单台App Server再强劲,也有其瓶劲,先来看一下下面这个真实的场景。

当时这个工程是这样的,tomcat这一段被称为web zone,里面用spring+ws,还装了一个jboss的规则引擎Guvnor5.x,全部是ws没有service layer也没有dao layer。
然后App Zone这边是weblogic,传输用的是spring rmi,然后App Zone这块全部是service layer, dao layer和数据库打交道。
用户这边用的是.net,以ws和web zone连的。
时间一长,数据一多,就出问题了。
拿Loader Runner跑下来,发觉是Web Zone这块,App Server已经被用到极限了。因为客户钱不多,所以当时的Web Zone是2台服务器,且都是32位的,内存不少,有8GB,测试下来后发觉cpu loader又不高,但是web server这边的吞吐量始终上不去,且和.net客户端那边响应越来越慢。
分析了一下原因:单台tomcat能够承受的最大负载已经到头了,单台tomcat的吞吐量就这么点,还要负担Guvnor的运行,Guvnor内有数百条业务规则要执行。
再看了一下其它方面的代码、SQL调优都已经到了极限了,所以最后没办法,客户又不肯拿钱投在内存和新机器上或者是再买台Weblogic,只能取舍一下,搞Tomcat集群了。

Tomcat作集群的逻辑架构是上面这样的一张图,关键是我们的production环境还需要规划好我们的物理架构。
比如说,有两台Tomcat,分别运行在2台物理机上,好处是最大的即CPU扩展,内存也扩展了,处理能力也扩展了。

即,两个Tomcat的实例运行在一台物理器上,充分利用原有内存,CPU未得到扩展。

2.3
横向还是纵向
一般来说,广为人们接受的是横向扩展的集群,可做大规模集群布署。但是我们这个case受制于客户即:
ü 不会再投入新机器了
ü 不会增加内存了
但是呢,通过压力测试报告我们可知:
ü 原有TomcatServer的CPU Loader不高,在23%左右
ü 原有TomcatServer上有8GB内存,而且是32位的,单台Tomcat只使用了1800MB左右的内存
ü 网络流量不高,单块千兆以太网卡完全可以处理掉
因此,我们只能做熊掌与鱼不能兼得的事,即采用了:纵向集群。
ü Load Balance
简称LB即负载均衡,相当于1000根线程每个集群节点:Node负责处理500个,这样的效率是最高的。
ü High Available
简称HA即高可用性,相当于1000根线程还是交给一台机器去慢慢处理,如果这台机器崩了,另一台机器顶上。
集群规划好了怎么分,这不等于就可以开始实现集群了,一旦你的系统实现了集群,随之而来的问题就会出现了。
我们原有系统中有这样几个问题,在集群环境中是需要解决的,来看:
3.1
解决上传文件同步的问题
集群后就是两个Tomcat了,即和两个线程读同一个resource的问题是一样的,还好,我们原有上传文件是专门有一台文件伺服器的,这个问题不大,两个tomcat都往一台file server里上传,文件伺服器已经帮我们解决了同名文件冲突的这个问题了
,如果原先的做法是把文件上传到Tomcat的目录中,那问题就大了,来看:
集群环境中,对于用户来说一切操作都是透明的,他也不知道我有几个Tomcat的实例运行在那边。
用户一点上传,可能上传到了Tomcat2中,但是下次要显示这个文件时,可能用到的是Tomcat1内的jsp或者是class,对不对?
于是,因为你把图片存在了Tomcat的目录中,因此导致了Tomcat1在显示图片时,取不到Tomcat2目录中存放的图片。
因此我们在工程一开始就强调存图片时要用一台专门的文件服务器或者是FTP服务器来存,就是为了避免将来出现这样的问题。
3.2
解决Quartz在集群环境中的同步问题
我们的系统用到一个Quartz(一个定时服务组件)来定时触发一些自动机制,现在有了两个Tomcat,粗想想每个Tomcat里运行自己的Quartz不就行了?
但是问题来了,如果两个Quartz在同一时间都触发了处理同一条定单,即该条定单会被处理两边。。。这不是影响效率和增加出错机率了吗?
因为本身Quartz所承受的压力几乎可以忽略不计的,它只是定时会触发脚本去运行,关键在于这个定时脚本的同步性,一致性的问题上。
我们曾想过的解决方法:
我们可以让一个Tomcat布署Quartz,另一个Tomcat里不布署Quartz
但这样做的结果就是如果布署Quartz的这个Tomcat崩溃掉了,这个Quartz是不是也崩啦?
最后解决的办法:
所以我们还是必须在两台Tomcat里布署Quartz,然后使用HA的原则,即一个Quartz在运行时,另一台Quartz在监视着,并且不断的和另一个Quartz之间保持勾通,一旦运行着的Quartz崩掉了,另一个Quartz在指定的秒数内起来接替原有的Quartz继续运行,对于Quartz,我们同样也是面临着一个熊掌与鱼不能皆得的问题了,Quartz本身是支持集群的,而它支持的集群方式正是HA,和我们想的是一致的。
具体Quartz是如何在集群环境下作布署的,请见我的另一篇文章:quartz在集群环境下的最终解决方案
解决了上述的问题后基本我们可以开始布署Tomcat这个集群了。
准备两个版本一致的Tomcat,分别起名为tomcat1,tomcat2。
² worker.properties文件内容的修改
打开Apache HttpServer中的apache安装目录/conf/work.properties文件,大家还记得这个文件吗?
这是原有文件内容:
|
workers.tomcat_home=d:/tomcat2
workers.java_home=C:/jdk1.6.32
ps=/
worker.list=ajp13
worker.ajp13.port=8009
worker.ajp13.host=localhost
worker.ajp13.type=ajp13
|
现在开始改动成下面这样的内容(把原有的
worker.properties
中的内容前面都加上
#
注释掉
):
|
#workers.tomcat_home=d:/tomcat2
#workers.java_home=C:/jdk1.6.32
#ps=/
#worker.list=ajp13
#worker.ajp13.port=8009
#worker.ajp13.host=localhost
#worker.ajp13.type=ajp13
worker.list = controller
#tomcat1
worker.tomcat1.port=8009
worker.tomcat1.host=localhost
worker.tomcat1.type=ajp13
worker.tomcat1.lbfactor=1
#tomcat2
worker.tomcat2.port=9009
worker.tomcat2.host=localhost
worker.tomcat2.type=ajp13
worker.tomcat2.lbfactor=1
#========controller========
worker.controller.type=lb
worker.controller.balance_workers=tomcat1,tomcat2
worker.lbcontroller.sticky_session=0
worker.controller.sticky_session_force=true
worker.connection_pool_size=3000
worker.connection_pool_minsize=50
worker.connection_pool_timeout=50000
|
上面的这些设置的意思用中文来表达就是:
ü 两个tomcat,都位于localhost
ü 两个tomcat,tomcat1用8009,tomcat2用9009与apache保持jk_mod的通讯
ü 不采用sticky_session的机制
sticky_session即:假设现在用户正连着tomcat1,而tomcat1崩了,那么此时它的session应该被复制到tomcat2上,由tomcat2继续负责该用户的操作,这就是load balance,此时这个用户因该可以继续操作。
如果你的sticky_session设成了1,那么当你连的这台tomcat崩了后,你的操作因为是sticky(粘)住被指定的集群节点的,因此你的session是不会被复制和同步到另一个还存活着的tomcat节点上的。
ü 两台tomcat被分派到的任务的权重(lbfactor)为一致
你也可以设tomcat1 的worker.tomcat2.lbfactor=10,而tomcat2的worker.tomcat2.lbfactor=2,这个值越高,该tomcat节点被分派到的任务数就越多
² httpd.conf文件内容的修改
找到下面这一行:
|
Include conf/extra/httpd-ssl.conf
|
我们将它注释掉,因为我们在集群环境中不打算采用https,如果采用是https也一样,只是为了减省开销(很多人都是用自己的开发电脑在做实验哦
)。
|
#Include conf/extra/httpd-ssl.conf
|
找到原来的“<VirtualHost>”段
改成如下形式:
|
<VirtualHost *>
DocumentRoot d:/www
<Directory "d:/www/cbbs">
AllowOverride None
Order allow,deny
Allow from all
</Directory>
<Directory "d:/www/cbbs/WEB-INF">
Order deny,allow
Deny from all
</Directory>
ServerAdmin localhost
DocumentRoot d:/www/
ServerName shnlap93:80
DirectoryIndex index.html index.htm index.jsp index.action
ErrorLog logs/shsc-error_log.txt
CustomLog logs/shsc-access_log.txt common
JkMount /*WEB-INF controller
JkMount /*j_spring_security_check controller
JkMount /*.action controller
JkMount /servlet/* controller
JkMount /*.jsp controller
JkMount /*.do controller
JkMount /*.action controller
JkMount /*fckeditor/editor/filemanager/connectors/*.* controller
JkMount /fckeditor/editor/filemanager/connectors/* controller
</VirtualHost>
|
注意:
原来的JKMount *** 后的 ajp13变成了什么了?
controller
可以拿原有的tomcat复制成另一个tomcat,分别为d:\tomcat, d:\tomcat2。
打开tomcat中的conf目录中的server.xml,找到下面这行
1)
|
<Server port="8005" shutdown="SHUTDOWN">
|
记得:
一定要把
tomcat2
中的这边的
”SHUTDOWN”
的
port
改成另一个端口号,两个
tomcat
如果是在集群环境中,此处的端口号绝不能一样。
2)找到
|
<Connector port="8080" protocol="HTTP/1.1"
|
确保tomcat2中此处的端口不能为8080,我们就使用9090这个端口吧
3)把两个tomcat中原有的https的配置,整段去除
4)找到
|
<Connector port="8080" protocol="HTTP/1.1"
URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000"
acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5"
useURIValidationHack="false"
compression="on" compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain"
redirectPort="8443" />
|
确保tomcat2中这边的redirectPort为9443
5)找到
|
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443"
|
改为:
|
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443"
URIEncoding="UTF-8" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" disableUploadTimeout="true" connectionTimeout="20000"
acceptCount="300" maxThreads="300" maxProcessors="1000" minProcessors="5"
useURIValidationHack="false"
compression="on" compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain"
/>
|
确保
tomcat2
的
server.xml
中此处的
8009
被改成了
9009
且其它内容与上述内容一致(redirectPort
不要忘了改成
9443
)
6)找到
|
<Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1">
|
改成
|
<!-- You should set jvmRoute to support load-balancing via AJP ie :
<Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1">
-->
<Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat1
">
|
同时把tomcat2中此处内容改成
|
<!-- You should set jvmRoute to support load-balancing via AJP ie :
<Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm1">
-->
<Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat2
">
|
7)
在刚才的
|
<Engine name="Standalone" defaultHost="localhost" jvmRoute="tomcat1
">
|
的下面与在
|
<!-- The request dumper valve dumps useful debugging information about
the request and response data received and sent by Tomcat.
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.valves.RequestDumperValve"/>
-->
|
之上,在这之间加入如下一大陀的东西:
|
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"
channelSendOptions="6">
<Manager className="org.apache.catalina.ha.session.BackupManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"
mapSendOptions="6"/>
<Channel className="org.apache.catalina.tribes.group.GroupChannel">
<Membership className="org.apache.catalina.tribes.membership.McastService"
bind="127.0.0.1"
address="228.0.0.4"
port="45564"
frequency="500"
dropTime="3000"/>
<Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver"
address="auto"
port="4001"
selectorTimeout="100"
maxThreads="6"/>
<Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter">
<Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender" timeout="60000"/>
</Sender>
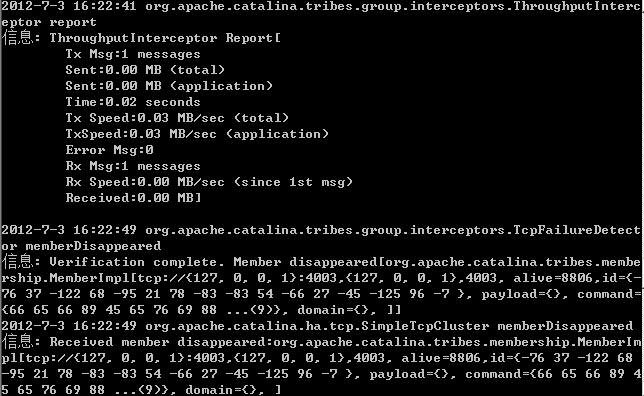
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.ThroughputInterceptor"/>
</Channel>
<Valve className="org.apache.catalina.ha.tcp.ReplicationValve"
filter=".*\.gif;.*\.js;.*\.jpg;.*\.png;.*\.htm;.*\.html;.*\.css;.*\.txt;"/>
<ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/>
</Cluster>
|
此处有一个Receiver port=”xxxx”,两个tomcat中此处的端口号必须唯一,即tomcat中我们使用的是port=4001,那么我们在tomcat2中将使用port=4002
8)把系统环境变更中的CATALINA_HOME与TOMCAT_HOME这两个变量去除掉
9)在每个tomcat的webapps目录下布署同样的一个工程,在布署工程前先确保你把工程中的WEB-INF\we b.xml文件做了如下的修改,在web.xml文件的最未尾即“</web-app>”这一行前加入如下的一行:
使该工程中的session可以被tomcat的集群节点进行轮循复制。
好了,现在启动tomcat1, 启动tomcat2(其实无所谓顺序的),来看效果:
分别访问http://localhost:8080/cbbs
与http://localhost:9090/cbbs
确保两个tomcat节点都起来了,然后此时,我们启动Apache
然后访问直接用http://localhost/cbbs
不加端口的形式访问:
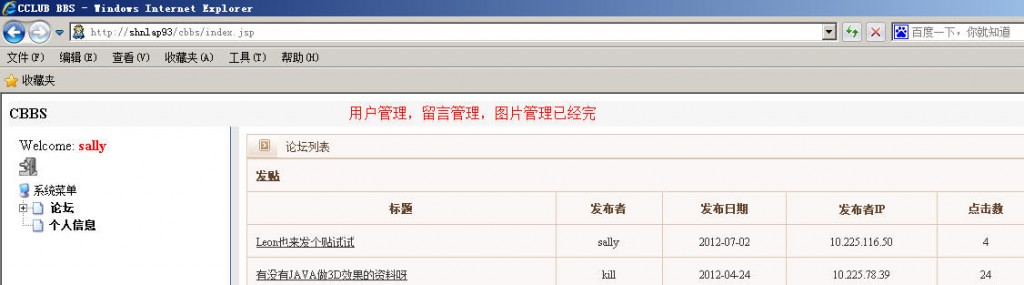
用sally/abcdefg登录,瞧,应用起来了。
然后我们拿另一台物理客户端,登录这个web应用,我们可以看到:
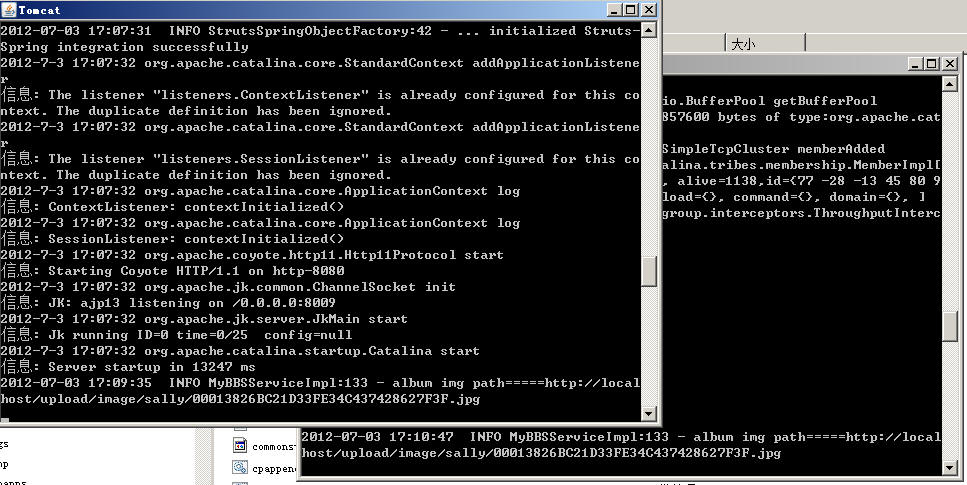
第一个tomcat正在负责处理我们第一次登录的请求。
当有第二个HTTP请求时,另一个tomcat自动开始肩负起我们第二个HTTP请求了,这就是Load Balance。
分享到:




相关推荐
【计算机求职笔试】资源
# 基于Apache Spark Mllib的Bronze机器学习平台 ## 项目简介 Bronze是一个构建在Apache Spark Mllib之上的机器学习平台,旨在提供全面的数据接入、转换、训练、测试和输出功能。该平台支持多种机器学习算法模型,并提供丰富的插件来处理数据预处理、特征工程、模型训练和验证等任务。 ## 项目的主要特性和功能 ### 数据处理流程 1. 数据采集从各种数据源(如Fake、File、HDFS)接入数据。 2. 数据预处理对数据进行清洗、转换和格式化。 3. 特征工程生成和选择特征,包括特征提取、转换和选择。 4. 模型训练使用多种分类和回归模型进行训练。 5. 模型验证对训练好的模型进行验证和评估。 6. 模型持久化将训练好的模型保存到持久化存储中。 7. 模型结果输出输出模型的最终结果。 ### 支持的算法模型 #### 分类模型 逻辑回归支持大规模特征和无限训练样例,输出类别数小于1000万。
Java项目基于Springboot框架的课程设计,包含LW+ppt
资源内项目源码是均来自个人的课程设计、毕业设计或者具体项目,代码都测试ok,都是运行成功后才上传资源,答辩评审绝对信服的,拿来就能用。放心下载使用!源码、数据集、部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.dataset.txt文件,仅供学习参考, 切勿用于商业用途。 4、如有侵权请私信博主,感谢支持
内容概要:本文详细探讨了全球定位系统(GPS)的信号产生、捕获和追踪三个核心步骤,并通过Matlab源码实现相关算法。首先介绍了GPS信号产生的关键要素,包括伪随机码生成、数据编码和信号发射。接着讨论了信号捕获过程,涉及天线接收、码相位测量及其常用方法如滑动相关法。最后阐述了信号追踪的三边测量原理及误差修正措施,如电离层延迟补偿、地形效应补偿和多路径效应修正。通过具体Matlab代码示例展示了整个流程的实现,并附带了详细的运行步骤和结果分析。 适合人群:对GPS系统有兴趣的研究人员和技术爱好者,尤其是有一定编程基础并希望深入了解GPS内部机制的人群。 使用场景及目标:适用于学术研究、工程开发等领域,旨在帮助读者掌握GPS信号处理的基本理论和实践技能,提升定位精度和可靠性。 其他说明:文中提供的Matlab代码已在特定版本下测试通过,但不同版本可能存在差异。此外,还列举了一些参考文献供进一步学习。
基于Andorid条形二维码识别设计实现源码,主要针对计算机相关专业的正在做毕设的学生和需要项目实战练习的学习者,也可作为课程设计、期末大作业。
NRF24L01收发例程
AcWing算法基础课Notion笔记html页面
[Excel在财务管理中的应用(第六版)(微课版)]配书资源
# 基于多线程的Web客户端程序 ## 项目简介 本项目是一个基于多线程的Web客户端程序,旨在并发地从Web服务器获取多个文件。通过使用多线程技术,程序能够高效地处理多个文件请求,提高整体性能。 ## 项目的主要特性和功能 多线程并发请求支持同时从多个Web服务器获取文件,提高请求效率。 TCP连接管理每个线程负责建立TCP连接并发送HTTP GET请求。 线程同步与通信使用互斥锁和条件变量确保线程间的同步和数据一致性。 命令行参数解析支持解析命令行参数,获取连接的最大数量和要获取的文件列表。 文件处理每个线程负责读取服务器的响应并处理文件内容。 ## 安装使用步骤 1. 下载源码假设用户已经下载了本项目的源码文件。 2. 编译项目使用合适的编译器(如GCC)编译项目源码。 bash gcc o webclient main.c lpthread
中学学生“诚信”教育班会课件
1、文件说明: Centos8操作系统tacacs-devel-F4.0.4.28.7fb~20231005g4fdf178-2.el8.rpm以及相关依赖,全打包为一个tar.gz压缩包 2、安装指令: #Step1、解压 tar -zxvf tacacs-devel-F4.0.4.28.7fb~20231005g4fdf178-2.el8.tar.gz #Step2、进入解压后的目录,执行安装 sudo rpm -ivh *.rpm
内容概要:本文详细介绍了如何利用LabVIEW通过网口与西门子PLC进行高效通讯的方法和技术细节。首先解释了西门子S7Comm协议的三层结构(TPKT+COTP+S7),并通过具体实例展示了如何构造和发送十六进制命令帧。接着提供了完整的LabVIEW代码片段,涵盖从TCP连接建立、命令帧发送、响应接收及数据解析的全过程。文中还分享了多种实用技巧,如批量读写、强制写入、自动重连机制等,并对比了原生TCP与OPC UA的性能差异。最后,通过实际案例验证了该方案在工业应用中的优越性和稳定性。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是熟悉LabVIEW和西门子PLC的用户。 使用场景及目标:适用于需要与西门子PLC进行高效、稳定的网口通讯的应用场景,旨在提高通讯效率、降低系统复杂度和成本。 其他说明:文中提供的代码和技巧可以帮助开发者更好地理解和掌握LabVIEW与西门子PLC之间的通讯机制,从而应用于各种工业控制系统中。
matlab
内容概要:本文详细介绍了基于CH579芯片的以太网转串口服务器的实现过程。首先,文章讲解了硬件配置,包括使用的芯片及其特性,如CH579M、PHY芯片HR911105A和电平转换电路SGM48017。接着,重点剖析了网络初始化代码,强调了PHY复位时序、MAC地址传递和硬件协议栈处理ARP和ICMP协议的重要性。随后,文章深入探讨了串口数据处理,展示了环形缓冲区的实现和中断服务函数的优化。此外,还介绍了协议转换的状态机实现,以及内存池分配的精妙之处。最后,文章总结了资源管理策略,如DMA自动搬运数据、中断嵌套机制和零拷贝技术,使得服务器能够实现稳定的3Mbps转发速率。 适合人群:具有一定嵌入式开发经验的研发人员,尤其是对以太网转串口服务器感兴趣的工程师。 使用场景及目标:适用于需要深入了解嵌入式系统中以太网转串口服务器的工作原理和技术实现的人群。目标是掌握CH579芯片的硬件配置、网络初始化、串口数据处理、协议转换和资源管理等方面的知识。 其他说明:文中提供了详细的代码示例和硬件设计要点,帮助读者更好地理解和应用相关技术。建议读者结合实际项目进行实践,逐步掌握核心技术。
Java项目基于Springboot框架的课程设计,包含LW+ppt
Java项目基于Springboot框架的课程设计,包含LW+ppt
2025清华大学:迈向未来的AI教学实验-393页.pdf
亲子教育“正面管教”教案课件
全遥控数字音量控制的D类功率放大器