在搜索引擎的开发中,我们需要对网页的Html内容进行检索,难免的就需要对Html进行解析。拆分每一个节点并且获取节点间的内容。此文介绍两种C#解析Html的方法。
第一种方法:
用System.Net.WebClient下载Web Page存到本地文件或者String中,用正则表达式来分析。这个方法可以用在Web Crawler等需要分析很多Web Page的应用中。
估计这也是大家最直接,最容易想到的一个方法。
转自网上的一个实例:所有的href都抽取出来:

usingSystem;
usingSystem.Net;
usingSystem.Text;
usingSystem.Text.RegularExpressions;
namespaceHttpGet
{
classClass1
{
[STAThread]
staticvoidMain(string[]args)
{
System.Net.WebClientclient=newWebClient();
byte[]page=client.DownloadData("http://www.google.com");
stringcontent=System.Text.Encoding.UTF8.GetString(page);
stringregex="href=[\\\"\\\'](http:\\/\\/|\\.\\/|\\/)?\\w+(\\.\\w+)*(\\/\\w+(\\.\\w+)?)*(\\/|\\?\\w*=\\w*(&\\w*=\\w*)*)?[\\\"\\\']";
Regexre=newRegex(regex);
MatchCollectionmatches=re.Matches(content);
System.Collections.IEnumeratorenu=matches.GetEnumerator();
while(enu.MoveNext()&&enu.Current!=null)
{
Matchmatch=(Match)(enu.Current);
Console.Write(match.Value+"\r\n");
}
}
}
}
一些爬虫的HTML解析中也是用的类似的方法。
第二种方法:
利用Winista.Htmlparser.Net 解析Html。这是.NET平台下解析Html的开源代码,网上有源码下载,百度一下就能搜到,这里就不提供了。并且有英文的帮助文档。找不到的留下邮箱。
个人认为这是.net平台下解析html不错的解决方案,基本上能够满足我们对html的解析工作。
自己做了个实例:
usingSystem;
usingSystem.Collections.Generic;
usingSystem.ComponentModel;
usingSystem.Data;
usingSystem.Drawing;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Windows.Forms;
usingWinista.Text.HtmlParser;
usingWinista.Text.HtmlParser.Lex;
usingWinista.Text.HtmlParser.Util;
usingWinista.Text.HtmlParser.Tags;
usingWinista.Text.HtmlParser.Filters;
namespaceHTMLParser
{
publicpartialclassForm1:Form
{
publicForm1()
{
InitializeComponent();
AddUrl();
}
privatevoidbtnParser_Click(objectsender,EventArgse)
{
#region获得网页的html
try
{
txtHtmlWhole.Text="";
stringurl=CBUrl.SelectedItem.ToString().Trim();
System.Net.WebClientaWebClient=newSystem.Net.WebClient();
aWebClient.Encoding=System.Text.Encoding.Default;
stringhtml=aWebClient.DownloadString(url);
txtHtmlWhole.Text=html;
}
catch(Exceptionex)
{
MessageBox.Show(ex.Message);
}
#endregion
#region分析网页html节点
Lexerlexer=newLexer(this.txtHtmlWhole.Text);
Parserparser=newParser(lexer);
NodeListhtmlNodes=parser.Parse(null);
this.treeView1.Nodes.Clear();
this.treeView1.Nodes.Add("root");
TreeNodetreeRoot=this.treeView1.Nodes[0];
for(inti=0;i<htmlNodes.Count;i++)
{
this.RecursionHtmlNode(treeRoot,htmlNodes[i],false);
}
#endregion
}
privatevoidRecursionHtmlNode(TreeNodetreeNode,INodehtmlNode,boolsiblingRequired)
{
if(htmlNode==null||treeNode==null)return;
TreeNodecurrent=treeNode;
TreeNodecontent;
//currentnode
if(htmlNodeisITag)
{
ITagtag=(htmlNodeasITag);
if(!tag.IsEndTag())
{
stringnodeString=tag.TagName;
if(tag.Attributes!=null&&tag.Attributes.Count>0)
{
if(tag.Attributes["ID"]!=null)
{
nodeString=nodeString+"{id=\""+tag.Attributes["ID"].ToString()+"\"}";
}
if(tag.Attributes["HREF"]!=null)
{
nodeString=nodeString+"{href=\""+tag.Attributes["HREF"].ToString()+"\"}";
}
}
current=newTreeNode(nodeString);
treeNode.Nodes.Add(current);
}
}
//获取节点间的内容
if(htmlNode.Children!=null&&htmlNode.Children.Count>0)
{
this.RecursionHtmlNode(current,htmlNode.FirstChild,true);
content=newTreeNode(htmlNode.FirstChild.GetText());
treeNode.Nodes.Add(content);
}
//thesiblingnodes
if(siblingRequired)
{
INodesibling=htmlNode.NextSibling;
while(sibling!=null)
{
this.RecursionHtmlNode(treeNode,sibling,false);
sibling=sibling.NextSibling;
}
}
}
privatevoidAddUrl()
{
CBUrl.Items.Add("http://www.hao123.com");
CBUrl.Items.Add("http://www.sina.com");
CBUrl.Items.Add("http://www.heuet.edu.cn");
}
}
}
运行效果: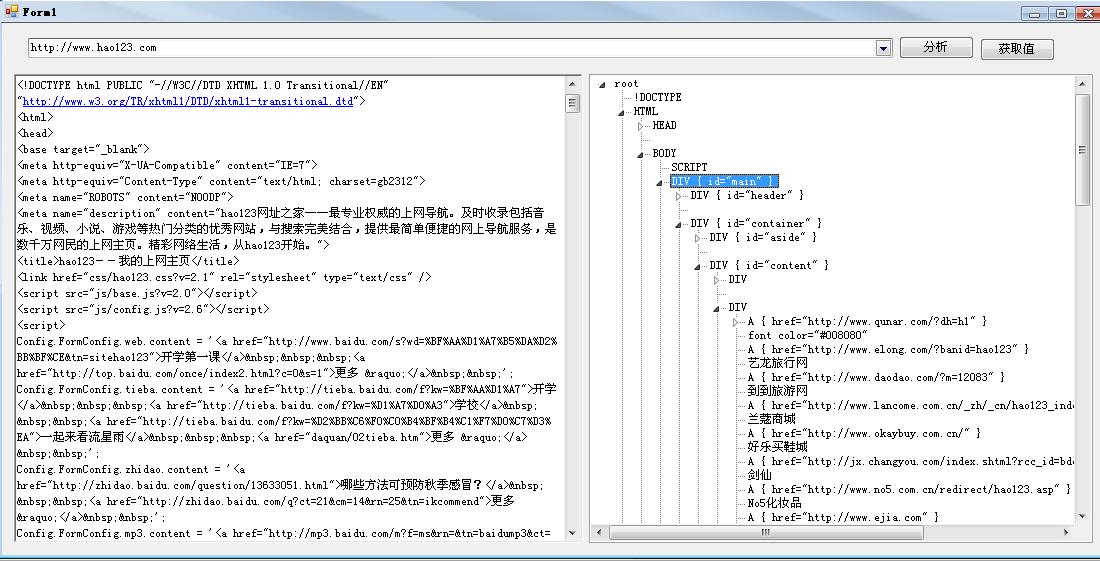
实现取来很容易,结合Winista.Htmlparser源码很快就可以实现想要的效果。
小结:
简单介绍了两种解析Html的方法,大家有什么其他好的方法还望指教。
分享到:




相关推荐
**使用HtmlAgilityPack解析HTML** 首先,确保已通过NuGet包管理器或手动下载将HtmlAgilityPack库添加到项目中。以下是一些基本的使用示例: 1. **加载HTML**: ```csharp var htmlDoc = new HtmlDocument(); ...
C#解析html类库NSoup.dll 调用代码如下: string html = "<html><head><title>First!</title></head><body><p title='test'>First post!</p></body></html>"; Document...
在提供的HTML文件"C# 解析JSON格式数据 - CSDN博客.html"中,可能包含了更详细的示例和解析技巧,配合"C# 解析JSON格式数据 - CSDN博客_files"中的资源,读者可以深入学习并实践C#解析JSON的各种方法。通过学习和...
以HtmlAgilityPack为例,安装NuGet包后,可以这样解析HTML: ```csharp HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(responseFromServer); var titleNode = doc.DocumentNode.SelectSingleNode("//title...
HTMLParser库的核心功能是解析HTML文档,将其转化为易于操作的对象模型。它能够解析HTML标记、属性以及嵌套结构,提供了一种结构化的方式来访问和修改网页内容。这对于数据抓取、网页自动化和前端与后端之间的交互...
能够快速解析HTML源码,找到指定位置处的的Url 用法如下: var list = new List(); HtmlTag tag; while (!parser.Eof) { if (!parser.ParseNext("dl", out tag)) continue; if (!(tag.Attributes.ContainsKey...
### C#解析HTML的方法 #### 一、使用正则表达式解析HTML 在C#中,使用正则表达式解析HTML是一种常见的做法,尤其适用于快速提取网页中的特定信息。正则表达式允许开发者通过模式匹配的方式查找字符串中的特定格式...
C# 解析HTML格式字符串(HtmlAgilityPack)-附件资源
用于解析html字符串,利用XPATH语法读取 格式化后的html
一款方便用于解析HTML代码的C# dll 程序集,内包涵各种方便快捷的操作方法,可以大大提高开发效率,可以像使用JS一样,根据id查找找指定的标签,等等。。。(纯中文注释,方便更多的开发者快速理解方法含义)
在C#中解析HTML是常见的任务,特别是在开发网络爬虫或进行网页数据提取时。本文将详细介绍两种不同的方法,帮助开发者有效地处理HTML内容。 第一种方法是使用`System.Net.WebClient`类配合正则表达式。`WebClient`...
1. **解析HTML**:HtmlAgilityPack可以解析HTML字符串或从URL加载HTML文档。它能处理不规范的HTML,即使HTML缺少结束标签或格式不正确,也能正确构建DOM树。 2. **文档对象模型(DOM)**:该库提供了一个类`...
在C#中,处理HTML通常需要解析HTML字符串或文件,查找并操作特定元素。而`HTMLHelper.cs`这个类文件,就是为了解决这个问题,它提供了封装好的方法,使得这些操作变得简单易行。 该类可能包含以下功能: 1. **获取...
当我们谈论"C# HTML解析"时,我们指的是使用C#来处理和理解HTML文档的程序设计技术。在本案例中,我们将深入探讨如何在Visual Studio 2010环境下利用C#进行HTML解析。 首先,让我们了解一下HTML解析的基本概念。...
在本项目"包含html页面解析的网络爬虫程序C#实现"中,开发者使用C#语言构建了一个能够解析HTML页面并将其转化为树形结构的爬虫。这个程序的核心功能包括HTML解析、内容提取以及数据存储。 1. **HTML页面解析**:...
1. **HTML解析**:首先,我们需要了解如何使用C#解析HTML。这通常涉及到使用如HtmlAgilityPack或AngleSharp等第三方库,它们能够解析HTML文档并提供DOM(Document Object Model)接口,以便我们可以遍历和操作HTML...
C#在解析HTML时,会将这些元素作为对象进行操作。 在C#中,有多个库可以帮助我们解析HTML,其中最常用的是HtmlAgilityPack(简称HAP)和AngleSharp。这两个库都是开源的,提供了丰富的API来解析和操作HTML文档。 ...
在这个项目中,我们聚焦于"C#邮件解析(sina)",意味着我们将探讨如何使用C#语言来处理和解析新浪邮件系统中的数据。 首先,我们需要了解邮件的基本结构。邮件通常由MIME(多用途互联网邮件扩展)格式定义,包含...