- µÁÅÞºê: 71587 µ¼í
- µÇºÕê½:

- µØÑÞç¬: µ¡ªµ▒ë
-

þñ¥Õî║þëêÕØù
- µêæþÜäÞÁäÞ«» ( 0)
- µêæþÜäÞ«║ÕØø ( 0)
- µêæþÜäÚù«þ¡ö ( 0)
Õ¡ÿµíúÕêåþ▒╗
- 2017-12 ( 2)
- 2017-11 ( 6)
- 2015-09 ( 1)
- µø┤ÕñÜÕ¡ÿµíú...
µ£Çµû░Þ»äÞ«║
-
spring_springmvc´╝Ü
spring mvc demoµòÖþ¿ïµ║Éõ╗úþáüõ©ïÞ¢¢´╝îÕ£░ÕØÇ´╝Ühttp: ...
springmvc -
mrhuangok´╝Ü
┬á µûçþ½áµØíþÉ嵩àµÖ░´╝îÕ©«õ║åµêæÕñºÕ┐ÖÒÇé
springmvc -
kunsyliu´╝Ü
...
getÕèáÕ»å -
JeffreyJia´╝Ü
õ©║õ╗Çõ╣êõ¢┐þö¿JMS Õ░▒Õ┐àÚí╗õ¢┐þö¿ MDBÕæó´╝ƒµ▓íµ£ëÕ┐àÞªüÕɺ´╝ƒ
Õƒ║õ║ÄSpringµëôÚÇáþ«ÇÕìòÚ½ÿµòêÚÇÜþö¿þÜäÕ╝鵡Ñõ╗╗ÕèíÕñäþÉåþ│╗þ╗ƒ
1.Õ╝òÞ¿Ç
Hibernate µÿ»µ£ÇµÁüÞíîþÜäÕ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëÕ╝òµôÄõ╣ïõ©Ç´╝îÕ«âµÅÉõ¥øõ║åµò░µì«µîüõ╣àÕîûÕÆÑÞ»óµ£ìÕèíÒÇé
Õ£¿õ¢áþÜäÚí╣þø«õ©¡Õ╝òÕàÑHibernateÕ╣ÂÞ«®Õ«âÞÀæÞÁÀµØѵÿ»Õ¥êÕ«╣µÿôþÜäÒÇéõ¢åµÿ»´╝îÞªüÞ«®Õ«âÞÀæÕ¥ùÕÑ¢Õì┤µÿ»Ú£ÇÞªüÕ¥êÕñܵùÂÚù┤ÕÆîþ╗ÅÚ¬îþÜäÒÇé
ÚÇÜÞ┐çµêæõ╗¼þÜäõ¢┐þö¿Hibernate 3.3.1ÕÆîOracle 9iþÜäÞ⢵║ÉÚí╣þø«õ©¡þÜäõ©Çõ║øõ¥ïÕ¡É´╝îµ£¼µûçµÂÁþøûõ║åÕ¥êÕñÜHibernateÞ░âõ╝ÿµèǵ£»ÒÇéÕàÂõ©¡Þ┐ÿµÅÉõ¥øõ║åõ©Çõ║øµÄîµÅíHibernateÞ░âõ╝ÿµèǵ£»µëÇÕ┐àÚ£ÇþÜäµò░µì«Õ║ôþƒÑÞ»åÒÇé
µêæõ╗¼ÕüçÞ«¥Þ»╗ÞÇàÕ»╣Hibernateµ£ëõ©Çõ©¬Õƒ║µ£¼þÜäõ║åÞºúÒÇéÕªéµ×£õ©Çõ©¬Þ░âõ╝ÿµû╣µ│òÕ£¿Hibernate ÕÅéÞÇâµûçµíú´╝êõ©ïµûçþ«Çþº░HRD´╝ëµêûÕàÂõ╗ûÞ░âõ╝ÿµûçþ½áõ©¡µ£ëÞ»ªþ╗åµÅÅÞ┐░´╝îµêæõ╗¼õ╗àµÅÉõ¥øõ©Çõ©¬Õ»╣޻ѵûçµíúþÜäÕ╝òþö¿Õ╣Âõ╗Äõ©ìÕÉîÞºÆÕ║ªÕ»╣ÕàÂÕüÜþ«ÇÕìòÞ»┤µÿÄÒÇéµêæõ╗¼Õà│µ│¿õ║ÄÚéúõ║øÞíîõ╣ïµ£ëµòê´╝îõ¢åÕÅêþ╝║õ╣ŵûçµíúþÜäÞ░âõ╝ÿµû╣µ│òÒÇé
2.HibernateµÇºÞâ¢Þ░âõ╝ÿ
Þ░âõ╝ÿµÿ»õ©Çõ©¬Þ┐¡õ╗úþÜäÒÇüµîüþ╗¡Þ┐øÞíîþÜäÞ┐çþ¿ï´╝îµÂëÕÅèÞ¢»õ╗ÂÕ╝ÇÕÅæþöƒÕæ¢Õ濵£ƒ´╝êSDLC´╝ëþÜäµëǵ£ëÚÿµ«ÁÒÇéÕ£¿õ©Çõ©¬Õà©Õ×ïþÜäõ¢┐þö¿HibernateÞ┐øÞíîµîüõ╣àÕîûþÜäJava EEÕ║öþö¿þ¿ïÕ║Åõ©¡´╝îÞ░âõ╝ÿõ╝ܵÂëÕÅèõ╗Ñõ©ïÕçáõ©¬µû╣ÚØó´╝Ü
- õ©ÜÕèíÞºäÕêÖÞ░âõ╝ÿ
- Þ«¥Þ«íÞ░âõ╝ÿ
- HibernateÞ░âõ╝ÿ
- Java GCÞ░âõ╝ÿ
- Õ║öþö¿þ¿ïÕ║ÅÕ«╣ÕÖ¿Þ░âõ╝ÿ
- Õ║òÕ▒éþ│╗þ╗ƒÞ░âõ╝ÿ´╝îÕîàµï¼µò░µì«Õ║ôÕÆîOSÒÇé
µ▓íµ£ëõ©ÇÕÑùþ▓¥Õ┐âÞ«¥Þ«íþÜäµû╣µíêÕ░▒ÕÄ╗Þ┐øÞíîõ╗Ñõ©èÞ░âõ╝ÿµÿ»ÚØ×Õ©©ÞÇùµùÂþÜä´╝îÞÇîõ©öÕ¥êÕÅ»Þ⢵öµòêþöÜÕ¥«ÒÇéÕÑ¢þÜäÞ░âõ╝ÿµû╣µ│òþÜäÚçìÞªüÚâ¿Õêåµÿ»õ©║Þ░âõ╝ÿÕåàÕ«╣ÕêÆÕêåõ╝ÿÕàêþ║ºÒÇéÕÅ»õ╗Ñþö¿ParetoÕ«ÜÕ¥ï´╝êÕÅêþº░ÔÇ£80/20µ│òÕêÖÔÇØ´╝ëµØÑÞºúÚçèÞ┐Öõ©Çþé╣´╝îÕì│ÚÇÜÕ©©80%þÜäÕ║öþö¿þ¿ïÕ║ŵǺÞ⢵ö╣Õûäµ║ÉÞç¬Õñ┤20%þÜäµÇºÞâ¢Úù«Úóÿ[5] ÒÇé
þø©µ»öÕƒ║õ║ÄþúüþøÿÕÆîþ¢æþ╗£þÜäÞ«┐Úù«´╝îÕƒ║õ║ÄÕåàÕ¡ÿÕÆîCPUþÜäÞ«┐Úù«Þ⢵ÅÉõ¥øµø┤õ¢ÄþÜäÕ╗ÂÞ┐ƒÕÆîµø┤Ú½ÿþÜäÕÉ×ÕÉÉÚçÅÒÇéÞ┐ÖþºìÕƒ║õ║ÄIOþÜäHibernateÞ░âõ╝ÿõ©ÄÕ║òÕ▒éþ│╗þ╗ƒIOÚâ¿ÕêåþÜäÞ░âõ╝ÿÕ║öÞ»Ñõ╝ÿÕàêõ║ÄÕƒ║õ║ÄCPUÕÆîÕåàÕ¡ÿþÜäÕ║òÕ▒éþ│╗þ╗ƒGCÒÇüCPUÕÆîÕåàÕ¡ÿÚâ¿ÕêåþÜäÞ░âõ╝ÿÒÇé
Þîâõ¥ï1
µêæõ╗¼Þ░âõ╝ÿõ║åõ©Çõ©¬ÚÇëµï®þöÁµÁüþÜäHQLµƒÑÞ»ó´╝îµèèÕ«âõ╗Ä30þºÆÚÖìÕê░õ║å1þºÆõ╗ÑÕåàÒÇéÕªéµ×£µêæõ╗¼Õ£¿Õ×âÕ£¥Õø×µöµû╣ÚØóõ©ïÕèƒÕñ½´╝îÕÅ»Þ⢵öµòêþöÜÕ¥«ÔÇöÔÇöõ╣ƒÞ«©ÕŬµ£ëÕçáµ»½þºÆµêûÞÇൣÇÕñÜÕçáþºÆ´╝îþø©µ»öHQLþÜäµö╣Þ┐ø´╝îGCµû╣ÚØóþÜäµö╣ÕûäÕÅ»õ╗ÑÕ┐¢þòÑõ©ìÞ«íÒÇé
ÕÑ¢þÜäÞ░âõ╝ÿµû╣µ│òþÜäÕŪõ©Çõ©¬ÚçìÞªüÚâ¿Õêåµÿ»Õå│Õ«Üõ¢òµùÂõ╝ÿÕîû[4] ÒÇé
þº»µ×üõ╝ÿÕîûþÜäµÅÉÕÇíÞÇàõ©╗Õ╝áÕ╝ÇÕºïµùÂÕ░▒Þ┐øÞíîÞ░âõ╝ÿ´╝îõ¥ïÕªéÕ£¿õ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íÚÿµ«Á´╝îÕ£¿µò┤õ©¬SDLCÚ⢵îüþ╗¡Þ┐øÞíîõ╝ÿÕîû´╝îÕøáõ©║õ╗ûõ╗¼Þ«ñõ©║ÕÉĵ£ƒµö╣ÕÅÿõ©ÜÕèíÞºäÕêÖÕÆîÚçìµû░Þ«¥Þ«íõ╗úõ╗ÀÕñ¬ÕñºÒÇé
ÕŪõ©Çµ┤¥õ║║µÅÉÕÇíÕ£¿SDLCµ£½µ£ƒÞ┐øÞíîÞ░âõ╝ÿ´╝îÕøáõ©║õ╗ûõ╗¼µè▒µÇ¿Õëìµ£ƒÞ░âõ╝ÿþ╗ÅÕ©©õ╝ÜÞ«®Þ«¥Þ«íÕÆîþ╝ûþáüÕÅÿÕ¥ùÕñìµØéÒÇéõ╗ûõ╗¼þ╗ÅÕ©©Õ╝òþö¿Donald KnuthþÜäÕÉìÞ¿ÇÔÇ£Þ┐çµù®õ╝ÿÕîûµÿ»õ©çµüÂõ╣ïµ║É ÔÇØ [6] ÒÇé
õ©║õ║åÕ╣│ÞííÞ░âõ╝ÿÕÆîþ╝ûþáüÚ£ÇÞªüõ©Çõ║øµØâÞííÒÇéµá╣µì«þ¼öÞÇàþÜäþ╗ÅÚ¬î´╝îÚÇéÕ¢ôþÜäÕëìµ£ƒÞ░âõ╝ÿÞâ¢Õ©ªµØѵø┤µÿĵÖ║þÜäÞ«¥Þ«íÕÆîþ╗åÞç┤þÜäþ╝ûþáüÒÇéÕ¥êÕñÜÚí╣þø«Õ░▒Õñ▒Þ┤ÑÕ£¿Õ║öþö¿þ¿ïÕ║ÅÞ░âõ╝ÿõ©è´╝îÕøáõ©║õ©èÚØóµÅÉÕê░þÜäÔÇ£Þ┐çµù®õ╝ÿÕîûÔÇØÚÿµ«ÁÕ£¿Þó½Õ╝òþö¿µùÂÞä▒þª╗õ║åõ©èõ©ïµûç´╝îÞÇîõ©öþø©Õ║öþÜäÞ░âõ╝ÿõ©ìµÿ»Þó½µÄ¿Þ┐ƒÕ¥ùÕñ¬µÖÜÕ░▒µÿ»µèòÕàÑÞÁäµ║ÉÞ┐çÕ░æÒÇé
õ¢åµÿ»´╝îÞªüÕüÜÕ¥êÕñÜÕëìµ£ƒÞ░âõ╝ÿõ╣ƒõ©ìÕñ¬ÕÅ»Þ⢴╝îÕøáõ©║µ▓íµ£ëþ╗ÅÞ┐çÕëûµ×É´╝îõ¢áÕ╣Âõ©ìÞâ¢þí«Õ«ÜÕ║öþö¿þ¿ïÕ║ÅþÜäþôÂÚóêþ®Âþ½ƒÕ£¿õ¢òÕñä´╝îÕ║öþö¿þ¿ïÕ║Åõ©ÇÞê¼Ú⢵ÿ»Þ┐ÖµáÀµ╝öÕîûþÜäÒÇé
Õ»╣µêæõ╗¼þÜäÕñÜþ║┐þ¿ïõ╝üõ©Üþ║ºÕ║öþö¿þ¿ïÕ║ÅþÜäÕëûµ×Éõ╣ƒÞí¿þÄ░Õç║ÕñºÕñܵò░Õ║öþö¿þ¿ïÕ║ÅÕ╣│ÕØçÕŬµ£ë20-50%þÜäCPUõ¢┐þö¿þÄçÒÇéÕë®õ¢ÖþÜäCPUÕ╝ÇÚöÇÕŬµÿ»Õ£¿þ¡ëÕ¥àµò░µì«Õ║ôÕÆîþ¢æþ╗£þø©Õà│þÜäIOÒÇé
Õƒ║õ║Äõ©èÞ┐░Õêåµ×É´╝îµêæõ╗¼Õ¥ùÕç║Þ┐ÖµáÀõ©Çõ©¬þ╗ôÞ«║´╝îþ╗ôÕÉêõ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íþÜäHibernateÞ░âõ╝ÿÕ£¿ParetoÕ«ÜÕ¥ïõ©¡20%þÜäÚéúõ©¬Úâ¿Õêå´╝îþø©Õ║öþÜäÕ«âõ╗¼þÜäõ╝ÿÕàêþ║ºµø┤Ú½ÿÒÇé
õ©Çþºìµ»öÞ¥âÕ«×ÚÖàþÜäÕüܵ│òµÿ»´╝Ü
- Þ»åÕê½Õç║õ©╗ÞªüþôÂÚóê´╝îÕÅ»õ╗ÑÚóäÞºüÕàÂõ©¡Õñܵò░µÿ»HibernateÒÇüõ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íµû╣ÚØóþÜä´╝êÕàµò░ÚçÅÞºåõ¢áþÜäÞ░âõ╝ÿþø«µáçÞÇîÕ«Ü´╝øõ¢åõ©ëÕê░õ║öõ©¬µÿ»õ©ìÚöÖþÜäÕ╝Çþ½»´╝ëÒÇé
- õ┐«µö╣Õ║öþö¿þ¿ïÕ║Åõ╗Ñõ¥┐µÂêÚÖñÞ┐Öõ║øþôÂÚóêÒÇé
- µÁïÞ»òÕ║öþö¿þ¿ïÕ║Å´╝îþäÂÕÉÄÚçìÕñ쵡ÑÚ¬ñ1´╝îþø┤Õê░Þ¥¥Õê░õ¢áþÜäÞ░âõ╝ÿþø«µáçõ©║µ¡óÒÇé
õ¢áÞâ¢Õ£¿Jack ShiraziþÜäÒÇèJava Performance TuningÒÇï [7] õ©Çõ╣ªõ©¡µë¥Õê░µø┤ÕñÜÕà│õ║ĵǺÞâ¢Þ░âõ╝ÿÚÿµ«ÁþÜäÕ©©ÞºüÕ╗║Þ««ÒÇé
õ©ïÚØóþÜäþ½áÞèéõ©¡´╝îµêæõ╗¼õ╝ܵîëþàºÞ░âõ╝ÿþÜäÕñºÞç┤Úí║Õ║Å´╝êÕêùÕ£¿ÕëìÚØóþÜäÚÇÜÕ©©Õ¢▒Õôìµ£ÇÕñº´╝ëÕÄ╗ÞºúÚçèõ©Çõ║øþë╣Õ«ÜþÜäÞ░âõ╝ÿµèǵ£»ÒÇé
3. þøæµÄºÕÆîÕëûµ×É
µ▓íµ£ëÕ»╣HibernateÕ║öþö¿þ¿ïÕ║ÅþÜäµ£ëµòêþøæµÄºÕÆîÕëûµ×É´╝îõ¢áµùáµ│òÕ¥ùþƒÑµÇºÞâ¢þôÂÚóêõ╗ÑÕÅèõ¢òÕñäÚ£ÇÞªüÞ░âõ╝ÿÒÇé
3.1.1 þøæµÄºSQLþöƒµêÉ
Õ░¢þ«íõ¢┐þö¿HibernateþÜäõ©╗Þªüþø«þÜäµÿ»Õ░åõ¢áõ╗Äþø┤µÄÑõ¢┐þö¿SQLþÜäþùøÞïªõ©¡ÞºúµòæÕç║µØÑ´╝îõ©║õ║åÕ»╣Õ║öþö¿þ¿ïÕ║ÅÞ┐øÞíîÞ░âõ╝ÿ´╝îõ¢áÕ┐àÚí╗þƒÑÚüôHibernateþöƒµêÉõ║åÕô¬õ║ø SQLÒÇéJoeSploskyÕ£¿õ╗ûþÜäÒÇèThe Law of Leaky AbstractionsÒÇïõ©Çµûçõ©¡Þ»ªþ╗åµÅÅÞ┐░õ║åÞ┐Öõ©¬Úù«ÚóÿÒÇé
õ¢áÕÅ»õ╗ÑÕ£¿log4jõ©¡Õ░åorg.hibernate.SQL ÕîàþÜäµùÑÕ┐ùþ║ºÕê½Þ«¥õ©║DEBUG´╝îÞ┐ÖµáÀõ¥┐Þâ¢þ£ïÕê░þöƒµêÉþÜäµëǵ£ëSQLÒÇéõ¢áÞ┐ÿÕÅ»õ╗ÑÕ░åÕàÂõ╗ûÕîàþÜäµùÑÕ┐ùþ║ºÕê½Þ«¥õ©║DEBUG´╝îþöÜÞç│TRACEµØÑÕ«Üõ¢ìõ©Çõ║øµÇºÞâ¢Úù«ÚóÿÒÇé
3.1.2 µƒÑþ£ïHibernateþ╗ƒÞ«í
Õªéµ×£Õ╝ÇÕÉ»hibernate.generate.statistics ´╝îHibernateõ╝ÜÕ»╝Õç║Õ«×õ¢ôÒÇüÚøåÕÉêÒÇüõ╝ÜÞ»ØÒÇüõ║îþ║ºþ╝ôÕ¡ÿÒÇüµƒÑÞ»óÕÆîõ╝ÜÞ»ØÕÀÑÕÄéþÜäþ╗ƒÞ«íõ┐íµü»´╝îÞ┐ÖÕ»╣ÚÇÜÞ┐çSessionFactory.getStatistics() Þ┐øÞíîþÜäÞ░âõ╝ÿե굣ëÕ©«Õè®ÒÇéõ©║õ║åþ«ÇÕìòÞÁÀÞºü´╝îHibernateÞ┐ÿÕÅ»õ╗Ñõ¢┐þö¿MBeanÔÇ£org.hibernate.jmx.StatisticsService ÔÇØÚÇÜÞ┐çJMXµØÑÕ»╝Õç║þ╗ƒÞ«íõ┐íµü»ÒÇéõ¢áÕÅ»õ╗ÑÕ£¿Þ┐Öõ©¬þ¢æþ½Öµë¥Õê░Úàìþ¢«Þîâõ¥ï ÒÇé
3.1.3 Õëûµ×É
õ©Çõ©¬ÕÑ¢þÜäÕëûµ×ÉÕÀÑÕàÀõ©ìõ╗ൣëÕê®õ║ÄHibernateÞ░âõ╝ÿ´╝îÞ┐ÿÞâ¢õ©║Õ║öþö¿þ¿ïÕ║ÅþÜäÕàÂõ╗ûÚâ¿ÕêåÕ©ªµØÑÕÑ¢ÕñäÒÇéþäÂÞÇî´╝îÕñºÕñܵò░Õòåõ©ÜÕÀÑÕàÀ´╝êõ¥ïÕªéJProbe [10] ´╝ëÚâ¢Õ¥êµÿéÞ┤ÁÒÇéÕ╣©Þ┐ÉþÜäµÿ»Sun/OracleþÜäJDK1.6Þç¬Õ©ªõ║åõ©Çõ©¬ÕÉìõ©║ÔÇ£Java VisualVMÔÇØ [11] þÜäÞ░âÞ»òµÄÑÕÅúÒÇéÞÖ¢þäµ»öÞÁÀÚéúõ║øÕòåõ©Üþ½×õ║ëÕ»╣µëï´╝îÕ«âÞ┐ÿþø©Õ¢ôÕƒ║þíÇ´╝îõ¢åÕ«âµÅÉõ¥øõ║åÕ¥êÕñÜÞ░âÞ»òÕÆîÞ░âõ╝ÿõ┐íµü»ÒÇé
4. Þ░âõ╝ÿµèǵ£»
4.1 õ©ÜÕèíÞºäÕêÖõ©ÄÞ«¥Þ«íÞ░âõ╝ÿ
Õ░¢þ«íõ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íÞ░âõ╝ÿÕ╣Âõ©ìÕ▒×õ║ÄHibernateÞ░âõ╝ÿþÜäÞîâþò┤´╝îõ¢åµ¡ñÕñäþÜäÕå│Õ«ÜÕ»╣ÕÉÄÚØóHibernateþÜäÞ░âõ╝ÿµ£ëÕ¥êÕñºÕ¢▒ÕôìÒÇéÕøᵡñµêæõ╗¼þë╣µäŵîçÕç║õ©Çõ║øõ©ÄHibernateÞ░âõ╝ÿµ£ëÕà│þÜäþé╣ÒÇé
Õ£¿õ©ÜÕèíڣǵ▒éµöÂÚøåõ©ÄÞ░âõ╝ÿÞ┐çþ¿ïõ©¡´╝îõ¢áÚ£ÇÞªüþƒÑÚüô´╝Ü
- µò░µì«ÞÄÀÕÅûþë╣µÇºÕîàµï¼Õ╝òþö¿µò░µì«´╝êreference data´╝ëÒÇüÕŬ޻╗µò░µì«ÒÇüÞ»╗Õêåþ╗ä´╝êread group´╝ëÒÇüÞ»╗ÕÅûÕñºÕ░ÅÒÇüµÉ£þ┤óµØíõ╗Âõ╗ÑÕÅèµò░µì«Õêåþ╗äÕÆîÞüÜÕÉêÒÇé
- µò░µì«õ┐«µö╣þë╣µÇºÕîàµï¼µò░µì«ÕÅÿµø┤ÒÇüÕÅÿµø┤þ╗äÒÇüÕÅÿµø┤ÕñºÕ░ÅÒÇüµùáµòêõ┐«µö╣ÞíÑÕü┐ÒÇüµò░µì«Õ║ô´╝êµëǵ£ëÕÅÿµø┤Úâ¢Õ£¿õ©Çõ©¬µò░µì«Õ║ôõ©¡µêûÕ£¿ÕñÜõ©¬µò░µì«Õ║ôõ©¡´╝ëÒÇüÕÅÿµø┤ÚóæþÄçÕÆîÕ╣ÂÕÅæµÇº´╝îõ╗ÑÕÅèÕÅÿµø┤ÕôìÕ║öÕÆîÕÉ×ÕÉÉÚçÅÞªüµ▒éÒÇé
- µò░µì«Õà│þ│╗´╝îõ¥ïÕªéÕà│Þüö´╝êassociation´╝ëÒÇüµ│øÕîû´╝êgeneralization´╝ëÒÇüÕ«×þÄ░´╝êrealization´╝ëÕÆîõ¥ØÞÁû´╝êdependency´╝ëÒÇé
Õƒ║õ║Äõ©ÜÕèíڣǵ▒é´╝îõ¢áõ╝ÜÕ¥ùÕê░õ©Çõ©¬µ£Çõ╝ÿÞ«¥Þ«í´╝îÕàÂõ©¡Õå│Õ«Üõ║åÕ║öþö¿þ¿ïÕ║Åþ▒╗Õ×ï´╝êµÿ»OLTPÞ┐ÿµÿ»µò░µì«õ╗ôÕ║ô´╝îõ║ªµêûÞÇàõ©ÄÕàÂõ©¡µƒÉõ©Çþºìµ»öÞ¥âµÄÑÞ┐æ´╝ëÕÆîÕêåÕ▒éþ╗ôµ×ä´╝êÕ░åµîüõ╣àÕ▒éÕÆîµ£ìÕèí Õ▒éÕêåþª╗Þ┐ÿµÿ»ÕÉêÕ╣´╝ë´╝îÕêøÕ╗║ÚóåÕƒƒÕ»╣Þ▒í´╝êÚÇÜÕ©©µÿ»POJO´╝ë´╝îÕå│իܵò░µì«ÞüÜÕÉêþÜäÕ£░µû╣´╝êÕ£¿µò░µì«Õ║ôõ©¡Þ┐øÞíîÞüÜÕÉêÞâ¢Õê®þö¿Õ╝║ÕñºþÜäµò░µì«Õ║ôÕèƒÞ⢴╝îÞèéþ£üþ¢æþ╗£Õ©ªÕ«¢´╝øõ¢åµÿ»ÚÖñõ║åÕâÅ COUNTÒÇüSUMÒÇüAVGÒÇüMINÕÆîMAXÞ┐ÖµáÀþÜäµáçÕçåÞüÜÕÉê´╝îÕàÂõ╗ûþÜäÞüÜÕÉêÚÇÜÕ©©õ©ìÕàÀµ£ëþº╗µñìµÇºÒÇéÕ£¿Õ║öþö¿µ£ìÕèíÕÖ¿õ©èÞ┐øÞíîÞüÜÕÉêÕàüÞ«©õ¢áÕ║öþö¿µø┤ÕñìµØéþÜäõ©ÜÕèíÚÇ╗Þ¥æ´╝øõ¢åõ¢áÚ£ÇÞªü ÕàêÕ£¿Õ║öþö¿þ¿ïÕ║Åõ©¡Þ¢¢ÕàÑÞ»ªþ╗åþÜäµò░µì«´╝ëÒÇé
Þîâõ¥ï2
Õêåµ×ÉÕæÿÚ£ÇÞªüµƒÑþ£ïõ©Çõ©¬ÕÅûÞç¬Õñºµò░µì«Þí¿þÜäþöÁµÁüISO´╝êIndependent System Operator´╝ëÞüÜÕÉêÕêùÞí¿ÒÇéµ£ÇÕ╝ÇÕºïõ╗ûõ╗¼µâ│Þªüµÿ¥þñ║ÕñºÕñܵò░Õ¡ùµ«Á´╝îÕ░¢þ«íµò░µì«Õ║ôÞâ¢Õ£¿1ÕêåÚƃÕåàÕüÜÕç║ÕôìÕ║ö´╝îÕ║öþö¿þ¿ïÕ║Åõ╣ƒÞªüÞè▒30ÕêåÚƃÕ░å1þÖ¥õ©çÞíîµò░µì«ÕèáÞ¢¢Õê░Õëìþ½»UIÒÇéþ╗Å Þ┐çÚçìµû░Õêåµ×É´╝îÕêåµ×ÉÕæÿõ┐ØþòÖõ║å14õ©¬Õ¡ùµ«ÁÒÇéÕøáõ©║ÕÄ╗µÄëõ║åÕ¥êÕñÜÕÅ»ÚÇëþÜäÚ½ÿÞüÜÕÉêÕ║ªÕ¡ùµ«Á´╝îõ╗ÄÕë®õ©ïþÜäÕ¡ùµ«Áõ©¡Þ┐øÞíîÞüÜÕÉêÕêåþ╗äÞ┐öÕø×þÜäµò░µì«ÞªüÕ░æÕ¥êÕñÜ´╝îÞÇîõ©öÕñºÕñܵò░µâàÕåÁõ©ïþÜäµò░µì«ÕèáÞ¢¢µù Úù┤õ╣ƒþ╝®Õ░ÅÕê░õ║åÕÅ»µÄÑÕÅùþÜäÞîâÕø┤ÕåàÒÇé
Þîâõ¥ï3
Þ┐ç24õ©¬ÔÇ£ÚØ×µáçÕçåÔÇØ´╝êshaped´╝îÞí¿þñ║µ»ÅÕ░ŵùÂÚâ¢ÕÅ»õ╗ѵ£ëÞç¬ÕÀ▒þÜäþöÁÚçÅÕÆîõ╗Àµá╝´╝øÕªéµ×£µëǵ£ë24Õ░ŵùÂþÜäþöÁÚçÅÕÆîõ╗Àµá╝þø©ÕÉî´╝îµêæõ╗¼þº░õ╣ïõ©║ÔÇ£µáçÕçåÔÇØ´╝ëÕ░ŵùÂõ╝Üõ┐«µö╣Õ░ŵùÂþöÁµÁüõ║ñµÿô´╝îÕàÂõ©¡Õîàµï¼2õ©¬Õ▒׵Ǻ´╝ܵ»ÅÕ░ŵùÂþöÁÚçÅÕÆîõ╗Àµá╝ÒÇéÞÁÀÕêصêæõ╗¼õ¢┐þö¿HibernateþÜäselect-before-update þë╣µÇº´╝îÕ░▒µÿ»µø┤µû░24Þíîµò░µì«Ú£ÇÞªü24µ¼íÚÇëµï®ÒÇéÕøáõ©║µêæõ╗¼ÕŬڣÇÞªü2õ©¬Õ▒׵Ǻ´╝îÞÇîõ©öÕªéµ×£õ©ìõ┐«µö╣þöÁÚçŵêûõ╗Àµá╝þÜäÞ»Øõ╣ƒµ▓íµ£ëõ©ÜÕèíÞºäÕêÖþªüµ¡óµùáµòêõ┐«µö╣´╝îµêæõ╗¼Õ░▒Õà│Úù¡õ║åselect-before-update þë╣µÇº´╝îÚü┐Õàìõ║å24µ¼íÚÇëµï®ÒÇé
4.2þ╗ºµë┐µÿáÕ░äÞ░âõ╝ÿ
Õ░¢þ«íþ╗ºµë┐µÿáÕ░äµÿ»ÚóåÕƒƒÕ»╣Þ▒íþÜäõ©ÇÚâ¿Õêå´╝îÕç║õ║ÄÕ«âþÜäÚçìÞªüµÇºµêæõ╗¼Õ░åÕ«âÕìòþï¼Õç║µØÑÒÇéHRD [1] õ©¡þÜäþ¼¼9þ½áÔÇ£þ╗ºµë┐µÿáÕ░äÔÇØ ÕÀ▓þ╗ÅÞ»┤Õ¥ùե굩àµÑÜõ║å´╝îµëÇõ╗ѵêæõ╗¼Õ░åÕà│µ│¿SQLþöƒµêÉÕÆîÚÆêÕ»╣µ»Åõ©¬þ¡ûþòÑþÜäÞ░âõ╝ÿÕ╗║Þ««ÒÇé
õ╗Ñõ©ïµÿ»HRDõ©¡Þîâõ¥ïþÜäþ▒╗Õø¥´╝Ü
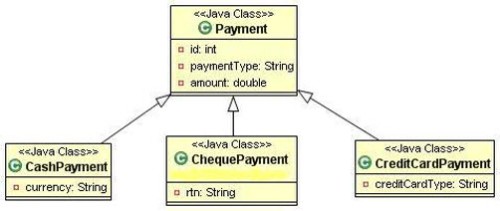
4.2.1 µ»Åõ©¬þ▒╗Õ▒éµ¼íõ©ÇÕ╝áÞí¿
ÕŬڣÇÞªüõ©ÇÕ╝áÞí¿´╝îõ©ÇµØíÕñܵÇüµƒÑÞ»óþöƒµêÉþÜäSQLÕñºµªéµÿ»Þ┐ÖµáÀþÜä´╝Ü
select id, payment_type, amount, currency, rtn, credit_card_type from payment
ÚÆêÕ»╣ÕàÀõ¢ôÕ¡Éþ▒╗´╝êõ¥ïÕªéCashPayment´╝ëþÜ䵃ÑÞ»óþöƒµêÉþÜäSQLµÿ»Þ┐ÖµáÀþÜä´╝Ü
select id, amount, currency from payment where payment_type=ÔÇÖCASHÔÇÖ
Þ┐ÖµáÀÕüÜþÜäõ╝ÿþé╣Õîàµï¼ÕŬµ£ëõ©ÇÕ╝áÞí¿ÒÇüµƒÑÞ»óþ«ÇÕìòõ╗ÑÕÅèÕ«╣µÿôõ©ÄÕàÂõ╗ûÞí¿Þ┐øÞíîÕà│ÞüöÒÇéþ¼¼õ║îõ©¬µƒÑÞ»óõ©¡õ©ìÚ£ÇÞªüÕîàÕɽÕàÂõ╗ûÕ¡Éþ▒╗õ©¡þÜäÕ▒׵ǺÒÇéµëǵ£ëÞ┐Öõ║øþë╣µÇºÞ«®Þ»Ñþ¡ûþòÑþÜäµÇºÞâ¢Þ░âõ╝ÿÞªüµ»öÕàÂõ╗ûþ¡ûþòÑÕ«╣µÿôÕ¥ùÕñÜÒÇéÞ┐Öþºìµû╣µ│òÚÇÜÕ©©µ»öÞ¥âÚÇéÕÉêµò░µì«õ╗ôÕ║ôþ│╗þ╗ƒ´╝îÕøáõ©║µëǵ£ëµò░µì«Úâ¢Õ£¿õ©ÇÕ╝áÞí¿Úçî´╝îõ©ìÚ£ÇÞªüÕüÜÞí¿Þ┐×µÄÑÒÇé
õ©╗ÞªüþÜäþ╝║þé╣µò┤õ©¬þ▒╗Õ▒éµ¼íõ©¡þÜäµëǵ£ëÕ▒׵ǺÚ⢵îñÕ£¿õ©ÇÕ╝áÕñºÞí¿Úçî´╝îÕªéµ×£µ£ëÕ¥êÕñÜÕ¡Éþ▒╗þë╣µ£ëþÜäÕ▒׵Ǻ´╝îµò░µì«Õ║ôõ©¡Õ░▒õ╝ܵ£ëÕñ¬ÕñÜÕ¡ùµ«ÁþÜäÕÅûÕÇ╝õ©║null´╝îÞ┐Öõ©║Õ¢ôÕëìÕƒ║õ║ÄÞíîþÜäµò░µì«Õ║ô ´╝êõ¢┐þö¿Õƒ║õ║ÄÕêùþÜäDBMSþÜäµò░µì«õ╗ôÕ║ôÕñäþÉåÞ┐Öõ©¬õ╝ܵø┤ÕÑ¢õ║ø´╝ëþÜäSQLÞ░âõ╝ÿÕó×Õèáõ║åÚÜ¥Õ║ªÒÇéÚÖñÚØ×Þ┐øÞíîÕêåÕî║´╝îÕɪÕêÖÕö»õ©ÇþÜäµò░µì«Þí¿õ╝ܵêÉõ©║þâ¡þé╣´╝îOLTPþ│╗þ╗ƒÚÇÜÕ©©Õ£¿Þ┐Öµû╣ÚØóÚâ¢õ©ì Õñ¬ÕÑ¢ÒÇé
4.2.2µ»Åõ©¬Õ¡Éþ▒╗õ©ÇÕ╝áÞí¿
Ú£ÇÞªü4Õ╝áÞí¿´╝îÕñܵÇüµƒÑÞ»óþöƒµêÉþÜäSQLÕªéõ©ï´╝Ü
select id, payment_type, amount, currency, rtn, credit_card type,         case when c.payment_id is not null then 1      when ck.payment_id is not null then 2      when cc.payment_id is not null then 3      when p.id is not null then 0 end as clazz from payment p left join cash_payment c on p.id=c.payment_id left join    cheque_payment ck on p.id=ck.payment_id left join    credit_payment cc on p.id=cc.payment_id;
ÚÆêÕ»╣ÕàÀõ¢ôÕ¡Éþ▒╗´╝êõ¥ïÕªéCashPayment´╝ëþÜ䵃ÑÞ»óþöƒµêÉþÜäSQLµÿ»Þ┐ÖµáÀþÜä´╝Ü
select id, payment_type, amount, currency from payment p left join cash_payment c on p.id=c.payment_id;
õ╝ÿþé╣Õîàµï¼µò░µì«Þí¿µ»öÞ¥âþ┤ºÕçæ´╝êµ▓íµ£ëõ©ìÚ£ÇÞªüþÜäÕÅ»þ®║Õ¡ùµ«Á´╝ë´╝îµò░µì«ÞÀ¿õ©ëõ©¬Õ¡Éþ▒╗þÜäÞí¿Þ┐øÞíîÕêåÕî║´╝îÕ«╣µÿôõ¢┐þö¿ÞÂàþ▒╗þÜäÞí¿õ©ÄÕàÂõ╗ûÞí¿Þ┐øÞíîÕà│ÞüöÒÇéþ┤ºÕçæþÜäµò░µì«Þí¿ÕÅ»õ╗ÑÚÆêÕ»╣Õƒ║õ║ÄÞíîþÜä µò░µì«Õ║ôÕüÜÕ¡ÿÕé¿ÕØùõ╝ÿÕîû´╝îÞ«®SQLµëºÞíîÕ¥ùµø┤ÕÑ¢ÒÇéµò░µì«ÕêåÕî║Õó×Õèáõ║åµò░µì«õ┐«µö╣þÜäÕ╣ÂÕÅæµÇº´╝êÚÖñõ║åÞÂàþ▒╗´╝îµ▓íµ£ëþâ¡þé╣´╝ë´╝îOLTPþ│╗þ╗ƒÚÇÜÕ©©õ╝ܵø┤ÕÑ¢õ║øÒÇé
ÕÉîµáÀþÜä´╝îþ¼¼õ║îõ©¬µƒÑÞ»óõ©ìÚ£ÇÞªüÕîàÕɽÕàÂõ╗ûÕ¡Éþ▒╗þÜäÕ▒׵ǺÒÇé
þ╝║þé╣µÿ»Õ£¿µëǵ£ëþ¡ûþòÑõ©¡Õ«âõ¢┐þö¿þÜäÞí¿ÕÆîÞí¿Þ┐×µÄѵ£ÇÕñÜ´╝îSQLÞ»¡ÕÅÑþ¿ìµÿ¥ÕñìµØé´╝êþ£ïþ£ïHibernateÕ迵ÇüÚë┤Õê½ÕÖ¿þÜäÚò┐CASEÕ¡ÉÕÅÑ´╝ëÒÇéþø©µ»öÕìòÕ╝áÞí¿´╝îµò░µì«Õ║ôÞªüÞè▒µø┤ÕñܵùÂÚù┤Þ░âõ╝ÿµò░µì«Þí¿Þ┐×µÄÑ´╝îµò░µì«õ╗ôÕ║ôÕ£¿õ¢┐þö¿Þ»Ñþ¡ûþòѵùÂÚÇÜÕ©©õ©ìÕñ¬þÉåµâ│ÒÇé
Õøáõ©║õ©ìÞâ¢ÞÀ¿ÞÂàþ▒╗ÕÆîÕ¡Éþ▒╗þÜäÕ¡ùµ«ÁµØÑÕ╗║þ½ïÕñìÕÉêþ┤óÕ╝ò´╝îÕªéµ×£Ú£ÇÞªüµîëÞ┐Öõ║øÕêùÞ┐øÞíÑÞ»ó´╝îµÇºÞâ¢õ╝ÜÕÅùÕ¢▒ÕôìÒÇéõ╗╗õ¢òÕ¡Éþ▒╗µò░µì«þÜäõ┐«µö╣Ú⢵ÂëÕÅèõ©ñÕ╝áÞí¿´╝ÜÞÂàþ▒╗þÜäÞí¿ÕÆîÕ¡Éþ▒╗þÜäÞí¿ÒÇé
4.2.3µ»Åõ©¬ÕàÀõ¢ôþ▒╗õ©ÇÕ╝áÞí¿
µÂëÕÅèõ©ëÕ╝áµêûµø┤ÕñÜþÜäÞí¿´╝îÕñܵÇüµƒÑÞ»óþöƒµêÉþÜäSQLµÿ»Þ┐ÖµáÀþÜä´╝Ü
select p.id, p.amount, p.currency, p.rtn, p. credit_card_type, p.clazz from (select id, amount, currency, null as rtn,null as credit_card type, 1 as clazz from cash_payment union all select id, amount, null as currency, rtn,null as credit_card type, 2 as clazz from cheque_payment union all select id, amount, null as currency, null as rtn,credit_card type, 3 as clazz from credit_payment) p;
ÚÆêÕ»╣ÕàÀõ¢ôÕ¡Éþ▒╗´╝êõ¥ïÕªéCashPayment´╝ëþÜ䵃ÑÞ»óþöƒµêÉþÜäSQLµÿ»Þ┐ÖµáÀþÜä´╝Ü
select id, payment_type, amount, currency from cash_payment;
õ╝ÿþé╣ÕÆîõ©èÚØóþÜäÔÇ£µ»Åõ©¬Õ¡Éþ▒╗õ©ÇÕ╝áÞí¿ÔÇØþ¡ûþòÑþø©õ╝╝ÒÇéÕøáõ©║ÞÂàþ▒╗ÚÇÜÕ©©µÿ»µè¢Þ▒íþÜä´╝îµëÇõ╗ÑÕàÀõ¢ôþÜäõ©ëÕ╝áÞí¿µÿ»Õ┐àÚí╗þÜä[Õ╝ÇÕñ┤ÕñäÞ»┤þÜä3Õ╝áµêûµø┤ÕñÜþÜäÞí¿µÿ»Õ┐àÚí╗þÜä]´╝îõ╗╗õ¢òÕ¡Éþ▒╗þÜäµò░µì«õ┐«µö╣ÕŬµÂëÕÅèõ©ÇÕ╝áÞí¿´╝îÞ┐ÉÞíîÞÁÀµØѵø┤Õ┐½ÒÇé
þ╝║þé╣µÿ»SQL´╝êfromÕ¡ÉÕÅÑÕÆîunion allաɵƒÑÞ»ó´╝ëÕñ¬ÕñìµØéÒÇéõ¢åµÿ»ÕñºÕñܵò░µò░µì«Õ║ôÕ»╣µ¡ñþ▒╗SQLþÜäÞ░âõ╝ÿÚâ¢Õ¥êÕÑ¢ÒÇé
Õªéµ×£õ©Çõ©¬þ▒╗µâ│ÕÆîPaymentÞÂàþ▒╗Õà│Þüö´╝îµò░µì«Õ║ôµùáµ│òõ¢┐þö¿Õ╝òþö¿Õ«îµò┤µÇº´╝êreferential integrity´╝ëµØÑÕ«×þÄ░Õ«â´╝øÕ┐àÚí╗õ¢┐þö¿ÞºªÕÅæÕÖ¿µØÑÕ«×þÄ░Õ«âÒÇéÞ┐ÖÕ»╣µò░µì«Õ║ôµÇºÞ⢵£ëõ║øÕ¢▒ÕôìÒÇé
4.2.4õ¢┐þö¿ÚÜÉÕ╝ÅÕñܵÇüÕ«×þÄ░µ»Åõ©¬ÕàÀõ¢ôþ▒╗õ©ÇÕ╝áÞí¿
ÕŬڣÇÞªüõ©ëÕ╝áÞí¿ÒÇéÕ»╣õ║ÄPaymentþÜäÕñܵÇüµƒÑÞ»óþöƒµêÉõ©ëµØíþï¼þ½ïþÜäSQLÞ»¡ÕÅÑ´╝îµ»Åõ©¬Õ»╣Õ║öõ©Çõ©¬Õ¡Éþ▒╗ÒÇéHibernateÕ╝òµôÄÚÇÜÞ┐çJavaÕÅìÕ░äµë¥Õç║PaymentþÜäµëǵ£ëõ©ëõ©¬Õ¡Éþ▒╗ÒÇé
ÕàÀõ¢ôÕ¡Éþ▒╗þÜ䵃ÑÞ»óÕŬþöƒµêÉÞ»ÑÕ¡Éþ▒╗þÜäSQLÒÇéÞ┐Öõ║øSQLÞ»¡ÕÅÑÚâ¢Õ¥êþ«ÇÕìò´╝îÞ┐ÖÚçîÕ░▒õ©ìÕåìÚÿÉÞ┐░õ║åÒÇé
Õ«âþÜäõ╝ÿþé╣ÕÆîõ©èÞèéþ▒╗õ╝╝´╝Üþ┤ºÕçæµò░µì«Þí¿ÒÇüÞÀ¿õ©ëõ©¬ÕàÀõ¢ôÕ¡Éþ▒╗þÜäµò░µì«ÕêåÕî║õ╗ÑÕÅèÕ»╣Õ¡Éþ▒╗õ╗╗µäŵò░µì«þÜäõ┐«µö╣Úâ¢ÕŬµÂëÕÅèõ©ÇÕ╝áÞí¿ÒÇé
þ╝║þé╣µÿ»þö¿õ©ëµØíþï¼þ½ïþÜäSQLÞ»¡ÕÅÑõ╗úµø┐õ║åõ©ÇµØíÞüöÕÉêSQL´╝îÞ┐Öõ╝ÜÕ©ªµØѵø┤ÕñÜþ¢æþ╗£IOÒÇéJavaÕÅìÕ░äõ╣ƒÚ£ÇÞªüµùÂÚù┤ÒÇéÕüçÞ«¥Õªéµ×£õ¢áµ£ëõ©ÇÕñºÕáåÚóåÕƒƒÕ»╣Þ▒í´╝îõ¢áõ╗ĵ£Çõ©èÕ▒éþÜäObjectþ▒╗Þ┐øÞíîÚÜÉÕ╝ÅÚÇëµï®µƒÑÞ»ó´╝îÚéúÞ»ÑÚ£ÇÞªüÕñÜÚò┐µùÂÚù┤Õòè´╝ü
µá╣µì«õ¢áþÜäµÿáÕ░äþ¡ûþòÑÕêÂÕ«ÜÕÉêþÉåþÜäÚÇëµï®µƒÑÞ»óÕ╣ÂÚØ×µÿôõ║ï´╝øÞ┐ÖÚ£ÇÞªüõ¢áõ╗öþ╗åÞ░âõ╝ÿõ©ÜÕèíڣǵ▒é´╝îÕƒ║õ║Äþë╣Õ«ÜþÜäµò░µì«Õ£║µÖ»ÕêÂÕ«ÜÕÉêþÉåþÜäÞ«¥Þ«íÕå│þ¡ûÒÇé
õ╗Ñõ©ïµÿ»õ©Çõ║øÕ╗║Þ««´╝Ü
- Þ«¥Þ«íþ╗åþ▓ÆÕ║ªþÜäþ▒╗Õ▒éµ¼íÕÆîþ▓ùþ▓ÆÕ║ªþÜäµò░µì«Þí¿ÒÇéþ╗åþ▓ÆÕ║ªþÜäµò░µì«Þí¿µäÅÕæ│þØǵø┤Õñܵò░µì«Þí¿Þ┐×µÄÑ´╝îþø©Õ║öþÜ䵃ÑÞ»óõ╣ƒõ╝ܵø┤ÕñìµØéÒÇé
- ÕªéÚØ×Õ┐àÞªü´╝îõ©ìÞªüõ¢┐þö¿ÕñܵÇüµƒÑÞ»óÒÇ鵡úÕªéõ©èµûçµëÇþñ║´╝îÕ»╣ÕàÀõ¢ôþ▒╗þÜ䵃ÑÞ»óÕŬÚÇëµï®Ú£ÇÞªüþÜäµò░µì«´╝îµ▓íµ£ëõ©ìÕ┐àÞªüþÜäÞí¿Þ┐×µÄÑÕÆîÞüöÕÉêÒÇé
- ÔÇ£µ»Åõ©¬þ▒╗Õ▒éµ¼íõ©ÇÕ╝áÞí¿ÔÇØÕ»╣µ£ëÚ½ÿÕ╣ÂÕÅæÒÇüþ«ÇÕìòµƒÑÞ»óÕ╣Âõ©öµ▓íµ£ëÕà▒õ║½ÕêùþÜäOLTPþ│╗þ╗ƒµØÑÞ»┤µÿ»õ©¬õ©ìÚöÖþÜäÚÇëµï®ÒÇéÕªéµ×£õ¢áµâ│þö¿µò░µì«Õ║ôþÜäÕ╝òþö¿Õ«îµò┤µÇºµØÑÕüÜÕà│Þüö´╝îÚéúÕ«âõ╣ƒµÿ»õ©¬ÕÉêÚÇéþÜäÚÇëµï®ÒÇé
- ÔÇ£µ»Åõ©¬ÕàÀõ¢ôþ▒╗õ©ÇÕ╝áÞí¿ÔÇØÕ»╣µ£ëÚ½ÿÕ╣ÂÕÅæÒÇüÕñìµØ鵃ÑÞ»óÕ╣Âõ©öµ▓íµ£ëÕà▒õ║½ÕêùþÜäOLTPþ│╗þ╗ƒµØÑÞ»┤µÿ»õ©¬õ©ìÚöÖþÜäÚÇëµï®ÒÇéÕ¢ôþäÂõ¢áõ©ìÕ¥ùõ©ìþë║þë▓ÞÂàþ▒╗õ©ÄÕàÂõ╗ûþ▒╗õ╣ïÚù┤þÜäÕà│ÞüöÒÇé
- Úççþö¿µÀÀÕÉêþ¡ûþòÑ´╝îõ¥ïÕªéÔÇ£µ»Åõ©¬þ▒╗Õ▒éµ¼íõ©ÇÕ╝áÞí¿ÔÇØõ©¡ÕÁîÕàÑÔÇ£µ»Åõ©¬Õ¡Éþ▒╗õ©ÇÕ╝áÞí¿ÔÇØ´╝îÞ┐ÖµáÀÕÅ»õ╗ÑÕê®þö¿õ©ìÕÉîþ¡ûþòÑþÜäõ╝ÿÕè┐ÒÇéÚÜÅþØÇõ¢áÚí╣þø«þÜäÞ┐øÕîû´╝îÕªéµ×£õ¢áÞªüÕÅìÕñìÚçìµû░µÿáÕ░ä´╝îÚéúõ¢áÕÅ»Þâ¢õ╣ƒõ╝ÜÚççþö¿Þ»Ñþ¡ûþòÑÒÇé
- ÔÇ£õ¢┐þö¿ÚÜÉÕ╝ÅÕñܵÇüÕ«×þÄ░µ»Åõ©¬ÕàÀõ¢ôþ▒╗õ©ÇÕ╝áÞí¿ÔÇØÞ┐ÖþºìÕüܵ│òÕ╣Âõ©ìµÄ¿ÞìÉ´╝îÕøáõ©║ÕàÂÚàìþ¢«Þ┐çõ║Äþ╣üþ╝øÒÇüõ¢┐þö¿ÔÇ£anyÔÇØÕàâþ┤áþÜäÕñìµØéÕà│ÞüöÞ»¡µ│òÕÆîÚÜÉÕ╝ŵƒÑÞ»óþÜäµ¢£Õ£¿Õì▒ÚÖ®µÇºÒÇé
Þîâõ¥ï4
õ©ïÚØóµÿ»õ©Çõ©¬õ║ñµÿôµÅÅÞ┐░Õ║öþö¿þ¿ïÕ║ÅþÜäÚâ¿ÕêåÚóåÕƒƒþ▒╗Õø¥´╝Ü
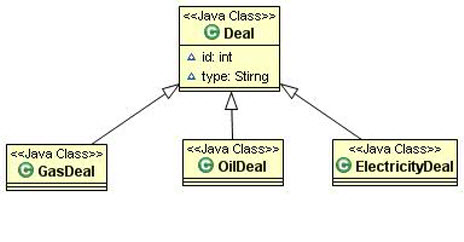
Õ╝ÇÕºïµù´╝îÚí╣þø«ÕŬµ£ëGasDealÕÆîÕ░æµò░þö¿µêÀ´╝îÕ«âõ¢┐þö¿ÔÇ£µ»Åõ©¬þ▒╗Õ▒éµ¼íõ©ÇÕ╝áÞí¿ÔÇØÒÇé
OilDealÕÆîElectricityDealµÿ»ÕÉĵ£ƒõ║ºþöƒµø┤ÕñÜõ©ÜÕèíڣǵ▒éÕÉÄÕèáÕàÑþÜäÒÇéµ▓íµ£ëµö╣ÕÅÿµÿáÕ░äþ¡ûþòÑÒÇéõ¢åµÿ»ElectricityDealµ£ëÕñ¬ÕñÜÞç¬ÕÀ▒þÜäÕ▒׵Ǻ´╝îÕøᵡñµ£ëÕ¥êÕñÜþöÁþø©Õà│þÜäÕÅ»þ®║Õ¡ùµ«ÁÕèáÕàÑõ║åDealÞí¿ÒÇéÕøáõ©║þö¿µêÀÚçÅõ╣ƒÕ£¿Õó×Úò┐´╝îµò░µì«õ┐«µö╣ÕÅÿÕ¥ùÞÂèµØÑÞÂèµàóÒÇé
Úçìµû░Þ«¥Þ«íµùµêæõ╗¼õ¢┐þö¿õ║åõ©ñÕ╝áÕìòþï¼þÜäÞí¿´╝îÕêåÕê½ÚÆêÕ»╣µ░ö/µ▓╣ÕÆîþöÁþø©Õà│þÜäÕ▒׵ǺÒÇéµû░þÜäµÿáÕ░äµÀÀÕÉêõ║åÔÇ£µ»Åõ©¬þ▒╗Õ▒éµ¼íõ©ÇÕ╝áÞí¿ÔÇØÕÆîÔÇ£µ»Åõ©¬Õ¡Éþ▒╗õ©ÇÕ╝áÞí¿ÔÇØÒÇéµêæõ╗¼Þ┐ÿÚçìµû░Þ«¥Þ«íõ║嵃ÑÞ»ó´╝îõ╗Ñõ¥┐ÕàüÞ«©ÚÆêÕ»╣ÕàÀõ¢ôõ║ñµÿôÕ¡Éþ▒╗Þ┐øÞíîÚÇëµï®´╝îµÂêÚÖñõ©ìÕ┐àÞªüþÜäÕêùÕÆîÞí¿Þ┐×µÄÑÒÇé
4.3 ÚóåÕƒƒÕ»╣Þ▒íÞ░âõ╝ÿ
Õƒ║õ║Ä4.1 Þèé õ©¡Õ»╣õ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íþÜäÞ░âõ╝ÿ´╝îõ¢áÕ¥ùÕê░õ║åõ©Çõ©¬þö¿POJOµØÑÞí¿þñ║þÜäÚóåÕƒƒÕ»╣Þ▒íþÜäþ▒╗Õø¥ÒÇéµêæõ╗¼Õ╗║Þ««´╝Ü
4.3.1 POJOÞ░âõ╝ÿ
-
õ╗ÄÞ»╗ÕåÖµò░µì«õ©¡Õ░åþ▒╗õ╝╝Õ╝òþö¿Þ┐ÖµáÀþÜäÕŬ޻╗µò░µì«ÕÆîõ╗ÑÞ»╗õ©║õ©╗þÜäµò░µì«Õêåþª╗Õç║µØÑÒÇé
ÕŬ޻╗µò░µì«þÜäõ║îþ║ºþ╝ôÕ¡ÿµÿ»µ£Çµ£ëµòêþÜä´╝îÕർíµÿ»õ╗ÑÞ»╗õ©║õ©╗þÜäµò░µì«þÜäÚØ×õ©Ñµá╝Þ»╗ÕåÖÒÇéÕ░åÕŬ޻╗POJOµáçÞ»åõ©║õ©ìÕÅ»µø┤µö╣þÜä´╝êimmutable´╝ëõ╣ƒµÿ»õ©Çõ©¬Þ░âõ╝ÿþé╣ÒÇéÕªéµ×£õ©Çõ©¬µ£ìÕèíÕ▒éµû╣µ│òÕŬÕñäþÉåÕŬ޻╗µò░µì«´╝îÕÅ»õ╗ÑÕ░åÕ«âþÜäõ║ïÕèíµáçõ©║ÕŬ޻╗´╝îÞ┐Öµÿ»õ╝ÿÕîûHibernateÕÆîÕ║òÕ▒éJDBCÚ®▒Õè¿þÜäõ©Çõ©¬µû╣µ│òÒÇé -
þ╗åþ▓ÆÕ║ªþÜäPOJOÕÆîþ▓ùþ▓ÆÕ║ªþÜäµò░µì«Þí¿ÒÇé
Õƒ║õ║ĵò░µì«þÜäõ┐«µö╣Õ╣ÂÕÅæÚçÅÕÆîÚóæþÄçþ¡ëÕåàÕ«╣µØÑÕêåÞºúÕñºþÜäPOJOÒÇéÕ░¢þ«íõ¢áÕÅ»õ╗ÑÕ«Üõ╣ëõ©Çõ©¬þ▓ÆÕ║ªÚØ×Õ©©þ╗åþÜäÕ»╣Þ▒íµ¿íÕ×ï´╝îõ¢åþ▓ÆÕ║ªÞ┐çþ╗åþÜäÞí¿õ╝ÜÕ»╝Þç┤ÕñºÚçÅÞí¿Þ┐×µÄÑ´╝îÞ┐ÖÕ»╣µò░µì«õ╗ôÕ║ôµØÑÞ»┤µÿ»õ©ìÞ⢵ÄÑÕÅùþÜäÒÇé -
õ╝ÿÕàêõ¢┐þö¿ÚØ×finalþÜäþ▒╗ÒÇé
HibernateÕŬõ╝ÜÚÆêÕ»╣ÚØ×finalþÜäþ▒╗õ¢┐þö¿CGLIBõ╗úþÉåµØÑÕ«×þÄ░Õ╗µùÂÕà│ÞüöÞÄÀÕÅûÒÇéÕªéµ×£Þó½Õà│ÞüöþÜäþ▒╗µÿ»finalþÜä´╝îHibernateõ╝Üõ©Çµ¼íÕèáÞ¢¢µëǵ£ëÕåàÕ«╣´╝îÞ┐ÖÕ»╣µÇºÞâ¢õ╝ܵ£ëÕ¢▒ÕôìÒÇé -
õ¢┐þö¿õ©ÜÕèíÚö«õ©║Õêåþª╗´╝êdetached´╝ëÕ«×õ¥ïÕ«×þÄ░equals()ÕÆîhashCode()µû╣µ│òÒÇé
Õ£¿ÕñÜÕ▒éþ│╗þ╗ƒõ©¡´╝îþ╗ÅÕ©©ÕÅ»õ╗ÑÕ£¿Õêåþª╗Õ»╣Þ▒íõ©èõ¢┐þö¿õ╣ÉÞºéÚöüµØѵÅÉÕìçþ│╗þ╗ƒÕ╣ÂÕÅæµÇº´╝îÞ¥¥Õê░µø┤Ú½ÿþÜäµÇºÞâ¢ÒÇé -
Õ«Üõ╣ëõ©Çõ©¬þëêµ£¼µêûµùÂÚù┤µê│Õ▒׵ǺÒÇé
õ╣ÉÞºéÚöüÚ£ÇÞªüÞ┐Öõ©¬Õ¡ùµ«ÁµØÑÕ«×þÄ░Úò┐Õ»╣޻ش╝êÕ║öþö¿þ¿ïÕ║Åõ║ïÕèí´╝ë[Þ»æµ│¿´╝ÜsessionÞ»æõ©║õ╝Ü޻ش╝îconversionÞ»æõ©║Õ»╣޻ش╝îõ╗Ñþñ║Õî║Õê½]ÒÇé -
õ╝ÿÕàêõ¢┐þö¿þ╗äÕÉêPOJOÒÇé
õ¢áþÜäÕëìþ½»UIþ╗ÅÕ©©Ú£ÇÞªüµØÑÞç¬ÕñÜõ©¬õ©ìÕÉîPOJOþÜäµò░µì«ÒÇéõ¢áÕ║öÞ»ÑÕÉæUIõ╝áÚÇÆõ©Çõ©¬þ╗äÕÉêPOJOÞÇîõ©ìµÿ»þï¼þ½ïþÜäPOJOõ╗ÑÞÄÀÕ¥ùµø┤ÕÑ¢þÜäþ¢æþ╗£µÇºÞâ¢ÒÇé
µ£ëõ©ñþºìµû╣Õ╝ÅÕ£¿µ£ìÕèíÕ▒éµ×äÕ╗║þ╗äÕÉêPOJOÒÇéõ©Çþºìµÿ»Õ£¿Õ╝ÇÕºïµùÂÕèá3.2Þ¢¢µëǵ£ëÚ£ÇÞªüþÜäþï¼þ½ïPOJO´╝îÚÜÅÕÉĵè¢ÕÅûÚ£ÇÞªüþÜäÕ▒׵Ǻµö¥ÕàÑþ╗äÕÉêPOJO´╝øÕŪõ©Çþºìµÿ»õ¢┐þö¿HQLµèòÕ¢▒´╝îþø┤µÄÑõ╗ĵò░µì«Õ║ôõ©¡ÚÇëµï®Ú£ÇÞªüþÜäÕ▒׵ǺÒÇé
Õªéµ×£ÕàÂõ╗ûÕ£░µû╣õ╣ƒÞªüµƒÑµë¥Þ┐Öõ║øþï¼þ½ïPOJO´╝îÕÅ»õ╗ѵèèÕ«âõ╗¼µö¥Þ┐øõ║îþ║ºþ╝ôÕ¡ÿõ╗Ñõ¥┐Õà▒õ║½´╝îÞ┐ÖµùÂþ¼¼õ©Çþºìµû╣Õ╝ŵø┤ÕÑ¢´╝øÕàÂõ╗ûµâàÕåÁõ©ïþ¼¼õ║îþºìµû╣Õ╝ŵø┤ÕÑ¢ÒÇé
4.3.2 POJOõ╣ïÚù┤Õà│ÞüöþÜäÞ░âõ╝ÿ
- Õªéµ×£ÕÅ»õ╗Ñþö¿one-to-oneÒÇüone-to-manyµêûmany-to-oneþÜäÕà│Þüö´╝îÕ░▒õ©ìÞªüõ¢┐þö¿many-to-manyÒÇé
-
many-to-manyÕà│ÞüöÚ£ÇÞªüÚóØÕñûþÜäµÿáÕ░äÞí¿ÒÇé
Õ░¢þ«íõ¢áþÜäJavaõ╗úþáüÕŬڣÇÞªüÕñäþÉåõ©ñþ½»þÜäPOJO´╝îõ¢åµƒÑÞ»óµù´╝îµò░µì«Õ║ôÚ£ÇÞªüÚóØÕñûÕ£░Õà│ÞüöµÿáÕ░äÞí¿´╝îõ┐«µö╣µùÂÚ£ÇÞªüÚóØÕñûþÜäÕêáÚÖñÕÆîµÅÆÕàÑÒÇé -
ÕìòÕÉæÕà│Þüöõ╝ÿÕàêõ║ÄÕÅîÕÉæÕà│ÞüöÒÇé
þö▒õ║Ämany-to-manyþÜäþë╣µÇº´╝îÕ£¿ÕÅîÕÉæÕà│ÞüöþÜäõ©Çþ½»ÕèáÞ¢¢Õ»╣Þ▒íõ╝ÜÞºªÕÅæÕŪõ©Çþ½»þÜäÕèáÞ¢¢´╝îÞ┐Öõ╝ÜÞ┐øõ©Çµ¡ÑÞºªÕÅæÕăպïþ½»ÕèáÞ¢¢µø┤ÕñÜþÜäµò░µì«´╝îþ¡ëþ¡ëÒÇé
one-to-manyÕÆîmany-to-oneþÜäÕÅîÕÉæÕà│Þüöõ╣ƒµÿ»þ▒╗õ╝╝þÜä´╝îÕ¢ôõ¢áõ╗ÄÕñÜþ½»´╝êÕ¡ÉÕ«×õ¢ô´╝ëÕ«Üõ¢ìÕê░õ©Çþ½»´╝êþêÂÕ«×õ¢ô´╝ë ÒÇé
Þ┐ÖµáÀþÜäµØÑÕø×ÕèáÞ¢¢Õ¥êÞÇùµù´╝îÞÇîõ©öÕÅ»Þâ¢õ╣ƒõ©ìµÿ»õ¢áµëǵ£ƒµ£øþÜäÒÇé -
õ©ìÞªüõ©║õ║åÕà│ÞüöÞÇîÕ«Üõ╣ëÕà│Þüö´╝øÕŬգ¿õ¢áÚ£ÇÞªüõ©ÇÞÁÀÕèáÞ¢¢Õ«âõ╗¼µùµëìÞ┐Öõ╣êÕüÜ´╝îÞ┐ÖÕ║öÞ»Ñþö▒õ¢áþÜäõ©ÜÕèíÞºäÕêÖÕÆîÞ«¥Þ«íµØÑÕå│Õ«Ü´╝êÞºüÞîâõ¥ï
5
´╝ëÒÇé
ÕŪÕñû´╝îõ¢áÞªüõ╣êõ©ìÕ«Üõ╣ëõ╗╗õ¢òÕà│Þüö´╝îÞªüõ╣êÕ£¿Õ¡ÉPOJOõ©¡Õ«Üõ╣ëõ©Çõ©¬ÕÇ╝þ▒╗Õ×ïþÜäÕ▒׵ǺµØÑÞí¿þñ║þêÂPOJOþÜäID´╝êÕŪõ©Çõ©¬µû╣ÕÉæõ╣ƒµÿ»þ▒╗õ╝╝þÜä´╝ëÒÇé -
ÚøåÕÉêÞ░âõ╝ÿ
Õªéµ×£ÚøåÕÉêµÄÆÕ║ÅÚÇ╗Þ¥æÞâ¢þö▒Õ║òÕ▒éµò░µì«Õ║ôÕ«×þÄ░´╝îÕ░▒õ¢┐þö¿ÔÇ£order-byÔÇØÕ▒׵ǺµØÑõ╗úµø┐ÔÇ£sortÔÇØ´╝îÕøáõ©║ÚÇÜÕ©©µò░µì«Õ║ôÕ£¿Þ┐Öµû╣ÚØóÕüÜÕ¥ùµ»öõ¢áÕÑ¢ÒÇé
ÚøåÕÉêÕÅ»õ╗ѵÿ»ÕÇ╝þ▒╗Õ×ïþÜä´╝êÕàâþ┤áµêûþ╗äÕÉêÕàâþ┤á´╝ë´╝îõ╣ƒÕÅ»õ╗ѵÿ»Õ«×õ¢ôÕ╝òþö¿þ▒╗Õ×ïþÜä´╝êone-to-manyµêûmany-to-manyÕà│Þüö´╝ëÒÇéÕ»╣Õ╝òþö¿þ▒╗Õ×ïÚøåÕÉêþÜäÞ░âõ╝ÿõ©╗Þªüµÿ»Þ░âõ╝ÿÞÄÀÕÅûþ¡ûþòÑÒÇéÕ»╣õ║ÄÕÇ╝þ▒╗Õ×ïÚøåÕÉêþÜäÞ░âõ╝ÿ´╝îHRD [1] õ©¡þÜä20.5 ÞèéÔÇ£þÉåÞºúÚøåÕÉêµÇºÞâ¢ÔÇØ ÕÀ▓þ╗ÅÕüÜõ║åÕ¥êÕÑ¢þÜäÚÿÉÞ┐░ÒÇé - ÞÄÀÕÅûþ¡ûþòÑÞ░âõ╝ÿÒÇéÞ»ÀÞºü4.7 ÞèéþÜäÞîâõ¥ï 5 ÒÇé
Þîâõ¥ï5
µêæõ╗¼µ£ëõ©Çõ©¬ÕÉìõ©║ElectricityDealsþÜäµá©Õ┐âPOJOþö¿õ║ĵÅÅÞ┐░þöÁþÜäõ║ñµÿôÒÇéõ╗Äõ©ÜÕèíÞºÆÕ║ªµØÑþ£ï´╝îÕ«âµ£ëÕ¥êÕñÜmany-to-oneÕà│Þüö´╝îõ¥ïÕªéÕÆî PortfolioÒÇüStrategyÕÆîTraderþ¡ëþÜäÕà│ÞüöÒÇéÕøáõ©║Õ╝òþö¿µò░µì«ÕìüÕêåþ¿│Õ«Ü´╝îÕ«âõ╗¼Þó½þ╝ôÕ¡ÿÕ£¿Õëìþ½»´╝îÞâ¢Õƒ║õ║ÄÕàÂIDÕ▒׵ǺÕ┐½ÚǃիÜõ¢ìÕê░Õ«âõ╗¼ÒÇé
õ©║õ║åµ£ëÕÑ¢þÜäÕèáÞ¢¢µÇºÞ⢴╝îElectricityDealÕŬµÿáÕ░äÕàâµò░µì«´╝îÕì│Úéúõ║øÕ╝òþö¿POJOþÜäÕÇ╝þ▒╗Õ×ïIDÕ▒׵Ǻ´╝îÕøáõ©║Õ£¿Ú£ÇÞªüµù´╝îÕÅ»õ╗ÑÕ£¿Õëìþ½»ÚÇÜÞ┐çportfolioKeyõ╗Äþ╝ôÕ¡ÿõ©¡Õ┐½ÚǃµƒÑµë¥Portfolio´╝Ü
<property name ="portfolioKey " column ="PORTFOLIO_ID" type =" integer" />Þ┐ÖþºìÚÜÉÕ╝ÅÕà│ÞüöÚü┐Õàìõ║åµò░µì«Õ║ôÞí¿Þ┐×µÄÑÕÆîÚóØÕñûþÜäÕ¡ùµ«ÁÚÇëµï®´╝îÚÖìõ¢Äõ║åµò░µì«õ╝áÞ¥ôþÜäÕñºÕ░ÅÒÇé
4.4 Þ┐×µÄѵ▒áÞ░âõ╝ÿ
þö▒õ║ÄÕêøÕ╗║þë®þÉåµò░µì«Õ║ôÞ┐×µÄÑÚØ×Õ©©ÞÇùµù´╝îõ¢áÕ║öÞ»ÑÕºïþ╗êõ¢┐þö¿Þ┐×µÄѵ▒á´╝îÞÇîõ©öÕ║öÞ»ÑÕºïþ╗êõ¢┐þö¿þöƒõ║ºþ║ºÞ┐×µÄѵ▒áÞÇîÚØ×HibernateÕåàþ¢«þÜäÕƒ║µ£¼Þ┐×µÄѵ▒áþ«ùµ│òÒÇé
ÚÇÜÕ©©õ╝Üõ©║HibernateµÅÉõ¥øõ©Çõ©¬µ£ëÞ┐×µÄѵ▒áÕèƒÞâ¢þÜäµò░µì«µ║ÉÒÇéApache DBCPþÜäBasicDataSource[13] µÿ»õ©Çõ©¬µÁüÞíîþÜäÕ╝ǵ║Éþöƒõ║ºþ║ºµò░µì«µ║ÉÒÇéÕñºÕñܵò░µò░µì«Õ║ôÕÄéÕòåõ╣ƒÕ«×þÄ░õ║åÞç¬ÕÀ▒þÜäÕà╝Õ«╣JDBC 3.0þÜäÞ┐×µÄѵ▒áÒÇéõ©¥õ¥ïµØÑÞ»┤´╝îõ¢áõ╣ƒÕÅ»õ╗Ñõ¢┐þö¿Oracle ReaApplication Cluster [15] µÅÉõ¥øþÜäJDBCÞ┐×µÄѵ▒á[14] õ╗ÑÞÄÀÕ¥ùÞ┐×µÄÑþÜäÞ┤ƒÞ¢¢ÕØçÞííÕÆîÕñ▒Þ┤ÑÞ¢¼þº╗ÒÇé
õ©ìþö¿ÕñÜÞ»┤´╝îõ¢áÕ£¿þ¢æõ©èÞ⢵ë¥Õê░Õ¥êÕñÜÕà│õ║ÄÞ┐×µÄѵ▒áÞ░âõ╝ÿþÜäµèǵ£»´╝îÕøᵡñµêæõ╗¼ÕŬޫ¿Þ«║Úéúõ║øÕñºÕñܵò░Þ┐×µÄѵ▒áµëÇÕà▒µ£ëþÜäÚÇÜþö¿Þ░âõ╝ÿÕÅéµò░´╝Ü
- µ£ÇÕ░ŵ▒áÕñºÕ░Å´╝ÜÞ┐×µÄѵ▒áõ©¡ÕÅ»õ┐صîüþÜäµ£ÇÕ░ÅÞ┐×µÄѵò░ÒÇé
-
µ£ÇÕñºµ▒áÕñºÕ░Å´╝ÜÞ┐×µÄѵ▒áõ©¡ÕÅ»õ╗ÑÕêåÚàìþÜäµ£ÇÕñºÞ┐×µÄѵò░ÒÇé
Õªéµ×£Õ║öþö¿þ¿ïÕ║ŵ£ëÚ½ÿÕ╣ÂÕÅæ´╝îÞÇîµ£ÇÕñºµ▒áÕñºÕ░ÅÕÅêÕñ¬Õ░Å´╝îÞ┐×µÄѵ▒áÕ░▒õ╝Üþ╗ÅÕ©©þ¡ëÕ¥àÒÇéþø©ÕÅì´╝îÕªéµ×£µ£ÇÕ░ŵ▒áÕñºÕ░ÅÕñ¬Õñº´╝îÕÅêõ╝ÜÕêåÚàìõ©ìÚ£ÇÞªüþÜäÞ┐×µÄÑÒÇé - µ£ÇÕñºþ®║Úù▓µùÂÚù┤´╝ÜÞ┐×µÄѵ▒áõ©¡þÜäÞ┐×µÄÑÞó½þë®þÉåÕà│Úù¡ÕëìÞâ¢õ┐صîüþ®║Úù▓þÜäµ£ÇÕñºµùÂÚù┤ÒÇé
- µ£ÇÕñºþ¡ëÕ¥àµùÂÚù┤´╝ÜÞ┐×µÄѵ▒áþ¡ëÕ¥àÞ┐×µÄÑÞ┐öÕø×þÜäµ£ÇÕñºµùÂÚù┤ÒÇéÞ»ÑÕÅéµò░ÕÅ»õ╗ÑÚóäÚÿ▓Õñ▒µÄºõ║ïÕèí´╝êrunaway transaction´╝ëÒÇé
- Ú¬îÞ»üµƒÑÞ»ó´╝ÜÕ£¿Õ░åÞ┐×µÄÑÞ┐öÕø×þ╗ÖÞ░âþö¿µû╣Õëìþö¿õ║ÄÚ¬îÞ»üÞ┐×µÄÑþÜäSQLµƒÑÞ»óÒÇéÞ┐Öµÿ»Õøáõ©║õ©Çõ║øµò░µì«Õ║ôÞó½Úàìþ¢«õ©║õ╝ܵØǵÄëÚò┐µùÂÚù┤þ®║Úù▓þÜäÞ┐×µÄÑ´╝îþ¢æþ╗£µêûµò░µì«Õ║ôþø©Õà│þÜäÕ╝éÕ©©õ╣ƒÕÅ»Þâ¢õ╝ܵØǵ¡╗Þ┐×µÄÑÒÇéõ©║õ║åÕçÅÕ░浡ñþ▒╗Õ╝ÇÚöÇ´╝îÞ┐×µÄѵ▒áÕ£¿þ®║Úù▓µùÂõ╝ÜÞ┐ÉÞíîÞ»ÑÚ¬îÞ»üÒÇé
4.5õ║ïÕèíÕÆîÕ╣ÂÕÅæþÜäÞ░âõ╝ÿ
þƒ¡µò░µì«Õ║ôõ║ïÕèíÕ»╣õ╗╗õ¢òÚ½ÿµÇºÞâ¢ÒÇüÚ½ÿÕÅ»µë®Õ▒òµÇºþÜäÕ║öþö¿þ¿ïÕ║ŵØÑÞ»┤Ú⢵ÿ»Õ┐àõ©ìÕÅ»Õ░æþÜäÒÇéõ¢áõ¢┐þö¿Þí¿þñ║Õ»╣Þ»ØÞ»Àµ▒éþÜäõ╝Ü޻صØÑÕñäþÉåÕìòõ©¬ÕÀÑõ¢£ÕìòÕàâ´╝îõ╗ѵ¡ñµØÑÕñäþÉåõ║ïÕèíÒÇé
ÞÇâÞÖæÕê░ÕÀÑõ¢£ÕìòÕàâþÜäÞîâÕø┤ÕÆîõ║ïÕèíÞ¥╣þòîþÜäÕêÆÕêå´╝îµ£ë3õ©¡µ¿íÕ╝Å´╝Ü
- µ»Åµ¼íµôìõ¢£õ©Çõ©¬õ╝ÜÞ»ØÒÇé µ»Åµ¼íµò░µì«Õ║ôÞ░âþö¿Ú£ÇÞªüõ©Çõ©¬µû░õ╝ÜÞ»ØÕÆîõ║ïÕèíÒÇéÕøáõ©║þ£ƒÕ«×þÜäõ©ÜÕèíõ║ïÕèíÚÇÜÕ©©ÕîàÕɽÕñÜõ©¬µ¡ñþ▒╗µôìõ¢£ÕÆîÕñºÚçÅÕ░Åõ║ïÕèí´╝îÞ┐Öõ©ÇÞê¼õ╝ÜÕ╝òÞÁÀµø┤Õñܵò░µì«Õ║ôµ┤╗Õè¿´╝êõ©╗Þªüµÿ»µò░µì«Õ║ôµ»Åµ¼íµÅÉõ║ñÚ£ÇÞªüÕ░åÕÅÿµø┤ÕêÀµû░Õê░þúüþøÿõ©è´╝ë´╝îÕ¢▒ÕôìÕ║öþö¿þ¿ïÕ║ŵǺÞâ¢ÒÇéÞ┐Öµÿ»õ©ÇþºìÕÅ쵿íÕ╝Å´╝îõ©ìÞ»Ñõ¢┐þö¿Õ«âÒÇé
- õ¢┐þö¿Õêåþª╗Õ»╣Þ▒í´╝ŵ¼íÞ»Àµ▒éõ©Çõ©¬õ╝ÜÞ»ØÒÇé
µ»Åµ¼íÕ«óµêÀþ½»Þ»Àµ▒éµ£ëõ©Çõ©¬µû░õ╝ÜÞ»ØÕÆîõ©Çõ©¬õ║ïÕèí´╝îõ¢┐þö¿HibernateþÜäÔÇ£Õ¢ôÕëìõ╝ÜÞ»ØÔÇØþë╣µÇºÕ░åõ©ñÞÇàÕà│ÞüöÞÁÀµØÑÒÇé
Õ£¿õ©Çõ©¬ÕñÜÕ▒éþ│╗þ╗ƒõ©¡´╝îþö¿µêÀÚÇÜÕ©©õ╝ÜÕÅæÞÁÀÚò┐Õ»╣޻ش╝êµêûÕ║öþö¿þ¿ïÕ║Åõ║ïÕèí´╝ëÒÇéÕñºÕñܵò░µùÂÚù┤µêæõ╗¼õ¢┐þö¿HibernateþÜäÞç¬Õè¿þëêµ£¼ÕÆîÕêåþª╗Õ»╣Þ▒íµØÑÕ«×þÄ░õ╣ÉÞºéÕ╣ÂÕÅæµÄºÕêÂÕÆîÚ½ÿµÇºÞâ¢ÒÇé - Õ©ªµë®Õ▒ò´╝êµêûÚò┐´╝ëõ╝ÜÞ»ØþÜ䵻ŵ¼íÕ»╣Þ»Øõ©Çõ╝ÜÞ»ØÒÇé Õ£¿õ©Çõ©¬õ╣ƒÞ«©õ╝ÜÞÀ¿ÕñÜõ©¬õ║ïÕèíþÜäÚò┐Õ»╣Þ»Øõ©¡õ┐صîüõ╝ÜÞ»ØÕ╝ÇÕÉ»ÒÇéÕ░¢þ«íÞ┐ÖÞ⢵èèõ¢áõ╗ÄÚçìµû░Õà│Þüöõ©¡ÞºúÞä▒Õç║µØÑ´╝îõ¢åõ╝ÜÞ»ØÕÅ»Þâ¢õ╝ÜÕåàÕ¡ÿµ║óÕç║´╝îÕ£¿Ú½ÿÕ╣ÂÕÅæþ│╗þ╗ƒõ©¡ÕÅ»Þâ¢õ╝ܵ£ëµùºµò░µì«ÒÇé
õ¢áÞ┐ÿÕ║ö޻ѵ│¿µäÅõ╗Ñõ©ïÕçáþé╣ÒÇé┬á
- Õªéµ×£õ©ìÚ£ÇÞªüJTAÕ░▒þö¿µ£¼Õ£░õ║ïÕèí´╝îÕøáõ©║JTAÚ£ÇÞªüµø┤ÕñÜÞÁäµ║É´╝îµ»öµ£¼Õ£░õ║ïÕèíµø┤µàóÒÇéÕ░▒þ«ùõ¢áµ£ëÕñÜõ©¬µò░µì«µ║É´╝îÚÖñÚØ×µ£ëÞÀ¿ÕñÜõ©¬µò░µì«Õ║ôþÜäõ║ïÕèí´╝îÕɪÕêÖõ╣ƒõ©ìÚ£ÇÞªü JTAÒÇéÕ£¿µ£ÇÕÉÄþÜäõ©Çõ©¬Õ£║µÖ»õ©ï´╝îÕÅ»õ╗ÑÞÇâÞÖæÕ£¿µ»Åõ©¬µò░µì«µ║Éõ©¡õ¢┐þö¿µ£¼Õ£░õ║ïÕèí´╝îõ¢┐þö¿õ©Çþºìþ▒╗õ╝╝ÔÇ£Last Resource Commit OptimizationÔÇØ[16] þÜäµèǵ£»´╝êÞºüõ©ïÚØóþÜäÞîâõ¥ï 6 ´╝ëÒÇé
- Õªéµ×£õ©ìµÂëÕÅèµò░µì«ÕÅÿµø┤´╝îÕ░åõ║ïÕèíµáçÞ«░õ©║ÕŬ޻╗þÜä´╝îÕ░▒ÕâÅ4.3.1 Þèé µÅÉÕê░þÜäÚéúµáÀÒÇé
- µÇ╗µÿ»Þ«¥þ¢«Ú╗ÿÞ«ñõ║ïÕèíÞÂàµùÂÒÇéõ┐ØÞ»üÕ£¿µ▓íµ£ëÕôìÕ║öÞ┐öÕø×þ╗Öþö¿µêÀµù´╝îµ▓íµ£ëÞíîõ©║õ©ìÕ¢ôþÜäõ║ïÕèíõ╝ÜÕ«îÕà¿Õìáµ£ëÞÁäµ║ÉÒÇéÞ┐ÖÕ»╣µ£¼Õ£░õ║ïÕèíõ╣ƒÕÉîµáÀµ£ëµòêÒÇé
- Õªéµ×£Hibernateõ©ìµÿ»þï¼Õìáµò░µì«Õ║ôþö¿µêÀ´╝îõ╣ÉÞºéÚöüõ╝ÜÕñ▒µòê´╝îÚÖñÚØ×ÕêøÕ╗║µò░µì«Õ║ôÞºªÕÅæÕÖ¿õ©║ÕàÂõ╗ûÕ║öþö¿þ¿ïÕ║ÅÕ»╣þø©ÕÉîµò░µì«þÜäÕÅÿµø┤Õó×Õèáþëêµ£¼Õ¡ùµ«ÁÕÇ╝ÒÇé
Þîâõ¥ï6
µêæõ╗¼þÜäÕ║öþö¿þ¿ïÕ║ŵ£ëÕñÜõ©¬Õ£¿ÕñºÕñܵò░µâàÕåÁõ©ïÕŬÕÆîµò░µì«Õ║ôÔÇ£AÔÇصëôõ║ñÚüôþÜäµ£ìÕèíÕ▒éµû╣µ│ò´╝øÕ«âõ╗¼ÕüÂÕ░öõ╣ƒõ╝Üõ╗ĵò░µì«Õ║ôÔÇ£BÔÇØõ©¡ÞÄÀÕÅûÕŬ޻╗µò░µì«ÒÇéÕøáõ©║µò░µì«Õ║ôÔÇ£BÔÇØÕŬµÅÉõ¥øÕŬ޻╗µò░µì«´╝îµêæõ╗¼Õ»╣Þ┐Öõ║øµû╣µ│òÕ£¿Þ┐Öõ©ñõ©¬µò░µì«Õ║ôõ©èõ╗ìþäÂõ¢┐þö¿µ£¼Õ£░õ║ïÕèíÒÇé
µ£ìÕèíÕ▒éõ©èµ£ëõ©Çõ©¬µû╣µ│òÞ«¥Þ«íÕ£¿õ©ñõ©¬µò░µì«Õ║ôõ©èµëºÞíîµò░µì«ÕÅÿµø┤ÒÇéõ╗Ñõ©ïµÿ»õ╝¬õ╗úþáü´╝Ü
//Make sure a local transaction on database A exists @Transactional (readOnly=false , propagation=Propagation.REQUIRED ) public void saveIsoBids() { //it participates in the above annotated local transaction insertBidsInDatabaseA(); //it runs in its own local transaction on database B insertBidRequestsInDatabaseB(); //must be the last operationÕøáõ©║insertBidRequestsInDatabaseB() µÿ»saveIsoBids ()õ©¡þÜäµ£ÇÕÉÄõ©Çõ©¬µû╣µ│ò´╝îµëÇõ╗ÑÕŬµ£ëõ©ïÚØóþÜäÕ£║µÖ»õ╝ÜÚÇáµêɵò░µì«õ©ìõ©ÇÞç┤´╝Ü
Õ£¿saveIsoBids()µëºÞíîÞ┐öÕø×µù´╝îµò░µì«Õ║ôÔÇ£AÔÇØþÜäµ£¼Õ£░õ║ïÕèíµÅÉõ║ñÕñ▒Þ┤ÑÒÇé
õ¢åµÿ»´╝îÕ░▒þ«ùsaveIsoBids()õ¢┐þö¿JTA´╝îÕ£¿õ©ñÚÿµ«ÁµÅÉõ║ñ´╝ê2PC´╝ëþÜäþ¼¼õ║îõ©¬µÅÉõ║ñÚÿµ«ÁÕñ▒Þ┤ÑþÜäµùÂÕÇÖ´╝îõ¢áÞ┐ÿµÿ»õ╝Üþó░Õê░µò░µì«õ©ìõ©ÇÞç┤ÒÇéÕøᵡñÕªéµ×£õ¢áÞâ¢ÕñäþÉåÕÑ¢õ©èÞ┐░þÜäµò░µì«õ©ìõ©ÇÞç┤µÇº´╝îÞÇîõ©öõ©ìµâ│õ©║õ║åõ©Çõ©¬µêûÕ░æµò░Õçáõ©¬µû╣µ│òÕ╝òÕàÑJTAþÜäÕñìµØéµÇº´╝îõ¢áÕ║öÞ»Ñõ¢┐þö¿µ£¼Õ£░õ║ïÕèíÒÇé


- 2012-10-15 10:03
- µÁÅÞºê 664
- Þ»äÞ«║(0)
- Õêåþ▒╗:õ╝üõ©Üµ×µ×ä
- µƒÑþ£ïµø┤ÕñÜ
ÕÅæÞí¿Þ»äÞ«║

-
jclõ©ÄjulÒÇülog4j1ÒÇülog4j2ÒÇülogbackþÜäÚøåµêÉÕăþÉå
2017-12-01 15:59 550jclõ©ÄjulÒÇülog4j1ÒÇülog4j2ÒÇülogbac ... -
slf4jõ©ÄjulÒÇülog4j1ÒÇülog4j2ÒÇülogbackþÜäÚøåµêÉÕăþÉå
2017-12-01 15:52 438┬á ┬áµöÂÞùÅ ┬á jd ... -
Úóäþ╝ûÞ»æÕêåµ×É
2017-11-29 10:26 664õ©Ç´╝ÄÞâîµÖ»´╝Ü þö¿Mybatis+my ... -
Úóäþ╝ûÞ»æ
2017-11-29 09:57 718PreparedStatement Õ£¿Þ»┤PreparedS ... -
Spring BootÕ║öþö¿þÜäÕÉÄÕÅ░Þ┐ÉÞíîÚàìþ¢«
2017-11-21 14:26 551Spring BootÕ║öþö¿þÜäÕÉÄÕÅ░Þ┐ÉÞíîÚàìþ¢« Úà▒µ▓╣õ©Çþ»ç´╝îµò┤ ... -
þ╝ûþáü
2017-11-21 14:25 534ÕçáþºìÕ©©ÞºüþÜäþ╝ûþáüµá╝Õ╝Å õ©║õ╗Çõ╣êÞªüþ╝ûþáü õ©ìþƒÑÚüôÕñºÕ«Âµ£ëµ▓íµ£ëµâ│Þ┐çõ©Ç ... -
Spring BootÕ║öþö¿þÜäÕÉÄÕÅ░Þ┐ÉÞíîÚàìþ¢«
2017-11-29 09:58 749Spring BootÕ║öþö¿þÜäÕÉÄÕÅ░Þ┐ÉÞíîÚàìþ¢« Úà▒µ▓╣õ©Çþ»ç´╝î ... -
spring boot µ│¿Þºú
2017-11-01 10:58 353@EnableAutoConfigurationÕÆî@Spr ... -
µö»õ╗ÿÞ»ØÚóÿ
2015-09-09 11:45 1464µ£¼µûçµíúÚÇéþö¿õ║║Õæÿ´╝Üõ║ñµÿôÚóåÕƒƒþÜäõ║ºÕôüþáöÕÅæõ║║Õæÿ µÅÉþ║▓´╝Ü Úô ... -
µÀ▒ÕàÑÕêåµ×É Java õ©¡þÜäõ©¡µûçþ╝ûþáüÚù«Úóÿ
2014-12-19 10:21 610Õ£¿ IBM Bluemix õ║æÕ╣│ÕÅ░õ©èÕ╝ÇÕÅæÕ╣ÂÚâ¿þ¢▓µé¿þÜäõ©ïõ©Çõ©¬Õ║ö ... -
hashmapµ¡╗Õ¥¬þÄ»
2014-11-24 10:45 764þû½Þïù´╝ÜJava HashMapþÜ䵡╗Õ¥¬þÄ» ┬á Õ£¿µÀÿÕ«ØÕåà ... -
jquery
2014-02-07 09:03 787Õ¢ôõ¢áÕçåÕñçõ¢┐þö¿jQuery´╝îµêæÕ╝║þâêÕ╗║Þ««õ¢áÚüÁÕ¥¬õ©ïÚØóÞ┐Öõ║øµîçÕìù´╝Ü ... -
ÕçÅÞ¢╗ÚíÁÚØóÕÄïÕèø
2014-01-26 09:04 642þ¢æþ½ÖÕ┐½ÚǃÕèáÞ¢¢´╝îµÿ»µÅÉõ¥ø ... -
linux Õæ¢õ╗ñ
2014-01-23 09:20 414õ©Ç.linuxÕ┐½µìÀÚö« Ctrl+C : þ╗굡óÕ¢ôÕëìÕæ¢õ╗ñ C ... -
mina
2013-10-15 12:49 1396<!--StartFragment -->   ... -
spring þ║┐þ¿ïµ▒á
2013-10-12 14:35 691Spring þ║┐þ¿ïµ▒áõ¢┐þö¿ ┬á Spring┬á ... -
µÇºÞâ¢þøæµÄº
2013-07-08 10:34 804┬á ┬áspring´╝îþ£ƒµÿ»õ©Çõ©¬ÕÑ¢õ©£ÞÑ┐´╝øµÇºÞ⢴╝îþ£ƒµÿ»õ©¬Þ«®õ║║Õñ┤þû╝ÕÅêõ©ì ... -
java ftp
2013-06-24 11:05 896┬á Õ£¿Úí╣þø«õ©¡õ¢┐þö¿Õê░FTPÕèƒÞâ¢,õ║ĵÿ»Úççþö¿þ▒╗õ╝╝SpringþÜäÕÉäþºì ... -
json
2013-06-21 14:01 732JSONÕ░Åþ╗ôÒÇÉjson-libÒÇæ ┬á j ... -
Õƒ║õ║ÄSpringµëôÚÇáþ«ÇÕìòÚ½ÿµòêÚÇÜþö¿þÜäÕ╝鵡Ñõ╗╗ÕèíÕñäþÉåþ│╗þ╗ƒ
2013-05-21 14:24 3946ÞâîµÖ» ÚÜÅþØÇÕ║öþö¿þ│╗þ╗ƒÕèƒÞâ ...
þø©Õà│µÄ¿ÞìÉ
### Hibernate µÇºÞâ¢Þ░âõ╝ÿÞ»ªÞºú #### õ©ÇÒÇüµªéÞ┐░ Hibernate µÿ»õ©Çµ¼¥õ╝ÿþºÇþÜä Java µîüõ╣àÕ▒éµíåµ×´╝îÕ«âþ«ÇÕîûõ║åµò░µì«Õ║ôµôìõ¢£´╝îõ¢┐Õ╝ÇÕÅæÞÇàÞâ¢Õñƒµø┤ÕèáÕà│µ│¿õ©ÜÕèíÚÇ╗Þ¥æÞÇîõ©ìµÿ»Õ║òÕ▒éþÜäµò░µì«Þ«┐Úù«þ╗åÞèéÒÇéþäÂÞÇî´╝îÕ£¿Õ«×ÚÖàÕ║öþö¿õ©¡´╝îõ©║õ║åþí«õ┐ØÕ║öþö¿þÜäÚ½ÿµÇºÞâ¢õ©Ä...
### HibernateµÇºÞâ¢Þ░âõ╝ÿþƒÑÞ»åþé╣ #### õ©ÇÒÇüþÉåÞºúHibernateõ©ÄÕà│Þüöþ«íþÉå Õ£¿Hibernateõ©¡´╝îÕà│Þüöþ«íþÉåµÿ»µÇºÞâ¢õ╝ÿÕîûþÜäÕà│Úö«Õøáþ┤áõ╣ïõ©ÇÒÇéÕà│ÞüöÚÇÜÕ©©Õîàµï¼õ╗Ñõ©ïÕçáþºìþ▒╗Õ×ï´╝ÜÕìòÕÉæ`one-to-many`Õà│ÞüöÒÇüÕÅîÕÉæ`one-to-many`Õà│ÞüöÒÇü`many-to-one`Õà│Þüö...
µ£ÇÕÉÄ´╝îõ╣ªõ©¡õ╝ܵÄóÞ«¿Õªéõ¢òÕ£¿Õ«×ÚÖàÚí╣þø«õ©¡ÚøåµêÉÕÆîõ╝ÿÕîûHibernate´╝îÕîàµï¼õ║ïÕèíþ«íþÉåÒÇüµÇºÞâ¢Þ░âõ╝ÿÒÇüÚù«ÚóÿµÄƵƒÑþ¡ëÕ«×µêÿµèÇÕÀºÒÇéÞ┐Öµ£ëÕè®õ║ÄÕ╝ÇÕÅæÞÇàÕ£¿Õ«×ÚÖàÕ╝ÇÕÅæÞ┐çþ¿ïõ©¡µø┤ÕÑ¢Õ£░Õ║öþö¿Hibernate´╝îµÅÉÕìçÚí╣þø«þÜäþ¿│իܵǺÕÆîµòêþÄçÒÇé µÇ╗þÜäµØÑÞ»┤´╝îÒÇèþ▓¥ÚÇÜHibernate...
### HibernateþÜäÕ╝ÇÕÅæµ│¿µäÅÚí╣õ©ÄµÇºÞâ¢Þ░âõ╝ÿ Õ£¿Úò┐µ£ƒþÜäÞ¢»õ╗ÂÕ╝ÇÕÅæÞ┐çþ¿ïõ©¡´╝îHibernateõ¢£õ©║õ©Çµ¼¥µÁüÞíîþÜäORM´╝êÕ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝ëµíåµ×´╝îÞó½Õ╣┐µ│øÕ║öþö¿õ║ÄJavaÚí╣þø«õ©¡ÒÇéþäÂÞÇî´╝îÕ£¿Õ«×ÚÖàþÜäÕ║öþö¿Õ£║µÖ»õ©ï´╝îÕªéõ¢òÞ┐øÞíîµÇºÞâ¢Þ░âõ╝ÿµÿ»õ©Çõ©¬ÚØ×Õ©©ÚçìÞªüþÜäÞ»ØÚóÿÒÇé...
ÒÇèHibernateµèǵ£»µëïÕåîÒÇïµÿ»ÚÆêÕ»╣JavaÕ╝ÇÕÅæõ║║ÕæÿþÜäõ©Çõ╗¢Þ»ªÕ░¢µîçÕìù´╝îÕ«âµÀ▒ÕàÑÕëûµ×Éõ║åHibernateÞ┐Öõ©ÇµÁüÞíîþÜäµîüõ╣àÕîûµíåµ×ÂÒÇéHibernateµÿ»õ©Çõ©¬Õ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëÕÀÑÕàÀ´╝îÕ«âþ«ÇÕîûõ║åµò░µì«Õ║ôµôìõ¢£´╝îÕàüÞ«©Õ╝ÇÕÅæÞÇàõ¢┐þö¿ÚØóÕÉæÕ»╣Þ▒íþÜäµû╣Õ╝ÅÕñäþÉåµò░µì«Õ║ôõ║ñõ║Æ...
**hibernateµîüõ╣àÕîûµèǵ£»Þ»ªÞºú** Hibernateµÿ»õ©Çµ¼¥Õ╝║ÕñºþÜäJavaÕ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëµíåµ×´╝îÕ«âõ©║Õ╝ÇÕÅæÞÇàµÅÉõ¥øõ║åÕ£¿JavaÕ║öþö¿õ©¡µôìõ¢£µò░µì«Õ║ôþÜäÕ╝║ÕñºÕÀÑÕàÀÒÇéÚÇÜÞ┐çHibernate´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗ÑÕ░åµò░µì«Õ║ôµôìõ¢£Þ¢¼Õîûõ©║Õ»╣JavaÕ»╣Þ▒íþÜäµôìõ¢£´╝îÕñºÕñºÚÖìõ¢Äõ║å...
9. **Chapter 10**´╝ܵ£ÇÕÉÄ´╝îõ¢£ÞÇàÕÅ»Þâ¢Þ«¿Þ«║õ║åÕªéõ¢òÕ░åHibernateõ©ÄÕàÂõ╗ûµèǵ£»´╝êÕªéSpringµíåµ×´╝ëÚøåµêÉ´╝îõ╗ÑÕÅèÕ£¿Õ«×ÚÖàÚí╣þø«õ©¡Õªéõ¢òÞ┐øÞíîµ£Çõ¢│Õ«×ÞÀÁÕÆîµÇºÞâ¢Þ░âõ╝ÿÒÇé ÚÇÜÞ┐çÞ┐Öõ║øþ½áÞèéþÜäÕ¡ªõ╣á´╝îÞ»╗ÞÇàõ©ìõ╗àÕÅ»õ╗ÑþÉåÞºúHibernateþÜäÕÀÑõ¢£ÕăþÉå´╝îÞ┐ÿÞâ¢þåƒþ╗â...
µûçþ½áÚÇÜÞ┐çõ©Çõ©¬õ¢┐þö¿Hibernate 3.3.1ÕÆîOracle 9iþÜäÕ«×ÚÖàÚí╣þø«µíêõ¥ï´╝îÞ»ªþ╗åõ╗ïþ╗ìõ║åÕñÜõ©¬Þ░âõ╝ÿµèǵ£»´╝îÕ╣ÂÕ╝║Þ░âõ║åµò░µì«Õ║ôþƒÑÞ»åþÜäÚçìÞªüµÇºÒÇé µûçþ½áÚªûÕàêµîçÕç║´╝îÞ░âõ╝ÿµÿ»õ©Çõ©¬µîüþ╗¡þÜäÞ┐çþ¿ï´╝îµÂÁþøûõ║åõ╗Äõ©ÜÕèíÞºäÕêÖÕê░Õ║òÕ▒éþ│╗þ╗ƒÕÉäõ©¬Õ▒éÚØóÒÇéÕ£¿õ¢┐þö¿Hibernate...
8. **Appendix A, B, C**´╝ÜÚÖäÕ¢òÚÇÜÕ©©þö¿µØÑÞíÑÕàൡúµûçõ©¡þÜäÕåàÕ«╣´╝îÕÅ»Þ⢵ÿ»Õ»╣µƒÉõ║øÚ½ÿþ║ºõ©╗ÚóÿþÜäµÀ▒ÕàѵÄóÞ«¿´╝îÕªéµÇºÞâ¢Þ░âõ╝ÿÒÇüÞç¬Õ«Üõ╣ëþ▒╗Õ×ïÒÇüJPA´╝êJava Persistence API´╝ëõ©ÄHibernateþÜäÕà│þ│╗´╝îµêûÞÇàµÿ»Õ©©ÞºüÚù«ÚóÿÕÆîÞºúÕå│µû╣µíêþÜäÚøåÕÉêÒÇé ÚÇÜÞ┐çÕ¡ªõ╣á...
12. **þøæµÄºõ©ÄÞ░âõ╝ÿ**: õ¢┐þö¿µò░µì«Õ║ôµùÑÕ┐ùÒÇüþøæµÄºÕÀÑÕàÀ´╝êÕªéJProfiler´╝ëµêûHibernateþÜäþ╗ƒÞ«íõ┐íµü»µØÑÕêåµ×ɵë╣ÕñäþÉåþÜäµòêµ×£´╝îõ╗Ñõ¥┐Þ┐øõ©Çµ¡Ñõ╝ÿÕîûÒÇé µÇ╗þ╗ô´╝îHibernateþÜäµë╣ÕñäþÉåµÿ»Õñºµò░µì«Õ£║µÖ»õ©ïµÅÉÚ½ÿµÇºÞâ¢þÜäÕà│Úö«µèǵ£»õ╣ïõ©Ç´╝îÚ£ÇÞªüµá╣µì«ÕàÀõ¢ôõ©ÜÕèíڣǵ▒é...
### µÇºÞâ¢Þ░âõ╝ÿÕ©©ÞºäµëﵫÁÞ»ªÞºú #### õ©ÇÒÇüÕ╝òÞ¿Ç Õ£¿Õ¢ôõ╗èõ┐íµü»ÕîûµùÂõ╗ú´╝îµùáÞ«║µÿ»õ╝üõ©Üþ║ºÕ║öþö¿Þ┐ÿµÿ»õ©¬õ║║Þ¢»õ╗ÂÕ╝ÇÕÅæÚí╣þø«´╝îþ│╗þ╗ƒµÇºÞâ¢Ú⢵ÿ»Þç│Õà│ÚçìÞªüþÜäÞÇâÚçÅÕøáþ┤áõ╣ïõ©ÇÒÇé...µ£¬µØÑÚÜÅþØǵèǵ£»þÜäÕÅæÕ▒ò´╝îµÇºÞâ¢Þ░âõ╝ÿþÜäµû╣µ│òÕÆîµèǵ£»õ╣ƒÕ░åõ©ìµû¡Þ┐øµ¡ÑÕÆîÕ«îÕûäÒÇé
µÇ╗õ╣ï´╝îÒÇèHibernate4.0õ©¡µûçµûçµíúÒÇïµÿ»JavaÕ╝ÇÕÅæÞÇàþÜäÕ┐àÕñçÞ»╗þë®´╝îÕ«âÞªåþøûõ║åHibernateþÜäµëǵ£ëµá©Õ┐⵪éÕ┐ÁÕÆîµèǵ£»´╝îÕ©«Õè®Õ╝ÇÕÅæÞÇàÚ½ÿµòêÕ£░Õê®þö¿HibernateÞ┐øÞíîµò░µì«Õ║ôµôìõ¢£´╝îõ╗ÄÞÇîµÅÉÚ½ÿÕ╝ÇÕÅæµòêþÄçÕ╣ÂÚÖìõ¢Äþ╗┤µèñµêɵ£¼ÒÇéÚÇÜÞ┐çµÀ▒ÕàÑÕ¡ªõ╣áÕÆîÕ«×ÞÀÁ´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗Ñ...
**EJB´╝êEnterprise JavaBeans´╝ëõ©ÄHibernateþÜäµò┤ÕÉêµÿ»Javaõ╝üõ©Üþ║ºÕ╝ÇÕÅæõ©¡þÜäõ©ÇÚí╣ÚçìÞªüµèǵ£»þ╗ôÕÉê´╝îõ©╗Þªüþø«þÜäµÿ»õ©║õ║åÕ£¿EJBÕ«╣ÕÖ¿õ©¡ÕààÕêåÕê®þö¿HibernateþÜäµîüõ╣àÕîûÞâ¢Õèø´╝îµÅÉÚ½ÿµò░µì«þ«íþÉåþÜäþüÁµ┤╗µÇºÕÆîµòêþÄçÒÇé** EJB´╝îÕà¿þº░õ©║Enterprise ...
Struts2µÅÉõ¥øõ║åÕ╝║ÕñºþÜäµïªµê¬ÕÖ¿µ£║Õê´╝îÕÅ»õ╗ÑþüÁµ┤╗Õ£░ÕñäþÉåÞ»Àµ▒éÕÆîÕôìÕ║ö´╝îµö»µîüÕñÜþºìÞºåÕø¥µèǵ£»ÕªéJSPÒÇüFreeMarkerþ¡ë´╝îÕ╣Âõ©öÕÅ»õ╗Ñõ©ÄÕÉäþºìµîüõ╣àÕ▒éµíåµ×ÂÕªéHibernateÚøåµêÉÒÇé **Hibernate** µÿ»õ©Çõ©¬Õ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëµíåµ×´╝îÕ«âþ«ÇÕîûõ║åJavaÕ║öþö¿õ©Ä...
**Hibernate µíåµ×µªéÞ┐░** Hibernate µÿ»õ©Çõ©¬Õ╝ǵ║ÉþÜäÕ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëµíåµ×´╝îÕ«âÕàüÞ«©Õ╝ÇÕÅæÞÇàþö¿ÚØóÕÉæÕ»╣Þ▒íþÜä...ÚÇÜÞ┐çÕ¡ªõ╣áÞ┐Öõ║øµòÖþ¿ïÕÆîõ╣ªþ▒ì´╝îõ¢áÕÅ»õ╗ѵø┤ÕÑ¢Õ£░þÉåÞºúÕÆîµÄîµÅí ORM µèǵ£»´╝îµÅÉÕìçÕ╝ÇÕÅæµòêþÄç´╝îÕçÅÕ░æõ©Äµò░µì«Õ║ôõ║ñõ║ƵùÂþÜäÚöÖÞ»»ÕÆîÕñìµØéµÇºÒÇé
ÒÇɵÅÅÞ┐░ÒÇæ´╝ÜÞ┐Öõ©¬Úí╣þø«µÿ»õ©Çõ©¬Õƒ║õ║ÄJavaµèǵ£»µáêþÜäÞ«║ÕØøþ│╗þ╗ƒÕ«×þÄ░´╝îõ©╗ÞªüÕê®þö¿õ║åHibernate ORMµíåµ×Âõ©ÄJSP´╝êJavaServer Pages´╝ëÞ┐øÞíîÕ╝ÇÕÅæ´╝îµÿ»ÚÇéÕÉêÕ¡ªþöƒõ¢£õ©║µ»òõ©ÜÞ«║µûçÚí╣þø«þÜäÕ«×õ¥ïÒÇéÕ«âÕ▒òþñ║õ║åÕªéõ¢òÕ░åµò░µì«Õ║ôµôìõ¢£õ©ÄWebþòîÚØóþø©þ╗ôÕÉê´╝îõ©║þö¿µêÀ...
7. **µÇºÞâ¢Þ░âõ╝ÿ**´╝ܵÅÉõ¥øõ©Çþ│╗ÕêùµèÇÕÀºÕÆîµ£Çõ¢│Õ«×ÞÀÁ´╝îÕ©«Õè®Õ╝ÇÕÅæÞÇàõ╝ÿÕîû Hibernate Õ║öþö¿þ¿ïÕ║ÅþÜäµÇºÞâ¢ÒÇé 8. **Ú½ÿþ║ºõ©╗Úóÿ**´╝Üõ╗ïþ╗ì Hibernate þÜäõ©Çõ║øÚ½ÿþ║ºþë╣µÇº´╝îÕªéþ╝ôÕ¡ÿµ£║ÕêÂÒÇüµë╣Úçŵø┤µû░/ÕêáÚÖñþ¡ëÒÇé #### Õà¡ÒÇüþø«µáçÞ»╗ÞÇàþ¥ñõ¢ô Þ┐Öµ£¼õ╣ªõ©╗Þªü...
Õ£¿ITÞíîõ©Üõ©¡´╝îµò░µì«Õ║ôÞ┐×µÄѵ▒áµÿ»õ╝ÿÕîûµò░µì«Õ║ôÞ«┐Úù«µÇºÞâ¢þÜäÚçìÞªüµèǵ£»õ╣ïõ©Ç´╝îÞÇîHibernateõ¢£õ©║õ©Çµ¼¥µÁüÞíîþÜäJavaÕ»╣Þ▒íÕà│þ│╗µÿáÕ░ä´╝êORM´╝ëµíåµ×´╝îµÅÉõ¥øõ║åõ©ÄÕÉäþºìÞ┐×µÄѵ▒áþÜäÚøåµêÉ´╝îÕîàµï¼ProxoolÒÇéµ£¼þ»çÕ░åÞ»ªþ╗åõ╗ïþ╗ìÕªéõ¢òÕ£¿Hibernateõ©¡õ¢┐þö¿Proxoolõ¢£õ©║...
4. µÇºÞâ¢õ╝ÿÕîû´╝ÜÕÅ»Þâ¢ÕîàÕɽõ║åÚÆêÕ»╣SpringÕÆîHibernateþÜäµÇºÞâ¢Þ░âõ╝ÿþ¡ûþòÑ´╝îÕªéþ╝ôÕ¡ÿµ£║ÕêÂÒÇüµë╣ÕñäþÉåµôìõ¢£þ¡ëÒÇé 5. Õ«ëÕ࿵ǺÕó×Õ╝║´╝ÜÕÅ»Þâ¢ÚøåµêÉõ║åÕ«ëÕ࿵íåµ×ÂÕªéSpring Security´╝îµÅÉõ¥øþö¿µêÀÞ«ñÞ»üÕÆîµÄêµØâÕèƒÞâ¢ÒÇé 6. µùÑÕ┐ùÕÆîþøæµÄº´╝ÜÕÅ»Þâ¢Õ«×þÄ░õ║åÞ»ªþ╗åþÜäµùÑÕ┐ù...