传统的hash
算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。产生的两个签名,如果相等,说明原始内容在一定概率 下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。从这个意义上来 说,要设计一个
hash
算法,对相似的内容产生的签名也相近,是更为艰难的任务,因为它的签名值除了提供原始内容是否相等的信息外,还能额外提供不相等的 原始内容的差异程度的信息。
而Google
的
simhash
算法产生的签名,可以用来比较原始内容的相似度时,便很想了解这种神奇的算法的原理。出人意料,这个算法并不深奥,其思想是非常清澈美妙的。
Simhash算法
simhash算法的输入是一个向量,输出是一个
f
位的签名值。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。
simhash
算法如下:
1,将一个
f
维的向量
V
初始化为
0
;
f
位的二进制数
S
初始化为
0
;
2,对每一个特征:用传统的
hash
算法对该特征产生一个
f
位的签名
b
。对
i=1
到
f
:
如果b
的第
i
位为
1
,则
V
的第
i
个元素加上该特征的权重;
否则,V
的第
i
个元素减去该特征的权重。
3,如果
V
的第
i
个元素大于
0
,则
S
的第
i
位为
1
,否则为
0
;
4,输出
S
作为签名。


![]()
![]()
算法几何意义和原理
这个算法的几何意义非常明了。它首先将每一个特征映射为f
维空间的一个向量,这个映射规则具体是怎样并不重要,只要对很多不同的特征来说,它们对所对应的 向量是均匀随机分布的,并且对相同的特征来说对应的向量是唯一的就行。比如一个特征的
4
位
hash
签名的二进制表示为
1010
,那么这个特征对应的
4
维向量就是
(1, -1, 1, -1)
T
,即hash
签名的某一位为
1
,映射到的向量的对应位就为
1
,否则为
-1
。然后,将一个文档中所包含的各个特征对应的向量加权求和, 加权的系数等于该特征的权重。
得到的和向量即表征了这个文档,我们可以用向量之间的夹角来衡量对应文档之间的相似度。最后,为了得到一个
f
位的签名,需要 进一步将其压缩,如果和向量的某一维大于
0
,则最终签名的对应位为
1
,否则为
0
。这样的压缩相当于只留下了和向量所在的象限这个信息,而
64
位的签名可以 表示多达
2
64
个象限,因此只保存所在象限的信息也足够表征一个文档了。
比较相似度
海明距离:
两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。一个有效编码集中,
任意两个码字的海明距离的最小值称为该编码集的海明距离。举例如下:
10101
和
00110
从第一位开始依次有第一位、第四、第五位不同,则海明距离为
3.
异或:
只有在两个比较的位不同时其结果是1
,否则结果为
0
对每篇文档根据SimHash
算出签名后,再计算两个签名的海明距离(两个二进制异或后
1
的个数)即可。根据经验值,对
64
位的
SimHash
,海明距离在
3
以内的可以认为相似度比较高。
假设对64
位的
SimHash
,我们要找海明距离在
3
以内的所有签名。我们可以把
64
位的二进制签名均分成
4
块,每块
16
位。根据鸽巢原理(也成抽屉原理,见组合数学),如果两个签名的海明距离在
3
以内,它们必有一块完全相同。
我们把上面分成的4
块中的每一个块分别作为前
16
位来进行查找。
建立倒排索引。
![]()
![]()
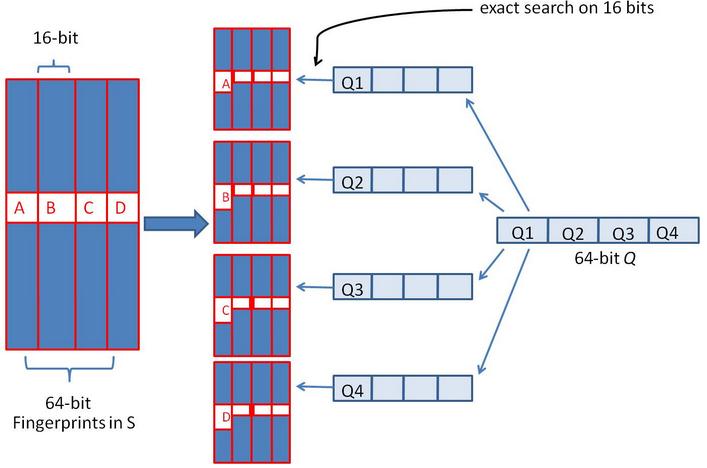
如果库中有2^34
个(大概
10
亿)签名,那么匹配上每个块的结果最多有
2^(34-16)=262144
个候选结果
(假设数据是均匀分布,
16
位的数据,产生的像限为
2^16
个,则平均每个像限分布的文档数则
2^34/2^16 = 2^(34-16))
,四个块返回的总结果数为 4* 262144
(大概
100
万)。原本需要比较
10
亿次,经过索引,大概就只需要处理
100
万次了。由此可见,确实大大减少了计算量。
Java 代码实现:
package com.gemantic.nlp.commons.simhash;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
public class SimHash {
private String tokens;
private BigInteger intSimHash;
private String strSimHash;
private int hashbits = 64;
public SimHash(String tokens) {
this.tokens = tokens;
this.intSimHash = this.simHash();
}
public SimHash(String tokens, int hashbits) {
this.tokens = tokens;
this.hashbits = hashbits;
this.intSimHash = this.simHash();
}
public BigInteger simHash() {
int[] v = new int[this.hashbits];
StringTokenizer stringTokens = new StringTokenizer(this.tokens);
while (stringTokens.hasMoreTokens()) {
String temp = stringTokens.nextToken();
BigInteger t = this.hash(temp);
for (int i = 0; i < this.hashbits; i++) {
BigInteger bitmask = new BigInteger("1").shiftLeft(i);
if (t.and(bitmask).signum() != 0) {
v[i] += 1;
} else {
v[i] -= 1;
}
}
}
BigInteger fingerprint = new BigInteger("0");
StringBuffer simHashBuffer = new StringBuffer();
for (int i = 0; i < this.hashbits; i++) {
if (v[i] >= 0) {
fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i));
simHashBuffer.append("1");
}else{
simHashBuffer.append("0");
}
}
this.strSimHash = simHashBuffer.toString();
System.out.println(this.strSimHash + " length " + this.strSimHash.length());
return fingerprint;
}
private BigInteger hash(String source) {
if (source == null || source.length() == 0) {
return new BigInteger("0");
} else {
char[] sourceArray = source.toCharArray();
BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7);
BigInteger m = new BigInteger("1000003");
BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(
new BigInteger("1"));
for (char item : sourceArray) {
BigInteger temp = BigInteger.valueOf((long) item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(source.length())));
if (x.equals(new BigInteger("-1"))) {
x = new BigInteger("-2");
}
return x;
}
}
/**
* 取两个二进制的异或,统计为1的个数,就是海明距离
* @param other
* @return
*/
public int hammingDistance(SimHash other) {
BigInteger x = this.intSimHash.xor(other.intSimHash);
int tot = 0;
//统计x中二进制位数为1的个数
//我们想想,一个二进制数减去1,那么,从最后那个1(包括那个1)后面的数字全都反了,对吧,然后,n&(n-1)就相当于把后面的数字清0,
//我们看n能做多少次这样的操作就OK了。
while (x.signum() != 0) {
tot += 1;
x = x.and(x.subtract(new BigInteger("1")));
}
return tot;
}
/**
* calculate Hamming Distance between two strings
* 二进制怕有错,当成字符串,作一个,比较下结果
* @author
* @param str1 the 1st string
* @param str2 the 2nd string
* @return Hamming Distance between str1 and str2
*/
public int getDistance(String str1, String str2) {
int distance;
if (str1.length() != str2.length()) {
distance = -1;
} else {
distance = 0;
for (int i = 0; i < str1.length(); i++) {
if (str1.charAt(i) != str2.charAt(i)) {
distance++;
}
}
}
return distance;
}
/**
* 如果海明距离取3,则分成四块,并得到每一块的bigInteger值 ,作为索引值使用
* @param simHash
* @param distance
* @return
*/
public List<BigInteger> subByDistance(SimHash simHash, int distance){
int numEach = this.hashbits/(distance+1);
List<BigInteger> characters = new ArrayList();
StringBuffer buffer = new StringBuffer();
int k = 0;
for( int i = 0; i < this.intSimHash.bitLength(); i++){
boolean sr = simHash.intSimHash.testBit(i);
if(sr){
buffer.append("1");
}
else{
buffer.append("0");
}
if( (i+1)%numEach == 0 ){
BigInteger eachValue = new BigInteger(buffer.toString(),2);
System.out.println("----" +eachValue );
buffer.delete(0, buffer.length());
characters.add(eachValue);
}
}
return characters;
}
public static void main(String[] args) {
String s = "This is a test string for testing";
SimHash hash1 = new SimHash(s, 64);
System.out.println(hash1.intSimHash + " " + hash1.intSimHash.bitLength());
hash1.subByDistance(hash1, 3);
System.out.println("\n");
s = "This is a test string for testing, This is a test string for testing abcdef";
SimHash hash2 = new SimHash(s, 64);
System.out.println(hash2.intSimHash+ " " + hash2.intSimHash.bitCount());
hash1.subByDistance(hash2, 3);
s = "This is a test string for testing als";
SimHash hash3 = new SimHash(s, 64);
System.out.println(hash3.intSimHash+ " " + hash3.intSimHash.bitCount());
hash1.subByDistance(hash3, 3);
System.out.println("============================");
int dis = hash1.getDistance(hash1.strSimHash,hash2.strSimHash);
System.out.println(hash1.hammingDistance(hash2) + " "+ dis);
int dis2 = hash1.getDistance(hash1.strSimHash,hash3.strSimHash);
System.out.println(hash1.hammingDistance(hash3) + " " + dis2);
}
}
参考:
http://blog.sina.com.cn/s/blog_72995dcc010145ti.html
http://blog.sina.com.cn/s/blog_56d8ea900100y41b.html
http://blog.csdn.net/meijia_tts/article/details/7928579
![]()
分享到:





相关推荐
simhash 算法的 java 实现。特点计算字符串的 simhash通过构建智能索引来计算所有字符串之间的相似性,因此可以处理大数据使用使用输入文件和输出文件运行 Maininputfile 的格式(参见 src / test_in):一个文件每...
在提供的"simhash-java-master"文件中,应该包含了Java实现SimHash算法的源代码,可以参考其结构和方法来理解和使用SimHash。这个实现可能包括了上述步骤的封装,便于在项目中直接调用。通过阅读和理解代码,开发者...
总的来说,Java实现的中文分词SimHash算法结合了Sanford分词库的分词功能和SimHash的相似度检测,为中文文本的相似度分析提供了一种高效且准确的方法。在实际应用中,这种技术广泛应用于搜索引擎的去重、推荐系统、...
SimHash是一种用于文本相似度计算的算法,它在大数据领域,尤其是搜索引擎和推荐系统中有着广泛应用。SimHash的原理是将一个长文本...通过Java实现,我们可以将这个理论应用于实际项目,提升文本处理的效率和准确性。
在`simhash-master`这个压缩包中,可能包含了完整的Java实现代码,包括上述步骤的详细实现,以及可能的示例和测试用例。通过阅读和理解这些代码,你可以更深入地了解SimHash算法,并将其应用到实际项目中。记得根据...
- 在 Java 中实现 Simhash 算法,可以先定义数据结构存储文档的特征和权重,然后实现哈希函数生成签名,最后按照算法步骤进行计算。 - 关键部分包括特征的哈希编码、向量的更新以及签名的生成。 Simhash 算法在...
Java实现simHash算法,对应博客http://www.cnblogs.com/hxsyl/p/4518506.html
Java实现simHash算法
Simhash4J是一个Java实现的Simhash算法库,主要用于文本相似度计算。Simhash是一种高效且精准的近似哈希技术,广泛应用于大数据去重、推荐系统和搜索引擎等领域。在这个项目中,它依赖于两个重要的组件:结巴分词和...
Java实现Elasticsearch的简单实例主要涉及以下几个关键知识点: 1. **Elasticsearch基础**:Elasticsearch(ES)是一个开源的、分布式全文搜索引擎,它提供了实时数据分析的能力,广泛用于日志分析、监控、搜索应用...
总之,Java实现文档指纹主要依赖于SimHash算法,该算法通过高效地计算文本的哈希值来识别文档的相似性。在实际应用中,开发者需要理解算法原理,预处理和向量化文档,以及计算和比较SimHash值。通过学习和使用提供的...
在Java中实现SimHash,我们可以使用如上代码所示的方法。以下是对这段代码的详细解释: 首先,我们看到代码定义了一个名为`MySimHash`的类,该类包含了计算SimHash的主要逻辑。类中有三个成员变量:`tokens`用于...
本主题将深入探讨中文文本相似度匹配算法中的simHash、海明距离以及IK分词技术。 首先,simHash是一种高效的近似哈希算法,主要用于大数据量文本的相似性检测。它的核心思想是将长文本转化为短的哈希值,使得相似的...
本文将深入探讨二进制串模糊搜索的Java实现,基于标题"二进制串模糊搜索的Java实现0.11",以及描述中提及的链接,我们能够推断出这是关于一种特定算法的实现,该算法可能基于SimHash,一种常用于相似性检测的技术。...
在这个eclipse工程中,可能包含了SimHash的Java实现,包括数据预处理、向量表示、SimHash计算和相似性比较等功能模块。开发人员可以借此了解SimHash的完整流程,并将其应用于自己的项目中。 在Java实现SimHash时,...
在这个名为“二进制串模糊搜索的Java实现0.2”的项目中,开发者显然对前一版本(可能为0.1)进行了更新和改进,增加了新的特性和优化。 "simhash"是这个项目中的一个关键标签,它指的是SimHash算法。SimHash是一种...
java实现的SimHash算法,用于海量的网页去重和打拼量的文本相似度检测
【海量分词java版】是针对大规模文本处理的Java实现,其主要目的是高效地对大量文本进行分词,这是自然语言处理(NLP)中的基础任务。在这个版本中,开发者利用JNI(Java Native Interface)技术进行了优化,允许...
本项目聚焦于使用Java编程语言结合HanLP分词器来实现这一功能。下面我们将深入探讨相关知识点。 首先,**文本比对**是文本挖掘中的基础操作,它旨在确定两段或多段文本之间的相似性或差异性。通常,我们可以通过...
simhash高效的文本相似度去重算法实现simhash是什么Google发明的的文本去重算法,适合于大批量文档的相似度计算主要步骤对文本分词,得到N维特征向量(默认为64维)为分词设置权重(tf-idf)为特征向量计算哈希对...