http://www.cppblog.com/guogangj/archive/2009/11/13/100876.html
十四、排序(Sort)
这可能是最有趣的一节。排序的考题,在各大公司的笔试里最喜欢出了,但我看多数考得都很简单,通常懂得冒泡排序就差不多了,确实,我在刚学数据机构时候,觉得冒泡排序真的很“精妙”,我怎么就想不出呢?呵呵,其实冒泡通常是效率最差的排序算法,差多少?请看本文,你一定不会后悔的。
1、冒泡排序(Bubbler Sort)
前面刚说了冒泡排序的坏话,但冒泡排序也有其优点,那就是好理解,稳定,再就是空间复杂度低,不需要额外开辟数组元素的临时保存控件,当然了,编写起来也容易。
其算法很简单,就是比较数组相邻的两个值,把大的像泡泡一样“冒”到数组后面去,一共要执行N的平方除以2这么多次的比较和交换的操作(N为数组元素),其复杂度为Ο(n²),如图:
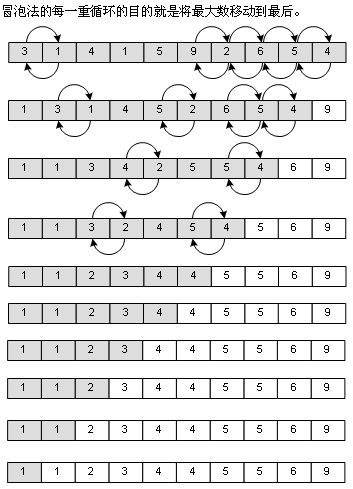
2、直接插入排序(Straight Insertion Sort)
冒泡法对于已经排好序的部分(上图中,数组显示为白色底色的部分)是不再访问的,插入排序却要,因为它的方法就是从未排序的部分中取出一个元素,插入到已经排好序的部分去,插入的位置我是从后往前找的,这样可以使得如果数组本身是有序(顺序)的话,速度会非常之快,不过反过来,数组本身是逆序的话,速度也就非常之慢了,如图:
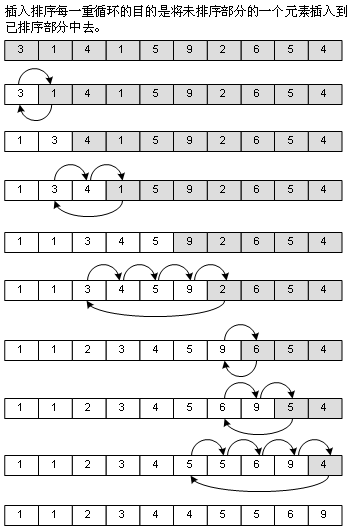
3、二分插入排序(Binary Insertion Sort)
这是对直接插入排序的改进,由于已排好序的部分是有序的,所以我们就能使用二分查找法确定我们的插入位置,而不是一个个找,除了这点,它跟插入排序没什么区别,至于二分查找法见我前面的文章(本系列文章的第四篇)。图跟上图没什么差别,差别在于插入位置的确定而已,性能却能因此得到不少改善。(性能分析后面会提到)
4、直接选择排序(Straight Selection Sort)
这是我在学数据结构前,自己能够想得出来的排序法,思路很简单,用打擂台的方式,找出最大的一个元素,和末尾的元素交换,然后再从头开始,查找第1个到第N-1个元素中最大的一个,和第N-1个元素交换……其实差不多就是冒泡法的思想,但整个过程中需要移动的元素比冒泡法要少,因此性能是比冒泡法优秀的。看图:
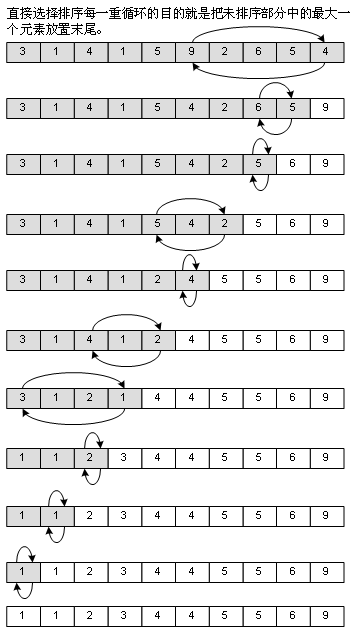
5、快速排序(Quick Sort)
快速排序是非常优秀的排序算法,初学者可能觉得有点难理解,其实它是一种“分而治之”的思想,把大的拆分为小的,小的再拆分为更小的,所以你一会儿从代码中就能很清楚地看到,用了递归。如图:
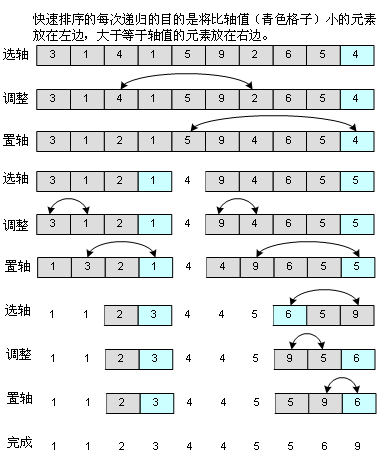
其中要选择一个轴值,这个轴值在理想的情况下就是中轴,中轴起的作用就是让其左边的元素比它小,它右边的元素不小于它。(我用了“不小于”而不是“大于”是考虑到元素数值会有重复的情况,在代码中也能看出来,如果把“>=”运算符换成“>”,将会出问题)当然,如果中轴选得不好,选了个最大元素或者最小元素,那情况就比较糟糕,我选轴值的办法是取出第一个元素,中间的元素和最后一个元素,然后从这三个元素中选中间值,这已经可以应付绝大多数情况。
6、改进型快速排序(Improved Quick Sort)
快速排序的缺点是使用了递归,如果数据量很大,大量的递归调用会不会导致性能下降呢?我想应该会的,所以我打算作这么种优化,考虑到数据量很小的情况下,直接选择排序和快速排序的性能相差无几,那当递归到子数组元素数目小于30的时候,我就是用直接选择排序,这样会不会提高一点性能呢?我后面分析。排序过程可以参考前面两个图,我就不另外画了。
7、桶排序(Bucket Sort)
这是迄今为止最快的一种排序法,其时间复杂度仅为Ο(n),也就是线性复杂度!不可思议吧?但它是有条件的。举个例子:一年的全国高考考生人数为500万,分数使用标准分,最低100,最高900,没有小数,你把这500万元素的数组排个序。我们抓住了这么个非常特殊的条件,就能在毫秒级内完成这500万的排序,那就是:最低100,最高900,没有小数,那一共可出现的分数可能有多少种呢?一共有900-100+1=801,那么多种,想想看,有没有什么“投机取巧”的办法?方法就是创建801个“桶”,从头到尾遍历一次数组,对不同的分数给不同的“桶”加料,比如有个考生考了500分,那么就给500分的那个桶(下标为500-100)加1,完成后遍历一下这个桶数组,按照桶值,填充原数组,100分的有1000人,于是从0填到999,都填1000,101分的有1200人,于是从1000到2019,都填入101……如图:
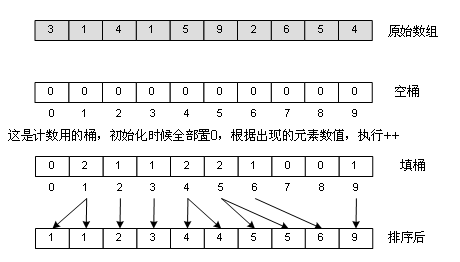
很显然,如果分数不是从100到900的整数,而是从0到2亿,那就要分配2亿个桶了,这是不可能的,所以桶排序有其局限性,适合元素值集合并不大的情况。
8、基数排序(Radix Sort)
基数排序是对桶排序的一种改进,这种改进是让“桶排序”适合于更大的元素值集合的情况,而不是提高性能。它的思想是这样的,比如数值的集合是8位整数,我们很难创建一亿个桶,于是我们先对这些数的个位进行类似桶排序的排序(下文且称作“类桶排序”吧),然后再对这些数的十位进行类桶排序,再就是百位……一共做8次,当然,我说的是思路,实际上我们通常并不这么干,因为C++的位移运算速度是比较快,所以我们通常以“字节”为单位进行桶排序。但下图为了画图方便,我是以半字节(4 bit)为单位进行类桶排序的,因为字节为单位进行桶排得画256个桶,有点难画,如图:
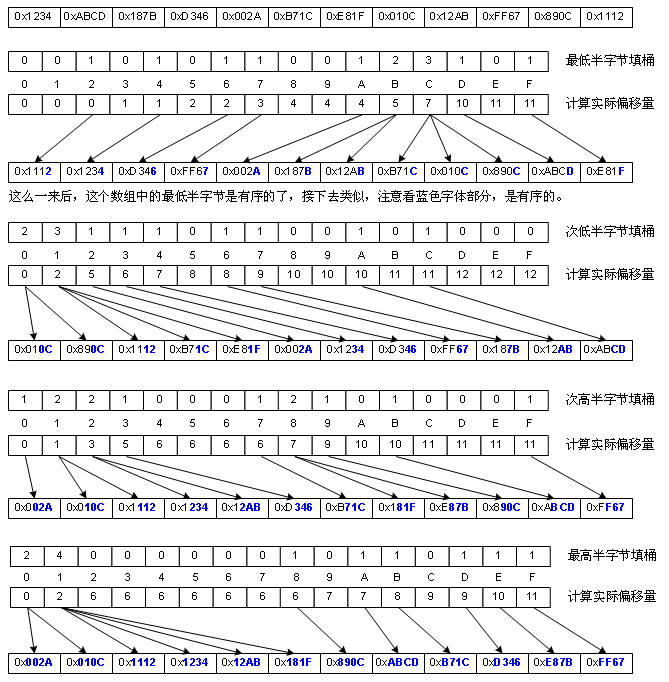
基数排序适合数值分布较广的情况,但由于需要额外分配一个跟原始数组一样大的暂存空间,它的处理也是有局限性的,对于元素数量巨大的原始数组而言,空间开销较大。性能上由于要多次“类桶排序”,所以不如桶排序。但它的复杂度跟桶排序一样,也是Ο(n),虽然它用了多次循环,但却没有循环嵌套。
9、性能分析和总结
先不分析复杂度为Ο(n)的算法,因为速度太快,而且有些条件限制,我们先分析前六种算法,即:冒泡,直接插入,二分插入,直接选择,快速排序和改进型快速排序。
我的分析过程并不复杂,尝试产生一个随机数数组,数值范围是0到7FFF,这正好可以用C++的随机函数rand()产生随机数来填充数组,然后尝试不同长度的数组,同一种长度的数组尝试10次,以此得出平均值,避免过多波动,最后用Excel对结果进行分析,OK,上图了。
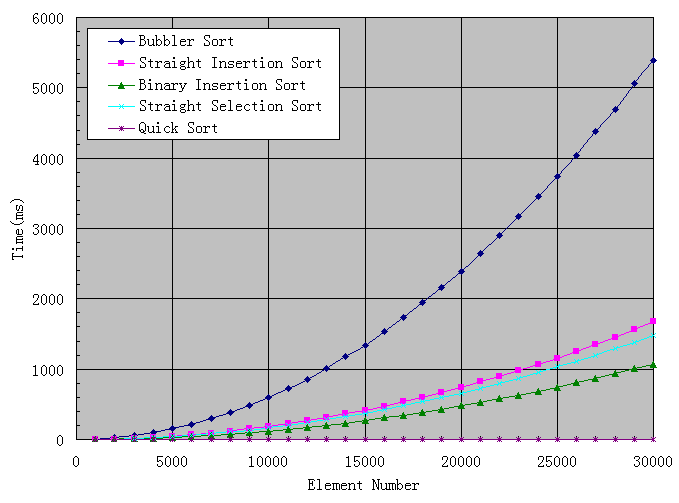
最差的一眼就看出来了,是冒泡,直接插入和直接选择旗鼓相当,但我更偏向于使用直接选择,因为思路简单,需要移动的元素相对较少,况且速度还稍微快一点呢,从图中看,二分插入的速度比直接插入有了较大的提升,但代码稍微长了一点点。
令人感到比较意外的是快速排序,3万点以内的快速排序所消耗的时间几乎可以忽略不计,速度之快,令人振奋,而改进型快速排序的线跟快速排序重合,因此不画出来。看来要对快速排序进行单独分析,我加大了数组元素的数目,从5万到150万,画出下图:
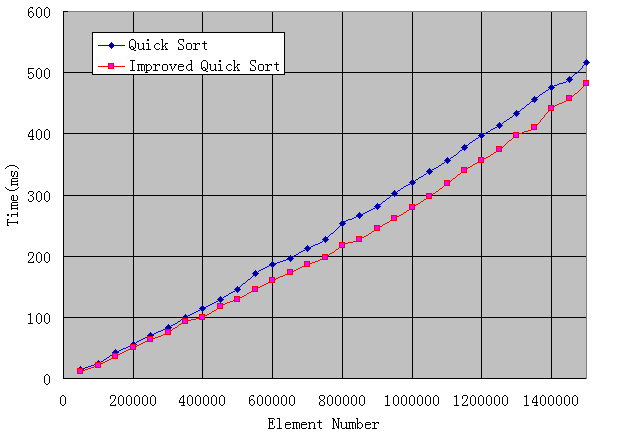
可以看到,即便到了150万点,两种快速排序也仅需差不多半秒钟就完成了,实在快,改进型快速排序性能确实有微略提高,但并不明显,从图中也能看出来,是不是我设置的最小快速排序元素数目不太合适?但我尝试了好几个值都相差无几。
最后看线性复杂度的排序,速度非常惊人,我从40万测试到1200万,结果如图:
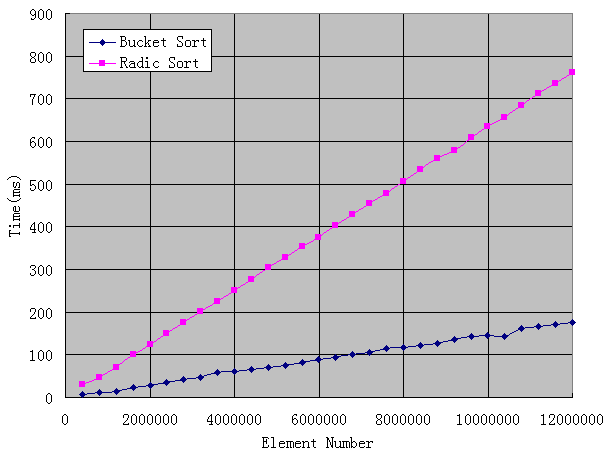
可见稍微调整下算法,速度可以得到质的飞升,而不是我们以前所认为的那样:再快也不会比冒泡法快多少啊?
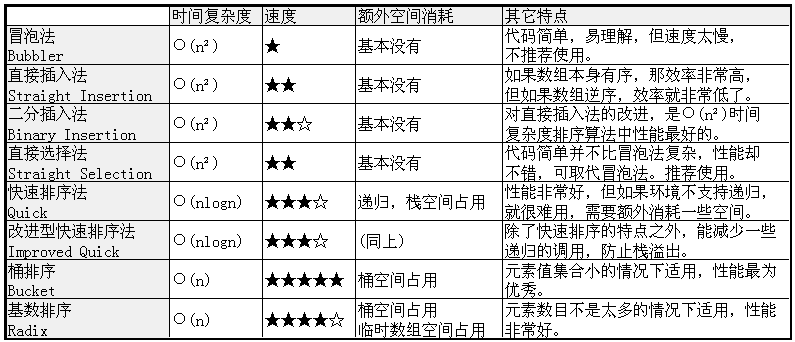
我最后制作一张表,比较一下这些排序法:
还有一个最后:附上我的代码。
#include "stdio.h"
#include "stdlib.h"
#include "time.h"
#include "string.h"
void BubblerSort(int *pArray, int iElementNum);
void StraightInsertionSort(int *pArray, int iElementNum);
void BinaryInsertionSort(int *pArray, int iElementNum);
void StraightSelectionSort(int *pArray, int iElementNum);
void QuickSort(int *pArray, int iElementNum);
void ImprovedQuickSort(int *pArray, int iElementNum);
void BucketSort(int *pArray, int iElementNum);
void RadixSort(int *pArray, int iElementNum);
//Tool functions.
void PrintArray(int *pArray, int iElementNum);
void StuffArray(int *pArray, int iElementNum);
inline void Swap(int& a, int& b);
#define SINGLE_TEST
int main(int argc, char* argv[])
{
srand(time(NULL));
#ifndef SINGLE_TEST
int i, j, iTenTimesAvg;
for(i=50000; i<=1500000; i+=50000)
{
iTenTimesAvg = 0;
for(j=0; j<10; j++)
{
int iElementNum = i;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
ImprovedQuickSort(pArr, iElementNum);
//PrintArray(pArr, iElementNum);
clock_t ctEnd = clock();
delete[] pArr;
iTenTimesAvg += ctEnd-ctBegin;
}
printf("%d\t%d\n", i, iTenTimesAvg/10);
}
#else
//Single test
int iElementNum = 100;
int *pArr = new int[iElementNum];
StuffArray(pArr, iElementNum);
PrintArray(pArr, iElementNum);
clock_t ctBegin = clock();
QuickSort(pArr, iElementNum);
clock_t ctEnd = clock();
PrintArray(pArr, iElementNum);
delete[] pArr;
int iTenTimesAvg = ctEnd-ctBegin;
printf("%d\t%d\n", iElementNum, iTenTimesAvg);
#endif
return 0;
}
void BubblerSort(int *pArray, int iElementNum)
{
int i, j, x;
for(i=0; i<iElementNum-1; i++)
{
for(j=0; j<iElementNum-1-i; j++)
{
if(pArray[j]>pArray[j+1])
{
//Frequent swap calling may lower performance.
//Swap(pArray[j], pArray[j+1]);
//Do you think bit operation is better? No! Please have a try.
//pArray[j] ^= pArray[j+1];
//pArray[j+1] ^= pArray[j];
//pArray[j] ^= pArray[j+1];
//This kind of traditional swap is the best.
x = pArray[j];
pArray[j] = pArray[j+1];
pArray[j+1] = x;
}
}
}
}
void StraightInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
for(j=i; j>0; j--)
{
if(iHandling>=pArray[j-1])
break;
}
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void BinaryInsertionSort(int *pArray, int iElementNum)
{
int i, j, k;
for(i=0; i<iElementNum; i++)
{
int iHandling = pArray[i];
int iLeft = 0;
int iRight = i-1;
while(iLeft<=iRight)
{
int iMiddle = (iLeft+iRight)/2;
if(iHandling < pArray[iMiddle])
{
iRight = iMiddle-1;
}
else if(iHandling > pArray[iMiddle])
{
iLeft = iMiddle+1;
}
else
{
j = iMiddle + 1;
break;
}
}
if(iLeft>iRight)
j = iLeft;
for(k=i; k>j; k--)
pArray[k] = pArray[k-1];
pArray[j] = iHandling;
}
}
void StraightSelectionSort(int *pArray, int iElementNum)
{
int iEndIndex, i, iMaxIndex, x;
for(iEndIndex=iElementNum-1; iEndIndex>0; iEndIndex--)
{
for(i=0, iMaxIndex=0; i<iEndIndex; i++)
{
if(pArray[i]>=pArray[iMaxIndex])
iMaxIndex = i;
}
x = pArray[iMaxIndex];
pArray[iMaxIndex] = pArray[iEndIndex];
pArray[iEndIndex] = x;
}
}
void BucketSort(int *pArray, int iElementNum)
{
//This is really buckets.
int buckets[RAND_MAX];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[pArray[i]-1];
}
int iAdded = 0;
for(i=0; i<RAND_MAX; i++)
{
while((buckets[i]--)>0)
{
pArray[iAdded++] = i;
}
}
}
void RadixSort(int *pArray, int iElementNum)
{
int *pTmpArray = new int[iElementNum];
int buckets[0x100];
memset(buckets, 0, sizeof(buckets));
int i;
for(i=0; i<iElementNum; i++)
{
++buckets[(pArray[i])&0xFF];
}
//Convert number to offset
int iPrevNum = buckets[0];
buckets[0] = 0;
int iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pTmpArray[buckets[(pArray[i])&0xFF]++] = pArray[i];
}
//////////////////////////////////////////////////////////////////////////
memset(buckets, 0, sizeof(buckets));
for(i=0; i<iElementNum; i++)
{
++buckets[(pTmpArray[i]>>8)&0xFF];
}
//Convert number to offset
iPrevNum = buckets[0];
buckets[0] = 0;
iThisNum;
for(i=1; i<0x100; i++)
{
iThisNum = buckets[i];
buckets[i] = buckets[i-1] + iPrevNum;
iPrevNum = iThisNum;
}
for(i=0; i<iElementNum; i++)
{
pArray[buckets[((pTmpArray[i]>>8)&0xFF)]++] = pTmpArray[i];
}
delete[] pTmpArray;
}
void QuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>1)
QuickSort(pArray, iLeft);
if(iElementNum-iLeft-1>=1)
QuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void ImprovedQuickSort(int *pArray, int iElementNum)
{
int iTmp;
//Select the pivot make it to the right side.
int& iLeftIdx = pArray[0];
int& iRightIdx = pArray[iElementNum-1];
int& iMiddleIdx = pArray[(iElementNum-1)/2];
if(iLeftIdx>iMiddleIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iRightIdx>iMiddleIdx)
{
iTmp = iRightIdx;
iRightIdx = iMiddleIdx;
iMiddleIdx = iTmp;
}
if(iLeftIdx>iRightIdx)
{
iTmp = iLeftIdx;
iLeftIdx = iRightIdx;
iRightIdx = iTmp;
}
//Make pivot's left element and right element.
int iLeft = 0;
int iRight = iElementNum-2;
int& iPivot = pArray[iElementNum-1];
while (1)
{
while (iLeft<iRight && pArray[iLeft]<iPivot) ++iLeft;
while (iLeft<iRight && pArray[iRight]>=iPivot) --iRight;
if(iLeft>=iRight)
break;
iTmp = pArray[iLeft];
pArray[iLeft] = pArray[iRight];
pArray[iRight] = iTmp;
}
//Make the i
if(pArray[iLeft]>iPivot)
{
iTmp = pArray[iLeft];
pArray[iLeft] = iPivot;
iPivot = iTmp;
}
if(iLeft>30)
ImprovedQuickSort(pArray, iLeft);
else
StraightSelectionSort(pArray, iLeft);
if(iElementNum-iLeft-1>=30)
ImprovedQuickSort(&pArray[iLeft+1], iElementNum-iLeft-1);
else
StraightSelectionSort(&pArray[iLeft+1], iElementNum-iLeft-1);
}
void StuffArray(int *pArray, int iElementNum)
{
int i;
for(i=0; i<iElementNum; i++)
{
pArray[i] = rand();
}
}
void PrintArray(int *pArray, int iElementNum)
{
int i;
for(i=0; i<iElementNum; i++)
{
printf("%d ", pArray[i]);
}
printf("\n\n");
}
void Swap(int& a, int& b)
{
int c = a;
a = b;
b = c;
}
分享到:





相关推荐
《图解数据结构》是一本深受程序员喜爱的书籍,它以直观易懂的方式介绍了各种重要的数据结构及其在C++中的实现。源码是学习和理解数据结构的关键辅助工具,能够帮助读者更深入地掌握每种数据结构的工作原理。在这个...
排列算法是计算机科学中的一种基本算法,用于对数据进行排序。常见的排序算法有八种,即选择排序、冒泡排序、插入排序、归并排序、快速排序、堆排序、.radix 排序和基数排序。 一、分类 内部排序和外部排序是两种...
《图解数据结构使用Python》是一本以Python语言为载体,深入浅出讲解数据结构的书籍。这本书由吴灿明撰写,旨在帮助读者通过实际的编程示例理解各种数据结构的实现与应用。在这个名为"DataStructure-UsingPython-...
二叉树、平衡树(如AVL树、红黑树)和搜索树(如BST)是重要的树形数据结构,它们在搜索、排序和数据组织中有广泛应用。 5. **图**:图结构用于表示对象之间的复杂关系,如网络、交通路线等。图的遍历算法(深度...
《SQL Server 2000 图解教程——上》是一份专为初学者设计的数据库学习资源,通过图文并茂的方式深入浅出地讲解了SQL Server 2000的基础知识和操作技巧。本教程旨在帮助读者快速掌握SQL Server 2000的基本概念和功能...
《尚硅谷韩顺平图解Java数据结构和算法》是一份综合性的学习资源,涵盖了Java编程中的核心概念——数据结构和算法。这份压缩包“data-structures.zip”包含了一系列的知识文档和配套的Java源代码,旨在帮助学习者...
6. **堆排序**:堆排序利用了数据结构——堆的特性。堆是一个近似完全二叉树的结构,并同时满足堆的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序可以分为建堆和调整堆两步,时间复杂度为O(n ...
**哈希表**(Hash table,也称为散列表)是一种重要的数据结构,主要用于实现高效的键值对存储和检索。它通过一个特定的散列函数将键映射到表的一个位置,从而能够快速地访问记录。 - **散列函数**:这是哈希表的...
本书内容涵盖了数据结构和算法的基础知识,包括排序、图的算法等高级主题。它不仅为读者提供了理论知识,还注重了算法的实际应用和设计技术的讲解。为了使内容易于理解,作者使用通俗语言描述算法,并用伪代码形式...
同时,这一部分还涉及一些较为复杂的算法和数据结构,如树、傅里叶变换、并行算法、MapReduce、反向索引、布隆过滤器、局部敏感的散列算法、Diffie-Hellman密钥交换等,这些在实际应用中广泛使用。 为了确保真正掌握...
随着疫情的缓解,我继续前进,开始接触更深层次的编程知识——数据结构与算法。我通过AcWing平台进行在线练习,并购买了算法基础课程。快速排序、归并排序、二分查找、双指针、前缀和、位运算、单调栈、KMP算法这些...
NumPy是Python中用于科学计算的核心库,它提供了一种高效的数据结构——多维数组对象,也称为数组或NDArray。本篇文章将详细介绍NumPy在数据处理中的基本操作,包括一维数组(向量)、二维数组(矩阵)以及更高维度...
《轻松学C#(图解版)》完整扫描版================================================================ 基本信息 作者:谷涛、扶晓、毕国锋 丛书名:轻松学开发 出版社:电子工业出版社 ISBN:978-7-121-20223-0 出版...
### 数据结构期末考试知识点解析 #### 一、计算题 (63分) ##### 1. 是否为最大堆?为什么?并图示之。(8分) **题目解析:** 本题考查的是最大堆(Max Heap)的基本概念及其性质。最大堆是一种特殊的完全二叉树...
《高级数据结构在Java中的应用——20181 Unisinos补充教程》 本教程主要聚焦于Java语言中高级数据结构的运用,是2018年Unisinos大学的一项教学补充材料。数据结构是计算机科学的重要组成部分,它涉及到如何在内存中...
其次,"数据结构与算法分析——Java语言描述"这本书可能会详细讲解如何使用Java来实现和理解各种数据结构(如数组、链表、栈、队列、树、图等)以及基础算法(排序、搜索、图遍历等)。数据结构是存储和组织数据的...
leetcode 分类 好好学习,天天向上~ LeetCode 题解 C# 版本~ 推荐书籍 《图解算法》 推荐文章 ...排序 选择排序(Selection ...—— 简单直观的排序算法,O(n^2) ...的题目,是一些数据结构或排序算法的实现 Bas
Oracle 10g提供了强大的图形化工具——Oracle Enterprise Manager (EM),通过它可以在Web界面上方便地管理Oracle数据库。Oracle EM可以通过浏览器访问,地址通常是`http://localhost:1158/em`。在这里,管理员可以...
第12章 数据结构 第13章 C预处理 第14章 C语言的其他专题 第15章 基于Allegro C函数库的游戏编程 第16章 排序:更深入的透视 第17章 C99简介 第18章 C++,一个更好的C;介绍对象技术 第19章 类与对象简介 第20章 类...