В
дҪңиҖ…пјҡCCP Curt иҜ‘иҖ…пјҡCCP Lion
В
гҖҖгҖҖеӨ§еӨҡж•°зҶҹжӮүEVEзҡ„дәәйғҪзҹҘйҒ“пјҢе®ғжҳҜз”ЁPythonиҜӯиЁҖзј–еҶҷзҡ„пјҢеҰӮжһңиҰҒиҜҙеҫ—жӣҙе…·дҪ“зӮ№пјҢйӮЈе°ұжҳҜStackless PythonгҖӮStacklessжҳҜеңЁPythonеҹәзЎҖдёҠзј–еҶҷзҡ„дёҖеҘ—еҫ®зәҝзЁӢжЎҶжһ¶пјҢе®ғиғҪеңЁдёҚдә§з”ҹеӨ§йҮҸPythonиҮӘиә«йўқеӨ–ејҖй”Җзҡ„жғ…еҶөдёӢеҗҢж—¶е®№зәіж•°зҷҫдёҮжқЎзҡ„зәҝзЁӢгҖӮдҪҶиҜқиҝҳжҳҜиҰҒиҜҙеӣһжқҘпјҢе®ғжҜ•з«ҹиҝҳжҳҜPythonпјҢеӣ жӯӨж‘Ҷи„ұдёҚдәҶвҖңи§ЈйҮҠеҷЁе…ЁеұҖй”ҒвҖқпјҲGlobal Interpreter LockпјҢдёӢж–Үе°Ҷе…¶з®Җз§°дёәGILпјүгҖӮ
гҖҖгҖҖGILжҳҜдёҖдёӘеәҸеҲ—й”ҒпјҢз”ЁжқҘдҝқиҜҒеңЁд»»дҪ•ж—¶еҖҷйғҪеҸӘиғҪжңүдёҖдёӘзәҝзЁӢеҲ©з”ЁPythonи§ЈйҮҠеҷЁпјҲеҢ…жӢ¬е…¶жүҖжңүж•°жҚ®пјүжқҘиҝҗиЎҢиҮӘе·ұгҖӮеӣ жӯӨпјҢе°Ҫз®ЎStackless Pythonж„ҹи§үдёҠеҘҪеғҸе…·еӨҮеӨҡзәҝзЁӢеӨ„зҗҶиғҪеҠӣпјҢдҪҶе®һйҷ…дёҠе®ғиҝҳжҳҜеҚ•зәҝзЁӢзҡ„пјҢеҸӘдёҚиҝҮиҝҗз”ЁдәҶд»»еҠЎеҲҶзҰ»гҖҒйў‘йҒ“гҖҒе®ҡж—¶еҷЁеҸҠе…ұдә«еҶ…еӯҳзӯүдёҖзі»еҲ—жӢӣж•°иҖҢе·ІгҖӮе…¶е®һиҝҮеҺ»жңүдәӣеҚҸдҪңејҸзҡ„еӨҡд»»еҠЎж“ҚдҪңзі»з»ҹд№ҹжҳҜиҝҷж ·е№Ізҡ„пјҢе…¶еҘҪеӨ„жҳҜдҝқиҜҒдәҶжүҖжңүзәҝзЁӢйғҪиғҪиў«жү§иЎҢпјҢдёҚдјҡеҮәзҺ°иў«ж“ҚдҪңзі»з»ҹжҸҗеүҚз»“жқҹиҝҷдёҖжғ…еҶөпјҲйҷӨйқһиў«ж“ҚдҪңзі»з»ҹжҖҖз–‘йқһжі•е®•жңәпјүгҖӮGILзҡ„еӯҳеңЁдҪҝеҫ—зЁӢеәҸе‘ҳеңЁзј–еҶҷжёёжҲҸйҖ»иҫ‘ж—¶иғҪиҮӘдҝЎжҺЁж–ӯеҮәзЁӢеәҸзҡ„е…ЁеұҖзҠ¶жҖҒпјҢзңҒеҺ»дәҶдёҖеӨ§е ҶйҮҮз”ЁејӮжӯҘеӣһи°ғеҮҪж•°зҡ„йә»зғҰгҖӮ
гҖҖгҖҖдҪҶиҝҷж ·жңүдёҖеӨ§зјәзӮ№пјҡз”ұдәҺEVEдёӯжңүйғЁеҲҶжЎҶжһ¶зҡ„д»Јз ҒжҳҜз”ЁPythonзј–еҶҷзҡ„пјҢеӣ жӯӨе®ғ们йғҪе…ҚдёҚдәҶGILйҖ жҲҗзҡ„иҙҹйқўеҪұе“ҚгҖӮжҜ”еҰӮпјҢдёҖж®өз”ЁжқҘиҜ»еҸ–Pythonж•°жҚ®зҡ„C++иҜӯиЁҖд»Јз Ғеҝ…йЎ»еңЁиҺ·еҫ—GILеҗҺжүҚиғҪиҜ»еҸ–дёҖдёӘеӯ—з¬ҰдёІгҖӮ
В
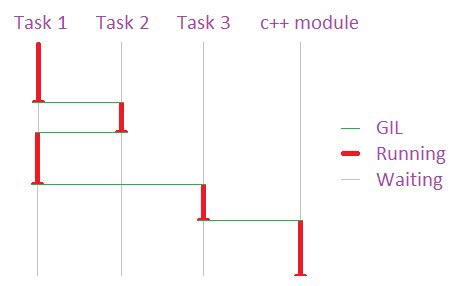
дҪҝз”ЁPythonзҡ„д»»еҠЎйғҪиҰҒиҺ·еҫ—GILжүҚиғҪеҗҲжі•ең°иў«еӨ„зҗҶпјҢиҝҷж ·зӯүеҗҢдәҺPythonд»»еҠЎйғҪжҳҜеҚ•зәҝзЁӢжү§иЎҢгҖӮ
пјҲиҝҷеӣҫз”»еҫ—дёҚеӨӘеҘҪзңӢпјҢдәә家еҸӘжҳҜдёӘзЁӢеәҸе‘ҳпјҢдёҚжҳҜзҫҺжңҜеёҲе“Ұпјү
гҖҖгҖҖдёҖиЁҖд»Ҙи”Ҫд№ӢпјҢStackless Python д»Јз Ғзҡ„иҝҗиЎҢйҖҹеәҰдёҚдјҡй«ҳдәҺдҪ жңҖеҝ«зҡ„йӮЈдёӘCPUж ёеҝғзҡ„йҖҹеәҰгҖӮеңЁдёҖеҸ°4ж ёжҲ–8ж ёCPUзҡ„жңҚеҠЎеҷЁдёҠпјҢе…¶дёӯеҸӘжңүдёҖж ёеңЁи¶…иҙҹиҚ·иҝҗдҪңпјҢе…¶д»–йғҪжІЎжҙҫдёҠз”ЁеңәгҖӮеҪ“然пјҢдёәдәҶи®©иҝҷдәӣCPUж ёеҝғзү©е°Ҫе…¶з”ЁпјҢжҲ‘们еҸҜд»ҘеңЁе®ғ们иә«дёҠеҠ иҪҪжӣҙеӨҡзҡ„иҠӮзӮ№гҖӮеҜ№дәҺEVEдёӯи®ёеӨҡж— зҠ¶жҖҒжҲ–еҜ№е…ұдә«зҠ¶жҖҒдҫқиө–еәҰжһҒдҪҺзҡ„д»Јз ҒиҖҢиЁҖпјҢиҝҷжІЎд»Җд№Ҳй—®йўҳгҖӮдҪҶеҜ№дәҺеғҸеӨӘз©әжЁЎжӢҹжҲ–з©әй—ҙз«ҷиЎҢиө°иҝҷж ·й«ҳеәҰдҫқиө–е…ұдә«зҠ¶жҖҒзҡ„д»Јз ҒиҖҢиЁҖпјҢе°ұжҲҗдәҶдёҖдёӘеӨ§й—®йўҳгҖӮ
гҖҖгҖҖеҒҮи®ҫдёҖдёӘCPUж ёеҝғе°ұиғҪеӨ„зҗҶжүҖжңүзҡ„йҖ»иҫ‘并且еҶҷеҮәжқҘзҡ„Pythonд»Јз Ғиҫғдёәжё…жҷ°пјҢйӮЈжҲ‘д№ӢеүҚиҜҙзҡ„йғҪдёҚжҳҜд»Җд№Ҳй—®йўҳгҖӮдёҚиҝҮпјҢжғіеҝ…жҲ‘дёҚз”ЁиҜҙеӨ§е®¶д№ҹзҹҘйҒ“пјҢе°Ҫз®ЎGridlockзӯүе°Ҹз»„е·Із»ҸеңЁдјҳеҢ–е·ҘдҪңж–№йқўеҒҡеҲ°дәҶе…¶жһҒиҮҙпјҢдҪҶжҲ‘们зҺ°еңЁйқўдёҙзҡ„жғ…еҶөдҫқж—§жҳҜеҚ•дёӘCPUе·Із»Ҹж— жі•еӨ„зҗҶдёҖеңәеӨ§еһӢдјҡжҲҳдәҶгҖӮжңҖиҝ‘дёҠеёӮзҡ„CPUйҖҹеәҰжҳҜжӣҙеҝ«гҖҒзј“еӯҳе®№йҮҸд№ҹжӣҙеӨ§гҖҒжҖ»зәҝд№ҹжӣҙе®Ҫ裕并且具еӨҮжӣҙеҘҪзҡ„жү§иЎҢжөҒж°ҙзәҝпјҢдҪҶеңЁEVEйңҖиҰҒе…¶з»ҷеҠӣзҡ„ең°ж–№пјҢеҚҙжІЎжңүд»»дҪ•иҝӣжӯҘгҖӮиҝ‘жңҹпјҲд№ҹеҸҜиғҪеҢ…жӢ¬дёӯй•ҝжңҹпјүзҡ„и¶ӢеҠҝжҳҜвҖңжЁӘеҗ‘еўһй•ҝвҖқпјҢеҚіеҗҢж—¶иҝҗиЎҢеӨҡдёӘCPUж ёеҝғгҖӮ
гҖҖгҖҖжҖ»дҪ“иҖҢиЁҖпјҢеӨҡж ёCPUзҡ„жөҒиЎҢеҜ№EVEзҡ„й•ҝиҝңеҸ‘еұ•жҳҜдёҖеӨ§еҲ©еҘҪгҖӮжңӘжқҘйӮЈдәӣ30д№ғиҮі60ж ёCPUзҡ„жңәеҷЁиғҪеӨҹеҫҲеҘҪең°дҪ“зҺ°EVEйӣҶзҫӨйғЁзҪІж–№ејҸзҡ„дјҳеҠҝпјҢиҝҷжҳҜеӣ дёәCPUж ёеҝғд№Ӣй—ҙеҲҮжҚўзҡ„ж•ҲзҺҮе°ҶиҝңиҝңеӨ§дәҺзәҝзЁӢд№Ӣй—ҙеҲҮжҚўзҡ„ж•ҲзҺҮгҖӮдҪҶе°ұзӣ®еүҚиҖҢиЁҖпјҢдёәдәҶжҸҗеҚҮжёёжҲҸиҝҗиЎҢйҖҹеәҰпјҢжҲ‘们йңҖиҰҒжҠҠзҪ‘з»ңеҸҠйҖҡз”ЁиҜ»еҶҷиҝҷж ·зҡ„EVEжЁЎеқ—д»ҺGILдёӯи§Јж”ҫеҮәжқҘгҖӮ
еӨҡж ёеҝғгҖҒи¶…ж ҮйҮҸзҡ„硬件еҜ№еҪ“д»Ҡзҡ„зҪ‘з»ңжёёжҲҸжқҘиҜҙпјҢйғҪжҳҜдёӘеҘҪж¶ҲжҒҜгҖӮиҝҷдәӣжёёжҲҸеҫҲйҖӮеҗҲиҝҷз§Қжһ¶жһ„пјҢ并且иғҪеҫҲе®№жҳ“ең°иҝӣиЎҢ并иЎҢеӨ„зҗҶгҖӮеҸҜжғңеҜ№дәҺдҫқиө–Pythonзҡ„EVEжқҘиҜҙпјҢиҝҷе°ұз®—дёҚеҫ—еҘҪж¶ҲжҒҜдәҶгҖӮйӮЈдәӣеҜ№иҝҗиЎҢйҖҹеәҰиҰҒжұӮжһҒй«ҳгҖҒдёҚйңҖиҰҒPythonдҫҝеҲ©ејҖеҸ‘дјҳеҠҝзҡ„EVEзі»з»ҹйңҖиҰҒе°Ҫж—©ж‘Ҷи„ұGILзҡ„жқҹзјҡгҖӮCarbonIOеңЁиҝҷдёӘж–№еҗ‘дёҠеҸҜд»ҘиҜҙжҳҜеҗ‘еүҚиҝҲиҝӣдәҶдёҖеӨ§жӯҘгҖӮ
гҖҖгҖҖCarbonIO жҳҜеңЁStacklessIO еҹәзЎҖдёҠзҡ„дёҖдёӘиҮӘ然жҸҗеҚҮгҖӮе®ғе®һйҷ…дёҠжҳҜдёӘд»ҺеӨҙеҶҷиө·зҡ„е…Ёж–°еј•ж“ҺпјҢзӣ®ж ҮйқһеёёжҳҺзЎ®пјҡи®©зҪ‘з»ңжөҒйҮҸж‘Ҷи„ұGILзҡ„жқҹзјҡпјҢ并且让任дҪ•C++д»Јз Ғд№ҹиғҪиҝҷж ·еҒҡгҖӮеҗҺеҚҠдёӘзӣ®зҡ„жҳҜйҮҚеӨҙжҲҸпјҢжҲ‘们иҠұдәҶеӨ§еҚҠе№ҙжүҚжҠҠе®ғе®ҢжҲҗгҖӮ
гҖҖгҖҖиҝҷйҮҢдёҚеҫ—дёҚе…ҲзЁҚеҫ®жҸҗдёҖдёӢStacklessIOгҖӮеҜ№Stackless Pythonзҡ„зҪ‘з»ңйҖҡдҝЎиҖҢиЁҖпјҢе®ғеҸҜд»ҘиҜҙжҳҜдёӘиҙЁзҡ„йЈһи·ғгҖӮйҖҡиҝҮи®©зҪ‘з»ңж“ҚдҪңеҸҳеҫ—е…·жңүвҖңж— е Ҷж Ҳзҡ„ж„ҸиҜҶвҖқпјҢStacklessIOеҸҜд»Ҙе°ҶдёҖдёӘиў«й”ҒдҪҸзҡ„ж“ҚдҪңиҪ¬з§»еҲ°дёҖдёӘжңӘиў«GILй”ҒдҪҸзҡ„зәҝзЁӢдёҠпјҢиҝҷж ·иҜҘж“ҚдҪңе°ұеҸҜд»Ҙ继з»ӯзӯүеҖҷпјҢиҖҢStacklessеҲҷ继з»ӯеӨ„зҗҶе…¶д»–дәӢеҠЎгҖӮ然еҗҺпјҢиҜҘж“ҚдҪңйҮҚж–°иҺ·еҫ—GILпјҢе‘ҠиҜүStacklessе…¶ж“ҚдҪңе·Іе®ҢжҲҗгҖӮиҝҷж ·пјҢжҺҘ收з«Ҝе°ұеҸҜд»ҘеҗҢжӯҘиҝӣиЎҢпјҢдҪҝеҫ—йҖҡи®ҜйҖҹеәҰеҸҜд»ҘиҫҫеҲ°ж“ҚдҪңзі»з»ҹзә§еҲ«пјҢ并且иғҪеҹәжң¬дёҠеңЁз¬¬дёҖж—¶й—ҙеҶ…еӣһжҠҘз»ҷPythonгҖӮ
В
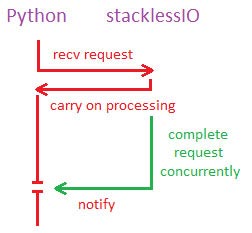
StacklessIOеңЁжІЎжңүGILзҡ„жғ…еҶөдёӢе®ҢжҲҗPythonиҜ·жұӮ
гҖҖгҖҖCarbonIOеңЁжӯӨеҹәзЎҖдёҠжӣҙдёҠдёҖеұӮжҘјгҖӮз”ұдәҺе®ғжҳҜеңЁе®Ңе…Ёи„ұзҰ»дәҺGILзҡ„жғ…еҶөдёӢиҝҗиЎҢеӨҡзәҝзЁӢйҖҡдҝЎеј•ж“ҺпјҢеӣ жӯӨPythonдёҺиҜҘзі»з»ҹд№Ӣй—ҙзҡ„дәӨдә’дҫҝжҳҜе®Ңе…ЁзӢ¬з«ӢдәҶгҖӮжІЎжңүPythonзҡ„иҰҒжұӮпјҢе®ғд№ҹиғҪ收еҸ‘ж•°жҚ®гҖӮ
гҖҖгҖҖиҜ·е…Ғи®ёжҲ‘еҶҚејәи°ғдёҖдёӢпјҡCarbonIOиғҪеңЁPythonдёҚдҪңд»»дҪ•иҰҒжұӮзҡ„жғ…еҶөдёӢ收еҸ‘ж•°жҚ®гҖӮиҝҷжҳҜ并еҸ‘жҖ§зҡ„пјҢдёҚйңҖиҰҒGILгҖӮ
гҖҖгҖҖеҪ“дёҖдёӘиҝһжҺҘйҖҡиҝҮCarbonIOиў«е»әз«ӢеҗҺпјҢзі»з»ҹдјҡи°ғз”ЁWSARecv()ејҖе§ӢжҺҘ收数жҚ®гҖӮдёҺPythonиҝӣзЁӢ并иЎҢзҡ„зәҝзЁӢжұ е°Ҷиҝҷдәӣж•°жҚ®и§ЈеҜҶгҖҒи§ЈеҺӢ缩然еҗҺиҪ¬д№үеҲ°ж•°жҚ®еҢ…йҮҢгҖӮиҝҷдәӣж•°жҚ®еҢ…дјҡжҺ’йҳҹпјҢзӯүзқҖPythonжқҘеӨ„зҗҶгҖӮ
гҖҖгҖҖеҪ“Pythonи§үеҫ—е®ғйңҖиҰҒдёҖдёӘж•°жҚ®еҢ…ж—¶пјҢе®ғдјҡеҫҖдёӢи°ғз”ЁвҖңеҸҜиғҪе·Іе°ҶжӯӨеҢ…еҮҶеӨҮе°ұз»ӘвҖқзҡ„CarbonIOгҖӮиҝҷж„Ҹе‘ізқҖж•°жҚ®еңЁзҰ»ејҖйҳҹеҲ—иў«иҝ”еӣһж•ҙдёӘиҝҮзЁӢдёӯж №жң¬жІЎжңүз”ЁеҲ°GILгҖӮиҝҷжҳҜдёҖдёӘзһ¬ж—¶иҝҮзЁӢпјҢиҮіе°‘д№ҹжңүзәіз§’йӮЈд№Ҳеҝ«гҖӮиҝҷдёӘ并иЎҢиҜ»еҸ–иғҪеҠӣжҳҜCarbonIOзҡ„第дёҖеӨ§еҘҪеӨ„гҖӮ
гҖҖгҖҖ第дәҢеӨ§еҘҪеӨ„дҫҝжҳҜеҸ‘йҖҒдәҶгҖӮж•°жҚ®д»Ҙе…¶еҺҹе§ӢеҪўејҸжҺ’еңЁе·ҘдҪңзәҝзЁӢйҳҹеҲ—йҮҢпјҢ然еҗҺдҫҝзӯүзқҖPythonжқҘи°ғз”ЁдәҶгҖӮе…¶й—ҙзҡ„еҺӢзј©гҖҒеҠ еҜҶгҖҒжү“еҢ…еҸҠWSASend()и°ғз”ЁйғҪжІЎжңүи§ҰеҸҠGILиҖҢеҸ‘з”ҹеңЁеҸҰдёҖдёӘзәҝзЁӢйҮҢпјҢиҝҷж ·ж“ҚдҪңзі»з»ҹдҫҝеҸҜд»Ҙе®үжҺ’е®ғиҝҗиЎҢеңЁеҸҰдёҖйў—CPUдёҠдәҶгҖӮC++д»Јз Ғд№ҹеҸҜд»Ҙи°ғз”ЁдёҖдёӘж–№жі•жқҘиҝҷж ·еҒҡпјҢ并дёҚйңҖиҰҒзү№еҲ«зҡ„жһ¶жһ„еҸҳжӣҙгҖӮStacklessIOд№ҹеҸҜд»ҘйӮЈж ·еҒҡпјҢдҪҶеңЁи„ұзҰ»дёҠиҝ°иғҢжҷҜзҡ„жғ…еҶөдёӢпјҢиҝҷдјҡеҸҳеҫ—еҫҲжІЎж„Ҹд№үгҖӮ
гҖҖгҖҖи®©жҲ‘们еҶҚжқҘеӣһйЎҫдёҖдёӢд№ӢеүҚжҸҗеҲ°зҡ„вҖңе·Іе°ҶжӯӨеҢ…еҮҶеӨҮе°ұз»ӘвҖқгҖӮдҪҶеҰӮжһңжҲ‘们иҰҒе®үзҪ®дёҖдёӘC++еӣһи°ғй’©еӯҗеҮҪж•°пјҢдҪҝеҫ—йқһPythonжЁЎеқ—иғҪеңЁдёҚи§ҰеҸҠMachonetзҡ„жғ…еҶөдёӢиҺ·еҫ—йӮЈдёӘж•°жҚ®пјҢиҝҷеҸҜиЎҢеҗ—пјҹиЎҢе•ҠпјҢиҝҷж—¶жҲ‘们иҰҒз”Ёзҡ„е°ұжҳҜBlueNetдәҶгҖӮ
В
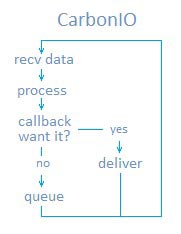
CarbonIOдёҚеҒңең°иҝӣиЎҢж•°жҚ®жҺҘ收пјҢ并且иғҪеңЁж— Pythonд»Ӣе…Ҙзҡ„жғ…еҶөдёӢе‘ҠиҜүC++жЁЎеқ—ж•°жҚ®е·Іж”¶еҲ°гҖӮ
гҖҖгҖҖMachonetжҳҜдёҖдёӘеӨ§еһӢеҠҹиғҪйӣҶеҗҲпјҢе®ғиҙҹиҙЈеҜ№дјҡиҜқиҝӣиЎҢеҲҶжөҒгҖҒеҜјеҗ‘еҸҠз®ЎзҗҶпјҢиҙҹиҙЈеҜ№ж•°жҚ®еҢ…зҡ„ж—¶й—ҙи®ЎеҲ’/еҸ‘йҖҒд»ҘеҸҠе…¶д»–дёҖзі»еҲ—е°ҶEVEж’®еҗҲжҲҗдёҖдёӘжңүжңәж•ҙдҪ“зҡ„еҠҹиғҪгҖӮз”ұдәҺе®ғжҳҜдёӘPythonжЁЎеқ—пјҢеӣ жӯӨжүҖжңүзҡ„ж•°жҚ®иҝҹж—©йғҪеҝ…йЎ»и§ҰеҸҠйӮЈеҖ’йңүзҡ„GILпјҢж— и®әж•°жҚ®еңЁе“ӘдёӘиҠӮзӮ№гҖӮж— и®әдёҖдёӘC++жЁЎеқ—зҡ„йҖҹеәҰжңүеӨҡеҝ«пјҢGILд»Қ然жҳҜдёӘз»•дёҚиҝҮзҡ„瓶йўҲгҖӮиҝҷдҪҝеҫ—жҲ‘们жӣҫз»ҸйғҪдёҚеӨӘж„ҝж„ҸеҒҡеӨ§йҮҸзҡ„C++дјҳеҢ–пјҢеӣ дёәд»»дҪ•дјҳеҢ–еҗҺеҸ–еҫ—зҡ„дјҳеҠҝйғҪдјҡиў«Machonet дёӯзҡ„GILеҗһеҷ¬гҖӮ
гҖҖгҖҖдҪҶзҺ°еңЁжғ…еҶөдёҚдёҖж ·дәҶгҖӮ
гҖҖгҖҖзҺ°еңЁC++зҡ„зі»з»ҹиғҪйҖҡиҝҮBlueNet收еҸ‘ж•°жҚ®еҢ…пјҢж— йңҖеҶҚзҗҶдјҡGILгҖӮиҝҷеҺҹжқҘжҳҜдё“й—ЁдёәдәҶз©әй—ҙз«ҷиЎҢиө°и®ҫи®Ўзҡ„гҖӮз©әй—ҙз«ҷиЎҢиө°еҠҹиғҪйңҖиҰҒеҸ‘йҖҒеӨ§йҮҸзҡ„иЎЁзӨә移еҠЁзҡ„ж•°жҚ®гҖӮEVEдёӯеӨӘз©әйЈһиЎҢзҡ„йӮЈйғЁеҲҶеҠҹиғҪжүҖйңҖиҰҒ收еҸ‘зҡ„ж•°жҚ®пјҢжҲ‘们д»ҘеүҚеҸҜд»Ҙз”Ёж—Ғй—Ёе·ҰйҒ“зҡ„ж–№жі•жқҘи§ЈеҶіпјҢдҪҶеҜ№дәҺеҰӮжӯӨиҝ‘и·қзҰ»зҡ„дәәзү©еҠЁдҪңпјҢе°ұдёҚиЎҢдәҶгҖӮд№ӢеүҚжҲ‘们еҒҡзҡ„йў„жөӢжҳҫзӨәпјҢеҚідҪҝжҠҠз©әй—ҙз«ҷиЎҢиө°еҸ‘йҖҒж•°жҚ®зҡ„йў‘зҺҮжҺ§еҲ¶еңЁдёҖиҲ¬зЁӢеәҰпјҢиҜҘеҠҹиғҪд№ҹдјҡжҠҠж•ҙдёӘжңҚеҠЎеҷЁйӣҶзҫӨжӢ–еһ®гҖӮйҖҡиҝҮеңЁжІЎжңүGILе№Іжү°зҡ„жғ…еҶөдёӢеҜ№жөҒе…Ҙ/жөҒеҮәC++еҺҹз”ҹзі»з»ҹпјҲжҜ”еҰӮзү©зҗҶзі»з»ҹпјүзҡ„ж•°жҚ®иҝӣиЎҢеҲҶжөҒпјҢBlueNetжҲҗеҠҹең°и§ЈеҶідәҶиҜҘй—®йўҳгҖӮз”ұдәҺеңЁиҝҷз§Қжғ…еҶөдёӢпјҢж•°жҚ®иҝҳжҳҜдҝқжҢҒзқҖе…¶еҺҹз”ҹжҖҒпјҢеӣ жӯӨж•ҙдёӘзі»з»ҹиҝҗиЎҢзҡ„йҖҹеәҰе°ұжҜ”д№ӢеүҚжҸҗй«ҳдәҶгҖӮ
гҖҖгҖҖиҝҷдёӘе…·дҪ“жҳҜжҖҺд№ҲиҝҗдҪңзҡ„е‘ўпјҹBlueNetдҝқеӯҳзқҖдёҖд»ҪжүҖжңүеҝ…иҰҒMachonetз»“жһ„зҡ„еҸӘиҜ»жӢ·иҙқпјҢеҸҰеӨ–пјҢжүҖжңүзҡ„ж•°жҚ®еҢ…еүҚйғҪдјҡйҷ„дёҠеҫҲе°Ҹзҡ„дёҖж®өпјҲ8еҲ°10дёӘеӯ—иҠӮзҡ„пјүж•°жҚ®еӨҙгҖӮиҝҷдёӘж•°жҚ®еӨҙйҮҢеҗ«жңүи·Ҝеҫ„дҝЎжҒҜгҖӮеҪ“BlueNetжҺҘеҲ°дёҖдёӘж•°жҚ®еҢ…ж—¶пјҢе®ғдјҡеҜ№е…¶иҝӣиЎҢжЈҖжөӢпјҢ然еҗҺеҗҲзҗҶең°еҶҚеҲҶеҸ‘пјҡиҰҒд№ҲиҪ¬еҸ‘еҲ°еҸҰдёҖдёӘиҠӮзӮ№дёҠпјҢиҰҒд№ҲдәӨз»ҷиў«жң¬ең°зҡ„е·ІжіЁеҶҢзҡ„C++еә”з”ЁзЁӢеәҸгҖӮеҰӮжһңе®ғиҪ¬еҸ‘пјҢйӮЈиҝҷдёӘиҝҮзЁӢдёӯе°Ҷз”ЁдёҚеҲ°GILпјҢж №жң¬дёҚдјҡи°ғз”ЁMachonet/PythonгҖӮиҝҷж„Ҹе‘ізқҖжҲ‘们зҡ„д»ЈзҗҶжңҚеҠЎеҷЁе®Ңе…ЁиғҪд»Ҙ并иЎҢж–№ејҸеҜ№BlueNetзҡ„ж•°жҚ®еҢ…иҝӣиЎҢеҲҶжөҒпјҢиҖҢдёҚеҝ…еҺ»з»ҸиҝҮPythonеҜјиҮҙйўқеӨ–ејҖй”Җзҡ„дә§з”ҹгҖӮйӮЈиҝҷж•ҲзҺҮ究з«ҹжҸҗй«ҳдәҶеӨҡе°‘е‘ўпјҹжҲ‘们иҝҳж— жі•зЎ®е®ҡпјҢдҪҶеңЁйҷҚдҪҺжңәеҷЁиҙҹиҪҪеҸҠ延иҝҹж–№йқўпјҢе®ғиҝҳжҳҜйқһеёёйқһеёёжҳҺжҳҫзҡ„гҖӮе®һйҷ…дёҠжҲ‘们иҝҳдёҚиғҪе°Ҷж•°жҚ®е…¬ејҖпјҢеӣ дёәе®ғ们еҘҪеҫ—йҡҫд»ҘзҪ®дҝЎгҖӮ
гҖҖгҖҖйҷӨжӯӨд№ӢеӨ–пјҢCarbonIOд№ҹеҢ…еҗ«дәҶеӨ§йҮҸеә•еұӮдјҳеҢ–пјҢз»қеӨ§еӨҡж•°йғҪжҳҜе°Ҹ规模зҡ„йҖҹеәҰжҸҗеҚҮпјҢдҪҶжҠҠиҝҷдәӣз»ҹз»ҹеҸ еҠ иө·жқҘпјҢж•ҙдёӘзі»з»ҹзҡ„иҝҗиЎҢйҖҹеәҰд№ҹе°ұжңүдәҶжҳҫи‘—жҸҗй«ҳгҖӮд»ҘдёӢеҮ зӮ№еҖјеҫ—дёҖжҸҗпјҡ
е·ҘдҪңеҲҶз»„
гҖҖгҖҖиҷҪ然жҲ‘еҫҲйҡҫеңЁжң¬ж–ҮдёӯжҠҠиҝҷдәӢе„ҝиҜҙеҫ—еӨӘз»ҶпјҢдҪҶCarbonIOйқһеёёеҮәиүІең°е°Ҷе·ҘдҪңеҲҶз»„жқҘеӨ„зҗҶгҖӮз®ҖиҖҢиЁҖд№ӢпјҢе°ұжҳҜжҹҗдәӣж“ҚдҪңжңүдәҶдёҖдёӘеӣәе®ҡзҡ„ејҖй”ҖгҖӮзҪ‘з»ңеј•ж“Һжңүи®ёеӨҡиҝҷж ·зҡ„ејҖй”ҖпјҢдҪҶе…¶д»–жүҖжңүе…·жңүйҮҚиҰҒж„Ҹд№үзҡ„д»Јз Ғд№ҹжңүеӨ§йҮҸејҖй”ҖгҖӮйҖҡиҝҮдёҖдәӣеҲ«еҮәеҝғиЈҒзҡ„жҠҖе·§пјҢжҲ‘们жҳҜеҸҜд»Ҙе°Ҷи®ёеӨҡиҝҷж ·зҡ„е·ҘдҪңеҗҲ并еңЁдёҖиө·пјҢиҝҷж ·е°ұеҸӘдә§з”ҹдёҖж¬ЎејҖй”ҖгҖӮе°ұеғҸжҠҠйҖ»иҫ‘ж•°жҚ®еҢ…йғҪз»„еҗҲеңЁдёҖиө·еҸ‘йҖҒеңЁдёҖдёӘTCP/IP MTUйҮҢдёҖж ·пјҲEVEдёҖзӣҙе°ұжҳҜиҝҷж ·е№Ізҡ„пјүпјҢCarbonIOе°ҶиҝҷдёҖеҒҡжі•иҝӣдёҖжӯҘж·ұеҢ–гҖӮдёҖдёӘжҜ”иҫғз®ҖеҚ•зҡ„дҫӢеӯҗе°ұжҳҜGILиҺ·еҸ–йӣҶеҗҲгҖӮ
гҖҖгҖҖ第дёҖдёӘиҰҒе°қиҜ•еҸ–еҫ—GILзҡ„зәҝзЁӢдјҡе…Ҳе»әз«Ӣиө·дёҖдёӘйҳҹеҲ—пјҢиҝҷж ·е…¶д»–иҰҒиҺ·еҸ–GILзҡ„зәҝзЁӢеҸӘйңҖе°ҶиҮӘе·ұзҡ„е”ӨйҶ’и°ғз”ЁжҺ’еңЁйҳҹеҲ—жң«е°ҫ然еҗҺиҝ”еӣһзәҝзЁӢжұ е°ұиЎҢгҖӮйӮЈGILжңҖеҗҺиў«еҸ–еҫ—ж—¶пјҢ第дёҖдёӘзәҝзЁӢдјҡеҗёе№Іж•ҙдёӘйҳҹеҲ—пјҢдёҚеҝ…еңЁжҜҸж¬ЎIOе”ӨйҶ’ж—¶йҮҠж”ҫ/йҮҚжӢҫGILгҖӮеңЁдёҖдёӘз№Ғеҝҷзҡ„жңҚеҠЎеҷЁдёҠиҝҷз§Қжғ…еҶөеҫҲеӨҡпјҢеӣ жӯӨиҝҷз§Қж”№иҝӣеҜ№жҲ‘们жқҘиҜҙжҳҜдёҖеӨ§еҲ©еҘҪгҖӮ
openSSL ж•ҙеҗҲ
гҖҖгҖҖCarbonIOз”ЁopenSSLжқҘе®һзҺ°SSLпјҢ并且иғҪеңЁдёҚй”Ғе®ҡGILзҡ„жғ…еҶөдёӢдёҺиҜҘеҚҸи®®ж•°жҚ®йҖҡдҝЎгҖӮиҜҘеә“еҸӘжҳҜз”ЁдҪңдёҖдёӘBIOеҜ№иҖҢе·ІпјҢжүҖжңүзҡ„ж•°жҚ®еҜјиҲӘиҝҳжҳҜз”ұCarbonIOйҖҡиҝҮе®ҢжҲҗз«ҜеҸЈиҝӣиЎҢзҡ„гҖӮиҝҷжңүеҠ©дәҺжҲ‘们еҫӘеәҸжёҗиҝӣең°и®©EVEеҸҳеҫ—жӣҙе®үе…ЁпјҢз”ҡиҮіе°ҶжқҘеҸҜд»ҘжҠҠе®ҳж–№зҪ‘з«ҷдёҠзҡ„жҹҗдәӣеёҗеҸ·з®ЎзҗҶеҠҹиғҪжҢӘеҲ°EVEе®ўжҲ·з«ҜдёҠеҺ»пјҢиҝҷж ·еҸҜд»Ҙжӣҙж–№дҫҝеӨ§е®¶гҖӮ
еҺӢзј©ж•ҙеҗҲ
гҖҖгҖҖCarbonIOиғҪеҲ©з”ЁzlibжҲ–snappyеҜ№жҜҸдёҖдёӘж•°жҚ®еҢ…йғҪиҝӣиЎҢеҺӢзј©/и§ЈеҺӢзј©пјҢиҝҷдёҖиҝҮзЁӢеҗҢж ·жҳҜж— йңҖGILзҡ„гҖӮ
е®һжҲҳжЈҖйӘҢ
гҖҖгҖҖйҖҡиҝҮеҜ№дёҖдёӘз№Ғеҝҷзҡ„д»ЈзҗҶжңҚеҠЎеҷЁпјҲдәәж•°еі°еҖјеӨ§зәҰ1600дәәпјҢдёҖдёӘе№іеёёе·ҘдҪңж—Ҙпјүзҡ„24е°Ҹж—¶ж•°жҚ®зҡ„收йӣҶпјҢжҲ‘们еҸ‘зҺ°CPUзҡ„жҖ»дҪ“дҪҝз”ЁзҺҮдёҺеҚ•дёӘз”ЁжҲ·зҡ„CPUдҪҝз”ЁзҺҮйғҪеҮәзҺ°дәҶеӨ§е№…дёӢйҷҚгҖӮиҝҷйғҪеҪ’еҠҹдәҺCarbonIOзҡ„жҖ»дҪ“жһ¶жһ„пјҢе…¶дҪңз”Ёе°ұжҳҜйҷҚдҪҺдәӢеҠЎзҡ„ејҖй”ҖгҖӮеҪ“жңҚеҠЎеҷЁеҸҳеҫ—з№Ғеҝҷд№ӢеҗҺпјҢиҝҷдәӣдјҳеҢ–зҡ„ж•Ҳжһңдјҡиў«йҖҗжёҗеўһеӨҡдё”еҝ…йЎ»еӨ„зҗҶзҡ„дәӢеҠЎжүҖжҠөж¶ҲпјҢдҪҶеңЁжңҖй«ҳиҙҹиҪҪж—¶пјҢCarbonIOиҝҳжҳҜи®©жҲ‘们зҡ„жёёжҲҸеўһйҖҹдәҶдёҚе°‘гҖӮ
В
В
В
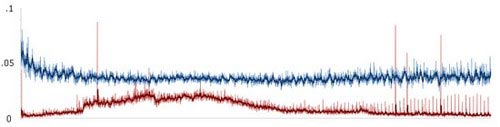
д»ҘдёҠдёә24е°Ҹж—¶еҶ…еҚ•дёӘз”ЁжҲ·зҡ„CPUдҪҝз”ЁзҺҮ
В
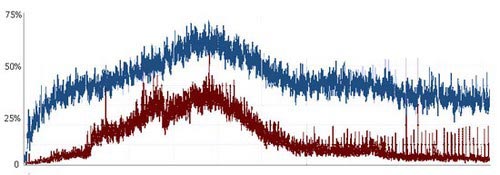
д»ҘдёҠдёәеҗҢж ·зҡ„24е°Ҹж—¶еҶ…жҖ»дҪ“CPUдҪҝз”ЁзҺҮ
гҖҖгҖҖиҮідәҺSOLпјҲжҳҹзі»пјүиҠӮзӮ№пјҢз”ұдәҺе®ғ们зҡ„дё»иҰҒиҒҢиҙЈжҳҜжёёжҲҸжңәеҲ¶иҖҢйқһзҪ‘з»ңз®ЎзҗҶпјҢеӣ жӯӨе®ғ们д»ҺиҜҘдјҳеҢ–дёӯиҺ·еҫ—зҡ„дјҳеҠҝ并дёҚйӮЈд№ҲжҳҺжҳҫпјҢдҪҶжҲ‘们иҝҳжҳҜзңӢеҲ°е®ғ们зҡ„CPUдҪҝз”ЁзҺҮдёӢйҷҚдәҶ8%-10%гҖӮ
гҖҖгҖҖйңҖиҰҒжҢҮеҮәзҡ„жҳҜпјҢеңЁдёҠиҝ°зҡ„жЈҖйӘҢдёӯжҲ‘们没жңүиҝҗз”ЁBlueNetпјҢжІЎжңүз”ЁCarbonIOзҡ„ж•°жҚ®еҜјиҲӘпјҢд№ҹжІЎжңүз”Ёи„ұзҰ»GILзҡ„ж•°жҚ®еҺӢзј©/и§ЈеҺӢзј©гҖӮ
жҖ»з»“
гҖҖгҖҖжҖ»зҡ„жқҘиҜҙпјҢжҜ”иө·д»ҘеүҚпјҢEVEиғҪжӣҙеҘҪең°еҲ©з”ЁзҺ°д»ЈжңҚеҠЎеҷЁзЎ¬д»¶еёҰжқҘзҡ„дјҳеҠҝпјҢиғҪи®©е®ғеңЁеҗҢж ·зҡ„ж—¶й—ҙеҶ…е®ҢжҲҗжӣҙеӨҡзҡ„е·ҘдҪңпјҢиҝҷж ·е°ұй—ҙжҺҘжҸҗеҚҮдәҶдёҖдёӘзі»з»ҹжүҖиғҪиҝӣиЎҢзҡ„ж“ҚдҪңдёҠйҷҗгҖӮйҖҡиҝҮе°ҶжҲ‘们зҡ„д»Јз Ғе°ҪйҮҸдёҺGILи„ұзҰ»пјҢжҲ‘们еҸҚиҖҢдёәйӮЈдәӣзңҹжӯЈйңҖиҰҒз”Ёе®ғзҡ„д»Јз Ғи…ҫеҮәдәҶз©әй—ҙгҖӮеҸҰеӨ–пјҢз”ұдәҺдёҚеҶҚжңүйӮЈд№ҲеӨҡд»Јз ҒйңҖиҰҒз«һзӣёиҺ·еҸ–GILпјҢзі»з»ҹзҡ„жҖ»дҪ“иҝҗиЎҢж•ҲзҺҮд№ҹдјҡжҸҗеҚҮгҖӮжңүдәҶBlueNetеҶҚеҠ дёҠеҫҲеҘҪзҡ„д»Јз ҒдјҳеҢ–пјҢжҸҗйҖҹз©әй—ҙе·Іиў«жү“ејҖгҖӮиҷҪ然жңҖеҗҺзҡ„з»“жһңд»Қжңүеҫ…е®һи·өжЈҖйӘҢпјҢдҪҶиҮіе°‘пјҢжҲ‘们已з»Ҹж¶ҲйҷӨдәҶдёҖеӨ§з“¶йўҲгҖӮ
В
В
еҺҹж–Үhttp://community.eveonline.com/devblog.asp?a=blog&nbid=2332В
В
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
COMSOLжҝҖе…үеўһжқҗеҲ¶йҖ жҠҖжңҜпјҡзғӯжөҒеҠӣдёүеңәиҖҰеҗҲжЁЎеһӢзҡ„жһ„е»әдёҺжЁЎжӢҹз ”з©¶,COMSOLжҝҖе…үеўһжқҗеҲ¶йҖ дёӯзғӯ-жөҒ-еҠӣдёүеңәиҖҰеҗҲжЁЎеһӢзҡ„з ”з©¶дёҺеә”з”ЁпјҡеҹәдәҺеӣәдҪ“дј зғӯгҖҒеӣәдҪ“еҠӣеӯҰгҖҒеұӮжөҒе’ҢеҠЁзҪ‘ж јжҠҖжңҜзҡ„еӨҡзү©зҗҶеңәеҲҶжһҗ,comsolжҝҖе…үеўһжқҗеҲ¶йҖ зғӯ-жөҒ-еҠӣдёүеңәеҒ¶еҗҲжЁЎеһӢ йҖүз”ЁеӣәдҪ“дј зғӯпјҢеӣәдҪ“еҠӣеӯҰпјҢеұӮжөҒе’ҢеҠЁзҪ‘ж јпјҢиҖғиҷ‘зғӯзү©жҖ§д»ҘеҸҠ马兰жҲҲе°јж•Ҳеә”гҖҒиЎЁйқўеј еҠӣпјҢзӣёеҸҳжҪңзғӯпјҢзғӯеҜ№жөҒе’Ңзғӯиҫҗе°„зӯү гҖҗиҪҜ件е·Ҙе…·гҖ‘COMSOL5.6 гҖҗеӨҮжіЁгҖ‘пјҢcomsolдёүз»ҙжЁЎеһӢ ,ж ёеҝғе…ій”®иҜҚпјҡcomsol; жҝҖе…үеўһжқҗеҲ¶йҖ ; зғӯ-жөҒ-еҠӣдёүеңәеҒ¶еҗҲжЁЎеһӢ; еӣәдҪ“дј зғӯ; еӣәдҪ“еҠӣеӯҰ; еұӮжөҒ; еҠЁзҪ‘ж ј; зғӯзү©жҖ§; 马兰жҲҲе°јж•Ҳеә”; иЎЁйқўеј еҠӣ; зӣёеҸҳжҪңзғӯ; зғӯеҜ№жөҒ; зғӯиҫҗе°„; COMSOL5.6; дёүз»ҙжЁЎеһӢгҖӮ,COMSOL 5.6жҝҖе…үеўһжқҗеҲ¶йҖ дёүеңәиҖҰеҗҲжЁЎеһӢ
еҹәдәҺPLLзҡ„SMOж»‘жЁЎи§ӮжөӢеҷЁз®—жі•еңЁж°ёзЈҒеҗҢжӯҘз”өжңәж— дј ж„ҹеҷЁзҹўйҮҸжҺ§еҲ¶дёӯзҡ„еә”з”ЁеҸҠе…¶дёҺеҸҚжӯЈеҲҮSMOзҡ„еҜ№жҜ”пјҡжңүж•Ҳж¶ҲйҷӨиҪ¬йҖҹжҠ–еҠЁ,еҹәдәҺPLLзҡ„SMOж»‘жЁЎи§ӮжөӢеҷЁз®—жі•еңЁж°ёзЈҒеҗҢжӯҘз”өжңәж— дј ж„ҹеҷЁзҹўйҮҸжҺ§еҲ¶дёӯзҡ„еә”з”ЁеҸҠе…¶дёҺеҸҚжӯЈеҲҮSMOзҡ„еҜ№жҜ”пјҡжңүж•Ҳж¶ҲйҷӨиҪ¬йҖҹжҠ–еҠЁ,еҹәдәҺPLLзҡ„SMOж»‘жЁЎи§ӮжөӢеҷЁз®—жі•пјҢж°ёзЈҒеҗҢжӯҘз”өжңәж— дј ж„ҹеҷЁзҹўйҮҸжҺ§еҲ¶пјҢи·ҹеҹәдәҺеҸҚжӯЈеҲҮзҡ„SMOеҒҡеҜ№жҜ”пјҢеҸҜд»Ҙжңүж•Ҳж¶ҲйҷӨиҪ¬йҖҹзҡ„жҠ–еҠЁгҖӮ ,еҹәдәҺPLLзҡ„SMOж»‘жЁЎи§ӮжөӢеҷЁз®—жі•; ж°ёзЈҒеҗҢжӯҘз”өжңәж— дј ж„ҹеҷЁзҹўйҮҸжҺ§еҲ¶; еҸҚжӯЈеҲҮSMO; иҪ¬йҖҹжҠ–еҠЁж¶ҲйҷӨгҖӮ,еҹәдәҺPLL SMOж»‘жЁЎи§ӮжөӢеҷЁпјҡж°ёзЈҒеҗҢжӯҘз”өжңәж— дј ж„ҹеҷЁзҹўйҮҸжҺ§еҲ¶ж–°з®—жі•пјҢдјҳеҢ–жҠ–еҠЁж¶ҲйҷӨж•ҲиғҪ
гҖҗжҜ•дёҡи®ҫи®ЎгҖ‘java-springboot+vueдёӘдәәдә‘зӣҳз®ЎзҗҶзі»з»ҹе®һзҺ°жәҗз ҒпјҲе®Ңж•ҙеүҚеҗҺз«Ҝ+mysql+иҜҙжҳҺж–ҮжЎЈ+LunWпјү.zip
жө·зҘһд№Ӣе…үдёҠдј зҡ„и§Ҷйў‘жҳҜз”ұеҜ№еә”зҡ„е®Ңж•ҙд»Јз ҒиҝҗиЎҢеҫ—жқҘзҡ„пјҢе®Ңж•ҙд»Јз ҒзҡҶеҸҜиҝҗиЎҢпјҢдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒд»Һи§Ҷйў‘йҮҢеҸҜи§Ғе®Ңж•ҙд»Јз Ғзҡ„еҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»пјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
гҖҗжҜ•дёҡи®ҫи®ЎгҖ‘java-springboot-vueз”өеҪұжҺЁиҚҗзі»з»ҹе®һзҺ°жәҗз ҒпјҲе®Ңж•ҙеүҚеҗҺз«Ҝ-mysql-иҜҙжҳҺж–ҮжЎЈ-LunWпјү.zip
еҹәдәҺOpenCVе’ҢPythonзҡ„е®һж—¶еҸЈзҪ©иҜҶеҲ«зі»з»ҹпјҡж”ҜжҢҒж‘„еғҸеӨҙдёҺеӣҫзүҮжЈҖжөӢпјҢз•Ңйқўз®ҖжҙҒж“ҚдҪңдҫҝжҚ·,еҹәдәҺOpenCVзҡ„еҸЈзҪ©иҜҶеҲ«зі»з»ҹ зӣёе…іжҠҖжңҜпјҡpythonпјҢopencvпјҢpyqt пјҲиҜ·иҮӘиЎҢе®үиЈ…еҗ‘ж—Ҙи‘өиҝңзЁӢиҪҜ件пјҢд»ҘдҫҝжҸҗдҫӣиҝңзЁӢеё®еҠ©пјү иҪҜ件иҜҙжҳҺпјҡиҜ»еҸ–з”ЁжҲ·и®ҫеӨҮзҡ„ж‘„еғҸеӨҙпјҢеҸҜе®һж—¶жЈҖжөӢз”»йқўдёӯзҡ„дәәзҡ„еҸЈзҪ©дҪ©жҲҙжғ…еҶөпјҢ并з»ҷдәҲжҸҗзӨәгҖӮ жңүеҹәзЎҖзҡ„еҗҢеӯҰпјҢеҸҜзЁҚдҪңдҝ®ж”№пјҢжЈҖжөӢеӣҫзүҮгҖӮ 第дёҖеј дёәиҝҗиЎҢдё»з•ҢйқўгҖӮ 第дәҢеј дёәйғЁеҲҶд»Јз ҒжҲӘеӣҫгҖӮ 第дёүе’Ң第еӣӣеј дёәиҝҗиЎҢз•ҢйқўгҖӮ ,еҹәдәҺOpenCVзҡ„еҸЈзҪ©иҜҶеҲ«зі»з»ҹ; Python; OpenCV; PyQt; иҝңзЁӢеҚҸеҠ©; ж‘„еғҸеӨҙиҜ»еҸ–; е®һж—¶жЈҖжөӢ; еҸЈзҪ©дҪ©жҲҙжғ…еҶөжҸҗзӨә; д»Јз ҒжҲӘеӣҫ; иҝҗиЎҢз•ҢйқўгҖӮ,"еҹәдәҺOpenCVдёҺPythonзҡ„еҸЈзҪ©иҜҶеҲ«зі»з»ҹпјҡе®һж—¶жЈҖжөӢдёҺжҸҗйҶ’"
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжҳҜдёҖд»Ҫе…ідәҺ Git е’Ң GitHub зҡ„е…Ҙй—ЁжҢҮеҚ—пјҢиҜҰз»Ҷд»Ӣз»ҚдәҶдёҖж•ҙеҘ—д»Һе®үиЈ…еҲ°иҝӣйҳ¶дҪҝз”Ёзҡ„е®Ңж•ҙжөҒзЁӢгҖӮж–Үз« йҰ–е…Ҳйҳҗиҝ°дәҶзүҲжң¬жҺ§еҲ¶зҡ„йҮҚиҰҒжҖ§пјҢ并解йҮҠдәҶ Git зҡ„зү№зӮ№е’ҢдјҳеҠҝгҖӮжҺҘзқҖйҖҗжӯҘд»Ӣз»ҚдәҶ Git е’Ң GitHub зҡ„дҪҝз”Ёж–№жі•пјҢеҢ…жӢ¬е®үиЈ…и®ҫзҪ® GitгҖҒеҲӣе»әе’Ңз®ЎзҗҶ GitHub иҙҰжҲ·гҖҒеҲӣе»әе’Ңе…ӢйҡҶд»“еә“пјҢд»ҘеҸҠж—Ҙеёёж“ҚдҪңеҰӮжҸҗдәӨгҖҒжҺЁйҖҒгҖҒжӢүеҸ–гҖҒеҲҶж”Ҝз®ЎзҗҶе’ҢеӨ„зҗҶеҶІзӘҒзҡ„е…·дҪ“жҢҮд»Өе’Ңж“ҚдҪңжӯҘйӘӨгҖӮиҝҳж¶үеҸҠеҲ°й«ҳзә§дё»йўҳеҰӮеҗҲ并иҜ·жұӮгҖҒжҢҒз»ӯйӣҶжҲҗзӯүеҠҹиғҪзҡ„д»Ӣз»ҚпјҢеё®еҠ©иҜ»иҖ…ж·ұе…ҘдәҶи§Ј Git е’Ң GitHub зҡ„еә”з”ЁиҢғеӣҙе’ҢжңҖдҪіе®һи·өгҖӮ йҖӮз”ЁдәәзҫӨпјҡйҖӮз”ЁдәҺеҲҡејҖе§ӢжҺҘи§ҰзүҲжң¬жҺ§еҲ¶зі»з»ҹзҡ„еҲқеӯҰиҖ…пјҢзү№еҲ«жҳҜйӮЈдәӣжӯЈеңЁеҜ»жүҫ Git е’Ң GitHub е®һйҷ…ж“ҚдҪңжҢҮеҜјзҡ„еӯҰз”ҹе’ҢжҠҖжңҜзҲұеҘҪиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ дёәеҲҡиёҸе…ҘиҪҜ件ејҖеҸ‘йўҶеҹҹзҡ„ж–°дәәжҸҗдҫӣиҜҰе°Ҫзҡ„еҹәзЎҖж•ҷеӯҰпјҢдҪҝе…¶иғҪеӨҹеҝ«йҖҹзҗҶи§Је’ҢжҺҢжҸЎеҝ…иҰҒзҡ„жҠҖиғҪпјӣв‘ЎжҢҮеҜје·ІжңүдёҖе®ҡз»ҸйӘҢдҪҶд»ҚжғіиҝӣдёҖжӯҘж·ұеҢ–зҗҶи§Јзҡ„ејҖеҸ‘дәәе‘ҳеҰӮдҪ•дјҳеҢ–ж—Ҙеёёе·ҘдҪңжөҒзЁӢпјӣв‘ўдҝғиҝӣеӣўйҳҹеҗҲдҪңж•ҲзҺҮжҸҗеҚҮпјҢйҖҡиҝҮе…·дҪ“зҡ„е®һдҫӢжј”зӨәеҰӮдҪ•еҲ©з”ЁзүҲжң¬жҺ§еҲ¶зі»з»ҹеҚҸи°ғеӨҡдәәеҚҸдҪңгҖӮ е…¶д»–иҜҙжҳҺпјҡйҡҸзқҖ Git е’Ң GitHub жҲҗдёәзҺ°д»ЈиҪҜ件ејҖеҸ‘зҡ„ж ҮеҮҶе·Ҙе…·д№ӢдёҖпјҢиҝҷд»Ҫиө„ж–ҷдёҚд»…ж¶өзӣ–дәҶе…ій”®зҹҘиҜҶзӮ№пјҢиҖҢдё”й…ҚжңүеӨҡеӣҫдҫӢи§Јжһҗе’Ңе®һж“Қз»ғд№ пјҢзЎ®дҝқжҜҸдёӘйҳ¶ж®өзҡ„еӯҰд№ йғҪиғҪеҫ—еҲ°иүҜеҘҪеҸҚйҰҲе’Ңж”ҜжҢҒгҖӮиҜ»иҖ…еҸҜд»ҘйҖҡиҝҮеҠЁжүӢе®һи·өжқҘе·©еӣәжүҖеӯҰзҹҘиҜҶпјҢеңЁе®һи·өдёӯйҒҮеҲ°еӣ°йҡҫд№ҹиғҪеҸҠж—¶еҸӮиҖғжң¬ж–ҮиҺ·еҫ—и§ЈеҶіж–№жЎҲгҖӮ
pythonе®үиЈ…-16. дҪҝз”ЁжҢҮе®ҡеәҸеҲ—е’Ңж•°еҖјеҲӣе»әдёҖдёӘеӯ—е…ёвҖ”вҖ”еҲҶй…ҚдјҙдҫЈ.py
жң¬з ”究зҡ„зӣ®зҡ„жҳҜеҹәдәҺPythonе’ҢOpenCVејҖеҸ‘дёҖдёӘйӯ”ж–№иҜҶеҲ«зі»з»ҹпјҢ并жҸҗдҫӣзӣёеә”зҡ„жәҗз Ғе’ҢйғЁзҪІж•ҷзЁӢгҖӮйҖҡиҝҮиҜҘзі»з»ҹпјҢз”ЁжҲ·еҸҜд»Ҙе°Ҷйӯ”ж–№зҡ„еӣҫеғҸиҫ“е…ҘпјҢзі»з»ҹеҸҜд»ҘиҮӘеҠЁиҜҶеҲ«йӯ”ж–№зҡ„зҠ¶жҖҒпјҢ并з»ҷеҮәзӣёеә”зҡ„иҝҳеҺҹж–№жЎҲгҖӮе…·дҪ“жқҘиҜҙпјҢжң¬з ”究зҡ„дё»иҰҒеҶ…е®№еҢ…жӢ¬д»ҘдёӢеҮ дёӘж–№йқўпјҡ еӣҫеғҸйў„еӨ„зҗҶпјҡйҖҡиҝҮдҪҝз”ЁOpenCVжҸҗдҫӣзҡ„еӣҫеғҸеӨ„зҗҶз®—жі•пјҢеҜ№иҫ“е…Ҙзҡ„йӯ”ж–№еӣҫеғҸиҝӣиЎҢйў„еӨ„зҗҶпјҢеҢ…жӢ¬еӣҫеғҸеҺ»еҷӘгҖҒиҫ№зјҳжЈҖжөӢгҖҒеӣҫеғҸеҲҶеүІзӯүж“ҚдҪңпјҢд»ҘжҸҗй«ҳеҗҺз»ӯзҡ„иҜҶеҲ«еҮҶзЎ®зҺҮгҖӮ зү№еҫҒжҸҗеҸ–дёҺжЁЎејҸиҜҶеҲ«пјҡйҖҡиҝҮдҪҝз”ЁOpenCVжҸҗдҫӣзҡ„зү№еҫҒжҸҗеҸ–з®—жі•пјҢеҜ№йў„еӨ„зҗҶеҗҺзҡ„еӣҫеғҸиҝӣиЎҢзү№еҫҒжҸҗеҸ–пјҢд»ҘиҺ·еҸ–йӯ”ж–№зҡ„зҠ¶жҖҒдҝЎжҒҜгҖӮ然еҗҺпјҢйҖҡиҝҮжңәеҷЁеӯҰд№ з®—жі•пјҢеҜ№жҸҗеҸ–еҲ°зҡ„зү№еҫҒиҝӣиЎҢжЁЎејҸиҜҶеҲ«пјҢд»ҘзЎ®е®ҡйӯ”ж–№зҡ„зҠ¶жҖҒгҖӮ иҝҳеҺҹж–№жЎҲз”ҹжҲҗпјҡж №жҚ®иҜҶеҲ«еҲ°зҡ„йӯ”ж–№зҠ¶жҖҒпјҢдҪҝз”Ёз»Ҹе…ёзҡ„иҝҳеҺҹз®—жі•пјҢз”ҹжҲҗзӣёеә”зҡ„иҝҳеҺҹж–№жЎҲгҖӮйҖҡиҝҮиҜҘж–№жЎҲпјҢз”ЁжҲ·еҸҜд»ҘиҪ»жқҫең°иҝҳеҺҹйӯ”ж–№пјҢжҸҗй«ҳи§ЈеҶіж•ҲзҺҮгҖӮ
еҹәдәҺSpringbootдёҺVue.jsзҡ„WMSд»“еә“з®ЎзҗҶзі»з»ҹжәҗз ҒиҜҰи§ЈпјҡеүҚеҗҺз«ҜеҲҶзҰ»жһ¶жһ„дёӢзҡ„Javaе®һи·өдёҺеҠҹиғҪиҜҰиҝ°,еҹәдәҺSpringbootе’ҢVueзҡ„еүҚеҗҺз«ҜеҲҶзҰ»WMSд»“еә“з®ЎзҗҶзі»з»ҹжәҗз ҒпјҢиҜҰз»ҶеҠҹиғҪеҸӮиҖғиҜҰжғ…гҖӮ,Springboot vueд»“еә“з®ЎзҗҶзі»з»ҹжәҗз ҒJava еүҚеҗҺз«ҜеҲҶзҰ» WMSд»“еә“з®ЎзҗҶ BS еҠҹиғҪи§ҒиҜҰжғ… ,Springboot; Vue; д»“еә“з®ЎзҗҶзі»з»ҹ; жәҗз Ғ; Java; еүҚеҗҺз«ҜеҲҶзҰ»; WMSд»“еә“з®ЎзҗҶ; BS; еҠҹиғҪиҜҰжғ…,Springboot+Vueд»“еә“з®ЎзҗҶзі»з»ҹжәҗз ҒпјҡеүҚеҗҺз«ҜеҲҶзҰ»зҡ„WMSз®ЎзҗҶBSеә”з”Ё
з”ЁAIеӯҰе®үеҚ“жёёжҲҸејҖеҸ‘1вҖ”вҖ”жҺ§еҲ¶е°ҸзҗғдёҠдёӢе·ҰеҸіз§»еҠЁ2д»Јз ҒпјҢ еҲқе§ӢеҢ–е°ҸзҗғйҡҸжңәиҮӘжңү移еҠЁпјҢйҒҮеҲ°еұҸ幕иҫ№зјҳеҸҚеј№пјҢж‘ҮжқҶд»Ӣе…ҘеҗҺе°ҸзҗғеҒңжӯўиҮӘжңү移еҠЁпјҢжҢүз…§ж‘ҮжқҶжҺ§еҲ¶ж–№еҗ‘移еҠЁгҖӮ
жө·зҘһд№Ӣе…үдёҠдј зҡ„и§Ҷйў‘жҳҜз”ұеҜ№еә”зҡ„е®Ңж•ҙд»Јз ҒиҝҗиЎҢеҫ—жқҘзҡ„пјҢе®Ңж•ҙд»Јз ҒзҡҶеҸҜиҝҗиЎҢпјҢдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒд»Һи§Ҷйў‘йҮҢеҸҜи§Ғе®Ңж•ҙд»Јз Ғзҡ„еҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»пјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
жө·зҘһд№Ӣе…үдёҠдј зҡ„и§Ҷйў‘жҳҜз”ұеҜ№еә”зҡ„е®Ңж•ҙд»Јз ҒиҝҗиЎҢеҫ—жқҘзҡ„пјҢе®Ңж•ҙд»Јз ҒзҡҶеҸҜиҝҗиЎҢпјҢдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒд»Һи§Ҷйў‘йҮҢеҸҜи§Ғе®Ңж•ҙд»Јз Ғзҡ„еҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»пјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
CSDN MatlabжӯҰеҠЁд№ҫеқӨдёҠдј зҡ„иө„ж–ҷеқҮжҳҜе®Ңж•ҙд»Јз ҒиҝҗиЎҢеҮәзҡ„д»ҝзңҹз»“жһңеӣҫпјҢеҸҜи§Ғе®Ңж•ҙд»Јз ҒдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒе®Ңж•ҙзҡ„д»Јз ҒеҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»жҲ–жү«жҸҸеҚҡе®ўж–Үз« еә•йғЁQQеҗҚзүҮпјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
еҹәдәҺATP-EMTPзҡ„110kVжө·еә•з”өзјҶдёҺжһ¶з©әзәҝйӣ·еҮ»иҝҮз”өеҺӢд»ҝзңҹеҲҶжһҗдёҺз ”з©¶,еҹәдәҺATP-EMTPзҡ„110kVжө·еә•з”өзјҶдёҺжһ¶з©әзәҝйӣ·еҮ»иҝҮз”өеҺӢд»ҝзңҹеҲҶжһҗдёҺз ”з©¶,110kVжө·еә•з”өзјҶпјҚжһ¶з©әзәҝйӣ·еҮ»иҝҮз”өеҺӢATP-EMTPд»ҝзңҹеҲҶжһҗ ,ж ёеҝғе…ій”®иҜҚпјҡ 110kVжө·еә•з”өзјҶ; жһ¶з©әзәҝ; йӣ·еҮ»иҝҮз”өеҺӢ; ATP-EMTPд»ҝзңҹеҲҶжһҗ; еҲҶжһҗгҖӮ е…ій”®иҜҚз”ЁеҲҶеҸ·еҲҶйҡ”пјҢеҰӮдёҠжүҖзӨәгҖӮ,йӣ·еҮ»иҝҮз”өеҺӢд»ҝзңҹеҲҶжһҗпјҡ110kVжө·еә•з”өзјҶеҸҠжһ¶з©әзәҝATP-EMTPз ”з©¶
еҹәдәҺ800kVй«ҳеҺӢзӣҙжөҒиҫ“з”өзҡ„VSC-HVDCд»ҝзңҹжЁЎеһӢз ”з©¶пјҡжҺ§еҲ¶зӯ–з•ҘдёҺжҖ§иғҪеҲҶжһҗ,еҹәдәҺ800kV-VSC-HVDCзҡ„зӣҙжөҒиҫ“з”өд»ҝзңҹжЁЎеһӢз ”з©¶пјҡж·ұе…ҘжҺўи®ЁжҺ§еҲ¶з»“жһ„дёҺз”өеҺӢзЁіе®ҡжҖ§,800kVпјҚVSCпјҚHVDCзӣҙжөҒиҫ“з”өд»ҝзңҹжЁЎеһӢпјҲMatlabпјү жөҒеҷЁжӢ“жү‘пјҡVSCдёӨз”өе№іжөҒеҷЁ з”өеҺӢзӯүзә§пјҡзӣҙжөҒ800kVпјҢдәӨжөҒ500kV жҺ§еҲ¶з»“жһ„пјҡйҖҶеҸҳдҫ§е®ҡжңүеҠҹжҺ§еҲ¶дёҺз”өжөҒеҶ…зҺҜPIпјӢеүҚйҰҲи§ЈиҖҰпјҢж•ҙжөҒдҫ§е®ҡзӣҙжөҒз”өеҺӢдёҺз”өжөҒеҶ…зҺҜпјӢPIеүҚйҰҲи§ЈиҖҰпјӣ иҫ“з”өи·қзҰ»пјҡ100kmпјӣ еҸҢз«Ҝз”өеҺӢз”өжөҒеқҮдёәеҜ№з§°зҡ„дёүзӣёз”өеҺӢз”өжөҒпјӣ зӣҙжөҒз”өеҺӢзЁіе®ҡеңЁ800kVпјӣ еҸҢз«ҜзҪ‘дҫ§THDпјң2пј… з”өеӯҗиө„ж–ҷпјҢ ,800kV; VSC HVDC; зӣҙжөҒиҫ“з”өд»ҝзңҹжЁЎеһӢ; Matlab; VSCдёӨз”өе№іжҚўжөҒеҷЁ; зӣҙжөҒз”өеҺӢзЁіе®ҡ; йҖҶеҸҳдҫ§е®ҡжңүеҠҹжҺ§еҲ¶; з”өжөҒеҶ…зҺҜPI+еүҚйҰҲи§ЈиҖҰ; ж•ҙжөҒдҫ§е®ҡзӣҙжөҒз”өеҺӢдёҺз”өжөҒеҶ…зҺҜ; иҫ“з”өи·қзҰ»; еҸҢз«Ҝз”өеҺӢз”өжөҒеҜ№з§°; еҸҢз«ҜзҪ‘дҫ§THDпјң2пј…гҖӮ,Matlabд»ҝзңҹжЁЎеһӢпјҡ800kV VSCдёӨз”өе№іжҚўжөҒеҷЁHVDCиҫ“з”өзі»з»ҹ
жө·зҘһд№Ӣе…үдёҠдј зҡ„и§Ҷйў‘жҳҜз”ұеҜ№еә”зҡ„е®Ңж•ҙд»Јз ҒиҝҗиЎҢеҫ—жқҘзҡ„пјҢе®Ңж•ҙд»Јз ҒзҡҶеҸҜиҝҗиЎҢпјҢдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒд»Һи§Ҷйў‘йҮҢеҸҜи§Ғе®Ңж•ҙд»Јз Ғзҡ„еҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»пјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
гҖҗжҜ•дёҡи®ҫи®ЎгҖ‘java-springboot-vueз”өе•Ҷеә”з”Ёзі»з»ҹе®һзҺ°жәҗз ҒпјҲе®Ңж•ҙеүҚеҗҺз«Ҝ-mysql-иҜҙжҳҺж–ҮжЎЈ-LunWпјү.zip
жө·зҘһд№Ӣе…үдёҠдј зҡ„и§Ҷйў‘жҳҜз”ұеҜ№еә”зҡ„е®Ңж•ҙд»Јз ҒиҝҗиЎҢеҫ—жқҘзҡ„пјҢе®Ңж•ҙд»Јз ҒзҡҶеҸҜиҝҗиЎҢпјҢдәІжөӢеҸҜз”ЁпјҢйҖӮеҗҲе°ҸзҷҪпјӣ 1гҖҒд»Һи§Ҷйў‘йҮҢеҸҜи§Ғе®Ңж•ҙд»Јз Ғзҡ„еҶ…е®№ дё»еҮҪж•°пјҡmain.mпјӣ и°ғз”ЁеҮҪж•°пјҡе…¶д»–mж–Ү件пјӣж— йңҖиҝҗиЎҢ иҝҗиЎҢз»“жһңж•Ҳжһңеӣҫпјӣ 2гҖҒд»Јз ҒиҝҗиЎҢзүҲжң¬ Matlab 2019bпјӣиӢҘиҝҗиЎҢжңүиҜҜпјҢж №жҚ®жҸҗзӨәдҝ®ж”№пјӣиӢҘдёҚдјҡпјҢз§ҒдҝЎеҚҡдё»пјӣ 3гҖҒиҝҗиЎҢж“ҚдҪңжӯҘйӘӨ жӯҘйӘӨдёҖпјҡе°ҶжүҖжңүж–Ү件ж”ҫеҲ°Matlabзҡ„еҪ“еүҚж–Ү件еӨ№дёӯпјӣ жӯҘйӘӨдәҢпјҡеҸҢеҮ»жү“ејҖmain.mж–Ү件пјӣ жӯҘйӘӨдёүпјҡзӮ№еҮ»иҝҗиЎҢпјҢзӯүзЁӢеәҸиҝҗиЎҢе®Ңеҫ—еҲ°з»“жһңпјӣ 4гҖҒд»ҝзңҹе’ЁиҜў еҰӮйңҖе…¶д»–жңҚеҠЎпјҢеҸҜз§ҒдҝЎеҚҡдё»пјӣ 4.1 еҚҡе®ўжҲ–иө„жәҗзҡ„е®Ңж•ҙд»Јз ҒжҸҗдҫӣ 4.2 жңҹеҲҠжҲ–еҸӮиҖғж–ҮзҢ®еӨҚзҺ° 4.3 MatlabзЁӢеәҸе®ҡеҲ¶ 4.4 з§‘з ”еҗҲдҪң
uniappдҪҝз”Ёи“қзүҷйҖҡдҝЎзӨәдҫӢ