- 浏览: 1414551 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
sdgxxtc:
[quo[color=red]te][/color]
C#使用OleDb读取Excel,生成SQL语句 -
zcs302567601:
博主,你好,一直都有个问题没有搞明白,就是 2.x的版本是通过 ...
NGUI所见即所得之UIPanel -
一样的追寻:
感谢楼主!
有向强连通和网络流大讲堂——史无前例求解最大流(最小割)、最小费用最大流 -
cp1993518:
感谢!从你的博客里学到了很多
Unity日志工具——封装,跳转 -
cp1993518:
学习了~,话说现在的版本custom还真的变委托了
NGUI所见即所得之UIGrid & UITable
Bloom Filter一站式学习
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合(一般来说,我们会用HASH表来存储集合中的数据,好处是快速准确,缺点是存储效率低,在海量数据时一般服务器无法存储。Bloom Filter针对哈希表存储效率低的问题,而衍生出来的一种算法。)。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。

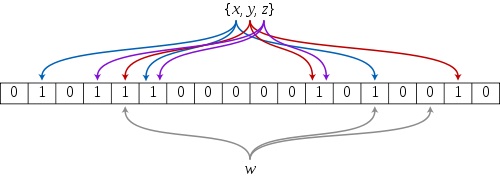
Bloom Filter算法
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(1) 加入字符串过程
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。

图1.Bloom Filter加入字符串过程
这样就将字符串str映射到BitSet中的k个二进制位了,很简单吧。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
(3) 删除字符串过程
字符串加入了就被不能删除了,因为删除会影响到其他字符串。实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
错误率估计
前面我们已经提到了,Bloom Filter在判断一个元素是否属于它表示的集合时会有一定的错误率(false positive rate),下面我们就来估计错误率的大小。在估计之前为了简化模型,我们假设kn<m且各个哈希函数是完全随机的。当集合S={x1, x2,…,xn}的所有元素都被k个哈希函数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:

其中1/m表示任意一个哈希函数选中这一位的概率(前提是哈希函数是完全随机的),(1-1/m)表示哈希一次没有选中这一位的概率。要把S完全映射到位数组中,需要做kn次哈希。某一位还是0意味着kn次哈希都没有选中它,因此这个概率就是(1-1/m)的kn次方。令p = e-kn/m是为了简化运算,这里用到了计算e时常用的近似:

令ρ为位数组中0的比例,则ρ的数学期望E(ρ)= p’。在ρ已知的情况下,要求的错误率(false positive rate)为:

(1-ρ)为位数组中1的比例,(1-ρ)k就表示k次哈希都刚好选中1的区域,即false positive rate。上式中第二步近似在前面已经提到了,现在来看第一步近似。p’只是ρ的数学期望,在实际中ρ的值有可能偏离它的数学期望值。M. Mitzenmacher已经证明[2] ,位数组中0的比例非常集中地分布在它的数学期望值的附近。因此,第一步的近似得以成立。分别将p和p’代入上式中,得:


相比p’和f’,使用p和f通常在分析中更为方便。
最优的哈希函数个数
既然Bloom Filter要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
先用p和f进行计算。注意到f = exp(k ln(1 − e−kn/m)),我们令g = k ln(1 − e−kn/m),只要让g取到最小,f自然也取到最小。由于p = e-kn/m,我们可以将g写成

根据对称性法则可以很容易看出当p = 1/2,也就是k = ln2· (m/n)时,g取得最小值。在这种情况下,最小错误率f等于(1/2)k ≈ (0.6185)m/n。另外,注意到p是位数组中某一位仍是0的概率,所以p = 1/2对应着位数组中0和1各一半。换句话说,要想保持错误率低,最好让位数组有一半还空着。
需要强调的一点是,p = 1/2时错误率最小这个结果并不依赖于近似值p和f。同样对于f’ = exp(k ln(1 − (1 − 1/m)kn)),g’ = k ln(1 − (1 − 1/m)kn),p’ = (1 − 1/m)kn,我们可以将g’写成

同样根据对称性法则可以得到当p’ = 1/2时,g’取得最小值。
位数组的大小
下面我们来看看,在不超过一定错误率的情况下,Bloom Filter至少需要多少位才能表示全集中任意n个元素的集合。假设全集中共有u个元素,允许的最大错误率为є,下面我们来求位数组的位数m。
假设X为全集中任取n个元素的集合,F(X)是表示X的位数组。那么对于集合X中任意一个元素x,在s = F(X)中查询x都能得到肯定的结果,即s能够接受x。显然,由于Bloom Filter引入了错误,s能够接受的不仅仅是X中的元素,它还能够є (u - n)个false positive。因此,对于一个确定的位数组来说,它能够接受总共n + є (u - n)个元素。在n + є (u - n)个元素中,s真正表示的只有其中n个,所以一个确定的位数组可以表示

个集合。m位的位数组共有2m个不同的组合,进而可以推出,m位的位数组可以表示

个集合。全集中n个元素的集合总共有

个,因此要让m位的位数组能够表示所有n个元素的集合,必须有

即:

上式中的近似前提是n和єu相比很小,这也是实际情况中常常发生的。根据上式,我们得出结论:在错误率不大于є的情况下,m至少要等于n log2(1/є)才能表示任意n个元素的集合。
上一小节中我们曾算出当k = ln2· (m/n)时错误率f最小,这时f = (1/2)k = (1/2)mln2 / n。现在令f≤є,可以推出

这个结果比前面我们算得的下界n log2(1/є)大了log2 e ≈ 1.44倍。这说明在哈希函数的个数取到最优时,要让错误率不超过є,m至少需要取到最小值的1.44倍。
下面这张图可以很好的表示n和m取不同的值的时候,p的值。

根据这张图。我们可以计算出所需要的内存使用量。如果把错误率控制在1%以下的话。
| 1万 | 64KB |
| 10万 | 1MB |
| 100万 | 16MB |
| 1000万 | 256MB |
| 1亿 | <4GB |
可见占用的空间在key的数量在百万级别还是很划算的,但到了上亿的级别就不那么划算了。
Bloom Filter的插入和查询都是常数级别的,所以最大的问题就是占用内存过大。而初次分配内存的时候,如果没有能够确认槽位的个数。如果分配过多会导致内存浪费,太少就会倒是错误率过高。下面提到的两个改进方案可以分别解决这两个问题。
折叠
折叠是指当你初始化一个Bloom Filter的时候,可以分配足够大的槽位,等到Key导入完毕后,可以对使用的槽位进行合并操作。具体方法是将槽位切成两半,一边完全叠加到另一边上。减少内存的使用量。检查key的代码要做稍许改变。例:

通过这个操作,可以使实际使用的内存量减半。多执行几次,能减少更多。
动态扩展
通过折叠操作,可以解决分配过大的问题,但是如果一开始分配过小,就需要扩展槽位才行。如何扩展呢?只要按原尺寸再建立一个Bloom Filter数组。原来的那个保存起来,不再写入。有新的写请求的时候,就将数据写入到新的那个Bloom Filter数组里面去。等到新的也写满了,就再建立一个,以此类推。查询的时候,就需要遍历每一个Bloom Filter数组才行。但因为查询一个Bloom Filter数组的速度很快,查询一组Bloom Filter数组也不会太影响性能。使用这种手段可以是Bloom Filter的大小可以轻易的扩展。但这样做有个的缺陷,就是错误率会随着数组的增加而上升,因为实际的数组长度并没有增加。
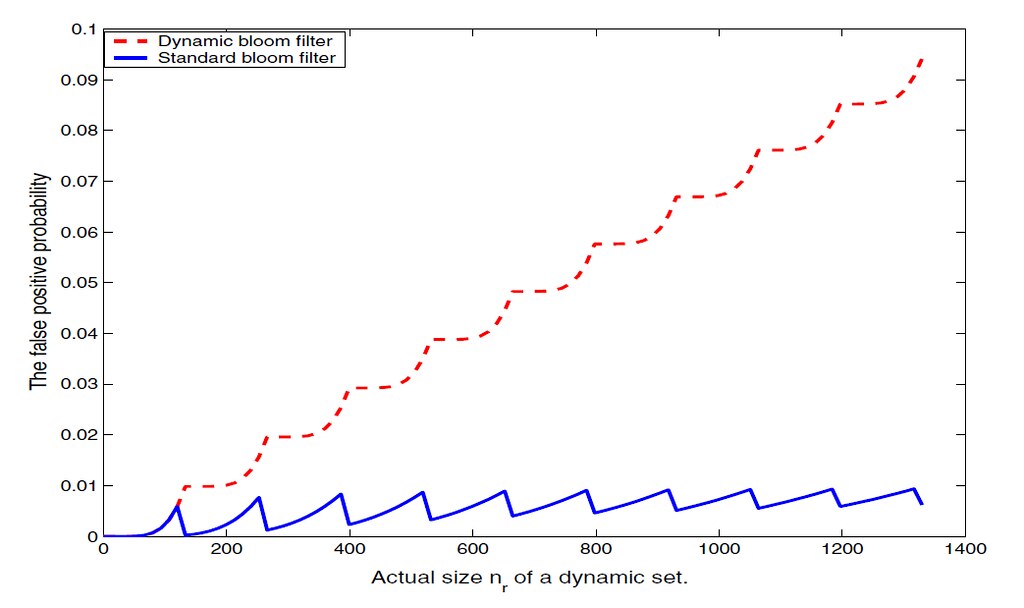
通过上面的两个方法,就可以解决BloomFilter的分配内存的问题。但无论哪种方法都有自己局限性,折叠每次只能减半,不是很精确。动态增加的方法会造成错误率增加。最好还是能预先估计到这个BloomFilter的容量。
Bloom Filter扩展
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。更多内容可查阅参考②相关文章。
应用举例
1.有10亿个url,如何判断一个新的url是否在这个url的集合中?
一个url平均长度为52,如果用Hash表解决的话,由于Hash表的存储效率一般只有50%,因此10个url大概需要100G内存,一般服务器无法存储。使用Bloom Filter,要求错误率小于万分之一。此时,输入元素n=10亿,最大错误率E=0.0001,可计算出:m=nlg(1/E)*1.44=57.6亿,大概需要7.2亿(57.6亿/8)个字节,即720M内存。Hash函数个数:k=(ln2)*(m/n) 大概4个Hash函数。
2.假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
1). 将访问过的URL保存到数据库。
2). 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
3). URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。
4). Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
方法4消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。
总结
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
参考:
①yfkiss: http://blog.csdn.net/yfkiss/article/details/6948616
②jiaomeng: http://blog.csdn.net/jiaomeng/article/details/1495500
③heaad: http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
④我自然
: http://www.yankay.com/%E6%9F%A5%E8%AF%A2%E5%88%A9%E5%99%A8-bloom-filter%E8%AF%A6%E8%A7%A3/


发表评论

-
C# 调用Delegate.CreateDelegate方法出现“未处理ArgumentException”错误解决
2013-05-31 12:24 3594在C# 调用Delegate.Create ... -
数组问题集结号
2012-12-06 22:01 0数组是最简单的数据结构,数组问题作为公司招聘的笔试和面试题目 ... -
算法问题分析笔记
2012-12-05 11:59 01.Crash Balloon Zhejiang Univer ... -
Java基础进阶整理
2012-11-26 09:59 2343Java学习笔记整理 ... -
Java学习笔记整理
2012-11-24 23:43 211Java学习笔记整理 本文档是我个人 ... -
《C++必知必会》学习笔记
2012-11-24 23:40 2664《C++必知必会》学� ... -
《C++必知必会》学习笔记
2012-11-24 23:34 1《C++必知必会》学习笔� ... -
C语言名题精选百则——排序
2012-11-04 23:29 128第5章排 序 问题5.1 二分插入法(BIN ... -
C语言名题精选百则——查找
2012-11-04 23:29 4182尊重他人的劳动,支持原创 本篇博文,D.S.Q ... -
基本技术——贪心法、分治法、动态规划三大神兵
2012-11-03 19:30 0基本技术——贪心法、分治法、动态规划三大神兵 -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:12 35698优先队列三大利器——二项堆、斐波那契堆、Pairing ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:01 3优先队列三大利器——二项堆、斐波那契堆、Pairing 堆 ... -
排序算法群星豪华大汇演
2012-10-30 00:09 3172排序算法群星豪华大汇演 排序算法相对简单些,但是由于 ... -
分布排序(distribution sorts)算法大串讲
2012-10-29 15:33 4689分布排序(distribution sorts)算法大串讲 ... -
归并排序(merge sorts)算法大串讲
2012-10-29 10:04 8336归并排序(merge sorts)算法大串讲 ... -
交换排序(exchange sorts)算法大串讲
2012-10-29 00:22 4440交换排序(exchange sorts)算法大串讲 本 ... -
选择排序(selection sorts)算法大串讲
2012-10-28 12:55 3749选择排序(selection sorts)算法大串讲 本文内 ... -
插入排序(insertion sorts)算法大串讲
2012-10-28 11:30 2770插入排序(insertion sorts� ... -
伸展树(Splay Tree)尽收眼底
2012-10-27 15:11 5606伸展树(Splay Tree)尽收眼底 本文内容 ... -
红黑树(Red-Black Tree)不在话下
2012-10-26 20:54 2257红黑树(Red-Black Tree) 红黑树定义 红黑树 ...
相关推荐
本文提出了一个名为“单哈希布鲁姆过滤器”(One-Hashing Bloom Filter,OHBF)的新型布鲁姆过滤器变种,旨在降低哈希计算开销,同时保持接近理想布鲁姆过滤器的理论误判率。 OHBF仅需使用一个基础哈希函数,并通过...
8. **性能优化**:对于大量MD5哈希值的查询,可能涉及到哈希表或Bloom Filter等数据结构,以提高查询效率。 9. **API认证与授权**:可能包含API密钥、OAuth等认证方式,限制对API的访问权限。 10. **响应式编程**...
7. 云原生特性:在云计算环境下,云HBase通常与其他云服务(如Hadoop、Spark、Kafka等)紧密集成,提供一站式的大数据解决方案。此外,云服务提供商通常会对云HBase进行优化,例如提供自动扩容、监控告警、安全策略...
同时,Bloom Filter的使用也帮助减少了不必要的计算资源消耗。 为了应对大规模业务和频繁的资源变更,微博构建了Cache Service服务化架构。这一架构包括configService、cache proxy、captain、L1和L1 main HA等组件...
Hutool是一个全面而强大的Java基础工具库,它的核心目标是简化开发过程中的常见任务,为开发者提供了一站式的解决方案。在v4.0.6版本中,Hutool进一步提升了其稳定性和功能性,使得Java开发变得更加高效和便捷。 ...
- **扩展**:布隆过滤器(Bloom Filter)作为BitMap的扩展,可以用于快速判断元素是否可能存在。 ### Bloom Filter - **概念**:一种空间效率极高的概率型数据结构,用于测试一个元素是否在一个集合中。 - **特点**...