- µÁÅÞºê: 511447 µ¼í
- µÇºÕê½:

- µØÑÞç¬: µ▓êÚÿ│
-

µûçþ½áÕêåþ▒╗
- Õà¿Úâ¿ÕìÜÕ«ó (437)
- WindowsÞ«¥þ¢« (2)
- oracleµò░µì«Õ║ô (39)
- bug--jsp (4)
- j2se (13)
- js (40)
- bug-tomcatõ©ìÞâ¢ÕÉ»Õè¿þ¿ïÕ║Å (1)
- Hibernate (29)
- eclipse (20)
- java (65)
- Þ«¥Þ«íµ¿íÕ╝Å (6)
- bug (18)
- PL/SQL (11)
- ÕëìÕÅ░ (5)
- µØéÞ░ê (25)
- UML (1)
- jdbcþ╝ûþ¿ï (2)
- µèǵ£»Þ░âþáö (1)
- µò░µì«ÚÇÜõ┐í (2)
- ios (1)
- servletÞç¬Õ¡ªþ¼öÞ«░ (10)
- tomcat (9)
- SQLÕ¡ªõ╣áþ¼öÞ«░ (6)
- javaÕÀÑÕàÀ (1)
- µò░µì«Õ║ôÞ«¥Þ«í (4)
- javascript (10)
- jsp (11)
- struts (17)
- ajax (7)
- linix/Unix (6)
- ÞÁäµ║É (3)
- spring (14)
- þ«ùµ│ò (5)
- Þ«íþ«ùµ£║þ¢æþ╗£ (2)
- http (5)
- c++ (2)
- webÕ║öþö¿ (3)
- jvm (5)
- javaõ©¡þÜäÕ¡ùþ¼ªþ╝ûþáü (14)
- javaõ╗úþáüÕ║ô (2)
- classloader (1)
- Þ»╗õ╣ªþ¼öÞ«░ (1)
- c (1)
- Õ╝ǵ║ÉÞ¢»õ╗ (1)
- svn (1)
- AOP (1)
- javaÕ║ÅÕêùÕîû (1)
- ÕñÜþ║┐þ¿ï (4)
- The legendary programmers (1)
- Apache http Server (1)
- html tag (3)
- struts1.XÕ¡ªõ╣áþ¼öÞ«░ (5)
- buffalo (1)
- Þç¬ÕÀ▒µöÂÞùÅ (0)
- TOEFL(IBT) (1)
- þ¢æþ╗£þ┐╗ÕóÖ (0)
- þ╝ûÞ»æÕăþÉå (1)
- õ╣ªþ▒ìµÄ¿ÞìÉ (1)
- css (10)
- javaeeþÄ»ÕóâµÉ¡Õ╗║ÞÁäµûÖ (1)
- Õ╝ǵ║ÉÕÀÑÕàÀ (1)
- þ¥ÄÕø¢þöƒµ┤╗ (1)
- springÞç¬Õ¡ª (3)
- log4j (3)
- þ«ùµ│òõ©Äµò░µì«þ╗ôµ×ä (5)
- þùൻƴ╝îµÅÆõ╗ÂÕñäþÉåÕñºÕà¿ (1)
- flex (2)
- webservice (1)
- git (7)
- cs (1)
- html (4)
- javaee (6)
- Õ╝ÇÞ¢ª (0)
- springmvc (3)
- õ║ÆÞüöþ¢æµ×µ×ä (2)
- intellij idea (18)
- maven (15)
- mongodb (2)
- nginx (1)
- react (3)
- javaÕƒ║þíÇõ¥ïÕ¡É (2)
- springboot (2)
- Õƒ╣Þ«¡ (5)
- mysql (3)
- µò░µì«Õ║ô (3)
- þöƒµ┤╗ (2)
- intellij (3)
- linux (2)
- os (3)
þñ¥Õî║þëêÕØù
- µêæþÜäÞÁäÞ«» ( 0)
- µêæþÜäÞ«║ÕØø ( 2)
- µêæþÜäÚù«þ¡ö ( 0)
Õ¡ÿµíúÕêåþ▒╗
- 2019-02 ( 1)
- 2018-12 ( 2)
- 2018-11 ( 1)
- µø┤ÕñÜÕ¡ÿµíú...
µ£Çµû░Þ»äÞ«║
-
µ¢çµ┤ÆÕñ®µÂ»´╝Ü
[color=blue][color=cyan]        ...
oracle ÚÇÜÞ┐ç nvl( )Õ碵ò░sql µƒÑÞ»óµùÂõ©║ þ®║ÕÇ╝ ÞÁïÚ╗ÿÞ«ñÕÇ╝ -
hekai1990´╝Ü
ÕÅùµòÖõ║å..
oracleõ©¡þÜävarchar2
þ«Çõ╗ï´╝Ü┬áÕªéµ×£õ¢áÕŬþƒÑÚüôÕ«×þÄ░ Serializable µÄÑÕÅúþÜäÕ»╣Þ▒í´╝îÕÅ»õ╗ÑÕ║ÅÕêùÕîûõ©║µ£¼Õ£░µûçõ╗ÂÒÇéÚéúõ¢áµ£ÇÕÑ¢ÕåìÚÿàÞ»╗Þ»Ñþ»çµûçþ½á´╝îµûçþ½áÕ»╣Õ║ÅÕêùÕîûÞ┐øÞíîõ║åµø┤µÀ▒õ©Çµ¡ÑþÜäÞ«¿Þ«║´╝îþö¿Õ«×ÚÖàþÜäõ¥ïÕ¡Éõ╗úþáüÞ«▓Þ┐░õ║åÕ║ÅÕêùÕîûþÜäÚ½ÿþ║ºÞ«ñÞ»å´╝îÕîàµï¼þêÂþ▒╗Õ║ÅÕêù ÕîûþÜäÚù«ÚóÿÒÇüÚØÖµÇüÕÅÿÚçÅÚù«ÚóÿÒÇütransient Õà│Úö«Õ¡ùþÜäÕ¢▒ÕôìÒÇüÕ║ÅÕêùÕîû ID Úù«ÚóÿÒÇéÕ£¿þ¼öÞÇàÕ«×ÚÖàÕ╝ÇÕÅæÞ┐çþ¿ïõ©¡´╝îÕ░▒Õñܵ¼íÚüçÕê░Õ║ÅÕêùÕîûþÜäÚù«Úóÿ´╝îÕ£¿Þ»Ñµûçþ½áõ©¡õ╣ƒõ╝Üõ©ÄÞ»╗ÞÇàÕêåõ║½ÒÇé
Õ░å Java Õ»╣Þ▒íÕ║ÅÕêùÕîûõ©║õ║îÞ┐øÕêµûçõ╗ÂþÜä Java Õ║ÅÕêùÕîûµèǵ£»µÿ» Java þ│╗Õêùµèǵ£»õ©¡õ©Çõ©¬Þ¥âõ©║ÚçìÞªüþÜäµèǵ£»þé╣´╝îÕ£¿ÕñºÚâ¿ÕêåµâàÕåÁõ©ï´╝îÕ╝ÇÕÅæõ║║ÕæÿÕŬڣÇÞªüõ║åÞºúÞó½Õ║ÅÕêùÕîûþÜäþ▒╗Ú£ÇÞªüÕ«×þÄ░ Serializable µÄÑÕÅú´╝îõ¢┐þö¿ ObjectInputStream ÕÆî ObjectOutputStream Þ┐øÞíîÕ»╣Þ▒íþÜäÞ»╗ÕåÖÒÇéþäÂÞÇîÕ£¿µ£ëõ║øµâàÕåÁõ©ï´╝îÕàëþƒÑÚüôÞ┐Öõ║øÞ┐ÿÞ┐£Þ┐£õ©ìÕñƒ´╝îµûçþ½áÕêùõ©¥õ║åþ¼öÞÇàÚüçÕê░þÜäõ©Çõ║øþ£ƒÕ«×µâàÕóâ´╝îÕ«âõ╗¼õ©Ä Java Õ║ÅÕêùÕîûþø©Õà│´╝îÚÇÜÞ┐çÕêåµ×ɵâàÕóâÕç║þÄ░þÜäÕăÕøá´╝îõ¢┐Þ»╗ÞÇàÞ¢╗µØ¥þëóÞ«░ Java Õ║ÅÕêùÕîûõ©¡þÜäõ©Çõ║øÚ½ÿþ║ºÞ«ñÞ»åÒÇé
µ£¼µûçÕ░åÚÇÉõ©ÇþÜäõ╗ïþ╗ìÕçáõ©¬µâàÕóâ´╝îÚí║Õ║ÅÕªéõ©ïÚØóþÜäÕêùÞí¿ÒÇé
- Õ║ÅÕêùÕîû ID þÜäÚù«Úóÿ
- ÚØÖµÇüÕÅÿÚçÅÕ║ÅÕêùÕîû
- þêÂþ▒╗þÜäÕ║ÅÕêùÕîûõ©Ä Transient Õà│Úö«Õ¡ù
- Õ»╣µòŵäƒÕ¡ùµ«ÁÕèáÕ»å
- Õ║ÅÕêùÕîûÕ¡ÿÕé¿ÞºäÕêÖ
ÕêùÞí¿þÜäµ»Åõ©ÇÚâ¿ÕêåÞ«▓Þ┐░õ║åõ©Çõ©¬Õìòþï¼þÜäµâàÕóâ´╝îÞ»╗ÞÇàÕÅ»õ╗ÑÕêåÕê½µƒÑþ£ïÒÇé
µâàÕóâ´╝Üõ©ñõ©¬Õ«óµêÀþ½» A ÕÆî B Þ»òÕø¥ÚÇÜÞ┐çþ¢æþ╗£õ╝áÚÇÆÕ»╣Þ▒íµò░µì«´╝îA þ½»Õ░åÕ»╣Þ▒í C Õ║ÅÕêùÕîûõ©║õ║îÞ┐øÕêµò░µì«Õåìõ╝áþ╗Ö B´╝îB ÕÅìÕ║ÅÕêùÕîûÕ¥ùÕê░ CÒÇé
Úù«Úóÿ´╝ÜC Õ»╣Þ▒íþÜäÕà¿þ▒╗ÞÀ»Õ¥äÕüçÞ«¥õ©║ com.inout.Test´╝îÕ£¿ A ÕÆî B þ½»Ú⢵£ëÞ┐Öõ╣êõ©Çõ©¬þ▒╗µûçõ╗´╝îÕèƒÞâ¢õ╗úþáüÕ«îÕà¿õ©ÇÞç┤ÒÇéõ╣ƒÚâ¢Õ«×þÄ░õ║å Serializable µÄÑÕÅú´╝îõ¢åµÿ»ÕÅìÕ║ÅÕêùÕîûµùµÇ╗µÿ»µÅÉþñ║õ©ìµêÉÕèƒÒÇé
ÞºúÕå│´╝ÜÞÖܵ£║µÿ»ÕɪÕàüÞ«©ÕÅìÕ║ÅÕêùÕîû´╝îõ©ìõ╗àÕÅûÕå│õ║Äþ▒╗ÞÀ»Õ¥äÕÆîÕèƒÞâ¢õ╗úþáüµÿ»Õɪõ©ÇÞç┤´╝îõ©Çõ©¬ÚØ×Õ©©ÚçìÞªüþÜäõ©Çþé╣µÿ»õ©ñõ©¬þ▒╗þÜäÕ║ÅÕêùÕîû ID µÿ»Õɪõ©ÇÞç┤´╝êÕ░▒µÿ» private static final long serialVersionUID = 1L´╝ëÒÇ鵩àÕìò 1 õ©¡´╝îÞÖ¢þäÂõ©ñõ©¬þ▒╗þÜäÕèƒÞâ¢õ╗úþáüÕ«îÕà¿õ©ÇÞç┤´╝îõ¢åµÿ»Õ║ÅÕêùÕîû ID õ©ìÕÉî´╝îõ╗ûõ╗¼µùáµ│òþø©õ║ÆÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûÒÇé
µ©àÕìò 1. þø©ÕÉîÕèƒÞâ¢õ╗úþáüõ©ìÕÉîÕ║ÅÕêùÕîû ID þÜäþ▒╗Õ»╣µ»ö
package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 2L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
|
 
Õ║ÅÕêùÕîû ID Õ£¿ Eclipse õ©ïµÅÉõ¥øõ║åõ©ñþºìþöƒµêÉþ¡ûþòÑ´╝îõ©Çõ©¬µÿ»Õø║Õ«ÜþÜä 1L´╝îõ©Çõ©¬µÿ»ÚÜŵ£║þöƒµêÉõ©Çõ©¬õ©ìÚçìÕñìþÜä long þ▒╗Õ×ïµò░µì«´╝êÕ«×ÚÖàõ©èµÿ»õ¢┐þö¿ JDK ÕÀÑÕàÀþöƒµêÉ´╝ë´╝îÕ£¿Þ┐ÖÚçîµ£ëõ©Çõ©¬Õ╗║Þ««´╝îÕªéµ×£µ▓íµ£ëþë╣µ«èڣǵ▒é´╝îÕ░▒µÿ»þö¿Ú╗ÿÞ«ñþÜä 1L Õ░▒ÕÅ»õ╗Ñ´╝îÞ┐ÖµáÀÕÅ»õ╗Ñþí«õ┐Øõ╗úþáüõ©ÇÞç┤µùÂÕÅìÕ║ÅÕêùÕîûµêÉÕèƒÒÇéÚéúõ╣êÚÜŵ£║þöƒµêÉþÜäÕ║ÅÕêùÕîû ID µ£ëõ╗Çõ╣êõ¢£þö¿Õæó´╝îµ£ëõ║øµùÂÕÇÖ´╝îÚÇÜÞ┐çµö╣ÕÅÿÕ║ÅÕêùÕîû ID ÕÅ»õ╗Ñþö¿µØÑÚÖÉÕ굃Éõ║øþö¿µêÀþÜäõ¢┐þö¿ÒÇé
þë╣µÇºõ¢┐þö¿µíêõ¥ï
Þ»╗ÞÇàÕ║öÞ»ÑÕɼÞ┐ç Fa├ºade µ¿íÕ╝Å´╝îÕ«âµÿ»õ©║Õ║öþö¿þ¿ïÕ║ŵÅÉõ¥øþ╗ƒõ©ÇþÜäÞ«┐Úù«µÄÑÕÅú´╝îµíêõ¥ïþ¿ïÕ║Åõ©¡þÜä Client Õ«óµêÀþ½»õ¢┐þö¿õ║å޻ѵ¿íÕ╝Å´╝îµíêõ¥ïþ¿ïÕ║Åþ╗ôµ×äÕø¥ÕªéÕø¥ 1 µëÇþñ║ÒÇé

Client þ½»ÚÇÜÞ┐ç Fa├ºade Object µëìÕÅ»õ╗Ñõ©Äõ©ÜÕèíÚÇ╗Þ¥æÕ»╣Þ▒íÞ┐øÞíîõ║ñõ║ÆÒÇéÞÇîÕ«óµêÀþ½»þÜä Fa├ºade Object õ©ìÞâ¢þø┤µÄÑþö▒ Client þöƒµêÉ´╝îÞÇîµÿ»Ú£ÇÞªü Server þ½»þöƒµêÉ´╝îþäÂÕÉÄÕ║ÅÕêùÕîûÕÉÄÚÇÜÞ┐çþ¢æþ╗£Õ░åõ║îÞ┐øÕêÂÕ»╣Þ▒íµò░µì«õ╝áþ╗Ö Client´╝îClient Þ┤ƒÞ┤úÕÅìÕ║ÅÕêùÕîûÕ¥ùÕê░ Fa├ºade Õ»╣Þ▒íÒÇé޻ѵ¿íÕ╝ÅÕÅ»õ╗Ñõ¢┐Õ¥ù Client þ½»þ¿ïÕ║ÅþÜäõ¢┐þö¿Ú£ÇÞªüµ£ìÕèíÕÖ¿þ½»þÜäÞ«©ÕÅ»´╝îÕÉîµù Client þ½»ÕÆîµ£ìÕèíÕÖ¿þ½»þÜä Fa├ºade Object þ▒╗Ú£ÇÞªüõ┐صîüõ©ÇÞç┤ÒÇéÕ¢ôµ£ìÕèíÕÖ¿þ½»µâ│ÞªüÞ┐øÞíîþëêµ£¼µø┤µû░µù´╝îÕŬުüÕ░åµ£ìÕèíÕÖ¿þ½»þÜä Fa├ºade Object þ▒╗þÜäÕ║ÅÕêùÕîû ID Õåìµ¼íþöƒµêÉ´╝îÕ¢ô Client þ½»ÕÅìÕ║ÅÕêùÕîû Fa├ºade Object Õ░▒õ╝ÜÕñ▒Þ┤Ñ´╝îõ╣ƒÕ░▒µÿ»Õ╝║Õê Client þ½»õ╗ĵ£ìÕèíÕÖ¿þ½»ÞÄÀÕÅûµ£Çµû░þ¿ïÕ║ÅÒÇé
µâàÕóâ´╝ܵƒÑþ£ïµ©àÕìò 2 þÜäõ╗úþáüÒÇé
µ©àÕìò 2. ÚØÖµÇüÕÅÿÚçÅÕ║ÅÕêùÕîûÚù«Úóÿõ╗úþáü
public class Test implements Serializable {
private static final long serialVersionUID = 1L;
public static int staticVar = 5;
public static void main(String[] args) {
try {
//ÕêØÕºïµùÂstaticVarõ©║5
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new Test());
out.close();
//Õ║ÅÕêùÕîûÕÉÄõ┐«µö╣õ©║10
Test.staticVar = 10;
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t = (Test) oin.readObject();
oin.close();
//ÕåìÞ»╗ÕÅû´╝îÚÇÜÞ┐çt.staticVarµëôÕì░µû░þÜäÕÇ╝
System.out.println(t.staticVar);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
|
 
µ©àÕìò 2 õ©¡þÜä main µû╣µ│ò´╝îÕ░åÕ»╣Þ▒íÕ║ÅÕêùÕîûÕÉÄ´╝îõ┐«µö╣ÚØÖµÇüÕÅÿÚçÅþÜäµò░ÕÇ╝´╝îÕåìÕ░åÕ║ÅÕêùÕîûÕ»╣Þ▒íÞ»╗ÕÅûÕç║µØÑ´╝îþäÂÕÉÄÚÇÜÞ┐çÞ»╗ÕÅûÕç║µØÑþÜäÕ»╣Þ▒íÞÄÀÕ¥ùÚØÖµÇüÕÅÿÚçÅþÜäµò░ÕÇ╝Õ╣µëôÕì░Õç║µØÑÒÇéõ¥Øþີ©àÕìò 2´╝îÞ┐Öõ©¬ System.out.println(t.staticVar) Þ»¡ÕÅÑÞ¥ôÕç║þÜäµÿ» 10 Þ┐ÿµÿ» 5 Õæó´╝ƒ
µ£ÇÕÉÄþÜäÞ¥ôÕç║µÿ» 10´╝îÕ»╣õ║ĵùáµ│òþÉåÞºúþÜäÞ»╗ÞÇàÞ«ñõ©║´╝îµëôÕì░þÜä staticVar µÿ»õ╗ÄÞ»╗ÕÅûþÜäÕ»╣Þ▒íÚçîÞÄÀÕ¥ùþÜä´╝îÕ║ö޻ѵÿ»õ┐ØÕ¡ÿµùÂþÜäþèµÇüµëìÕ»╣ÒÇéõ╣ïµëÇõ╗ѵëôÕì░ 10 þÜäÕăÕøáÕ£¿õ║ÄÕ║ÅÕêùÕîûµù´╝îÕ╣Âõ©ìõ┐ØÕ¡ÿÚØÖµÇüÕÅÿÚçÅ´╝îÞ┐ÖÕàÂÕ«×µ»öÞ¥âÕ«╣µÿôþÉåÞºú´╝îÕ║ÅÕêùÕîûõ┐ØÕ¡ÿþÜäµÿ»Õ»╣Þ▒íþÜäþèµÇü´╝îÚØÖµÇüÕÅÿÚçÅÕ▒×õ║Äþ▒╗þÜäþèµÇü´╝îÕøᵡñ┬áÕ║ÅÕêùÕîûÕ╣Âõ©ìõ┐ØÕ¡ÿÚØÖµÇüÕÅÿÚçÅÒÇé
þêÂþ▒╗þÜäÕ║ÅÕêùÕîûõ©Ä Transient Õà│Úö«Õ¡ù
µâàÕóâ´╝Üõ©Çõ©¬Õ¡Éþ▒╗Õ«×þÄ░õ║å Serializable µÄÑÕÅú´╝îÕ«âþÜäþêÂþ▒╗Ú⢵▓íµ£ëÕ«×þÄ░ Serializable µÄÑÕÅú´╝îÕ║ÅÕêùÕîûÞ»ÑÕ¡Éþ▒╗Õ»╣Þ▒í´╝îþäÂÕÉÄÕÅìÕ║ÅÕêùÕîûÕÉÄÞ¥ôÕç║þêÂþ▒╗Õ«Üõ╣ëþÜ䵃ÉÕÅÿÚçÅþÜäµò░ÕÇ╝´╝îÞ»ÑÕÅÿÚçŵò░ÕÇ╝õ©ÄÕ║ÅÕêùÕîûµùÂþÜäµò░ÕÇ╝õ©ìÕÉîÒÇé
ÞºúÕå│´╝ÜÞªüµâ│Õ░åþêÂþ▒╗Õ»╣Þ▒íõ╣ƒÕ║ÅÕêùÕîû´╝îÕ░▒Ú£ÇÞªüÞ«®þêÂþ▒╗õ╣ƒÕ«×þÄ░Serializable µÄÑÕÅúÒÇéÕªéµ×£þêÂþ▒╗õ©ìÕ«×þÄ░þÜäÞ»ØþÜä´╝îÕ░▒┬áÚ£ÇÞªüµ£ëÚ╗ÿÞ«ñþÜäµùáÕÅéþÜäµ×äÚÇáÕ碵ò░ÒÇé Õ£¿þêÂþ▒╗µ▓íµ£ëÕ«×þÄ░ Serializable µÄÑÕÅúµù´╝îÞÖܵ£║µÿ»õ©ìõ╝ÜÕ║ÅÕêùÕîûþêÂÕ»╣Þ▒íþÜä´╝îÞÇîõ©Çõ©¬ Java Õ»╣Þ▒íþÜäµ×äÚÇáÕ┐àÚí╗Õàêµ£ëþêÂÕ»╣Þ▒í´╝îµëìµ£ëÕ¡ÉÕ»╣Þ▒í´╝îÕÅìÕ║ÅÕêùÕîûõ╣ƒõ©ìõ¥ïÕñûÒÇéµëÇõ╗ÑÕÅìÕ║ÅÕêùÕîûµù´╝îõ©║õ║åµ×äÚÇáþêÂÕ»╣Þ▒í´╝îÕŬÞâ¢Þ░âþö¿þêÂþ▒╗þÜäµùáÕÅéµ×äÚÇáÕ碵ò░õ¢£õ©║Ú╗ÿÞ«ñþÜäþêÂÕ»╣Þ▒íÒÇéÕøᵡñÕ¢ôµêæõ╗¼ÕÅû þêÂÕ»╣Þ▒íþÜäÕÅÿÚçÅÕÇ╝µù´╝îÕ«âþÜäÕÇ╝µÿ»Þ░âþö¿þêÂþ▒╗µùáÕÅéµ×äÚÇáÕ碵ò░ÕÉÄþÜäÕÇ╝ÒÇéÕªéµ×£õ¢áÞÇâÞÖæÕê░Þ┐ÖþºìÕ║ÅÕêùÕîûþÜäµâàÕåÁ´╝îÕ£¿þêÂþ▒╗µùáÕÅéµ×äÚÇáÕ碵ò░õ©¡Õ»╣ÕÅÿÚçÅÞ┐øÞíîÕêØÕºïÕîû´╝îÕɪÕêÖþÜä޻ش╝îþêÂþ▒╗ÕÅÿÚçÅÕÇ╝Ú⢠µÿ»Ú╗ÿÞ«ñÕú░µÿÄþÜäÕÇ╝´╝îÕªé int Õ×ïþÜäÚ╗ÿÞ«ñµÿ» 0´╝îstring Õ×ïþÜäÚ╗ÿÞ«ñµÿ» nullÒÇé
Transient Õà│Úö«Õ¡ùþÜäõ¢£þö¿µÿ»µÄºÕêÂÕÅÿÚçÅþÜäÕ║ÅÕêùÕîû´╝îÕ£¿ÕÅÿÚçÅÕú░µÿÄÕëìÕèáõ©èÞ»ÑÕà│Úö«Õ¡ù´╝îÕÅ»õ╗ÑÚÿ╗µ¡óÞ»ÑÕÅÿÚçÅÞó½Õ║ÅÕêùÕîûÕê░µûçõ╗Âõ©¡´╝îÕ£¿Þó½ÕÅìÕ║ÅÕêùÕîûÕÉÄ´╝îtransient ÕÅÿÚçÅþÜäÕÇ╝Þó½Þ«¥õ©║ÕêØÕºïÕÇ╝´╝îÕªé int Õ×ïþÜäµÿ» 0´╝îÕ»╣Þ▒íÕ×ïþÜäµÿ» nullÒÇé
þë╣µÇºõ¢┐þö¿µíêõ¥ï
µêæõ╗¼þ僵éëõ¢┐þö¿ Transient Õà│Úö«Õ¡ùÕÅ»õ╗Ñõ¢┐Õ¥ùÕ¡ùµ«Áõ©ìÞó½Õ║ÅÕêùÕîû´╝îÚéúõ╣êÞ┐ÿµ£ëÕê½þÜäµû╣µ│òÕÉù´╝ƒµá╣µì«þêÂþ▒╗Õ»╣Þ▒íÕ║ÅÕêùÕîûþÜäÞºäÕêÖ´╝îµêæõ╗¼ÕÅ»õ╗ÑÕ░åõ©ìÚ£ÇÞªüÞó½Õ║ÅÕêùÕîûþÜäÕ¡ùµ«Áµè¢ÕÅûÕç║µØѵö¥Õê░þêÂþ▒╗õ©¡´╝îÕ¡Éþ▒╗Õ«×þÄ░ Serializable µÄÑÕÅú´╝îþêÂþ▒╗õ©ìÕ«×þÄ░´╝îµá╣µì«þêÂþ▒╗Õ║ÅÕêùÕîûÞºäÕêÖ´╝îþêÂþ▒╗þÜäÕ¡ùµ«Áµò░µì«Õ░åõ©ìÞó½Õ║ÅÕêùÕîû´╝îÕ¢óµêÉþ▒╗Õø¥ÕªéÕø¥ 2 µëÇþñ║ÒÇé

õ©èÕø¥õ©¡ÕÅ»õ╗Ñþ£ïÕç║´╝îattr1ÒÇüattr2ÒÇüattr3ÒÇüattr5 Úâ¢õ©ìõ╝ÜÞó½Õ║ÅÕêùÕîû´╝îµö¥Õ£¿þêÂþ▒╗õ©¡þÜäÕÑ¢ÕñäÕ£¿õ║ÄÕ¢ôµ£ëÕŪÕñûõ©Çõ©¬ Child þ▒╗µù´╝îattr1ÒÇüattr2ÒÇüattr3 õ¥ØþäÂõ©ìõ╝ÜÞó½Õ║ÅÕêùÕîû´╝îõ©ìþö¿ÚçìÕñìµèÆÕåÖ transient´╝îõ╗úþáüþ«Çµ┤üÒÇé
µâàÕóâ´╝ܵ£ìÕèíÕÖ¿þ½»þ╗ÖÕ«óµêÀþ½»ÕÅæÚÇüÕ║ÅÕêùÕîûÕ»╣Þ▒íµò░µì«´╝îÕ»╣Þ▒íõ©¡µ£ëõ©Çõ║øµò░µì«µÿ»µòŵäƒþÜä´╝îµ»öÕªéÕ»åþáüÕ¡ùþ¼ªõ©▓þ¡ë´╝îÕ©îµ£øÕ»╣Þ»ÑÕ»åþáüÕ¡ùµ«ÁÕ£¿Õ║ÅÕêùÕîûµù´╝îÞ┐øÞíîÕèáÕ»å´╝îÞÇîÕ«óµêÀþ½»Õªéµ×£µïѵ£ëÞºúÕ»åþÜäÕ»åÚÆÑ´╝îÕŬµ£ëÕ£¿Õ«óµêÀþ½»Þ┐øÞíîÕÅìÕ║ÅÕêùÕîûµù´╝îµëìÕÅ»õ╗ÑÕ»╣Õ»åþáüÞ┐øÞíîÞ»╗ÕÅû´╝îÞ┐ÖµáÀÕÅ»õ╗Ñõ©ÇÕ«Üþ¿ïÕ║ªõ┐ØÞ»üÕ║ÅÕêùÕîûÕ»╣Þ▒íþÜäµò░µì«Õ«ëÕà¿ÒÇé
ÞºúÕå│´╝ÜÕ£¿Õ║ÅÕêùÕîûÞ┐çþ¿ïõ©¡´╝îÞÖܵ£║õ╝ÜÞ»òÕø¥Þ░âþö¿Õ»╣Þ▒íþ▒╗ÚçîþÜä writeObject ÕÆî readObject µû╣µ│ò´╝îÞ┐øÞíîþö¿µêÀÞç¬Õ«Üõ╣ëþÜäÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîû´╝îÕªéµ×£µ▓íµ£ëÞ┐ÖµáÀþÜäµû╣µ│ò´╝îÕêÖÚ╗ÿÞ«ñÞ░âþö¿µÿ» ObjectOutputStream þÜä defaultWriteObject µû╣µ│òõ╗ÑÕÅè ObjectInputStream þÜä defaultReadObject µû╣µ│òÒÇéþö¿µêÀÞç¬Õ«Üõ╣ëþÜä writeObject ÕÆî readObject µû╣µ│òÕÅ»õ╗ÑÕàüÞ«©þö¿µêÀµÄºÕêÂÕ║ÅÕêùÕîûþÜäÞ┐çþ¿ï´╝îµ»öÕªéÕÅ»õ╗ÑÕ£¿Õ║ÅÕêùÕîûþÜäÞ┐çþ¿ïõ©¡Õ迵Çüµö╣ÕÅÿÕ║ÅÕêùÕîûþÜäµò░ÕÇ╝ÒÇéÕƒ║õ║ÄÞ┐Öõ©¬ÕăþÉå´╝îÕÅ»õ╗ÑÕ£¿Õ«×ÚÖàÕ║öþö¿õ©¡Õ¥ùÕê░õ¢┐þö¿´╝îþö¿õ║ĵòŵäƒÕ¡ùµ«ÁþÜäÕèáÕ»åÕÀÑõ¢£´╝î µ©àÕìò 3 Õ▒òþñ║õ║åÞ┐Öõ©¬Þ┐çþ¿ïÒÇé
µ©àÕìò 2. ÚØÖµÇüÕÅÿÚçÅÕ║ÅÕêùÕîûÚù«Úóÿõ╗úþáü
private static final long serialVersionUID = 1L;
private String password = "pass";
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
private void writeObject(ObjectOutputStream out) {
try {
PutField putFields = out.putFields();
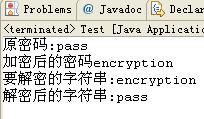
System.out.println("Õăջåþáü:" + password);
password = "encryption";//µ¿íµïƒÕèáÕ»å
putFields.put("password", password);
System.out.println("ÕèáÕ»åÕÉÄþÜäÕ»åþáü" + password);
out.writeFields();
} catch (IOException e) {
e.printStackTrace();
}
}
private void readObject(ObjectInputStream in) {
try {
GetField readFields = in.readFields();
Object object = readFields.get("password", "");
System.out.println("ÞªüÞºúÕ»åþÜäÕ¡ùþ¼ªõ©▓:" + object.toString());
password = "pass";//µ¿íµïƒÞºúÕ»å,Ú£ÇÞªüÞÄÀÕ¥ùµ£¼Õ£░þÜäÕ»åÚÆÑ
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new Test());
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t = (Test) oin.readObject();
System.out.println("ÞºúÕ»åÕÉÄþÜäÕ¡ùþ¼ªõ©▓:" + t.getPassword());
oin.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
|
 
Õ£¿µ©àÕìò 3 þÜä writeObject µû╣µ│òõ©¡´╝îÕ»╣Õ»åþáüÞ┐øÞíîõ║åÕèáÕ»å´╝îÕ£¿ readObject õ©¡ÕêÖÕ»╣ password Þ┐øÞíîÞºúÕ»å´╝îÕŬµ£ëµïѵ£ëÕ»åÚÆÑþÜäÕ«óµêÀþ½»´╝îµëìÕÅ»õ╗ѵ¡úþí«þÜäÞºúµ×ÉÕç║Õ»åþáü´╝îþí«õ┐Øõ║åµò░µì«þÜäÕ«ëÕà¿ÒÇéµëºÞíàÕìò 3 ÕÉĵĺÕêÂÕÅ░Þ¥ôÕç║ÕªéÕø¥ 3 µëÇþñ║ÒÇé
þë╣µÇºõ¢┐þö¿µíêõ¥ï
RMI µèǵ£»µÿ»Õ«îÕà¿Õƒ║õ║Ä Java Õ║ÅÕêùÕîûµèǵ£»þÜä´╝îµ£ìÕèíÕÖ¿þ½»µÄÑÕÅúÞ░âþö¿µëÇÚ£ÇÞªüþÜäÕÅéµò░Õ»╣Þ▒íµØÑÞç│õ║ÄÕ«óµêÀþ½»´╝îÕ«âõ╗¼ÚÇÜÞ┐çþ¢æþ╗£þø©õ║Æõ╝áÞ¥ôÒÇéÞ┐ÖÕ░▒µÂëÕÅè RMI þÜäÕ«ëÕà¿õ╝áÞ¥ôþÜäÚù«ÚóÿÒÇéõ©Çõ║øµòŵäƒþÜäÕ¡ùµ«Á´╝îÕªéþö¿µêÀÕÉìÕ»åþáü´╝êþö¿µêÀþÖ╗Õ¢òµùÂÚ£ÇÞªüÕ»╣Õ»åþáüÞ┐øÞíîõ╝áÞ¥ô´╝ë´╝îµêæõ╗¼Õ©îµ£øÕ»╣ÕàÂÞ┐øÞíîÕèáÕ»å´╝îÞ┐Öµù´╝îÕ░▒ÕÅ»õ╗ÑÚççþö¿µ£¼Þèéõ╗ïþ╗ìþÜäµû╣µ│òÕ£¿Õ«óµêÀþ½»Õ»╣Õ»å þáüÞ┐øÞíîÕèáÕ»å´╝îµ£ìÕèíÕÖ¿þ½»Þ┐øÞíîÞºúÕ»å´╝îþí«õ┐صò░µì«õ╝áÞ¥ôþÜäÕ«ëÕ࿵ǺÒÇé
µâàÕóâ´╝ÜÚù«Úóÿõ╗úþáüժ鵩àÕìò 3 µëÇþñ║ÒÇé
µ©àÕìò 3. Õ¡ÿÕé¿ÞºäÕêÖÚù«Úóÿõ╗úþáü
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
Test test = new Test();
//Þ»òÕø¥Õ░åÕ»╣Þ▒íõ©ñµ¼íÕåÖÕàѵûçõ╗Â
out.writeObject(test);
out.flush();
System.out.println(new File("result.obj").length());
out.writeObject(test);
out.close();
System.out.println(new File("result.obj").length());
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
//õ╗ĵûçõ╗Âõ¥Øµ¼íÞ»╗Õç║õ©ñõ©¬µûçõ╗Â
Test t1 = (Test) oin.readObject();
Test t2 = (Test) oin.readObject();
oin.close();
//Õêñµû¡õ©ñõ©¬Õ╝òþö¿µÿ»ÕɪµîçÕÉæÕÉîõ©Çõ©¬Õ»╣Þ▒í
System.out.println(t1 == t2);
|
 
µ©àÕìò 3 õ©¡Õ»╣ÕÉîõ©ÇÕ»╣Þ▒íõ©ñµ¼íÕåÖÕàѵûçõ╗´╝îµëôÕì░Õç║ÕåÖÕàÑõ©Çµ¼íÕ»╣Þ▒íÕÉÄþÜäÕ¡ÿÕé¿ÕñºÕ░ÅÕÆîÕåÖÕàÑõ©ñµ¼íÕÉÄþÜäÕ¡ÿÕé¿ÕñºÕ░Å´╝îþäÂÕÉÄõ╗ĵûçõ╗Âõ©¡ÕÅìÕ║ÅÕêùÕîûÕç║õ©ñõ©¬Õ»╣Þ▒í´╝îµ»öÞ¥âÞ┐Öõ©ñõ©¬Õ»╣Þ▒íµÿ»Õɪõ©║ÕÉîõ©ÇÕ»╣Þ▒íÒÇéõ©Ç Þê¼þÜäµÇØþ╗┤µÿ»´╝îõ©ñµ¼íÕåÖÕàÑÕ»╣Þ▒í´╝îµûçõ╗ÂÕñºÕ░Åõ╝ÜÕÅÿõ©║õ©ñÕÇìþÜäÕñºÕ░Å´╝îÕÅìÕ║ÅÕêùÕîûµù´╝îþö▒õ║Äõ╗ĵûçõ╗ÂÞ»╗ÕÅû´╝îþöƒµêÉõ║åõ©ñõ©¬Õ»╣Þ▒í´╝îÕêñµû¡þø©þ¡ëµùÂÕ║ö޻ѵÿ»Þ¥ôÕàÑ false µëìÕ»╣´╝îõ¢åµÿ»µ£ÇÕÉÄþ╗ôµ×£Þ¥ôÕç║ÕªéÕø¥ 4 µëÇþñ║ÒÇé

µêæõ╗¼þ£ïÕê░´╝îþ¼¼õ║îµ¼íÕåÖÕàÑÕ»╣Þ▒íµùµûçõ╗ÂÕŬÕó×Õèáõ║å 5 Õ¡ùÞèé´╝îÕ╣Âõ©öõ©ñõ©¬Õ»╣Þ▒íµÿ»þø©þ¡ëþÜä´╝îÞ┐Öµÿ»õ©║õ╗Çõ╣êÕæó´╝ƒ
Þºúþ¡ö´╝ÜJava Õ║ÅÕêùÕîûµ£║ÕêÂõ©║õ║åÞèéþ£üþúüþøÿþ®║Úù┤´╝îÕàÀµ£ëþë╣Õ«ÜþÜäÕ¡ÿÕé¿ÞºäÕêÖ´╝îÕ¢ôÕåÖÕàѵûçõ╗ÂþÜäõ©║ÕÉîõ©ÇÕ»╣Þ▒íµù´╝îÕ╣Âõ©ìõ╝ÜÕåìÕ░åÕ»╣Þ▒íþÜäÕåàÕ«╣Þ┐øÞíîÕ¡ÿÕé¿´╝îÞÇîÕŬµÿ»Õåìµ¼íÕ¡ÿÕé¿õ©Çõ╗¢Õ╝òþö¿´╝îõ©èÚØóÕó×ÕèáþÜä 5 Õ¡ùÞèéþÜäÕ¡ÿÕé¿þ®║Úù┤Õ░▒µÿ»µû░Õó×Õ╝òþö¿ÕÆîõ©Çõ║øµÄºÕêÂõ┐íµü»þÜäþ®║Úù┤ÒÇéÕÅìÕ║ÅÕêùÕîûµù´╝îµüóÕñìÕ╝òþö¿Õà│þ│╗´╝îõ¢┐Õ¥ùµ©àÕìò 3 õ©¡þÜä t1 ÕÆî t2 µîçÕÉæÕö»õ©ÇþÜäÕ»╣Þ▒í´╝îõ║îÞÇàþø©þ¡ë´╝îÞ¥ôÕç║ trueÒÇéÞ»ÑÕ¡ÿÕé¿ÞºäÕêÖµ×üÕñºþÜäÞèéþ£üõ║åÕ¡ÿÕé¿þ®║Úù┤ÒÇé
þë╣µÇºµíêõ¥ïÕêåµ×É
µƒÑþ£ïµ©àÕìò 4 þÜäõ╗úþáüÒÇé
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj"));
Test test = new Test();
test.i = 1;
out.writeObject(test);
out.flush();
test.i = 2;
out.writeObject(test);
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
Test t1 = (Test) oin.readObject();
Test t2 = (Test) oin.readObject();
System.out.println(t1.i);
System.out.println(t2.i);
|
 
µ©àÕìò 4 þÜäþø«þÜäµÿ»Õ©îµ£øÕ░å test Õ»╣Þ▒íõ©ñµ¼íõ┐ØÕ¡ÿÕê░ result.obj µûçõ╗Âõ©¡´╝îÕåÖÕàÑõ©Çµ¼íõ╗ÑÕÉÄõ┐«µö╣Õ»╣Þ▒íÕ▒׵ǺÕÇ╝Õåìµ¼íõ┐ØÕ¡ÿþ¼¼õ║îµ¼í´╝îþäÂÕÉÄõ╗Ä result.obj õ©¡Õåìõ¥Øµ¼íÞ»╗Õç║õ©ñõ©¬Õ»╣Þ▒í´╝îÞ¥ôÕç║Þ┐Öõ©ñõ©¬Õ»╣Þ▒íþÜä i Õ▒׵ǺÕÇ╝ÒÇéµíêõ¥ïõ╗úþáüþÜäþø«þÜäÕăµ£¼µÿ»Õ©îµ£øõ©Çµ¼íµÇºõ╝áÞ¥ôÕ»╣Þ▒íõ┐«µö╣ÕëìÕÉÄþÜäþèµÇüÒÇé
þ╗ôµ×£õ©ñõ©¬Þ¥ôÕç║þÜäÚ⢵ÿ» 1´╝î ÕăÕøáÕ░▒µÿ»þ¼¼õ©Çµ¼íÕåÖÕàÑÕ»╣Þ▒íõ╗ÑÕÉÄ´╝îþ¼¼õ║îµ¼íÕåìÞ»òÕø¥ÕåÖþÜäµùÂÕÇÖ´╝îÞÖܵ£║µá╣µì«Õ╝òþö¿Õà│þ│╗þƒÑÚüôÕÀ▓þ╗ŵ£ëõ©Çõ©¬þø©ÕÉîÕ»╣Þ▒íÕÀ▓þ╗ÅÕåÖÕàѵûçõ╗´╝îÕøᵡñÕŬõ┐ØÕ¡ÿþ¼¼õ║îµ¼íÕåÖþÜäÕ╝òþö¿´╝îµëÇõ╗ÑÞ»╗ÕÅûµù´╝îÚ⢠µÿ»þ¼¼õ©Çµ¼íõ┐ØÕ¡ÿþÜäÕ»╣Þ▒íÒÇéÞ»╗ÞÇàÕ£¿õ¢┐þö¿õ©Çõ©¬µûçõ╗ÂÕñܵ¼í writeObject Ú£ÇÞªüþë╣Õê½µ│¿µäÅÞ┐Öõ©¬Úù«ÚóÿÒÇé
µ£¼µûçÚÇÜÞ┐çÕçáõ©¬ÕàÀõ¢ôþÜäµâàµÖ»´╝îõ╗ïþ╗ìõ║å Java Õ║ÅÕêùÕîûþÜäõ©Çõ║øÚ½ÿþ║ºþƒÑÞ»å´╝îÞÖ¢Þ»┤Ú½ÿþ║º´╝îÕ╣Âõ©ìµÿ»Þ»┤Þ»╗ÞÇàõ╗¼Úâ¢õ©ìõ║åÞºú´╝îÕ©îµ£øþö¿þ¼öÞÇàõ╗ïþ╗ìþÜäµâàµÖ»Þ«®Þ»╗ÞÇàÕèáµÀ▒Õì░Þ▒í´╝îÞâ¢Õñƒµø┤ÕèáÕÉêþÉåþÜäÕê®þö¿ Java Õ║ÅÕêùÕîûµèǵ£»´╝îÕ£¿µ£¬µØÑÕ╝ÇÕÅæõ╣ïÞÀ»õ©èÚüçÕê░Õ║ÅÕêùÕîûÚù«Úóÿµù´╝îÕÅ»õ╗ÑÕÅèµùÂþÜäÞºúÕå│ÒÇéþö▒õ║ĵ£¼õ║║þƒÑÞ»åµ░┤Õ╣│µ£ëÚÖÉ´╝îµûçþ½áõ©¡ÕÇÿÞïѵ£ëÚöÖÞ»»þÜäÕ£░µû╣´╝îµ¼óÞ┐ÄÞüöþ│╗µêæµë╣Þ»äµî絡úÒÇé
 
serialVersionUID Õ£¿Pointþ▒╗õ©¡µ£ëÞ┐ÖµáÀõ©ÇÕÅÑ޻ش╝Ü ┬á┬áprivate static final long serialVersionUID = 2208L; Õ«âµÿ»õ╗Çõ╣êµäŵÇØÕæó´╝ƒ ┬á┬áõ╗╗µäÅÞ«┐Úù«õ┐«ÚÑ░þ¼ª static final long serialVersionUID = µƒÉõ©¬longÕÇ╝; µëÇõ╗ÑÕ£¿õ¥ïÕ¡Éõ©¡Õ«Üõ╣ëÕ«âþÜäÞ«┐Úù«Õ▒׵Ǻµÿ»private´╝îÕ╣Âþ╗ÖÕ«âÞÁïõ║åõ©¬ÚÜŵäÅþÜälongÕÇ╝2208ÒÇé Þ«▓Õê░Þ┐ÖÚçî´╝îµ£¼þ½áÞ»Ñþ╗ôµØƒõ║åÒÇéÕ£¿Þ«▓ÞºúJavaþÜäÞ¥ôÕàÑÞ¥ôÕç║µû╣ÚØó´╝îµ£¼µòÖþ¿ïõ©ïõ║åµ×üÕñºþÜäÕèƒÕñ½´╝îÕªéµ×£õ¢áµø¥þ╗ÅÞ»╗Þ┐çÕàÂõ╗ûµòÖþ¿ï´╝êþ¢æõ©èÕÆîþ¢æõ©ïþÜä´╝ëÕ░▒õ╝Üõ¢ôõ╝ÜÕê░Þ┐Öõ©Çþé╣ÒÇéI/OþÜäõ©ñõ©¬ÚçìÞªüÕ║öþö¿µÿ»Õ»╣ZIPµûçõ╗ÂÒÇüJARµûçõ╗ÂÞ┐øÞíîÞ»╗ÕåÖÒÇéµêæõ╗¼þƒÑÚüô´╝îWinzipµÿ»þ¢æþ╗£õ©èÕ©©þö¿þÜäÕÄïþ╝®ÕÆîÞºúÕÄïþ╝®ÕÀÑÕàÀ´╝îÕÄïþ╝®ÕÉÄþÜäµò░µì«µûçõ╗ÂÕÅ»õ╗ÑÕ£¿Internetõ©èÕ┐½Úǃõ╝áÞ¥ô´╝øJARµûçõ╗µá╝Õ╝ÅÕêÖµÿ»JavaµÅÉõ¥øþÜäÕŪõ©Çþºìµûçõ╗ÂÕÄïþ╝®µû╣Õ╝Å´╝îõ╣ƒÕ¥êÕ©©þö¿ÒÇéµ£ëÕà┤ÞÂúþÜäÞ»╗ÞÇàÕÅ»õ╗ÑÕÅéþ£ïjava.util.zipÕîàÕÆîjava.util.jarÕîàþÜäÕ©«Õ讵ûçµíú´╝îÞ┐Öõ©ñõ©¬ÕîàÕÉäÕîàÕɽõ©Çõ║øþø©Õà│þÜäþ▒╗´╝îÕŻի×þÄ░ÕÄïþ╝®ÕÆîÞºúÕÄïþ╝®ÒÇéÕæÁÕæÁ´╝îÞ┐ÖÚçîÕ░▒õ©ìÕñÜÞ»┤ÕòªÒÇéõ©ïõ©Çþ½áÕ╝ÇÕºï´╝îÕ░åÕà¿ÚØóÞ┐øÕàÑÕø¥Õ¢óþòîÚØóþÜäþ╝ûþ¿ï´╝îÚéúÕÅêµÿ»õ©Çõ©¬µû░õ©ûþòî
ÒÇÇÒÇÇÚí¥ÕÉìµÇØõ╣ë´╝îserialVersionUIDÕ¡ùµ«Áµÿ»ÔÇ£Õ║ÅÕêùþëêµ£¼ÚÇÜþö¿µáçþñ║ÕÅÀÔÇØÒÇéÕ«âþÜäÞ«┐Úù«Õ▒׵ǺÕÅ»õ╗ѵÿ»publicÒÇüprivateÒÇüprotected´╝îÞ┐ÖÚ⢵ùáµëÇÞ░ô´╝îõ¢åÕ┐àÚí╗µÿ»ÚØÖµÇü´╝êstatic´╝ëÒÇüµ£Çþ╗ê´╝êfinal´╝ëþÜälongÕ×ïÕ¡ùµ«ÁÒÇéÕ«âþÜäÕ«Üõ╣ëµá╝Õ╝Åõ©║´╝Ü
ÒÇÇÒÇÇserialVersionUIDÕ£¿þ▒╗õ©¡õ©ìÕÅéõ©Äõ╗╗õ¢òµû╣µ│ò´╝îõ╣ƒõ©ìÕ║öÕÆîþ▒╗þÜäÕàÂõ╗ûÕ¡ùµ«Áµ£ëõ╗╗õ¢òÕà│þ│╗´╝îµëÇõ╗ÑÕ»╣õ║Äþ▒╗µ£¼Þ║½µ▓íµ£ëõ╗╗õ¢òþö¿ÕñäÒÇéÕªéµ×£õ©ìµÅÉõ¥øserialVersionUIDÕ¡ùµ«Á´╝îÕÅæÚÇüÞÇàþÜäJavaþ╝ûÞ»æÕÖ¿õ╝ÜÕ»╣ÕÅ»Õ║ÅÕêùÕîûþ▒╗þöƒµêÉõ©Çõ©¬serialVersionUIDÕÇ╝Õ╣ÂÕÅæþ╗ÖµÄѵöÂÞÇà´╝îÕ«âµÿ»µá╣µì«þ▒╗ÕÉìÒÇüµÄÑÕÅúÕÉìÒÇüµêÉÕæÿµû╣µ│òÕÅèÕ▒׵Ǻþ¡ëþöƒµêÉþÜäõ©Çõ©¬64õ¢ìÕôêÕ©îÕÇ╝ÒÇéµÄѵöÂÞÇàÕèáÞ¢¢Þ»ÑÕ»╣Þ▒íþÜäþ▒╗µù´╝îõ╣ƒõ╝ÜÞ«íþ«ùõ©Çõ©¬serialVersionUIDÕÇ╝ÒÇéÕªéµ×£Þ┐Öõ©ñõ©¬ÕÇ╝þø©þ¡ë´╝îÕêÖÕÅ»õ╗ÑÕÅìÕ║ÅÕêùÕîû´╝øÕªéµ×£õ©ìþø©þ¡ë´╝îÕêÖõ╝ܵèøÕç║InvalidClassExceptionÕ╝éÕ©©´╝îÕÅìÕ║ÅÕêùÕîûõ╝ÜÕñ▒Þ┤ÑÒÇéµëÇõ╗ÑÕì│õ¢┐þ╝ûþ¿ïÞÇàõ©ìµÅÉõ¥øÞ┐Öõ©¬Õ¡ùµ«Á´╝îþ│╗þ╗ƒõ╣ƒõ╝ÜÞç¬Õè¿Þ«íþ«ùserialVersionUIDÕÇ╝þÜäÒÇéµêæõ╝░Þ«íSunÕà¼ÕÅ©Þ┐ÖµáÀÕüÜ´╝îµÿ»õ©║õ║åÚÿ▓µ¡óµûçõ╗ÂÕ£¿þ¢æþ╗£õ©èÞó½þ»íµö╣ÒÇé
ÒÇÇÒÇÇõ¢åµÿ»´╝îÕÅæÚÇüÞÇàþÜäJavaþ╝ûÞ»æÕÖ¿ÕÆîµÄÑÕÅùÞÇàþÜäJavaþ╝ûÞ»æÕÖ¿µ£¬Õ┐àþø©ÕÉî´╝îõ©ìÕÉîþ╝ûÞ»æÕÖ¿Þ«íþ«ùÕç║µØÑþÜäserialVersionUIDÕÇ╝ÕÅ»Þâ¢õ©ìõ©ÇµáÀ´╝îÞ┐ÖµáÀÕ£¿ÕÅìÕ║ÅÕêùÕîûÞ┐çþ¿ïõ©¡ÕÅ»Þâ¢õ╝ÜÕ»╝Þç┤µäÅÕñûþÜäInvalidClassExceptionÒÇéµëÇõ╗Ñõ©║õ║åõ┐ØÞ»üserialVersionUIDÕ£¿õ©ìÕÉîþÜäJavaþ╝ûÞ»æÕÖ¿ÕàÀµ£ëÕÉîõ©Çõ©¬ÕÇ╝´╝îJavaÕ©«Õ讵ûçõ╗ÂÕ╝║þâêÕ╗║Þ««´╝ÜÕÅ»Õ║ÅÕêùÕîûþÜäþ▒╗µ£ÇÕÑ¢Õú░µÿÄõ©Çõ©¬Õ¡ùµ«ÁserialVersionUIDÒÇéÞ┐ÖÕ░▒µÿ»Õ£¿õ¥ïÕ¡Éõ©¡Õó×ÕèáÕ«âþÜäÕăÕøáÒÇé
 


- 2012-09-12 13:48
- µÁÅÞºê 852
- Þ»äÞ«║(0)
- Õêåþ▒╗:þ╝ûþ¿ïÞ»¡Þ¿Ç
- µƒÑþ£ïµø┤ÕñÜ
ÕÅæÞí¿Þ»äÞ«║

-
ÒÇÉÞ¢¼ÒÇæSpringþÜäDAOÕ╝éÕ©©-õ¢áÕÅ»Þâ¢Õ┐¢ÞºåþÜäÕ╝éÕ©©
2018-10-11 05:04 556SpringþÜäDAOµíåµ×µ▓íµ£ëµèøÕç║õ©Äþë╣իܵèǵ£»þø©Õà│þÜäÕ╝éÕ©©´╝îõ¥ïÕªé ... -
ÒÇÉÞ¢¼ÒÇæjava8 Optional
2018-10-05 02:39 483https://my.oschina.net/wangz ... -
java double checked locking broken
2018-09-15 01:56 500// Double-check idiom for lazy ... -
ÒÇÉÞ¢¼ÒÇæJAVAµ│øÕ×ïÚÇÜÚàìþ¼ª´╝êPECS´╝ë
2018-07-29 10:43 532Õ£¿JAVAþÜäµ│øÕ×ïÚøåÕÉêõ©¡´╝îÚ╗ÿÞ«ñÚâ¢ÕÅ»õ╗ѵÀ╗Õèánull´╝îÚÖñµ¡ñõ╗ÑÕñû´╝î ... -
Differences between notify() and notifyAll()
2018-07-16 09:01 534Notification to number of th ... -
ÒÇÉÞ¢¼ÒÇæµÀ▒Õ║ªÞºúµ×ÉJavaÕñÜþ║┐þ¿ïþÜäÕåàÕ¡ÿµ¿íÕ×ï
2018-07-16 09:00 500https://www.jianshu.com/p/a3f ... -
mavenÚí╣þø«srcµ║Éõ╗úþáüõ©ïþÜäÞÁäµ║ɵûçõ╗Âõ©ìÞç¬Õè¿ÕñìÕêÂÕê░classesµûçõ╗ÂÕñ╣þÜäÞºúÕå│µû╣µ│ò
2018-07-01 23:34 1205POMµûçõ╗ <build><resour ... -
javaÕÑ¢þö¿þÜäÕ╝ǵ║ÉÕ║ô
2018-04-28 23:40 0guava--googleþ¼¼õ©ëµû╣µò░µì«þ╗ôµ×äÕ╝ǵ║ÉÕîà Vardu ... -
ÒÇÉÞ¢¼ÒÇæjava rmi
2018-01-03 18:57 419µ¡ñÕñäÞ«▓þÜäµÿ»Javaõ©¡þÜäRMI´ ... -
ÒÇÉÞ¢¼ÒÇæÕ¡ùþ¼ªþ╝ûþáüþ¼öÞ«░´╝ÜASCII´╝îUnicode ÕÆî UTF-8
2017-12-12 19:09 468õ╗èÕñ®õ©¡Õìê´╝îµêæþ¬üþäµâ│µÉ×µ©àµÑÜ Unicode ÕÆî UTF-8 õ╣ï ... -
ÒÇÉÞ¢¼ÒÇæJava web Õ¡ªõ╣áÞÀ»þ║┐
2017-06-14 15:55 718JSP -> Servlet -> Java ... -
µ£ëµäŵÇØþÜäASCIIþ¿ïÕ║ŵ│¿Úçè
2017-06-14 10:39 752  /** * * create ... -
ÒÇÉÞ¢¼ÒÇæJavaÕƒ║þíÇþƒÑÞ»åµÇ╗þ╗ô´╝êþ╗ØÕ»╣þ╗ÅÕà©´╝ë
2017-06-13 14:13 548µ£¼õ║║Õ¡ªõ╣ájavaµù´╝îÕüÜþÜäjavaÕƒ║þíÇþƒÑÞ»åµÇ╗þ╗ô´╝Ü ÕøáÕåàÕ«╣Þ¥â ... -
javaիܵùÂõ╗╗Õèí
2017-03-27 10:08 426import java.util.concurrent.Ex ... -
õ║îÕê嵃ѵë¥(javaÕ«×þÄ░)
2017-03-21 11:02 499õ║îÕêåµƒÑµë¥ þ«ùµ│òµÇصâ│´╝ÜÕÅêÕŽµèÿÕì赃ѵ르╝îÞªüµ▒éեൃѵë¥þÜäÕ║ÅÕêùµ£ëÕ║ÅÒÇ鵻Š... -
javaþÄ»ÕóâÚàìþ¢«
2017-03-15 15:46 457Õó×Õèáþ│╗þ╗ƒÕÅÿÚçÅ´╝Ü JAVA_HOME C:\Program ... -
Javaõ©¡þÜäBig(Little)-endianÚù«ÚóÿþÜäõ©ÇþºìÞºúÕå│µû╣µ│ò
2017-03-08 15:47 1048http://blog.sina.com.cn/s/blo ... -
ÒÇÉÞ¢¼ÒÇæSpring3.3 µò┤ÕÉê Hibernate3ÒÇüMyBatis3.2 Úàìþ¢«Õñܵò░µì«µ║É/Õ迵ÇüÕêçµìóµò░µì«µ║É µû╣µ│ò
2016-12-13 15:07 716http://www.cnblogs.com/hoojo ... -
ÒÇÉÞ¢¼ÒÇæJNDIÕ¡ªõ╣áµÇ╗þ╗ô(õ©ë)ÔÇöÔÇöTomcatõ©ïõ¢┐þö¿DruidÚàìþ¢«JNDIµò░µì«µ║É
2016-12-13 14:50 1310http://www.cuomi.com/html/co ... -
ÒÇÉÞ¢¼ÒÇæJNDIÕ¡ªõ╣áµÇ╗þ╗ô(õ║î)ÔÇöÔÇöTomcatõ©ïõ¢┐þö¿C3P0Úàìþ¢«JNDIµò░µì«µ║É
2016-12-13 14:48 740http://blog.csdn.net/samjustin ...
þø©Õà│µÄ¿ÞìÉ
### JavaÕ║ÅÕêùÕîûþÜäÚ½ÿþ║ºÞ«ñÞ»å JavaÕ║ÅÕêùÕîûõ¢£õ©║Javaµèǵ£»õ¢ôþ│╗õ©¡þÜäõ©Çõ©¬ÚçìÞªüþ╗äµêÉÚâ¿Õêå´╝îÕàµá©Õ┐âÕèƒÞâ¢Õ£¿õ║ÄÞâ¢ÕñƒÕ░åJavaÕ»╣Þ▒íÞ¢¼µìóµêÉÕ¡ùÞèéµÁü´╝îõ╗ÄÞÇîÕ«×þÄ░Õ»╣Þ▒íþÜäµîüõ╣àÕîûÕ¡ÿÕ鿵êûµÿ»ÚÇÜÞ┐çþ¢æþ╗£õ╝áÞ¥ôÒÇéþäÂÞÇî´╝îÕ║ÅÕêùÕîûþÜäÕ║öþö¿Þ┐£õ©ìµ¡óõ║ĵ¡ñ´╝îÕ«âÞ┐ÿµÂëÕÅèÕê░õ©Ç...
µÇ╗õ╣ï´╝îJavaÕ║ÅÕêùÕîûÞÖ¢þäµû╣õ¥┐´╝îõ¢åõ╣ƒµÂëÕÅèõ©Çõ║øÕñìµØéµÇºÕÆîµ¢£Õ£¿ÚúÄÚÖ®´╝îÕ╝ÇÕÅæÞÇàÕ║öþÉåÞºúÞ┐Öõ║øÚ½ÿþ║ºµªéÕ┐Á´╝îõ╗Ñõ¥┐Õ£¿Õ«×ÚÖàÕ║öþö¿õ©¡ÕüÜÕç║ÚÇéÕ¢ôþÜäÕå│þ¡ûÒÇéÕ£¿Þ«¥Þ«íÕÅ»Õ║ÅÕêùÕîûþÜäþ▒╗µù´╝îÕ║öÞÇâÞÖæÕ»╣Þ▒íþÜäþöƒÕæ¢Õ濵£ƒÒÇüÕ«ëÕ࿵Ǻڣǵ▒éÕÆîþëêµ£¼µÄºÕêÂþ¡ëÕøáþ┤áÒÇéÚÇÜÞ┐çÕÉêþÉåõ¢┐þö¿`...
µ£¼µûçÕ░åÚÇÜÞ┐çÕ«×õ¥ïµÀ▒ÕàÑõ║åÞºú Java Õ║ÅÕêùÕîû´╝îÕêåµ×Éõ©Çõ║øþ£ƒÕ«×µâàÕóâ´╝îÕ©«Õè®Þ»╗ÞÇàÞ¢╗µØ¥þëóÞ«░ Java Õ║ÅÕêùÕîûõ©¡þÜäõ©Çõ║øÚ½ÿþ║ºÞ«ñÞ»åÒÇé Õ║ÅÕêùÕîû ID Úù«Úóÿ ---------------- Õ£¿ Java Õ║ÅÕêùÕîûõ©¡´╝îÕ║ÅÕêùÕîû ID µÿ»õ©Çõ©¬ÚØ×Õ©©ÚçìÞªüþÜäõ©Çþé╣ÒÇéÕ«âÕå│Õ«Üõ║åõ©ñõ©¬þ▒╗...
Õ£¿Javaþ╝ûþ¿ïÞ»¡Þ¿Çõ©¡´╝î`Serializable`µÄÑÕÅúµÿ»õ©Çõ©¬ÚØ×Õ©©ÚçìÞªüþÜ䵪éÕ┐Á´╝îÕ«âµÿ»Õ«×þÄ░Õ»╣Þ▒íµîüõ╣àÕîûþÜäÕà│Úö«ÒÇéµ£¼µûçÕ░åµÀ▒ÕàѵÄóÞ«¿`Serializable`µÄÑÕÅúþÜäþ╗åÞèé...ÚÇÜÞ┐çÚÿàÞ»╗ÒÇèJava_Õ║ÅÕêùÕîûþÜäÚ½ÿþ║ºÞ«ñÞ»å.docÒÇïµûçµíú´╝îõ¢áÕÅ»õ╗ÑÞÄÀÕ¥ùµø┤µÀ▒ÕàÑþÜäÞºüÞºúÕÆîÕ«×ÞÀÁþ╗ÅÚ¬îÒÇé
- Þ¥ôÕàÑ/Þ¥ôÕç║µÁüþÜäÚ½ÿþ║ºµôìõ¢£´╝îµ»öÕªéÕ»╣Þ▒íÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûÒÇé - NIOþÜäµû░þë╣µÇº´╝îÕîàµï¼ÚÇÜÚüô´╝êChannel´╝ëÕÆîþ╝ôÕå▓Õî║´╝êBuffer´╝ëÒÇé 6. **þ¢æþ╗£þ╝ûþ¿ï**´╝Ü - þ¢æþ╗£þ╝ûþ¿ïÕƒ║þíÇ´╝îÕªéÕÑùµÄÑÕ¡ù´╝êSocket´╝ëþÜäõ¢┐þö¿ÒÇé - Ú½ÿþ║ºþ¢æþ╗£þ╝ûþ¿ïµèǵ£»´╝îÕªéÚØ×...
Õ║ÅÕêùÕîûõ©ÄÕÅìÕ║ÅÕêùÕîûµÿ»Javaþ╝ûþ¿ïõ©¡Õ©©ÞºüþÜäµò░µì«µôìõ¢£µû╣Õ╝Å´╝îÕƒ╣Þ«¡õ╝ÜÕ╝║Þ░âÕ£¿Þ┐øÞíîÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûµôìõ¢£µù´╝îÕ║öÕà│µ│¿µò░µì«þÜäÕ«îµò┤µÇºÕÆîÕ«ëÕ࿵Ǻ´╝îÚÿ▓µ¡óõ¥ïÕªéÕÅìÕ║ÅÕêùÕîûµ╝ŵ┤×Õ»╝Þç┤þÜäÕ«ëÕà¿ÚúÄÚÖ®ÒÇé ÕñÜþ║┐þ¿ïÕ«ëÕ࿵ÿ»JavaÚ½ÿþ║ºþ╝ûþ¿ïõ©¡Õ┐àÚí╗µ│¿µäÅþÜäÚù«ÚóÿÒÇéÕ£¿...
Õ£¿õ╗úþáüõ©¡´╝îµêæõ╗¼þ£ïÕê░õ║å`serialVersionUID`Õ¡ùµ«Á´╝îÞ┐Öµÿ»JavaÕ║ÅÕêùÕîûµ£║ÕêÂþÜäõ©ÇÚâ¿Õêå´╝îþö¿õ║Äõ┐صîüÕ»╣Þ▒íÕ£¿Õ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûÞ┐çþ¿ïõ©¡þÜäÕà╝Õ«╣µÇºÒÇéÕ¢ôþ▒╗þëêµ£¼µø┤µû░µù´╝îÕªéµ×£Õ║ÅÕêùÕîûµáçÞ»åþ¼ªõ©ìÕÅÿ´╝îÕÅìÕ║ÅÕêùÕîûõ¥ØþäÂÞ⢵¡úþí«Þ»åÕê½Õ»╣Þ▒íÒÇé µ¡ñÕñû´╝î`get...
4. **Java IO**´╝Ü031203_ÒÇÉþ¼¼12þ½á´╝ÜJAVA IOÒÇæ_Õ¡ùÞèéµÁüõ©ÄÕ¡ùþ¼ªµÁüþ¼öÞ«░.pdf ÕÆî 031217_ÒÇÉþ¼¼12þ½á´╝ÜJAVA IOÒÇæ_Õ»╣Þ▒íÕ║ÅÕêùÕîûþ¼öÞ«░.pdf´╝îIOµÿ»Javaõ©¡ÕñäþÉåÞ¥ôÕàÑÞ¥ôÕç║þÜäÚçìÞªüµ¿íÕØù´╝îÞ┐ÖÚçîÞ«▓Þºúõ║åÕ¡ùÞèéµÁüÕÆîÕ¡ùþ¼ªµÁüþÜäÕî║Õê½õ©Äõ¢┐þö¿´╝îõ╗ÑÕÅèÕªéõ¢òÕ«×þÄ░...
031217_ÒÇÉþ¼¼12þ½á´╝ÜJAVA IOÒÇæ_Õ»╣Þ▒íÕ║ÅÕêùÕîûþ¼öÞ«░.pdf 031218_ÒÇûþ¼¼12þ½á´╝ÜJAVA IOÒÇù_Õ«×õ¥ïµôìõ¢£ÔÇöÕìòõ║║õ┐íµü»þ«íþÉåþ¿ïÕ║Åþ¼öÞ«░.pdf 031219_ÒÇûþ¼¼12þ½á´╝ÜJAVA IOÒÇù_Õ«×õ¥ïµôìõ¢£´╝ܵèòþÑ¿þ¿ïÕ║Åþ¼öÞ«░.pdf 031301_ÒÇÉþ¼¼13þ½á´╝ÜJavaþ▒╗ÚøåÒÇæ_Þ«ñÞ»åþ▒╗ÚøåÒÇü...
"JavaÕ║ÅÕêùÕîûþÜäÚ½ÿþ║ºÞ«ñÞ»å"µÂëÕÅèÕªéõ¢òÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûÕ»╣Þ▒í´╝îÞ┐ÖÕ»╣õ║ĵò░µì«µîüõ╣àÕîûÕÆîþ¢æþ╗£õ╝áÞ¥ôÞç│Õà│ÚçìÞªüÒÇéÕ║ÅÕêùÕîûÕÅ»Þâ¢Õ»╝Þç┤þÜäÕ«ëÕà¿Úù«Úóÿõ╣ƒµÿ»Õ╝ÇÕÅæÞÇàÚ£ÇÞªüµ│¿µäÅþÜä´╝îÕªé`ObjectInputStream`ÕÅ»Þâ¢Õ»╝Þç┤þÜäÕåàÕ¡ÿµ│äµ╝Å´╝îÞ┐ÖÕ£¿"Õëûµ×Éõ¢┐þö¿...
õ╣ªõ©¡õ╝ÜÞ«▓ÞºúÕ¡ùÞèéµÁüÒÇüÕ¡ùþ¼ªµÁüÒÇüÕ»╣Þ▒íÕ║ÅÕêùÕîûõ╗ÑÕÅèNIO´╝êÚØ×Úÿ╗Õí×I/O´╝ëþ¡ë´╝îÕ©«Õè®Õ╝ÇÕÅæÞÇàÚ½ÿµòêÕ£░ÕñäþÉåµò░µì«õ╝áÞ¥ôÒÇé JavaþÜäÕñÜþ║┐þ¿ïþ╝ûþ¿ïµÿ»Õ╣ÂÕÅæÕñäþÉåþÜäÕƒ║þíÇÒÇéõ╣ªõ©¡õ╝Üõ╗ïþ╗ìþ║┐þ¿ïþÜäÕêøÕ╗║õ©Äþ«íþÉå´╝îÕÉѵ£║Õê´╝êÕªésynchronizedÒÇüLock´╝ëÒÇüÕ╣ÂÕÅæÕÀÑÕàÀþ▒╗...
þ¼¼õ©âþ½áÕÅ»Þâ¢õ╝ܵÂÁþøûÞ¥ôÕàÑ/Þ¥ôÕç║µÁü(I/O Stream)´╝îÕîàµï¼µûçõ╗µôìõ¢£ÒÇüÕ»╣Þ▒íÕ║ÅÕêùÕîûÕÆîþ¢æþ╗£ÚÇÜõ┐í´╝îÞ┐ÖÕ»╣õ║ÄÕñäþÉåµò░µì«þÜäÞ»╗ÕåÖÕÆîÞÀ¿Þ«¥ÕñçÚÇÜõ┐íÞç│Õà│ÚçìÞªüÒÇé þ¼¼Õà½þ½áõ╝ÜÞ«▓ÞºúJavaþÜäÕñÜþ║┐þ¿ïþ╝ûþ¿ï´╝îÕîàµï¼þ║┐þ¿ïþÜäÕêøÕ╗║ÒÇüÕÉѵ£║Õê´╝êÕªésynchronizedÕà│Úö«Õ¡ùÕÆî...
Õ£¿ÞÀ¿Õ╣│ÕÅ░ÚÇÜõ┐íõ©¡´╝îµò░µì«þÜäÕ║ÅÕêùÕîûÕÆîÕÅìÕ║ÅÕêùÕîûµÿ»Õà│Úö«ÒÇéþö▒õ║ÄC/C++ÕÆîJavaþÜäµò░µì«Þí¿þñ║µû╣Õ╝ÅÕÅ»Þâ¢Õ¡ÿÕ£¿ÕÀ«Õ╝é´╝îµêæõ╗¼Ú£ÇÞªüþí«õ┐ØÕèáÕ»åÕÉÄþÜäÕ¡ùÞèéÕ║ÅÕêùÕ£¿õ©ñÞÇàþÜäþÄ»Õóâõ©¡Úâ¢Þ⢵¡úþí«Þºúµ×ÉÒÇéõ¥ïÕªé´╝îC/C++õ©¡þÜäÕ¡ùÞèéÕ║ÅÕÅ»Þ⢵ÿ»Õñºþ½»µêûÕ░Åþ½»´╝îÞÇîJavaÚ╗ÿÞ«ñõ¢┐þö¿...
µ¡ñÕñû´╝îÕ»╣Javaþ▒╗Õ║ôÒÇüI/Oµôìõ¢£ÒÇüÕñÜþ║┐þ¿ïþ╝ûþ¿ïÒÇüþ¢æþ╗£þ╝ûþ¿ïÒÇüJavaÚøåÕÉêµíåµ×Âþ¡ëõ╣ƒµ£ëÕêص¡ÑþÜäÞ«ñÞ»åÕÆîÕ║öþö¿Þâ¢ÕèøÒÇé Þ┐Öµ£¼õ╣ªÕ»╣õ║ÄÚéúõ║øÕ©îµ£øµÄîµÅíJavaþ╝ûþ¿ï´╝îõ║åÞºúÕàÂÞâîÕÉÄþÜäÕăþÉåÕÆîµèǵ£»ÕÅæÕ▒òþÜäÕêØÕ¡ªÞÇàµØÑÞ»┤´╝îµÿ»õ©Çµ£¼ÚØ×Õ©©Õ«×þö¿þÜäÕàÑÚù¿µòÖµØÉÒÇéÚÇÜÞ┐çµ£¼õ╣ªþÜä...
7. **IOµÁü**´╝ÜÞ«▓ÞºúÞ¥ôÕàÑ/Þ¥ôÕç║µÁüþÜ䵪éÕ┐Á´╝îÕîàµï¼µûçõ╗µôìõ¢£ÒÇüÕ»╣Þ▒íÕ║ÅÕêùÕîûÒÇüþ¢æþ╗£ÚÇÜõ┐íþ¡ë´╝îµÿ»ÕñäþÉåµò░µì«õ╝áÞ¥ôþÜäÕà│Úö«µèǵ£»ÒÇé 8. **ÕñÜþ║┐þ¿ï**´╝ÜÞ«¿Þ«║Õ╣ÂÕÅæþ╝ûþ¿ï´╝îÕªéõ¢òÕêøÕ╗║ÕÆîþ«íþÉåþ║┐þ¿ï´╝îõ╗ÑÕÅèÕÉѵ£║ÕêÂÕªésynchronizedÕà│Úö«Õ¡ùÕÆîwait/notifyµ£║ÕêÂ...
- Õ»╣Þ▒íÕ║ÅÕêùÕîûõ©ÄÕÅìÕ║ÅÕêùÕîû´╝ÜÕ«×þÄ░SerializableµÄÑÕÅú´╝îþö¿õ║ĵîüõ╣àÕîûÕ»╣Þ▒íÒÇé 8. ÕñÜþ║┐þ¿ï - Threadþ▒╗ÕÆîRunnableµÄÑÕÅú´╝ÜÕêøÕ╗║Õ╣µëºÞíîþ║┐þ¿ïÒÇé - þ║┐þ¿ïÕÉѴ╝ÜsynchronizedÕà│Úö«Õ¡ùÒÇüwait()ÒÇünotify()ÕÆînotifyAll()µû╣µ│òÒÇé 9. Java ...
Javaµö»µîüÕ║ÅÕêùÕîû´╝îÕÅ»õ╗ÑÕ░åÕ»╣Þ▒íþÜäþèµÇüõ┐ØÕ¡ÿÕê░þúüþøÿ´╝îõ╗Ñõ¥┐þ¿ìÕÉĵüóÕñìÒÇé 13. **þ¢æþ╗£Þüöµ£║** JavaÕàÀµ£ëÕ╝║ÕñºþÜäþ¢æþ╗£þ╝ûþ¿ïÞâ¢Õèø´╝îÕÅ»õ╗ÑÕêøÕ╗║TCP/IPÞ┐×µÄÑ´╝îÕÅæÚÇüÕÆîµÄѵöµò░µì«ÒÇé 14. **µò░µì«þ╗ôµ×ä** Õ¡ªõ╣áÕªéõ¢òõ¢┐þö¿JavaÚøåÕÉêµíåµ×´╝îÕªéµò░þ╗äÕêùÞí¿...
ÒÇ赣ǵû░Thinking in Javaþ¼¼Õøøþëêþ╗ÅÕà©þëêÒÇïÕ»╣Java I/OµÁüÞ┐øÞíîõ║åÞ»ªÕ░¢þÜäõ╗ïþ╗ì´╝îõ╗ÄÕƒ║µ£¼þÜäÞ¥ôÕàÑÞ¥ôÕç║Õê░õ¢┐þö¿µûçõ╗Âþ│╗þ╗ƒ´╝îõ╗ĵò░µì«þÜäÕ║ÅÕêùÕîûÕê░þ¢æþ╗£þ╝ûþ¿ï´╝îÚâ¢õ©║Þ»╗ÞÇàµÅÉõ¥øõ║åõ©░Õ»îþÜäþƒÑÞ»åÒÇéJava I/OÕ║ôþ╗ÅÞ┐çþ▓¥Õ┐âÞ«¥Þ«í´╝îÞâ¢Õñƒµ╗íÞÂ│ÕñºÕñܵò░µò░µì«ÕñäþÉåڣǵ▒é...
5. **Þ¥ôÕàÑÞ¥ôÕç║µÁü**´╝ܵÄîµÅíI/OµÁüþÜ䵪éÕ┐Á´╝îÕ¡ªõ╣áµûçõ╗ÂÞ»╗ÕåÖÒÇüþ¢æþ╗£ÚÇÜõ┐íõ╗ÑÕÅèµò░µì«Õ║ÅÕêùÕîûÒÇé 6. **þ║┐þ¿ïþ╝ûþ¿ï**´╝ÜÕ¡ªõ╣áÕªéõ¢òÕêøÕ╗║ÕÆîþ«íþÉåþ║┐þ¿ï´╝îþÉåÞºúÕÉÑÕÆîõ║ƵûÑ´╝îõ╗ÑÕÅèþ║┐þ¿ïÕ«ëÕà¿Úù«ÚóÿÒÇé 7. **ÕÅìÕ░äµ£║ÕêÂ**´╝Üõ║åÞºúJavaÕÅìÕ░äµ£║Õê´╝îÕÅ»õ╗ÑÕ迵ÇüÞÄÀÕÅû...
ÚÇÜÞ┐çÞ┐Öõ║øþ½áÞèéþÜäÕ¡ªõ╣á´╝îõ¢áÕÅ»õ╗ÑÚÇɵ¡ÑÕ╗║þ½ïÞÁÀÕ»╣Javaþ╝ûþ¿ïþÜäÕƒ║þíÇÞ«ñÞ»å´╝îõ║åÞºúÕªéõ¢òþ╝ûÕåÖµ£ëµòêþÜäJavaõ╗úþáü´╝îÕ╣Âõ©║µÀ▒ÕàÑÕ¡ªõ╣áÚ½ÿþ║ºþë╣µÇº´╝îÕªéÕñÜþ║┐þ¿ïÒÇüþ¢æþ╗£þ╝ûþ¿ïÒÇüµò░µì«Õ║ôµôìõ¢£ÒÇüÕÅìÕ░äþ¡ëµëôõ©ïÕØÜÕ«×þÜäÕƒ║þíÇÒÇéÕ«×ÚÖàµôìõ¢£Þ┐Öõ║øµ║Éõ╗úþáü´╝îõ║▓Þç¬Õ迵ëïÕ«×ÞÀÁ´╝îµÿ»...