求解问题如下:
在本地磁盘里面有file1和file2两个文件,每一个文件包含500万条随机整数(可以重复),最大不超过2147483648也就是一个int表示范围。要求写程序将两个文件中都含有的整数输出到一个新文件中。
要求:
1.程序的运行时间不超过5秒钟。
2.没有内存泄漏。
3.代码规范,能要考虑到出错情况。
4.代码具有高度可重用性及可扩展性,以后将要在该作业基础上更改需求。
初一看,觉得很简单,不就是求两个文件的并集嘛,于是很快写出了下面的代码。
#include<iostream>
#include<vector>
#include<cstdlib>
#include<algorithm>
#include<fstream>
using namespace std;
void merge(const vector<int> &, const vector<int>&, vector<int> &);
int main(){
vector<int> v1, v2;
vector<int> result;
char buf[512];
FILE *fp;
fp = fopen("file1", "r");
if(fp < 0){
cout<<"Open file failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v1.push_back(atoi(buf));
}
sort(v1.begin(), v1.end());
fclose(fp);
fp = fopen("file2", "r");
if(fp < 0){
cout<<"Open file2 failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v2.push_back(atoi(buf));
}
sort(v2.begin(), v2.end());
cout<<v1[v1.size() - 1]<<endl;
cout<<v2[v2.size() - 1]<<endl;
fclose(fp);
merge(v1, v2, result);
cout<<result.size();
ofstream output;
output.open("result");
if(output.fail()){
cerr<<"crete file failed!\n";
exit(1);
}
vector<int>::const_iterator p = result.begin();
for(; p != result.end(); p++){
output<<*p<<endl;
}
output.close();
return 0;
}
void merge(const vector<int>& v1, const vector<int>& v2, vector<int> &result){
vector<int>::const_iterator p1, p2;
p1 = v1.begin();
p2 = v2.begin();
while((p1 != v1.end()) && p2 != v2.end()){
if(*p1 < *p2){
p1++;
}else if(*p1 > *p2){
p2++;
}else{
result.push_back(*p1);
p1++;
p2++;
}
}
}
编译运行。
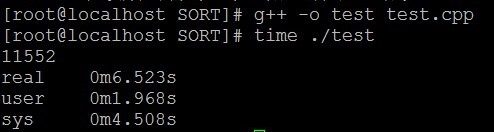
一看,不行,不满足上面的5秒之内,于是又想了很久,上面不是显示sys调用花了很长时间嘛,于是有写了一个程序,用快速排序+二分查找法实现,代码如下:
#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
#include <cstdio>
#define MAXLINE 32
using namespace std;
void qsort(vector<int>&, int, int);
int partition(vector<int>&, int, int);
bool binarySearch(const vector<int>&, int);
int main(){
vector<int> v1, result;
int temp;
char buf[MAXLINE];
FILE *fd;
fd = fopen("file1", "r");
if(fd == NULL){
cerr<<"Open file1 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
v1.push_back(atoi(buf));
}
fclose(fd);
//cout<<v1.size()<<endl;
qsort(v1, 0, v1.size() - 1);
/*vector<int>::const_iterator p = v1.begin();
for(; p != v1.end(); p++){
cout<<*p<<endl;
sleep(1);
}*/
fd = fopen("file2", "r");
if(fd == NULL){
cerr<<"open file2 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
temp = atoi(buf);
if(binarySearch(v1, temp)){
result.push_back(temp);
}
}
cout<<result.size();
return 0;
}
void qsort(vector<int> &v, int low, int hight){
if(low < hight){
int mid = partition(v, low, hight);
qsort(v, low, mid - 1);
qsort(v, mid + 1, hight);
}
}
int partition(vector<int> &v, int min, int max){
int temp = v[min];
while(min < max){
while(min < max && v[max] >= temp)
max--;
v[min] = v[max];
while(min < max && v[min] <= temp)
min++;
v[max] = v[min];
}
v[min] = temp;
return min;
}
bool binarySearch(const vector<int> &v, int key){
int low, hight, mid;
low = 0;
hight = v.size() - 1;
while(low <= hight){
mid = (low + hight) /2;
if(v[mid] == key){
return true;
}else if(v[mid] < key){
low = mid + 1;
}else{
hight = mid - 1;
}
}
return false;
}
正乐着呢,编译运行:
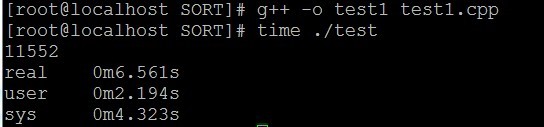
结果发现,user时间是2.194秒,整个时间还要比以前长,显然这种方法还是不行,原因就是两个文件太大了,500万条,不是一般小,且上面花的时间主要用在排序上面去了,于是就想,能不能不用排序完成?这时有个朋友和我说了一下位图法,灵感一来,自己又去改写了代码:
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
#define SHIFT 5
#define MAXLINE 32
#define MASK 0x1F
using namespace std;
void setbit(int *bitmap, int i){
bitmap[i >> SHIFT] |= (1 << (i & MASK));
}
bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
}
size_t getFileSize(ifstream &in, size_t &size){
in.seekg(0, ios::end);
size = in.tellg();
in.seekg(0, ios::beg);
return size;
}
char * fillBuf(const char *filename){
size_t size = 0;
ifstream in(filename);
if(in.fail()){
cerr<< "open " << filename << " failed!" << endl;
exit(1);
}
getFileSize(in, size);
char *buf = (char *)malloc(sizeof(char) * size + 1);
if(buf == NULL){
cerr << "malloc buf error!" << endl;
exit(1);
}
in.read(buf, size);
in.close();
buf[size] = '\0';
return buf;
}
void setBitMask(const char *filename, int *bit){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
//cout<<p<<endl;
setbit(bit, atoi(p));
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
void compareBit(const char *filename, int *bit, vector<int> &result){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
if(getbit(bit, atoi(p))){
result.push_back(atoi(p));
}
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
int main(){
vector<int> result;
unsigned int MAX = (unsigned int)(1 << 31);
unsigned int size = MAX >> 5;
int *bit1;
bit1 = (int *)malloc(sizeof(int) * (size + 1));
if(bit1 == NULL){
cerr<<"Malloc bit1 error!"<<endl;
exit(1);
}
memset(bit1, 0, size + 1);
setBitMask("file1", bit1);
compareBit("file2", bit1, result);
delete bit1;
cout<<result.size();
sort(result.begin(), result.end());
vector< int >::iterator it = unique(result.begin(), result.end());
ofstream of("result");
ostream_iterator<int> output(of, "\n");
copy(result.begin(), it, output);
return 0;
}
这是利用位图法实现的程序,编译运行
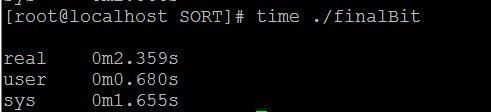
运行时间明显比前两个少,但是这个程序是以空间换取时间,程序运行的时候分配了几百兆的空间。可见在程序设计中,方法很重要。什么情况选用什么方法。但是还是觉得前面两个方法还行,因为需要的空间比较少。
分享到:





相关推荐
总的来说,海量数据处理分析方法涉及数据库选择、程序优化、数据分区、索引建立、缓存管理、虚拟内存调整、分批处理等多个层面,这些技术和策略的综合运用是应对大数据时代的关键。通过不断学习和实践,工程师可以...
- **大数据处理平台**:探讨在大数据环境下,C++如何帮助处理海量数据集,提高数据处理效率。 #### 五、总结 《大规模C++程序设计》不仅是对C++语言特性的深入研究,更是对软件工程实践的一种探索。通过对上述知识...
在IT行业中,面对中等规模的海量数据处理是一项常见的挑战。在这个实例分析中,我们将探讨如何利用一台普通服务器高效地处理近60亿PV(页面浏览量)的数据。这一问题的核心在于优化数据处理策略,充分利用有限的计算...
此外,通过Java本地接口(JNI)技术,可以实现Java代码和C/C++代码(CUDA代码)之间的相互调用,这样GPU上运行的CUDA程序的结果能够被MapReduce框架的Map函数接收并继续处理。 5. 高效的数据处理流程: 通过上述...
在海量数据处理系统的平台搭建方面,文章介绍了Measurement Studio for Visual C++所提供的C++类库,这些类库包含了超过12个专门用于数据处理的类,例如3DGraph、Analysis、Common等。这些类库为系统提供了强大的...
《C++程序设计与数据结构基础》第一章主要探讨了C++程序设计的基础概念,以及计算机与程序设计的历史和发展。以下是关于这些内容的详细解析: 1. 计算机的定义:计算机通常被定义为一个能够执行预先编程指令的设备...
它不仅提供了一个用于编写C++代码的编辑器,还包含了调试器、资源编辑器等工具,使得开发者能够一站式完成软件的编写、编译和调试工作。其中,MFC是一组预先封装好的C++类库,它为创建Windows应用程序提供了便捷的...
高性能日志文件数据处理分析程序的设计与实现是一个关键任务,特别是在大数据时代,高效的数据处理能力是衡量系统性能的重要指标。本程序旨在快速处理文件服务器的日志文件,通过对这些日志进行深度分析,生成实时的...
1. 运行速度较慢:由于MATLAB程序是解释性语言,只能在MATLAB环境下运行,面对海量数据处理时,处理速度会较慢。 2. 源代码可读性强:MATLAB的程序文件是ASCII码文件,具有良好的可读性,这虽然便于调试,但同时也...
数据挖掘在数据仓库环境中尤为有用,因为它可以帮助用户从海量数据中提取有意义的洞察。 K-means聚类是数据挖掘中的一种无监督学习方法,主要用于分类和分组相似对象。在这个实验中,K-means被应用到图像处理上。...
源码指的是用于处理数据的程序代码,可能包括脚本语言(如Python、JavaScript、Perl)或编程语言(如Java、C++)。选择合适的编程语言取决于数据类型、性能需求、可维护性等因素。例如,Python因其丰富的数据处理库...
在计算机处理能力飞速提升的当下,对能够处理海量数据的程序的需求也在不断增加,而算法效率问题随之变得更加重要。本书通过分析具体问题来展示如何通过精心设计的算法将处理大量数据的时间从数年缩短至数秒,以直观...
通过C++实现,Scribe确保了在处理大数据时的性能优势,并且能够灵活地与其他数据处理系统集成。在实际应用中,根据具体需求,开发者可以选择Scribe与其他工具搭配使用,构建更完善的大数据处理架构。
互联网企业海量数据处理往往涉及到大数据技术,如分布式计算框架Hadoop、Spark,数据存储系统HBase、Cassandra等。面试时可能考察如何利用这些技术解决大规模数据的问题,以及如何优化数据处理流程。 总之,C++和...
本研究中提到的关键技术包括航天测试、大容量数据、数据处理、Visual C++ 6.0以及应用程序接口(API)。在航天测试领域,"大容量数据"意味着数据的规模非常庞大,涉及到的数据量可能是几个GB甚至几十GB。而数据处理...
1. 数据处理:如大数据分析、机器学习和人工智能等领域,需要高效地处理海量数据。 2. 图形学:图像识别、渲染和游戏开发中,算法起到关键作用。 3. 网络技术:路由算法、负载均衡和网络安全等方面。 4. 操作系统...
这些章节将教会读者如何从海量数据中提取所需信息,进行数据分析和处理。 第七章至第九章则可能涉及更高级的主题,如窗体和报表的创建,它们是用户与数据库交互的界面。窗体可以用于输入和查看数据,而报表则用于...
《算法学习与设计课程——基于C++程序语言的算法分析与设计》主要涵盖了算法分析的基础知识,包括算法复杂度、渐近...这不仅涉及到编写正确的代码,更关乎能否在海量数据和复杂问题面前,设计出高效、实用的解决方案。
综上所述,基于Python的网络爬虫程序设计不仅提高了信息搜索的效率,还能够帮助用户在海量数据中快速定位和提取有价值的信息。这在数据分析、信息检索、市场研究等领域具有广泛的应用前景。通过使用Python开发网络...
7. **扩展性**:为了处理海量数据,分布式文件系统必须具备良好的扩展性。这个C++实现可能通过水平扩展(添加更多节点)来增加存储和处理能力。 8. **并发访问**:支持多用户和多任务并发访问是必要的,这需要良好...