consistent hashing¬†зЃЧж≥ХжЧ©еЬ®¬†1997¬†еєіе∞±еЬ®иЃЇжЦЗ¬†Consistent hashing and random trees¬†дЄ≠襀жПРеЗЇпЉМзЫЃеЙНеЬ®¬†cache¬†з≥їзїЯдЄ≠еЇФзФ®иґКжЭ•иґКеєњж≥ЫпЉЫ
1¬†еЯЇжЬђеЬЇжЩѓ
жѓФе¶Вдљ†жЬЙ¬†N¬†дЄ™¬†cache¬†жЬНеК°еЩ®пЉИеРОйЭҐзЃАзІ∞¬†cache¬†пЉЙпЉМйВ£дєИе¶ВдљХе∞ЖдЄАдЄ™еѓєи±°¬†object¬†жШ†е∞ДеИ∞¬†N¬†дЄ™¬†cache¬†дЄКеСҐпЉМдљ†еЊИеПѓиГљдЉЪйЗЗзФ®з±їдЉЉдЄЛйЭҐзЪДйАЪзФ®жЦєж≥ХиЃ°зЃЧ¬†object¬†зЪД¬†hash¬†еАЉпЉМзДґеРОеЭЗеМАзЪДжШ†е∞ДеИ∞еИ∞¬†N¬†дЄ™¬†cache¬†пЉЫ
hash(object)%N
дЄАеИЗйГљињРи°Мж≠£еЄЄпЉМеЖНиАГиЩСе¶ВдЄЛзЪДдЄ§зІНжГЕеЖµпЉЫ
1¬†дЄАдЄ™¬†cache¬†жЬНеК°еЩ®¬†m down¬†жОЙдЇЖпЉИеЬ®еЃЮйЩЕеЇФзФ®дЄ≠ењЕй°їи¶БиАГиЩСињЩзІНжГЕеЖµпЉЙпЉМињЩж†ЈжЙАжЬЙжШ†е∞ДеИ∞¬†cache m¬†зЪДеѓєи±°йГљдЉЪ姱жХИпЉМжАОдєИеКЮпЉМйЬАи¶БжКК¬†cache m¬†дїО¬†cache¬†дЄ≠зІїйЩ§пЉМињЩжЧґеАЩ¬†cache¬†жШѓ¬†N-1¬†еП∞пЉМжШ†е∞ДеЕђеЉПеПШжИРдЇЖ¬†hash(object)%(N-1)¬†пЉЫ
2¬†зФ±дЇОиЃњйЧЃеК†йЗНпЉМйЬАи¶БжЈїеК†¬†cache¬†пЉМињЩжЧґеАЩ¬†cache¬†жШѓ¬†N+1¬†еП∞пЉМжШ†е∞ДеЕђеЉПеПШжИРдЇЖ¬†hash(object)%(N+1)¬†пЉЫ
1¬†еТМ¬†2¬†жДПеС≥зЭАдїАдєИпЉЯињЩжДПеС≥зЭАз™БзДґдєЛйЧіеЗ†дєОжЙАжЬЙзЪД¬†cache¬†йÚ姱жХИдЇЖгАВеѓєдЇОжЬНеК°еЩ®иАМи®АпЉМињЩжШѓдЄАеЬЇзБЊйЪЊпЉМжі™ж∞іиИђзЪДиЃњйЧЃйГљдЉЪзЫіжО•еЖ≤еРСеРОеП∞жЬНеК°еЩ®пЉЫ
еЖНжЭ•иАГиЩСзђђдЄЙдЄ™йЧЃйҐШпЉМзФ±дЇОз°ђдїґиГљеКЫиґКжЭ•иґКеЉЇпЉМдљ†еПѓиГљжГ≥иЃ©еРОйЭҐжЈїеК†зЪДиКВзВєе§ЪеБЪзВєжіїпЉМжШЊзДґдЄКйЭҐзЪД¬†hash¬†зЃЧж≥ХдєЯеБЪдЄНеИ∞гАВ
¬†¬†жЬЙдїАдєИжЦєж≥ХеПѓдї•жФєеПШињЩдЄ™зКґеЖµеСҐпЉМињЩе∞±жШѓ¬†consistent hashing...
2 hash¬†зЃЧж≥ХеТМеНХи∞ГжАІ
гААгАА¬†Hash¬†зЃЧж≥ХзЪДдЄАдЄ™и°°йЗПжМЗж†ЗжШѓеНХи∞ГжАІпЉИ¬†Monotonicity¬†пЉЙпЉМеЃЪдєЙе¶ВдЄЛпЉЪ
гААгААеНХи∞ГжАІжШѓжМЗе¶ВжЮЬеЈ≤зїПжЬЙдЄАдЇЫеЖЕеЃєйАЪињЗеУИеЄМеИЖжіЊеИ∞дЇЖзЫЄеЇФзЪДзЉУеЖ≤дЄ≠пЉМеПИжЬЙжЦ∞зЪДзЉУеЖ≤еК†еЕ•еИ∞з≥їзїЯдЄ≠гАВеУИеЄМзЪДзїУжЮЬеЇФиГље§ЯдњЭиѓБеОЯжЬЙеЈ≤еИЖйЕНзЪДеЖЕеЃєеσ俕襀жШ†е∞ДеИ∞жЦ∞зЪДзЉУеЖ≤дЄ≠еОїпЉМиАМдЄНдЉЪ襀жШ†е∞ДеИ∞жЧІзЪДзЉУеЖ≤йЫЖеРИдЄ≠зЪДеЕґдїЦзЉУеЖ≤еМЇгАВ
еЃєжШУзЬЛеИ∞пЉМдЄКйЭҐзЪДзЃАеНХ¬†hash¬†зЃЧж≥Х¬†hash(object)%N¬†йЪЊдї•жї°иґ≥еНХи∞ГжАІи¶Бж±ВгАВ
3 consistent hashing¬†зЃЧж≥ХзЪДеОЯзРЖ
consistent hashing¬†жШѓдЄАзІН¬†hash¬†зЃЧж≥ХпЉМзЃАеНХзЪДиѓіпЉМеЬ®зІїйЩ§¬†/¬†жЈїеК†дЄАдЄ™¬†cache¬†жЧґпЉМеЃГиГље§Яе∞љеПѓиГље∞ПзЪДжФєеПШеЈ≤е≠ШеЬ®¬†key¬†жШ†е∞ДеЕ≥з≥їпЉМе∞љеПѓиГљзЪДжї°иґ≥еНХи∞ГжАІзЪДи¶Бж±ВгАВ
дЄЛйЭҐе∞±жЭ•жМЙзЕІ¬†5¬†дЄ™ж≠•й™§зЃАеНХиЃ≤иЃ≤¬†consistent hashing¬†зЃЧж≥ХзЪДеЯЇжЬђеОЯзРЖгАВ
3.1¬†з΃嚥hash¬†з©ЇйЧі
иАГиЩСйАЪеЄЄзЪД¬†hash¬†зЃЧж≥ХйГљжШѓе∞Ж¬†value¬†жШ†е∞ДеИ∞дЄАдЄ™¬†32¬†дЄЇзЪД¬†key¬†еАЉпЉМдєЯеН≥жШѓ¬†0~2^32-1¬†жђ°жЦєзЪДжХ∞еАЉз©ЇйЧіпЉЫжИСдїђеПѓдї•е∞ЖињЩдЄ™з©ЇйЧіжГ≥и±°жИРдЄАдЄ™й¶ЦпЉИ¬†0¬†пЉЙе∞ЊпЉИ¬†2^32-1¬†пЉЙзЫЄжО•зЪДеЬЖзОѓпЉМе¶ВдЄЛйЭҐеЫЊ¬†1¬†жЙАз§ЇзЪДйВ£ж†ЈгАВ

еЫЊ¬†1¬†з΃嚥¬†hash¬†з©ЇйЧі
3.2¬†жККеѓєи±°жШ†е∞ДеИ∞hash¬†з©ЇйЧі
жО•дЄЛжЭ•иАГиЩС¬†4¬†дЄ™еѓєи±°¬†object1~object4¬†пЉМйАЪињЗ¬†hash¬†еЗљжХ∞иЃ°зЃЧеЗЇзЪД¬†hash¬†еАЉ¬†key¬†еЬ®зОѓдЄКзЪДеИЖеЄГе¶ВеЫЊ¬†2¬†жЙАз§ЇгАВ
hash(object1) = key1;
вА¶ вА¶
hash(object4) = key4;

еЫЊ¬†2 4¬†дЄ™еѓєи±°зЪД¬†key¬†еАЉеИЖеЄГ
3.3¬†жККcache¬†жШ†е∞ДеИ∞hash¬†з©ЇйЧі
Consistent hashing¬†зЪДеЯЇжЬђжАЭжГ≥е∞±жШѓе∞Жеѓєи±°еТМ¬†cache¬†йГљжШ†е∞ДеИ∞еРМдЄАдЄ™¬†hash¬†жХ∞еАЉз©ЇйЧідЄ≠пЉМеєґдЄФдљњзФ®зЫЄеРМзЪДhash¬†зЃЧж≥ХгАВ
еБЗиЃЊељУеЙНжЬЙ¬†A,B¬†еТМ¬†C¬†еЕ±¬†3¬†еП∞¬†cache¬†пЉМйВ£дєИеЕґжШ†е∞ДзїУжЮЬе∞Же¶ВеЫЊ¬†3¬†жЙАз§ЇпЉМдїЦдїђеЬ®¬†hash¬†з©ЇйЧідЄ≠пЉМдї•еѓєеЇФзЪД¬†hashеАЉжОТеИЧгАВ
hash(cache A) = key A;
вА¶ вА¶
hash(cache C) = key C;

еЫЊ¬†3 cache¬†еТМеѓєи±°зЪД¬†key¬†еАЉеИЖеЄГ
 
иѓіеИ∞ињЩйЗМпЉМй°ЇдЊњжПРдЄАдЄЛ¬†cache¬†зЪД¬†hash¬†иЃ°зЃЧпЉМдЄАиИђзЪДжЦєж≥ХеПѓдї•дљњзФ®¬†cache¬†жЬЇеЩ®зЪД¬†IP¬†еЬ∞еЭАжИЦиАЕжЬЇеЩ®еРНдљЬдЄЇhash¬†иЊУеЕ•гАВ
3.4¬†жККеѓєи±°жШ†е∞ДеИ∞cache
зО∞еЬ®¬†cache¬†еТМеѓєи±°йГљеЈ≤зїПйАЪињЗеРМдЄАдЄ™¬†hash¬†зЃЧж≥ХжШ†е∞ДеИ∞¬†hash¬†жХ∞еАЉз©ЇйЧідЄ≠дЇЖпЉМжО•дЄЛжЭ•и¶БиАГиЩСзЪДе∞±жШѓе¶ВдљХе∞Жеѓєи±°жШ†е∞ДеИ∞¬†cache¬†дЄКйЭҐдЇЖгАВ
еЬ®ињЩдЄ™з΃嚥穯йЧідЄ≠пЉМе¶ВжЮЬж≤њзЭАй°ЇжЧґйТИжЦєеРСдїОеѓєи±°зЪД¬†key¬†еАЉеЗЇеПСпЉМзЫіеИ∞йБЗиІБдЄАдЄ™¬†cache¬†пЉМйВ£дєИе∞±е∞Жиѓ•еѓєи±°е≠ШеВ®еЬ®ињЩдЄ™¬†cache¬†дЄКпЉМеЫ†дЄЇеѓєи±°еТМ¬†cache¬†зЪД¬†hash¬†еАЉжШѓеЫЇеЃЪзЪДпЉМеЫ†ж≠§ињЩдЄ™¬†cache¬†ењЕзДґжШѓеФѓдЄАеТМз°ЃеЃЪзЪДгАВињЩж†ЈдЄНе∞±жЙЊеИ∞дЇЖеѓєи±°еТМ¬†cache¬†зЪДжШ†е∞ДжЦєж≥ХдЇЖеРЧпЉЯпЉБ
дЊЭзДґзїІзї≠дЄКйЭҐзЪДдЊЛе≠РпЉИеПВиІБеЫЊ¬†3¬†пЉЙпЉМйВ£дєИж†єжНЃдЄКйЭҐзЪДжЦєж≥ХпЉМеѓєи±°¬†object1¬†е∞Ж襀е≠ШеВ®еИ∞¬†cache A¬†дЄКпЉЫ¬†object2еТМ¬†object3¬†еѓєеЇФеИ∞¬†cache C¬†пЉЫ¬†object4¬†еѓєеЇФеИ∞¬†cache B¬†пЉЫ
3.5¬†иАГеѓЯcache¬†зЪДеПШеК®
еЙНйЭҐиЃ≤ињЗпЉМйАЪињЗ¬†hash¬†зДґеРОж±ВдљЩзЪДжЦєж≥ХеЄ¶жЭ•зЪДжЬАе§ІйЧЃйҐШе∞±еЬ®дЇОдЄНиГљжї°иґ≥еНХи∞ГжАІпЉМељУ¬†cache¬†жЬЙжЙАеПШеК®жЧґпЉМcache¬†дЉЪ姱жХИпЉМињЫиАМеѓєеРОеП∞жЬНеК°еЩ®йА†жИРеЈ®е§ІзЪДеЖ≤еЗїпЉМзО∞еЬ®е∞±жЭ•еИЖжЮРеИЖжЮР¬†consistent hashing¬†зЃЧж≥ХгАВ
3.5.1¬†зІїйЩ§¬†cache
иАГиЩСеБЗиЃЊ¬†cache B¬†жМВжОЙдЇЖпЉМж†єжНЃдЄКйЭҐиЃ≤еИ∞зЪДжШ†е∞ДжЦєж≥ХпЉМињЩжЧґеПЧељ±еУНзЪДе∞ЖдїЕжШѓйВ£дЇЫж≤њ¬†cache B¬†йАЖжЧґйТИйБНеОЖзЫіеИ∞дЄЛдЄАдЄ™¬†cache¬†пЉИ¬†cache C¬†пЉЙдєЛйЧізЪДеѓєи±°пЉМдєЯеН≥жШѓжЬђжЭ•жШ†е∞ДеИ∞¬†cache B¬†дЄКзЪДйВ£дЇЫеѓєи±°гАВ
еЫ†ж≠§ињЩйЗМдїЕйЬАи¶БеПШеК®еѓєи±°¬†object4¬†пЉМе∞ЖеЕґйЗНжЦ∞жШ†е∞ДеИ∞¬†cache C¬†дЄКеН≥еПѓпЉЫеПВиІБеЫЊ¬†4¬†гАВ

еЫЊ¬†4 Cache B¬†иҐЂзІїйЩ§еРОзЪД¬†cache¬†жШ†е∞Д
3.5.2¬†жЈїеК†¬†cache
еЖНиАГиЩСжЈїеК†дЄАеП∞жЦ∞зЪД¬†cache D¬†зЪДжГЕеЖµпЉМеБЗиЃЊеЬ®ињЩдЄ™з΃嚥¬†hash¬†з©ЇйЧідЄ≠пЉМ¬†cache D¬†иҐЂжШ†е∞ДеЬ®еѓєи±°¬†object2¬†еТМobject3¬†дєЛйЧігАВињЩжЧґеПЧељ±еУНзЪДе∞ЖдїЕжШѓйВ£дЇЫж≤њ¬†cache D¬†йАЖжЧґйТИйБНеОЖзЫіеИ∞дЄЛдЄАдЄ™¬†cache¬†пЉИ¬†cache B¬†пЉЙдєЛйЧізЪДеѓєи±°пЉИеЃГдїђжШѓдєЯжЬђжЭ•жШ†е∞ДеИ∞¬†cache C¬†дЄКеѓєи±°зЪДдЄАйГ®еИЖпЉЙпЉМе∞ЖињЩдЇЫеѓєи±°йЗНжЦ∞жШ†е∞ДеИ∞¬†cache D¬†дЄКеН≥еПѓгАВ
 
еЫ†ж≠§ињЩйЗМдїЕйЬАи¶БеПШеК®еѓєи±°¬†object2¬†пЉМе∞ЖеЕґйЗНжЦ∞жШ†е∞ДеИ∞¬†cache D¬†дЄКпЉЫеПВиІБеЫЊ¬†5¬†гАВ

еЫЊ¬†5¬†жЈїеК†¬†cache D¬†еРОзЪДжШ†е∞ДеЕ≥з≥ї
4¬†иЩЪжЛЯиКВзВє
иАГйЗП¬†Hash¬†зЃЧж≥ХзЪДеП¶дЄАдЄ™жМЗж†ЗжШѓеє≥и°°жАІ¬†(Balance)¬†пЉМеЃЪдєЙе¶ВдЄЛпЉЪ
еє≥и°°жАІ
гААгААеє≥и°°жАІжШѓжМЗеУИеЄМзЪДзїУжЮЬиГље§Яе∞љеПѓиГљеИЖеЄГеИ∞жЙАжЬЙзЪДзЉУеЖ≤дЄ≠еОїпЉМињЩж†ЈеПѓдї•дљњеЊЧжЙАжЬЙзЪДзЉУеЖ≤з©ЇйЧійГљеЊЧеИ∞еИ©зФ®гАВ
hash¬†зЃЧж≥ХеєґдЄНжШѓдњЭиѓБзїЭеѓєзЪДеє≥и°°пЉМе¶ВжЮЬ¬†cache¬†иЊГе∞СзЪДиѓЭпЉМеѓєи±°еєґдЄНиÚ襀еЭЗеМАзЪДжШ†е∞ДеИ∞¬†cache¬†дЄКпЉМжѓФе¶ВеЬ®дЄКйЭҐзЪДдЊЛе≠РдЄ≠пЉМдїЕйГ®зљ≤¬†cache A¬†еТМ¬†cache C¬†зЪДжГЕеЖµдЄЛпЉМеЬ®¬†4¬†дЄ™еѓєи±°дЄ≠пЉМ¬†cache A¬†дїЕе≠ШеВ®дЇЖ¬†object1¬†пЉМиАМ¬†cache C¬†еИЩе≠ШеВ®дЇЖ¬†object2¬†гАБ¬†object3¬†еТМ¬†object4¬†пЉЫеИЖеЄГжШѓеЊИдЄНеЭЗи°°зЪДгАВ
дЄЇдЇЖиІ£еЖ≥ињЩзІНжГЕеЖµпЉМ¬†consistent hashing¬†еЉХеЕ•дЇЖвАЬиЩЪжЛЯиКВзВєвАЭзЪДж¶ВењµпЉМеЃГеПѓдї•е¶ВдЄЛеЃЪдєЙпЉЪ
вАЬиЩЪжЛЯиКВзВєвАЭпЉИ¬†virtual node¬†пЉЙжШѓеЃЮйЩЕиКВзВєеЬ®¬†hash¬†з©ЇйЧізЪДе§НеИґеУБпЉИ¬†replica¬†пЉЙпЉМдЄАеЃЮйЩЕдЄ™иКВзВєеѓєеЇФдЇЖиЛ•еє≤дЄ™вАЬиЩЪжЛЯиКВзВєвАЭпЉМињЩдЄ™еѓєеЇФдЄ™жХ∞дєЯжИРдЄЇвАЬе§НеИґдЄ™жХ∞вАЭпЉМвАЬиЩЪжЛЯиКВзВєвАЭеЬ®¬†hash¬†з©ЇйЧідЄ≠дї•¬†hash¬†еАЉжОТеИЧгАВ
дїНдї•дїЕйГ®зљ≤¬†cache A¬†еТМ¬†cache C¬†зЪДжГЕеЖµдЄЇдЊЛпЉМеЬ®еЫЊ¬†4¬†дЄ≠жИСдїђеЈ≤зїПзЬЛеИ∞пЉМ¬†cache¬†еИЖеЄГеєґдЄНеЭЗеМАгАВзО∞еЬ®жИСдїђеЉХеЕ•иЩЪжЛЯиКВзВєпЉМеєґиЃЊзљЃвАЬе§НеИґдЄ™жХ∞вАЭдЄЇ¬†2¬†пЉМињЩе∞±жДПеС≥зЭАдЄАеЕ±дЉЪе≠ШеЬ®¬†4¬†дЄ™вАЬиЩЪжЛЯиКВзВєвАЭпЉМ¬†cache A1, cache A2¬†дї£и°®дЇЖ¬†cache A¬†пЉЫ¬†cache C1, cache C2¬†дї£и°®дЇЖ¬†cache C¬†пЉЫеБЗиЃЊдЄАзІНжѓФиЊГзРЖжГ≥зЪДжГЕеЖµпЉМеПВиІБеЫЊ¬†6¬†гАВ

еЫЊ¬†6¬†еЉХеЕ•вАЬиЩЪжЛЯиКВзВєвАЭеРОзЪДжШ†е∞ДеЕ≥з≥ї
 
ж≠§жЧґпЉМеѓєи±°еИ∞вАЬиЩЪжЛЯиКВзВєвАЭзЪДжШ†е∞ДеЕ≥з≥їдЄЇпЉЪ
objec1->cache A2¬†пЉЫ¬†objec2->cache A1¬†пЉЫ¬†objec3->cache C1¬†пЉЫ¬†objec4->cache C2¬†пЉЫ
еЫ†ж≠§еѓєи±°¬†object1¬†еТМ¬†object2¬†йÚ襀жШ†е∞ДеИ∞дЇЖ¬†cache A¬†дЄКпЉМиАМ¬†object3¬†еТМ¬†object4¬†жШ†е∞ДеИ∞дЇЖ¬†cache C¬†дЄКпЉЫеє≥и°°жАІжЬЙдЇЖеЊИе§ІжПРйЂШгАВ
еЉХеЕ•вАЬиЩЪжЛЯиКВзВєвАЭеРОпЉМжШ†е∞ДеЕ≥з≥їе∞±дїО¬†{¬†еѓєи±°¬†->¬†иКВзВє¬†}¬†иљђжНҐеИ∞дЇЖ¬†{¬†еѓєи±°¬†->¬†иЩЪжЛЯиКВзВє¬†}¬†гАВжߕ胥зЙ©дљУжЙАеЬ®¬†cacheжЧґзЪДжШ†е∞ДеЕ≥з≥їе¶ВеЫЊ¬†7¬†жЙАз§ЇгАВ
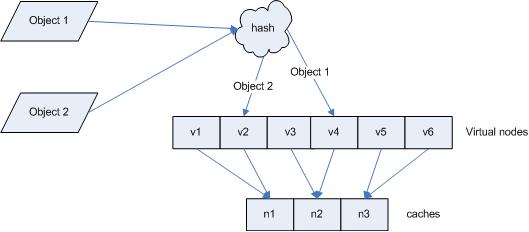
еЫЊ¬†7¬†жߕ胥僺豰жЙАеЬ®¬†cache
 
вАЬиЩЪжЛЯиКВзВєвАЭзЪД¬†hash¬†иЃ°зЃЧеПѓдї•йЗЗзФ®еѓєеЇФиКВзВєзЪД¬†IP¬†еЬ∞еЭАеК†жХ∞е≠ЧеРОзЉАзЪДжЦєеЉПгАВдЊЛе¶ВеБЗиЃЊ¬†cache A¬†зЪД¬†IP¬†еЬ∞еЭАдЄЇ202.168.14.241¬†гАВ
еЉХеЕ•вАЬиЩЪжЛЯиКВзВєвАЭеЙНпЉМиЃ°зЃЧ¬†cache A¬†зЪД¬†hash¬†еАЉпЉЪ
Hash(вАЬ202.168.14.241вАЭ);
еЉХеЕ•вАЬиЩЪжЛЯиКВзВєвАЭеРОпЉМиЃ°зЃЧвАЬиЩЪжЛЯиКВвАЭзВє¬†cache A1¬†еТМ¬†cache A2¬†зЪД¬†hash¬†еАЉпЉЪ
Hash(вАЬ202.168.14.241#1вАЭ);¬†¬†// cache A1
Hash(вАЬ202.168.14.241#2вАЭ);¬†¬†// cache A2
5¬†е∞ПзїУ
Consistent hashing¬†зЪДеЯЇжЬђеОЯзРЖе∞±жШѓињЩдЇЫпЉМеЕЈдљУзЪДеИЖеЄГжАІз≠ЙзРЖиЃЇеИЖжЮРеЇФиѓ•жШѓеЊИе§НжЭВзЪДпЉМдЄНињЗдЄАиИђдєЯзФ®дЄНеИ∞гАВ
http://weblogs.java.net/blog/2007/11/27/consistent-hashing¬†дЄКйЭҐжЬЙдЄАдЄ™¬†java¬†зЙИжЬђзЪДдЊЛе≠РпЉМеПѓдї•еПВиАГгАВ
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx¬†иљђиљљдЇЖдЄАдЄ™¬†PHP¬†зЙИзЪДеЃЮзО∞дї£з†БгАВ
http://www.codeproject.com/KB/recipes/lib-conhash.aspx¬†Cиѓ≠и®АзЙИжЬђ
 
дЄАдЇЫеПВиАГиµДжЦЩеЬ∞еЭАпЉЪ
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
 http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx
 
 
еИЖдЇЂеИ∞пЉЪ




зЫЄеЕ≥жО®иНР
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМпЉИDistributed Hash Table, DHTпЉЙжКАжЬѓпЉМеЃГиІ£еЖ≥дЇЖеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖзЙЗеТМиіЯиљљеЭЗи°°зЪДйЧЃйҐШгАВеЬ®дЉ†зїЯзЪДеУИеЄМзЃЧж≥ХдЄ≠пЉМе¶ВжЮЬеҐЮеК†жИЦеЗПе∞СжЬНеК°еЩ®иКВзВєпЉМдЉЪеѓЉиЗіе§ІйЗПжХ∞жНЃйЗНжЦ∞еИЖйЕНпЉМиАМдЄАиЗіжАІеУИеЄМ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжЬАеИЭзФ±йЇїзЬБзРЖеЈ•е≠¶йЩҐзЪДKз≠ЙдЇЇжПРеЗЇпЉМ庴襀府ж≥ЫеЇФзФ®дЇОеИЖеЄГеЉПз≥їзїЯдЄ≠пЉМдї•иІ£еЖ≥иКВзВєеК®жАБеПШеМЦжЧґжХ∞жНЃдЄАиЗіжАІйЧЃйҐШгАВеЕґж†ЄењГжАЭжГ≥жШѓйАЪињЗеЉХеЕ•еУИеЄМзОѓпЉМе∞ЖжХ∞жНЃеѓєи±°еЭЗеМАеИЖеЄГеЬ®еУИеЄМзОѓдЄКзЪДдЄНеРМиКВзВєдЄ≠пЉМдї•ж≠§йЩНдљОиКВзВєеПШжЫіеѓє...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠иІ£еЖ≥жХ∞жНЃеИЖзЙЗеТМиіЯиљљеЭЗи°°йЧЃйҐШзЪДзЃЧж≥ХпЉМеЃГдЄїи¶БиІ£еЖ≥дЇЖеЬ®еК®жАБжЈїеК†жИЦзІїйЩ§иКВзВєжЧґпЉМе∞љеПѓиГље∞СеЬ∞жФєеПШеЈ≤зїПе≠ШеЬ®зЪДжХ∞жНЃеИЖеЄГгАВеЬ®дЇСиЃ°зЃЧеТМе§ІжХ∞жНЃе§ДзРЖйҐЖеЯЯпЉМдЄАиЗіжАІеУИеЄМ襀府ж≥ЫеЇФзФ®пЉМдЊЛе¶ВеЬ®еИЖеЄГеЉП...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМзЃЧж≥ХпЉМдЄїи¶БеЇФзФ®дЇОеИЖеЄГеЉПзЉУе≠ШгАБиіЯиљљеЭЗи°°з≠ЙйҐЖеЯЯпЉМдЊЛе¶ВMemcachedеТМRedisз≠Йз≥їзїЯгАВеЃГиІ£еЖ≥дЇЖеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖзЙЗдЄОиКВзВєеК®жАБеҐЮеЗПжЧґпЉМе∞љйЗПеЗПе∞СжХ∞жНЃињБзІїзЪДйЧЃйҐШгАВеЄ¶иЩЪжЛЯ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХйАЪињЗе∞ЖеУИеЄМеАЉз©ЇйЧізїДзїЗжИРдЄАдЄ™иЩЪжЛЯзЪДзОѓзКґзїУжЮДпЉМдљњеЊЧжѓПдЄ™е≠ШеВ®иКВзВєдїЕиіЯиі£зОѓдЄКзЪДдЄАжЃµеМЇеЯЯпЉМдїОиАМжЬЙжХИеЗПе∞СдЇЖиКВзВєеПШеМЦжЧґзЪДжХ∞жНЃињБзІїйЗПгАВзДґиАМпЉМдЄАиЗіжАІеУИеЄМзЃЧж≥ХдєЯе≠ШеЬ®дЄАдЇЫйЧЃйҐШпЉМжѓФе¶ВеЬ®иКВзВєжХ∞йЗПиЊГе∞СжЧґпЉМиКВзВєйЧізЪД...
жЬђжЦЗйТИеѓєињЩдЄАйЧЃйҐШпЉМжЈ±еЕ•з†Фз©ґдЇЖдЄАиЗіжАІеУИеЄМзЃЧж≥ХеЬ®еИЖеЄГеЉПжХ∞жНЃеЇУжЙ©е±ХдЄ≠зЪДеЇФзФ®пЉМеєґжПРеЗЇдЇЖдЄАзІНеИЫжЦ∞зЪДжЙ©е±ХжЦєж≥ХпЉМжЧ®еЬ®жПРйЂШжЙ©е±ХжХИзОЗпЉМйЩНдљОжЙ©е±ХжИРжЬђпЉМдЄЇе§ІжХ∞жНЃзОѓеҐГдЄЛзЪДжХ∞жНЃеЇУзЃ°зРЖеЄ¶жЭ•жЦ∞зЪДдЉШеМЦжЦєж°ИгАВ дЄАиЗіжАІеУИеЄМзЃЧж≥ХжЬАеИЭзФ±...
гАРдЄАиЗіжАІеУИеЄМдЄОChord1гАСжШѓдЄАзѓЗеЕ≥дЇОеИЖеЄГеЉПеУИеЄМзЃЧж≥ХзЪДжЦЗзЂ†пЉМдЄїи¶БиЃ®иЃЇдЇЖдЄАиЗіжАІеУИеЄМеТМжЩЃйАЪеУИеЄМзЪДеМЇеИЂпЉМдї•еПКе¶ВдљХйАЪињЗеЉХеЕ•иЩЪжЛЯиКВзВєжЭ•дЉШеМЦдЄАиЗіжАІеУИеЄМзЪДеИЖеЄГйЧЃйҐШгАВ 1. **жЩЃйАЪеУИеЄМзЃЧж≥Х**пЉЪ - JavaдЄ≠зЪД`HashMap`з±їжШѓдЄАдЄ™еЕЄеЮЛ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМи°®пЉИDHTпЉЙдЄ≠зФ®дЇОиІ£еЖ≥жХ∞жНЃеИЖзЙЗеТМиіЯиљљеЭЗи°°йЧЃйҐШзЪДзЃЧж≥ХгАВеЬ®е§ІеЮЛеИЖеЄГеЉПз≥їзїЯдЄ≠пЉМдЊЛе¶ВзЉУе≠Шз≥їзїЯгАБеИЖеЄГеЉПжХ∞жНЃеЇУз≠ЙпЉМдЄАиЗіжАІеУИеЄМиГље§Яз°ЃдњЭељУиКВзВєеК†еЕ•жИЦз¶їеЉАжЧґпЉМе∞љеПѓиГље∞СзЪДжХ∞жНЃйЬАи¶БињБзІїпЉМдїОиАМдњЭжМБ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМпЉИDistributed Hash Table, DHTпЉЙжКАжЬѓпЉМжЧ®еЬ®иІ£еЖ≥еЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖеЄГдЄНеЭЗеМАзЪДйЧЃйҐШгАВKetamaзЃЧж≥ХжШѓеЯЇдЇОдЄАиЗіжАІеУИеЄМзЪДдЄАзІНдЉШеМЦеЃЮзО∞пЉМзФ±Last.fmеЕђеПЄзЪДSimon WillisonжПРеЗЇпЉМеЕґзЫЃж†ЗжШѓеЬ®...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНзЙєжЃКзЪДеУИеЄМзЃЧж≥ХпЉМеЃГеЬ®еИЖеЄГеЉПзЉУе≠ШеТМиіЯиљљеЭЗи°°з≠ЙеЬЇжЩѓдЄ≠襀府ж≥ЫеЇФзФ®гАВеЃГйАЪињЗе∞ЖжХ∞жНЃеТМжЬНеК°еЩ®иКВзВєжШ†е∞ДеИ∞дЄАдЄ™еУИеЄМзОѓдЄКпЉМжПРдЊЫдЇЖдЄАзІНеЬ®иКВзВєеҐЮеЗПжЧґиГље§ЯжЬАе∞ПеМЦжХ∞жНЃйЗНжЦ∞еИЖйЕНзЪДжЬЇеИґгАВжЬђжЦЗе∞Ж...
гАКMycatдЄАиЗіжАІеУИеЄМеИЖзЙЗзЃЧж≥Хиѓ¶иІ£гАЛ еЬ®еИЖеЄГеЉПжХ∞жНЃеЇУз≥їзїЯдЄ≠пЉМжХ∞жНЃеИЖзЙЗжШѓеЃЮзО∞йЂШеПѓзФ®жАІеТМеПѓжЙ©е±ХжАІзЪДйЗНи¶БжЙЛжЃµгАВMycatдљЬдЄЇдЄАжђЊеЉАжЇРзЪДеИЖеЄГеЉПжХ∞жНЃеЇУдЄ≠йЧідїґпЉМеЕґж†ЄењГзЙєжАІдєЛдЄАе∞±жШѓжХ∞жНЃеИЖзЙЗз≠ЦзХ•пЉМиАМдЄАиЗіжАІеУИеЄМеИЖзЙЗзЃЧж≥ХеЬ®еЕґдЄ≠жЙЃжЉФ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠зФ®дЇОиІ£еЖ≥жХ∞жНЃеИЖеПСеТМиіЯиљљеЭЗи°°йЧЃйҐШзЪДзЃЧж≥ХгАВйЪПзЭАдЇТиБФзљСжКАжЬѓзЪДењЂйАЯеПСе±ХпЉМеИЖеЄГеЉПз≥їзїЯеЈ≤зїПжИРдЄЇжФѓжТСе§ІиІДж®°жЬНеК°зЪДеЕ≥йФЃжКАжЬѓдєЛдЄАгАВеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМе§ЪдЄ™иКВзВєйАЪињЗзљСзїЬеНПеРМеЈ•дљЬпЉМжПРдЊЫйЂШеПѓзФ®жАІ...
### дЄАиЗіжАІеУИеЄМзЃЧж≥ХеПКеЕґеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДеЇФзФ® #### жСШи¶Б дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНзФ®дЇОиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄ≠иКВзВєеК®жАБеПШеМЦеѓЉиЗізЪДжХ∞жНЃйЗНжЦ∞еИЖеЄГйЧЃйҐШзЪДеЕ≥йФЃжКАжЬѓгАВеЃГйАЪињЗе∞ЖеУИеЄМз©ЇйЧіжШ†е∞ДеИ∞дЄАдЄ™еЊ™зОѓзЪДз©ЇйЧідЄ≠пЉМеЃЮзО∞дЇЖжХ∞жНЃиКВзВєзЪДйЂШжХИ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠иІ£еЖ≥иіЯиљљеЭЗи°°еТМжХ∞жНЃеИЖеЄГйЧЃйҐШзЪДжЬЙжХИжЦєж≥ХгАВеЬ®дЉ†зїЯзЪДеУИеЄМзЃЧж≥ХдЄ≠пЉМељУжЈїеК†жИЦзІїйЩ§жЬНеК°еЩ®иКВзВєжЧґпЉМе§ІйГ®еИЖжХ∞жНЃйЬАи¶БйЗНжЦ∞жШ†е∞ДпЉМеѓЉиЗіе§ІиІДж®°зЪДжХ∞жНЃињБзІїгАВиАМдЄАиЗіжАІеУИеЄМзЃЧж≥ХйАЪињЗзЙєеЃЪзЪДиЃЊиЃ°пЉМиГље§Я...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХеЇФзФ®еПКдЉШеМЦжШѓITйҐЖеЯЯдЄ≠еИЖеЄГеЉПз≥їзїЯиЃЊиЃ°зЪДж†ЄењГжКАжЬѓдєЛдЄАпЉМзЙєеИЂжШѓеЬ®е§ДзРЖе§ІиІДж®°жХ∞жНЃеИЖеЄГдЄОзЉУе≠Шз≥їзїЯдЄ≠пЉМеЕґйЗНи¶БжАІдЄНи®АиАМеЦїгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®дЄАиЗіжАІеУИеЄМзЃЧж≥ХзЪДеЯЇжЬђж¶ВењµгАБеЈ•дљЬеОЯзРЖдї•еПКеЬ®еЃЮйЩЕеЬЇжЩѓдЄ≠зЪДеЇФзФ®еТМдЉШеМЦ...
Mycat дЄАиЗіжАІеУИеЄМеИЖзЙЗзЃЧж≥Х MycatжШѓдЄАжђЊеЉАжЇРзЪДжХ∞жНЃеЇУдЄ≠йЧідїґпЉМжФѓжМБеРДзІНжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯпЉМеМЕжЛђ MySQLгАБ PostgreSQLгАБOracle з≠ЙгАВMycat зЪДж†ЄењГеКЯиГљдєЛдЄАжШѓеИЖзЙЗпЉИShardingпЉЙпЉМеЃГеПѓдї•е∞Же§ІйЗПжХ∞жНЃеИЖеЄГеЉПе≠ШеВ®еЬ®е§ЪдЄ™жХ∞жНЃеЇУиКВзВє...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХзЪДphpзЙИпЉМеЄМжЬЫиГљеЄЃеИ∞phperдЇЖиІ£дЄАиЗіжАІеУИеЄМ
еЬ®дЉЧе§ЪзЪДиіЯиљљеЭЗи°°зЃЧж≥ХдЄ≠пЉМMaglevдЄАиЗіжАІеУИеЄМзЃЧж≥ХеЫ†еЕґйЂШжХИеТМиЙѓе•љзЪДиіЯиљљеЭЗи°°зЙєжАІиАМеПЧеИ∞дЇЖеєњж≥ЫзЪДеЕ≥ж≥®гАВ MaglevдЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓи∞Јж≠МеЈ•з®ЛеЄИиЃЊиЃ°еєґеЇФзФ®еЬ®еЕґMaglevиіЯиљљеЭЗи°°еЩ®дЄ≠зЪДзЃЧж≥ХгАВиѓ•зЃЧж≥ХиГље§ЯеЬ®жЬНеК°еЩ®иКВзВєеЗЇзО∞еҐЮеЗПжЧґпЉМ...
жЬђжЦЗжПРеЗЇзЪДеЯЇдЇОж†Зз≠ЊдЄАиЗіжАІеУИеЄМзЪДиЈ®ж®°жАБж£А糥зЃЧж≥ХпЉМе∞±жШѓдЄЇдЇЖиІ£еЖ≥ињЩдЄАйЧЃйҐШгАВ й¶ЦеЕИпЉМдЄАиЗіжАІеУИеЄМжКАжЬѓиГље§ЯжПРдЊЫдЄАзІНеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДиіЯиљљеЭЗи°°жЦєж°ИпЉМе∞ЖжХ∞жНЃзВєжШ†е∞ДеИ∞дЄАдЄ™з΃嚥穯йЧідЄКпЉМдљњеЊЧжХ∞жНЃзВєдЄОеУИеЄМеАЉдєЛйЧіеЕЈжЬЙйЂШеЇ¶зЪДдЄАиЗіжАІеТМ...