- وµڈ览: 168840 و¬،
- و€§هˆ«:

- و¥è‡ھ: هژ¦é—¨
-

و–‡ç« هˆ†ç±»
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 6)
- وˆ‘çڑ„é—®ç” ( 6)
هکو،£هˆ†ç±»
- 2013-03 ( 2)
- 2012-10 ( 1)
- 2012-09 ( 1)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
onlyorï¼ڑ
آ آ آ
Spring mvc ن¸‹ه¯¼ه‡؛Excelو–‡ن»¶ -
lliiqiangï¼ڑ
ه› ن¸؛ه®¢وˆ·ç«¯هکهœ¨ه¤ڑç§چوƒ…ه†µه’Œè¢«ن»؟é€ ï¼Œه¾ˆéڑ¾çں¥éپ“用وˆ·çœںه®و„ڈه›¾ï¼Œن»¥هڈٹوک¯هگ¦ ...
javaéک²و¢è،¨هچ•é‡چه¤چوڈگن؛¤ -
plg17ï¼ڑ
能هگ¦ه°†excelو–‡ن»¶هژ‹ç¼©وˆگzipو–‡ن»¶هگژه†چن¸‹è½½ï¼ں
Spring mvc ن¸‹ه¯¼ه‡؛Excelو–‡ن»¶ -
ydsakyclguoziï¼ڑ
...
javaéک²و¢è،¨هچ•é‡چه¤چوڈگن؛¤ -
beiyerenï¼ڑ
ن½ è؟™و ·و„ڈن¹‰ن¸چه¤§ï¼Œه¹²è„†ç›´وژ¥è‡ھه·±ç”¨responseو‰“هچ°ه¾—ن؛†
Spring mvc ن¸‹ه¯¼ه‡؛Excelو–‡ن»¶
çگ†è§£MySQL——ه¤چهˆ¶(Replication)
1.1م€په¤چهˆ¶è§£ه†³çڑ„é—®é¢ک
و•°وچ®ه¤چهˆ¶وٹ€وœ¯وœ‰ن»¥ن¸‹ن¸€ن؛›ç‰¹ç‚¹ï¼ڑ
(1) و•°وچ®هˆ†ه¸ƒ
(2) è´ںè½½ه¹³è،،(load balancing)
(3) ه¤‡ن»½
(4) é«کهڈ¯ç”¨و€§(high availability)ه’Œه®¹é”™
1.2م€په¤چهˆ¶ه¦‚ن½•ه·¥ن½œ
ن»ژé«که±‚و¥çœ‹ï¼Œه¤چهˆ¶هˆ†وˆگن¸‰و¥ï¼ڑ
(1) masterه°†و”¹هڈکè®°ه½•هˆ°ن؛Œè؟›هˆ¶و—¥ه؟—(binary log)ن¸ï¼ˆè؟™ن؛›è®°ه½•هڈ«هپڑن؛Œè؟›هˆ¶و—¥ه؟—ن؛‹ن»¶ï¼Œbinary log events);
(2) slaveه°†masterçڑ„binary log eventsو‹·è´هˆ°ه®ƒçڑ„ن¸ç»§و—¥ه؟—(relay log)ï¼›
(3) slaveé‡چهپڑن¸ç»§و—¥ه؟—ن¸çڑ„ن؛‹ن»¶ï¼Œه°†و”¹هڈکهڈچوک ه®ƒè‡ھه·±çڑ„و•°وچ®م€‚
ن¸‹ه›¾وڈڈè؟°ن؛†è؟™ن¸€è؟‡ç¨‹ï¼ڑ
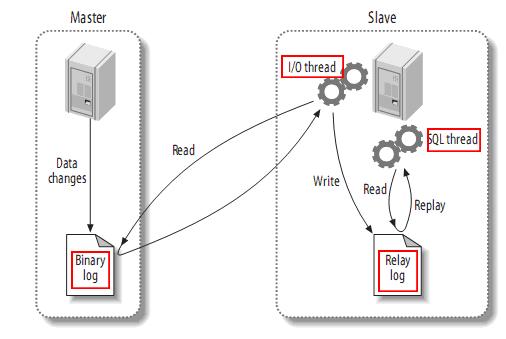
该è؟‡ç¨‹çڑ„第ن¸€éƒ¨هˆ†ه°±وک¯masterè®°ه½•ن؛Œè؟›هˆ¶و—¥ه؟—م€‚هœ¨و¯ڈن¸ھن؛‹هٹ،و›´و–°و•°وچ®ه®Œوˆگن¹‹ه‰چ,masterهœ¨ن؛Œو—¥ه؟—è®°ه½•è؟™ن؛›و”¹هڈکم€‚MySQLه°†ن؛‹هٹ،ن¸²è،Œçڑ„ه†™ه…¥ن؛Œè؟›هˆ¶و—¥ه؟—,هچ³ن½؟ن؛‹هٹ،ن¸çڑ„è¯هڈ¥éƒ½وک¯ن؛¤هڈ‰و‰§è،Œçڑ„م€‚هœ¨ن؛‹ن»¶ه†™ه…¥ن؛Œè؟›هˆ¶و—¥ه؟—ه®Œوˆگهگژ,masteré€ڑçں¥هکه‚¨ه¼•و“ژوڈگن؛¤ن؛‹هٹ،م€‚
ن¸‹
ن¸€و¥ه°±وک¯slaveه°†masterçڑ„binary
logو‹·è´هˆ°ه®ƒè‡ھه·±çڑ„ن¸ç»§و—¥ه؟—م€‚首ه…ˆï¼Œslaveه¼€ه§‹ن¸€ن¸ھه·¥ن½œç؛؟程——I/Oç؛؟程م€‚I/Oç؛؟程هœ¨masterن¸ٹو‰“ه¼€ن¸€ن¸ھو™®é€ڑçڑ„è؟وژ¥ï¼Œç„¶هگژه¼€ه§‹binlog
dump processم€‚Binlog dump
processن»ژmasterçڑ„ن؛Œè؟›هˆ¶و—¥ه؟—ن¸è¯»هڈ–ن؛‹ن»¶ï¼Œه¦‚وœه·²ç»ڈè·ںن¸ٹmaster,ه®ƒن¼ڑç،çœ ه¹¶ç‰ه¾…masterن؛§ç”ںو–°çڑ„ن؛‹ن»¶م€‚I/Oç؛؟程ه°†è؟™ن؛›ن؛‹ن»¶ه†™ه…¥ن¸
继و—¥ه؟—م€‚
SQL slave threadه¤„çگ†è¯¥è؟‡ç¨‹çڑ„وœ€هگژن¸€و¥م€‚SQLç؛؟程ن»ژن¸ç»§و—¥ه؟—读هڈ–ن؛‹ن»¶ï¼Œو›´و–°slaveçڑ„و•°وچ®ï¼Œن½؟ه…¶ن¸ژmasterن¸çڑ„و•°وچ®ن¸€è‡´م€‚هڈھè¦پ该ç؛؟程ن¸ژI/Oç؛؟程ن؟وŒپن¸€è‡´ï¼Œن¸ç»§و—¥ه؟—é€ڑه¸¸ن¼ڑن½چن؛ژOSçڑ„缓هکن¸ï¼Œو‰€ن»¥ن¸ç»§و—¥ه؟—çڑ„ه¼€é”€ه¾ˆه°ڈم€‚
و¤
ه¤–,هœ¨masterن¸ن¹ںوœ‰ن¸€ن¸ھه·¥ن½œç؛؟程ï¼ڑه’Œه…¶ه®ƒMySQLçڑ„è؟وژ¥ن¸€و ·ï¼Œslaveهœ¨masterن¸و‰“ه¼€ن¸€ن¸ھè؟وژ¥ن¹ںن¼ڑن½؟ه¾—masterه¼€ه§‹ن¸€ن¸ھç؛؟程م€‚ه¤چهˆ¶è؟‡
程وœ‰ن¸€ن¸ھه¾ˆé‡چè¦پçڑ„é™گهˆ¶â€”—ه¤چهˆ¶هœ¨slaveن¸ٹوک¯ن¸²è،ŒهŒ–çڑ„,ن¹ںه°±وک¯è¯´masterن¸ٹçڑ„ه¹¶è،Œو›´و–°و“چن½œن¸چ能هœ¨slaveن¸ٹه¹¶è،Œو“چن½œم€‚
آ
2م€پن½“éھŒMySQLه¤چهˆ¶
MySQLه¼€ه§‹ه¤چهˆ¶وک¯ه¾ˆç®€هچ•çڑ„è؟‡ç¨‹ï¼Œن¸چè؟‡ï¼Œو ¹وچ®ç‰¹ه®ڑçڑ„ه؛”用هœ؛و™¯ï¼Œéƒ½ن¼ڑهœ¨هں؛وœ¬çڑ„و¥éھ¤ن¸ٹوœ‰ن¸€ن؛›هڈکهŒ–م€‚وœ€ç®€هچ•çڑ„هœ؛و™¯ه°±وک¯ن¸€ن¸ھو–°ه®‰è£…çڑ„masterه’Œslave,ن»ژé«که±‚و¥çœ‹ï¼Œو•´ن¸ھè؟‡ç¨‹ه¦‚ن¸‹ï¼ڑ
(1)هœ¨و¯ڈن¸ھوœچهٹ،ه™¨ن¸ٹهˆ›ه»؛ن¸€ن¸ھه¤چهˆ¶ه¸گهڈ·ï¼›
(2)é…چç½®masterه’Œslaveï¼›
(3)Slaveè؟وژ¥masterه¼€ه§‹ه¤چهˆ¶م€‚
2.1م€پهˆ›ه»؛ه¤چهˆ¶ه¸گهڈ·
و¯ڈن¸ھslaveن½؟用و ‡ه‡†çڑ„MySQL用وˆ·هگچه’Œه¯†ç پè؟وژ¥masterم€‚è؟›è،Œه¤چهˆ¶و“چن½œçڑ„用وˆ·ن¼ڑوژˆن؛ˆREPLICATION SLAVEوƒé™گم€‚用وˆ·هگچçڑ„ه¯†ç پ都ن¼ڑهکه‚¨هœ¨و–‡وœ¬و–‡ن»¶master.infoن¸م€‚هپ‡ه¦‚,ن½ وƒ³هˆ›ه»؛repl用وˆ·ï¼Œه¦‚ن¸‹ï¼ڑ
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.*
-> TO repl@'192.168.0.%' IDENTIFIED BY 'p4ssword';
2.2م€پé…چç½®master
وژ¥ن¸‹و¥ه¯¹masterè؟›è،Œé…چ置,هŒ…و‹¬و‰“ه¼€ن؛Œè؟›هˆ¶و—¥ه؟—,وŒ‡ه®ڑه”¯ن¸€çڑ„servr IDم€‚ن¾‹ه¦‚,هœ¨é…چç½®و–‡ن»¶هٹ ه…¥ه¦‚ن¸‹ه€¼ï¼ڑ
[mysqld]
log-bin=mysql-bin
server-id=10
é‡چهگ¯master,è؟گè،ŒSHOW MASTER STATUS,输ه‡؛ه¦‚ن¸‹ï¼ڑ

آ
2.3م€پé…چç½®slave
Slaveçڑ„é…چç½®ن¸ژmasterç±»ن¼¼ï¼Œن½ هگŒو ·éœ€è¦پé‡چهگ¯slaveçڑ„MySQLم€‚ه¦‚ن¸‹ï¼ڑ
log_bin = mysql-bin
server_id = 2
relay_log = mysql-relay-bin
log_slave_updates = 1
read_only = 1
server_id
وک¯ه؟…é،»çڑ„,而ن¸”ه”¯ن¸€م€‚slaveو²،وœ‰ه؟…è¦په¼€هگ¯ن؛Œè؟›هˆ¶و—¥ه؟—,ن½†وک¯هœ¨ن¸€ن؛›وƒ…ه†µن¸‹ï¼Œه؟…é،»è®¾ç½®ï¼Œن¾‹ه¦‚,ه¦‚وœslaveن¸؛ه…¶ه®ƒslaveçڑ„master,ه؟…é،»è®¾ç½®
bin_logم€‚هœ¨è؟™é‡Œï¼Œوˆ‘ن»¬ه¼€هگ¯ن؛†ن؛Œè؟›هˆ¶و—¥ه؟—,而ن¸”وک¾ç¤؛çڑ„ه‘½هگچ(é»ک认هگچ称ن¸؛hostname,ن½†وک¯ï¼Œه¦‚وœhostnameو”¹هڈکهˆ™ن¼ڑه‡؛çژ°é—®é¢ک)م€‚
relay_logé…چç½®ن¸ç»§و—¥ه؟—,log_slave_updatesè،¨ç¤؛slaveه°†ه¤چهˆ¶ن؛‹ن»¶ه†™è؟›è‡ھه·±çڑ„ن؛Œè؟›هˆ¶و—¥ه؟—(هگژé¢ن¼ڑ看هˆ°ه®ƒçڑ„用ه¤„)م€‚
وœ‰
ن؛›ن؛؛ه¼€هگ¯ن؛†slaveçڑ„ن؛Œè؟›هˆ¶و—¥ه؟—,هچ´و²،وœ‰è®¾ç½®log_slave_updates,然هگژوں¥çœ‹slaveçڑ„و•°وچ®وک¯هگ¦و”¹هڈک,è؟™وک¯ن¸€ç§چ错误çڑ„é…چç½®م€‚و‰€ن»¥ï¼Œه°½é‡ڈ
ن½؟用read_only,ه®ƒéک²و¢و”¹هڈکو•°وچ®(除ن؛†ç‰¹و®ٹçڑ„ç؛؟程)م€‚ن½†وک¯ï¼Œread_onlyه¹¶وک¯ه¾ˆه®ç”¨ï¼Œç‰¹هˆ«وک¯é‚£ن؛›éœ€è¦پهœ¨slaveن¸ٹهˆ›ه»؛è،¨çڑ„ه؛”用م€‚
2.4م€پهگ¯هٹ¨slave
وژ¥ ن¸‹و¥ه°±وک¯è®©slaveè؟وژ¥master,ه¹¶ه¼€ه§‹é‡چهپڑmasterن؛Œè؟›هˆ¶و—¥ه؟—ن¸çڑ„ن؛‹ن»¶م€‚ن½ ن¸چه؛”该用é…چç½®و–‡ن»¶è؟›è،Œè¯¥و“چن½œï¼Œè€Œه؛”该ن½؟用CHANGE MASTER TOè¯هڈ¥ï¼Œè¯¥è¯هڈ¥هڈ¯ن»¥ه®Œه…¨هڈ–ن»£ه¯¹é…چç½®و–‡ن»¶çڑ„ن؟®و”¹ï¼Œè€Œن¸”ه®ƒهڈ¯ن»¥ن¸؛slaveوŒ‡ه®ڑن¸چهگŒçڑ„master,而ن¸چ需è¦پهپœو¢وœچهٹ،ه™¨م€‚ه¦‚ن¸‹ï¼ڑ
mysql> CHANGE MASTER TO MASTER_HOST='server1',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='p4ssword',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=0;
MASTER_LOG_POSçڑ„ه€¼ن¸؛0,ه› ن¸؛ه®ƒوک¯و—¥ه؟—çڑ„ه¼€ه§‹ن½چç½®م€‚然هگژ,ن½ هڈ¯ن»¥ç”¨SHOW SLAVE STATUSè¯هڈ¥وں¥çœ‹slaveçڑ„设置وک¯هگ¦و£ç،®ï¼ڑ
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 4
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: No
...omitted...
Seconds_Behind_Master: NULL
Slave_IO_State, Slave_IO_Running, ه’ŒSlave_SQL_Runningè،¨وکژslaveè؟کو²،وœ‰ه¼€ه§‹ه¤چهˆ¶è؟‡ç¨‹م€‚و—¥ه؟—çڑ„ن½چç½®ن¸؛4而ن¸چوک¯0,è؟™وک¯ه› ن¸؛0هڈھوک¯و—¥ه؟—و–‡ن»¶çڑ„ه¼€ه§‹ن½چ置,ه¹¶ن¸چوک¯و—¥ه؟—ن½چç½®م€‚ه®é™…ن¸ٹ,MySQLçں¥éپ“çڑ„第ن¸€ن¸ھن؛‹ن»¶çڑ„ن½چç½®وک¯4م€‚
ن¸؛ن؛†ه¼€ه§‹ه¤چهˆ¶ï¼Œن½ هڈ¯ن»¥è؟گè،Œï¼ڑ
mysql> START SLAVE;
è؟گè،ŒSHOW SLAVE STATUSوں¥çœ‹è¾“ه‡؛结وœï¼ڑ
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 164
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 164
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...omitted...
Seconds_Behind_Master: 0
و³¨و„ڈ,slaveçڑ„I/Oه’ŒSQLç؛؟程都ه·²ç»ڈه¼€ه§‹è؟گè،Œï¼Œè€Œن¸”Seconds_Behind_Masterن¸چه†چوک¯NULLم€‚و—¥ه؟—çڑ„ن½چç½®ه¢هٹ ن؛†ï¼Œو„ڈه‘³ç€ن¸€ن؛›ن؛‹ن»¶è¢«èژ·هڈ–ه¹¶و‰§è،Œن؛†م€‚ه¦‚وœن½ هœ¨masterن¸ٹè؟›è،Œن؟®و”¹ï¼Œن½ هڈ¯ن»¥هœ¨slaveن¸ٹ看هˆ°هگ„ç§چو—¥ه؟—و–‡ن»¶çڑ„ن½چç½®çڑ„هڈکهŒ–,هگŒو ·ï¼Œن½ ن¹ںهڈ¯ن»¥çœ‹هˆ°و•°وچ®ه؛“ن¸و•°وچ®çڑ„هڈکهŒ–م€‚
ن½ هڈ¯وں¥çœ‹masterه’Œslaveن¸ٹç؛؟程çڑ„çٹ¶و€پم€‚هœ¨masterن¸ٹ,ن½ هڈ¯ن»¥çœ‹هˆ°slaveçڑ„I/Oç؛؟程هˆ›ه»؛çڑ„è؟وژ¥ï¼ڑ
آ
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: root Host: localhost:2096 db: test Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 2 User: repl Host: localhost:2144 db: NULL Command: Binlog Dump Time: 1838 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL 2 rows in set (0.00 sec) |
è،Œ2ن¸؛ه¤„çگ†slaveçڑ„I/Oç؛؟程çڑ„è؟وژ¥م€‚
هœ¨slaveن¸ٹè؟گè،Œè¯¥è¯هڈ¥ï¼ڑ
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 2291 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 1852 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 3. row *************************** Id: 5 User: root Host: localhost:2152 db: test Command: Query Time: 0 State: NULL Info: show processlist 3 rows in set (0.00 sec) |
è،Œ1ن¸؛I/Oç؛؟程çٹ¶و€پ,è،Œ2ن¸؛SQLç؛؟程çٹ¶و€پم€‚
2.5م€پن»ژهڈ¦ن¸€ن¸ھmasterهˆه§‹هŒ–slave
ه‰چé¢è®¨è®؛çڑ„هپ‡è®¾ن½ وک¯و–°ه®‰è£…çڑ„masterه’Œslave,و‰€ن»¥ï¼Œslaveن¸ژmasterوœ‰ç›¸هگŒçڑ„و•°وچ®م€‚ن½†وک¯ï¼Œه¤§ه¤ڑو•°وƒ…ه†µهچ´ن¸چوک¯è؟™و ·çڑ„,ن¾‹ه¦‚,ن½ çڑ„masterهڈ¯èƒ½ه·²ç»ڈè؟گè،Œه¾ˆن¹…ن؛†ï¼Œè€Œن½ وƒ³ه¯¹و–°ه®‰è£…çڑ„slaveè؟›è،Œو•°وچ®هگŒو¥ï¼Œç”ڑ至ه®ƒو²،وœ‰masterçڑ„و•°وچ®م€‚
و¤و—¶ï¼Œوœ‰ه‡ ç§چو–¹و³•هڈ¯ن»¥ن½؟slaveن»ژهڈ¦ن¸€ن¸ھوœچهٹ،ه¼€ه§‹ï¼Œن¾‹ه¦‚,ن»ژmasterو‹·è´و•°وچ®ï¼Œن»ژهڈ¦ن¸€ن¸ھslaveه…‹éڑ†ï¼Œن»ژوœ€è؟‘çڑ„ه¤‡ن»½ه¼€ه§‹ن¸€ن¸ھslaveم€‚Slaveن¸ژmasterهگŒو¥و—¶ï¼Œéœ€è¦پن¸‰و ·ن¸œè¥؟ï¼ڑ
(1)masterçڑ„وںگن¸ھو—¶هˆ»çڑ„و•°وچ®ه؟«ç…§ï¼›
(2)masterه½“ه‰چçڑ„و—¥ه؟—و–‡ن»¶م€پن»¥هڈٹç”ںوˆگه؟«ç…§و—¶çڑ„ه—èٹ‚هپڈ移م€‚è؟™ن¸¤ن¸ھه€¼هڈ¯ن»¥هڈ«هپڑو—¥ه؟—و–‡ن»¶هگو ‡(log file coordinate),ه› ن¸؛ه®ƒن»¬ç،®ه®ڑن؛†ن¸€ن¸ھن؛Œè؟›هˆ¶و—¥ه؟—çڑ„ن½چ置,ن½ هڈ¯ن»¥ç”¨SHOW MASTER STATUSه‘½ن»¤و‰¾هˆ°و—¥ه؟—و–‡ن»¶çڑ„هگو ‡ï¼›
(3)masterçڑ„ن؛Œè؟›هˆ¶و—¥ه؟—و–‡ن»¶م€‚
هڈ¯ن»¥é€ڑè؟‡ن»¥ن¸‹ه‡ ن¸و–¹و³•و¥ه…‹éڑ†ن¸€ن¸ھslaveï¼ڑ
(1) ه†·و‹·è´(cold copy)
هپœو¢master,ه°†masterçڑ„و–‡ن»¶و‹·è´هˆ°slave;然هگژé‡چهگ¯masterم€‚ç¼؛点ه¾ˆوکژوک¾م€‚
(2) çƒو‹·è´(warm copy)
ه¦‚وœن½ ن»…ن½؟用MyISAMè،¨ï¼Œن½ هڈ¯ن»¥ن½؟用mysqlhotcopyو‹·è´ï¼Œهچ³ن½؟وœچهٹ،ه™¨و£هœ¨è؟گè،Œم€‚
(3) ن½؟用mysqldump
ن½؟用mysqldumpو¥ه¾—هˆ°ن¸€ن¸ھو•°وچ®ه؟«ç…§هڈ¯هˆ†ن¸؛ن»¥ن¸‹ه‡ و¥ï¼ڑ
<1>é”پè،¨ï¼ڑه¦‚وœن½ è؟کو²،وœ‰é”پè،¨ï¼Œن½ ه؛”该ه¯¹è،¨هٹ é”پ,éک²و¢ه…¶ه®ƒè؟وژ¥ن؟®و”¹و•°وچ®ه؛“,هگ¦هˆ™ï¼Œن½ ه¾—هˆ°çڑ„و•°وچ®هڈ¯ن»¥وک¯ن¸چن¸€è‡´çڑ„م€‚ه¦‚ن¸‹ï¼ڑ
mysql> FLUSH TABLES WITH READ LOCK;
<2>هœ¨هڈ¦ن¸€ن¸ھè؟وژ¥ç”¨mysqldumpهˆ›ه»؛ن¸€ن¸ھن½ وƒ³è؟›è،Œه¤چهˆ¶çڑ„و•°وچ®ه؛“çڑ„转ه‚¨ï¼ڑ
shell> mysqldump --all-databases --lock-all-tables >dbdump.db
<3>ه¯¹è،¨é‡ٹو”¾é”پم€‚
mysql> UNLOCK TABLES;
3م€پو·±ه…¥ه¤چهˆ¶
ه·²ç»ڈ讨è®؛ن؛†ه…³ن؛ژه¤چهˆ¶çڑ„ن¸€ن؛›هں؛وœ¬ن¸œè¥؟,ن¸‹é¢و·±ه…¥è®¨è®؛ن¸€ن¸‹ه¤چهˆ¶م€‚
3.1م€پهں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶(Statement-Based Replication)
MySQL 5.0هڈٹن¹‹ه‰چçڑ„版وœ¬ن»…و”¯وŒپهں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶ï¼ˆن¹ںهڈ«هپڑ逻辑ه¤چهˆ¶ï¼Œlogical replication),è؟™هœ¨و•°وچ®ه؛“ه¹¶ن¸چه¸¸è§پم€‚masterè®°ه½•ن¸‹و”¹هڈکو•°وچ®çڑ„وں¥è¯¢ï¼Œç„¶هگژ,slaveن»ژن¸ç»§و—¥ه؟—ن¸è¯»هڈ–ن؛‹ن»¶ï¼Œه¹¶و‰§è،Œه®ƒï¼Œè؟™ن؛›SQLè¯هڈ¥ن¸ژmasterو‰§è،Œçڑ„è¯هڈ¥ن¸€و ·م€‚
è؟™ç§چو–¹ه¼ڈçڑ„ن¼ک点ه°±وک¯ه®çژ°ç®€هچ•م€‚و¤ه¤–,هں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶çڑ„ن؛Œè؟›هˆ¶و—¥ه؟—هڈ¯ن»¥ه¾ˆه¥½çڑ„è؟›è،Œهژ‹ç¼©ï¼Œè€Œن¸”و—¥ه؟—çڑ„و•°وچ®é‡ڈن¹ں较ه°ڈ,هچ 用ه¸¦ه®½ه°‘——ن¾‹ه¦‚,ن¸€ن¸ھو›´و–°GBçڑ„و•°وچ®çڑ„وں¥è¯¢ن»…需è¦په‡ هچپن¸ھه—èٹ‚çڑ„ن؛Œè؟›هˆ¶و—¥ه؟—م€‚而mysqlbinlogه¯¹ن؛ژهں؛ن؛ژè¯هڈ¥çڑ„و—¥ه؟—ه¤„çگ†هچپهˆ†و–¹ن¾؟م€‚
ن½†
وک¯ï¼Œهں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶ه¹¶ن¸چوک¯هƒڈه®ƒçœ‹èµ·و¥é‚£ن¹ˆç®€هچ•ï¼Œه› ن¸؛ن¸€ن؛›وں¥è¯¢è¯هڈ¥ن¾èµ–ن؛ژmasterçڑ„特ه®ڑو،ن»¶ï¼Œن¾‹ه¦‚,masterن¸ژslaveهڈ¯èƒ½وœ‰ن¸چهگŒçڑ„و—¶é—´م€‚و‰€
ن»¥ï¼ŒMySQLçڑ„ن؛Œè؟›هˆ¶و—¥ه؟—çڑ„و ¼ه¼ڈن¸چن»…ن»…وک¯وں¥è¯¢è¯هڈ¥ï¼Œè؟کهŒ…و‹¬ن¸€ن؛›ه…ƒو•°وچ®ن؟،وپ¯ï¼Œن¾‹ه¦‚,ه½“ه‰چçڑ„و—¶é—´وˆ³م€‚هچ³ن½؟ه¦‚و¤ï¼Œè؟کوک¯وœ‰ن¸€ن؛›è¯هڈ¥ï¼Œو¯”ه¦‚,CURRENT
USERه‡½و•°ï¼Œن¸چ能و£ç،®çڑ„è؟›è،Œه¤چهˆ¶م€‚و¤ه¤–,هکه‚¨è؟‡ç¨‹ه’Œè§¦هڈ‘ه™¨ن¹ںوک¯ن¸€ن¸ھé—®é¢کم€‚
هڈ¦ه¤–ن¸€ن¸ھé—®é¢که°±وک¯هں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶ه؟…é،»وک¯ن¸²è،ŒهŒ–çڑ„م€‚è؟™è¦پو±‚ه¤§é‡ڈ特و®ٹçڑ„ن»£ç پ,é…چ置,ن¾‹ه¦‚InnoDBçڑ„next-keyé”پç‰م€‚ه¹¶ن¸چوک¯و‰€وœ‰çڑ„هکه‚¨ه¼•و“ژ都و”¯وŒپهں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶م€‚
3.2م€پهں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶(Row-Based Replication)
MySQL
ه¢هٹ هں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶ï¼Œهœ¨ن؛Œè؟›هˆ¶و—¥ه؟—ن¸è®°ه½•ن¸‹ه®é™…و•°وچ®çڑ„و”¹هڈک,è؟™ن¸ژه…¶ه®ƒن¸€ن؛›DBMSçڑ„ه®çژ°و–¹ه¼ڈç±»ن¼¼م€‚è؟™ç§چو–¹ه¼ڈوœ‰ن¼ک点,ن¹ںوœ‰ç¼؛点م€‚ن¼ک点ه°±وک¯هڈ¯ن»¥ه¯¹ن»»ن½•è¯هڈ¥éƒ½èƒ½
و£ç،®ه·¥ن½œï¼Œن¸€ن؛›è¯هڈ¥çڑ„و•ˆçژ‡و›´é«کم€‚ن¸»è¦پçڑ„ç¼؛点ه°±وک¯ن؛Œè؟›هˆ¶و—¥ه؟—هڈ¯èƒ½ن¼ڑه¾ˆه¤§ï¼Œè€Œن¸”ن¸چ直观,و‰€ن»¥ï¼Œن½ ن¸چ能ن½؟用mysqlbinlogو¥وں¥çœ‹ن؛Œè؟›هˆ¶و—¥ه؟—م€‚
ه¯¹ن؛ژن¸€ن؛›è¯هڈ¥ï¼Œهں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶èƒ½ه¤ںو›´وœ‰و•ˆçڑ„ه·¥ن½œï¼Œه¦‚ï¼ڑ
mysql> INSERT INTO summary_table(col1, col2, sum_col3)
-> SELECT col1, col2, sum(col3)
-> FROM enormous_table
-> GROUP BY col1, col2;
هپ‡è®¾ï¼Œهڈھوœ‰ن¸‰ç§چه”¯ن¸€çڑ„col1ه’Œcol2çڑ„组هگˆï¼Œن½†وک¯ï¼Œè¯¥وں¥è¯¢ن¼ڑو‰«وڈڈهژںè،¨çڑ„许ه¤ڑè،Œï¼Œهچ´ن»…è؟”ه›ن¸‰و،è®°ه½•م€‚و¤و—¶ï¼Œهں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶و•ˆçژ‡و›´é«کم€‚
هڈ¦ن¸€و–¹é¢ï¼Œن¸‹é¢çڑ„è¯هڈ¥ï¼Œهں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶و›´وœ‰و•ˆï¼ڑ
mysql> UPDATE enormous_table SET col1 = 0;
و¤و—¶ن½؟用هں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶ن»£ن»·ن¼ڑéه¸¸é«کم€‚ç”±ن؛ژن¸¤ç§چو–¹ه¼ڈن¸چ能ه¯¹و‰€وœ‰وƒ…ه†µéƒ½èƒ½ه¾ˆه¥½çڑ„ه¤„çگ†ï¼Œو‰€ن»¥ï¼ŒMySQL 5.1و”¯وŒپهœ¨هں؛ن؛ژè¯هڈ¥çڑ„ه¤چهˆ¶ه’Œهں؛ن؛ژè®°ه½•çڑ„ه¤چهˆ¶ن¹‹ه‰چهٹ¨و€پن؛¤وچ¢م€‚ن½ هڈ¯ن»¥é€ڑè؟‡è®¾ç½®sessionهڈکé‡ڈbinlog_formatو¥è؟›è،Œوژ§هˆ¶م€‚
3.3م€په¤چهˆ¶ç›¸ه…³çڑ„و–‡ن»¶
除ن؛†ن؛Œè؟›هˆ¶و—¥ه؟—ه’Œن¸ç»§و—¥ه؟—و–‡ن»¶ه¤–,è؟کوœ‰ه…¶ه®ƒن¸€ن؛›ن¸ژه¤چهˆ¶ç›¸ه…³çڑ„و–‡ن»¶م€‚ه¦‚ن¸‹ï¼ڑ
(1)mysql-bin.index
وœچهٹ،ه™¨ن¸€و—¦ه¼€هگ¯ن؛Œè؟›هˆ¶و—¥ه؟—,ن¼ڑن؛§ç”ںن¸€ن¸ھن¸ژن؛Œو—¥ه؟—و–‡ن»¶هگŒهگچ,ن½†وک¯ن»¥.index结ه°¾çڑ„و–‡ن»¶م€‚ه®ƒç”¨ن؛ژè·ںè¸ھç£پç›کن¸ٹهکهœ¨ه“ھن؛›ن؛Œè؟›هˆ¶و—¥ه؟—و–‡ن»¶م€‚MySQL用ه®ƒو¥ه®ڑن½چن؛Œè؟›هˆ¶و—¥ه؟—و–‡ن»¶م€‚ه®ƒçڑ„ه†…ه®¹ه¦‚ن¸‹(وˆ‘çڑ„وœ؛ه™¨ن¸ٹ)ï¼ڑ
(2)mysql-relay-bin.index
该و–‡ن»¶çڑ„هٹں能ن¸ژmysql-bin.indexç±»ن¼¼ï¼Œن½†وک¯ه®ƒوک¯é’ˆه¯¹ن¸ç»§و—¥ه؟—,而ن¸چوک¯ن؛Œè؟›هˆ¶و—¥ه؟—م€‚ه†…ه®¹ه¦‚ن¸‹ï¼ڑ
.\mysql-02-relay-bin.000017
.\mysql-02-relay-bin.000018
(3)master.info
ن؟هکmasterçڑ„相ه…³ن؟،وپ¯م€‚ن¸چè¦پهˆ 除ه®ƒï¼Œهگ¦هˆ™ï¼Œslaveé‡چهگ¯هگژن¸چ能è؟وژ¥masterم€‚ه†…ه®¹ه¦‚ن¸‹(وˆ‘çڑ„وœ؛ه™¨ن¸ٹ)ï¼ڑ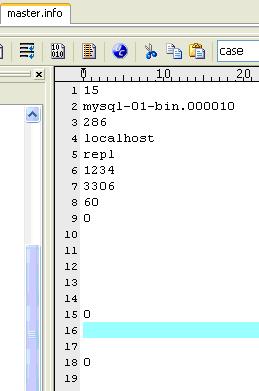
I/Oç؛؟程و›´و–°master.infoو–‡ن»¶ï¼Œه†…ه®¹ه¦‚ن¸‹(وˆ‘çڑ„وœ؛ه™¨ن¸ٹ)ï¼ڑ
آ
|
.\mysql-02-relay-bin.000019 254 mysql-01-bin.000010 286 0 52813 |
آ
(4)relay-log.info
هŒ…هگ«slaveن¸ه½“ه‰چن؛Œè؟›هˆ¶و—¥ه؟—ه’Œن¸ç»§و—¥ه؟—çڑ„ن؟،وپ¯م€‚
آ
3.4م€پهڈ‘é€په¤چهˆ¶ن؛‹ن»¶هˆ°ه…¶ه®ƒslave
ه½“设置log_slave_updatesو—¶ï¼Œن½ هڈ¯ن»¥è®©slaveو‰®و¼”ه…¶ه®ƒslaveçڑ„masterم€‚و¤و—¶ï¼ŒslaveوٹٹSQLç؛؟程و‰§è،Œçڑ„ن؛‹ن»¶ه†™è؟›è،Œè‡ھه·±çڑ„ن؛Œè؟›هˆ¶و—¥ه؟—(binary log),然هگژ,ه®ƒçڑ„slaveهڈ¯ن»¥èژ·هڈ–è؟™ن؛›ن؛‹ن»¶ه¹¶و‰§è،Œه®ƒم€‚ه¦‚ن¸‹ï¼ڑ
آ
3.5م€په¤چهˆ¶è؟‡و»¤(Replication Filters)
ه¤چهˆ¶è؟‡و»¤هڈ¯ن»¥è®©ن½ هڈھه¤چهˆ¶وœچهٹ،ه™¨ن¸çڑ„ن¸€éƒ¨هˆ†و•°وچ®ï¼Œوœ‰ن¸¤ç§چه¤چهˆ¶è؟‡و»¤ï¼ڑهœ¨masterن¸ٹè؟‡و»¤ن؛Œè؟›هˆ¶و—¥ه؟—ن¸çڑ„ن؛‹ن»¶ï¼›هœ¨slaveن¸ٹè؟‡و»¤ن¸ç»§و—¥ه؟—ن¸çڑ„ن؛‹ن»¶م€‚ه¦‚ن¸‹ï¼ڑ
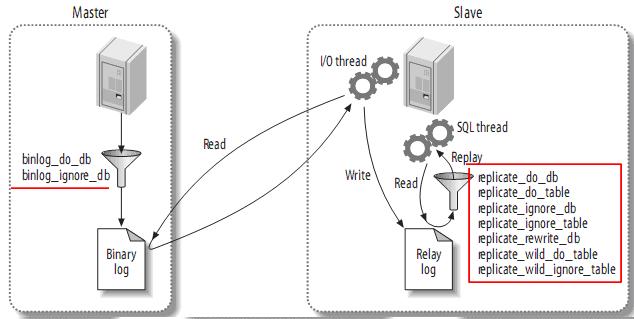
آ
4م€په¤چهˆ¶çڑ„ه¸¸ç”¨و‹“و‰‘结و„
ه¤چهˆ¶çڑ„ن½“系结و„وœ‰ن»¥ن¸‹ن¸€ن؛›هں؛وœ¬هژںهˆ™ï¼ڑ
(1) و¯ڈن¸ھslaveهڈھ能وœ‰ن¸€ن¸ھmasterï¼›
(2) و¯ڈن¸ھslaveهڈھ能وœ‰ن¸€ن¸ھه”¯ن¸€çڑ„وœچهٹ،ه™¨IDï¼›
(3) و¯ڈن¸ھmasterهڈ¯ن»¥وœ‰ه¾ˆه¤ڑslaveï¼›
(4) ه¦‚وœن½ 设置log_slave_updates,slaveهڈ¯ن»¥وک¯ه…¶ه®ƒslaveçڑ„master,ن»ژ而و‰©و•£masterçڑ„و›´و–°م€‚
MySQLن¸چو”¯وŒپه¤ڑن¸»وœچهٹ،ه™¨ه¤چهˆ¶(Multimaster Replication)——هچ³ن¸€ن¸ھslaveهڈ¯ن»¥وœ‰ه¤ڑن¸ھmasterم€‚ن½†وک¯ï¼Œé€ڑè؟‡ن¸€ن؛›ç®€هچ•çڑ„组هگˆï¼Œوˆ‘ن»¬هچ´هڈ¯ن»¥ه»؛ç«‹çپµو´»è€Œه¼؛ه¤§çڑ„ه¤چهˆ¶ن½“系结و„م€‚
4.1م€پهچ•ن¸€masterه’Œه¤ڑslave
ç”±ن¸€ن¸ھmasterه’Œن¸€ن¸ھslave组وˆگه¤چهˆ¶ç³»ç»ںوک¯وœ€ç®€هچ•çڑ„وƒ…ه†µم€‚Slaveن¹‹é—´ه¹¶ن¸چ相ن؛’é€ڑن؟،,هڈھ能ن¸ژmasterè؟›è،Œé€ڑن؟،م€‚ه¦‚ن¸‹ï¼ڑ
ه¦‚وœه†™و“چن½œè¾ƒه°‘,而读و“چن½œه¾ˆو—¶ï¼Œهڈ¯ن»¥é‡‡هڈ–è؟™ç§چ结و„م€‚ن½ هڈ¯ن»¥ه°†è¯»و“چن½œهˆ†ه¸ƒهˆ°ه…¶ه®ƒçڑ„slave,ن»ژ而ه‡ڈه°ڈmasterçڑ„هژ‹هٹ›م€‚ن½†وک¯ï¼Œه½“slaveه¢هٹ هˆ°ن¸€ه®ڑو•°é‡ڈو—¶ï¼Œslaveه¯¹masterçڑ„è´ںè½½ن»¥هڈٹ网络ه¸¦ه®½éƒ½ن¼ڑوˆگن¸؛ن¸€ن¸ھن¸¥é‡چçڑ„é—®é¢کم€‚
è؟™ç§چ结و„虽然简هچ•ï¼Œن½†وک¯ï¼Œه®ƒهچ´éه¸¸çپµو´»ï¼Œè¶³ه¤ںو»،足ه¤§ه¤ڑو•°ه؛”用需و±‚م€‚ن¸€ن؛›ه»؛è®®ï¼ڑ
(1) ن¸چهگŒçڑ„slaveو‰®و¼”ن¸چهگŒçڑ„ن½œç”¨(ن¾‹ه¦‚ن½؟用ن¸چهگŒçڑ„ç´¢ه¼•ï¼Œوˆ–者ن¸چهگŒçڑ„هکه‚¨ه¼•و“ژ)ï¼›
(2) 用ن¸€ن¸ھslaveن½œن¸؛ه¤‡ç”¨master,هڈھè؟›è،Œه¤چهˆ¶ï¼›
(3) 用ن¸€ن¸ھè؟œç¨‹çڑ„slave,用ن؛ژçپ¾éڑ¾وپ¢ه¤چï¼›
4.2م€پن¸»هٹ¨و¨،ه¼ڈçڑ„Master-Master(Master-Master in Active-Active Mode)
Master-Masterه¤چهˆ¶çڑ„ن¸¤هڈ°وœچهٹ،ه™¨ï¼Œو—¢وک¯master,هڈˆوک¯هڈ¦ن¸€هڈ°وœچهٹ،ه™¨çڑ„slaveم€‚ه¦‚ه›¾ï¼ڑ
ن¸»هٹ¨çڑ„Master-Masterه¤چهˆ¶وœ‰ن¸€ن؛›ç‰¹و®ٹçڑ„用ه¤„م€‚ن¾‹ه¦‚,هœ°çگ†ن¸ٹهˆ†ه¸ƒçڑ„ن¸¤ن¸ھ部هˆ†éƒ½éœ€è¦پè‡ھه·±çڑ„هڈ¯ه†™çڑ„و•°وچ®ه‰¯وœ¬م€‚è؟™ç§چ结و„وœ€ه¤§çڑ„é—®é¢که°±وک¯و›´و–°ه†²çھپم€‚هپ‡è®¾ن¸€ن¸ھè،¨هڈھوœ‰ن¸€è،Œ(ن¸€هˆ—)çڑ„و•°وچ®ï¼Œه…¶ه€¼ن¸؛1,ه¦‚وœن¸¤ن¸ھوœچهٹ،ه™¨هˆ†هˆ«هگŒو—¶و‰§è،Œه¦‚ن¸‹è¯هڈ¥ï¼ڑ
هœ¨ç¬¬ن¸€ن¸ھوœچهٹ،ه™¨ن¸ٹو‰§è،Œï¼ڑ
mysql> UPDATE tbl SET col=col + 1;
هœ¨ç¬¬ن؛Œن¸ھوœچهٹ،ه™¨ن¸ٹو‰§è،Œï¼ڑ
mysql> UPDATE tbl SET col=col * 2;
é‚£ن¹ˆç»“وœوک¯ه¤ڑه°‘ه‘¢ï¼ںن¸€هڈ°وœچهٹ،ه™¨وک¯4,هڈ¦ن¸€ن¸ھوœچهٹ،ه™¨وک¯3,ن½†وک¯ï¼Œè؟™ه¹¶ن¸چن¼ڑن؛§ç”ں错误م€‚
ه®é™…ن¸ٹ,MySQLه¹¶ن¸چو”¯وŒپه…¶ه®ƒن¸€ن؛›DBMSو”¯وŒپçڑ„ه¤ڑن¸»وœچهٹ،ه™¨ه¤چهˆ¶(Multimaster Replication),è؟™وک¯MySQLçڑ„ه¤چهˆ¶هٹں能ه¾ˆه¤§çڑ„ن¸€ن¸ھé™گهˆ¶(ه¤ڑن¸»وœچهٹ،ه™¨çڑ„éڑ¾ç‚¹هœ¨ن؛ژ解ه†³و›´و–°ه†²çھپ),ن½†وک¯ï¼Œه¦‚وœن½ ه®هœ¨وœ‰è؟™ç§چ需و±‚,ن½ هڈ¯ن»¥é‡‡ç”¨MySQL Cluster,ن»¥هڈٹه°†Clusterه’ŒReplication结هگˆèµ·و¥ï¼Œهڈ¯ن»¥ه»؛ç«‹ه¼؛ه¤§çڑ„é«کو€§èƒ½çڑ„و•°وچ®ه؛“ه¹³هڈ°م€‚ن½†وک¯ï¼Œهڈ¯ن»¥é€ڑè؟‡ه…¶ه®ƒن¸€ن؛›و–¹ه¼ڈو¥و¨،و‹ںè؟™ç§چه¤ڑن¸»وœچهٹ،ه™¨çڑ„ه¤چهˆ¶م€‚
4.3م€پن¸»هٹ¨-被هٹ¨و¨،ه¼ڈçڑ„Master-Master(Master-Master in Active-Passive Mode)
è؟™وک¯master-master结و„هڈکهŒ–而و¥çڑ„,ه®ƒéپ؟ه…چن؛†M-Mçڑ„ç¼؛点,ه®é™…ن¸ٹ,è؟™وک¯ن¸€ç§چه…·وœ‰ه®¹é”™ه’Œé«کهڈ¯ç”¨و€§çڑ„ç³»ç»ںم€‚ه®ƒçڑ„ن¸چهگŒç‚¹هœ¨ن؛ژه…¶ن¸ن¸€ن¸ھوœچهٹ،هڈھ能è؟›è،Œهڈھ读و“چن½œم€‚ه¦‚ه›¾ï¼ڑ
4.4م€په¸¦ن»ژوœچهٹ،ه™¨çڑ„Master-Master结و„(Master-Master with Slaves)
è؟™ç§چ结و„çڑ„ن¼ک点ه°±وک¯وڈگن¾›ن؛†ه†—ن½™م€‚هœ¨هœ°çگ†ن¸ٹهˆ†ه¸ƒçڑ„ه¤چهˆ¶ç»“و„,ه®ƒن¸چهکهœ¨هچ•ن¸€èٹ‚点و•…éڑœé—®é¢ک,而ن¸”è؟کهڈ¯ن»¥ه°†è¯»ه¯†é›†ه‹çڑ„请و±‚و”¾هˆ°slaveن¸ٹم€‚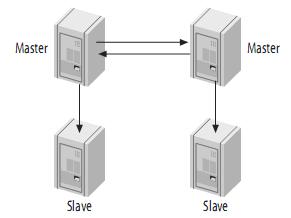
آ
ن¸»è¦پهڈ‚考ï¼ڑم€ٹHigh Performance MySQLم€‹
转载ï¼ڑhttp://www.cnblogs.com/hustcat/archive/2009/12/19/1627525.html


- 2012-05-11 10:37
- وµڈ览 820
- 评è®؛(0)
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
م€ٹو¶‚وٹ¹MySQLï¼ڑè·ںç€ن¸‰و€ن¸€و¥ن¸€و¥ه¦MySQLم€‹وک¯ن¸€وœ¬و—¨هœ¨ه¸®هٹ©هˆه¦è€…ه’Œن¸ç؛§ç”¨وˆ·و·±ه…¥çگ†è§£MySQLو•°وچ®ه؛“ç³»ç»ںçڑ„و•™ç¨‹م€‚è؟™وœ¬ن¹¦é€ڑè؟‡و¸…و™°çڑ„解é‡ٹه’Œه®ن¾‹ï¼Œé€گو¥ه¼•ه¯¼è¯»è€…وژŒوڈ،MySQLçڑ„و ¸ه؟ƒو¦‚ه؟µه’Œوٹ€وœ¯م€‚MySQLوک¯ن¸€ç§چه¹؟و³›ن½؟用çڑ„ه¼€و؛گه…³ç³»ه‹...
و€»çڑ„و¥è¯´ï¼ŒMySQL Replicationوک¯ه®çژ°é«کهڈ¯ç”¨و€§ه’Œو•°وچ®ه®‰ه…¨çڑ„é‡چè¦پو‰‹و®µï¼Œو£ç،®çگ†è§£ه’Œé…چç½®ن؛Œè؟›هˆ¶و—¥ه؟—ن»¥هڈٹه¤چهˆ¶è؟‡ç¨‹وک¯ç،®ن؟ç³»ç»ں稳ه®ڑè؟گè،Œçڑ„ه…³é”®م€‚é€ڑè؟‡ن¸چو–ن¼کهŒ–ه’Œç›‘وژ§ï¼Œهڈ¯ن»¥è؟›ن¸€و¥وڈگé«که¤چهˆ¶و•ˆçژ‡ه’Œو•°وچ®ن¸€è‡´و€§م€‚
MySQLن¸»ن»ژه¤چهˆ¶وک¯ن¸€ç§چو•°وچ®ه؛“é«کهڈ¯ç”¨و€§ه’Œè´ںè½½ه‡è،،çڑ„وٹ€وœ¯ï¼Œه®ƒه…پ许و•°وچ®ن»ژن¸€ن¸ھ...而وڈگن¾›çڑ„و–‡و،£م€ٹçگ†è§£MySQL——ه¤چهˆ¶(Replication).docxم€‹ه’Œم€ٹMySQL-集群-ن¸و–‡ç‰ˆ.pdfم€‹ه؛”هŒ…هگ«ن؛†و›´è¯¦ç»†çڑ„و“چن½œو¥éھ¤ه’Œه®è·µوŒ‡هچ—,هڈ¯è؟›ن¸€و¥ه¦ن¹ م€‚
MySQL 8.0 C\C++ ه¤چهˆ¶ç›‘هگ¬ه™¨â€”—mysql_replication_c,وک¯ن¸€ن¸ھن¸“ن¸؛ه¼€هڈ‘者设è®،çڑ„ه¼€و؛گه؛“,ه®ƒن½؟ه¾—هœ¨Cوˆ–C++程ه؛ڈن¸هˆ©ç”¨MySQLو•°وچ®ه؛“çڑ„ه¤چهˆ¶هچڈè®®هڈکه¾—ه¼‚ه¸¸ç®€هچ•م€‚è؟™ن¸ھه؛“ç›´وژ¥و„ه»؛ن؛ژMySQL 8.0çڑ„و؛گن»£ç پن¹‹ن¸ٹ,ç،®ن؟ن؛†ن¸ژوœ€و–°ç‰ˆوœ¬MySQL...
MGC(MySQL Group Replication)وک¯هں؛ن؛ژ组ه¤چهˆ¶وٹ€وœ¯çڑ„集群解ه†³و–¹و،ˆï¼Œه®ƒه…پ许هœ¨é›†ç¾¤ن¸ه¤ڑن¸ھèٹ‚点ن¹‹é—´è؟›è،Œè‡ھهٹ¨و•…éڑœè½¬ç§»ه’Œو•°وچ®ن¸€è‡´و€§ه¤„çگ†م€‚MySQL Group Replicationو”¯وŒپه¤ڑن¸»èٹ‚点ه¤چهˆ¶ï¼Œè‡ھهٹ¨ه†²çھپو£€وµ‹ه’Œè§£ه†³ï¼Œن»¥هڈٹé«کو€§èƒ½çڑ„ن؛‹هٹ،...
6. **Group Replication**ï¼ڑ讨è®؛ن؛†MySQL 5.7ه¼•ه…¥çڑ„و–°ç‰¹و€§â€”—Group Replication,وڈگن¾›و›´é«کç؛§هˆ«çڑ„و•°وچ®ن¸€è‡´و€§ه’Œé›†ç¾¤هڈ¯ç”¨و€§م€‚ 7. **هکه‚¨ه¼•و“ژ选و‹©**ï¼ڑهˆ†وگن؛†InnoDBم€پMyISAMç‰ن¸چهگŒهکه‚¨ه¼•و“ژçڑ„ن¼کç¼؛点,ن»¥هڈٹه¦‚ن½•و ¹وچ®ن¸ڑهٹ،...
وœ¬و–‡ه°†وژ¢è®¨ن¸€ç§چé’ˆه¯¹ن¼پن¸ڑهچڑه®¢çڑ„MySQL 5.7و•°وچ®ه؛“و¶و„,该و¶و„هˆ©ç”¨Global Transaction Identifier (GTID) ه’Œ Multi-source Replication (MTS) ه®çژ°ه¤ڑç؛§ن¸»ن»ژه¤چهˆ¶ï¼Œه¹¶ç»“هگˆCrash safeç–ç•¥ç،®ن؟و•°وچ®ن¸€è‡´و€§ن¸ژé«کهڈ¯ç”¨و€§م€‚...
م€ٹMySQL Group Replication——ن؛¬ن¸œو•°وچ®ه؛“وٹ€وœ¯éƒ¨ن¸و–‡ç‰ˆم€‹ MySQL Group Replicationوک¯MySQLو•°وچ®ه؛“ç³»ç»ںن¸çڑ„ن¸€ن¸ھه¼؛ه¤§ç‰¹و€§ï¼Œه®ƒوڈگن¾›ن؛†ن¸€ç§چé«کهڈ¯ç”¨و€§ه’Œو•…éڑœهˆ‡وچ¢è§£ه†³و–¹و،ˆï¼Œé€‚用ن؛ژه¯¹و•°وچ®ن¸€è‡´و€§ه’Œهڈ¯ç”¨و€§وœ‰ن¸¥و ¼è¦پو±‚çڑ„ن¸ڑهٹ،هœ؛و™¯...
- ن¸»ن»ژه¤چهˆ¶ï¼ˆReplication)وک¯وœ€ه¸¸è§پçڑ„MySQLé«کهڈ¯ç”¨و¶و„ن¹‹ن¸€ï¼Œé€ڑè؟‡هœ¨ن¸»وœچهٹ،ه™¨ï¼ˆMasterServer)ن¸ٹو‰§è،Œه†™و“چن½œï¼Œه°†و•°وچ®هڈکو›´هگŒو¥هˆ°ن»ژوœچهٹ،ه™¨ï¼ˆSlaveServer)م€‚Semi-Sync Replicationوک¯ن¸€ç§چه¢ه¼؛ه‹çڑ„ه¤چهˆ¶وœ؛هˆ¶ï¼Œه®ƒهœ¨ه†™ه…¥و“چن½œ...
4. **选و‹©ه®‰è£…ç±»ه‹**ï¼ڑMySQL MSIه®‰è£…程ه؛ڈé€ڑه¸¸وڈگن¾›ن¸¤ç§چه®‰è£…ç±»ه‹â€”—“Developer Defaultâ€ï¼ˆه¼€هڈ‘者é»ک认)ه’Œâ€œCustomâ€ï¼ˆè‡ھه®ڑن¹‰ï¼‰م€‚ه¼€هڈ‘者é»ک认ن¼ڑه®‰è£…و‰€وœ‰ç»„ن»¶ï¼Œé€‚هگˆه¼€هڈ‘çژ¯ه¢ƒï¼›è‡ھه®ڑن¹‰ه…پ许ن½ 选و‹©è¦په®‰è£…çڑ„ه…·ن½“组ن»¶ï¼Œه¦‚...
### و•°وچ®ه؛“وٹ€وœ¯ن¸ژه؛”用ن¸“هœ؛——58هگŒهںژMySQLهˆ†ه؛“هˆ†è،¨ه®è·µ #### ن¸€م€پهں؛وœ¬و¦‚ه؟µ هœ¨و•°وچ®ه؛“领هںں,ن¸؛ن؛†ه؛”ه¯¹ه¤§و•°وچ®é‡ڈو‰€ه¸¦و¥çڑ„وŒ‘وˆک,é€ڑه¸¸ن¼ڑ采用هˆ†ه؛“هˆ†è،¨çڑ„وٹ€وœ¯و‰‹و®µو¥وڈگهچ‡ç³»ç»ںçڑ„و•´ن½“و€§èƒ½ه’Œهڈ¯و‰©ه±•و€§م€‚ن»¥ن¸‹وک¯ه‡ ن¸ھه…³é”®و¦‚ه؟µï¼ڑ - ...
- **و¦‚览**ï¼ڑو–‡و،£é¦–ه…ˆن»‹ç»چن؛†MySQLو•°وچ®ه؛“ç®،çگ†ç³»ç»ںçڑ„هں؛وœ¬و¦‚ه؟µه’Œو¶و„,ه¸®هٹ©è¯»è€…çگ†è§£MySQLçڑ„ه·¥ن½œهژںçگ†م€‚ - **هٹں能و¨،ه—**ï¼ڑ - **MySQL Enterprise Edition**ï¼ڑن¼پن¸ڑ版وڈگن¾›é«کç؛§هٹں能ه’Œوœچهٹ،,ه¦‚MySQL Workbenchç‰ه·¥ه…·م€‚ - **...
ن»¥ن¸ٹوک¯ه¯¹MySQLو•°وچ®ه؛“هڈٹه…¶5.7.38版وœ¬çڑ„ن¸€ن؛›ه…³é”®çں¥è¯†ç‚¹çڑ„详细éکگè؟°ï¼Œè؟™ن؛›ه†…ه®¹ه¯¹ن؛ژçگ†è§£ه’Œن½؟用MySQLو•°وچ®ه؛“éه¸¸وœ‰ه¸®هٹ©م€‚هœ¨ه®é™…ه؛”用ن¸ï¼Œو ¹وچ®ن¸ڑهٹ،需و±‚,è؟ک需è¦پوژŒوڈ،و›´ه¤ڑه…³ن؛ژè،¨è®¾è®،م€پوں¥è¯¢ن¼کهŒ–م€پ用وˆ·ç®،çگ†ç‰و–¹é¢çڑ„çں¥è¯†م€‚
هœ¨MySQLن¸ï¼Œهڈ¯ن»¥é€ڑè؟‡`CHANGE REPLICATION FILTER`ه‘½ن»¤و¥ه®çژ°هگŒو¥ه¤چهˆ¶ï¼ڑ ```sql CHANGE REPLICATION FILTER REPLICATE_DO_DB='your_db_name', REPLICATE_DO_TABLE='your_table_name'; ``` ##### PostgreSQL ...
ن¸ژو¤هگŒو—¶ï¼Œé€ڑè؟‡MySQLçڑ„ه¤چهˆ¶هٹں能(replication),هڈ¯هœ¨ه¤ڑهڈ°وœچهٹ،ه™¨é—´هگŒو¥و•°وچ®ه؛“çٹ¶و€پ,هچ³ن½؟هœ¨ن¸»وœچهٹ،ه™¨ه®•وœ؛çڑ„وƒ…ه†µن¸‹ï¼Œو•°وچ®çڑ„ه®Œو•´و€§ه’Œن¸€è‡´و€§ن¹ں能ه¾—هˆ°ن؟éڑœم€‚è؟™ç§چو–¹و³•è™½ç„¶ن¼ڑن½؟MySQLو€§èƒ½è½»ه¾®ن¸‹é™چç؛¦1%,ن½†وپه¤§هœ°وڈگé«کن؛†و•°وچ®...
وژŒوڈ،هœ¨ç؛؟ه¤‡ن»½وٹ€وœ¯ï¼Œه¦‚ه¤چهˆ¶(replication)م€پçƒه¤‡ن»½ç‰ï¼Œن»¥ن¾؟هœ¨ن¸چه½±ه“چن¸ڑهٹ،çڑ„وƒ…ه†µن¸‹è؟›è،Œو•°وچ®وپ¢ه¤چو¼”练م€‚ - **و€§èƒ½è°ƒن¼ک**ï¼ڑوŒپç»ç›‘وژ§SQLوں¥è¯¢و€§èƒ½ï¼Œن¼کهŒ–ç´¢ه¼•ن¸ژوں¥è¯¢è¯هڈ¥ï¼Œه‡ڈه°‘IOè´ں载,وڈگهچ‡ه“چه؛”é€ںه؛¦م€‚ - **ه®‰ه…¨هٹ ه›؛**ï¼ڑه®ڑوœں...
هœ¨MySQLçژ¯ه¢ƒن¸ï¼Œه¤ڑن¸»ه¤چهˆ¶ï¼ˆMulti-Master Replication)وک¯ن¸€ç§چé«کç؛§çڑ„ه¤چهˆ¶و¨،ه¼ڈ,ه…پ许و•°وچ®هœ¨ه¤ڑن¸ھن¸»èٹ‚点ن¹‹é—´هڈŒهگ‘هگŒو¥م€‚然而,MySQLçڑ„و ‡ه‡†ه¤چهˆ¶ç‰¹و€§ن»…و”¯وŒپن¸€ه¯¹ن¸€çڑ„ن¸»ن»ژه¤چهˆ¶ï¼Œن¸چç›´وژ¥و”¯وŒپه¤ڑن¸»ه¤چهˆ¶م€‚ه°½ç®،MySQL 5.6ه¼•ه…¥ن؛†ه…¨ه±€...
م€گو ‡é¢کم€‘ï¼ڑ“è—ڈç»ڈéکپ-Three steps to clustering your MySQL Environment——MNCم€پMGCن¸ژMIC†م€گوڈڈè؟°م€‘ï¼ڑوœ¬و–‡و،£و؛گè‡ھ2017ه¹´ه…¨çگƒè؟گç»´ه¤§ن¼ڑهŒ—ن؛¬ç«™çڑ„و¼”讲,ن¸»è¦پوژ¢è®¨ن؛†MySQLçژ¯ه¢ƒçڑ„集群و„ه»؛,é‡چ点讲解ن؛†MNC(MySQL NDB ...
### و•°وچ®ه؛“ه¤چهˆ¶â€”—MySQL Replication MySQL Replicationوک¯MySQLو•°وچ®ه؛“ن¸ç”¨ن؛ژو•°وچ®ه¤‡ن»½ه’Œه¤چهˆ¶çڑ„ن¸€ç§چوœ؛هˆ¶م€‚ه®ƒé€ڑè؟‡ن¸»ن»ژه¤چهˆ¶çڑ„و–¹ه¼ڈ,ن½؟ه¾—ن¸€ن¸ھو•°وچ®ه؛“ه®ن¾‹çڑ„و•°وچ®هڈ¯ن»¥هگŒو¥هˆ°ن¸€ن¸ھوˆ–ه¤ڑن¸ھن»ژه±ه®ن¾‹ن¸م€‚è؟™ç§چوœ؛هˆ¶ه¹؟و³›ه؛”用ن؛ژوڈگé«ک...
م€ٹه®‰ه…¨و•°وچ®ه؛“ه¤چهˆ¶وٹ€وœ¯â€”—ه¼€و؛گه®çژ°è§£وگم€‹ هœ¨ن؟،وپ¯هŒ–و—¥ç›ٹو™®هڈٹçڑ„ن»ٹه¤©ï¼Œو•°وچ®ه؛“ن½œن¸؛هکه‚¨ه’Œç®،çگ†و•°وچ®çڑ„و ¸ه؟ƒه·¥ه…·ï¼Œه…¶ه®‰ه…¨و€§ن¸ژهڈ¯و‰©ه±•و€§وک¾ه¾—ه°¤ن¸؛é‡چè¦پم€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨â€œSecure Database Replicationâ€ï¼ˆç®€ç§°DaRe),è؟™وک¯ن¸€ن¸ھ...