iluoxuan
- 浏览: 584725 次
- 性别:

- 来自: 北京
-

最新评论
-
liu_jiaqiang:
写的挺好
maven多项目管理 -
H972900846:
我想知道哪里整的,如果是自己写的,那有点牛呀如果是抄的请说明出 ...
SSL身份认证原理 -
春天好:
博主写的很好,赞一个,多谢分享 *(^-^*)分享一个免费好用 ...
定向网站爬虫---初级例子 -
fenglingabc:
经过测试,parameterType="java.u ...
mybatis获取主键和存储过程返回值 -
jyghqpkl:
[u][/u] ...
Cookie的secure 属性
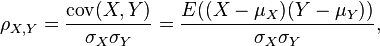
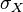 和
和  是
是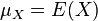 ,
,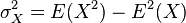 ,同样地,对于
,同样地,对于 ,可以写成
,可以写成





相关推荐
在众多的推荐算法中,皮尔逊相关度算法是一种常用且有效的策略,它基于用户评分数据来计算物品之间的相似性。这篇研究深入探讨了如何运用皮尔逊相关度算法构建推荐系统,并提供了相应的代码实现,旨在提升推荐的准确...
通过计算指标间的相关系数,如皮尔逊相关系数,可以量化它们之间的线性关系强度和方向。 接着,使用线性相似度算法,例如余弦相似度或欧几里得距离,来评估每对指标之间的相似度。这些算法可以测量两个向量(即两个...
常见的计算方法有余弦相似度、Jaccard相似度、皮尔逊相关系数等。 3. **用户画像**:基于用户的行为数据,构建一个抽象的、代表用户特征的模型,包括用户的年龄、性别、职业、兴趣、消费习惯等,用于更准确地理解和...
- **相似度计算**:在UCF中,通常使用余弦相似度或皮尔逊相关系数来衡量用户之间的相似性。当计算两个用户u和v的相似度时,会考虑他们共同评价过的电影,并根据他们的评分计算相似度。 - **预测评分**:对于目标...
每个元素(i, j)表示用户i和用户j之间的相似度,通常通过计算他们共同评价过的物品的余弦相似度或者皮尔逊相关系数来得到。这种矩阵可以帮助我们找出具有相似兴趣的用户群体。 描述中提到的核心代码位于`test`包下...
通过计算这些用户与A的皮尔逊相关系数,找出相关系数较高的用户群体,然后依据这些用户的喜好来推荐电影给A。 MATLAB是一种广泛应用于工程计算、数据分析、算法开发等领域的高性能数值计算和可视化软件。MATLAB拥有...
- 计算用户之间的相似度(通常使用余弦相似度或皮尔逊相关系数)。 - 找出与目标用户最相似的一组用户。 - 推荐这些用户喜欢但目标用户尚未接触过的图书。 - **优点**:能够捕捉用户的个人兴趣,推荐结果更加个性...
这一步通常使用余弦相似度或者皮尔逊相关系数等方法。相似度高的用户意味着他们可能有类似的口味,因此他们的游戏选择可以作为参考。同样,服务间的相似度也可以帮助找出在特征上相近的游戏。 然后,通过预测用户对...
在推荐系统中,它可以用于计算用户与用户或物品与物品之间的关联度。缺点是它不考虑重叠数量,且需要数据符合正态分布。 2. **欧几里德距离**(Euclidean Distance): 欧几里德距离是多维空间中两点间的直线距离...
- 物品相似度计算:基于用户对物品的评分,计算每对物品之间的相似度,常用的相似度指标有余弦相似度、皮尔逊相关系数等。 - 推荐生成:对于一个目标用户,找出其已评分物品中最相似的N个物品,然后推荐这些物品中...
相似度的计算方法可以有很多,比如皮尔逊相关系数、余弦相似度等。其次,算法还需要考虑用户之间的信任关系,这是本研究中提出的算法与其他传统算法的不同之处。信任关系的建立可以通过用户间的直接评价、共同行为的...
- 用户评价信息(评分、评论、点赞等) 这些数据需要经过预处理,如数据清洗(去除无效或重复数据)、数据标准化(确保数据格式一致)等步骤,以确保后续算法的有效运行。 ##### 2. 计算用户相似度 用户相似度计算...
- **相似度计算**:常用的相似度计算方法有皮尔逊相关系数、余弦相似度等。 - **邻居选择**:确定一个合适的邻居数量K值,选择最相似的K个用户或物品作为参考对象。 - **推荐策略**:根据邻居用户或物品的行为为当前...
- 稀疏性问题:用户评价数据往往非常稀疏。 - 解决方案: - 使用皮尔逊相关系数计算相似度。 - 考虑共同打分物品的数量,通过归一化处理提高推荐准确性。 - **混合推荐算法**: - 结合多种推荐技术的优势,提供...
这里可以使用余弦相似度或者皮尔逊相关系数来衡量用户之间的相似性。Python的Scipy库提供了计算这类相似度的函数。 在得到相似度矩阵后,推荐系统的核心部分就是预测用户对未评价书籍的评分。对于用户-用户协同过滤...
- **相似度度量**:协同过滤中常见的相似度度量包括皮尔逊相关系数、曼哈顿距离、欧几里得距离、余弦相似度和Jaccard相似度。皮尔逊系数用于度量两个变量的线性相关性,而其他距离和相似度指标则用于衡量用户或物品...
在推荐系统中,皮尔逊相关系数可以用来衡量两个用户评分向量之间的相似度。 - 余弦相似度(Cosine Similarity):它是通过测量两个向量的夹角的余弦值来确定它们之间差异的一种方法。在推荐系统中,余弦相似度可以...