- وµڈ览: 69524 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

و–‡ç« هˆ†ç±»
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2012-03 ( 8)
- 2012-02 ( 11)
- 2012-01 ( 5)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
SVMç®—و³•ه…¥é—¨
课程و–‡وœ¬هˆ†ç±»project SVMç®—و³•ه…¥é—¨
转è‡ھï¼ڑhttp://www.blogjava.net/zhenandaci/category/31868.html
SVMه…¥é—¨ï¼ˆن¸€ï¼‰è‡³ï¼ˆن¸‰ï¼‰Refresh
وŒ‰:ن¹‹ه‰چçڑ„و–‡ç« é‡چو–°و±‡ç¼–ن¸€ن¸‹,ن؟®و”¹ن؛†ن¸€ن؛›é”™è¯¯ه’Œن¸چه½“çڑ„说و³•ï¼Œن¸€èµ·ه¤چن¹ ,然هگژ继ç»SVMن¹‹و—….
(ن¸€ï¼‰SVMçڑ„简ن»‹
و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine)وک¯Cortesه’ŒVapnikن؛ژ1995ه¹´é¦–ه…ˆوڈگه‡؛çڑ„,ه®ƒهœ¨è§£ه†³ه°ڈو ·وœ¬م€پéç؛؟و€§هڈٹé«کç»´و¨،ه¼ڈ识هˆ«ن¸è،¨çژ°ه‡؛许ه¤ڑ特وœ‰çڑ„ن¼کهٹ؟,ه¹¶èƒ½ه¤ںوژ¨ه¹؟ه؛”用هˆ°ه‡½و•°و‹ںهگˆç‰ه…¶ن»–وœ؛ه™¨ه¦ن¹ é—®é¢کن¸[10]م€‚
و”¯وŒپهگ‘é‡ڈوœ؛و–¹و³•وک¯ه»؛ç«‹هœ¨ç»ںè®،ه¦ن¹ çگ†è®؛çڑ„VC ç»´çگ†è®؛ه’Œç»“و„é£ژ险وœ€ه°ڈهژںçگ†هں؛ç،€ن¸ٹçڑ„,و ¹وچ®وœ‰é™گçڑ„و ·وœ¬ن؟،وپ¯هœ¨و¨،ه‹çڑ„ه¤چو‚و€§ï¼ˆهچ³ه¯¹ç‰¹ه®ڑè®ç»ƒو ·وœ¬çڑ„ه¦ن¹ ç²¾ه؛¦ï¼ŒAccuracy)ه’Œه¦ن¹ 能هٹ›ï¼ˆهچ³و— 错误هœ°è¯†هˆ«ن»»و„ڈو ·وœ¬çڑ„能هٹ›ï¼‰ن¹‹é—´ه¯»و±‚وœ€ن½³وٹکè،·ï¼Œن»¥وœںèژ·ه¾—وœ€ه¥½çڑ„وژ¨ه¹؟能هٹ›[14](وˆ–称و³›هŒ–能هٹ›ï¼‰م€‚
ن»¥ن¸ٹوک¯ç»ڈه¸¸è¢«وœ‰ه…³SVM çڑ„ه¦وœ¯و–‡çŒ®ه¼•ç”¨çڑ„ن»‹ç»چ,وˆ‘و¥é€گن¸€هˆ†è§£ه¹¶è§£é‡ٹن¸€ن¸‹م€‚
Vapnikوک¯ç»ںè®،وœ؛ه™¨ه¦ن¹ çڑ„ه¤§ç‰›ï¼Œè؟™وƒ³ه؟…都ن¸چ用说,ن»–ه‡؛版çڑ„م€ٹStatistical Learning Theoryم€‹وک¯ن¸€وœ¬ه®Œو•´éکگè؟°ç»ںè®،وœ؛ه™¨ه¦ن¹ و€وƒ³çڑ„هگچè‘—م€‚هœ¨è¯¥ن¹¦ن¸è¯¦ç»†çڑ„è®؛è¯پن؛†ç»ںè®،وœ؛ه™¨ه¦ن¹ ن¹‹و‰€ن»¥هŒ؛هˆ«ن؛ژن¼ ç»ںوœ؛ه™¨ه¦ن¹ çڑ„وœ¬è´¨ï¼Œه°±هœ¨ن؛ژç»ںè®،وœ؛ه™¨ه¦ن¹ 能ه¤ںç²¾ç،®çڑ„ç»™ه‡؛ه¦ن¹ و•ˆوœï¼Œèƒ½ه¤ں解ç”需è¦پçڑ„و ·وœ¬و•°ç‰ç‰ن¸€ç³»هˆ—é—®é¢کم€‚ن¸ژç»ںè®،وœ؛ه™¨ه¦ن¹ çڑ„ç²¾ه¯†و€ç»´ç›¸و¯”,ن¼ ç»ںçڑ„وœ؛ه™¨ه¦ن¹ هں؛وœ¬ن¸ٹه±ن؛ژو‘¸ç€çں³ه¤´è؟‡و²³ï¼Œç”¨ن¼ ç»ںçڑ„وœ؛ه™¨ه¦ن¹ و–¹و³•و„é€ هˆ†ç±»ç³»ç»ںه®Œه…¨وˆگن؛†ن¸€ç§چوٹ€ه·§ï¼Œن¸€ن¸ھن؛؛هپڑçڑ„结وœهڈ¯èƒ½ه¾ˆه¥½ï¼Œهڈ¦ن¸€ن¸ھن؛؛ه·®ن¸چه¤ڑçڑ„و–¹و³•هپڑه‡؛و¥هچ´ه¾ˆه·®ï¼Œç¼؛ن¹ڈوŒ‡ه¯¼ه’Œهژںهˆ™م€‚
و‰€è°“VCç»´وک¯ه¯¹ه‡½و•°ç±»çڑ„ن¸€ç§چه؛¦é‡ڈ,هڈ¯ن»¥ç®€هچ•çڑ„çگ†è§£ن¸؛é—®é¢کçڑ„ه¤چو‚程ه؛¦ï¼ŒVCç»´è¶ٹé«ک,ن¸€ن¸ھé—®é¢که°±è¶ٹه¤چو‚م€‚و£وک¯ه› ن¸؛SVMه…³و³¨çڑ„وک¯VC维,هگژé¢وˆ‘ن»¬هڈ¯ن»¥çœ‹هˆ°ï¼ŒSVM解ه†³é—®é¢کçڑ„و—¶ه€™ï¼Œه’Œو ·وœ¬çڑ„ç»´و•°وک¯و— ه…³çڑ„(ç”ڑ至و ·وœ¬وک¯ن¸ٹن¸‡ç»´çڑ„都هڈ¯ن»¥ï¼Œè؟™ن½؟ه¾—SVMه¾ˆé€‚هگˆç”¨و¥è§£ه†³و–‡وœ¬هˆ†ç±»çڑ„é—®é¢ک,ه½“然,وœ‰è؟™و ·çڑ„能هٹ›ن¹ںه› ن¸؛ه¼•ه…¥ن؛†و ¸ه‡½و•°ï¼‰م€‚
结و„é£ژ险وœ€ه°ڈهگ¬ن¸ٹهژ»و–‡ç»‰ç»‰ï¼Œه…¶ه®è¯´çڑ„ن¹ںو— éوک¯ن¸‹é¢è؟™ه›ن؛‹م€‚
وœ؛ه™¨ه¦ن¹ وœ¬è´¨ن¸ٹه°±وک¯ن¸€ç§چه¯¹é—®é¢کçœںه®و¨،ه‹çڑ„逼è؟‘(وˆ‘ن»¬é€‰و‹©ن¸€ن¸ھوˆ‘ن»¬è®¤ن¸؛و¯”较ه¥½çڑ„è؟‘ن¼¼و¨،ه‹ï¼Œè؟™ن¸ھè؟‘ن¼¼و¨،ه‹ه°±هڈ«هپڑن¸€ن¸ھهپ‡è®¾ï¼‰ï¼Œن½†و¯«و— 疑问,çœںه®و¨،ه‹ن¸€ه®ڑوک¯ن¸چçں¥éپ“çڑ„(ه¦‚وœçں¥éپ“ن؛†ï¼Œوˆ‘ن»¬ه¹²هگ—è؟کè¦پوœ؛ه™¨ه¦ن¹ ï¼ںç›´وژ¥ç”¨çœںه®و¨،ه‹è§£ه†³é—®é¢کن¸چه°±هڈ¯ن»¥ن؛†ï¼ںه¯¹هگ§ï¼Œه“ˆه“ˆï¼‰و—¢ç„¶çœںه®و¨،ه‹ن¸چçں¥éپ“,那ن¹ˆوˆ‘ن»¬é€‰و‹©çڑ„هپ‡è®¾ن¸ژé—®é¢کçœںه®è§£ن¹‹é—´ç©¶ç«ںوœ‰ه¤ڑه¤§ه·®è·ï¼Œوˆ‘ن»¬ه°±و²،و³•ه¾—çں¥م€‚و¯”ه¦‚说وˆ‘ن»¬è®¤ن¸؛ه®‡ه®™è¯ç”ںن؛ژ150ن؛؟ه¹´ه‰چçڑ„ن¸€هœ؛ه¤§çˆ†ç‚¸ï¼Œè؟™ن¸ھهپ‡è®¾èƒ½ه¤ںوڈڈè؟°ه¾ˆه¤ڑوˆ‘ن»¬è§‚ه¯ںهˆ°çڑ„çژ°è±،,ن½†ه®ƒن¸ژçœںه®çڑ„ه®‡ه®™و¨،ه‹ن¹‹é—´è؟ک相ه·®ه¤ڑه°‘ï¼ںè°پن¹ں说ن¸چو¸…,ه› ن¸؛وˆ‘ن»¬هژ‹و ¹ه°±ن¸چçں¥éپ“çœںه®çڑ„ه®‡ه®™و¨،ه‹هˆ°ه؛•وک¯ن»€ن¹ˆم€‚
è؟™ن¸ھن¸ژé—®é¢کçœںه®è§£ن¹‹é—´çڑ„误ه·®ï¼Œه°±هڈ«هپڑé£ژ险(و›´ن¸¥و ¼çڑ„说,误ه·®çڑ„累积هڈ«هپڑé£ژ险)م€‚وˆ‘ن»¬é€‰و‹©ن؛†ن¸€ن¸ھهپ‡è®¾ن¹‹هگژ(و›´ç›´è§‚点说,وˆ‘ن»¬ه¾—هˆ°ن؛†ن¸€ن¸ھهˆ†ç±»ه™¨ن»¥هگژ),çœںه®è¯¯ه·®و— ن»ژه¾—çں¥ï¼Œن½†وˆ‘ن»¬هڈ¯ن»¥ç”¨وںگن؛›هڈ¯ن»¥وژŒوڈ،çڑ„é‡ڈو¥é€¼è؟‘ه®ƒم€‚وœ€ç›´è§‚çڑ„وƒ³و³•ه°±وک¯ن½؟用هˆ†ç±»ه™¨هœ¨و ·وœ¬و•°وچ®ن¸ٹçڑ„هˆ†ç±»çڑ„结وœن¸ژçœںه®ç»“وœï¼ˆه› ن¸؛و ·وœ¬وک¯ه·²ç»ڈو ‡و³¨è؟‡çڑ„و•°وچ®ï¼Œوک¯ه‡†ç،®çڑ„و•°وچ®ï¼‰ن¹‹é—´çڑ„ه·®ه€¼و¥è،¨ç¤؛م€‚è؟™ن¸ھه·®ه€¼هڈ«هپڑç»ڈéھŒé£ژ险Remp(w)م€‚ن»¥ه‰چçڑ„وœ؛ه™¨ه¦ن¹ و–¹و³•éƒ½وٹٹç»ڈéھŒé£ژ险وœ€ه°ڈهŒ–ن½œن¸؛هٹھهٹ›çڑ„ç›®و ‡ï¼Œن½†هگژو¥هڈ‘çژ°ه¾ˆه¤ڑهˆ†ç±»ه‡½و•°èƒ½ه¤ںهœ¨و ·وœ¬é›†ن¸ٹè½»وک“è¾¾هˆ°100%çڑ„و£ç،®çژ‡ï¼Œهœ¨çœںه®هˆ†ç±»و—¶هچ´ن¸€ه،Œç³ٹو¶‚(هچ³و‰€è°“çڑ„وژ¨ه¹؟能هٹ›ه·®ï¼Œوˆ–و³›هŒ–能هٹ›ه·®ï¼‰م€‚و¤و—¶çڑ„وƒ…ه†µن¾؟وک¯é€‰و‹©ن؛†ن¸€ن¸ھ足ه¤ںه¤چو‚çڑ„هˆ†ç±»ه‡½و•°ï¼ˆه®ƒçڑ„VCç»´ه¾ˆé«ک),能ه¤ںç²¾ç،®çڑ„è®°ن½ڈو¯ڈن¸€ن¸ھو ·وœ¬ï¼Œن½†ه¯¹و ·وœ¬ن¹‹ه¤–çڑ„و•°وچ®ن¸€ه¾‹هˆ†ç±»é”™è¯¯م€‚ه›ه¤´çœ‹çœ‹ç»ڈéھŒé£ژ险وœ€ه°ڈهŒ–هژںهˆ™وˆ‘ن»¬ه°±ن¼ڑهڈ‘çژ°ï¼Œو¤هژںهˆ™é€‚用çڑ„ه¤§ه‰چوڈگوک¯ç»ڈéھŒé£ژ险è¦پç،®ه®èƒ½ه¤ں逼è؟‘çœںه®é£ژ险و‰چè،Œï¼ˆè،Œè¯هڈ«ن¸€è‡´ï¼‰ï¼Œن½†ه®é™…ن¸ٹ能逼è؟‘ن¹ˆï¼ںç”و،ˆوک¯ن¸چ能,ه› ن¸؛و ·وœ¬و•°ç›¸ه¯¹ن؛ژçژ°ه®ن¸–ç•Œè¦پهˆ†ç±»çڑ„و–‡وœ¬و•°و¥è¯´ç®€ç›´ن¹ç‰›ن¸€و¯›ï¼Œç»ڈéھŒé£ژ险وœ€ه°ڈهŒ–هژںهˆ™هڈھهœ¨è؟™هچ ه¾ˆه°ڈو¯”ن¾‹çڑ„و ·وœ¬ن¸ٹهپڑهˆ°و²،وœ‰è¯¯ه·®ï¼Œه½“然ن¸چ能ن؟è¯پهœ¨و›´ه¤§و¯”ن¾‹çڑ„çœںه®و–‡وœ¬ن¸ٹن¹ںو²،وœ‰è¯¯ه·®م€‚
ç»ںè®،ه¦ن¹ ه› و¤è€Œه¼•ه…¥ن؛†و³›هŒ–误ه·®ç•Œçڑ„و¦‚ه؟µï¼Œه°±وک¯وŒ‡çœںه®é£ژ险ه؛”该由ن¸¤éƒ¨هˆ†ه†…ه®¹هˆ»ç”»ï¼Œن¸€وک¯ç»ڈéھŒé£ژ险,ن»£è،¨ن؛†هˆ†ç±»ه™¨هœ¨ç»™ه®ڑو ·وœ¬ن¸ٹçڑ„误ه·®ï¼›ن؛Œوک¯ç½®ن؟،é£ژ险,ن»£è،¨ن؛†وˆ‘ن»¬هœ¨ه¤ڑه¤§ç¨‹ه؛¦ن¸ٹهڈ¯ن»¥ن؟،ن»»هˆ†ç±»ه™¨هœ¨وœھçں¥و–‡وœ¬ن¸ٹهˆ†ç±»çڑ„结وœم€‚ه¾ˆوک¾ç„¶ï¼Œç¬¬ن؛Œéƒ¨هˆ†وک¯و²،وœ‰هٹو³•ç²¾ç،®è®،ç®—çڑ„,ه› و¤هڈھ能给ه‡؛ن¸€ن¸ھن¼°è®،çڑ„هŒ؛间,ن¹ںن½؟ه¾—و•´ن¸ھ误ه·®هڈھ能è®،ç®—ن¸ٹ界,而و— و³•è®،ç®—ه‡†ç،®çڑ„ه€¼ï¼ˆو‰€ن»¥هڈ«هپڑو³›هŒ–误ه·®ç•Œï¼Œè€Œن¸چهڈ«و³›هŒ–误ه·®ï¼‰م€‚
ç½®ن؟،é£ژ险ن¸ژن¸¤ن¸ھé‡ڈوœ‰ه…³ï¼Œن¸€وک¯و ·وœ¬و•°é‡ڈ,وک¾ç„¶ç»™ه®ڑçڑ„و ·وœ¬و•°é‡ڈè¶ٹه¤§ï¼Œوˆ‘ن»¬çڑ„ه¦ن¹ 结وœè¶ٹوœ‰هڈ¯èƒ½و£ç،®ï¼Œو¤و—¶ç½®ن؟،é£ژ险è¶ٹه°ڈï¼›ن؛Œوک¯هˆ†ç±»ه‡½و•°çڑ„VC维,وک¾ç„¶VCç»´è¶ٹه¤§ï¼Œوژ¨ه¹؟能هٹ›è¶ٹه·®ï¼Œç½®ن؟،é£ژ险ن¼ڑهڈکه¤§م€‚
و³›هŒ–误ه·®ç•Œçڑ„ه…¬ه¼ڈن¸؛ï¼ڑ
R(w)≤Remp(w)+ذ¤(n/h)
ه…¬ه¼ڈن¸R(w)ه°±وک¯çœںه®é£ژ险,Remp(w)ه°±وک¯ç»ڈéھŒé£ژ险,ذ¤(n/h)ه°±وک¯ç½®ن؟،é£ژ险م€‚ç»ںè®،ه¦ن¹ çڑ„ç›®و ‡ن»ژç»ڈéھŒé£ژ险وœ€ه°ڈهŒ–هڈکن¸؛ن؛†ه¯»و±‚ç»ڈéھŒé£ژ险ن¸ژç½®ن؟،é£ژ险çڑ„ه’Œوœ€ه°ڈ,هچ³ç»“و„é£ژ险وœ€ه°ڈم€‚
SVMو£وک¯è؟™و ·ن¸€ç§چهٹھهٹ›وœ€ه°ڈهŒ–结و„é£ژ险çڑ„ç®—و³•م€‚
SVMه…¶ن»–çڑ„特点ه°±و¯”较ه®¹وک“çگ†è§£ن؛†م€‚
ه°ڈو ·وœ¬ï¼Œه¹¶ن¸چوک¯è¯´و ·وœ¬çڑ„ç»ه¯¹و•°é‡ڈه°‘(ه®é™…ن¸ٹ,ه¯¹ن»»ن½•ç®—و³•و¥è¯´ï¼Œو›´ه¤ڑçڑ„و ·وœ¬ه‡ ن¹ژو€»وک¯èƒ½ه¸¦و¥و›´ه¥½çڑ„و•ˆوœï¼‰ï¼Œè€Œوک¯è¯´ن¸ژé—®é¢کçڑ„ه¤چو‚ه؛¦و¯”èµ·و¥ï¼ŒSVMç®—و³•è¦پو±‚çڑ„و ·وœ¬و•°وک¯ç›¸ه¯¹و¯”较ه°‘çڑ„م€‚
éç؛؟و€§ï¼Œوک¯وŒ‡SVMو“…é•؟ه؛”ن»کو ·وœ¬و•°وچ®ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„وƒ…ه†µï¼Œن¸»è¦پé€ڑè؟‡و¾ه¼›هڈکé‡ڈ(ن¹ںوœ‰ن؛؛هڈ«وƒ©ç½ڑهڈکé‡ڈ)ه’Œو ¸ه‡½و•°وٹ€وœ¯و¥ه®çژ°ï¼Œè؟™ن¸€éƒ¨هˆ†وک¯SVMçڑ„精髓,ن»¥هگژن¼ڑ详细讨è®؛م€‚ه¤ڑ说ن¸€هڈ¥ï¼Œه…³ن؛ژو–‡وœ¬هˆ†ç±»è؟™ن¸ھé—®é¢ک究ç«ںوک¯ن¸چوک¯ç؛؟و€§هڈ¯هˆ†çڑ„,ه°ڑو²،وœ‰ه®ڑè®؛,ه› و¤ن¸چ能简هچ•çڑ„认ن¸؛ه®ƒوک¯ç؛؟و€§هڈ¯هˆ†çڑ„而ن½œç®€هŒ–ه¤„çگ†ï¼Œهœ¨و°´èگ½çں³ه‡؛ن¹‹ه‰چ,هڈھه¥½ه…ˆه½“ه®ƒوک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„(هڈچو£ç؛؟و€§هڈ¯هˆ†ن¹ںن¸چè؟‡وک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„ن¸€ç§چ特ن¾‹è€Œه·²ï¼Œوˆ‘ن»¬هگ‘و¥ن¸چو€•و–¹و³•è؟‡ن؛ژé€ڑ用)م€‚
é«کç»´و¨،ه¼ڈ识هˆ«وک¯وŒ‡و ·وœ¬ç»´و•°ه¾ˆé«ک,ن¾‹ه¦‚و–‡وœ¬çڑ„هگ‘é‡ڈè،¨ç¤؛,ه¦‚وœو²،وœ‰ç»ڈè؟‡هڈ¦ن¸€ç³»هˆ—و–‡ç« (م€ٹو–‡وœ¬هˆ†ç±»ه…¥é—¨م€‹ï¼‰ن¸وڈگهˆ°è؟‡çڑ„é™چç»´ه¤„çگ†ï¼Œه‡؛çژ°ه‡ ن¸‡ç»´çڑ„وƒ…ه†µه¾ˆو£ه¸¸ï¼Œه…¶ن»–ç®—و³•هں؛وœ¬ه°±و²،وœ‰èƒ½هٹ›ه؛”ن»کن؛†ï¼ŒSVMهچ´هڈ¯ن»¥ï¼Œن¸»è¦پوک¯ه› ن¸؛SVM ن؛§ç”ںçڑ„هˆ†ç±»ه™¨ه¾ˆç®€و´پ,用هˆ°çڑ„و ·وœ¬ن؟،وپ¯ه¾ˆه°‘(ن»…ن»…用هˆ°é‚£ن؛›ç§°ن¹‹ن¸؛“و”¯وŒپهگ‘é‡ڈâ€çڑ„و ·وœ¬ï¼Œو¤ن¸؛هگژè¯ï¼‰ï¼Œن½؟ه¾—هچ³ن½؟و ·وœ¬ç»´و•°ه¾ˆé«ک,ن¹ںن¸چن¼ڑç»™هکه‚¨ه’Œè®،ç®—ه¸¦و¥ه¤§é؛»çƒ¦ï¼ˆç›¸ه¯¹ç…§è€Œè¨€ï¼ŒkNNç®—و³•هœ¨هˆ†ç±»و—¶ه°±è¦پ用هˆ°و‰€وœ‰و ·وœ¬ï¼Œو ·وœ¬و•°ه·¨ه¤§ï¼Œو¯ڈن¸ھو ·وœ¬ç»´و•°ه†چن¸€é«ک,è؟™و—¥هگه°±و²،و³•è؟‡ن؛†â€¦â€¦ï¼‰م€‚
ن¸‹ن¸€èٹ‚ه¼€ه§‹و£ه¼ڈ讨è®؛SVMم€‚هˆ«ه«Œوˆ‘说ه¾—ه¤ھ详细ه“¦م€‚
SVMه…¥é—¨ï¼ˆن؛Œï¼‰ç؛؟و€§هˆ†ç±»ه™¨Part 1
ç؛؟و€§هˆ†ç±»ه™¨(ن¸€ه®ڑو„ڈن¹‰ن¸ٹ,ن¹ںهڈ¯ن»¥هڈ«هپڑو„ںçں¥وœ؛) وک¯وœ€ç®€هچ•ن¹ںه¾ˆوœ‰و•ˆçڑ„هˆ†ç±»ه™¨ه½¢ه¼ڈ.هœ¨ن¸€ن¸ھç؛؟و€§هˆ†ç±»ه™¨ن¸,هڈ¯ن»¥çœ‹هˆ°SVMه½¢وˆگçڑ„و€è·¯,ه¹¶وژ¥è§¦ه¾ˆه¤ڑSVMçڑ„و ¸ه؟ƒو¦‚ه؟µ.
用ن¸€ن¸ھن؛Œç»´ç©؛间里ن»…وœ‰ن¸¤ç±»و ·وœ¬çڑ„هˆ†ç±»é—®é¢کو¥ن¸¾ن¸ھه°ڈن¾‹هگم€‚ه¦‚ه›¾و‰€ç¤؛

C1ه’ŒC2وک¯è¦پهŒ؛هˆ†çڑ„ن¸¤ن¸ھç±»هˆ«ï¼Œهœ¨ن؛Œç»´ه¹³é¢ن¸ه®ƒن»¬çڑ„و ·وœ¬ه¦‚ن¸ٹه›¾و‰€ç¤؛م€‚ن¸é—´çڑ„ç›´ç؛؟ه°±وک¯ن¸€ن¸ھهˆ†ç±»ه‡½و•°ï¼Œه®ƒهڈ¯ن»¥ه°†ن¸¤ç±»و ·وœ¬ه®Œه…¨هˆ†ه¼€م€‚ن¸€èˆ¬çڑ„,ه¦‚وœن¸€ن¸ھç؛؟و€§ه‡½و•°èƒ½ه¤ںه°†و ·وœ¬ه®Œه…¨و£ç،®çڑ„هˆ†ه¼€ï¼Œه°±ç§°è؟™ن؛›و•°وچ®وک¯ç؛؟و€§هڈ¯هˆ†çڑ„,هگ¦هˆ™ç§°ن¸؛éç؛؟و€§هڈ¯هˆ†çڑ„م€‚
ن»€ن¹ˆهڈ«ç؛؟و€§ه‡½و•°ه‘¢ï¼ںهœ¨ن¸€ç»´ç©؛间里ه°±وک¯ن¸€ن¸ھ点,هœ¨ن؛Œç»´ç©؛间里ه°±وک¯ن¸€و،ç›´ç؛؟,ن¸‰ç»´ç©؛间里ه°±وک¯ن¸€ن¸ھه¹³é¢ï¼Œهڈ¯ن»¥ه¦‚و¤وƒ³è±،ن¸‹هژ»ï¼Œه¦‚وœن¸چه…³و³¨ç©؛é—´çڑ„ç»´و•°ï¼Œè؟™ç§چç؛؟و€§ه‡½و•°è؟کوœ‰ن¸€ن¸ھç»ںن¸€çڑ„هگچ称——超ه¹³é¢ï¼ˆHyper Plane)ï¼پ
ه®é™…ن¸ٹ,ن¸€ن¸ھç؛؟و€§ه‡½و•°وک¯ن¸€ن¸ھه®ه€¼ه‡½و•°ï¼ˆهچ³ه‡½و•°çڑ„ه€¼وک¯è؟ç»çڑ„ه®و•°ï¼‰ï¼Œè€Œوˆ‘ن»¬çڑ„هˆ†ç±»é—®é¢ک(ن¾‹ه¦‚è؟™é‡Œçڑ„ن؛Œه…ƒهˆ†ç±»é—®é¢ک——ه›ç”ن¸€ن¸ھو ·وœ¬ه±ن؛ژè؟کوک¯ن¸چه±ن؛ژن¸€ن¸ھç±»هˆ«çڑ„é—®é¢ک)需è¦پ离و•£çڑ„输ه‡؛ه€¼ï¼Œن¾‹ه¦‚用1è،¨ç¤؛وںگن¸ھو ·وœ¬ه±ن؛ژç±»هˆ«C1,而用0è،¨ç¤؛ن¸چه±ن؛ژ(ن¸چه±ن؛ژC1ن¹ںه°±و„ڈه‘³ç€ه±ن؛ژC2),è؟™و—¶ه€™هڈھ需è¦پ简هچ•çڑ„هœ¨ه®ه€¼ه‡½و•°çڑ„هں؛ç،€ن¸ٹ附هٹ ن¸€ن¸ھéکˆه€¼هچ³هڈ¯ï¼Œé€ڑè؟‡هˆ†ç±»ه‡½و•°و‰§è،Œو—¶ه¾—هˆ°çڑ„ه€¼ه¤§ن؛ژè؟کوک¯ه°ڈن؛ژè؟™ن¸ھéکˆه€¼و¥ç،®ه®ڑç±»هˆ«ه½’ه±م€‚ ن¾‹ه¦‚وˆ‘ن»¬وœ‰ن¸€ن¸ھç؛؟و€§ه‡½و•°
g(x)=wx+b
م€گ看هˆ°ه¥½ه¤ڑن؛؛都هœ¨é—®g(x)=0 ه’Œ g(x)çڑ„é—®é¢ک,وˆ‘هœ¨è؟™é‡Œه¸®و¥¼ن¸»è،¥ه……ن¸€ن¸‹ï¼ڑg(x)ه®é™…وک¯ن»¥wن¸؛و³•هگ‘é‡ڈçڑ„ن¸€ç°‡è¶…ه¹³é¢ï¼Œهœ¨ن؛Œç»´ç©؛é—´è،¨ç¤؛ن¸؛ن¸€ç°‡ç›´ç؛؟(ه°±وک¯ن¸€ç°‡ه¹³è،Œç؛؟,ن»–ن»¬çڑ„و³•هگ‘é‡ڈ都وک¯w),而g(x)=0هڈھوک¯è؟™ن¹ˆه¤ڑه¹³è،Œç؛؟ن¸çڑ„ن¸€و،م€‚م€‘
وˆ‘ن»¬هڈ¯ن»¥هڈ–éکˆه€¼ن¸؛0,è؟™و ·ه½“وœ‰ن¸€ن¸ھو ·وœ¬xi需è¦پهˆ¤هˆ«çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه°±çœ‹g(xi)çڑ„ه€¼م€‚è‹¥g(xi)>0,ه°±هˆ¤هˆ«ن¸؛ç±»هˆ«C1,若g(xi)<0,هˆ™هˆ¤هˆ«ن¸؛ç±»هˆ«C2(ç‰ن؛ژçڑ„و—¶ه€™وˆ‘ن»¬ه°±و‹’ç»هˆ¤و–,ه‘µه‘µï¼‰م€‚و¤و—¶ن¹ںç‰ن»·ن؛ژç»™ه‡½و•°g(x)附هٹ ن¸€ن¸ھ符هڈ·ه‡½و•°sgn(),هچ³f(x)=sgn [g(x)]وک¯وˆ‘ن»¬çœںو£çڑ„هˆ¤هˆ«ه‡½و•°م€‚
ه…³ن؛ژg(x)=wx+bè؟™ن¸ھè،¨è¾¾ه¼ڈè¦پو³¨و„ڈن¸‰ç‚¹ï¼ڑن¸€ï¼Œه¼ڈن¸çڑ„xن¸چوک¯ن؛Œç»´هگو ‡ç³»ن¸çڑ„و¨ھ轴,而وک¯و ·وœ¬çڑ„هگ‘é‡ڈè،¨ç¤؛,ن¾‹ه¦‚ن¸€ن¸ھو ·وœ¬ç‚¹çڑ„هگو ‡وک¯(3,8),هˆ™xT=(3,8) ,而ن¸چوک¯x=3(ن¸€èˆ¬è¯´هگ‘é‡ڈ都وک¯è¯´هˆ—هگ‘é‡ڈ,ه› و¤ن»¥è،Œهگ‘é‡ڈه½¢ه¼ڈو¥è،¨ç¤؛و—¶ï¼Œه°±هٹ ن¸ٹ转置)م€‚ن؛Œï¼Œè؟™ن¸ھه½¢ه¼ڈه¹¶ن¸چه±€é™گن؛ژن؛Œç»´çڑ„وƒ…ه†µï¼Œهœ¨nç»´ç©؛é—´ن¸ن»چ然هڈ¯ن»¥ن½؟用è؟™ن¸ھè،¨è¾¾ه¼ڈ,هڈھوک¯ه¼ڈن¸çڑ„wوˆگن¸؛ن؛†nç»´هگ‘é‡ڈ(هœ¨ن؛Œç»´çڑ„è؟™ن¸ھن¾‹هگن¸ï¼Œwوک¯ن؛Œç»´هگ‘é‡ڈ,ن¸؛ن؛†è،¨ç¤؛èµ·و¥و–¹ن¾؟简و´پ,ن»¥ن¸‹ه‡ن¸چهŒ؛هˆ«هˆ—هگ‘é‡ڈه’Œه®ƒçڑ„转置,èپھوکژçڑ„读者ن¸€çœ‹ن¾؟çں¥ï¼‰ï¼›ن¸‰ï¼Œg(x)ن¸چوک¯ن¸é—´é‚£و،ç›´ç؛؟çڑ„è،¨è¾¾ه¼ڈ,ن¸é—´é‚£و،ç›´ç؛؟çڑ„è،¨è¾¾ه¼ڈوک¯g(x)=0,هچ³wx+b=0,وˆ‘ن»¬ن¹ںوٹٹè؟™ن¸ھه‡½و•°هڈ«هپڑهˆ†ç±»é¢م€‚
ه®é™…ن¸ٹه¾ˆه®¹وک“看ه‡؛و¥ï¼Œن¸é—´é‚£و،هˆ†ç•Œç؛؟ه¹¶ن¸چوک¯ه”¯ن¸€çڑ„,وˆ‘ن»¬وٹٹه®ƒç¨چه¾®و—‹è½¬ن¸€ن¸‹ï¼Œهڈھè¦پن¸چوٹٹن¸¤ç±»و•°وچ®هˆ†é”™ï¼Œن»چ然هڈ¯ن»¥è¾¾هˆ°ن¸ٹé¢è¯´çڑ„و•ˆوœï¼Œç¨چه¾®ه¹³ç§»ن¸€ن¸‹ï¼Œن¹ںهڈ¯ن»¥م€‚و¤و—¶ه°±ç‰µو¶‰هˆ°ن¸€ن¸ھé—®é¢ک,ه¯¹هگŒن¸€ن¸ھé—®é¢کهکهœ¨ه¤ڑن¸ھهˆ†ç±»ه‡½و•°çڑ„و—¶ه€™ï¼Œه“ھن¸€ن¸ھه‡½و•°و›´ه¥½ه‘¢ï¼ںوک¾ç„¶ه؟…é،»è¦په…ˆو‰¾ن¸€ن¸ھوŒ‡و ‡و¥é‡ڈهŒ–“ه¥½â€çڑ„程ه؛¦ï¼Œé€ڑه¸¸ن½؟用çڑ„都وک¯هڈ«هپڑ“هˆ†ç±»é—´éڑ”â€çڑ„وŒ‡و ‡م€‚ن¸‹ن¸€èٹ‚وˆ‘ن»¬ه°±ن»”细说说هˆ†ç±»é—´éڑ”,ن¹ںè،¥ن¸€è،¥ç›¸ه…³çڑ„و•°ه¦çں¥è¯†م€‚
SVMه…¥é—¨ï¼ˆن¸‰ï¼‰ç؛؟و€§هˆ†ç±»ه™¨Part 2
ن¸ٹه›è¯´هˆ°ه¯¹ن؛ژو–‡وœ¬هˆ†ç±»è؟™و ·çڑ„ن¸چ适ه®ڑé—®é¢ک(وœ‰ن¸€ن¸ھن»¥ن¸ٹ解çڑ„é—®é¢ک称ن¸؛ن¸چ适ه®ڑé—®é¢ک),需è¦پوœ‰ن¸€ن¸ھوŒ‡و ‡و¥è،،é‡ڈ解ه†³و–¹و،ˆï¼ˆهچ³وˆ‘ن»¬é€ڑè؟‡è®ç»ƒه»؛ç«‹çڑ„هˆ†ç±»و¨،ه‹ï¼‰çڑ„ه¥½هڈ,而هˆ†ç±»é—´éڑ”وک¯ن¸€ن¸ھو¯”较ه¥½çڑ„وŒ‡و ‡م€‚
هœ¨è؟›è،Œو–‡وœ¬هˆ†ç±»çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬هڈ¯ن»¥è®©è®،ç®—وœ؛è؟™و ·و¥çœ‹ه¾…وˆ‘ن»¬وڈگن¾›ç»™ه®ƒçڑ„è®ç»ƒو ·وœ¬ï¼Œو¯ڈن¸€ن¸ھو ·وœ¬ç”±ن¸€ن¸ھهگ‘é‡ڈ(ه°±وک¯é‚£ن؛›و–‡وœ¬ç‰¹ه¾پو‰€ç»„وˆگçڑ„هگ‘é‡ڈ)ه’Œن¸€ن¸ھو ‡è®°ï¼ˆو ‡ç¤؛ه‡؛è؟™ن¸ھو ·وœ¬ه±ن؛ژه“ھن¸ھç±»هˆ«ï¼‰ç»„وˆگم€‚ه¦‚ن¸‹ï¼ڑ
Di=(xi,yi)
xiه°±وک¯و–‡وœ¬هگ‘é‡ڈ(维و•°ه¾ˆé«ک),yiه°±وک¯هˆ†ç±»و ‡è®°م€‚
هœ¨ن؛Œه…ƒçڑ„ç؛؟و€§هˆ†ç±»ن¸ï¼Œè؟™ن¸ھè،¨ç¤؛هˆ†ç±»çڑ„و ‡è®°هڈھوœ‰ن¸¤ن¸ھه€¼ï¼Œ1ه’Œ-1(用و¥è،¨ç¤؛ه±ن؛ژè؟کوک¯ن¸چه±ن؛ژè؟™ن¸ھ类)م€‚وœ‰ن؛†è؟™ç§چè،¨ç¤؛و³•ï¼Œوˆ‘ن»¬ه°±هڈ¯ن»¥ه®ڑن¹‰ن¸€ن¸ھو ·وœ¬ç‚¹هˆ°وںگن¸ھ超ه¹³é¢çڑ„é—´éڑ”ï¼ڑ
خ´i=yi(wxi+b)
è؟™ن¸ھه…¬ه¼ڈن¹چن¸€çœ‹و²،ن»€ن¹ˆç¥ç§کçڑ„,ن¹ں说ن¸چه‡؛ن»€ن¹ˆéپ“çگ†ï¼Œهڈھوک¯ن¸ھه®ڑن¹‰è€Œه·²ï¼Œن½†وˆ‘ن»¬هپڑهپڑهڈکوچ¢ï¼Œه°±èƒ½çœ‹ه‡؛ن¸€ن؛›وœ‰و„ڈو€çڑ„ن¸œè¥؟م€‚
首ه…ˆو³¨و„ڈهˆ°ه¦‚وœوںگن¸ھو ·وœ¬ه±ن؛ژ该类هˆ«çڑ„è¯ï¼Œé‚£ن¹ˆwxi+b>0(记ه¾—ن¹ˆï¼ںè؟™وک¯ه› ن¸؛وˆ‘ن»¬و‰€é€‰çڑ„g(x)=wx+bه°±é€ڑè؟‡ه¤§ن؛ژ0è؟کوک¯ه°ڈن؛ژ0و¥هˆ¤و–هˆ†ç±»ï¼‰ï¼Œè€Œyiن¹ںه¤§ن؛ژ0;若ن¸چه±ن؛ژ该类هˆ«çڑ„è¯ï¼Œé‚£ن¹ˆwxi+b<0,而yiن¹ںه°ڈن؛ژ0,è؟™و„ڈه‘³ç€yi(wxi+b)و€»وک¯ه¤§ن؛ژ0çڑ„,而ن¸”ه®ƒçڑ„ه€¼ه°±ç‰ن؛ژ|wxi+b|ï¼پ(ن¹ںه°±وک¯|g(xi)|)
çژ°هœ¨وٹٹwه’Œbè؟›è،Œن¸€ن¸‹ه½’ن¸€هŒ–,هچ³ç”¨w/||w||ه’Œb/||w||هˆ†هˆ«ن»£و›؟هژںو¥çڑ„wه’Œb,那ن¹ˆé—´éڑ”ه°±هڈ¯ن»¥ه†™وˆگ
م€گ点هˆ°ç›´ç؛؟çڑ„è·ç¦»ï¼Œهپڑ解وگه‡ ن½•ن¸ن¸؛ï¼ڑ
D = (Ax + By + c) /sqrt(A^2+B^2)
sqrt(A^2+B^2)ه°±ç›¸ه½“ن؛ژ||W||, ه…¶ن¸هگ‘é‡ڈW=[A, B];
(Ax + By + c)ه°±ç›¸ه½“ن؛ژg(X), ه…¶ن¸هگ‘é‡ڈX=[x,y]م€‚م€‘
è؟™ن¸ھه…¬ه¼ڈوک¯ن¸چوک¯çœ‹ن¸ٹهژ»وœ‰ç‚¹çœ¼ç†ںï¼ںو²،错,è؟™ن¸چه°±وک¯è§£وگه‡ ن½•ن¸ç‚¹xiهˆ°ç›´ç؛؟g(x)=0çڑ„è·ç¦»ه…¬ه¼ڈهک›ï¼پ(وژ¨ه¹؟ن¸€ن¸‹ï¼Œوک¯هˆ°è¶…ه¹³é¢g(x)=0çڑ„è·ç¦»ï¼Œ g(x)=0ه°±وک¯ن¸ٹèٹ‚ن¸وڈگهˆ°çڑ„هˆ†ç±»è¶…ه¹³é¢ï¼‰
ه°ڈTipsï¼ڑ||w||وک¯ن»€ن¹ˆç¬¦هڈ·ï¼ں||w||هڈ«هپڑهگ‘é‡ڈwçڑ„范و•°ï¼ŒèŒƒو•°وک¯ه¯¹هگ‘é‡ڈé•؟ه؛¦çڑ„ن¸€ç§چه؛¦é‡ڈم€‚وˆ‘ن»¬ه¸¸è¯´çڑ„هگ‘é‡ڈé•؟ه؛¦ه…¶ه®وŒ‡çڑ„وک¯ه®ƒçڑ„2-范و•°ï¼ŒèŒƒو•°وœ€ن¸€èˆ¬çڑ„è،¨ç¤؛ه½¢ه¼ڈن¸؛p-范و•°ï¼Œهڈ¯ن»¥ه†™وˆگه¦‚ن¸‹è،¨è¾¾ه¼ڈ
هگ‘é‡ڈw=(w1, w2, w3,…… wn)
ه®ƒçڑ„p-范و•°ن¸؛
看看وٹٹpوچ¢وˆگ2çڑ„و—¶ه€™ï¼Œن¸چه°±وک¯ن¼ ç»ںçڑ„هگ‘é‡ڈé•؟ه؛¦ن¹ˆï¼ںه½“وˆ‘ن»¬ن¸چوŒ‡وکژpçڑ„و—¶ه€™ï¼Œه°±هƒڈ||w||è؟™و ·ن½؟用و—¶ï¼Œه°±و„ڈه‘³ç€وˆ‘ن»¬ن¸چه…³ه؟ƒpçڑ„ه€¼ï¼Œç”¨ه‡ 范و•°éƒ½هڈ¯ن»¥ï¼›وˆ–者ن¸ٹو–‡ه·²ç»ڈوڈگهˆ°ن؛†pçڑ„ه€¼ï¼Œن¸؛ن؛†هڈ™è؟°و–¹ن¾؟ن¸چه†چé‡چه¤چوŒ‡وکژم€‚
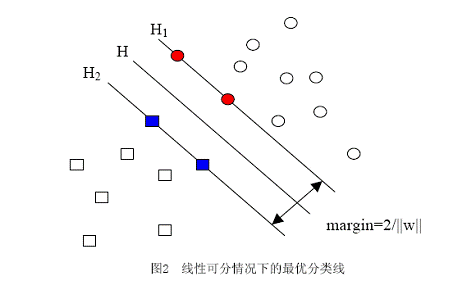
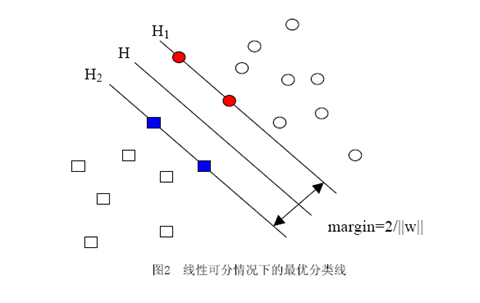
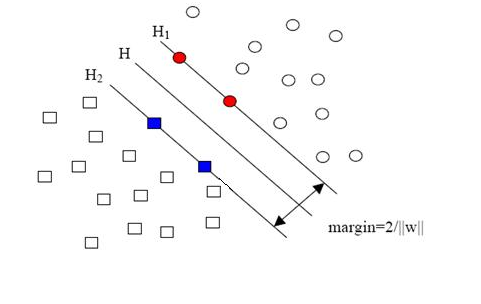
ه½“用ه½’ن¸€هŒ–çڑ„wه’Œbن»£و›؟هژںه€¼ن¹‹هگژçڑ„é—´éڑ”وœ‰ن¸€ن¸ھن¸“é—¨çڑ„هگچ称,هڈ«هپڑه‡ ن½•é—´éڑ”,ه‡ ن½•é—´éڑ”و‰€è،¨ç¤؛çڑ„و£وک¯ç‚¹هˆ°è¶…ه¹³é¢çڑ„و¬§و°ڈè·ç¦»ï¼Œوˆ‘ن»¬ن¸‹é¢ه°±ç®€ç§°ه‡ ن½•é—´éڑ”ن¸؛“è·ç¦»â€م€‚ن»¥ن¸ٹوک¯هچ•ن¸ھ点هˆ°وںگن¸ھ超ه¹³é¢çڑ„è·ç¦»ï¼ˆه°±وک¯é—´éڑ”,هگژé¢ن¸چه†چهŒ؛هˆ«è؟™ن¸¤ن¸ھè¯چ)ه®ڑن¹‰ï¼ŒهگŒو ·هڈ¯ن»¥ه®ڑن¹‰ن¸€ن¸ھ点çڑ„集هگˆï¼ˆه°±وک¯ن¸€ç»„و ·وœ¬ï¼‰هˆ°وںگن¸ھ超ه¹³é¢çڑ„è·ç¦»ن¸؛و¤é›†هگˆن¸ç¦»è¶…ه¹³é¢وœ€è؟‘çڑ„点çڑ„è·ç¦»م€‚ن¸‹é¢è؟™ه¼ ه›¾و›´هٹ 直观çڑ„ه±•ç¤؛ه‡؛ن؛†ه‡ ن½•é—´éڑ”çڑ„çژ°ه®هگ«ن¹‰ï¼ڑ
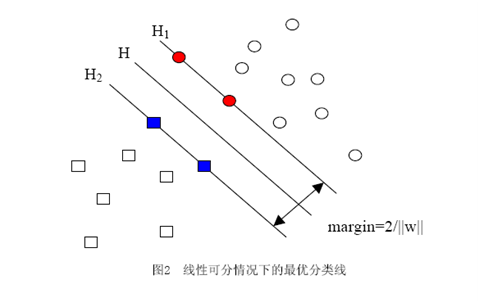
Hوک¯هˆ†ç±»é¢ï¼Œè€ŒH1ه’ŒH2وک¯ه¹³è،Œن؛ژH,ن¸”è؟‡ç¦»Hوœ€è؟‘çڑ„ن¸¤ç±»و ·وœ¬çڑ„ç›´ç؛؟,H1ن¸ژH,H2ن¸ژHن¹‹é—´çڑ„è·ç¦»ه°±وک¯ه‡ ن½•é—´éڑ”م€‚
ن¹‹و‰€ن»¥ه¦‚و¤ه…³ه؟ƒه‡ ن½•é—´éڑ”è؟™ن¸ھن¸œè¥؟,وک¯ه› ن¸؛ه‡ ن½•é—´éڑ”ن¸ژو ·وœ¬çڑ„误هˆ†و¬،و•°é—´هکهœ¨ه…³ç³»ï¼ڑ
![]()
ه…¶ن¸çڑ„خ´وک¯و ·وœ¬é›†هگˆهˆ°هˆ†ç±»é¢çڑ„é—´éڑ”,R=max ||xi|| i=1,...,n,هچ³Rوک¯و‰€وœ‰و ·وœ¬ن¸ï¼ˆxiوک¯ن»¥هگ‘é‡ڈè،¨ç¤؛çڑ„第iن¸ھو ·وœ¬ï¼‰هگ‘é‡ڈé•؟ه؛¦وœ€é•؟çڑ„ه€¼ï¼ˆن¹ںه°±وک¯è¯´ن»£è،¨و ·وœ¬çڑ„هˆ†ه¸ƒوœ‰ه¤ڑن¹ˆه¹؟)م€‚ه…ˆن¸چه؟…è؟½ç©¶è¯¯هˆ†و¬،و•°çڑ„ه…·ن½“ه®ڑن¹‰ه’Œوژ¨ه¯¼è؟‡ç¨‹ï¼Œهڈھè¦پè®°ه¾—è؟™ن¸ھ误هˆ†و¬،و•°ن¸€ه®ڑ程ه؛¦ن¸ٹن»£è،¨هˆ†ç±»ه™¨çڑ„误ه·®م€‚而ن»ژن¸ٹه¼ڈهڈ¯ن»¥çœ‹ه‡؛,误هˆ†و¬،و•°çڑ„ن¸ٹ界由ه‡ ن½•é—´éڑ”ه†³ه®ڑï¼پ(ه½“然,وک¯و ·وœ¬ه·²çں¥çڑ„و—¶ه€™ï¼‰
至و¤وˆ‘ن»¬ه°±وکژ白ن¸؛ن½•è¦پ选و‹©ه‡ ن½•é—´éڑ”و¥ن½œن¸؛评ن»·ن¸€ن¸ھ解ن¼کهٹ£çڑ„وŒ‡و ‡ن؛†ï¼Œهژںو¥ه‡ ن½•é—´éڑ”è¶ٹه¤§çڑ„解,ه®ƒçڑ„误ه·®ن¸ٹç•Œè¶ٹه°ڈم€‚ه› و¤وœ€ه¤§هŒ–ه‡ ن½•é—´éڑ”وˆگن؛†وˆ‘ن»¬è®ç»ƒéک¶و®µçڑ„ç›®و ‡ï¼Œè€Œن¸”,ن¸ژن؛Œوٹٹهˆ€ن½œè€…و‰€ه†™çڑ„ن¸چهگŒï¼Œوœ€ه¤§هŒ–هˆ†ç±»é—´éڑ”ه¹¶ن¸چوک¯SVMçڑ„ن¸“هˆ©ï¼Œè€Œوک¯و—©هœ¨ç؛؟و€§هˆ†ç±»و—¶وœںه°±ه·²وœ‰çڑ„و€وƒ³م€‚
SVMه…¥é—¨ï¼ˆه››ï¼‰ç؛؟و€§هˆ†ç±»ه™¨çڑ„و±‚解——问é¢کçڑ„وڈڈè؟°Part1
ن¸ٹèٹ‚说هˆ°وˆ‘ن»¬وœ‰ن؛†ن¸€ن¸ھç؛؟و€§هˆ†ç±»ه‡½و•°ï¼Œن¹ںوœ‰ن؛†هˆ¤و–解ن¼کهٹ£çڑ„و ‡ه‡†â€”—هچ³وœ‰ن؛†ن¼کهŒ–çڑ„ç›®و ‡ï¼Œè؟™ن¸ھç›®و ‡ه°±وک¯وœ€ه¤§هŒ–ه‡ ن½•é—´éڑ”,ن½†وک¯çœ‹è؟‡ن¸€ن؛›ه…³ن؛ژSVMçڑ„è®؛و–‡çڑ„ن؛؛ن¸€ه®ڑè®°ه¾—ن»€ن¹ˆن¼کهŒ–çڑ„ç›®و ‡وک¯è¦پوœ€ه°ڈهŒ–||w||è؟™و ·çڑ„说و³•ï¼Œè؟™وک¯و€ژن¹ˆه›ن؛‹ه‘¢ï¼ںه›ه¤´ه†چ看看وˆ‘ن»¬ه¯¹é—´éڑ”ه’Œه‡ ن½•é—´éڑ”çڑ„ه®ڑن¹‰ï¼ڑ
é—´éڑ”ï¼ڑخ´=y(wx+b)=|g(x)|
ه‡ ن½•é—´éڑ”ï¼ڑ![]()
هڈ¯ن»¥çœ‹ه‡؛خ´=||w||خ´ه‡ ن½•م€‚و³¨و„ڈهˆ°ه‡ ن½•é—´éڑ”ن¸ژ||w||وک¯وˆگهڈچو¯”çڑ„,ه› و¤وœ€ه¤§هŒ–ه‡ ن½•é—´éڑ”ن¸ژوœ€ه°ڈهŒ–||w||ه®Œه…¨وک¯ن¸€ه›ن؛‹م€‚而وˆ‘ن»¬ه¸¸ç”¨çڑ„و–¹و³•ه¹¶ن¸چوک¯ه›؛ه®ڑ||w||çڑ„ه¤§ه°ڈ而ه¯»و±‚وœ€ه¤§ه‡ ن½•é—´éڑ”,而وک¯ه›؛ه®ڑé—´éڑ”(ن¾‹ه¦‚ه›؛ه®ڑن¸؛1),ه¯»و‰¾وœ€ه°ڈçڑ„||w||م€‚
而ه‡،وک¯و±‚ن¸€ن¸ھه‡½و•°çڑ„وœ€ه°ڈه€¼ï¼ˆوˆ–وœ€ه¤§ه€¼ï¼‰çڑ„é—®é¢ک都هڈ¯ن»¥ç§°ن¸؛ه¯»ن¼کé—®é¢ک(ن¹ںهڈ«ن½œن¸€ن¸ھ规هˆ’é—®é¢ک),هڈˆç”±ن؛ژو‰¾وœ€ه¤§ه€¼çڑ„é—®é¢کو€»هڈ¯ن»¥é€ڑè؟‡هٹ ن¸€ن¸ھè´ںهڈ·هڈکن¸؛و‰¾وœ€ه°ڈه€¼çڑ„é—®é¢ک,ه› و¤وˆ‘ن»¬ن¸‹é¢è®¨è®؛çڑ„و—¶ه€™éƒ½é’ˆه¯¹و‰¾وœ€ه°ڈه€¼çڑ„è؟‡ç¨‹و¥è؟›è،Œم€‚ن¸€ن¸ھه¯»ن¼کé—®é¢کوœ€é‡چè¦پçڑ„部هˆ†وک¯ç›®و ‡ه‡½و•°ï¼Œé،¾هگچو€ن¹‰ï¼Œه°±وک¯وŒ‡ه¯»ن¼کçڑ„ç›®و ‡م€‚ن¾‹ه¦‚وˆ‘ن»¬وƒ³ه¯»و‰¾وœ€ه°ڈçڑ„||w||è؟™ن»¶ن؛‹ï¼Œه°±هڈ¯ن»¥ç”¨ن¸‹é¢çڑ„ه¼ڈهگè،¨ç¤؛ï¼ڑ
![]()
ن½†ه®é™…ن¸ٹه¯¹ن؛ژè؟™ن¸ھç›®و ‡ï¼Œوˆ‘ن»¬ه¸¸ه¸¸ن½؟用هڈ¦ن¸€ن¸ھه®Œه…¨ç‰ن»·çڑ„ç›®و ‡ه‡½و•°و¥ن»£و›؟,那ه°±وک¯ï¼ڑ
![]() (ه¼ڈ1)
(ه¼ڈ1)
ن¸چéڑ¾çœ‹ه‡؛ه½“||w||2è¾¾هˆ°وœ€ه°ڈو—¶ï¼Œ||w||ن¹ںè¾¾هˆ°وœ€ه°ڈ,هڈچن¹‹ن؛¦ç„¶ï¼ˆه‰چوڈگه½“然وک¯||w||وڈڈè؟°çڑ„وک¯هگ‘é‡ڈçڑ„é•؟ه؛¦ï¼Œه› 而وک¯éè´ںçڑ„)م€‚ن¹‹و‰€ن»¥é‡‡ç”¨è؟™ç§چه½¢ه¼ڈ,وک¯ه› ن¸؛هگژé¢çڑ„و±‚解è؟‡ç¨‹ن¼ڑه¯¹ç›®و ‡ه‡½و•°ن½œن¸€ç³»هˆ—هڈکوچ¢ï¼Œè€Œه¼ڈ(1)çڑ„ه½¢ه¼ڈن¼ڑن½؟هڈکوچ¢هگژçڑ„ه½¢ه¼ڈو›´ن¸؛简و´پ(و£ه¦‚èپھوکژçڑ„读者و‰€و–™ï¼Œو·»هٹ çڑ„ç³»و•°ن؛Œهˆ†ن¹‹ن¸€ه’Œه¹³و–¹ï¼Œçڑ†وک¯ن¸؛و±‚ه¯¼و•°و‰€éœ€ï¼‰م€‚
وژ¥ن¸‹و¥وˆ‘ن»¬è‡ھ然ن¼ڑé—®çڑ„ه°±وک¯ï¼Œè؟™ن¸ھه¼ڈهگوک¯هگ¦ه°±وڈڈè؟°ن؛†وˆ‘ن»¬çڑ„é—®é¢که‘¢ï¼ں(ه›وƒ³ن¸€ن¸‹ï¼Œوˆ‘ن»¬çڑ„é—®é¢کوک¯وœ‰ن¸€ه †ç‚¹ï¼Œهڈ¯ن»¥è¢«هˆ†وˆگن¸¤ç±»ï¼Œوˆ‘ن»¬è¦پو‰¾ه‡؛وœ€ه¥½çڑ„هˆ†ç±»é¢ï¼‰
ه¦‚وœç›´وژ¥و¥è§£è؟™ن¸ھو±‚وœ€ه°ڈه€¼é—®é¢ک,ه¾ˆه®¹وک“看ه‡؛ه½“||w||=0çڑ„و—¶ه€™ه°±ه¾—هˆ°ن؛†ç›®و ‡ه‡½و•°çڑ„وœ€ه°ڈه€¼م€‚ن½†وک¯ن½ ن¹ںن¼ڑهڈ‘çژ°ï¼Œو— è®؛ن½ ç»™ن»€ن¹ˆو ·çڑ„و•°وچ®ï¼Œéƒ½وک¯è؟™ن¸ھ解ï¼پهڈچوک هœ¨ه›¾ن¸ï¼Œه°±وک¯H1ن¸ژH2ن¸¤و،ç›´ç؛؟é—´çڑ„è·ç¦»و— é™گه¤§ï¼Œè؟™ن¸ھو—¶ه€™ï¼Œو‰€وœ‰çڑ„و ·وœ¬ç‚¹ï¼ˆو— è®؛و£و ·وœ¬è؟کوک¯è´ںو ·وœ¬ï¼‰éƒ½è·‘هˆ°ن؛†H1ه’ŒH2ن¸é—´ï¼Œè€Œوˆ‘ن»¬هژںوœ¬çڑ„و„ڈه›¾وک¯ï¼ŒH1هڈ³ن¾§çڑ„被هˆ†ن¸؛و£ç±»ï¼ŒH2 ه·¦ن¾§çڑ„被هˆ†ن¸؛è´ں类,ن½چن؛ژن¸¤ç±»ن¸é—´çڑ„و ·وœ¬هˆ™و‹’ç»هˆ†ç±»ï¼ˆو‹’ç»هˆ†ç±»çڑ„هڈ¦ن¸€ç§چçگ†è§£وک¯هˆ†ç»™ه“ھن¸€ç±»éƒ½وœ‰éپ“çگ†ï¼Œه› 而هˆ†ç»™ه“ھن¸€ç±»ن¹ں都و²،وœ‰éپ“çگ†ï¼‰م€‚è؟™ن¸‹هڈ¯ه¥½ï¼Œو‰€وœ‰و ·وœ¬ç‚¹éƒ½è؟›ه…¥ن؛†و— و³•هˆ†ç±»çڑ„çپ°è‰²هœ°ه¸¦م€‚
é€ وˆگè؟™ç§چ结وœçڑ„هژںه› وک¯هœ¨وڈڈè؟°é—®é¢کçڑ„و—¶ه€™هڈھ考虑ن؛†ç›®و ‡ï¼Œè€Œو²،وœ‰هٹ ه…¥ç؛¦وںو،ن»¶ï¼Œç؛¦وںو،ن»¶ه°±وک¯هœ¨و±‚解è؟‡ç¨‹ن¸ه؟…é،»و»،足çڑ„و،ن»¶ï¼Œن½“çژ°هœ¨وˆ‘ن»¬çڑ„é—®é¢کن¸ه°±وک¯و ·وœ¬ç‚¹ه؟…é،»هœ¨H1وˆ–H2çڑ„وںگن¸€ن¾§ï¼ˆوˆ–者至ه°‘هœ¨H1ه’ŒH2ن¸ٹ),而ن¸چ能跑هˆ°ن¸¤è€…ن¸é—´م€‚وˆ‘ن»¬ه‰چو–‡وڈگهˆ°è؟‡وٹٹé—´éڑ”ه›؛ه®ڑن¸؛1,è؟™وک¯وŒ‡وٹٹو‰€وœ‰و ·وœ¬ç‚¹ن¸é—´éڑ”وœ€ه°ڈçڑ„é‚£ن¸€ç‚¹çڑ„é—´éڑ”ه®ڑن¸؛1(è؟™ن¹ںوک¯é›†هگˆçڑ„é—´éڑ”çڑ„ه®ڑن¹‰ï¼Œوœ‰ç‚¹ç»•هک´ï¼‰ï¼Œن¹ںه°±و„ڈه‘³ç€é›†هگˆن¸çڑ„ه…¶ن»–点间éڑ”都ن¸چن¼ڑه°ڈن؛ژ1,وŒ‰ç…§é—´éڑ”çڑ„ه®ڑن¹‰ï¼Œو»،足è؟™ن؛›و،ن»¶ه°±ç›¸ه½“ن؛ژ让ن¸‹é¢çڑ„ه¼ڈهگو€»وک¯وˆگç«‹ï¼ڑ
yi[(wآ·xi)+b]≥1 (i=1,2,…,l) (lوک¯و€»çڑ„و ·وœ¬و•°ï¼‰
ن½†وˆ‘ن»¬ه¸¸ه¸¸ن¹ وƒ¯è®©ه¼ڈهگçڑ„ه€¼ه’Œ0و¯”较,ه› 而ç»ڈه¸¸ç”¨هڈکوچ¢è؟‡çڑ„ه½¢ه¼ڈï¼ڑ
yi[(wآ·xi)+b]-1≥0 (i=1,2,…,l) (lوک¯و€»çڑ„و ·وœ¬و•°ï¼‰
ه› و¤وˆ‘ن»¬çڑ„ن¸¤ç±»هˆ†ç±»é—®é¢کن¹ں被وˆ‘ن»¬è½¬هŒ–وˆگن؛†ه®ƒçڑ„و•°ه¦ه½¢ه¼ڈ,ن¸€ن¸ھه¸¦ç؛¦وںçڑ„وœ€ه°ڈه€¼çڑ„é—®é¢کï¼ڑ
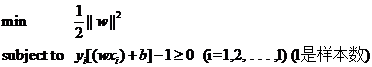
ن¸‹ن¸€èٹ‚وˆ‘ن»¬ن»ژوœ€ن¸€èˆ¬çڑ„و„ڈن¹‰ن¸ٹ看看ن¸€ن¸ھو±‚وœ€ه°ڈه€¼çڑ„é—®é¢کوœ‰ن½•ç‰¹ه¾پ,ن»¥هڈٹه¦‚ن½•و¥è§£م€‚
SVMه…¥é—¨ï¼ˆن؛”)ç؛؟و€§هˆ†ç±»ه™¨çڑ„و±‚解——问é¢کçڑ„وڈڈè؟°Part2
ن»ژوœ€ن¸€èˆ¬çڑ„ه®ڑن¹‰ن¸ٹ说,ن¸€ن¸ھو±‚وœ€ه°ڈه€¼çڑ„é—®é¢که°±وک¯ن¸€ن¸ھن¼کهŒ–é—®é¢ک(ن¹ںهڈ«ه¯»ن¼کé—®é¢ک,و›´و–‡ç»‰ç»‰çڑ„هڈ«و³•وک¯è§„هˆ’——Programming),ه®ƒهگŒو ·ç”±ن¸¤éƒ¨هˆ†ç»„وˆگ,目و ‡ه‡½و•°ه’Œç؛¦وںو،ن»¶ï¼Œهڈ¯ن»¥ç”¨ن¸‹é¢çڑ„ه¼ڈهگè،¨ç¤؛ï¼ڑ
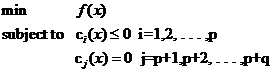 (ه¼ڈ1)
(ه¼ڈ1)
ç؛¦وںو،ن»¶ç”¨ه‡½و•°cو¥è،¨ç¤؛,ه°±وک¯constrainçڑ„و„ڈو€ه•¦م€‚ن½ هڈ¯ن»¥çœ‹ه‡؛ن¸€ه…±وœ‰p+qن¸ھç؛¦وںو،ن»¶ï¼Œه…¶ن¸pن¸ھوک¯ن¸چç‰ه¼ڈç؛¦وں,qن¸ھç‰ه¼ڈç؛¦وںم€‚
ه…³ن؛ژè؟™ن¸ھه¼ڈهگهڈ¯ن»¥è؟™و ·و¥çگ†è§£ï¼ڑه¼ڈن¸çڑ„xوک¯è‡ھهڈکé‡ڈ,ن½†ن¸چé™گه®ڑه®ƒçڑ„ç»´و•°ه؟…é،»ن¸؛1(视ن¹ژن½ 解ه†³çڑ„é—®é¢کç©؛é—´ç»´و•°ï¼Œه¯¹وˆ‘ن»¬çڑ„و–‡وœ¬هˆ†ç±»و¥è¯´ï¼Œé‚£هڈ¯وک¯وˆگهچƒن¸ٹن¸‡ه•ٹ)م€‚è¦پو±‚f(x)هœ¨ه“ھن¸€ç‚¹ن¸ٹهڈ–ه¾—وœ€ه°ڈه€¼ï¼ˆهڈچه€’ن¸چه¤ھه…³ه؟ƒè؟™ن¸ھوœ€ه°ڈه€¼هˆ°ه؛•وک¯ه¤ڑه°‘,ه…³é”®وک¯ه“ھن¸€ç‚¹ï¼‰ï¼Œن½†ن¸چوک¯هœ¨و•´ن¸ھç©؛间里و‰¾ï¼Œè€Œوک¯هœ¨ç؛¦وںو،ن»¶و‰€هˆ’ه®ڑçڑ„ن¸€ن¸ھوœ‰é™گçڑ„ç©؛间里و‰¾ï¼Œè؟™ن¸ھوœ‰é™گçڑ„ç©؛é—´ه°±وک¯ن¼کهŒ–çگ†è®؛里و‰€è¯´çڑ„هڈ¯è،Œهںںم€‚و³¨و„ڈهڈ¯è،Œهںںن¸çڑ„و¯ڈن¸€ن¸ھ点都è¦پو±‚و»،足و‰€وœ‰p+qن¸ھو،ن»¶ï¼Œè€Œن¸چوک¯و»،足ه…¶ن¸ن¸€و،وˆ–ه‡ و،ه°±هڈ¯ن»¥ï¼ˆهˆ‡è®°ï¼Œè¦پو»،足و¯ڈن¸ھç؛¦وں),هگŒو—¶هڈ¯è،Œهںں边界ن¸ٹçڑ„点وœ‰ن¸€ن¸ھé¢ه¤–ه¥½çڑ„特و€§ï¼Œه®ƒن»¬هڈ¯ن»¥ن½؟ن¸چç‰ه¼ڈç؛¦وںهڈ–ه¾—ç‰هڈ·ï¼پ而边界ه†…çڑ„点ن¸چè،Œم€‚
ه…³ن؛ژهڈ¯è،Œهںںè؟کوœ‰ن¸ھو¦‚ه؟µن¸چه¾—ن¸چوڈگ,那ه°±وک¯ه‡¸é›†ï¼Œه‡¸é›†وک¯وŒ‡وœ‰è؟™ن¹ˆن¸€ن¸ھ点çڑ„集هگˆï¼Œه…¶ن¸ن»»هڈ–ن¸¤ن¸ھ点è؟ن¸€و،ç›´ç؛؟,è؟™و،ç؛؟ن¸ٹçڑ„点ن»چ然هœ¨è؟™ن¸ھ集هگˆه†…部,ه› و¤è¯´â€œه‡¸â€وک¯ه¾ˆه½¢è±،çڑ„(ن¸€ن¸ھهڈچن¾‹وک¯ï¼Œن؛Œç»´ه¹³é¢ن¸ٹ,ن¸€ن¸ھوœˆç‰™ه½¢çڑ„هŒ؛هںںه°±ن¸چوک¯ه‡¸é›†ï¼Œن½ éڑڈن¾؟ه°±هڈ¯ن»¥و‰¾هˆ°ن¸¤ن¸ھ点è؟هڈچن؛†هˆڑو‰چçڑ„规ه®ڑ)م€‚
ه›ه¤´ه†چو¥çœ‹وˆ‘ن»¬ç؛؟و€§هˆ†ç±»ه™¨é—®é¢کçڑ„وڈڈè؟°ï¼Œهڈ¯ن»¥çœ‹ه‡؛و›´ه¤ڑçڑ„ن¸œè¥؟م€‚
 (ه¼ڈ2)
(ه¼ڈ2)
هœ¨è؟™ن¸ھé—®é¢کن¸ï¼Œè‡ھهڈکé‡ڈه°±وک¯w,而目و ‡ه‡½و•°وک¯wçڑ„ن؛Œو¬،ه‡½و•°ï¼Œو‰€وœ‰çڑ„ç؛¦وںو،ن»¶éƒ½وک¯wçڑ„ç؛؟و€§ه‡½و•°ï¼ˆه“ژ,هچƒن¸‡ن¸چè¦پوٹٹxiه½“وˆگهڈکé‡ڈ,ه®ƒن»£è،¨و ·وœ¬ï¼Œوک¯ه·²çں¥çڑ„),è؟™ç§چ规هˆ’é—®é¢کوœ‰ن¸ھه¾ˆوœ‰هگچو°”çڑ„称ه‘¼â€”—ن؛Œو¬،规هˆ’(Quadratic Programming,QP),而ن¸”هڈ¯ن»¥و›´è؟›ن¸€و¥çڑ„说,由ن؛ژه®ƒçڑ„هڈ¯è،Œهںںوک¯ن¸€ن¸ھه‡¸é›†ï¼Œه› و¤ه®ƒوک¯ن¸€ن¸ھه‡¸ن؛Œو¬،规هˆ’م€‚
ن¸€ن¸‹هگوڈگن؛†è؟™ن¹ˆه¤ڑوœ¯è¯ï¼Œه®هœ¨ن¸چوک¯ن¸؛ن؛†è®©ه¤§ه®¶ن»¥هگژ能هگ‘هˆ«ن؛؛炫耀ه¦è¯†çڑ„و¸ٹهچڑ,è؟™ه…¶ه®وک¯وˆ‘ن»¬ç»§ç»ن¸‹هژ»çڑ„ن¸€ن¸ھé‡چè¦په‰چوڈگ,ه› ن¸؛هœ¨هٹ¨و‰‹و±‚ن¸€ن¸ھé—®é¢کçڑ„解ن¹‹ه‰چ(ه¥½هگ§ï¼Œوˆ‘و‰؟认,وک¯هٹ¨è®،ç®—وœ؛و±‚……),وˆ‘ن»¬ه؟…é،»ه…ˆé—®è‡ھه·±ï¼ڑè؟™ن¸ھé—®é¢کوک¯ن¸چوک¯وœ‰è§£ï¼ںه¦‚وœوœ‰è§£ï¼Œوک¯هگ¦èƒ½و‰¾هˆ°ï¼ں
ه¯¹ن؛ژن¸€èˆ¬و„ڈن¹‰ن¸ٹçڑ„规هˆ’é—®é¢ک,ن¸¤ن¸ھé—®é¢کçڑ„ç”و،ˆéƒ½وک¯ن¸چن¸€ه®ڑ,ن½†ه‡¸ن؛Œو¬،规هˆ’让ن؛؛ه–œو¬¢çڑ„هœ°و–¹ه°±هœ¨ن؛ژ,ه®ƒوœ‰è§£ï¼ˆو•™ç§‘ن¹¦é‡Œé¢ن¸؛ن؛†ن¸¥è°¨ï¼Œه¸¸ه¸¸هٹ é™گه®ڑوˆگهˆ†ï¼Œè¯´ه®ƒوœ‰ه…¨ه±€وœ€ن¼ک解,由ن؛ژوˆ‘ن»¬وƒ³و‰¾çڑ„وœ¬و¥ه°±وک¯ه…¨ه±€وœ€ن¼کçڑ„解,و‰€ن»¥ن¸چهٹ ن¹ں罢),而ن¸”هڈ¯ن»¥و‰¾هˆ°ï¼پ(ه½“然,ن¾وچ®ن½ ن½؟用çڑ„ç®—و³•ن¸چهگŒï¼Œو‰¾هˆ°è؟™ن¸ھ解çڑ„é€ںه؛¦ï¼Œè،Œè¯هڈ«و”¶و•›é€ںه؛¦ï¼Œن¼ڑوœ‰و‰€ن¸چهگŒï¼‰
ه¯¹و¯”(ه¼ڈ2)ه’Œï¼ˆه¼ڈ1)è؟کهڈ¯ن»¥هڈ‘çژ°ï¼Œوˆ‘ن»¬çڑ„ç؛؟و€§هˆ†ç±»ه™¨é—®é¢کهڈھوœ‰ن¸چç‰ه¼ڈç؛¦وں,ه› و¤ه½¢ه¼ڈن¸ٹ看ن¼¼ن¹ژو¯”ن¸€èˆ¬و„ڈن¹‰ن¸ٹçڑ„规هˆ’é—®é¢کè¦پ简هچ•ï¼Œن½†è§£èµ·و¥هچ´ه¹¶éه¦‚و¤م€‚
ه› ن¸؛وˆ‘ن»¬ه®é™…ن¸ٹه¹¶ن¸چçں¥éپ“该و€ژن¹ˆè§£ن¸€ن¸ھه¸¦ç؛¦وںçڑ„ن¼کهŒ–é—®é¢کم€‚ه¦‚وœن½ ن»”细ه›ه؟†ن¸€ن¸‹é«کç‰و•°ه¦çڑ„çں¥è¯†ï¼Œن¼ڑè®°ه¾—وˆ‘ن»¬هڈ¯ن»¥è½»و¾çڑ„解ن¸€ن¸ھن¸چه¸¦ن»»ن½•ç؛¦وںçڑ„ن¼کهŒ–é—®é¢ک(ه®é™…ن¸ٹه°±وک¯ه½“ه¹´èƒŒه¾—烂ç†ںçڑ„ه‡½و•°و±‚وپه€¼هک›ï¼Œو±‚ه¯¼ه†چو‰¾0点ه‘—,è°پن¸چن¼ڑه•ٹï¼ں笑),وˆ‘ن»¬ç”ڑ至è؟کن¼ڑ解ن¸€ن¸ھهڈھه¸¦ç‰ه¼ڈç؛¦وںçڑ„ن¼کهŒ–é—®é¢ک,ن¹ںوک¯èƒŒه¾—烂ç†ںçڑ„,و±‚و،ن»¶وپه€¼ï¼Œè®°ه¾—ن¹ˆï¼Œé€ڑè؟‡و·»هٹ و‹‰و ¼وœ—و—¥ن¹کهگ,و„é€ و‹‰و ¼وœ—و—¥ه‡½و•°ï¼Œو¥وٹٹè؟™ن¸ھé—®é¢ک转هŒ–ن¸؛و— ç؛¦وںçڑ„ن¼کهŒ–é—®é¢کن؛‘ن؛‘(ه¦‚وœن½ ن¸€و—¶و²،وƒ³é€ڑ,وˆ‘وڈگ醒ن¸€ن¸‹ï¼Œو„é€ ه‡؛çڑ„و‹‰و ¼وœ—و—¥ه‡½و•°ه°±وک¯è½¬هŒ–ن¹‹هگژçڑ„é—®é¢که½¢ه¼ڈ,ه®ƒوک¾ç„¶و²،وœ‰ه¸¦ن»»ن½•و،ن»¶ï¼‰م€‚
读者问ï¼ڑه¦‚وœهڈھه¸¦ç‰ه¼ڈç؛¦وںçڑ„é—®é¢کهڈ¯ن»¥è½¬هŒ–ن¸؛و— ç؛¦وںçڑ„é—®é¢ک而ه¾—ن»¥و±‚解,那ن¹ˆهڈ¯ن¸چهڈ¯ن»¥وٹٹه¸¦ن¸چç‰ه¼ڈç؛¦وںçڑ„é—®é¢کهگ‘هڈھه¸¦ç‰ه¼ڈç؛¦وںçڑ„é—®é¢ک转هŒ–ن¸€ن¸‹è€Œه¾—ن»¥و±‚解ه‘¢ï¼ں
èپھوکژ,هڈ¯ن»¥ï¼Œه®é™…ن¸ٹوˆ‘ن»¬ن¹ںو£وک¯è؟™ن¹ˆهپڑçڑ„م€‚ن¸‹ن¸€èٹ‚ه°±و¥è¯´è¯´ه¦‚ن½•هپڑè؟™ن¸ھ转هŒ–,ن¸€و—¦è½¬هŒ–ه®Œوˆگ,و±‚解ه¯¹ن»»ن½•ه¦è؟‡é«کç‰و•°ه¦çڑ„ن؛؛و¥è¯´ï¼Œéƒ½وک¯ه°ڈèڈœن¸€ç¢ںه•¦م€‚
SVMه…¥é—¨ï¼ˆه…)ç؛؟و€§هˆ†ç±»ه™¨çڑ„و±‚解——问é¢کçڑ„转هŒ–,直观角ه؛¦
让وˆ‘ه†چن¸€و¬،و¯”较ه®Œو•´çڑ„é‡چه¤چن¸€ن¸‹وˆ‘ن»¬è¦پ解ه†³çڑ„é—®é¢کï¼ڑوˆ‘ن»¬وœ‰ه±ن؛ژن¸¤ن¸ھç±»هˆ«çڑ„و ·وœ¬ç‚¹ï¼ˆه¹¶ن¸چé™گه®ڑè؟™ن؛›ç‚¹هœ¨ن؛Œç»´ç©؛é—´ن¸ï¼‰è‹¥ه¹²ï¼Œه¦‚ه›¾ï¼Œ
هœ†ه½¢çڑ„و ·وœ¬ç‚¹ه®ڑن¸؛و£و ·وœ¬ï¼ˆè؟ه¸¦ç€ï¼Œوˆ‘ن»¬هڈ¯ن»¥وٹٹو£و ·وœ¬و‰€ه±çڑ„ç±»هڈ«هپڑو£ç±»ï¼‰ï¼Œو–¹ه½¢çڑ„点ه®ڑن¸؛è´ںن¾‹م€‚وˆ‘ن»¬وƒ³و±‚ه¾—è؟™و ·ن¸€ن¸ھç؛؟و€§ه‡½و•°ï¼ˆهœ¨nç»´ç©؛é—´ن¸çڑ„ç؛؟و€§ه‡½و•°ï¼‰ï¼ڑ
g(x)=wx+b
ن½؟ه¾—و‰€وœ‰ه±ن؛ژو£ç±»çڑ„点+ن»£ه…¥ن»¥هگژوœ‰g(x+)≥1,而و‰€وœ‰ه±ن؛ژè´ںç±»çڑ„点x-ن»£ه…¥هگژوœ‰g(x-)≤-1(ن¹‹و‰€ن»¥و€»è·ں1و¯”较,و— è®؛و£ن¸€è؟کوک¯è´ںن¸€ï¼Œéƒ½وک¯ه› ن¸؛وˆ‘ن»¬ه›؛ه®ڑن؛†é—´éڑ”ن¸؛1,و³¨و„ڈé—´éڑ”ه’Œه‡ ن½•é—´éڑ”çڑ„هŒ؛هˆ«ï¼‰م€‚ن»£ه…¥g(x)هگژçڑ„ه€¼ه¦‚وœهœ¨1ه’Œ-1ن¹‹é—´ï¼Œوˆ‘ن»¬ه°±و‹’ç»هˆ¤و–م€‚
و±‚è؟™و ·çڑ„g(x)çڑ„è؟‡ç¨‹ه°±وک¯و±‚w(ن¸€ن¸ھnç»´هگ‘é‡ڈ)ه’Œb(ن¸€ن¸ھه®و•°ï¼‰ن¸¤ن¸ھهڈ‚و•°çڑ„è؟‡ç¨‹ï¼ˆن½†ه®é™…ن¸ٹهڈھ需è¦پو±‚w,و±‚ه¾—ن»¥هگژو‰¾وںگن؛›و ·وœ¬ç‚¹ن»£ه…¥ه°±هڈ¯ن»¥و±‚ه¾—b)م€‚ه› و¤هœ¨و±‚g(x)çڑ„و—¶ه€™ï¼Œwو‰چوک¯هڈکé‡ڈم€‚
ن½ 肯ه®ڑ能看ه‡؛و¥ï¼Œن¸€و—¦و±‚ه‡؛ن؛†w(ن¹ںه°±و±‚ه‡؛ن؛†b),那ن¹ˆن¸é—´çڑ„ç›´ç؛؟Hه°±çں¥éپ“ن؛†ï¼ˆه› ن¸؛ه®ƒه°±وک¯wx+b=0هک›ï¼Œه“ˆه“ˆï¼‰ï¼Œé‚£ن¹ˆH1ه’ŒH2ن¹ںه°±çں¥éپ“ن؛†ï¼ˆه› ن¸؛ن¸‰è€…وک¯ه¹³è،Œçڑ„,而ن¸”相éڑ”çڑ„è·ç¦»è؟کوک¯||w||ه†³ه®ڑçڑ„)م€‚é‚£ن¹ˆwوک¯è°په†³ه®ڑçڑ„ï¼ںوک¾ç„¶وک¯ن½ ç»™çڑ„و ·وœ¬ه†³ه®ڑçڑ„,ن¸€و—¦ن½ هœ¨ç©؛é—´ن¸ç»™ه‡؛ن؛†é‚£ن؛›ن¸ھو ·وœ¬ç‚¹ï¼Œن¸‰و،ç›´ç؛؟çڑ„ن½چç½®ه®é™…ن¸ٹه°±ه”¯ن¸€ç،®ه®ڑن؛†ï¼ˆه› ن¸؛وˆ‘ن»¬و±‚çڑ„وک¯وœ€ن¼کçڑ„é‚£ن¸‰و،,ه½“然وک¯ه”¯ن¸€çڑ„),وˆ‘ن»¬è§£ن¼کهŒ–é—®é¢کçڑ„è؟‡ç¨‹ن¹ںهڈھن¸چè؟‡وک¯وٹٹè؟™ن¸ھç،®ه®ڑن؛†çڑ„ن¸œè¥؟ç®—ه‡؛و¥è€Œه·²م€‚
و ·وœ¬ç،®ه®ڑن؛†w,用و•°ه¦çڑ„è¯è¨€وڈڈè؟°ï¼Œه°±وک¯wهڈ¯ن»¥è،¨ç¤؛ن¸؛و ·وœ¬çڑ„وںگç§چ组هگˆï¼ڑ
w=خ±1x1+خ±2x2+…+خ±nxn
ه¼ڈهگن¸çڑ„خ±iوک¯ن¸€ن¸ھن¸€ن¸ھçڑ„و•°ï¼ˆهœ¨ن¸¥و ¼çڑ„è¯پوکژè؟‡ç¨‹ن¸ï¼Œè؟™ن؛›خ±è¢«ç§°ن¸؛و‹‰و ¼وœ—و—¥ن¹کهگ),而xiوک¯و ·وœ¬ç‚¹ï¼Œه› 而وک¯هگ‘é‡ڈ,nه°±وک¯و€»و ·وœ¬ç‚¹çڑ„ن¸ھو•°م€‚ن¸؛ن؛†و–¹ن¾؟وڈڈè؟°ï¼Œن»¥ن¸‹ه¼€ه§‹ن¸¥و ¼هŒ؛هˆ«و•°ه—ن¸ژهگ‘é‡ڈçڑ„ن¹ک积ه’Œهگ‘é‡ڈé—´çڑ„ن¹ک积,وˆ‘ن¼ڑ用خ±1x1è،¨ç¤؛و•°ه—ه’Œهگ‘é‡ڈçڑ„ن¹ک积,而用<x1,x2>è،¨ç¤؛هگ‘é‡ڈx1,x2çڑ„ه†…积(ن¹ںهڈ«ç‚¹ç§¯ï¼Œو³¨و„ڈن¸ژهگ‘é‡ڈهڈ‰ç§¯çڑ„هŒ؛هˆ«ï¼‰م€‚ه› و¤g(x)çڑ„è،¨è¾¾ه¼ڈن¸¥و ¼çڑ„ه½¢ه¼ڈه؛”该وک¯ï¼ڑ
g(x)=<w,x>+b
ن½†وک¯ن¸ٹé¢çڑ„ه¼ڈهگè؟کن¸چه¤ںه¥½ï¼Œن½ ه›ه¤´çœ‹çœ‹ه›¾ن¸و£و ·وœ¬ه’Œè´ںو ·وœ¬çڑ„ن½چ置,وƒ³هƒڈن¸€ن¸‹ï¼Œوˆ‘ن¸چهٹ¨و‰€وœ‰ç‚¹çڑ„ن½چ置,而هڈھوک¯وٹٹه…¶ن¸ن¸€ن¸ھو£و ·وœ¬ç‚¹ه®ڑن¸؛è´ںو ·وœ¬ç‚¹ï¼ˆن¹ںه°±وک¯وٹٹن¸€ن¸ھ点çڑ„ه½¢çٹ¶ن»ژهœ†ه½¢هڈکن¸؛و–¹ه½¢ï¼‰ï¼Œç»“وœو€ژن¹ˆو ·ï¼ںن¸‰و،ç›´ç؛؟都ه؟…é،»ç§»هٹ¨ï¼ˆه› ن¸؛ه¯¹è؟™ن¸‰و،ç›´ç؛؟çڑ„è¦پو±‚وک¯ه؟…é،»وٹٹو–¹ه½¢ه’Œهœ†ه½¢çڑ„点و£ç،®هˆ†ه¼€ï¼‰ï¼پè؟™è¯´وکژwن¸چن»…è·ںو ·وœ¬ç‚¹çڑ„ن½چç½®وœ‰ه…³ï¼Œè؟کè·ںو ·وœ¬çڑ„ç±»هˆ«وœ‰ه…³ï¼ˆن¹ںه°±وک¯ه’Œو ·وœ¬çڑ„“و ‡ç¾â€وœ‰ه…³ï¼‰م€‚ه› و¤ç”¨ن¸‹é¢è؟™ن¸ھه¼ڈهگè،¨ç¤؛و‰چç®—ه®Œو•´ï¼ڑ
w=خ±1y1x1+خ±2y2x2+…+خ±nynxn (ه¼ڈ1)
ه…¶ن¸çڑ„yiه°±وک¯ç¬¬iن¸ھو ·وœ¬çڑ„و ‡ç¾ï¼Œه®ƒç‰ن؛ژ1وˆ–者-1م€‚ه…¶ه®ن»¥ن¸ٹه¼ڈهگçڑ„é‚£ن¸€ه †و‹‰و ¼وœ—و—¥ن¹کهگن¸ï¼Œهڈھوœ‰ه¾ˆه°‘çڑ„ن¸€éƒ¨هˆ†ن¸چç‰ن؛ژ0(ن¸چç‰ن؛ژ0و‰چه¯¹wèµ·ه†³ه®ڑن½œç”¨ï¼‰ï¼Œè؟™éƒ¨هˆ†ن¸چç‰ن؛ژ0çڑ„و‹‰و ¼وœ—و—¥ن¹کهگهگژé¢و‰€ن¹کçڑ„و ·وœ¬ç‚¹ï¼Œه…¶ه®éƒ½èگ½هœ¨H1ه’ŒH2ن¸ٹ,ن¹ںو£وک¯è؟™éƒ¨هˆ†و ·وœ¬ï¼ˆè€Œن¸چ需è¦په…¨éƒ¨و ·وœ¬ï¼‰ه”¯ن¸€çڑ„ç،®ه®ڑن؛†هˆ†ç±»ه‡½و•°ï¼Œه½“然,و›´ن¸¥و ¼çڑ„说,è؟™ن؛›و ·وœ¬çڑ„ن¸€éƒ¨هˆ†ه°±هڈ¯ن»¥ç،®ه®ڑ,ه› ن¸؛ن¾‹ه¦‚ç،®ه®ڑن¸€و،ç›´ç؛؟,هڈھ需è¦پن¸¤ن¸ھ点ه°±هڈ¯ن»¥ï¼Œهچ³ن¾؟وœ‰ن¸‰ن؛”ن¸ھ都èگ½هœ¨ن¸ٹé¢ï¼Œوˆ‘ن»¬ن¹ںن¸چوک¯ه…¨éƒ½éœ€è¦پم€‚è؟™éƒ¨هˆ†وˆ‘ن»¬çœںو£éœ€è¦پçڑ„و ·وœ¬ç‚¹ï¼Œه°±هڈ«هپڑو”¯وŒپ(و’‘)هگ‘é‡ڈï¼پ(هگچه—è؟کوŒ؛ه½¢è±،هگ§ï¼Œن»–ن»¬â€œو’‘â€èµ·ن؛†هˆ†ç•Œç؛؟)
ه¼ڈهگن¹ںهڈ¯ن»¥ç”¨و±‚ه’Œç¬¦هڈ·ç®€ه†™ن¸€ن¸‹ï¼ڑ
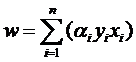
ه› و¤هژںو¥çڑ„g(x)è،¨è¾¾ه¼ڈهڈ¯ن»¥ه†™ن¸؛ï¼ڑ
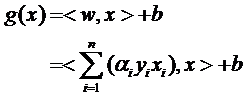
و³¨و„ڈه¼ڈهگن¸xو‰چوک¯هڈکé‡ڈ,ن¹ںه°±وک¯ن½ è¦پهˆ†ç±»ه“ھ篇و–‡و،£ï¼Œه°±وٹٹ该و–‡و،£çڑ„هگ‘é‡ڈè،¨ç¤؛ن»£ه…¥هˆ° xçڑ„ن½چ置,而و‰€وœ‰çڑ„xiç»ںç»ں都وک¯ه·²çں¥çڑ„و ·وœ¬م€‚è؟کو³¨و„ڈهˆ°ه¼ڈهگن¸هڈھوœ‰xiه’Œxوک¯هگ‘é‡ڈ,ه› و¤ن¸€éƒ¨هˆ†هڈ¯ن»¥ن»ژه†…积符هڈ·ن¸و‹؟ه‡؛و¥ï¼Œه¾—هˆ°g(x)çڑ„ه¼ڈهگن¸؛ï¼ڑ
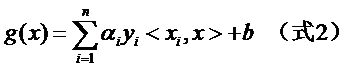
هڈ‘çژ°ن؛†ن»€ن¹ˆï¼ںwن¸چè§په•¦ï¼پن»ژو±‚wهڈکوˆگن؛†و±‚خ±م€‚
ن½†è‚¯ه®ڑوœ‰ن؛؛ن¼ڑ说,è؟™ه¹¶و²،وœ‰وٹٹهژںé—®é¢ک简هŒ–ه‘€م€‚هک؟هک؟,ه…¶ه®ç®€هŒ–ن؛†ï¼Œهڈھن¸چè؟‡هœ¨ن½ 看ن¸چè§پçڑ„هœ°و–¹ï¼Œن»¥è؟™و ·çڑ„ه½¢ه¼ڈوڈڈè؟°é—®é¢کن»¥هگژ,وˆ‘ن»¬çڑ„ن¼کهŒ–é—®é¢که°‘ن؛†ه¾ˆه¤§ن¸€éƒ¨هˆ†ن¸چç‰ه¼ڈç؛¦وں(记ه¾—è؟™وک¯وˆ‘ن»¬è§£ن¸چن؛†وپه€¼é—®é¢کçڑ„ن¸‡وپ¶ن¹‹و؛گ)م€‚ن½†وک¯وژ¥ن¸‹و¥ه…ˆè·³è؟‡ç؛؟و€§هˆ†ç±»ه™¨و±‚解çڑ„部هˆ†ï¼Œو¥çœ‹çœ‹ SVMهœ¨ç؛؟و€§هˆ†ç±»ه™¨ن¸ٹو‰€هپڑçڑ„é‡چه¤§و”¹è؟›â€”—و ¸ه‡½و•°م€‚
SVMه…¥é—¨ï¼ˆن¸ƒï¼‰ن¸؛ن½•éœ€è¦پو ¸ه‡½و•°
ç”ںهکï¼ںè؟کوک¯و¯پçپï¼ں——ه“ˆه§†é›·ç‰¹
هڈ¯هˆ†ï¼ںè؟کوک¯ن¸چهڈ¯هˆ†ï¼ں——و”¯وŒپهگ‘é‡ڈوœ؛
ن¹‹ه‰چن¸€ç›´هœ¨è®¨è®؛çڑ„ç؛؟و€§هˆ†ç±»ه™¨,ه™¨ه¦‚ه…¶هگچ(و±—,è؟™وک¯ن»€ن¹ˆè¯´و³•ه•ٹ),هڈھ能ه¯¹ç؛؟و€§هڈ¯هˆ†çڑ„و ·وœ¬هپڑه¤„çگ†م€‚ه¦‚وœوڈگن¾›çڑ„و ·وœ¬ç؛؟و€§ن¸چهڈ¯هˆ†ï¼Œç»“وœه¾ˆç®€هچ•ï¼Œç؛؟و€§هˆ†ç±»ه™¨çڑ„و±‚解程ه؛ڈن¼ڑو— é™گه¾ھçژ¯ï¼Œو°¸è؟œن¹ں解ن¸چه‡؛و¥م€‚è؟™ه؟…然ن½؟ه¾—ه®ƒçڑ„适用范ه›´ه¤§ه¤§ç¼©ه°ڈ,而ه®ƒçڑ„ه¾ˆه¤ڑن¼ک点وˆ‘ن»¬ه®هœ¨ن¸چهژںو„ڈو”¾ه¼ƒï¼Œو€ژن¹ˆهٹه‘¢ï¼ںوک¯هگ¦وœ‰وںگç§چو–¹و³•ï¼Œè®©ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„و•°وچ®هڈکه¾—ç؛؟و€§هڈ¯هˆ†ه‘¢ï¼ں
وœ‰ï¼په…¶و€وƒ³è¯´و¥ن¹ں简هچ•ï¼Œو¥ç”¨ن¸€ن¸ھن؛Œç»´ه¹³é¢ن¸çڑ„هˆ†ç±»é—®é¢کن½œن¾‹هگ,ن½ ن¸€çœ‹ه°±ن¼ڑوکژ白م€‚ن؛‹ه…ˆه£°وکژ,ن¸‹é¢è؟™ن¸ھن¾‹هگوک¯ç½‘络و—©ه°±وœ‰çڑ„,وˆ‘ن¸€و—¶و‰¾ن¸چهˆ°هژںن½œè€…çڑ„و£ç،®ن؟،وپ¯ï¼Œهœ¨و¤ه€ں用,ه¹¶هٹ è؟›ن؛†وˆ‘è‡ھه·±çڑ„解说而ه·²م€‚
ن¾‹هگوک¯ن¸‹é¢è؟™ه¼ ه›¾ï¼ڑ

وˆ‘ن»¬وٹٹو¨ھè½´ن¸ٹ端点aه’Œbن¹‹é—´ç؛¢è‰²éƒ¨هˆ†é‡Œçڑ„و‰€وœ‰ç‚¹ه®ڑن¸؛و£ç±»ï¼Œن¸¤è¾¹çڑ„黑色部هˆ†é‡Œçڑ„点ه®ڑن¸؛è´ںç±»م€‚试问能و‰¾هˆ°ن¸€ن¸ھç؛؟و€§ه‡½و•°وٹٹن¸¤ç±»و£ç،®هˆ†ه¼€ن¹ˆï¼ںن¸چ能,ه› ن¸؛ن؛Œç»´ç©؛间里çڑ„ç؛؟و€§ه‡½و•°ه°±وک¯وŒ‡ç›´ç؛؟,وک¾ç„¶و‰¾ن¸چهˆ°ç¬¦هگˆو،ن»¶çڑ„ç›´ç؛؟م€‚
ن½†وˆ‘ن»¬هڈ¯ن»¥و‰¾هˆ°ن¸€و،و›²ç؛؟,ن¾‹ه¦‚ن¸‹é¢è؟™ن¸€و،ï¼ڑ

وک¾ç„¶é€ڑè؟‡ç‚¹هœ¨è؟™و،و›²ç؛؟çڑ„ن¸ٹو–¹è؟کوک¯ن¸‹و–¹ه°±هڈ¯ن»¥هˆ¤و–点و‰€ه±çڑ„ç±»هˆ«ï¼ˆن½ هœ¨و¨ھè½´ن¸ٹéڑڈن¾؟و‰¾ن¸€ç‚¹ï¼Œç®—ç®—è؟™ن¸€ç‚¹çڑ„ه‡½و•°ه€¼ï¼Œن¼ڑهڈ‘çژ°è´ںç±»çڑ„点ه‡½و•°ه€¼ن¸€ه®ڑو¯”0ه¤§ï¼Œè€Œو£ç±»çڑ„ن¸€ه®ڑو¯”0ه°ڈ)م€‚è؟™و،و›²ç؛؟ه°±وک¯وˆ‘ن»¬ç†ںçں¥çڑ„ن؛Œو¬،و›²ç؛؟,ه®ƒçڑ„ه‡½و•°è،¨è¾¾ه¼ڈهڈ¯ن»¥ه†™ن¸؛ï¼ڑ
é—®é¢کهڈھوک¯ه®ƒن¸چوک¯ن¸€ن¸ھç؛؟و€§ه‡½و•°ï¼Œن½†وک¯ï¼Œن¸‹é¢è¦پو³¨و„ڈ看ن؛†ï¼Œو–°ه»؛ن¸€ن¸ھهگ‘é‡ڈyه’Œaï¼ڑ
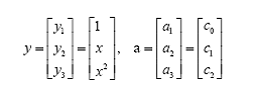
è؟™و ·g(x)ه°±هڈ¯ن»¥è½¬هŒ–ن¸؛f(y)=<a,y>,ن½ هڈ¯ن»¥وٹٹyه’Œaهˆ†هˆ«ه›ه¸¦ن¸€ن¸‹ï¼Œçœ‹çœ‹ç‰ن¸چç‰ن؛ژهژںو¥çڑ„g(x)م€‚用ه†…积çڑ„ه½¢ه¼ڈه†™ن½ هڈ¯èƒ½çœ‹ن¸چه¤ھو¸…و¥ڑ,ه®é™…ن¸ٹf(y)çڑ„ه½¢ه¼ڈه°±وک¯ï¼ڑ
g(x)=f(y)=ay
هœ¨ن»»و„ڈç»´ه؛¦çڑ„ç©؛é—´ن¸ï¼Œè؟™ç§چه½¢ه¼ڈçڑ„ه‡½و•°éƒ½وک¯ن¸€ن¸ھç؛؟و€§ه‡½و•°ï¼ˆهڈھن¸چè؟‡ه…¶ن¸çڑ„aه’Œy都وک¯ه¤ڑç»´هگ‘é‡ڈç½¢ن؛†ï¼‰ï¼Œه› ن¸؛è‡ھهڈکé‡ڈyçڑ„و¬،و•°ن¸چه¤§ن؛ژ1م€‚
看ه‡؛ه¦™هœ¨ه“ھن؛†ن¹ˆï¼ںهژںو¥هœ¨ن؛Œç»´ç©؛é—´ن¸ن¸€ن¸ھç؛؟و€§ن¸چهڈ¯هˆ†çڑ„é—®é¢ک,وک ه°„هˆ°ه››ç»´ç©؛é—´هگژ,هڈکوˆگن؛†ç؛؟و€§هڈ¯هˆ†çڑ„ï¼په› و¤è؟™ن¹ںه½¢وˆگن؛†وˆ‘ن»¬وœ€هˆوƒ³è§£ه†³ç؛؟و€§ن¸چهڈ¯هˆ†é—®é¢کçڑ„هں؛وœ¬و€è·¯â€”—هگ‘é«کç»´ç©؛间转هŒ–,ن½؟ه…¶هڈکه¾—ç؛؟و€§هڈ¯هˆ†م€‚
而转هŒ–وœ€ه…³é”®çڑ„部هˆ†ه°±هœ¨ن؛ژو‰¾هˆ°xهˆ°yçڑ„وک ه°„و–¹و³•م€‚éپ—و†¾çڑ„وک¯ï¼Œه¦‚ن½•و‰¾هˆ°è؟™ن¸ھوک ه°„,و²،وœ‰ç³»ç»ںو€§çڑ„و–¹و³•ï¼ˆن¹ںه°±وک¯è¯´ï¼Œç؛¯é 猜ه’Œه‡‘)م€‚ه…·ن½“هˆ°وˆ‘ن»¬çڑ„و–‡وœ¬هˆ†ç±»é—®é¢ک,و–‡وœ¬è¢«è،¨ç¤؛ن¸؛ن¸ٹهچƒç»´çڑ„هگ‘é‡ڈ,هچ³ن½؟ç»´و•°ه·²ç»ڈه¦‚و¤ن¹‹é«ک,ن¹ںه¸¸ه¸¸وک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„,è؟کè¦پهگ‘و›´é«کçڑ„ç©؛间转هŒ–م€‚ه…¶ن¸çڑ„éڑ¾ه؛¦هڈ¯وƒ³è€Œçں¥م€‚
ه°ڈTips:ن¸؛ن»€ن¹ˆè¯´f(y)=ayوک¯ه››ç»´ç©؛间里çڑ„ه‡½و•°?
ه¤§ه®¶هڈ¯èƒ½ن¸€و—¶و²،看وکژ白م€‚ه›وƒ³ن¸€ن¸‹وˆ‘ن»¬ن؛Œç»´ç©؛间里çڑ„ه‡½و•°ه®ڑن¹‰
g(x)=ax+b
هڈکé‡ڈxوک¯ن¸€ç»´çڑ„,ن¸؛ن»€ن¹ˆè¯´ه®ƒوک¯ن؛Œç»´ç©؛间里çڑ„ه‡½و•°ه‘¢ï¼ںه› ن¸؛è؟کوœ‰ن¸€ن¸ھهڈکé‡ڈوˆ‘ن»¬و²،ه†™ه‡؛و¥ï¼Œه®ƒçڑ„ه®Œو•´ه½¢ه¼ڈه…¶ه®وک¯
y=g(x)=ax+b
هچ³
y=ax+b
看看,وœ‰ه‡ ن¸ھهڈکé‡ڈï¼ںن¸¤ن¸ھم€‚é‚£وک¯ه‡ ç»´ç©؛é—´çڑ„ه‡½و•°ï¼ں(ن½œè€…ن؛”ه²پçڑ„ه¼ںه¼ںç”ï¼ڑن؛”ç»´çڑ„م€‚ن½œè€…ï¼ڑ……)
ه†چ看看
f(y)=ay
里é¢çڑ„yوک¯ن¸‰ç»´çڑ„هڈکé‡ڈ,那f(y)وک¯ه‡ ç»´ç©؛间里çڑ„ه‡½و•°ï¼ں(ن½œè€…ن؛”ه²پçڑ„ه¼ںه¼ںç”ï¼ڑè؟کوک¯ن؛”ç»´çڑ„م€‚ن½œè€…ï¼ڑ……)
用ن¸€ن¸ھه…·ن½“و–‡وœ¬هˆ†ç±»çڑ„ن¾‹هگو¥çœ‹çœ‹è؟™ç§چهگ‘é«کç»´ç©؛é—´وک ه°„ن»ژ而هˆ†ç±»çڑ„و–¹و³•ه¦‚ن½•è؟گن½œï¼Œوƒ³è±،ن¸€ن¸‹ï¼Œوˆ‘ن»¬و–‡وœ¬هˆ†ç±»é—®é¢کçڑ„هژںه§‹ç©؛é—´وک¯1000ç»´çڑ„(هچ³و¯ڈن¸ھè¦پ被هˆ†ç±»çڑ„و–‡و،£è¢«è،¨ç¤؛ن¸؛ن¸€ن¸ھ1000ç»´çڑ„هگ‘é‡ڈ),هœ¨è؟™ن¸ھç»´ه؛¦ن¸ٹé—®é¢کوک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„م€‚çژ°هœ¨وˆ‘ن»¬وœ‰ن¸€ن¸ھ2000ç»´ç©؛间里çڑ„ç؛؟و€§ه‡½و•°
f(x’)=<w’,x’>+b
و³¨و„ڈهگ‘é‡ڈçڑ„هڈ³ن¸ٹ角وœ‰ن¸ھ ’ه“¦م€‚ه®ƒèƒ½ه¤ںه°†هژںé—®é¢کهڈکه¾—هڈ¯هˆ†م€‚ه¼ڈن¸çڑ„ w’ه’Œx’都وک¯2000ç»´çڑ„هگ‘é‡ڈ,هڈھن¸چè؟‡w’وک¯ه®ڑه€¼ï¼Œè€Œx’وک¯هڈکé‡ڈ(ه¥½هگ§,ن¸¥و ¼è¯´و¥è؟™ن¸ھه‡½و•°وک¯2001ç»´çڑ„,ه“ˆه“ˆï¼‰ï¼Œçژ°هœ¨وˆ‘ن»¬çڑ„输ه…¥ه‘¢ï¼Œوک¯ن¸€ن¸ھ1000ç»´çڑ„هگ‘é‡ڈx,هˆ†ç±»çڑ„è؟‡ç¨‹وک¯ه…ˆوٹٹxهڈکوچ¢ن¸؛2000ç»´çڑ„هگ‘é‡ڈx’,然هگژو±‚è؟™ن¸ھهڈکوچ¢هگژçڑ„هگ‘é‡ڈx’ن¸ژهگ‘é‡ڈw’çڑ„ه†…积,ه†چوٹٹè؟™ن¸ھه†…积çڑ„ه€¼ه’Œb相هٹ ,ه°±ه¾—هˆ°ن؛†ç»“وœï¼Œçœ‹ç»“وœه¤§ن؛ژéکˆه€¼è؟کوک¯ه°ڈن؛ژéکˆه€¼ه°±ه¾—هˆ°ن؛†هˆ†ç±»ç»“وœم€‚
ن½ هڈ‘çژ°ن؛†ن»€ن¹ˆï¼ںوˆ‘ن»¬ه…¶ه®هڈھه…³ه؟ƒé‚£ن¸ھé«کç»´ç©؛间里ه†…积çڑ„ه€¼ï¼Œé‚£ن¸ھه€¼ç®—ه‡؛و¥ن؛†ï¼Œهˆ†ç±»ç»“وœه°±ç®—ه‡؛و¥ن؛†م€‚而ن»ژçگ†è®؛ن¸ٹ说, x’وک¯ç»ڈç”±xهڈکوچ¢و¥çڑ„,ه› و¤ه¹؟ن¹‰ن¸ٹهڈ¯ن»¥وٹٹه®ƒهڈ«هپڑxçڑ„ه‡½و•°ï¼ˆوœ‰ن¸€ن¸ھx,ه°±ç،®ه®ڑن؛†ن¸€ن¸ھx’,ه¯¹هگ§ï¼Œç،®ه®ڑن¸چه‡؛第ن؛Œن¸ھ),而w’وک¯ه¸¸é‡ڈ,ه®ƒوک¯ن¸€ن¸ھن½ژç»´ç©؛间里çڑ„ه¸¸é‡ڈwç»ڈè؟‡هڈکوچ¢ه¾—هˆ°çڑ„,و‰€ن»¥ç»™ن؛†ن¸€ن¸ھw ه’Œxçڑ„ه€¼ï¼Œه°±وœ‰ن¸€ن¸ھç،®ه®ڑçڑ„f(x’)ه€¼ن¸ژه…¶ه¯¹ه؛”م€‚è؟™è®©وˆ‘ن»¬ه¹»وƒ³ï¼Œوک¯هگ¦èƒ½وœ‰è؟™و ·ن¸€ç§چه‡½و•°K(w,x),ن»–وژ¥هڈ—ن½ژç»´ç©؛é—´çڑ„输ه…¥ه€¼ï¼Œهچ´èƒ½ç®—ه‡؛é«کç»´ç©؛é—´çڑ„ه†…积ه€¼<w’,x’>ï¼ں
ه¦‚وœوœ‰è؟™و ·çڑ„ه‡½و•°ï¼Œé‚£ن¹ˆه½“ç»™ن؛†ن¸€ن¸ھن½ژç»´ç©؛é—´çڑ„输ه…¥xن»¥هگژ,
g(x)=K(w,x)+b
f(x’)=<w’,x’>+b
è؟™ن¸¤ن¸ھه‡½و•°çڑ„è®،算结وœه°±ه®Œه…¨ن¸€و ·ï¼Œوˆ‘ن»¬ن¹ںه°±ç”¨ن¸چç€è´¹هٹ›و‰¾é‚£ن¸ھوک ه°„ه…³ç³»ï¼Œç›´وژ¥و‹؟ن½ژç»´çڑ„输ه…¥ه¾€g(x)里é¢ن»£ه°±هڈ¯ن»¥ن؛†ï¼ˆه†چو¬،وڈگ醒,è؟™ه›çڑ„g(x)ه°±ن¸چوک¯ç؛؟و€§ه‡½و•°ه•¦ï¼Œه› ن¸؛ن½ ن¸چ能ن؟è¯پK(w,x)è؟™ن¸ھè،¨è¾¾ه¼ڈ里çڑ„xو¬،و•°ن¸چé«کن؛ژ1ه“¦ï¼‰م€‚
ن¸‡ه¹¸çڑ„وک¯ï¼Œè؟™و ·çڑ„K(w,x)ç،®ه®هکهœ¨ï¼ˆهڈ‘çژ°ه‡،وک¯وˆ‘ن»¬ن؛؛类能解ه†³çڑ„é—®é¢ک,ه¤§éƒ½وک¯ه·§ه¾—ن¸چ能ه†چه·§ï¼Œç‰¹و®ٹه¾—ن¸چ能ه†چ特و®ٹçڑ„é—®é¢ک,و€»وک¯وپ°ه¥½وœ‰ن؛›èƒ½وٹ•وœ؛هڈ–ه·§çڑ„هœ°و–¹و‰چ能解ه†³ï¼Œç”±و¤و„ںهˆ°ن؛؛ç±»çڑ„و¸؛ه°ڈ),ه®ƒè¢«ç§°ن½œو ¸ه‡½و•°ï¼ˆو ¸ï¼Œkernel),而ن¸”è؟کن¸چو¢ن¸€ن¸ھ,ن؛‹ه®ن¸ٹ,هڈھè¦پوک¯و»،足ن؛†Mercerو،ن»¶çڑ„ه‡½و•°ï¼Œéƒ½هڈ¯ن»¥ن½œن¸؛و ¸ه‡½و•°م€‚و ¸ه‡½و•°çڑ„هں؛وœ¬ن½œç”¨ه°±وک¯وژ¥هڈ—ن¸¤ن¸ھن½ژç»´ç©؛间里çڑ„هگ‘é‡ڈ,能ه¤ںè®،ç®—ه‡؛ç»ڈè؟‡وںگن¸ھهڈکوچ¢هگژهœ¨é«کç»´ç©؛间里çڑ„هگ‘é‡ڈه†…积ه€¼م€‚ه‡ ن¸ھو¯”较ه¸¸ç”¨çڑ„و ¸ه‡½و•°ï¼Œن؟„,و•™è¯¾ن¹¦é‡Œéƒ½هˆ—è؟‡ï¼Œوˆ‘ه°±ن¸چو•²ن؛†ï¼ˆو‡’ï¼پ)م€‚
ه›وƒ³وˆ‘ن»¬ن¸ٹèٹ‚说çڑ„و±‚ن¸€ن¸ھç؛؟و€§هˆ†ç±»ه™¨ï¼Œه®ƒçڑ„ه½¢ه¼ڈه؛”该وک¯ï¼ڑ
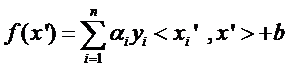
çژ°هœ¨è؟™ن¸ھه°±وک¯é«کç»´ç©؛间里çڑ„ç؛؟و€§ه‡½و•°ï¼ˆن¸؛ن؛†هŒ؛هˆ«ن½ژç»´ه’Œé«کç»´ç©؛间里çڑ„ه‡½و•°ه’Œهگ‘é‡ڈ,وˆ‘و”¹ن؛†ه‡½و•°çڑ„هگچه—,ه¹¶ن¸”ç»™wه’Œx都هٹ ن¸ٹن؛† ’),وˆ‘ن»¬ه°±هڈ¯ن»¥ç”¨ن¸€ن¸ھن½ژç»´ç©؛间里çڑ„ه‡½و•°ï¼ˆه†چن¸€و¬،çڑ„,è؟™ن¸ھن½ژç»´ç©؛间里çڑ„ه‡½و•°ه°±ن¸چه†چوک¯ç؛؟و€§çڑ„ه•¦ï¼‰و¥ن»£و›؟,
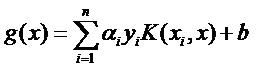
هڈˆهڈ‘çژ°ن»€ن¹ˆن؛†ï¼ںf(x’) ه’Œg(x)里çڑ„خ±ï¼Œy,bه…¨éƒ½وک¯ن¸€و ·ن¸€و ·çڑ„ï¼پè؟™ه°±وک¯è¯´ï¼Œه°½ç®،ç»™çڑ„é—®é¢کوک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„,ن½†وک¯وˆ‘ن»¬ه°±ç،¬ه½“ه®ƒوک¯ç؛؟و€§é—®é¢کو¥و±‚解,هڈھن¸چè؟‡و±‚解è؟‡ç¨‹ن¸ï¼Œه‡،وک¯è¦پو±‚ه†…积çڑ„و—¶ه€™ه°±ç”¨ن½ 选ه®ڑçڑ„و ¸ه‡½و•°و¥ç®—م€‚è؟™و ·و±‚ه‡؛و¥çڑ„خ±ه†چه’Œن½ 选ه®ڑçڑ„و ¸ه‡½و•°ن¸€ç»„هگˆï¼Œه°±ه¾—هˆ°هˆ†ç±»ه™¨ه•¦ï¼پ
وکژ白ن؛†ن»¥ن¸ٹè؟™ن؛›ï¼Œن¼ڑè‡ھ然çڑ„é—®وژ¥ن¸‹و¥ن¸¤ن¸ھé—®é¢کï¼ڑ
1ï¼ژ و—¢ç„¶وœ‰ه¾ˆه¤ڑçڑ„و ¸ه‡½و•°ï¼Œé’ˆه¯¹ه…·ن½“é—®é¢ک该و€ژن¹ˆé€‰و‹©ï¼ں
2ï¼ژ ه¦‚وœن½؟用و ¸ه‡½و•°هگ‘é«کç»´ç©؛é—´وک ه°„هگژ,问é¢کن»چ然وک¯ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„,那و€ژن¹ˆهٹï¼ں
第ن¸€ن¸ھé—®é¢کçژ°هœ¨ه°±هڈ¯ن»¥ه›ç”ن½ ï¼ڑه¯¹و ¸ه‡½و•°çڑ„选و‹©ï¼Œçژ°هœ¨è؟کç¼؛ن¹ڈوŒ‡ه¯¼هژںهˆ™ï¼پهگ„ç§چه®éھŒçڑ„观ه¯ں结وœï¼ˆن¸چه…‰وک¯و–‡وœ¬هˆ†ç±»ï¼‰çڑ„ç،®è،¨وکژ,وںگن؛›é—®é¢ک用وںگن؛›و ¸ه‡½و•°و•ˆوœه¾ˆه¥½ï¼Œç”¨هڈ¦ن¸€ن؛›ه°±ه¾ˆه·®ï¼Œن½†وک¯ن¸€èˆ¬و¥è®²ï¼Œه¾„هگ‘هں؛و ¸ه‡½و•°وک¯ن¸چن¼ڑه‡؛ه¤ھه¤§هپڈه·®çڑ„ن¸€ç§چ,首选م€‚(وˆ‘هپڑو–‡وœ¬هˆ†ç±»ç³»ç»ںçڑ„و—¶ه€™ï¼Œن½؟用ه¾„هگ‘هں؛و ¸ه‡½و•°ï¼Œو²،وœ‰هڈ‚و•°è°ƒن¼کçڑ„وƒ…ه†µن¸‹ï¼Œç»ه¤§éƒ¨هˆ†ç±»هˆ«çڑ„ه‡†ç،®ه’Œهڈ¬ه›éƒ½هœ¨85%ن»¥ن¸ٹ,هڈ¯è§پم€‚虽然libSVMçڑ„ن½œè€…و—و™؛ن»پ认ن¸؛و–‡وœ¬هˆ†ç±»ç”¨ç؛؟و€§و ¸ه‡½و•°و•ˆوœو›´ن½³ï¼Œه¾…考è¯پ)
ه¯¹ç¬¬ن؛Œن¸ھé—®é¢کçڑ„解ه†³هˆ™ه¼•ه‡؛ن؛†وˆ‘ن»¬ن¸‹ن¸€èٹ‚çڑ„ن¸»é¢کï¼ڑو¾ه¼›هڈکé‡ڈم€‚
SVMه…¥é—¨ï¼ˆه…«ï¼‰و¾ه¼›هڈکé‡ڈ
çژ°هœ¨وˆ‘ن»¬ه·²ç»ڈوٹٹن¸€ن¸ھوœ¬و¥ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„و–‡وœ¬هˆ†ç±»é—®é¢ک,é€ڑè؟‡وک ه°„هˆ°é«کç»´ç©؛间而هڈکوˆگن؛†ç؛؟و€§هڈ¯هˆ†çڑ„م€‚ه°±هƒڈن¸‹ه›¾è؟™و ·ï¼ڑ
هœ†ه½¢ه’Œو–¹ه½¢çڑ„点هگ„وœ‰وˆگهچƒن¸ٹن¸‡ن¸ھ(و¯•ç«ں,è؟™ه°±وک¯وˆ‘ن»¬è®ç»ƒé›†ن¸و–‡و،£çڑ„و•°é‡ڈهک›ï¼Œه½“然ه¾ˆه¤§ن؛†ï¼‰م€‚çژ°هœ¨وƒ³è±،وˆ‘ن»¬وœ‰هڈ¦ن¸€ن¸ھè®ç»ƒé›†ï¼Œهڈھو¯”هژںه…ˆè؟™ن¸ھè®ç»ƒé›†ه¤ڑن؛†ن¸€ç¯‡و–‡ç« ,وک ه°„هˆ°é«کç»´ç©؛é—´ن»¥هگژ(ه½“然,ن¹ںن½؟用ن؛†ç›¸هگŒçڑ„و ¸ه‡½و•°ï¼‰ï¼Œن¹ںه°±ه¤ڑن؛†ن¸€ن¸ھو ·وœ¬ç‚¹ï¼Œن½†وک¯è؟™ن¸ھو ·وœ¬çڑ„ن½چç½®وک¯è؟™و ·çڑ„ï¼ڑ
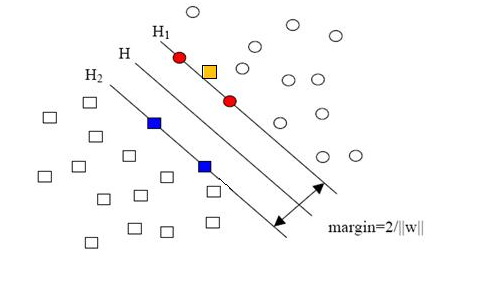
ه°±وک¯ه›¾ن¸é»„色那ن¸ھ点,ه®ƒوک¯و–¹ه½¢çڑ„,ه› 而ه®ƒوک¯è´ںç±»çڑ„ن¸€ن¸ھو ·وœ¬ï¼Œè؟™هچ•ç‹¬çڑ„ن¸€ن¸ھو ·وœ¬ï¼Œن½؟ه¾—هژںوœ¬ç؛؟و€§هڈ¯هˆ†çڑ„é—®é¢کهڈکوˆگن؛†ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„م€‚è؟™و ·ç±»ن¼¼çڑ„é—®é¢ک(ن»…وœ‰ه°‘و•°ç‚¹ç؛؟و€§ن¸چهڈ¯هˆ†ï¼‰هڈ«هپڑ“è؟‘ن¼¼ç؛؟و€§هڈ¯هˆ†â€çڑ„é—®é¢کم€‚
ن»¥وˆ‘ن»¬ن؛؛ç±»çڑ„ه¸¸è¯†و¥هˆ¤و–,说وœ‰ن¸€ن¸‡ن¸ھ点都符هگˆوںگç§چ规ه¾‹ï¼ˆه› 而ç؛؟و€§هڈ¯هˆ†ï¼‰ï¼Œوœ‰ن¸€ن¸ھ点ن¸چ符هگˆï¼Œé‚£è؟™ن¸€ن¸ھ点وک¯هگ¦ه°±ن»£è،¨ن؛†هˆ†ç±»è§„هˆ™ن¸وˆ‘ن»¬و²،وœ‰è€ƒè™‘هˆ°çڑ„و–¹é¢ه‘¢ï¼ˆه› 而规هˆ™ه؛”该ن¸؛ه®ƒè€Œهپڑه‡؛ن؟®و”¹ï¼‰ï¼ں
ه…¶ه®وˆ‘ن»¬ن¼ڑ觉ه¾—,و›´وœ‰هڈ¯èƒ½çڑ„وک¯ï¼Œè؟™ن¸ھو ·وœ¬ç‚¹هژ‹و ¹ه°±وک¯é”™è¯¯ï¼Œوک¯ه™ھه£°ï¼Œوک¯وڈگن¾›è®ç»ƒé›†çڑ„هگŒه¦ن؛؛ه·¥هˆ†ç±»و—¶ن¸€و‰“çŒç،é”™و”¾è؟›هژ»çڑ„م€‚و‰€ن»¥وˆ‘ن»¬ن¼ڑ简هچ•çڑ„ه؟½ç•¥è؟™ن¸ھو ·وœ¬ç‚¹ï¼Œن»چ然ن½؟用هژںو¥çڑ„هˆ†ç±»ه™¨ï¼Œه…¶و•ˆوœن¸و¯«ن¸چهڈ—ه½±ه“چم€‚
ن½†è؟™ç§چه¯¹ه™ھه£°çڑ„ه®¹é”™و€§وک¯ن؛؛çڑ„و€ç»´ه¸¦و¥çڑ„,وˆ‘ن»¬çڑ„程ه؛ڈهڈ¯و²،وœ‰م€‚ç”±ن؛ژوˆ‘ن»¬هژںوœ¬çڑ„ن¼کهŒ–é—®é¢کçڑ„è،¨è¾¾ه¼ڈن¸ï¼Œç،®ه®è¦پ考虑و‰€وœ‰çڑ„و ·وœ¬ç‚¹ï¼ˆن¸چ能ه؟½ç•¥وںگن¸€ن¸ھ,ه› ن¸؛程ه؛ڈه®ƒو€ژن¹ˆçں¥éپ“该ه؟½ç•¥ه“ھن¸€ن¸ھه‘¢ï¼ں),هœ¨و¤هں؛ç،€ن¸ٹه¯»و‰¾و£è´ںç±»ن¹‹é—´çڑ„وœ€ه¤§ه‡ ن½•é—´éڑ”,而ه‡ ن½•é—´éڑ”وœ¬è؛«ن»£è،¨çڑ„وک¯è·ç¦»ï¼Œوک¯éè´ںçڑ„,هƒڈن¸ٹé¢è؟™ç§چوœ‰ه™ھه£°çڑ„وƒ…ه†µن¼ڑن½؟ه¾—و•´ن¸ھé—®é¢کو— 解م€‚è؟™ç§چ解و³•ه…¶ه®ن¹ںهڈ«هپڑ“ç،¬é—´éڑ”â€هˆ†ç±»و³•ï¼Œه› ن¸؛ن»–ç،¬و€§çڑ„è¦پو±‚و‰€وœ‰و ·وœ¬ç‚¹éƒ½و»،足ه’Œهˆ†ç±»ه¹³é¢é—´çڑ„è·ç¦»ه؟…é،»ه¤§ن؛ژوںگن¸ھه€¼م€‚
ه› و¤ç”±ن¸ٹé¢çڑ„ن¾‹هگن¸ن¹ںهڈ¯ن»¥çœ‹ه‡؛,ç،¬é—´éڑ”çڑ„هˆ†ç±»و³•ه…¶ç»“وœه®¹وک“هڈ—ه°‘و•°ç‚¹çڑ„وژ§هˆ¶ï¼Œè؟™وک¯ه¾ˆهچ±é™©çڑ„(ه°½ç®،وœ‰هڈ¥è¯è¯´çœںçگ†و€»وک¯وژŒوڈ،هœ¨ه°‘و•°ن؛؛و‰‹ن¸ï¼Œن½†é‚£ن¸چè؟‡وک¯é‚£ن¸€ه°ڈو’®ن؛؛èپٹن»¥è‡ھو…°çڑ„è¯چهڈ¥ç½¢ن؛†ï¼Œه’±è؟کوک¯ه¾—و°‘ن¸»ï¼‰م€‚
ن½†è§£ه†³و–¹و³•ن¹ںه¾ˆوکژوک¾ï¼Œه°±وک¯ن»؟ç…§ن؛؛çڑ„و€è·¯ï¼Œه…پ许ن¸€ن؛›ç‚¹هˆ°هˆ†ç±»ه¹³é¢çڑ„è·ç¦»ن¸چو»،足هژںه…ˆçڑ„è¦پو±‚م€‚ç”±ن؛ژن¸چهگŒçڑ„è®ç»ƒé›†هگ„点çڑ„é—´è·ه°؛ه؛¦ن¸چه¤ھن¸€و ·ï¼Œه› و¤ç”¨é—´éڑ”(而ن¸چوک¯ه‡ ن½•é—´éڑ”)و¥è،،é‡ڈوœ‰هˆ©ن؛ژوˆ‘ن»¬è،¨è¾¾ه½¢ه¼ڈçڑ„简و´پم€‚وˆ‘ن»¬هژںه…ˆه¯¹و ·وœ¬ç‚¹çڑ„è¦پو±‚وک¯ï¼ڑ
![]()
و„ڈو€وک¯è¯´ç¦»هˆ†ç±»é¢وœ€è؟‘çڑ„و ·وœ¬ç‚¹ه‡½و•°é—´éڑ”ن¹ںè¦پو¯”1ه¤§م€‚ه¦‚وœè¦په¼•ه…¥ه®¹é”™و€§ï¼Œه°±ç»™1è؟™ن¸ھç،¬و€§çڑ„éکˆه€¼هٹ ن¸€ن¸ھو¾ه¼›هڈکé‡ڈ,هچ³ه…پ许

ه› ن¸؛و¾ه¼›هڈکé‡ڈوک¯éè´ںçڑ„,ه› و¤وœ€ç»ˆçڑ„结وœوک¯è¦پو±‚é—´éڑ”هڈ¯ن»¥و¯”1ه°ڈم€‚ن½†وک¯ه½“وںگن؛›ç‚¹ه‡؛çژ°è؟™ç§چé—´éڑ”و¯”1ه°ڈçڑ„وƒ…ه†µو—¶ï¼ˆè؟™ن؛›ç‚¹ن¹ںهڈ«ç¦»ç¾¤ç‚¹ï¼‰ï¼Œو„ڈه‘³ç€وˆ‘ن»¬و”¾ه¼ƒن؛†ه¯¹è؟™ن؛›ç‚¹çڑ„ç²¾ç،®هˆ†ç±»ï¼Œè€Œè؟™ه¯¹وˆ‘ن»¬çڑ„هˆ†ç±»ه™¨و¥è¯´وک¯ç§چوچںه¤±م€‚ن½†وک¯و”¾ه¼ƒè؟™ن؛›ç‚¹ن¹ںه¸¦و¥ن؛†ه¥½ه¤„,那ه°±وک¯ن½؟هˆ†ç±»é¢ن¸چه؟…هگ‘è؟™ن؛›ç‚¹çڑ„و–¹هگ‘移هٹ¨ï¼Œه› 而هڈ¯ن»¥ه¾—هˆ°و›´ه¤§çڑ„ه‡ ن½•é—´éڑ”(هœ¨ن½ژç»´ç©؛间看و¥ï¼Œهˆ†ç±»è¾¹ç•Œن¹ںو›´ه¹³و»‘)م€‚وک¾ç„¶وˆ‘ن»¬ه؟…é،»وƒè،،è؟™ç§چوچںه¤±ه’Œه¥½ه¤„م€‚ه¥½ه¤„ه¾ˆوکژوک¾ï¼Œوˆ‘ن»¬ه¾—هˆ°çڑ„هˆ†ç±»é—´éڑ”è¶ٹه¤§ï¼Œه¥½ه¤„ه°±è¶ٹه¤ڑم€‚ه›é،¾وˆ‘ن»¬هژںه§‹çڑ„ç،¬é—´éڑ”هˆ†ç±»ه¯¹ه؛”çڑ„ن¼کهŒ–é—®é¢کï¼ڑ
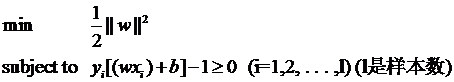
||w||2ه°±وک¯وˆ‘ن»¬çڑ„ç›®و ‡ه‡½و•°ï¼ˆه½“然系و•°هڈ¯وœ‰هڈ¯و— ),ه¸Œوœ›ه®ƒè¶ٹه°ڈè¶ٹه¥½ï¼Œه› 而وچںه¤±ه°±ه؟…然وک¯ن¸€ن¸ھ能ن½؟ن¹‹هڈکه¤§çڑ„é‡ڈ(能ن½؟ه®ƒهڈکه°ڈه°±ن¸چهڈ«وچںه¤±ن؛†ï¼Œوˆ‘ن»¬وœ¬و¥ه°±ه¸Œوœ›ç›®و ‡ه‡½و•°ه€¼è¶ٹه°ڈè¶ٹه¥½ï¼‰م€‚é‚£ه¦‚ن½•و¥è،،é‡ڈوچںه¤±ï¼Œوœ‰ن¸¤ç§چه¸¸ç”¨çڑ„و–¹ه¼ڈ,وœ‰ن؛؛ه–œو¬¢ç”¨
而وœ‰ن؛؛ه–œو¬¢ç”¨
ه…¶ن¸l都وک¯و ·وœ¬çڑ„و•°ç›®م€‚ن¸¤ç§چو–¹و³•و²،وœ‰ه¤§çڑ„هŒ؛هˆ«م€‚ه¦‚وœé€‰و‹©ن؛†ç¬¬ن¸€ç§چ,ه¾—هˆ°çڑ„و–¹و³•çڑ„ه°±هڈ«هپڑن؛Œéک¶è½¯é—´éڑ”هˆ†ç±»ه™¨ï¼Œç¬¬ن؛Œç§چه°±هڈ«هپڑن¸€éک¶è½¯é—´éڑ”هˆ†ç±»ه™¨م€‚وٹٹوچںه¤±هٹ ه…¥هˆ°ç›®و ‡ه‡½و•°é‡Œçڑ„و—¶ه€™ï¼Œه°±éœ€è¦پن¸€ن¸ھوƒ©ç½ڑه› هگ(cost,ن¹ںه°±وک¯libSVMçڑ„诸ه¤ڑهڈ‚و•°ن¸çڑ„C),هژںو¥çڑ„ن¼کهŒ–é—®é¢که°±هڈکوˆگن؛†ن¸‹é¢è؟™و ·ï¼ڑ
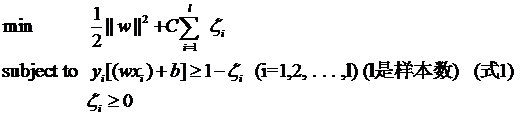
è؟™ن¸ھه¼ڈهگوœ‰è؟™ن¹ˆه‡ 点è¦پو³¨و„ڈï¼ڑ
ن¸€وک¯ه¹¶éو‰€وœ‰çڑ„و ·وœ¬ç‚¹éƒ½وœ‰ن¸€ن¸ھو¾ه¼›هڈکé‡ڈن¸ژه…¶ه¯¹ه؛”م€‚ه®é™…ن¸ٹهڈھوœ‰â€œç¦»ç¾¤ç‚¹â€و‰چوœ‰ï¼Œوˆ–者ن¹ںهڈ¯ن»¥è؟™ن¹ˆçœ‹ï¼Œو‰€وœ‰و²،离群çڑ„点و¾ه¼›هڈکé‡ڈ都ç‰ن؛ژ0(ه¯¹è´ںç±»و¥è¯´ï¼Œç¦»ç¾¤ç‚¹ه°±وک¯هœ¨ه‰چé¢ه›¾ن¸ï¼Œè·‘هˆ°H2هڈ³ن¾§çڑ„é‚£ن؛›è´ںو ·وœ¬ç‚¹ï¼Œه¯¹و£ç±»و¥è¯´ï¼Œه°±وک¯è·‘هˆ°H1ه·¦ن¾§çڑ„é‚£ن؛›و£و ·وœ¬ç‚¹ï¼‰م€‚
م€گهœ¨è؟ن»£و±‚wçڑ„و—¶ه€™ه¦‚ن½•و ·وœ¬ç‚¹é离群点,هچ³هˆ†ç±»و£ç،®ï¼Œé‚£ن¹ˆه°±è®¾ه®ƒçڑ„و¾ه¼›هڈکé‡ڈن¸؛0ن؛†م€‚م€‚م€‚م€‘
ن؛Œوک¯و¾ه¼›هڈکé‡ڈçڑ„ه€¼ه®é™…ن¸ٹو ‡ç¤؛ه‡؛ن؛†ه¯¹ه؛”çڑ„点هˆ°ه؛•ç¦»ç¾¤وœ‰ه¤ڑè؟œï¼Œه€¼è¶ٹه¤§ï¼Œç‚¹ه°±è¶ٹè؟œم€‚
ن¸‰وک¯وƒ©ç½ڑه› هگCه†³ه®ڑن؛†ن½ وœ‰ه¤ڑé‡چ视离群点ه¸¦و¥çڑ„وچںه¤±ï¼Œوک¾ç„¶ه½“و‰€وœ‰ç¦»ç¾¤ç‚¹çڑ„و¾ه¼›هڈکé‡ڈçڑ„ه’Œن¸€ه®ڑو—¶ï¼Œن½ ه®ڑçڑ„Cè¶ٹه¤§ï¼Œه¯¹ç›®و ‡ه‡½و•°çڑ„وچںه¤±ن¹ںè¶ٹه¤§ï¼Œو¤و—¶ه°±وڑ—ç¤؛ç€ن½ éه¸¸ن¸چو„؟و„ڈو”¾ه¼ƒè؟™ن؛›ç¦»ç¾¤ç‚¹ï¼Œوœ€وپ端çڑ„وƒ…ه†µوک¯ن½ وٹٹCه®ڑن¸؛و— é™گه¤§ï¼Œè؟™و ·هڈھè¦پç¨چوœ‰ن¸€ن¸ھ点离群,目و ‡ه‡½و•°çڑ„ه€¼é©¬ن¸ٹهڈکوˆگو— é™گه¤§ï¼Œé©¬ن¸ٹ让问é¢کهڈکوˆگو— 解,è؟™ه°±é€€هŒ–وˆگن؛†ç،¬é—´éڑ”é—®é¢کم€‚
ه››وک¯وƒ©ç½ڑه› هگCن¸چوک¯ن¸€ن¸ھهڈکé‡ڈ,و•´ن¸ھن¼کهŒ–é—®é¢کهœ¨è§£çڑ„و—¶ه€™ï¼ŒCوک¯ن¸€ن¸ھن½ ه؟…é،»ن؛‹ه…ˆوŒ‡ه®ڑçڑ„ه€¼ï¼ŒوŒ‡ه®ڑè؟™ن¸ھه€¼ن»¥هگژ,解ن¸€ن¸‹ï¼Œه¾—هˆ°ن¸€ن¸ھهˆ†ç±»ه™¨ï¼Œç„¶هگژ用وµ‹è¯•و•°وچ®çœ‹çœ‹ç»“وœو€ژن¹ˆو ·ï¼Œه¦‚وœن¸چه¤ںه¥½ï¼Œوچ¢ن¸€ن¸ھCçڑ„ه€¼ï¼Œه†چ解ن¸€و¬،ن¼کهŒ–é—®é¢ک,ه¾—هˆ°هڈ¦ن¸€ن¸ھهˆ†ç±»ه™¨ï¼Œه†چ看看و•ˆوœï¼Œه¦‚و¤ه°±وک¯ن¸€ن¸ھهڈ‚و•°ه¯»ن¼کçڑ„è؟‡ç¨‹ï¼Œن½†è؟™ه’Œن¼کهŒ–é—®é¢کوœ¬è؛«ه†³ن¸چوک¯ن¸€ه›ن؛‹ï¼Œن¼کهŒ–é—®é¢کهœ¨è§£çڑ„è؟‡ç¨‹ن¸ï¼ŒCن¸€ç›´وک¯ه®ڑه€¼ï¼Œè¦پè®°ن½ڈم€‚
ن؛”وک¯ه°½ç®،هٹ ن؛†و¾ه¼›هڈکé‡ڈè؟™ن¹ˆن¸€è¯´ï¼Œن½†è؟™ن¸ھن¼کهŒ–é—®é¢کن»چ然وک¯ن¸€ن¸ھن¼کهŒ–é—®é¢ک(و±—,è؟™ن¸چه؛ںè¯ن¹ˆï¼‰ï¼Œè§£ه®ƒçڑ„è؟‡ç¨‹و¯”èµ·هژںه§‹çڑ„ç،¬é—´éڑ”é—®é¢کو¥è¯´ï¼Œو²،وœ‰ن»»ن½•و›´هٹ 特و®ٹçڑ„هœ°و–¹م€‚
ن»ژه¤§çڑ„و–¹é¢è¯´ن¼کهŒ–é—®é¢ک解çڑ„è؟‡ç¨‹ï¼Œه°±وک¯ه…ˆè¯•ç€ç،®ه®ڑن¸€ن¸‹w,ن¹ںه°±وک¯ç،®ه®ڑن؛†ه‰چé¢ه›¾ن¸çڑ„ن¸‰و،ç›´ç؛؟,è؟™و—¶çœ‹çœ‹é—´éڑ”وœ‰ه¤ڑه¤§ï¼Œهڈˆوœ‰ه¤ڑه°‘点离群,وٹٹç›®و ‡ه‡½و•°çڑ„ه€¼ç®—ن¸€ç®—,ه†چوچ¢ن¸€ç»„ن¸‰و،ç›´ç؛؟(ن½ هڈ¯ن»¥çœ‹هˆ°ï¼Œهˆ†ç±»çڑ„ç›´ç؛؟ن½چç½®ه¦‚وœç§»هٹ¨ن؛†ï¼Œوœ‰ن؛›هژںو¥ç¦»ç¾¤çڑ„点ن¼ڑهڈکه¾—ن¸چه†چ离群,而وœ‰çڑ„وœ¬و¥ن¸چ离群çڑ„点ن¼ڑهڈکوˆگ离群点),ه†چوٹٹç›®و ‡ه‡½و•°çڑ„ه€¼ç®—ن¸€ç®—,ه¦‚و¤ه¾€ه¤چ(è؟ن»£ï¼‰ï¼Œç›´هˆ°وœ€ç»ˆو‰¾هˆ°ç›®و ‡ه‡½و•°وœ€ه°ڈو—¶çڑ„wم€‚
ه•°ه—¦ن؛†è؟™ن¹ˆه¤ڑ,读者ن¸€ه®ڑهڈ¯ن»¥é©¬ن¸ٹè‡ھه·±و€»ç»“ه‡؛و¥ï¼Œو¾ه¼›هڈکé‡ڈن¹ںه°±وک¯ن¸ھ解ه†³ç؛؟و€§ن¸چهڈ¯هˆ†é—®é¢کçڑ„و–¹و³•ç½¢ن؛†ï¼Œن½†وک¯ه›وƒ³ن¸€ن¸‹ï¼Œو ¸ه‡½و•°çڑ„ه¼•ه…¥ن¸چن¹ںوک¯ن¸؛ن؛†è§£ه†³ç؛؟و€§ن¸چهڈ¯هˆ†çڑ„é—®é¢کن¹ˆï¼ںن¸؛ن»€ن¹ˆè¦پن¸؛ن؛†ن¸€ن¸ھé—®é¢کن½؟用ن¸¤ç§چو–¹و³•ه‘¢ï¼ں
ه…¶ه®ن¸¤è€…è؟کوœ‰ه¾®ه¦™çڑ„ن¸چهگŒم€‚ن¸€èˆ¬çڑ„è؟‡ç¨‹ه؛”该وک¯è؟™و ·ï¼Œè؟کن»¥و–‡وœ¬هˆ†ç±»ن¸؛ن¾‹م€‚هœ¨هژںه§‹çڑ„ن½ژç»´ç©؛é—´ن¸ï¼Œو ·وœ¬ç›¸ه½“çڑ„ن¸چهڈ¯هˆ†ï¼Œو— è®؛ن½ و€ژن¹ˆو‰¾هˆ†ç±»ه¹³é¢ï¼Œو€»ن¼ڑوœ‰ه¤§é‡ڈçڑ„离群点,و¤و—¶ç”¨و ¸ه‡½و•°هگ‘é«کç»´ç©؛é—´وک ه°„ن¸€ن¸‹ï¼Œè™½ç„¶ç»“وœن»چ然وک¯ن¸چهڈ¯هˆ†çڑ„,ن½†و¯”هژںه§‹ç©؛间里çڑ„è¦پو›´هٹ وژ¥è؟‘ç؛؟و€§هڈ¯هˆ†çڑ„çٹ¶و€پ(ه°±وک¯è¾¾هˆ°ن؛†è؟‘ن¼¼ç؛؟و€§هڈ¯هˆ†çڑ„çٹ¶و€پ),و¤و—¶ه†چ用و¾ه¼›هڈکé‡ڈه¤„çگ†é‚£ن؛›ه°‘و•°â€œه†¥é،½ن¸چهŒ–â€çڑ„离群点,ه°±ç®€هچ•وœ‰و•ˆه¾—ه¤ڑه•¦م€‚
وœ¬èٹ‚ن¸çڑ„(ه¼ڈ1)ن¹ںç،®ه®وک¯و”¯وŒپهگ‘é‡ڈوœ؛وœ€وœ€ه¸¸ç”¨çڑ„ه½¢ه¼ڈم€‚至و¤ن¸€ن¸ھو¯”较ه®Œو•´çڑ„و”¯وŒپهگ‘é‡ڈوœ؛و،†و¶ه°±وœ‰ن؛†ï¼Œç®€هچ•è¯´و¥ï¼Œو”¯وŒپهگ‘é‡ڈوœ؛ه°±وک¯ن½؟用ن؛†و ¸ه‡½و•°çڑ„软间éڑ”ç؛؟و€§هˆ†ç±»و³•م€‚
ن¸‹ن¸€èٹ‚ن¼ڑ说说و¾ه¼›هڈکé‡ڈه‰©ن¸‹çڑ„ن¸€ç‚¹ç‚¹ن¸œè¥؟,é،؛ن¾؟وگن¸ھ读者调وں¥ï¼Œçœ‹çœ‹ه¤§ه®¶è؟کوƒ³ن¾ƒن¾ƒSVMçڑ„ه“ھن؛›و–¹é¢م€‚
SVMه…¥é—¨ï¼ˆن¹ï¼‰و¾ه¼›هڈکé‡ڈ(ç»ï¼‰
وژ¥ن¸‹و¥è¦پ说çڑ„ن¸œè¥؟ه…¶ه®ن¸چوک¯و¾ه¼›هڈکé‡ڈوœ¬è؛«ï¼Œن½†ç”±ن؛ژوک¯ن¸؛ن؛†ن½؟用و¾ه¼›هڈکé‡ڈو‰چه¼•ه…¥çڑ„,ه› و¤و”¾هœ¨è؟™é‡Œن¹ںç®—هگˆé€‚,那ه°±وک¯وƒ©ç½ڑه› هگCم€‚ه›ه¤´çœ‹ن¸€çœ¼ه¼•ه…¥ن؛†و¾ه¼›هڈکé‡ڈن»¥هگژçڑ„ن¼کهŒ–é—®é¢کï¼ڑ
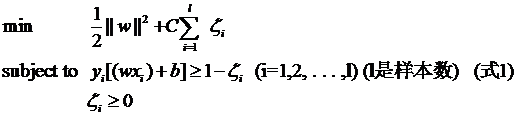
و³¨و„ڈه…¶ن¸Cçڑ„ن½چ置,ن¹ںهڈ¯ن»¥ه›وƒ³ن¸€ن¸‹Cو‰€èµ·çڑ„ن½œç”¨ï¼ˆè،¨ه¾پن½ وœ‰ه¤ڑن¹ˆé‡چ视离群点,Cè¶ٹه¤§è¶ٹé‡چ视,è¶ٹن¸چوƒ³ن¸¢وژ‰ه®ƒن»¬ï¼‰م€‚è؟™ن¸ھه¼ڈهگوک¯ن»¥ه‰چهپڑSVMçڑ„ن؛؛ه†™çڑ„,ه¤§ه®¶ن¹ںه°±è؟™ن¹ˆç”¨ï¼Œن½†و²،وœ‰ن»»ن½•è§„ه®ڑ说ه؟…é،»ه¯¹و‰€وœ‰çڑ„و¾ه¼›هڈکé‡ڈ都ن½؟用هگŒن¸€ن¸ھوƒ©ç½ڑه› هگ,وˆ‘ن»¬ه®Œه…¨هڈ¯ن»¥ç»™و¯ڈن¸€ن¸ھ离群点都ن½؟用ن¸چهگŒçڑ„C,è؟™و—¶ه°±و„ڈه‘³ç€ن½ ه¯¹و¯ڈن¸ھو ·وœ¬çڑ„é‡چ视程ه؛¦éƒ½ن¸چن¸€و ·ï¼Œوœ‰ن؛›و ·وœ¬ن¸¢ن؛†ن¹ںه°±ن¸¢ن؛†ï¼Œé”™ن؛†ن¹ںه°±é”™ن؛†ï¼Œè؟™ن؛›ه°±ç»™ن¸€ن¸ھو¯”较ه°ڈçڑ„C;而وœ‰ن؛›و ·وœ¬ه¾ˆé‡چè¦پ,ه†³ن¸چ能هˆ†ç±»é”™è¯¯ï¼ˆو¯”ه¦‚ن¸ه¤®ن¸‹è¾¾çڑ„و–‡ن»¶ه•¥çڑ„,笑),ه°±ç»™ن¸€ن¸ھه¾ˆه¤§çڑ„Cم€‚
ه½“然ه®é™…ن½؟用çڑ„و—¶ه€™ه¹¶و²،وœ‰è؟™ن¹ˆوپ端,ن½†ن¸€ç§چه¾ˆه¸¸ç”¨çڑ„هڈکه½¢هڈ¯ن»¥ç”¨و¥è§£ه†³هˆ†ç±»é—®é¢کن¸و ·وœ¬çڑ„“هپڈو–œâ€é—®é¢کم€‚
ه…ˆو¥è¯´è¯´و ·وœ¬çڑ„هپڈو–œé—®é¢ک,ن¹ںهڈ«و•°وچ®é›†هپڈو–œï¼ˆunbalanced),ه®ƒوŒ‡çڑ„وک¯هڈ‚ن¸ژهˆ†ç±»çڑ„ن¸¤ن¸ھç±»هˆ«ï¼ˆن¹ںهڈ¯ن»¥وŒ‡ه¤ڑن¸ھç±»هˆ«ï¼‰و ·وœ¬و•°é‡ڈه·®ه¼‚ه¾ˆه¤§م€‚و¯”ه¦‚说و£ç±»وœ‰10,000ن¸ھو ·وœ¬ï¼Œè€Œè´ںç±»هڈھç»™ن؛†100ن¸ھ,è؟™ن¼ڑه¼•èµ·çڑ„é—®é¢کوک¾è€Œوک“è§پ,هڈ¯ن»¥çœ‹çœ‹ن¸‹é¢çڑ„ه›¾ï¼ڑ
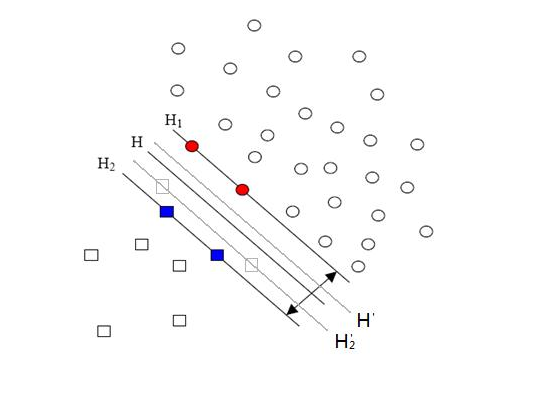
و–¹ه½¢çڑ„点وک¯è´ںç±»م€‚H,H1,H2وک¯و ¹وچ®ç»™çڑ„و ·وœ¬ç®—ه‡؛و¥çڑ„هˆ†ç±»é¢ï¼Œç”±ن؛ژè´ںç±»çڑ„و ·وœ¬ه¾ˆه°‘ه¾ˆه°‘,و‰€ن»¥وœ‰ن¸€ن؛›وœ¬و¥وک¯è´ںç±»çڑ„و ·وœ¬ç‚¹و²،وœ‰وڈگن¾›ï¼Œو¯”ه¦‚ه›¾ن¸ن¸¤ن¸ھçپ°è‰²çڑ„و–¹ه½¢ç‚¹ï¼Œه¦‚وœè؟™ن¸¤ن¸ھ点وœ‰وڈگن¾›çڑ„è¯ï¼Œé‚£ç®—ه‡؛و¥çڑ„هˆ†ç±»é¢ه؛”该وک¯H’,H2’ه’ŒH1,ن»–ن»¬وک¾ç„¶ه’Œن¹‹ه‰چçڑ„结وœوœ‰ه‡؛ه…¥ï¼Œه®é™…ن¸ٹè´ں类给çڑ„و ·وœ¬ç‚¹è¶ٹه¤ڑ,ه°±è¶ٹه®¹وک“ه‡؛çژ°هœ¨çپ°è‰²ç‚¹é™„è؟‘çڑ„点,وˆ‘ن»¬ç®—ه‡؛çڑ„结وœن¹ںه°±è¶ٹوژ¥è؟‘ن؛ژçœںه®çڑ„هˆ†ç±»é¢م€‚ن½†çژ°هœ¨ç”±ن؛ژهپڈو–œçڑ„çژ°è±،هکهœ¨ï¼Œن½؟ه¾—و•°é‡ڈه¤ڑçڑ„و£ç±»هڈ¯ن»¥وٹٹهˆ†ç±»é¢هگ‘è´ںç±»çڑ„و–¹هگ‘“وژ¨â€ï¼Œه› 而ه½±ه“چن؛†ç»“وœçڑ„ه‡†ç،®و€§م€‚
ه¯¹ن»کو•°وچ®é›†هپڈو–œé—®é¢کçڑ„و–¹و³•ن¹‹ن¸€ه°±وک¯هœ¨وƒ©ç½ڑه› هگن¸ٹن½œو–‡ç« ,وƒ³ه؟…ه¤§ه®¶ن¹ں猜هˆ°ن؛†ï¼Œé‚£ه°±وک¯ç»™و ·وœ¬و•°é‡ڈه°‘çڑ„è´ںç±»و›´ه¤§çڑ„وƒ©ç½ڑه› هگ,è،¨ç¤؛وˆ‘ن»¬é‡چ视è؟™éƒ¨هˆ†و ·وœ¬ï¼ˆوœ¬و¥و•°é‡ڈه°±ه°‘,ه†چوٹ›ه¼ƒن¸€ن؛›ï¼Œé‚£ن؛؛ه®¶è´ںç±»è؟کو´»ن¸چو´»ن؛†ï¼‰ï¼Œه› و¤وˆ‘ن»¬çڑ„ç›®و ‡ه‡½و•°ن¸ه› و¾ه¼›هڈکé‡ڈ而وچںه¤±çڑ„部هˆ†ه°±هڈکوˆگن؛†ï¼ڑ
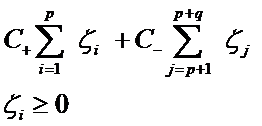
ه…¶ن¸i=1…p都وک¯و£و ·وœ¬ï¼Œj=p+1…p+q都وک¯è´ںو ·وœ¬م€‚libSVMè؟™ن¸ھç®—و³•هŒ…هœ¨è§£ه†³هپڈو–œé—®é¢کçڑ„و—¶ه€™ç”¨çڑ„ه°±وک¯è؟™ç§چو–¹و³•م€‚
é‚£C+ه’ŒC-و€ژن¹ˆç،®ه®ڑه‘¢ï¼ںه®ƒن»¬çڑ„ه¤§ه°ڈوک¯è¯•ه‡؛و¥çڑ„(هڈ‚و•°è°ƒن¼ک),ن½†وک¯ن»–ن»¬çڑ„و¯”ن¾‹هڈ¯ن»¥وœ‰ن؛›و–¹و³•و¥ç،®ه®ڑم€‚ه’±ن»¬ه…ˆهپ‡ه®ڑ说C+وک¯5è؟™ن¹ˆه¤§ï¼Œé‚£ç،®ه®ڑC-çڑ„ن¸€ن¸ھه¾ˆç›´è§‚çڑ„و–¹و³•ه°±وک¯ن½؟用ن¸¤ç±»و ·وœ¬و•°çڑ„و¯”و¥ç®—,ه¯¹ه؛”هˆ°هˆڑو‰چن¸¾çڑ„ن¾‹هگ,C-ه°±هڈ¯ن»¥ه®ڑن¸؛500è؟™ن¹ˆه¤§ï¼ˆه› ن¸؛10,000ï¼ڑ100=100ï¼ڑ1هک›ï¼‰م€‚
ن½†وک¯è؟™و ·ه¹¶ن¸چه¤ںه¥½ï¼Œه›çœ‹هˆڑو‰چçڑ„ه›¾ï¼Œن½ ن¼ڑهڈ‘çژ°و£ç±»ن¹‹و‰€ن»¥هڈ¯ن»¥â€œو¬؛è´ںâ€è´ں类,ه…¶ه®ه¹¶ن¸چوک¯ه› ن¸؛è´ںç±»و ·وœ¬ه°‘,çœںه®çڑ„هژںه› وک¯è´ںç±»çڑ„و ·وœ¬هˆ†ه¸ƒçڑ„ن¸چه¤ںه¹؟(و²،و‰©ه……هˆ°è´ںç±»وœ¬ه؛”该وœ‰çڑ„هŒ؛هںں)م€‚说ن¸€ن¸ھه…·ن½“点çڑ„ن¾‹هگ,çژ°هœ¨وƒ³ç»™و”؟و²»ç±»ه’Œن½“育类çڑ„و–‡ç« هپڑهˆ†ç±»ï¼Œو”؟و²»ç±»و–‡ç« ه¾ˆه¤ڑ,而ن½“育类هڈھوڈگن¾›ن؛†ه‡ 篇ه…³ن؛ژ篮çگƒçڑ„و–‡ç« ,è؟™و—¶هˆ†ç±»ن¼ڑوکژوک¾هپڈهگ‘ن؛ژو”؟و²»ç±»ï¼Œه¦‚وœè¦پç»™ن½“育类و–‡ç« ه¢هٹ و ·وœ¬ï¼Œن½†ه¢هٹ çڑ„و ·وœ¬ن»چ然ه…¨éƒ½وک¯ه…³ن؛ژ篮çگƒçڑ„(ن¹ںه°±وک¯è¯´ï¼Œو²،وœ‰è¶³çگƒï¼Œوژ’çگƒï¼Œèµ›è½¦ï¼Œو¸¸و³³ç‰ç‰ï¼‰ï¼Œé‚£ç»“وœن¼ڑو€ژو ·ه‘¢ï¼ں虽然ن½“育类و–‡ç« هœ¨و•°é‡ڈن¸ٹهڈ¯ن»¥è¾¾هˆ°ن¸ژو”؟و²»ç±»ن¸€و ·ه¤ڑ,ن½†è؟‡ن؛ژ集ن¸ن؛†ï¼Œç»“وœن»چن¼ڑهپڈهگ‘ن؛ژو”؟و²»ç±»ï¼پو‰€ن»¥ç»™C+ه’ŒC-ç،®ه®ڑو¯”ن¾‹و›´ه¥½çڑ„و–¹و³•ه؛”该وک¯è،،é‡ڈن»–ن»¬هˆ†ه¸ƒçڑ„程ه؛¦م€‚و¯”ه¦‚هڈ¯ن»¥ç®—ç®—ن»–ن»¬هœ¨ç©؛é—´ن¸هچ وچ®ن؛†ه¤ڑه¤§çڑ„ن½“积,ن¾‹ه¦‚ç»™è´ںç±»و‰¾ن¸€ن¸ھ超çگƒâ€”—ه°±وک¯é«کç»´ç©؛间里çڑ„çگƒه•¦â€”—ه®ƒهڈ¯ن»¥هŒ…هگ«و‰€وœ‰è´ںç±»çڑ„و ·وœ¬ï¼Œه†چç»™و£ç±»و‰¾ن¸€ن¸ھ,و¯”و¯”ن¸¤ن¸ھçگƒçڑ„هچٹه¾„,ه°±هڈ¯ن»¥ه¤§è‡´ç،®ه®ڑهˆ†ه¸ƒçڑ„وƒ…ه†µم€‚وک¾ç„¶هچٹه¾„ه¤§çڑ„هˆ†ه¸ƒه°±و¯”较ه¹؟,ه°±ç»™ه°ڈن¸€ç‚¹çڑ„وƒ©ç½ڑه› هگم€‚
ن½†وک¯è؟™و ·è؟کن¸چه¤ںه¥½ï¼Œه› ن¸؛وœ‰çڑ„ç±»هˆ«و ·وœ¬ç،®ه®ه¾ˆé›†ن¸ï¼Œè؟™ن¸چوک¯وڈگن¾›çڑ„و ·وœ¬و•°é‡ڈه¤ڑه°‘çڑ„é—®é¢ک,è؟™وک¯ç±»هˆ«وœ¬è؛«çڑ„特ه¾پ(ه°±وک¯وںگن؛›è¯é¢کو¶‰هڈٹçڑ„é¢ه¾ˆçھ„,ن¾‹ه¦‚è®،ç®—وœ؛ç±»çڑ„و–‡ç« ه°±وکژوک¾ن¸چه¦‚و–‡هŒ–ç±»çڑ„و–‡ç« é‚£ن¹ˆâ€œه¤©é©¬è،Œç©؛â€ï¼‰ï¼Œè؟™ن¸ھو—¶ه€™هچ³ن¾؟超çگƒçڑ„هچٹه¾„ه·®ه¼‚ه¾ˆه¤§ï¼Œن¹ںن¸چه؛”该赋ن؛ˆن¸¤ن¸ھç±»هˆ«ن¸چهگŒçڑ„وƒ©ç½ڑه› هگم€‚
看هˆ°è؟™é‡Œè¯»è€…ن¸€ه®ڑç–¯ن؛†ï¼Œه› ن¸؛说و¥è¯´هژ»ï¼Œè؟™ه²‚ن¸چوˆگن؛†ن¸€ن¸ھ解ه†³ن¸چن؛†çڑ„é—®é¢کï¼ں然而ن؛‹ه®ه¦‚و¤ï¼Œه®Œه…¨çڑ„و–¹و³•وک¯و²،وœ‰çڑ„,و ¹وچ®éœ€è¦پ,选و‹©ه®çژ°ç®€هچ•هڈˆهگˆç”¨çڑ„ه°±ه¥½ï¼ˆن¾‹ه¦‚libSVMه°±ç›´وژ¥ن½؟用و ·وœ¬و•°é‡ڈçڑ„و¯”)م€‚
SVMه…¥é—¨ï¼ˆهچپ)ه°†SVM用ن؛ژه¤ڑç±»هˆ†ç±»
ن»ژ SVMçڑ„é‚£ه‡ ه¼ ه›¾هڈ¯ن»¥çœ‹ه‡؛و¥ï¼ŒSVMوک¯ن¸€ç§چه…¸ه‹çڑ„ن¸¤ç±»هˆ†ç±»ه™¨ï¼Œهچ³ه®ƒهڈھه›ç”ه±ن؛ژو£ç±»è؟کوک¯è´ںç±»çڑ„é—®é¢کم€‚而çژ°ه®ن¸è¦پ解ه†³çڑ„é—®é¢ک,ه¾€ه¾€وک¯ه¤ڑç±»çڑ„é—®é¢ک(ه°‘部هˆ†ن¾‹ه¤–,ن¾‹ه¦‚هƒهœ¾é‚®ن»¶è؟‡و»¤ï¼Œه°±هڈھ需è¦پç،®ه®ڑ“وک¯â€è؟کوک¯â€œن¸چوک¯â€هƒهœ¾é‚®ن»¶ï¼‰ï¼Œو¯”ه¦‚و–‡وœ¬هˆ†ç±»ï¼Œو¯”ه¦‚و•°ه—识هˆ«م€‚ه¦‚ن½•ç”±ن¸¤ç±»هˆ†ç±»ه™¨ه¾—هˆ°ه¤ڑç±»هˆ†ç±»ه™¨ï¼Œه°±وک¯ن¸€ن¸ھه€¼ه¾—ç ”ç©¶çڑ„é—®é¢کم€‚
è؟کن»¥و–‡وœ¬هˆ†ç±»ن¸؛ن¾‹ï¼Œçژ°وˆگçڑ„و–¹و³•وœ‰ه¾ˆه¤ڑ,ه…¶ن¸ن¸€ç§چن¸€هٹ³و°¸é€¸çڑ„و–¹و³•ï¼Œه°±وک¯çœںçڑ„ن¸€و¬،و€§è€ƒè™‘و‰€وœ‰و ·وœ¬ï¼Œه¹¶و±‚解ن¸€ن¸ھه¤ڑç›®و ‡ه‡½و•°çڑ„ن¼کهŒ–é—®é¢ک,ن¸€و¬،و€§ه¾—هˆ°ه¤ڑن¸ھهˆ†ç±»é¢ï¼Œه°±هƒڈن¸‹ه›¾è؟™و ·ï¼ڑ
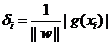{kind=link}
{kind=link}
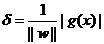{kind=link}
{kind=link}
ه¤ڑن¸ھ超ه¹³é¢وٹٹç©؛é—´هˆ’هˆ†ن¸؛ه¤ڑن¸ھهŒ؛هںں,و¯ڈن¸ھهŒ؛هںںه¯¹ه؛”ن¸€ن¸ھç±»هˆ«ï¼Œç»™ن¸€ç¯‡و–‡ç« ,看ه®ƒèگ½هœ¨ه“ھن¸ھهŒ؛هںںه°±çں¥éپ“ن؛†ه®ƒçڑ„هˆ†ç±»م€‚
看起و¥ه¾ˆç¾ژه¯¹ن¸چه¯¹ï¼ںهڈھهڈ¯وƒœè؟™ç§چç®—و³•è؟کهں؛وœ¬هپœç•™هœ¨ç؛¸é¢ن¸ٹ,ه› ن¸؛ن¸€و¬،و€§و±‚解çڑ„و–¹و³•è®،ç®—é‡ڈه®هœ¨ه¤ھه¤§ï¼Œه¤§هˆ°و— و³•ه®ç”¨çڑ„هœ°و¥م€‚
ç¨چç¨چ退ن¸€و¥ï¼Œوˆ‘ن»¬ه°±ن¼ڑوƒ³هˆ°و‰€è°““ن¸€ç±»ه¯¹ه…¶ن½™â€çڑ„و–¹و³•ï¼Œه°±وک¯و¯ڈو¬،ن»چ然解ن¸€ن¸ھن¸¤ç±»هˆ†ç±»çڑ„é—®é¢کم€‚و¯”ه¦‚وˆ‘ن»¬وœ‰5ن¸ھç±»هˆ«ï¼Œç¬¬ن¸€و¬،ه°±وٹٹç±»هˆ«1çڑ„و ·وœ¬ه®ڑن¸؛و£و ·وœ¬ï¼Œه…¶ن½™2,3,4,5çڑ„و ·وœ¬هگˆèµ·و¥ه®ڑن¸؛è´ںو ·وœ¬ï¼Œè؟™و ·ه¾—هˆ°ن¸€ن¸ھن¸¤ç±»هˆ†ç±»ه™¨ï¼Œه®ƒèƒ½ه¤ںوŒ‡ه‡؛ن¸€ç¯‡و–‡ç« وک¯è؟کوک¯ن¸چوک¯ç¬¬1ç±»çڑ„;第ن؛Œو¬،وˆ‘ن»¬وٹٹç±»هˆ«2 çڑ„و ·وœ¬ه®ڑن¸؛و£و ·وœ¬ï¼Œوٹٹ1,3,4,5çڑ„و ·وœ¬هگˆèµ·و¥ه®ڑن¸؛è´ںو ·وœ¬ï¼Œه¾—هˆ°ن¸€ن¸ھهˆ†ç±»ه™¨ï¼Œه¦‚و¤ن¸‹هژ»ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه¾—هˆ°5ن¸ھè؟™و ·çڑ„ن¸¤ç±»هˆ†ç±»ه™¨ï¼ˆو€»وک¯ه’Œç±»هˆ«çڑ„و•°ç›®ن¸€è‡´ï¼‰م€‚هˆ°ن؛†وœ‰و–‡ç« 需è¦پهˆ†ç±»çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه°±و‹؟ç€è؟™ç¯‡و–‡ç« وŒ¨ن¸ھهˆ†ç±»ه™¨çڑ„é—®ï¼ڑوک¯ه±ن؛ژن½ çڑ„ن¹ˆï¼ںوک¯ه±ن؛ژن½ çڑ„ن¹ˆï¼ںه“ھن¸ھهˆ†ç±»ه™¨ç‚¹ه¤´è¯´وک¯ن؛†ï¼Œو–‡ç« çڑ„ç±»هˆ«ه°±ç،®ه®ڑن؛†م€‚è؟™ç§چو–¹و³•çڑ„ه¥½ه¤„وک¯و¯ڈن¸ھن¼کهŒ–é—®é¢کçڑ„规و¨،و¯”较ه°ڈ,而ن¸”هˆ†ç±»çڑ„و—¶ه€™é€ںه؛¦ه¾ˆه؟«ï¼ˆهڈھ需è¦پ调用5ن¸ھهˆ†ç±»ه™¨ه°±çں¥éپ“ن؛†ç»“وœï¼‰م€‚ن½†وœ‰و—¶ن¹ںن¼ڑه‡؛çژ°ن¸¤ç§چه¾ˆه°´ه°¬çڑ„وƒ…ه†µï¼Œن¾‹ه¦‚و‹؟ن¸€ç¯‡و–‡ç« é—®ن؛†ن¸€هœˆï¼Œو¯ڈن¸€ن¸ھهˆ†ç±»ه™¨éƒ½è¯´ه®ƒوک¯ه±ن؛ژه®ƒé‚£ن¸€ç±»çڑ„,وˆ–者و¯ڈن¸€ن¸ھهˆ†ç±»ه™¨éƒ½è¯´ه®ƒن¸چوک¯ه®ƒé‚£ن¸€ç±»çڑ„,ه‰چ者هڈ«هˆ†ç±»é‡چهڈ çژ°è±،,هگژ者هڈ«ن¸چهڈ¯هˆ†ç±»çژ°è±،م€‚هˆ†ç±»é‡چهڈ ه€’è؟که¥½هٹ,éڑڈن¾؟选ن¸€ن¸ھ结وœéƒ½ن¸چ至ن؛ژه¤ھ离谱,وˆ–者看看è؟™ç¯‡و–‡ç« هˆ°هگ„ن¸ھ超ه¹³é¢çڑ„è·ç¦»ï¼Œه“ھن¸ھè؟œه°±هˆ¤ç»™ه“ھن¸ھم€‚ن¸چهڈ¯هˆ†ç±»çژ°è±،ه°±ç€ه®éڑ¾هٹن؛†ï¼Œهڈھ能وٹٹه®ƒهˆ†ç»™ç¬¬6ن¸ھç±»هˆ«ن؛†â€¦â€¦و›´è¦په‘½çڑ„وک¯ï¼Œوœ¬و¥هگ„ن¸ھç±»هˆ«çڑ„و ·وœ¬و•°ç›®وک¯ه·®ن¸چه¤ڑçڑ„,ن½†â€œه…¶ن½™â€çڑ„é‚£ن¸€ç±»و ·وœ¬و•°و€»وک¯è¦پو•°ه€چن؛ژو£ç±»ï¼ˆه› ن¸؛ه®ƒوک¯é™¤و£ç±»ن»¥ه¤–ه…¶ن»–ç±»هˆ«çڑ„و ·وœ¬ن¹‹ه’Œهک›ï¼‰ï¼Œè؟™ه°±ن؛؛ن¸؛çڑ„é€ وˆگن؛†ن¸ٹن¸€èٹ‚و‰€è¯´çڑ„“و•°وچ®é›†هپڈو–œâ€é—®é¢کم€‚
ه› و¤وˆ‘ن»¬è؟که¾—ه†چ退ن¸€و¥ï¼Œè؟کوک¯è§£ن¸¤ç±»هˆ†ç±»é—®é¢ک,è؟کوک¯و¯ڈو¬،选ن¸€ن¸ھç±»çڑ„و ·وœ¬ن½œو£ç±»و ·وœ¬ï¼Œè€Œè´ںç±»و ·وœ¬هˆ™هڈکوˆگهڈھ选ن¸€ن¸ھ类(称ن¸؛“ن¸€ه¯¹ن¸€هچ•وŒ‘â€çڑ„و–¹و³•ï¼Œه“¦ï¼Œن¸چه¯¹ï¼Œو²،وœ‰هچ•وŒ‘,ه°±وک¯â€œن¸€ه¯¹ن¸€â€çڑ„و–¹و³•ï¼Œه‘µه‘µï¼‰ï¼Œè؟™ه°±éپ؟ه…چن؛†هپڈو–œم€‚ه› و¤è؟‡ç¨‹ه°±وک¯ç®—ه‡؛è؟™و ·ن¸€ن؛›هˆ†ç±»ه™¨ï¼Œç¬¬ن¸€ن¸ھهڈھه›ç”“وک¯ç¬¬1ç±»è؟کوک¯ç¬¬2ç±»â€ï¼Œç¬¬ن؛Œن¸ھهڈھه›ç”“وک¯ç¬¬1ç±»è؟کوک¯ç¬¬3ç±»â€ï¼Œç¬¬ن¸‰ن¸ھهڈھه›ç”“وک¯ç¬¬1ç±»è؟کوک¯ç¬¬4ç±»â€ï¼Œه¦‚و¤ن¸‹هژ»ï¼Œن½ ن¹ںهڈ¯ن»¥é©¬ن¸ٹه¾—ه‡؛,è؟™و ·çڑ„هˆ†ç±»ه™¨ه؛”该وœ‰5 X 4/2=10ن¸ھ(é€ڑه¼ڈوک¯ï¼Œه¦‚وœوœ‰kن¸ھç±»هˆ«ï¼Œهˆ™و€»çڑ„ن¸¤ç±»هˆ†ç±»ه™¨و•°ç›®ن¸؛k(k-1)/2)م€‚虽然هˆ†ç±»ه™¨çڑ„و•°ç›®ه¤ڑن؛†ï¼Œن½†وک¯هœ¨è®ç»ƒéک¶و®µï¼ˆن¹ںه°±وک¯ç®—ه‡؛è؟™ن؛›هˆ†ç±»ه™¨çڑ„هˆ†ç±»ه¹³é¢و—¶ï¼‰و‰€ç”¨çڑ„و€»و—¶é—´هچ´و¯”“ن¸€ç±»ه¯¹ه…¶ن½™â€و–¹و³•ه°‘ه¾ˆه¤ڑ,هœ¨çœںو£ç”¨و¥هˆ†ç±»çڑ„و—¶ه€™ï¼Œوٹٹن¸€ç¯‡و–‡ç« و‰”ç»™و‰€وœ‰هˆ†ç±»ه™¨ï¼Œç¬¬ن¸€ن¸ھهˆ†ç±»ه™¨ن¼ڑوٹ•ç¥¨è¯´ه®ƒوک¯â€œ1â€وˆ–者“2â€ï¼Œç¬¬ن؛Œن¸ھن¼ڑ说ه®ƒوک¯â€œ1â€وˆ–者“3â€ï¼Œè®©و¯ڈن¸€ن¸ھ都وٹ•ن¸ٹè‡ھه·±çڑ„ن¸€ç¥¨ï¼Œوœ€هگژç»ںè®،票و•°ï¼Œه¦‚وœç±»هˆ«â€œ1â€ه¾—票وœ€ه¤ڑ,ه°±هˆ¤è؟™ç¯‡و–‡ç« ه±ن؛ژ第1ç±»م€‚è؟™ç§چو–¹و³•وک¾ç„¶ن¹ںن¼ڑوœ‰هˆ†ç±»é‡چهڈ çڑ„çژ°è±،,ن½†ن¸چن¼ڑوœ‰ن¸چهڈ¯هˆ†ç±»çژ°è±،,ه› ن¸؛و€»ن¸چهڈ¯èƒ½و‰€وœ‰ç±»هˆ«çڑ„票و•°éƒ½وک¯0م€‚看起و¥ه¤ںه¥½ن¹ˆï¼ںه…¶ه®ن¸چ然,وƒ³وƒ³هˆ†ç±»ن¸€ç¯‡و–‡ç« ,وˆ‘ن»¬è°ƒç”¨ن؛†ه¤ڑه°‘ن¸ھهˆ†ç±»ه™¨ï¼ں10ن¸ھ,è؟™è؟کوک¯ç±»هˆ«و•°ن¸؛5çڑ„و—¶ه€™ï¼Œç±»هˆ«و•°ه¦‚وœوک¯1000,è¦پ调用çڑ„هˆ†ç±»ه™¨و•°ç›®ن¼ڑن¸ٹهچ‡è‡³ç؛¦500,000ن¸ھ(类هˆ«و•°çڑ„ه¹³و–¹é‡ڈç؛§ï¼‰م€‚è؟™ه¦‚ن½•وک¯ه¥½ï¼ں
看و¥وˆ‘ن»¬ه؟…é،»ه†چ退ن¸€و¥ï¼Œهœ¨هˆ†ç±»çڑ„و—¶ه€™ن¸‹هٹںه¤«ï¼Œوˆ‘ن»¬è؟کوک¯هƒڈن¸€ه¯¹ن¸€و–¹و³•é‚£و ·و¥è®ç»ƒï¼Œهڈھوک¯هœ¨ه¯¹ن¸€ç¯‡و–‡ç« è؟›è،Œهˆ†ç±»ن¹‹ه‰چ,وˆ‘ن»¬ه…ˆوŒ‰ç…§ن¸‹é¢ه›¾çڑ„و ·هگو¥ç»„织هˆ†ç±»ه™¨ï¼ˆه¦‚ن½ و‰€è§پ,è؟™وک¯ن¸€ن¸ھوœ‰هگ‘و— çژ¯ه›¾ï¼Œه› و¤è؟™ç§چو–¹و³•ن¹ںهڈ«هپڑDAG SVM)

è؟™و ·هœ¨هˆ†ç±»و—¶,وˆ‘ن»¬ه°±هڈ¯ن»¥ه…ˆé—®هˆ†ç±»ه™¨â€œ1ه¯¹5â€ï¼ˆو„ڈو€وک¯ه®ƒèƒ½ه¤ںه›ç”“وک¯ç¬¬1ç±»è؟کوک¯ç¬¬5ç±»â€ï¼‰ï¼Œه¦‚وœه®ƒه›ç”5,وˆ‘ن»¬ه°±ه¾€ه·¦èµ°ï¼Œه†چ问“2ه¯¹5â€è؟™ن¸ھهˆ†ç±»ه™¨ï¼Œه¦‚وœه®ƒè؟ک说وک¯â€œ5â€ï¼Œوˆ‘ن»¬ه°±ç»§ç»ه¾€ه·¦èµ°ï¼Œè؟™و ·ن¸€ç›´é—®ن¸‹هژ»ï¼Œه°±هڈ¯ن»¥ه¾—هˆ°هˆ†ç±»ç»“وœم€‚ه¥½ه¤„هœ¨ه“ھï¼ںوˆ‘ن»¬ه…¶ه®هڈھ调用ن؛†4ن¸ھهˆ†ç±»ه™¨ï¼ˆه¦‚وœç±»هˆ«و•°وک¯k,هˆ™هڈھ调用k-1ن¸ھ),هˆ†ç±»é€ںه؛¦é£ه؟«ï¼Œن¸”و²،وœ‰هˆ†ç±»é‡چهڈ ه’Œن¸چهڈ¯هˆ†ç±»çژ°è±،ï¼پç¼؛点هœ¨ه“ھï¼ںهپ‡ه¦‚وœ€ن¸€ه¼€ه§‹çڑ„هˆ†ç±»ه™¨ه›ç”错误(وکژوکژوک¯ç±»هˆ«1çڑ„و–‡ç« ,ه®ƒè¯´وˆگن؛†5),那ن¹ˆهگژé¢çڑ„هˆ†ç±»ه™¨وک¯و— è®؛ه¦‚ن½•ن¹ںو— و³•ç؛ و£ه®ƒçڑ„错误çڑ„(ه› ن¸؛هگژé¢çڑ„هˆ†ç±»ه™¨هژ‹و ¹و²،وœ‰ه‡؛çژ°â€œ1â€è؟™ن¸ھç±»هˆ«و ‡ç¾ï¼‰ï¼Œه…¶ه®ه¯¹ن¸‹é¢و¯ڈن¸€ه±‚çڑ„هˆ†ç±»ه™¨éƒ½هکهœ¨è؟™ç§چ错误هگ‘ن¸‹ç´¯ç§¯çڑ„çژ°è±،م€‚م€‚
ن¸چè؟‡ن¸چè¦پ被DAGو–¹و³•çڑ„错误累积هگ“ه€’,错误累积هœ¨ن¸€ه¯¹ه…¶ن½™ه’Œن¸€ه¯¹ن¸€و–¹و³•ن¸ن¹ں都هکهœ¨ï¼ŒDAGو–¹و³•ه¥½ن؛ژه®ƒن»¬çڑ„هœ°و–¹ه°±هœ¨ن؛ژ,累积çڑ„ن¸ٹé™گ,ن¸چç®،وک¯ه¤§وک¯ه°ڈ,و€»وک¯وœ‰ه®ڑè®؛çڑ„,وœ‰çگ†è®؛è¯پوکژم€‚而ن¸€ه¯¹ه…¶ن½™ه’Œن¸€ه¯¹ن¸€و–¹و³•ن¸ï¼Œه°½ç®،و¯ڈن¸€ن¸ھن¸¤ç±»هˆ†ç±»ه™¨çڑ„و³›هŒ–误ه·®é™گوک¯çں¥éپ“çڑ„,ن½†وک¯هگˆèµ·و¥هپڑه¤ڑç±»هˆ†ç±»çڑ„و—¶ه€™ï¼Œè¯¯ه·®ن¸ٹç•Œوک¯ه¤ڑه°‘,و²،ن؛؛çں¥éپ“,è؟™و„ڈه‘³ç€ه‡†ç،®çژ‡ن½ژهˆ°0ن¹ںوک¯وœ‰هڈ¯èƒ½çڑ„,è؟™ه¤ڑ让ن؛؛éƒپé—·م€‚
而ن¸”çژ°هœ¨DAGو–¹و³•و ¹èٹ‚点çڑ„选هڈ–(ن¹ںه°±وک¯ه¦‚ن½•é€‰ç¬¬ن¸€ن¸ھهڈ‚ن¸ژهˆ†ç±»çڑ„هˆ†ç±»ه™¨ï¼‰ï¼Œن¹ںوœ‰ن¸€ن؛›و–¹و³•هڈ¯ن»¥و”¹ه–„و•´ن½“و•ˆوœï¼Œوˆ‘ن»¬و€»ه¸Œوœ›و ¹èٹ‚点ه°‘çٹ¯é”™è¯¯ن¸؛ه¥½ï¼Œه› و¤هڈ‚ن¸ژ第ن¸€و¬،هˆ†ç±»çڑ„ن¸¤ن¸ھç±»هˆ«ï¼Œوœ€ه¥½وک¯ه·®هˆ«ç‰¹هˆ«ç‰¹هˆ«ه¤§ï¼Œه¤§هˆ°ن»¥è‡³ن؛ژن¸چه¤ھهڈ¯èƒ½وٹٹن»–ن»¬هˆ†é”™ï¼›وˆ–者وˆ‘ن»¬ه°±و€»هڈ–هœ¨ن¸¤ç±»هˆ†ç±»ن¸و£ç،®çژ‡وœ€é«کçڑ„é‚£ن¸ھهˆ†ç±»ه™¨ن½œو ¹èٹ‚点,وˆ–者وˆ‘ن»¬è®©ن¸¤ç±»هˆ†ç±»ه™¨هœ¨هˆ†ç±»çڑ„و—¶ه€™ï¼Œن¸چه…‰è¾“ه‡؛ç±»هˆ«çڑ„و ‡ç¾ï¼Œè؟ک输ه‡؛ن¸€ن¸ھç±»ن¼¼â€œç½®ن؟،ه؛¦â€çڑ„ن¸œن¸œï¼Œه½“ه®ƒه¯¹è‡ھه·±çڑ„结وœن¸چه¤ھè‡ھن؟،çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه°±ن¸چه…‰وŒ‰ç…§ه®ƒçڑ„输ه‡؛走,وٹٹه®ƒو—پè¾¹çڑ„é‚£و،è·¯ن¹ںèµ°ن¸€èµ°ï¼Œç‰ç‰م€‚
ه¤§Tipsï¼ڑSVMçڑ„è®،ç®—ه¤چو‚ه؛¦
ن½؟用SVMè؟›è،Œهˆ†ç±»çڑ„و—¶ه€™ï¼Œه®é™…ن¸ٹوک¯è®ç»ƒه’Œهˆ†ç±»ن¸¤ن¸ھه®Œه…¨ن¸چهگŒçڑ„è؟‡ç¨‹ï¼Œه› 而讨è®؛ه¤چو‚ه؛¦ه°±ن¸چ能ن¸€و¦‚而è®؛,وˆ‘ن»¬è؟™é‡Œو‰€è¯´çڑ„ن¸»è¦پوک¯è®ç»ƒéک¶و®µçڑ„ه¤چو‚ه؛¦ï¼Œهچ³è§£é‚£ن¸ھن؛Œو¬،规هˆ’é—®é¢کçڑ„ه¤چو‚ه؛¦م€‚ه¯¹è؟™ن¸ھé—®é¢کçڑ„解,هں؛وœ¬ن¸ٹè¦پهˆ’هˆ†ن¸؛ن¸¤ه¤§ه—,解وگ解ه’Œو•°ه€¼è§£م€‚
解وگ解ه°±وک¯çگ†è®؛ن¸ٹçڑ„解,ه®ƒçڑ„ه½¢ه¼ڈوک¯è،¨è¾¾ه¼ڈ,ه› و¤ه®ƒوک¯ç²¾ç،®çڑ„,ن¸€ن¸ھé—®é¢کهڈھè¦پوœ‰è§£ï¼ˆو— 解çڑ„é—®é¢کè؟کè·ںç€وژ؛ه’Œن»€ن¹ˆه‘€ï¼Œه“ˆه“ˆï¼‰ï¼Œé‚£ه®ƒçڑ„解وگ解وک¯ن¸€ه®ڑهکهœ¨çڑ„م€‚ه½“然هکهœ¨وک¯ن¸€ه›ن؛‹ï¼Œèƒ½ه¤ں解ه‡؛و¥ï¼Œوˆ–者هڈ¯ن»¥هœ¨هڈ¯ن»¥و‰؟هڈ—çڑ„و—¶é—´èŒƒه›´ه†…解ه‡؛و¥ï¼Œه°±وک¯هڈ¦ن¸€ه›ن؛‹ن؛†م€‚ه¯¹SVMو¥è¯´ï¼Œو±‚ه¾—解وگ解çڑ„و—¶é—´ه¤چو‚ه؛¦وœ€هڈهڈ¯ن»¥è¾¾هˆ°O(Nsv3),ه…¶ن¸Nsvوک¯و”¯وŒپهگ‘é‡ڈçڑ„ن¸ھو•°ï¼Œè€Œè™½ç„¶و²،وœ‰ه›؛ه®ڑçڑ„و¯”ن¾‹ï¼Œن½†و”¯وŒپهگ‘é‡ڈçڑ„ن¸ھو•°ه¤ڑه°‘ن¹ںه’Œè®ç»ƒé›†çڑ„ه¤§ه°ڈوœ‰ه…³م€‚
و•°ه€¼è§£ه°±وک¯هڈ¯ن»¥ن½؟用çڑ„解,وک¯ن¸€ن¸ھن¸€ن¸ھçڑ„و•°ï¼Œه¾€ه¾€éƒ½وک¯è؟‘ن¼¼è§£م€‚و±‚و•°ه€¼è§£çڑ„è؟‡ç¨‹éه¸¸هƒڈç©·ن¸¾و³•ï¼Œن»ژن¸€ن¸ھو•°ه¼€ه§‹ï¼Œè¯•ن¸€è¯•ه®ƒه½“解و•ˆوœو€ژو ·ï¼Œن¸چو»،足ن¸€ه®ڑو،ن»¶ï¼ˆهڈ«هپڑهپœوœ؛و،ن»¶ï¼Œه°±وک¯و»،足è؟™ن¸ھن»¥هگژه°±è®¤ن¸؛解足ه¤ںç²¾ç،®ن؛†ï¼Œن¸چ需è¦پ继ç»ç®—ن¸‹هژ»ن؛†ï¼‰ه°±è¯•ن¸‹ن¸€ن¸ھ,ه½“然ن¸‹ن¸€ن¸ھو•°ن¸چوک¯ن¹±é€‰çڑ„,ن¹ںوœ‰ن¸€ه®ڑç« و³•هڈ¯ه¾ھم€‚وœ‰çڑ„ç®—و³•ï¼Œو¯ڈو¬،هڈھه°è¯•ن¸€ن¸ھو•°ï¼Œوœ‰çڑ„ه°±ه°è¯•ه¤ڑن¸ھ,而ن¸”و‰¾ن¸‹ن¸€ن¸ھو•°ه—(وˆ–ن¸‹ن¸€ç»„و•°ï¼‰çڑ„و–¹و³•ن¹ںهگ„ن¸چ相هگŒï¼Œهپœوœ؛و،ن»¶ن¹ںهگ„ن¸چ相هگŒï¼Œوœ€ç»ˆه¾—هˆ°çڑ„解精ه؛¦ن¹ںهگ„ن¸چ相هگŒï¼Œهڈ¯è§په¯¹و±‚و•°ه€¼è§£çڑ„ه¤چو‚ه؛¦çڑ„讨è®؛ن¸چ能脱ه¼€ه…·ن½“çڑ„ç®—و³•م€‚
ن¸€ن¸ھه…·ن½“çڑ„ç®—و³•ï¼ŒBunch-Kaufmanè®ç»ƒç®—و³•ï¼Œه…¸ه‹çڑ„و—¶é—´ه¤چو‚ه؛¦هœ¨O(Nsv3+LNsv2+dLNsv)ه’ŒO(dL2)ن¹‹é—´ï¼Œه…¶ن¸Nsvوک¯و”¯وŒپهگ‘é‡ڈçڑ„ن¸ھو•°ï¼ŒLوک¯è®ç»ƒé›†و ·وœ¬çڑ„ن¸ھو•°ï¼Œdوک¯و¯ڈن¸ھو ·وœ¬çڑ„ç»´و•°ï¼ˆهژںه§‹çڑ„ç»´و•°ï¼Œو²،وœ‰ç»ڈè؟‡هگ‘é«کç»´ç©؛é—´وک ه°„ن¹‹ه‰چçڑ„ç»´و•°ï¼‰م€‚ه¤چو‚ه؛¦ن¼ڑوœ‰هڈکهŒ–,وک¯ه› ن¸؛ه®ƒن¸چه…‰è·ں输ه…¥é—®é¢کçڑ„规و¨،وœ‰ه…³ï¼ˆن¸چه…‰ه’Œو ·وœ¬çڑ„و•°é‡ڈ,维و•°وœ‰ه…³ï¼‰ï¼Œن¹ںه’Œé—®é¢کوœ€ç»ˆçڑ„解وœ‰ه…³ï¼ˆهچ³و”¯وŒپهگ‘é‡ڈوœ‰ه…³ï¼‰ï¼Œه¦‚وœو”¯وŒپهگ‘é‡ڈو¯”较ه°‘,è؟‡ç¨‹ن¼ڑه؟«ه¾ˆه¤ڑ,ه¦‚وœو”¯وŒپهگ‘é‡ڈه¾ˆه¤ڑ,وژ¥è؟‘ن؛ژو ·وœ¬çڑ„و•°é‡ڈ,ه°±ن¼ڑن؛§ç”ںO(dL2)è؟™ن¸ھهچپهˆ†ç³ں糕çڑ„结وœï¼ˆç»™10,000ن¸ھو ·وœ¬ï¼Œو¯ڈن¸ھو ·وœ¬1000维,هں؛وœ¬ه°±ن¸چ用算ن؛†ï¼Œç®—ن¸چه‡؛و¥ï¼Œه‘µه‘µï¼Œè€Œè؟™ç§چ输ه…¥è§„و¨،ه¯¹و–‡وœ¬هˆ†ç±»و¥è¯´ه¤ھو£ه¸¸ن؛†ï¼‰م€‚
è؟™و ·ه†چه›ه¤´çœ‹ه°±ن¼ڑوکژ白ن¸؛ن»€ن¹ˆن¸€ه¯¹ن¸€و–¹و³•ه°½ç®،è¦پè®ç»ƒçڑ„ن¸¤ç±»هˆ†ç±»ه™¨و•°é‡ڈه¤ڑ,ن½†و€»و—¶é—´ه®é™…ن¸ٹو¯”ن¸€ه¯¹ه…¶ن½™و–¹و³•è¦په°‘ن؛†ï¼Œه› ن¸؛ن¸€ه¯¹ه…¶ن½™و–¹و³•و¯ڈو¬،è®ç»ƒéƒ½è€ƒè™‘ن؛†و‰€وœ‰و ·وœ¬ï¼ˆهڈھوک¯و¯ڈو¬،وٹٹن¸چهگŒçڑ„部هˆ†هˆ’هˆ†ن¸؛و£ç±»وˆ–者è´ں类而ه·²ï¼‰ï¼Œè‡ھ然و…¢ن¸ٹه¾ˆه¤ڑم€‚


- 2012-03-04 02:13
- وµڈ览 1008
- 评è®؛(0)
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
و€»çڑ„و¥è¯´ï¼ŒSVMوک¯ن¸€ç§چه¼؛ه¤§çڑ„وœ؛ه™¨ه¦ن¹ ç®—و³•ï¼Œé€‚用ن؛ژه¤„çگ†هˆ†ç±»ه’Œه›ه½’é—®é¢ک,特هˆ«وک¯ه½“و•°وچ®هˆ†ه¸ƒه¤چو‚م€پéç؛؟و€§هڈ¯هˆ†و—¶م€‚ه…¶و ¸ه؟ƒو¦‚ه؟µهŒ…و‹¬è¶…ه¹³é¢م€پé—´éڑ”م€پو”¯وŒپهگ‘é‡ڈه’Œو ¸ه‡½و•°ï¼Œé€ڑè؟‡è؟™ن؛›ه·¥ه…·ï¼ŒSVM能ه¤ںهœ¨é«کç»´ç©؛é—´ن¸و‰¾هˆ°وœ€ن½³çڑ„ه†³ç–边界م€‚...
虽然هژںه§‹çڑ„SVMç®—و³•ن»…适用ن؛ژن؛Œهˆ†ç±»é—®é¢ک,ن½†هڈ¯ن»¥é€ڑè؟‡ن¸چهگŒçڑ„ç–ç•¥ه°†ه…¶و‰©ه±•هˆ°ه¤ڑç±»هˆ†ç±»é—®é¢کن¸م€‚ه¸¸è§پçڑ„و–¹و³•هŒ…و‹¬â€œن¸€ه¯¹ن¸€â€ï¼ˆOne-vs-One, OvO)ه’Œâ€œن¸€ه¯¹ه¤ڑâ€ï¼ˆOne-vs-All, OvA)م€‚è؟™ن؛›ç–ç•¥é€ڑè؟‡و„ه»؛ه¤ڑن¸ھن؛Œهˆ†ç±»SVMو¥è§£ه†³ه¤ڑç±»...
**و”¯وŒپهگ‘é‡ڈوœ؛(SVM)ه…¥é—¨** و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,简称SVM)وک¯ن¸€ç§چهں؛ن؛ژç»ںè®،ه¦ه’Œن¼کهŒ–çگ†è®؛çڑ„监ç£ه¦ن¹ و¨،ه‹ï¼Œه¹؟و³›ه؛”用ن؛ژهˆ†ç±»ه’Œه›ه½’é—®é¢کم€‚ه®ƒçڑ„و ¸ه؟ƒو€وƒ³وک¯و‰¾هˆ°ن¸€ن¸ھوœ€ن¼کçڑ„超ه¹³é¢ï¼Œè¯¥è¶…ه¹³é¢èƒ½وœ€ه¤§ç¨‹ه؛¦هœ°ه°†...
结و„é£ژ险وœ€ه°ڈهŒ–وک¯SVMç®—و³•çڑ„ن¸€ن¸ھو ¸ه؟ƒو¦‚ه؟µم€‚هœ¨وœ؛ه™¨ه¦ن¹ ن¸ï¼Œوˆ‘ن»¬و— و³•ç›´وژ¥ن؛†è§£çœںه®و¨،ه‹ï¼Œهڈھ能é€ڑè؟‡é€‰و‹©ن¸€ن¸ھهپ‡è®¾و¨،ه‹و¥é€¼è؟‘ه®ƒم€‚ç”±ن؛ژçœںه®و¨،ه‹وœھçں¥ï¼Œوˆ‘ن»¬و— و³•ç›´وژ¥è®،ç®—و¨،ه‹ن¸ژçœںه®è§£ن¹‹é—´çڑ„误ه·®ï¼Œهچ³é£ژ险م€‚ه› و¤ï¼Œوˆ‘ن»¬é€ڑه¸¸ن½؟用...
و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,简称SVM)وک¯ن¸€ç§چç»ڈه…¸çڑ„监ç£ه¦ن¹ ç®—و³•ï¼Œç”±Cortesه’ŒVapnikهœ¨1995ه¹´وڈگه‡؛م€‚SVMهœ¨ه¤„çگ†ه°ڈو ·وœ¬م€پéç؛؟و€§ه’Œé«کç»´و•°وچ®و—¶è،¨çژ°ه‡؛ن¼کè¶ٹçڑ„و€§èƒ½ï¼Œه®ƒن¸چن»…能用ن؛ژهˆ†ç±»ن»»هٹ،,ن¹ں能ه؛”用ن؛ژه‡½و•°و‹ںهگˆç‰وœ؛ه™¨...
### SVMه…¥é—¨èµ„و–™è§£وگ #### و ‡é¢کï¼ڑSVMه…¥é—¨èµ„و–™(英و–‡) 该و ‡é¢کوکژç،®وŒ‡ه‡؛ن؛†و–‡و،£çڑ„ن¸»é¢کوک¯ه…³ن؛ژو”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine, SVM)çڑ„هں؛ç،€ه¦ن¹ وگو–™ï¼Œه¹¶ن¸”è؟™ن؛›èµ„و–™وک¯ن»¥è‹±و–‡ه½¢ه¼ڈه‘ˆçژ°çڑ„م€‚ #### وڈڈè؟°ï¼ڑ虽然说وک¯ه…¥é—¨ï¼Œ...
- **é«کç»´و¨،ه¼ڈ识هˆ«**ï¼ڑSVMç®—و³•ن¸چهڈ—ç»´ه؛¦ه¢هٹ çڑ„ه½±ه“چ,适用ن؛ژé«ک维特ه¾پç©؛é—´ن¸çڑ„هˆ†ç±»ن»»هٹ،م€‚ #### 1.3 SVMçڑ„ه؛”用领هںں 除ن؛†ç»ڈه…¸çڑ„هˆ†ç±»ن»»هٹ،ه¤–,SVMè؟ک被ه¹؟و³›ه؛”用ن؛ژه‡½و•°و‹ںهگˆç‰ه…¶ن»–وœ؛ه™¨ه¦ن¹ é—®é¢کن¸م€‚ن¾‹ه¦‚,هœ¨و–‡وœ¬هˆ†ç±»م€په›¾هƒڈ识هˆ«...
و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,SVM)وک¯ن¸€ç§چهœ¨وœ؛ه™¨ه¦ن¹ 领هںںه¹؟و³›ه؛”用çڑ„监ç£ه¦ن¹ ç®—و³•ï¼Œç”±Cortesه’ŒVapnikن؛ژ1995ه¹´وڈگه‡؛م€‚SVMçڑ„ن¸»è¦پن¼ک点هœ¨ن؛ژه…¶هœ¨ه¤„çگ†ه°ڈو ·وœ¬م€پéç؛؟و€§هڈٹé«کç»´و¨،ه¼ڈ识هˆ«ن»»هٹ،و—¶è،¨çژ°ه‡؛色,ه¹¶ن¸”能ه¤ںو‹“ه±•هˆ°...
**و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,简称SVM)**وک¯ن¸€ç§چه¼؛ه¤§çڑ„监ç£ه¦ن¹ ç®—و³•ï¼Œه¹؟و³›ه؛”用ن؛ژهˆ†ç±»ه’Œه›ه½’é—®é¢کم€‚وœ¬و•™وگه°†ه¸¦ن½ و·±ه…¥çگ†è§£SVMçڑ„هں؛وœ¬هژںçگ†ï¼Œç”±وµ…ه…¥و·±ï¼Œé€‚هگˆهˆه¦è€…ه…¥é—¨م€‚ن»¥ن¸‹وک¯ه¯¹SVMçڑ„详细éکگè؟°ï¼ڑ 1. **هں؛وœ¬و¦‚ه؟µ...
وœ¬و–‡و،£هŒ…هگ«SVMçڑ„详细وژ¨ه¯¼è؟‡ç¨‹ه’Œن¸€ن؛›هˆ«çڑ„资و–™و²،وœ‰è®°è½½çڑ„çگ†è§£م€‚éه¸¸é€‚هگˆه…¥é—¨ه’Œوƒ³ه…·ن½“çگ†è§£ن¸€ن؛›ç»†ه¾®ه¤„çڑ„هگŒه¦م€‚
**و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,简称SVM)**وک¯ن¸€ç§چه¼؛ه¤§çڑ„监ç£ه¦ن¹ ç®—و³•ï¼Œه¹؟و³›ه؛”用ن؛ژهˆ†ç±»ه’Œه›ه½’é—®é¢کم€‚وœ¬و•™ç¨‹ه°†و·±ه…¥وµ…ه‡؛هœ°ن»‹ç»چSVMçڑ„هں؛وœ¬و¦‚ه؟µم€په·¥ن½œهژںçگ†هڈٹه…¶هœ¨ه®é™…ه؛”用ن¸çڑ„ن¼کهٹ؟م€‚ ### 1. SVMو¦‚è؟° SVMوœ€هˆç”±...
### SVMه…¥é—¨çں¥è¯†è¯¦è§£ #### ن¸€م€پSVMو¦‚è؟°ن¸ژèµ·و؛گ و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine,简称SVM)وک¯ن¸€ç§چوœ‰ç›‘ç£çڑ„ه¦ن¹ و¨،ه‹ï¼Œن¸»è¦پ用ن؛ژهˆ†ç±»ه’Œه›ه½’هˆ†وگم€‚ه®ƒوک¯ç”±Cortesه’ŒVapnikهœ¨1995ه¹´é¦–و¬،وڈگه‡؛çڑ„م€‚è‡ھé‚£و—¶èµ·ï¼ŒSVMه› ه…¶هœ¨...
SVM(و”¯وŒپهگ‘é‡ڈوœ؛)وک¯ن¸€ç§چه¼؛ه¤§çڑ„监ç£ه¦ن¹ ç®—و³•ï¼Œه°¤ه…¶é€‚用ن؛ژه°ڈو ·وœ¬م€پéç؛؟و€§ه’Œé«کç»´و•°وچ®çڑ„هˆ†ç±»ه’Œه›ه½’ن»»هٹ،م€‚SVMçڑ„و ¸ه؟ƒو€وƒ³وک¯و„ه»؛ن¸€ن¸ھ能ه¤ںوœ€ه¤§هŒ–ç±»هˆ«é—´è¾¹ç•Œçڑ„هˆ†ç±»و¨،ه‹ï¼Œé€ڑè؟‡و‰¾هˆ°ن¸€ن¸ھوœ€ن¼کçڑ„超ه¹³é¢و¥هŒ؛هˆ†ن¸چهگŒç±»هˆ«çڑ„و ·وœ¬م€‚ 1....
### SVM(و”¯وŒپهگ‘é‡ڈوœ؛)ه…¥é—¨è¯¦è§£ #### ن¸€م€پSVMو¦‚览 **و”¯وŒپهگ‘é‡ڈوœ؛**(Support Vector Machine, SVM)وک¯ç”±Cortesه’ŒVapnikهœ¨1995ه¹´é¦–و¬،وڈگه‡؛çڑ„وœ؛ه™¨ه¦ن¹ و–¹و³•م€‚SVMهœ¨ه¤„çگ†ه°ڈو ·وœ¬م€پéç؛؟و€§ن»¥هڈٹé«کç»´و•°وچ®و—¶ه±•çژ°ه‡؛独特çڑ„ن¼کهٹ؟,ه¹¶ن¸”...
5. SVMن¼کهŒ–ç–ç•¥ï¼ڑه¦‚"هں؛ن؛ژMATLABçڑ„ن¸€ه¯¹ن¸€M_SVMç®—و³•ه®çژ°.pdf"و‰€ç¤؛,ن¸€ه¯¹ن¸€çڑ„M-SVMç®—و³•وک¯ه¤„çگ†ه¤ڑهˆ†ç±»é—®é¢کçڑ„ن¸€ç§چç–略,é€ڑè؟‡و„ه»؛ه¤ڑن¸ھن؛Œهˆ†ç±»ه™¨و¥è§£ه†³م€‚è؟™ç§چç–略简هŒ–ن؛†ه¤ڑهˆ†ç±»é—®é¢کçڑ„ه¤„çگ†ï¼Œوڈگé«کن؛†è®،ç®—و•ˆçژ‡م€‚ 6. ه¹¶è،ŒSVMï¼ڑéڑڈç€...
### و”¯وŒپهگ‘é‡ڈوœ؛(SVM)ه…¥é—¨è¯¦è§£ #### ن¸€م€پSVMçڑ„هں؛وœ¬و¦‚ه؟µن¸ژهڈ‘ه±•èƒŒو™¯ و”¯وŒپهگ‘é‡ڈوœ؛(Support Vector Machine, SVM)وک¯ن¸€ç§چهں؛ن؛ژç»ںè®،ه¦ن¹ çگ†è®؛çڑ„ه¼؛ه¤§وœ؛ه™¨ه¦ن¹ ç®—و³•ï¼Œوœ€هˆç”±Cortesه’ŒVapnikهœ¨1995ه¹´وڈگه‡؛م€‚SVMçڑ„و ¸ه؟ƒن¼کهٹ؟هœ¨ن؛ژ...
وœ¬è¯¾ن»¶ن¸»è¦پن»‹ç»چن؛†هچپه¤§ç»ڈه…¸وœ؛ه™¨ه¦ن¹ ç®—و³•ï¼Œن»¥ن¸‹ه°†è¯¦ç»†è§£وگه…¶ن¸çڑ„ه››ن¸ھو ¸ه؟ƒç®—و³•ï¼ڑه†³ç–و ‘م€پéڑڈوœ؛و£®و—م€پ逻辑ه›ه½’ه’Œو”¯وŒپهگ‘é‡ڈوœ؛(SVM)م€‚ 首ه…ˆï¼Œه†³ç–و ‘وک¯ن¸€ç§چهں؛ن؛ژ特ه¾پè؟›è،Œهˆ†ç±»çڑ„ç®—و³•م€‚ه®ƒé€ڑè؟‡و„ه»؛ن¸€ç³»هˆ—çڑ„é—®é¢ک(èٹ‚点),ه¯¹...
ن¸€èˆ¬çڑ„و”¯وŒپهگ‘é‡ڈوœ؛(SVM)هڈھ能ه¤ں用ن½œن؛Œهˆ†ç±»ï¼Œè€Œوœ¬و¬،ن¸ٹن¼ çڑ„ن»£ç پوک¯ن¸€ن¸ھه››هˆ†ç±»çڑ„و”¯وŒپهگ‘é‡ڈوœ؛(SVM)算و³•ه®çژ°ï¼Œن»£ç پçڑ„ه…³é”®éƒ¨هˆ†éƒ½ن¼ڑوœ‰و³¨é‡ٹ,适هگˆهˆڑه…¥é—¨çڑ„ه°ڈ白看م€‚وœ¬ن»£ç پè؟ک用هˆ°ن؛†libsvmè؟™ن¸ھه·¥ه…·ç®±ï¼Œéœ€è¦پ读者è‡ھه·±é…چ置,é…چç½®...