
KMP算法:
是在一个“主文本字符串” S 内查找一个“词” W
的出现,通过观察发现,在不匹配发生的时候这个词自身包含足够的信息来确定下一个匹配将在哪里开始,以此避免对以前匹配过的字符重新检查。
常规的比较方法: KMP方法:
被查找串:a b c a b c a b d a b b 被查找串:a b c a b c a b d a b b
模式串:a b c a b d 模式串:a b c a b d
|| ||
(下一次匹配) || (下一次匹配) ||
被查找串:a b c a b c a b d a b b 被查找串:a b c a b c a b d a b b
模式串: a b c a b d 模式串: a b c a b d
KMP字符串模式匹配通俗点就是在一个字符串中定位另一个串的高效算法。简单匹配算法事件的复杂度为O(m*n),KMP匹配算法的时间复杂度为O(m+n)。
对于上例(字符串从0计数),在模式串中T[5]=d,主串中S[5]=c:发生不匹配。而next[5]=2.所以下一次就是比较S[5]和T[2]。所以KMP的关键是求串的模式函数值next[n]。
共有两种方法来定义next函数值,并且对应这两种next值有两种方式的移动模式串的方式,但是产生的效果是相同的。
第一种方法:
定义:
(1).next[0]=-1.
(2).next[j]=-1: 模式串T中下标为j的字符如果与首字符相同,且j前面的1---k个字符与1--k个字符不等
(或者相等但是T[k]=T[j])(1=<k<j) 如:T="abcabcad",next[6]=-1.
(3).next[j]=k: 模式串中下标为j的字符,j前面的k的字符与开头的k的字符相等,并且T[j]!=T[k]。
(有点感觉像最长的字符串前缀=字符串后缀的)(1=<k<j)
(4).next[j]=0: 除了(1)(2)(3)的三种情况。
举例:
| 下标 | 0 | 1 | 2 | 3 | 4 |
| T | a | b | c | a | c |
| next | -1 | 0 | 0 | -1 | 1 |
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| T | a | b | a | b | c | a | a | b | c |
| next | -1 | 0 | -1 | 0 | 2 | -1 | 1 | 0 | 2 |
另解图表:
2:说明前面有个长度为2的对称子串
0:说明前面有一个长度为1的对称子串,但是T[j]=t[1]
-1:说明前面没有对称子串
此处的对称是指最两端的对称块
代码:
void get_nextval(const char* T,int next[])
{
int j=0,k=-1;
next[0]=-1;
while(T[j]!='/0')
{
if(k==-1||T[j]==T[K])
{
++j;++k;
if(T[j]!=T[k])
next[j]=k;
else
next[j]=next[k];//A
}
else
k=next[k];
}
程序分析:k=-1说明将要从头开始进行匹配。k记录着已经匹配成功的字符的个数,其实就是从开头开始已经匹配到第几个字符了。当第一次进行匹配时,进入if条件句。++k表示第一个字符,++i表示要匹配的第一个字符。如果不相等,将此刻k的值赋值给nexti。如果相等,就要看nextk的值,并把nextk的值赋给nexti。其实就是看nextk里面有没有对称的字符。
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| T | a | t | a | m | a | t | a | m | t |
| next | -1 | 0 | -1 | 1 | -1 | -1 | -1 | 1 | 4 |
k是记录到目前为止已经有几个匹配成功的字符。
j是记录当前的字符
next[j]是记录当前字符的模式函数值
next[k]是记录已经匹配成功的字符里面有没有对称的子串。例如next[3]说明已经匹配成功的ata里面有1个对称子串。
当j=7时可以看到k=3.而此时T[7]=T[3].故按照规矩2,next[7]=-1.但是我们看到此时,next[k]也就是
next[3]=1说明有一个对称子串在里面,就是T[2]=T[0].而此时根据对称关系k=3的这个字符的前一个字符
(T[2])是与j=7的前一个字符相等的,也就是能得到T[0]是与j=7的前一个字符相等的。并且T[7]与T[2]也间接
比较了,因为T[7]=T[k],而nextk=1,也就是说T[k]!=T[1]的,所以T[7]!=T[1].所以在这个条件下我们就
得到next[7]=next[3]=1.
又例如j=6时,可以看到k=2,而此时T[6]=T[2].按照规矩2,next[6]=-1.并且此时next[k]也就是next[2]=
-1.所以next[6]=next[2]=-1.
又例如next[3]=1,此时j=3,k=1;T[3]!=T[1].k=next[k]=next[1]=0.说明没有子串,否则就会从有子串
的k开始进行下次匹配,也就是第k+1个字符开始匹配。当j=8时,k=4;next[8]=4.因为T[8!]=T[4],所以将
k=next[k]=next[4]=-1.说明没有子串,我们需要从头开始匹配。如果next[4]=1.即说明T[3]=T[0],又有
T[7]=T[3].我们得到T[7]=T[0].然后我们将比较T[1]和T[9]就可以了。但是此时next[4]=-1,我们需要比较
T[0]和T[9].
使用next[j]:
在字符串S中查找模式串T,若S[m]!=T[n],那么:
(1).next[n]=-1表示S[m]和T[0]已经间接比较过了(我们可以看到所有为-1的nextj都是与第一个字符相同,
如果S[m]!=T[n],则S[m]!=T[0]),下一次比较S[m+1]和T[0].
(2).next[n]=0表示比较过程中产生了不相等,下一次比较S[m]和T[0].
(3).next[n]=k>0但<n,表示S[m]的前k个字符与T中开始的前k个字符已经间接比较相等了,下一次比较S[m]和
T[k].S[m]和T[n]不相等,说明m前面的字符和n前面的字符是相等的,由于
next[n]=k,说明n前面的k个字符和最前面的k个字符是相等的。所以m前面的k个
字符等于n最前面的k个字符。字符是从0开始计数的,所以此时我们比较S[m]
和T[k]就可以了。
完整代码使用:
其他资源:http://blog.csdn.net/oneil_sally/article/details/3440784
http://blog.csdn.net/sparkliang/article/details/5284579
http://www.zhiwenweb.cn/Category/Security/1267.htm
方法二就是数组前缀法:其实本质上是相同的就是next函数的求法不同以及使用起来也不同
| 位置i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 子串 | a | g | c | t | a | g | c | a | g | c | t | a | g | c | t | g |
| 前缀next | 0 | 0 | 0 | 0 | 1 | 2 | 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 4 | 0 |
表格解释:包含当前字符的字符串的前缀和后缀的最长对称子串。这里的对称是指块对称就是:abcab,前后两个ab是
对称的,我们思路就是得出前缀next的值,也就是对称的大小以及如何使用next值来进行kmp优化。
还有一个难点就是在13 字符和14 字符的前缀变化是如何得来的。说白了就是第一种方法中的子串的原因。
规则:
(1).当前面字符的前一个字符的对称程度为0的时候,只要将当前字符与子串第一个字符进行比较。
(2).如果前面一个字符的next值是1,那么我们就把当前字符与子串第二个字符进行比较,因为前面的是1,说明前面的字 符已经和第一个相等了,如果这个又与第二个相等了,说明对称程度就是2了。
(3).按照上面的推理,如果一直相等,就一直累加.如果遇到下一个不相等了,那么说明不能继承前面的对称性了,这种情况 只能说明没有那么多对称了,但是不能说明一点对称性都没有,所以遇到这种情况就要重新来考虑,这个也是难点所 在。
不相等后的情况分析:
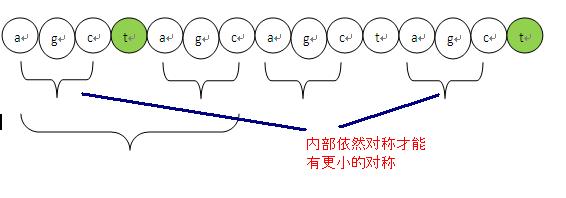
位置i=0到14如下,我加的括号只是用来说明问题:
(a g c t a g c )( a g c t a g c) t
我们可以看到这段,最后这个t之前的对称程度分别是:1,2,3,4,5,6,7,倒数第二个c往前看有7个字符对 称,所以对称为7。但是到最后这个t就没有继承前面的对称程度next值,所以这个t的对称性就要重新来求。
这里首要要申明几个事实:
1、t 如果要存在对称性,那么对称程度肯定比前面这个c 的对称程度小,所以要找个更小的对称,这个不用解释 了吧,如果大那么t就继承前面的对称性了。
2、要找更小的对称,必然在对称内部还存在子对称,而且这个t必须紧接着在子对称之后。
如下图说明:
从上面的理论我们就能得到下面的前缀next数组的求解算法:
void SetPrefix(const char *Pattern, int prefix[])
{
int len=CharLen(Pattern);//模式字符串长度。
prefix[0]=0;
for(int i=1; i<len; i++)
{
int k=prefix[i-1];
//不断递归判断是否存在子对称,k=0说明不再有子对称,Pattern[i] != Pattern[k]说明虽然 对称,但是对称后面的值和当前的字符值不相等,所以继续递推
while( Pattern[i] != Pattern[k] && k!=0 )
k=prefix[k-1];
//继续递归,其实就是看前面有没有更小的对称
if( Pattern[i] == Pattern[k])
//找到了这个子对称,或者是直接继承了前面的对称性,这两种都在前面的基础上++
prefix[i]=k+1;
else
prefix[i]=0;
//如果遍历了所有子对称都无效,说明这个新字符不具有对称性,清0
}
}
k表示已经存在的对称子串的长度。如k=p[13]=7,说明在进行字符14的处理时前面已经有2个长度为7的对称子串,开始比对P[14]和P[7],由于从0开始计数,P[7]就代表字符串的第八个字符。此时不相等,我们令k=p[6].
p[6]是第7个字符,与p[14]的前一个字符是相等的,因为有对称关系,并且p[0...6]=p[7....13]。现在我们看p[6]的值就是想看钱7个字符有没有对称的子串。我们发现p[6]=3,所以p[012]=p[456]=p[789]=p[11,12,13]
此时,k=p[6]=3,说明存在紧贴着字符14的子对称,也说明这个子对称的长度为3。有p[012]=p[11,12,13]。说明再进行对称匹配时,最开始的3个字符和字符14之前的3个字符已经相等,此时我们只需要比较字符14和第四个字符也就是字符3即可。
如果字符串变成:agctagcd agctagcd t 最后一个t没找到对称,则下一次匹配由于没有对称子串,将会从头开始
得到next后的使用也就是完整代码:
int KMP(const char *Text,const char* Pattern){if( !Text||!Pattern|| Pattern[0]=='/0' || Text[0]=='/0' )//return -1;//空指针或空串,返回-1。int len=0;const char * c=Pattern;while(*c++!='/0')//移动指针比移动下标快。{++len;//字符串长度。}int *next=new int[len+1];SetPrefix(Pattern,next);//求Pattern的next函数值int j=0;for(int i=0;i<n;){while(j>0&&(B[j]!=A[i]))j=p[j-1];//第i个字符前j个字符与最开始的前j个字符相等。故i和第j+1个字符开始比较,也就是字符j,因为计数是从零开始if(A[j]==B[i])j+=1;if(j==len-1)对齐,对齐点是字符i-len,也就是第i-m+1个字符;}delete []next;if(Pattern[j]=='/0')return index;// 匹配成功elsereturn -1;}资源:http://blog.csdn.net/yearn520/article/details/6729426
http://www.matrix67.com/blog/archives/115/
在理解了第一种方法之后,我们发现第二种方法的实质是与第一种相同的但是第二种方法感觉上要直观很多,好理解很多。



发表评论

-
析构函数为虚函数的原因
2012-09-09 11:42 858我们知道,用C++开发的时候,用来做基类的类的析构函数 ... -
hash的应用
2012-08-31 23:02 975第一部分为一道百度面试题Top K算法的详解;第二部分为关 ... -
微软智力题
2012-08-29 19:59 580第一组1.烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有 ... -
C++不能被继承的类
2012-08-27 20:16 1073一个类不能被继承,� ... -
括号对齐问题
2012-08-27 10:47 1431解法一:左右括号成一对则抵消 可以 ... -
树的遍历
2012-08-19 10:43 742/****************************** ... -
堆排序
2012-08-16 14:24 901堆:(二叉)堆数据结构是一种数组对象。它可以被视为一棵完全 ... -
多态赋值
2012-08-14 16:16 846#include <iostream> usi ... -
static变量与static函数(转)
2012-08-13 10:15 759一、 static 变量 static变量大致分为三种用法 ... -
不用sizeof判断16位32位
2012-08-10 15:21 1721用C++写个程序,如何判断一个操作系统是16位还是3 ... -
找出连续最长的数字串(百度面试)
2012-08-09 15:15 1167int maxContinuNum(const char*in ... -
顺序栈和链栈
2012-08-06 10:01 823顺序栈:话不多说直接上代码 #include ... -
队列的数组实现和链表实现
2012-08-05 16:20 1042话不多少,数组实现上代码: #include<i ... -
字符串的最长连续重复子串
2012-08-01 15:05 9804两种方法: 循环两次寻找最长的子串: <方法一> ... -
寻找一个字符串连续出现最多的子串的方法(转)
2012-07-31 21:19 1026算法描述首先获得后缀数组,然后1.第一行第一个字符a,与第二行 ... -
字符串的循环移位
2012-07-31 16:52 997假设字符串:abcdefg 左循环两位:cdefgab 右 ... -
一次谷歌面试趣事(转)
2012-07-31 15:26 789很多年前我进入硅谷� ... -
约瑟夫环问题(循环链表)
2012-07-30 21:31 1313题目描述:n只猴子要选大王,选举方法如下:所有猴子按 1, ... -
面试之单链表
2012-07-30 20:18 7411、编程实现一个单链表的建立/测长/打印。 ... -
多重继承内存地址问题
2012-07-30 15:55 735[cpp] view plaincopy ...
相关推荐
KMP 算法详解 KMP 算法是字符串模式匹配的一种高效算法,解决了字符串中模式匹配的问题。该算法可以在 O(m+n) 的时间复杂度内完成字符串模式匹配。 简单匹配算法 简单匹配算法的思想是直截了当的,将主串 S 中...
KMP算法详解 KMP算法详解 KMP算法详解
### KMP算法详解 #### 一、KMP算法概述 KMP算法,全称为Knuth-Morris-Pratt算法,是一种高效的字符串匹配算法,由Donald Knuth、James H. Morris和Vaughan Pratt三位计算机科学家共同提出。该算法主要用于解决在主...
"kmp算法详解" KMP 字符串模式匹配算法是高效的字符串匹配算法,时间复杂度为 O(m+n),其中 m 和 n 分别是主串和模式串的长度。KMP 算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。 KMP 算法的...
### KMP算法详解:原理与应用 #### 引言 KMP算法,全称为Knuth-Morris-Pratt算法,是一种高效的字符串匹配算法,由Donald E. Knuth、James H. Morris以及Vaughan Pratt三位计算机科学家共同提出。相较于传统的模式...
### 模式匹配的KMP算法详解 #### 一、KMP算法背景及传统模式匹配算法 KMP算法,即Knuth-Morris-Pratt算法,是由Donald E. Knuth、James H. Morris和Vaughan R. Pratt三位计算机科学家在1977年共同提出的一种高效的...
严蔚敏数据结构kmp算法详解PPT学习教案.pptx 本资源摘要信息将对严蔚敏数据结构kmp算法的学习教案进行详细的讲解和分析。KMP算法是字符串匹配算法中的一种重要算法,它可以高效地进行字符串匹配。 首先,我们需要...
【KMP算法详解】 KMP(Knuth-Morris-Pratt)算法是一种高效地进行字符串模式匹配的算法,由D.E.Knuth、J.H.Morris和V.R.Pratt三位学者独立提出。它解决了在主串(S)中查找模式串(T)出现的位置问题,避免了在匹配...
### 字符串模式匹配KMP算法详解 #### 一、引言 在计算机科学领域,字符串模式匹配是一项基本且重要的任务。它涉及到在一个较大的文本字符串(通常称为“主串”或“目标串”)中寻找一个较小的字符串(称为“模式串...
严蔚敏-数据结构-kmp算法详解.ppt该文档详细且完整,值得借鉴下载使用,欢迎下载使用,有问题可以第一时间联系作者~
《KMP算法详解》 KMP(Knuth-Morris-Pratt)算法是一种在字符串中查找子串出现位置的高效算法,由Donald Knuth、James H. Morris和 Vaughan Pratt共同提出。该算法避免了在匹配过程中对已匹配部分的重新比较,显著...
"KMP算法详解" 一、KMP字符串模式匹配算法 KMP字符串模式匹配算法是一种高效的字符串模式匹配算法,能够在一个字符串中快速地定位另一个字符串。该算法的时间复杂度为O(m+n),远远优于简单匹配算法的时间复杂度O(m...
KMP算法详解.mhtml
KMP、Mancher和扩展KMP算法详解,但是其中的参考代码有一点小错误,请自行参考网络
相比于简单的暴力匹配算法,KMP算法显著提高了性能,避免了不必要的字符回溯。它的核心在于构造一个模式函数next,也称为部分匹配表,用于存储模式串中每个位置的最长前缀和后缀的公共长度。 简单匹配算法,也称为...
本文介绍了KMP算法的原理和基本实现方法,附带算法模板的代码和详解。如想了解更多内容,欢迎关注微信公众号:信息学竞赛从入门到巅峰。
KMP算法的核心在于构建一个称为“部分匹配表”或“next数组”,用于存储模式串中每个位置的前缀和后缀的最大公共长度。 在构建next数组的过程中,我们需要遵循以下两个条件: 1. 当比较到某个位置时,如果模式串的...