- жµПиІИ: 116412 жђ°
- жАІеИЂ:

- жЭ•иЗ™: ж≠¶ж±Й
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (98)
- java (27)
- jms (2)
- jta (0)
- жАІиГљи∞ГдЉШеПКеЖЕе≠ШеИЖжЮР (4)
- иЃЊиЃ°ж®°еЉП (14)
- ж°ЖжЮґ (6)
- еЕґеЃГ (9)
- job (1)
- maven (1)
- жЬНеК°еЩ® (2)
- еИЖеЄГеЉП (3)
- ibatis (1)
- linux (0)
- mysql (0)
- еєґеПСзЉЦз®Л (0)
- javaе§ЪзЇњз®Л (2)
- еЙНзЂѓиЈ®еЯЯ (1)
- зЇњз®ЛdumpеИЖжЮР (0)
- velocity (0)
- жХ∞жНЃеЇУ (2)
- еНПиЃЃ (0)
- зЫСжОІ (0)
- еЉАжЇРиљѓдїґ (2)
- зЃЧж≥Х (0)
- зљСзїЬ (1)
- spring (1)
- зЉЦз†Б (0)
- жХ∞жНЃзїУжЮД (0)
- HTableеТМHTablePoolдљњзФ®ж≥®жДПдЇЛй°є (0)
- opencms (0)
- android (16)
- жУНдљЬз≥їзїЯ (2)
- top (0)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2013-01 ( 3)
- 2012-12 ( 6)
- 2012-11 ( 2)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
hold_onпЉЪ
   @Override      public boolea ...
android listviewзЪДHeadViewеЈ¶еП≥еИЗжНҐеЫЊзЙЗпЉИдїњжЦ∞жµ™пЉМзљСжШУпЉМзЩЊеЇ¶з≠ЙеИЗжНҐеЫЊзЙЗпЉЙ -
achersnakeпЉЪ
123
ServletдЄ≠listenerпЉИзЫСеРђеЩ®пЉЙеТМfilterзЪДжАїзїУ -
angel243flyпЉЪ
жИСзФ®дЇЖињЩдЄ™жЦєж≥ХпЉМињШжШѓжК•еРМж†ЈзЪДйФЩиѓѓпЉМињШжЬЙдїАдєИеїЇиЃЃеРЧпЉЯ
eclipseжПРз§ЇCreateProcess error=87йФЩиѓѓзЪДиІ£еЖ≥жЦєж≥Х
 
иљђпЉЪhttp://blog.csdn.net/v_JULY_v/article/details/6530142
дљЬиАЕпЉЪ July гАБweedgeгАБ Frankie гАВзЉЦз®ЛиЙЇжЬѓеЃ§еЗЇеУБгАВ
иѓіжШОпЉЪжЬђжЦЗдїО B ж†СеЉАеІЛи∞ИиµЈпЉМзДґеРОиЃЇињ∞ B+ж†СгАБB* ж†СпЉМжЬАеРОи∞ИеИ∞ R ж†СгАВеЕґдЄ≠ B ж†СгАБ B+ ж†СеПКB*ж†СйГ®еИЖзФ±weedgeеЃМжИРпЉМ R ж†СйГ®еИЖзФ± Frankie еЃМжИРпЉМеЕ®жЦЗжЬАзїИзФ± July зїЯз®њдњЃиЃҐеЃМжИРгАВ
еЗЇе§ДпЉЪhttp://blog.csdn.net/v_JULY_v ¬† гАВ
 
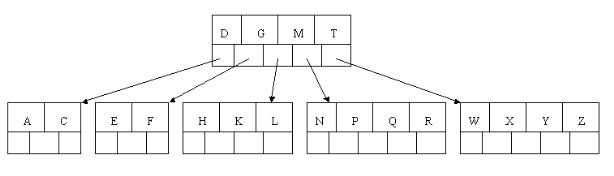
зђђдЄАиКВгАБ B ж†СгАБ B+ ж†СгАБB*ж†С
1. еЙНи®АпЉЪ
еК®жАБжЯ•жЙЊж†СдЄїи¶БжЬЙпЉЪдЇМеПЙжЯ•жЙЊж†СпЉИBinary Search TreeпЉЙпЉМеє≥и°°дЇМеПЙжЯ•жЙЊж†СпЉИBalanced Binary Search TreeпЉЙпЉМзЇҐйїСж†С (Red-Black Tree )пЉМB-tree/B+ -tree/ B* -tree (B~Tree)гАВеЙНдЄЙиАЕжШѓеЕЄеЮЛзЪДдЇМеПЙжЯ•жЙЊж†СзїУжЮДпЉМеЕґжЯ•жЙЊзЪДжЧґйЧіе§НжЭВеЇ¶O (log2N ) дЄОж†СзЪДжЈ±еЇ¶зЫЄеЕ≥пЉМйВ£дєИйЩНдљОж†СзЪДжЈ±еЇ¶иЗ™зДґдЉЪжПРйЂШжЯ•жЙЊжХИзОЗгАВ
дљЖжШѓеТ±дїђжЬЙйЭҐеѓєињЩж†ЈдЄАдЄ™еЃЮйЩЕйЧЃйҐШпЉЪе∞±жШѓе§ІиІДж®°жХ∞жНЃе≠ШеВ®дЄ≠пЉМеЃЮзО∞糥еЉХжߕ胥ињЩж†ЈдЄАдЄ™еЃЮйЩЕиГМжЩѓдЄЛпЉМж†СиКВзВєе≠ШеВ®зЪДеЕГзі†жХ∞йЗПжШѓжЬЙйЩРзЪДпЉИе¶ВжЮЬеЕГзі†жХ∞йЗПйЭЮеЄЄе§ЪзЪДиѓЭпЉМжЯ•жЙЊе∞±йААеМЦжИРиКВзВєеЖЕйГ®зЪДзЇњжАІжЯ•жЙЊдЇЖпЉЙпЉМињЩж†ЈеѓЉиЗідЇМеПЙжЯ•жЙЊж†СзїУжЮДзФ±дЇОж†СзЪДжЈ±еЇ¶ињЗе§ІиАМйА†жИРз£БзЫШI/OиѓїеЖЩињЗдЇОйҐСзєБпЉМињЫиАМеѓЉиЗіжߕ胥жХИзОЗдљОдЄЛ пЉИдЄЇдїАдєИдЉЪеЗЇзО∞ињЩзІНжГЕеЖµпЉМеЊЕдЉЪеЬ®е§ЦйГ®е≠ШеВ®еЩ®-з£БзЫШдЄ≠жЬЙжЙАиІ£йЗКпЉЙпЉМйВ£дєИе¶ВдљХеЗПе∞Сж†СзЪДжЈ±еЇ¶пЉИељУзДґжШѓдЄНиГљеЗПе∞Сжߕ胥зЪДжХ∞жНЃйЗПпЉЙпЉМдЄАдЄ™еЯЇжЬђзЪДжГ≥ж≥Хе∞±жШѓпЉЪйЗЗзФ®е§ЪеПЙж†С зїУжЮДпЉИзФ±дЇОж†СиКВзВєеЕГзі†жХ∞йЗПжШѓжЬЙйЩРзЪДпЉМиЗ™зДґиѓ•иКВзВєзЪДе≠Рж†СжХ∞йЗПдєЯе∞±жШѓжЬЙйЩРзЪДпЉЙгАВ
дєЯ е∞±жШѓиѓіпЉМеЫ†дЄЇз£БзЫШзЪДжУНдљЬиієжЧґиієиµДжЇРпЉМе¶ВжЮЬињЗдЇОйҐСзєБзЪДе§Ъжђ°жЯ•жЙЊеКњењЕжХИзОЗдљОдЄЛгАВйВ£дєИе¶ВдљХжПРйЂШжХИзОЗпЉМеН≥е¶ВдљХйБњеЕНз£БзЫШињЗдЇОйҐСзєБзЪДе§Ъжђ°жЯ•жЙЊеСҐпЉЯж†єжНЃз£БзЫШжЯ•жЙЊе≠ШеПЦзЪДжђ° жХ∞еЊАеЊАзФ±ж†СзЪДйЂШеЇ¶жЙАеЖ≥еЃЪпЉМжЙАдї•пЉМеП™и¶БжИСдїђйАЪињЗжЯРзІНиЊГе•љзЪДж†СзїУжЮДеЗПе∞Сж†СзЪДзїУжЮДе∞љйЗПеЗПе∞Сж†СзЪДйЂШеЇ¶пЉМйВ£дєИжШѓдЄНжШѓдЊњиГљжЬЙжХИеЗПе∞Сз£БзЫШжЯ•жЙЊе≠ШеПЦзЪДжђ°жХ∞еСҐпЉЯйВ£ињЩзІНжЬЙжХИзЪД ж†СзїУжЮДжШѓдЄАзІНжАОж†ЈзЪДж†СеСҐпЉЯ
ињЩж†ЈжИСдїђе∞±жПРеЗЇдЇЖдЄАдЄ™жЦ∞зЪДжЯ•жЙЊж†СзїУжЮДвАФвАФе§ЪиЈѓжЯ•жЙЊж†СгАВж†єжНЃеє≥и°°дЇМеПЙж†СзЪДеРѓеПСпЉМиЗ™зДґе∞±жГ≥еИ∞еє≥и°°е§ЪиЈѓжЯ•жЙЊж†СзїУжЮДпЉМдєЯе∞±жШѓињЩзѓЗжЦЗзЂ†жЙАи¶БйШРињ∞зЪДзђђдЄАдЄ™дЄїйҐШB~treeпЉМ еН≥Bж†СзїУжЮД(еРОйЭҐпЉМжИСдїђе∞ЖзЬЛеИ∞пЉМBж†СзЪДеРДзІНжУНдљЬиГљдљњBж†СдњЭжМБиЊГдљОзЪДйЂШеЇ¶пЉМдїОиАМиЊЊеИ∞жЬЙжХИйБњеЕНз£БзЫШињЗдЇОйҐСзєБзЪДжЯ•жЙЊе≠ШеПЦжУНдљЬпЉМдїОиАМжЬЙжХИжПРйЂШжЯ•жЙЊжХИзОЗ)гАВ
B-treeпЉИB-treeж†СеН≥Bж†С пЉМBеН≥BalancedпЉМеє≥и°°зЪДжДПжАЭпЉЙињЩж£µз•Юе•ЗзЪДж†СжШѓеЬ® Rudolf Bayer ,¬†Edward M. McCreight (1970) еЖЩзЪДдЄАзѓЗиЃЇжЦЗгАК Organization and Maintenance of Large Ordered Indices гАЛдЄ≠й¶Цжђ°жПРеЗЇзЪДпЉИ wikipedia дЄ≠пЉЪ http://en.wikipedia.org/wiki/B-tree пЉМйШРињ∞дЇЖ B-tree еРНе≠ЧжЭ•жЇРдї•еПКзЫЄеЕ≥зЪДеЉАжЇРеЬ∞еЭАпЉЙгАВ
еЬ®еЉАеІЛдїЛзїН B~tree дєЛеЙНпЉМеЕИдЇЖиІ£дЄЛзЫЄеЕ≥зЪДз°ђдїґзЯ•иѓЖпЉМжЙНиГљеЊИе•љзЪДдЇЖиІ£дЄЇдїАдєИйЬАи¶Б B~tree ињЩзІНе§Це≠ШжХ∞жНЃзїУжЮДгАВ ¬†
 
2. е§Це≠ШеВ®еЩ® вАФ з£БзЫШ
иЃ°зЃЧжЬЇе≠ШеВ®иЃЊе§ЗдЄАиИђеИЖдЄЇдЄ§зІН пЉЪ еЖЕе≠ШеВ®еЩ® (main memory) еТМе§Це≠ШеВ®еЩ® (external memory) гАВ еЖЕе≠Ше≠ШеПЦйАЯеЇ¶ењЂпЉМдљЖеЃєйЗПе∞ПпЉМдїЈж†ЉжШВиіµпЉМиАМдЄФдЄНиГљйХњжЬЯдњЭе≠ШжХ∞жНЃ ( еЬ®дЄНйАЪзФµжГЕеЖµдЄЛжХ∞жНЃдЉЪжґИ姱 ) гАВ
е§Це≠ШеВ®еЩ®вАФз£БзЫШжШѓдЄАзІНзЫіжО•е≠ШеПЦзЪДе≠ШеВ®иЃЊе§З (DASD) гАВеЃГжШѓдї•е≠ШеПЦжЧґйЧіеПШеМЦдЄНе§ІдЄЇзЙєеЊБзЪДгАВеПѓдї•зЫіжО•е≠ШеПЦдїїдљХе≠Чзђ¶зїДпЉМдЄФеЃєйЗПе§ІгАБйАЯеЇ¶иЊГеЕґеЃГе§Це≠ШиЃЊе§ЗжЫіењЂгАВ
2.1 з£БзЫШзЪДжЮДйА†
з£БзЫШжШѓдЄАдЄ™жЙБеє≥зЪДеЬЖзЫШ ( дЄОзФµеФ±жЬЇзЪДеФ±зЙЗз±їдЉЉ ) гАВзЫШйЭҐдЄКжЬЙиЃЄе§ЪзІ∞дЄЇз£БйБУзЪДеЬЖеЬИпЉМжХ∞жНЃе∞±иЃ∞ељХеЬ®ињЩдЇЫз£БйБУдЄКгАВз£БзЫШеПѓдї•жШѓеНХзЙЗзЪДпЉМдєЯеПѓдї•жШѓзФ±иЛ•еє≤зЫШзЙЗзїДжИРзЪДзЫШзїДпЉМжѓПдЄАзЫШзЙЗдЄКжЬЙдЄ§дЄ™йЭҐгАВе¶ВдЄЛеЫЊ11.3дЄ≠жЙАз§ЇзЪД 6 зЙЗзЫШзїДдЄЇдЊЛпЉМйЩ§еОїжЬАй°ґзЂѓеТМжЬАеЇХзЂѓзЪДе§ЦдЊІйЭҐдЄНе≠ШеВ®жХ∞жНЃдєЛе§ЦпЉМдЄАеЕ±жЬЙ 10 дЄ™йЭҐеПѓдї•зФ®жЭ•дњЭе≠Шдњ°жБѓгАВ
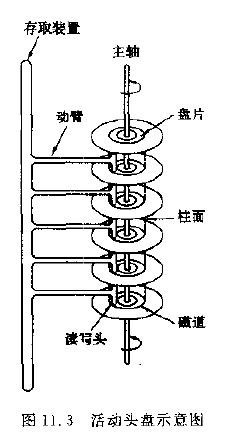                            
                           
 
ељУз£БзЫШй©±еК®еЩ®жЙІи°Миѓї / еЖЩеКЯиГљжЧґгАВзЫШзЙЗи£ЕеЬ®дЄАдЄ™дЄїиљідЄКпЉМеєґзїХдЄїиљійЂШйАЯжЧЛиљђпЉМељУз£БйБУеЬ®иѓї / еЖЩе§і ( еПИеПЂз£Бе§і ) дЄЛйАЪињЗжЧґпЉМе∞±еПѓдї•ињЫи°МжХ∞жНЃзЪДиѓї / еЖЩдЇЖгАВ
дЄАиИђз£БзЫШеИЖдЄЇеЫЇеЃЪе§ізЫШ ( з£Бе§іеЫЇеЃЪ ) еТМжіїеК®е§ізЫШгАВеЫЇеЃЪе§ізЫШзЪДжѓПдЄАдЄ™з£БйБУдЄКйГљжЬЙзЛђзЂЛзЪДз£Бе§іпЉМеЃГжШѓеЫЇеЃЪдЄНеК®зЪДпЉМдЄУйЧ®иіЯиі£ињЩдЄАз£БйБУдЄКжХ∞жНЃзЪДиѓї / еЖЩгАВ
жіїеК®е§ізЫШ ( е¶ВдЄКеЫЊ ) зЪДз£Бе§іжШѓеПѓзІїеК®зЪДгАВжѓПдЄАдЄ™зЫШйЭҐдЄКеП™жЬЙдЄАдЄ™з£Бе§і ( з£Бе§іжШѓеПМеРСзЪДпЉМеЫ†ж≠§ж≠£еПНзЫШйЭҐйГљиГљиѓїеЖЩ ) гАВеЃГеПѓдї•дїОиѓ•йЭҐзЪДдЄАдЄ™з£БйБУзІїеК®еИ∞еП¶дЄАдЄ™з£БйБУгАВжЙАжЬЙз£Бе§ійГљи£ЕеЬ®еРМдЄАдЄ™еК®иЗВдЄКпЉМеЫ†ж≠§дЄНеРМзЫШйЭҐдЄКзЪДжЙАжЬЙз£Бе§ійГљжШѓеРМжЧґзІїеК®зЪД ( и°МеК®жХійљРеИТдЄА ) гАВељУзЫШзЙЗзїХдЄїиљіжЧЛиљђзЪДжЧґеАЩпЉМз£Бе§ідЄОжЧЛиљђзЪДзЫШзЙЗ嚥жИРдЄАдЄ™еЬЖжЯ±дљУгАВеРДдЄ™зЫШйЭҐдЄКеНКеЊДзЫЄеРМзЪДз£БйБУзїДжИРдЇЖдЄАдЄ™еЬЖжЯ±йЭҐпЉМжИСдїђзІ∞дЄЇжЯ±йЭҐ гАВеЫ†ж≠§пЉМжЯ±йЭҐзЪДдЄ™жХ∞дєЯе∞±жШѓзЫШйЭҐдЄКзЪДз£БйБУжХ∞гАВ ¬†
2.2 з£БзЫШзЪДиѓї / еЖЩеОЯзРЖеТМжХИзОЗ
з£БзЫШдЄКжХ∞жНЃењЕй°їзФ®дЄАдЄ™дЄЙзїіеЬ∞еЭАеФѓдЄАж†Зз§ЇпЉЪжЯ±йЭҐеПЈгАБзЫШйЭҐеПЈгАБеЭЧеПЈ ( з£БйБУдЄКзЪДзЫШеЭЧ ) гАВ
иѓї / еЖЩз£БзЫШдЄКжЯРдЄАжМЗеЃЪжХ∞жНЃйЬАи¶БдЄЛйЭҐ 3 дЄ™ж≠•й™§пЉЪ
(1)¬† й¶ЦеЕИзІїеК®иЗВж†єжНЃжЯ±йЭҐеПЈдљњз£Бе§ізІїеК®еИ∞жЙАйЬАи¶БзЪДжЯ±йЭҐдЄКпЉМињЩдЄАињЗз®Л襀зІ∞дЄЇеЃЪдљНжИЦжЯ•жЙЊ гАВ
(2)¬† е¶ВдЄКеЫЊ11.3дЄ≠жЙАз§ЇзЪД 6 зЫШзїДз§ЇжДПеЫЊдЄ≠пЉМжЙАжЬЙз£Бе§ійГљеЃЪдљНеИ∞дЇЖ 10 дЄ™зЫШйЭҐзЪД 10 жЭ°з£БйБУдЄК ( з£Бе§ійГљжШѓеПМеРСзЪД ) гАВињЩжЧґж†єжНЃзЫШйЭҐеПЈжЭ•з°ЃеЃЪжМЗеЃЪзЫШйЭҐдЄКзЪДз£БйБУгАВ
(3) зЫШйЭҐз°ЃеЃЪдї•еРОпЉМзЫШзЙЗеЉАеІЛжЧЛиљђпЉМе∞ЖжМЗеЃЪеЭЧеПЈзЪДз£БйБУжЃµзІїеК®иЗ≥з£Бе§ідЄЛгАВ
зїПињЗдЄКйЭҐдЄЙдЄ™ж≠•й™§пЉМжМЗеЃЪжХ∞жНЃзЪДе≠ШеВ®дљНзљЃе∞±иҐЂжЙЊеИ∞гАВињЩжЧґе∞±еПѓдї•еЉАеІЛиѓї / еЖЩжУНдљЬдЇЖгАВ
иЃњйЧЃжЯРдЄАеЕЈдљУдњ°жБѓпЉМзФ± 3 йГ®еИЖжЧґйЧізїДжИРпЉЪ
вЧП жЯ•жЙЊжЧґйЧі (seek time) Ts: еЃМжИРдЄКињ∞ж≠•й™§ (1) жЙАйЬАи¶БзЪДжЧґйЧігАВињЩйГ®еИЖжЧґйЧідї£дїЈжЬАйЂШпЉМжЬАе§ІеПѓиЊЊеИ∞ 0.1s еЈ¶еП≥гАВ
вЧП з≠ЙеЊЕжЧґйЧі (latency time) Tl: еЃМжИРдЄКињ∞ж≠•й™§ (3) жЙАйЬАи¶БзЪДжЧґйЧігАВзФ±дЇОзЫШзЙЗзїХдЄїиљіжЧЛиљђйАЯеЇ¶еЊИењЂпЉМдЄАиИђдЄЇ 7200 иљђ / еИЖ ( зФµиДСз°ђзЫШзЪДжАІиГљжМЗж†ЗдєЛдЄА , еЃґзФ®зЪДжЩЃйАЪз°ђзЫШзЪДиљђйАЯдЄАиИђжЬЙ 5400rpm( зђФиЃ∞жЬђ ) гАБ 7200rpm еЗ†зІН ) гАВ еЫ†ж≠§дЄАиИђжЧЛиљђдЄАеЬИе§ІзЇ¶ 0.0083s гАВ
вЧП дЉ†иЊУжЧґйЧі (transmission time) Tt: жХ∞жНЃйАЪињЗз≥їзїЯжАїзЇњдЉ†йАБеИ∞еЖЕе≠ШзЪДжЧґйЧіпЉМдЄАиИђдЉ†иЊУдЄАдЄ™е≠ЧиКВ (byte) е§Іж¶В 0.02us=2*10^(-8)s
з£БзЫШиѓїеПЦжХ∞жНЃжШѓдї•зЫШеЭЧ (block) дЄЇеЯЇжЬђеНХдљНзЪДгАВ дљНдЇОеРМдЄАзЫШеЭЧдЄ≠зЪДжЙАжЬЙжХ∞жНЃйГљиÚ襀дЄАжђ°жАІеЕ®йГ®иѓїеПЦеЗЇжЭ•гАВиАМз£БзЫШ IO дї£дїЈдЄїи¶БиК±иієеЬ®жЯ•жЙЊжЧґйЧі Ts дЄКгАВеЫ†ж≠§жИСдїђеЇФиѓ•е∞љйЗПе∞ЖзЫЄеЕ≥дњ°жБѓе≠ШжФЊеЬ®еРМдЄАзЫШеЭЧпЉМеРМдЄАз£БйБУдЄ≠гАВжИЦиАЕиЗ≥е∞СжФЊеЬ®еРМдЄАжЯ±йЭҐжИЦзЫЄйВїжЯ±йЭҐдЄКпЉМдї•ж±ВеЬ®иѓї / еЖЩдњ°жБѓжЧґе∞љйЗПеЗПе∞Сз£Бе§іжЭ•еЫЮзІїеК®зЪДжђ°жХ∞пЉМйБњеЕНињЗе§ЪзЪДжЯ•жЙЊжЧґйЧі Ts гАВ
жЙАдї•пЉМеЬ®е§ІиІДж®°жХ∞жНЃе≠ШеВ®жЦєйЭҐпЉМе§ІйЗПжХ∞жНЃе≠ШеВ®еЬ®е§Це≠Шз£БзЫШдЄ≠пЉМиАМеЬ®е§Це≠Шз£БзЫШдЄ≠иѓїеПЦ / еЖЩеЕ•еЭЧ (block) дЄ≠жЯРжХ∞жНЃжЧґпЉМй¶ЦеЕИйЬАи¶БеЃЪдљНеИ∞з£БзЫШдЄ≠зЪДжЯРеЭЧпЉМе¶ВдљХжЬЙжХИеЬ∞жЯ•жЙЊз£БзЫШдЄ≠зЪДжХ∞жНЃпЉМйЬАи¶БдЄАзІНеРИзРЖйЂШжХИзЪДе§Це≠ШжХ∞жНЃзїУжЮДпЉМе∞±жШѓдЄЛйЭҐжЙАи¶БйЗНзВєйШРињ∞зЪД B-tree зїУжЮДпЉМдї•еПКзЫЄеЕ≥зЪДеПШзІНзїУжЮДпЉЪ B+ -treeзїУжЮДеТМB* -treeзїУжЮДгАВ
3. B- ж†С ¬†
¬†еЕЈдљУиЃ≤иІ£дєЛеЙНпЉМжЬЙдЄАзВєпЉМеЖНжђ°еЉЇи∞ГдЄЛпЉЪB-ж†СпЉМеН≥дЄЇBж†С гАВеЫ†дЄЇBж†СзЪДеОЯиЛ±жЦЗеРНзІ∞дЄЇB-treeпЉМиАМеЫљеЖЕеЊИе§ЪдЇЇеЦЬ搥жККB-treeиѓСдљЬB-ж†СпЉМеЕґеЃЮпЉМињЩжШѓдЄ™йЭЮеЄЄдЄНе•љзЪДзЫіиѓСпЉМеЊИеЃєжШУиЃ©дЇЇдЇІзФЯиѓѓиІ£гАВе¶ВдЇЇдїђеПѓиГљдЉЪдї•дЄЇB-ж†СжШѓдЄАзІНж†СпЉМиАМBж†СеПИжШѓдЄАзІНдЄАзІНж†СгАВиАМдЇЛеЃЮдЄКжШѓпЉМB-treeе∞±жШѓжМЗзЪДBж†С гАВзЙєж≠§иѓіжШОгАВ
жИС дїђзЯ•йБУпЉМB ж†СжШѓдЄЇдЇЖз£БзЫШжИЦеЕґеЃГе≠ШеВ®иЃЊе§ЗиАМиЃЊиЃ°зЪДдЄАзІНе§ЪеПЙпЉИдЄЛйЭҐдљ†дЉЪзЬЛеИ∞пЉМзЫЄеѓєдЇОдЇМеПЙпЉМBж†СжѓПдЄ™еЖЕзїУзВєжЬЙе§ЪдЄ™еИЖжФѓпЉМеН≥е§ЪеПЙпЉЙеє≥и°°жЯ•жЙЊж†СгАВдЄОжЬђblogдєЛеЙНдїЛзїНзЪДзЇҐйїСж†С еЊИзЫЄдЉЉпЉМдљЖеЬ®йЩНдљОз£БзЫШI/0жУНдљЬжЦєйЭҐи¶БжЫіе•љдЄАдЇЫгАВиЃЄе§ЪжХ∞жНЃеЇУз≥їзїЯйГљдЄАиИђдљњзФ®Bж†СжИЦиАЕBж†СзЪДеРДзІНеПШ嚥зїУжЮДпЉМе¶ВдЄЛжЦЗеН≥е∞Жи¶БдїЛзїНзЪДB+ж†СпЉМB*ж†СжЭ•е≠ШеВ®дњ°жБѓгАВ
¬†B ж†СдЄОзЇҐйїСж†СжЬАе§ІзЪДдЄНеРМеЬ®дЇОпЉМBж†СзЪДзїУзВєеПѓдї•жЬЙиЃЄе§Ъе≠Ре•≥пЉМдїОеЗ†дЄ™еИ∞еЗ†еНГдЄ™гАВйВ£дЄЇдїАдєИеПИиѓіBж†СдЄОзЇҐйїСж†СеЊИзЫЄдЉЉеСҐ?еЫ†дЄЇдЄОзЇҐйїСж†СдЄАж†ЈпЉМдЄАж£µеРЂnдЄ™зїУзВєзЪДBж†СзЪДйЂШ еЇ¶дєЯдЄЇOпЉИlgnпЉЙпЉМдљЖеПѓиГљжѓФдЄАж£µзЇҐйїСж†СзЪДйЂШеЇ¶е∞ПиЃЄе§ЪпЉМеЇФдЄЇеЃГзЪДеИЖжФѓеЫ†е≠РжѓФиЊГе§ІгАВжЙАдї•пЉМBж†СеПѓдї•еЬ®OпЉИlognпЉЙжЧґйЧіеЖЕпЉМеЃЮзО∞еРДзІНе¶ВжПТеЕ• пЉИinsertпЉЙпЉМеИ†йЩ§пЉИdeleteпЉЙз≠ЙеК®жАБйЫЖеРИжУНдљЬгАВ
е¶В дЄЛеЫЊжЙАз§ЇпЉМеН≥жШѓдЄАж£µBж†СпЉМдЄАж£µеЕ≥йФЃе≠ЧдЄЇиЛ±иѓ≠дЄ≠иЊЕйЯ≥е≠ЧжѓНзЪДBж†СпЉМзО∞еЬ®и¶БдїОж†СзІНжЯ•жЙЊе≠ЧжѓНRпЉИеМЕеРЂn[x]дЄ™еЕ≥йФЃе≠ЧзЪДеЖЕзїУзВєxпЉМxжЬЙn[x]+1]дЄ™е≠Ре•≥пЉИдєЯе∞± жШѓиѓіпЉМдЄАдЄ™еЖЕзїУзВєxиЛ•еРЂжЬЙn[x]дЄ™еЕ≥йФЃе≠ЧпЉМйВ£дєИxе∞ЖеРЂжЬЙn[x]+1дЄ™е≠Ре•≥пЉЙгАВжЙАжЬЙзЪДеПґзїУзВєйГље§ДдЇОзЫЄеРМзЪДжЈ±еЇ¶пЉМеЄ¶йШіељ±зЪДзїУзВєдЄЇжЯ•жЙЊе≠ЧжѓНRжЧґи¶Бж£АжЯ•зЪДзїУ зВєпЉЙпЉЪ
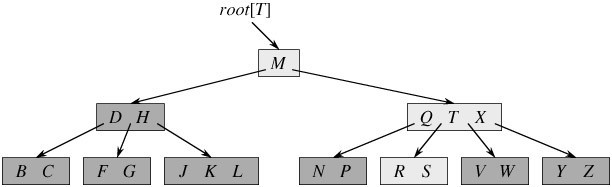  
 
зЫЄдњ°пЉМдїОдЄКеЫЊдљ†иГљиљїжШУзЪДзЬЛеИ∞пЉМдЄАдЄ™еЖЕзїУзВєxиЛ•еРЂжЬЙn[x]дЄ™еЕ≥йФЃе≠ЧпЉМйВ£дєИxе∞ЖеРЂжЬЙn[x]+1дЄ™е≠Ре•≥гАВе¶ВеРЂжЬЙ2дЄ™еЕ≥йФЃе≠ЧD H зЪДеЖЕзїУзВєжЬЙ3дЄ™е≠Ре•≥пЉМиАМеРЂжЬЙ3дЄ™еЕ≥йФЃе≠ЧQ T X зЪДеЖЕзїУзВєжЬЙ4дЄ™е≠Ре•≥гАВ
 
B ж†СеПИеПЂеє≥и°°е§ЪиЈѓжЯ•жЙЊж†СгАВдЄАж£µ m йШґзЪД B ж†С (m еПЙж†С ) зЪДзЙєжАІе¶ВдЄЛ пЉЪ
-
ж†СдЄ≠жѓПдЄ™зїУзВєжЬАе§ЪеРЂжЬЙmдЄ™е≠©е≠РпЉИm>=2пЉЙпЉЫ
-
йЩ§ж†єзїУзВєеТМеПґе≠РзїУзВєе§ЦпЉМеЕґеЃГжѓПдЄ™зїУзВєиЗ≥е∞СжЬЙ[ceil(m / 2)]дЄ™е≠©е≠РпЉИеЕґдЄ≠ceil(x)жШѓдЄАдЄ™еПЦдЄКйЩРзЪДеЗљжХ∞ пЉЙпЉЫ
-
иЛ•ж†єзїУзВєдЄНжШѓеПґе≠РзїУзВєпЉМеИЩиЗ≥е∞СжЬЙ2дЄ™е≠©е≠РпЉИзЙєжЃКжГЕеЖµпЉЪж≤°жЬЙе≠©е≠РзЪДж†єзїУзВєпЉМеН≥ж†єзїУзВєдЄЇеПґе≠РзїУзВєпЉМжХіж£µж†СеП™жЬЙдЄАдЄ™ж†єиКВзВєпЉЙпЉЫ
-
жЙАжЬЙеПґе≠РзїУзВєйГљеЗЇзО∞еЬ®еРМдЄАе±ВпЉМеПґе≠РзїУзВєдЄНеМЕеРЂдїїдљХеЕ≥йФЃе≠Чдњ°жБѓ(еПѓдї•зЬЛеБЪжШѓе§ЦйГ®жО•зВєжИЦжߕ胥姱賕зЪДжО•зВєпЉМеЃЮйЩЕдЄКињЩдЇЫзїУзВєдЄНе≠ШеЬ®пЉМжМЗеРСињЩдЇЫзїУзВєзЪДжМЗйТИйГљдЄЇnull)пЉЫпЉИиѓїиАЕеПНй¶И@еЖЈе≤≥ пЉЪињЩйЗМжЬЙйФЩпЉМеПґе≠РиКВзВєеП™жШѓж≤°жЬЙе≠©е≠РеТМжМЗеРСе≠©е≠РзЪДжМЗйТИпЉМињЩдЇЫиКВзВєдєЯе≠ШеЬ®пЉМдєЯжЬЙеЕГзі†гАВ@JULYпЉЪеЕґеЃЮпЉМеЕ≥йФЃжШѓжККдїАдєИељУеБЪеПґе≠РзїУзВєпЉМеЫ†дЄЇе¶ВзЇҐйїСж†СдЄ≠пЉМжѓПдЄАдЄ™NULLжМЗйТИеН≥ељУеБЪеПґе≠РзїУзВєпЉМеП™жШѓж≤°зФїеЗЇжЭ•иАМеЈ≤ пЉЙгАВ
-
жѓПдЄ™йЭЮзїИзЂѓзїУзВєдЄ≠еМЕеРЂжЬЙnдЄ™еЕ≥йФЃе≠Чдњ°жБѓпЉЪ (nпЉМP0пЉМK1пЉМP1пЉМK2пЉМP2пЉМ......пЉМKnпЉМPn)гАВеЕґдЄ≠пЉЪ
¬†¬†¬†¬† ¬†¬†a)¬†¬† Ki (i=1...n)дЄЇеЕ≥йФЃе≠ЧпЉМдЄФеЕ≥йФЃе≠ЧжМЙй°ЇеЇПеНЗеЇПжОТеЇПK(i-1)< KiгАВ
¬†¬†¬†¬† ¬†¬†b)¬†¬† PiдЄЇжМЗеРСе≠Рж†Сж†єзЪДжО•зВєпЉМдЄФжМЗйТИP(i-1)жМЗеРСе≠Рж†СзІНжЙАжЬЙзїУзВєзЪДеЕ≥йФЃе≠ЧеЭЗе∞ПдЇОKiпЉМдљЖйГље§ІдЇОK(i-1)гАВ¬†
¬†¬†¬†¬†¬†¬†¬†c)¬†¬† еЕ≥йФЃе≠ЧзЪДдЄ™жХ∞nењЕй°їжї°иґ≥пЉЪ [ceil(m / 2)-1]<= n <= m-1гАВ е¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

¬† ¬† йТИеѓєдЄКйЭҐзђђ5зВєпЉМеЖНйШРињ∞дЄЛпЉЪBж†СдЄ≠жѓПдЄАдЄ™зїУзВєиГљеМЕеРЂзЪДеЕ≥йФЃе≠ЧпЉИе¶ВдєЛеЙНдЄКйЭҐзЪДD H еТМQ T X пЉЙжХ∞жЬЙдЄАдЄ™дЄКзХМеТМдЄЛзХМгАВињЩдЄ™дЄЛзХМеПѓдї•зФ®дЄАдЄ™зІ∞дљЬBж†СзЪДжЬАе∞ПеЇ¶жХ∞пЉИзЃЧж≥ХеѓЉиЃЇдЄ≠жЦЗзЙИдЄКиѓСдљЬеЇ¶жХ∞пЉМжЬАе∞ПеЇ¶жХ∞еН≥еЖЕиКВзВєдЄ≠иКВзВєжЬАе∞Пе≠©е≠РжХ∞зЫЃ пЉЙtпЉИt>=2пЉЙи°®з§ЇгАВ
-
жѓПдЄ™йЭЮж†єзЪДзїУзВєењЕй°їиЗ≥е∞СеРЂжЬЙt-1дЄ™еЕ≥йФЃе≠ЧгАВжѓПдЄ™йЭЮж†єзЪДеЖЕзїУзВєиЗ≥е∞СжЬЙtдЄ™е≠Ре•≥гАВе¶ВжЮЬж†СжШѓйЭЮз©ЇзЪДпЉМеИЩж†єзїУзВєиЗ≥е∞СеМЕеРЂдЄАдЄ™еЕ≥йФЃе≠ЧпЉЫ
-
жѓПдЄ™зїУзВєеПѓеМЕеРЂдєЛе§Ъ2t-1дЄ™еЕ≥йФЃе≠ЧгАВжЙАдї•дЄАдЄ™еЖЕзїУзВєиЗ≥е§ЪеПѓжЬЙ2tдЄ™е≠Ре•≥гАВе¶ВжЮЬдЄАдЄ™зїУзВєжБ∞е•љжЬЙ2t-1дЄ™еЕ≥йФЃе≠ЧпЉМжИСдїђе∞±иѓіињЩдЄ™зїУзВєжШѓжї°зЪДпЉИиАМз®НеРОдїЛзїНзЪДB*ж†СдљЬдЄЇBж†СзЪДдЄАзІНеЄЄзФ®еПШ嚥пЉМB*ж†СдЄ≠и¶Бж±ВжѓПдЄ™еЖЕзїУзВєиЗ≥е∞СдЄЇ2/3жї°пЉМиАМдЄНжШѓеГПињЩйЗМзЪДBж†СжЙАи¶Бж±ВзЪДиЗ≥е∞СеНКжї° пЉЙпЉЫ
-
ељУеЕ≥йФЃе≠ЧжХ∞t=2пЉИt=2зЪДжДПжАЭжШѓпЉМt min =2пЉМtеПѓдї•>=2пЉЙжЧґзЪДBж†СжШѓжЬАзЃАеНХзЪД пЉИ жЬЙеЊИе§ЪдЇЇдЉЪеЫ†ж≠§иѓѓиЃ§дЄЇBж†Се∞±жШѓдЇМеПЙжЯ•жЙЊж†СпЉМдљЖдЇМеПЙжЯ•жЙЊж†Се∞±жШѓдЇМеПЙжЯ•жЙЊж†СпЉМBж†Се∞±жШѓBж†СпЉМBж†СзЪДзЬЯж≠£жЬАеЗЖз°ЃзЪДеЃЪдєЙдЄЇпЉЪдЄАж£µеРЂжЬЙtпЉИt>=2пЉЙдЄ™еЕ≥йФЃе≠ЧзЪДеє≥и°°е§ЪиЈѓжЯ•жЙЊж†СпЉЙ гАВжѓПдЄ™еЖЕзїУзВєеПѓиГљеЫ†ж≠§иАМеРЂжЬЙ2дЄ™гАБ3дЄ™жИЦ4дЄ™е≠Ре•≥пЉМдЇ¶еН≥дЄАж£µ2-3-4ж†СпЉМзДґиАМеЬ®еЃЮйЩЕдЄ≠пЉМйАЪеЄЄйЗЗзФ®е§ІеЊЧе§ЪзЪДtеАЉгАВ
¬† ¬† Bж†СдЄ≠зЪДжѓПдЄ™зїУзВєж†єжНЃеЃЮйЩЕжГЕеЖµеПѓдї•еМЕеРЂе§ІйЗПзЪДеЕ≥йФЃе≠Чдњ°жБѓеТМеИЖжФѓ(ељУзДґжШѓдЄНиГљиґЕињЗз£БзЫШеЭЧзЪДе§Іе∞ПпЉМж†єжНЃз£БзЫШй©±еК®(disk drives)зЪДдЄНеРМпЉМдЄАиИђеЭЧзЪДе§Іе∞ПеЬ®1k~4kеЈ¶еП≥)пЉЫињЩж†Јж†СзЪДжЈ±еЇ¶йЩНдљОдЇЖпЉМињЩе∞±жДПеС≥зЭАжЯ•жЙЊдЄАдЄ™еЕГзі†еП™и¶БеЊИе∞СзїУзВєдїОе§Це≠Шз£БзЫШдЄ≠иѓїеЕ•еЖЕе≠ШпЉМеЊИењЂиЃњйЧЃеИ∞и¶БжЯ• жЙЊзЪДжХ∞жНЃгАВ
¬† ¬† Bж†СзЪДз±їеЮЛеТМиКВзВєеЃЪдєЙе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

 
 
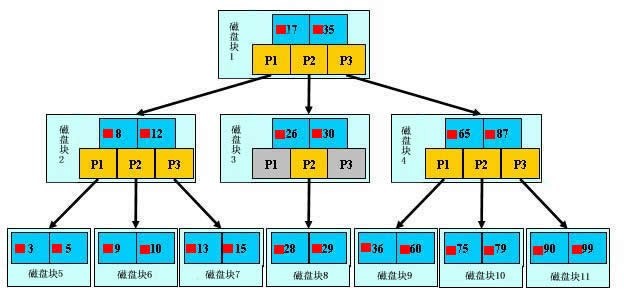
 
дЄЇдЇЖзЃАеНХпЉМињЩйЗМзФ®е∞СйЗПжХ∞жНЃжЮДйА†дЄАж£µ3еПЙж†СзЪД嚥еЉПпЉМеЃЮйЩЕеЇФзФ®дЄ≠зЪД B ж†СзїУзВєдЄ≠еЕ≥йФЃе≠ЧеЊИе§ЪзЪДгАВдЄКйЭҐзЪДеЫЊдЄ≠жѓФе¶Вж†єзїУзВєпЉМеЕґдЄ≠ 17и°®з§ЇдЄАдЄ™з£БзЫШ жЦЗдїґзЪДжЦЗдїґеРНпЉЫе∞ПзЇҐжЦєеЭЧи°®з§ЇињЩдЄ™17жЦЗдїґеЖЕеЃєеЬ®з°ђзЫШдЄ≠зЪДе≠ШеВ®дљНзљЃпЉЫp1и°®з§ЇжМЗеРС 17 еЈ¶е≠Рж†СзЪДжМЗйТИгАВ
еЕґзїУжЮДеПѓдї•зЃАеНХеЃЪдєЙдЄЇпЉЪ
typedef struct {
¬†¬†¬† /* жЦЗдїґжХ∞*/
    int   file_num;
¬†¬†¬† /* жЦЗдїґеРН(key)*/
    char * file_name[max_file_num];
¬†¬†¬† /* жМЗеРСе≠РиКВзВєзЪДжМЗйТИ*/
     BTNode * BTptr[max_file_num+1];
¬†¬†¬†¬† /* жЦЗдїґеЬ®з°ђзЫШдЄ≠зЪДе≠ШеВ®дљНзљЃ*/
     FILE_HARD_ADDR offset[max_file_num];
}BTNode;
еБЗе¶ВжѓПдЄ™зЫШеЭЧеПѓдї•ж≠£е•ље≠ШжФЊдЄАдЄ™Bж†СзЪДзїУзВєпЉИж≠£е•ље≠ШжФЊ 2 дЄ™жЦЗдїґеРНпЉЙгАВйВ£дєИдЄАдЄ™BTNODEзїУзВєе∞±дї£и°®дЄАдЄ™зЫШеЭЧпЉМиАМе≠Рж†СжМЗйТИе∞±жШѓе≠ШжФЊеП¶е§ЦдЄАдЄ™зЫШеЭЧ зЪДеЬ∞еЭАгАВ
дЄЛйЭҐпЉМеТ±дїђжЭ•ж®°жЛЯдЄЛжЯ•жЙЊжЦЗдїґ29зЪДињЗз®ЛпЉЪ
-
ж†єжНЃж†єзїУзВєжМЗйТИжЙЊеИ∞жЦЗдїґзЫЃељХзЪДж†єз£БзЫШеЭЧ1пЉМе∞ЖеЕґдЄ≠зЪДдњ°жБѓеѓЉеЕ•еЖЕе≠ШгАВгАРз£БзЫШ IO жУНдљЬ 1жђ°гАС ¬†¬†¬†¬†
-
ж≠§жЧґеЖЕе≠ШдЄ≠жЬЙдЄ§дЄ™жЦЗдїґеРН17гАБ 35 еТМдЄЙдЄ™е≠ШеВ®еЕґдїЦз£БзЫШй°µйЭҐеЬ∞еЭАзЪДжХ∞жНЃгАВж†єжНЃзЃЧж≥ХжИСдїђеПСзО∞17<29<35пЉМеЫ†ж≠§жИСдїђжЙЊеИ∞жМЗйТИ p2 гАВ
-
ж†єжНЃp2 жМЗйТИпЉМжИСдїђеЃЪдљНеИ∞з£БзЫШеЭЧ3пЉМеєґе∞ЖеЕґдЄ≠зЪДдњ°жБѓеѓЉеЕ•еЖЕе≠ШгАВгАРз£БзЫШ IO жУНдљЬ 2жђ°гАС ¬†¬†¬†¬†
-
ж≠§жЧґеЖЕе≠ШдЄ≠жЬЙдЄ§дЄ™жЦЗдїґеРН26пЉМ 30 еТМдЄЙдЄ™е≠ШеВ®еЕґдїЦз£БзЫШй°µйЭҐеЬ∞еЭАзЪДжХ∞жНЃгАВж†єжНЃзЃЧж≥ХжИСдїђеПС,26<29<30пЉМеЫ†ж≠§жИСдїђжЙЊеИ∞жМЗйТИ p2 гАВ
-
ж†єжНЃp2 жМЗйТИпЉМжИСдїђеЃЪдљНеИ∞з£БзЫШеЭЧ8пЉМеєґе∞ЖеЕґдЄ≠зЪДдњ°жБѓеѓЉеЕ•еЖЕе≠ШгАВгАРз£БзЫШ IO жУНдљЬ 3жђ°гАС ¬†¬†¬†¬†
-
ж≠§жЧґеЖЕе≠ШдЄ≠жЬЙдЄ§дЄ™жЦЗдїґеРН28пЉМ 29 гАВж†єжНЃзЃЧж≥ХжИСдїђжЯ•жЙЊеИ∞жЦЗдїґеРН29пЉМеєґеЃЪдљНдЇЖиѓ•жЦЗдїґеЖЕе≠ШзЪДз£БзЫШеЬ∞еЭАгАВ
еИЖжЮРдЄКйЭҐзЪДињЗз®ЛпЉМеПСзО∞йЬАи¶Б3 жђ°з£БзЫШIOжУНдљЬеТМ 3 жђ°еЖЕе≠ШжЯ•жЙЊ жУНдљЬгАВеЕ≥дЇОеЖЕе≠ШдЄ≠зЪДжЦЗдїґеРНжЯ•жЙЊпЉМзФ±дЇОжШѓдЄАдЄ™жЬЙеЇПи°®зїУжЮДпЉМеПѓдї•еИ©зФ®жКШеНКжЯ•жЙЊжПРйЂШжХИзОЗгАВиЗ≥дЇО IO жУНдљЬжШѓељ±еУНжХідЄ™ Bж†СжЯ•жЙЊжХИзОЗзЪДеЖ≥еЃЪеЫ†зі†гАВ
ељУзДґпЉМе¶ВжЮЬжИСдїђдљњзФ®еє≥и°°дЇМеПЙж†СзЪДз£БзЫШе≠ШеВ®зїУжЮДжЭ•ињЫи°МжЯ•жЙЊпЉМз£БзЫШ 4 жђ°пЉМжЬАе§Ъ5жђ°пЉМиАМдЄФжЦЗдїґиґКе§ЪпЉМ B ж†СжѓФеє≥и°°дЇМеПЙж†СжЙАзФ®зЪДз£БзЫШ IOжУНдљЬжђ°жХ∞е∞ЖиґКе∞СпЉМжХИзОЗдєЯиґКйЂШ гАВ
Bж†СзЪДйЂШеЇ¶
¬†¬†¬† ж†єжНЃдЄКйЭҐзЪДдЊЛе≠РжИСдїђеПѓдї•зЬЛеЗЇпЉМеѓєдЇОиЊЕе≠ШеБЪIOиѓїзЪДжђ°жХ∞еПЦеЖ≥дЇОBж†СзЪДйЂШеЇ¶гАВиАМBж†СзЪДйЂШеЇ¶зФ±дїАдєИеЖ≥еЃЪзЪДеСҐпЉЯ
¬†¬†¬†¬† ж†єжНЃBж†СзЪДйЂШеЇ¶еЕђеЉП:¬†¬†¬†¬†![]()
¬†¬†¬†¬†¬† еЕґдЄ≠TдЄЇеЇ¶жХ∞пЉИжѓПдЄ™иКВзВєеМЕеРЂзЪДеЕГзі†дЄ™жХ∞пЉЙпЉМеН≥жЙАи∞УзЪДйШґжХ∞пЉМNдЄЇжАїеЕГзі†дЄ™жХ∞жИЦжАїеЕ≥йФЃе≠ЧжХ∞гАВ
¬†¬†¬†¬† жИСдїђеПѓдї•зЬЛеЗЇTеѓєдЇОж†СзЪДйЂШеЇ¶жЬЙеЖ≥еЃЪжАІзЪДељ±еУНгАВеЫ†ж≠§е¶ВжЮЬжѓПдЄ™иКВзВєеМЕеРЂжЫіе§ЪзЪДеЕГзі†дЄ™жХ∞пЉМеЬ®еЕГзі†дЄ™жХ∞зЫЄеРМзЪДжГЕеЖµдЄЛпЉМеИЩжЫіжЬЙеПѓиГљеЗПе∞СBж†СзЪДйЂШеЇ¶гАВињЩдєЯжШѓдЄЇдїАдєИ SQL ServerдЄ≠йЬАи¶Бе∞љйЗПдї•з™ДйФЃеїЇзЂЛиБЪйЫЖ糥еЉХгАВеЫ†дЄЇSQL ServerдЄ≠жѓПдЄ™иКВзВєзЪДе§Іе∞ПдЄЇ8092е≠ЧиКВпЉМе¶ВжЮЬеЗПе∞СйФЃзЪДе§Іе∞ПпЉМеИЩеПѓдї•еЃєзЇ≥жЫіе§ЪзЪДеЕГзі†пЉМдїОиАМеЗПе∞СдЇЖBж†СзЪДйЂШеЇ¶пЉМжПРеНЗдЇЖжߕ胥зЪДжАІиГљгАВ
¬†¬†¬† дЄКйЭҐBж†СйЂШеЇ¶зЪДеЕђеЉПдєЯеПѓдї•ињЫи°МжО®еѓЉеЊЧеЗЇпЉМе∞ЖжѓПдЄАе±ВзЇІзЪДзЪДеЕГзі†дЄ™жХ∞еК†иµЈжЭ•пЉМжѓФе¶ВеЇ¶дЄЇTзЪДиКВзВєпЉМж†єдЄЇ1дЄ™иКВзВєпЉМзђђдЇМе±ВиЗ≥е∞СдЄЇ2дЄ™иКВзВєпЉМзђђдЄЙе±ВиЗ≥е∞СдЄЇ2tдЄ™иКВзВєпЉМзђђеЫЫе±ВиЗ≥е∞СдЄЇ2t*tдЄ™иКВзВєгАВе∞ЖжЙАжЬЙжЬАе∞ПиКВзВєзЫЄеК†пЉМдїОиАМеЊЧеИ∞иКВзВєдЄ™жХ∞NзЪДеЕђеЉП:
               ![]()
¬†¬†¬† дЄ§иЊєеПЦеѓєжХ∞пЉМеИЩеПѓдї•еЊЧеИ∞ж†СзЪДйЂШеЇ¶еЕђеЉПгАВ
¬†¬†¬† ињЩдєЯе∞±жШѓиѓіжѓПдЄ™иКВзВєењЕй°їиЗ≥е∞СжЬЙдЄ§дЄ™е≠РеЕГзі†пЉМеЫ†дЄЇж†єжНЃйЂШеЇ¶еЕђеЉПпЉМе¶ВжЮЬжѓПдЄ™иКВзВєеП™жЬЙдЄАдЄ™еЕГзі†пЉМдєЯе∞±жШѓT=1зЪДиѓЭпЉМйВ£дєИйЂШеЇ¶е∞ЖдЉЪиґЛдЇОж≠£жЧ†з©ЈгАВ
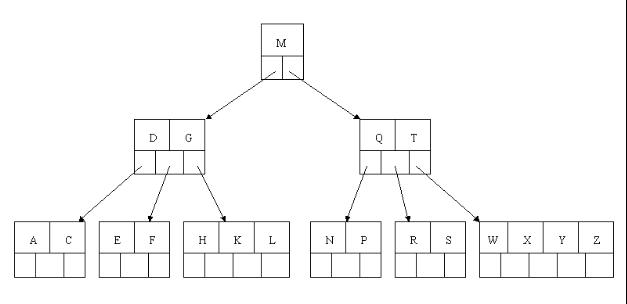
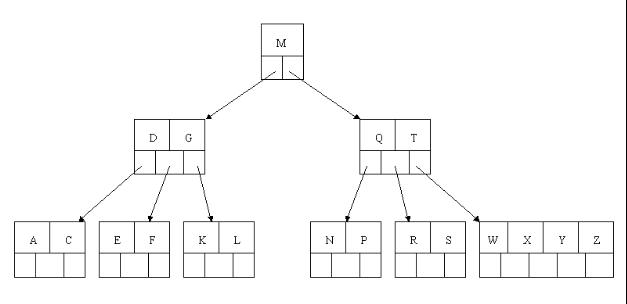
4. B+ -tree
B+ -tree пЉЪжШѓеЇФжЦЗдїґз≥їзїЯжЙАйЬАиАМдЇІзФЯзЪДдЄАзІН B-tree зЪДеПШ嚥ж†СгАВ
дЄАж£µ m йШґзЪД B+ ж†СеТМ m йШґзЪД B ж†СзЪДеЈЃеЉВеЬ®дЇОпЉЪ
¬†¬†¬†¬†¬† 1. жЬЙ n ж£µе≠Рж†СзЪДзїУзВєдЄ≠еРЂжЬЙ n дЄ™еЕ≥йФЃе≠ЧпЉЫ ¬†(иАМB ж†С жШѓ n ж£µе≠Рж†СжЬЙ n-1 дЄ™еЕ≥йФЃе≠Ч )
¬†¬†¬†¬†¬† 2. жЙАжЬЙзЪДеПґе≠РзїУзВєдЄ≠еМЕеРЂдЇЖеЕ®йГ®еЕ≥йФЃе≠ЧзЪДдњ°жБѓпЉМеПКжМЗеРСеРЂжЬЙињЩдЇЫеЕ≥йФЃе≠ЧиЃ∞ељХзЪДжМЗйТИпЉМдЄФеПґе≠РзїУзВєжЬђиЇЂдЊЭеЕ≥йФЃе≠ЧзЪДе§Іе∞ПиЗ™е∞ПиАМе§ІзЪДй°ЇеЇПйУЊжО•гАВ (иАМB ж†С зЪДеПґе≠РиКВзВєеєґж≤°жЬЙеМЕжЛђеЕ®йГ®йЬАи¶БжЯ•жЙЊзЪДдњ°жБѓ )
¬†¬†¬†¬†¬† 3. жЙАжЬЙзЪДйЭЮзїИзЂѓзїУзВєеПѓдї•зЬЛжИРж؃糥еЉХйГ®еИЖ пЉМзїУзВєдЄ≠дїЕеРЂжЬЙеЕґе≠Рж†Сж†єзїУзВєдЄ≠жЬАе§ІпЉИжИЦжЬАе∞ПпЉЙеЕ≥йФЃе≠ЧгАВ (иАМB ж†С зЪДйЭЮзїИиКВзВєдєЯеМЕеРЂйЬАи¶БжЯ•жЙЊзЪДжЬЙжХИдњ°жБѓ )
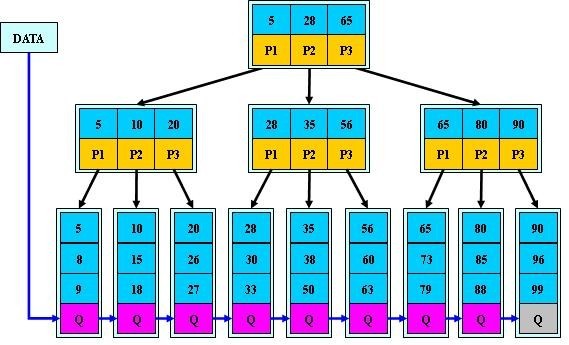  
 
 
a) ¬†¬†¬†¬† дЄЇдїАдєИиѓі B+ -tree жѓФ B ж†С жЫійАВеРИеЃЮйЩЕеЇФзФ®дЄ≠жУНдљЬз≥їзїЯзЪДжЦЗ俴糥еЉХеТМжХ∞жНЃеЇУ糥еЉХпЉЯ
1) B+ -tree зЪДз£БзЫШиѓїеЖЩдї£дїЈжЫідљО
B+ -tree зЪДеЖЕйГ®зїУзВєеєґж≤°жЬЙжМЗеРСеЕ≥йФЃе≠ЧеЕЈдљУдњ°жБѓзЪДжМЗйТИгАВеЫ†ж≠§еЕґеЖЕйГ®зїУзВєзЫЄеѓє B ж†С жЫіе∞ПгАВе¶ВжЮЬжККжЙАжЬЙеРМдЄАеЖЕйГ®зїУзВєзЪДеЕ≥йФЃе≠Че≠ШжФЊеЬ®еРМдЄАзЫШеЭЧдЄ≠пЉМйВ£дєИзЫШеЭЧжЙАиГљеЃєзЇ≥зЪДеЕ≥йФЃе≠ЧжХ∞йЗПдєЯиґКе§ЪгАВдЄАжђ°жАІиѓїеЕ•еЖЕе≠ШдЄ≠зЪДйЬАи¶БжЯ•жЙЊзЪДеЕ≥йФЃе≠ЧдєЯе∞±иґКе§ЪгАВзЫЄеѓєжЭ•иѓі IO иѓїеЖЩжђ°жХ∞дєЯе∞±йЩНдљОдЇЖгАВ
¬†¬†¬† дЄЊдЄ™дЊЛе≠РпЉМеБЗиЃЊз£БзЫШдЄ≠зЪДдЄАдЄ™зЫШеЭЧеЃєзЇ≥ 16bytes пЉМиАМдЄАдЄ™еЕ≥йФЃе≠Ч 2bytes пЉМдЄАдЄ™еЕ≥йФЃе≠ЧеЕЈдљУдњ°жБѓжМЗйТИ 2bytes гАВдЄАж£µ 9 йШґ B-tree ( дЄАдЄ™зїУзВєжЬАе§Ъ 8 дЄ™еЕ≥йФЃе≠Ч ) зЪДеЖЕйГ®зїУзВєйЬАи¶Б 2 дЄ™зЫШењЂгАВиАМ B+ ж†СеЖЕйГ®зїУзВєеП™йЬАи¶Б 1 дЄ™зЫШењЂгАВељУйЬАи¶БжККеЖЕйГ®зїУзВєиѓїеЕ•еЖЕе≠ШдЄ≠зЪДжЧґеАЩпЉМ B ж†С е∞±жѓФ B+ ж†Се§ЪдЄАжђ°зЫШеЭЧжЯ•жЙЊжЧґйЧі ( еЬ®з£БзЫШдЄ≠е∞±жШѓзЫШзЙЗжЧЛиљђзЪДжЧґйЧі ) гАВ
2) B+ -tree зЪДжߕ胥жХИзОЗжЫіеК†з®≥еЃЪ
зФ±дЇОйЭЮзїИзїУзВєеєґдЄНжШѓжЬАзїИжМЗеРСжЦЗдїґеЖЕеЃєзЪДзїУзВєпЉМиАМеП™жШѓеПґе≠РзїУзВєдЄ≠еЕ≥йФЃе≠ЧзЪД糥еЉХгАВжЙАдї•дїїдљХеЕ≥йФЃе≠ЧзЪДжЯ•жЙЊењЕй°їиµ∞дЄАжЭ°дїОж†єзїУзВєеИ∞еПґе≠РзїУзВєзЪДиЈѓгАВжЙАжЬЙеЕ≥йФЃе≠Чжߕ胥зЪДиЈѓеЊДйХњеЇ¶зЫЄеРМпЉМеѓЉиЗіжѓПдЄАдЄ™жХ∞жНЃзЪДжߕ胥жХИзОЗзЫЄељУгАВ
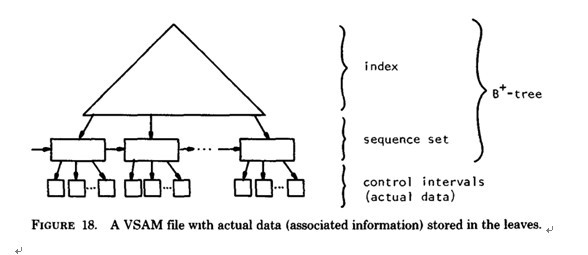
b) ¬†¬†¬† B+ -tree зЪДеЇФзФ®: VSAM( иЩЪжЛЯе≠ШеВ®е≠ШеПЦж≥Х ) жЦЗдїґ ( жЭ•жЇРиЃЇжЦЗ the ubiquitous Btree дљЬиАЕпЉЪ D COMER - 1979 )
 
 
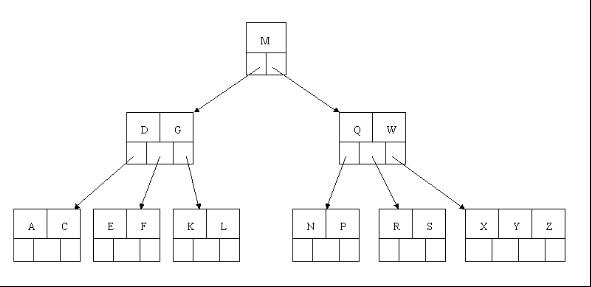
5. B* -tree
B*-tree жШѓ B+ -tree зЪДеПШдљУпЉМеЬ® B+ ж†СйЭЮж†єеТМйЭЮеПґе≠РзїУзВєеЖНеҐЮеК†жМЗеРСеЕДеЉЯзЪДжМЗйТИпЉЫ B* ж†СеЃЪдєЙдЇЖйЭЮеПґе≠РзїУзВєеЕ≥йФЃе≠ЧдЄ™жХ∞иЗ≥е∞СдЄЇ (2/3)*M пЉМеН≥еЭЧзЪДжЬАдљОдљњзФ®зОЗдЄЇ 2/3 пЉИдї£жЫњ B+ ж†СзЪД 1/2 пЉЙгАВзїЩеЗЇдЇЖдЄАдЄ™зЃАеНХеЃЮдЊЛпЉМе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
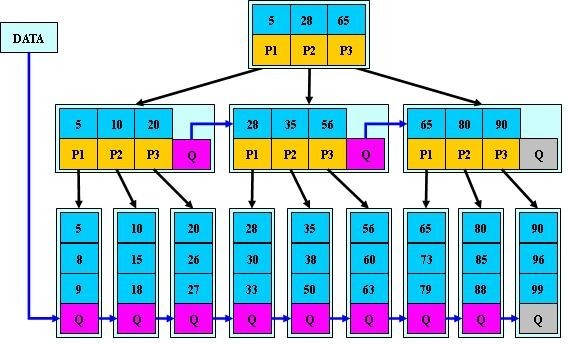
 
B+ ж†СзЪДеИЖи£ВпЉЪељУдЄАдЄ™зїУзВєжї°жЧґпЉМеИЖйЕНдЄАдЄ™жЦ∞зЪДзїУзВєпЉМеєґе∞ЖеОЯзїУзВєдЄ≠ 1/2 зЪДжХ∞жНЃе§НеИґеИ∞жЦ∞зїУзВєпЉМжЬАеРОеЬ®зИґзїУзВєдЄ≠еҐЮеК†жЦ∞зїУзВєзЪДжМЗйТИпЉЫ B+ ж†СзЪДеИЖи£ВеП™ељ±еУНеОЯзїУзВєеТМзИґзїУзВєпЉМиАМдЄНдЉЪељ±еУНеЕДеЉЯзїУзВєпЉМжЙАдї•еЃГдЄНйЬАи¶БжМЗеРСеЕДеЉЯзЪДжМЗйТИгАВ
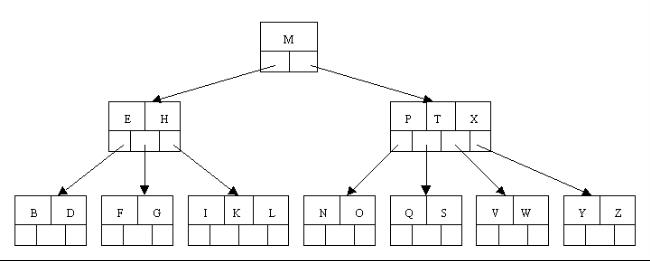
B* ж†СзЪДеИЖи£ВпЉЪељУдЄАдЄ™зїУзВєжї°жЧґпЉМе¶ВжЮЬеЃГзЪДдЄЛдЄАдЄ™еЕДеЉЯзїУзВєжЬ™жї°пЉМйВ£дєИе∞ЖдЄАйГ®еИЖжХ∞жНЃзІїеИ∞еЕДеЉЯзїУзВєдЄ≠пЉМеЖНеЬ®еОЯзїУзВєжПТеЕ•еЕ≥йФЃе≠ЧпЉМжЬАеРОдњЃжФєзИґзїУзВєдЄ≠еЕДеЉЯзїУзВєзЪДеЕ≥йФЃе≠ЧпЉИеЫ†дЄЇеЕДеЉЯзїУзВєзЪДеЕ≥йФЃе≠ЧиМГеЫіжФєеПШдЇЖпЉЙпЉЫе¶ВжЮЬеЕДеЉЯдєЯжї°дЇЖпЉМеИЩеЬ®еОЯзїУзВєдЄОеЕДеЉЯзїУзВєдєЛйЧіеҐЮеК†жЦ∞зїУзВєпЉМеєґеРДе§НеИґ 1/3 зЪДжХ∞жНЃеИ∞жЦ∞зїУзВєпЉМжЬАеРОеЬ®зИґзїУзВєеҐЮеК†жЦ∞зїУзВєзЪДжМЗйТИгАВ
жЙАдї•пЉМ B* ж†СеИЖйЕНжЦ∞зїУзВєзЪДж¶ВзОЗжѓФ B+ ж†Си¶БдљОпЉМз©ЇйЧідљњзФ®зОЗжЫійЂШпЉЫ
 
6гАБBж†СзЪДжПТеЕ•гАБеИ†йЩ§жУНдљЬ
-
ж†СдЄ≠жѓПдЄ™зїУзВєеРЂжЬЙжЬАе§ЪеРЂжЬЙmдЄ™е≠©е≠РпЉМеН≥mжї°иґ≥пЉЪceil(m /2) <=m <=mгАВ
-
йЩ§ж†єзїУзВєеТМеПґе≠РзїУзВєе§ЦпЉМеЕґеЃГжѓПдЄ™зїУзВєиЗ≥е∞СжЬЙ[ceil(m / 2)]дЄ™е≠©е≠РпЉИеЕґдЄ≠ceil(x)жШѓдЄАдЄ™еПЦдЄКйЩРзЪДеЗљжХ∞ пЉЙпЉЫ
-
иЛ•ж†єзїУзВєдЄНжШѓеПґе≠РзїУзВєпЉМеИЩиЗ≥е∞СжЬЙ2дЄ™е≠©е≠РпЉИзЙєжЃКжГЕеЖµпЉЪж≤°жЬЙе≠©е≠РзЪДж†єзїУзВєпЉМеН≥ж†єзїУзВєдЄЇеПґе≠РзїУзВєпЉМжХіж£µж†СеП™жЬЙдЄАдЄ™ж†єиКВзВєпЉЙпЉЫ
-
жЙАжЬЙеПґе≠РзїУзВєйГљеЗЇзО∞еЬ®еРМдЄАе±ВпЉМеПґе≠РзїУзВєдЄНеМЕеРЂдїїдљХеЕ≥йФЃе≠Чдњ°жБѓ(еПѓдї•зЬЛеБЪжШѓе§ЦйГ®жО•зВєжИЦжߕ胥姱賕зЪДжО•зВєпЉМеЃЮйЩЕдЄКињЩдЇЫзїУзВєдЄНе≠ШеЬ®пЉМжМЗеРСињЩдЇЫзїУзВєзЪДжМЗйТИйГљдЄЇnull)пЉЫ
-
жѓПдЄ™йЭЮзїИзЂѓзїУзВєдЄ≠еМЕеРЂжЬЙnдЄ™еЕ≥йФЃе≠Чдњ°жБѓпЉЪ (nпЉМP0пЉМK1пЉМP1пЉМK2пЉМP2пЉМ......пЉМKnпЉМPn)гАВеЕґдЄ≠пЉЪ
¬†¬†¬†¬† ¬†¬†a)¬†¬† Ki (i=1...n)дЄЇеЕ≥йФЃе≠ЧпЉМдЄФеЕ≥йФЃе≠ЧжМЙй°ЇеЇПеНЗеЇПжОТеЇПK(i-1)< KiгАВ
¬†¬†¬†¬† ¬†¬†b)¬†¬† PiдЄЇжМЗеРСе≠Рж†Сж†єзЪДжО•зВєпЉМдЄФжМЗйТИP(i-1)жМЗеРСе≠Рж†СзІНжЙАжЬЙзїУзВєзЪДеЕ≥йФЃе≠ЧеЭЗе∞ПдЇОKiпЉМдљЖйГље§ІдЇОK(i-1)гАВ¬†
¬†¬†¬†¬†¬†¬†¬†c)¬†¬† йЩ§ж†єзїУзВєдєЛе§ЦзЪДзїУзВєзЪДеЕ≥йФЃе≠ЧзЪДдЄ™жХ∞nењЕй°їжї°иґ≥пЉЪ [ceil(m / 2)-1]<= n <= m-1пЉИеПґе≠РзїУзВєдєЯењЕй°їжї°иґ≥ж≠§жЭ°еЕ≥дЇОеЕ≥йФЃе≠ЧжХ∞зЪДжАІиі®пЉМж†єзїУзВєйЩ§е§Ц пЉЙгАВ
okпЉМдЄЛйЭҐеТ±дїђдї•дЄАж£µ5йШґ пЉИеН≥ж†СдЄ≠дїїдЄАзїУзВєиЗ≥е§ЪеРЂжЬЙ4дЄ™еЕ≥йФЃе≠ЧпЉМ5ж£µе≠Рж†С пЉЙB ж†СеЃЮдЊЛињЫи°МиЃ≤иІ£ ( е¶ВдЄЛеЫЊжЙАз§Ї ) пЉЪ
е§Зж≥®пЉЪ
- еЕ≥йФЃе≠ЧжХ∞пЉИ2-4дЄ™пЉЙйТИеѓє--йЭЮж†єзїУзВєпЉИеМЕжЛђеПґе≠РзїУзВєеЬ®еЖЕпЉЙпЉМе≠©е≠РжХ∞пЉИ3-5дЄ™пЉЙ--йТИеѓєж†єзїУзВєеТМеПґе≠РзїУзВєдєЛе§ЦзЪДеЖЕзїУзВєгАВељУзДґпЉМж†єзїУзВєжШѓењЕй°їиЗ≥е∞СжЬЙ2дЄ™е≠©е≠РзЪДпЉМдЄНзДґе∞±жИРзЫізЇњеЮЛжРЬ糥ж†СдЇЖ гАВ
- жЫЊеЬ®дЄАжђ°йЭҐиѓХдЄ≠襀йЧЃеИ∞пЉМ дЄАж£µеРЂжЬЙNдЄ™жАїеЕ≥йФЃе≠ЧжХ∞зЪДmйШґзЪДBж†СзЪДжЬАе§ІйЂШеЇ¶жШѓе§Ъе∞С ?з≠ФжЫ∞пЉЪlog_ceilпЉИm/2пЉЙN пЉИдЄКйЭҐдЄ≠еЕ≥дЇОmйШґBж†СзЪДзђђ1зВєзЙєжАІеЈ≤зїПжПРеИ∞пЉЪж†СдЄ≠жѓПдЄ™зїУзВєеРЂжЬЙжЬАе§ЪеРЂжЬЙmдЄ™е≠©е≠РпЉМеН≥mжї°иґ≥пЉЪceil(m /2) <=m <=mгАВиАМ ж†СдЄ≠жѓПдЄ™зїУзВєеРЂе≠©е≠РжХ∞иґКе∞СпЉМж†СзЪДйЂШеЇ¶еИЩиґКе§ІпЉМжХЕе¶Вж≠§пЉЙгАВеЬ®2012еЊЃиљѓ4жЬИдїљзЪДзђФиѓХдЄ≠дєЯйЧЃеИ∞дЇЖж≠§йЧЃйҐШгАВжЫіе§ЪеОЯзРЖиѓЈзЬЛдЄКжЦЗзђђ3 е∞ПиКВжЬЂпЉЪBж†СзЪДйЂШеЇ¶гАВ
дЄЛеЫЊдЄ≠еЕ≥йФЃе≠ЧдЄЇе§ІеЖЩе≠ЧжѓНпЉМй°ЇеЇПдЄЇе≠ЧжѓНеНЗеЇПгАВ
зїУзВєеЃЪдєЙе¶ВдЄЛпЉЪ
typedef   struct {
¬†¬†¬† int ¬†Count;¬†¬†¬†¬†¬†¬†¬†¬†¬† //¬† ељУеЙНиКВзВєдЄ≠еЕ≥йФЃеЕГзі†жХ∞зЫЃ
¬†¬†¬†ItemType¬†Key[ 4 ];¬†¬†¬† //¬† е≠ШеВ®еЕ≥йФЃе≠ЧеЕГзі†зЪДжХ∞зїД
¬†¬†¬† long ¬†Branch[ 5 ];¬†¬†¬†¬† //¬† дЉ™жМЗйТИжХ∞зїДпЉМ(иЃ∞ељХжХ∞зЫЃ)жЦєдЊњеИ§жЦ≠еРИеєґеТМеИЖи£ВзЪДжГЕеЖµ
} NodeType;
 
6.1гАБжПТеЕ•пЉИinsert пЉЙжУНдљЬ
жПТеЕ•дЄАдЄ™еЕГзі†жЧґпЉМй¶ЦеЕИеЬ®B ж†СдЄ≠жШѓеР¶е≠ШеЬ®пЉМе¶ВжЮЬдЄНе≠ШеЬ®пЉМеН≥еЬ®еПґе≠РзїУзВєе§ДзїУжЭЯпЉМзДґеРОеЬ®еПґе≠РзїУзВєдЄ≠жПТеЕ•иѓ•жЦ∞зЪДеЕГзі†пЉМж≥®жДПпЉЪе¶ВжЮЬеПґе≠РзїУзВєз©ЇйЧіиґ≥е§ЯпЉМињЩйЗМйЬАи¶БеРСеП≥зІїеК®иѓ•еПґе≠РзїУзВєдЄ≠е§ІдЇОжЦ∞жПТеЕ•еЕ≥йФЃе≠ЧзЪДеЕГзі†пЉМе¶ВжЮЬз©ЇйЧіжї°дЇЖдї•иЗіж≤°жЬЙиґ≥е§ЯзЪДз©ЇйЧіеОїжЈїеК†жЦ∞зЪДеЕГзі†пЉМеИЩе∞Жиѓ• зїУзВє ињЫ и°МвАЬеИЖи£ВвАЭпЉМе∞ЖдЄАеНКжХ∞йЗПзЪДеЕ≥йФЃе≠ЧеЕГзі†еИЖи£ВеИ∞жЦ∞зЪДеЕґзЫЄйВїеП≥зїУзВєдЄ≠пЉМдЄ≠йЧіеЕ≥йФЃе≠ЧеЕГзі†дЄКзІїеИ∞зИґзїУзВєдЄ≠пЉИељУзДґпЉМе¶ВжЮЬзИґзїУзВєз©ЇйЧіжї°дЇЖпЉМдєЯеРМж†ЈйЬАи¶БвАЬеИЖи£ВвАЭжУНдљЬпЉЙпЉМиАМ дЄФељУзїУзВєдЄ≠еЕ≥йФЃеЕГзі†еРСеП≥зІїеК®дЇЖпЉМзЫЄеЕ≥зЪДжМЗйТИдєЯйЬАи¶БеРСеП≥зІїгАВе¶ВжЮЬеЬ®ж†єзїУзВєжПТеЕ•жЦ∞еЕГзі†пЉМз©ЇйЧіжї°дЇЖпЉМеИЩињЫи°МеИЖи£ВжУНдљЬпЉМињЩж†ЈеОЯжЭ•зЪДж†єзїУзВєдЄ≠зЪДдЄ≠йЧіеЕ≥йФЃе≠ЧеЕГзі†еРСдЄКзІї еК®еИ∞жЦ∞зЪДж†єзїУзВєдЄ≠пЉМеЫ†ж≠§еѓЉиЗіж†СзЪДйЂШеЇ¶еҐЮеК†дЄАе±ВгАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

1гАБOKпЉМдЄЛйЭҐеТ±дїђйАЪињЗдЄАдЄ™еЃЮдЊЛжЭ•йАРж≠•иЃ≤иІ£дЄЛгАВжПТеЕ•дї•дЄЛе≠Чзђ¶е≠ЧжѓНеИ∞дЄАж£µз©ЇзЪДB¬† ж†СдЄ≠пЉИйЭЮж†єзїУзВєеЕ≥йФЃе≠ЧжХ∞ е∞ПдЇЖпЉИе∞ПдЇО2дЄ™пЉЙе∞±еРИеєґпЉМе§ІдЇЖпЉИиґЕињЗ4дЄ™пЉЙе∞±еИЖи£В пЉЙпЉЪ C¬†N¬†G¬†A¬†H¬†E¬†K¬†Q¬†M¬†F¬†W¬†L¬†T¬†Z¬†D¬†P¬†R¬†X¬†Y¬†S пЉМй¶ЦеЕИпЉМзїУзВєз©ЇйЧіиґ≥е§ЯпЉМ 4 дЄ™е≠ЧжѓНжПТеЕ•зЫЄеРМзЪДзїУзВєдЄ≠пЉМе¶ВдЄЛеЫЊпЉЪ
 
2гАБељУеТ±дїђиѓХзЭАжПТеЕ•H жЧґпЉМзїУзВєеПСзО∞з©ЇйЧідЄНе§ЯпЉМдї•иЗіе∞ЖеЕґеИЖи£ВжИР 2 дЄ™зїУзВєпЉМзІїеК®дЄ≠йЧіеЕГзі† G дЄКзІїеИ∞жЦ∞зЪДж†єзїУзВєдЄ≠пЉМеЬ®еЃЮзО∞ињЗз®ЛдЄ≠пЉМеТ±дїђжКК A еТМ C зХЩеЬ®ељУеЙНзїУзВєдЄ≠пЉМиАМ H еТМ N жФЊзљЃжЦ∞зЪДеЕґеП≥йВїе±ЕзїУзВєдЄ≠гАВе¶ВдЄЛеЫЊпЉЪ
 
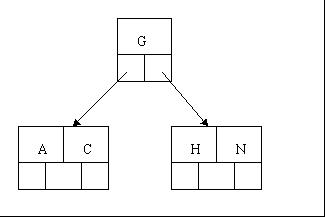
3гАБељУеТ±дїђжПТеЕ•E,K,Q жЧґпЉМдЄНйЬАи¶БдїїдљХеИЖи£ВжУНдљЬ
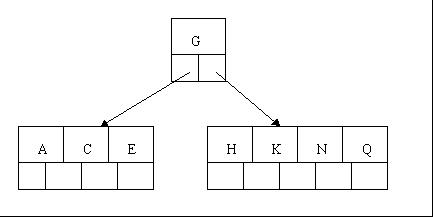
 
 
 
 
 
 
 
 
 
 
 
 
4гАБжПТеЕ•M йЬАи¶БдЄАжђ°еИЖи£ВпЉМж≥®жДП M жБ∞е•љжШѓдЄ≠йЧіеЕ≥йФЃе≠ЧеЕГзі†пЉМдї•иЗіеРСдЄКзІїеИ∞зИґиКВзВєдЄ≠
 
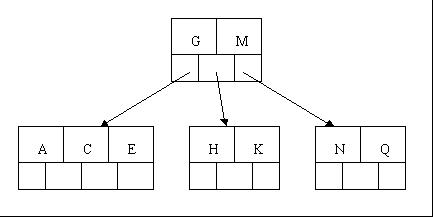
5гАБжПТеЕ•F,W,L,T дЄНйЬАи¶БдїїдљХеИЖи£ВжУНдљЬ
 
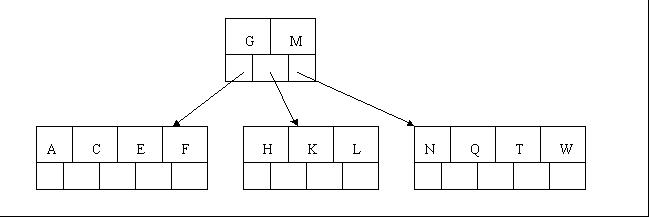
6гАБжПТеЕ•Z жЧґпЉМжЬАеП≥зЪДеПґе≠РзїУзВєз©ЇйЧіжї°дЇЖпЉМйЬАи¶БињЫи°МеИЖи£ВжУНдљЬпЉМдЄ≠йЧіеЕГзі† T дЄКзІїеИ∞зИґиКВзВєдЄ≠пЉМж≥®жДПйАЪињЗдЄКзІїдЄ≠йЧіеЕГзі†пЉМж†СжЬАзїИињШжШѓдњЭжМБеє≥и°°пЉМеИЖи£ВзїУжЮЬзЪДзїУзВєе≠ШеЬ® 2 дЄ™еЕ≥йФЃе≠ЧеЕГзі†гАВ
 

7гАБжПТеЕ•D жЧґпЉМеѓЉиЗіжЬАеЈ¶иЊєзЪДеПґе≠РзїУзº襀еИЖи£ВпЉМ D жБ∞е•љдєЯжШѓдЄ≠йЧіеЕГзі†пЉМдЄКзІїеИ∞зИґиКВзВєдЄ≠пЉМзДґеРОе≠ЧжѓН P,R,X,Y йЩЖзї≠жПТеЕ•дЄНйЬАи¶БдїїдљХеИЖи£ВжУНдљЬпЉИеИЂењШдЇЖпЉМж†СдЄ≠иЗ≥е§Ъ5дЄ™е≠©е≠РпЉЙгАВ
 
8гАБжЬАеРОпЉМељУжПТеЕ•S жЧґпЉМеРЂжЬЙ N,P,Q,R зЪДзїУзВєйЬАи¶БеИЖи£ВпЉМжККдЄ≠йЧіеЕГзі† Q дЄКзІїеИ∞зИґиКВзВєдЄ≠пЉМдљЖжШѓжГЕеЖµжЭ•дЇЖпЉМзИґиКВзВєдЄ≠з©ЇйЧіеЈ≤зїПжї°дЇЖпЉМжЙАдї•дєЯи¶БињЫи°МеИЖи£ВпЉМе∞ЖзИґиКВзВєдЄ≠зЪДдЄ≠йЧіеЕГзі† M дЄКзІїеИ∞жЦ∞嚥жИРзЪДж†єзїУзВєдЄ≠пЉМж≥®жДПдї•еЙНеЬ®зИґиКВзВєдЄ≠зЪДзђђдЄЙдЄ™жМЗйТИеЬ®дњЃжФєеРОеМЕжЛђ D еТМ G иКВзВєдЄ≠гАВињЩж†ЈеЕЈдљУжПТеЕ•жУНдљЬзЪДеЃМжИРпЉМдЄЛйЭҐдїЛзїНеИ†йЩ§жУНдљЬпЉМеИ†йЩ§жУНдљЬзЫЄеѓєдЇОжПТеЕ•жУНдљЬи¶БиАГиЩСзЪДжГЕеЖµе§ЪзВєгАВ
 
6.2гАБеИ†йЩ§(delete) жУНдљЬ
й¶ЦеЕИжЯ•жЙЊB ж†СдЄ≠йЬАеИ†йЩ§зЪДеЕГзі† , е¶ВжЮЬиѓ•еЕГзі†еЬ® B ж†СдЄ≠е≠ШеЬ®пЉМеИЩе∞Жиѓ•еЕГзі†еЬ®еЕґзїУзВєдЄ≠ињЫи°МеИ†йЩ§пЉМе¶ВжЮЬеИ†йЩ§иѓ•еЕГзі†еРОпЉМй¶ЦеЕИеИ§жЦ≠иѓ•еЕГзі†жШѓеР¶жЬЙеЈ¶еП≥е≠©е≠РзїУзВєпЉМе¶ВжЮЬжЬЙпЉМеИЩдЄКзІїе≠©е≠РзїУзВєдЄ≠зЪДжЯРзЫЄињСеЕГзі†еИ∞зИґиКВзВєдЄ≠пЉМзДґеРО жШѓ зІїеК®дєЛеРО зЪД жГЕеЖµпЉЫе¶ВжЮЬж≤°жЬЙпЉМзЫіжО• еИ†йЩ§еРОпЉМ зІїеК®дєЛеРОзЪДжГЕеЖµ гАВ
еИ†йЩ§еЕГзі†пЉМзІїеК®зЫЄеЇФеЕГзі†дєЛеРОпЉМ е¶ВжЮЬжЯРзїУзВєдЄ≠еЕГзі†жХ∞зЫЃпЉИеН≥еЕ≥йФЃе≠ЧжХ∞пЉЙе∞ПдЇО ceil(m/2)-1 пЉМеИЩйЬАи¶БзЬЛеЕґжЯРзЫЄйВїеЕДеЉЯзїУзВєжШѓеР¶дЄ∞жї°пЉИзїУзВєдЄ≠еЕГзі†дЄ™жХ∞е§ІдЇОceil(m/2)-1пЉЙпЉИињШ иЃ∞еЊЧзђђдЄАиКВдЄ≠еЕ≥дЇОBж†СзЪДзђђ5дЄ™зЙєжАІдЄ≠зЪДcзВєдєИ?пЉЪ¬†c)йЩ§ж†єзїУзВєдєЛе§ЦзЪДзїУзВєпЉИеМЕжЛђеПґе≠РзїУзВєпЉЙзЪДеЕ≥йФЃе≠ЧзЪДдЄ™жХ∞nењЕй°їжї°иґ≥пЉЪ пЉИceil(m / 2)-1пЉЙ<= n <= m-1гАВmи°®з§ЇжЬАе§ЪеРЂжЬЙmдЄ™е≠©е≠РпЉМnи°®з§ЇеЕ≥йФЃе≠ЧжХ∞гАВеЬ®жЬђе∞ПиКВдЄ≠дЄЊзЪДдЄАйҐЧBж†СзЪДз§ЇдЊЛдЄ≠пЉМеЕ≥йФЃе≠ЧжХ∞nжї°иґ≥пЉЪ2<=n<=4 пЉЙпЉМе¶ВжЮЬдЄ∞жї°пЉМеИЩеРСзИґиКВзВєеАЯдЄАдЄ™еЕГзі†жЭ•жї°иґ≥жЭ°дїґпЉЫе¶ВжЮЬеЕґзЫЄйВїеЕДеЉЯйГљеИЪиД±иіЂпЉМеН≥еАЯдЇЖдєЛеРОеЕґзїУзВєжХ∞зЫЃе∞ПдЇОceil(m/2)-1 пЉМеИЩиѓ•зїУзВєдЄОеЕґзЫЄйВїзЪДжЯРдЄАеЕДеЉЯзїУзВєињЫи°М вАЬ еРИеєґ вАЭжИРдЄАдЄ™зїУзВєпЉМдї•ж≠§жЭ•жї°иґ≥жЭ°дїґгАВйВ£еТ±дїђйАЪињЗдЄЛйЭҐеЃЮдЊЛжЭ•иѓ¶зїЖдЇЖиІ£еРІгАВ
дї•дЄКињ∞жПТеЕ•жУНдљЬжЮДйА†зЪДдЄАж£µ5йШґB ж†СпЉИж†СдЄ≠жЬАе§ЪеРЂжЬЙmпЉИm=5пЉЙдЄ™е≠©е≠РпЉМеЫ†ж≠§еЕ≥йФЃе≠ЧжХ∞жЬАе∞ПдЄЇceil(m / 2)-1=2гАВ ињШжШѓињЩеП•иѓЭпЉМеЕ≥йФЃе≠ЧжХ∞ е∞ПдЇЖпЉИе∞ПдЇО2дЄ™пЉЙе∞±еРИеєґпЉМе§ІдЇЖпЉИиґЕињЗ4дЄ™пЉЙе∞±еИЖи£В пЉЙдЄЇдЊЛпЉМдЊЭжђ°еИ†йЩ§ H,T,R,E гАВ
1гАБй¶ЦеЕИеИ†йЩ§еЕГзі†H пЉМељУзДґй¶ЦеЕИжЯ•жЙЊ H пЉМ H еЬ®дЄАдЄ™еПґе≠РзїУзВєдЄ≠пЉМдЄФиѓ•еПґе≠РзїУзВєеЕГзі†жХ∞зЫЃ 3 е§ІдЇОжЬАе∞ПеЕГзі†жХ∞зЫЃ ceil(m/2)-1=2 пЉМеИЩжУНдљЬеЊИзЃАеНХпЉМеТ±дїђеП™йЬАи¶БзІїеК® K иЗ≥еОЯжЭ• H зЪДдљНзљЃпЉМзІїеК® L иЗ≥ K зЪДдљНзљЃпЉИдєЯе∞±жШѓзїУзВєдЄ≠еИ†йЩ§еЕГзі†еРОйЭҐзЪДеЕГзі†еРСеЙНзІїеК®пЉЙ
 
2гАБдЄЛдЄАж≠•пЉМеИ†йЩ§T, еЫ†дЄЇ T ж≤°жЬЙеЬ®еПґе≠РзїУзВєдЄ≠пЉМиАМжШѓеЬ®дЄ≠йЧізїУзВєдЄ≠жЙЊеИ∞пЉМеТ±дїђеПСзО∞дїЦзЪДзїІжЙњиАЕ W( е≠ЧжѓНеНЗеЇПзЪДдЄЛдЄ™еЕГзі† ) пЉМе∞Ж W дЄКзІїеИ∞ T зЪДдљНзљЃпЉМзДґеРОе∞ЖеОЯеМЕеРЂ W зЪДе≠©е≠РзїУзВєдЄ≠зЪД W ињЫи°МеИ†йЩ§пЉМињЩйЗМжБ∞е•љеИ†йЩ§ W еРОпЉМиѓ•е≠©е≠РзїУзВєдЄ≠еЕГзі†дЄ™жХ∞е§ІдЇО 2 пЉМжЧ†йЬАињЫи°МеРИеєґжУНдљЬгАВ
 
3гАБдЄЛдЄАж≠•еИ†йЩ§R пЉМ R еЬ®еПґе≠РзїУзВєдЄ≠ , дљЖжШѓиѓ•зїУзВєдЄ≠еЕГзі†жХ∞зЫЃдЄЇ 2 пЉМеИ†йЩ§еѓЉиЗіеП™жЬЙ 1 дЄ™еЕГзі†пЉМеЈ≤зїПе∞ПдЇОжЬАе∞ПеЕГзі†жХ∞зЫЃ ceil(5/2)-1=2,иАМзФ±еЙНйЭҐжИСдїђеЈ≤зїПзЯ•йБУпЉЪ е¶ВжЮЬеЕґжЯРдЄ™зЫЄйВїеЕДеЉЯзїУзВєдЄ≠жѓФиЊГдЄ∞жї°пЉИеЕГзі†дЄ™жХ∞е§ІдЇО ceil(5/2)-1=2 пЉЙпЉМеИЩеПѓдї•еРСзИґзїУзВєеАЯдЄАдЄ™еЕГзі†пЉМзДґеРОе∞ЖжЬАдЄ∞жї°зЪДзЫЄйВїеЕДеЉЯзїУзВєдЄ≠дЄКзІїжЬАеРОжИЦжЬАеЙНдЄАдЄ™еЕГзі†еИ∞зИґиКВзВєдЄ≠ пЉИжЬЙж≤°жЬЙзЬЛеИ∞зЇҐйїСж†СдЄ≠еЈ¶жЧЛжУНдљЬзЪДељ±е≠Р?пЉЙпЉМеЬ®ињЩдЄ™еЃЮдЊЛдЄ≠пЉМеП≥зЫЄйВїеЕДеЉЯзїУзВєдЄ≠жѓФиЊГдЄ∞жї°пЉИ 3 дЄ™еЕГзі†е§ІдЇО 2 пЉЙпЉМжЙАдї•еЕИеРСзИґиКВзВєеАЯдЄАдЄ™еЕГзі† W дЄЛзІїеИ∞иѓ•еПґе≠РзїУзВєдЄ≠пЉМдї£жЫњеОЯжЭ• S зЪДдљНзљЃпЉМ S еЙНзІїпЉЫзДґеРО X еЬ®зЫЄйВїеП≥еЕДеЉЯзїУзВєдЄ≠дЄКзІїеИ∞зИґзїУзВєдЄ≠пЉМжЬАеРОеЬ®зЫЄйВїеП≥еЕДеЉЯзїУзВєдЄ≠еИ†йЩ§ X пЉМеРОйЭҐеЕГзі†еЙНзІїгАВ
 

4гАБжЬАеРОдЄАж≠•еИ†йЩ§E пЉМ¬†еИ†йЩ§еРОдЉЪеѓЉиЗіеЊИе§ЪйЧЃйҐШпЉМеЫ†дЄЇ E жЙАеЬ®зЪДзїУзВєжХ∞зЫЃеИЪе•љиЊЊж†ЗпЉМеИЪе•љжї°иґ≥жЬАе∞ПеЕГзі†дЄ™жХ∞пЉИ ceil(5/2)-1=2 пЉЙ ,иАМзЫЄйВїзЪДеЕДеЉЯзїУзВєдєЯжШѓеРМж†ЈзЪДжГЕеЖµпЉМеИ†йЩ§дЄАдЄ™еЕГзі†йГљдЄНиГљжї°иґ≥жЭ°дїґпЉМжЙАдї•йЬАи¶Биѓ•иКВзВєдЄОжЯРзЫЄйВїеЕДеЉЯзїУзВєињЫи°МеРИеєґжУНдљЬ пЉЫй¶ЦеЕИзІїеК®зИґзїУзВєдЄ≠зЪДеЕГзі†пЉИиѓ•еЕГзі†еЬ®дЄ§дЄ™йЬАи¶БеРИеєґзЪДдЄ§дЄ™зїУзВєеЕГзі†дєЛйЧіпЉЙдЄЛзІїеИ∞еЕґе≠РзїУзВєдЄ≠пЉМзДґеРОе∞ЖињЩдЄ§дЄ™зїУзВєињЫи°МеРИеєґжИРдЄАдЄ™зїУзВєгАВжЙАдї•еЬ®иѓ•еЃЮдЊЛдЄ≠пЉМеТ±дїђй¶ЦеЕИе∞ЖзИґиКВзВєдЄ≠зЪДеЕГзі† D дЄЛзІїеИ∞еЈ≤зїПеИ†йЩ§ E иАМеП™жЬЙ F зЪДзїУзВєдЄ≠пЉМзДґеРОе∞ЖеРЂжЬЙ D еТМ F зЪДзїУзВєеТМеРЂжЬЙ A,C зЪДзЫЄйВїеЕДеЉЯзїУзВєињЫи°МеРИеєґжИРдЄАдЄ™зїУзВєгАВ
 
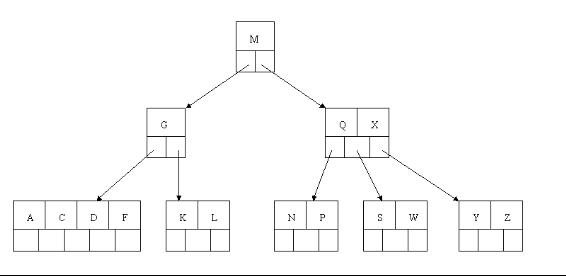
5гАБдєЯиЃЄдљ†иЃ§дЄЇињЩж†ЈеИ†йЩ§жУНдљЬеЈ≤зїПзїУжЭЯдЇЖпЉМеЕґеЃЮдЄНзДґпЉМеЬ®зЬЛзЬЛдЄКеЫЊпЉМеѓєдЇОињЩзІНзЙєжЃКжГЕеЖµпЉМдљ†зЂЛеН≥дЉЪеПСзО∞зИґиКВзВєеП™еМЕеРЂдЄАдЄ™еЕГзі†G пЉМж≤°иЊЊж†ЗпЉИеЫ†дЄЇйЭЮж†єиКВзВєеМЕжЛђеПґе≠РзїУзВєзЪДеЕ≥йФЃе≠ЧжХ∞nењЕй°їжї°иґ≥дЇО2=<n<=4пЉМиАМж≠§е§ДзЪДn=1 пЉЙпЉМињЩжШѓдЄНиГље§ЯжО•еПЧзЪДгАВе¶ВжЮЬињЩдЄ™йЧЃйҐШзїУзВєзЪДзЫЄйВїеЕДеЉЯжѓФиЊГдЄ∞жї°пЉМеИЩеПѓдї•еРСзИґзїУзВєеАЯдЄАдЄ™еЕГзі†гАВеБЗиЃЊињЩжЧґеП≥еЕДеЉЯзїУзВєпЉИеРЂжЬЙ Q,X пЉЙжЬЙдЄАдЄ™дї•дЄКзЪДеЕГзі†пЉИ Q еП≥иЊєињШжЬЙеЕГзі†пЉЙпЉМзДґеРОеТ±дїђе∞Ж M дЄЛзІїеИ∞еЕГзі†еЊИе∞СзЪДе≠РзїУзВєдЄ≠пЉМе∞Ж Q дЄКзІїеИ∞ M зЪДдљНзљЃпЉМињЩжЧґпЉМ Q зЪДеЈ¶е≠Рж†Се∞ЖеПШжИР M зЪДеП≥е≠Рж†СпЉМдєЯе∞±жШѓеРЂжЬЙ N пЉМ P зїУзº襀дЊЭйЩДеЬ® M зЪДеП≥жМЗйТИдЄКгАВжЙАдї•еЬ®ињЩдЄ™еЃЮдЊЛдЄ≠пЉМеТ±дїђж≤°жЬЙеКЮж≥ХеОїеАЯдЄАдЄ™еЕГзі†пЉМеП™иГљдЄОеЕДеЉЯзїУзВєињЫи°МеРИеєґжИРдЄАдЄ™зїУзВєпЉМиАМж†єзїУзВєдЄ≠зЪДеФѓдЄАеЕГзі† M дЄЛзІїеИ∞е≠РзїУзВєпЉМињЩж†ЈпЉМж†СзЪДйЂШеЇ¶еЗПе∞СдЄАе±ВгАВ
 

дЄЇдЇЖињЫдЄАж≠•иѓ¶зїЖиЃ®иЃЇеИ†йЩ§зЪДжГЕеЖµпЉМеЖНдЄЊеП¶е§ЦдЄАдЄ™еЃЮдЊЛ пЉЪ
ињЩйЗМжШѓдЄАж£µдЄНеРМзЪД5 еЇП B ж†СпЉМйВ£еТ±дїђиѓХзЭАеИ†йЩ§ C
 
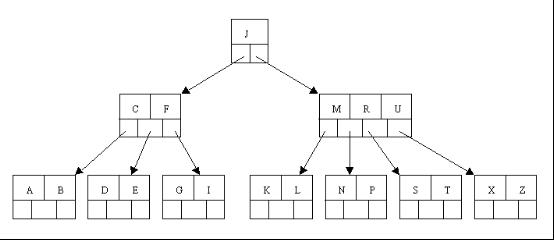
дЇОжШѓе∞ЖеИ†йЩ§еЕГзі†C зЪДеП≥е≠РзїУзВєдЄ≠зЪД D еЕГзі†дЄКзІїеИ∞ C зЪДдљНзљЃпЉМдљЖжШѓеЗЇзО∞дЄКзІїеЕГзі†еРОпЉМеП™жЬЙдЄАдЄ™еЕГзі†зЪДзїУзВєзЪДжГЕеЖµгАВ
еПИеЫ†дЄЇеРЂжЬЙE зЪДзїУзВєпЉМеЕґзЫЄйВїеЕДеЉЯзїУзВєжЙНеИЪиД±иіЂпЉИжЬАе∞СеЕГзі†дЄ™жХ∞дЄЇ 2 пЉЙпЉМдЄНеПѓиГљеРСзИґиКВзВєеАЯеЕГзі†пЉМжЙАдї•еП™иГљињЫи°МеРИеєґжУНдљЬпЉМдЇОжШѓињЩйЗМе∞ЖеРЂжЬЙ A,B зЪДеЈ¶еЕДеЉЯзїУзВєеТМеРЂжЬЙ E зЪДзїУзВєињЫи°МеРИеєґжИРдЄАдЄ™зїУзВєгАВ
 

ињЩж†ЈеПИеЗЇзО∞еП™еРЂжЬЙдЄАдЄ™еЕГзі†F зїУзВєзЪДжГЕеЖµпЉМињЩжЧґпЉМеЕґзЫЄйВїзЪДеЕДеЉЯзїУзВєжШѓдЄ∞жї°зЪДпЉИеЕГзі†дЄ™жХ∞дЄЇ 3> жЬАе∞ПеЕГзі†дЄ™жХ∞ 2 пЉЙ пЉМињЩж†Је∞±еПѓдї•жГ≥зИґзїУзВєеАЯеЕГзі†дЇЖпЉМжККзИґзїУзВєдЄ≠зЪДJ дЄЛзІїеИ∞иѓ•зїУзВєдЄ≠пЉМзЫЄеЇФзЪДе¶ВжЮЬзїУзВєдЄ≠ J еРОжЬЙеЕГзі†еИЩеЙНзІїпЉМзДґеРОзЫЄйВїеЕДеЉЯзїУзВєдЄ≠зЪДзђђдЄАдЄ™еЕГзі†пЉИжИЦиАЕжЬАеРОдЄАдЄ™еЕГзі†пЉЙдЄКзІїеИ∞зИґиКВзВєдЄ≠пЉМеРОйЭҐзЪДеЕГзі†пЉИжИЦиАЕеЙНйЭҐзЪДеЕГзі†пЉЙеЙНзІїпЉИжИЦиАЕеРОзІїпЉЙпЉЫж≥®жДПеРЂжЬЙ K пЉМ L зЪДзїУзВєдї•еЙНдЊЭйЩДеЬ® M зЪДеЈ¶иЊєпЉМзО∞еЬ®еПШдЄЇдЊЭйЩДеЬ® J зЪДеП≥иЊєгАВињЩж†ЈжѓПдЄ™зїУзВєйГљжї°иґ≥ B ж†СзїУжЮДжАІиі®гАВ
 
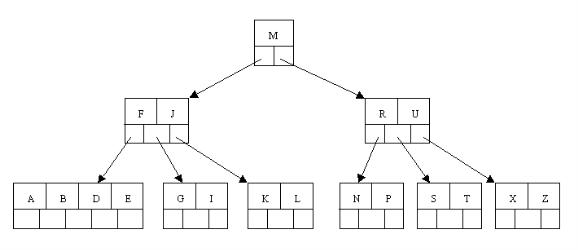
дїОдї•дЄКжУНдљЬеПѓзЬЛеЗЇпЉЪйЩ§ж†єзїУзВєдєЛе§ЦзЪДзїУзВєпЉИеМЕжЛђеПґе≠РзїУзВєпЉЙзЪДеЕ≥йФЃе≠ЧзЪДдЄ™жХ∞nжї°иґ≥пЉЪпЉИceil(m / 2)-1пЉЙ<= n <= m-1пЉМеН≥2<=n<=4гАВињЩдєЯдљРиѓБдЇЖеТ±дїђдєЛеЙНзЪДиІВзВєгАВ еИ†йЩ§жУНдљЬеЃМгАВ
 
7. жАїзїУ
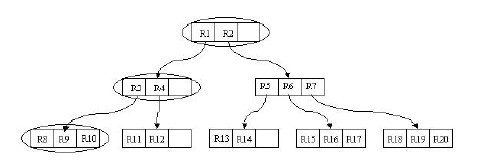
йАЪињЗдї•дЄКдїЛзїНпЉМе§ІиЗіе∞ЖBж†СпЉМB+ж†СпЉМB*ж†СжАїзїУе¶ВдЄЛпЉЪ
Bж†СпЉЪжЬЙеЇПжХ∞зїД+еє≥и°°е§ЪеПЙж†СпЉЫ
B+ж†СпЉЪжЬЙеЇПжХ∞зїДйУЊи°®+еє≥и°°е§ЪеПЙж†СпЉЫ
B*ж†СпЉЪдЄАж£µдЄ∞жї°зЪДB+ж†СгАВ
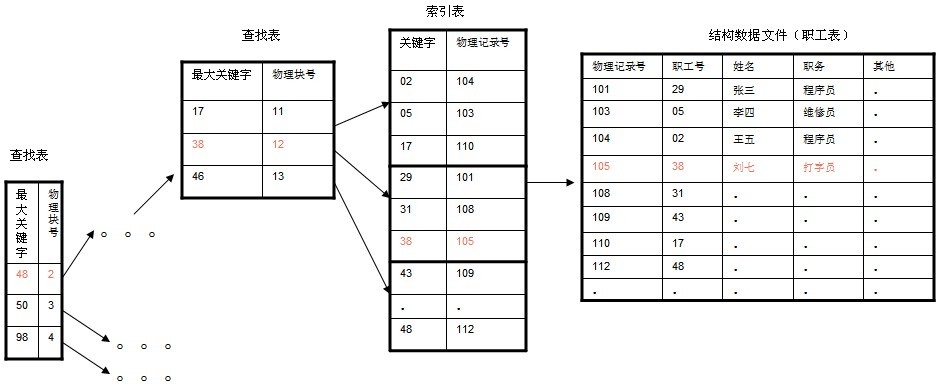
¬†¬†¬† еЬ®е§ІиІДж®°жХ∞жНЃе≠ШеВ®зЪДжЦЗдїґз≥їзїЯдЄ≠пЉМ B~tree з≥їеИЧжХ∞жНЃзїУжЮДпЉМиµЈзЭАеЊИйЗНи¶БзЪДдљЬзФ®пЉМеѓєдЇОе≠ШеВ®дЄНеРМзЪДжХ∞жНЃпЉМиКВзВєзЫЄеЕ≥зЪДдњ°жБѓдєЯжШѓжЬЙжЙАдЄНеРМпЉМињЩйЗМж†єжНЃиЗ™еЈ±зЪДзРЖиІ£пЉМзФїзЪДдЄАдЄ™жЯ•жЙЊдї•иБМеЈ•еПЈдЄЇеЕ≥йФЃе≠ЧпЉМиБМеЈ•еПЈдЄЇ 38 зЪДиЃ∞ељХзЪДзЃАеНХз§ЇжДПеЫЊгАВ ( ињЩйЗМеБЗиЃЊжѓПдЄ™зЙ©зРЖеЭЧеЃєзЇ≥ 3 䪙糥еЉХпЉМз£БзЫШзЪД I/O жУНдљЬзЪДеЯЇжЬђеНХдљНжШѓеЭЧпЉИ block), з£БзЫШиЃњйЧЃеЊИиієжЧґпЉМйЗЗзФ® B+ ж†СжЬЙжХИзЪДеЗПе∞СдЇЖиЃњйЧЃз£БзЫШзЪДжђ°жХ∞гАВпЉЙ
еѓєдЇОеГП MySQL пЉМ DB2 пЉМ Oracle з≠ЙжХ∞жНЃеЇУдЄ≠зЪД糥еЉХзїУжЮДеЊЧжЬЙиЊГжЈ±еЕ•зЪДдЇЖиІ£жЙНи°МпЉМеїЇиЃЃеОїжЙЊдЄАдЇЫB ж†С зЫЄеЕ≥зЪДеЉАжЇРдї£з†Бз†Фз©ґгАВ
иµ∞ињЫжРЬ糥еЉХжУОзЪДдљЬиАЕжҐБжЦМиАБеЄИ йТИеѓєB ж†СгАБB+ ж†СзїЩеЗЇдЇЖдїЦзЪДжДПиІБпЉИдЄЇдЇЖзЬЯеЃЮжАІпЉМзЙєеЉХзФ®еЕґеОЯиѓЭпЉМжЬ™дљЬдїїдљХжФєеК®пЉЙпЉЪ ¬†вАЬ B+ ж†СињШжЬЙдЄАдЄ™жЬАе§ІзЪДе•ље§ДпЉМжЦєдЊњжЙЂеЇУпЉМB ж†СењЕй°їзФ®дЄ≠еЇПйБНеОЖзЪДжЦєж≥ХжМЙеЇПжЙЂеЇУпЉМиАМB+ ж†СзЫіжО•дїОеПґе≠РзїУзВєжМ®дЄ™жЙЂдЄАйБНе∞±еЃМдЇЖпЉМB+ ж†СжФѓжМБrange-query йЭЮеЄЄжЦєдЊњпЉМиАМB ж†СдЄНжФѓжМБгАВињЩжШѓжХ∞жНЃеЇУйАЙзФ®B+ ж†СзЪДжЬАдЄїи¶БеОЯеЫ†гАВ
¬†¬†¬† жѓФе¶Ви¶БжЯ• 5-10 дєЛйЧізЪДпЉМB+ ж†СдЄАжККеИ∞5 ињЩдЄ™ж†ЗиЃ∞пЉМеЖНдЄАжККеИ∞10 пЉМзДґеРОдЄ≤иµЈжЭ•е∞±и°МдЇЖпЉМB ж†Се∞±йЭЮеЄЄйЇїзГ¶гАВB ж†СзЪДе•ље§ДпЉМе∞±жШѓжИРеКЯжߕ胥зЙєеИЂжЬЙеИ©пЉМеЫ†дЄЇж†СзЪДйЂШеЇ¶жАїдљУи¶БжѓФB+ ж†СзЯЃгАВдЄНжИРеКЯзЪДжГЕеЖµдЄЛпЉМB ж†СдєЯжѓФB+ ж†Сз®Нз®НеН†дЄАзВєзВєдЊњеЃЬгАВ
    B
ж†СжѓФе¶Вдљ†зЪДдЊЛе≠РдЄ≠жЯ•пЉМ17
зЪДиѓЭпЉМдЄАжККе∞±еЊЧеИ∞зїУжЮЬдЇЖпЉМ
жЬЙеЊИе§ЪеЯЇдЇОйҐСзОЗзЪДжРЬ糥жШѓйАЙзФ®B
ж†СпЉМиґКйҐСзєБquery
зЪДзїУзВєиґКеЊАж†єдЄКиµ∞пЉМеЙНжПРжШѓйЬАи¶Беѓєquery
еБЪзїЯиЃ°пЉМиАМдЄФи¶Беѓєkey
еБЪдЄАдЇЫеПШеМЦгАВ
¬†¬†¬† еП¶е§ЦB ж†СдєЯе•љB+ ж†СдєЯе•љпЉМж†єжИЦиАЕдЄКйЭҐеЗ†е±Веۆ䪯襀еПНе§Нquery пЉМжЙАдї•ињЩеЗ†еЭЧеЯЇжЬђйГљеЬ®еЖЕе≠ШдЄ≠пЉМдЄНдЉЪеЗЇзО∞иѓїз£БзЫШIO пЉМдЄАиИђеЈ≤еРѓеК®зЪДжЧґеАЩпЉМе∞±дЉЪдЄїеК®жНҐеЕ•еЖЕе≠ШгАВвАЭйЭЮеЄЄжДЯи∞ҐгАВ
¬†¬†¬† Bucket Li пЉЪ"mysql еЇХе±Ве≠ШеВ®жШѓзФ®B+ж†СеЃЮзО∞зЪДпЉМзЯ•йБУдЄЇдїАдєИдєИгАВеЖЕе≠ШдЄ≠B+ж†СжШѓж≤°жЬЙдЉШеКњзЪДпЉМдљЖжШѓдЄАеИ∞з£БзЫШпЉМB+ж†СзЪДе®БеКЫе∞±еЗЇжЭ•дЇЖ"гАВ
 
 
зђђдЇМиКВгАБ R ж†СпЉЪе§ДзРЖз©ЇйЧіе≠ШеВ®йЧЃйҐШ
зЫЄдњ°зїПињЗдЄКйЭҐзђђдЄАиКВзЪДдїЛзїНпЉМдљ†еЈ≤зїПеѓє B ж†СжИЦиАЕ B+ ж†СжЬЙжЙАдЇЖиІ£гАВињЩзІНж†СеПѓдї•йЭЮеЄЄе•љзЪДе§ДзРЖдЄАзїіз©ЇйЧіе≠ШеВ®зЪДйЧЃйҐШгАВ B ж†СжШѓдЄАж£µеє≥и°°ж†СпЉМеЃГжШѓжККдЄАзїізЫізЇњеИЖдЄЇиЛ•еє≤жЃµзЇњжЃµпЉМељУжИСдїђжЯ•жЙЊжї°иґ≥жЯРдЄ™и¶Бж±ВзЪДзВєзЪДжЧґеАЩпЉМеП™и¶БеОїжЯ•жЙЊеЃГжЙАе±ЮзЪДзЇњжЃµеН≥еПѓгАВдЊЭжИСзЬЛжЭ•пЉМињЩзІНжАЭжГ≥еЕґеЃЮе∞±жШѓеЕИжЙЊдЄАдЄ™е§ІзЪДз©ЇйЧіпЉМеЖНйАРж≠•зЉ©е∞ПжЙАи¶БжЯ•жЙЊзЪДз©ЇйЧіпЉМжЬАзїИеЬ®дЄАдЄ™иЗ™еЈ±иЃЊеЃЪзЪДжЬАе∞ПдЄНеПѓеИЖз©ЇйЧіеЖЕжЙЊеЗЇжї°иґ≥и¶Бж±ВзЪДиІ£гАВдЄАдЄ™еЕЄеЮЛзЪД B ж†СжЯ•жЙЊе¶ВдЄЛпЉЪ
 
и¶БжЯ•жЙЊжЯРдЄАжї°иґ≥жЭ°дїґзЪДзВєпЉМеЕИеОїжЙЊеИ∞жї°иґ≥жЭ°дїґзЪДзЇњжЃµпЉМзДґеРОйБНеОЖжЙАеЬ®зЇњжЃµдЄКзЪДзВєпЉМеН≥еПѓжЙЊеИ∞з≠Фж°ИгАВ
B ж†СжШѓдЄАзІНзЫЄеѓєжЭ•иѓіжѓФиЊГе§НжЭВзЪДжХ∞жНЃзїУжЮДпЉМе∞§еЕґжШѓеЬ®еЃГзЪДеИ†йЩ§дЄОжПТеЕ•жУНдљЬињЗз®ЛдЄ≠пЉМеЫ†дЄЇеЃГжґЙеПКеИ∞дЇЖеПґе≠РзїУзВєзЪДеИЖиІ£дЄОеРИеєґгАВзФ±дЇОжЬђжЦЗзђђдЄАиКВеЈ≤зїПиѓ¶зїЖдїЛзїНдЇЖ B ж†СеТМ B+ ж†СпЉМдЄЛйЭҐзЫіжО•еЉАеІЛдїЛзїНжИСдїђзЪДзђђдЇМдЄ™дЄїиІТпЉЪ R ж†СгАВ
 
зЃАдїЛ
1984 еєіпЉМеК†еЈЮе§Іе≠¶дЉѓеЕЛеИ©еИЖж†°зЪД Guttman еПСи°®дЇЖдЄАзѓЗйҐШдЄЇ вАЬR-trees: a dynamic index structure for spatial searchingвАЭ зЪДиЃЇжЦЗпЉМеРСдЄЦдЇЇдїЛзїНдЇЖ R ж†СињЩзІНе§ДзРЖйЂШзїіз©ЇйЧіе≠ШеВ®йЧЃйҐШзЪДжХ∞жНЃзїУжЮДгАВжЬђжЦЗдЊњжШѓеЯЇдЇОињЩзѓЗиЃЇжЦЗеЖЩдљЬеЃМжИРзЪДпЉМеЫ†ж≠§е¶ВжЮЬе§ІеЃґеѓє R ж†СйЭЮеЄЄжЬЙеЕіиґ£пЉМжИСжГ≥жЬАе•љињШжШѓеПВиАГдЄАдЄЛеОЯиСЧеРІпЉЪпЉЙгАВдЄЇи°®з§ЇеѓєињЩдљНзЙЫдЇЇзЪДе∞КйЗНпЉМзїЩдЄ™еЉХзФ®еЕИпЉЪ
Guttman, A.; вАЬR-trees: a dynamic index structure for spatial searching,вАЭ ACM, 1984 , 14
Rж†С еЬ®жХ∞жНЃеЇУз≠ЙйҐЖеЯЯеБЪеЗЇзЪДеКЯзї©жШѓйЭЮеЄЄжШЊиСЧзЪДгАВеЃГеЊИе•љзЪДиІ£еЖ≥дЇЖеЬ®йЂШзїіз©ЇйЧіжРЬ糥з≠ЙйЧЃйҐШгАВдЄЊдЄ™ R ж†СеЬ®зО∞еЃЮйҐЖеЯЯдЄ≠иГље§ЯиІ£еЖ≥зЪДдЊЛе≠РеРІпЉЪжЯ•жЙЊ 20 иЛ±йЗМдї•еЖЕжЙАжЬЙзЪДй§РеОЕгАВе¶ВжЮЬж≤°жЬЙ R ж†Сдљ†дЉЪжАОдєИиІ£еЖ≥пЉЯдЄАиИђжГЕеЖµдЄЛжИСдїђдЉЪжККй§РеОЕзЪДеЭРж†З (x,y) еИЖдЄЇдЄ§дЄ™е≠ЧжЃµе≠ШжФЊеЬ®жХ∞жНЃеЇУдЄ≠пЉМдЄАдЄ™е≠ЧжЃµиЃ∞ељХзїПеЇ¶пЉМеП¶дЄАдЄ™е≠ЧжЃµиЃ∞ељХзЇђеЇ¶гАВињЩж†ЈзЪДиѓЭжИСдїђе∞±йЬАи¶БйБНеОЖжЙАжЬЙзЪДй§РеОЕиОЈеПЦеЕґдљНзљЃдњ°жБѓпЉМзДґеРОиЃ°зЃЧжШѓеР¶жї°иґ≥и¶Бж±ВгАВе¶ВжЮЬдЄАдЄ™еЬ∞еМЇжЬЙ 100 еЃґй§РеОЕзЪДиѓЭпЉМжИСдїђе∞±и¶БињЫи°М 100 жђ°дљНзљЃиЃ°зЃЧжУНдљЬдЇЖпЉМе¶ВжЮЬеЇФзФ®еИ∞и∞Јж≠МеЬ∞еЫЊињЩзІНиґЕе§ІжХ∞жНЃеЇУдЄ≠пЉМжИСжГ≥ињЩзІНжЦєж≥ХиВѓеЃЪдЄНеПѓи°МеРІгАВ
R ж†Се∞±еЊИе•љзЪДиІ£еЖ≥дЇЖињЩзІНйЂШзїіз©ЇйЧіжРЬ糥йЧЃйҐШгАВеЃГжКК B ж†СзЪДжАЭжГ≥еЊИе•љзЪДжЙ©е±ХеИ∞дЇЖе§Ъзїіз©ЇйЧіпЉМйЗЗзФ®дЇЖ B ж†СеИЖеЙ≤з©ЇйЧізЪДжАЭжГ≥пЉМеєґеЬ®жЈїеК†гАБеИ†йЩ§жУНдљЬжЧґйЗЗзФ®еРИеєґгАБеИЖиІ£зїУзВєзЪДжЦєж≥ХпЉМдњЭиѓБж†СзЪДеє≥и°°жАІгАВеЫ†ж≠§пЉМ R ж†Се∞±жШѓдЄАж£µзФ®жЭ•е≠ШеВ®йЂШзїіжХ∞жНЃзЪДеє≥и°°ж†СгАВ
е•љдЇЖзЃАдїЛе∞±еИ∞ж≠§дЄЇж≠ҐгАВдї•дЄЛпЉМжЬђжЦЗе∞Жиѓ¶зїЖдїЛзїН R ж†СзЪДжХ∞жНЃзїУжЮДдї•еПК R ж†СзЪДжУНдљЬгАВиЗ≥дЇО R ж†СзЪДжЙ©е±ХдЄО R ж†СзЪДжАІиГљйЧЃйҐШпЉМжИСе∞±дїЕдїЕеЬ®жЦЗжЬЂзЃАеНХдїЛзїНдЄАдЄЛеРІпЉМињЩдЇЫйЧЃйҐШжЬАе•љжЯ•йШЕзЫЄеЕ≥иЃЇжЦЗжѓФиЊГеРИйАВгАВ
 
R ж†СзЪДжХ∞жНЃзїУжЮД
е¶ВдЄКжЙАињ∞пЉМ R ж†СжШѓ B ж†СеЬ®йЂШзїіз©ЇйЧізЪДжЙ©е±ХпЉМжШѓдЄАж£µеє≥и°°ж†СгАВжѓПдЄ™ R ж†СзЪДеПґе≠РзїУзВєеМЕеРЂдЇЖе§ЪдЄ™жМЗеРСдЄНеРМжХ∞жНЃзЪДжМЗйТИпЉМињЩдЇЫжХ∞жНЃеПѓдї•жШѓе≠ШжФЊеЬ®з°ђзЫШдЄ≠зЪДпЉМдєЯеПѓдї•жШѓе≠ШеЬ®еЖЕе≠ШдЄ≠гАВж†єжНЃ R ж†СзЪДињЩзІНжХ∞жНЃзїУжЮДпЉМељУжИСдїђйЬАи¶БињЫи°МдЄАдЄ™йЂШзїіз©ЇйЧіжߕ胥жЧґпЉМжИСдїђеП™йЬАи¶БйБНеОЖе∞СжХ∞еЗ†дЄ™еПґе≠РзїУзВєжЙАеМЕеРЂзЪДжМЗйТИпЉМжЯ•зЬЛињЩдЇЫжМЗйТИжМЗеРСзЪДжХ∞жНЃжШѓеР¶жї°иґ≥и¶Бж±ВеН≥еПѓгАВињЩзІНжЦєеЉПдљњжИСдїђдЄНењЕйБНеОЖжЙАжЬЙжХ∞жНЃеН≥еПѓиОЈеЊЧз≠Фж°ИпЉМжХИзОЗжШЊиСЧжПРйЂШгАВдЄЛеЫЊ1жШѓRж†СзЪДдЄАдЄ™зЃАеНХеЃЮдЊЛпЉЪ
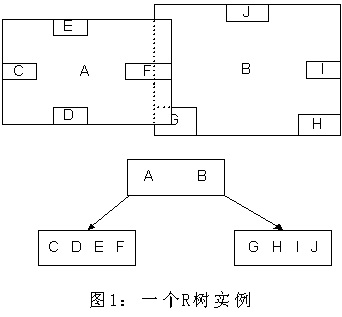
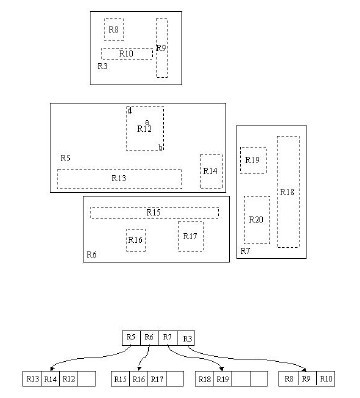
жИСдїђеЬ®дЄКйЭҐиѓіињЗпЉМ R ж†СињРзФ®дЇЖз©ЇйЧіеИЖеЙ≤зЪДзРЖењµпЉМињЩзІНзРЖењµжШѓе¶ВдљХеЃЮзО∞зЪДеСҐпЉЯ R ж†СйЗЗзФ®дЇЖдЄАзІНзІ∞дЄЇ MBR(Minimal Bounding Rectangle) зЪДжЦєж≥ХпЉМеЬ®ж≠§жИСжККеЃГиѓСдљЬвАЬжЬАе∞ПиЊєзХМзߩ嚥вАЭгАВдїОеПґе≠РзїУзВєеЉАеІЛзФ®зߩ嚥пЉИ rectangle пЉЙе∞Жз©ЇйЧіж°ЖиµЈжЭ•пЉМзїУзВєиґКеЊАдЄКпЉМж°ЖдљПзЪДз©ЇйЧіе∞±иґКе§ІпЉМдї•ж≠§еѓєз©ЇйЧіињЫи°МеИЖеЙ≤гАВжЬЙзВєдЄНжЗВпЉЯж≤°еЕ≥з≥їпЉМзїІзї≠еЊАдЄЛзЬЛгАВеЬ®ињЩйЗМжИСињШжГ≥жПРдЄАдЄЛпЉМ R ж†СдЄ≠зЪД R еЇФиѓ•дї£и°®зЪДжШѓ Rectangle пЉИж≠§е§ДеПВиАГ wikipedia пЉЙпЉМиАМдЄНжШѓе§Іе§ЪжХ∞еЫљеЖЕжХЩжЭРдЄ≠жЙАиѓізЪД Region пЉИеЊИе§Ъдє¶жКК R ж†СзІ∞дЄЇеМЇеЯЯж†СпЉМињЩжШѓжЬЙиѓѓзЪДпЉЙгАВжИСдїђе∞±жЛњдЇМзїіз©ЇйЧіжЭ•дЄЊдЊЛеРІгАВдЄЛеЫЊжШѓ Guttman иЃЇжЦЗдЄ≠зЪДдЄАеєЕеЫЊгАВ
 
жИСжЭ•иѓ¶зїЖиІ£йЗКдЄАдЄЛињЩеЉ†еЫЊгАВеЕИжЭ•зЬЛеЫЊпЉИ b пЉЙеРІгАВй¶ЦеЕИжИСдїђеБЗиЃЊжЙАжЬЙжХ∞жНЃйГљжШѓдЇМзїіз©ЇйЧідЄЛзЪДзВєпЉМеЫЊдЄ≠дїЕдїЕж†ЗењЧдЇЖ R8 еМЇеЯЯдЄ≠зЪДжХ∞жНЃпЉМдєЯе∞±жШѓйВ£дЄ™ shape of data object гАВеИЂжККйВ£дЄАеЭЧдЄНиІДеИЩеی嚥зЬЛжИРдЄАдЄ™жХ∞жНЃпЉМжИСдїђжККеЃГзЬЛдљЬжШѓе§ЪдЄ™жХ∞жНЃеЫіжИРзЪДдЄАдЄ™еМЇеЯЯгАВдЄЇдЇЖеЃЮзО∞ R ж†СзїУжЮДпЉМжИСдїђзФ®дЄАдЄ™жЬАе∞ПиЊєзХМзߩ嚥жБ∞е•љж°ЖдљПињЩдЄ™дЄНиІДеИЩеМЇеЯЯпЉМињЩж†ЈпЉМжИСдїђе∞±жЮДйА†еЗЇдЇЖдЄАдЄ™еМЇеЯЯпЉЪ R8 гАВ R8 зЪДзЙєзВєеЊИжШОжШЊпЉМе∞±жШѓж≠£ж≠£е•ље•љж°ЖдљПжЙАжЬЙеЬ®ж≠§еМЇеЯЯдЄ≠зЪДжХ∞жНЃгАВеЕґдїЦеЃЮзЇњеМЕеЫідљПзЪДеМЇеЯЯпЉМе¶В R9 пЉМ R10 пЉМ R12 з≠ЙйГљжШѓеРМж†ЈзЪДйБУзРЖгАВињЩж†ЈдЄАжЭ•пЉМжИСдїђдЄАеЕ±еЊЧеИ∞дЇЖ 12 дЄ™жЬАжЬАеЯЇжЬђзЪДжЬАе∞Пзߩ嚥гАВињЩдЇЫзߩ嚥йГље∞Ж襀е≠ШеВ®еЬ®е≠РзїУзВєдЄ≠гАВдЄЛдЄАж≠•жУНдљЬе∞±жШѓињЫи°МйЂШдЄАе±Вжђ°зЪДе§ДзРЖгАВжИСдїђеПСзО∞ R8 пЉМ R9 пЉМ R10 дЄЙдЄ™зߩ嚥иЈЭз¶їжЬАдЄЇйЭ†ињСпЉМеЫ†ж≠§е∞±еПѓдї•зФ®дЄАдЄ™жЫіе§ІзЪДзߩ嚥 R3 жБ∞е•љж°ЖдљПињЩ 3 дЄ™зߩ嚥гАВеРМж†ЈйБУзРЖпЉМ R15 пЉМ R16 襀 R6 жБ∞е•љж°ЖдљПпЉМ R11 пЉМ R12 襀 R4 жБ∞е•љж°ЖдљПпЉМз≠Йз≠ЙгАВжЙАжЬЙжЬАеЯЇжЬђзЪДжЬАе∞ПиЊєзХМзߩ嚥襀ж°ЖеЕ•жЫіе§ІзЪДзߩ嚥дЄ≠дєЛеРОпЉМеЖНжђ°ињ≠дї£пЉМзФ®жЫіе§ІзЪДж°ЖеОїж°ЖдљПињЩдЇЫзߩ嚥гАВжИСжГ≥е§ІеЃґйГљеЇФиѓ•зРЖиІ£ињЩдЄ™жХ∞жНЃзїУжЮДзЪДзЙєеЊБдЇЖгАВзФ®еЬ∞еЫЊзЪДдЊЛе≠РжЭ•иІ£йЗКпЉМе∞±жШѓжЙАжЬЙзЪДжХ∞жНЃйГљжШѓй§РеОЕжЙАеѓєеЇФзЪДеЬ∞зВєпЉМеЕИжККзЫЄйВїзЪДй§РеОЕеИТеИЖеИ∞еРМдЄАеЭЧеМЇеЯЯпЉМеИТеИЖе•љжЙАжЬЙй§РеОЕдєЛеРОпЉМеЖНжККйВїињСзЪДеМЇеЯЯеИТеИЖеИ∞жЫіе§ІзЪДеМЇеЯЯпЉМеИТеИЖеЃМжѓХеРОеЖНжђ°ињЫи°МжЫійЂШе±Вжђ°зЪДеИТеИЖпЉМзЫіеИ∞еИТеИЖеИ∞еП™еЙ©дЄЛдЄ§дЄ™жЬАе§ІзЪДеМЇеЯЯдЄЇж≠ҐгАВи¶БжЯ•жЙЊзЪДжЧґеАЩе∞±жЦєдЊњдЇЖеРІ гАВ
дЄЛйЭҐе∞±еПѓдї•жККињЩдЇЫе§Іе§Іе∞Пе∞ПзЪДзߩ嚥е≠ШеЕ•жИСдїђзЪД R ж†СдЄ≠еОїдЇЖгАВж†єзїУзВєе≠ШжФЊзЪДжШѓдЄ§дЄ™жЬАе§ІзЪДзߩ嚥пЉМињЩдЄ§дЄ™жЬАе§ІзЪДзߩ嚥ж°ЖдљПдЇЖжЙАжЬЙзЪДеЙ©дљЩзЪДзߩ嚥пЉМељУзДґдєЯе∞±ж°ЖдљПдЇЖжЙАжЬЙзЪДжХ∞жНЃгАВдЄЛдЄАе±ВзЪДзїУзВєе≠ШжФЊдЇЖжђ°е§ІзЪДзߩ嚥пЉМињЩдЇЫзߩ嚥犩е∞ПдЇЖиМГеЫігАВжѓПдЄ™еПґе≠РзїУзВєйГљжШѓе≠ШжФЊзЪДжЬАе∞ПзЪДзߩ嚥пЉМињЩдЇЫзߩ嚥дЄ≠еПѓиГљеМЕеРЂжЬЙ n дЄ™жХ∞жНЃгАВ
еЬ®ињЩйЗМпЉМиѓїиАЕеЕИдЄНи¶БеОїзЇ†зїУдЇОе¶ВдљХеИТеИЖжХ∞жНЃеИ∞жЬАе∞ПеМЇеЯЯзߩ嚥пЉМдєЯдЄНи¶БзЇ†зїУжАОж†ЈзФ®жЫіе§ІзЪДзߩ嚥ж°ЖдљПе∞Пзߩ嚥пЉМињЩдЇЫйГљжШѓдЄЛдЄАиКВжИСдїђи¶БиЃ®иЃЇзЪДгАВ
иЃ≤еЃМдЇЖеЯЇжЬђзЪДжХ∞жНЃзїУжЮДпЉМжИСдїђжЭ•иЃ≤дЄ™еЃЮдЊЛпЉМе¶ВдљХжߕ胥зЙєеЃЪзЪДжХ∞жНЃеРІгАВеПИдї•й§РеОЕдЄЇдЊЛеРІгАВеБЗиЃЊжИСи¶Бжߕ胥府еЈЮеЄВ姩ж≤≥е̯姩ж≤≥еЯОйЩДињСдЄАеЕђйЗМзЪДжЙАжЬЙй§РеОЕеЬ∞еЭАжАОдєИеКЮпЉЯжЙУеЉАеЬ∞еЫЊпЉИдєЯе∞±жШѓжХідЄ™ R ж†СпЉЙпЉМ еЕИйАЙжЛ©еЫљеЖЕињШжШѓеЫље§ЦпЉИдєЯе∞±жШѓж†єзїУзВєпЉЙгАВзДґеРОйАЙжЛ©еНОеНЧеЬ∞еМЇпЉИеѓєеЇФзђђдЄАе±ВзїУзВєпЉЙпЉМйАЙжЛ©еєњеЈЮеЄВпЉИеѓєеЇФзђђдЇМе±ВзїУзВєпЉЙпЉМеЖНйАЙж˩姩ж≤≥еМЇпЉИеѓєеЇФзђђдЄЙе±ВзїУзВєпЉЙпЉМжЬАеРОйАЙж˩姩 ж≤≥еЯОжЙАеЬ®зЪДйВ£дЄ™еМЇеЯЯпЉИеѓєеЇФеПґе≠РзїУзВєпЉМе≠ШжФЊжЬЙжЬАе∞Пзߩ嚥пЉЙпЉМйБНеОЖжЙАжЬЙеЬ®ж≠§еМЇеЯЯеЖЕзЪДзїУзВєпЉМзЬЛжШѓеР¶жї°иґ≥жИСдїђзЪДи¶Бж±ВеН≥еПѓгАВжАОдєИж†ЈпЉМеЕґеЃЮ R ж†СзЪДжЯ•жЙЊиІДеИЩиЈЯжЯ•еЬ∞еЫЊеЊИеГПеРІпЉЯеѓєеЇФдЄЛеЫЊпЉЪ
дЄАж£µ R ж†Сжї°иґ≥е¶ВдЄЛзЪДжАІиі®пЉЪ
1. ¬†¬†¬†¬† йЩ§йЭЮеЃГжШѓж†єзїУзВєдєЛе§ЦпЉМжЙАжЬЙеПґе≠РзїУзВєеМЕеРЂжЬЙ m иЗ≥ M дЄ™иЃ∞ељХ糥еЉХпЉИжЭ°зЫЃпЉЙгАВдљЬдЄЇж†єзїУзВєзЪДеПґе≠РзїУзВєжЙАеЕЈжЬЙзЪДиЃ∞ељХдЄ™жХ∞еПѓдї•е∞СдЇО m гАВйАЪеЄЄпЉМ m=M/2 гАВ
2. ¬†¬†¬†¬† еѓєдЇОжЙАжЬЙеЬ®еПґе≠РдЄ≠е≠ШеВ®зЪДиЃ∞ељХпЉИжЭ°зЫЃпЉЙпЉМ I жШѓжЬАе∞ПзЪДеПѓдї•еЬ®з©ЇйЧідЄ≠еЃМеЕ®и¶ЖзЫЦињЩдЇЫиЃ∞ељХжЙАдї£и°®зЪДзВєзЪДзߩ嚥пЉИж≥®жДПпЉЪж≠§е§ДжЙАиѓізЪДвАЬзߩ嚥вАЭжШѓеПѓдї•жЙ©е±ХеИ∞йЂШзїіз©ЇйЧізЪДпЉЙгАВ
3. ¬†¬†¬†¬† жѓПдЄАдЄ™й£ЮеПґе≠РзїУзВєжЛ•жЬЙ m иЗ≥ M дЄ™е≠©е≠РзїУзВєпЉМйЩ§йЭЮеЃГжШѓж†єзїУзВєгАВ
4. ¬†¬†¬†¬† еѓєдЇОеЬ®йЭЮеПґе≠РзїУзВєдЄКзЪДжѓПдЄАдЄ™жЭ°зЫЃпЉМ i жШѓжЬАе∞ПзЪДеПѓдї•еЬ®з©ЇйЧідЄКеЃМеЕ®и¶ЖзЫЦињЩдЇЫжЭ°зЫЃжЙАдї£и°®зЪДеЇЧзЪДзߩ嚥пЉИеРМжАІиі® 2 пЉЙгАВ
5. ¬†¬†¬†¬† жЙАжЬЙеПґе≠РзїУзВєйГљдљНдЇОеРМдЄАе±ВпЉМеЫ†ж≠§ R ж†СдЄЇеє≥и°°ж†СгАВ
 
еПґе≠РзїУзВєзЪДзїУжЮД
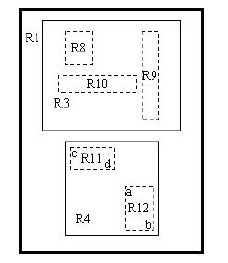
еЕИжЭ•жОҐз©ґдЄАдЄЛеПґе≠РзїУзВєзЪДзїУжЮДеРІгАВеПґе≠РзїУзВєжЙАдњЭе≠ШзЪДжХ∞ж́嚥еЉПдЄЇпЉЪ (I, tuple-identifier) гАВ
¬†¬†¬†¬†¬† еЕґдЄ≠пЉМ tuple-identifier и°®з§ЇзЪДжШѓдЄАдЄ™е≠ШжФЊдЇОжХ∞жНЃеЇУдЄ≠зЪД tuple пЉМдєЯе∞±жШѓдЄАжЭ°иЃ∞ељХпЉМеЃГжШѓ n зїізЪДгАВ I жШѓдЄАдЄ™ n зїіз©ЇйЧізЪДзߩ嚥пЉМеєґеПѓдї•жБ∞е•љж°ЖдљПињЩдЄ™еПґе≠РзїУзВєдЄ≠жЙАжЬЙиЃ∞ељХдї£и°®зЪД n зїіз©ЇйЧідЄ≠зЪДзВєгАВ I=(I0 ,I1 ,вА¶,In-1 ) гАВеЕґзїУжЮДе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

дЄЛеЫЊжППињ∞зЪДе∞±жШѓеЬ®дЇМзїіз©ЇйЧідЄ≠зЪДеПґе≠РзїУзВєжЙАи¶Бе≠ШеВ®зЪДдњ°жБѓгАВ
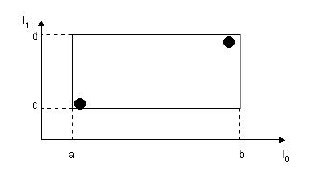  
 
еЬ®ињЩеЉ†еЫЊдЄ≠пЉМ I жЙАдї£и°®зЪДе∞±жШѓеЫЊдЄ≠зЪДзߩ嚥пЉМеЕґиМГеЫіжШѓ a<=I0 <=b пЉМ c<=I1 <=d гАВжЬЙдЄ§дЄ™ tuple-identifier пЉМеЬ®еЫЊдЄ≠еН≥и°®з§ЇдЄЇйВ£дЄ§дЄ™зВєгАВињЩзІН嚥еЉПеЃМеЕ®еПѓдї•жО®еєњеИ∞йЂШзїіз©ЇйЧігАВе§ІеЃґзЃАеНХжГ≥жГ≥дЄЙзїіз©ЇйЧідЄ≠зЪДж†Је≠Ре∞±еПѓдї•дЇЖгАВињЩж†ЈпЉМеПґе≠РзїУзВєзЪДзїУжЮДе∞±дїЛзїНеЃМдЇЖгАВ
 
йЭЮеПґе≠РзїУзВє
¬†¬†¬†¬†¬† йЭЮеПґе≠РзїУзВєзЪДзїУжЮДеЕґеЃЮдЄОеПґе≠РзїУзВєйЭЮеЄЄз±їдЉЉгАВжГ≥и±°дЄАдЄЛ B ж†Се∞±зЯ•йБУдЇЖпЉМ B ж†СзЪДеПґе≠РзїУзВєе≠ШжФЊзЪДжШѓзЬЯеЃЮе≠ШеЬ®зЪДжХ∞жНЃпЉМиАМйЭЮеПґе≠РзїУзВєе≠ШжФЊзЪДжШѓињЩдЇЫжХ∞жНЃзЪДвАЬиЊєзХМвАЭпЉМжИЦиАЕиѓідєЯзЃЧжШѓдЄАзІН糥еЉХпЉИжЬЙзЦСйЧЃзЪДиѓїиАЕеПѓдї•еЫЮй°ЊдЄАдЄЛдЄКињ∞зђђдЄАиКВдЄ≠иЃ≤иІ£Bж†СзЪДйГ®еИЖ пЉЙ гАВ
¬†¬†¬†¬†¬† еРМж†ЈйБУзРЖпЉМ R ж†СзЪДйЭЮеПґе≠РзїУзВєе≠ШжФЊзЪДжХ∞жНЃзїУжЮДдЄЇпЉЪ (I, child-pointer) гАВ
¬†¬†¬†¬†¬† еЕґдЄ≠пЉМ child-pointer жШѓжМЗеРСе≠©е≠РзїУзВєзЪДжМЗйТИпЉМ I жШѓи¶ЖзЫЦжЙАжЬЙе≠©е≠РзїУзВєеѓєеЇФзߩ嚥зЪДзߩ嚥гАВињЩиЊєжЬЙзВєжЛЧеП£пЉМдљЖжИСжГ≥дЄНжШѓеЊИйЪЊжЗВеРІпЉЯзїЩеЉ†еЫЊпЉЪ
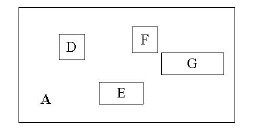  
 
D,E,F,G дЄЇе≠©е≠РзїУзВєжЙАеѓєеЇФзЪДзߩ嚥гАВ A дЄЇиГље§Яи¶ЖзЫЦињЩдЇЫзߩ嚥зЪДжЫіе§ІзЪДзߩ嚥гАВињЩдЄ™ A е∞± жШѓињЩдЄ™йЭЮеПґе≠РзїУзВєжЙАеѓєеЇФзЪДзߩ嚥гАВињЩжЧґеАЩдљ†еЇФиѓ•жВЯеИ∞дЇЖеРІпЉЯжЧ†иЃЇжШѓеПґе≠РзїУзВєињШжШѓйЭЮеПґе≠РзїУзВєпЉМеЃГдїђйГљеѓєеЇФзЭАдЄАдЄ™зߩ嚥гАВж†С嚥зїУжЮДдЄКе±ВзЪДзїУзВєжЙАеѓєеЇФзЪДзߩ嚥иГље§ЯеЃМеЕ®и¶Ж зЫЦеЃГзЪДе≠©е≠РзїУзВєжЙАеѓєеЇФзЪДзߩ嚥гАВж†єзїУзВєдєЯеФѓдЄАеѓєеЇФдЄАдЄ™зߩ嚥пЉМиАМињЩдЄ™зߩ嚥жШѓеПѓдї•и¶ЖзЫЦжЙАжЬЙжИСдїђжЛ•жЬЙзЪДжХ∞жНЃдњ°жБѓеЬ®з©ЇйЧідЄ≠дї£и°®зЪДзВєзЪДгАВ
жИСдЄ™дЇЇжДЯиІЙињЩеЉ†еЫЊзФїзЪДдЄНйВ£дєИз≤Њз°ЃпЉМеЇФиѓ•жШѓзߩ嚥 A и¶БжБ∞е•љи¶ЖзЫЦ D,E,F,G пЉМиАМдЄНеЇФиѓ•еЖНзХЩеЗЇињЩдєИе§Ъж≤°зФ®зЪДз©ЇйЧідЇЖгАВдљЖдЄЇе∞КйЗНеОЯеЫЊзЪДзїШеИґиАЕпЉМзЙєдЄНдљЬдњЃжФєгАВ
 
R ж†СзЪДжУНдљЬ
ињЩдЄАйГ®еИЖдєЯиЃЄжШѓзЉЦз®ЛиАЕжЬАеЕ≥ж≥®зЪДйЧЃйҐШдЇЖгАВињЩдєИйЂШжХИзЪДжХ∞жНЃзїУжЮДиѓ•е¶ВдљХеОїеЃЮзО∞еСҐпЉЯињЩдЊњжШѓињЩдЄАиКВйЬАи¶БйШРињ∞зЪДйЧЃйҐШгАВ
 
жРЬ糥
R ж†СзЪДжРЬ糥жУНдљЬеЊИзЃАеНХпЉМиЈЯ B ж†СдЄКзЪДжРЬ糥еНБеИЖзЫЄдЉЉгАВеЃГињФеЫЮзЪДзїУжЮЬжШѓжЙАжЬЙзђ¶еРИжЯ•жЙЊдњ°жБѓзЪДиЃ∞ељХжЭ°зЫЃгАВиАМиЊУеЕ•жШѓдїАдєИпЉЯе∞±жИСдЄ™дЇЇзЪДзРЖиІ£пЉМиЊУеЕ•дЄНдїЕдїЕжШѓдЄАдЄ™иМГеЫідЇЖпЉМеЃГжЫіеПѓдї•зЬЛжИРжШѓдЄАдЄ™з©ЇйЧідЄ≠зЪДзߩ嚥гАВдєЯе∞±жШѓиѓіпЉМжИСдїђиЊУеЕ•зЪДжШѓдЄАдЄ™жРЬ糥зߩ嚥гАВ
еЕИзїЩеЗЇдЉ™дї£з†БпЉЪ
Function пЉЪ Search
жППињ∞пЉЪеБЗиЃЊ T дЄЇдЄАж£µ R ж†СзЪДж†єзїУзВєпЉМжЯ•жЙЊжЙАжЬЙжРЬ糥зߩ嚥 S и¶ЖзЫЦзЪДиЃ∞ељХжЭ°зЫЃгАВ
S1:[ жЯ•жЙЊе≠Рж†С ] е¶ВжЮЬ T жШѓйЭЮеПґе≠РзїУзВєпЉМе¶ВжЮЬ T жЙАеѓєеЇФзЪДзߩ嚥дЄО S жЬЙйЗНеРИпЉМйВ£дєИж£АжЯ•жЙАжЬЙ T дЄ≠е≠ШеВ®зЪДжЭ°зЫЃпЉМеѓєдЇОжЙАжЬЙињЩдЇЫжЭ°зЫЃпЉМдљњзФ® Search жУНдљЬдљЬзФ®еЬ®жѓПдЄАдЄ™жЭ°зЫЃжЙАжМЗеРСзЪДе≠Рж†СзЪДж†єзїУзВєдЄКпЉИеН≥ T зїУзВєзЪДе≠©е≠РзїУзВєпЉЙгАВ
S2:[ жЯ•жЙЊеПґе≠РзїУзВє ] е¶ВжЮЬ T жШѓеПґе≠РзїУзВєпЉМе¶ВжЮЬ T жЙАеѓєеЇФзЪДзߩ嚥дЄО S жЬЙйЗНеРИпЉМйВ£дєИзЫіжО•ж£АжЯ• S жЙАжМЗеРСзЪДжЙАжЬЙиЃ∞ељХжЭ°зЫЃгАВињФеЫЮзђ¶еРИжЭ°дїґзЪДиЃ∞ељХгАВ
жИСдїђйАЪињЗдЄЛеЫЊжЭ•зРЖиІ£ињЩдЄ™ Search жУНдљЬгАВ
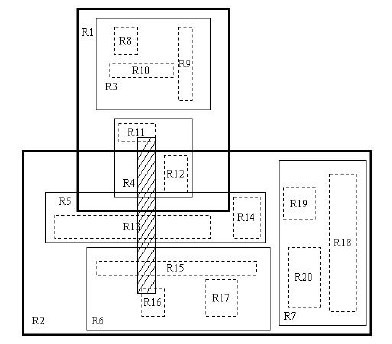  
 
йШіељ±йГ®еИЖжЙАеѓєеЇФзЪДзߩ嚥䪯жРЬ糥зߩ嚥гАВеЃГдЄОж†єзїУзВєеѓєеЇФзЪДжЬАе§ІзЪДзߩ嚥пЉИжЬ™зФїеЗЇпЉЙжЬЙйЗНеП†гАВињЩж†Је∞Ж Search жУНдљЬдљЬзФ®еЬ®еЕґдЄ§дЄ™е≠Рж†СдЄКгАВдЄ§дЄ™е≠Рж†СеѓєеЇФзЪДзߩ嚥еИЖеИЂдЄЇ R1 дЄО R2 гАВжРЬ糥 R1 пЉМеПСзО∞дЄО R1 дЄ≠зЪД R4 зߩ嚥жЬЙйЗНеП†пЉМзїІзї≠жРЬ糥 R4 гАВжЬАзїИеЬ® R4 жЙАеМЕеРЂзЪД R11 дЄО R12 дЄ§дЄ™зߩ嚥дЄ≠жЯ•жЙЊжШѓеР¶жЬЙзђ¶еРИжЭ°дїґзЪДиЃ∞ељХгАВжРЬ糥 R2 зЪДињЗз®ЛеРМж†Је¶Вж≠§гАВеЊИжШЊзДґпЉМиѓ•зЃЧж≥ХињЫи°МзЪДжШѓдЄАдЄ™ињ≠дї£жУНдљЬгАВ
 
жПТеЕ•
¬†¬†¬†¬†¬† R ж†СзЪДжПТеЕ•жУНдљЬдєЯеРМ B ж†СзЪДжПТеЕ•жУНдљЬз±їдЉЉгАВељУжЦ∞зЪДжХ∞жНЃиЃ∞ељХйЬАи¶Б襀棿еК†еЕ•еПґе≠РзїУзВєжЧґпЉМиЛ•еПґе≠РзїУзВєжЇҐеЗЇпЉМйВ£дєИжИСдїђйЬАи¶БеѓєеПґе≠РзїУзВєињЫи°МеИЖи£ВжУНдљЬгАВжШЊзДґпЉМеПґе≠РзїУзВєзЪДжПТеЕ•жУНдљЬдЉЪжѓФжРЬ糥жУНдљЬи¶Бе§НжЭВгАВжПТеЕ•жУНдљЬйЬАи¶БдЄАдЇЫиЊЕеК©жЦєж≥ХжЙНиГље§ЯеЃМжИРгАВ
жЭ•зЬЛдЄАдЄЛдЉ™дї£з†БпЉЪ
Function пЉЪ Insert
жППињ∞пЉЪе∞ЖжЦ∞зЪДиЃ∞ељХжЭ°зЫЃ E жПТеЕ•зїЩеЃЪзЪД R ж†СдЄ≠гАВ
I1 пЉЪ [ дЄЇжЦ∞иЃ∞ељХжЙЊеИ∞еРИйАВжПТеЕ•зЪДеПґе≠РзїУзВє ] еЉАеІЛ ChooseLeaf жЦєж≥ХйАЙжЛ©еПґе≠РзїУзВє L дї•жФЊзљЃиЃ∞ељХ E гАВ
I2 пЉЪ [ жЈїеК†жЦ∞иЃ∞ељХиЗ≥еПґе≠РзїУзВє ] е¶ВжЮЬ L жЬЙиґ≥е§ЯзЪДз©ЇйЧіжЭ•жФЊзљЃжЦ∞зЪДиЃ∞ељХжЭ°зЫЃпЉМеИЩеРС L дЄ≠жЈїеК† E гАВе¶ВжЮЬж≤°жЬЙиґ≥е§ЯзЪДз©ЇйЧіпЉМеИЩињЫи°М SplitNode жЦєж≥Хдї•иОЈеЊЧдЄ§дЄ™зїУзВє L дЄО LL пЉМињЩдЄ§дЄ™зїУзВєеМЕеРЂдЇЖжЙАжЬЙеОЯжЭ•еПґе≠РзїУзВє L дЄ≠зЪДжЭ°зЫЃдЄОжЦ∞жЭ°зЫЃ E гАВ
I3 пЉЪ [ е∞ЖеПШжНҐеРСдЄКдЉ†йАТ ] еЉАеІЛеѓєзїУзВє L ињЫи°М AdjustTree жУНдљЬпЉМе¶ВжЮЬињЫи°МдЇЖеИЖи£ВжУНдљЬпЉМйВ£дєИеРМжЧґйЬАи¶Беѓє LL ињЫи°М AdjustTree жУНдљЬгАВ
I4 пЉЪ [ еѓєж†СињЫи°МеҐЮйЂШжУНдљЬ ] е¶ВжЮЬзїУзВєеИЖи£ВпЉМдЄФиѓ•еИЖи£ВеРСдЄКдЉ†жТ≠еѓЉиЗідЇЖж†єзїУзВєзЪДеИЖи£ВпЉМйВ£дєИйЬАи¶БеИЫеїЇдЄАдЄ™жЦ∞зЪДж†єзїУзВєпЉМеєґдЄФиЃ©еЃГзЪДдЄ§дЄ™е≠©е≠РзїУзВєеИЖеИЂдЄЇеОЯжЭ•йВ£дЄ™ж†єзїУзВєеИЖи£ВеРОзЪДдЄ§дЄ™зїУзВєгАВ
 
Function пЉЪ ChooseLeaf
жППињ∞пЉЪйАЙжЛ©еПґе≠РзїУзВєдї•жФЊзљЃжЦ∞жЭ°зЫЃ E гАВ
CL1 пЉЪ [Initialize] иЃЊзљЃ N дЄЇж†єзїУзВєгАВ
CL2 пЉЪ [ еПґе≠РзїУзВєзЪДж£АжЯ• ] е¶ВжЮЬ N дЄЇеПґе≠РзїУзВєпЉМеИЩзЫіжО•ињФеЫЮ N гАВ
CL3 пЉЪ [ йАЙжЛ©е≠Рж†С ] е¶ВжЮЬ N дЄНжШѓеПґе≠РзїУзВєпЉМеИЩйБНеОЖ N дЄ≠зЪДзїУзВєпЉМжЙЊеЗЇжЈїеК† E.I жЧґжЙ©еЉ†жЬАе∞ПзЪДзїУзВєпЉМеєґжККиѓ•зїУзВєеЃЪдєЙдЄЇ F гАВе¶ВжЮЬжЬЙе§ЪдЄ™ињЩж†ЈзЪДзїУзВєпЉМйВ£дєИйАЙжЛ©йЭҐзІѓжЬАе∞ПзЪДзїУзВєгАВ
CL4 пЉЪ [ дЄЛйЩНиЗ≥еПґе≠РзїУзВє ] е∞Ж N иЃЊдЄЇ F пЉМдїО CL2 еЉАеІЛйЗНе§НжУНдљЬгАВ
 
Function пЉЪ AdjustTree
жППињ∞пЉЪеПґе≠РзїУзВєзЪДжФєеПШеРСдЄКдЉ†йАТиЗ≥ж†єзїУзВєдї•жФєеПШеРДдЄ™зЯ©йШµгАВеЬ®дЉ†йАТеПШжНҐзЪДињЗз®ЛдЄ≠еПѓиГљдЉЪдЇІзФЯзїУзВєзЪДеИЖи£ВгАВ
AT1 пЉЪ [ еИЭеІЛеМЦ ] е∞Ж N иЃЊдЄЇ L гАВ
AT2 пЉЪ [ ж£Ай™МжШѓеР¶еЃМжИР ] е¶ВжЮЬ N дЄЇж†єзїУзВєпЉМеИЩеБЬж≠ҐжУНдљЬгАВ
AT3 пЉЪ [ и∞ГжХізИґзїУзВєжЭ°зЫЃзЪДжЬАе∞ПиЊєзХМзߩ嚥 ] иЃЊ P дЄЇ N зЪДзИґиКВзВєпЉМ EN дЄЇжМЗеРСеЬ®зИґиКВзВє P дЄ≠жМЗеРС N зЪДжЭ°зЫЃгАВи∞ГжХі EN.I дї•дњЭиѓБжЙАжЬЙеЬ® N дЄ≠зЪДзߩ嚥йÚ襀жБ∞е•љеМЕеЫігАВ
AT4 пЉЪ [ еРСдЄКдЉ†йАТзїУзВєеИЖи£В ] е¶ВжЮЬ N жЬЙдЄАдЄ™еИЪеИЪ襀еИЖи£ВдЇІзФЯзЪДзїУзВє NN пЉМеИЩеИЫеїЇдЄАдЄ™жМЗеРС NN зЪДжЭ°зЫЃ ENN гАВе¶ВжЮЬ P жЬЙз©ЇйЧіжЭ•е≠ШжФЊ ENN пЉМеИЩе∞Ж ENN жЈїеК†еИ∞ P дЄ≠гАВе¶ВжЮЬж≤°жЬЙпЉМеИЩеѓє P ињЫи°М SplitNode жУНдљЬдї•еЊЧеИ∞ P еТМ PP гАВ
AT5 пЉЪ [ еНЗйЂШиЗ≥дЄЛдЄАзЇІ ] е¶ВжЮЬ N з≠ЙдЇО L дЄФеПСзФЯдЇЖеИЖи£ВпЉМеИЩжКК NN зљЃдЄЇ PP гАВдїО AT2 еЉАеІЛйЗНе§НжУНдљЬгАВ
 
еРМж†ЈпЉМжИСдїђзФ®еЫЊжЭ•жЫіеК†зЫіиІВзЪДзРЖиІ£ињЩдЄ™жПТеЕ•жУНдљЬгАВ
 
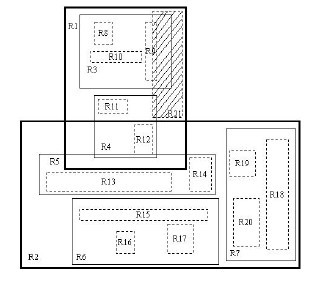  
 
¬†¬†¬† жИСдїђжЭ•йАЪињЗеЫЊеИЖжЮРдЄАдЄЛжПТеЕ•жУНдљЬгАВзО∞еЬ®жИСдїђйЬАи¶БжПТеЕ• R21 ињЩдЄ™зߩ嚥гАВеЉАеІЛжЧґжИСдїђињЫи°М ChooseLeaf жУНдљЬгАВеЬ®ж†єзїУзВєдЄ≠жЬЙдЄ§дЄ™жЭ°зЫЃпЉМеИЖеИЂдЄЇ R1 пЉМ R2 гАВеЕґеЃЮ R1 еЈ≤зїПеЃМеЕ®и¶ЖзЫЦдЇЖ R21 пЉМиАМиЛ•еРС R2 дЄ≠жЈїеК† R21 пЉМеИЩдЉЪдљњ R2.I еҐЮе§ІеЊИе§ЪгАВжШЊзДґжИСдїђйАЙжЛ© R1 жПТеЕ•гАВзДґеРОињЫи°МдЄЛдЄАзЇІзЪДжУНдљЬгАВзЫЄжѓФдЇО R4 пЉМеРС R3 дЄ≠жЈїеК† R21 дЉЪжЫіеРИйАВпЉМеЫ†дЄЇ R3 и¶ЖзЫЦ R21 жЙАйЬАеҐЮе§ІзЪДйЭҐзІѓзЫЄеѓєиЊГе∞ПгАВињЩж†Је∞±еЬ® B8 пЉМ B9 пЉМ B10 жЙАеЬ®зЪДеПґе≠РзїУзВєдЄ≠жПТеЕ• R21 гАВзФ±дЇОеПґе≠РзїУзВєж≤°жЬЙиґ≥е§Яз©ЇйЧіпЉМеИЩи¶БињЫи°МеИЖи£ВжУНдљЬгАВ
¬†¬†¬† жПТеЕ• жУНдљЬе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
 
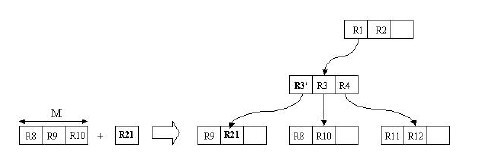
ињЩдЄ™жПТеЕ•жУНдљЬеЕґеЃЮз±їдЉЉдЇОзђђдЄАиКВдЄ≠ B ж†СзЪДжПТеЕ•жУНдљЬпЉМињЩйЗМдЄНеЖНеЕЈдљУдїЛзїНпЉМдЄНињЗжГ≥ењЕзЬЛињЗдЄКйЭҐзЪДдЉ™дї£з†Бе§ІеЃґеЇФиѓ•дєЯжЄЕж•ЪдЇЖгАВ
 
еИ†йЩ§
R ж†СзЪДеИ†йЩ§жУНдљЬдЄО B ж†СзЪДеИ†йЩ§жУНдљЬдЉЪжЬЙжЙАдЄНеРМпЉМдЄНињЗеРМ B ж†СдЄАж†ЈпЉМдЉЪжґЙеПКеИ∞еОЛзЉ©з≠ЙжУНдљЬгАВзЫЄдњ°иѓїиАЕзЬЛеЃМдї•дЄЛзЪДдЉ™дї£з†БдєЛеРОдЉЪжЬЙжЙАдљУдЉЪгАВ R ж†СзЪДеИ†йЩ§еРМж†ЈжШѓжѓФиЊГе§НжЭВзЪДпЉМйЬАи¶БзФ®еИ∞дЄАдЇЫиЊЕеК©еЗљжХ∞жЭ•еЃМжИРжХідЄ™жУНдљЬгАВ
дЉ™дї£з†Бе¶ВдЄЛпЉЪ
Function пЉЪ Delete
жППињ∞пЉЪе∞ЖдЄАжЭ°иЃ∞ељХ E дїОжМЗеЃЪзЪД R ж†СдЄ≠еИ†йЩ§гАВ
D1 пЉЪ [ жЙЊеИ∞еРЂжЬЙиЃ∞ељХзЪДеПґе≠РзїУзВє ] дљњзФ® FindLeaf жЦєж≥ХжЙЊеИ∞еМЕеРЂжЬЙиЃ∞ељХ E зЪДеПґе≠РзїУзВє L гАВе¶ВжЮЬжРЬ糥姱賕пЉМеИЩзЫіжО•зїИж≠ҐгАВ
D2 пЉЪ [ еИ†йЩ§иЃ∞ељХ ] е∞Ж E дїО L дЄ≠еИ†йЩ§гАВ
D3 пЉЪ [ дЉ†йАТиЃ∞ељХ ] еѓє L дљњзФ® CondenseTree жУНдљЬ
D4 пЉЪ [ зЉ©еЗПж†С ] ељУзїПињЗдї•дЄКи∞ГжХіеРОпЉМе¶ВжЮЬж†єзїУзВєеП™еМЕеРЂжЬЙдЄАдЄ™е≠©е≠РзїУзВєпЉМеИЩе∞ЖињЩдЄ™еФѓдЄАзЪДе≠©е≠РзїУзВєиЃЊдЄЇж†єзїУзВєгАВ
 
Function пЉЪ FindLeaf
жППињ∞пЉЪж†єзїУзВєдЄЇ T пЉМжЬЯжЬЫжЙЊеИ∞еМЕеРЂжЬЙиЃ∞ељХ E зЪДеПґе≠РзїУзВєгАВ
FL1 пЉЪ [ жРЬ糥е≠Рж†С ] е¶ВжЮЬ T дЄНжШѓеПґе≠РзїУзВєпЉМеИЩж£АжЯ•жѓПдЄАжЭ° T дЄ≠зЪДжЭ°зЫЃ F пЉМжЙЊеЗЇдЄО E жЙАеѓєеЇФзЪДзߩ嚥зЫЄйЗНеРИзЪД F пЉИдЄНењЕеЃМеЕ®и¶ЖзЫЦпЉЙгАВеѓєдЇОжЙАжЬЙжї°иґ≥жЭ°дїґзЪД F пЉМеѓєеЕґжМЗеРСзЪДе≠©е≠РзїУзВєињЫи°М FindLeaf жУНдљЬпЉМзЫіеИ∞еѓїжЙЊеИ∞ E жИЦиАЕжЙАжЬЙжЭ°зЫЃеЭЗ俕襀ж£АжЯ•ињЗгАВ
FL2 пЉЪ [ жРЬ糥еПґе≠РзїУзВєдї•жЙЊеИ∞иЃ∞ељХ ] е¶ВжЮЬ T жШѓеПґе≠РзїУзВєпЉМйВ£дєИж£АжЯ•жѓПдЄАдЄ™жЭ°зЫЃжШѓеР¶жЬЙ E е≠ШеЬ®пЉМе¶ВжЮЬжЬЙеИЩињФеЫЮ T гАВ
 
Function пЉЪ CondenseTree
жППињ∞пЉЪ L дЄЇеМЕеРЂжЬЙ襀еИ†йЩ§жЭ°зЫЃзЪДеПґе≠РзїУзВєгАВе¶ВжЮЬ L зЪДжЭ°зЫЃжХ∞ињЗе∞СпЉИе∞ПдЇОи¶Бж±ВзЪДжЬАе∞ПеАЉ m пЉЙпЉМеИЩењЕй°їе∞Жиѓ•еПґе≠РзїУзВє L дїОж†СдЄ≠еИ†йЩ§гАВзїПињЗињЩдЄАеИ†йЩ§жУНдљЬпЉМ L дЄ≠зЪДеЙ©дљЩжЭ°зЫЃењЕй°їйЗНжЦ∞жПТеЕ•ж†СдЄ≠гАВж≠§жУНдљЬе∞ЖдЄАзЫійЗНе§НзЫіиЗ≥еИ∞иЊЊж†єзїУзВєгАВеРМж†ЈпЉМи∞ГжХіеЬ®ж≠§дњЃжФєж†СзЪДињЗз®ЛжЙАзїПињЗзЪДиЈѓеЊДдЄКзЪДжЙАжЬЙзїУзВєеѓєеЇФзЪДзߩ嚥姲е∞ПгАВ
CT1 пЉЪ [ еИЭеІЛеМЦ ] дї§ N дЄЇ L гАВеИЭеІЛеМЦдЄАдЄ™зФ®дЇОе≠Ше®襀еИ†йЩ§зїУзВєеМЕеРЂзЪДжЭ°зЫЃзЪДйУЊи°® Q гАВ
CT2 пЉЪ [ жЙЊеИ∞зИґжЭ°зЫЃ ] е¶ВжЮЬ N дЄЇж†єзїУзВєпЉМйВ£дєИзЫіжО•иЈ≥иљђиЗ≥ CT6 гАВеР¶еИЩдї§ P дЄЇ N зЪДзИґзїУзВєпЉМдї§ EN дЄЇ P зїУзВєдЄ≠е≠ШеВ®зЪДжМЗеРС N зЪДжЭ°зЫЃгАВ
CT3 пЉЪ [ еИ†йЩ§дЄЛжЇҐзїУзВє ] е¶ВжЮЬ N еРЂжЬЙжЭ°зЫЃжХ∞е∞СдЇО m пЉМеИЩдїО P дЄ≠еИ†йЩ§ EN пЉМеєґжККзїУзВє N дЄ≠зЪДжЭ°зЫЃжЈїеК†еЕ•йУЊи°® Q дЄ≠гАВ
CT4 пЉЪ [ и∞ГжХіи¶ЖзЫЦзߩ嚥 ] е¶ВжЮЬ N ж≤°жЬЙ襀еИ†йЩ§пЉМеИЩи∞ГжХі EN .I дљњеЊЧеЕґеѓєеЇФзߩ嚥иГље§ЯжБ∞е•љи¶ЖзЫЦ N дЄ≠зЪДжЙАжЬЙжЭ°зЫЃжЙАеѓєеЇФзЪДзߩ嚥гАВ
CT5 пЉЪ [ еРСдЄКдЄАе±ВзїУзВєињЫи°МжУНдљЬ ] дї§ N з≠ЙдЇО P пЉМдїО CT2 еЉАеІЛйЗНе§НжУНдљЬгАВ
CT6 пЉЪ [ йЗНжЦ∞жПТеЕ•е≠§зЂЛзЪДжЭ°зЫЃ ] жЙАжЬЙеЬ® Q дЄ≠зЪДзїУзВєдЄ≠зЪДжЭ°зЫЃйЬАи¶Б襀йЗНжЦ∞жПТеЕ•гАВеОЯжЭ•е±ЮдЇОеПґе≠РзїУзВєзЪДжЭ°зЫЃеПѓдї•дљњзФ® Insert жУНдљЬињЫи°МйЗНжЦ∞жПТеЕ•пЉМиАМйВ£дЇЫе±ЮдЇОйЭЮеПґе≠РзїУзВєзЪДжЭ°зЫЃењЕй°їжПТеЕ•еИ†йЩ§дєЛеЙНжЙАеЬ®е±ВзЪДзїУзВєпЉМдї•з°ЃдњЭеЃГдїђжЙАжМЗеРСзЪДе≠Рж†СињШе§ДдЇОзЫЄеРМзЪДе±ВгАВ
 
¬†¬†¬†¬†¬† R ж†СеИ†йЩ§иЃ∞ељХињЗз®ЛдЄ≠зЪД CondenseTree жУНдљЬжШѓдЄНеРМдЇО B ж†СзЪДгАВжИСдїђзЯ•йБУпЉМ B ж†СеИ†йЩ§ињЗз®ЛдЄ≠пЉМе¶ВжЮЬеЗЇзО∞зїУзВєзЪДиЃ∞ељХжХ∞е∞СдЇОеНКжї°пЉИеН≥дЄЛжЇҐпЉЙзЪДжГЕеЖµпЉМеИЩзЫіжО•жККињЩдЇЫиЃ∞ељХдЄОеЕґдїЦеПґе≠РзЪДиЃ∞ељХвАЬиЮНеРИвАЭпЉМдєЯе∞±жШѓиѓідЄ§дЄ™зЫЄйВїзїУзВєеРИеєґгАВзДґиАМ R ж†СеНіжШѓзЫіжО•йЗНжЦ∞жПТеЕ•гАВ
 
еРМж†ЈпЉМжИСдїђзФ®еЫЊзЫіиІВзЪДиѓіжШОињЩдЄ™жУНдљЬгАВ
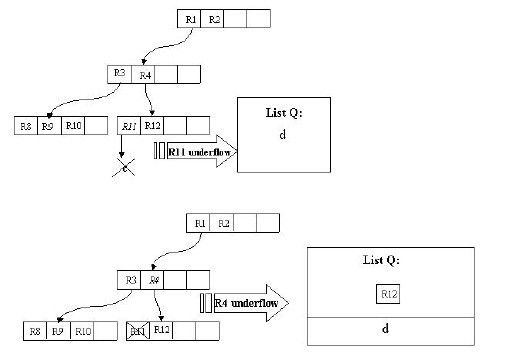
 
еБЗиЃЊзїУзВєжЬАе§ІжЭ°зЫЃжХ∞дЄЇ 4 пЉМжЬАе∞ПжЭ°зЫЃжХ∞дЄЇ 2 гАВеЬ®ињЩеЉ†еЫЊдЄ≠пЉМжИСдїђзЪДзЫЃж†ЗжШѓеИ†йЩ§иЃ∞ељХ c гАВй¶ЦеЕИдљњзФ® FindLeaf жУНдљЬжЙЊеИ∞ c жЙАе§ДеЬ®зЪДеПґе≠РзїУзВєзЪДдљНзљЃ вАФвАФR11 гАВељУ c дїО R11 еИ†йЩ§жЧґпЉМ R11 е∞±еП™жЬЙдЄАжЭ°иЃ∞ељХдЇЖпЉМе∞СдЇОжЬАе∞ПжЭ°зЫЃжХ∞ 2 пЉМеЗЇзО∞дЄЛжЇҐпЉМж≠§жЧґи¶Би∞ГзФ® CondenseTree жУНдљЬгАВињЩж†ЈпЉМ c 襀еИ†йЩ§пЉМ R11 еЙ©дљЩзЪДжЭ°зЫЃ вАФвАФ жМЗеРСиЃ∞ељХ d зЪДжМЗйТИ вАФвАФ иҐЂжПТеЕ•йУЊи°® Q гАВзДґеРОеРСжЫійЂШдЄАе±ВзЪДзїУзВєињЫи°Мж≠§жУНдљЬгАВињЩж†Ј R12 дЉЪ襀жПТеЕ•йУЊи°®дЄ≠гАВеОЯзРЖжШѓдЄАж†ЈзЪДпЉМеЬ®ињЩйЗМе∞±дЄНеЖНиµШињ∞гАВ
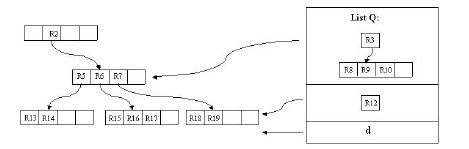
жЬЙдЄАзВєйЬАи¶БиІ£йЗКзЪДжШѓпЉМжИСдїђеПСзО∞ињЩдЄ™еИ†йЩ§жУНдљЬеРСдЄКдЉ†йАТдєЛеРОпЉМж†єзїУзВєзЪДжЭ°зЫЃ R1 дєЯ襀жПТеЕ•дЇЖ Q дЄ≠пЉМињЩж†Јж†єзїУзВєеП™еЙ©дЄЛдЇЖ R2 гАВеИЂзЭАжА•пЉМйЗНжЦ∞жПТеЕ•жУНдљЬдЉЪжЬЙжХИзЪДиІ£еЖ≥ињЩдЄ™йЧЃйҐШгАВжИСдїђжПТеЕ• R3 пЉМ R12 пЉМ d иЗ≥еЃГеОЯжЭ•жЙАе§ДзЪДе±ВгАВињЩж†ЈпЉМжИСдїђеПСзО∞ж†єзїУзВєеП™жЬЙдЄАдЄ™жЭ°зЫЃдЇЖпЉМж≠§жЧґж†єжНЃ Inert дЄ≠зЪДжУНдљЬпЉМжИСдїђжККињЩдЄ™ж†єзїУзВєеИ†йЩ§пЉМеЃГзЪДе≠©е≠РзїУзВєпЉМеН≥ R5 пЉМ R6 пЉМ R7 пЉМ R3 жЙАеЬ®зЪДзїУзº襀皁䪯憺зїУзВєгАВиЗ≥ж≠§пЉМеИ†йЩ§жУНдљЬзїУжЭЯгАВ
 
зїУиѓ≠
¬†¬†¬†¬†¬† R ж†СжШѓдЄАзІНиГље§ЯжЬЙжХИињЫи°МйЂШзїіз©ЇйЧіжРЬ糥зЪДжХ∞жНЃзїУжЮДпЉМеЃГеЈ≤зїП襀府ж≥ЫеЇФзФ®еЬ®еРДзІНжХ∞жНЃеЇУеПКеЕґзЫЄеЕ≥зЪДеЇФзФ®дЄ≠гАВдљЖ R ж†СзЪДе§ДзРЖдєЯеЕЈжЬЙе±АйЩРжАІпЉМеЃГзЪДжЬАдљ≥еЇФзФ®иМГеЫіжШѓе§ДзРЖ 2 иЗ≥ 6 зїізЪДжХ∞жНЃпЉМжЫійЂШзїізЪДе≠ШеВ®дЉЪеПШеЊЧйЭЮеЄЄе§НжЭВпЉМињЩж†Је∞±дЄНйАВзФ®дЇЖгАВињСеєіжЭ•пЉМ R ж†СдєЯеЗЇзО∞дЇЖеЊИе§ЪеПШдљУпЉМ R* ж†Се∞±жШѓеЕґдЄ≠зЪДдЄАзІНгАВињЩдЇЫеПШдљУжПРеНЗдЇЖ R ж†СзЪДжАІиГљпЉМжДЯеЕіиґ£зЪДиѓїиАЕеПѓдї•еПВиАГзЫЄеЕ≥жЦЗзМЃгАВжЦЗзЂ†жЬЙдїїдљХйФЩиѓѓпЉМињШжЬЫеРДдљНиѓїиАЕдЄНеРЭиµРжХЩгАВжЬђжЦЗеЃМгАВ
 
еПВиАГжЦЗзМЃдї•еПКзЫЄеЕ≥зљСеЭАпЉЪ
1.   Organization and Maintenance of Large Ordered Indices
2.   the ubiquitous B tree
3.¬†¬† http://en.wikipedia.org/wiki/Btree пЉИзїЩеЗЇдЇЖеЫље§ЦдЄАдЇЫеЉАжЇРеЬ∞еЭАпЉЙ
4.¬†¬† http://cis.stvincent.edu/html/tutorials/swd/btree/btree.html пЉИ include C++ source code пЉЙ
5.   http://slady.net/java/bt/view.php
пЉИе¶ВжЮЬдЇЖиІ£дЇЖ
B-tree
зїУжЮДпЉМиѓ•еЬ∞еЭАеПѓдї•еЬ®зЇњеѓєиѓ•зїУжЮДињЫи°МжЯ•жЙЊпЉИsearchпЉЙпЉМжПТеЕ•(insert)пЉМеИ†йЩ§(delete)жУНдљЬгАВпЉЙ
6.¬† Guttman, A.; вАЬR-trees: a dynamic index structure for spatial searching,вАЭ ACM, 1984, 14
7. ¬†http://www.cnblogs.com/CareySon/archive/2012/04/06/2435349.html гАВ


- 2012-06-14 19:41
- жµПиІИ 967
- иѓДиЃЇ(0)
- еИЖз±ї:жХ∞жНЃеЇУ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
hbase masterжМВжОЙ-zookeeperињЮжО•иґЕжЧґеОЯеЫ†
2012-10-26 15:59 0еєґи°МињРи°МhbaseеИ†и°®пЉМеїЇи°®жУНдљЬпЉМе§ЪдЄ™и°®е§ЪдЄ™regionпЉМ ... -
HBaseжАІиГљдЉШеМЦжЦєж≥ХжАїзїУпЉИеЫЫпЉЙпЉЪжХ∞жНЃиЃ°зЃЧ
2012-10-26 15:50 0жЬђжЦЗдЄїи¶БжШѓдїОHBaseеЇФзФ®з®ЛеЇПиЃЊиЃ°дЄОеЉАеПСзЪДиІТеЇ¶пЉМжАїзїУеЗ†зІНеЄЄ ... -
HBaseжАІиГљдЉШеМЦжЦєж≥ХжАїзїУпЉИдЄЙпЉЙпЉЪиѓїи°®жУНдљЬ
2012-10-26 15:38 0жЬђжЦЗдЄїи¶БжШѓдїОHBaseеЇФзФ®з®ЛеЇПиЃЊиЃ°дЄОеЉАеПСзЪДиІТеЇ¶пЉМжАїзїУеЗ†зІНеЄЄ ... -
HBaseжАІиГљдЉШеМЦжЦєж≥ХжАїзїУпЉИдЇМпЉЙпЉЪеЖЩи°®жУНдљЬ
2012-10-26 13:59 0жЬђжЦЗдЄїи¶БжШѓдїОHBaseеЇФзФ®з®ЛеЇПиЃЊиЃ°дЄОеЉАеПСзЪДиІТеЇ¶пЉМжАїзїУеЗ† ... -
HBaseжАІиГљдЉШеМЦжЦєж≥ХжАїзїУпЉИдЄАпЉЙпЉЪи°®зЪДиЃЊиЃ°
2012-10-26 13:42 0жЬђжЦЗдЄїи¶БжШѓдїОHBaseеЇФзФ®з®ЛеЇПиЃЊиЃ°дЄОеЉАеПСзЪДиІТеЇ¶пЉМжАїзїУеЗ†зІНеЄЄ ... -
hbaseеЖЕscan
2012-10-26 13:11 0Bugи°®зО∞пЉЪжКШжЙ£жРЬ糥дЄ≠пЉМжЯРдЄ™еЃЭиіЭеПВеК†дЇЖдЄАдЄ™жѓЂжЧ†зЫЄеЕ≥зЪДжКШжЙ£жії ... -
жХ∞жНЃеЇУпЉМschemaпЉМcatalogдЄЙиАЕзЪДжґµдєЙпЉИзЃАеНХжППињ∞пЉЙ
2012-07-17 10:59 0дљ†жШѓеР¶зїПеЄЄиІБеИ∞schemaпЉМc ... -
иБЪйЫЖ糥еЉХеТМйЭЮиБЪйЫЖ糥еЉХзЪДеМЇеИЂ
2012-07-06 09:50 0ж±Йиѓ≠е≠ЧеЕЄзЪДж≠£жЦЗжЬђиЇЂе∞±ж ... -
жВ≤иІВйФБеТМдєРиІВйФБ
2012-07-04 09:31 0http://www.mysqlops.com/2011/02 ... -
жХ∞жНЃеЇУдЇЛзЙ©еОЯзРЖ
2012-07-03 09:02 0дЇЛеК°зЪДеЈ•дљЬеОЯзРЖеЫЊ дЇЛеК°з°ЃдњЭжХ∞жНЃзЪДдЄАиЗіжАІеТМеПѓжБҐе§НжАІгАВдЇЛеК°зЪДеЈ•дљЬ ... -
дЄЇдїАдєИжЦЗдїґе≠ШеВ®и¶БйАЙзФ®B+ж†СињЩж†ЈзЪДжХ∞жНЃзїУжЮДпЉЯ
2012-06-14 19:43 1343иљђ:http://www.kongch.com/2011/09 ... -
bdbдљњзФ®жЙЛеЖМ
2012-04-12 11:14 0иљђпЉЪhttp://blog.csdn.ne ... -
еИЖеЇУеИЖи°®жАїзїУ
2012-02-11 11:28 0еНХеЇУеНХи°®жШѓжЬАеЄЄиІБзЪДжХ∞ж ...
зЫЄеЕ≥жО®иНР
### Bж†С-B+ж†С-B*ж†Си∞ИеИ∞Rж†С #### дЄАгАБеЉХи®А еЬ®иЃ°зЃЧжЬЇзІСе≠¶йҐЖеЯЯпЉМж†С嚥жХ∞жНЃзїУжЮДдљЬдЄЇдЄАзІНйЂШжХИзЪДжХ∞жНЃзїДзїЗжЦєеЉП襀府ж≥ЫеЇФзФ®гАВеЬ®дЉЧе§Ъж†С嚥зїУжЮДдЄ≠пЉМBж†СгАБB+ж†СгАБB*ж†СеТМRж†СеЫ†еЕґеЬ®е§ДзРЖе§ІиІДж®°жХ∞жНЃйЫЖжЧґи°®зО∞еЗЇзЪДдЉШзІАжАІиГљиАМе§ЗеПЧеЕ≥ж≥®гАВ...
ж†ЗйҐШдЄ≠зЪДвАЬдїОBж†СгАБB+ж†СгАБB*ж†Си∞ИеИ∞Rж†СвАЭжґµзЫЦдЇЖжХ∞жНЃеЇУ糥еЉХзїУжЮДдЄ≠зЪДеЗ†зІНйЗНи¶БжХ∞жНЃзїУжЮДгАВињЩдЇЫжХ∞жНЃзїУжЮДеЬ®е≠ШеВ®еТМж£А糥姲йЗПжХ∞жНЃжЧґиµЈзЭАеЕ≥йФЃдљЬзФ®пЉМе∞§еЕґеЬ®жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯгАБжЦЗдїґз≥їзїЯеТМеЬ∞зРЖдњ°жБѓз≥їзїЯз≠ЙйҐЖеЯЯгАВиЃ©жИСдїђйАРдЄАжОҐиЃ®ињЩдЇЫжХ∞жНЃ...
гАРBж†СгАБB+ж†СеТМB*ж†СпЉЪжХ∞жНЃзїУжЮДдЄ≠зЪДйЂШжХИ糥еЉХжКАжЬѓгАС еЬ®иЃ°зЃЧжЬЇзІСе≠¶дЄ≠пЉМжХ∞жНЃзїУжЮДзЪДйАЙжЛ©еѓєзЃЧж≥ХзЪДжХИзОЗиЗ≥еЕ≥йЗНи¶БгАВзЙєеИЂжШѓеЬ®е§ДзРЖе§ІиІДж®°жХ∞жНЃжЧґпЉМе¶ВдљХжЬЙжХИеЬ∞е≠ШеВ®еТМж£А糥䜰жБѓжШѓдЄАдЄ™еЕ≥йФЃйЧЃйҐШгАВBж†СпЉИB-treeпЉЙгАБB+ж†СпЉИB+treeпЉЙеТМB*ж†С...
### дїОBж†СгАБB+ж†СгАБB*ж†СеИ∞Rж†СпЉЪжЈ±еЕ•дЇЖиІ£жХ∞жНЃзїУжЮДзЪДеЇФзФ® #### дЄАгАБеЙНи®А еЬ®е§ІиІДж®°жХ∞жНЃе≠ШеВ®дЄОж£А糥йҐЖеЯЯпЉМж†С嚥жХ∞жНЃзїУжЮДжЙЃжЉФзЭАиЗ≥еЕ≥йЗНи¶БзЪДиІТиЙ≤гАВдЉ†зїЯдЇМеПЙжЯ•жЙЊж†СиЩљзДґжПРдЊЫдЇЖиЊГдЄЇйЂШжХИзЪДжЯ•жЙЊжАІиГљпЉМдљЖзФ±дЇОеЕґйЂШеЇ¶дЄОжХ∞жНЃйЗПжИРж≠£жѓФ...
жЬђжЦЗе∞ЖжОҐиЃ®дЄАзІНйТИеѓєе§ІиІДж®°жХ∞жНЃе≠ШеВ®дЉШеМЦзЪДжЯ•жЙЊж†СзїУжЮДвАФвАФBж†СгАБB+ж†СеТМB*ж†СпЉМдї•еПКеЬ®еЬ∞зРЖдњ°жБѓз≥їзїЯдЄ≠еєњж≥ЫдљњзФ®зЪДRж†СгАВињЩдЇЫжХ∞жНЃзїУжЮДдЄїи¶БзФ®дЇОиІ£еЖ≥е§Це≠ШеВ®еЩ®дЄ≠зЪДйЂШжХИжߕ胥йЧЃйҐШпЉМе∞§еЕґжШѓз£БзЫШI/OжУНдљЬгАВ й¶ЦеЕИпЉМжИСдїђжЭ•зЬЛBж†СпЉМињЩжШѓдЄА...
дЄАдЄ™Bж†СзЪДиКВзВєеПѓдї•еМЕеРЂдїОеЗ†дЄ™еИ∞дЄКеНГдЄ™еЕ≥йФЃе≠ЧпЉМдљњеЕґзЙєеИЂйАВеРИдЇОе≠ШеВ®е§ІйЗПжХ∞жНЃзЪДжХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯгАВ B+ж†СжШѓBж†СзЪДдЄАдЄ™еПШзІНпЉМеЃГе∞ЖжЙАжЬЙеЃЮйЩЕзЪДжХ∞жНЃйГљжФЊеЬ®еПґе≠РиКВзВєдЄКпЉМеПґе≠РиКВзВєдєЛйЧійАЪињЗжМЗйТИзЫЄињЮпЉМ嚥жИРдЄАдЄ™жЬЙеЇПйУЊи°®гАВињЩзІНзїУжЮД...
еЕґдЄ≠пЉМRгАБGгАБBеИЖеИЂдї£и°®зЇҐиЙ≤гАБзїњиЙ≤еТМиУЭиЙ≤еИЖйЗПпЉЫYгАБUгАБVеИЖеИЂеѓєеЇФеОЯеІЛзЪДYUVеАЉгАВеЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМињШйЬАи¶Бз°ЃдњЭжѓПдЄ™еИЖйЗПзЪДеАЉе§ДдЇО0еИ∞255дєЛйЧіпЉМдї•йБњеЕНжЇҐеЗЇжИЦдЄЛжЇҐгАВ ```matlab UU(1:2:row-1,1:2:col-1,frame)=U(:,:,frame); UU...
3. **дњ°еПЈзФЯжИР**пЉЪ`square(2*pi*10*t)`зФЯжИРдЇЖдЄАдЄ™еЯЇйҐСдЄЇ10HzзЪДжЦєж≥Ґдњ°еПЈпЉМеЕґдЄ≠`t`жШѓдїО0еИ∞1зЪДз≠ЙйЧійЪФжЧґйЧіеЇПеИЧпЉМйЗЗж†ЈйҐСзОЗ`fs`дЄЇ200HzгАВ 4. **йҐСзОЗеЯЯеИЖжЮР**пЉЪ`freqz(b, a)`еЗљжХ∞зФ®дЇОиЃ°зЃЧеєґжШЊз§Їжї§ж≥ҐеЩ®зЪДйҐСзОЗеУНеЇФгАВеЃГзїЩеЗЇдЇЖ...
гАРиАБзФЯи∞ИзЃЧж≥ХгАСMATLABеИЖ嚥еی嚥-ж†СеПґ MATLABжШѓдЄАзІНеЉЇе§ІзЪДжХ∞е≠¶иЃ°зЃЧиљѓдїґпЉМеЃГеЬ®зЃЧж≥ХеЃЮзО∞еТМеПѓиІЖеМЦжЦєйЭҐжЬЙзЭАеєњж≥ЫзЪДеЇФзФ®гАВеЬ®ињЩдЄ™жЦЗж°£дЄ≠пЉМжИСдїђеЕ≥ж≥®зЪДжШѓе¶ВдљХдљњзФ®MATLABзФЯжИРеИЖ嚥еی嚥пЉМеЕЈдљУжШѓдЄАдЄ™ж†Сеϴ嚥зКґзЪДеИЖ嚥еЫЊеГПгАВеИЖ嚥жШѓ...
ж≥®жДПеИ∞еѓєдЇОе§Ъй°єеЉПa,b,жИСдїђжЬЙG(a+b)=G(a)+G(b)гАВзФ±зЇњжАІйАТжО®еЉПзЪДеЃЪдєЙ,еѓєtвЙ•0 жИСдїђжЬЙвИСеЫЫ0am-1-+1-0,еН≥G(вИСm=xm-1r)x)-0гАВжЙАдї•иЃЊS(x)-вИС=0xm-1,жИС дїђе∞±жЬЙG(S(x)x)=0(tвЙ•0),еПИеЫ†дЄЇGa+b)=G(a)+G(b),жИСдїђе∞±жЬЙеѓєдїїжДП...
9. еЫЊзЪДж†СзКґзїУжЮДпЉЪ(5) и∞ИеИ∞дЇЖзФµиЈѓзЪДеЙ≤йЫЖпЉМдєЯе∞±жШѓжЙЊеИ∞дЄАдЄ™иЊєзЪДе≠РйЫЖпЉМдљњеЊЧзІїйЩ§ињЩдЇЫиЊєеРОпЉМеЫЊеПШжИРдЄАж£µж†СгАВињЩйЗМжПРеИ∞дЇЖ4зІНдЄНеРМзЪДеЙ≤йЫЖпЉМжДПеС≥зЭАжЬЙ4ж£µеРМжЮДзЪДзФЯжИРж†СгАВ 10. еЫЊиЃЇзїІзї≠пЉЪ(4) зЪДиѓБжШОеПѓиГљжґЙеПКеЫЊзЪДињЮйАЪжАІеИЖжЮРпЉМе¶В...
зЊОеЫљзЪДMFJеЕђеПЄжХ∞еєіеЙНжО®еЗЇзЪДMFJвАФ259еЮЛStanding Wave AnalyzerпЉМеПЧеИ∞дЇЖеєње§ІзЪДдЄЪдљЩжЧ†зЇњзФµзИ±е•љиАЕзЪД搥ињОпЉМеЫљеЖЕHAMжЙЛдЄ≠дєЯеЈ≤жЬЙдЇЖдЄАеЃЪжХ∞йЗПгАВзЙєеИЂжШѓиЗ™еЈ±еК®жЙЛи£Е姩篜зЪДзО©еЃґпЉМжЬЙдЇЖињЩдЄ™дї™еЩ®пЉМи∞Гжճ姩篜зЙєеИЂжЦєдЊњгАВеЃГзФ±и¶ЖзЫЦHFеТМVHF...
- **еЫЫеИЩињРзЃЧ**пЉЪе¶ВжЮЬжХ∞еИЧ{an}гАБ{bn}зЪДжЮБйЩРеИЖеИЂжШѓAеТМBпЉМйВ£дєИжХ∞еИЧ{an + bn}зЪДжЮБйЩРжШѓA + BпЉМжХ∞еИЧ{an * bn}зЪДжЮБйЩРжШѓA * BпЉИиЛ•BвЙ†0пЉЙгАВ 4. **жФґжХЫжХ∞еИЧ**пЉЪе¶ВжЮЬдЄАдЄ™жХ∞еИЧжЬЙжЮБйЩРпЉМжИСдїђе∞±иѓіињЩдЄ™жХ∞еИЧжШѓжФґжХЫзЪДгАВеПНдєЛпЉМе¶ВжЮЬдЄА...
дЉ†зїЯзЪДжХ∞жНЃзїУжЮДе¶ВйУЊи°®гАБжХ∞зїДгАБж†Сз≠ЙеЬ®жХ∞жНЃеЇУдЄ≠жЬЙзЭАзЫіжО•зЪДеЇФзФ®пЉМжѓФе¶ВBж†СгАБB+ж†Сз≠Й糥еЉХзїУжЮДзФ®дЇОеК†йАЯжߕ胥гАВеЬ®жХ∞жНЃеЇУиЃЊиЃ°дЄ≠пЉМеРИзРЖеЬ∞еИ©зФ®жХ∞жНЃзїУжЮДеПѓдї•жПРйЂШжХ∞жНЃзЪДе≠ШеВ®жХИзОЗеТМжߕ胥йАЯеЇ¶гАВ гАРжХ∞жНЃеЇУиЃЊиЃ°зЪДжЉФеПШгАС жХ∞жНЃеЇУжЬАеИЭжШѓ...
### дЄАгАБдїОеРСйЗПи∞ИиµЈ **1. еє≥йЭҐеРСйЗПз©ЇйЧі** \(\mathbb{R}^2\) еѓєдЇОеє≥йЭҐеРСйЗПз©ЇйЧі \(\mathbb{R}^2\) дЄ≠зЪДдїїжДПдЄ§дЄ™еРСйЗП \(\alpha\) еТМ \(\beta\)пЉМеЃЪдєЙдЇЖеК†ж≥ХеТМжХ∞дєШдЄ§зІНињРзЃЧпЉМињЩдЄ§зІНињРзЃЧжї°иґ≥дї•дЄЛеЕЂжЭ°ињРзЃЧеЊЛпЉЪ - **(A1)...
жОТеИЧзїДеРИжШѓжХ∞е≠¶дЄ≠зЪДдЄАзІНеЯЇжЬђж¶ВењµпЉМеЃГжґЙеПКеИ∞дїОдЄАзїДеѓєи±°дЄ≠йАЙжЛ©иЛ•еє≤еѓєи±°еєґиАГиЩСеЕґй°ЇеЇПзЪДйЧЃйҐШгАВеЬ®PHPдЄ≠пЉМжИСдїђеПѓдї•дљњзФ®йАТељТеЗљжХ∞жЭ•иІ£еЖ≥ињЩдЄ™йЧЃйҐШгАВ й¶ЦеЕИпЉМдїЛзїНзЪДжШѓеЯЇдЇОвАЬеИЖж≤їж≥ХвАЭзЪДзЫіжО•йАЙжЛ©жЦєж≥ХгАВињЩдЄ™жЦєж≥ХйАЪињЗдЇ§жНҐжХ∞зїДдЄ≠зЪД...
**жЛЉйЯ≥**: sh√≠ ni√°n sh√є m√є, b«Оi ni√°n sh√є r√©n **еЗЇе§Д**: гАКзЃ°е≠Р¬ЈжЭГдњЃгАЛ **еРЂдєЙ**: 嚥偺еЯєеЕїдЇЇжЙНжШѓдЄАй°єйХњињЬзЪДеЈ•дљЬпЉМйЬАи¶БеЊИйХњжЧґйЧіжЙНиГљиІБеИ∞жИРжХИгАВ #### еНБдЇ≤дєЭжХЕ **жЛЉйЯ≥**: sh√≠ qƒЂn ji«Ф g√є **еРЂдєЙ**:...
int(f(x), a, b)`пЉМдїОaеИ∞bиЃ°зЃЧеЃЪзІѓеИЖгАВ 3. **еєВињРзЃЧ**пЉЪ - `a^2` и°®з§ЇзЯ©йШµaзЪДеє≥жЦєпЉМеН≥зЯ©йШµзЫЄдєШгАВ - `a.^2` жШѓеЕГзі†зЇІзЪДеєВињРзЃЧпЉМжѓПдЄ™еЕГзі†еИЖеИЂиЗ™дєШгАВ 4. **иМГжХ∞иЃ°зЃЧ**пЉЪ - `norm(A)` иЃ°зЃЧзЯ©йШµAзЪДдЇМиМГжХ∞пЉМеН≥зЯ©йШµзЪД...
- \(S = 1 - \frac{3}{R' + G' + B'}\min(R', G', B')\) - \(H\) зЪДиЃ°зЃЧиЊГдЄЇе§НжЭВпЉМжґЙеПКеИ∞е§ЪдЄ™жЭ°дїґеИ§жЦ≠гАВ **пЉИ2пЉЙеѓєIеИЖйЗПињЫи°МзЫіжЦєеЫЊеЭЗи°°еМЦе§ДзРЖ** - **зЫЃж†З**: еҐЮеЉЇеЫЊеГПзЪДеѓєжѓФеЇ¶гАВ - **жЦєж≥Х**: зЫіжЦєеЫЊеЭЗи°°еМЦжШѓдЄАзІН...
дЊЛе¶ВпЉМзЫізЇњеЬ®еПВжХ∞з©ЇйЧідЄ≠зФ±жЦЬзОЗkеТМжИ™иЈЭbи°®з§ЇпЉМиАМеЬЖеИЩйАЪињЗеЬЖењГеЭРж†З(a, b)еТМеНКеЊДrзЪДжЦєз®Л(x-a)^2 + (y-b)^2 = r^2ињЫи°МжППињ∞гАВйАЪињЗињЩзІНжЦєеЉПпЉМеЫЊеГПдЄ≠жѓПдЄАзВєеѓєеЇФеПВжХ∞з©ЇйЧізЪДдЄАжЭ°зЇњпЉМиАМињЩдЇЫзЇњзЪДдЇ§зВєеѓєеЇФдЇОеЫЊеГПдЄ≠зЪДеЃЮйЩЕжЫ≤зЇњгАВ ...