mixer_a
- 浏览: 376922 次
-

最新评论
-
NIIT_zhu:
我现在要做一个 基于exchange 2010的webmail ...
Exchange 2003 升级到Exchange 2010 之申请证书并分配服务! -
yinren13:
实在不行试试简单易用的turbomeeting,连接速度很快的 ...
QQ远程协助没动静?QQ版本有讲究 -
jicu7766240:
写得很好。赞一个!2年开发的我深有感触。这些我觉得说得很对。要 ...
老程序员的忠告:不要做浮躁的软件工程师 -
haohao-xuexi02:
好像很多人都买起却看不起书。。找各种理由不看。。我的书也这样 ...
老程序员的忠告:不要做浮躁的软件工程师 -
Judy123456:
希望可以提供源代码噢,我最近正好在学这个底部菜单,非常希望楼 ...
Android仿微信底部菜单
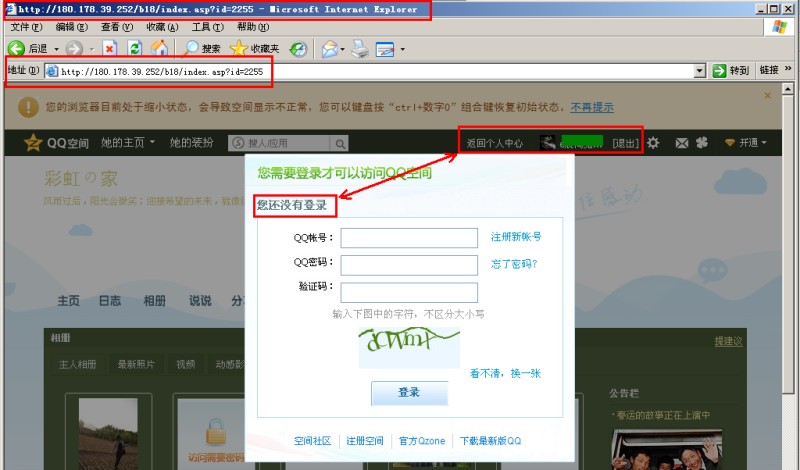
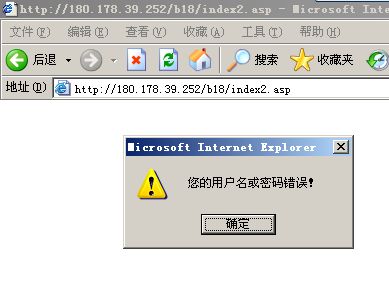
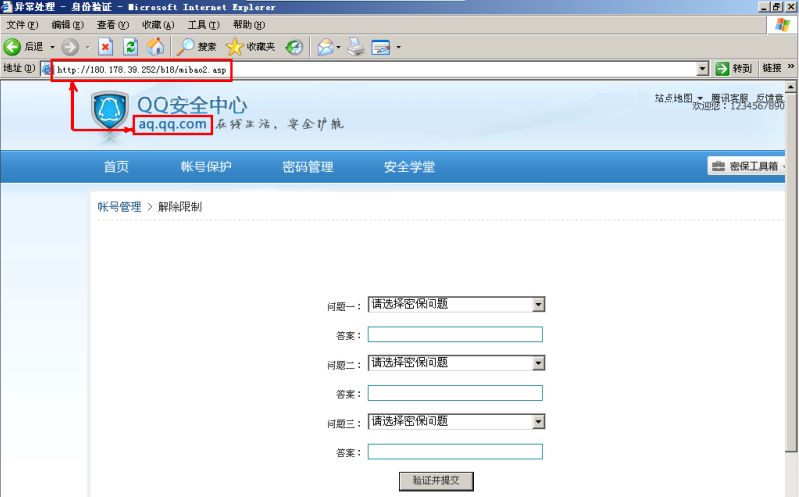
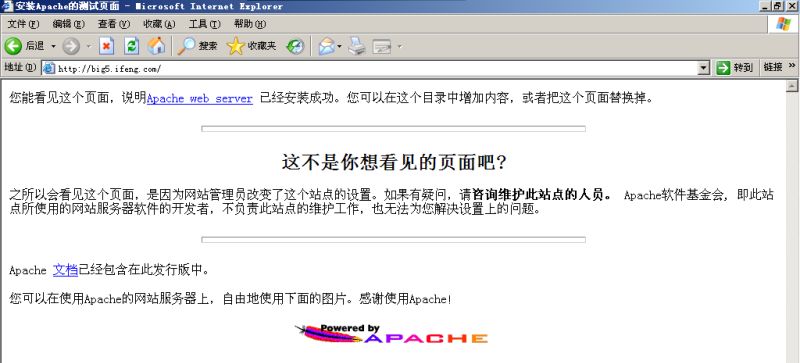
网友发来ifeng网址,打开后却是QQ空间,总提示QQ未登录?原来是一个阴险的诱骗网页





相关推荐
在IT行业中,开发一款"仿ifeng可翻阅滚动新闻"的应用是一项常见的需求,它能够为用户提供类似凤凰新闻(ifeng)的阅读体验,让用户能够自由地向上或向下浏览新闻内容。这一应用的设计和实现涉及多个技术领域,包括...
总的来说,"ifeng 图片左右滚动效果"是一个实用且美观的网页设计元素,它结合了JavaScript和CSS的力量,为用户提供了一种便捷的图片浏览方式,提升了网页的互动性和吸引力。在实际开发中,根据项目需求和用户群体,...
标题中的“ifeng新闻抓取”指的是通过编程技术从凤凰新闻网站上获取新闻数据的实践案例。这个案例采用的是Java语言,说明了在信息技术领域,如何利用编程手段抓取网络上的动态信息,尤其是新闻类数据。 描述中提到...
python爬取网页的表格内容, 并存入csv文件, 网页地址:http://app.finance.ifeng.com/data/stock/yjyg.php?symbol=000001
使用请求登录某些网站的API 文件资料 中文 英文 支持网站 网站 PC模式 移动模式 ScanQR模式 中文 Weibo ✓ ✓ ✓ 新浪微博 Douban ✓ ✗ ✗ 豆瓣 Github ✓ ✗ ✗ Github Music163 ✓ ✗ ✗ 网易云音乐 Zt12306 ...
【推广网站1077518】是一个关于网站推广策略的PPT,主要涵盖了通过博客平台进行内容营销以及在QQ群中发布信息的方法。以下是对这些知识点的详细阐述: 1. **博客推广策略**: - **内容原创性**:强调在博客上发布...
【CX】采集器免费版 2.6 是一款强大的网页数据抓取工具,适用于需要从互联网上批量收集信息的用户。本教程将详细介绍如何配置和使用该版本的采集规则,以便高效、准确地抓取所需的数据。 首先,我们来看采集规则的...
在PyQt5编程中,创建一个真实的用户界面往往需要加载各种资源文件,如图像、音频、字体等。在这个PyQt5教程中,我们专注于“QQ登录界面”的实现,特别是加载图像资源的部分。"images.rar"这个压缩包包含了实现这一...
6. **文件结构**:“weapp-sportsnews-master”这个文件名表明这是一个GitHub仓库的克隆,通常包含了一个完整的微信小程序项目结构,包括`app.js`(应用逻辑)、`app.json`(应用配置)、`app.wxss`(全局样式)、...
【标题】"仿凤凰网首页滚动焦点图"是一个网页设计项目,其目的是模仿知名新闻网站凤凰网首页的焦点图展示效果。这种效果通常用于在网站的显著位置展示一组动态切换的图片,吸引用户注意力并引导他们浏览更多内容。...
正则表达式`/\.sogou|soso|baidu|google|youdao|yahoo|bing|118114|biso|gougou|ifeng|ivc|sooule|niuhu|biso(\.[a-z0-9\-]+){1,2}\//ig`用于匹配用户来源中的域名部分,它检查`document.referrer`(即上一个页面的...
对于IT从业者来说,这个网站是寻找最新版软件的好去处。 #### 二、Android开发学习资源 - **火星老师视频**:虽然没有具体的链接,但提到的火星老师应该是Android开发领域内的知名讲师,其提供的视频教程有助于...
工具必须依赖Microsoft .NET Framework 2.0,如果是WIN7电脑不需要安装即可运行,如果是XP电脑必须下载安装Microsoft .NET Framework 2.0。... 软件支持SQL语句设置,只要写好SQL语句就可以将采集回来的新闻插入到...
PyQt5 实现QQ登录界面,这是使用Qt Designer创建的ui界面文件。如果不能使用,可以给我发邮件,ifeng12358@163.com
2. **`document.referrer`属性**:返回一个字符串,表示当前文档的前一个页面地址,即用户是从哪个页面链接过来的。 3. **条件判断**:如果`document.referrer`中包含指定搜索引擎的信息,则执行特定的跳转操作。 4....
人工智能-项目实践-新闻分类-朴素贝叶斯实现的文本分类(新闻分类) (文本分类)朴素贝叶斯实现的新闻分类 新闻共分7类,新闻信息在此采集: 1 财经 http://finance.qq.com/l/201108/scroll_17.htm 2 ...
【标题】:“react实现的一个凤凰新闻视频网站” 这个项目展示了如何使用React库构建一个类似于凤凰新闻的视频网站。React是Facebook开发的一个JavaScript库,用于构建用户界面,特别是单页应用程序(SPA)。它采用...
Scrapy是一个强大的Python爬虫框架,它为开发者提供了一套高效、灵活的工具,用于爬取网站并提取结构化数据。PyCharm是一款流行的Python IDE,它提供了丰富的开发功能,包括对Scrapy的支持,使得编写和调试Scrapy...
本文实例讲述了python实现的读取网页并分词功能。分享给大家供大家参考,具体如下: 这里使用分词使用最流行的分词包jieba,参考:https://github.com/fxsjy/jieba 或点击此处本站下载jieba库。 代码: import ...