- 浏览: 83407 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
qy1277378942:
博主,你好,请问你博客中的类图是用什么工具画出来的
Spring 框架的设计理念与设计模式分析
1 前言
流程引擎
内核仅是“满足Process基本运行”的最微小结构,而整个引擎则要复杂很多,包括“状态存储”、“事件处理”、“组织适配”、“时间调度”、“消息服
务”等等外围的服务性功能。引擎内核,仅包含最基本的对象和服务,以及用于解决流程运行问题的调度机制和执行机制。
如果,你掌握了一个流程引擎的灵魂,你才有能力理解它的全部。否则,一个引擎对你来说,可能只是一个复杂的结构,丰富多彩API、令人眼花缭乱的“功能”和“服务”而已。
本身工作流这个领域就是一个很“狭窄”的领域,国内的厂商也不是很多,其中有部分实现技术并不弱。但可能涉于安全等因素,并没有多少技术人员探讨“深度的
工作流技术实现问题”。而广大的开发爱好者却还在花费大量的时间在摸索“如何理解工作流、如何应用工作流”。
所以在此之前,国内尚未有一篇技术文章探讨工作流引擎内核的实现,当然也没有探讨jBpm引擎内核的文章了。
对于这方面的技术分享,开源是个不错的突破口。
本篇就是以jBpm为实例,来诠释工
作流引擎的内核设计思路和结构。但是这仅仅是从jBpm的实现角度来辅助大家理解,因为工作流引擎内核的设计、实现是有很多方式:这会因所选的模型、调度
算法、推进机制、状态变迁机制、执行机制等多方面的不一样,而会差别很大。比如基于Activity
Diagram模型的jBpm和基于FSM模型的OSWorkflow引擎内核之间就有很大的差别。
相比较而言,jBpm的模型比较复杂,而引擎内核实现的比较“精简”,非常便于大家“由浅入深的理解”。
2 阅读本篇的基础准备
2.1 概念的基础
本文的读者群主要是面向有一定工作流基本概念的开发人员。所以本文认为你已经具备了如下基本工作流知识:
(1) 初步了解工作流系统结构。比如理解工作流引擎在工作流系统中所处的位置和作用
(2) 对流程定义(Process Definition)和流程实例(Process Instance)相关对象有所了解。比如理解Process Instance代表什么,工作项(WorkItem)代表什么。
2.2 环境的基础
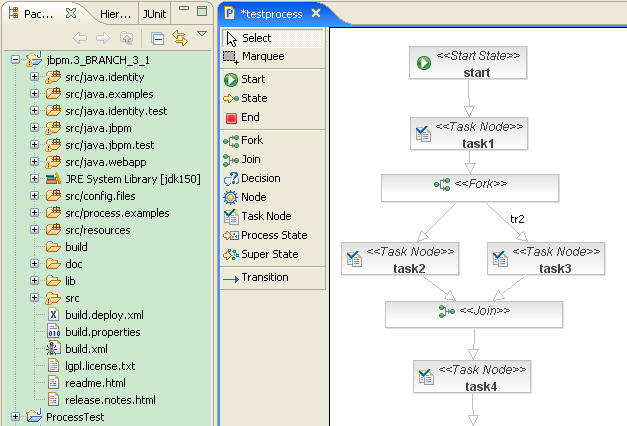
在阅读本篇的时候,如果你已经搭建了一套jbpm的开发环境,那么将有助于你更容易理解本篇的很多内容,也便于实际体验代码。从www.jbpm.org
官方网站下载jbpm-starters-kit开发包,按照其参考手册,可以很容易在eclipse开发环境中建立项目,效果图类似如下:
3 什么是流程引擎内核?
我比较推崇“微内核的流程引擎构架”,并在最近两三年内写了两篇探讨此方面的文章:第一篇是写于05年7月份的《微内核流程引擎架构体系》,第二篇是07年7月份的《微内核过程引擎的设计思路和构架》(受普元《银弹》杂志约稿所写,尚未对外公开)。
但至今对外阐述引擎内核到底是什么。
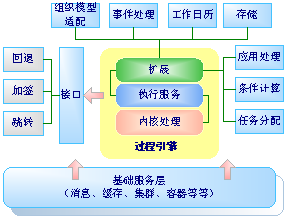
正如上面的两张图所示,我们可以通过“微内核”的构架来使得流程引擎的结构更加“清晰”。而能否实现“微内核”的根本,则是看你是否能够设计并抽象出“良好的引擎内核结构”。
很显然,要想设计出一套结构优良的引擎内核,首要条件就是:明白什么是引擎内核。
首先我们需要明白引擎是什么,引擎可以做什么。这在WfMC的《工作流参考模型》中已经有很详细的解答,本文不再重复。知道这个仅仅是不够的,你还需要很
清晰的明白如何去“为流程建模”,而这则在Aalst大师所著的《工作流管理——模型、方法、系统》一书有细致阐述,本文也不再重复。
但很可惜,至今尚未有一本专门的书籍来论述“过程建模方法”的,或者说如何利用这些既有的“过程建模方法(诸如FSM、PetriNet、EPC、
Activity Diagram等等)”来解决流程问题。这个只能分别查阅相关资料,此处也不叙述。因为文本只讲“引擎内核”。
如
果我们暂且把那复杂的流程业务性问题,诸如“组织模型分配”、“分支条件计算”、“事件处理”、“消息调度”、“工作项处理”、“存储”、“应用处理”、
以及那些“变态的诸如会签、回退之类的模型”都统统的抛弃,只留下“最单纯的过程性问题”,也就是“解决一个过程运行问题,按秩序的从一个节点到另一个节
点的执行”。——这就是引擎内核所关注的根本问题。
上面这句话,估计会引起很多人“拍砖”。在很多人看来,工作流之所以看起来很“难”,就是因为这些复杂多变的“业务性问题”都统统绑在一个“引擎”上造成的。
其实,这是两个“维度”的问题,也就是“引擎的抽象”和“引擎的应用”这两个不同维度,不同层面的问题。但这绝不是两个独立的问题,“引擎的抽象”的好与
坏,直接影响到“引擎的应用”的可复杂度和可支持度,当然我们也不能否认,“引擎的应用”问题也是一个很复杂的问题。但本文是站在“引擎的抽象”这个维度
来阐述问题的。对于“引擎的应用”问题,可参考我的前作:2003年11月份的《工作流模型分析》、2003年12月份的《工作流授权控制模型》、
2004年7月份的《工作流系统中组织模型应用解决方案》。
也就是说,本文不是指导大家如何去“使用jbpm”,而是阐述“jbpm的引擎的内核部分是如何构建的”。但本文的主旨不是告诉大家“jBpm是如何设计引擎内核的”,而是以jBpm为例,来介绍“引擎内核”。
4 引擎内核所关注的四个主要问题
引擎内核所关注的是一个非常“抽象”层面的问题,而不同引擎关注的“一套完整的执行环境”。或者我们可以这么来说,引擎内核的职责是非常“精简”的:确保流程按照既有的定义,从一个节点运行到另一个节点,并正确执行当前节点。
总的来说,引擎内核主要关注四个方面的问题:
(1) 流程定义问题:不是说如何图形化的定义流程,而是如何用一套定义对象,来诠释所定义的流程。
(2) 流程调度问题:提供什么的机制,可以确保流程能够处理复杂的“流程图结构”,诸如串行、并行、分支、聚合等等,并在这复杂结构中确保流程从一个节点运行到另一个节点。
(3) 流程执行问题:当流程运行到某个节点的时候,需要一套机制来解决:是否执行此节点,并如何执行此节点的问题,并维持节点状态生命周期。
(4) 流程实例对象:需要一整套流程实例对象来描述流程实例运行的状态和结果。
4.1 模型与定义对象
工作流引擎本身就是一种“base on model”的组件,流程实例的执行都是依赖于所定义的“流程定义”,而工作流引擎则是提供了这样一种环境,来维持流程实例的运行。
所以引擎内核,必须提供一套定义对象来描述“流程定义”,并且这些定义对象必须反映出一种“模型”。比如jBpm的定义对象,是与其所基于的Activity Diagram模型相对应的。
4.2 调度机制与算法
引擎内核的另一个重要功能,就是保证流程实例准确的从一个节点运行到另一个节点,而这则需要依赖于一套调度机制。
引擎的调度机制有很多种实现方法,有的甚至是与“所依赖的模型有关”。但普遍来讲,很多引擎都受到Petri Net的影响,而采用token来调度。
jBpm本身就吸纳的token这套机制,当然,与Petri Net的调度机制还是有所区别。我们将在下面的章节详细介绍。
4.3 执行机制与状态
经过引擎的调度,实例运行到某个节点了,此时必须必须提供一套机制,来判断当前节点是否可执行,如果可执行,那么需要提供一套runtime envrioment来执行节点——这就是引擎的执行机制。
复杂的流程引擎会依赖于“流程实例状态”或“活动实例状态”的约束和变迁来进行处理。之所有有时候我们会把一个流程引擎也叫做“状态机”,很大程度上也是这个原因。
4.4 实例对象与执行环境
每个一个流程实例,必须维护一套属于自己的“运行环境和数据”,而这则是实例对象的责任了。基本上实例对象会包含如下信息:
(1) 与流程实例的状态或控制信息
(2) 与活动实例的状态或控制信息。如果某些引擎不支持活动实例,那么必然会有某些其他实例信息,可以当前节点的状或控制信息。
(3) 一些临时的“执行”信息,便于引擎针对某种情况进行处理
5 jbpm,“精简”的开源流程引擎
好的开源工作流引擎不多,jbpm和osworkflow算是其中两个有特色而且比较容易实际应用的。目前一些国内的中小型流程应用项目,就是在jbpm
或osworkflow的基础上扩展实现。jBpm采用了Activity Diagram的模型,而osworkflow则是FSM的模型。
当然,这仅仅是jbpm3之后的事情。自从被Jboss收购之后,jbpm对早先的2.0构架进行了重组,整个结构完全本着“微内核”的思想进行设计。
现在这里从技术角度来分析jbpm3的优点,简单罗列几个大家都容易看见的:
(1) jbpm的模型是采用UML Activity Diagram的语义,所以便于开发人员理解流程。
(2) jbpm提供了可扩展的Event-Action机制,来辅助活动的扩展处理。
(3) jbpm提供了灵活的条件表达式机制,来辅助条件解析、脚本计算的处理。
(4) jbpm提供了可扩展的Task及分配机制,来满足复杂人工活动的处理。
(5) 借助hibernate的ORM的优势,jbpm能够很容易支持多种数据库。
当然,还有一些优点,是很多开发人员并不太注意的,比如:
(1) jbpm的Node机制非常灵活,开发人员可以很容易定制“业务化语义的节点”,并满足运行时候处理的需要。
有很多灵活的优点,当然也少不了存在一些“局限”。
(1) 很显然,只能有一个start-state。
(2) jbpm依靠Token来调度和计算,在同一个时刻中,一个ProcessInstance只允许一个Token对象只存在一个Node中(分支当然用Child Token对象处理)。所以本质上就不支持“multi-instance”模式。
(3) jbpm作为一款开源的工作流引擎,其更多的是关注“如何辅助你更容易的让流程运行完成”,但是并不记录“流程运行的历史和轨迹”。这一点可能是东西方文化的差异性所在,因为国内的流程应用,比较关注“运行轨迹”。
至于其他的一些局限,比如不支持“回退”、“跳转”等操作,这也是因为东西方文化的差异所在。西方人认为“往回流转的情况肯定也是一种业务规则所定义,那
么肯定可以通过分支或条件来解决”,而东方则把“回退作为一个人性化管理和处理的潜在特点”。所以诸如此类的一些“特定需求”,估计只能通过扩展jbpm
来实现了,甚至有时候,简单的扩展是无法解决问题的——正如上一节所说的那样,“引擎的抽象”会影响“引擎的应用”的复杂度支持。
但是,当你试图修改jbpm代码的时候,你会顾虑jbpm的LGPL协议吗?(很多国内企业从来不考虑这个协议问题,寒)。
6 jBpm流程模型与定义对象
6.1 首先解决如何形式化描述一个流程的问题
这里说的“定义流程”并不是说jbpm3中那个基于eclipse plugin的图形化建模工具。而是如何去解决“形式化的描述一个流程”的问题。
形式化的描述流程并不是一个简单的问题,从上世纪七十开始,人们就在探索用各种各样多的模型来描绘流程:Petri Net, FSM, EPC,
Activity Diagram, 以及近来的XPDL MetaModel等等,延伸到如今的BPEL,BPMN,BPMD等等。
jBpm采用了Activity Diagram的模型语义:其将用Start State、State、Action State(Task
Node)、End State、Fork、Join、Decision、Merge、Process
State这几个“元素”的组合来描述任何一个流程。其中Action State是Activity
Diagram中的标准语义,在jBpm为了便于大家理解和使用,jBpm采用了TaskNode这个语义。
在WfMC的Workflow Reference Model中,对流程引擎的功能描述,其中就包含一项:解析流程定义。如果想满足这这功能,前提条件就必须有最基本的两个:
(1) 有一套形式化的描述语言(通常为xml格式)。利用这个描述语言可以描述一个流程的定义。比如WfMC所提出的XPDL这个描述语言。当然,jBpm也有自己的一套,名为jPDL,也是一个xml格式的。
(2) 有一套对象集可以反映流程的定义模型和结果,一般叫做定义对象。流程引擎就需要把“xml格式的流程定义”解析为一套对象,而这套对象的结构则反映了流程的结构。
我们暂且不去探讨jPDL那个形式化的xml语言,而把重心放在jBpm那套定义对象中。因为这个定义对象是属于Engine Kernel的一部分。
6.2 抽象的节点(Node)和转移(Transition)
面向对象的继承性、多态性可以让我们从最抽象的部分来描述对象。那么这套定义对象也需要从最基础的“抽象”说起。
process
的本质就是“节点”和“有向弧”,当然你也可以说是Node和Link,或者Node和Transition,或者Activity和
Transition等等之类的。jBpm采用的是Node和Transition来表示“节点”和“有向弧”。于是乎,在jbpm中你可以看到这样的结
构关系:
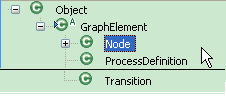
对于一个节点来说,从定义角度,其只关心几个事情:
(1) 这是个什么类型的节点。这个节点可能是start state,也可能是一个task node,或者是一个fork。
(2) 这个节点的转入Transition和转出Transition。
可能有的人会说,还需要关心节点的转入转出的类型,比如And Splite或者Xor
Join之类。这个并没有错,因为很多流程模型的节点元素需要考虑这个,比如WfMC的XPDL模型。但是jBpm的节点是没有这样的属性的,或者说的更
准确些,是Activity Diagram模型的节点没有这样的特性。活动图是采用“Fork”、“Join”这样的节点来解决“分支”问题。
6.3 流程:节点与转移的组合
仅利用节点和转移的组合,就可以表达一个“过程(Process)”。当然这个流程只能告诉人们“大概的业务过程”,当然不包括很复杂的信息。如下图所示: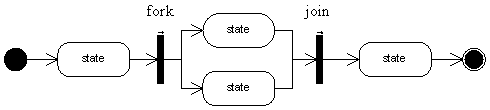
这是一张非常标准的“活动图”,如果我们用jbpm的设计器,看看这样一张“流程图”: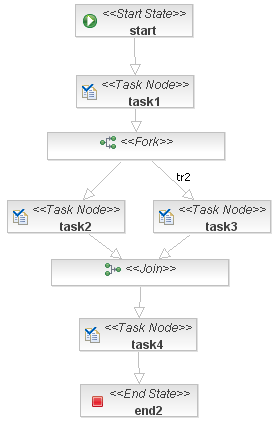
不论你如何绘画,改变不了这张图的本质:它就只有两个基本元素:节点和转移。只是有的节点是start-state,有的是task-node,有的是join,有的是end state而已。
6.4 节点的类型和扩展
我们可以通过定义自己的Node节点对象,来补充jbpm自定的节点对象。只需要extends
Node,并重写读写xml的read和write方法,重写负责执行的execute方法,在org/jbpm/graph/node
/node.types.xml中配置即可,当然,你可以写的更加复杂,更加业务化的节点。
7 jBpm的过程调度机制
7.1 吸纳自Petri Net思想
jBpm的过程调度机制是吸纳了Petri Net的一些思想。
jBpm采用Token来表示当前实例运行的位置,也利用token在流程各个点之间的转移来表示流程的推进,如下图所示:

当jbpm试图去启动一个流程的时候,首先是构造一个流程实例,并为此流程实例创建一个Root Token,并把这个Root Token放置在Start Node上。
以下截取部分代码实现,仅供参考。手头有jbpm3相应开发环境的朋友,可以打开ProcessInstance和Token这两个类。(注:以下所有参考代码,为了突出主题,都已经将实际代码中的event,log等处理删除)
|
public ProcessInstance( ProcessDefinition processDefinition ) { public Token(ProcessInstance processInstance) { |
jbpm是允许在start-state执行Task的,也允许在start-state创建工人任务。不过此处我们不予讨论。
7.2 Token的推进
当Token已经在Start-State节点了,我们可以开始往前推进,来促使流程实例往前运行。对于外部操作来说,触发流程实例往下运行的操作有两个:
(1) 强制执行ProcessInstance的signal操作
(2) 执行TaskInstance的end操作。
但是,这两个操作,都是通过“当前token的signal操作”来内部实现的,如下图所示:
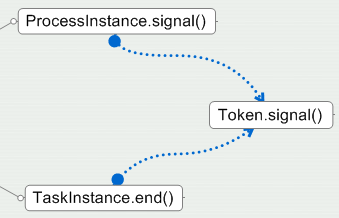
Token的Signal操作表示:实例需要离开当前token所在的节点,转移到下一个节点上。因为Node与Node之间是“Transition”
这个桥梁,所以,在转移过程中,会首先把Token放入相关连的Transtion对象中,再由Transition对象把Token交给下一个节点。
让我们来看看Token类中signal方法的部分代码实现,仅供参考:
|
public void signal() { void signal(Transition transition, ExecutionContext executionContext) { |
接下来,请注意node.leave()这个操作。这是一个很有意思的语义转换:我们是采用token的signal操作来表示往下一个节点推进,但是实际确实执行的node.leave ()操作。
如果这地方让你自己来实现,代码会不会就是这样子呢?不妨此处想一想。
|
//假设代码,仅供思考 void signal(Transition transition, ExecutionContext executionContext) { transition.take(executionContext); } |
前面说
过,jbpm的调度机制吸纳的Petri Net的思想。在Petri
Net中,并没有transition中驻留token这个语义,token只驻留在库所(Place)中。所以,jbpm此处的设计思路,是于此有一定
关系的。所以只是把一个ExecutionContext对象放在了transition中,而不是一个token对象。
让我们来看看node对象的leave方法:
|
public void leave(ExecutionContext executionContext, Transition transition) { Token token = executionContext.getToken(); token.setNode(this); executionContext.setTransition(transition); executionContext.setTransitionSource(this); transition.take(executionContext); } |
我们直接跟踪进Transition的take操作:
|
public void take(ExecutionContext executionContext) { executionContext.getToken().setNode(null); // pass the token to the destinationNode node to.enter(executionContext); } |
经过这么多的中间步骤,我们终于把ExecutionContext对象从一个node转移到下一个node了。让我们来看看Node对象的enter操作:
|
public void enter(ExecutionContext executionContext) { Token token = executionContext.getToken(); token.setNode(this); // remove the transition references from the runtime context executionContext.setTransition(null); executionContext.setTransitionSource(null); // execute the node if (isAsync) { } else { execute(executionContext); } } |
至此,jBpm成功的从一个节点转移到下一个节点了。—— 这就是jbpm的调度机制。
7.3 非常简单的调度机制
怎么样,是不是非常的简单?
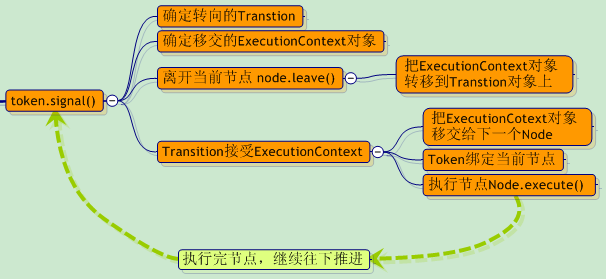
让我们把整个过程,用一张更清晰的“思维图”来展示一下:
8 jBpm的过程执行机制
8.1 执行机制
前面我们的“过程调度机制”是为了让流程可以正确的从“一个节点转移到下一个节点”,而本节所要讲解的jbpm“执行机制”,则是为提供一个运行机制,来保证“节点的正确执行”。
首先我们需要明确如下的概念:
(1) 节点有很多中,每种节点的执行方式肯定是不一样的
(2) 节点有自己的生命周期,不同的生命周期阶段,所处的状态不同。
在WfMC的《工作流参考模型》文档中,为活动实例归纳了几个可参考的生命周期。(仅供参考,实际很多工作流引擎的节点的生命周期要比这复杂)
但是,jbpm并没有突出“节点生命周期”这个理念,仅仅只是在“Event”中体现出出来。在我看来,可能的原因有两个:
(1) jBpm没有NodeInstance这个概念。利用Token和TaskInstance,jBpm足以持久化足够的信息,能够让流程实例迅速定位到当前运行的状态。
(2) jBpm的Event已经很丰富,并且这个Event是围绕“Token的转移”而设置的,并不是围绕Node的生命周期设置的。
(3) 通常我们需要在Active和Completed的生命周期内所要操作的分支与聚合,在jBpm模型中分别由Fork、Join之类的节点替代。所以jBpm过分关注Node生命周期的管理意义不是非常大。
作为个人,我并不行赏jBpm这样抛弃“节点生命周期管理”的实现方式,更行赏OBE(最早的基于XPDL模型的java工作流引擎之一)的生命周期约束
和管理。但是,也不得不承认,jBpm规避了“繁琐的状态维护”,反而让处理变得“简易”,也更容易被大家所理解和接受,而这也正是OBE逐渐消失的一个
原因:过于复杂和臃肿。
让我们在前面那张jBpm的“调度机制思维图”上,再稍稍补充一点(为了突出显示,与上图有所改动)。
这张图应该可以很好的诠释出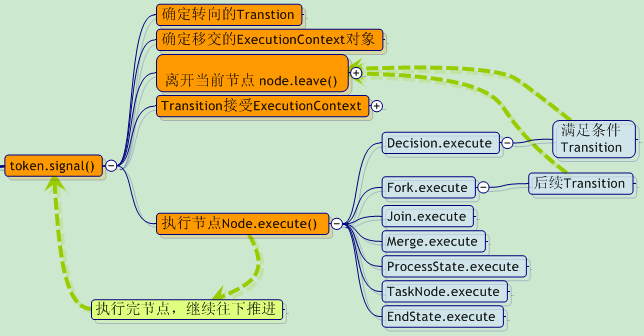 , jBpm是如何执行各种节点的,这也是得益于OO的“多态与继承”特性。
, jBpm是如何执行各种节点的,这也是得益于OO的“多态与继承”特性。
8.2 分支处理
jBpm的执行机制非常简单,但还是需要稍微补充一下有关“分支”方面的处理。
jBpm采用sub token的机制来解决分支方面的处理:当遇到有分支的时候,会为每个分支节点创建一个child token。在聚合节点(Join或Merge),则依赖其同步或异步的聚合方式,来分别处理。
比如我们参看Fork节点的执行代码(为了突出重点,省略部分代码):
|
public void execute(ExecutionContext executionContext) { Token token = executionContext.getToken(); Iterator iter = transitionNames.iterator(); while (iter.hasNext()) { String transitionName = (String) iter.next(); forkedTokens.add(createForkedToken(token, transitionName)); } iter = forkedTokens.iterator(); while( iter.hasNext() ) { //省略部分代码 ExecutionContext childExecutionContext = new ExecutionContext(childToken); leave(childExecutionContext, leavingTransitionName); } } protected ForkedToken createForkedToken(Token parent, String transitionName) { Token childToken = new Token(parent, getTokenName(parent, transitionName)); forkedToken = new ForkedToken(childToken, transitionName); return forkedToken; } |
至于Merge节点,我想此处不用在累赘的展示,有兴趣的,可以参看Merge类的execute方法,即可。
9 jBpm内核结构与实例对象
Jbpm引擎内核的结构非常“精简”。除了我们上面所说的那些定义对象(各种Node节点和Transtion),还有几个与“运行实例”相关的对象。如
下图所示,jbpm引擎内核对象主要是在org.jbpm.graph.def和org.jbpm.graph.exe包。
(1) 我们需要描述一个流程实例,所以需要一个ProcessInstance对象。
(2) 每个流程实例,都会维护一套属于其自己的“执行环境”,也就是ExecutionContext对象。注意,这里是一套,而不是一个。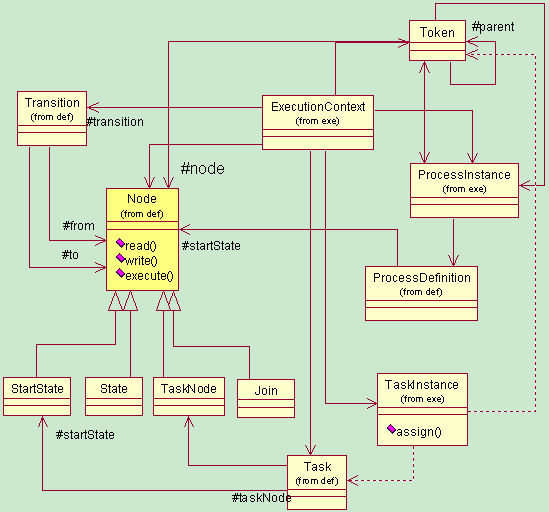
10 后记
上半年写了些bpm和SOA的文章,也被csdn的好友拉着忽悠了不少这方面的概念,弄的好像我开始搞这方面的工作似的。其实不然,本质工作与这有“天壤
之别”,完全是非常底层的java技术应用。而workflow,也有两三年没有从事这方面的开发了,所以写此篇文章,着实费了点功夫。
想痛痛快快写篇有关“引擎内核”的文章,这个想法由来以及了,却担心自己不足以诠释清楚,反而容易误导他人,遂中途多次放弃。
正如前面所说的那样,引擎内核的实现,并没有一套“固定的模式”或者“固定的实现体系”,会因为很多因素而造成实现不同。如果想把“引擎内核”的实现真正诠释清楚,必须把这些相关因素都诠释明朗——但这依然是一个浩大的工程。
前些日子,受朋友所托,为他们的公司学员讲了几节工作流的课程,期间尝试jBpm来诠释了一下引擎的实现思路,发现效果不错。——受此引发,遂萌发了以jBpm为实例,来简单诠释“流程引擎内核”想法。
耗时一周的业余时间,虽然还很难诠释自己的全部想法,但“点出几个要点”,还是应该有了。


发表评论

-
JBPM知识点------Transitions
2012-05-04 14:36 0JBPM知识点- ... -
JBPM知识点------state
2012-05-04 14:36 0JBPM知识点-- ... -
JBPM知识点------decision
2012-05-04 14:35 0JBPM知识点-- ... -
JBPM知识点------fork、join
2012-05-04 14:35 0JBPM知识点-- ... -
JBPM知识点------Actions
2012-05-04 14:34 0JBPM知识点-- ... -
JBPM知识点------exception-handler
2012-05-04 14:34 0JBPM知识点-- ... -
JBPM知识点------Superstates、event
2012-05-04 14:34 0JBPM知识点- ... -
JBPM知识点------node
2012-05-04 14:33 0JBPM知识点-- ... -
JBPM知识点------ContextInstance
2012-05-04 14:33 0JBPM知识点- ... -
JBPM知识点------tasknode
2012-05-04 14:32 842JBPM知� ... -
JBPM知识点------identity
2012-05-04 14:32 755JBPM知 ... -
JBPM知识点------timer、Scheduler
2012-05-04 14:31 896JBPM知识点- ... -
JBPM知识点------JPDL3.1规范
2012-05-04 14:29 808JBPM知识点- ...
相关推荐
全国大学生智能汽车竞赛自2006年起,由教育部高等教育司委托高等学校自动化类教学指导委员会举办,旨在加强学生实践、创新能力和培养团队精神的一项创意性科技竞赛。该竞赛至今已成功举办多届,吸引了众多高校学生的积极参与,此文件为智能车竞赛介绍
字卡v4.3.4 原版 三种UI+关键字卡控制+支持获取用户信息+支持强制关注 集卡模块从一开始的版本到助力版本再到现在的新规则版本。 集卡模块难度主要在于 如何控制各种不同的字卡组合 被粉丝集齐的数量。 如果不控制那么一定会出现超过数量的粉丝集到指定的字卡组合,造成奖品不够的混乱,如果大奖价值高的话,超过数量的粉丝集到大奖后,就造成商家的活动费用超支了。我们冥思苦想如何才能限制集到指定字卡组合的粉丝数,后我们想到了和支付宝一样的选一张关键字卡来进行规则设置的方式来进行限制,根据奖品所需的关键字卡数,设定规则就可以控制每种奖品所需字卡组合被粉丝集到的数量,规则可以在活动进行中根据需要进行修改,活动规则灵活度高。新版的集卡规则,在此次政府发布号的活动中经受了考验,集到指定字卡组合的粉丝没有超出规则限制。有了这个规则限制后,您无需盯着活动,建好活动后就无人值守让活动进行就行了,您只需要时不时来看下蹭蹭上涨的活动数据即可。 被封? 无需担心,模块内置有防封功能,支持隐藏主域名,显示炮灰域名,保护活动安全进行。 活动准备? 只需要您有一个认证服务号即可,支持订阅号借用认证服务号来做活动。如果您
出口设备线体程序详解:PLC通讯下的V90控制与开源FB284工艺对象实战指南,出口设备线体程序详解:PLC通讯与V90控制集成,工艺对象与FB284协同工作,开源学习V90控制技能,出口设备1200线体程序,多个plc走通讯,内部有多个v90,采用工艺对象与fb284 共同控制,功能快全部开源,能快速学会v90的控制 ,出口设备; 1200线体程序; PLC通讯; 多个V90; 工艺对象; FB284; 功能开源; V90控制。,V90工艺控制:开源功能快,快速掌握1200线体程序与PLC通讯
基于Arduino与DAC8031的心电信号模拟器资料:心电信号与正弦波的双重输出应用方案,Arduino与DAC8031心电信号模拟器:生成心电信号与正弦波输出功能详解,基于arduino +DAC8031的心电信号模拟器资料,可输出心电信号,和正弦波 ,基于Arduino;DAC8031;心电信号模拟器;输出心电信号;正弦波输出;模拟器资料,基于Arduino与DAC8031的心电信号模拟器:输出心电与正弦波
MATLAB口罩检测的基本流程 图像采集:通过摄像头或其他图像采集设备获取包含面部的图像。 图像预处理:对采集到的图像进行灰度化、去噪、直方图均衡化等预处理操作,以提高图像质量,便于后续的人脸检测和口罩检测。 人脸检测:利用Haar特征、LBP特征等经典方法或深度学习模型(如MTCNN、FaceBoxes等)在预处理后的图像中定位人脸区域。 口罩检测:在检测到的人脸区域内,进一步分析是否佩戴口罩。这可以通过检测口罩的边缘、纹理等特征,或使用已经训练好的口罩检测模型来实现。 结果输出:将检测结果以可视化方式展示,如在图像上标注人脸和口罩区域,或输出文字提示是否佩戴口罩。
1、文件内容:kernel-debug-devel-3.10.0-1160.119.1.el7.rpm以及相关依赖 2、文件形式:tar.gz压缩包 3、安装指令: #Step1、解压 tar -zxvf /mnt/data/output/kernel-debug-devel-3.10.0-1160.119.1.el7.tar.gz #Step2、进入解压后的目录,执行安装 sudo rpm -ivh *.rpm 4、更多资源/技术支持:公众号禅静编程坊
该文档提供了一个关于供应链管理系统开发的详细指南,重点介绍了项目安排、技术实现和框架搭建的相关内容。 文档分为以下几个关键部分: 项目安排:主要步骤包括搭建框架(1天),基础数据模块和权限管理(4天),以及应收应付和销售管理(5天)。 供应链概念:供应链系统的核心流程是通过采购商品放入仓库,并在销售时从仓库提取商品,涉及三个主要订单:采购订单、销售订单和调拨订单。 大数据的应用:介绍了数据挖掘、ETL(数据抽取)和BI(商业智能)在供应链管理中的应用。 技术实现:讲述了DAO(数据访问对象)的重用、服务层的重用、以及前端JS的继承机制、jQuery插件开发等技术细节。 系统框架搭建:包括Maven环境的配置、Web工程的创建、持久化类和映射文件的编写,以及Spring配置文件的实现。 DAO的需求和功能:供应链管理系统的各个模块都涉及分页查询、条件查询、删除、增加、修改操作等需求。 泛型的应用:通过示例说明了在Java语言中如何使用泛型来实现模块化和可扩展性。 文档非常技术导向,适合开发人员参考,用于构建供应链管理系统的架构和功能模块。
1.版本:matlab2014/2019a/2024a 2.附赠案例数据可直接运行matlab程序。 3.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。 4.适用对象:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业和毕业设计。
C#与VB实现欧姆龙PLC的Fins TCP通信案例源码:调用动态链接库进行数据读写,定时器与计数器数据区的简洁读写操作示例,C#与VB实现欧姆龙PLC的Fins TCP通信案例源码:调用动态链接库进行读写操作,涵盖定时器计数器数据区学习案例,C#欧姆龙plc Fins Tcp通信案例上位机源码,有c#和VB的Demo,c#上位机和欧姆龙plc通讯案例源码,调用动态链接库,可以实现上位机的数据连接,可以简单实现D区W区定时器计数器等数据区的读写,是一个非常好的学习案例 ,C#; 欧姆龙PLC; Fins Tcp通信; 上位机源码; 动态链接库; 数据连接; D区W区读写; 定时器计数器; 学习案例,C#实现欧姆龙PLC Fins Tcp通信上位机源码,读写数据区高效学习案例
可调谐石墨烯超材料吸收体的FDTD仿真模拟研究报告:吸收光谱的化学势调节策略与仿真源文件解析,可调谐石墨烯超材料吸收体:化学势调节光谱的FDTD仿真模拟研究,可调谐石墨烯超材料吸收体FDTD仿真模拟 【案例内容】该案例提供了一种可调谐石墨烯超材料吸收体,其吸收光谱可以通过改变施加于石墨烯的化学势来进行调节。 【案例文件】仿真源文件 ,可调谐石墨烯超材料吸收体; FDTD仿真模拟; 化学势调节; 仿真源文件,石墨烯超材料吸收体:FDTD仿真调节吸收光谱案例解析
RBF神经网络控制仿真-第二版
松下PLC与威纶通触摸屏转盘设备控制:FPWINPRO7与EBPRO智能编程与宏指令应用,松下PLC与威纶通触摸屏转盘设备控制解决方案:FPWINPRO7与EBPRO协同工作,实现多工位转盘加工与IEC编程模式控制,松下PLC+威纶通触摸屏的转盘设备 松下PLC工程使用程序版本为FPWINPRO7 7.6.0.0版本 威纶通HMI工程使用程序版本为EBPRO 6.07.02.410S 1.多工位转盘加工控制。 2.国际标准IEC编程模式。 3.触摸屏宏指令应用控制。 ,松下PLC; 威纶通触摸屏; 转盘设备控制; 多工位加工控制; IEC编程模式; 触摸屏宏指令应用,松下PLC与威纶通HMI联控的转盘设备控制程序解析
基于循环神经网络(RNN)的多输入单输出预测模型(适用于时间序列预测与回归分析,需Matlab 2021及以上版本),基于循环神经网络(RNN)的多输入单输出预测模型(matlab版本2021+),真实值与预测值对比,多种评价指标与线性拟合展示。,RNN预测模型做多输入单输出预测模型,直接替数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用ma
1.版本:matlab2014/2019a/2024a 2.附赠案例数据可直接运行matlab程序。 3.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。 4.适用对象:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业和毕业设计。
旅游管理系统中的功能模块主要是实现管理员;首页、个人中心、用户管理、旅游方案管理、旅游购买管理、系统管理,用户;首页、个人中心、旅游方案管理、旅游购买管理、我的收藏管理。前台首页;首页、旅游方案、旅游资讯、个人中心、后台管理等功能。经过认真细致的研究,精心准备和规划,最后测试成功,系统可以正常使用。分析功能调整与旅游管理系统实现的实际需求相结合,讨论了Java开发旅游管理系统的使用。 从上面的描述中可以基本可以实现软件的功能: 1、开发实现旅游管理系统的整个系统程序; 2、管理员;首页、个人中心、用户管理、旅游方案管理、旅游购买管理、系统管理等。 3、用户:首页、个人中心、旅游方案管理、旅游购买管理、我的收藏管理。 4、前台首页:首页、旅游方案、旅游资讯、个人中心、后台管理等相应操作; 5、基础数据管理:实现系统基本信息的添加、修改及删除等操作,并且根据需求进行交流查看及回复相应操作。
Boost二级升压光伏并网结构的Simulink建模与MPPT最大功率点追踪:基于功率反馈的扰动观察法调整电压方向研究,Boost二级升压光伏并网结构的Simulink建模与MPPT最大功率点追踪:基于功率反馈的扰动观察法调整电压方向研究,Boost二级升压光伏并网结构,Simulink建模,MPPT最大功率点追踪,扰动观察法采用功率反馈方式,若ΔP>0,说明电压调整的方向正确,可以继续按原方向进行“干扰”;若ΔP<0,说明电压调整的方向错误,需要对“干扰”的方向进行改变。 ,Boost升压;光伏并网结构;Simulink建模;MPPT最大功率点追踪;扰动观察法;功率反馈;电压调整方向。,光伏并网结构中Boost升压MPPT控制策略的Simulink建模与功率反馈扰动观察法
运行GUI版本,可二开
Deepseek相关主题资源及行业影响
WP Smush Pro 是一款专为 WordPress 网站设计的图像优化插件。 一、主要作用 图像压缩 它能够在不影响图像质量的前提下,大幅度减小图像文件的大小。例如,对于一些高分辨率的产品图片或者风景照片,它可以通过先进的压缩算法,去除图像中多余的数据。通常 JPEG 格式的图像经过压缩后,文件大小可以减少 40% – 70% 左右。这对于网站性能优化非常关键,因为较小的图像文件可以加快网站的加载速度。 该插件支持多种图像格式的压缩,包括 JPEG、PNG 和 GIF。对于 PNG 图像,它可以在保留透明度等关键特性的同时,有效地减小文件尺寸。对于 GIF 图像,也能在一定程度上优化文件大小,减少动画 GIF 的加载时间。 懒加载 WP Smush Pro 实现了图像懒加载功能。懒加载是一种延迟加载图像的技术,当用户滚动页面到包含图像的位置时,图像才会加载。这样可以避免一次性加载大量图像,尤其是在页面内容较多且包含许多图像的情况下。例如,在一个新闻网站的长文章页面,带有大量配图,懒加载可以让用户在浏览文章开头部分时,不需要等待所有图片加载,从而提高页面的初始加载速度,同时也能
Could not create share link. Missing file: C:\Users\xx\.conda\envs\omni\Lib\site-packages\gradio\frpc_windows_amd64_v0.3 1. Download this file: https://cdn-media.huggingface.co/frpc-gradio-0.3/frpc_windows_amd64.exe 2. Rename the downloaded file to: frpc_windows_amd64_v0.3 3. Move the file to this location: C:\Users\xx\.conda\envs\omni\Lib\site-packages\gradio