- 浏览: 483982 次
- 性别:

- 来自: 南阳
-

文章分类
最新评论
-
yuanhongb:
这么说来,感觉CGI和现在的JSP或ASP技术有点像啊
cgi -
draem0507:
放假了还这么勤啊
JXL操作Excel -
chenjun1634:
学习中!!
PHP/Java Bridge -
Jelen_123:
好文章,给了我好大帮助!多谢!
hadoop安装配置 ubuntu9.10 hadoop0.20.2 -
lancezhcj:
一直用job
Oracle存储过程定时执行2种方法(转)
开场白:
Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类 (Hive Storage Handlers), 大致意思如图所示:
口水:
对 hive_hbase-handler.jar 这个东东还有点兴趣,有空来磋磨一下。
一、2个注意事项:
1、需要的软件有 Hadoop、Hive、Hbase、Zookeeper,Hive与HBase的整合对Hive的版本有要求,所以不要下载.0.6.0以前的老版本,Hive.0.6.0的版本才支持与HBase对接,因此在Hive的lib目录下可以看见多了hive_hbase-handler.jar这个jar包,他是Hive扩展存储的Handler ,HBase 建议使用 0.20.6的版本,这次我没有启动HDFS的集群环境,本次所有测试环境都在一台机器上。
2、运行Hive时,也许会出现如下错误,表示你的JVM分配的空间不够,错误信息如下:
Invalid maximum heap size: -Xmx4096m
The specified size exceeds the maximum representable size.
Could not create the Java virtual machine.
解决方法:
/work/hive/bin/ext# vim util/execHiveCmd.sh 文件中第33行
修改,
HADOOP_HEAPSIZE=4096
为
HADOOP_HEAPSIZE=256
另外,在 /etc/profile/ 加入 export $HIVE_HOME=/work/hive
二、启动运行环境
1启动Hive
hive –auxpath /work/hive/lib/hive_hbase-handler.jar,/work/hive/lib/hbase-0.20.3.jar,/work/hive/lib/zookeeper-3.2.2.jar -hiveconf hbase.master=127.0.0.1:60000
加载 Hive需要的工具类,并且指向HBase的master服务器地址,我的HBase master服务器和Hive运行在同一台机器,所以我指向本地。
2启动HBase
/work/hbase/bin/hbase master start
3启动Zookeeper
/work/zookeeper/bin/zkServer.sh start
三、执行
在Hive中创建一张表,相互关联的表
CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
在运行一个在Hive中建表语句,并且将数据导入
建表
CREATE TABLE pokes (foo INT, bar STRING);
数据导入
LOAD DATA LOCAL INPATH '/work/hive/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
在Hive与HBase关联的表中 插入一条数据
INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=98;
运行成功后,如图所示:
插入数据时采用了MapReduce的策略算法,并且同时向HBase写入,如图所示:
在HBase shell中运行 scan 'xyz' 和describe "xyz" 命令,查看表结构,运行结果如图所示:
xyz是通过Hive在Hbase中创建的表,刚刚在Hive的建表语句中指定了映射的属性 "hbase.columns.mapping" = ":key,cf1:val" 和 在HBase中建表的名称 "hbase.table.name" = "xyz"
在hbase在运行put命令,插入一条记录
put 'xyz','10001','cf1:val','www.javabloger.com'
在hive上运行查询语句,看看刚刚在hbase中插入的数据有没有同步过来,
select * from hbase_table_1 WHERE key=10001;
如图所示:
最终的效果
以上整合过程和操作步骤已经执行完毕,现在Hive中添加记录HBase中有记录添加,同样你在HBase中添加记录Hive中也会添加, 表示Hive与HBase整合成功,对海量级别的数据我们是不是可以在HBase写入,在Hive中查询 喃?因为HBase 不支持复杂的查询,但是HBase可以作为基于 key 获取一行或多行数据,或者扫描数据区间,以及过滤操作。而复杂的查询可以让Hive来完成,一个作为存储的入口(HBase),一个作为查询的入口(Hive)。如下图示。

呵呵,见笑了,以上只是我面片的观点。
http://www.blogjava.net/ivanwan/archive/2011/01/10/342685.html
===========================================================
一 、简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类, 大致意思如图所示: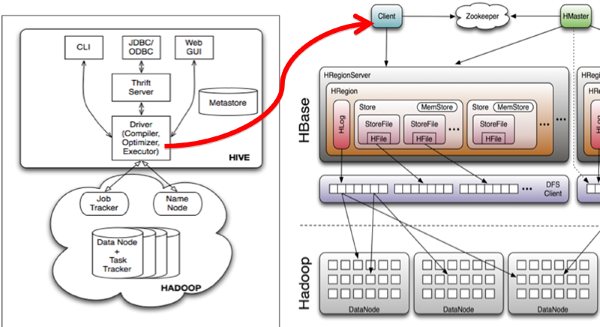
二、安装步骤:
1 .Hadoop和Hbase都已经成功安装了
Hadoop集群配置:http://blog.csdn.net/hguisu/article/details/723739
hbase安装配置:http://blog.csdn.net/hguisu/article/details/7244413
2 . 拷贝hbase-0.90.4.jar和zookeeper-3.3.2.jar到hive/lib下。
注意:如何hive/lib下已经存在这两个文件的其他版本(例如zookeeper-3.3.2.jar),建议删除后使用hbase下的相关版本。
2. 修改hive/conf下hive-site.xml文件,在底部添加如下内容:
- <!--
- <property>
- <name>hive.exec.scratchdir</name>
- <value>/usr/local/hive/tmp</value>
- </property>
- -->
- <property>
- <name>hive.querylog.location</name>
- <value>/usr/local/hive/logs</value>
- </property>
- <property>
- <name>hive.aux.jars.path</name>
- <value>file:///usr/local/hive/lib/hive-hbase-handler-0.8.0.jar,file:///usr/local/hive/lib/hbase-0.90.4.jar,file:///usr/local/hive/lib/zookeeper-3.3.2.jar</value>
- </property>
注意:如果hive-site.xml不存在则自行创建,或者把hive-default.xml.template文件改名后使用。
3. 拷贝hbase-0.90.4.jar到所有hadoop节点(包括master)的hadoop/lib下。
4. 拷贝hbase/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的hadoop/conf下。
注意,如果3,4两步跳过的话,运行hive时很可能出现如下错误:
- [html] view plaincopy
- org.apache.hadoop.hbase.ZooKeeperConnectionException: HBase is able to connect to ZooKeeper but the connection closes immediately.
- This could be a sign that the server has too many connections (30 is the default). Consider inspecting your ZK server logs for that error and
- then make sure you are reusing HBaseConfiguration as often as you can. See HTable's javadoc for more information. at org.apache.hadoop.
- hbase.zookeeper.ZooKeeperWatcher.
三、启动Hive
1.单节点启动
#bin/hive -hiveconf hbase.master=master:490001
2 集群启动:
#bin/hive -hiveconf hbase.zookeeper.quorum=node1,node2,node3
如何hive-site.xml文件中没有配置hive.aux.jars.path,则可以按照如下方式启动。
bin/hive --auxpath /usr/local/hive/lib/hive-hbase-handler-0.8.0.jar, /usr/local/hive/lib/hbase-0.90.5.jar, /usr/local/hive/lib/zookeeper-3.3.2.jar -hiveconf hbase.zookeeper.quorum=node1,node2,node3
四、测试:
1.创建hbase识别的数据库:
- CREATE TABLE hbase_table_1(key int, value string)
- STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
- WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
- TBLPROPERTIES ("hbase.table.name" = "xyz");
hbase.table.name 定义在hbase的table名称
hbase.columns.mapping 定义在hbase的列族
2.使用sql导入数据
1) 新建hive的数据表:
CREATE TABLE pokes (foo INT, bar STRING);
2)批量插入数据:
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE
3)使用sql导入hbase_table_1:
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=86;
3. 查看数据
hive> select * from hbase_table_1;
这时可以登录Hbase去查看数据了
#bin/hbase shell
hbase(main):001:0> describe 'xyz'
hbase(main):002:0> scan 'xyz'
hbase(main):003:0> put 'xyz','100','cf1:val','www.360buy.com'
这时在Hive中可以看到刚才在Hbase中插入的数据了。
4 hive访问已经存在的hbase
使用CREATE EXTERNAL TABLE:
- CREATE EXTERNAL TABLE hbase_table_2(key int, value string)
- STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
- WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf1:val")
- TBLPROPERTIES("hbase.table.name" = "some_existing_table");
内容参考:http://wiki.apache.org/hadoop/Hive/HBaseIntegration


发表评论

-
mysql 定时任务
2015-11-03 09:57 772定时任务 查看event是否开启: show variabl ... -
tomcat服务器大数量数据提交Post too large解决办法
2015-10-29 11:05 735tomcat默认设置能接收HTTP POST请求的大小最大 ... -
Tomcat启动内存设置
2015-10-20 15:40 688Tomcat的启动分为startupo.bat启动和注册为w ... -
Java串口包Javax.comm的安装
2015-10-12 16:32 696安装个java的串口包安装了半天,一直找不到串口,现在终于搞 ... -
在 Java 应用程序中访问 USB 设备
2015-10-10 17:49 956介绍 USB、jUSB 和 JSR- ... -
mysql定时器
2015-08-04 14:01 6005.1以后可以使用 ALTER EVENT `tes ... -
oracle安装成功后,更改字符集
2015-07-23 11:53 636看了网上的文章,乱码有以下几种可能 1. 操作系统的字符集 ... -
运用navicat for mysql实现定时备份
2015-06-05 15:02 1085使用navicat for mysql实现定时备份 首 ... -
利用html5调用本地摄像头拍照上传图片
2015-05-18 09:36 2607测试只有PC上可以,手机上不行 <!DOCTYPE ... -
必须Mark!最佳HTML5应用开发工具推荐
2015-05-15 22:50 962摘要:HTML5自诞生以来,作为新一代的Web标准,越来 ... -
Mobl试用二
2015-05-13 14:28 638最近有空又看了一下Mobl的一些说语法,备忘一下: 1 ... -
Nginx配置文件详细说明
2015-05-08 19:58 611在此记录下Nginx服务器nginx.conf的配置文件说明 ... -
axis调用cxf
2015-04-23 13:51 5521、写address时不用加?wsdl Service s ... -
Oracle10g数据文件太大,导致C盘空间不够用的解决方法
2015-03-19 15:22 928由于在安装的时候将Oracle安装到了C盘,表空间也创建到了C ... -
mysql 获取第一个汉字首字母
2015-03-18 17:48 647select dmlb, dmz, dmsm1, CHAR ... -
failed to install Tomcat6 service解决办法
2015-02-12 09:20 533最近我重装了一下tomcat 6.0,可不知为什么,总是安装 ... -
tomcat 分配java内存
2015-02-11 10:37 595//首先检查程序有没有限入死循环 这个问题主要还是由这个问 ... -
[Android算法] Android蓝牙开发浅谈
2014-12-15 15:27 663对于一般的软件开发人 ... -
Android 内存溢出解决方案(OOM) 整理总结
2014-11-21 10:12 747原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出 ... -
《HTML5从入门到精通》中文学习教程 PDF
2014-11-19 21:26 1125HTML5 草案的前身名为Web Applications ...
相关推荐
将Hive与HBase整合,主要是为了结合两者的优点,实现批量处理和实时查询的无缝对接。整合的关键在于Hive的外部表功能,通过创建指向HBase表的外部表,我们可以用Hive的HQL查询HBase中的数据。 整合步骤如下: 1. *...
【Hive与HBase整合详解】 Hive和HBase是两个大数据处理的重要组件。Hive提供了基于SQL的查询语言(HQL)来处理大规模的数据,适合于离线批处理;而HBase则是一个NoSQL数据库,它基于Google的Bigtable设计,提供高...
### 大数据工具篇之Hive与HBase整合完整教程 #### 一、引言 在大数据处理领域,Hive 和 HBase 是两种非常重要的工具。Hive 是一种数据仓库工具,可以用来进行数据提取、转换和加载(ETL),同时提供了一种 SQL ...
Hive与HBase整合后可以实现多样的使用场景,包括但不限于数据的批量迁移、实时更新、周期性加载以及复杂的数据分析操作。 整合Hive与HBase后,可以在Hive中进行数据的插入、查询、连接(JOIN)、分组(GROUPBY)...
在HIVE中创建HBASE的外表,是实现HIVE和HBASE整合的关键步骤。外表是一种虚拟表,它不存储实际数据,而是指向HBASE中的实际数据。通过创建外表,HIVE可以直接访问HBASE中的数据,并且可以使用类SQL和各种函数来操作...
1. **Hive与HBase的集成背景**:介绍为什么需要将Hive与HBase整合,通常是因为需要结合Hive的数据处理能力与HBase的实时查询和高并发性能。 2. **Hive-HBase连接器**:文件"hive-hbase-handler-1.2.1.jar"是Hive...
Hive与Hbase的整合,集中两者的优势,使用HiveQL语言,同时具备了实时性
hive和hbase整合的时候,如果出现不兼容的情况需要手动编译:hive-hbase-hander-1.2.2.jar把这个jar替换掉hive/lib里的那个jar包
在Java开发中,为了将这些组件整合在一起,你需要相关的jar包,例如包含Hive和HBase的API。这些API允许你在Scala程序中直接操作Hive和HBase,简化了数据处理的流程。例如,`scalatestOne`可能是一个Scala测试项目,...
6. Hive与HBase整合需要做哪些准备工作? **详细解答:** **1. MySQL的使用:** - 不需要在每个客户端安装MySQL,只需在服务器端安装即可。 - MySQL用于存储Hive的元数据,提高性能和可靠性。 **2. 客户端与...
hive和hbase的整合所需要的编译后的jar包。 注意:这里的hbase版本为:1.2.1 hive的版本为:1.2.1
HBase2.1.3整合Hive3.1.2,Hive官方的hive-hbase-handler-3.1.1.jar包不好用,自己编译后的,确认好用
#### 四、Hive与HBase的整合 Hive和HBase的整合使得Hive能够直接操作存储在HBase中的数据,而无需将数据导出到HDFS中再进行处理。 - **配置Hive连接HBase**: - 设置Hive连接HBase所需的配置项: - `SEThbase....
HIVE必须提供预先定义好的schema将文件和目录映射到列,并且HIVE与ACID不兼容。 HBASE查询是通过特定的语言来编写的,这种语言需要重新学习。类SQL的功能可以通过Apache Phonenix实现,但这是以必须提供schema为...
本文将详细介绍Hadoop、HBase和Hive的版本整合兼容性,以及如何确保它们在不同版本间顺畅协作。 首先,Hadoop作为基础平台,其版本选择会直接影响到HBase和Hive的运行。Hadoop的主要组件包括HDFS(分布式文件系统)...
**3.3 Hive与HBase整合** - **添加通信包**: 将`mysql-connector-java-5.1.10-bin.jar`和`hive-hbase-handler-0.13.0.jar`复制到Hive安装目录下的`lib`文件夹。 - **配置Hive与HBase的连接**: 在`hive-site.xml`中...
例如,在构建数据仓库时可以选择 Hive 进行数据整合和批量处理,而对于需要快速响应的在线查询应用,则可以采用 HBase。两种技术的有效结合可以充分发挥各自的优势,为大数据处理提供更加灵活和高效的支持。