Oozie所支持工作流,工作流定义通过将多个Hadoop Job的定义按照一定的顺序组织起来,然后作为一个整体按照既定的路径运行。一个工作流已经定义了,通过启动该工作流Job,就会执行该工作流中包含的多个Hadoop Job,直到完成,这就是工作流Job的生命周期。
那么,现在我们有一个工作流Job,希望每天半夜00:00启动运行,我们能够想到的就是通过写一个定时脚本来调度程序运行。如果我们有多个工作流Job,使用crontab的方式调用可能需要编写大量的脚本,还要通过脚本来控制好各个工作流Job的执行时序问题,不但脚本不好维护,而且监控也不方便。基于这样的背景,Oozie提出了Coordinator的概念,他们能够将每个工作流Job作为一个动作(Action)来运行,相当于工作流定义中的一个执行节点(我们可以理解为工作流的工作流),这样就能够将多个工作流Job组织起来,称为Coordinator Job,并指定触发时间和频率,还可以配置数据集、并发数等。一个Coordinator Job包含了在Job外部设置执行周期和频率的语义,类似于在工作流外部增加了一个协调器来管理这些工作流的工作流Job的运行。
运行Coordinator Job
我们先看一下官方发行包自带的一个简单的例子oozie-3.3.2\examples\src\main\apps\cron,它能够实现定时调度一个工作流Job运行,这个例子中给出的一个空的工作流Job,也是为了演示能够使用Coordinator系统给调度起来。这个例子有3个配置文件,我们不修改workflow.xml配置内容。修改后分别如下所示:
6 |
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron |
7 |
start=2014-03-04T19:00Z |
9 |
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron |
修改了Hadoop集群的配置,以及调度起止时间范围。
1 |
<workflow-app xmlns="uri:oozie:workflow:0.2" name="no-op-wf">
|
是一个空Job,没做任何修改。
01 |
<coordinator-app name="cron-coord" frequency="${coord:minutes(2)}" start="${start}"end="${end}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
|
04 |
<app-path>${workflowAppUri}</app-path>
|
07 |
<name>jobTracker</name>
|
08 |
<value>${jobTracker}</value>
|
12 |
<value>${nameNode}</value>
|
15 |
<name>queueName</name>
|
16 |
<value>${queueName}</value>
|
修改上述coordinator.xml配置文件,将定时调度频率改为2分钟,然后需要将他们上传到HDFS上:
1 |
hadoop fs -rm /user/shirdrn/examples/apps/cron/coordinator.xml
|
2 |
hadoop fs -put /home/shirdrn/cloud/programs/oozie-3.3.2/examples/target/oozie-examples-3.3.2-examples/examples/apps/cron/coordinator.xml /user/shirdrn/examples/apps/cron/
|
因为我之前已经上传过一次,所以修改了coordinator.xml文件配置内容后,一定要上传到HDFS中,而job.properties配置可以通过指定config选项来执行。启动一个Coordinator Job和启动一个Oozie工作流Job类似,执行如下命令即可:
1 |
bin/oozie job -oozie http://oozie-server:11000/oozie -config /home/shirdrn/cloud/programs/oozie-3.3.2/examples/target/oozie-examples-3.3.2-examples/examples/apps/cron/job.properties -run
|
运行上面命令,在控制台上会返回这个Job的ID,我们也可以通过Oozie的Web控制台来查看:
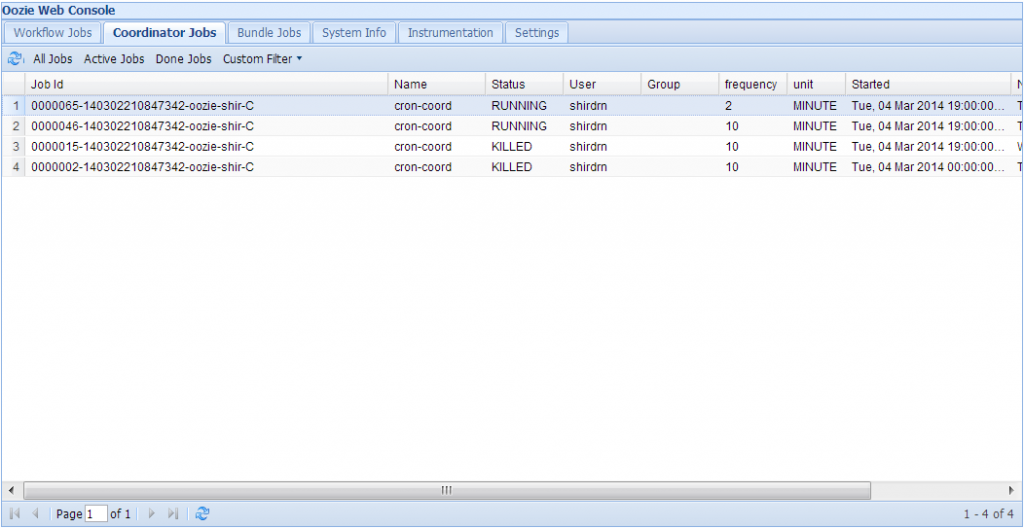
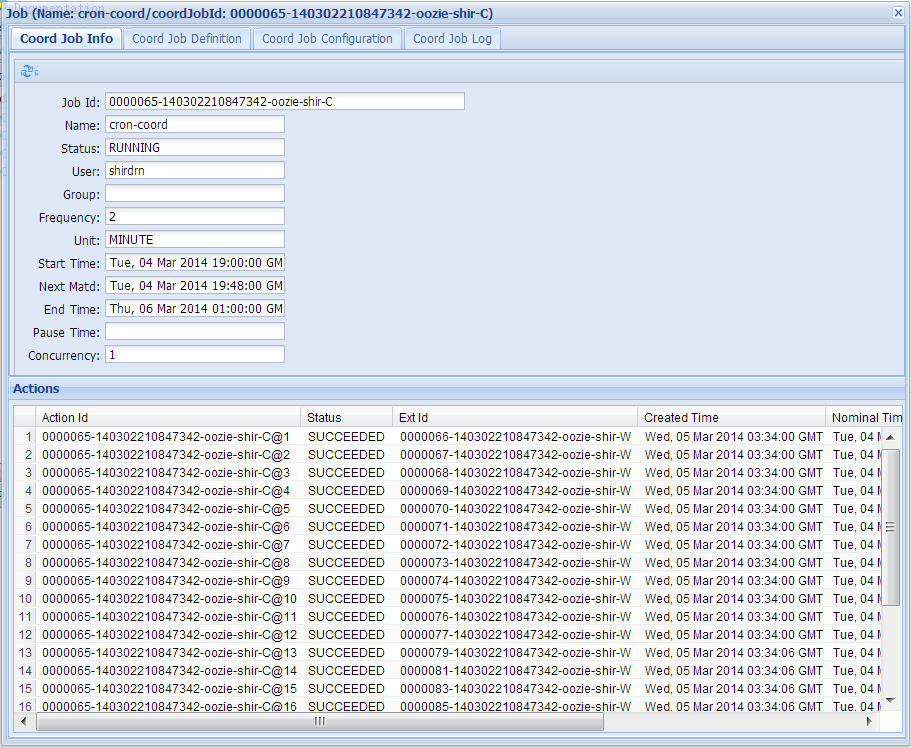
如果想要杀掉一个Job,需要指定Oozie的Job ID,可以执行如下命令:
Coordinator应用(Coordinator Application)
Coordinator应用是指当满足一定条件时,会触发Oozie工作流Job(在Coordinator中将工作流Job定义为一个动作(Action))。其中,触发条件可以是一个时间频率、一个dataset实例是否可用,或者可能是外部的其他事件。
Coordinator Job是一个Coordinator应用的运行实例,这个Coordinator Job是在Oozie提供的Coordinator引擎上运行的,并且这个实例从指定的时间开始,直到运行结束。一个Coordinator Job具有以上几个状态:
- PREP
- RUNNING
- RUNNINGWITHERROR
- PREPSUSPENDED
- SUSPENDED
- SUSPENDEDWITHERROR
- PREPPAUSED
- PAUSED
- PAUSEDWITHERROR
- SUCCEEDED
- DONEWITHERROR
- KILLED
- FAILED
从状态字符串的含义,我们大概就能知道它的含义,这里不做过多解释,可以查阅官方文档。现在,我们关注一下这些状态之间是怎样转移的,从一个状态变成哪些状态是合法的,如下表所示:
| 转移前状态 |
转以后状态集合 |
| PREP |
PREPSUSPENDED | PREPPAUSED | RUNNING | KILLED |
| RUNNING |
RUNNINGWITHERROR | SUSPENDED | PAUSED | SUCCEEDED | KILLED |
| RUNNINGWITHERROR |
RUNNING | SUSPENDEDWITHERROR | PAUSEDWITHERROR | DONEWITHERROR | KILLED | FAILED |
| PREPSUSPENDED |
PREP | KILLED |
| SUSPENDED |
RUNNING | KILLED |
| SUSPENDEDWITHERROR |
RUNNINGWITHERROR | KILLED |
| PREPPAUSED |
PREP | KILLED |
| PAUSED |
SUSPENDED | RUNNING | KILLED |
| PAUSEDWITHERROR |
SUSPENDEDWITHERROR | RUNNINGWITHERROR | KILLED |
我们可以看到,Coordinator Job的状态比一个基本的Oozie工作流Job的状态要复杂的多,因为Coordinator Job的基本执行单元可能是一个基本Oozie Job,而且外加了一些调度信息,必然要增加额外的状态来描述。
Coordinator动作(Coordinator Action)
一个Coordinator Job会创建并执行Coordinator 动作(Coordinator Action)。通常一个Coordinator 动作是一个工作流Job,这个工作流Job会生成一个dataset实例并处理这个数据集。当一个一个Coordinator 动作被创建以后,它会一直等待满足执行条件的所有输入事件的完成然后执行,或者发生超时。
每个Coordinator Job都有一个驱动事件,来决定它所包含的Coordinator动作的初始化(创建)。对于同步Coordinator Job(synchronous coordinator job)来说,触发执行频率(frequency)就是一个驱动事件。
同样,组成Coordinator Job的基本单元是Coordinator 动作(Coordinator Action),它不像Oozie工作流Job只有OK和Error两个执行结果,一个Coordinator 动作的状态集合,如下所示:
- WAITING
- READY
- SUBMITTED
- TIMEDOUT
- RUNNING
- KILLED
- SUCCEEDED
- FAILED
一个Coordinator 动作的状态变迁情况,如下表所示:
| 转移前状态 |
转以后状态集合 |
| WAITING |
READY | TIMEDOUT | KILLED |
| READY |
SUBMITTED | KILLED |
| SUBMITTED |
RUNNING | KILLED | FAILED |
| RUNNING |
SUCCEEDED | KILLED | FAILED |
Coordinator应用定义(Coordinator Application Definition)
一个同步的Coordinator应用定义的语法格式,如下所示:
01 |
<coordinator-app name="[NAME]" frequency="[FREQUENCY]" start="[DATETIME]" end="[DATETIME]"timezone="[TIMEZONE]" xmlns="uri:oozie:coordinator:0.1">
|
03 |
<timeout>[TIME_PERIOD]</timeout>
|
04 |
<concurrency>[CONCURRENCY]</concurrency>
|
05 |
<execution>[EXECUTION_STRATEGY]</execution>
|
08 |
<include>[SHARED_DATASETS]</include>
|
11 |
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]"timezone="[TIMEZONE]">
|
12 |
<uri-template>[URI_TEMPLATE]</uri-template>
|
17 |
<data-in name="[NAME]" dataset="[DATASET]">
|
18 |
<instance>[INSTANCE]</instance>
|
22 |
<data-in name="[NAME]" dataset="[DATASET]">
|
23 |
<start-instance>[INSTANCE]</start-instance>
|
24 |
<end-instance>[INSTANCE]</end-instance>
|
29 |
<data-out name="[NAME]" dataset="[DATASET]">
|
30 |
<instance>[INSTANCE]</instance>
|
36 |
<app-path>[WF-APPLICATION-PATH]</app-path>
|
39 |
<name>[PROPERTY-NAME]</name>
|
40 |
<value>[PROPERTY-VALUE]</value>
|
基于上述定义语法格式,我们分别说明对应元素的含义,如下所示:
control元素定义了一个Coordinator Job的控制信息,主要包括如下三个配置元素:
| 元素名称 |
含义说明 |
| timeout |
超时时间,单位为分钟。当一个Coordinator Job启动的时候,会初始化多个Coordinator动作,timeout用来限制这个初始化过程。默认值为-1,表示永远不超时,如果为0 则总是超时。 |
| concurrency |
并发数,指多个Coordinator Job并发执行,默认值为1。 |
| execution |
配置多个Coordinator Job并发执行的策略:默认是FIFO。另外还有两种:LIFO(最新的先执行)、LAST_ONLY(只执行最新的Coordinator Job,其它的全部丢弃)。 |
| throttle |
一个Coordinator Job初始化时,允许Coordinator动作处于WAITING状态的最大数量。 |
Coordinator Job中有一个Dataset的概念,它可以为实际计算提供计算的数据,主要是指HDFS上的数据目录或文件,能够配置数据集生成的频率(Frequency)、URI模板、时间等信息,下面看一下dataset的语法格式:
1 |
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
|
2 |
<uri-template>[URI TEMPLATE]</uri-template>
|
3 |
<done-flag>[FILE NAME]</done-flag>
|
举例如下:
1 |
<dataset name="stats_hive_table" frequency="${coord:days(1)}" initial-instance="2014-03-05T00:00Z" timezone="America/Los_Angeles">
|
5 |
<done-flag>donefile.flag</done-flag>
|
上面会每天都会生成一个用户事件表,可以供Hive查询分析,这里指定了这个数据集的位置,后续计算会使用这部分数据。其中,uri-template指定了一个匹配的模板,满足这个模板的路径都会被作为计算的基础数据。
另外,还有一种定义dataset集合的方式,将多个dataset合并成一个组来定义,语法格式如下所示:
2 |
<include>[SHARED_DATASETS]</include>
|
4 |
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]"timezone="[TIMEZONE]">
|
5 |
<uri-template>[URI TEMPLATE]</uri-template>
|
- input-events和output-events元素
一个Coordinator应用的输入事件指定了要执行一个Coordinator动作必须满足的输入条件,在Oozie当前版本,只支持使用dataset实例。
一个Coordinator动作可能会生成一个或多个dataset实例,在Oozie当前版本,输出事件只支持输出dataset实例。
EL常量
| 常量表示形式 |
含义说明 |
| ${coord:minutes(int n)} |
返回日期时间:从一开始,周期执行n分钟 |
| ${coord:hours(int n)} |
返回日期时间:从一开始,周期执行n * 60分钟 |
| ${coord:days(int n)} |
返回日期时间:从一开始,周期执行n * 24 * 60分钟 |
| ${coord:months(int n)} |
返回日期时间:从一开始,周期执行n * M * 24 * 60分钟(M表示一个月的天数) |
| ${coord:endOfDays(int n)} |
返回日期时间:从当天的最晚时间(即下一天)开始,周期执行n * 24 * 60分钟 |
| ${coord:endOfMonths(1)} |
返回日期时间:从当月的最晚时间开始(即下个月初),周期执行n * 24 * 60分钟 |
| ${coord:current(int n)} |
返回日期时间:从一个Coordinator动作(Action)创建时开始计算,第n个dataset实例执行时间 |
| ${coord:dataIn(String name)} |
在输入事件(input-events)中,解析dataset实例包含的所有的URI |
| ${coord:dataOut(String name)} |
在输出事件(output-events)中,解析dataset实例包含的所有的URI |
| ${coord:offset(int n, String timeUnit)} |
表示时间偏移,如果一个Coordinator动作创建时间为T,n为正数表示向时刻T之后偏移,n为负数向向时刻T之前偏移,timeUnit表示时间单位(选项有MINUTE、HOUR、DAY、MONTH、YEAR) |
| ${coord:hoursInDay(int n)} |
指定的第n天的小时数,n>0表示向后数第n天的小时数,n=0表示当天小时数,n<0表示向前数第n天的小时数 |
| ${coord:daysInMonth(int n)} |
指定的第n个月的天数,n>0表示向后数第n个月的天数,n=0表示当月的天数,n<0表示向前数第n个月的天数 |
| ${coord:tzOffset()} |
ataset对应的时区与Coordinator Job的时区所差的分钟数 |
| ${coord:latest(int n)} |
最近以来,当前可以用的第n个dataset实例 |
| ${coord:future(int n, int limit)} |
当前时间之后的dataset实例,n>=0,当n=0时表示立即可用的dataset实例,limit表示dataset实例的个数 |
| ${coord:nominalTime()} |
nominal时间等于Coordinator Job启动时间,加上多个Coordinator Job的频率所得到的日期时间。例如:start=”2009-01-01T24:00Z”,end=”2009-12-31T24:00Z”,frequency=”${coord:days(1)}”,frequency=”${coord:days(1)},则nominal时间为:2009-01-02T00:00Z、2009-01-03T00:00Z、2009-01-04T00:00Z、…、2010-01-01T00:00Z |
| ${coord:actualTime()} |
Coordinator动作的实际创建时间。例如:start=”2011-05-01T24:00Z”,end=”2011-12-31T24:00Z”,frequency=”${coord:days(1)}”,则实际时间为:2011-05-01,2011-05-02,2011-05-03,…,2011-12-31 |
| ${coord:user()} |
启动当前Coordinator Job的用户名称 |
| ${coord:dateOffset(String baseDate, int instance, String timeUnit)} |
计算新的日期时间的公式:newDate = baseDate + instance * timeUnit,如:baseDate=’2009-01-01T00:00Z’,instance=’2′,timeUnit=’MONTH’,则计算得到的新的日期时间为’2009-03-01T00:00Z’。 |
| ${coord:formatTime(String timeStamp, String format)} |
格式化时间字符串,format指定模式 |
配置举例
下面,根据官网上给出的例子,进行说明,配置例子如下所示:
01 |
<coordinator-app name="hello2-coord" frequency="${coord:days(7)}"
|
02 |
start="2009-01-07T24:00Z" end="2009-12-12T24:00Z" timezone="UTC"
|
03 |
xmlns="uri:oozie:coordinator:0.1">
|
05 |
<dataset name="logs" frequency="${coord:days(1)}"
|
06 |
initial-instance="2009-01-01T24:00Z" timezone="UTC">
|
10 |
<dataset name="weeklySiteAccessStats" frequency="${coord:days(7)}"
|
11 |
initial-instance="2009-01-07T24:00Z" timezone="UTC">
|
17 |
<data-in name="input" dataset="logs">
|
18 |
<start-instance>${coord:current(-6)}</start-instance>
|
19 |
<end-instance>${coord:current(0)}</end-instance>
|
23 |
<data-out name="output" dataset="siteAccessStats">
|
24 |
<instance>${coord:current(0)}</instance>
|
33 |
<value>${coord:dataIn('input')}</value>
|
37 |
<value>${coord:dataOut('output')}</value>
|
名称为logs的dataset实例频率为1天,它配置的初始实例时间为2009-01-07T24:00Z,则在input-events输入事件中开始实例(start-instance)时间为6天前,即2009-01-01T24:00Z,结束实例(end-instance)时间为当天时间。
后半部分中定义了action,其中${coord:dataIn(‘input’)}表示解析名称为input的输入事件所关联的URI(即HDFS上的文件或目录)。
原文链接:http://shiyanjun.cn/archives/684.html




相关推荐
3. **上传和验证工作流**:将工作流XML文件和相关的作业资源(如Hive脚本、MapReduce JAR文件)上传到HDFS,并使用Oozie客户端工具进行验证。 4. **提交和启动工作流**:通过Oozie客户端提交工作流,并启动作业。 5....
oozie配置mysql所需表结构。Apache Oozie是用于Hadoop平台的一种工作流调度引擎。
oozie工具使用
ExtJS和Oozie是两个在IT行业中广泛使用的开源工具,它们在大数据处理和Web应用程序开发方面发挥着重要作用。在本篇文章中,我们将深入探讨这两个技术以及它们之间的结合。 **ExtJS 2.2** ExtJS是一个基于JavaScript...
- 使用oozie的`oozie job -schedule`和`oozie job -unschedule`命令管理定时任务。 **Oozie客户端常用命令** - `oozie job -info <job_id>`:查看作业信息。 - `oozie job -status <job_id>`:查询作业状态。 - `...
### 使用Oozie Coordinator 设置定时任务详解 #### 一、Oozie Coordinator 概述 Oozie Coordinator 是 Apache Oozie 的一个组件,用于管理 Hadoop 作业的周期性调度。Coordinator 可以帮助用户定义复杂的依赖关系...
**Oozie配置文件详解** 在Hadoop生态系统中,Oozie是一个工作流调度系统,用于管理和协调Hadoop作业,包括Hive、Pig、MapReduce、Spark等。Oozie与Hadoop集群的其他组件紧密集成,提供了一种集中式的方式来管理作业...
同时,熟悉SQL语言和你所使用的数据库管理系统也是必不可少的技能,因为Oozie的元数据存储通常需要数据库支持。记得定期备份数据库,以防止数据丢失,并保持Oozie的版本与Hadoop和其他相关组件的版本兼容,以避免...
### Oozie 使用详解 #### 一、Oozie 概述 Oozie 是一个用于管理工作流和协调数据处理任务的开源工具,主要用于在 Hadoop 生态系统中实现复杂的工作流调度。它通过定义一系列任务及其之间的依赖关系来自动化执行大...
2.Oozie的功能及模块 3.Oozie的与MR的关系 4.Oozie的工作流实现原理 5.Oozie中的特殊概念Action 6.Hadoop的集成配置 7.Oozie的部署配置 第三章:Oozie调度开发实战 1.Shell脚本工作流调度开发实战 2.Hive...
* 相关文件说明:coordinator.xml 是 OOZIE coord 定时调度文件,workflow.xml 是 OOZIE 作业执行文件,job_h.properties 是作业按小时调度相关参数配置文件,job_test.properties 是测试 OOZIE 是否可以正常调度...
### 大数据技术之Oozie入门到精通 #### 一、Oozie简介与应用场景 **Oozie**是一款开源的工作流调度系统...通过深入学习Oozie的核心概念、架构设计及具体应用场景,可以帮助开发者更好地利用其强大功能解决复杂问题。
在生产环境中,Oozie的使用涉及到创建工作流定义(使用XML文件),提交工作流,监控运行状态,以及维护Oozie服务器的健康。运维方面,需要关注日志分析,定期备份,以及性能监控,以确保系统的高效运行。 总之,...
1. **控制流节点(Control Flow Nodes)**:这些节点主要在工作流的开始和结束处使用,如`start`、`end`和`kill`节点。`decision`节点根据条件控制流程走向,`fork`和`join`节点则用于任务的分支和合并。 2. **动作...
本文主要讲述在Hue平台使用Oozie工作流操作Sqoop工具将MySQL数据库的数据传输到HDFS中,并最终导入到Hive表中的经验。以下是详细知识点: 1. Hue平台和Oozie工作流简介: Hue是一种开源的用户界面,用于简化与...
**OozieWeb界面及其组件详解** 在大数据处理领域,Oozie是一个非常重要的工作流管理系统,主要用于协调Hadoop生态系统中的各种任务。OozieWeb界面是Oozie的用户交互部分,允许用户通过Web浏览器进行工作流的提交、...
5. 重启Oozie服务以应用更改,通常通过命令如 `service oozie restart` 或者使用CM(Cloudera Manager)界面来重启服务。 6. 最后,验证控制台是否可以正常访问和使用。如果之前出现错误,现在应该能够正常显示了。 ...
《Apache Oozie 4.3.1源码解析与应用指南》 Apache Oozie 是一个用于管理Hadoop作业的工作流调度系统,它能够协调Hadoop生态系统中的各种任务,如...同时,掌握Oozie的使用技巧,能够提升整个Hadoop集群的运营效率。
3. **协调器(Coordinator)**:除了基础的工作流程之外,oozie_demo可能还包含了`coordinator.xml`文件,用于定义基于时间或数据触发的工作流程实例。协调器允许你根据特定的时间间隔或数据可用性来自动启动工作...
### oozie 4.0.1 在 hadoop2.3.0 上的安装与配置详解 #### 一、概述 随着大数据技术的发展,越来越多的企业和机构选择使用Apache Hadoop来处理海量数据。Apache Oozie作为一款强大的工作流调度系统,能够帮助用户...