- 浏览: 4431855 次
- 性别:

- 来自: 厦门
-

文章分类
- 全部博客 (634)
- Oracle日常管理 (142)
- Oracle体系架构 (45)
- Oracle Tuning (52)
- Oracle故障诊断 (35)
- RAC/DG/OGG (64)
- Oracle11g New Features (48)
- DataWarehouse (15)
- SQL, PL/SQL (14)
- DB2日常管理 (9)
- Weblogic (11)
- Shell (19)
- AIX (12)
- Linux/Unix高可用性 (11)
- Linux/Unix日常管理 (66)
- Linux桌面应用 (37)
- Windows (2)
- 生活和工作 (13)
- 私人记事 (0)
- Python (9)
- CBO (15)
- Cognos (2)
- ORACLE 12c New Feature (2)
- PL/SQL (2)
- SQL (1)
- C++ (2)
- Hadoop大数据 (5)
- 机器学习 (3)
- 非技术 (1)
最新评论
-
di1984HIT:
xuexilee!!!
Oracle 11g R2 RAC高可用连接特性 – SCAN详解 -
aneyes123:
谢谢非常有用那
PL/SQL的存储过程和函数(原创) -
jcjcjc:
写的很详细
Oracle中Hint深入理解(原创) -
di1984HIT:
学习了,学习了
Linux NTP配置详解 (Network Time Protocol) -
avalonzst:
大写的赞..
AIX内存概述(原创)
一次某优化工具厂商的朋友,发来一个案例请求协助诊断,朋友的优化工具在客户的环境中执行某个 SQL 查询时,需要 10 分钟时间才能出结果,这是无法接受的,而同样的查询在其他环境上都可以快速的获得输出结果,数据库环境是 9.2.0.8 。
首先我获得了一个 10046 跟踪文件,通过 tkprof 格式化之后,这个 SQL 的输出结果展现出来。
首先该
SQL
代码如下:
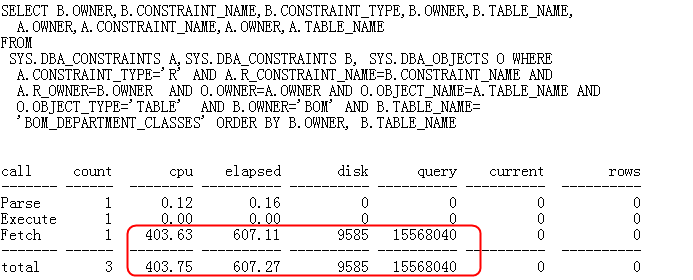
该段 SQL 的 Elapsed 时间超过了 600 秒, Query 模式逻辑读也非常高,对于一个优化工具来说显然是不可接受的。
接下来的跟踪文件中显示了 SQL 的执行计划:
Rows Row Source Operation
------- ---------------------------------------------------
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS
0 NESTED LOOPS
1935557 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
1 NESTED LOOPS
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
2863 TABLE ACCESS FULL CDEF$
2863 TABLE ACCESS BY INDEX ROWID CON$
2863 INDEX UNIQUE SCAN I_CON2 (object id 49)
2863 TABLE ACCESS CLUSTER USER$
2863 INDEX UNIQUE SCAN I_USER# (object id 11)
1935557 VIEW
1935557 UNION-ALL PARTITION
1935557 FILTER
1935557 NESTED LOOPS
2863 TABLE ACCESS BY INDEX ROWID USER$
2863 INDEX UNIQUE SCAN I_USER1 (object id 44)
1935557 TABLE ACCESS FULL OBJ$
0 TABLE ACCESS BY INDEX ROWID IND$
0 INDEX UNIQUE SCAN I_IND1 (object id 39)
0 FILTER
0 NESTED LOOPS
0 TABLE ACCESS BY INDEX ROWID USER$
0 INDEX UNIQUE SCAN I_USER1 (object id 44)
0 INDEX RANGE SCAN I_LINK1 (object id 113)
0 TABLE ACCESS BY INDEX ROWID CON$
1935557 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON1 (object id 48)
0 TABLE ACCESS BY INDEX ROWID CDEF$
0 INDEX UNIQUE SCAN I_CDEF1 (object id 50)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
以上执行计划中,最可疑的部分是对于 OBJ$ 的全表扫描,这个环节的行数返回有 1 , 935 , 557 行,这个量级一直向上传递,所以我们首先怀疑这里的执行计划选择错误,如果选择索引,执行性能肯定会有极大的不同。
可是 10046 的跟踪事件显示的信息比较有限不能够准确定位错误的原因,我请朋友通过 10053 事件来生成一个执行计划的跟踪, 10053 使用极为简便,通过如下方式就可以捕获 SQL 的解析过程:
alter session set events '10053 trace name context forever,level 1';
explain plan for you_select_query;
例如:
SQL> alter session set events '10053 trace name context forever,level 1';
Session altered.
SQL> explain plan for select count(*) from obj$;
Explained.
然后在 udump 目录下就可以找到 10053 生成的跟踪文件,在该文件中,找到了查询相关表的统计信息,其中 OBJ$ 的信息如下所示,其中 CDN ( CarDiNality )指表中包含的记录数量,此处显示 OBJ$ 表中有 24 万左右的记录,使用了 2941 个数据块:
***********************
Table stats Table: OBJ$ Alias: SYS_ALIAS_1
TOTAL :: CDN: 245313 NBLKS: 2941 AVG_ROW_LEN: 79
Column: OWNER# Col#: 3 Table: OBJ$ Alias: SYS_ALIAS_1
NDV: 221 NULLS: 0 DENS: 4.5249e-03 LO: 0 HI: 259
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_OBJ1 COL#: 1
TOTAL :: LVLS: 1 #LB: 632 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 4184
INDEX NAME: I_OBJ2 COL#: 3 4 5 12 13 6
TOTAL :: LVLS: 2 #LB: 1904 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 180286
INDEX NAME: I_OBJ3 COL#: 15
TOTAL :: LVLS: 1 #LB: 19 #DK: 2007 LB/K: 1 DB/K: 1 CLUF: 340
_OPTIMIZER_PERCENT_PARALLEL = 0
***************************************
而在前面的 10046 跟踪信息中,显示 OBJ$ 包含大约 200 万条记录,这是非常巨大的不同,对于 USER$ 表,显示具有 2863 条记录,而统计信息中显示仅有 253 条记录:
***********************
Table stats Table: USER$ Alias: U
TOTAL :: CDN: 253 NBLKS: 16 AVG_ROW_LEN: 82
Column: USER# Col#: 1 Table: USER$ Alias: U
NDV: 253 NULLS: 0 DENS: 3.9526e-03 LO: 0 HI: 261
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_USER# COL#: 1
TOTAL :: LVLS: 0 #LB: 1 #DK: 258 LB/K: 1 DB/K: 1 CLUF: 13
INDEX NAME: I_USER1 COL#: 2
TOTAL :: LVLS: 0 #LB: 1 #DK: 253 LB/K: 1 DB/K: 1 CLUF: 87
***********************
这说明数据字典中记录的统计信息与真实情况不符合,导致了 SQL 选择了错误的执行计划,在使用 CBO 的 Oracle9i 数据库中,这种情况极为普遍,通过删除表的统计信息,或者重新收集正确的统计信息,可以使 SQL 执行恢复到正常合理的范畴内。在 Oracle10g 开始的自动统计信息收集,就是为了防止出现统计信息陈旧的现象。
以下是通过 dbms_stats 包清除和重新收集表的统计信息的简单参考:
SQL> exec dbms_stats.delete_table_stats(user,'OBJ$');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats(user,'OBJ$');
PL/SQL procedure successfully completed.
基于这样的判断我们建议客户做出修正,最后的客户反馈结果是:按照你的建议,在更新
OBJ$
的统计信息后,该语句的执行时间由
10
分钟减少到了
2
分钟。接下来,按照类似的思路,又更新了
USER$
,
CON$,CDEF$
表的统计信息,这时,语句的执行时间减少到了零点几秒。至此,问题解决。
参考至:http://www.eygle.com/archives/2011/02/dba_event_10046_10053.html
如有错误,欢迎指正
邮箱:czmcj@163.com


评论
这篇是eyegle写的
发表评论

-
Oracle Redo 并行机制
2017-04-07 11:31 1015Redo log 是用于恢复和一个高级特性的重要数据,一个r ... -
Append Values and how not to break the database
2015-09-29 20:12 767With the advent of the /*+ APP ... -
基于案例学习sql优化第6周脚本
2015-04-13 04:29 0===============BEGIN=========== ... -
Oracle表高水平位的优化与监控
2015-02-13 09:21 2258高水平位虚高的案例 --构造表drop table t p ... -
Oracle行迁移和行链接详解(原创)
2015-02-13 09:00 12395行迁移成 因:当发出u ... -
Parse CPU to Parse Elapsd%的理解
2015-01-19 13:59 1467Parse CPU to Parse Elapsd%是指sq ... -
ALTER INDEX COALESCE: 10g Improvements
2014-08-02 21:34 954I thought it might be worth me ... -
Differences and Similarities Between Index Coalesce and Shrink Space
2014-08-02 21:21 998As already discussed, ALTER IN ... -
Alter index coalesce VS shrink space
2014-08-02 17:56 108610g中引入了对索引的shrink功能,索引shrink操 ... -
SQL Plan Management Creating SQL plan baselines(原创)
2014-08-01 23:56 1381SQL Plan Management SQL Plan ... -
WITH Clause : Subquery Factoring
2014-07-23 08:43 1212Subquery Factoring The WIT ... -
Query Transformations : Subquery unnesting(原创)
2014-07-23 08:42 2943Subquery Unnesting Subqueries ... -
Automating Parallelism
2014-07-17 17:49 866Parallel query, the essence of ... -
Parallel Execution: Large/Shared Pool and ORA-4031 (文档 ID 238680.1)
2014-07-17 17:47 2123Applies toOracle Database - En ... -
Optimizer Transformations: Star Transformation
2014-06-30 07:32 824Star transformation was intro ... -
Star Transformation And Cardinality Estimates
2014-06-30 07:33 920If you want to make use of Orac ... -
Optimizer statistics-driven direct path read decision for full table scans
2014-06-06 16:09 1112Hello all fellow Oracle geeks ... -
Cut out from Ask Tom-- Thanks for the question regarding "10053", version 9.2.6
2014-03-09 23:38 1458You AskedDear tom,A. your new ... -
ORACLE SQL TUNING各种技巧及复杂实例
2014-02-25 23:17 6554一.优化器模式ORACLE的优化器共有3种:a. RULE ... -
Oracle Predicate Pushing(原创)
2014-02-22 21:17 4660IntroductionThe join predicate ...
相关推荐
内容概要:本文探讨了模糊故障树(FFTA)在工业控制系统可靠性分析中的应用,解决了传统故障树方法无法处理不确定数据的问题。文中介绍了模糊数的基本概念和实现方式,如三角模糊数和梯形模糊数,并展示了如何用Python实现模糊与门、或门运算以及系统故障率的计算。此外,还详细讲解了最小割集的查找方法、单元重要度的计算,并通过实例说明了这些方法的实际应用场景。最后,讨论了模糊运算在处理语言变量方面的优势,强调了在可靠性分析中处理模糊性和优化计算效率的重要性。 适合人群:从事工业控制系统设计、维护的技术人员,以及对模糊数学和可靠性分析感兴趣的科研人员。 使用场景及目标:适用于需要评估复杂系统可靠性的场合,特别是在面对不确定数据时,能够提供更准确的风险评估。目标是帮助工程师更好地理解和预测系统故障,从而制定有效的预防措施。 其他说明:文中提供的代码片段和方法可用于初步方案验证和技术探索,但在实际工程项目中还需进一步优化和完善。
内容概要:本文详细探讨了双馈风力发电机(DFIG)在Simulink环境下的建模方法及其在不同风速条件下的电流与电压波形特征。首先介绍了DFIG的基本原理,即定子直接接入电网,转子通过双向变流器连接电网的特点。接着阐述了Simulink模型的具体搭建步骤,包括风力机模型、传动系统模型、DFIG本体模型和变流器模型的建立。文中强调了变流器控制算法的重要性,特别是在应对风速变化时,通过实时调整转子侧的电压和电流,确保电流和电压波形的良好特性。此外,文章还讨论了模型中的关键技术和挑战,如转子电流环控制策略、低电压穿越性能、直流母线电压脉动等问题,并提供了具体的解决方案和技术细节。最终,通过对故障工况的仿真测试,验证了所建模型的有效性和优越性。 适用人群:从事风力发电研究的技术人员、高校相关专业师生、对电力电子控制系统感兴趣的工程技术人员。 使用场景及目标:适用于希望深入了解DFIG工作原理、掌握Simulink建模技能的研究人员;旨在帮助读者理解DFIG在不同风速条件下的动态响应机制,为优化风力发电系统的控制策略提供理论依据和技术支持。 其他说明:文章不仅提供了详细的理论解释,还附有大量Matlab/Simulink代码片段,便于读者进行实践操作。同时,针对一些常见问题给出了实用的调试技巧,有助于提高仿真的准确性和可靠性。
内容概要:本文详细介绍了基于西门子S7-200 PLC和组态王软件构建的八层电梯控制系统。首先阐述了系统的硬件配置,包括PLC的IO分配策略,如输入输出信号的具体分配及其重要性。接着深入探讨了梯形图编程逻辑,涵盖外呼信号处理、轿厢运动控制以及楼层判断等关键环节。随后讲解了组态王的画面设计,包括动画效果的实现方法,如楼层按钮绑定、轿厢移动动画和门开合效果等。最后分享了一些调试经验和注意事项,如模拟困人场景、防抖逻辑、接线艺术等。 适合人群:从事自动化控制领域的工程师和技术人员,尤其是对PLC编程和组态软件有一定基础的人群。 使用场景及目标:适用于需要设计和实施小型电梯控制系统的工程项目。主要目标是帮助读者掌握PLC编程技巧、组态画面设计方法以及系统联调经验,从而提高项目的成功率。 其他说明:文中提供了详细的代码片段和调试技巧,有助于读者更好地理解和应用相关知识点。此外,还强调了安全性和可靠性方面的考量,如急停按钮的正确接入和硬件互锁设计等。
内容概要:本文介绍了如何将CarSim的动力学模型与Simulink的智能算法相结合,利用模型预测控制(MPC)实现车辆的智能超车换道。主要内容包括MPC控制器的设计、路径规划算法、联合仿真的配置要点以及实际应用效果。文中提供了详细的代码片段和技术细节,如权重矩阵设置、路径跟踪目标函数、安全超车条件判断等。此外,还强调了仿真过程中需要注意的关键参数配置,如仿真步长、插值设置等,以确保系统的稳定性和准确性。 适合人群:从事自动驾驶研究的技术人员、汽车工程领域的研究人员、对联合仿真感兴趣的开发者。 使用场景及目标:适用于需要进行自动驾驶车辆行为模拟的研究机构和企业,旨在提高超车换道的安全性和效率,为自动驾驶技术研发提供理论支持和技术验证。 其他说明:随包提供的案例文件已调好所有参数,可以直接导入并运行,帮助用户快速上手。文中提到的具体参数和配置方法对于初学者非常友好,能够显著降低入门门槛。
包括:源程序工程文件、Proteus仿真工程文件、论文材料、配套技术手册等 1、采用51单片机作为主控; 2、采用AD0809(仿真0808)检测"PH、氨、亚硝酸盐、硝酸盐"模拟传感; 3、采用DS18B20检测温度; 4、采用1602液晶显示检测值; 5、检测值同时串口上传,调试助手监看; 6、亦可通过串口指令对加热器、制氧机进行控制;
内容概要:本文详细介绍了双馈永磁风电机组并网仿真模型及其短路故障分析方法。首先构建了一个9MW风电场模型,由6台1.5MW双馈风机构成,通过升压变压器连接到120kV电网。文中探讨了风速模块的设计,包括渐变风、阵风和随疾风的组合形式,并提供了相应的Python和MATLAB代码示例。接着讨论了双闭环控制策略,即功率外环和电流内环的具体实现细节,以及MPPT控制用于最大化风能捕获的方法。此外,还涉及了短路故障模块的建模,包括三相电压电流特性和离散模型与phasor模型的应用。最后,强调了永磁同步机并网模型的特点和注意事项。 适合人群:从事风电领域研究的技术人员、高校相关专业师生、对风电并网仿真感兴趣的工程技术人员。 使用场景及目标:适用于风电场并网仿真研究,帮助研究人员理解和优化风电机组在不同风速条件下的性能表现,特别是在短路故障情况下的应对措施。目标是提高风电系统的稳定性和可靠性。 其他说明:文中提供的代码片段和具体参数设置有助于读者快速上手并进行实验验证。同时提醒了一些常见的错误和需要注意的地方,如离散化步长的选择、初始位置对齐等。
适用于空手道训练和测试场景
内容概要:本文介绍了金牌音乐作词大师的角色设定、背景经历、偏好特点、创作目标、技能优势以及工作流程。金牌音乐作词大师凭借深厚的音乐文化底蕴和丰富的创作经验,能够为不同风格的音乐创作歌词,擅长将传统文化元素与现代流行文化相结合,创作出既富有情感又触动人心的歌词。在创作过程中,会严格遵守社会主义核心价值观,尊重用户需求,提供专业修改建议,确保歌词内容健康向上。; 适合人群:有歌词创作需求的音乐爱好者、歌手或音乐制作人。; 使用场景及目标:①为特定主题或情感创作歌词,如爱情、励志等;②融合传统与现代文化元素创作独特风格的歌词;③对已有歌词进行润色和优化。; 阅读建议:阅读时可以重点关注作词大师的创作偏好、技能优势以及工作流程,有助于更好地理解如何创作出高质量的歌词。同时,在提出创作需求时,尽量详细描述自己的情感背景和期望,以便获得更贴合心意的作品。
linux之用户管理教程.md
包括:源程序工程文件、Proteus仿真工程文件、配套技术手册等 1、采用51/52单片机作为主控芯片; 2、采用1602液晶显示设置及状态; 3、采用L298驱动两个电机,模拟机械臂动力、移动底盘动力; 3、首先按键配置-待搬运物块的高度和宽度(为0不能开始搬运); 4、按下启动键开始搬运,搬运流程如下: 机械臂先把物块抓取到机器车上, 机械臂减速 机器车带着物块前往目的地 机器车减速 机械臂把物块放下来 机械臂减速 机器车回到物块堆积处(此时机器车是空车) 机器车减速 蜂鸣器提醒 按下复位键,结束本次搬运
内容概要:本文详细介绍了基于下垂控制的三相逆变器电压电流双闭环控制的仿真方法及其在MATLAB/Simulink和PLECS中的具体实现。首先解释了下垂控制的基本原理,即有功调频和无功调压,并给出了相应的数学表达式。随后讨论了电压环和电流环的设计与参数整定,强调了两者带宽的差异以及PI控制器的参数选择。文中还提到了一些常见的调试技巧,如锁相环的响应速度、LC滤波器的谐振点处理、死区时间设置等。此外,作者分享了一些实用的经验,如避免过度滤波、合理设置采样周期和下垂系数等。最后,通过突加负载测试展示了系统的动态响应性能。 适合人群:从事电力电子、微电网研究的技术人员,尤其是有一定MATLAB/Simulink和PLECS使用经验的研发人员。 使用场景及目标:适用于希望深入了解三相逆变器下垂控制机制的研究人员和技术人员,旨在帮助他们掌握电压电流双闭环控制的具体实现方法,提高仿真的准确性和效率。 其他说明:本文不仅提供了详细的理论讲解,还结合了大量的实战经验和调试技巧,有助于读者更好地理解和应用相关技术。
内容概要:本文详细介绍了光伏并网逆变器的全栈开发资料,涵盖了从硬件设计到控制算法的各个方面。首先,文章深入探讨了功率接口板的设计,包括IGBT缓冲电路、PCB布局以及EMI滤波器的具体参数和设计思路。接着,重点讲解了主控DSP板的核心控制算法,如MPPT算法的实现及其注意事项。此外,还详细描述了驱动扩展板的门极驱动电路设计,特别是光耦隔离和驱动电阻的选择。同时,文章提供了并联仿真的具体实现方法,展示了环流抑制策略的效果。最后,分享了许多宝贵的实战经验和调试技巧,如主变压器绕制、PWM输出滤波、电流探头使用等。 适合人群:从事电力电子、光伏系统设计的研发工程师和技术爱好者。 使用场景及目标:①帮助工程师理解和掌握光伏并网逆变器的硬件设计和控制算法;②提供详细的实战经验和调试技巧,提升产品的可靠性和性能;③适用于希望深入了解光伏并网逆变器全栈开发的技术人员。 其他说明:文中不仅提供了具体的电路设计和代码实现,还分享了许多宝贵的实际操作经验和常见问题的解决方案,有助于提高开发效率和产品质量。
内容概要:本文详细介绍了粒子群优化(PSO)算法与3-5-3多项式相结合的方法,在机器人轨迹规划中的应用。首先解释了粒子群算法的基本原理及其在优化轨迹参数方面的作用,随后阐述了3-5-3多项式的数学模型,特别是如何利用不同阶次的多项式确保轨迹的平滑过渡并满足边界条件。文中还提供了具体的Python代码实现,展示了如何通过粒子群算法优化时间分配,使3-5-3多项式生成的轨迹达到时间最优。此外,作者分享了一些实践经验,如加入惩罚项以避免超速,以及使用随机扰动帮助粒子跳出局部最优。 适合人群:对机器人运动规划感兴趣的科研人员、工程师和技术爱好者,尤其是有一定编程基础并对优化算法有初步了解的人士。 使用场景及目标:适用于需要精确控制机器人运动的应用场合,如工业自动化生产线、无人机导航等。主要目标是在保证轨迹平滑的前提下,尽可能缩短运动时间,提高工作效率。 其他说明:文中不仅给出了理论讲解,还有详细的代码示例和调试技巧,便于读者理解和实践。同时强调了实际应用中需要注意的问题,如系统的建模精度和安全性考量。
KUKA机器人相关资料
内容概要:本文详细探讨了光子晶体中的束缚态在连续谱中(BIC)及其与轨道角动量(OAM)激发的关系。首先介绍了光子晶体的基本概念和BIC的独特性质,随后展示了如何通过Python代码模拟二维光子晶体中的BIC,并解释了BIC在光学器件中的潜在应用。接着讨论了OAM激发与BIC之间的联系,特别是BIC如何增强OAM激发效率。文中还提供了使用有限差分时域(FDTD)方法计算OAM的具体步骤,并介绍了计算本征态和三维Q值的方法。此外,作者分享了一些实验中的有趣发现,如特定条件下BIC表现出OAM特征,以及不同参数设置对Q值的影响。 适合人群:对光子晶体、BIC和OAM感兴趣的科研人员和技术爱好者,尤其是从事微纳光子学研究的专业人士。 使用场景及目标:适用于希望通过代码模拟深入了解光子晶体中BIC和OAM激发机制的研究人员。目标是掌握BIC和OAM的基础理论,学会使用Python和其他工具进行模拟,并理解这些现象在实际应用中的潜力。 其他说明:文章不仅提供了详细的代码示例,还分享了许多实验心得和技巧,帮助读者避免常见错误,提高模拟精度。同时,强调了物理离散化方式对数值计算结果的重要影响。
内容概要:本文详细介绍了如何使用C#和Halcon 17.12构建一个功能全面的工业视觉项目。主要内容涵盖项目配置、Halcon脚本的选择与修改、相机调试、模板匹配、生产履历管理、历史图像保存以及与三菱FX5U PLC的以太网通讯。文中不仅提供了具体的代码示例,还讨论了实际项目中常见的挑战及其解决方案,如环境配置、相机控制、模板匹配参数调整、PLC通讯细节、生产数据管理和图像存储策略等。 适合人群:从事工业视觉领域的开发者和技术人员,尤其是那些希望深入了解C#与Halcon结合使用的专业人士。 使用场景及目标:适用于需要开发复杂视觉检测系统的工业应用场景,旨在提高检测精度、自动化程度和数据管理效率。具体目标包括但不限于:实现高效的视觉处理流程、确保相机与PLC的无缝协作、优化模板匹配算法、有效管理生产和检测数据。 其他说明:文中强调了框架整合的重要性,并提供了一些实用的技术提示,如避免不同版本之间的兼容性问题、处理实时图像流的最佳实践、确保线程安全的操作等。此外,还提到了一些常见错误及其规避方法,帮助开发者少走弯路。
内容概要:本文探讨了分布式电源(DG)接入对9节点配电网节点电压的影响。首先介绍了9节点配电网模型的搭建方法,包括定义节点和线路参数。然后,通过在特定节点接入分布式电源,利用Matlab进行潮流计算,模拟DG对接入点及其周围节点电压的影响。最后,通过绘制电压波形图,直观展示了不同DG容量和接入位置对配电网电压分布的具体影响。此外,还讨论了电压越限问题以及不同线路参数对电压波动的影响。 适合人群:电力系统研究人员、电气工程学生、从事智能电网和分布式能源研究的专业人士。 使用场景及目标:适用于研究分布式电源接入对配电网电压稳定性的影响,帮助优化分布式电源的规划和配置,确保电网安全稳定运行。 其他说明:文中提供的Matlab代码和图表有助于理解和验证理论分析,同时也为后续深入研究提供了有价值的参考资料。
内容概要:本文探讨了在两级电力市场环境中,针对省间交易商的最优购电模型的研究。文中提出了一个双层非线性优化模型,用于处理省内电力市场和省间电力交易的出清问题。该模型采用CVaR(条件风险价值)方法来评估和管理由新能源和负荷不确定性带来的风险。通过KKT条件和对偶理论,将复杂的双层非线性问题转化为更易求解的线性单层问题。此外,还通过实际案例验证了模型的有效性,展示了不同风险偏好设置对购电策略的影响。 适合人群:从事电力系统规划、运营以及风险管理的专业人士,尤其是对电力市场机制感兴趣的学者和技术专家。 使用场景及目标:适用于希望深入了解电力市场运作机制及其风险控制手段的研究人员和技术开发者。主要目标是为省间交易商提供一种科学有效的购电策略,以降低风险并提高经济效益。 其他说明:文章不仅介绍了理论模型的构建过程,还包括具体的数学公式推导和Python代码示例,便于读者理解和实践。同时强调了模型在实际应用中存在的挑战,如数据精度等问题,并指出了未来改进的方向。
内容概要:本文详细介绍了一套成熟的西门子1200 PLC轴运动控制程序模板,涵盖多轴伺服控制、电缸控制、PLC通讯、气缸报警块、完整电路图、威纶通触摸屏程序和IO表等方面的内容。该模板已在多个项目中成功应用,如海康威视的路由器外壳装配机,确保了系统的稳定性和可靠性。文中不仅提供了具体的代码示例,还分享了许多实战经验和技巧,如参数设置、异常处理机制、通讯优化等。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是那些需要进行PLC编程和轴运动控制的从业者。 使用场景及目标:适用于需要快速搭建稳定可靠的PLC控制系统的企业和个人开发者。通过学习和应用该模板,可以提高开发效率,减少调试时间和错误发生率,从而更好地满足项目需求。 其他说明:文章强调了程序模板的实用性,特别是在异常处理和参数配置方面的独特设计,能够有效应对复杂的工业环境挑战。此外,还提到了一些常见的陷阱和解决方案,帮助读者避开常见错误,顺利实施项目。
内容概要:本文详细探讨了微网电池储能容量优化配置的方法和技术。随着能源结构的转型和分布式能源的发展,微网作为新型电力系统受到广泛关注。文中介绍了混合整数规划(MILP)在储能容量优化配置中的应用,通过建立目标函数和约束条件,实现了储能系统运行成本最小化和经济效益最大化。具体而言,模型考虑了储能系统的初始投资成本、运维成本以及能量平衡、储能容量和充放电功率等约束条件。此外,文章还讨论了实际应用中的挑战,如数据获取困难、模型复杂性和求解器性能等问题,并提出了相应的改进建议。 适合人群:从事微网系统研究的技术人员、研究人员和相关领域的学生。 使用场景及目标:适用于需要优化微网储能系统配置的研究和工程项目,旨在降低运行成本、提高经济效益,并确保系统稳定运行。 其他说明:文章提供了详细的MATLAB代码示例,展示了如何使用intlinprog函数求解混合整数线性规划问题。同时,强调了在实际应用中需要根据具体情况调整模型和参数,以应对复杂多变的现实环境。