
第一部分为一道百度面试题Top K算法的详解;第二部分为关于Hash表算法的详细阐述;第三部分为打造一个最快的Hash表算法。 第一部分:Top K 算法详解 哈希表的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。 第一步:Query统计 但是题目中有明确要求,那就是内存不能超过1G,一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,这个条件就不满足要求了。 让我们回忆一下数据结构课程上的内容,当数据量比较大而且内存无法装下的时候,我们可以采用外排序的方法来进行排序,这里我们可以采用归并排序,因为归并排序有一个比较好的时间复杂度O(NlgN)。 排完序之后我们再对已经有序的Query文件进行遍历,统计每个Query出现的次数,再次写入文件中。 综合分析一下,排序的时间复杂度是O(NlgN),而遍历的时间复杂度是O(N),因此该算法的总体时间复杂度就是O(N+NlgN)=O(NlgN)。 2、Hash Table法 题目中说明了,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择,因为Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。 那么,我们的算法就有了:维护一个Key为Query字串,Value为该Query出现次数的HashTable,每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内完成了对该海量数据的处理。 本方法相比算法1:在时间复杂度上提高了一个数量级,为O(N),但不仅仅是时间复杂度上的优化,该方法只需要IO数据文件一次,而算法1的IO次数较多的,因此该算法2比算法1在工程上有更好的可操作性。 算法二:部分排序 不难分析出,这样,算法的最坏时间复杂度是N*K, 其中K是指top多少。 算法三:堆 分析一下,在算法二中,每次比较完成之后,需要的操作复杂度都是K,因为要把元素插入到一个线性表之中,而且采用的是顺序比较。这里我们注意一下,该数组是有序的,一次我们每次查找的时候可以采用二分的方法查找,这样操作的复杂度就降到了logK,可是,随之而来的问题就是数据移动,因为移动数据次数增多了。不过,这个算法还是比算法二有了改进。 基于以上的分析,我们想想,有没有一种既能快速查找,又能快速移动元素的数据结构呢?回答是肯定的,那就是堆。 思想与上述算法二一致,只是算法在算法三,我们采用了最小堆这种数据结构代替数组,把查找目标元素的时间复杂度有O(K)降到了O(logK)。
总结: 第二部分、Hash表 算法的详细解析 什么是Hash HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。 数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图: 元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的: 1,除法散列法 2,平方散列法 3,斐波那契(Fibonacci)散列法 平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。 1,对于16位整数而言,这个乘数是40503 这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。 对我们常见的32位整数而言,公式: 如果用这种斐波那契散列法的话,那上面的图就变成这样了: 适用范围 基本原理及要点 扩展 问题实例(海量数据处理) 第三部分、最快的Hash表算法 接下来,咱们来具体分析一下一个最快的Hasb表算法。 最合适的算法自然是使用HashTable(哈希表),先介绍介绍其中的基本知识,所谓Hash,一般是一个整数,通过某种算法,可以把一个字符串"压缩" 成一个整数。当然,无论如何,一个32位整数是无法对应回一个字符串的,但在程序中,两个字符串计算出的Hash值相等的可能非常小,下面看看在MPQ中的Hash算法: 函数一、以下的函数生成一个长度为0x500(合10进制数:1280)的cryptTable[0x500] void prepareCryptTable() 函数二、以下函数计算lpszFileName 字符串的hash值,其中dwHashType 为hash的类型,在下面的函数三、GetHashTablePos函数中调用此函数二,其可以取的值为0、1、2;该函数返回lpszFileName 字符串的hash值: unsigned long HashString( char *lpszFileName, unsigned long dwHashType ) 是不是把第一个算法改进一下,改成逐个比较字符串的Hash值就可以了呢,答案是,远远不够,要想得到最快的算法,就不能进行逐个的比较,通常是构造一个哈希表(Hash Table)来解决问题,哈希表是一个大数组,这个数组的容量根据程序的要求来定义,例如1024,每一个Hash值通过取模运算 (mod) 对应到数组中的一个位置,这样,只要比较这个字符串的哈希值对应的位置有没有被占用,就可以得到最后的结果了,想想这是什么速度?是的,是最快的O(1),现在仔细看看这个算法吧: typedef struct 函数三、下述函数为在Hash表中查找是否存在目标字符串,有则返回要查找字符串的Hash值,无则,return -1. int GetHashTablePos( har *lpszString, SOMESTRUCTURE *lpTable ) 然而Blizzard的程序员使用的方法则是更精妙的方法。基本原理就是:他们在哈希表中不是用一个哈希值而是用三个哈希值来校验字符串。 MPQ使用文件名哈希表来跟踪内部的所有文件。但是这个表的格式与正常的哈希表有一些不同。首先,它没有使用哈希作为下标,把实际的文件名存储在表中用于验证,实际上它根本就没有存储文件名。而是使用了3种不同的哈希:一个用于哈希表的下标,两个用于验证。这两个验证哈希替代了实际文件名。 函数四、lpszString 为要在hash表中查找的字符串;lpTable 为存储字符串hash值的hash表;nTableSize 为hash表的长度: int GetHashTablePos( char *lpszString, MPQHASHTABLE *lpTable, int nTableSize ) 上述程序解释: 1.计算出字符串的三个哈希值(一个用来确定位置,另外两个用来校验) ok,这就是本文中所说的最快的Hash表算法。什么?不够快?:D。欢迎,各位批评指正。 -------------------------------------------- /*key为一个字符串,nTableLength为哈希表的长度 补充2、一个完整测试程序: 17, 37, 79, 163, 331, 以下为该程序的完整源码,已在linux下测试通过: 相关引用:
------------------------------------
问题描述
百度面试题:
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
必备知识:
什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位(文章第二、三部分,会针对Hash表详细阐述)。
问题解析:
要统计最热门查询,首先就是要统计每个Query出现的次数,然后根据统计结果,找出Top 10。所以我们可以基于这个思路分两步来设计该算法。
即,此问题的解决分为以下俩个步骤:
Query统计有以下俩个方法,可供选择:
1、直接排序法
首先我们最先想到的的算法就是排序了,首先对这个日志里面的所有Query都进行排序,然后再遍历排好序的Query,统计每个Query出现的次数了。
在第1个方法中,我们采用了排序的办法来统计每个Query出现的次数,时间复杂度是NlgN,那么能不能有更好的方法来存储,而时间复杂度更低呢?
第二步:找出Top 10
算法一:普通排序
我想对于排序算法大家都已经不陌生了,这里不在赘述,我们要注意的是排序算法的时间复杂度是NlgN,在本题目中,三百万条记录,用1G内存是可以存下的。
题目要求是求出Top 10,因此我们没有必要对所有的Query都进行排序,我们只需要维护一个10个大小的数组,初始化放入10个Query,按照每个Query的统计次数由大到小排序,然后遍历这300万条记录,每读一条记录就和数组最后一个Query对比,如果小于这个Query,那么继续遍历,否则,将数组中最后一条数据淘汰,加入当前的Query。最后当所有的数据都遍历完毕之后,那么这个数组中的10个Query便是我们要找的Top10了。
在算法二中,我们已经将时间复杂度由NlogN优化到NK,不得不说这是一个比较大的改进了,可是有没有更好的办法呢?
借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此到这里,我们的算法可以改进为这样,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。
那么这样,采用堆数据结构,算法三,最终的时间复杂度就降到了N‘logK,和算法二相比,又有了比较大的改进。
至此,算法就完全结束了,经过上述第一步、先用Hash表统计每个Query出现的次数,O(N);然后第二步、采用堆数据结构找出Top 10,N*O(logK)。所以,我们最终的时间复杂度是:O(N) + N'*O(logK)。(N为1000万,N’为300万)。如果各位有什么更好的算法,欢迎留言评论。第一部分,完。
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。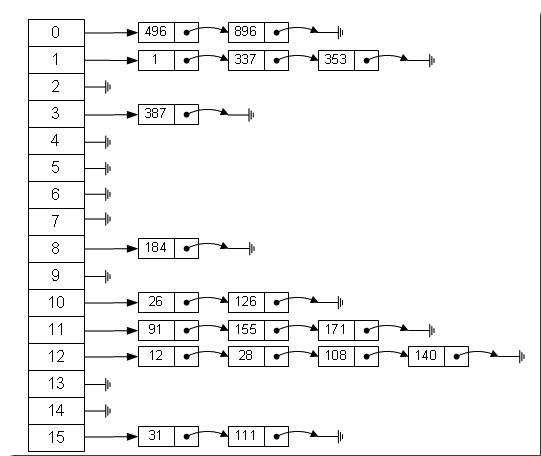
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
index = (value * 2654435769) >> 28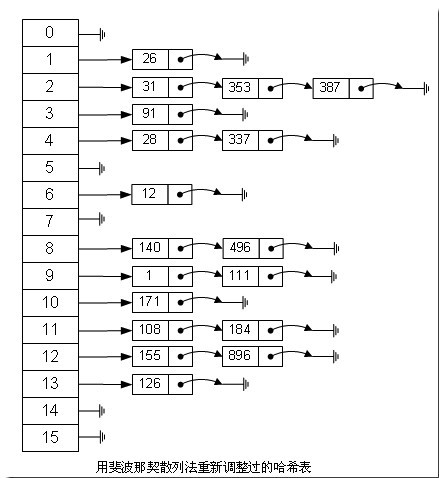
很明显,用斐波那契散列法调整之后要比原来的取摸散列法好很多。
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
我们知道hash 表在海量数据处理中有着广泛的应用,下面,请看另一道百度面试题:
题目:海量日志数据,提取出某日访问百度次数最多的那个IP。
方案:IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
我们由一个简单的问题逐步入手:有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了。
{
unsigned long seed = 0x00100001, index1 = 0, index2 = 0, i;
for( index1 = 0; index1 < 0x100; index1++ )
{
for( index2 = index1, i = 0; i < 5; i++, index2 += 0x100 )
{
unsigned long temp1, temp2;
seed = (seed * 125 + 3) % 0x2AAAAB;
temp1 = (seed & 0xFFFF) << 0x10;
seed = (seed * 125 + 3) % 0x2AAAAB;
temp2 = (seed & 0xFFFF);
cryptTable[index2] = ( temp1 | temp2 );
}
}
}
{
unsigned char *key = (unsigned char *)lpszFileName;
unsigned long seed1 = 0x7FED7FED;
unsigned long seed2 = 0xEEEEEEEE;
int ch;
while( *key != 0 )
{
ch = toupper(*key++);
seed1 = cryptTable[(dwHashType << 8) + ch] ^ (seed1 + seed2);
seed2 = ch + seed1 + seed2 + (seed2 << 5) + 3;
}
return seed1;
}
Blizzard的这个算法是非常高效的,被称为"One-Way Hash"( A one-way hash is a an algorithm that is constructed in such a way that deriving the original string (set of strings, actually) is virtually impossible)。举个例子,字符串"unitneutralacritter.grp"通过这个算法得到的结果是0xA26067F3。
{
int nHashA;
int nHashB;
char bExists;
......
} SOMESTRUCTRUE;
一种可能的结构体定义?
//lpszString要在Hash表中查找的字符串,lpTable为存储字符串Hash值的Hash表。
{
int nHash = HashString(lpszString); //调用上述函数二,返回要查找字符串lpszString的Hash值。
int nHashPos = nHash % nTableSize;
if ( lpTable[nHashPos].bExists && !strcmp( lpTable[nHashPos].pString, lpszString ) )
{ //如果找到的Hash值在表中存在,且要查找的字符串与表中对应位置的字符串相同,
return nHashPos; //则返回上述调用函数二后,找到的Hash值
}
else
{
return -1;
}
}
看到此,我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”,感谢大学里学的数据结构教会了这个百试百灵的法宝,我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。事情到此似乎有了完美的结局,如果是把问题独自交给我解决,此时我可能就要开始定义数据结构然后写代码了。
当然了,这样仍然会出现2个不同的文件名哈希到3个同样的哈希。但是这种情况发生的概率平均是:1:18889465931478580854784,这个概率对于任何人来说应该都是足够小的。现在再回到数据结构上,Blizzard使用的哈希表没有使用链表,而采用"顺延"的方式来解决问题,看看这个算法:
{
const int HASH_OFFSET = 0, HASH_A = 1, HASH_B = 2;
int nHash = HashString( lpszString, HASH_OFFSET );
int nHashA = HashString( lpszString, HASH_A );
int nHashB = HashString( lpszString, HASH_B );
int nHashStart = nHash % nTableSize;
int nHashPos = nHashStart;
while ( lpTable[nHashPos].bExists )
{
/*如果仅仅是判断在该表中时候存在这个字符串,就比较这两个hash值就可以了,不用对
*结构体中的字符串进行比较。这样会加快运行的速度?减少hash表占用的空间?这种
*方法一般应用在什么场合?*/
if ( lpTable[nHashPos].nHashA == nHashA
&& lpTable[nHashPos].nHashB == nHashB )
{
return nHashPos;
}
else
{
nHashPos = (nHashPos + 1) % nTableSize;
}
if (nHashPos == nHashStart)
break;
}
return -1;
}
2. 察看哈希表中的这个位置
3. 哈希表中这个位置为空吗?如果为空,则肯定该字符串不存在,返回-1。
4. 如果存在,则检查其他两个哈希值是否也匹配,如果匹配,则表示找到了该字符串,返回其Hash值。
5. 移到下一个位置,如果已经移到了表的末尾,则反绕到表的开始位置起继续查询
6. 看看是不是又回到了原来的位置,如果是,则返回没找到
7. 回到3
补充1、一个简单的hash函数:
*该函数得到的hash值分布比较均匀*/
unsigned long getHashIndex( const char *key, int nTableLength )
{
unsigned long nHash = 0;
while (*key)
{
nHash = (nHash<<5) + nHash + *key++;
}
return ( nHash % nTableLength );
}
哈希表的数组是定长的,如果太大,则浪费,如果太小,体现不出效率。合适的数组大小是哈希表的性能的关键。哈希表的尺寸最好是一个质数。当然,根据不同的数据量,会有不同的哈希表的大小。对于数据量时多时少的应用,最好的设计是使用动态可变尺寸的哈希表,那么如果你发现哈希表尺寸太小了,比如其中的元素是哈希表尺寸的2倍时,我们就需要扩大哈希表尺寸,一般是扩大一倍。
下面是哈希表尺寸大小的可能取值:
673, 1361, 2729, 5471, 10949,
21911, 43853, 87719, 175447, 350899,
701819, 1403641, 2807303, 5614657, 11229331,
22458671, 44917381, 89834777, 179669557, 359339171,
718678369, 1437356741, 2147483647
1、http://blog.redfox66.com/。
2、http://blog.csdn.net/wuliming_sc/。


发表评论

-
析构函数为虚函数的原因
2012-09-09 11:42 845我们知道,用C++开发的时候,用来做基类的类的析构函数 ... -
微软智力题
2012-08-29 19:59 575第一组1.烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有 ... -
C++不能被继承的类
2012-08-27 20:16 1065一个类不能被继承,� ... -
括号对齐问题
2012-08-27 10:47 1420解法一:左右括号成一对则抵消 可以 ... -
树的遍历
2012-08-19 10:43 729/****************************** ... -
堆排序
2012-08-16 14:24 890堆:(二叉)堆数据结构是一种数组对象。它可以被视为一棵完全 ... -
多态赋值
2012-08-14 16:16 839#include <iostream> usi ... -
static变量与static函数(转)
2012-08-13 10:15 751一、 static 变量 static变量大致分为三种用法 ... -
不用sizeof判断16位32位
2012-08-10 15:21 1714用C++写个程序,如何判断一个操作系统是16位还是3 ... -
找出连续最长的数字串(百度面试)
2012-08-09 15:15 1157int maxContinuNum(const char*in ... -
顺序栈和链栈
2012-08-06 10:01 811顺序栈:话不多说直接上代码 #include ... -
队列的数组实现和链表实现
2012-08-05 16:20 1034话不多少,数组实现上代码: #include<i ... -
KMP算法详解
2012-08-02 21:40 896KMP算法: 是在一个“主文本字符串” ... -
字符串的最长连续重复子串
2012-08-01 15:05 9792两种方法: 循环两次寻找最长的子串: <方法一> ... -
寻找一个字符串连续出现最多的子串的方法(转)
2012-07-31 21:19 1015算法描述首先获得后缀数组,然后1.第一行第一个字符a,与第二行 ... -
字符串的循环移位
2012-07-31 16:52 985假设字符串:abcdefg 左循环两位:cdefgab 右 ... -
一次谷歌面试趣事(转)
2012-07-31 15:26 777很多年前我进入硅谷� ... -
约瑟夫环问题(循环链表)
2012-07-30 21:31 1302题目描述:n只猴子要选大王,选举方法如下:所有猴子按 1, ... -
面试之单链表
2012-07-30 20:18 7321、编程实现一个单链表的建立/测长/打印。 ... -
多重继承内存地址问题
2012-07-30 15:55 732[cpp] view plaincopy ...
相关推荐
Hash表应用 (必做) (查找) [问题描述] 设计散列表实现身份证查找系统,对身份证号进行Hash。 [基本要求] (1) 设每个记录有下列数据项:身份证号码(虚构,位数和编码规则与真实一致即可)、姓名、地址; ...
MurmurHash算法由Austin Appleby创建于2008年,现已应用到Hadoop、libstdc 、nginx、libmemcached,Redis,Memcached,Cassandra,HBase,Lucene等开源系统。2011年Appleby被Google雇佣,随后Google推出其变种的...
标题中的"HASHIN.rar_ABAQUS_Hashin失效准则 abaqus_abaqus hashin_abaqus 三维Hashi"表明这是一个关于ABAQUS软件中应用Hashin失效准则进行三维分析的示例或教程。ABAQUS是一款广泛应用的有限元分析软件,尤其在结构...
Hashin失效准则是一种广泛应用的多向复合材料失效理论,由Shlomo Hashin于1962年提出,主要用于评估多向受力条件下复合材料的破坏可能性。本篇将深入探讨三维Hashin失效准则及其在复合材料失效模拟中的应用。 首先...
7. **应用范围**:3D Hashin准则广泛应用于航空航天、汽车和土木工程等领域中的复合材料结构设计,尤其是在需要预测复杂受力条件下材料性能的场合。 在提供的压缩包文件"3d.for"中,可能包含了用于进行3D Hashin...
##### 一致性Hash应用场景 - **分布式缓存**:如Memcached等,通过一致性Hash算法可以有效地解决数据分布问题。 - **负载均衡**:在多台服务器之间分发请求时,一致性Hash可以帮助实现请求到特定服务器的稳定映射。...
一致性hash应用于负载均衡算法,本实现由C++语言开发。 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1、平衡性(Balance)2、单调性(Monotonicity) 3、分散性(Spread)4、负载(Load)
Hashin破坏准则,由Shlomo Hashin于1962年提出,是一种广泛应用于复合材料的理论,它考虑了内部纤维断裂和基体开裂两种主要的破坏模式。这个准则基于能量原理,通过比较材料的内能与外加载荷导致的能量耗散来预测...
2. SHA(Secure Hash Algorithm)系列:包括SHA-1、SHA-256、SHA-512等,提供更高级别的安全性,广泛应用于数字签名和证书验证。 3. CRC(Cyclic Redundancy Check):主要用于检查数据传输或存储时的错误,不是...
通过阅读和理解这个文件,工程师们可以学习如何将Hashin失效准则应用到实际的工程计算中,从而更准确地模拟和预测复合材料结构的性能和寿命。 在实际应用中,Hashin失效准则与VUMAT的结合可以帮助解决许多关键问题...
在"HASH函数及其应用_朱全民.ppt"中,主要讨论了哈希函数的构造方法、冲突处理以及实际应用。 一、哈希函数构造方法 1. 直接取余法:这是最简单的哈希函数构造方式,通过将关键字k除以表长m取余数来确定哈希值。...
Hash算法在智能门锁中的应用.doc
hash_map
本文档介绍了几种常见的Hash算法及其应用场景。其中特别推荐了FNV1算法,该算法不仅计算效率高,而且具有良好的散列质量,非常适合在网络通信等场景中使用。对于不同的应用场景,可以根据实际需求选择合适的Hash算法...
在STM32F407上实现的哈希(Hash)算法是数字签名、数据完整性验证等安全应用中的关键组成部分。哈希算法能够将任意长度的输入数据转化为固定长度的输出,通常称为哈希值或消息摘要。 哈希算法的主要特性包括: 1. *...
本文将深入探讨Geohash的工作原理,如何在Java中实现以及在Android开发中的应用。 首先,我们来理解什么是Geohash。Geohash是由美国科学家Doug Lindsay在2008年提出的,基于分形几何和基数编码的一种地理位置编码...
在实际应用中,Hash值除了用于文件完整性验证,还常用于密码存储(尽管现代安全实践推荐使用更安全的密码哈希函数和加盐技术)、数字签名验证、数据索引等。这两个工具对于开发者、系统管理员和网络安全专业人士来说...
hash函数与消息认证讲义 包括 5.1 Hash函数概述 5.1.1 Hash函数定义 5.1.2 Hash函数的安全性 5.1.3 Hash函数的迭代构造法 5.2 Hash函数MD5 5.2.1 MD5算法 5.2.2 MD5的安全性 ...5.3 安全Hash算法SHA-1 ...5.5.3 应用
常见的哈希算法包括MD5(Message-Digest Algorithm 5)和SHA-1(Secure Hash Algorithm 1)。MD4是MD5的前身,虽然已知存在一些攻击方法,但在没有更好的替代方案之前,仍然被广泛使用。SHA-1虽然已被更安全的SHA-2...
在实际应用中,例如开发一个基于位置服务的Web应用,Node.js和ngeohash库可以协同工作,高效地处理地理位置数据。通过Geohash编码,可以快速查找附近的兴趣点、实现地图上的搜索过滤等功能,极大地优化了空间数据的...