- жµПиІИ: 47019 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еМЧдЇђ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2013-08 ( 1)
- 2013-01 ( 1)
- 2012-11 ( 5)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
http://www.blogjava.net/BucketLi/archive/2012/05/15/335618.html
 
жЬАињСйЬАи¶БзФ®еИ∞log4jеК®жАБеЃЪеИґLoggerзЪДеЬЇжЩѓпЉМзДґеРОеК†дЄКдї•еЙНеѓєдЇОињЩдЄ™жЧ•ењЧеЈ•еЕЈжЛњжЭ•е∞±зФ®иАМдЄНзЯ•еЕґеОЯзРЖзЪДеОЯеЫ†пЉМжЙАдї•еЖ≥еЃЪиК±зВєжЧґйЧізЬЛдЄЛеЃГзЪДжЇРз†БпЉМе¶ВжЮЬдљ†ињШеѓєlog4jе¶ВдљХдљњзФ®жДЯеИ∞еЫ∞жГСпЉМйВ£дєИиѓЈй¶ЦеЕИзЃАи¶БжµПиІИдЄЛеЃГзЪДеЃШзљСhttp://logging.apache.org/log4j/ Log4jеИЭеІЛеМЦзЪДдї£з†БжШѓеЬ®LogManagerзЪДйЭЩжАБеЭЧйЗМйЭҐпЉМињЩдЄ™йЭЩжАБеЭЧжЧ†иЃЇе¶ВдљХйГљдЉЪеЃЮдЊЛеМЦдЄАдЄ™жЧ•ењЧзЇІеИЂдЄЇDEBUGзЪДRootLoggerпЉМеєґдЄФеИЭеІЛеМЦдЄАдЄ™дї•ињЩдЄ™RootLoggerдЄЇж†єиКВзВєзЪДзЇІиБФзїУжЮДпЉМзДґеРОж£АжЯ•жЬЙж≤°жЬЙзФ®жИЈжМЗеЃЪйЗНеЖЩињЩдЄ™жЧ•ењЧз≥їзїЯзЪДеИЭеІЛеМЦеЈ•дљЬпЉМе¶ВжЮЬж≤°жЬЙпЉМйВ£дєИеЕИеОїжЙЊlog4j.xmlпЉМе¶ВжЮЬж≤°жЬЙжЙЊеИ∞пЉМйВ£дєИеЖНеОїжЙЊlog4j.properties(дєЯе∞±жШѓlog4j.xmlзЪДдЉШеЕИзЇІйЂШдЇОlog4j.properties),¬†еП™жЬЙжЙЊеИ∞ињЩдЄ§дЄ™йЕНзљЃжЦЗдїґзЪДеЕґдЄ≠дЄАдЄ™пЉМеЖНеИЭеІЛеМЦжЦЗдїґйЗМйЭҐеЖЕеЃєпЉМдЄїи¶БжШѓдЄАдЇЫйЕНзљЃжЦЗдїґдЄ≠жМЗеЃЪзЪДLoggerеИЭеІЛеМЦпЉМдї•еПКеРДдЄ™LoggerзЪДAppenderеИЧи°®иЃЊеЃЪпЉМеРДдЄ™AppenderзЪДеЕЈдљУеЃЮдЊЛпЉМLayoutз≠ЙгАВеЕґеЃЮпЉМж≤°жЙЊеИ∞дїїдљХlog4jйЕНзљЃжЦЗдїґдєЯж≤°дїАдєИеЕ≥з≥їпЉМеЫ†дЄЇеЈ≤зїПжЬЙRootLogger,жЧ•ењЧз≥їзїЯй™®жЮґеЈ≤зїПеЃМжИРдЇЖпЉМжЙАдї•дєЯеПѓдї•йАЪињЗе¶ВеЙНйЭҐзЪДдї£з†БжЈїеК†LoggerгАВ зЃАи¶БдїЛзїНеЃМLog4JзЪДеИЭеІЛеМЦеРОпЉМжИСдїђжЬЙењЕи¶БжЭ•зЬЛдЄЛдїОLogger myLogger =LogManager. getLogger(вАЬMY_ LOGвАЭ),еИ∞¬†myLogger.debug(вАЬsome messageвАЭ)зїУжЭЯдєЛеРОпЉМLog4jеИ∞еЇХдЄЇжИСдїђеБЪдЇЖдЇЫдїАдєИгАВ дЄЊдЄ™дЊЛе≠РпЉМжИСдїђдЄАиИђеПЦеЊЧдЄАдЄ™LoggerеЃЮдЊЛжШѓињЩж†ЈзЪДпЉМ¬†Logger log=LogManager.getLogger(Class class), Log4jе§ДзРЖжЦєеЉПдЄЇgetLogger(class.getName())пЉМињЩдєЯе∞±жШѓиѓіпЉМињЩдЄ™LoggerзЪДеРНе≠ЧжШѓеЄ¶еМЕеРНзЪДеЃМеЕ®йЩРеЃЪеРНе≠ЧпЉМжЙАдї•е¶ВжЮЬжИСдїђйАЪињЗеРНдЄЇa.b.c.aclass,a.b.c.d.bclassињЩдєИдЄ§дЄ™з±їеПЦеЊЧLoggerеЃЮдЊЛ,зДґеРОеЃЪдєЙеРНдЄЇa.b.cеТМa.b.c.d 2дЄ™Logger,йВ£дєИжАїеЕ±дЉЪзФЯжИРе¶ВдЄЛзЪДиКВзВє¬† ињЩж†ЈLogger a.b.cйЩ§дЇЖиЗ™иЇЂзЪДжЧ•ењЧиЊУеЗЇиЃЊзљЃдєЛе§ЦпЉМињШдЇЂеПЧrootLoggerзЪДиЊУеЗЇ(иЊУеЗЇзЇІеИЂпЉМAppenders)пЉМLogger a.b.c.dеРМжЧґдЇЂеПЧrootLoggerеТМa.b.cзЪДиЃЊзљЃпЉМa.b.c.d.bclassдЇЂеПЧrootLogger,a.b.c,a.b.c.dзЪДжЧ•ењЧиЊУеЗЇиЃЊеЃЪпЉМдєЯе∞±жШѓеПѓдї•еИЖеИЂеЃЪдєЙдЄАжЙєLoggerзЪДиЊУеЗЇзЇІеИЂеТМиЊУеǯ嚥еЉПдї•еПКеЕґдїЦе±ЮжАІпЉМељУзДґдєЯжЬЙжОІеИґеЉАеЕ≥жОІеИґињЩзІНзїІжЙњгАВдЄЛеЫЊиѓіжШОдЇЖдЄАдЇЫйЧЃйҐШгАВ иЗ≥ж≠§пЉМжХідЄ™жЧ•ењЧиЊУеЗЇињЗз®ЛзїУжЭЯгАВ дЄЛйЭҐдЄ§еєЕеЫЊеИЖеИЂжШѓLog4jзЪДжХідљУз±їеЫЊпЉМдЄНжШѓйЭЮеЄЄеЃМжХіпЉМдљЖжШѓе§Іж¶ВиГље§ЯдЇЖиІ£еИ∞жХідЄ™зїУжЮДгАВ
Log4jжАїдљУжЭ•иѓіжШѓдЄАдЄ™еПѓеЃЪеИґпЉМжФѓжМБеРМжЧґе§ЪзІН嚥еЉПиЊУеЗЇжЧ•ењЧпЉМеєґдЄФйЂШеЇ¶зїУжЮДеМЦзЪДжЧ•ењЧеЇУгАВеПѓеЃЪеИґпЉМдєЯе∞±жШѓжЧҐеПѓдї•йАЪињЗlog4j.propertiesжИЦиАЕlog4j.xmlеЃЪдєЙжЧ•ењЧиЊУеЗЇзЪДзЇІеИЂ(Level)пЉМ嚥еЉП(Appender)дї•еПКжЦЗжЬђж†ЉеЉП(Layout)пЉМдєЯеПѓдї•йАЪињЗLoggerз±їжИЦиАЕLogManagerз±їеПЦеЊЧLoggerеЃЮдЊЛпЉМеєґдЄФиЃЊзљЃжЧ•ењЧиЊУеЗЇзЇІеИЂ(Level)пЉМ嚥еЉП(Appender)дї•еПКжЦЗжЬђж†ЉеЉП(Layout),еПѓдї•иѓіжШѓзЫЄељУзЪДзЃАдЊњдЄОзБµжіїгАВдЄЛйЭҐдЄАжЃµдї£з†БзЃАеНХеЬ∞иѓіжШОдЇЖеРОиАЕзЪДеЃЮзО∞гАВ Logger¬†MY_LOG¬†=¬†Logger.getLogger("MY_LOG");//жЦЗ俴嚥еЉПзЪДиЊУеЗЇжЦєеЉПеЃЮдЊЛеМЦDailyRollingFileAppender¬†appender¬†=¬†new¬†DailyRollingFileAppender();appender.setName(name);appender.setAppend(true);appender.setEncoding("GBK");//жЦЗжЬђзЪДиЊУеЗЇж†ЉеЉПйЗЗзФ®PatternLayoutappender.setLayout(new¬†PatternLayout(pattern));appender.setFile(new¬†File(getLogPath(),¬†fileName).getAbsolutePath());appender.activateOptions();//е∞ЖappenderеК†еЕ•еИ∞MY_LOGзЪДappenderйЫЖеРИMY_LOG.addAppender(appender);//иЃЊеЃЪжЧ•ењЧиЊУеЗЇзЇІеИЂдЄЇINFOMY_LOG.setLevel(Level.INFO);
Logger¬†MY_LOG¬†=¬†Logger.getLogger("MY_LOG");//жЦЗ俴嚥еЉПзЪДиЊУеЗЇжЦєеЉПеЃЮдЊЛеМЦDailyRollingFileAppender¬†appender¬†=¬†new¬†DailyRollingFileAppender();appender.setName(name);appender.setAppend(true);appender.setEncoding("GBK");//жЦЗжЬђзЪДиЊУеЗЇж†ЉеЉПйЗЗзФ®PatternLayoutappender.setLayout(new¬†PatternLayout(pattern));appender.setFile(new¬†File(getLogPath(),¬†fileName).getAbsolutePath());appender.activateOptions();//е∞ЖappenderеК†еЕ•еИ∞MY_LOGзЪДappenderйЫЖеРИMY_LOG.addAppender(appender);//иЃЊеЃЪжЧ•ењЧиЊУеЗЇзЇІеИЂдЄЇINFOMY_LOG.setLevel(Level.INFO);
Hierarchy h = new Hierarchy(new RootLogger((Level) Level.DEBUG));
//жЬЙж≤°жМЗеЃЪlog4j.configuration(еЖЕйГ®дљњзФ®,дЄНзЯ•еЗЇдЇОдїАдєИзЫЃзЪДпЉМжЬ™жОҐз©ґ) if(configurationOptionStr¬†==¬†null)¬†{
if(configurationOptionStr¬†==¬†null)¬†{ ¬†¬†¬†¬†//еК†иљљclasspathдЄЛlog4j.xml¬†¬†¬†¬† url¬†=¬†Loader.getResource(DEFAULT_XML_CONFIGURATION_FILE);
¬†¬†¬†¬†//еК†иљљclasspathдЄЛlog4j.xml¬†¬†¬†¬† url¬†=¬†Loader.getResource(DEFAULT_XML_CONFIGURATION_FILE); ¬†¬†¬†if(url¬†==¬†null)¬†{¬†¬†¬†¬†¬†¬†¬†¬†//е¶ВжЮЬlog4j.xmlж≤°жЬЙпЉМеК†иљљlog4j.properties¬†¬†¬†¬†¬†¬†¬† url¬†=¬†Loader.getResource(DEFAULT_CONFIGURATION_FILE);
¬†¬†¬†if(url¬†==¬†null)¬†{¬†¬†¬†¬†¬†¬†¬†¬†//е¶ВжЮЬlog4j.xmlж≤°жЬЙпЉМеК†иљљlog4j.properties¬†¬†¬†¬†¬†¬†¬† url¬†=¬†Loader.getResource(DEFAULT_CONFIGURATION_FILE); ¬†¬†¬†¬†}}¬†else¬†{¬†¬†¬†¬†try¬†{¬†¬†¬†¬†url¬†=¬†new¬†URL(configurationOptionStr);¬†¬†¬†¬†}¬†catch¬†(MalformedURLException¬†ex)¬†{¬†¬†¬†¬†url¬†=¬†Loader.getResource(configurationOptionStr);¬†¬†¬†¬†¬†}
    }} else {    try {    url = new URL(configurationOptionStr);    } catch (MalformedURLException ex) {    url = Loader.getResource(configurationOptionStr);     } }
if(url¬†!=¬†null)¬†{¬†¬†¬†¬†LogLog.debug("Using¬†URL¬†["+url+"]¬†for¬†automatic¬†log4j¬†configuration.");¬†¬†¬†¬†¬†//еЉАеІЛзЬЯж≠£иІ£жЮРйЕНзљЃжЦЗдїґ¬†¬†¬†¬†¬†¬†¬†¬†¬†OptionConverter.selectAndConfigure(url,¬†configuratorClassName,LogManager.getLoggerRepository());}¬†else¬†{¬†¬†¬†¬†LogLog.debug("Could¬†not¬†find¬†resourceпЉЪ["+configurationOptionStr+"].");}
}
if(url¬†!=¬†null)¬†{¬†¬†¬†¬†LogLog.debug("Using¬†URL¬†["+url+"]¬†for¬†automatic¬†log4j¬†configuration.");¬†¬†¬†¬†¬†//еЉАеІЛзЬЯж≠£иІ£жЮРйЕНзљЃжЦЗдїґ¬†¬†¬†¬†¬†¬†¬†¬†¬†OptionConverter.selectAndConfigure(url,¬†configuratorClassName,LogManager.getLoggerRepository());}¬†else¬†{¬†¬†¬†¬†LogLog.debug("Could¬†not¬†find¬†resourceпЉЪ["+configurationOptionStr+"].");}

  
дЄКйЭҐињЩеєЕеЇПеИЧеЫЊдЄїи¶БжППињ∞зЪДињЗз®Ле∞±жШѓдїОLoggerManagerеПЦеЊЧдЄАдЄ™LoggerзЪДињЗз®ЛпЉМеЕґдЄ≠жЬАйЗНи¶БзЪДжУНдљЬеЬ®Hierarchyз±їдЄ≠пЉМињЩдЄ™з±їиѓізЩљдЇЖе∞±жШѓе≠ШеВ®LoggerзЪДдїУеЇУпЉМеЕґеЖЕйГ®дљњзФ®дЄАдЄ™HashMap htжЭ•е≠ШеВ®LoggerеТМProvisionNodeгАВ
ињЩйЗМйЬАи¶БиІ£йЗКдЄЛProvisionNodeпЉМињЩдЄ™з±їжШѓдЄАдЄ™VectorзЪДеЃЮзО∞пЉМдєЛеЙНжИСдїђи∞ИеИ∞ињЗеИЭеІЛеМЦзЪДдЄАеЉАеІЛпЉМдї•RootLoggerдЄЇж†єиКВзВєзЪДзЇІиБФзїУжЮДпЉИе∞±жШѓHierarchyеЃЮдЊЛпЉЙпЉМйВ£дєИињЩдЄ™ProvisionNodeжГ≥ељУдЇОињЩдЄ™зЇІиБФзїУжЮДдЄ≠зЪДж†СиКВзВєпЉМжѓФе¶ВжИСеЬ®еЃЪдєЙдЇЖдЄАдЄ™еРНе≠ЧдЄЇa.b.cзЪДLoggerпЉМйВ£дєИжАїеЕ±дЉЪзФЯжИРвАЭaвАЭ,вАЭa.bвАЭдЄ§дЄ™ProvisionNode,дї•еПКдЄАдЄ™еРНе≠ЧдЄЇвАЭa.b.cвАЭзЪДLoggerгАВHierarchyеєґж≤°жЬЙдЄАдЄ™йУЊи°®жЭ•зїіжК§дїЦдїђдєЛйЧізЪДй°ЇеЇПпЉМProvisionNodeдЉЪйАЪињЗеЕґжЬђиЇЂе∞±жШѓеРСйЗПзЪДзЙєжАІе∞Же±ЮдЇОеЃГзЪДLoggerињЫи°МжЬЙеЇПзЪДжОТеИЧпЉМиАМLoggerжЬђиЇЂеИЩйАЪињЗparentе±ЮжАІиЃ∞дљПдїЦдїђзЪДжЧ•ењЧе±ЮжАІеПѓдї•дїОеУ™йЗМзїІжЙњгАВ
ињЩж†ЈеБЪзЪДе•ље§ДжЬЙдЄ§зВєпЉМзђђдЄАзВєе∞±жШѓеП™и¶БеРНе≠ЧзЫЄеРМпЉМдїОLogManagerдЄ≠еПЦеЗЇжЭ•зЪДLoggerе∞±жШѓеРМдЄАдЄ™еЃЮдЊЛпЉМзђђдЇМзВєе•ље§Де∞±жШѓзЇІиБФзїУжЮДпЉМеПѓдї•еЃЪдєЙеЗЇеЈЃеЉВеМЦзЪДLoggerпЉМзЙєеИЂжШѓеЕґдї•a.b.c.dз±їдЉЉеМЕзїУжЮДзЪДжЛЖеИЖжЧ•ењЧиКВзВєпЉМдљњеЊЧеМЕзЇІеИЂзЪДжЧ•ењЧеЈЃеЉВеМЦиЊУеЗЇжЫіеК†зЪДеЃєжШУпЉМеєґдЄФињЩзІНзЙєжАІжПРдЊЫдЇЖжЧ•ењЧиКВзВєе±ЮжАІзїІжЙњзЪДеКЯиГљгАВ
            
            ProvisionNode: a,a.b
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†Logger:¬†a.b.cпЉИеК†еЕ•a,a.b 2дЄ™ProvisionNodeдЄ≠еєґдЄФparentдЄЇRootLoggerпЉЙ
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†a.b.c.d(еК†еЕ•a,a.b 2дЄ™ProvisionNodeдЄ≠пЉМеєґдЄФparentдЄЇa.b.c)
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† a.b.c.aclass¬† (еК†еЕ•еИ∞a,a.b 2дЄ™ProvisionNodeдЄ≠,еєґдЄФparentдЄЇa.b.c),¬†
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† a.b.c.d.bclass(еК†еЕ•еИ∞a,a.b 2дЄ™ProvisionNodeдЄ≠,еєґдЄФparentдЄЇa.b.c.d)
еЕґдЄ≠ProvisionNodeеПѓиГљеНЗзЇІдЄЇLogger,ељУеРМеРНзЪДLoggerеК†еЕ•жЧґпЉМиѓ•ProvisionNodeдЄ≠жЙАжЬЙдї•иѓ•ProvisionNodeдЄЇзИґиКВзВєзЪДе≠РиКВзВєдњЃжФєparentжМЗеРСжЦ∞зЪДLogger.final¬†private¬†void¬†updateChildren(ProvisionNode¬†pn,¬†Logger¬†logger)¬†{¬†¬†¬†¬†final¬†int¬†last¬†=¬†pn.size();¬†¬†¬†¬†¬†¬†¬†for(int¬†i¬†=¬†0;¬†i¬†<¬†last;¬†i++)¬†{¬†¬†¬†¬†¬†¬†¬†¬† Logger¬†l¬†=¬†(Logger)¬†pn.elementAt(i);¬†¬†¬†¬†¬†¬†¬†¬† ¬†//жЬЙеПѓиГље≠РиКВзВєзЪДзИґиКВзВєжМЗеРСжЫідљОдЄАзЇІзЪДиКВзВєпЉМжѓФе¶Ве≠ЩиКВзВєгАВињЩдЄ™еЇФиѓ•дЄНйЪЊзРЖиІ£гАВ
          if(!l.parent.name.startsWith(logger.name)) {             logger.parent = l.parent;             l.parent = logger;        }     }}

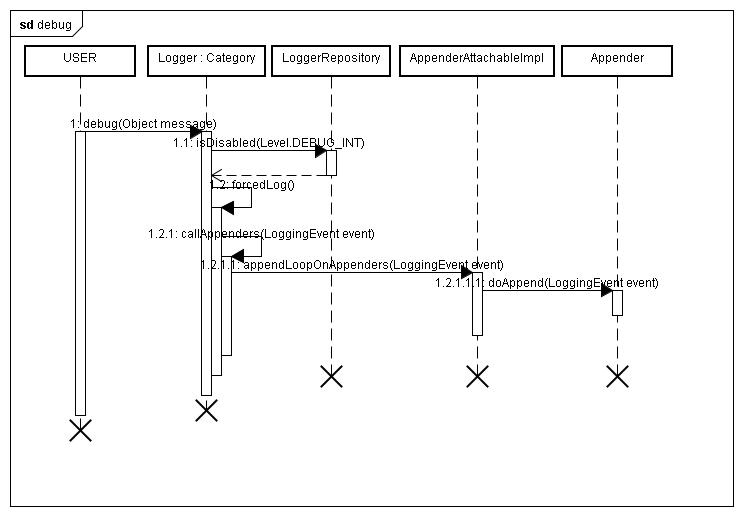
еПЦеЊЧLoggerдєЛеРОпЉМйЪПеРОе∞±жШѓйЬАи¶БжМЙжМЗеЃЪ嚥еЉПиЊУеЗЇжЧ•ењЧеЖЕеЃєпЉМй¶ЦеЕИйЬАи¶БеЬ®LoggerRepositoryдЄ≠еИ§еЃЪељУеЙНLevelжШѓеР¶еПѓдї•еБЪжЧ•ењЧиЊУеЗЇпЉМеМЕжЛђдЄОеЕ®е±АзЪДthresholdIntињЫи°МеИ§еЃЪ(зЫЄељУдЇОжАїеЉАеЕ≥пЉМињЩдЄ™зЇІеИЂйАЪдЄНињЗзЫіжО•ињФеЫЮпЉМдЄНеБЪдїїдљХдЇЛжГЕ)пЉМйАЪињЗеРОпЉМеЖНдЄОеЕґиЗ™иЇЂLoggerжЧ•ењЧзЇІеИЂжѓФиЊГпЉМе¶ВжЮЬж≤°жЬЙиЃЊеЃЪпЉМжЯ•еЕґзИґиКВзВєзЪДжЧ•ењЧзЇІеИЂпЉМдїНзДґж≤°жЬЙиЃЊеЃЪпЉМйВ£дєИжЯ•зИґиКВзВєзЪДзИґиКВзВєпЉМзЫіеИ∞жЯ•еИ∞жЬЙжЧ•ењЧзЇІеИЂиЃЊеЃЪжИЦиАЕжЬАзїИеИ∞RootLogger(еЕґйїШиЃ§дЄЇDebugзЇІеИЂ)пЉМжѓФиЊГйАЪињЗеРОпЉМе∞±еПѓдї•и∞ГзФ®callDependersињЫи°МжЧ•ењЧиЊУеЗЇдЇЖгАВ¬†
жЧ•ењЧзЇІеИЂдЄЇ¬†OFF>FATAL>ERROR>WARN>INFO>DEBUG>ALLпЉМеП™жЬЙиЊУеЗЇзЇІеИЂе§ІдЇОз≠ЙдЇОLoggerиЗ™иЇЂзЇІеИЂжЙНиГљињЫи°МиЊУеЗЇ,жѓФе¶В¬†logger.debugпЉМйВ£дєИеП™жЬЙиѓ•LoggerзЪДзЇІеИЂ(дєЯеПѓиГљжШѓеЕґеЕИиЊИиКВзВєзЪДжЧ•ењЧзЇІеИЂ)еЬ®DEBUGжИЦиАЕALLжЙНиГљеЕБ聪襀иЊУеЗЇгАВеЕ®е±АзЪДthresholdIntе¶ВжЮЬдЄНиЃЊеЃЪжШѓдњЭжМБеЬ®ALLзЇІеИЂгАВ
дЄАиИђLoggerдЉЪйАЪињЗAppenderAttachableImplзЪДеЃЮдЊЛжЭ•зїіжК§е§ЪдЄ™AppenderпЉМеєґдЄФеПѓдї•еЕ±дЇЂзИґиКВзВєзЪДAppender ListпЉИеМЕжЛђRootLoggerйЗМйЭҐеЃЪдєЙзЪДappendersпЉЙ,жЙАдї•жИСдїђдЄАиИђеЬ®log4j.xmlжИЦиАЕlog4j.propertiesйЗМйЭҐеЃЪдєЙдЄАдЄ™жЯРдЄ™еМЕдЄЛзЪДLoggerпЉМзДґеРОжМВжЬЙеЗ†дЄ™AppenderпЉМиАМз®ЛеЇПдЄ≠йАЪињЗеЃМеЕ®йЩРеЃЪзЪДз±їеРН(ињЩдЄ™з±їе±ЮдЇОеЙНйЭҐжМЗеЃЪзЪДеМЕ)еПЦеЊЧLoggerпЉМйВ£дєИељУињЩдЇЫLoggerиЊУеЗЇжЧ•ењЧзЪДжЧґеАЩпЉМеЕґжЬђиЇЂеєґж≤°жЬЙдїїдљХAppenderпЉМдљЖжШѓеНійАЪињЗеЕИиЊИиКВзВєеЃЪдєЙзЪДAppendersеЊЧдї•иЊУеЗЇгАВињЩйЗМйЬАи¶Бж≥®жДПзЪДжШѓпЉМе¶ВжЮЬеЬ®зЫіз≥їиКВзВєйЧіеЃЪдєЙзЫЄеРМзЪДappenderпЉМдЉЉдєОдЉЪе§Ъжђ°йЗНе§НиЊУеЗЇпЉМеЫ†дЄЇеЕґдЉЪйБНеОЖиЗ™иЇЂдї•еПКжЙАжЬЙеЕИиЊИиКВзВєзЪДAppender listеєґдЄФйАРдЄАињЫи°МdoAppendи∞ГзФ®пЉМиАМдЄНдЉЪеОїжОТйЗНпЉМеєґдЄФaddAppenderзЪДжЧґеАЩдєЯж≤°жЬЙйБНеОЖеЕИиЊИиКВзВєжОТйЗНгАВ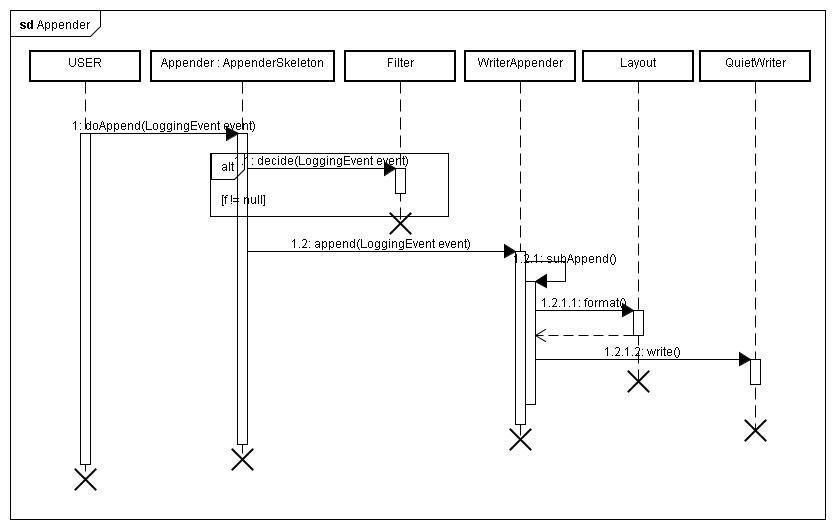
AppenderжМБжЬЙдЄАдЄ™FilterйУЊи°®пЉМdoAppendзЪДжЧґеАЩй¶ЦеЕИиµ∞дЄАйБНињЗжї§еЩ®пЉМзїУжЮЬжЬЙ3зІНпЉМFilter.DENYпЉИзЫіжО•жЛТзїЭињФеЫЮпЉЙпЉМFilter.ACCEPTпЉИжО•жФґиЊУеЗЇиѓЈж±ВпЉМеєґдЄФдЄНеЖНиµ∞дєЛеРОзЪДFilterпЉЙпЉМFilter.NEUTRALпЉИзїІзї≠жЙІи°МдЄЛдЄАдЄ™FilterпЉЙпЉМй°ЇеИ©йАЪињЗFilterйУЊдєЛеРОпЉМињЫеЕ•зЬЯж≠£зЪДиЊУеЗЇжЧ•ењЧињЗз®ЛпЉМињЩиЊєдї•WriteAppenderдЄЇдЊЛпЉМй¶ЦеЕИе∞ЖmessageйАЪињЗжМБжЬЙзЪДLayoutињЫи°Мж†ЉеЉПеМЦ(format)пЉМзДґеРОи∞ГзФ®иЊУеЗЇжµБиЊУеЗЇжЧ•ењЧеИ∞зЫЃж†ЗжЦЗдїґ(FileAppender)жИЦиАЕе±ПеєХ(ConsoleAppender)гАВ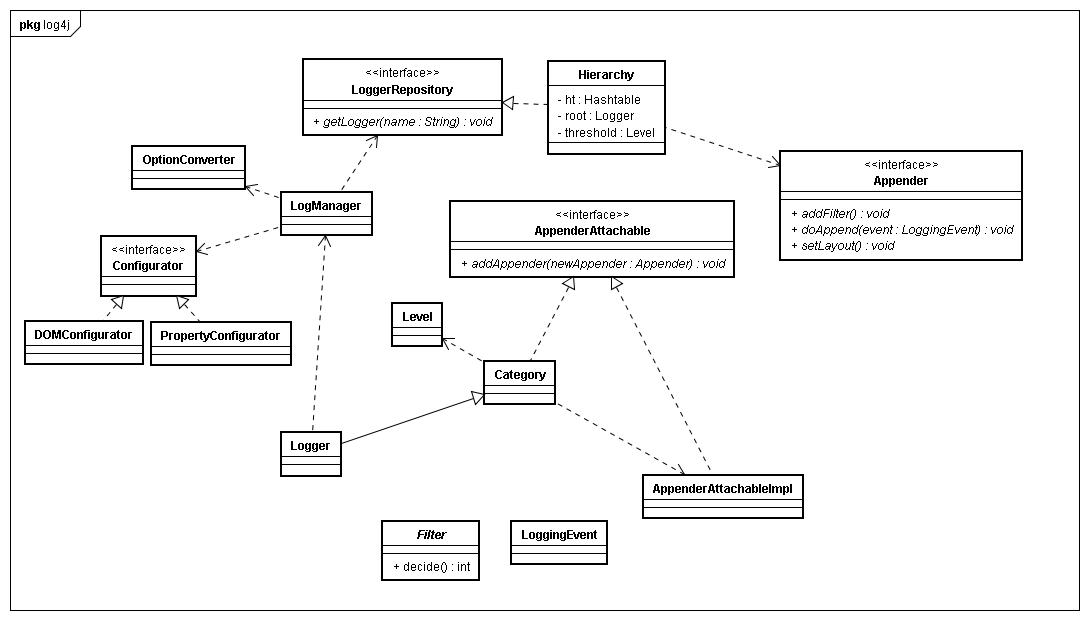
жАїзїУдЄЛпЉМlog4JеЗЇжЭ•еЈ≤зїПеЊИе§ЪеєідЇЖпЉМдї•еЙНеП™жШѓдљњзФ®дЄЛпЉМеєґж≤°жЬЙеОїжОҐз©ґйЗМйЭҐжЬЇеИґпЉМдљЖеЕґжЯРдЇЫжЬЇеИґињШжШѓзЫЄељУдЄНйФЩзЪДгАВжЦЗдЄ≠еПѓиГљеЗЇзО∞дЄАдЇЫйФЩиѓѓпЉМиѓЈеРДдљНиГље§ЯжМЗеЗЇгАВ
 


- 2012-07-05 10:44
- жµПиІИ 847
- иѓДиЃЇ(0)
- еИЖз±ї:зЉЦз®Лиѓ≠и®А
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
ResinжЬНеК°йЗНе§НеИЭеІЛеМЦ
2013-01-17 11:07 1270Resin WebеЃєеЩ®дЄЛжЬНеК°йЗНе§НеИЭеІЛеМЦпЉЪ ¬† йЧЃйҐШжППињ∞ ... -
еЗ†зІНеЇПеИЧеМЦеНПиЃЃ(protobuf,xstream,jackjson,jdk,hessian)зЫЄеЕ≥жХ∞жНЃеѓєжѓФ
2012-07-17 11:33 0еЗ†зІНеЇПеИЧеМЦеНПиЃЃ(protobuf,xstream,j ... -
ThreadзЪДrunпЉИпЉЙдЄОstartпЉИпЉЙзЪДеМЇеИЂ
2012-06-07 17:21 1016¬† ThreadзЪДrunпЉИпЉЙдЄОstartпЉИпЉЙзЪДеМЇеИЂ ... -
FastDateFormat,DateFormatUtils
2012-05-08 19:00 7457ж†ЉеЉПеМЦжЧ•жЬЯ йЧЃйҐШжПРеЗЇпЉЪSimpleDateFormatжШѓ ... -
гАРиљђгАСThreadLocal иІ£еЖ≥SimpleDateFormatйЭЮзЇњз®ЛеЃЙеЕ®
2012-05-08 18:52 1108еЬ®ж≠§з®НеЊЃиІ£йЗКдЄАдЄЛThreadLocalеТМзЇњз®ЛеРМж≠•пЉМеѓє ... -
maven groupId artifactId version
2012-04-26 16:08 3158Guide to naming conventions o ... -
Mavenе≠¶дє†зђФиЃ∞
2012-04-26 15:43 1088еОЯжЦЗеЬ∞еЭАпЉЪhttp://buzhucele.iteye.com ...
зЫЄеЕ≥жО®иНР
гАРеОЯеИЫжХізРЖпЉМдЄ•з¶БиљђиљљпЉМиљђиљљењЕз©ґгАС еПВиАГ жЦЗзМЃ [1]жЭОзїіеЃЙ;зОЛйєПз®Л;еЊРдЄЪеЭ§.жЕИеЦДжНР赆гАБжФњж≤їеЕ≥иБФдЄОеАЇеК°иЮНиµДвАФвАФж∞СиР•дЉБдЄЪдЄОZ FзЪДиµДжЇРдЇ§жНҐи°МдЄЇ[J].еНЧеЉАзЃ°зРЖиѓДиЃЇ,2015,18(01):4-14. [2] иЃЄеєіи°М;жЭОеУ≤.йЂШзЃ°иіЂеЫ∞зїПеОЖдЄОдЉБдЄЪжЕИеЦД...
жЬђдЇЇе≠¶дє†strutsзЪДе∞ПдЊЛе≠РпЉМеМЕеРЂе§Ъж®°еЭЧе§ДзРЖгАБдЄ≠жЦЗеМЦе§ДзРЖгАБжХ∞жНЃй™МиѓБгАБLog4JдљњзФ®гАБйЗНе§НжПРдЇ§иІ£еЖ≥з≠ЙйЧЃйҐШпЉМињШеМЕеРЂйГ®еИЖejbпЉМиљђиљљдЇЖmyeclipseйЕНзљЃweblogicеТМjbossзЪДжЦЗзЂ†гАВ еМЕеРЂжЇРдї£з†БгАВ
ињЩдЇЫjarеМЕеПѓиГљеМЕжЛђStruts2гАБSpringгАБHibernateзЪДеЇУпЉМдї•еПКеЕґдїЦе¶Вlog4jгАБservlet APIз≠ЙињРи°МжЙАйЬАзЪДз±їеЇУгАВеЉАеПСиАЕеПѓдї•йАЪињЗеИЖжЮРињЩдЇЫеЇУжЦЗдїґжЭ•зРЖиІ£й°єзЫЃзЪДжЮДеїЇзОѓеҐГеТМдЊЭиµЦзїУжЮДгАВ зїЉеРИжЭ•зЬЛпЉМињЩдЄ™й°єзЫЃжШѓдЄАдЄ™еЕ≥дЇОе¶ВдљХеИ©зФ®JSR 168...
8. **еЉВеЄЄе§ДзРЖдЄОжЧ•ењЧиЃ∞ељХ**пЉЪSpringBootжФѓжМБзїЯдЄАзЪДеЉВеЄЄе§ДзРЖжЬЇеИґпЉМеєґйЫЖжИРдЇЖLogbackжИЦLog4jз≠ЙжЧ•ењЧж°ЖжЮґпЉМдЊњдЇОи∞ГиѓХеТМзЫСжОІз≥їзїЯзКґжАБгАВ 9. **еНХеЕГжµЛиѓХдЄОйЫЖжИРжµЛиѓХ**пЉЪдЄЇдЇЖдњЭиѓБдї£з†Биі®йЗПпЉМй°єзЫЃдЄ≠еПѓиГљдЉЪеМЕеРЂJUnitжИЦSpockз≠ЙеНХеЕГ...
зђђ19зЂ† дљњзФ®log4jињЫи°МжЧ•ењЧжУНдљЬ 564 19.1 log4jдїЛзїН 564 19.1.1 loggerзїДдїґ 564 19.1.2 appenderзїДдїґ 566 19.1.3 layoutзїДдїґ 567 19.2 дљњзФ®log4j 568 19.3 log4jдљњзФ®еЃЮдЊЛ 572 19.4 ndcеТМmdc 585 19.5 е∞ПзїУ ...
7. **жЧ•ењЧиЃ∞ељХ**пЉЪдЄЇдЇЖињљиЄ™зИђиЩЂињРи°МзКґжАБеТМи∞ГиѓХйЧЃйҐШпЉМй°єзЫЃеПѓиГљдљњзФ®дЇЖжЧ•ењЧиЃ∞ељХеЈ•еЕЈпЉМе¶ВLog4jпЉМиЃ∞ељХзИђиЩЂињРи°МињЗз®ЛдЄ≠зЪДйЗНи¶Бдњ°жБѓгАВ 8. **URLзЃ°зРЖ**пЉЪдЄЇдЇЖйБњеЕНйЗНе§НзИђеПЦеРМдЄАдЄ™URLпЉМйАЪеЄЄдЉЪдљњзФ®URLйШЯеИЧжИЦйЫЖеРИжЭ•е≠ШеВ®еЈ≤иЃњйЧЃињЗзЪД...
зђђ19зЂ† дљњзФ®log4jињЫи°МжЧ•ењЧжУНдљЬ 564 19.1 log4jдїЛзїН 564 19.1.1 loggerзїДдїґ 564 19.1.2 appenderзїДдїґ 566 19.1.3 layoutзїДдїґ 567 19.2 дљњзФ®log4j 568 19.3 log4jдљњзФ®еЃЮдЊЛ 572 19.4 ndcеТМmdc 585 19.5 е∞ПзїУ ...
зђђ19зЂ† дљњзФ®log4jињЫи°МжЧ•ењЧжУНдљЬ 564 19.1 log4jдїЛзїН 564 19.1.1 loggerзїДдїґ 564 19.1.2 appenderзїДдїґ 566 19.1.3 layoutзїДдїґ 567 19.2 дљњзФ®log4j 568 19.3 log4jдљњзФ®еЃЮдЊЛ 572 19.4 ndcеТМmdc 585 19.5 е∞ПзїУ ...
зђђ19зЂ† дљњзФ®log4jињЫи°МжЧ•ењЧжУНдљЬ 564 19.1 log4jдїЛзїН 564 19.1.1 loggerзїДдїґ 564 19.1.2 appenderзїДдїґ 566 19.1.3 layoutзїДдїґ 567 19.2 дљњзФ®log4j 568 19.3 log4jдљњзФ®еЃЮдЊЛ 572 19.4 ndcеТМmdc 585 19.5 е∞ПзїУ ...