一、简介:
索引是一种特殊类型的数据库对象,它在数据库中的作用就像目录在书籍中的作用。为表增加索引,可以大大提高数据的检索效率。
二、导图
索引的导图如下:
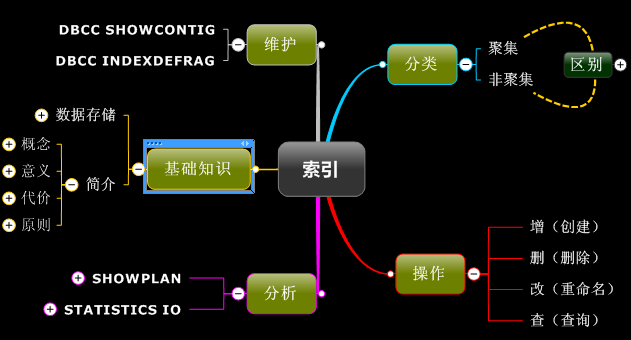
三、详介
1.基础知识
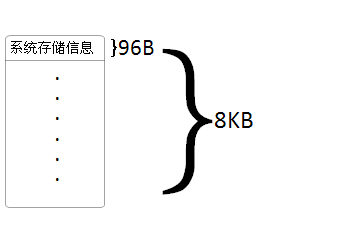
1)数据存储
说索引之间先来概述一下数据存储,存储的基本单位是页。每页开始部分是96B的页首,用于存储系统信息,如页的类型、页的可用空间量、拥有页的对象ID等。如下图所示
2)索引的概念
索引的基本结构就是以为单位构成的B树组织。索引内的每一页包含一个页首,页首后面跟着索引行。第个索引行都包含一个键值以及一个指向较低级页或数据行的指针。索引的每个页称为索引结点。B树的项端结点称为根结点,索引的底层结点称为叶结点,根与叶之间的任何索引级统称为中间级。
3)索引意义
索引是一个表中所包含值的列表,其中注明了表中包含各个值的行所在的存储位置,使用索引查找数据时,先从索引对象中获得相关列的存储位置,然后再直接去存储位置查找所需要信息,这样就无需对整个表进行扫描,从而可以快速找到所需数据
4)使用代价
万事皆有利弊,索引也不例外。使用索引可以的提高系统的性能,大大加快数据检索的速度,但却要付出一定的代价。
- 索引需要占用数据表以外的物理存储空间
- 创建索引和维护索引要花费一定的时间
- 当对表进行更新操作时,索引需要被重建,这样就降低了数据的维护速度。
5)建立原则
做事讲究度,把握好了度就能事半功倍。索引的建立也逃不出此原则。可概括为“一要两不要、一可一最好”
- 一要:主键列上一定要建立索引
-
两不要:查询中很少涉及的列、重复值比较多的列不要建立索引,定义为text、image和bit数据类型的列不要建立索引
- 一可:外键列可以建立索引
- 一最好:在经常查询的字段上最好建立索引
2.索引的分类
索引分为聚集索引和非聚集索引。为了便为理解,先来举一下例子。
汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“江”字,我们可以看到在查部首之后的检字表中“江”的页码是624页,检字表中“江”的上面是“污”字,但页码却是1326页,“江”的下面是“汛”字,页面是1436页。很显然,这些字并不是真正的分别位于“江”字的上下方,现在您看到的连续的“污、江、汛”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。
差别:
现在对索引有了个大概认识了吧。进一步引申一下,我们可以很容易的理解,每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序,非聚焦索引可以有多个。
下面引入专业术语表达的差别:
- 非聚集索引的数据行不按索引键的顺序排序和存储
- 非聚集索引的叶层不包含数据页
比较:
再来谈一个二者的性能比较
当进行单行查找时,聚焦索引的输入/输出速度比非聚焦索引快因为聚集索引的索引级别较小。聚集索引非常适合于范围查询,因为服务器可以缩小数据范围,先得到第一行,再进行扫描,无需要再次使用索引djd聚集索引速度稍慢,占用空间大,但也是一种较好的表扫描方法。非聚集索引可能覆盖了查询的全部过程。也就是说,假如所需数据在索引中,服务服就不必再到数据行中。
3.索引的操作(SQL语句)
1)创建索引(CREATE INDEX)
语法:
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED] INDEX索引名 ON {表名|视图名} {列名 [ASC|DESC][,...n]}
[WITH…………]
[ON filegroup]
说明:
-
[UNIQUE][CLUSTERED|NONCLUSTERED]用来指定创建索引的类型,依次为唯一索引、聚焦索引和非聚集索引。当省略UNIQUE时,建立的是非唯一索引,省略[CLUSTERED|NONCLUSTERED]选项时,建立的是非聚集索引。
-
ASC|DESC用来指定索引列的排序方式,ASC是升序,DESC是降序。如果省略则默认按升序排序。
-
ON filegroupet用来在给定的filegroup上创建指定的索引。该文件组必须已经通过执行CREATE DATABASE或ALTER DATABASE创建。
举例:
为tjgaoban数据库中的“九期”表创建基于“专业”列的非聚焦索引
USE tigaoban
GO
CREATE INDEX jq_zy_index on九期(专业)
GO
2)删除索引(DROP INDEX)
语法:
DROP INDEX表名.索引名[,...n]
说明:
-
在系统表的索引上不能指定DROPINDEX
-
若要除去为实现PRIMARYKEY或UNIQUE约束而创建的索引,必须除去约束。
- 在删除聚集索引时,表中的所有非聚集索引都将被重建
举例:
删除tigaoban数据库中“九期”表的“jq_学生”索引
USE tigaoban
GO
DROP INDEX 九期.jq_学生
GO
3)重命名索引(sp_rename)
语法:
EXEC sp_rename[@objname=]'object_name',[@newname:]'new_name'[,[@objtype:]'object_type']
说明:
-
object_name是需要更改的对象原名。如果要重命名的对象是表中的一列,那么object_name必须为table.column形式。如果命名是的索引,那么object_name必须为table.index形式。
-
new_name是对象更改后的名称。
-
object_type是对象类型
举例:
将tjgaoban数据库中的“九期”表的jq_zy_index索引名称更改为jq_zyindex
USE tigaoban
GO
EXEC sp_rename 'dbo.九期.jq_zy_index','js_zyindex'
GO
4)查询索引信息
可通过sp_helpindex或sp_help查看数据表的索引信息,sp_helpindex只能显示表的索引信息,sp_help除了显示索引信息外,还有表的定义、约束竺其他信息。两者的语法格式基本相同,下面以sp_helpindex为例说明。
说法:
{EXEC}sp_helpindex [@objname=]name
说明:
-
[@objname=]name是当前数据库中表或视图的名称
举例:
查看tigaoban数据库中"九期"表的索引信息
USE tigaoban
GO
EXEC sp_helpindex 九期
GO
4索引的分析与维护
索引创建之后,由于数据的增加、删除和修改等操作会使索引页产生碎片,因此必须对索引进行分析与维护
1)索引的分析
常用的分析语句有SHOWPLANT和STATISTICS IO
i.SHOWPLAN语句
SHOWPLAN语句用来显示查询语句的信息,包含查询过程中连接表时所采取的每个步骤以及选择了哪个索引。
语法:
SET SHOWPLAN_ALL {ON|OFF}和SETSHOWPLAN_TEXT {ON|OFF}
说明:
-
ON为显示查询执行信息
-
OFF为不显示查询执行信息(系统默认)
举例:
在tigaoban数据库中的“九期”表上查询所有男生的姓名和年龄,并显示查询处理过程
USE tigaoban
GO
SET SHOWPLAN_ALL ON
GO
SELECT 姓名,YEAR((GETDATE())-YEAR(出生日期) AS年龄
FROM 九期
WHERE 性别='男'
GO
ii.STATISTICS IO语句
STATISTICSIO语句用来显示执行数据检索语句所花费的磁盘活动量信息,可以得用这些信息来确定是否重新设计索引。
语法:
STATISTICSIO {ON|OFF}
说明:
-
设置为ON,所有后续T_SQL语句将返回统计信息,直到将该选项设置为OFF为止。
-
设置为OFF,不显示统计信息。
举例:
在tigaoban数据库中的“九期”表上查询所有男生的姓名和年龄,并显示查询处理过程中的磁盘活动统计信息
USE tigaoban
GO
SET SHOWPLAN_ALL ON
GO
SET STATISTICS IO ON
GO
SELECT 姓名,YEAR((GETDATE())-YEAR(出生日期) AS年龄
FROM 九期
WHERE 性别='男'
GO
2).索引的维护
常用的维护语句有DBCC SHOWCONTIG和DBCC INDEXDEFRAG语句
i.DBCC SHOWCONTIG语句
该语句用来显示指定表的数据和索引的碎片信息。当对表进行大量的修改或添加数据之后,应该该执行些语句来查看有无碎片。
语法:
DBCC SHOWONTIG [{table_name|table_id|view_name|view,index_name|index_id}]
说明:
-
table_name|table_id|view_name|view id是要对其碎片信息进行检查的表或视图。如果未指定任何名称,则对当前数据库中的所有表和索引视图进行检查。
-
当执行些语句时,重点看其扫描密度,其理想值为100%,如果小于这个值,表示表中已有碎片。可用DBCC INDEXDEFRAG语句来整理。
举例:
查看tigaoban数据库中所有表的碎片情况
USE tigaoban
GO
DBCC SHOWCONTIG
GO
Ii.DBCC INDEXDEFRAG语句
该语句的作用是整理指定的表或视图的聚集索引和辅助索引的碎片。
语法:
DBCC INDEXDEFRAG
({database_name|database_id|0}
,{tabel_name}|table_id|'view_name'|view_id}
,{index_name|index_id})
[WITHNO_INFOMSGS]
说明:
-
0表示使用当前数据库
-
WITH NO_INFOMSGS禁止显示所有信息性消息
举例:
整理tigaoban数据库中“九期”表的jq_zy_index索引上的碎片
USE tigaoban
GO
DBCC INDEXDEFRAG (student,九期,jq_zy_jndex)
GO
这些就是关于索引的介绍。
分享到:




相关推荐
在这个主题中,我们将深入探讨数据库索引的基础概念、设计原则、优化策略以及实际应用。 一、索引基础知识 索引是数据库系统为了加速查询而创建的数据结构,类似于书籍的目录,它提供了快速访问特定数据记录的途径...
### 数据库索引及优化详解 #### 一、数据库索引的重要性 数据库索引就像是图书中的目录,能够显著提升查询速度。例如,在执行查询 `SELECT * FROM table1 WHERE id = 44` 时,如果没有索引,系统需要逐行扫描整个...
在Java编程环境中,创建数据库文件索引是一项...以上这些知识点是实现“java 建立数据库文件索引”的基础,通过合理地组合和应用这些技术,你可以构建一个功能完善的系统,支持文件目录的数据库索引创建和FTP远程下载。
数据库是存储和管理数据的核心工具,它通过高效的数据组织方式来提供...通过深入学习《非聚集索引.docx》、《聚集索引.docx》和《索引模式.docx》等文档,可以更全面地了解这些概念并应用于实际的数据库管理工作中。
数据库原理及应用是信息技术领域中的核心课程之一,它主要探讨如何有效地存储、管理和检索数据,以支持各种业务和信息系统。本书详细介绍了数据库的基础概念、设计原则以及实际应用,旨在帮助读者深入理解数据库的...
数据库原理及应用是计算机科学中的核心课程之一,它主要研究如何高效、安全地存储和管理数据。本教程针对“数据库原理及应用教程(第二版)”进行了解析,旨在帮助学习者深入理解数据库系统的基本概念、设计方法以及...
《数据库系统原理及应用教程》由苗雪兰编著的第三版,是深入理解和掌握数据库理论与实践的重要教材。本教程结合课件和上机指导,旨在帮助学生全面了解数据库系统的概念、设计、实现以及在实际中的应用。 1. 数据库...
### 屏蔽数据库表索引的例子 在数据库管理与优化的过程中,索引是提高查询效率的重要工具之一。...然而,这也需要我们在理解和掌握数据库索引原理的基础上,合理运用这些技巧,才能发挥出最大的效果。
《使用Lucene.NET对数据库建立索引及搜索》 在信息技术领域,搜索引擎是不可或缺的一部分,尤其是在处理大量数据时。Lucene.NET是一个强大的全文搜索引擎库,它允许开发人员在应用程序中集成高级搜索功能。本文将...
浅析实时数据库的应用。并在其中介绍实时数据库的索引技术的应用和实现方法。和供学习实时数据库的研究使用。
Oracle数据库中的索引维护是数据库管理员日常工作中至关重要的一部分,尤其是在大型企业级应用中,高效的索引管理能够显著提升查询性能和数据库的整体效率。本文主要关注Oracle8i版本中的B-tree索引维护。 首先,...
数据库原理及开发应用是IT领域中的核心组成部分,它涉及到数据的存储、管理和检索,是支撑各种应用程序高效运行的基础。在实际工作中,掌握数据库原理及开发应用对于软件开发人员至关重要,因为这不仅要求对理论知识...
**MySQL数据库索引概述** 索引是数据库管理系统中不可或缺的一部分,尤其在处理大规模数据时,它的存在极大地提高了数据检索的效率。在MySQL中,索引是一个独立的、物理的数据库结构,它由表中一列或多列的集合以及...
B+树是一种自平衡的树数据结构,广泛应用于数据库索引。它的每个节点可以包含多个关键字,每个节点的子节点数与关键字数相同,且所有实际的数据都存储在叶子节点上,这样保证了从根节点到任何叶子节点的路径长度相同...
本主题聚焦于“Sybase数据库查询索引优化”,这是提升数据库性能的关键技术之一。索引是数据库系统中用于快速访问数据的一种数据结构,类似于书籍的目录,能够加速查询过程,降低I/O操作,从而提高整体系统的响应...
《数据库原理及应用教程(MySQL版)-习题答案及解析》是一份针对数据库学习者的珍贵资源,尤其适合正在学习MySQL数据库原理与应用的学生或初学者。这份文档详细解答了教材中的各种习题,帮助读者深入理解数据库的概念...
首先,B-Tree是数据库索引常用的数据结构之一,尤其在关系型数据库中广泛应用。B-Tree(B树)是一种自平衡的树,能够保持数据有序。它不同于二叉树,每个节点可以有多个子节点,通常用于存储大量数据,特别是磁盘等...
**使用Lucene对数据库建立索引及搜索** Lucene是一个高性能、可伸缩的信息检索库,它是Apache软件基金会的顶级项目之一。它提供了一个简单但功能强大的API,用于在各种数据源上创建全文搜索引擎,包括数据库。在本...
“数据库系统原理及应用”可能还会涉及数据库管理系统(DBMS)的工作原理,如查询优化、索引结构(B树、B+树、哈希索引等)、存储管理(包括内存管理、磁盘I/O操作)以及分布式数据库和云数据库的相关概念。...