dennis_zane
- 浏览: 950773 次
- 性别:

- 来自: 杭州
-

文章分类
最新评论
-
hw7777777:
非常感谢作者提供这么好的工具,在使用的过程中遇到一些问题?1、 ...
基于java nio的memcached客户端——xmemcached -
SINCE1978:
多久过去了时间能抹平一切
无路用的人 -
fangruanyjq:
[img][/img]引用
用osworkflow写一个请假例子(提供代码下载) -
thinkingmysky:
楼主,你确定,java memached client能处理并 ...
memcached java client性能测试的几点疑问和说明 -
hellostory:
aaa5131421 写道07年2月hibernate已经出来 ...
dozer与BeanUtils
今天有点空闲,想想用Ruby写个NFA试试。从正则表达式构造NFA采用经典的Thompson算法:正则表达式 -> 后缀表达式
->
构造NFA。构造了NFA后,用之匹配字符串。一句话,写了个玩具的正则表达式引擎,支持concatenation、alternation以及
*、?、+量词,不支持反向引用和转义符。测试了下与Ruby自带的正则表达式引擎的性能对比,慢了3倍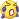 。构造NFA没什么问题,主要是匹配运行写的烂,有空再改改。
。构造NFA没什么问题,主要是匹配运行写的烂,有空再改改。
nfa.rb
module NFA
class NFA
def initialize(state)
@state=state
end
def step(clist,c)
return clist if clist.size==0;
nlist=[]
allNull = true
matched = false
clist.each do |t|
if !t.nil?
allNull = false if t.c!=-1
if t.c == c && t.end.type ==1 then
matched = true
nlist.push(t.end.out1) if !t.end.out1.end.nil?
nlist.push(t.end.out2) if !t.end.out2.end.nil?
elsif (t.c == c && t.end.type == 0) then
matched = true;
return ListUitls.new_list(t);
elsif (t.c == -1 && !t.end.nil?) then
nlist.push(t.end.out1);
nlist.push(t.end.out2);
end
end
end
return step(nlist, c) if (allNull)
return step(nlist, c) if (!matched)
nlist
end
def test?(s)
match(@state,s)
end
def match(state,s)
clist =[]
clist.push(state.out1);
clist.push(state.out2);
s.each_byte do |c|
c =c&0xFF;
clist = step(clist, c);
return false if clist.size==0
end
return is_match?(clist)
end
def is_match?(clist)
clist.each do |t|
return true if !t.nil? and t.c==-1 and t.end and t.end.is_matched?
end
false
end
end
class Paren
attr_accessor:n_alt,:n_atom
end
class State
attr_accessor :out1,:out2,:type
def initialize(out1,out2)
@out1=out1
@out2=out2
@type=1
end
def is_matched?
return @type==0
end
end
class Transition
attr_accessor :c,:end
def initialize(c)
@c=c
end
end
class Frame
attr_accessor :start,:outs
def initialize(start,outs)
@start=start
@outs=outs
end
end
class ListUitls
def self.link(list,state)
list.each{|t| t.end=state}
end
def self.append(list1,list2)
list1+list2
end
def self.new_list(out)
result=[]
result.push(out)
result
end
end
def self.compile(re)
post = re2post(re)
raise ArgumentError.new,"bad regexp!" if post.nil?
state = post2nfa(post);
raise RuntimeError.new,"construct nfa from postfix fail!" if state.nil?
return NFA.new(state);
end
def self.post2nfa(postfix)
stack=[]
s=nil
t=t1=t2=nil
e1=e2=e=nil
return nil if postfix.nil?
postfix.each_byte do |p|
case p.chr
when '.':
e2 = stack.pop()
e1 = stack.pop()
ListUitls.link(e1.outs, e2.start)
stack.push(Frame.new(e1.start, e2.outs))
when '|':
e2 = stack.pop()
e1 = stack.pop()
t1 = Transition.new(-1)
t2 = Transition.new(-1)
t1.end = e1.start
t2.end = e2.start
s = State.new(t1, t2)
stack.push(Frame.new(s, ListUitls.append(e1.outs, e2.outs)))
when '?':
e = stack.pop()
t1 = Transition.new(-1)
t2 = Transition.new(-1)
t1.end = e.start
s = State.new(t1, t2)
stack.push(Frame.new(s, ListUitls.append(e.outs, ListUitls.new_list(t2))))
when '*':
e = stack.pop()
t1 = Transition.new(-1)
t2 = Transition.new(-1)
t1.end = e.start
s = State.new(t1, t2)
ListUitls.link(e.outs, s)
stack.push(Frame.new(s, ListUitls.new_list(s.out2)))
when '+':
e = stack.pop()
t1 = Transition.new(-1)
t2 = Transition.new(-1)
t1.end = e.start
s = State.new(t1, t2)
ListUitls.link(e.outs, s)
stack.push(Frame.new(e.start, ListUitls.new_list(t2)))
else
t = Transition.new(p)
s = State.new(t, Transition.new(-1))
stack.push(Frame.new(s, ListUitls.new_list(s.out1)))
end
end
e = stack.pop()
return nil if stack.size()>0
end_state = State.new(nil, nil)
end_state.type=0
e.outs.each do |tran|
if tran.c!=-1
t1 = Transition.new(-1)
t2 = Transition.new(-1)
s=State.new(t1,t2)
tran.end=s
s.out1.end=end_state
s.out2.end=end_state
else
tran.end=end_state
end
end
start = e.start
return start
end
def self.re2post(re)
n_alt = n_atom = 0
result=""
paren=[]
re.each_byte do |c|
case c.chr
when '(' then
if (n_atom > 1) then
n_atom-=1
result<<"."
end
p =Paren.new
p.n_alt = n_alt
p.n_atom = n_atom
paren.push(p)
n_alt = n_atom = 0
when '|' then
if (n_atom == 0)
return nil
end
while (n_atom-=1) > 0
result<<"."
end
n_alt+=1
when ')' then
if (paren.size() == 0)
return nil
end
if (n_atom == 0)
return nil
end
while (n_atom-=1)>0
result<<"."
end
while(n_alt>0)
result<<"|"
n_alt-=1
end
p = paren.pop()
n_alt = p.n_alt
n_atom = p.n_atom
n_atom+=1
when '*','+','?':
if (n_atom == 0)
return nil
end
result<<c
else
if (n_atom > 1)
n_atom-=1
result<<"."
end
result<<c
n_atom+=1
end
end
return nil if paren.size()>0
while ( (n_atom-=1)> 0)
result<<"."
end
while(n_alt>0)
n_alt-=1
result<<"|"
end
result
end
end
使用的话:
nfa = NFA::compile("a(bb)+a(cdf)*")
assert nfa.test?("abba")
assert nfa.test?("abbbba")
assert !nfa.test?("a")
assert !nfa.test?("aa")
assert nfa.test?("abbacdf")
assert nfa.test?("abbbbacdfcdf")
assert !nfa.test?("bbbbacdfcdf")
assert !nfa.test?("abbbacdfcdf")
assert !nfa.test?("abbbbacdfdf")
assert !nfa.test?("abbbbacdfdfg")
6
顶
顶
2
踩
踩
分享到:


发表评论

-
使用Ruby amb解决说谎者谜题
2008-11-15 18:50 1629说谎者谜题是sicp4.3.2小节的一道题目,题目本身 ... -
swfheader 0.10 Released
2008-10-11 23:41 1541swfheader是一个处理swf文件的工具脚本,可用 ... -
Ruby 1.9概要(1)新的语法和语义
2008-10-01 13:37 1846一、新的语法和语义 1、新的Hash定义语法: 例如{a:2 ... -
Ruby 1.9概要(2)Kernel和Object
2008-10-01 13:48 1428二、Kernel 和 Object 1、引 ... -
Ruby 1.9概要(3)类和模块
2008-10-01 13:52 1428三、类和模块 1、Module#instance_method ... -
Ruby 1.9概要(4) Block和Proc
2008-10-02 13:54 13741、Proc加了新方法Proc#yield ,这只是Proc# ... -
Ruby 1.9概要(5) 异常
2008-10-03 13:26 13511、异常的相等性 ,如果两个异常的class、message和 ... -
Ruby Tip——读文件
2008-10-07 09:38 1875Ruby如何简洁地读整个文件,你可以这样做: f = Fil ... -
Ruby写Servlet的小例子
2008-07-23 12:05 2425Ruby也能写servlet?是的,没开玩笑,而且挺 ... -
JRuby中调用java带可变参数的方法
2008-06-14 22:41 1309今天同事遇到的问题,用JRuby调用一个java方 ... -
Ruby中实现stream
2008-05-08 22:36 1350流是通过延时求值实现的,Ruby中实现stream也 ... -
lua 5.0的实现(翻译)1,2,3部分
2008-04-07 17:28 4009三个多月前翻译的,今天又找出来看看,后面的整理再发。 原文: ... -
Ruby代码调整性能优化的几个Tip
2008-03-27 09:49 2221数据都是在我的 ... -
使用JProfiler监控JRuby脚本的运行
2008-03-24 15:32 1620jruby本质上也是启动一个jvm,然后去读Ru ... -
发布swf-util 0.01
2008-03-11 14:49 1857swf-util是一个使用Ruby读取swf头信息(高度、宽度 ... -
Ruby小技巧:处理方法调用中的nil
2008-02-19 13:41 3781读blog看到的一个小技巧,原文在这里。 我们 ... -
expectations——轻量级的单元测试框架
2008-02-16 10:05 1750项目主页:http://expectations.rubyfo ... -
JRuby中使用接口和抽象类
2008-02-15 14:36 1730要在JRuby中实现java接口,接口include进 ... -
google translator 0.2
2008-02-14 11:17 1925过去写的那个利用google在线翻译的小脚本工具一 直 ... -
JRuby的性能优化
2008-01-31 19:02 1762越来越觉的JRuby是个很有前途的项目,结合Ruby的 ...
相关推荐
"Rocklov-180:自动机Ruby 180" 是一个可能的项目或工具,专注于使用Ruby编程语言实现自动机的相关功能。在IT领域,自动机通常指的是计算理论中的自动化结构,如有限状态自动机(Finite State Machines, FSMs)、...
用js实现的简易语言介绍该仓库为《计算的本质》一书的学习笔记,并用JS(书籍为Ruby)实现了书籍的代码部分。学习笔记小步语义设计一个抽象机器维护一些执行状态,然后定义一些规则约规则,这些规则详细说明了如何对...
- NFA则是通过正则表达式来匹配文本串,它会尝试多个路径直到找到匹配的结果。 - NFA的缺点是速度相对较慢,因为它需要反复尝试不同的匹配路径;优点是可以提供更多的功能和灵活性。 这两种算法的不同之处体现在...
5. **文本处理(Text Processing)**:这个项目将涉及大量的文本处理任务,包括分割字符串、去除标点符号、大小写转换等,以确保有效识别地址。 6. **数据结构(Data Structures)**:为了存储和操作提取的地址,...
正则表达式是一种强大的文本匹配工具,它通过一系列特殊字符的组合来构建表达式,用以描述和匹配特定的字符串模式。正则表达式的强大之处在于它几乎可以匹配任何形式的文本,从简单的字母数字组合到复杂的字符串结构...
如果您看一些用正则表达式(Perl,Ruby等)内置支持的语言编写的源代码,您可能还会发现其他残酷的用法。 问题在于正则表达式使编写生成大量代码且速度慢的表达式变得非常容易(请参见理论背景信息)。 这种方法使...
忽略大小写... 14 单词分界符... 15 小结... 16 可选项元素... 17 其他量词:重复出现... 18 括号及反向引用... 20 神奇的转义... 22 基础知识拓展... 23 语言的差异... 23 正则表达式的目标... 23 更多...
接着,作者介绍了几种不同类型的计算模型,如确定性有限自动机(DFA)、非确定性有限自动机(NFA)、正则表达式,以及它们的等价性。然后是下推自动机(DPDA和NPDA),这些模型进一步增加了计算能力,特别是在分析...