
ن¸ٹ篇说ن؛†هچٹه¤©ï¼Œهچ´ه›éپ؟ن؛†ن¸€ن¸ھé‡چè¦پçڑ„é—®é¢کï¼ڑن¸؛ن»€ن¹ˆè¦پ用ه¼‚و¥ه‘¢ï¼Œه®ƒوœ‰ن»€ن¹ˆو ·çڑ„ه¥½ه¤„ï¼ںه¦çژ‡çڑ„说,وˆ‘ه¯¹è؟™ç‚¹çڑ„认识ن¸چوک¯ه¤ھو·±هˆ»ï¼ˆه¥—هڈ¥ن؟—è¯ï¼Œهڈھهڈ¯و„ڈن¼ڑ,ن¸چهڈ¯è¨€ن¼ )م€‚è؟کوک¯ن¸¾ن¸ھن¾‹هگهگ§ï¼ڑ
و¯”ه¦‚Clientهگ‘Serverهڈ‘é€پن¸€ن¸ھrequest,Serverو”¶هˆ°هگژ需è¦پ100msçڑ„ه¤„çگ†و—¶é—´ï¼Œن¸؛ن؛†و–¹ن¾؟èµ·è§پ,وˆ‘ن»¬ه؟½ç•¥وژ‰ç½‘络çڑ„ه»¶è؟ں,ه¹¶ن¸”,وˆ‘ن»¬è®¤ن¸؛Server端çڑ„ه¤„çگ†èƒ½هٹ›وک¯و— ç©·ه¤§çڑ„م€‚هœ¨è؟™ن¸ھuse caseن¸‹ï¼Œه¦‚وœé‡‡ç”¨هگŒو¥وœ؛هˆ¶ï¼Œهچ³Clientهڈ‘é€پrequest -> ç‰ه¾…结وœ -> 继ç»هڈ‘é€پ,那ن¹ˆï¼Œن¸€ن¸ھç؛؟程ن¸€ç§’é’ںن¹‹ه†…هڈھ能ه¤ںهڈ‘é€پ10ن¸ھrequest,ه¦‚وœه¸Œوœ›è¾¾هˆ°10000 request/sçڑ„هڈ‘é€پهژ‹هٹ›ï¼Œé‚£ن¹ˆClient端ه°±éœ€è¦پهˆ›ه»؛1000ن¸ھç؛؟程,而è؟™ن¹ˆه¤ڑç؛؟程çڑ„context switchه°±وˆگن¸؛clientçڑ„è´ںو‹…ن؛†م€‚而采用ه¼‚و¥وœ؛هˆ¶ï¼Œه°±ن¸چهکهœ¨è؟™ن¸ھé—®é¢کن؛†م€‚Clientه°†requestهڈ‘é€په‡؛هژ»هگژ,立هچ³هڈ‘é€پن¸‹ن¸€ن¸ھrequest,çگ†è®؛ن¸ٹ,ه®ƒèƒ½ه¤ںè¾¾هˆ°ç½‘هچ،هڈ‘é€پو•°وچ®çڑ„وپé™گم€‚ه½“然,هگŒو—¶éœ€è¦پوœ‰وœ؛هˆ¶ن¸چو–çڑ„وژ¥و”¶و¥è‡ھServer端çڑ„responseم€‚
ن»¥ن¸ٹçڑ„ن¾‹هگه…¶ه®ه°±وک¯è؟™ç¯‡çڑ„ن¸»é¢ک,ه¼‚و¥çڑ„و¶ˆوپ¯وœ؛هˆ¶ï¼Œهں؛وœ¬çڑ„وµپ程وک¯è؟™و ·çڑ„ï¼ڑ
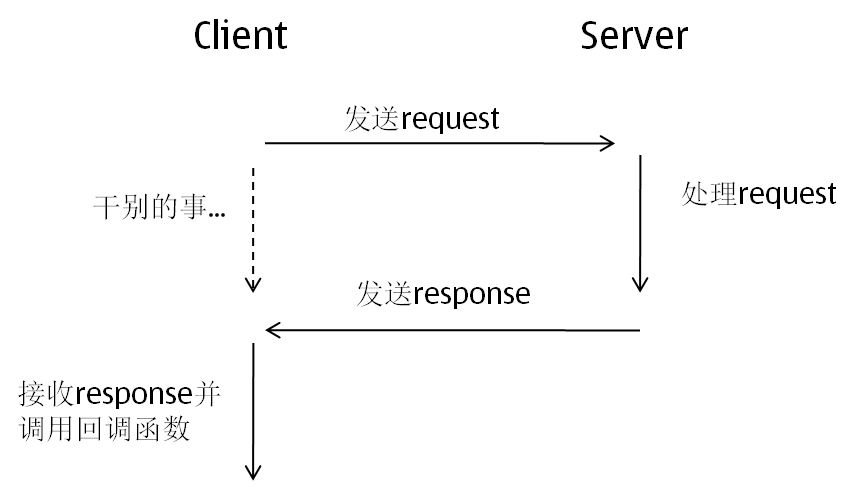
ه¦‚وœن»”细çگ¢ç£¨çڑ„è¯ï¼Œن¼ڑهڈ‘çژ°è؟™ن¸ھوµپ程ن¸وœ‰ن¸¤ن¸ھه¾ˆé‡چè¦پçڑ„é—®é¢ک需è¦پ解ه†³ï¼ڑ
1. ه½“clientوژ¥و”¶هˆ°responseهگژ,و€ژو ·ç،®è®¤ه®ƒهˆ°ه؛•وک¯ن¹‹ه‰چه“ھن¸ھrequestçڑ„responseه‘¢ï¼ں
2. ه¦‚وœهڈ‘é€پن¸€ن¸ھrequestهگژ,è؟™ن¸ھrequestه¯¹ه؛”çڑ„responseç”±ن؛ژç§چç§چهژںه› (و¯”ه¦‚server端ه‡؛é—®é¢کن؛†ï¼‰ن¸€ç›´و²،وœ‰è؟”ه›م€‚clientو€ژن¹ˆèƒ½ه¤ںهڈ‘çژ°ç±»ن¼¼è؟™و ·é•؟و—¶é—´و²،وœ‰و”¶هˆ°responseçڑ„requestه‘¢ï¼ں
ه¯¹ن؛ژ第ن¸€ن¸ھé—®é¢ک,ن¸€èˆ¬ن¼ڑه°è¯•ç»™و¯ڈن¸ھrequestهˆ†é…چن¸€ن¸ھ独ن¸€و— ن؛Œçڑ„ID,è؟”ه›çڑ„Responseن¼ڑهگŒو—¶وگ؛ه¸¦è؟™ن¸ھID,è؟™و ·ه°±èƒ½ه¤ںه°†requestه’Œresponseه¯¹ه؛”ن¸ٹن؛†م€‚
ه¯¹ن؛ژ第ن؛Œن¸ھé—®é¢ک,需è¦پوœ‰ن¸€ن¸ھtimeoutوœ؛هˆ¶ï¼Œه¯¹ن؛ژو¯ڈن¸€ن¸ھrequest都وœ‰ن¸€ن¸ھه®ڑو—¶ه™¨ï¼Œه¦‚وœهˆ°وŒ‡ه®ڑو—¶é—´ن»چ然و²،وœ‰è؟”ه›ç»“وœï¼Œé‚£ن¹ˆن¼ڑ触هڈ‘timeoutو“چن½œم€‚ه¤ڑ说ن¸€هڈ¥ï¼Œtimeoutوœ؛هˆ¶ه…¶ه®ه¯¹ن؛ژو¶‰هڈٹ网络çڑ„هگŒو¥وœ؛هˆ¶ن¹ںوک¯éه¸¸وœ‰ه؟…è¦پçڑ„,ه› ن¸؛وœ‰هڈ¯èƒ½clientن¸ژserverن¹‹é—´çڑ„链وژ¥هڈن؛†ï¼Œهœ¨وپ端وƒ…ه†µن¸‹ï¼Œclientن¼ڑ被ن¸€ç›´éک»ه،ن½ڈم€‚
ç؛¸ن¸ٹè°ˆه…µن؛†è؟™ن¹ˆن¹…,è؟کوک¯çœ‹ن¸€ن¸ھه®é™…çڑ„ن¾‹هگم€‚وˆ‘هœ¨è؟™é‡Œç”¨Hadoopçڑ„RPCن»£ç پن¸¾ن¾‹م€‚è؟™é‡Œéœ€è¦پن؛‹ه…ˆè¯´وکژçڑ„وک¯ï¼ŒHadoopçڑ„RPCه¯¹ه¤–çڑ„وژ¥هڈ£ه…¶ه®وک¯هگŒو¥çڑ„,ن½†وک¯ï¼ŒRPCçڑ„ه†…部ه®çژ°ه…¶ه®وک¯ه¼‚و¥و¶ˆوپ¯وœ؛هˆ¶م€‚ه¤ڑ说و— ç›ٹ,直وژ¥çœ‹ن»£ç پهگ§ï¼ˆè®¨è®؛çڑ„و‰€وœ‰ن»£ç پ都هœ¨org.apache.hadoop.ipc.Client.java 里)ï¼ڑ
آ
- publicآ Writableآ call(Writableآ param,آ ConnectionIdآ remoteId)آ آ آ آ
- آ آ آ آ throwsآ InterruptedException,آ IOExceptionآ {آ آ
- آ آ آ آ //ه…·ن½“çڑ„ن»£ç پن¸€ن¼ڑه†چ看... آ آ
- }آ آ
آ
è؟™ه°±وک¯Client.javaه¯¹ه¤–وڈگن¾›çڑ„وژ¥هڈ£م€‚ن¸€ه…±وœ‰ن¸¤ن¸ھهڈ‚و•°ï¼Œparamوک¯ه¸Œوœ›هڈ‘é€پçڑ„request,remoteIdوک¯وŒ‡è؟œç¨‹serverه¯¹ه؛”çڑ„Idم€‚ه‡½و•°çڑ„è؟”ه›ه°±وک¯response(ن¹ںوک¯ç»§و‰؟è‡ھwritable)م€‚و‰€ن»¥è¯´ï¼Œè؟™وک¯ن¸€ن¸ھهگŒو¥è°ƒç”¨ï¼Œن¸€و—¦callه‡½و•°è؟”ه›ï¼Œé‚£ن¹ˆresponseن¹ںه°±و‹؟هˆ°ن؛†م€‚
callه‡½و•°çڑ„ه…·ن½“ه®çژ°ن¸€ن¼ڑه†چ看,ه…ˆن»‹ç»چClientن¸ن¸¤ن¸ھé‡چè¦پçڑ„ه†…部类ï¼ڑ
آ
- آ privateآ classآ Callآ {آ آ
- آ آ آ intآ id;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ callآ id آ آ
- آ آ آ Writableآ param;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ parameter آ آ
- آ آ آ Writableآ value;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ value,آ nullآ ifآ error آ آ
- آ آ آ IOExceptionآ error;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ exception,آ nullآ ifآ value آ آ
- آ آ آ booleanآ done;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ trueآ whenآ callآ isآ done آ آ
- آ آ آ protectedآ Call(Writableآ param)آ {آ آ
- آ آ آ آ آ this.paramآ =آ param;آ آ
- آ آ آ آ آ synchronizedآ (Client.this)آ {آ آ
- آ آ آ آ آ آ آ this.idآ =آ counter++;آ آ
- آ آ آ آ آ }آ آ
- آ آ آ }آ آ
- آ آ آ protectedآ synchronizedآ voidآ callComplete()آ {آ آ
- آ آ آ آ آ this.doneآ =آ true;آ آ
- آ آ آ آ آ notify();آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ notifyآ caller آ آ
- آ آ آ }آ آ
- //......... آ آ
- آ آ آ آ آ
- آ آ آ publicآ synchronizedآ voidآ setValue(Writableآ value)آ {آ آ
- آ آ آ آ آ this.valueآ =آ value;آ آ
- آ آ آ آ آ callComplete();آ آ
- آ آ آ }آ آ
- آ آ آ آ آ
- آ آ آ publicآ synchronizedآ Writableآ getValue()آ {آ آ
- آ آ آ آ آ returnآ value;آ آ
- آ آ آ }آ آ
- آ }آ آ
آ
callè؟™ن¸ھç±»ه¯¹ه؛”çڑ„ه°±وک¯ن¸€و¬،ه¼‚و¥è¯·و±‚م€‚ه®ƒçڑ„ه‡ ن¸ھوˆگه‘کهڈکé‡ڈï¼ڑ
idï¼ڑ è؟™ن¸ھه°±وک¯ن¹‹ه‰چوڈگè؟‡çڑ„,ه¯¹ن؛ژو¯ڈن¸€ن¸ھrequest都需è¦پهˆ†é…چن¸€ن¸ھه”¯ن¸€و ‡ç¤؛符,è؟™و ·وژ¥و”¶هˆ°responseهگژو‰چ能çں¥éپ“هˆ°ه؛•ه¯¹ه؛”ه“ھن¸ھrequestï¼›
paramï¼ڑ 需è¦پهڈ‘é€پهˆ°serverçڑ„requestï¼›
valueï¼ڑ ن»ژserverهڈ‘é€پè؟‡و¥çڑ„responseï¼›
errorï¼ڑ هڈ¯èƒ½هڈ‘ç”ںçڑ„ه¼‚ه¸¸ï¼ˆو¯”ه¦‚网络读ه†™é”™è¯¯ï¼ŒserverوŒ‚ن؛†ï¼Œç‰ç‰ï¼‰ï¼›
done:آ è،¨ç¤؛è؟™ن¸ھcallوک¯هگ¦وˆگهٹںه®Œوˆگن؛†ï¼Œهچ³وک¯هگ¦وژ¥و”¶هˆ°ن؛†responseï¼›
آ
آ
- privateآ classآ Connectionآ extendsآ Threadآ {آ آ
- آ آ آ آ privateآ InetSocketAddressآ server;آ آ آ آ آ آ آ آ آ آ آ آ آ //آ serverآ ip:port آ آ
- آ آ آ آ آ آ
- آ آ آ آ //آ ......... آ آ
- آ آ آ آ آ آ
- آ آ آ آ privateآ Socketآ socketآ =آ null;آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ connectedآ socket آ آ
- آ آ آ آ privateآ DataInputStreamآ in;آ آ
- آ آ آ آ privateآ DataOutputStreamآ out;آ آ
- آ آ آ آ آ آ
- //............آ آ آ آ آ آ
- آ آ آ آ //آ currentlyآ activeآ calls آ آ
- آ آ آ آ privateآ Hashtable<Integer,آ Call>آ callsآ =آ newآ Hashtable<Integer,آ Call>();آ آ
- آ آ آ آ
- //آ ....... آ آ
- آ آ آ privateآ synchronizedآ booleanآ addCall(Callآ call)آ {آ آ
- آ آ آ آ آ آ ifآ (shouldCloseConnection.get())آ آ
- آ آ آ آ آ آ آ آ returnآ false;آ آ
- آ آ آ آ آ آ calls.put(call.id,آ call);آ آ
- آ آ آ آ آ آ notify();آ آ
- آ آ آ آ آ آ returnآ true;آ آ
- }آ آ
- آ آ آ آ privateآ voidآ receiveResponse()آ {آ آ
- آ آ آ آ آ آ ifآ (shouldCloseConnection.get())آ {آ آ
- آ آ آ آ آ آ آ آ return;آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ touch();آ آ
- آ آ آ آ آ آ آ آ
- آ آ آ آ آ آ tryآ {آ آ
- آ آ آ آ آ آ آ آ intآ idآ =آ in.readInt();آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ tryآ toآ readآ anآ id آ آ
- آ آ آ آ آ آ آ آ ifآ (LOG.isDebugEnabled())آ آ
- آ آ آ آ آ آ آ آ آ آ LOG.debug(getName()آ +آ "آ gotآ valueآ #"آ +آ id);آ آ
- آ آ آ آ آ آ آ آ Callآ callآ =آ calls.get(id);آ آ
- آ آ آ آ آ آ آ آ intآ stateآ =آ in.readInt();آ آ آ آ آ //آ readآ callآ status آ آ
- آ آ آ آ آ آ آ آ ifآ (stateآ ==آ Status.SUCCESS.state)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ Writableآ valueآ =آ ReflectionUtils.newInstance(valueClass,آ conf);آ آ
- آ آ آ آ آ آ آ آ آ آ value.readFields(in);آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ readآ value آ آ
- آ آ آ آ آ آ آ آ آ آ call.setValue(value);آ آ
- آ آ آ آ آ آ آ آ آ آ calls.remove(id);آ آ
- آ آ آ آ آ آ آ آ }آ elseآ ifآ (stateآ ==آ Status.ERROR.state)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ call.setException(newآ RemoteException(WritableUtils.readString(in),آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ WritableUtils.readString(in)));آ آ
- آ آ آ آ آ آ آ آ آ آ calls.remove(id);آ آ
- آ آ آ آ آ آ آ آ }آ elseآ ifآ (stateآ ==آ Status.FATAL.state)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ //آ Closeآ theآ connection آ آ
- آ آ آ آ آ آ آ آ آ آ markClosed(newآ RemoteException(WritableUtils.readString(in),آ آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ WritableUtils.readString(in)));آ آ
- آ آ آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ }آ catchآ (IOExceptionآ e)آ {آ آ
- آ آ آ آ آ آ آ آ markClosed(e);آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ }آ آ
- آ آ آ آ آ آ
- آ آ آ آ publicآ voidآ run()آ {آ آ
- آ آ آ آ آ آ ifآ (LOG.isDebugEnabled())آ آ
- آ آ آ آ آ آ آ آ LOG.debug(getName()آ +آ ":آ starting,آ havingآ connectionsآ "آ آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ +آ connections.size());آ آ
- آ آ آ آ آ آ tryآ {آ آ
- آ آ آ آ آ آ آ آ whileآ (waitForWork())آ {//waitآ hereآ forآ workآ -آ readآ orآ closeآ connection آ آ
- آ آ آ آ آ آ آ آ آ آ receiveResponse();آ آ
- آ آ آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ }آ catchآ (Throwableآ t)آ {آ آ
- آ آ آ آ آ آ آ آ LOG.warn("Unexpectedآ errorآ readingآ responsesآ onآ connectionآ "آ +آ this,آ t);آ آ
- آ آ آ آ آ آ آ آ markClosed(newآ IOException("Errorآ readingآ responses",آ t));آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ آ آ
- آ آ آ آ آ آ close();آ آ
- آ آ آ آ آ آ آ آ
- آ آ آ آ آ آ ifآ (LOG.isDebugEnabled())آ آ
- آ آ آ آ آ آ آ آ LOG.debug(getName()آ +آ ":آ stopped,آ remainingآ connectionsآ "آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ +آ connections.size());آ آ
- آ آ آ آ }آ آ
- آ آ آ آ publicآ voidآ sendParam(Callآ call)آ {آ آ
- آ آ آ آ آ آ ifآ (shouldCloseConnection.get())آ {آ آ
- آ آ آ آ آ آ آ آ return;آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ DataOutputBufferآ d=null;آ آ
- آ آ آ آ آ آ tryآ {آ آ
- آ آ آ آ آ آ آ آ synchronizedآ (this.out)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ ifآ (LOG.isDebugEnabled())آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ LOG.debug(getName()آ +آ "آ sendingآ #"آ +آ call.id);آ آ
- آ آ آ آ آ آ آ آ آ آ آ آ
- آ آ آ آ آ آ آ آ آ آ //forآ serializingآ the آ آ
- آ آ آ آ آ آ آ آ آ آ //dataآ toآ beآ written آ آ
- آ آ آ آ آ آ آ آ آ آ dآ =آ newآ DataOutputBuffer();آ آ
- آ آ آ آ آ آ آ آ آ آ d.writeInt(call.id);آ آ
- آ آ آ آ آ آ آ آ آ آ call.param.write(d);آ آ
- آ آ آ آ آ آ آ آ آ آ byte[]آ dataآ =آ d.getData();آ آ
- آ آ آ آ آ آ آ آ آ آ intآ dataLengthآ =آ d.getLength();آ آ
- آ آ آ آ آ آ آ آ آ آ out.writeInt(dataLength);آ آ آ آ آ آ //firstآ putآ theآ dataآ length آ آ
- آ آ آ آ آ آ آ آ آ آ out.write(data,آ 0,آ dataLength);//writeآ theآ data آ آ
- آ آ آ آ آ آ آ آ آ آ out.flush();آ آ
- آ آ آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ }آ catch(IOExceptionآ e)آ {آ آ
- آ آ آ آ آ آ آ آ markClosed(e);آ آ
- آ آ آ آ آ آ }آ finallyآ {آ آ
- آ آ آ آ آ آ آ آ //theآ bufferآ isآ justآ anآ in-memoryآ buffer,آ butآ itآ isآ stillآ politeآ to آ آ
- آ آ آ آ آ آ آ آ //آ closeآ early آ آ
- آ آ آ آ آ آ آ آ IOUtils.closeStream(d);آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ }آ آ آ آ
- }آ آ
آ
Connectionè؟™ن¸ھç±»è¦پو¯”ن¹‹ه‰چçڑ„Callه¤چو‚ه¾—ه¤ڑ,و‰€ن»¥وˆ‘çœپç•¥ن؛†ه¾ˆه¤ڑè؟™é‡Œن¸چن¼ڑ被讨è®؛çڑ„ن»£ç پم€‚
Connectionه¯¹ه؛”ن؛ژن¸€ن¸ھè؟وژ¥ï¼Œهچ³ن¸€ن¸ھsocketم€‚ن½†هگŒو—¶ï¼Œه®ƒهڈˆç»§و‰؟è‡ھThread,و‰€وœ‰ه®ƒوœ¬è؛«هڈˆه¯¹ه؛”ن؛ژن¸€ن¸ھç؛؟程م€‚هڈ¯ن»¥çœ‹ه‡؛,هœ¨Hadoopçڑ„RPCن¸ï¼Œن¸€ن¸ھè؟وژ¥ه¯¹ه؛”ن؛ژن¸€ن¸ھç؛؟程م€‚ه…ˆçœ‹ن»–çڑ„وˆگه‘کهڈکé‡ڈï¼ڑ
serverï¼ڑ è؟™وک¯è؟œç¨‹serverçڑ„هœ°ه€ï¼›
socketï¼ڑ ه¯¹ه؛”çڑ„socketï¼›
in / out: socketçڑ„输ه…¥وµپه’Œè¾“ه‡؛وµپï¼›
callsï¼ڑ é‡چè¦پçڑ„وˆگه‘کهڈکé‡ڈم€‚ه®ƒوک¯ن¸€ن¸ھhashè،¨ï¼Œ ç»´وٹ¤ن؛†è؟™ن¸ھconnectionو£هœ¨è؟›è،Œçڑ„و‰€وœ‰callه’Œه®ƒن»¬ه¯¹ه؛”çڑ„idن¹‹é—´çڑ„ه…³ç³»م€‚ه½“读هڈ–هˆ°ن¸€ن¸ھresponseهگژ,ه°±é€ڑè؟‡idهœ¨è؟™ه¼ è،¨ن¸و‰¾هˆ°ه¯¹ه؛”çڑ„callï¼›
ه†چ看看ه®ƒçڑ„run()ه‡½و•°م€‚è؟™وک¯Connectionè؟™ن¸ھç؛؟程çڑ„هگ¯هٹ¨ه‡½و•°ï¼Œوˆ‘è´´çڑ„ن»£ç پن¸è؟™ن¸ھه‡½و•°و²،هپڑن»»ن½•çڑ„هˆ ه‡ڈ,ن½ هڈ¯ن»¥هڈ‘çژ°ï¼Œهˆ¨é™¤ن¸€ن؛›ه†—ن½™ن»£ç پ,è؟™ن¸ھه‡½و•°ه…¶ه®ه°±هڈھهپڑن؛†ن¸€ن»¶ن؛‹ï¼ڑreceiveResponse,هچ³ç‰ه¾…وژ¥و”¶responseم€‚
آ
OKم€‚ه›هˆ°call()è؟™ن¸ھه‡½و•°ï¼Œçœ‹çœ‹ه®ƒهˆ°ه؛•هپڑن؛†ن»€ن¹ˆï¼ڑ
آ
- publicآ Writableآ call(Writableآ param,آ ConnectionIdآ remoteId)آ آ آ آ
- آ آ آ آ آ آ throwsآ InterruptedException,آ IOExceptionآ {آ آ
- آ آ آ آ Callآ callآ =آ newآ Call(param);آ آ
- آ آ آ آ Connectionآ connectionآ =آ getConnection(remoteId,آ call);آ آ
- آ آ آ آ connection.sendParam(call);آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ sendآ theآ parameter آ آ
- آ آ آ آ booleanآ interruptedآ =آ false;آ آ
- آ آ آ آ synchronizedآ (call)آ {آ آ
- آ آ آ آ آ آ whileآ (!call.done)آ {آ آ
- آ آ آ آ آ آ آ آ tryآ {آ آ
- آ آ آ آ آ آ آ آ آ آ call.wait();آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ //آ waitآ forآ theآ result آ آ
- آ آ آ آ آ آ آ آ }آ catchآ (InterruptedExceptionآ ie)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ //آ saveآ theآ factآ thatآ weآ wereآ interrupted آ آ
- آ آ آ آ آ آ آ آ آ آ interruptedآ =آ true;آ آ
- آ آ آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ ifآ (interrupted)آ {آ آ
- آ آ آ آ آ آ آ آ //آ setآ theآ interruptآ flagآ nowآ thatآ weآ areآ doneآ waiting آ آ
- آ آ آ آ آ آ آ آ Thread.currentThread().interrupt();آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ ifآ (call.errorآ !=آ null)آ {آ آ
- آ آ آ آ آ آ آ آ ifآ (call.errorآ instanceofآ RemoteException)آ {آ آ
- آ آ آ آ آ آ آ آ آ آ call.error.fillInStackTrace();آ آ
- آ آ آ آ آ آ آ آ آ آ throwآ call.error;آ آ
- آ آ آ آ آ آ آ آ }آ elseآ {آ //آ localآ exception آ آ
- آ آ آ آ آ آ آ آ آ آ throwآ wrapException(remoteId.getAddress(),آ call.error);آ آ
- آ آ آ آ آ آ آ آ }آ آ
- آ آ آ آ آ آ }آ elseآ {آ آ
- آ آ آ آ آ آ آ آ returnآ call.value;آ آ
- آ آ آ آ آ آ }آ آ
- آ آ آ آ }آ آ
- آ آ }آ آ
آ
首ه…ˆï¼Œه®ƒهˆ›ه»؛ن؛†ن¸€ن¸ھو–°çڑ„call(è؟™ن¸ھcallوک¯Callç±»çڑ„ه®ن½“,و³¨و„ڈه’Œcall()ه‡½و•°çڑ„هŒ؛هˆ†ï¼‰ï¼Œç„¶هگژو ¹وچ®remoteIdو‰¾هˆ°ه¯¹ه؛”çڑ„connection(Clientç±»ن¸ç»´وٹ¤ن؛†ن¸€ن¸ھconnection pool),然هگژ调用connection.sendParam()م€‚ن»ژه‰چé¢و‰¾هˆ°è؟™ن¸ھه‡½و•°ï¼Œن½ ن¼ڑهڈ‘çژ°ه®ƒه°±وک¯ه°†requestه†™ه…¥هˆ°socket,هڈ‘é€په‡؛هژ»م€‚
ن½†ه€¼ه¾—ن¸€وڈگçڑ„وک¯ï¼Œه®ƒن½؟用çڑ„writeوک¯وœ€و™®é€ڑçڑ„blocking IO,ن¹ںوک¯هگŒو¥IO(هگژé¢ن¼ڑ看هˆ°ï¼Œه®ƒè¯»هڈ–responseن¹ںوک¯ç”¨çڑ„blcoking IO,و‰€ن»¥ï¼Œhadoop RPC虽然وک¯ه¼‚و¥وœ؛هˆ¶ï¼Œن½†وک¯é‡‡ç”¨çڑ„وک¯هگŒو¥blocking IO,و‰€ن»¥ï¼Œه¼‚و¥و¶ˆوپ¯وœ؛هˆ¶è؟ک采用ن»€ن¹ˆو ·çڑ„IOوœ؛هˆ¶وک¯و²،وœ‰ه…³ç³»çڑ„)م€‚
وژ¥ن¸‹و¥ï¼Œè°ƒç”¨ن؛†call.wait(),ه°†ç؛؟程éک»ه،هœ¨è؟™é‡Œم€‚ç›´هˆ°هœ¨وںگن¸ھهœ°و–¹è°ƒç”¨ن؛†call.notify(),ه®ƒو‰چé‡چو–°è؟گè،Œèµ·و¥ï¼Œç„¶هگژن¸€é€ڑهˆ¤و–هگژè؟”ه›call.value,هچ³وژ¥و”¶هˆ°çڑ„responseم€‚
و‰€ن»¥ï¼Œه‰©ن¸‹çڑ„é—®é¢کوک¯ï¼Œهˆ°ه؛•وک¯ه“ھ调用ن؛†call.notify()ï¼ں
ه›هˆ°connectionçڑ„receiveResponseه‡½و•°ï¼ڑ
首ه…ˆï¼Œه®ƒن»ژsocketçڑ„输ه…¥وµپن¸è¯»هˆ°ن¸€ن¸ھid,然هگژو ¹وچ®è؟™ن¸ھidو‰¾هˆ°ه¯¹ه؛”çڑ„call,调用call.setValueه°†ن»ژsocketن¸è¯»هڈ–çڑ„responseو”¾ه…¥هˆ°callçڑ„valueن¸ï¼Œç„¶هگژ调用calls.remove(id)ه°†è؟™ن¸ھcallن»ژéکںهˆ—ن¸ç§»é™¤م€‚è؟™é‡Œè¦پو³¨و„ڈçڑ„وک¯call.setValue,è؟™ن¸ھه‡½و•°ه°†value设置ه¥½ن¹‹هگژ,调用ن؛†call.notify()ï¼پ
ه¥½ن؛†ï¼Œè®©وˆ‘ن»¬ه†چé‡چه¤´ه°†وµپ程وچ‹ن¸€éپچï¼ڑ
è؟™é‡Œه…¶ه®وœ‰ن¸¤ن¸ھç؛؟程,ن¸€ن¸ھç؛؟程وک¯è°ƒç”¨Client.call(),ه¸Œوœ›هگ‘è؟œç¨‹serverهڈ‘é€پ请و±‚çڑ„ç؛؟程,هڈ¦ه¤–ن¸€ن¸ھç؛؟程ه°±وک¯connectionه¯¹ه؛”çڑ„é‚£ن¸ھç؛؟程م€‚ه½“然,虽然وœ‰ن¸¤ن¸ھç؛؟程,ن½†serverه¯¹ه؛”çڑ„هڈھوœ‰ن¸€ن¸ھsocketم€‚第ن¸€ن¸ھç؛؟程هˆ›ه»؛call,然هگژ调用call.sendParamه°†requesté€ڑè؟‡è؟™ن¸ھsocketهڈ‘é€په‡؛هژ»ï¼›è€Œç¬¬ن؛Œن¸ھç؛؟程ن¸چو–çڑ„ن»ژsocketن¸è¯»هڈ–responseم€‚ه› و¤ï¼Œrequestçڑ„هڈ‘é€په’Œresponseçڑ„وژ¥و”¶è¢«هˆ†éڑ”هˆ°ن¸چهگŒçڑ„ç؛؟程ن¸و‰§è،Œï¼Œè€Œن¸”è؟™ن¸¤ن¸ھç؛؟程ن¹‹é—´ه…³ن؛ژsocketçڑ„读ه†™ه¹¶و²،وœ‰ن»»ن½•çڑ„هگŒو¥وœ؛هˆ¶ï¼Œه› و¤وˆ‘认ن¸؛è؟™ن¸ھRPCوک¯ه¼‚و¥و¶ˆوپ¯وœ؛هˆ¶ه®çژ°çڑ„,هڈھن¸چè؟‡é€ڑè؟‡call.wait()/call.notify()ن½؟ه¾—ه¯¹ه¤–çڑ„وژ¥هڈ£çœ‹ن¸ٹهژ»هƒڈوک¯هگŒو¥م€‚
ه¥½ن؛†ï¼ŒHadoopçڑ„RPCن»‹ç»چه®Œن؛†ï¼ˆè™½ç„¶وˆ‘ç•¥وژ‰ن؛†ه¾ˆه¤ڑه†…ه®¹ï¼Œو¯”ه¦‚timeoutوœ؛هˆ¶وˆ‘è؟™é‡Œه°±و²،ه†™ï¼‰ï¼Œè¯´è¯´وˆ‘ن¸ھن؛؛çڑ„评ن»·هگ§م€‚وˆ‘认ن¸؛,Hadoopçڑ„è؟™ن¸ھ设è®،è؟کوک¯وŒ؛ه·§ه¦™çڑ„,ه؛•ه±‚采用çڑ„وک¯ه¼‚و¥وœ؛هˆ¶ï¼Œن½†ه¯¹ه¤–çڑ„وژ¥هڈ£وڈگن¾›çڑ„هڈˆوک¯ن¸€èˆ¬ن؛؛و¯”较ن¹ وƒ¯çڑ„هگŒو¥و–¹ه¼ڈم€‚ن½†وک¯ï¼Œوˆ‘觉ç€ç¼؛点ن¸چوک¯و²،وœ‰ï¼Œن¸€ن¸ھé—®é¢کوک¯ن¸€ن¸ھ链وژ¥ه°±è¦پن؛§ç”ںن¸€ن¸ھç؛؟程,è؟™ن¸ھه¦‚وœوک¯هœ¨ه‡ هچƒهڈ°çڑ„clusterن¸ï¼Œن»چ然ن¼ڑه¸¦و¥ه·¨ه¤§çڑ„ç؛؟程context switchçڑ„ه¼€é”€ï¼›هڈ¦ن¸€ن¸ھé—®é¢کوک¯ه¯¹ن؛ژهگŒن¸€ن¸ھremote serverهڈھوœ‰ن¸€ن¸ھsocketو¥è؟›è،Œو•°وچ®çڑ„هڈ‘é€په’Œوژ¥و”¶ï¼Œè؟™و ·çڑ„设è®،网络çڑ„هگهگگé‡ڈه¾ˆوœ‰هڈ¯èƒ½ن¸ٹن¸چهژ»م€‚(ن¸€ه®¶ن¹‹è¨€ï¼Œو¬¢è؟ژوŒ‡و£ï¼‰
وœھه®Œه¾…ç»~



相ه…³وژ¨èچگ
هœ¨`RPC.Server`ن¸ï¼Œهڈ¯ن»¥çœ‹هˆ°ه¯¹è¯·و±‚çڑ„وژ¥و”¶م€په¤„çگ†ه’Œه“چه؛”çڑ„逻辑م€‚ ه…م€پو€»ç»“ Hadoopçڑ„RPCوœ؛هˆ¶وک¯ه…¶هˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„é‡چè¦پ组وˆگ部هˆ†ï¼Œه®ƒç®€هŒ–ن؛†هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸‹çڑ„é€ڑن؟،,وڈگé«کن؛†و•ˆçژ‡م€‚çگ†è§£ه¹¶وژŒوڈ،RPCçڑ„ه·¥ن½œهژںçگ†ه¯¹ن؛ژن¼کهŒ–Hadoop集群...
* é«کو€§èƒ½ï¼ڑHadoop RPC ن½؟用ه¼‚و¥ééک»ه،çڑ„و–¹ه¼ڈو¥ه¤„çگ†ه®¢وˆ·ç«¯çڑ„调用请و±‚,ن»ژ而وڈگé«کن؛†ç³»ç»ںçڑ„و€§èƒ½م€‚ * هڈ¯و‰©ه±•و€§ï¼ڑHadoop RPC çڑ„و¶و„设è®،ن½؟ه¾—ه®ƒهڈ¯ن»¥ه¾ˆه®¹وک“هœ°و‰©ه±•هˆ°ه¤§è§„و¨،çڑ„هˆ†ه¸ƒه¼ڈç³»ç»ںن¸م€‚ * هڈ¯é و€§ï¼ڑHadoop RPC ن½؟用ن؛†ه¤ڑç§چ...
Hadoop RPCوک¯Hadoopو،†و¶ن¸ç”¨ن؛ژè؟›ç¨‹é—´é€ڑن؟،çڑ„ن¸€ç§چوœ؛هˆ¶ï¼Œه®ƒه…پ许ن¸€ن¸ھè؟›ç¨‹è°ƒç”¨هڈ¦ن¸€ن¸ھè؟œç¨‹è؟›ç¨‹ن¸ه®ڑن¹‰çڑ„و–¹و³•ï¼Œن»؟ن½›è؟™ن¸ھو–¹و³•وک¯هœ¨وœ¬هœ°و‰§è،Œن¸€و ·م€‚è؟™ç§چé€ڈوکژو€§ن½؟ه¾—ه¼€هڈ‘者هڈ¯ن»¥ن¸“و³¨ن؛ژن¸ڑهٹ،逻辑,而و— 需ه…³ه؟ƒه؛•ه±‚é€ڑن؟،细èٹ‚م€‚ ### ه·¥ن½œ...
5. **org.apache.hadoop.ipc**: è؟™ن¸ھهŒ…وڈگن¾›ن؛†è؟›ç¨‹é—´é€ڑن؟،(IPC)çڑ„هں؛ç،€ه·¥ه…·ï¼Œن½؟ه¾—ه®¢وˆ·ç«¯ه’Œوœچهٹ،端能é€ڑè؟‡ç½‘络è؟›è،Œه¼‚و¥é€ڑن؟،م€‚`Protocol`وژ¥هڈ£ه®ڑن¹‰ن؛†وœچهٹ،端وڈگن¾›çڑ„وœچهٹ،,而`RPC`ç±»ه®çژ°ن؛†RPC调用çڑ„逻辑م€‚ 6. **org.apache....
Hadoopçڑ„RPCو،†و¶ه°±وک¯هں؛ن؛ژè؟™ن¸ھçگ†ه؟µو„ه»؛çڑ„,ه®ƒه®çژ°ن؛†ه®¢وˆ·ç«¯ن¸ژوœچهٹ،ه™¨ç«¯ن¹‹é—´çڑ„é«کو•ˆم€په®‰ه…¨çڑ„é€ڑن؟،وœ؛هˆ¶م€‚ è¦پن½؟用Hadoopçڑ„RPCو،†و¶ï¼Œن½ 需è¦په®Œوˆگن»¥ن¸‹و¥éھ¤ï¼ڑ 1. **ه®ڑن¹‰هچڈè®®**ï¼ڑهˆ›ه»؛ن¸€ن¸ھوژ¥هڈ£ï¼Œه£°وکژه®¢وˆ·ç«¯ه’Œوœچهٹ،ه™¨ç«¯éœ€è¦پن؛¤ن؛’çڑ„...
Javaه¹³هڈ°ن¸ٹçڑ„RPCو،†و¶وœ‰ه¾ˆه¤ڑ,ه¦‚Hadoopçڑ„Hadoop RPCم€پApache Thriftم€پGoogleçڑ„gRPCç‰ï¼Œè€Œâ€œnfs-rpcâ€هˆ™وک¯ن¸€ن¸ھن¸“é—¨هں؛ن؛ژJavaه¼€هڈ‘çڑ„é«کو€§èƒ½RPCو،†و¶م€‚è؟™ن¸ھو،†و¶çڑ„设è®،ç›®و ‡وک¯وڈگن¾›é«کو•ˆم€پ稳ه®ڑم€پوک“用çڑ„跨网络وœچهٹ،调用能هٹ›م€‚ ...
Hadoopن½؟用è؟œç¨‹è؟‡ç¨‹è°ƒç”¨ï¼ˆRPC)وœ؛هˆ¶و¥ه®çژ°èٹ‚点间çڑ„é€ڑن؟،,و¯”ه¦‚NameNodeن¸ژDataNodeن¹‹é—´çڑ„é€ڑن؟،م€‚RPCه…پ许ن¸€ن¸ھ程ه؛ڈ调用هڈ¦ن¸€ن¸ھهœ¨ç½‘络هڈ¦ن¸€ç«¯çڑ„程ه؛ڈ,è؟™هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸ه°¤ه…¶é‡چè¦پم€‚Hadoopçڑ„RPCوک¯هں؛ن؛ژprotobufهچڈè®®çڑ„,هڈ¯ن»¥é€ڑè؟‡...
وœ€هگژ,netty-3.6.2.Final.jarوک¯ن¸€ن¸ھé«کو€§èƒ½çڑ„ه¼‚و¥ن؛‹ن»¶é©±هٹ¨çڑ„网络ه؛”用程ه؛ڈو،†و¶ï¼Œه®ƒهœ¨Hadoopن¸ç”¨ن؛ژ网络é€ڑن؟،,特هˆ«وک¯هœ¨ه¤„çگ†RPC(Remote Procedure Call)请و±‚و—¶ï¼Œوڈگن¾›é«کو•ˆçڑ„网络I/O能هٹ›م€‚ و€»çڑ„و¥è¯´ï¼ŒHadoop Eclipse ...
- **هں؛ن؛ژو¶ˆوپ¯çڑ„RPC**ï¼ڑه¦‚AMQP(Advanced Message Queuing Protocol)ن¸ٹçڑ„RPC,é€ڑè؟‡و¶ˆوپ¯éکںهˆ—ه®çژ°ه¼‚و¥RPCم€‚ - **هں؛ن؛ژهچڈ议缓ه†²هŒ؛çڑ„RPC**ï¼ڑه¦‚gRPC,ن½؟用Googleçڑ„protobufه®ڑن¹‰وœچهٹ،وژ¥هڈ£ه’Œو•°وچ®ç»“و„,وڈگن¾›é«کو€§èƒ½م€پن½ژه»¶è؟ںçڑ„...
Apacheوڈگن¾›ن؛†ه¤ڑç§چRPCه®çژ°ï¼Œه¦‚Apache Thriftم€پApache Avroه’ŒHadoopçڑ„RPCç‰م€‚ **Apache Thrift** Apache Thriftوک¯ن¸€ç§چ软ن»¶و،†و¶ï¼Œç”¨ن؛ژو„ه»؛هڈ¯ن¼¸ç¼©çڑ„م€پè·¨è¯è¨€çڑ„وœچهٹ،م€‚ه®ƒه°†وœچهٹ،ه®ڑن¹‰ن¸؛وژ¥هڈ£ه®ڑن¹‰è¯è¨€ï¼ˆIDL),ه…پ许ه¼€هڈ‘者...
综ن¸ٹو‰€è؟°ï¼Œه®çژ°ن¸€ن¸ھهں؛ن؛ژNettyçڑ„è‡ھه®ڑن¹‰RPCو،†و¶ï¼Œéœ€è¦پçگ†è§£Nettyçڑ„ه¼‚و¥I/Oو¨،ه‹ï¼Œè®¾è®،هگˆçگ†çڑ„RPCé€ڑن؟،هچڈ议,هˆ©ç”¨Zookeeperè؟›è،Œوœچهٹ،و³¨ه†Œن¸ژهڈ‘çژ°ï¼ŒهگŒو—¶è€ƒè™‘وœچهٹ،çڑ„é«کهڈ¯ç”¨و€§ه’Œو€§èƒ½ن¼کهŒ–م€‚é€ڑè؟‡هˆ†وگوڈگن¾›çڑ„هژ‹ç¼©هŒ…و–‡ن»¶ï¼Œوˆ‘ن»¬هڈ¯ن»¥و·±ه…¥...
هœ¨SOAن¸ï¼Œوœچهٹ،هڈ¯ن»¥é€ڑè؟‡Web Services(ه¦‚SOAPوˆ–RESTful API)è؟›è،Œن؛¤ن؛’,وˆ–者é€ڑè؟‡و¶ˆوپ¯éکںهˆ—è؟›è،Œه¼‚و¥é€ڑن؟،م€‚ RPCه’ŒSOAن¹‹é—´çڑ„ه…³ç³»هœ¨ن؛ژ,RPCهڈ¯ن»¥ن½œن¸؛ه®çژ°SOAçڑ„ن¸€ç§چوٹ€وœ¯و‰‹و®µم€‚هœ¨SOAو¶و„ن¸ï¼Œوœچهٹ،é—´çڑ„é€ڑن؟،هڈ¯èƒ½é€ڑè؟‡RPCو¥ه®Œوˆگ,...
“Lecture.04è؟œç¨‹è°ƒç”¨.pdfâ€ه’Œâ€œLecture.05é—´وژ¥è°ƒç”¨.pdfâ€هڈ¯èƒ½ن¼ڑ讨è®؛هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸çڑ„é€ڑن؟،وœ؛هˆ¶ï¼Œو¯”ه¦‚RPC(è؟œç¨‹è؟‡ç¨‹è°ƒç”¨ï¼‰ه’Œو¶ˆوپ¯éکںهˆ—,ه®ƒن»¬وک¯ن¸چهگŒèٹ‚点间هچڈن½œçڑ„ه…³é”®م€‚è؟œç¨‹è°ƒç”¨ه…پ许程ه؛ڈè·¨è¶ٹ网络边界调用ه…¶ن»–وœچهٹ،,而...
Avroوک¯Hadoopç”ںو€پç³»ç»ںن¸çڑ„ن¸€ن¸ھه…³é”®ç»„ن»¶ï¼Œç”±Apache软ن»¶هں؛金ن¼ڑه¼€هڈ‘,ن¸»è¦پ用ن½œو•°وچ®ه؛ڈهˆ—هŒ–ç³»ç»ںم€‚ه®ƒوڈگن¾›ن؛†ن¸€ç§چé«کو•ˆçڑ„م€پè¯è¨€و— ه…³çڑ„م€پ版وœ¬هŒ–çڑ„و•°وچ®ه؛ڈهˆ—هŒ–وœ؛هˆ¶ï¼Œن½؟ه¾—ن¸چهگŒç¼–程è¯è¨€ن¹‹é—´هڈ¯ن»¥و–¹ن¾؟هœ°ن؛¤وچ¢و•°وچ®م€‚Avro RPCهˆ™وک¯Avroçڑ„...
RPC(Remote Procedure Call)و،†و¶وک¯è½¯ن»¶ه¼€هڈ‘ن¸çڑ„ن¸€ن¸ھé‡چè¦پو¦‚ه؟µï¼Œه®ƒه…پ许ن¸€ن¸ھ程ه؛ڈهœ¨ن¸چçگ†è§£ه؛•ه±‚网络细èٹ‚çڑ„وƒ…ه†µن¸‹ï¼Œè°ƒç”¨è؟گè،Œهœ¨هڈ¦ن¸€ن¸ھè®،ç®—وœ؛ن¸ٹçڑ„程ه؛ڈم€‚è؟™ن¸ھè؟‡ç¨‹ه°±هƒڈوک¯وœ¬هœ°è°ƒç”¨ن¸€و ·ï¼Œوپه¤§هœ°ç®€هŒ–ن؛†هˆ†ه¸ƒه¼ڈç³»ç»ںن¹‹é—´çڑ„é€ڑن؟،م€‚وœ¬...
Dubboوک¯éک؟里ه·´ه·´ه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈوœچهٹ،و،†و¶ï¼Œè€ŒZookeeperوک¯Apache Hadoopçڑ„ن¸€ن¸ھهگé،¹ç›®ï¼Œن¸»è¦پ用و¥ه®çژ°هˆ†ه¸ƒه¼ڈوœچهٹ،çڑ„é…چç½®ç®،çگ†م€په‘½هگچوœچهٹ،ه’Œهˆ†ه¸ƒه¼ڈهگŒو¥م€‚è؟™ن¸ھوœچهٹ،端é،¹ç›®هŒ…هگ«çڑ„و؛گç پç»ڈè؟‡ن؛†ن¸¥و ¼çڑ„وµ‹è¯•ï¼Œç،®ن؟هڈ¯ن»¥ç›´وژ¥è؟گè،Œï¼Œن¸؛...
Dubbo-RPCهˆ†ه¸ƒه¼ڈوœچهٹ،و،†و¶ Dubbo وک¯éک؟里ه·´ه·´ه¼€هڈ‘çڑ„ن¸€ن¸ھهˆ†ه¸ƒه¼ڈوœچهٹ،و،†و¶ï¼Œو¯ڈه¤©ن¸؛2هچƒه¤ڑن¸ھوœچهٹ،وڈگن¾›ه¤§ن؛ژ30ن؛؟و¬،çڑ„è®؟é—®é‡ڈو”¯وŒپ,ه¹¶è¢«ه¹؟و³›ه؛”用ن؛ژéک؟里ه·´ه·´é›†ه›¢çڑ„هگ„وˆگه‘ک站点م€‚ Dubbo وœ€و–°çڑ„版وœ¬وک¯ 2.5.3م€‚ Dubbox وک¯ه½“ه½“网هں؛ن؛ژ...
0.99.2版وœ¬çڑ„`HBaseRpcController`ه’Œ`RpcServer`ه®çژ°ن؛†ه¼‚و¥è°ƒç”¨ه’Œè¯·و±‚è°ƒه؛¦ï¼Œوپه¤§هœ°وڈگهچ‡ن؛†ç³»ç»ںهگهگگé‡ڈم€‚هگŒو—¶ï¼ŒHBaseè؟کو”¯وŒپه¤ڑç§چو•°وچ®هژ‹ç¼©ç®—و³•ï¼Œه¦‚Snappyه’ŒLZO,é€ڑè؟‡`Compression`و¨،ه—çڑ„و؛گç پ,هڈ¯ن»¥ن؛†è§£ه…¶هژ‹ç¼©ه’Œè§£هژ‹ç¼©çڑ„...
2. و¶ˆوپ¯éکںهˆ—ï¼ڑه…پ许è؟›ç¨‹ه¼‚و¥é€ڑن؟،,و•°وچ®ن»¥و¶ˆوپ¯çڑ„ه½¢ه¼ڈهکه‚¨هœ¨éکںهˆ—ن¸ï¼Œç‰ه¾…وژ¥و”¶و–¹ه¤„çگ†م€‚ 3. ه…±ن؛«ه†…هکï¼ڑه¤ڑن¸ھè؟›ç¨‹هڈ¯ن»¥ç›´وژ¥è®؟é—®هگŒن¸€ه—ه†…هکهŒ؛هںں,é«کو•ˆن½†éœ€è°¨و…ژç®،çگ†هگŒو¥م€‚ 4. ه¥—وژ¥ه—(Sockets)ï¼ڑé€ڑ用çڑ„网络é€ڑن؟،وژ¥هڈ£ï¼Œو”¯وŒپTCP/...
4. **و¶ˆوپ¯éکںهˆ—**ï¼ڑه¦‚RabbitMQم€پKafkaوˆ–ActiveMQ,Javaو¶و„ه¸ˆéœ€è¦پç†ںو‚‰و¶ˆوپ¯éکںهˆ—çڑ„ه·¥ن½œهژںçگ†ï¼Œن»¥ه®çژ°ه¼‚و¥ه¤„çگ†ه’Œè§£è€¦وœچهٹ،م€‚ 5. **JVM**ï¼ڑو·±ه…¥çگ†è§£Javaè™ڑو‹ںوœ؛(JVM)وک¯ه؟…è¦پçڑ„,هŒ…و‹¬ه†…هکç®،çگ†م€پهƒهœ¾و”¶é›†م€پو€§èƒ½ن¼کهŒ–ه’Œç±»هٹ è½½...