1.TF-IDF:
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数(TF)成正比增加,但是同时会随着它在语料库中出现的频率(IDF)成反比下降。
TFIDF的主要思想:如果某个词或者短语在一篇文章中出现的频率TF高,并且在其他的文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF:词条在文档d中出现的频率。IDF:包含某词条的文档越少,IDF越大,说明此词条具有很好的区分能力。略显矛盾之处:如果一个词条在一个类的文档中频繁出现说明该词条能够很好代表这个类的文本特征,应该给这样的词条赋予较高的权重,并选来作为该类文本的特征词以区别与其他类文档。
计算公式:

 其中,分母:包含詞語
其中,分母:包含詞語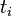 的文件數目(即
的文件數目(即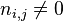 的文件數目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件數目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用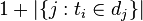 。
。
更多介绍:http://blog.csdn.net/yuike2008/article/details/2581291。
分享到:




相关推荐
动态加权方法是一种在数据分析和决策过程中广泛应用的技术,特别是在综合评价模型的构建中。它能够根据各个评价指标的重要性和变化情况动态地分配权重,从而提高评价结果的准确性和客观性。这种方法通常用于处理复杂...
网络中节点重要性度量对于信息的扩散、产品的曝光、传染性疾病的检测等都具有重大的理论...基于SIR模型的四个实证网络,实验结果表明加权方法比特征向量中心性、度中心性、紧密度中心性和介数中心性方法的效果更显著。
并且针对以上问题,提出了分段加权和RVP补偿去斜脉压加权2种加权方法,有效地提高了大波门条件下的加权性能,通过仿真和实测数据对算法进行验证,结果证实了理论分析的正确性,有效地降低了波门宽度对加权性能的影响...
针对存在概念漂移的数据流分类问题,提出一种基于实例加权方法的数据流分类算法(EWAMDS),根据基分类器在训练实例上的分类结果调整该实例的权值,以增强漂移实例在新分类器中的影响,同时引入动态的权值修改因子以...
### ChatGPT技术的对话历史排序和重要性加权方法 #### 一、引言 随着人工智能技术的迅速发展,自然语言处理领域的成果显著,聊天机器人成为了一个热门的应用方向。ChatGPT作为这一领域的杰出代表,凭借其强大的...
本主题“电信设备-一种基于信息增益率的属性加权方法及文本分类方法”探讨的就是如何利用信息增益率来优化特征选择,并以此提升文本分类的准确性。 首先,我们需要理解什么是信息增益率。信息增益是决策树算法中...
本文档“上行信道多用户接收装置中的软判决与软判决加权方法”深入探讨了这一领域的核心算法和技术。软判决(Soft Decision)和软判决加权(Soft Decision Weighting)方法在降低误码率、提高系统性能方面具有显著...
《因子选股系列研究》之五十三详细探讨了基于因子组合FMP(Factor Multiplication Product)的因子加权方法。FMP是因子分析中的一个重要概念,它允许将多个因子的影响合并到一个单一的度量标准中,从而更有效地评估...
通过分析特征词与类别间的相关性, 提出了一种新的特征加权方法, 依据特征词在特定类中出现的次数、特征词在某一类中的集中程度、特征词在特定类中的均匀分布程度来计算特征权值。通过与TF-IDF进行实验对比, 新提出的...
2. 计算IC:使用皮尔逊相关系数或其他相关性测量方法计算每个因子与未来收益的IC。 3. 构建权重矩阵:根据因子的IC值和其它因素(如稳定性、可解释性等)构建初始权重矩阵。 4. 优化权重:通过迭代算法(如梯度下降...
一种基于特征重要度的文本分类特征加权方法 本文提出了一种基于特征重要度的文本分类特征加权方法,以解决文本分类问题中的特征选择和权重分配问题。该方法通过计算每个特征的重要度,来确定每个特征在文本分类中的...
6. **时延估计比较**:比较不同的加权方法对于时延估计的影响,可以帮助我们选择最佳的策略。这通常涉及到计算不同方法的误差性能,如均方误差或概率密度函数。 在“gcc.m”这个MATLAB文件中,很可能是实现了一系列...
道夫-切比雪夫加权方法能够在给定的旁瓣高度下获得最窄的主瓣,或者在给定主瓣宽度下获得最低的旁瓣,这使得它在特定的应用场景下非常有效。然而,传统道夫-切比雪夫加权方法在实际应用中存在一个显著问题:当阵列...
2. **加权方法**:常见的加权方法包括最小均方误差(Minimum Mean Square Error, MMSE)、最大似然(Maximum Likelihood, ML)和匹配滤波器等。MMSE加权考虑了噪声功率和信号功率的比值,以找到最能降低误差平方和的...
基于伪距残差的GNSS接收机自主完整性监控的局部加权方法
这里,我们主要讨论这两个概念及其应用,并结合“IDW距离反比加权方法”进行深入解析。 首先,切比雪夫加权源于数学中的切比雪夫多项式,它在滤波器设计、信号处理和数值分析中扮演着关键角色。切比雪夫加权的特点...
Taylor加权方法是解决相控阵雷达中的一种权值分配问题,以实现均匀的旁瓣电平或者最小化旁瓣电平,提高雷达的探测性能和抗干扰能力。 描述中提到的“泰勒加权函数,用于相控阵雷达程序仿真。出自电子扫描阵列基础”...