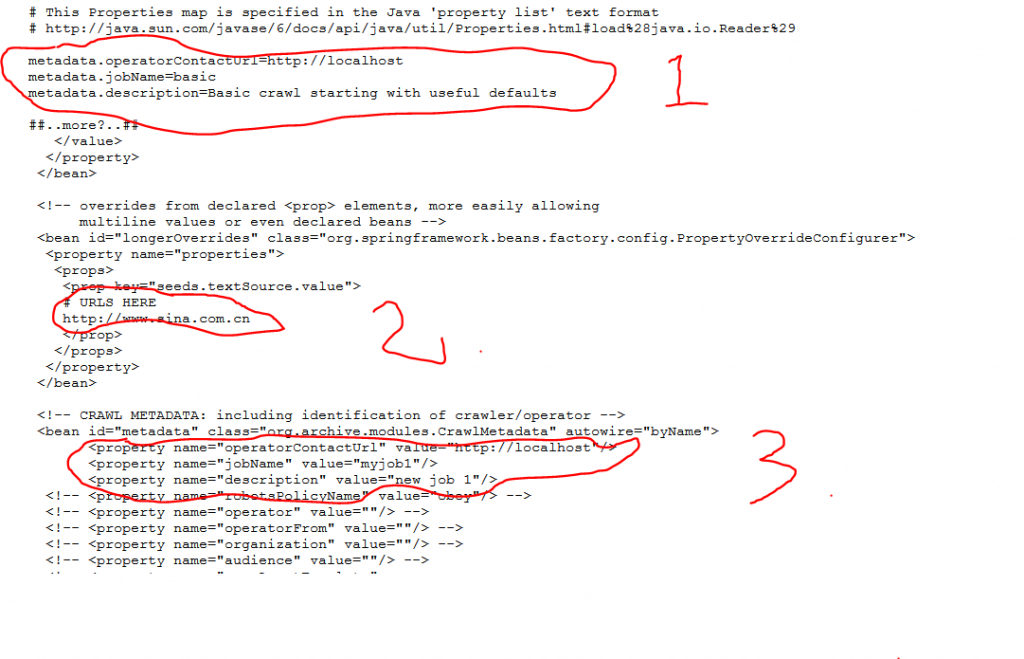
配置1和3的配置内容是一样的,operatorContactUrl写成http://localhost, jobName和description随便写点东西即可。
配置2则是配置搜索种子网站的列表,我这里先写了一个http://www.sina.com.cn,先抓取新浪网站试试。
点击最上面的“Save changes"保存所有的配置文件。
这三个地方配置好就可以运行这个抓取任务试试了。
这时候需要执行如下操作(回到myjob的配置界面),让任务运行起来:
1)点击“build”编译当前的配置。
2)点击“launch”按钮运行当前任务至挂起状态,如果job已经运行,则先点击“teardown”按钮;
3)这时任务处于挂起状态,点击“unpause”即立即启动任务。
如果系统正常运行,会有如下类似提示信息:

在项目的jobs\myjob\20120623061610\warcs目录下有一个逐步增大的文件,这就是抓取下来的网页。
如果要看到每个抓取的页面,可以将配置文件的warcWriter这个bean的class改为org.archive.modules.writer.MirrorWriterProcessor,这样就下载的网页是以镜像文件的形式保存在,一般存放在项目根目录下的mirror目录下。
从现在开始慢慢研究Heritrix吧。
今天按照上面转载的文档搭建了一下heritirx3.1的环境,基本上还是成功的,可以成功的运行,但是在运行的时候报了一个错误,错误如下:
严重: TLD list unavailable
java.lang.NullPointerException
at java.io.Reader.<init>(Reader.java:61)
at java.io.InputStreamReader.<init>(InputStreamReader.java:55)
at org.archive.util.ArchiveUtils.<clinit>(ArchiveUtils.java:874)
at org.archive.crawler.Heritrix.instanceMain(Heritrix.java:380)
at org.archive.crawler.Heritrix.main(Heritrix.java:189)
Heritrix version: UNKNOWN
无法显示版本号,这个问题暂时还没有找到是什么引起的,运行界面是可以正常运行的!
由于本人还算是个相对的完美主义者,对于上面的错误,心里还是觉得很难受的!!别扭!
于是刚才花了几分钟看了下源代码,是heritrix在启动的时候会到org.archive.util下面读取3个配置文件,分别是:
version.txt
timestamp.txt
tlds-alpha-by-domain.txt
这三个文件在src的zip包里面并不存在,但是可以在dist.zip的lib目录下,找到heritrix-commons-3.1.0.jar这个文件,
在里面的org.archive.util下面找到上面的3个txt文件,拷贝到你的项目的src\org\archive\util下面,在重新运行,问题完美解决!!
分享到:




相关推荐
### Heritrix 3.1 官方指导手册 #### 一、简介 Heritrix 是互联网档案馆推出的一款开源、可扩展、可伸缩、具备高质量归档能力的网络爬虫工具。它旨在帮助用户高效地从互联网上抓取数据,并将其归档保存。Heritrix ...
Heritrix 3.1是互联网档案馆开发的一款开源网络爬虫工具,专门用于抓取和保存网页。这款强大的爬虫软件广泛应用于学术研究、数据分析、网站备份等多个领域。了解Heritrix 3.1的默认配置以及类之间的关系对于有效使用...
Heritrix 3.1.0 是一个强大的网络爬虫软件,主要被用于网页抓取、数据挖掘和互联网档案管理。这个源码包包含了项目的源代码以及构建后的可分发文件,让开发者能够深入理解其工作原理并进行定制化开发。 源码分析: ...
Heritrix 3.1.0 是一个强大的网络爬虫工具,主要用于抓取和存档互联网上的网页。这个最新版本的jar包包含了Heritrix的核心功能,为用户提供了一个高效的网页抓取框架。Heritrix的设计理念是模块化和可配置性,使得它...
Heritrix是一款强大的开源网络爬虫工具,由互联网档案馆(Internet Archive)开发,用于抓取和保存网页内容。这款工具被设计为可扩展和高度配置的,允许用户根据特定需求定制爬取策略。在本工程中,Heritrix已经被预...
本节将详细介绍如何在Eclipse环境中搭建Heritrix,并进行必要的配置,以便能够顺利地启动Heritrix并执行抓取任务。 ##### 2.1 在Eclipse中搭建MyHeritrix工程 1. **新建Java工程** 在Eclipse中新建一个名为`...
在搭建Heritrix工程时,将"heritrix-1.14.0"中的jar包导入到开发环境中(如Eclipse或IntelliJ IDEA)是必要的步骤。这通常涉及到创建一个新的Java项目,然后将lib目录下的所有jar文件添加到项目的类路径中。确保正确...
其在Windows环境下成功运行的过程及配置细节,涉及到了Java环境的搭建、Heritrix软件的安装与配置、以及运行参数的设置,以下是对这些知识点的详细解析: ### 一、Java环境搭建 Heritrix基于Java平台运行,因此...
在Heritrix 3.0和3.1版本中,引入了一个基于Spring-container的配置系统,这使得设置管理更加灵活。此外,3.X版本的另一个显著改变是采用了一种新的模型,允许在同一个作业目录下重启作业,而无需每次都创建新的作业...
Heritrix是一款强大的开源网络爬虫工具,由互联网档案馆(Internet Archive)开发,主要用于抓取和保存网页内容。Heritrix 1.14.4是该软件的一个较早版本,但依然具有广泛的适用性,尤其对于学习和研究网络爬虫技术...
Heritrix是一款强大的开源网络爬虫工具,专为构建自定义搜索引擎而设计。这款软件由互联网档案馆(Internet Archive)开发,旨在系统地抓取、保存并归档互联网上的网页内容。通过使用Heritrix,开发者可以构建自己的...
### Heritrix爬虫安装部署知识点详解 #### 一、Heritrix爬虫简介 Heritrix是一款由互联网档案馆(Internet Archive)开发的开源网络爬虫框架,它使用Java语言编写,支持高度定制化的需求。Heritrix的设计初衷是为了...
通过以上步骤,你可以成功地搭建起一个运行中的Heritrix实例,进一步探索其丰富的功能和可能性。不过,需要注意的是,Heritrix的配置文件和代码结构可能会随着新版本的发布而有所变化,因此在更新到新版本时,可能...
Heritrix是一款开源的网络爬虫软件,专为大规模网页抓取而设计。这款工具主要用于构建互联网档案馆、搜索引擎的数据源以及其他需要大量网页数据的项目。Heritrix由Internet Archive开发,支持高度可配置和扩展,能够...
Heritrix 1.14.2 是一个开源的网络爬虫工具,它主要用于抓取互联网上的网页和其他在线资源。这个版本的Heritrix在2007年左右发布,虽然较旧,但它仍然是理解网络爬虫技术的一个重要参考。 Heritrix是一个由Internet...
Heritrix是一款强大的开源网络爬虫工具,专为大规模、深度网页抓取设计。这款工具由互联网档案馆(Internet Archive)开发,旨在提供灵活、可扩展的网页抓取框架,适用于学术研究、数据挖掘和历史记录保存等多种用途...
Heritrix是一个强大的Java开发的开源网络爬虫,主要用于从互联网上抓取各种资源。它由www.archive.org提供,以其高度的可扩展性而著称,允许开发者自定义抓取逻辑,通过扩展其内置组件来适应不同的抓取需求。本文将...