最近有一个需要支持unicode的项目在上传和下载文件时遇到文件名乱码问题. 项目背景, 这个项目关键之处在于需要支持unicode以及支持Micorosoft Internet Explorer和Netscape Navigator两种浏览器. 为了解决这个问题, 我使用以下环境进行了尝试.
J2SE : 1.5.0_04
Tomcat : 5.5.17
Microsoft Internet Explorer 6.0 with SP2
Netscape Navigator 7.1
Firefox 1.5
以及Struts 1.1 (这个基本上对此次测试不是非常重要)
上传文件对于unicode的页面进行上传文件的时候, 我使用一个text box和一个file upload box来进行比较. 页面如下.
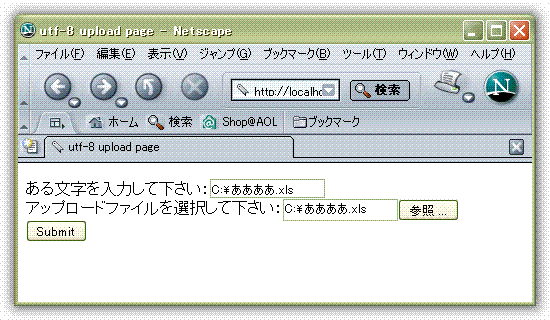
通过此页面进行文件上传后, IE, NC以及FF所传输的数据均相同. 如下
Content-Type: multipart/form-data; boundary=---------------------------282302224217945
Content-Length: 27980
-----------------------------282302224217945
Content-Disposition: form-data; name="theText"
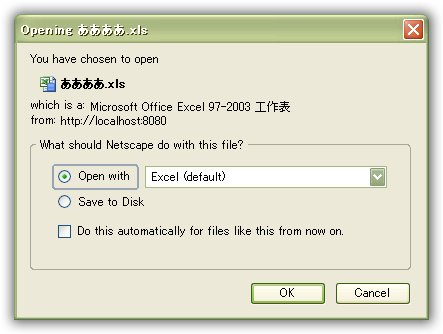
C:\縺ゅ≠縺ゅ≠.xls
-----------------------------282302224217945
Content-Disposition: form-data; name="theFile"; filename="縺ゅ≠縺ゅ≠.xls"
Content-Type: application/vnd.ms-excel
可以看出, 对text box和file upload box中的文件名所有浏览器均采取了相同的编码. 经证实, 是上传页面的编码方式——所有浏览器均对unicode数据(utf-8)采取了本地的编码方式(这里是ms932).
在服务器端对上传的数据进行解码.
解码的方式有很多, 这里我使用最普遍以及正规的request.setCharacterEncoding的方法. 发现form表单中的text box可以被正常解码, 但是file upload box中的文件名无法通过这种方式解码. 所以只能使用手工解码.
String fixedFileName = new String(fileName.getBytes("SJIS"), "UTF-8");
其中SJIS是客户端系统的编码, UTF-8是客户端页面的编码.
上传文件测试中, 所有浏览器表现一致, 需要注意的是文件名和表单数据的不同处理方式.
下载文件
使用一个unicode的JSP页面, 在页面上有一个固定的超链接, 传递给服务器一个文件名. 服务器依照这个文件名把服务器端的文件传递给客户端.
下载页面
<%@ page language="java" contentType="text/html; charset=utf-8"%>

<meta http-equiv="content-type" content="text/html; charset=utf-8">
<a href="download.do?name=ああああ.xls">ダウンロード</a>
对于这样一个页面, 当点击超链接后, 各浏览器处理方式不同
IE会把超链接依照页面当前编码方式编码(这里是utf-8)后, 发送给服务器端
GET /nsupload/download.do?name=縺ゅ≠縺ゅ≠.xls HTTP/1.1
NC和FF会把超链接依照页面编码方式编码(这里是utf-8)后, 再通过url encoding后, 发送给服务器端
GET /nsupload/download.do?name=%E3%81%82%E3%81%82%E3%81%82%E3%81%82.xls HTTP/1.1
(经证实, E38182是「あ」的unicode代码)
在服务器收到提交的数据后, 需要对其进行解码. 需要注意的是这种方式下使用request.setCharacterEncoding无效. 所以必须手工解码.
name = new String(name.getBytes("ISO-8859-1"), "UTF-8");
其中ISO-8859-1是Tomcat服务器的特性, Tomcat会把所有的数据先转换为ISO-8859-1的形式. UTF-8是实际的编码方式.
在得到文件名后, 就可以正确地读取文件, 然后把文件传递给客户端了. 其中, 文件名是保存在Http报头(header)的Content-Disposition中.
response.setHeader("Content-Disposition", "inline; filename=" + _filename);
//或者
response.setHeader("Content-Disposition", "attachment; filename=" + _filename);
经实验证明, 使用inline或者attachment对文件名的编码方式
没有影响.
另外一个需要设置的是Content-Type.
response.setContentType("application/vnd.ms-excel");
//或者
response.setContentType("application/vnd.ms-excel; charset=UTF-8");
//或者
response.setContentType("application/x-download; name=" + _filename);
经试验证明, 使用application/*的任何形式都对文件名的编码方式
没有影响.
第二点, 经试验证明, 这里的charset设置会被三种浏览器忽略, 所以设置与否
不影响文件名的编码方式.
第三点, 经试验证明, 这里的name设置对文件名
没有任何影响.
可能还有一个属性需要注意, 就是Content-Language. 经试验证明, Content-Language有无, 或者为何值, 对文件名没有任何影响.
那么对于non-ascii的文件名如何操作才可以保证客户端可以得到正确的显示呢?
经过调查, 有三种方法(在网上搜索后认为可能这篇文章是对于这个问题探讨最深入的文章)
第一, 使用URLEncoding方法. 即对文件名进行URLEncoding.
name = URLEncoder.encode(name, "UTF-8");
这种方式适用于IE, 但是不适用于NC和FF. 在这种方式下, 网络上传输的是url encoding后的ascii编码.
Content-Disposition: inline; filename=%E3%81%82%E3%81%82%E3%81%82%E3%81%82.xls
NC和FF不能对这样的文件名进行有效的解码.
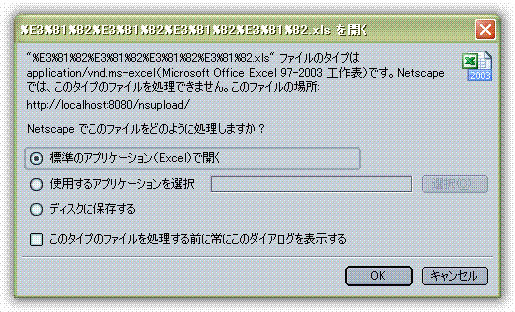
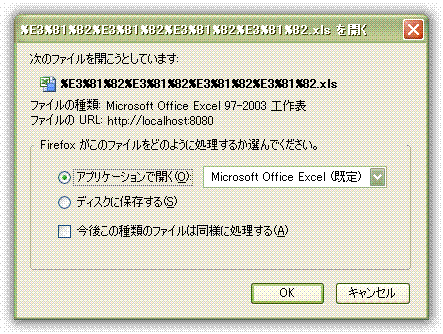
第二, 使用字符串字符集强行转换为本地字符集方法, 这样做的原理是JVM底层全部为unicode. 所以一旦一个字符串表示了正确的字符集而被存储后, 这个字符串会被转换为任意字符集.
原理二是, IE和FF对非url encoding的non-ascii文件名采用客户端系统本地的编码方式进行转换.
name = new String(name.getBytes("Shift_JIS"), "ISO-8859-1");
需要注意的是, 这里的name原本是utf-8的.
在网络上传输的为
Content-Disposition: inline; filename=ああああ.xls
经过试验, IE和FF支持这种方式, NC不支持. 表现为NC无法解析文件名.
第三种, 使用Base64编码文件名. 原理是这种做法符合RFC2047的定义.
name = javax.mail.internet.MimeUtility.encodeText(name, "UTF-8", "B");
使用到了JavaMail中的Base64编码的类MimeUtility.
在网络上传输的为经过Base64编码的ascii字符.
Content-Disposition: inline; filename==?UTF-8?B?44GC44GC44GC44GCLnhscw==?=
只有FF支持这种方式, IE表现为无法解析文件名, NC表现为忽略Base64编码.

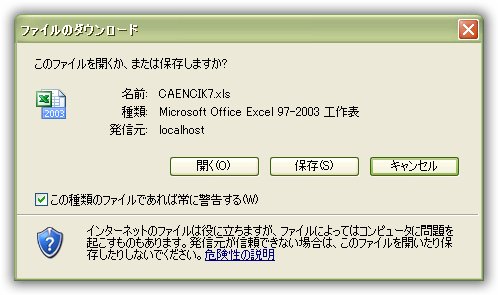
以上三种方法是目前来讲, 使浏览器可以正确下载non-ascii文件名的方法. 其中IE支持两种(url encoding和force transform), FF支持两种(force transform和base64 encoding), NC一种都不支持.
关于这次调查的结果, 对于NC多说两句, 我以为这个结果是由于NC 7.1和Tomcat 5.5不兼容造成的. Tomcat 5.5要求必须把所有报头先转变为ISO-8859-1的格式, 而NC 7.1却无法直接对ISO-8859-1进行正确的解析或者说是解析功能比较弱. 如果有时间, 我会继续验证非unicode的情况以及NC 8的情况.
---2006年9月14日21:00 补充---
在NC 8.1上进行了测试, 测试结果是NC 8.1支持方法三, 即base64 encoding.
分享到:





相关推荐
### Java中压缩与解压——中文文件名乱码解决办法 #### 一、问题背景及原理分析 在Java中处理文件的压缩与解压时...通过上述步骤,可以有效地解决Java中压缩与解压时中文文件名乱码的问题,使得程序更加健壮和实用。
这个问题在处理包含非ASCII字符(例如中文字符)的文件时经常出现,因为标准的ZIP库可能不支持Unicode编码,导致解压时中文文件名显示为乱码。 在C++中,标准库并不直接支持ZIP文件的操作,因此开发者通常需要借助...
首先,我们需要理解问题的核心:浏览器在请求服务器上的资源,特别是文件时,如果文件名包含中文字符,可能会因为编码不一致导致乱码。这主要涉及到字符编码的两个关键概念——Unicode和字符编码转换。 1. **...
感谢你的下载,文件说明如下: *jsch的源文件 *jsch的依赖包 *用jsch源文件及依赖包构建的项目,便于修改其源码* 修改源码后重新导出的jar包 *我写的一段小程序,实现的主要功能是同步sftp上的文件夹(sftp->本地) ...
在Linux系统中,由于字符编码的问题,我们可能会遇到文件名显示为乱码的情况。...通过上述方法,你应该能够有效地处理和避免文件名乱码问题,确保文件管理的顺利进行。记得在操作过程中要谨慎,避免误改重要文件。
在IT领域,尤其是Web开发中,文件下载是一个常见的功能,而处理中文文件名乱码问题则是一个常见的挑战。本篇主要探讨如何解决使用`response.setHeader()`方法下载中文文件名时出现的乱码问题,以及与之相关的HTTP...
首先,关于乱码问题,这通常是因为FFmpeg在Windows上默认不支持Unicode编码,尤其是在命令行环境下,可能会对非ASCII字符(如中文字符)处理不当。为了解决这个问题,开发者可能对FFmpeg进行了编译配置修改,使其...
然而,当涉及到非英文的文件名,特别是中文文件名时,可能会出现编码问题,导致上传或下载过程中出现乱码。这个问题主要源于不同的字符编码格式不兼容,如UTF-8和GBK之间的转换不当。 首先,我们需要理解JavaScript...
在处理文件上传和下载时,Struts2可能会遇到一个常见的问题,即中文文件名的乱码问题。这是因为不同的系统和软件对字符编码的支持不同,尤其是涉及到网络传输时,编码的兼容性尤为重要。 在“struts2 中文文件名...
本文将深入探讨如何使用ZipOutputStream进行文件压缩,并解决可能出现的乱码问题。 首先,我们来看`ZipOutputStream`的基本用法。这个类继承自`FilterOutputStream`,提供了创建ZIP文件的功能。以下是一个简单的...
针对Win11和Win10系统中的中文文件名乱码问题,我们提供以下解决方案: ##### 步骤1:打开区域设置 - 使用快捷键`Win+R`调出运行对话框,输入`intl.cpl`,回车打开“区域”设置窗口。 - 或者在Windows搜索栏中输入...
解决docker容器中文乱码问题
在使用SAS EG(Enterprise Guide)导入编码为UTF-8的文本数据文件时,用户可能会遇到中文乱码问题。UTF-8编码的文本文件在处理中文字符时,如果没有正确设置编码,可能会导致中文字符显示不正确,即出现乱码现象。...
- 当从ZIP文件中提取文件时,确保文件名的解码与压缩时的编码一致,否则仍可能出现乱码。 - 如果ZIP文件包含多级目录,且目录名包含中文,需要对整个路径进行正确的编码和解码。 - 在读写文件内容时,要根据实际...
以下是关于解决“解压文件时中文乱码”问题的相关知识点: 1. **编码概念**:编码是将字符转换为二进制数据的过程,以便计算机存储和处理。常见的字符编码标准有ASCII、GBK、GB2312、Big5和Unicode(包括其变体UTF-...
在读取ZIP文件时,我们首先需要打开ZIP文件并创建一个ZIP文件对象。然后,通过迭代这个对象,我们可以访问每个条目(即压缩的文件或目录),获取其文件名和内容。关键在于正确处理文件名的编码。在某些情况下,...
当我们在Android应用程序中读取文件时,如果不指定正确的字符编码,就会导致乱码问题的发生。 #### 三、解决策略 为了有效解决中文乱码问题,我们需要采取以下几种策略: 1. **识别文件的编码格式**:首先需要...
在Java编程中,中文乱码是一个常见的问题。为了解决这个问题,我们需要从多个方面入手。首先,我们需要将Eclipse的编码方式设置为UTF-8,以便正确地显示中文字符。其次,我们需要在浏览器中将字符设置为unicode,...
在跨平台传输文件时,确保服务器和客户端的编码设置匹配是至关重要的。 总之,解决Server-U中的乱码问题需要理解字符编码的机制,并正确配置FTP服务器的相关设置。通过以上步骤,大多数情况下可以有效地解决中文...
本文将深入探讨SmartUpload上传文件时如何解决中文乱码的问题。 首先,我们要理解乱码产生的原因。在计算机系统中,不同的文件系统和编程语言可能使用不同的字符编码标准,如ASCII、GBK、UTF-8等。如果在读取或写入...