- 浏览: 4415094 次
- 性别:

- 来自: 厦门
-

文章分类
- 全部博客 (634)
- Oracle日常管理 (142)
- Oracle体系架构 (45)
- Oracle Tuning (52)
- Oracle故障诊断 (35)
- RAC/DG/OGG (64)
- Oracle11g New Features (48)
- DataWarehouse (15)
- SQL, PL/SQL (14)
- DB2日常管理 (9)
- Weblogic (11)
- Shell (19)
- AIX (12)
- Linux/Unix高可用性 (11)
- Linux/Unix日常管理 (66)
- Linux桌面应用 (37)
- Windows (2)
- 生活和工作 (13)
- 私人记事 (0)
- Python (9)
- CBO (15)
- Cognos (2)
- ORACLE 12c New Feature (2)
- PL/SQL (2)
- SQL (1)
- C++ (2)
- Hadoop大数据 (5)
- 机器学习 (3)
- 非技术 (1)
最新评论
-
di1984HIT:
xuexilee!!!
Oracle 11g R2 RAC高可用连接特性 – SCAN详解 -
aneyes123:
谢谢非常有用那
PL/SQL的存储过程和函数(原创) -
jcjcjc:
写的很详细
Oracle中Hint深入理解(原创) -
di1984HIT:
学习了,学习了
Linux NTP配置详解 (Network Time Protocol) -
avalonzst:
大写的赞..
AIX内存概述(原创)
在 Oracle 数据库的运行过程中,可能会因为一些异常遇到数据库挂起失去响应的状况,在这种状况下,我们可以通过对系统状态进行转储,获得跟踪文件进行数据库问题分析;很多时候数据库也会自动转储出现问题的进程或系统信息;这些转储信息成为我们分析故障、排查问题的重要依据。
本章通过实际案例的详细分析,讲解如何逐层入手、层层剖析的分析数据库故障。
1.1 状态转储的常用命令
当数据库出现一些挂起状态时,往往会严重影响到数据库使用,进程级的问题影响范围较小,而系统级的问题则会影响全局。
在出现数据库系统或进程失去响应时,如果
SQL*Plus
工具仍然可以连接,可能视图查询没有相应,但是可以通过
oradebug
工具来进行进程及系统状态信息的转储,从而可以进行
Hang
分析。
DUMP
进程状态可以使用:
alter sessions set events 'immediate trace name processstate level <level>' ;
或者使用:
oradebug setmypid
oradebug ulimit
oradebug dump processstate<level>
当诊断数据库挂起时,可以使用 DUMP 命令转储整个系统状态:
alter sessions set events 'immediate trace name systemstate level <level>' ;
或:
oradebug setmypid
oradebug ulimit
oradebug dump systemstate <level>
如果为了获取全面一点的信息,可以使用 Level 10 。
SQL> oradebug setmypid
SQL> oradebug unlimit
SQL> oradebug dump systemstate 10
另外如果系统挂起,无法用 SQL*Plus 连接,从 Oracle 10g 开始,可以使用 sqlplus -prelim 选项强制登录,然后即可进行系统状态信息转储:
sqlplus -prelim '/ as sysdba'
oradebug setmypid
oradebug unlimit;
oradebug dump systemstate 10
1.2 WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! 案例
在一次客户现场培训中,客户提出一个系统正遇到问题,请求我协助诊断解决,理论联系实践,这是我在培训中极力主张的,我们的案例式培训业正好遇到了实践现场。
问题是这样的:
此前一个 Job 任务可以在秒级完成,而现在运行了数小时也无法结束,一直挂起在数据库中,杀掉进程重新手工执行,尝试多次,同样无法完成。
客户的数据库环境为:
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - 64bit Production
With the Partitioning, OLAP and Data Mining options
Node name: SF2900 Release: 5.9 Version: Generic_118558-33 Machine: sun4u
介入问题诊断首先需要收集数据,我最关注两方面的信息:
1. 告警日志文件,检查是否出现过异常
2. 生成 AWR 报告,检查数据库内部的运行状况
通常有了这两部信息,我们就可以做出初步判断了。
检查数据库的告警日志文件,我们发现其中出现过一个如下错误:
>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<
这个错误提示出现在 7 点左右,正是 JOB 的调度时间附近,显然这是一个高度相关的可能原因。
1.3 DUMP 转储文件分析定位问题
这个异常生成了转储的 DUMP 文件,获得该文件进行进一步的详细分析。
该文件得头部信息如下:
Redo thread mounted by this instance: 1
Oracle process number: 29
Unix process pid: 8371 , image: oracleEDW@SF2900
*** 2010-03-27 06:54:00.114
*** ACTION NAME:() 2010-03-27 06:54:00.106
*** MODULE NAME:(SQL*Plus) 2010-03-27 06:54:00.106
*** SERVICE NAME:(EDW) 2010-03-27 06:54:00.106
*** SESSION ID:(120.46138) 2010-03-27 06:54:00.106
>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<
row cache enqueue: session: 6c10508e8, mode: N, request: S
ROW CACHE 队列锁无法获得,表明数据库在 SQL 解析时,遇到问题, DC 层面出现竞争,导致超时。 Row Cache 位于 Shared Pool 中的 Data Dictionary Cache ,是用于存储表列定义、权限等相关信息的。
注意以上信息中的重要内容包括:
1. 超时告警的时间是 06:54: 2010-03-27 06:54:00.106
2. 出现等待超时的数据库进程号是 29 : Oracle process number: 29
3. 等待超时的 29 号进程的 OS 进程号为 8317 : Unix process pid: 8371
4. 进程时通过 SQL*Plus 调度执行的: MODULE NAME:(SQL*Plus)
5. 会话的 ID 、 Serial# 信息为 120.46138 : SESSION ID:(120.46138)
6. 进程的 State Object 为 6c10508e8 : row cache enqueue: session: 6c10508e8
7. 队列锁的请求模式为共享( S ): mode: N, request: S
有了这些重要的信息,我们就可以开始一些基本的分析。
首先可以在跟踪文件中找到 29 号进程,查看其中的相关信息。经过检查可以发现这些内容与跟踪文件完全相符合:
PROCESS 29:
----------------------------------------
SO: 6c1006740 , type: 2, owner: 0, flag: INIT/-/-/0x00
(process) Oracle pid=29, calls cur/top: 6c1097430/6c1096bf0 , flag: (0) -
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 109 0 4
last post received-location: kslpsr
last process to post me: 6c1002800 1 6
last post sent: 0 0 24
last post sent-location: ksasnd
last process posted by me: 6c1002800 1 6
(latch info) wait_event=0 bits=0
Process Group: DEFAULT, pseudo proc: 4f818c298
O/S info: user: oracle, term: UNKNOWN, ospid: 8371
OSD pid info: Unix process pid: 8371 , image: oracleEDW@SF2900
进一步的向下检查可以找到 SO 对象 6c10508e8 ,这里显示该进程确实由客户端的 SQL*Plus 发起,并且客户端的主机名称及进程的 OSPID 都记录在案:
SO: 6c10508e8 , type: 4, owner: 6c1006740, flag: INIT/-/-/0x00
(session) sid: 120 trans: 6c285ea98, creator: 6c1006740, flag: (100041) USR/- BSY/-/-/-/-/-
DID: 0001-001D-001BC795, short-term DID: 0000-0000-00000000
txn branch: 0
oct: 2, prv: 0, sql: 4f528d510, psql: 491cbe3e8, user: 56/CACI
O/S info: user: Administrator, term: HOST03, ospid: 37692:38132, machine:
program: sqlplus.exe
application name: SQL*Plus, hash value=3669949024
接下来的信息显示,进程一直在等待,等待事件为 'ksdxexeotherwait' :
last wait for 'ksdxexeotherwait' blocking sess=0x0 seq=36112 wait_time=5 seconds since wait started=3
=0, =0, =0
Dumping Session Wait History
for 'ksdxexeotherwait' count=1 wait_time=5
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=5
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=3
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=5
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=4
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=3
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=4
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=4
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=3
=0, =0, =0
for 'ksdxexeotherwait' count=1 wait_time=3
=0, =0, =0
temporary object counter: 0
在这个进程跟踪信息的最后部分,有如下一个 SO 对象继承关系列表,注意这里的 OWNER 具有级联关系,下一层隶属于上一层的 Owner ,第一个 SO 对象的 Owner 6c1006740 就是 PROCESS 29 的 SO 号。
到了最后一个级别的 SO 4e86f03e8 上,请求出现阻塞。
Row cache enqueue 有一个( count=1 )共享模式( request=S )的请求被阻塞:
----------------------------------------
SO: 6c1096bf0, type: 3, owner: 6c1006740 , flag: INIT/-/-/0x00
(call) sess: cur 6c10508e8, rec 6c10508e8, usr 6c10508e8; depth: 0
----------------------------------------
SO: 6c1096eb0, type: 3, owner: 6c1096bf0 , flag: INIT/-/-/0x00
(call) sess: cur 6c10508e8, rec 6c10691f8, usr 6c10508e8; depth: 1
----------------------------------------
SO: 6c1097430, type: 3, owner: 6c1096eb0 , flag: INIT/-/-/0x00
(call) sess: cur 6c10691f8, rec 6c10691f8, usr 6c10508e8; depth: 2
----------------------------------------
SO: 4e86f03e8, type: 50, owner: 6c1097430 , flag: INIT/-/-/0x00
row cache enqueue: count=1 session=6c10508e8 object=4f4e57138 , request=S
savepoint=0xf67b
回过头去对比一下跟踪文件最初的信息,注意这里的 session 信息正是跟踪文件头上列出的 session 信息:
>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<
row cache enqueue: session: 6c10508e8, mode: N, request: S
至此我们找到了出现问题的根源,这里也显示请求的对象是
object=4f4e57138
。
1.4 ROW CACHE 对象的定位
跟踪文件向下显示了更进一步的信息,地址为 4f4e57138 的 Row Cache Parent Object 紧跟着之前的信息显示出来,跟踪信息同时显示是在 DC_OBJECTS 层面出现的问题。
跟踪信息显示对象的锁定模式为排他锁定( mode=X )。
下图是跟踪文件的截取,我们可以看到
Oracle
的记录方式:
进一步的,跟踪文件里也显示了 29 号进程执行的 SQL 为 INSERT 操作:
----------------------------------------
SO: 4f2e82c88, type: 53, owner: 6c10508e8, flag: INIT/-/-/0x00
LIBRARY OBJECT LOCK: lock=4f2e82c88 handle=4f528d510 mode=N
call pin=0 session pin=0 hpc=0000 hlc=0000
htl=4f2e82d08[4f2de4dd8,4f2e844c0] htb=4e84c5db0 ssga=4e84c57c8
user=6c10508e8 session=6c10508e8 count=1 flags=[0000] savepoint=0x4bad2ee7
LIBRARY OBJECT HANDLE: handle=4f528d510 mtx=4f528d640(1) cdp=1
name=INSERT /*+ APPEND*/ INTO CACI_INV_BLB_DC NOLOGGING SELECT :B1 , T.*, SYSDATE FROM CACI_INV_BLB T
hash=6734e347f90993bcd607836585310c4d timestamp=03-24-2010 06:01:54
namespace=CRSR flags=RON/KGHP/TIM/PN0/MED/KST/DBN/MTX/[500100d0]
kkkk-dddd-llll=0000-0001-0001 lock=N pin=0 latch#=12 hpc=ffec hlc=ffec
lwt=4f528d5b8[4f528d5b8,4f528d5b8] ltm=4f528d5c8[4f528d5c8,4f528d5c8]
pwt=4f528d580[4f528d580,4f528d580] ptm=4f528d590[4f528d590,4f528d590]
ref=4f528d5e8[4f528d5e8,4f528d5e8] lnd=4f528d600[4f581b4d8,4f5d190a8]
LIBRARY OBJECT: object=4a7227a50
type=CRSR flags=EXS[0001] pflags=[0000] status=VALD load=0
CHILDREN: size=16
child# table reference handle
------ -------- --------- --------
0 4a7227518 4a7227188 4ae9ed1f0
1 4a7227518 4a7227420 494cd5878
DATA BLOCKS:
data# heap pointer status pins change whr
----- -------- -------- --------- ---- ------ ---
0 4aebaa950 4a7227b68 I/P/A/-/- 0 NONE 00
----------------------------------------
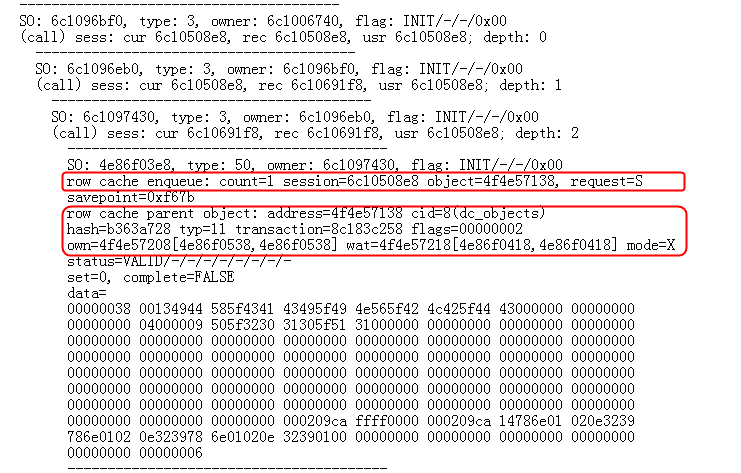
好了,那么现在我们来看看是哪一个进程排他的锁定了之前的 4f4e57138 对象。在跟踪文件中搜索 4f4e57138 就可以很容易的找到这个持有排他锁定的 SO 对象。
以下显示了相关信息, Row Cache 对象的信息在此同样有所显示:
----------------------------------------
SO: 4e86f0508 , type: 50, owner: 8c183c258, flag: INIT/-/-/0x00
row cache enqueue: count=1 session=8c005d7c8 object=4f4e57138, mode=X
savepoint=0x2716
row cache parent object: address=4f4e57138 cid=8(dc_objects)
hash=b363a728 typ=11 transaction=8c183c258 flags=00000002
own=4f4e57208[4e86f0538,4e86f0538] wat=4f4e57218[4e86f0418,4e86f0418] mode=X
status=VALID/-/-/-/-/-/-/-/-
set=0, complete=FALSE
data=
00000038 00134944 585f4341 43495f49 4e565f42 4c425f44 43000000 00000000
00000000 04000009 505f3230 31305f51 31000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 000209ca ffff0000 000209ca 14786e01 020e3239
786e0102 0e323978 6e01020e 32390100 00000000 00000000 00000000 00000000
00000000 00000006
----------------------------------------
再向上找到这个进程的信息,发现其进程号为 16 :
PROCESS 16:
----------------------------------------
SO: 8c00037d0, type: 2, owner: 0, flag: INIT/-/-/0x00
(process) Oracle pid=16, calls cur/top: 8c0095028/8c0094aa8, flag: (0) -
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 115 0 4
last post received-location: kslpsr
last process to post me: 6c1002800 1 6
last post sent: 0 0 24
last post sent-location: ksasnd
last process posted by me: 6c1002800 1 6
(latch info) wait_event=0 bits=0
Process Group: DEFAULT, pseudo proc: 4f818c298
O/S info: user: oracle, term: UNKNOWN, ospid: 8200
OSD pid info: Unix process pid: 8200, image: oracle@SF2900 (J000)
在这里可以看到 16 号进程是一个 JOB 进程,其进程为 J000 ,那么这个 JOB 进程在执行什么操作呢?下面的信息可以看出一些端倪, JOB 由 DBMS_SCHEDULER 调度,执行 AUTO_SPACE_ADVISOR_JOB 任务,处于 Wait for shrink lock 等待:
Job Slave State Object
Slave ID: 0, Job ID: 8913
----------------------------------------
SO: 8c005d7c8, type: 4, owner: 8c00037d0, flag: INIT/-/-/0x00
(session) sid: 45 trans: 8c183c258, creator: 8c00037d0, flag: (48100041) USR/- BSY/-/-/-/-/-
DID: 0001-0010-0007BFA6, short-term DID: 0000-0000-00000000
txn branch: 0
oct: 0, prv: 0, sql: 0, psql: 0, user: 0/SYS
O/S info: user: oracle, term: UNKNOWN, ospid: 8200, machine: SF2900
program: oracle@SF2900 (J000)
application name: DBMS_SCHEDULER, hash value=2478762354
action name: AUTO_SPACE_ADVISOR_JOB, hash value=348111556
waiting for 'Wait for shrink lock' blocking sess=0x0 seq=5909 wait_time=0 seconds since wait started=3101
object_id=0, lock_mode=0, =0
Dumping Session Wait History
for 'Wait for shrink lock' count=1 wait_time=380596
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107262
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107263
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107246
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107139
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107248
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107003
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107169
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107233
object_id=0, lock_mode=0, =0
for 'Wait for shrink lock' count=1 wait_time=107069
object_id=0, lock_mode=0, =0
temporary object counter: 3
进一步向下查找,可以找到 Shrink 操作执行的 SQL 语句:
----------------------------------------
SO: 4e8a2c6c0, type: 53, owner: 8c005d7c8, flag: INIT/-/-/0x00
LIBRARY OBJECT LOCK: lock=4e8a2c6c0 handle=4c3c1ce60 mode=N
call pin=0 session pin=0 hpc=0000 hlc=0000
htl=4e8a2c740[4e81436e0,4e8c80c98] htb=4e8937910 ssga=4e8936e48
user=8c005d7c8 session=8c005d7c8 count=1 flags=[0000] savepoint=0x4bad2eec
LIBRARY OBJECT HANDLE: handle=4c3c1ce60 mtx=4c3c1cf90(1) cdp=1
name=alter index "CACI"."IDX_CACI_INV_BLB_DC" modify partition "P_2010_Q1" shrink space CHECK
hash=0ed1a6f7b2cf775661d314b8d1b7659b timestamp=03-25-2010 22:05:09
namespace=CRSR flags=RON/KGHP/TIM/PN0/MED/KST/DBN/MTX/[500100d0]
kkkk-dddd-llll=0000-0001-0001 lock=N pin=0 latch#=15 hpc=0002 hlc=0002
lwt=4c3c1cf08[4c3c1cf08,4c3c1cf08] ltm=4c3c1cf18[4c3c1cf18,4c3c1cf18]
pwt=4c3c1ced0[4c3c1ced0,4c3c1ced0] ptm=4c3c1cee0[4c3c1cee0,4c3c1cee0]
ref=4c3c1cf38[4c3c1cf38,4c3c1cf38] lnd=4c3c1cf50[4c3c1cf50,4c3c1cf50]
LIBRARY OBJECT: object=4aa2bf668
type=CRSR flags=EXS[0001] pflags=[0000] status=VALD load=0
CHILDREN: size=16
child# table reference handle
------ -------- --------- --------
0 49efa3fe8 49efa3c58 4c3ad91a8
1 49efa3fe8 49efa3ed8 4c3941608
DATA BLOCKS:
data# heap pointer status pins change whr
----- -------- -------- --------- ---- ------ ---
0 4c3589b38 4aa2bf780 I/P/A/-/- 0 NONE 00
----------------------------------------
至此,真相大白于天下:
1. 系统通过 DBMS_SCHEDULER 调度执行 AUTO_SPACE_ADVISOR_JOB 任务
发出了 SQL 语句:
alter index "CACI"."IDX_CACI_INV_BLB_DC" modify partition "P_2010_Q1" shrink space CHECK
2. 定时任务不能及时完成产生了排他锁定
3. 客户端执行的 INSERT 操作挂起
INSERT 语句为:
INSERT /*+ APPEND*/ INTO CACI_INV_BLB_DC NOLOGGING SELECT :B1 , T.*, SYSDATE FROM CACI_INV_BLB T
Shrink Space 的语句所以不能成功完成是因为该索引的相关数据表的数据量过为巨大。在 Oracle10g 中,缺省的有一个任务定时进行分析为用户提供空间管理建议,在进行空间建议前, Oracle 执行 Shrink Space Check ,这个检查工作和 Shrink 的具体内部工作完全相同,只是不执行具体动作。
这个 Shrink Space 的检查对于客户环境显得多余。
现场解决这个问题,只需要将 16 号进程 Kill 掉,即可释放了锁定,后面的操作可以顺利进行下去。
参考至:http://www.eygle.com/archives/2011/05/dbasystem_state_rowcache.html
http://www.eygle.com/archives/2011/05/dbasystem_state_file.html
如有错误,欢迎指正
邮箱:czmcj@163.com


发表评论

-
AIX平台下磁盘的PVID对ASM磁盘的破坏
2014-03-19 20:53 2745这篇文章将通过两篇MOS文章来讨论AIX平台下为磁盘分配 ... -
Bug 9020054,ORA-8103 BEING HIT DURING GATHERING OF STATISTICS ON TABLE PARTITION
2013-12-01 09:22 1887Bug 9020054 : ORA-8103 ... -
oracle数据库hanganalyze(原创)
2013-06-23 14:11 8341为什么要使用hanganalyzeOracle 数据库“真 ... -
Oracle:并行操作为什么无法执行(老白)
2013-06-23 10:30 5745在一次系统割接的时候,我们碰到一个十分奇怪的现象。由于进行 ... -
补写的2小节DBA日记
2013-06-05 21:52 13956月8日 ITL等待引发的RAC性能问题 从这几天的情况 ... -
ORA-27054故障排除
2013-03-08 17:57 12976在数据备份过程中,由于目标是使用NFS文件系统,因此在导入 ... -
长时间latch free等待——记一次系统异常的诊断过程
2013-01-09 19:17 3749今天发现一个报表数据库中SQL运行异常,简单记录一下问题的诊断 ... -
ORA-15063: ASM discovered an insufficient number of disks for diskgroup(原创)
2012-11-25 16:59 13099ORA-15063: ASM discovered an in ... -
libpthread.so.0: cannot open shared object file解决方法(原创)
2012-11-24 17:33 17774在linux 5上装10G RAC时,常常会碰到“libpth ... -
ora-02020故障诊断详解(原创)
2012-07-16 12:54 3215ORA-2020错发生在一个分布式事务使用的dblink数超过 ... -
Oracle数据库CPU 100%故障诊断实例(原创)
2012-07-05 13:55 16927前言 这两天一只对外提供查询的数据库CPU使用率 ... -
ORA-02050故障诊断一例
2012-04-05 17:20 8588昨天客户反映说在下午某时间段有几个事务失败了,让我查下当时数据 ... -
ORA-00308: cannot open archived log(原创)
2012-03-23 09:36 16272笔者在为客户配置DG时发现主备库日志无法正常传输,经仔细检查后 ... -
ORA-00600: internal error code, arguments: [kcblasm_1], [103]原创
2012-03-23 09:36 3121故障报错 Mon Mar 19 11:30:03 GMT ... -
ORA-00600: internal error code, arguments: [kglhdda-bad-free](原创)
2012-03-22 09:16 2968故障报错如下 Thu Mar 15 09:51:29 G ... -
ORA-27300,ORA-27301,ORA-27302: failure occurred at: skgpalive1(原创)
2012-03-22 08:58 3359故障报错如下 Wed Mar 07 16:4 ... -
ora-07445错误相关内容
2012-03-01 17:14 1834本文档主要介绍ora-07445 错误相关内容,并给出了对这 ... -
记一次Oracle 生产库还原归档日志经历(原创)
2012-02-17 10:12 4394中午刚去吃饭,就接到同事电话说急着要恢复生产库上的归档日志。系 ... -
SMON: Parallel transaction recovery tried 引发的问题
2012-01-04 11:26 2405SMON: Parallel transaction rec ... -
ORA-00444,ORA-07446故障排查
2011-12-14 16:58 4658phenomenon startup ORA-00 ...
相关推荐
当系统遇到严重错误时,会生成一个包含内核内存状态的转储文件,以便开发者或者系统管理员分析问题原因。`dumplib`是一个用Python编写的工具,专门用于解析和分析这些Windows内核转储文件,为故障排查提供便利。 ...
iOS崩溃转储分析书本书HTML版本“ iOS崩溃转储分析”如下所示: 语关联英语 中国人 本书随附的是“分析故障排除”工作表。 可以从以下位置购买Kindle版本: , 和其他Amazon地理区域。 可以在以下位置购买平装印刷版...
- 第4章 虚拟机性能监控、故障处理工具- 4.2 基础故障处理工具JDK提供jhat(JVM Heap Analysis Tool)命令与jmap搭配使用,来
Java线程转储分析器这是用Java编写的Java线程转储分析器。 执照Java Thread Dump Analyzer是根据,版权属于Spotify AB。本地测试npm installnpm test 使用npm 6.13.7和node v13.8.0测试。去做在“同步器”部分中,使...
### 深入解析Windows操作系统之崩溃转储分析 #### 1. Windows为什么会崩溃 Windows系统的崩溃,通常指的是系统在运行过程中遇到了无法处理的错误,从而导致系统进入一种非正常的状态,这种状态往往表现为所谓的...
河岸R 中的密码转储分析,现在具有额外的松脆包-y 优点! 很大程度上基于由@digininja。 要在本地运行命令行或 GUI(闪亮的应用程序),您显然需要 R 和devtools包。 注意:如果您是 R 的新手,一个很好的入门方式...
在某些情况下,使用WinDbg分析内存转储非常复杂。 该工具旨在为托管应用程序转储自动化此类分析。 WinDbgTool 还能够解析一些 WinDbg 命令输出和显示结果,而不是使用纯文本,而是通过可以过滤和排序数据的网格控件...
"深入解析Windows操作系统之崩溃转储分析实用.pdf" 本文档对Windows操作系统的崩溃转储分析进行了深入的解析。崩溃转储是指在系统崩溃时刻的系统内存的纪录,它可以帮助用户找出是哪个组件导致了这次系统崩溃。文章...
- 大型转储:对于大型数据库,可能需要分块导出和导入,以优化性能和管理大量数据。 8. **实战应用**: - 数据迁移:在不同的Oracle实例之间迁移数据,或者在开发、测试和生产环境之间同步数据。 - 故障恢复:当...
UB转储订单的配置和操作。介绍工厂间UB转储,带交货单的UB转储订单操作。对应配置过程,测试过程等,内容比较全
该存储库包含用于从Wikidata提取,转换和分析书目数据的脚本。 该项目的当前状态是实验性的 概述 可以从每周提供的Wikidata转储中提取书目数据,如。 从2014年10月开始,将旧的JSON转储存储在Internet Archive中。...
公司代码间库存转储 本文档介绍了公司代码间库存转储的过程,旨在在不同的公司代码之间转储物料。该过程可以通过一步转储或两步转储来完成,具体来说,一步转储是指在同一个事务中完成发货和收货,而两步转储是指先...
Eclipse Memory Analyzer(MAT)是一款强大的Java内存分析工具,它能帮助开发者诊断和解决与内存泄漏、内存占用过高以及垃圾收集性能问题相关的问题。在Java应用程序中,如果内存管理不当,可能会导致系统运行缓慢,...
将 IMDB 转储解析为 CSV 和关系数据库插入查询使用来自: : IMDB 转储 要求 Python 3.x 配置 所有配置数据都保存在idp/settings.py.example 您需要将此文件复制为settings.py并在运行项目之前编辑此文件 cd idp cp...
我添加了几个功能,例如“转储”,“搜索”,“显示”。 搜索对于搜索内存中的敏感信息(密码等)很有用。 包括示例二进制文件。用法 android_dump_memory <dump> <pid> <start> <total> [search string]dump:将...
在 Windows 系统中,当应用程序崩溃时,系统会自动将内存转储到 dump 文件中,以便开发人员可以通过 dump 文件来定位问题。为了实现这个功能,我们需要在 Windows 注册表中设置调试器的相关配置。 在 HKEY_LOCAL_...
分析Java线程转储对于诊断Java应用程序中的性能问题、死锁、线程阻塞等状况至关重要。 在《Analyzing Java Thread Dumps.pdf》和《Java Thread Dumps 分析.pdf》这两份文档中,你可以深入理解以下几个关键知识点: ...
- **All at Once: Postmortem Logs and Dump Files**:讲解如何同时处理后事日志和转储文件,以便快速定位问题根源。 - **Common Mistakes**: - **Not Looking at Full Stack Traces**:强调了查看完整栈跟踪的...
4. **错误检测**:可能包含基本的语法错误检查,帮助用户在编写或修改转储文件时及时发现潜在问题。 5. **格式化**:允许用户格式化代码,保持代码整洁有序。 6. **集成调试**:虽然Access转储文件不是执行文件,...