一、什么是数据规范化
数据规范化是数据挖掘中数据变换的一种方式,数据变换将数据转换或统一成适合于挖掘的形式。而数据规范化是指将被挖掘对象的属性数据按比例缩放,使其落入一个小的特定区间(如[-1, 1]或[0,1])。
二、数据规范化的作用
对属性值进行规范化常用于涉及神经网络或距离度量的分类算法和聚类算法中。比如使用神经网络向后传播算法进行分类挖掘时,对训练元组中度量每个属性的输入值进行规范化有助于加快学习阶段的速度。对于基于距离度量相异度的方法,数据规范化可以让所有的属性具有相同的权重。
三、数据规范化的三种方法
数据规范化的常用方法有三种:按小数定标规范化、最小-最大值规范化和z-score规范化。
1、按小数定标规范化
通过移动属性值的小数点位置进行规范化,通俗的说就是将属性值除以10的j次幂。公式为:

其中,j 是使得Max(| |)<1的最大整数。比如,假设属性A的取值区间是A
|)<1的最大整数。比如,假设属性A的取值区间是A [-986,917]。则A的最大绝对值为986,显然只要将属性A中的值分别除以1000,就满足Max(||)<1,这时j=3。-986规范化后为-0.986,而917被规范化为0.917。达到了将属性值缩到小的特定区间[-1,1]的目标。
[-986,917]。则A的最大绝对值为986,显然只要将属性A中的值分别除以1000,就满足Max(||)<1,这时j=3。-986规范化后为-0.986,而917被规范化为0.917。达到了将属性值缩到小的特定区间[-1,1]的目标。
优点:直观简单。
缺点:并没有消除属性间的权重差异。
2、最小-最大值规范化
最小-最大值规范化对原始数据进行了线性变化。假设 和
和 分别表示属性A的最小值和最大值。则最小-最大值规范化计算公式为:
分别表示属性A的最小值和最大值。则最小-最大值规范化计算公式为:
公式中, 表示对象i的原属性值,表示规范化得到属性值。[
表示对象i的原属性值,表示规范化得到属性值。[ ,
, ]表示A属性的所有值规范化后落入的区间。
]表示A属性的所有值规范化后落入的区间。
举例应用:假设公司中员工工资income的最小和最大值分别12000美元和98000美元,现在要把income映射到区间[0,1]中。对income值为73600美元进行最小-最大值规范化后的结果。
根据描述,=12000,=98000,规范化后属性取值区间为[0,1],即=1,=0,代入公式计算:

优点:可灵活指定规范化后的取值区间,可以消除不同属性之间的权重差异。
缺点:需要预先知道该属性的最大值与最小值;另一方面,该方法保持原始数据值之间的联系,如果今后的输入落在原始数据值域之外,该方法将发生“越界”错误。对离群点敏感。(离群点是只偏离中心水平的哪些极大值和极小值)
3、z-score规范化
这种方法是基于属性的均值和标准差进行规范化。计算公式为:
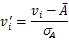
其中 表示对象i的原属性值,
表示规范化的属性值,
 表示属性A的平均值,
表示属性A的平均值, 表示属性A的标准差,两者的计算公式如下:
表示属性A的标准差,两者的计算公式如下:

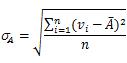
举例应用:假设属性income的均值和标准差分别为54000美元和16000美元。使用z-score规范化,值73600美元转换为:
对于离群点进行规范化时,可以用均值绝对偏差代替标准差进行规范化获得更好的鲁棒性。均值绝对偏差计算公式为:
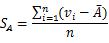
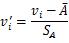
优点:不需要知道数据集的最大值和最小值,对离群点规范化效果好;
缺点:计算复杂度高。
分享到:



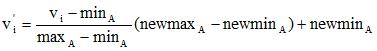
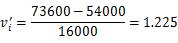

相关推荐
本文实例讲述了Python数据预处理之数据规范化。分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个...
同时,理解数据预处理的基本步骤,如数据清洗、数据转换、特征选择和数据规范化,对于提高模型的性能至关重要。最后,通过实际操作和练习,你将逐步提升自己在数据预处理领域的技能,为未来的数据分析项目打下坚实...
数据预处理是数据分析的重要步骤之一,主要用于对采集到的海量数据信息进行挖掘整合,按照统一规范的组织形式存储到DSM数据仓库,供图1系统体系结构分析研究使用。数据预处理的工作质量很大程度上决定最终服务数据的...
首先,数据预处理的目的是为了清洗、转换和规范化原始数据,使之更适合机器学习算法的输入需求。这通常包括以下几个方面: 1. 数据清洗:去除重复值、处理缺失值(填充或删除)、消除异常值和噪声。例如,对于缺失...
数据变换则包括数据标准化、规范化、编码转换等,目的是使数据适合特定的分析方法或模型。 4. **数据归约**:数据归约是为了降低数据复杂性,通过采样、特征选择、降维等手段减少数据的规模,同时尽量保持数据集的...
3. **数据变换**:规范化数据、平滑数据、聚集数据等。 4. **数据规约**:减少数据量的同时保持数据质量。 通过对数据进行有效的预处理,可以显著提高数据分析结果的质量和准确性,从而为后续的数据挖掘和机器学习...
常见的数据变换操作包括规范化(Nomalization),它用于将数据按比例缩放至特定范围;离散化(Discretization),将连续属性转换为离散属性;特征构造(Feature Construction),通过已有数据创建新的特征来增强数据...
数据预处理的步骤包括数据清洗、数据转换、数据规约等,这些步骤可帮助我们处理数据集中的噪声和异常值、填补缺失值、统一数据格式以及标准化和规范化数据。数据预处理需要依据具体的应用场景和模型需求来定制,而...
数据预处理是机器学习、深度学习等领域的基础,它旨在将原始数据转化为高质量的数据集,使之适合后续模型的训练与分析。在预处理过程中,必须解决数据的不完整性、偏态、噪声、特征不均衡、特征维度、缺失值和错误值...
数据变换通常包括规范化和标准化,使不同尺度或分布的数据具有可比性;数据集成则涉及到多个来源的数据合并,需要解决数据格式、编码和不一致性的问题;而数据融合则是将来自不同源的相似或互补信息整合在一起,以...
* 数据变换:规范化和聚集。 * 数据归约:得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果。 * 离散化和概念分层生成:通过概念分层和数据的离散化来规约数据,对数字型数据特别重要。 3. 数据质量...
归一化(最小-最大规范化)则将数据缩放到0到1之间。这两种方法有助于消除特征间的量纲差异,使得不同特征对模型的影响更均衡。对于“wine_data.csv”,我们可以应用这两种技术,使各特征在数值上具有一致性。 4. ...
在Python数据挖掘实验中,数据的预处理和探索是至关重要的步骤,特别是在处理真实世界的数据集...在这个过程中,掌握数据处理的技巧,如缺失值处理、异常值检测、数据规范化和可视化,将对我们的数据分析能力大有裨益。
在商务智能(Business Intelligence, BI)领域,数据预处理是至关重要的一个环节,它是从原始数据转化为可分析、可洞察信息的关键步骤。在本讲中,我们将深入探讨数据预处理的过程,包括其重要性、常用方法以及在...
数据预处理旨在清洗、转换和规范化这些数据,使其更适合用于模型训练。这一过程包括缺失值处理、异常值检测、数据归一化、特征编码等多个步骤。 1. 缺失值处理:数据集中时常存在缺失值,这可能是由于数据采集时的...
### 数据预处理详解 #### 一、数据预处理概述 数据预处理是在数据分析与挖掘之前对数据进行的一系列处理步骤,旨在确保数据的质量与适用性。预处理过程通常包括数据清洗、数据集成、数据变换和数据规约四个关键...
数据变换涉及将数据从一种格式转换到另一种格式,例如规范化,以及进行数据的归约。数据归约的目标是通过各种方法如聚集、删除冗余属性或聚类来压缩数据量。 数据离散化和概念分层是数据预处理中的高级技术,通过...